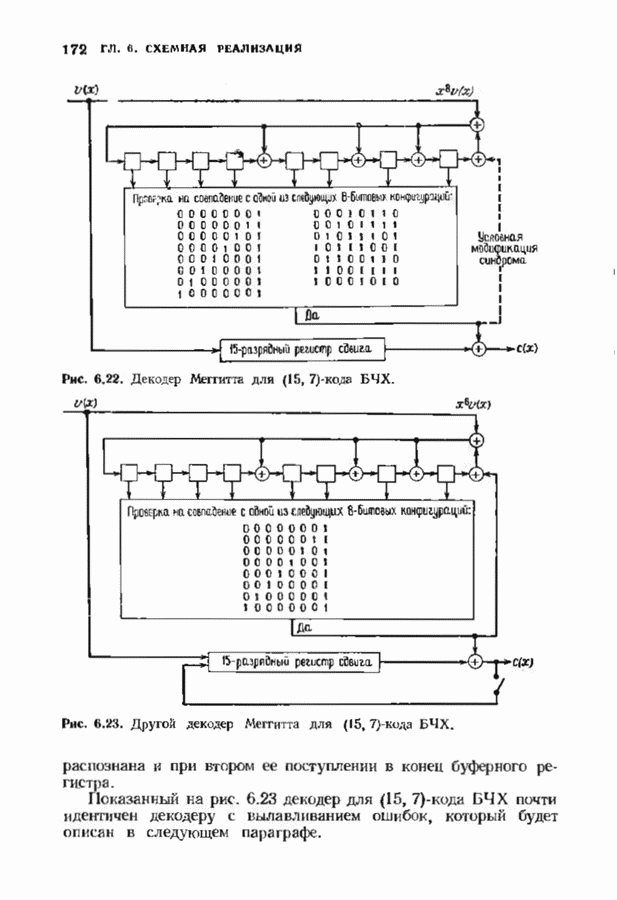
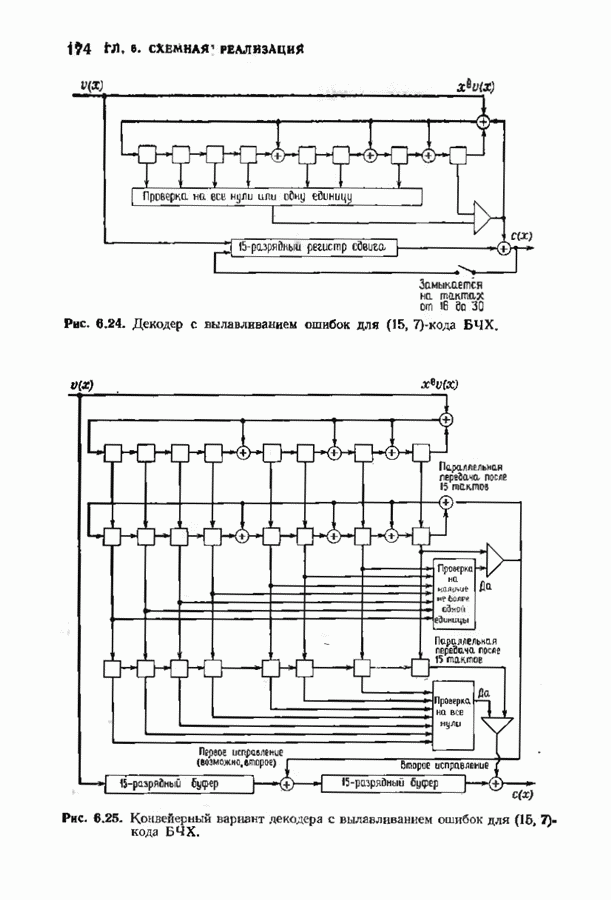
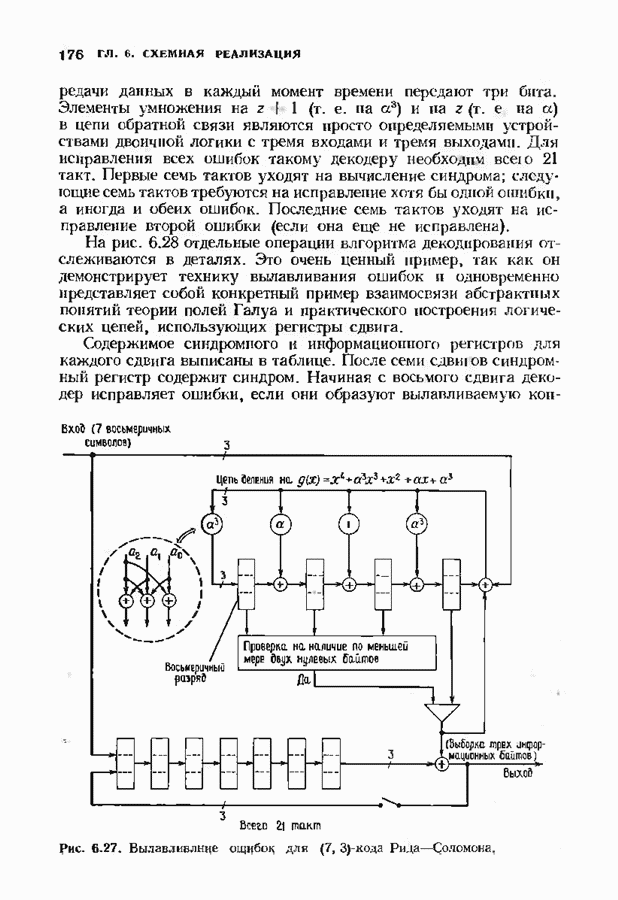
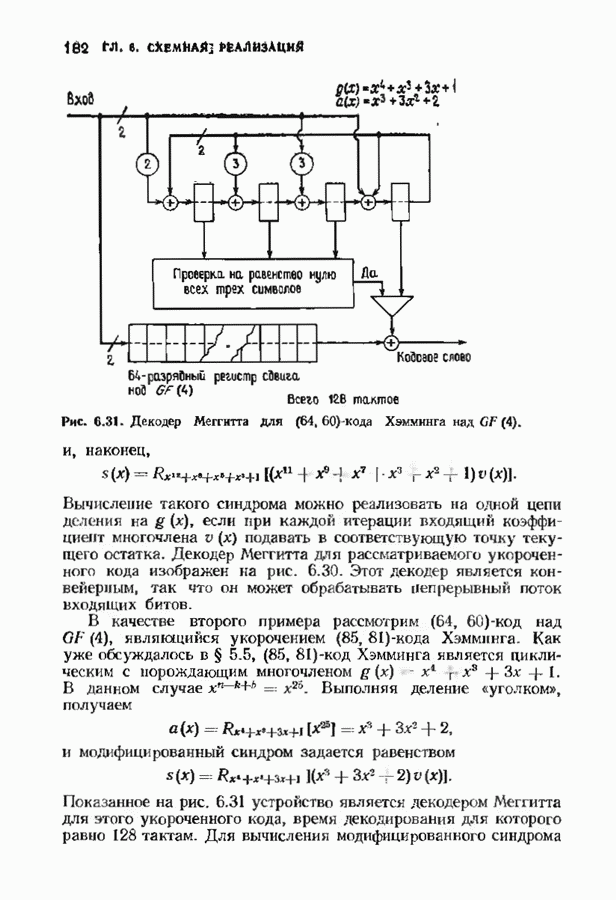
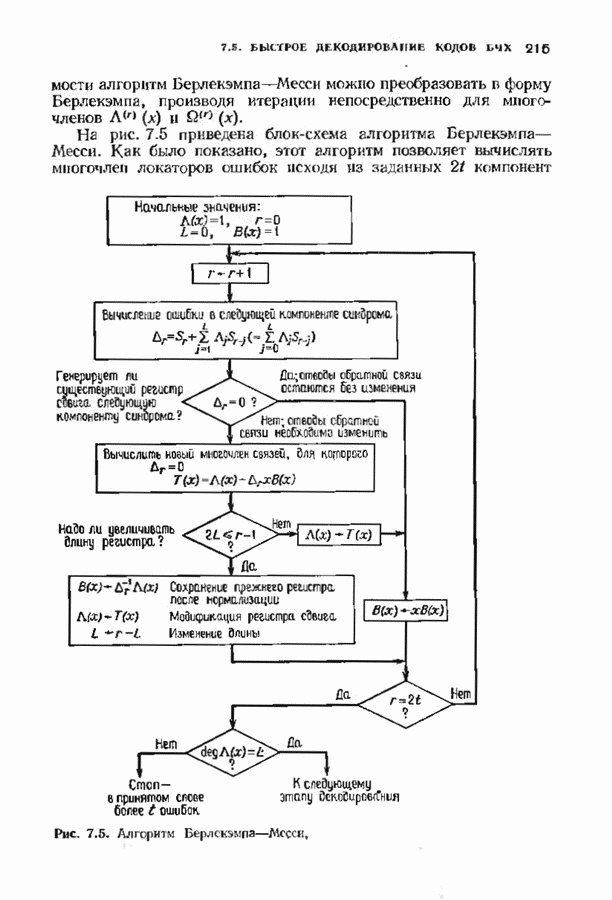
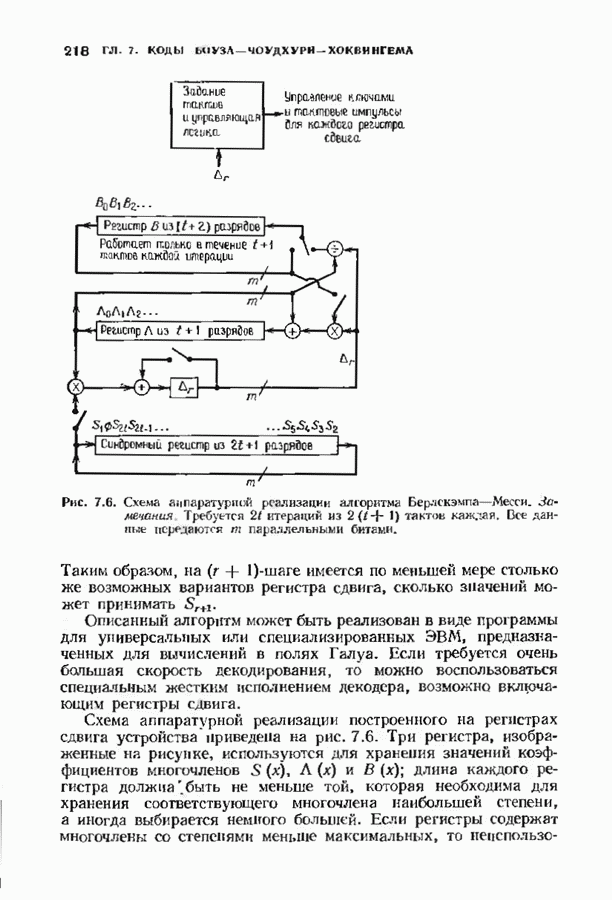
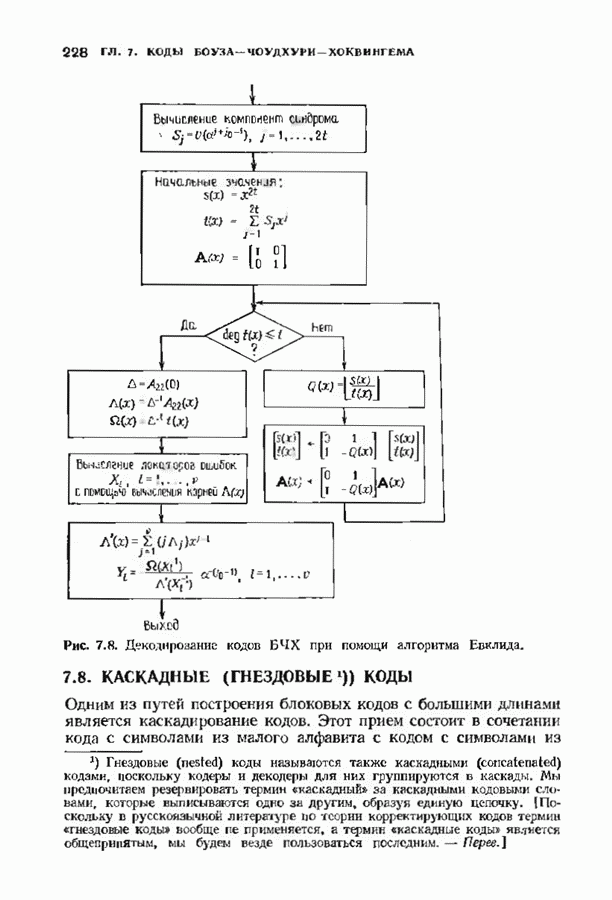
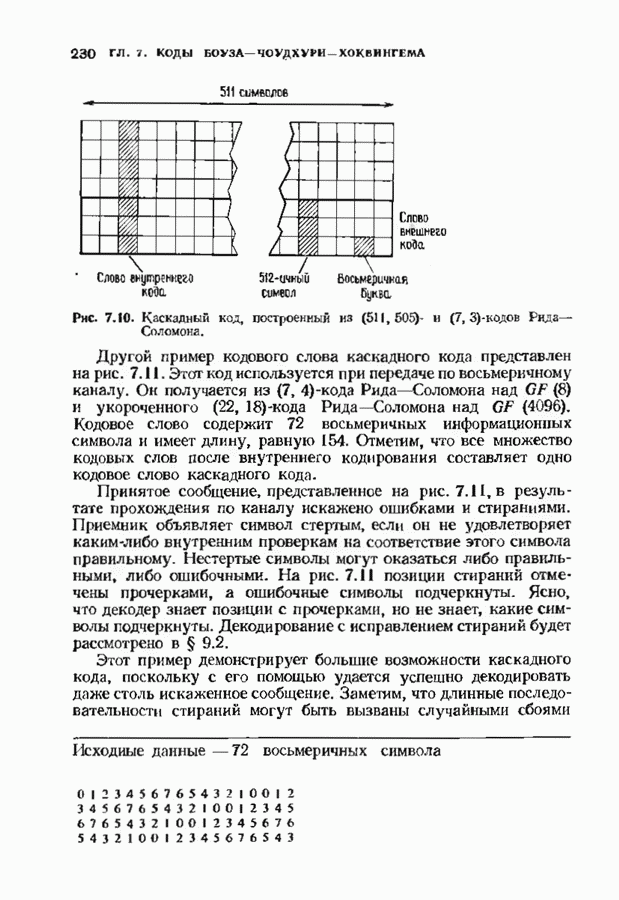
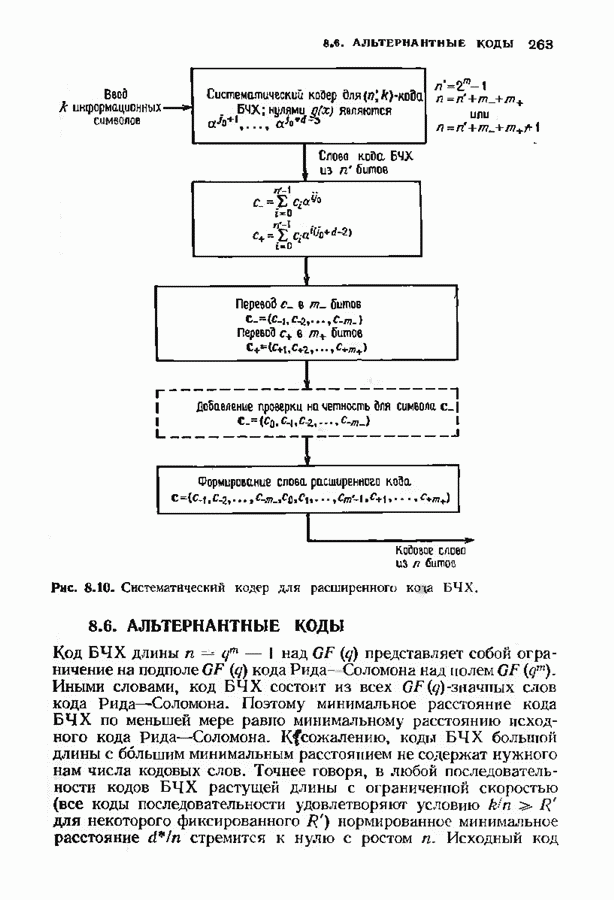
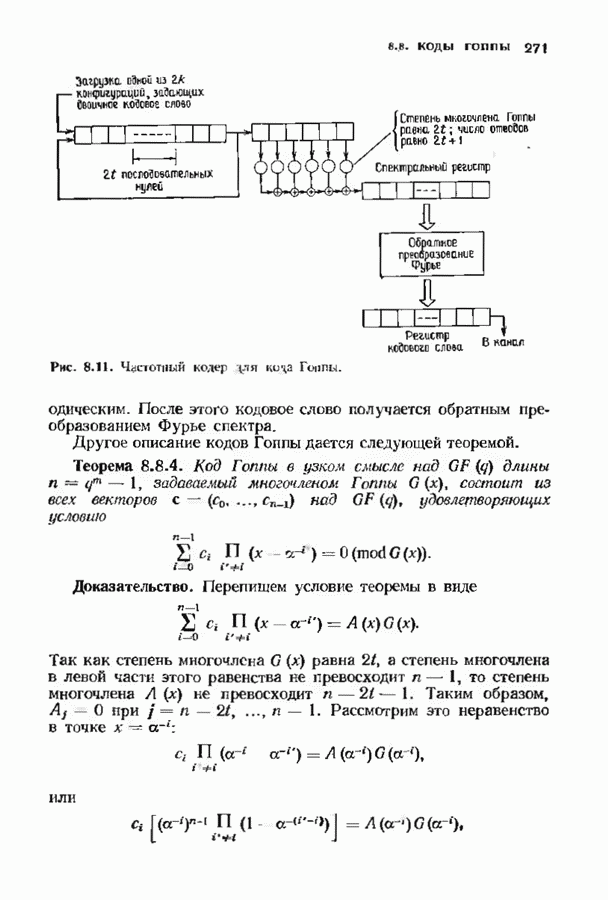
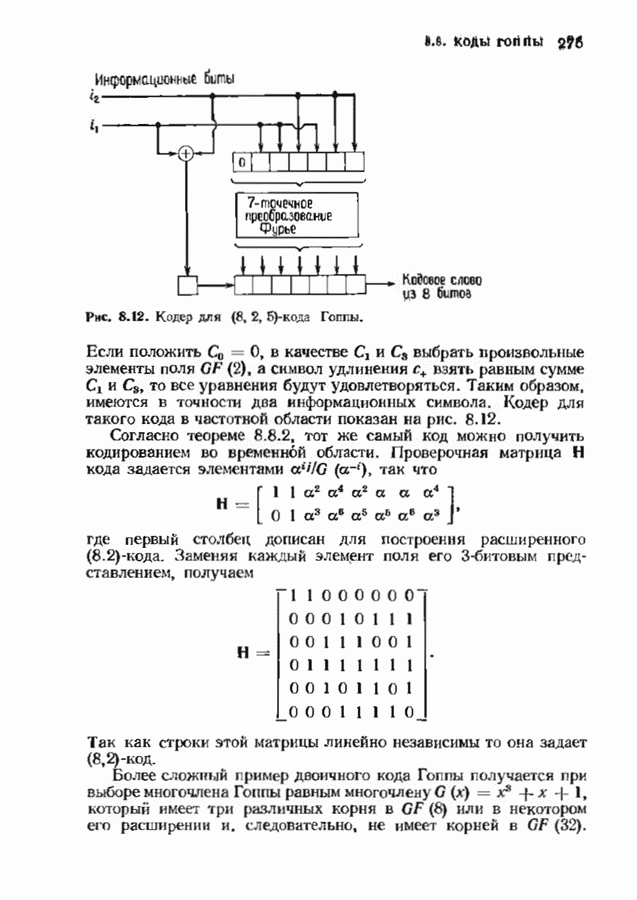
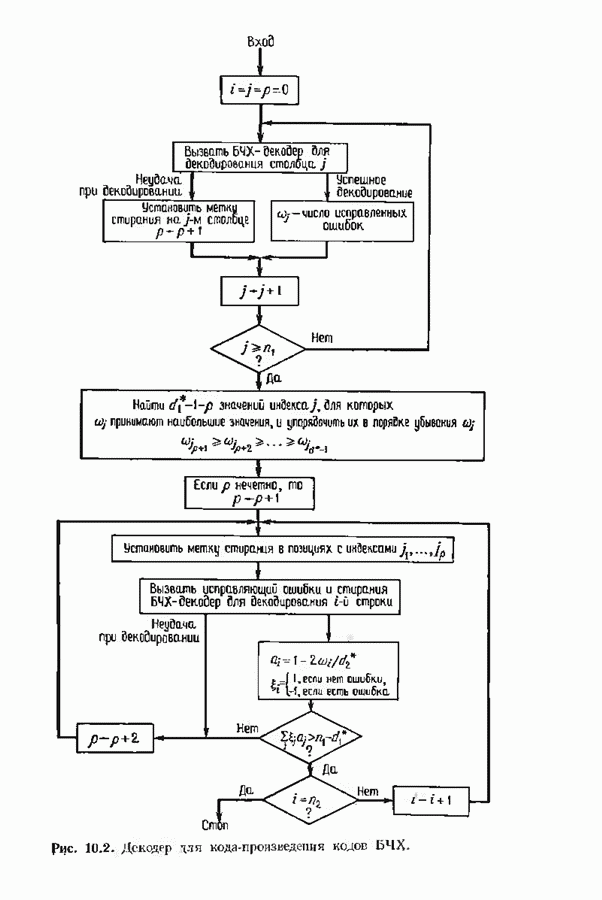
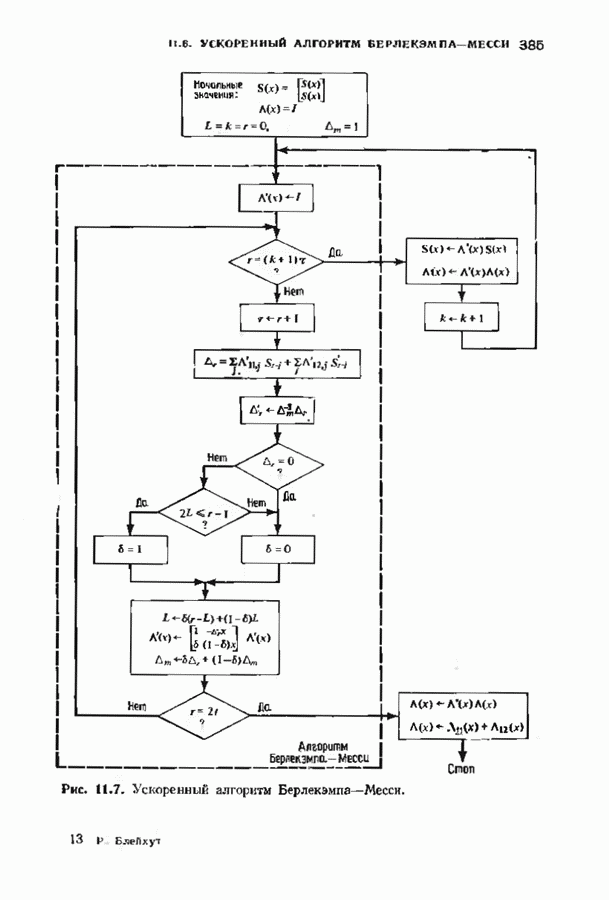
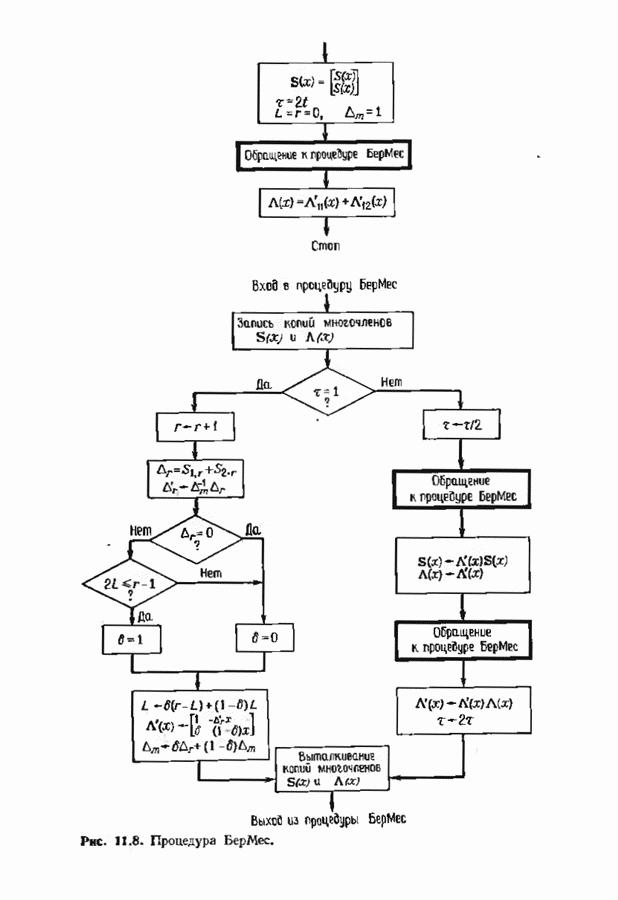
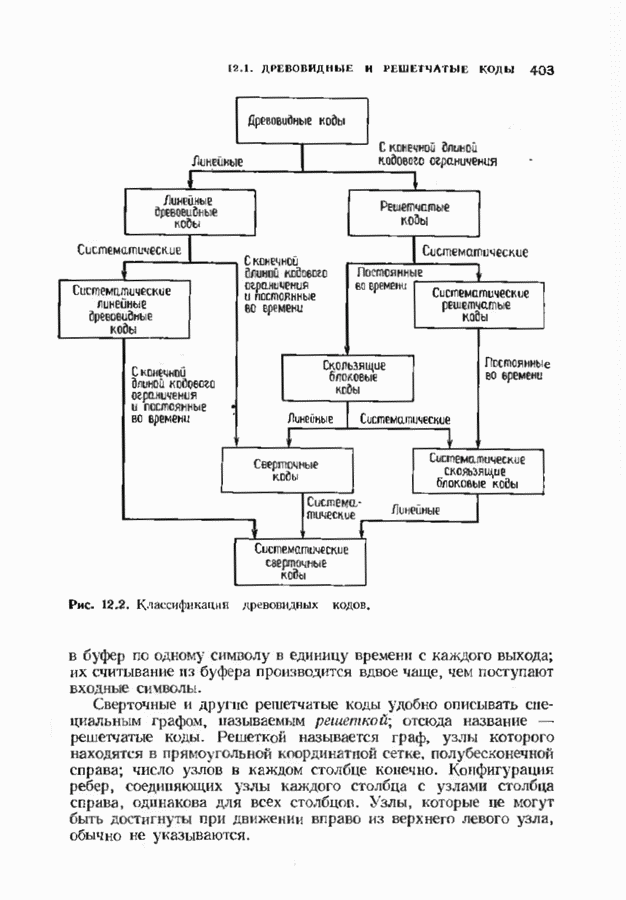
Пред.
След.
Макеты страниц
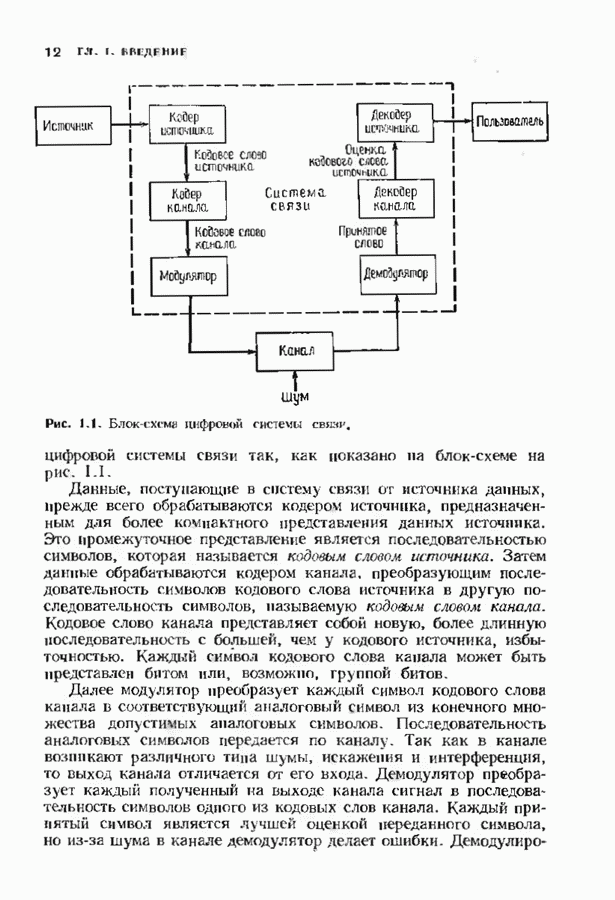
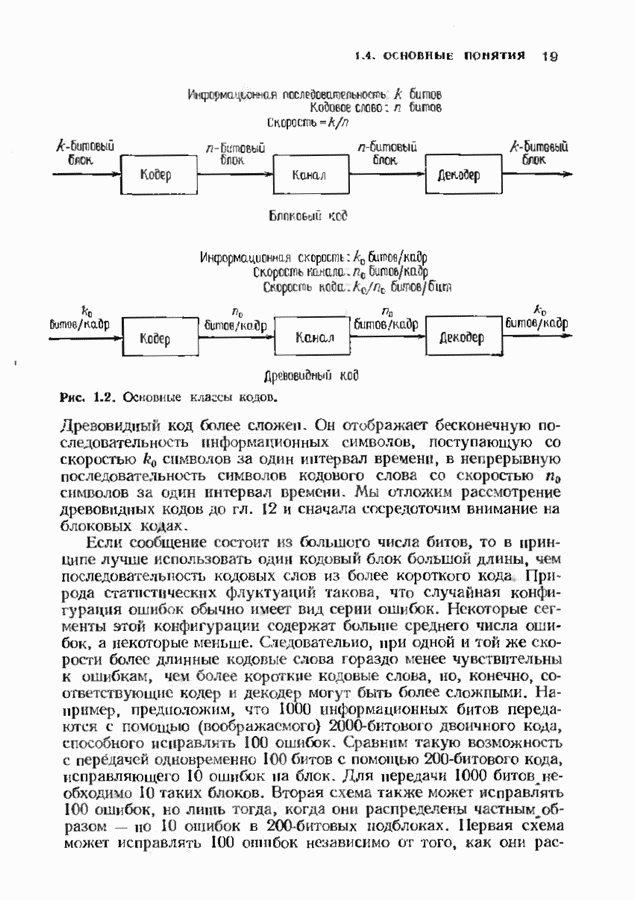
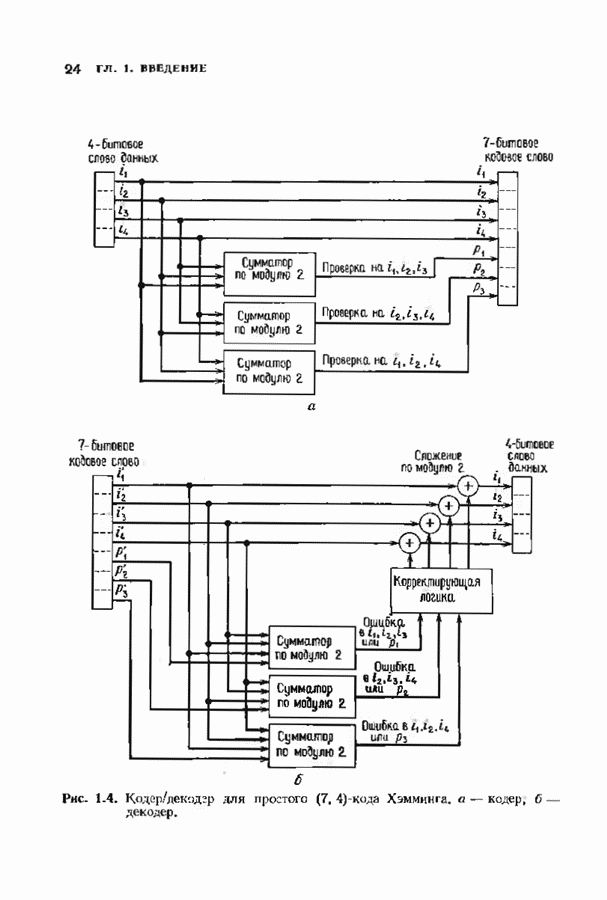
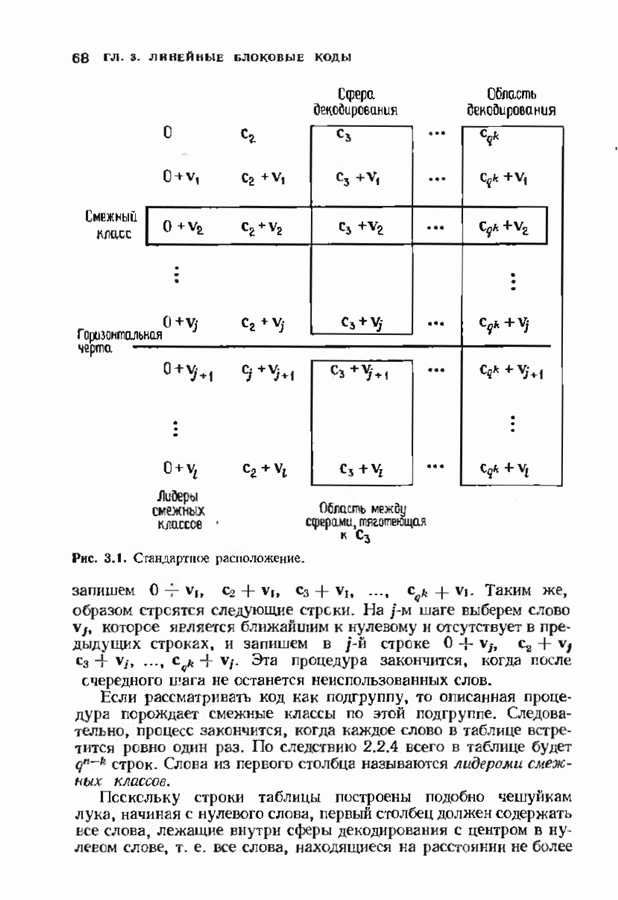
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
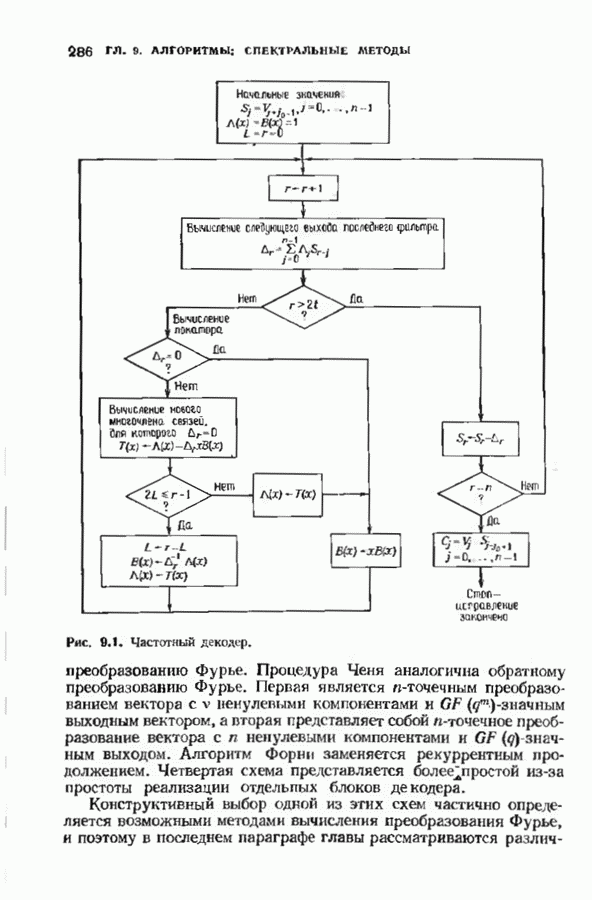
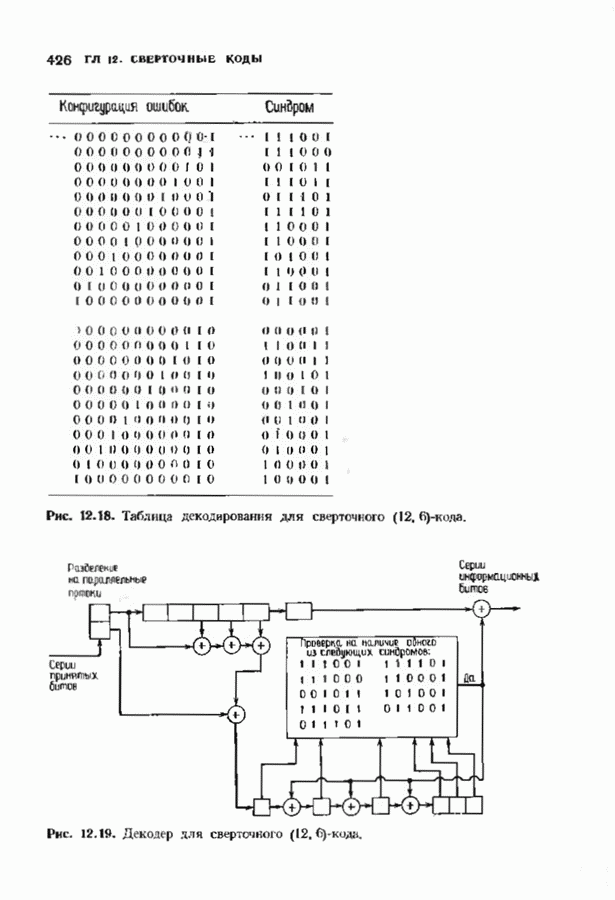
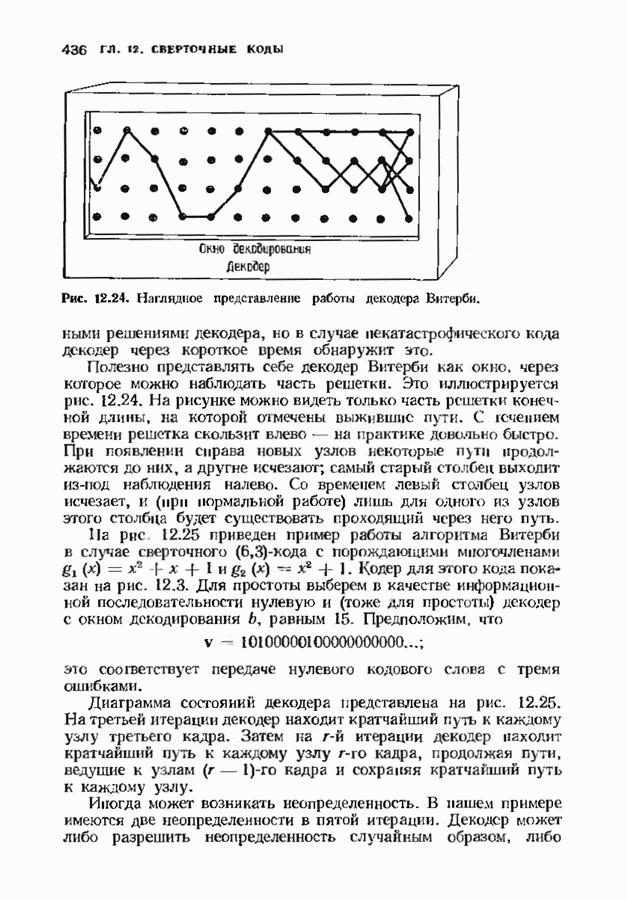
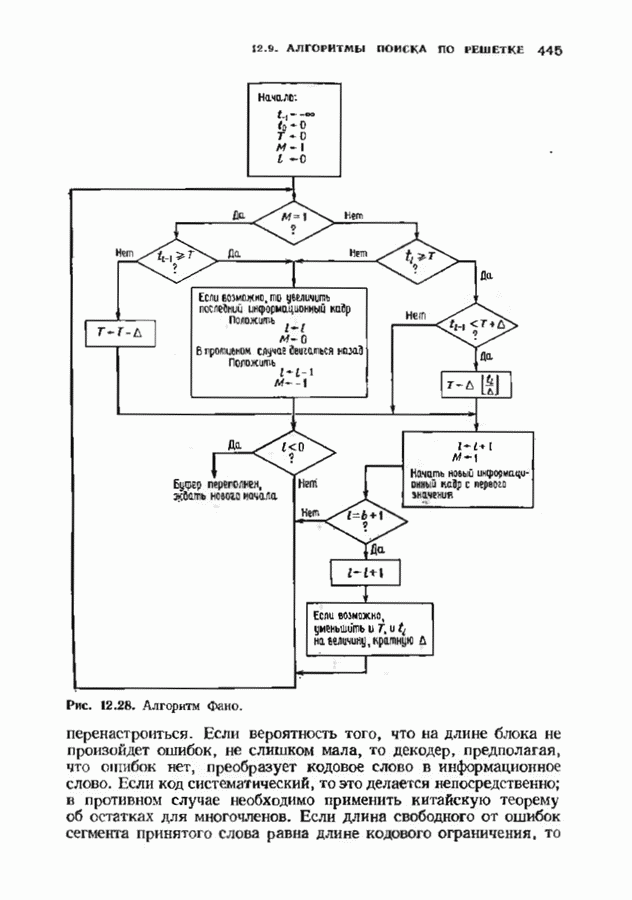
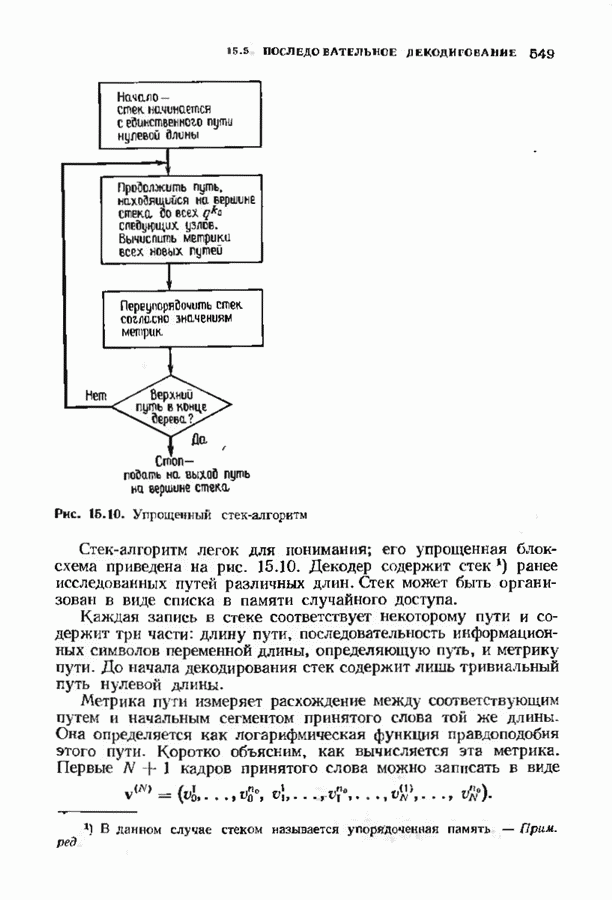
12.8. АЛГОРИТМ ДЕКОДИРОВАНИЯ ВИТЕРБИАлгоритм декодирования Витерби является полным алгоритмом декодирования сверточных кодов. Так как он является полным, вероятность отказа от декодирования равна нулю; однако при фиксированном коде вероятность ошибки декодирования будет больше, чем у неполного декодера. Этот алгоритм практически употребляется для двоичных кодов с малой длиной кодового ограничения — в настоящее время пределом являются длины кодового ограничения от 7 до 10 Недвоичные коды декодировать декодером Виберби труднее, и это возможно лишь при очень малых длинах кодового ограничения. Ниже будет описана процедура, которая называется декодированием по минимуму расстояния и приводит к неплохому (в принципе) декодеру для сверточных кодов. Этот декодер является декодером по максимуму правдоподобия в случае двоичного шума без памяти. Выберем окно декодирования ширины Конечно, для сверточных кодов даже весьма умеренной сложности эта процедура совершенно непрактична, однако знакомство с процедурой декодирования по минимуму расстояния полезно с теоретической точки зрения В дальнейшем мы опишем практическую реализацию декодера по минимуму расстояния для коротких сверточных кодов. Непосредственно реализовать декодер по минимум) расстояния трудно. Однако существует эффективный метод реализации такого декодера (в какой-то мере аналогичный использованию БПФ-алгоритма Кули-Тьюки для оценки дискретного преобразования Фурье и использованию алгоритма Берлекэмпа-Месси для синтеза авторегрессионного фильтра). Он называется алгоритмом Витерби и основывается на методах теории динамического программирования. Как и в других случаях, практически полезными оказываются трудные для понимания, но эффективные в вычислительном смысле алгоритмы. Поэтому теоретически лучше изучать декодер по минимуму расстояния, а в реальном декодере, если это возможно, использовать алгоритм Витерби. Декодер Витерби итеративно обрабатывает кадр за кадром, двигаясь по решетке, аналогичной используемой кодером, и пытаясь повторить путь кодера. В любой момент времени декодер не знает, в каком узле находится кодер и поэтому не пытается декодировать этот узел. Вместо этого декодер но при питой последовательности определяет наиболее правдоподобный путь к каждому узлу и определяет расстояние между каждым таким путем и принятой последовательностью. Это расстояние называется мерой расходимости пути. Если все пути в множестве наиболее правдоподобных путей начинаются одинаково, то декодер, как правило, знает начало пути, пройденного кодером. В следующем кадре декодер определяет наиболее правдоподобный путь к каждому из новых узлов этого кадра. Но путь в каждый новый узел должен пройти через один из старых узлов. Возможные пути к новому узлу можно получить, продолжая к этому узлу те старые пути, которые можно к нему продолжить. Наиболее правдоподобный путь находится прибавлением приращения меры расходимости на продолжениях старых путей к мере расходимости путей, ведущих в старый узел. В каждый новый узел веде Рассмотрим множество выживших путей, ведущих в множесгво узлов в Для построения декодера Витерби требуется выбрать ширину окна декодирования Затем декодер отбрасывает первое ребро и используег новый кадр принятого слова для следующей итерации. Если вновь все выжившие пути проходят через тот же узел самого старого среди оставшихся кадров, этот информационный кадр декодируется. Такой процесс декодирования кадров продолжается бесконечно. Если Иногда декодер принимает однозначное, но ошибочное решение. Оно обязательно сопровождается дополнительными
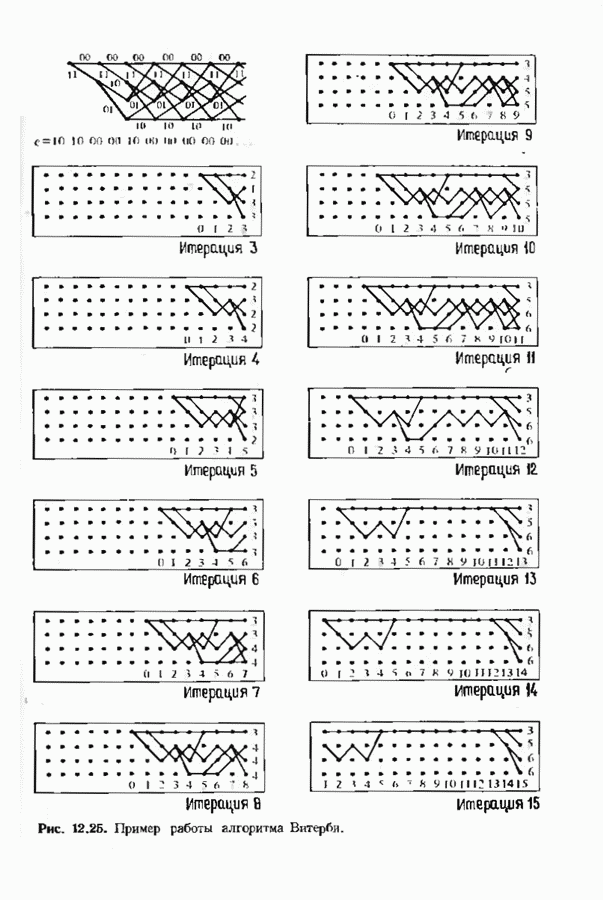
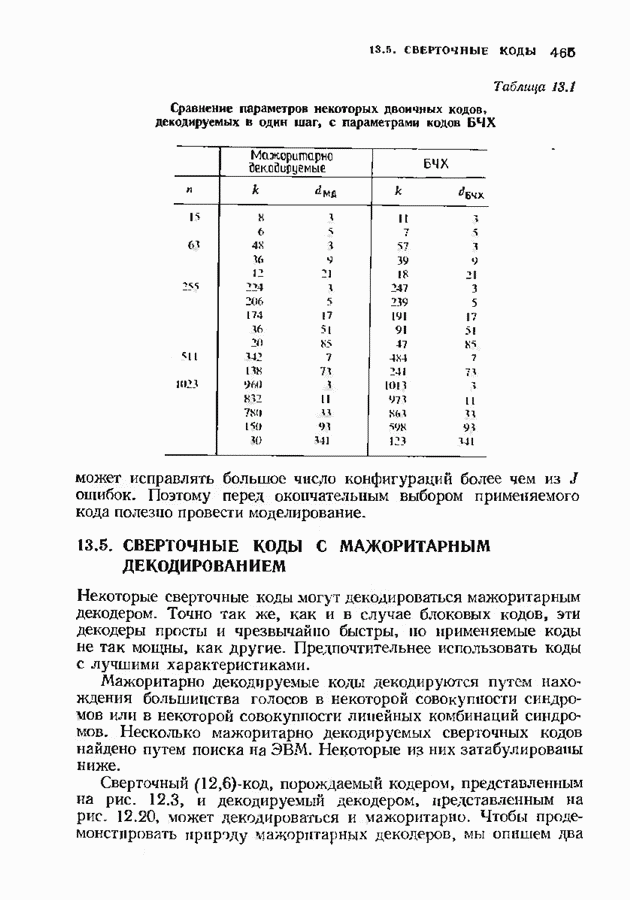
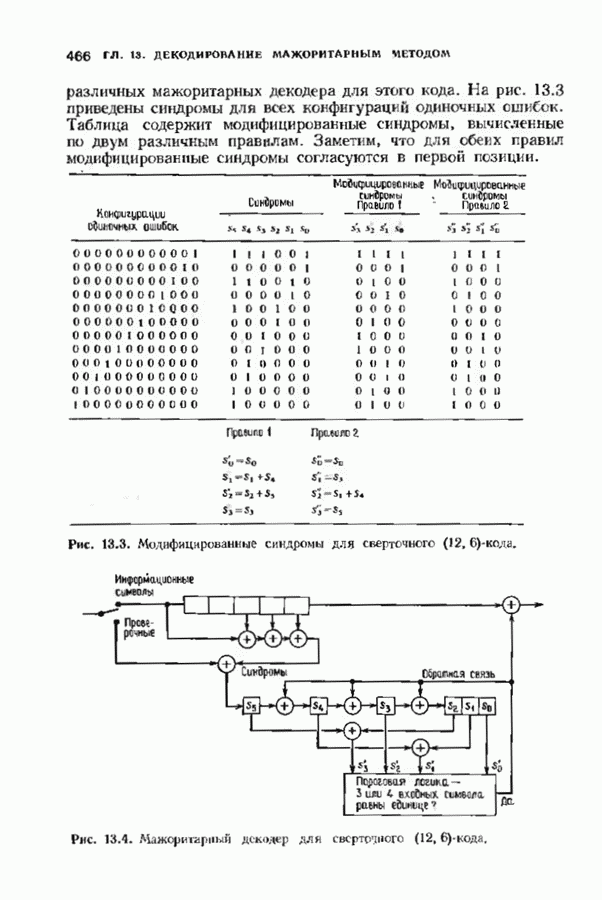
Рис. 12.24. Наглядное представление работы декодера Витерби. ошибочными решениями декодера, но в случае иекатастрофического кода декодер через короткое время обнаружит это. Полезно представлять себе декодер Витерби как окно, через которое можно наблюдать часть решетки. Это иллюстрируется рис. 12.24. На рисунке можно видеть только часть решетки конечной длины, на которой отмечены выжившие пути. С течением времени решетка скользит влево — на практике довольно быстро. При появлении справа новых узлов некоторые пути продолжаются до них, а другие исчезают; самый старый столбец выхолит из-под наблюдения налево. Со временем левый столбец узлов исчезает, и (при нормальной работе) лишь для одного из узлов этого столбца будет существовать проходящий через него путь. На рис 12.25 приведен пример работы алгоритма Витерби в случае сверточного
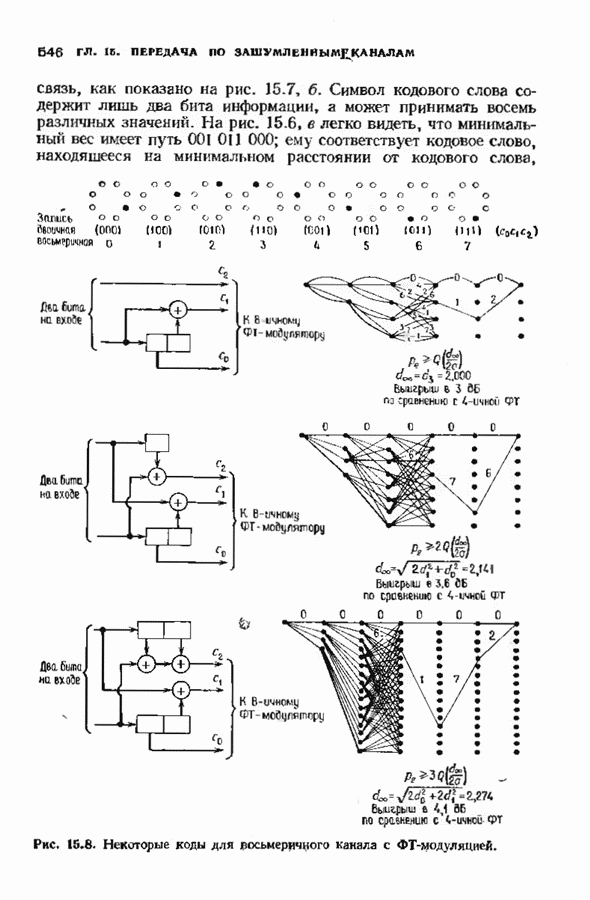
это соответствует передаче нулевого кодового слова с тремя ошибками. Диаграмма состояний декодера представлена на рис. 12.25. На третьей итерации декодер находит кратчайший путь к каждому узлу третьего кадра. Затем на Иногда может возникать неопределенность. В нашем примере имеются две неопределенности в пятой итерации. Декодер может либо разрешить неопределенность случайным образом, либо
(кликните для просмотра скана) сохранять оба пути, относительно которых Существует нёопрё-деленность. В нашем примере неопределенности сохраняются до тех пор, пока не выявляется более правдоподобный путь или сомнительный участок не исчезает из поля зрения декодера. По мере продвижения декодера к последующим кадрам из его памяти выводятся более ранние кадры. Если в самом старом кадре существует лишь один узел, через который проходит путь, то декодирование является полным. Если таких путей несколько, то принимается решение об обнаружении неиснравляемой конфигурации ошибок. Она либо отмечается в качестве таковой, либо производится случайный выбор. В нашем примере информационная последовательность может быть декодирована либо как
либо как
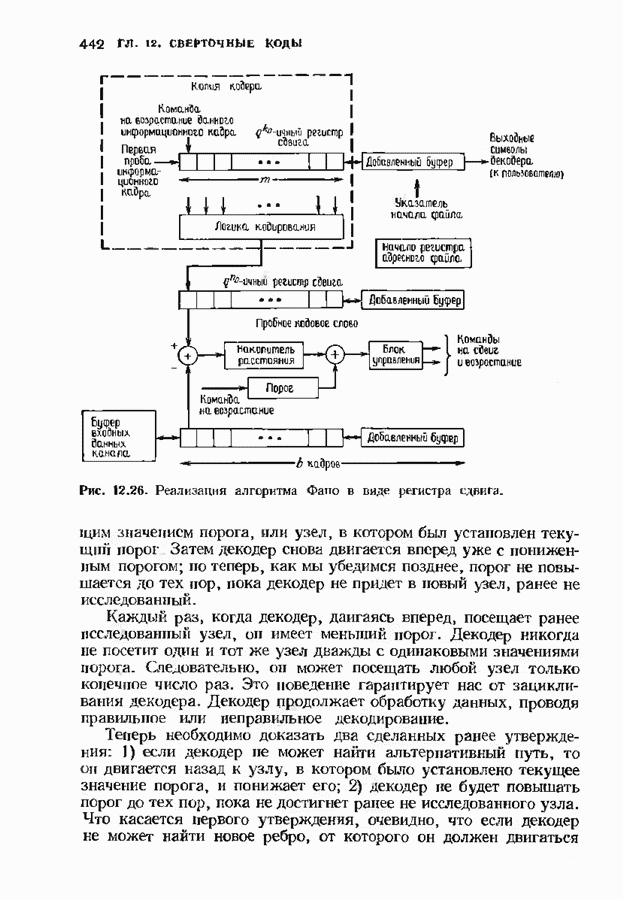
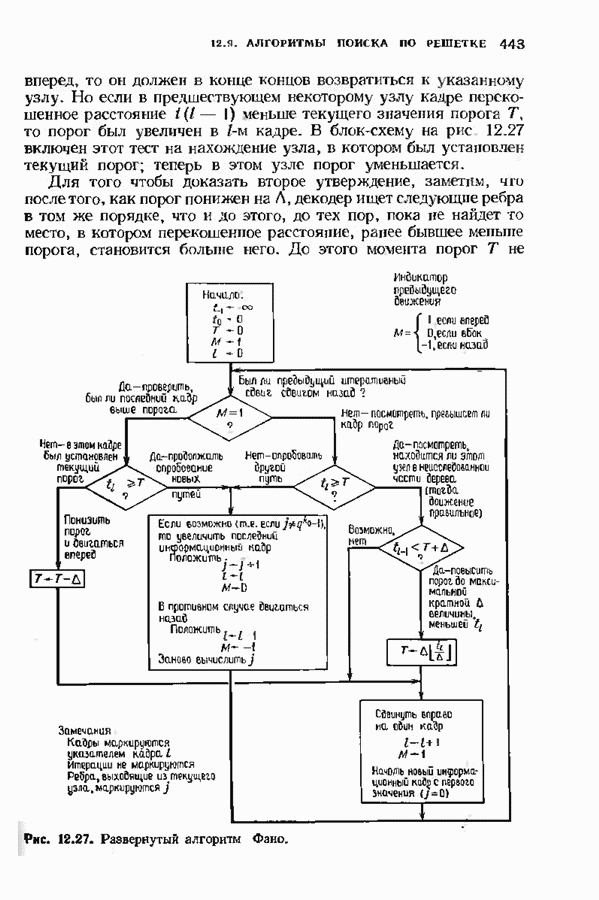
Если сделать ширину окна декодирования более 15, то ошибка по-прежнему останется неисправляемой. Для исправления этой конфигурации ошибок требуется код с большим свободным расстоянием. Декодер, символически изображенный на рис. 12.25, при практической реализации выглядит совершенно иначе. Например, выжившие пути через решетку представляются таблицей По мере продвижения декодера накопленная мера расходимости увеличивается. Для того чтобы избежать проблемы переполнения, необходимо время от времени уменьшать эту меру. Простая процедура состоит в периодическом вычитании из всех мер расходимости наименьшей такой меры. Очевидно, что это не повлияет на выбор максимвлыюго расхождения. В случае когда длина кодового ограничения мала, декодеры Витерби могут работать очень быстро. Например, практически возможно построить декодер со 128 узлами на каждом уровне, который производит 10 миллионов итераций в секунду.
|
 |
Оглавление
|

































































































































































































































































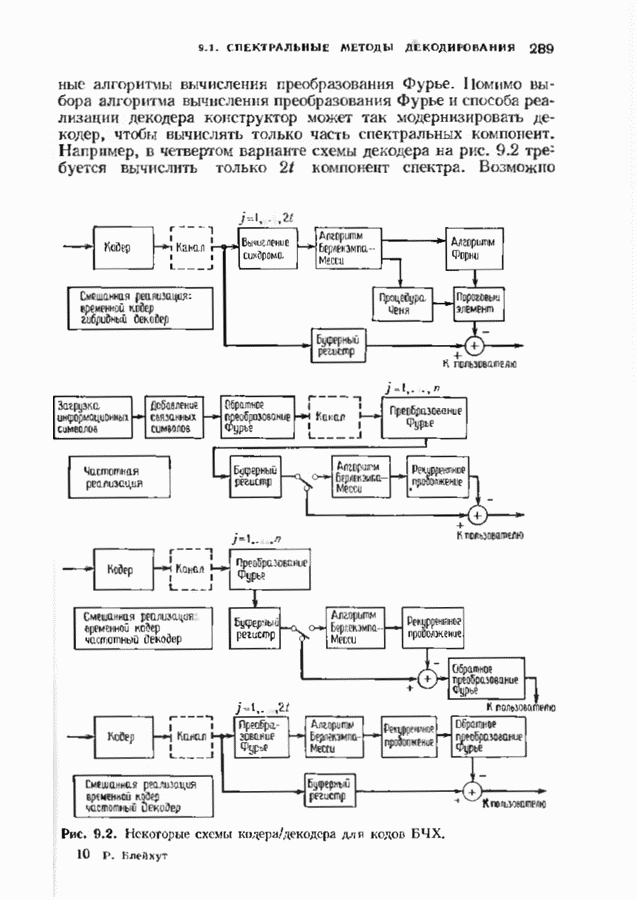



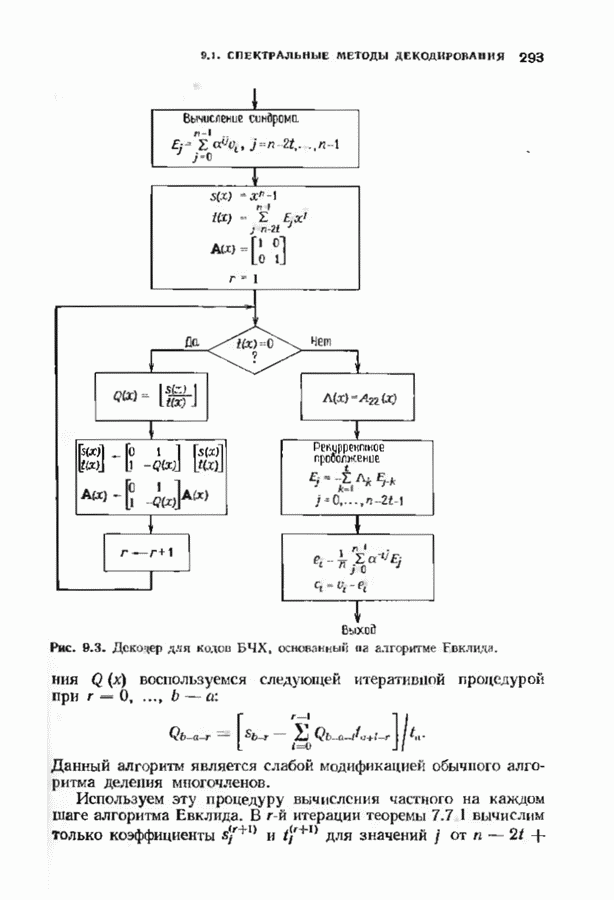





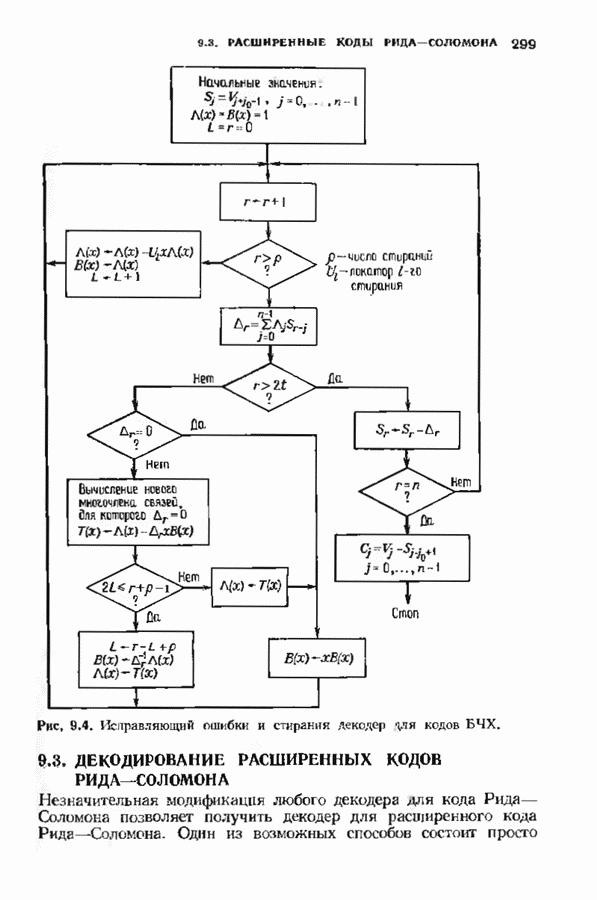


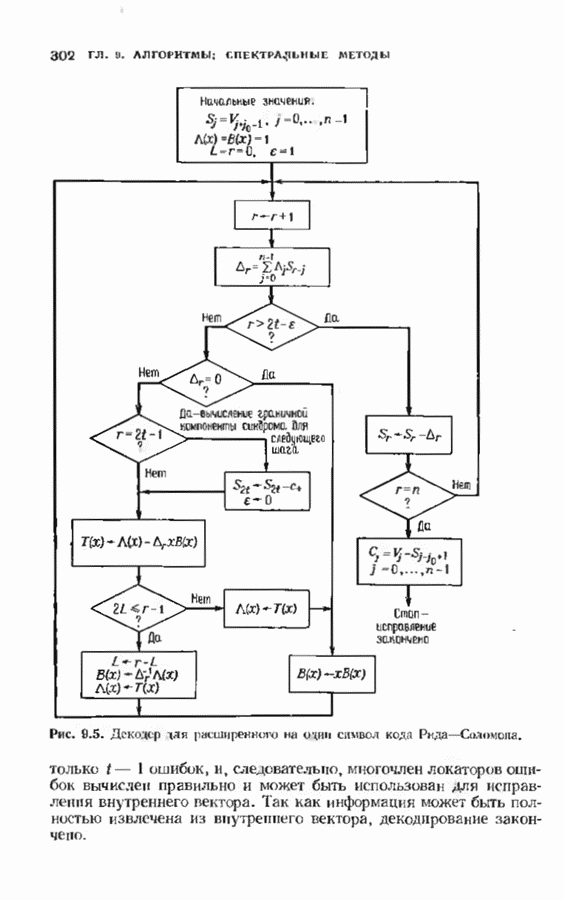














































































































































































































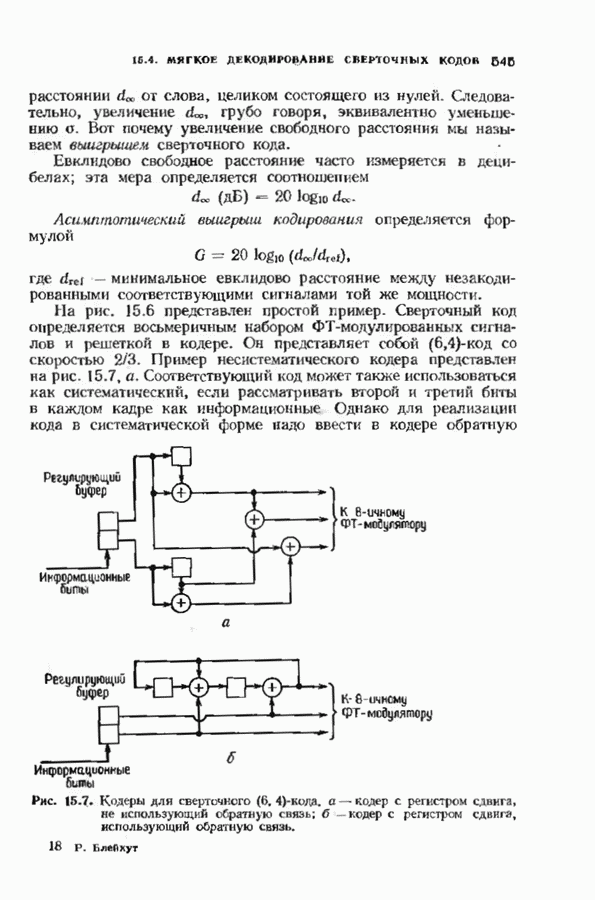
















 превышающей длину блока
превышающей длину блока  вычислим все кодовые слова длины
вычислим все кодовые слова длины  сравним принятое слово с каждым из них и выберем кодовое слово, ближайшее к принятому слову. Первый информационный кадр выбранного кодового слова берем в качестве первого информационного кадра декодированною кодового слова. Декодированный первый информационный кадр затем кодируется вновь и вычитается из принятого слова. После этого в декодер вводится
сравним принятое слово с каждым из них и выберем кодовое слово, ближайшее к принятому слову. Первый информационный кадр выбранного кодового слова берем в качестве первого информационного кадра декодированною кодового слова. Декодированный первый информационный кадр затем кодируется вновь и вычитается из принятого слова. После этого в декодер вводится  новых символов, а первые
новых символов, а первые  символов сбрасываются, и процесс повторяется для нахождения следующего информационного кадра.
символов сбрасываются, и процесс повторяется для нахождения следующего информационного кадра.
 таких путей, и иуть с наименьшей мерой расходимости является наиболее правдоподобным путем к новому узлу. Этот процесс повторяется для каждого из новых узлов. В конце итерации декодер знает наиболее правдоподобный путь к каждому из узлов в новом кадре.
таких путей, и иуть с наименьшей мерой расходимости является наиболее правдоподобным путем к новому узлу. Этот процесс повторяется для каждого из новых узлов. В конце итерации декодер знает наиболее правдоподобный путь к каждому из узлов в новом кадре.
 и временной кадр. Эти пути проходят через одни или более узлов в первом временном кадре. Если все пути проходят через один и тот же узел в первом временном кадре, то вне зависимости от того, в каком узле кодер находится в
и временной кадр. Эти пути проходят через одни или более узлов в первом временном кадре. Если все пути проходят через один и тот же узел в первом временном кадре, то вне зависимости от того, в каком узле кодер находится в  временной кадр, мы знаем наиболее правдоподобный среди посещенных им в первый временной кадр узлов. Иначе говоря, мы знаем первый информационный кадр, хотя еще не приняли решение об
временной кадр, мы знаем наиболее правдоподобный среди посещенных им в первый временной кадр узлов. Иначе говоря, мы знаем первый информационный кадр, хотя еще не приняли решение об  кадре.
кадре.
 которая обычно в несколько раз превосходит длину блока, и оценить работу декодера путем моделирования на ЭВМ. В
которая обычно в несколько раз превосходит длину блока, и оценить работу декодера путем моделирования на ЭВМ. В  временной кадр декодер проверяет, все ли выжившие пути имеют одинаковое первое ребро. Если первое ребро одинаково, то оно определяет первый декодированный информационный кадр, который подается на выход декодера.
временной кадр декодер проверяет, все ли выжившие пути имеют одинаковое первое ребро. Если первое ребро одинаково, то оно определяет первый декодированный информационный кадр, который подается на выход декодера.
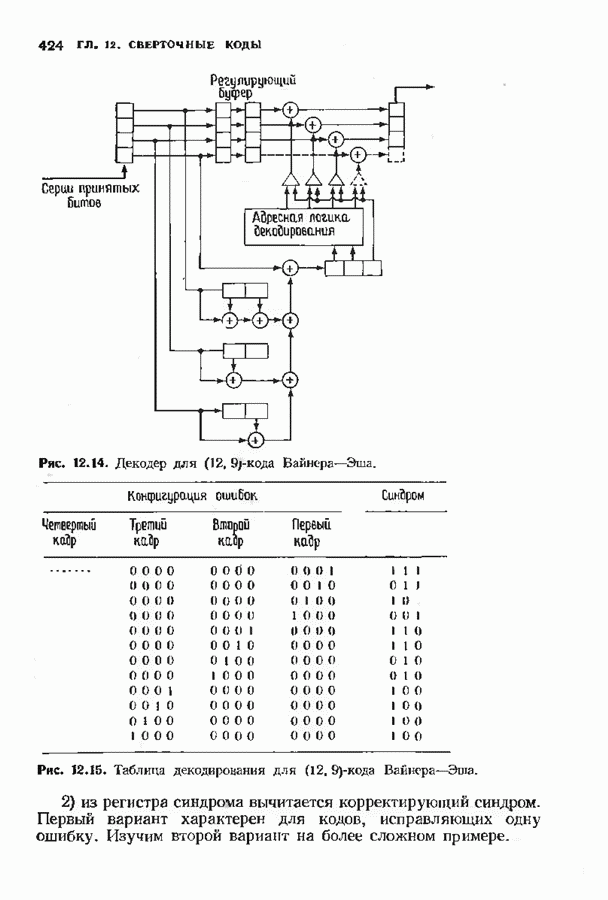
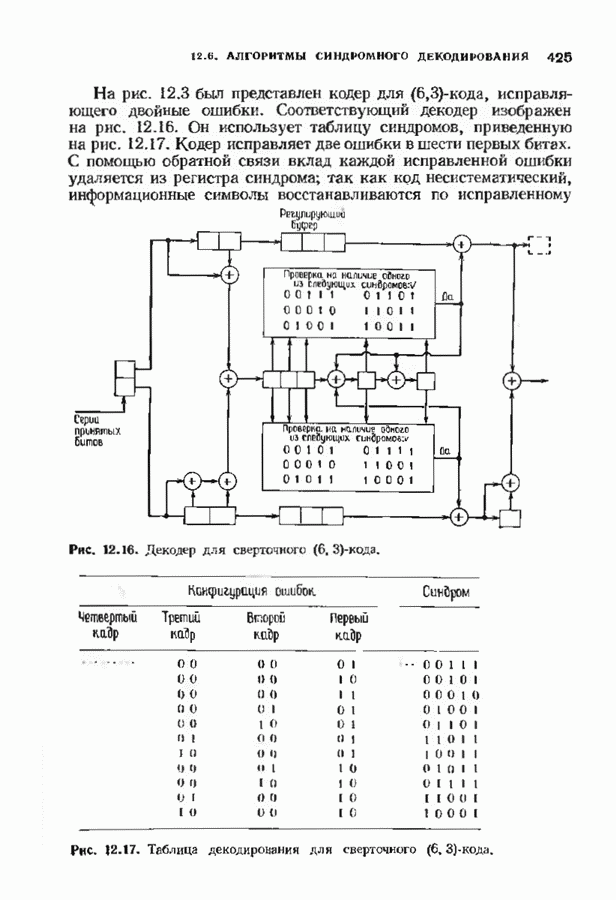
 выбрано достаточно большим, то во временном кадре почти всегда может быть принято однозначное решение. Если для данного канала код построен надлежащим образом, то это решение с большой вероятностью будет правильным. Этому, однако, может помешать несколько обстоятельств. Не все выжившие пути могут проходить через один и тот же узел. В этом случае процесс декодирования нарушается. Декодер может разрешит
выбрано достаточно большим, то во временном кадре почти всегда может быть принято однозначное решение. Если для данного канала код построен надлежащим образом, то это решение с большой вероятностью будет правильным. Этому, однако, может помешать несколько обстоятельств. Не все выжившие пути могут проходить через один и тот же узел. В этом случае процесс декодирования нарушается. Декодер может разрешит  неопределенность, используя любое произвольное правило. Другая возможность состоит в том, что декодер не принимает решения, а отмечает этот участок как сегмент кодового слова, который невозможно исправить. В этом случае декодер становится неполным декодером. Лучше всего это понять на примере, который будет приведен ниже.
неопределенность, используя любое произвольное правило. Другая возможность состоит в том, что декодер не принимает решения, а отмечает этот участок как сегмент кодового слова, который невозможно исправить. В этом случае декодер становится неполным декодером. Лучше всего это понять на примере, который будет приведен ниже.

 -кода с порождающими многочленами
-кода с порождающими многочленами  Кодер для этого кода показан на рис. 12.3. Для простоты выберем в качестве информационной последовательности нулевую и (тоже для простоты) декодер с окном декодирования
Кодер для этого кода показан на рис. 12.3. Для простоты выберем в качестве информационной последовательности нулевую и (тоже для простоты) декодер с окном декодирования  равным
равным  . Предположим, что
. Предположим, что

 итерации декодер находит кратчайший путь к каждому узлу
итерации декодер находит кратчайший путь к каждому узлу  кадра, продолжая пути, ведущие к узлам
кадра, продолжая пути, ведущие к узлам  кадра и сохраняя кратчайший путь к каждому узлу.
кадра и сохраняя кратчайший путь к каждому узлу.



 -битовых чисел. На каждой итерации некоторые
-битовых чисел. На каждой итерации некоторые  -битовые числа сдвигаются влево, причем левый бит сбрасывается, а справа добавляется новый бит. Другие
-битовые числа сдвигаются влево, причем левый бит сбрасывается, а справа добавляется новый бит. Другие  -битовые числа не наращиваются, а сбрасываются из таблицы.
-битовые числа не наращиваются, а сбрасываются из таблицы.