Пред.
След.
Макеты страниц
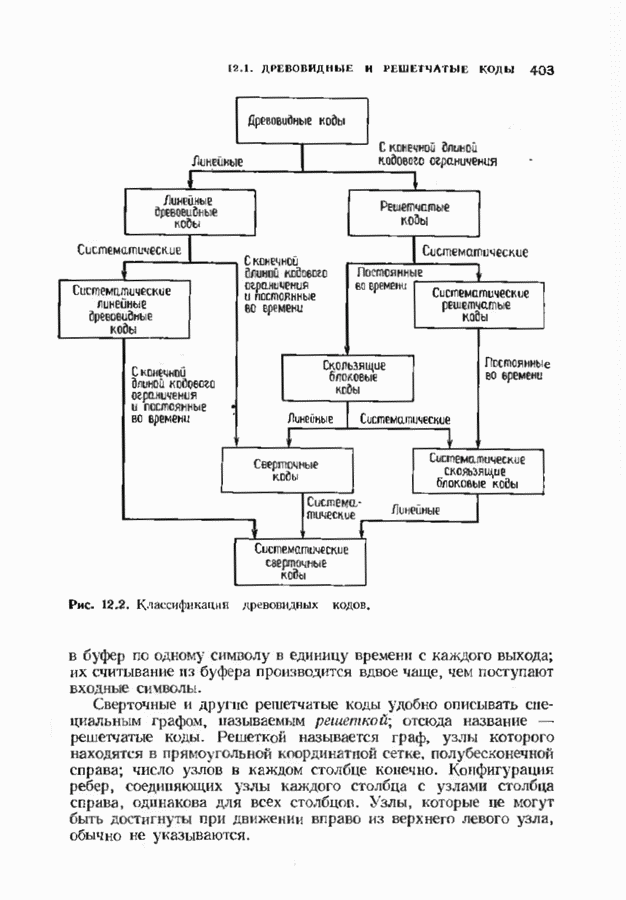
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
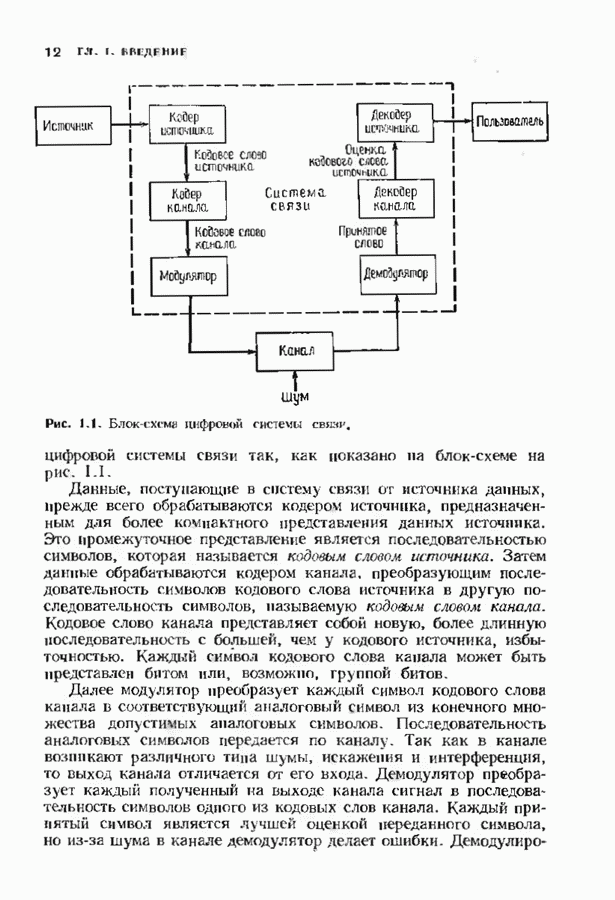
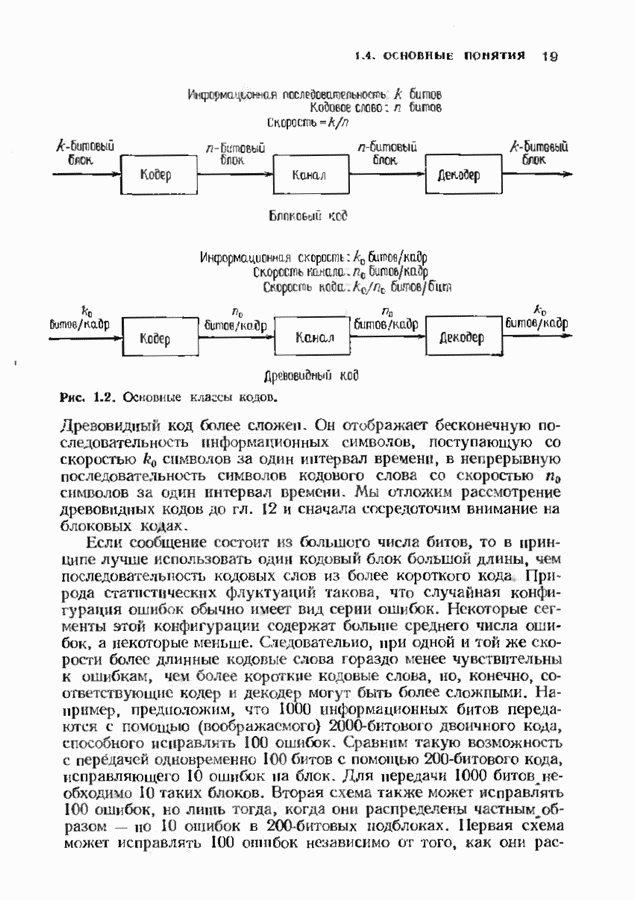
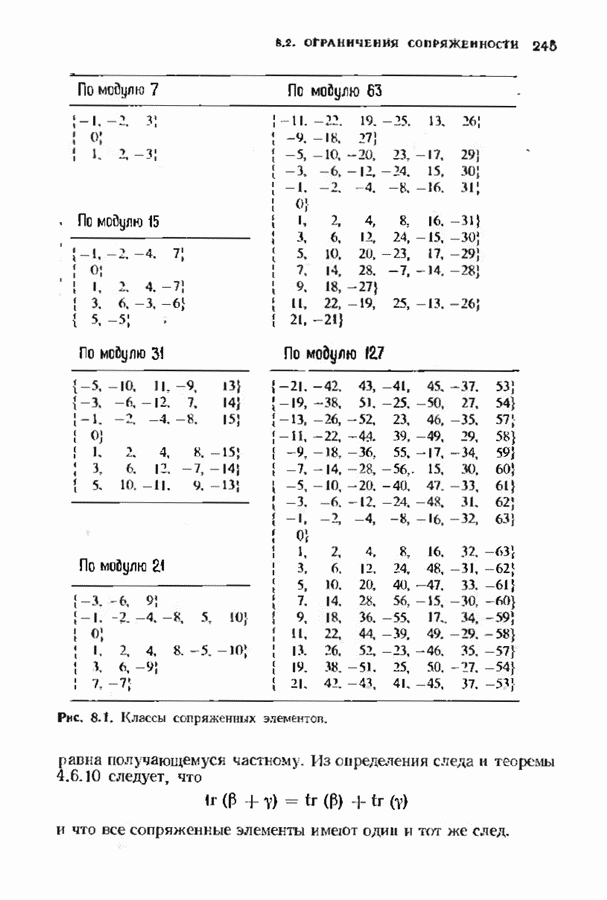
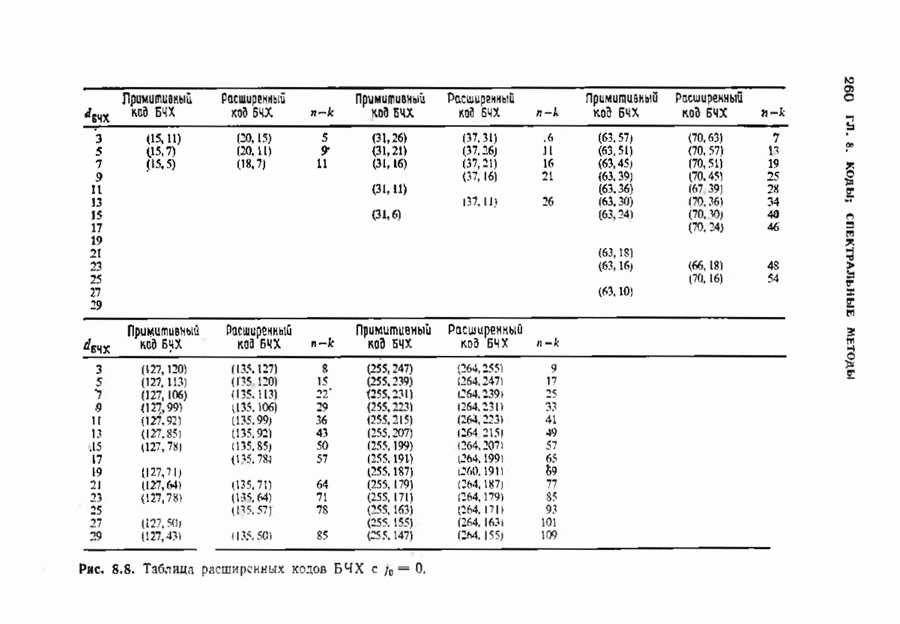
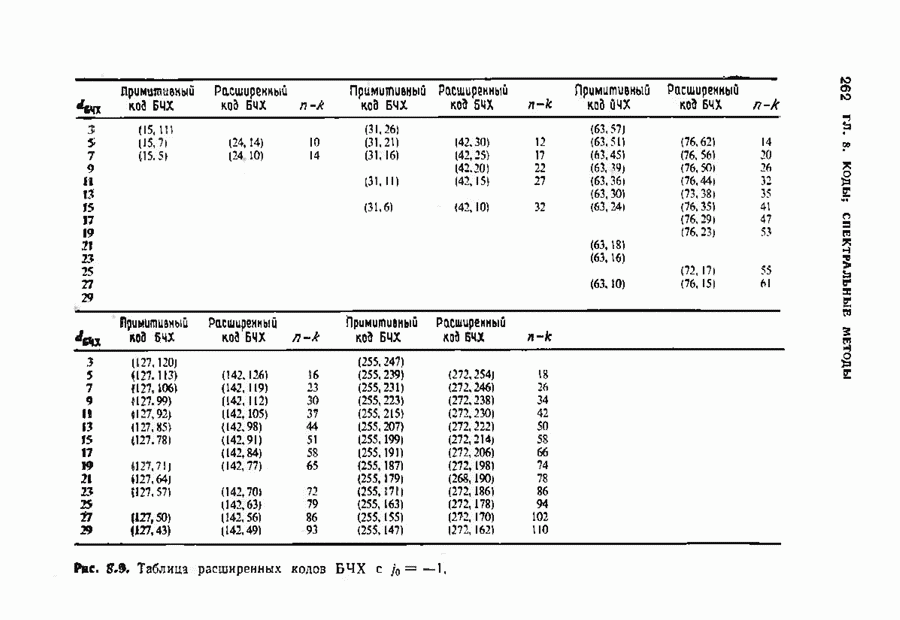
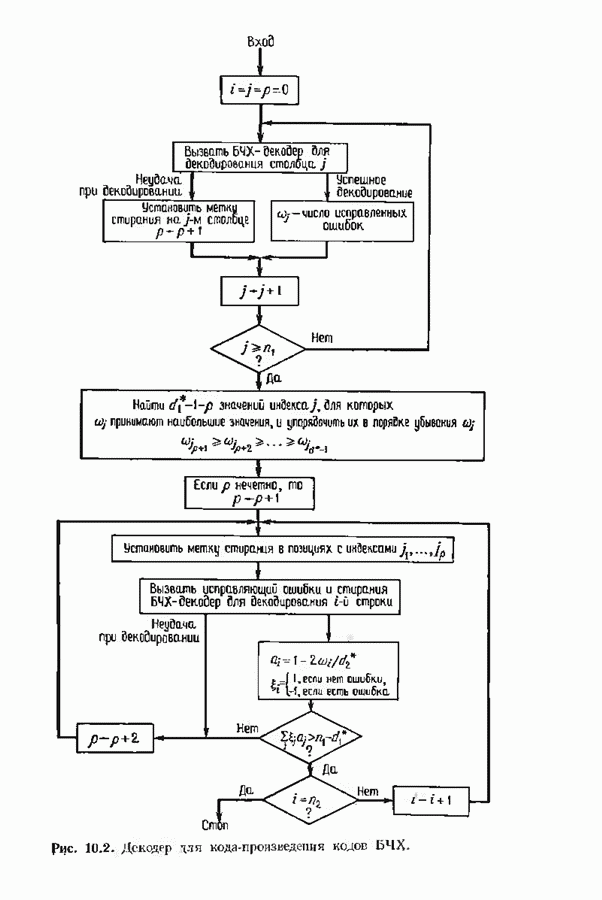
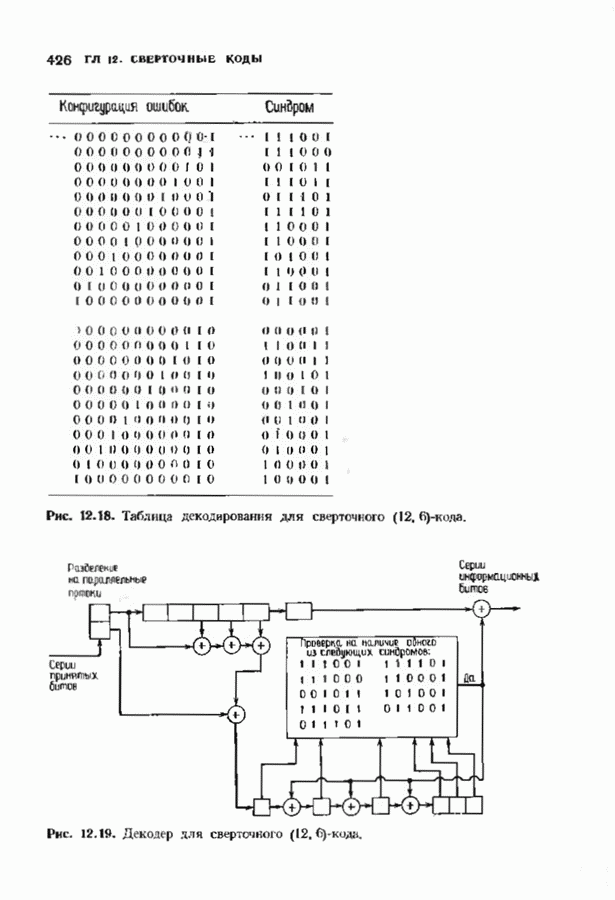
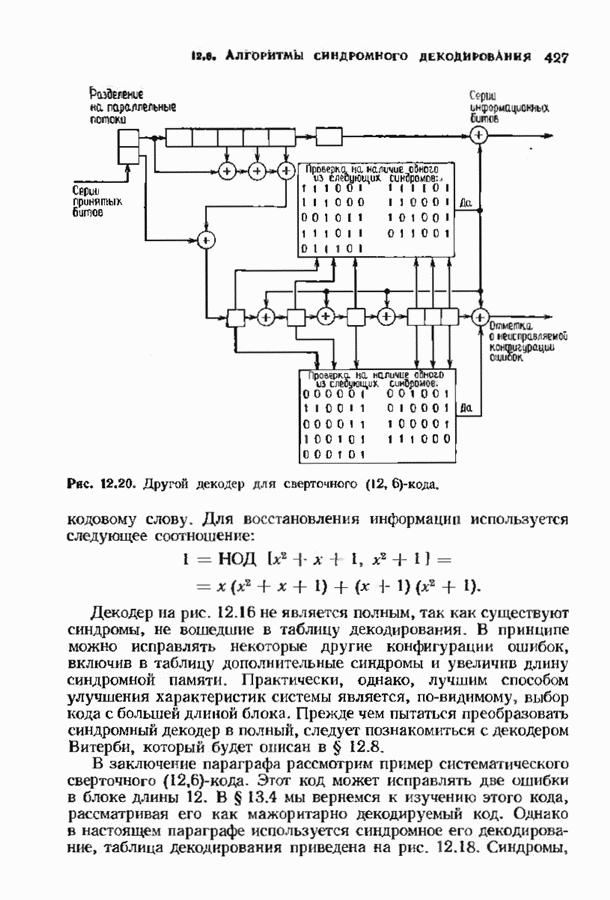
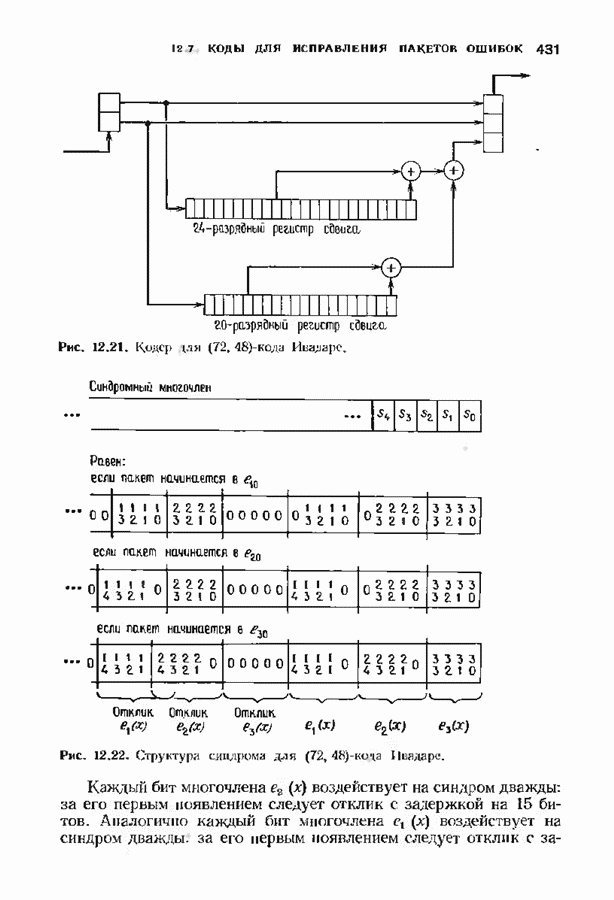
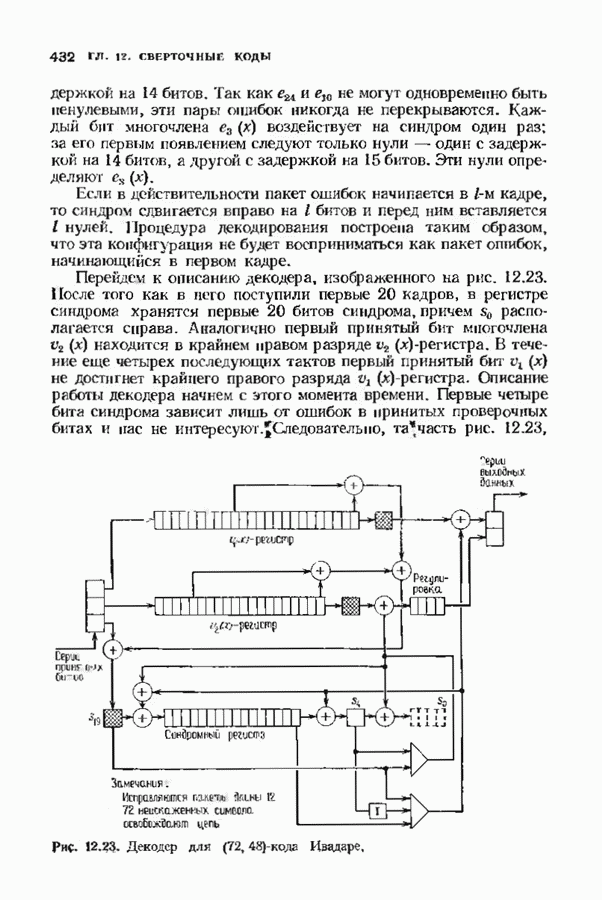
9.2. ИСПРАВЛЕНИЕ СТИРАНИЙ И ОШИБОККонтролирующие ошибки кода могут быть использованы в каналах, в которых кроме ошибок происходят и стирания. Принятое по такому каналу слово состоит из входных символов канала (часть из них может быть ошибочными) и пробелов (или эквивалентных символов), обозначающих стирания. Декодер должен исправить ошибки и восстановить стертые символы. Код с минимальным расстоянием
Наибольшее Чтобы декодировать принятое слово с по определению параметра Один из возможных способов декодирования состоит в угадывании стертых позиций с последующим применением любой процедуры исправления ошибок. Если процедура приводит к исправлению не более Как мы видели, частный класс кодов БЧХ допускает многие сильные алгоритмы декодирования. Все они могут быть обобщены на случай декодирования ошибок и стираний. Для простоты будем полагать
Пусть
Пусть
Теперь задача состоит в декодировании вектора Следующий шаг построения алгоритма состоит в выборе вектора
Этот многочлен специально определен так, чтобы компоненты обратного преобразования вектора V были равны нулю, как только
Но вектор V отличен от нуля только на блоке длины
что задает достаточное число компонент синдрома для исправления модифицированного вектора ошибок. Итак, точно так же, как в случае наличия только ошибок (при условии, что их не более
Обратное преобразование Фурье вектора
и многочлен чтобы рекуррентио продолжить вектор
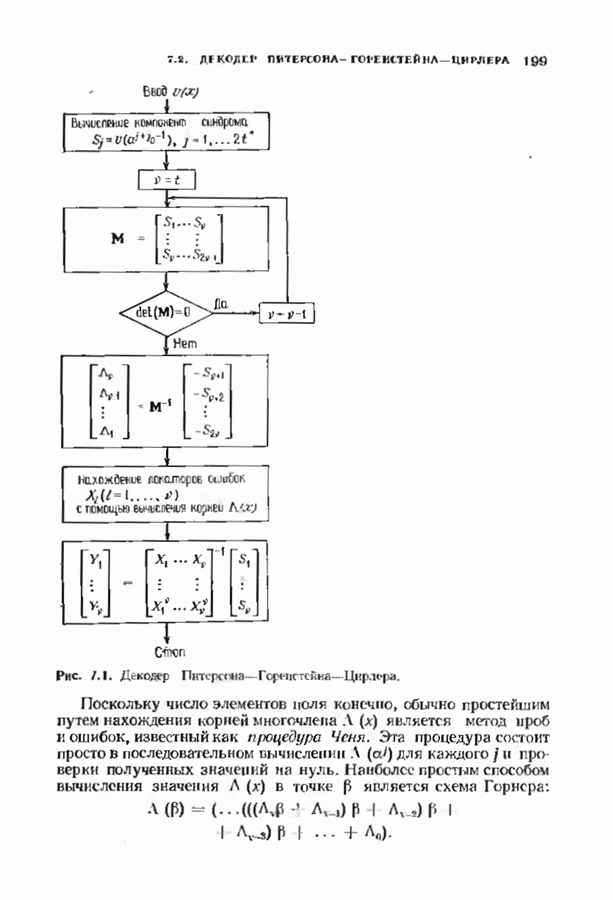
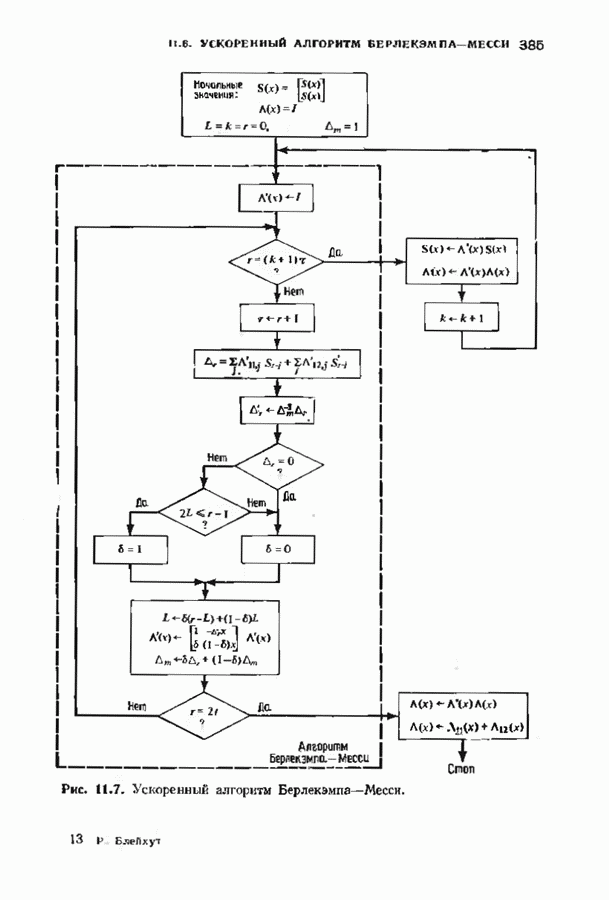
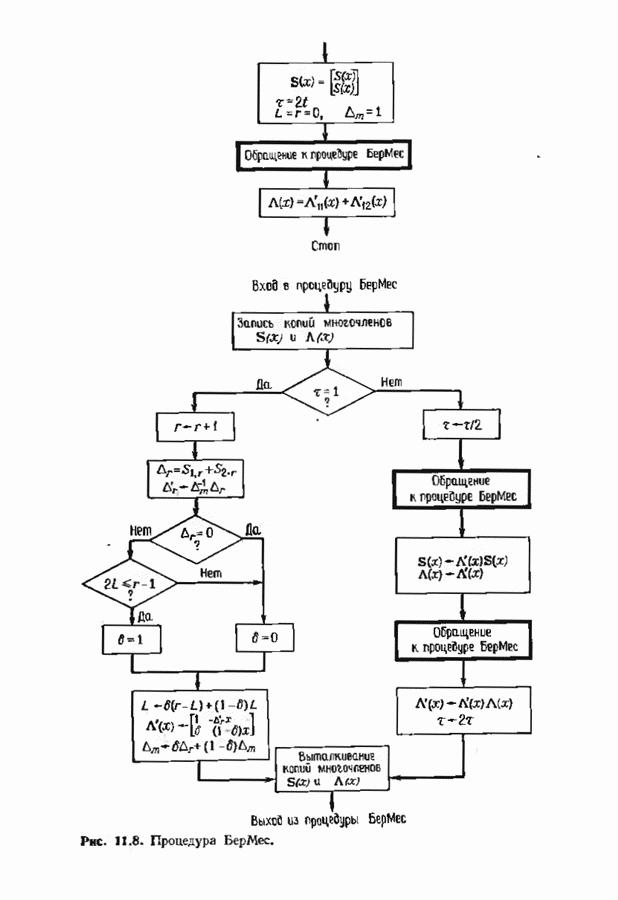
Обратное преобразование Фурье завершает декодирование. Вычисление многочлена локаторов ошибок но модифицированному значению синдрома можно выполнить с помощью алгоритма Берлекэмпа-Месси. Можно, однако, сделать это гораздо лучше, если скомбинировать несколько шагов. Идея алгоритма Берлекэмпа-Месси состоит в рекуррентной процедуре вычисления многочлена В случае наличия стираний в уравнении для невязки А, компоненты синдрома заменяются компонентами модифицированного синдрома:
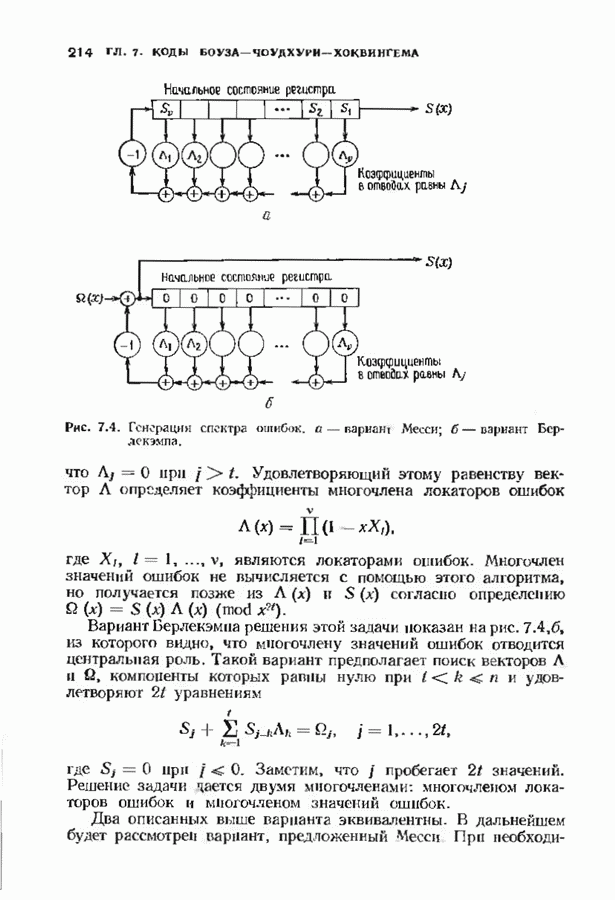
Многочлен локаторов ошибок вычисляется с помощью Но что произойдет, если заменить начальные условия на
Если мы временно определим
то
Итак, если в качестве начальной точки в алгоритме Берлекэмпа—Месси вместо 1 выбрать многочлен
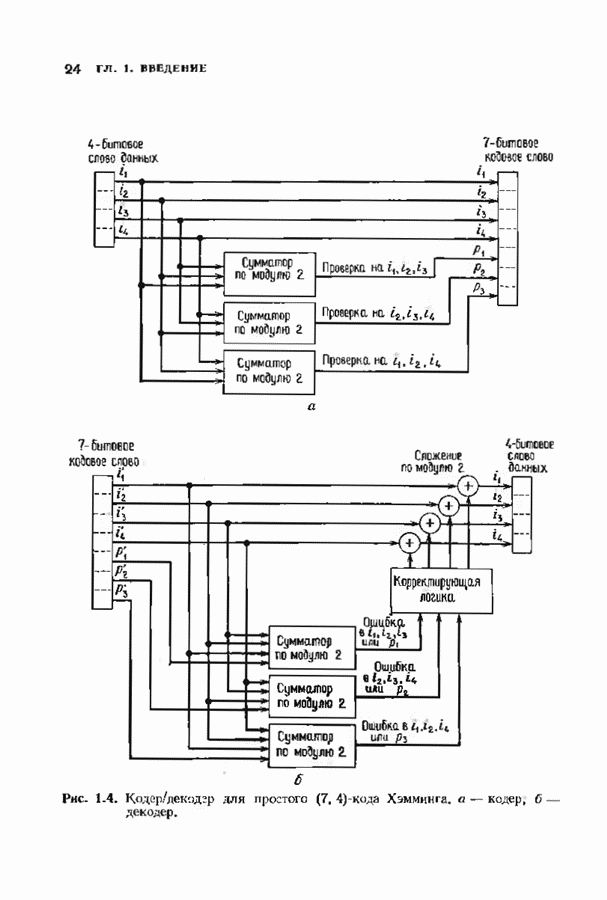
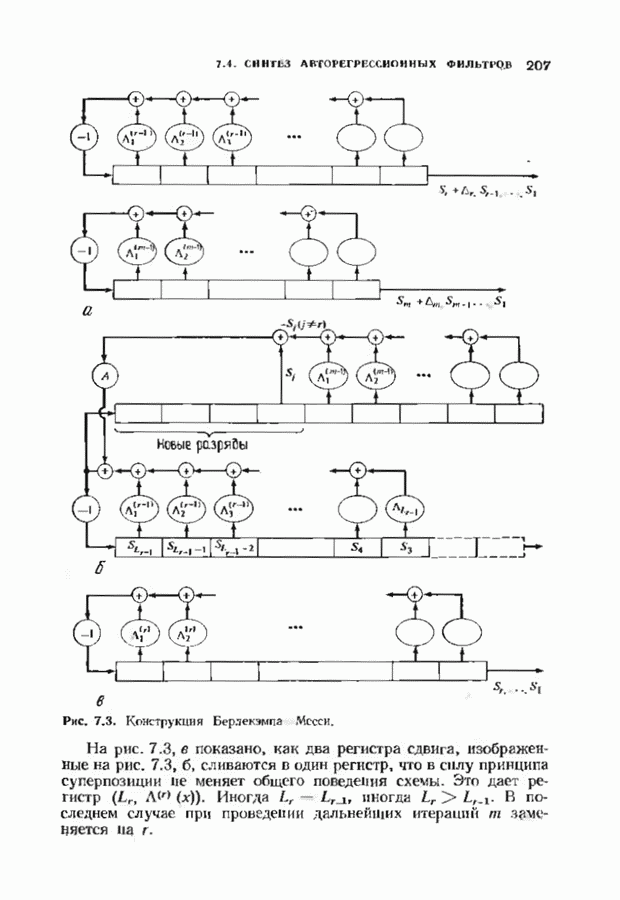
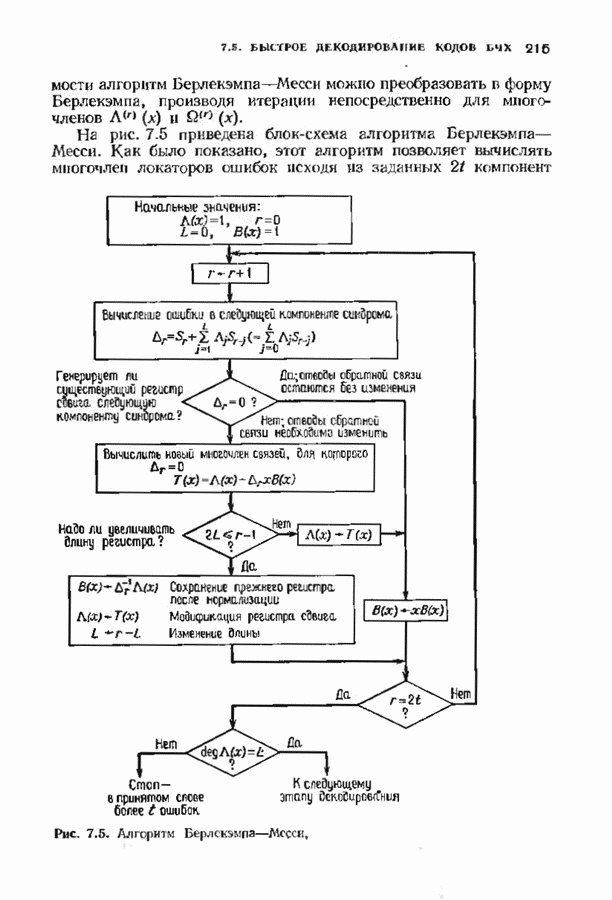
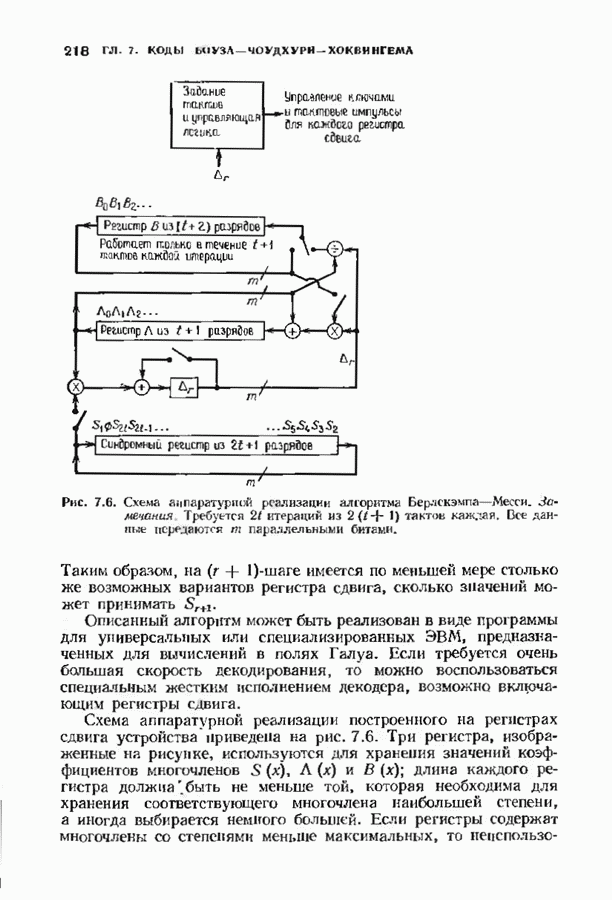
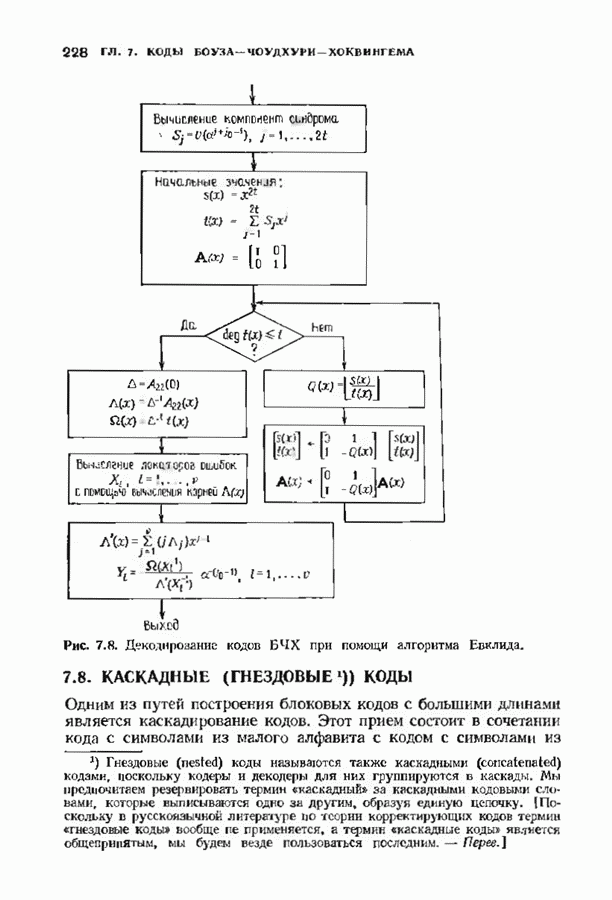
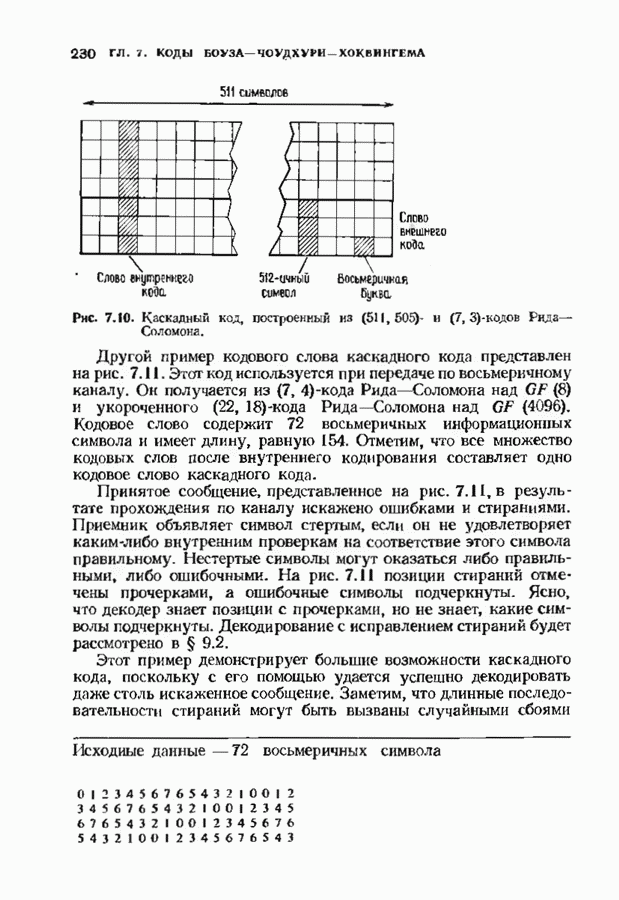
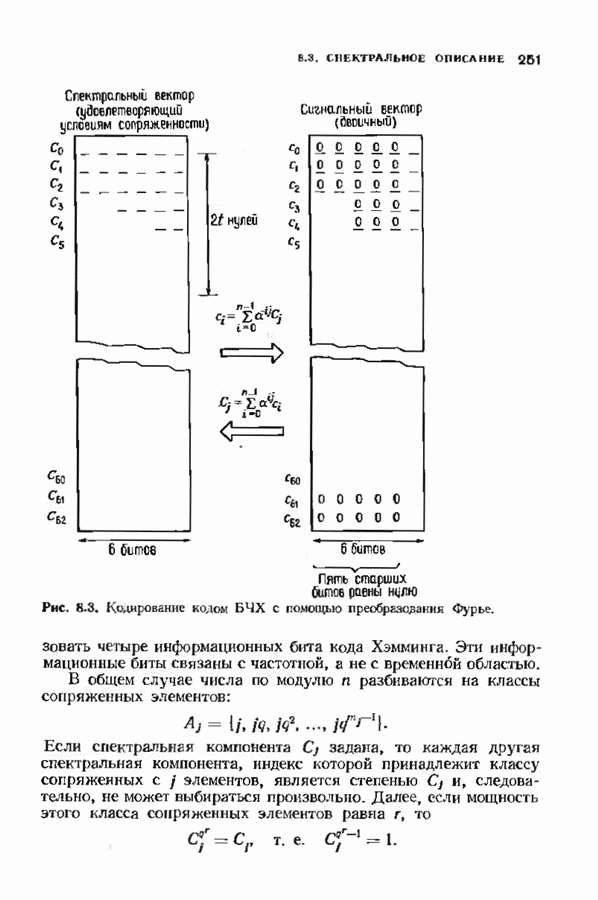
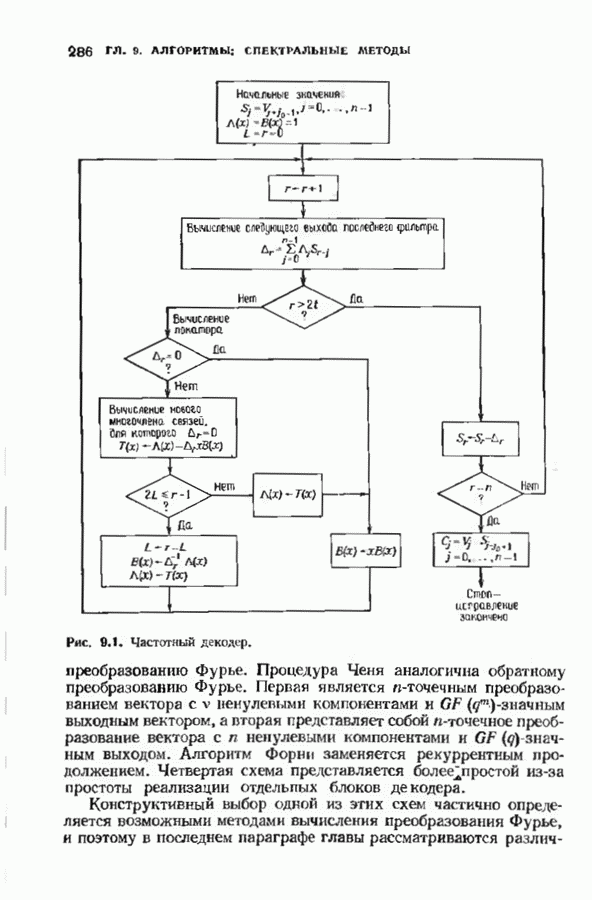
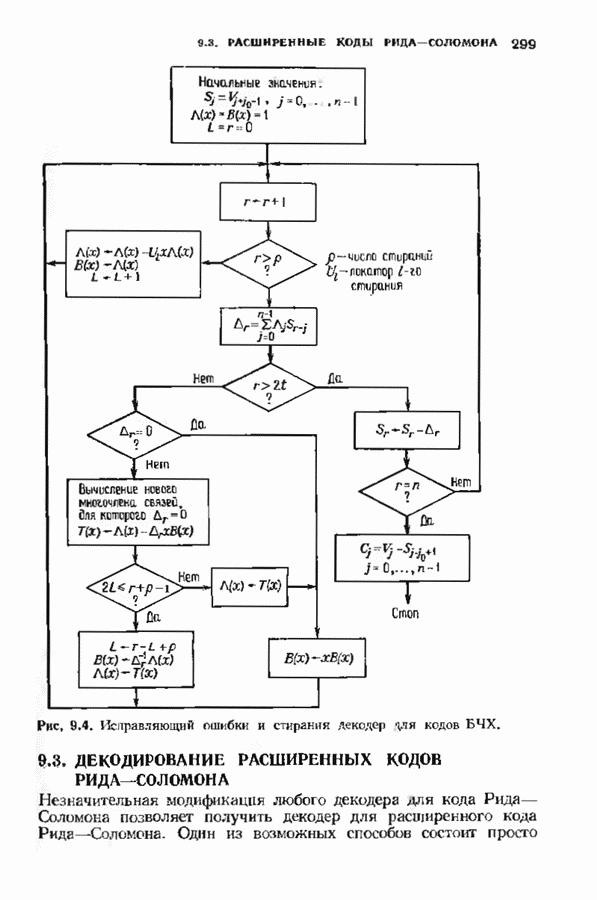
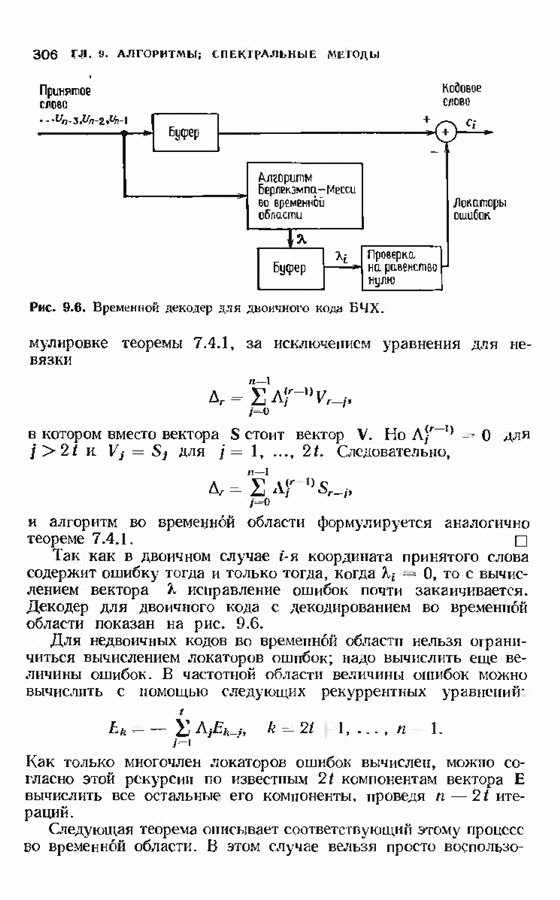
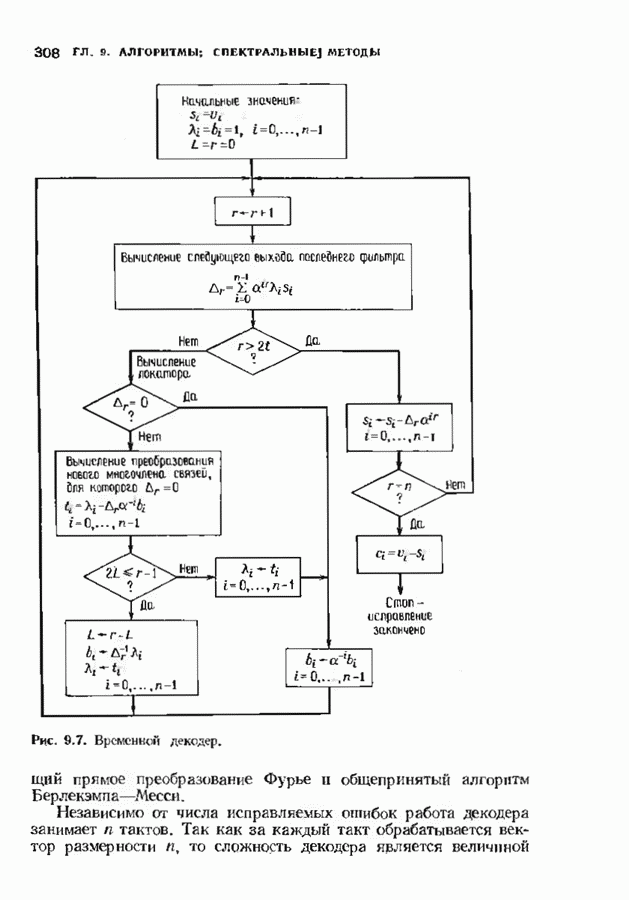
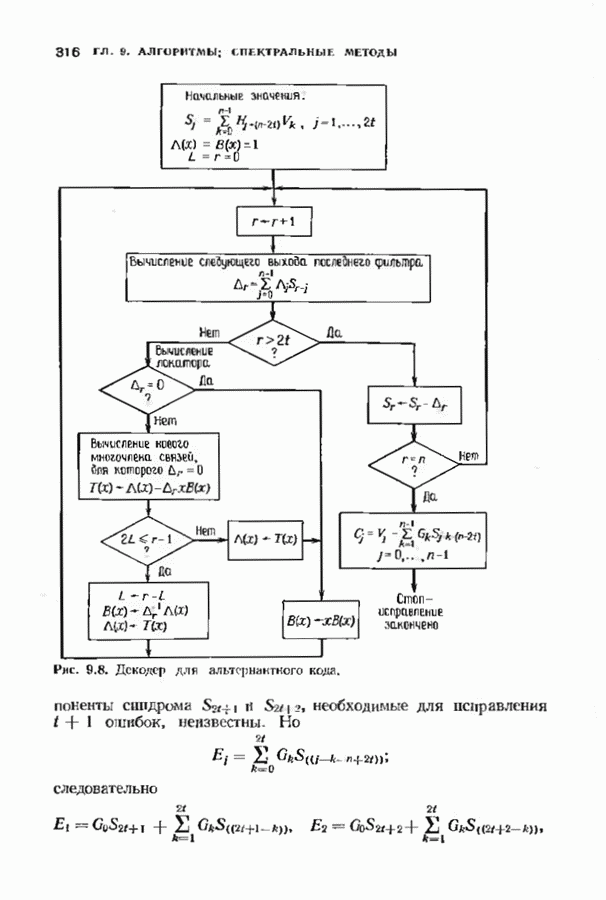
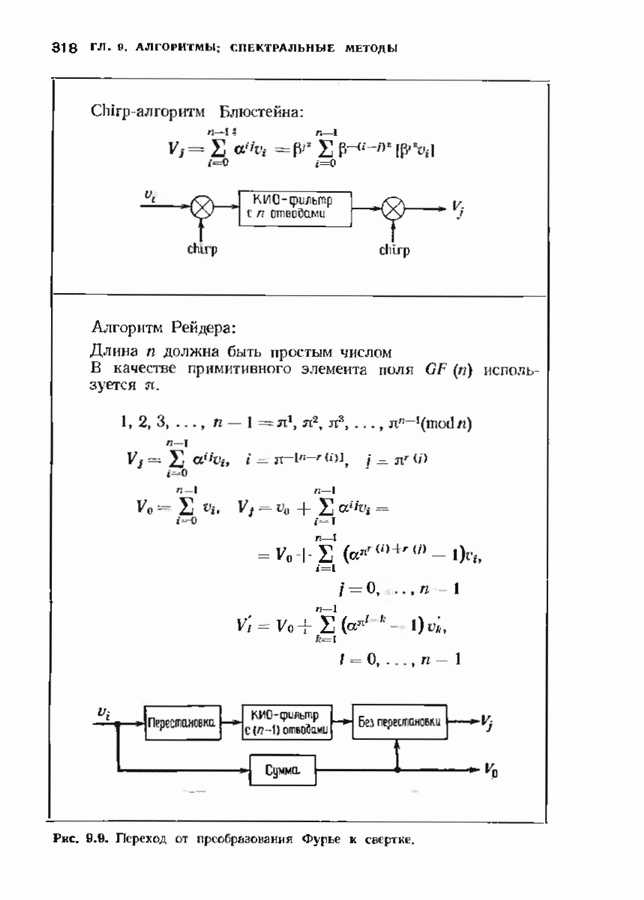
Дополненный правилами восстановления стираний алгоритм Берлекэмпа-Месси приведен на рис. 9.4. Сопоставим его с алгоритмом на рис. 9.1. Единственное изменение по сравнению с алгоритмом для исправления только ошибок состоит в вычислении многочлена локаторов стираний; сравнительно с остальными вычислениями алгоритма оно является тривиальным. Это вычисление производится с помощью показанной на рис. 9.4 специальной вспомогательной цепи, содержащей первые Прежде чем закончить данный параграф, заметим, что вместо пробела, обозначающего стирание, можно оставить лучше всего угаданный символ, пометив факт наличия в данной компоненте стирания некоторым специальным образом. Такие стирания назовем помеченными. Эти позиции не влияют на алгоритм декодирования, так как стоящие в них символы заменяются нулями. Иногда вне основного декодера удается использовать дополнительные блоки, извлекающие пользу из этой слабой информации. Например, можно отказаться от полученного на выходе декодера слова, если слишком многие из помеченных стираний не совпадают с результатом декодирования. Рис. 9.4. (см. скан) Исправляющий ошибки и стирания декодер для кодов БЧХ.
|
 |
Оглавление
|















































































































































































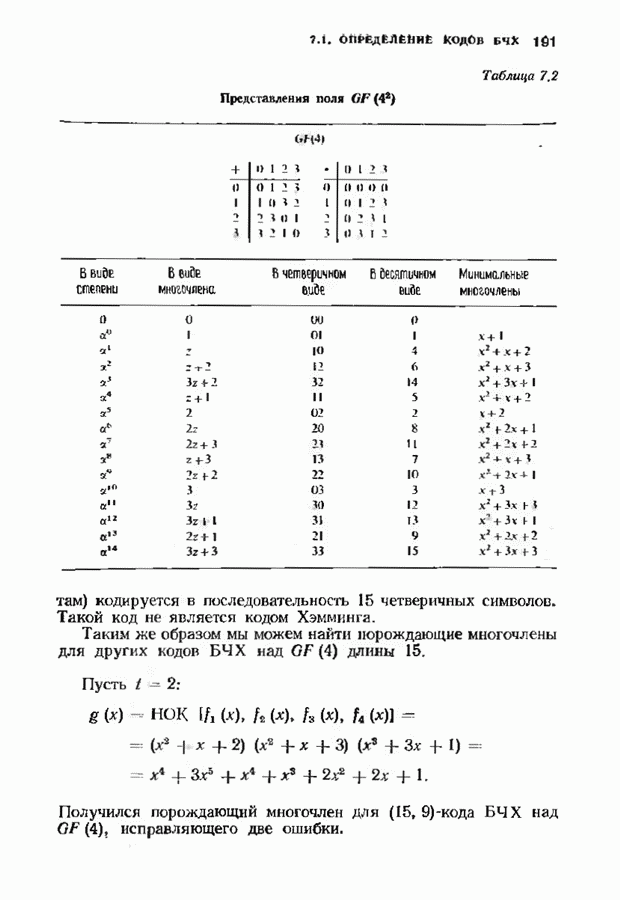




























































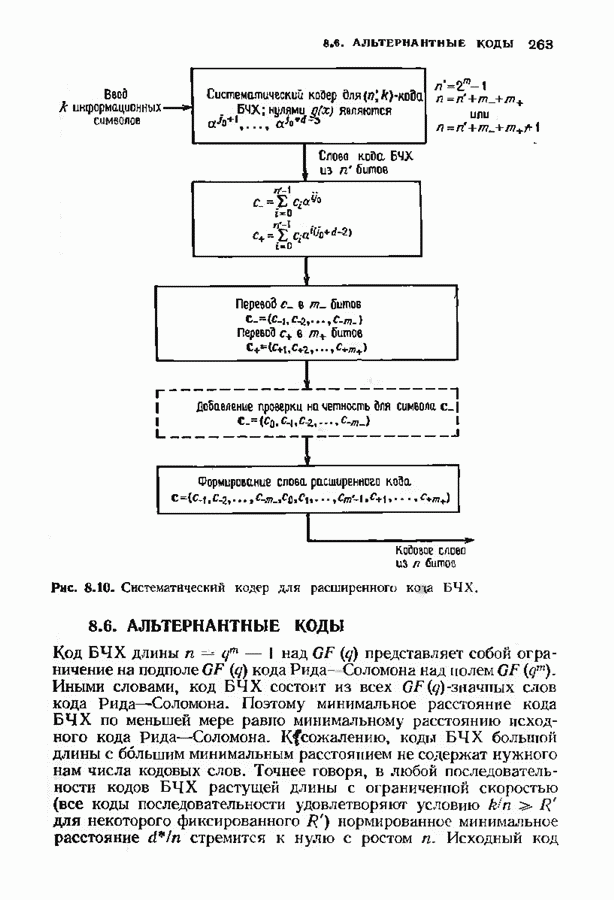










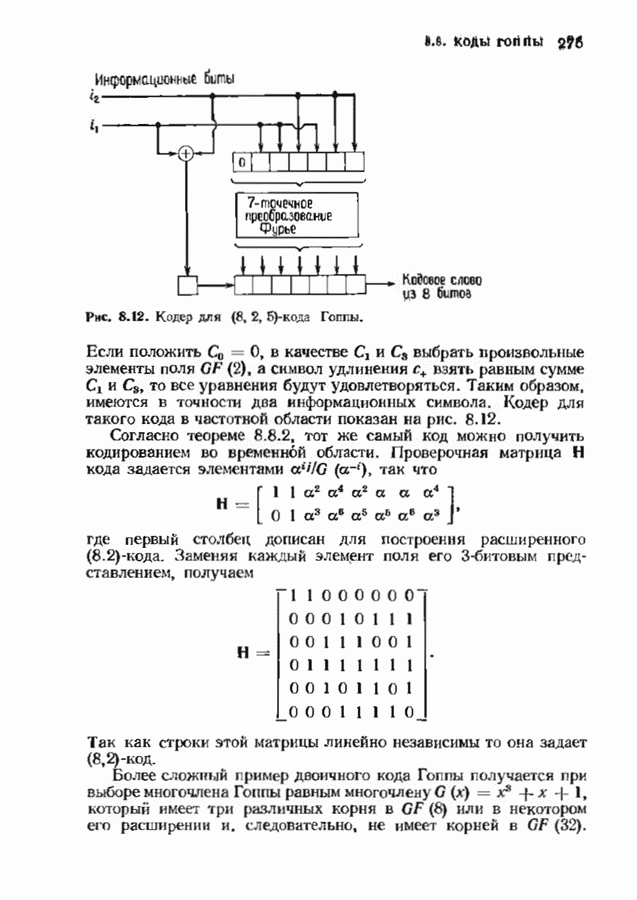












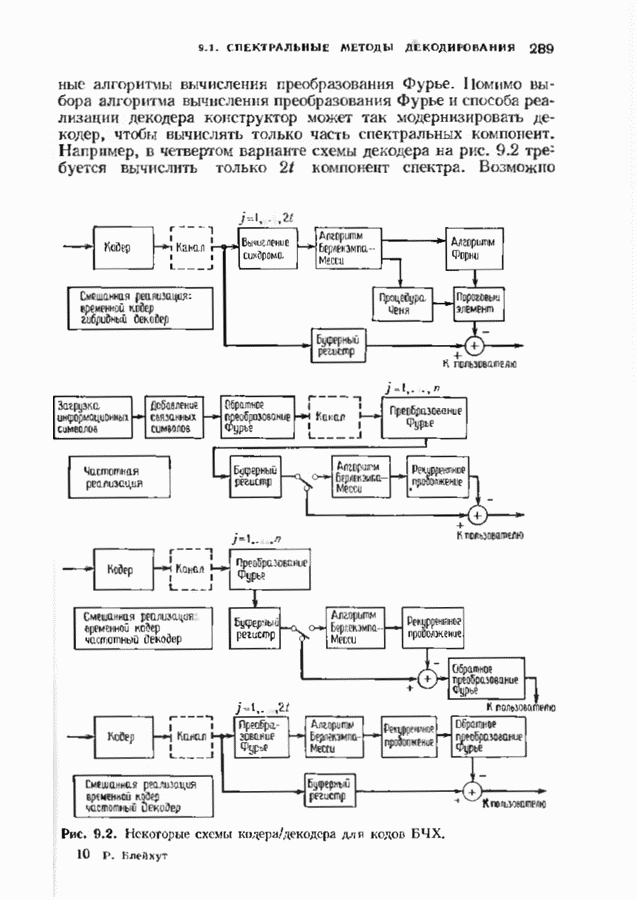



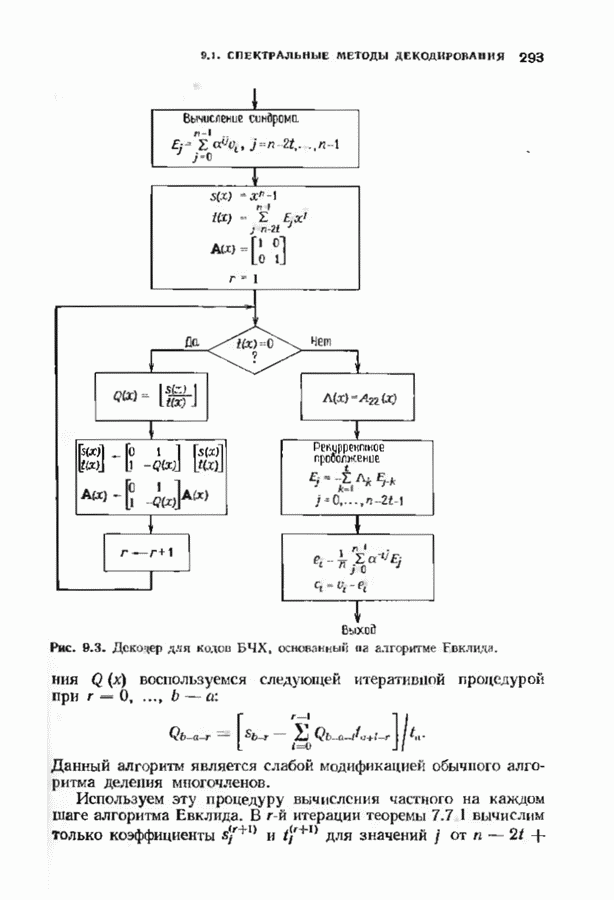







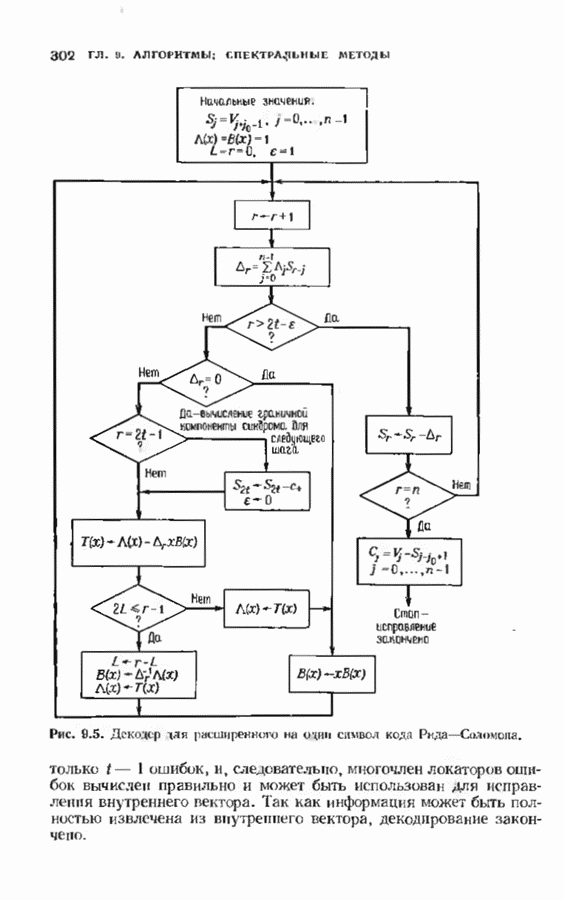









































































































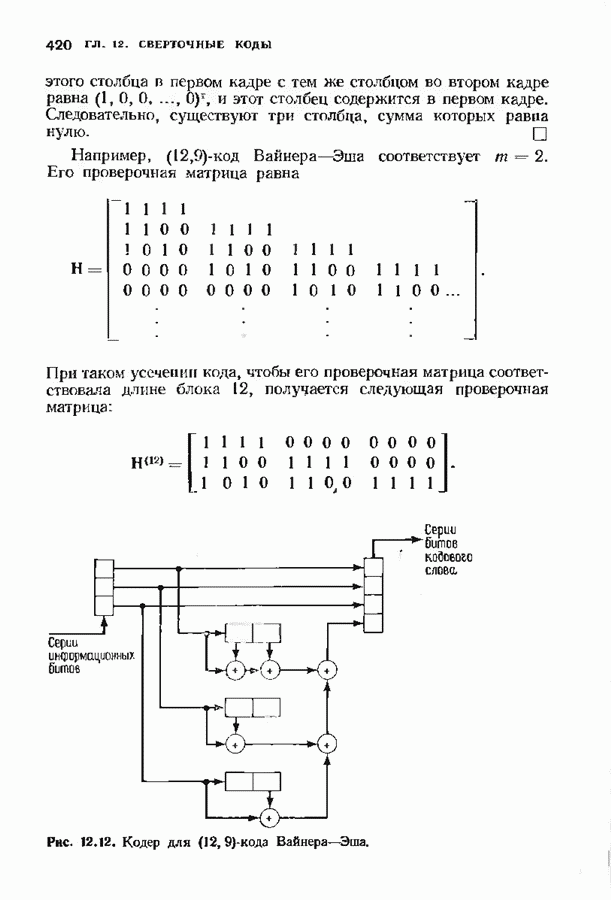
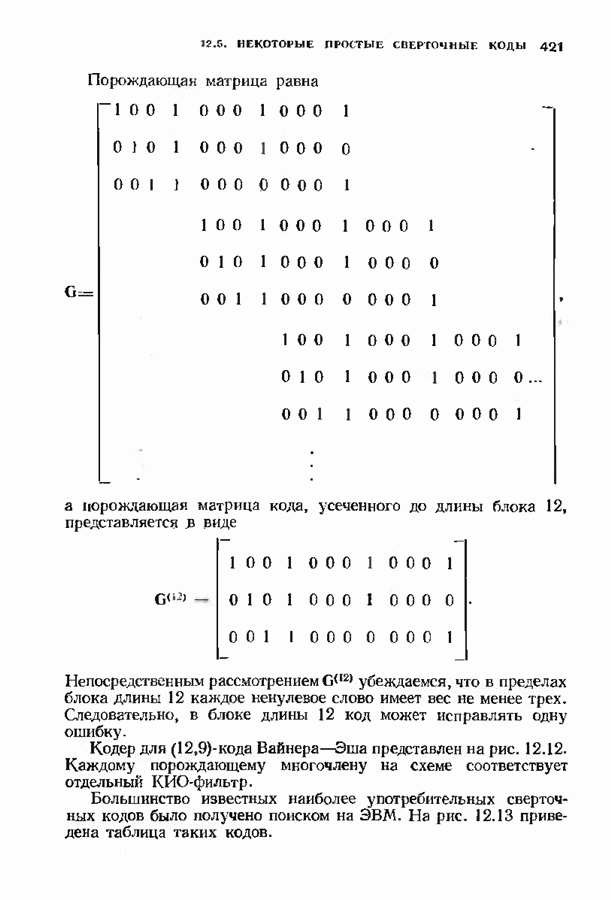


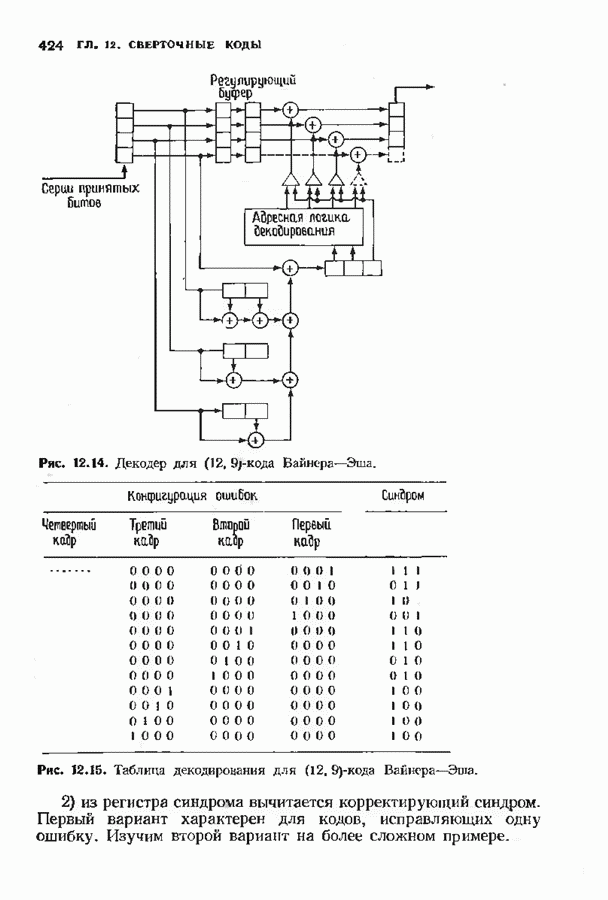
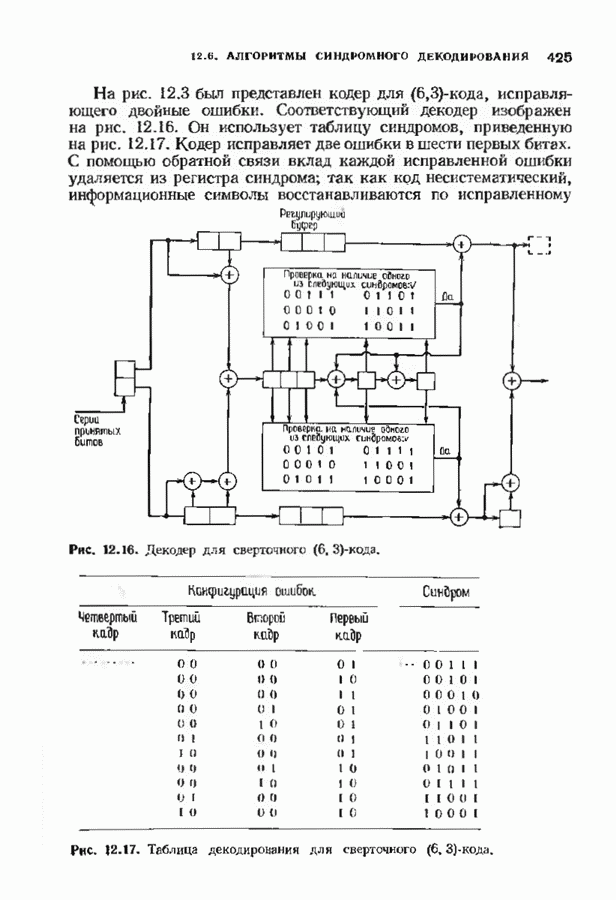






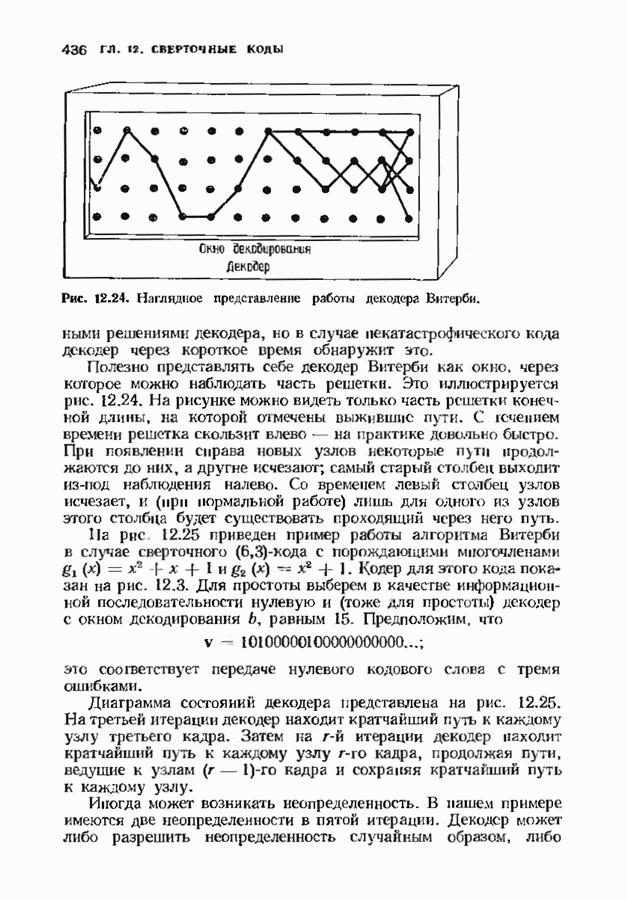
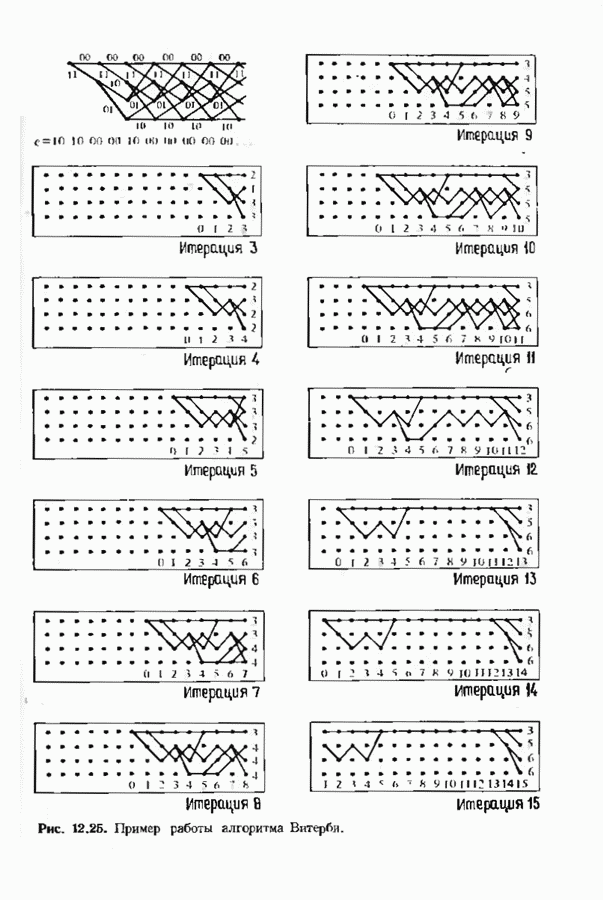




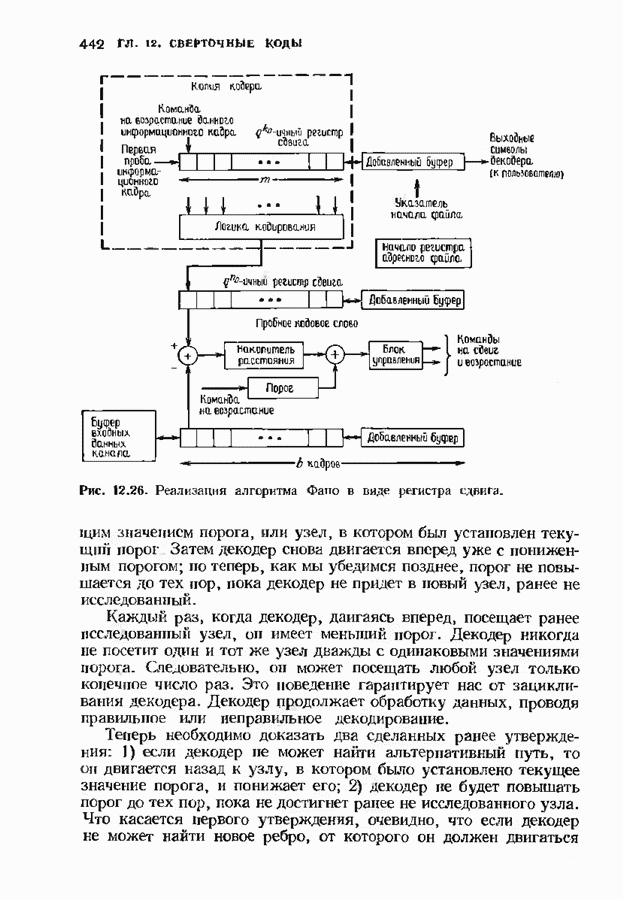
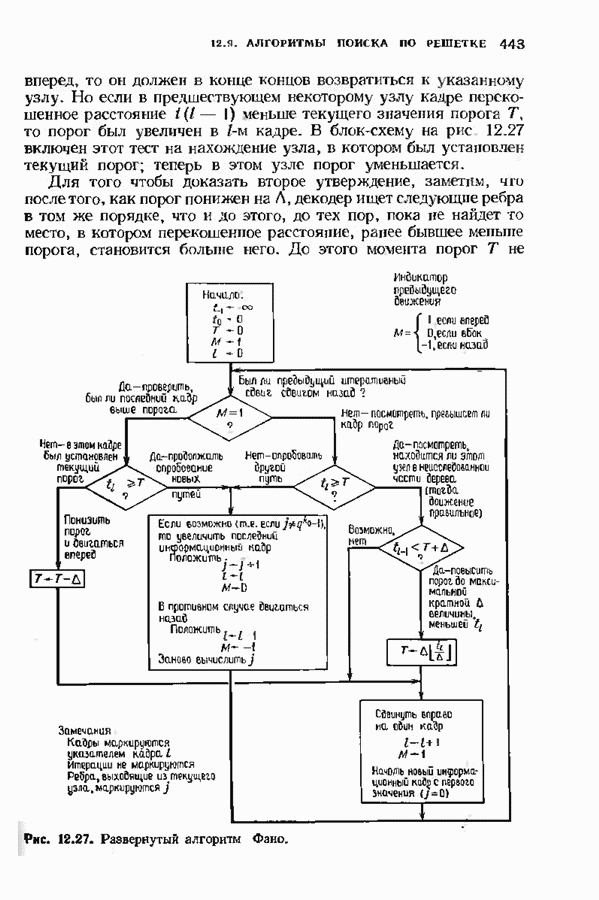

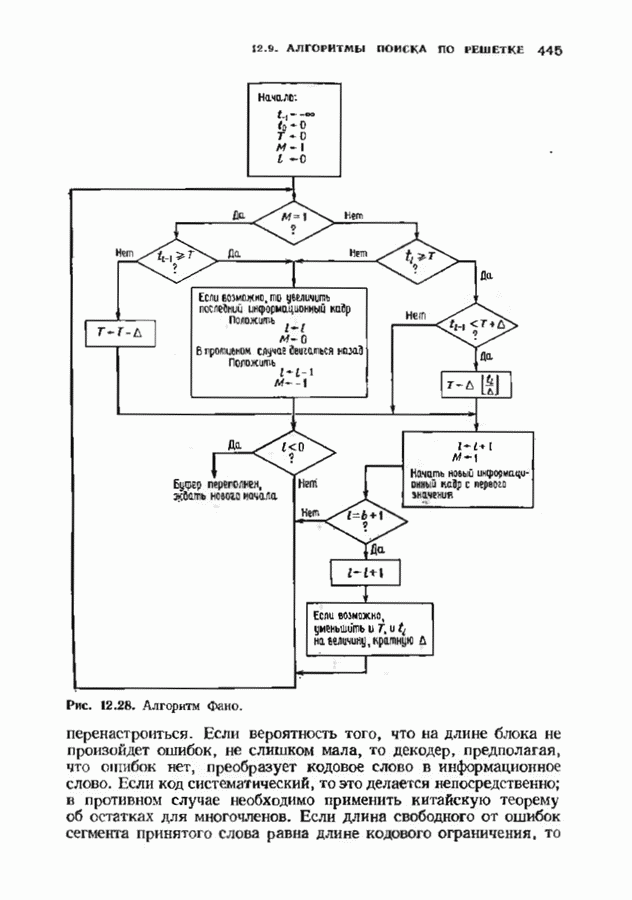



















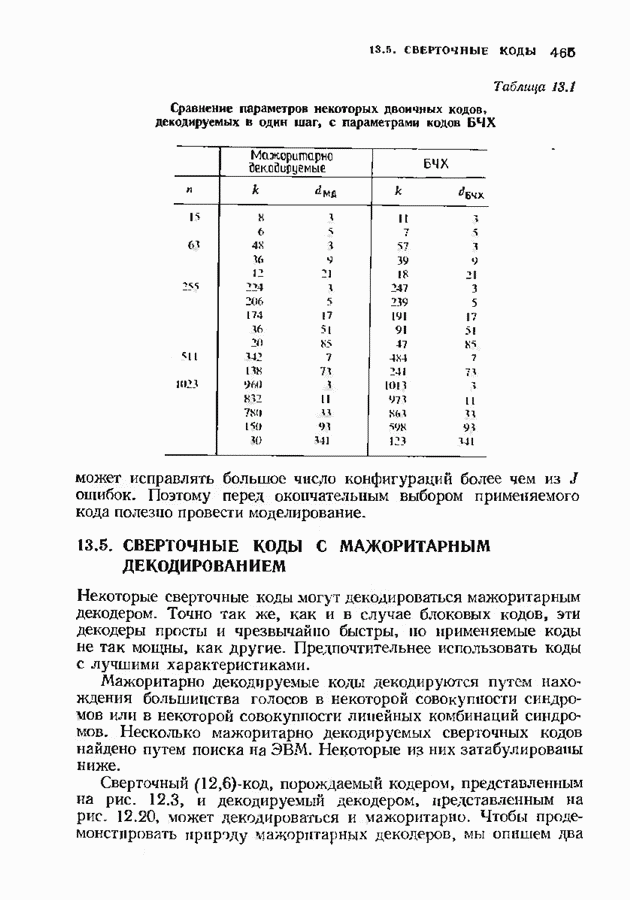
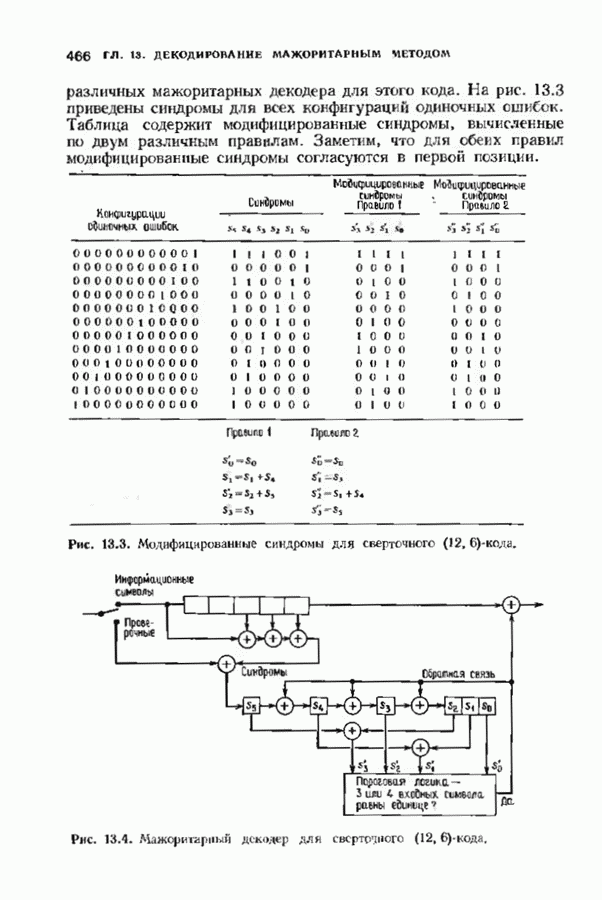
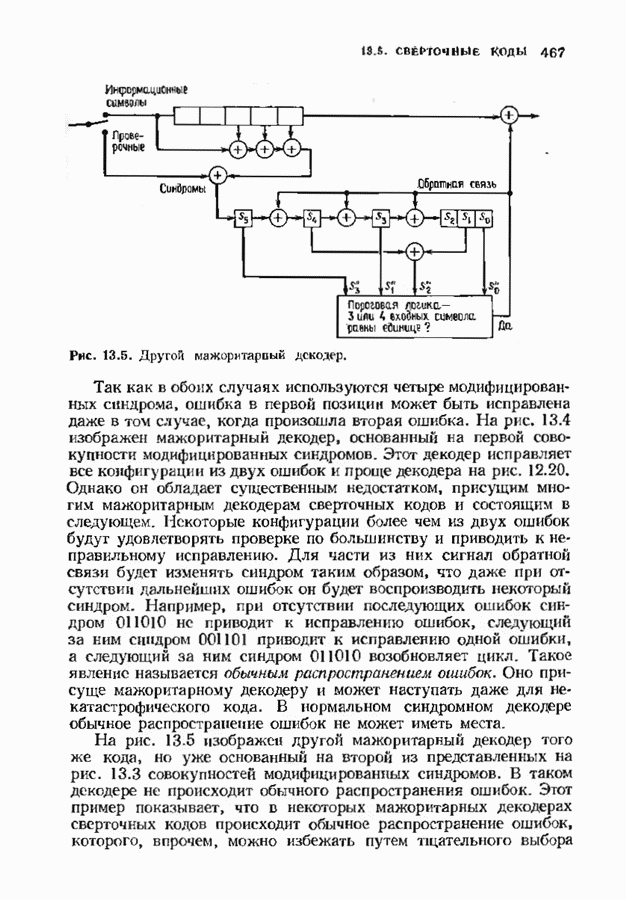





















































































 позволяет декодировать любую конфигурацию, содержащую
позволяет декодировать любую конфигурацию, содержащую  ошибок
ошибок  стираний, при условии, что
стираний, при условии, что

 удовлетворяющее этому неравенству, обозначим через
удовлетворяющее этому неравенству, обозначим через 
 стираниями, необходимо найти кодовое слово, которое в нестертых позициях отличается от принятого слова не более чем в символах. Поскольку
стираниями, необходимо найти кодовое слово, которое в нестертых позициях отличается от принятого слова не более чем в символах. Поскольку
 такое слово единственно, разыскивается любое подходящее слово. Нам нужно только найти какое-либо решение, так как мы знаем, что оно лишь одно.
такое слово единственно, разыскивается любое подходящее слово. Нам нужно только найти какое-либо решение, так как мы знаем, что оно лишь одно.
 ошибок в нестертых позициях (и, возможно, некоторых угаданных символах в стертых позициях), то кодовое слово восстанавливается. Если необходимо исправлять слишком много ошибок, то делается новая попытка угадать стертые символы. При этом любая подходящая для данного кода процедура исправления ошибок может быть модифицирована в процедуру исправления ошибок и стираний. Практически она подходит в тех случаях, когда число комбинаций угадываемых стертых символов мало. В противном случае такая процедура проб и ошибок становится практически неприемлемой. В таких случаях восстановление стертых символов должно осуществляться некоторым регулярным способом, входящим в алгоритм декодирования.
ошибок в нестертых позициях (и, возможно, некоторых угаданных символах в стертых позициях), то кодовое слово восстанавливается. Если необходимо исправлять слишком много ошибок, то делается новая попытка угадать стертые символы. При этом любая подходящая для данного кода процедура исправления ошибок может быть модифицирована в процедуру исправления ошибок и стираний. Практически она подходит в тех случаях, когда число комбинаций угадываемых стертых символов мало. В противном случае такая процедура проб и ошибок становится практически неприемлемой. В таких случаях восстановление стертых символов должно осуществляться некоторым регулярным способом, входящим в алгоритм декодирования.

 обозначают символы принятого вектора. Предположим, что стирания произошли в позициях
обозначают символы принятого вектора. Предположим, что стирания произошли в позициях  всех этих позициях принятое слово содержит пробелы, которые мы сначала заполним нулями. Определим
всех этих позициях принятое слово содержит пробелы, которые мы сначала заполним нулями. Определим  -мерный вектор стираний, положив символы в стертых позициях равными
-мерный вектор стираний, положив символы в стертых позициях равными  а в остальных позициях равными нулю. Тогда
а в остальных позициях равными нулю. Тогда

 произвольный вектор, символы которого равны нулю в каждой позиции стирания и только в них. Тогда
произвольный вектор, символы которого равны нулю в каждой позиции стирания и только в них. Тогда  Определим модифицированное принятое слово равенством
Определим модифицированное принятое слово равенством  модифицированный вектор ошибок равенством
модифицированный вектор ошибок равенством  и модифицированное кодовое слово равенством
и модифицированное кодовое слово равенством  (Модифицированный вектор ошибок содержит ошибки в тех же позициях, что и исходный вектор ошибок
(Модифицированный вектор ошибок содержит ошибки в тех же позициях, что и исходный вектор ошибок  Тогда последнее равенство приводится к виду
Тогда последнее равенство приводится к виду

 и сводится к задаче вычисления вектора
и сводится к задаче вычисления вектора  которую мы умеем решать при достаточном числе компонент синдрома.
которую мы умеем решать при достаточном числе компонент синдрома.
 , основанном на некоторых проводимых в частотной области рассуждениях. Пусть
, основанном на некоторых проводимых в частотной области рассуждениях. Пусть  для
для  обозначают локаторы стираний. Определим многочлен локаторов стираний равенством
обозначают локаторы стираний. Определим многочлен локаторов стираний равенством

 Следовательно,
Следовательно,  . В частотной области это дает
. В частотной области это дает

 а по построению кода
а по построению кода  вектор С имеет нулевые компоненты в блоке длины
вектор С имеет нулевые компоненты в блоке длины  Следовательно, свертка
Следовательно, свертка  равна нулю в блоке длины
равна нулю в блоке длины  Полагая
Полагая  определим на этом блоке модифицированный синдром. Тогда
определим на этом блоке модифицированный синдром. Тогда

 по этим
по этим  известным компонентам вектора
известным компонентам вектора  можно найти многочлен локаторов ошибок
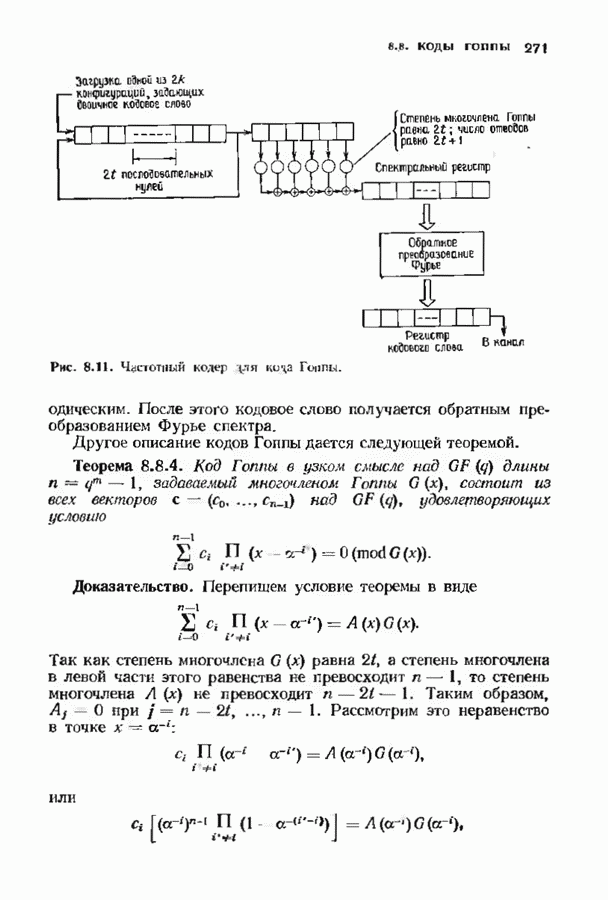
можно найти многочлен локаторов ошибок  Коль скоро многочлен локаторов ошибок известен, можно скомбинировать его с многочленом локаторов стираний и дальнейшее декодирование проводить так же, как и в случае наличия только ошибок. Чтобы проделать это, определим сначала многочлен локаторов ошибок и стираний.
Коль скоро многочлен локаторов ошибок известен, можно скомбинировать его с многочленом локаторов стираний и дальнейшее декодирование проводить так же, как и в случае наличия только ошибок. Чтобы проделать это, определим сначала многочлен локаторов ошибок и стираний.

 содержит нуль в позиции каждой ошибки и каждого стирания. Таким образом,
содержит нуль в позиции каждой ошибки и каждого стирания. Таким образом,  если
если  или
или  Следовательно,
Следовательно, 

 отличеп от нуля в блоке длины, не превышающей
отличеп от нуля в блоке длины, не превышающей  Следовательно, используя известные компоненты вектора
Следовательно, используя известные компоненты вектора  и
и  известных компонент вектора
известных компонент вектора  можно воспользоваться этим содержащим свертку уравнением для того,
можно воспользоваться этим содержащим свертку уравнением для того,
 до всех
до всех  компопент. Затем вычисляются
компопент. Затем вычисляются

 за
за  итераций, начиная с оценок
итераций, начиная с оценок 

 итераций при начальных условиях
итераций при начальных условиях 
 Заметим, что в этом случае
Заметим, что в этом случае

 и будем вычислять невязку А, по формуле
и будем вычислять невязку А, по формуле


 то модифицированный синдром вычисляется неявно и нет необходимости вводить его в явном внде. Отбросим теперь обозначение
то модифицированный синдром вычисляется неявно и нет необходимости вводить его в явном внде. Отбросим теперь обозначение  заменив его на
заменив его на  и назвав многочленом локаторов ошибок и стираний. При начальных условиях, даваемых многочленом
и назвав многочленом локаторов ошибок и стираний. При начальных условиях, даваемых многочленом  алгоритм Берлекэмпа-Месси рекуррентно порождает многочлен локаторов ошибок и стираний в соответствии с уравнениями
алгоритм Берлекэмпа-Месси рекуррентно порождает многочлен локаторов ошибок и стираний в соответствии с уравнениями

 итераций. Индекс
итераций. Индекс  используется в качестве счетчика для первых
используется в качестве счетчика для первых  итераций, а после вычисления многочлена стираний в качестве счетчика последующих итераций алгоритма Берлекэмпа-Месси до тех пор, пока
итераций, а после вычисления многочлена стираний в качестве счетчика последующих итераций алгоритма Берлекэмпа-Месси до тех пор, пока  не превзойдет
не превзойдет  При каждом стирании длина
При каждом стирании длина  регистра сдвига возрастает на единицу, а затем изменяется в соответствии с обычными правилами процедуры алгоритма Берлекэмпа-Месси. Поскольку, однако, этот алгоритм не учитывал стираний, то в конце приходится добавитьисправления стираний и заменить
регистра сдвига возрастает на единицу, а затем изменяется в соответствии с обычными правилами процедуры алгоритма Берлекэмпа-Месси. Поскольку, однако, этот алгоритм не учитывал стираний, то в конце приходится добавитьисправления стираний и заменить  на
на  соответственно.
соответственно.