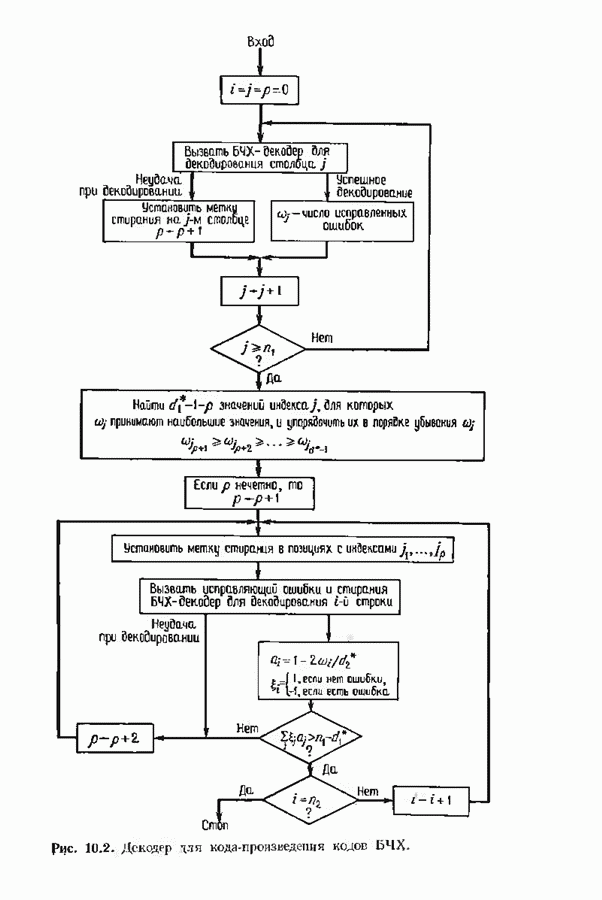
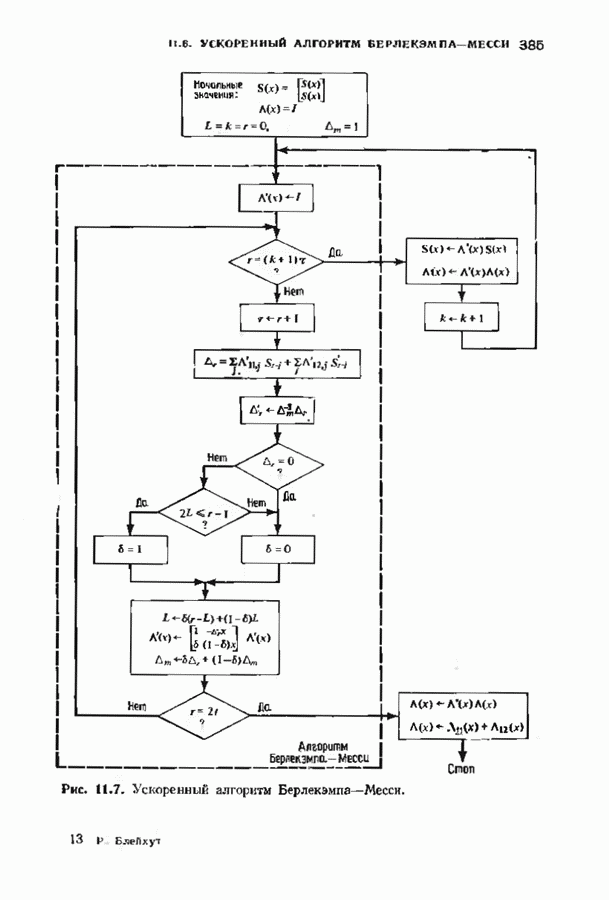
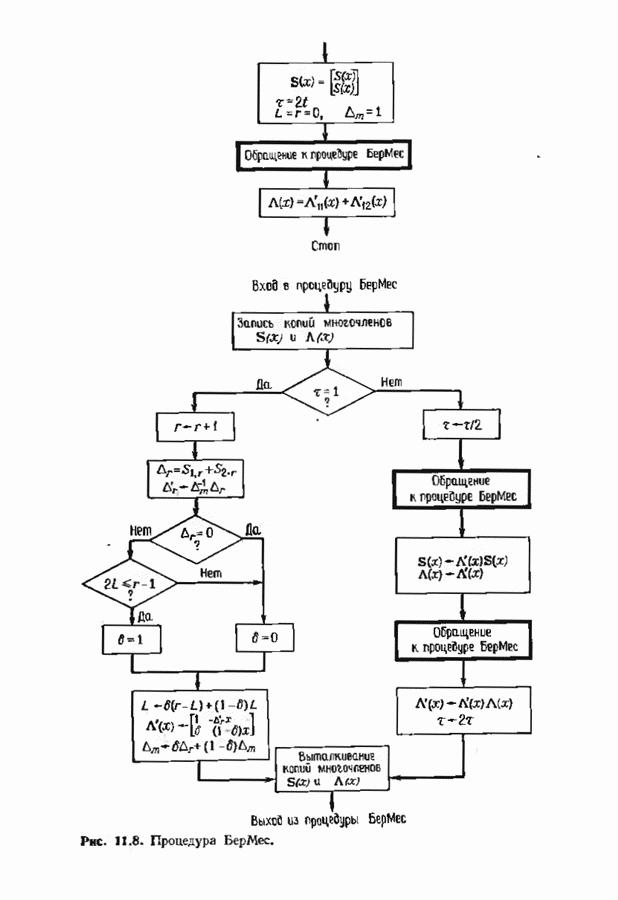
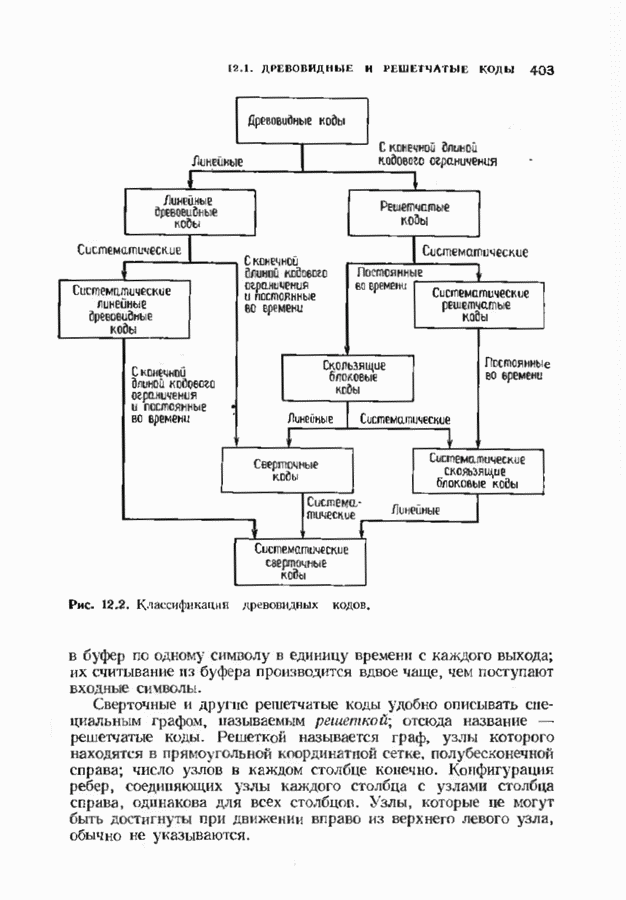
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
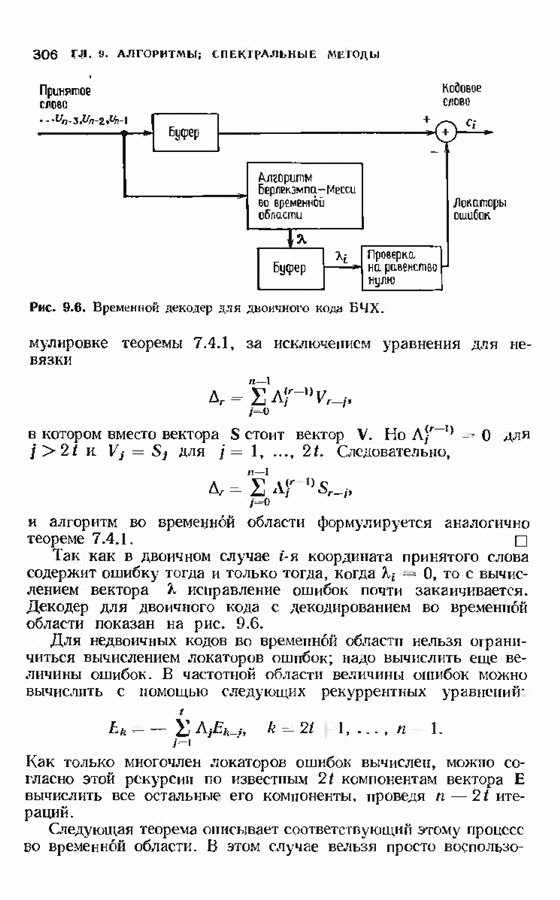
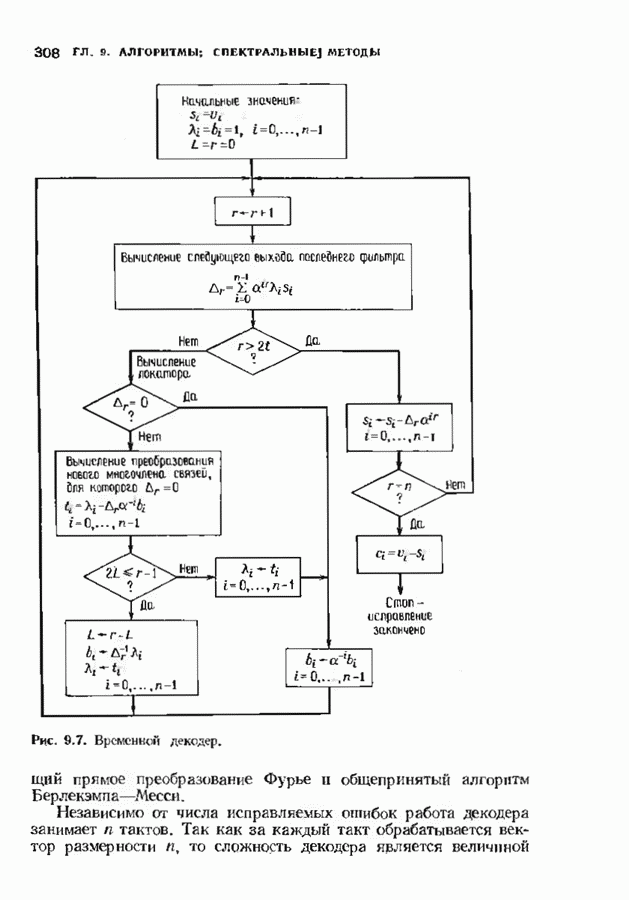
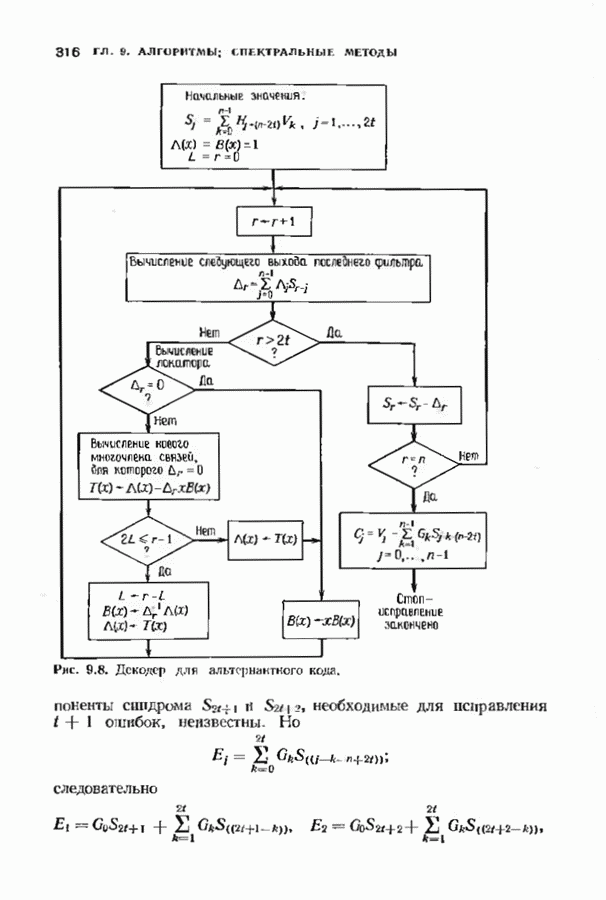
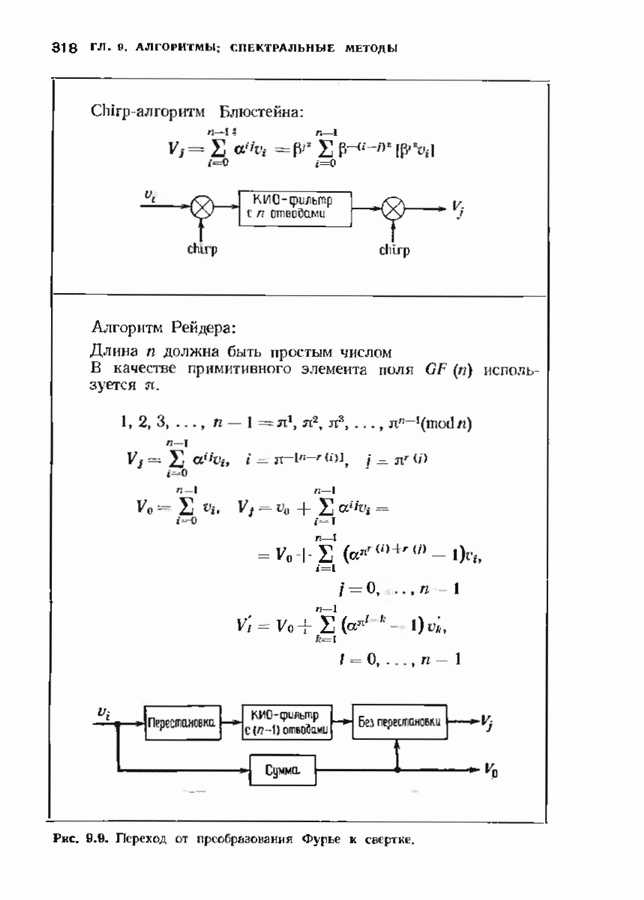
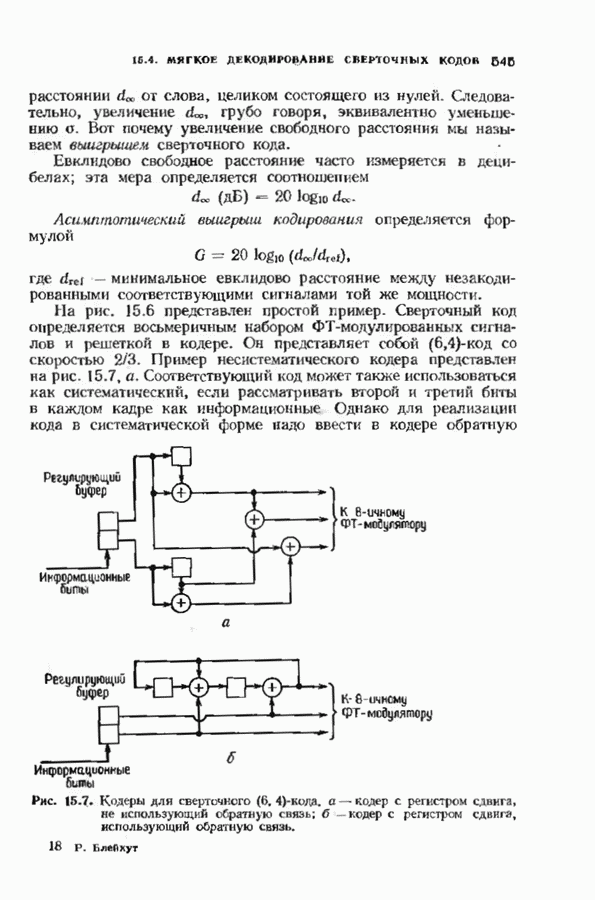
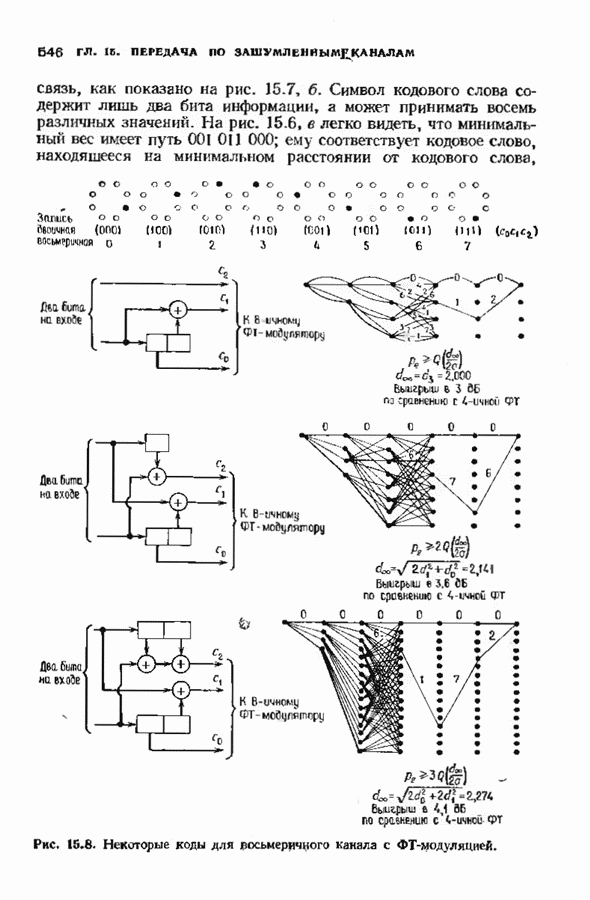
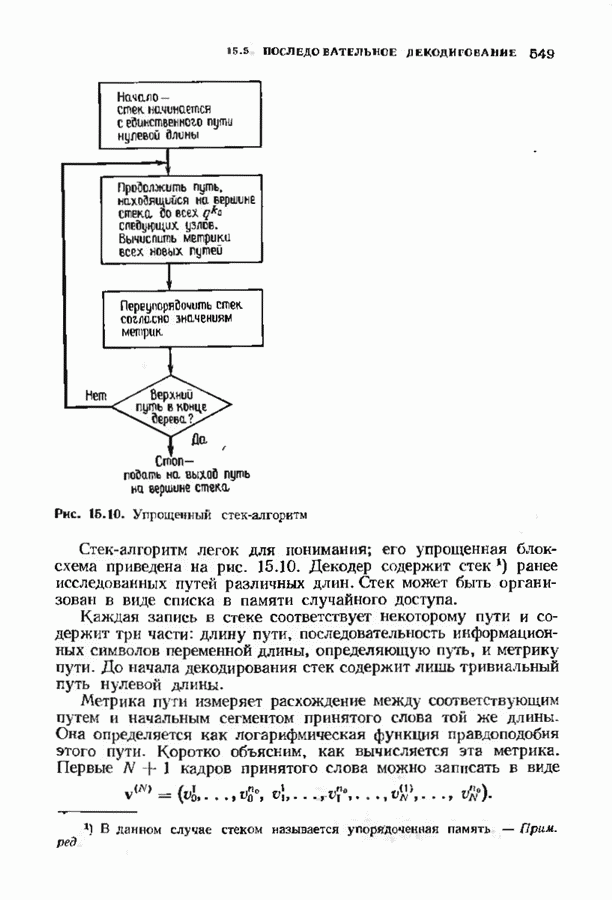
1.2. ИСТОРИЯ КОДИРОВАНИЯ, КОНТРОЛИРУЮЩЕГО ОШИБКИИстория кодирования, контролирующего ошибки, началась в 1948 г. публикацией знаменитой статьи Клода Шеннона. Шеннон показал, что с каждым каналом связано измеряемое в битах в секунду и называемое пропускной способностью канала число С, имеющее следующее значение. Если требуемая от системы связи скорость передачи информации R (измеряемая в битах в секунду) меньше С, то, используя коды, контролирующие ошибки, для данного канала можно построить такую систему связи, что вероятность ошибки на выходе будет сколь угодно мала. В самом деле, из шепноновской теории информации следует тот важный вывод, что построение слишком хороших каналов является расточительством; экономически выгоднее использовать кодирование. Шеннон, однако, не указал, как найти подходящие коды, а лишь доказал их существование. В пятидесятые годы много усилий было потрачено на попытки построения в явном виде классов кодов, позволяющих получить обещанную сколь угодно малую вероятность ошибки, но результаты были скудными. В следующем десятилетии решению этой увлекательной задачи уделялось меньше внимания; вместо этого исследователи кодов предприняли длительную атаку по двум основным направлениям. Первое направление носило чисто алгебраический характер и преимущественно рассматривало блоковые коды. Первые блоковые коды были введены в 1950 г., когда Хэмминг описал класс блоковых кодов, исправляющих одиночные ошибки. Коды Хэмминга были разочаровывающе слабы по сравнению, с обещанными Шелноном гораздо более сильными кодами. Несмотря на усиленные исследования, до конца пятидесятых годов не было построено лучшего класса кодов. В течение эгого периода без какой-либо общей теории были найдены многие коды с малой длиной блока. Основной сдвиг произошел, когда Боуз и Рой-Чоудхури [1960] и Хоквингем [1959) нашли большой класс кодов, исправляющих кратные ошибки (коды БЧХ), а Рид и Соломон [1960] нашли связанный с кодами БЧХ класс кодов для недвоичных каналов. Хотя эти коды остаются среди наиболее важных классов кодов, общая теория блоковых кодов, контролирующих ошибки, с тех пор успешно развивалась, и время от времени удавалось открывать новые коды. Открытие кодов БЧХ привело к поиску практических методов построения жестких или мягких реализаций кодеров и декодеров. Первый хороший алгоритм был предложен Питерсоном. Впоследствии мощный алгоритм выполнения описанных Питерсоном вычислений был предложен Берлекэмпом и Месси, и их реализация вошла в практику как только стала доступной новая цифровая техника. Второе направление исследований по кодированию носило скорее вероятностный характер. Ранние исследования были связаны с оценками вероятностей ошибки для лучших семейств блоковых кодов, несмотря на то что эти лучшие коды не были известны. С этими исследованиями были связаны попытки понять кодирование и декодирование с вероятностной точки зрения, и эти попытки привели к появлению последовательного декодирования. В последовательном декодировании вводится класс неблоковых кодов бесконечной длины, которые можно описать деревом и декодировать с помощью алгоритмов поиска по дереву. Наиболее полезными древовидными кодами являются коды с тонкой структурой, известные под названием сверточных кодов. Эти коды можно генерировать с помощью пеней линейных регистров сдвига, выполняющих операцию свертки информационной последовательности. В конце 50-х годов для сверточных кодов были успешно разработаны алюритмы последовательного декодирования. Интересно, что наиболее простой алгоритм декодирования — алгоритм Витерби - не был разработан для этих кодов до 1967 г. Применительно к сверточным кодам умеренной сложности алгоритм Витерби пользуется широкой популярностью, но для более мощных сверточных кодов он не практичен. В 70-х годах эти два направления исследований опять стали переплетаться. Теорией сверточных кодов занялись алгебраисты, представившие ее в новом свете. В теории блоковых кодов за это время удалось приблизиться к кодам, обещанным Шенноном: были предложены две различные схемы кодирования (одна Юстесеном, а другая Гопгюй), позволяющие строить семейства кодов, которые одновременно могут иметь очень большую длину блока и очень хорошие характеристики. Обе схемы, однако, имеют практические ограничения и надо ждать дальнейших успехов. Между тем к началу 80-х годов кодеры и декодеры начали появляться в новейших конструкциях цифровых систем связи и цифровых систем памяти.
|
 |
Оглавление
|