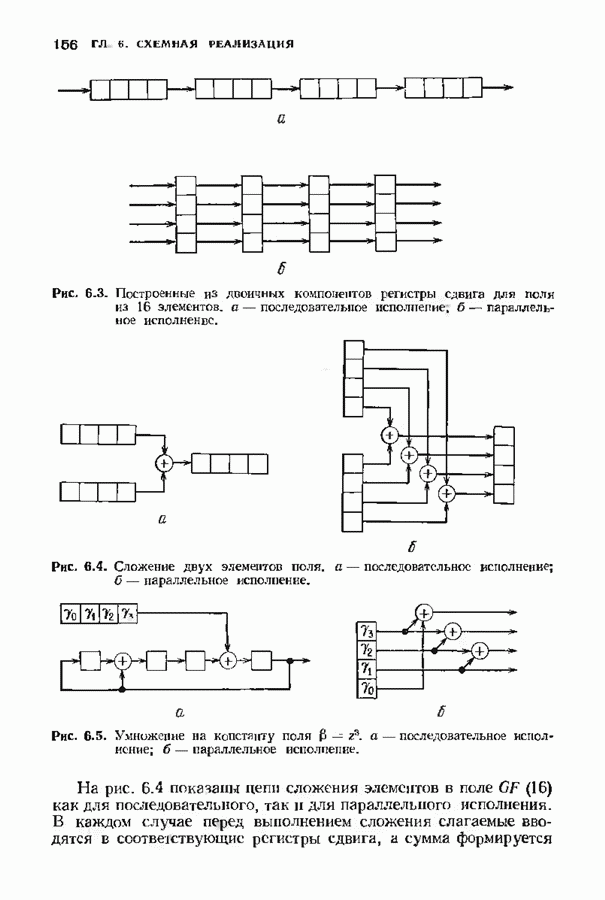
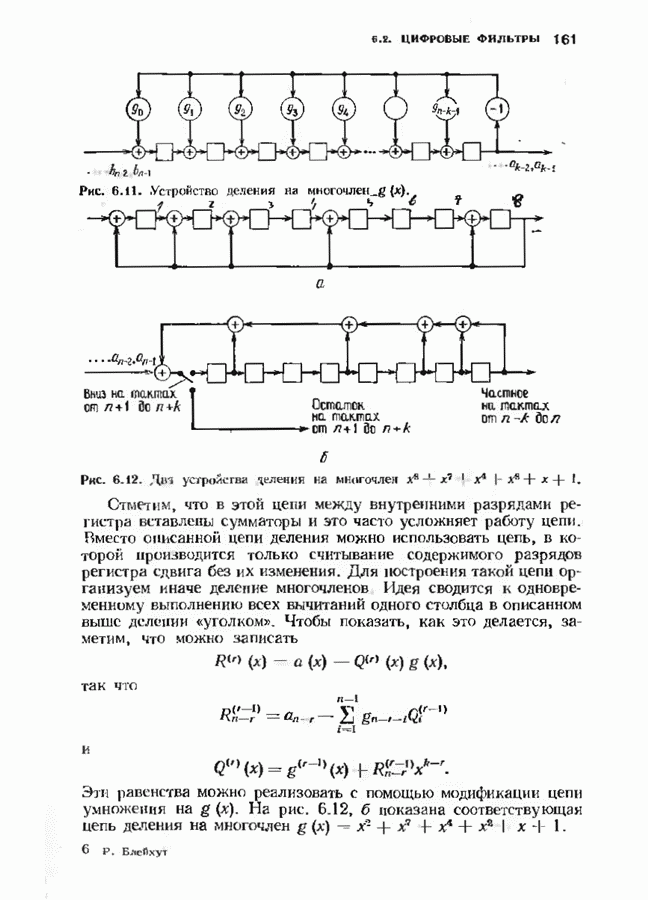
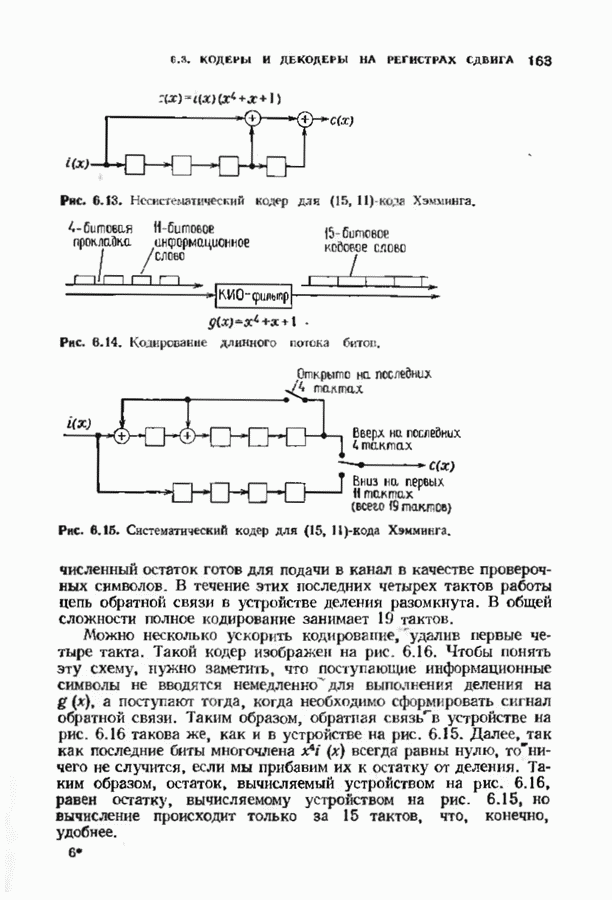
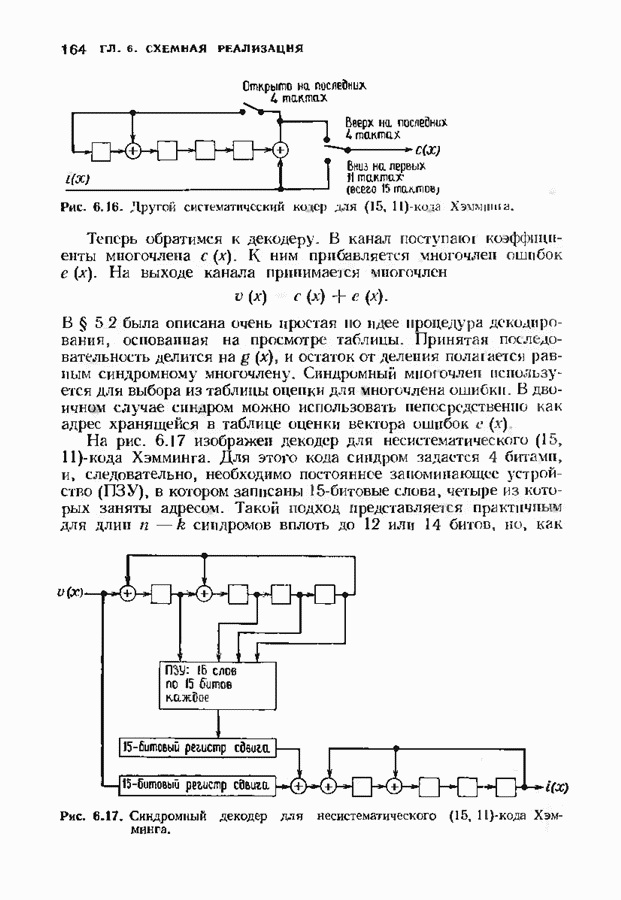
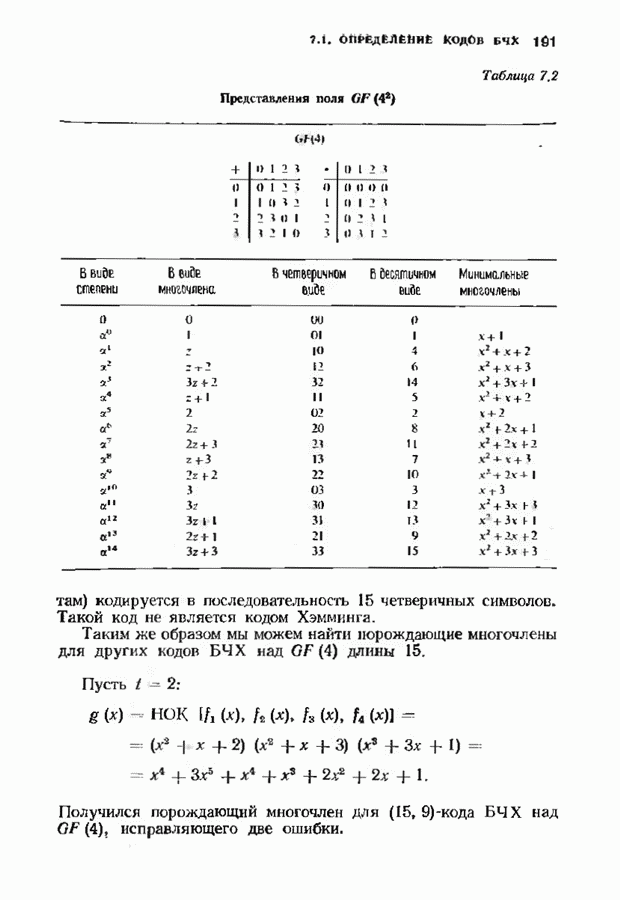
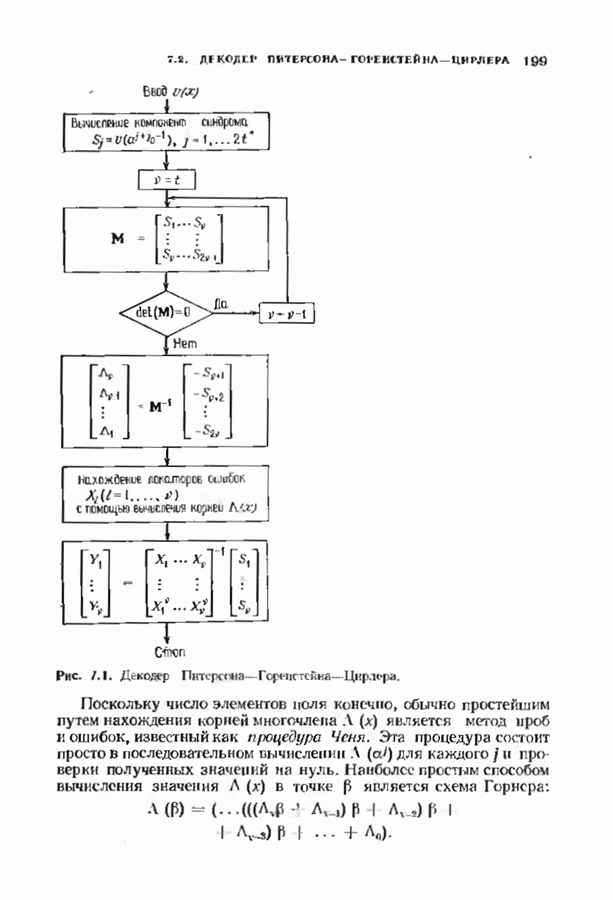
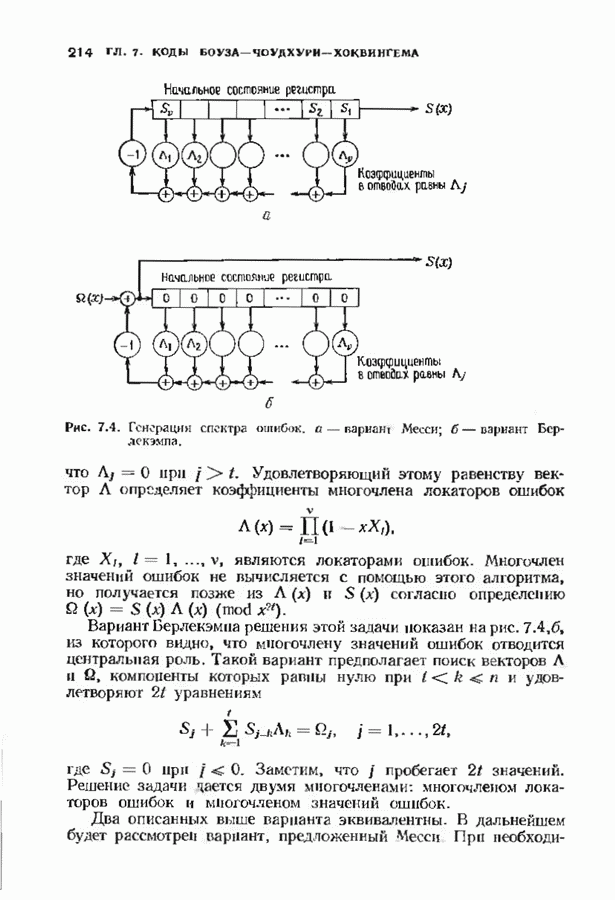
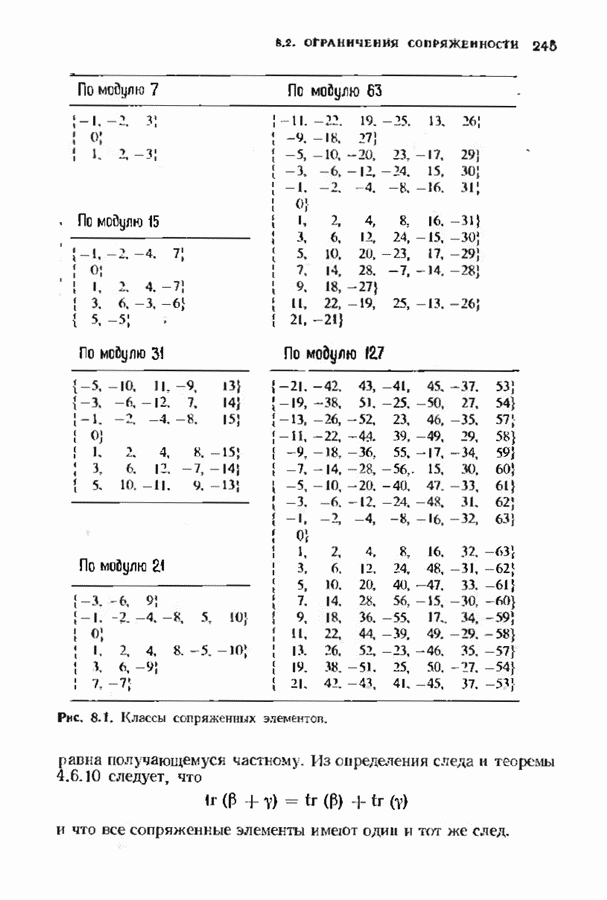
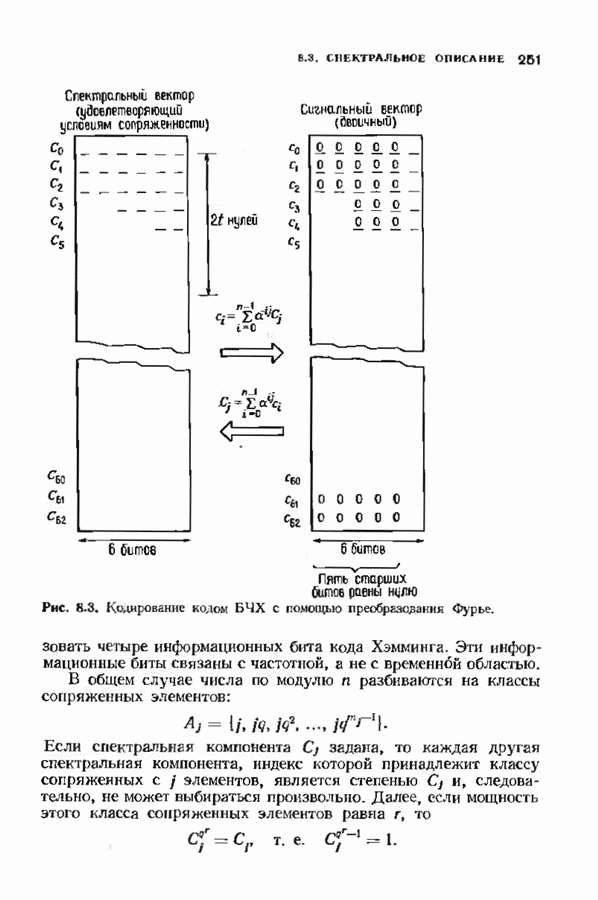
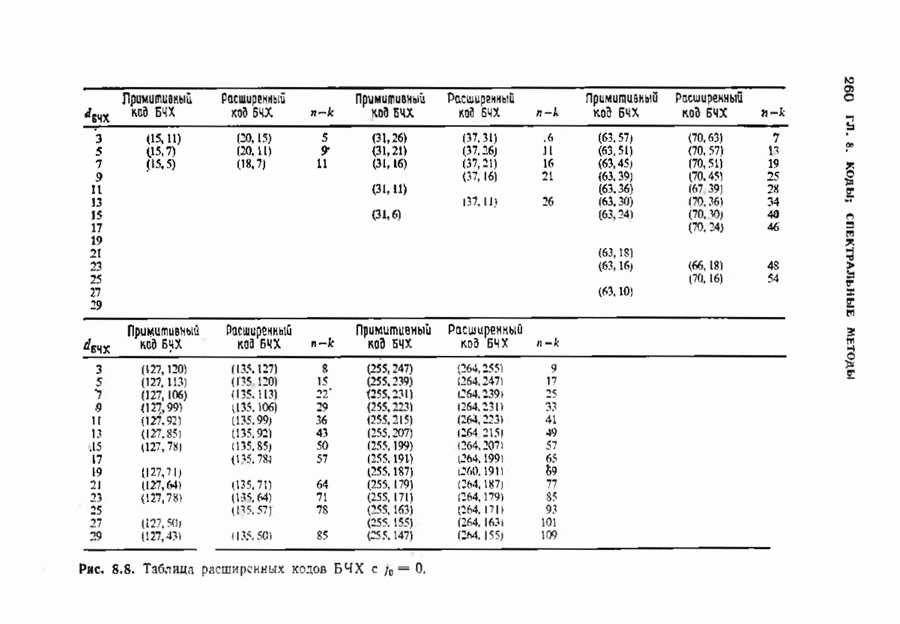
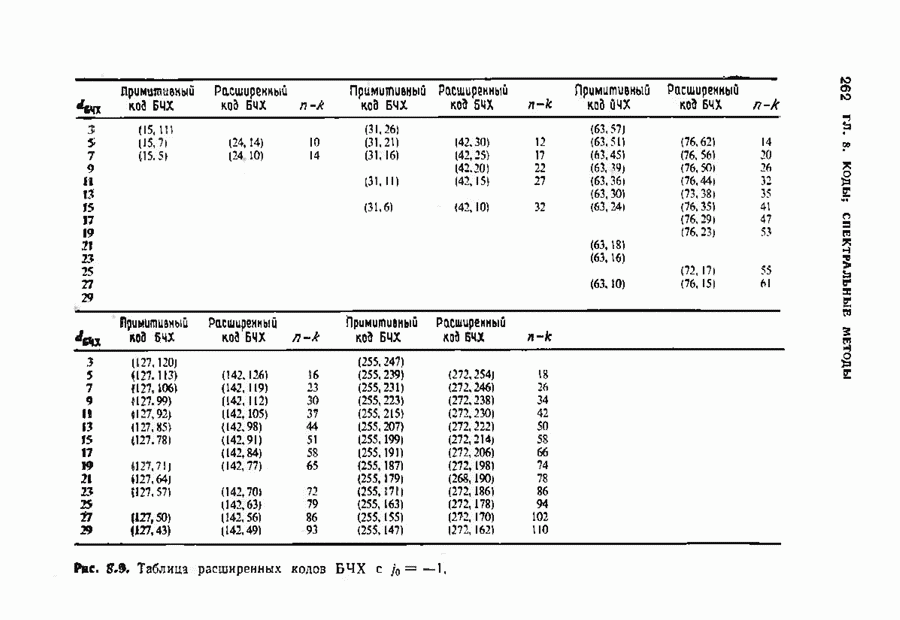
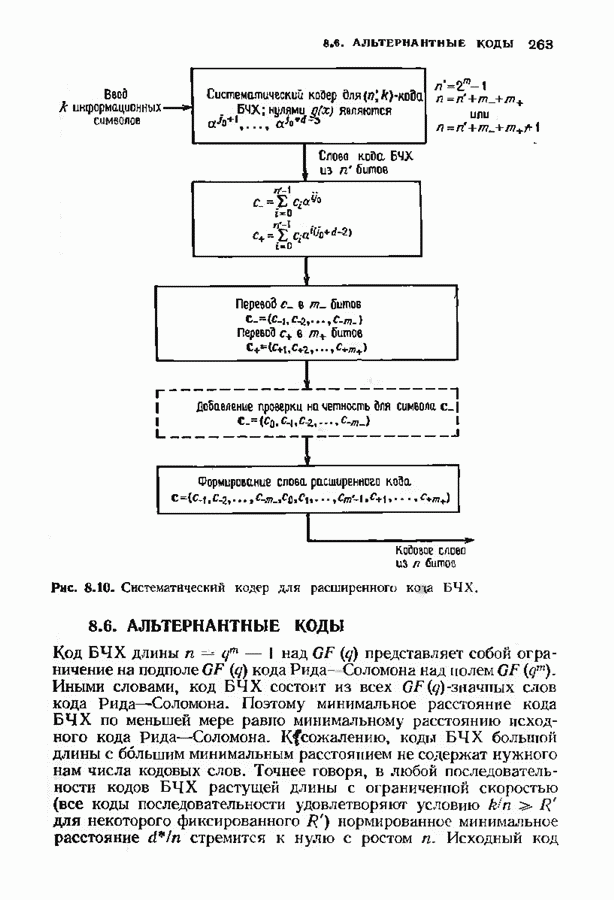
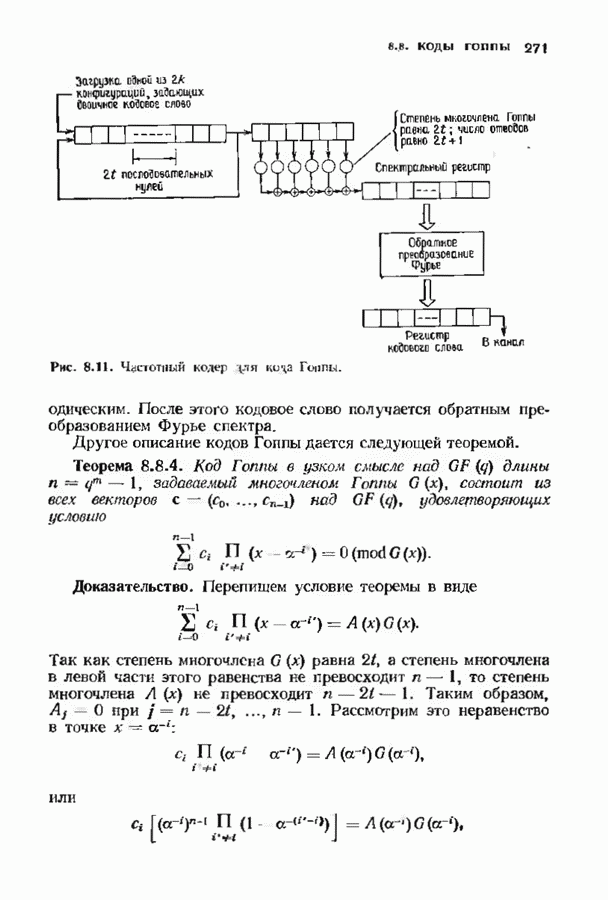
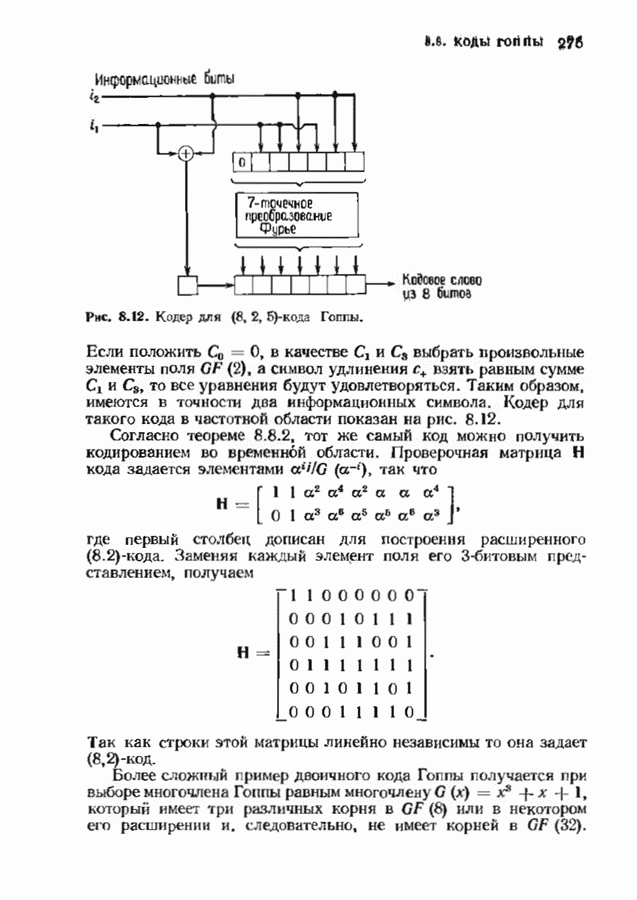
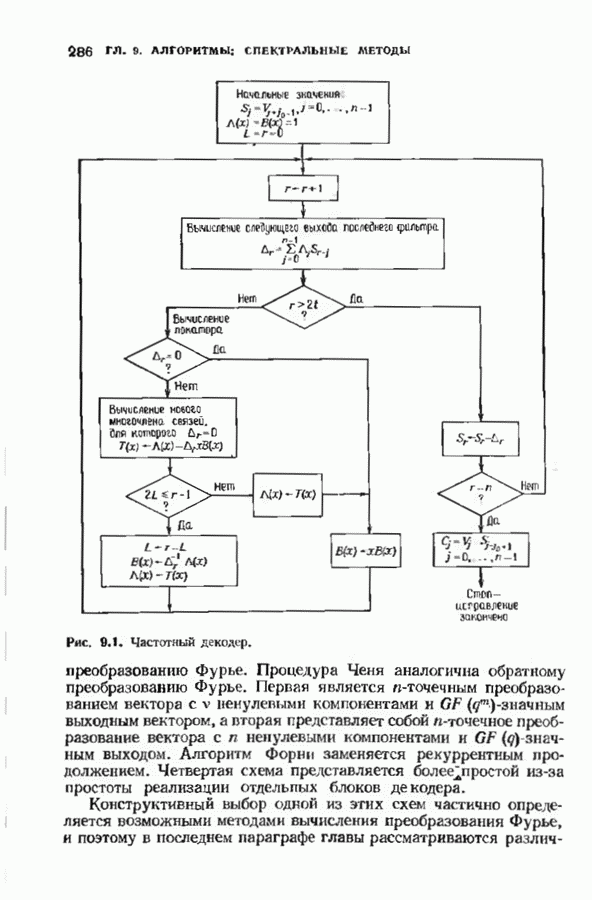
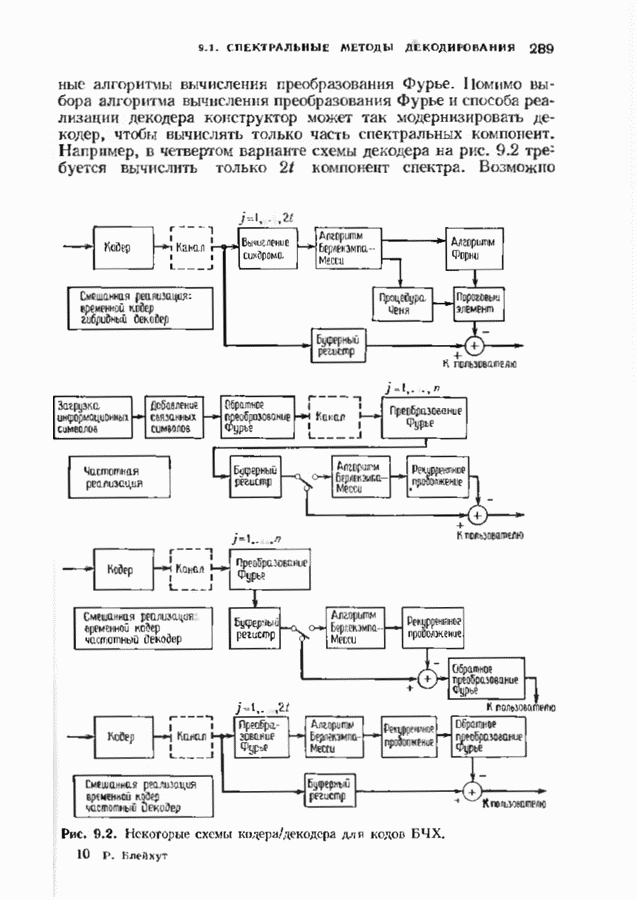
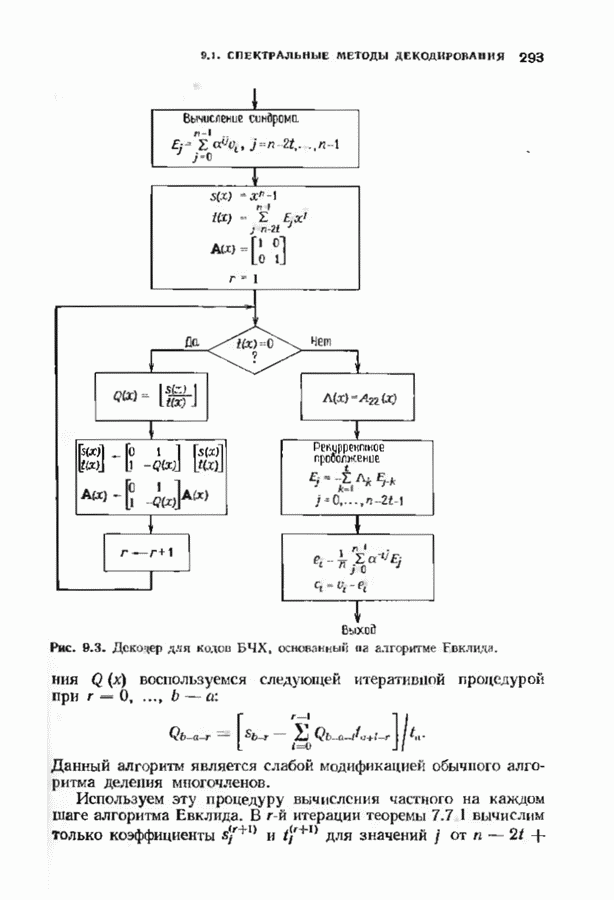
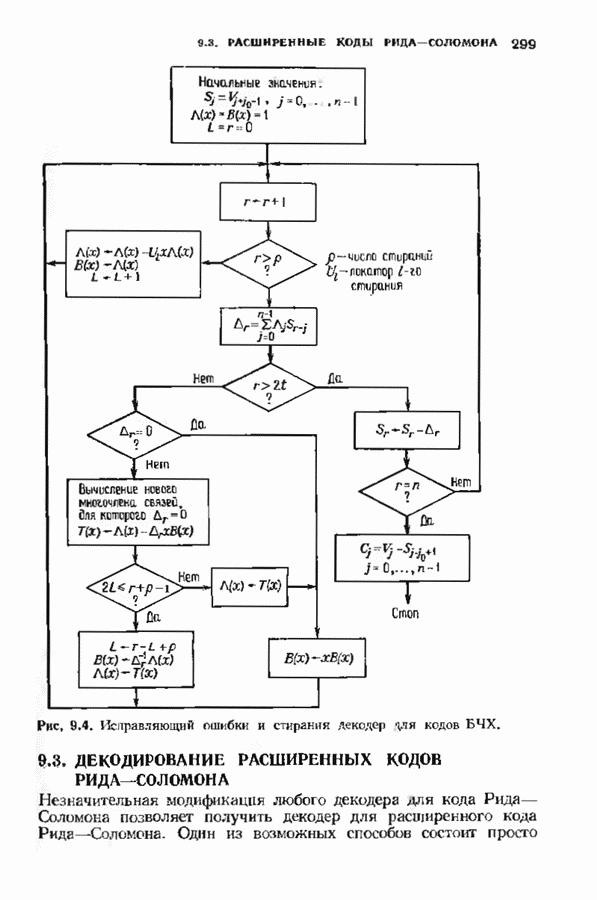
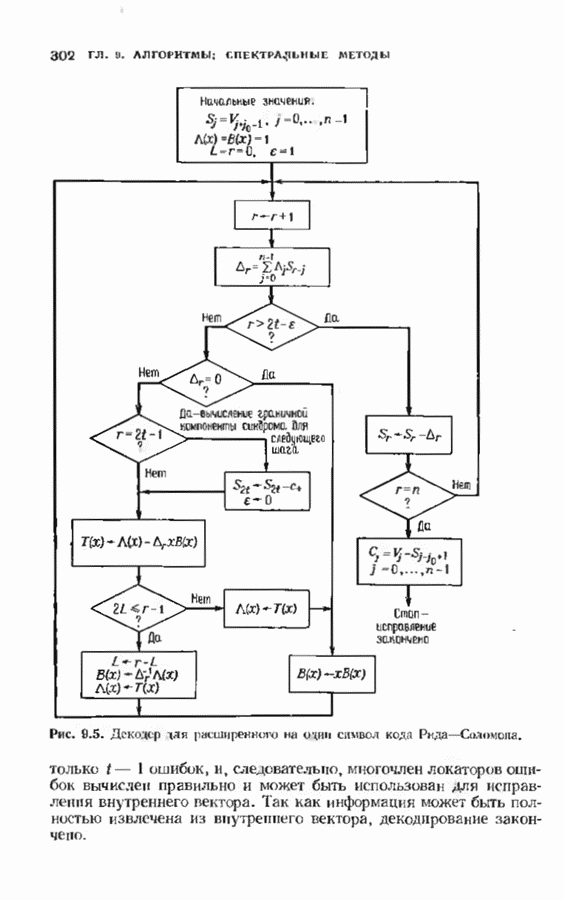
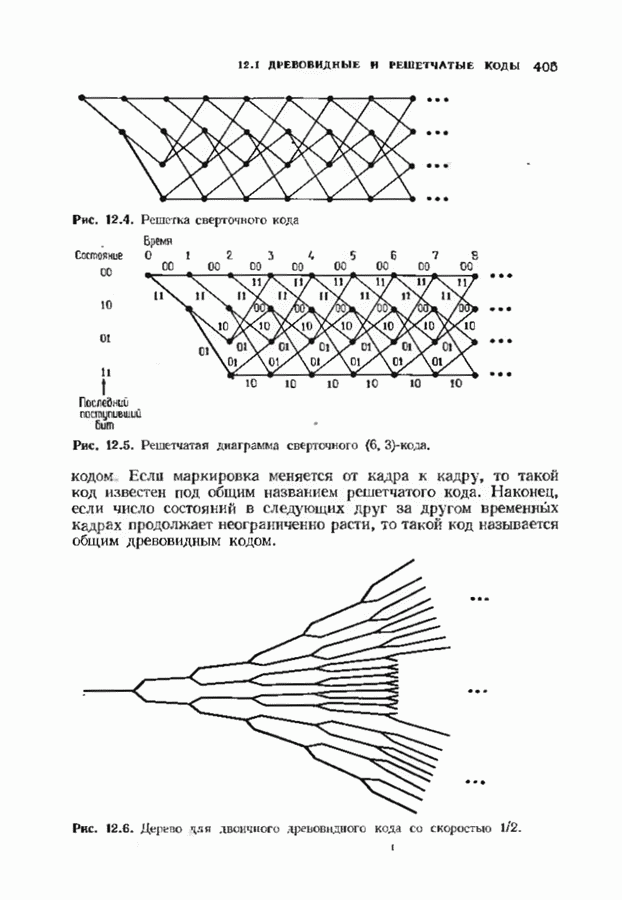
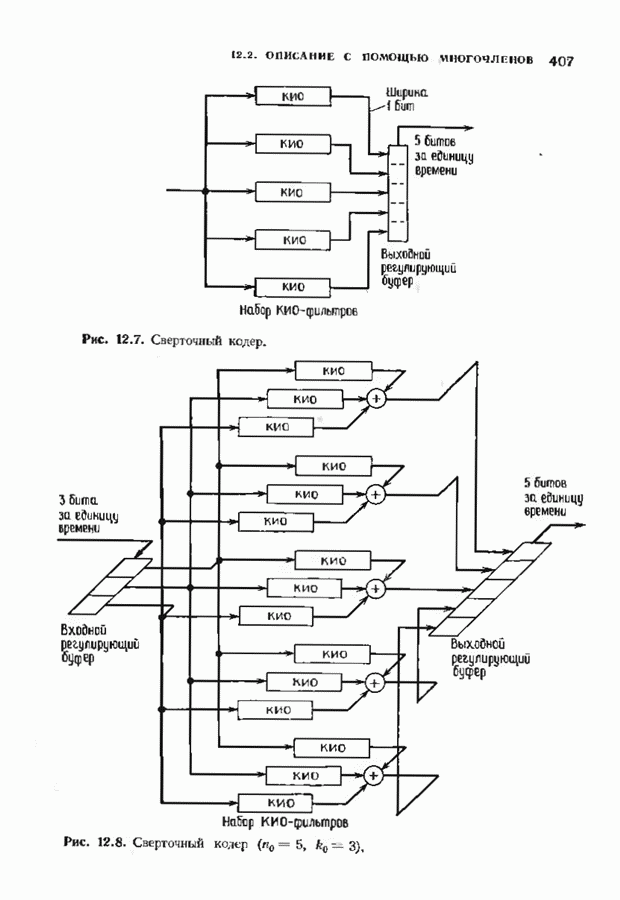
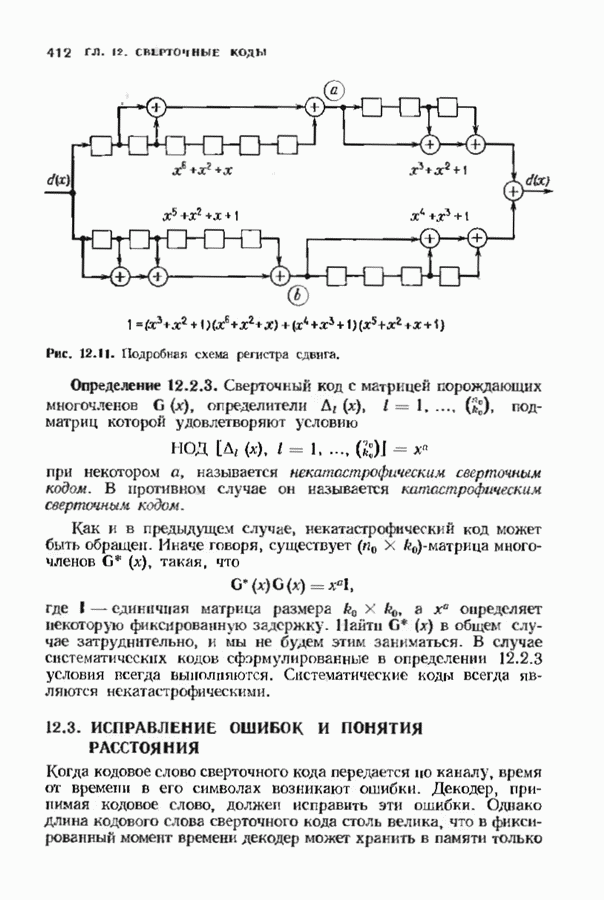
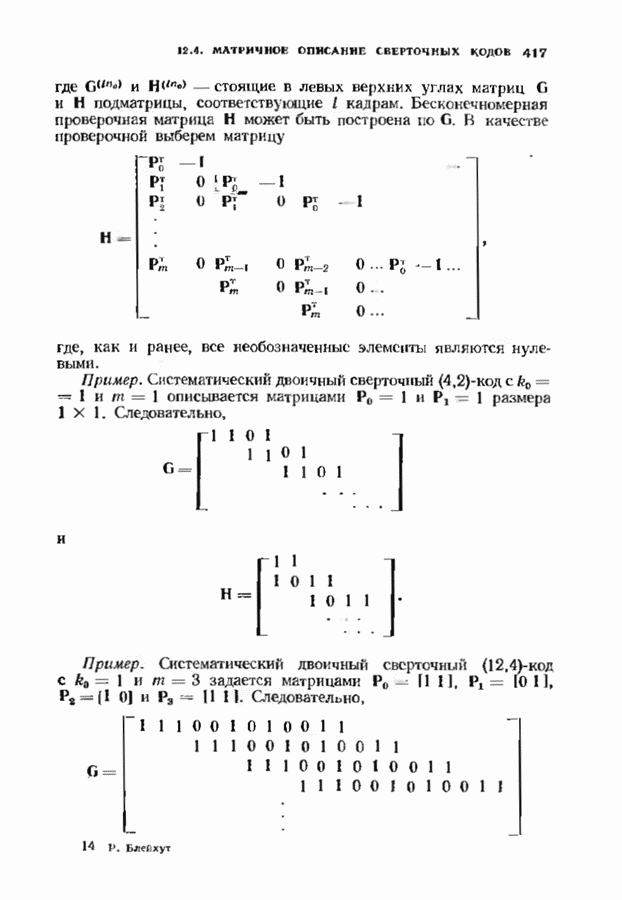
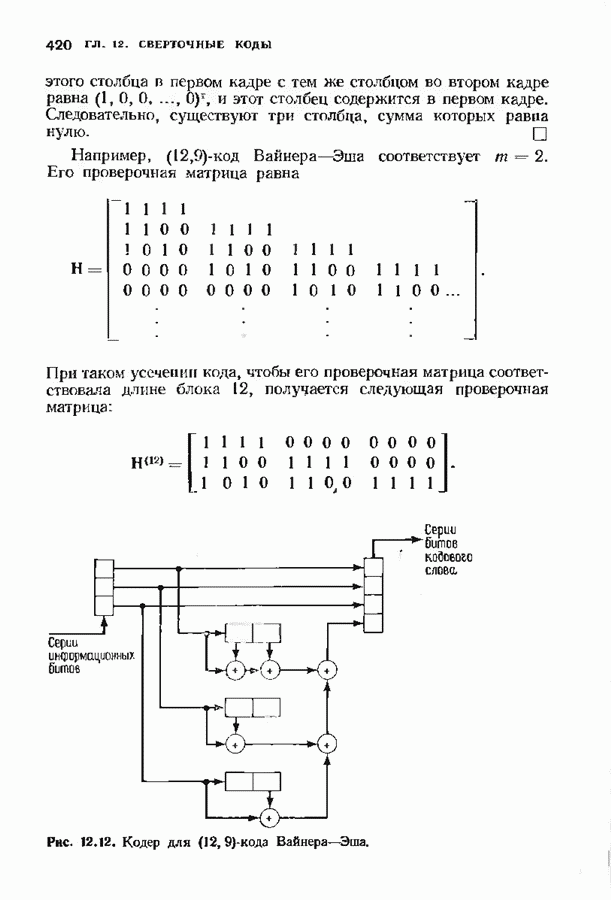
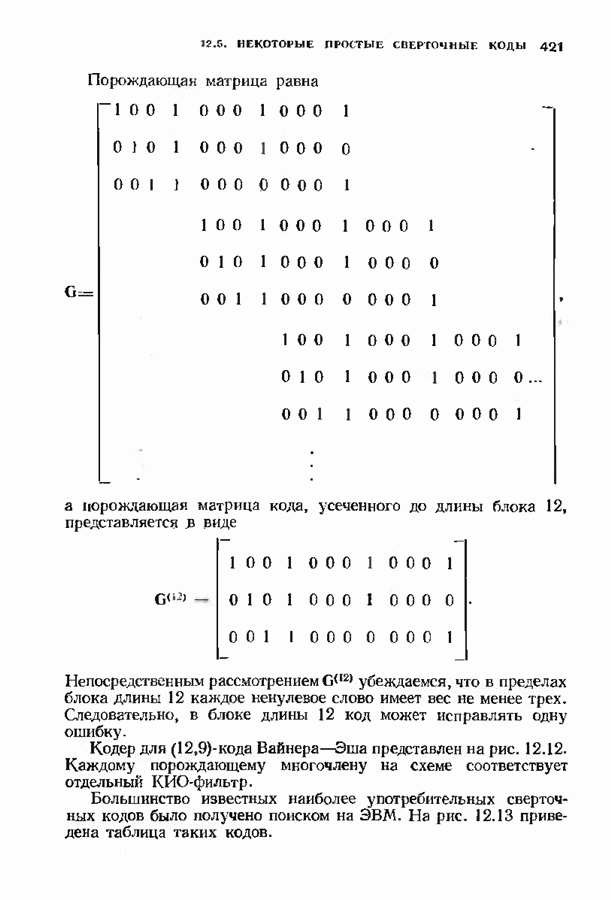
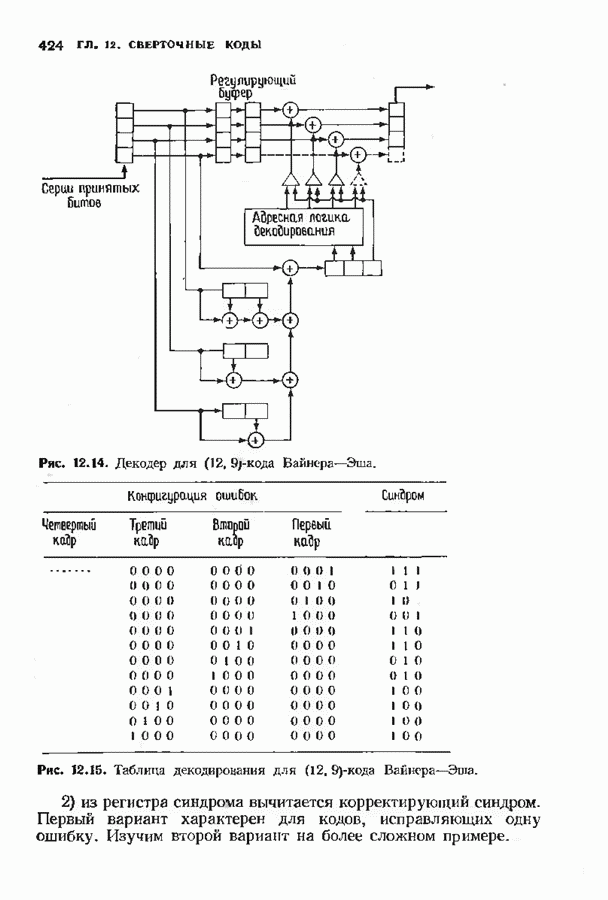
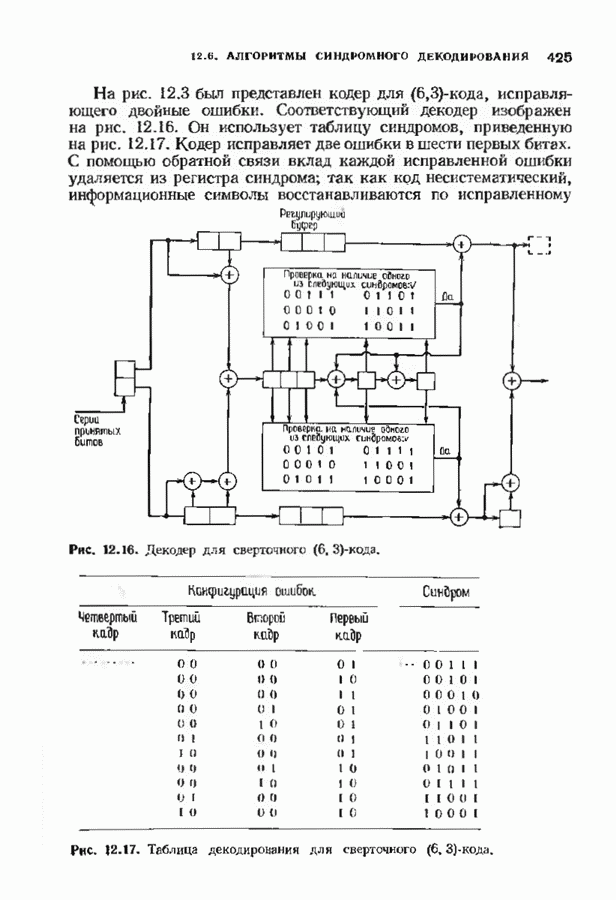
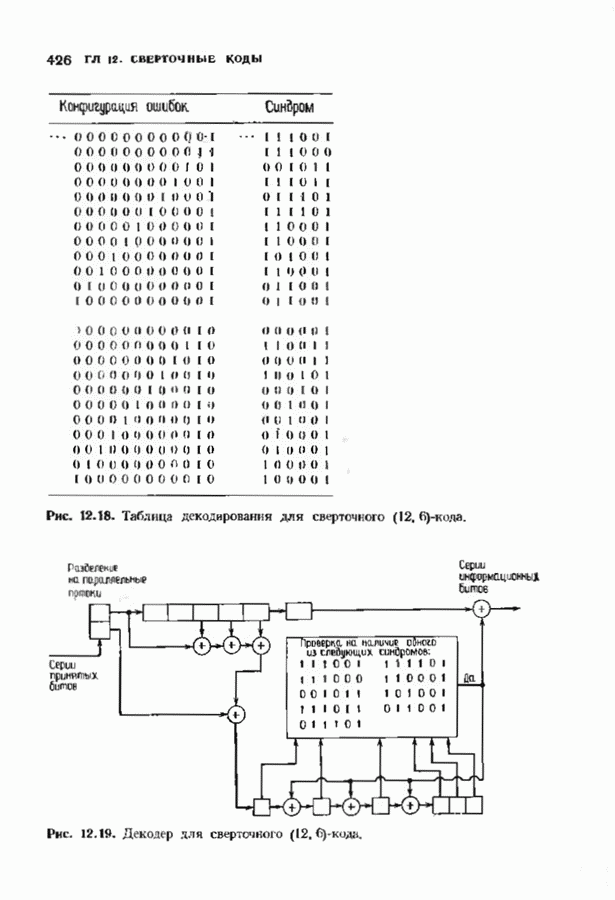
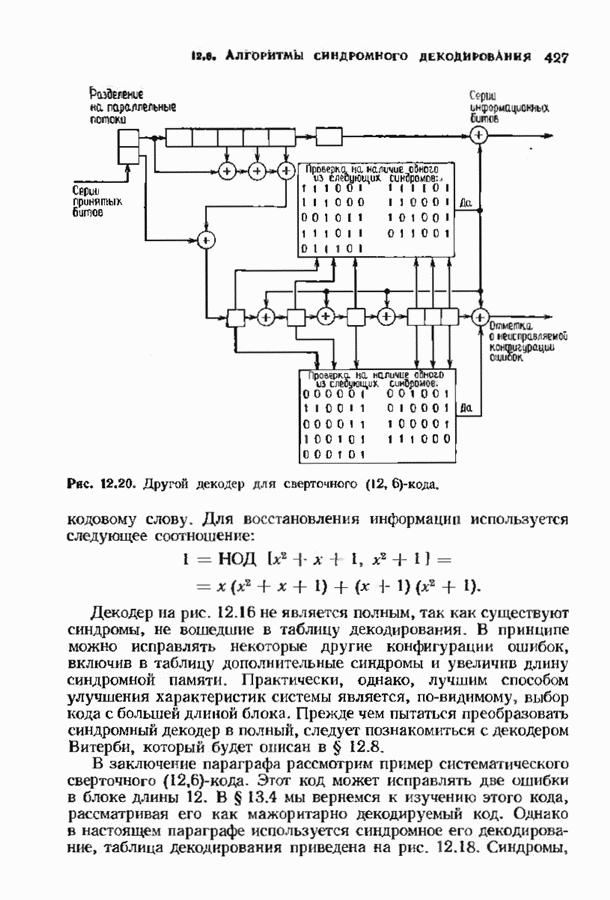
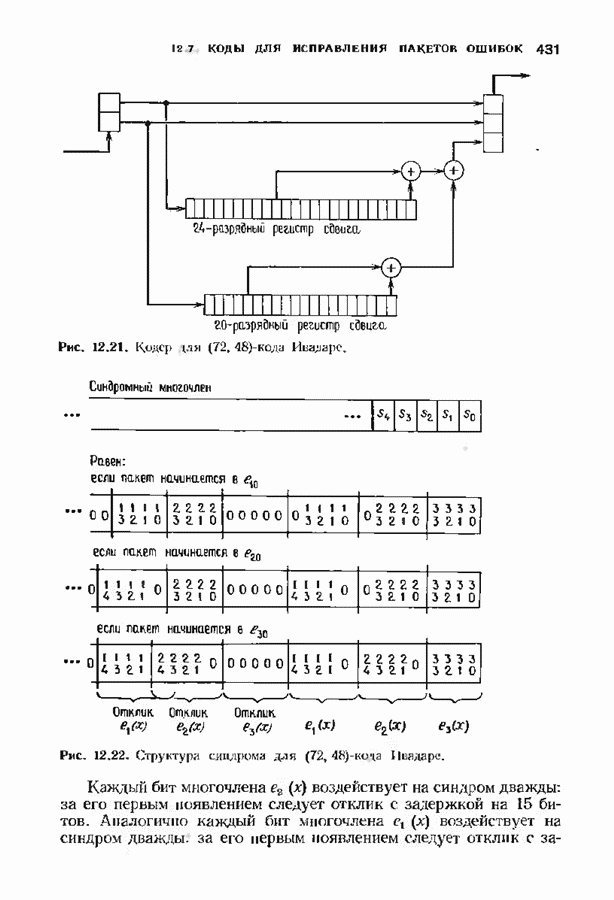
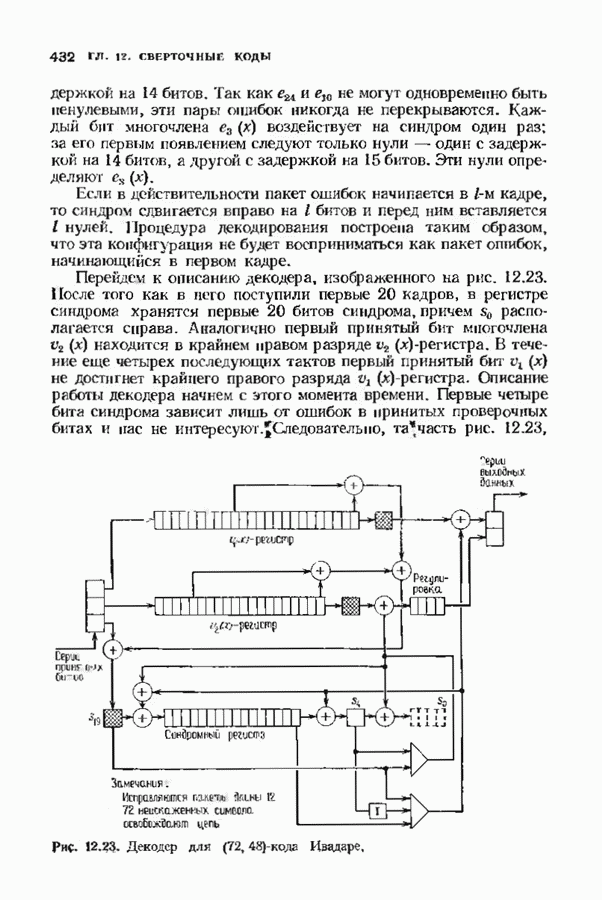
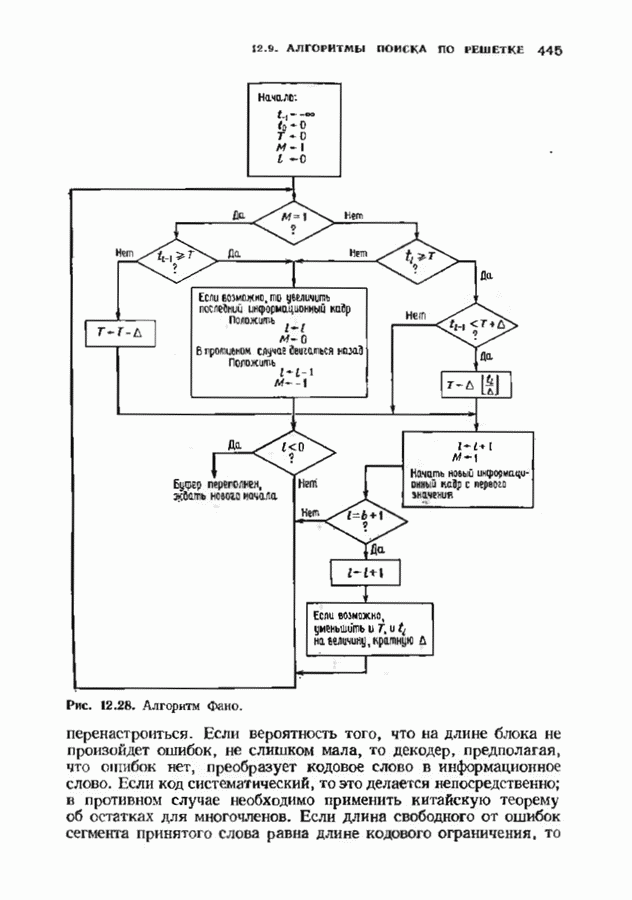
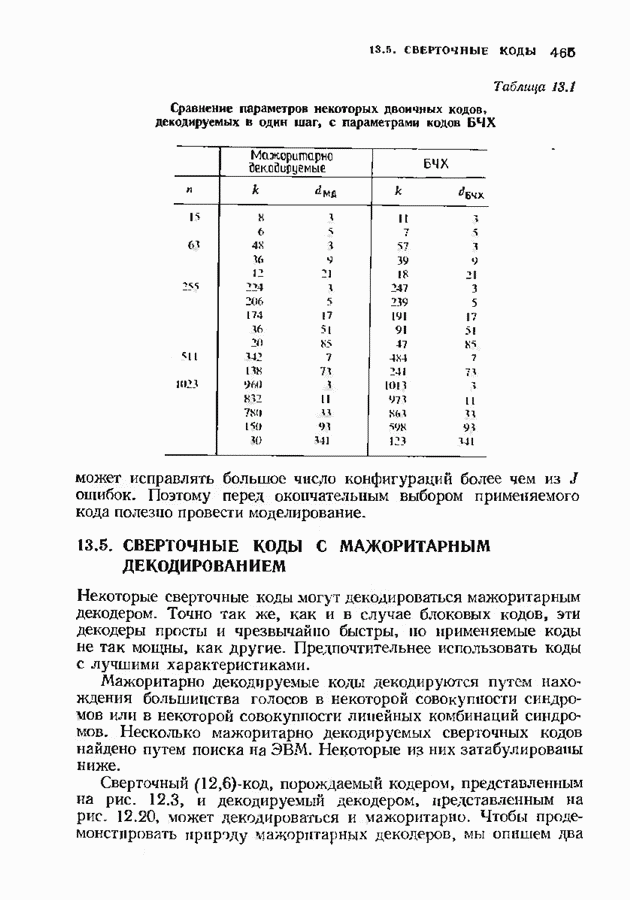
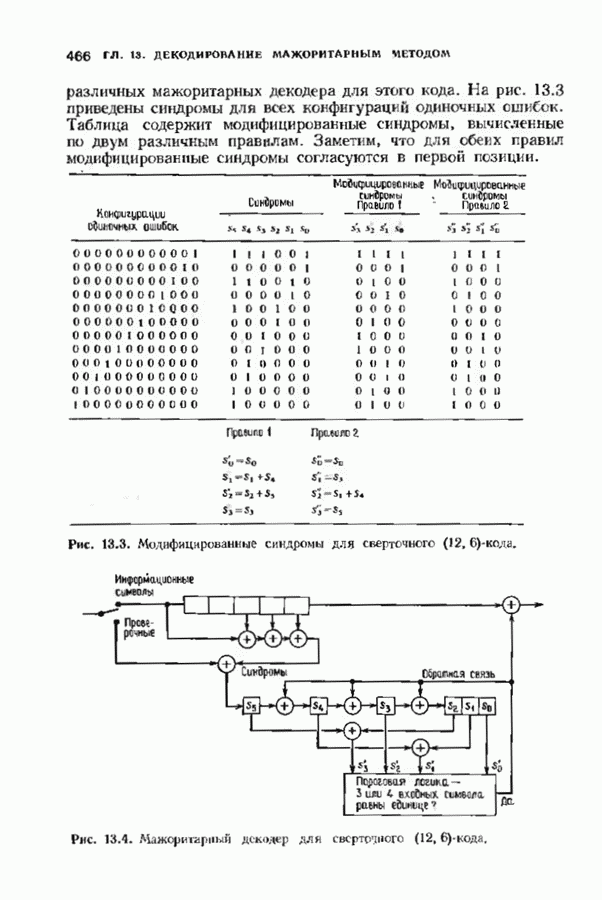
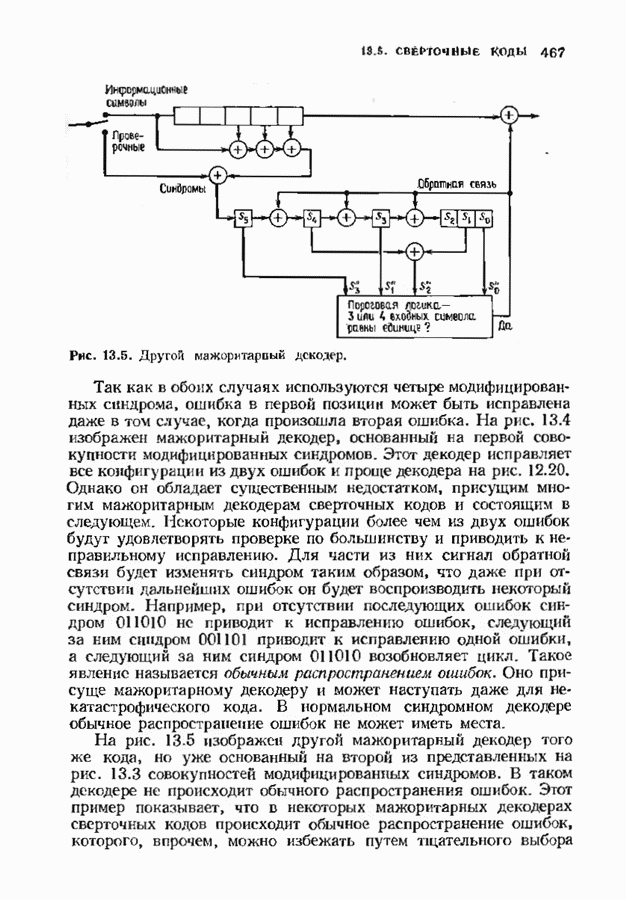
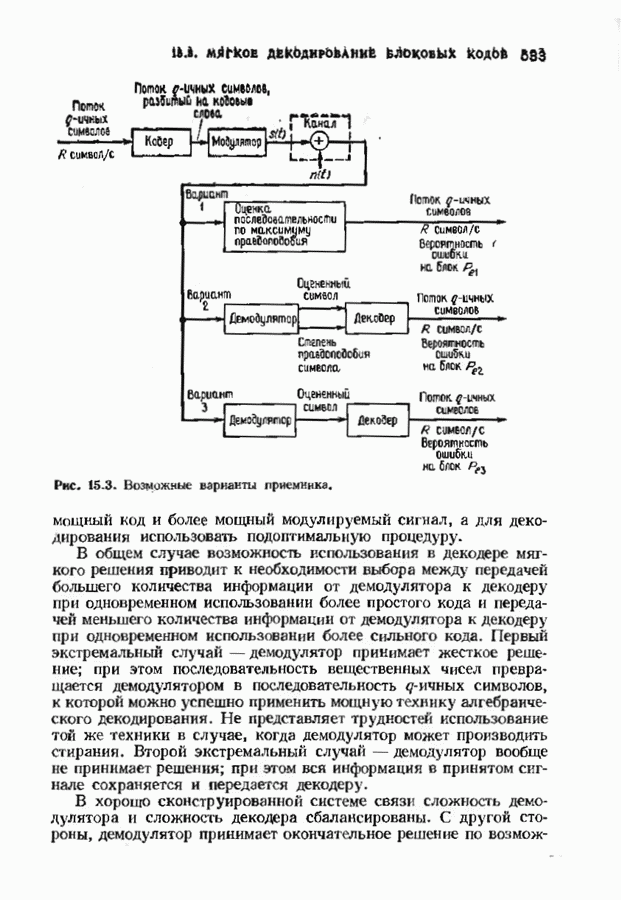
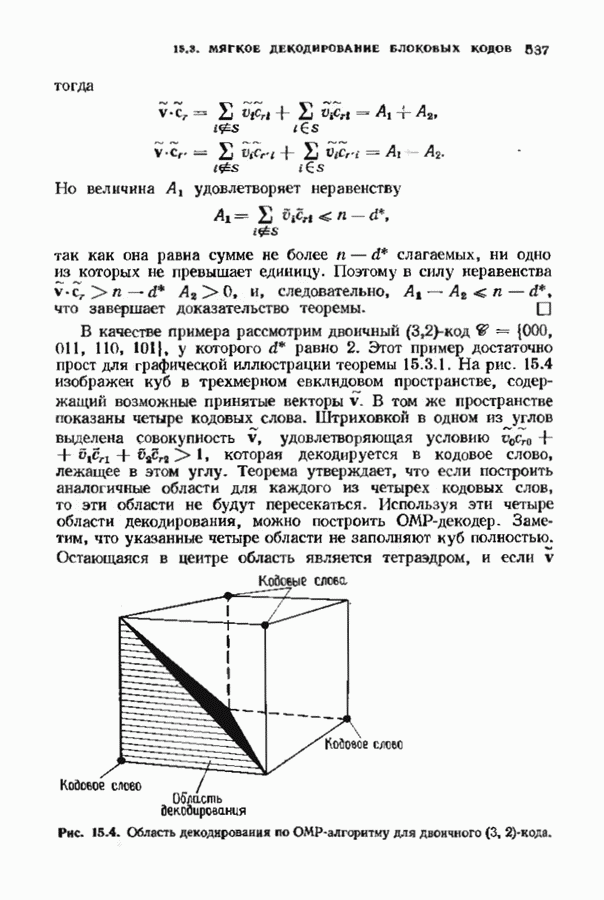
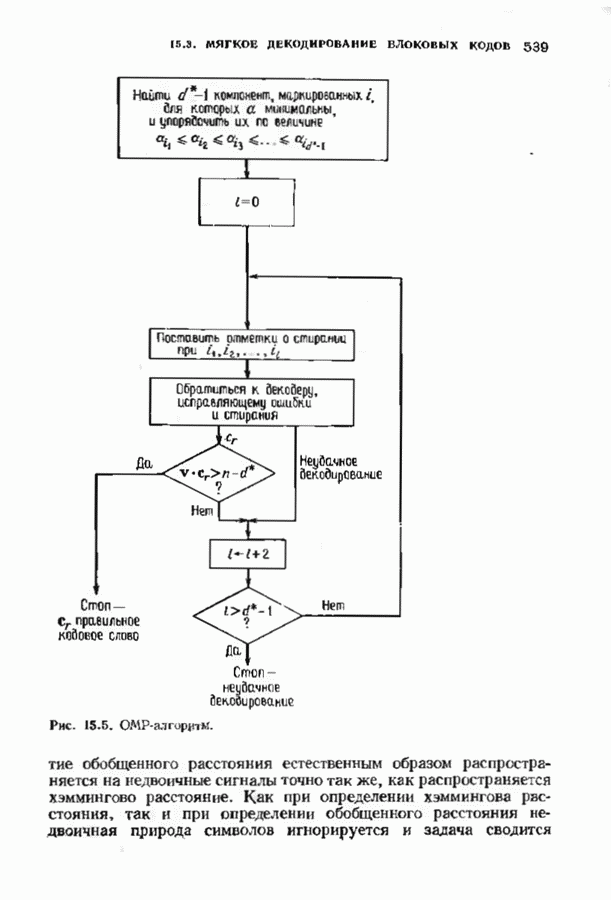
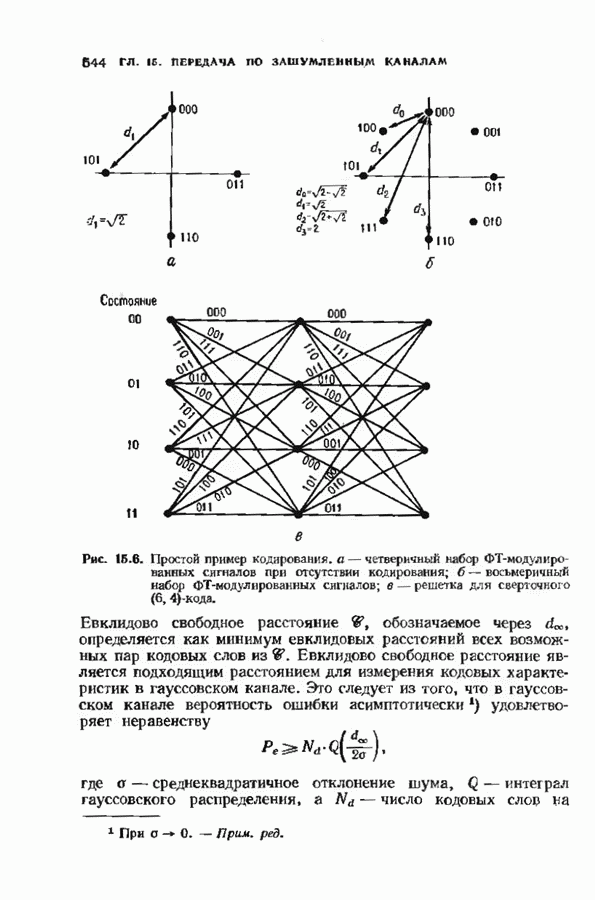
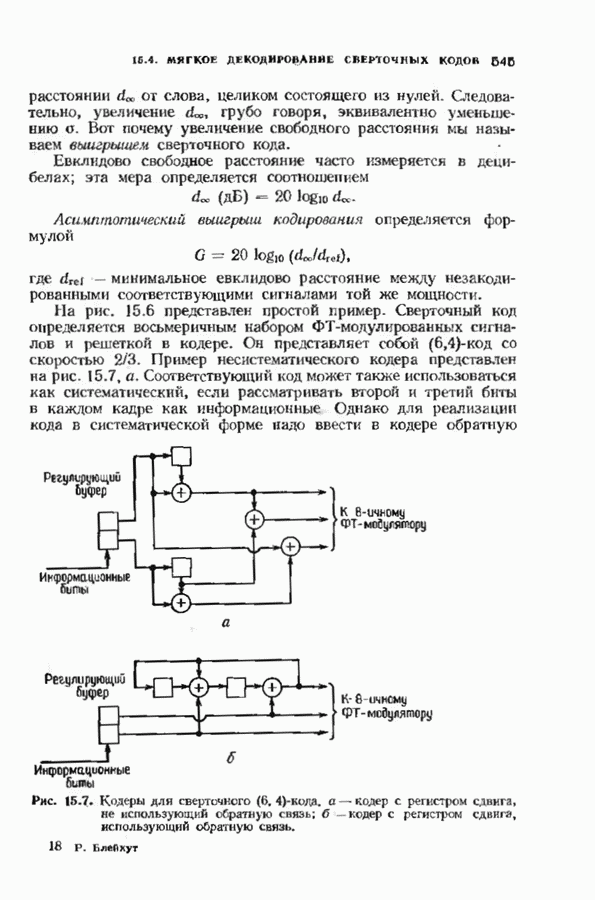
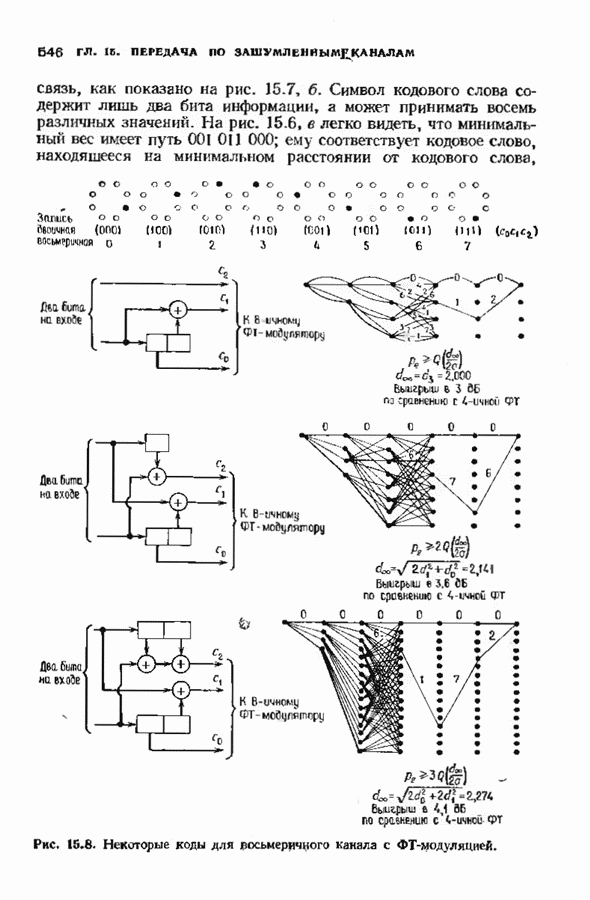
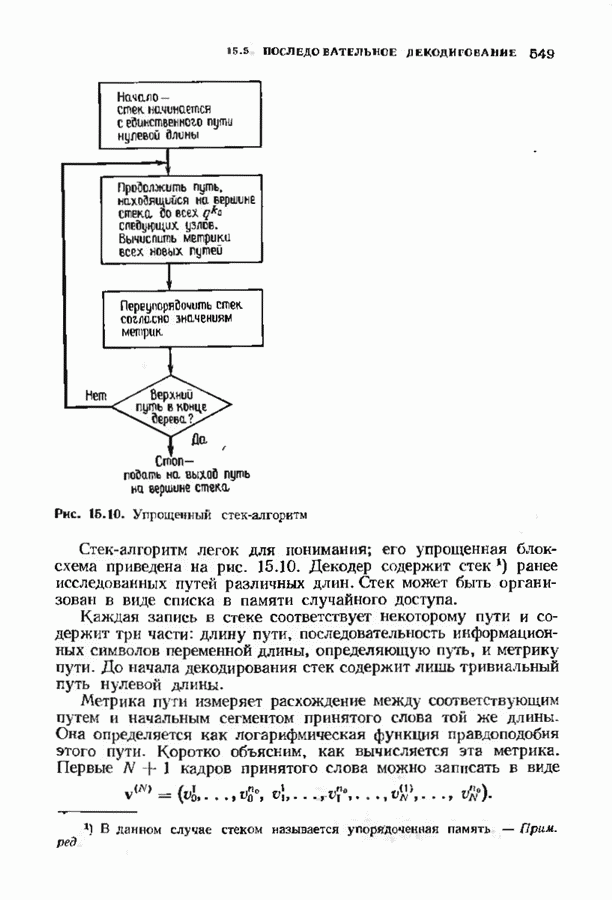
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
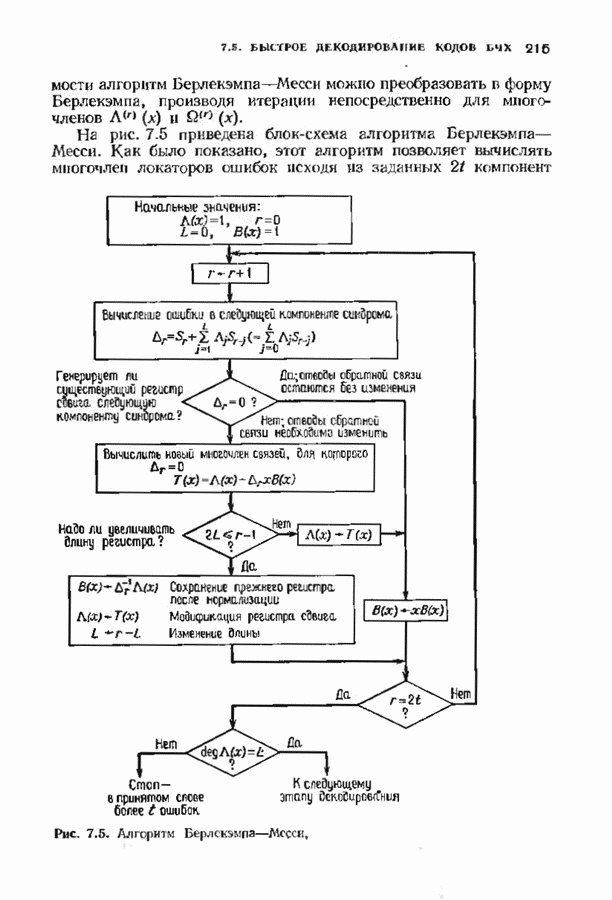
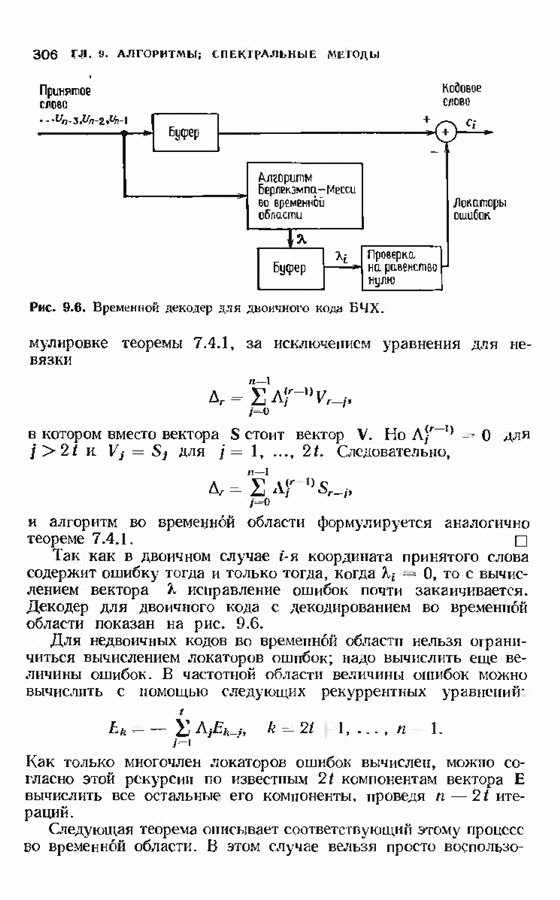
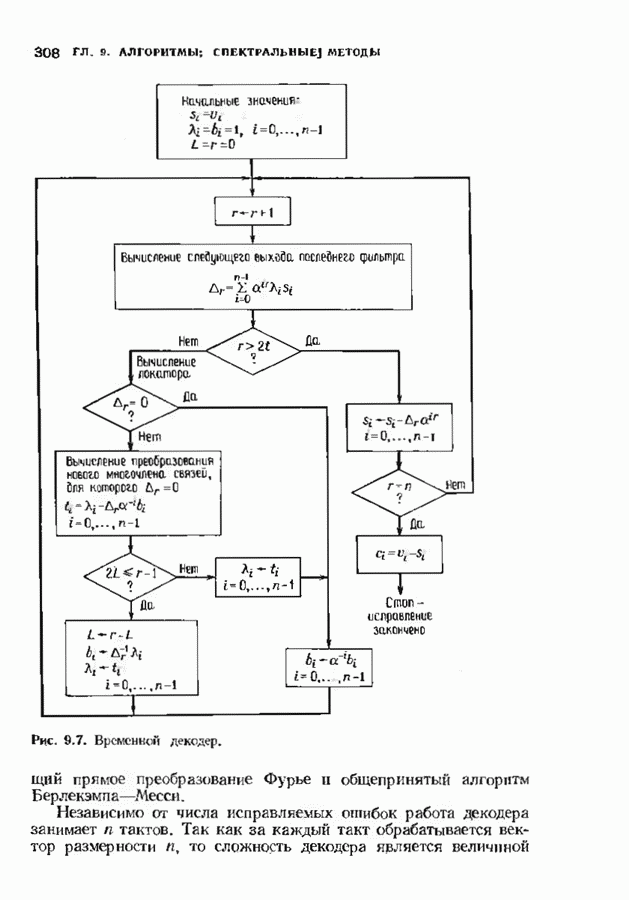
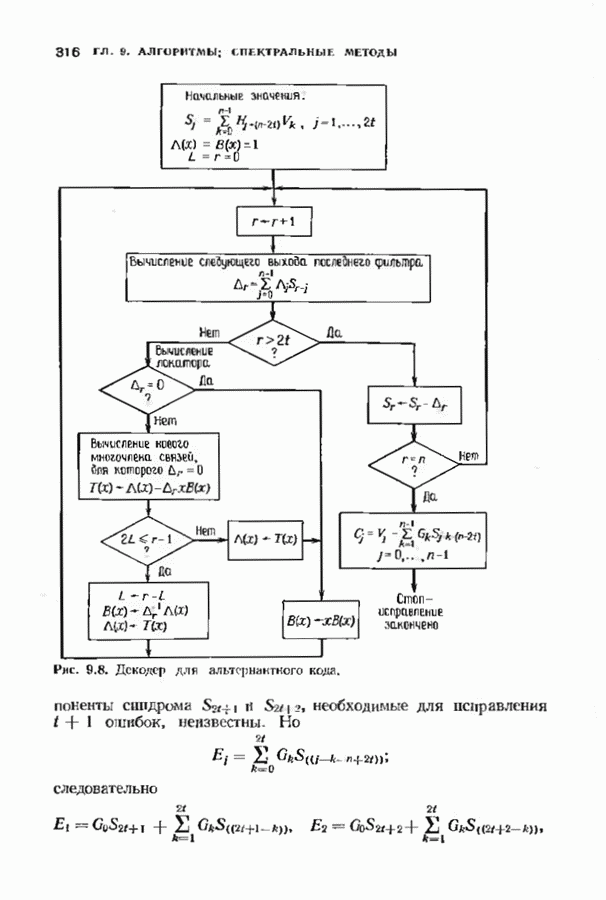
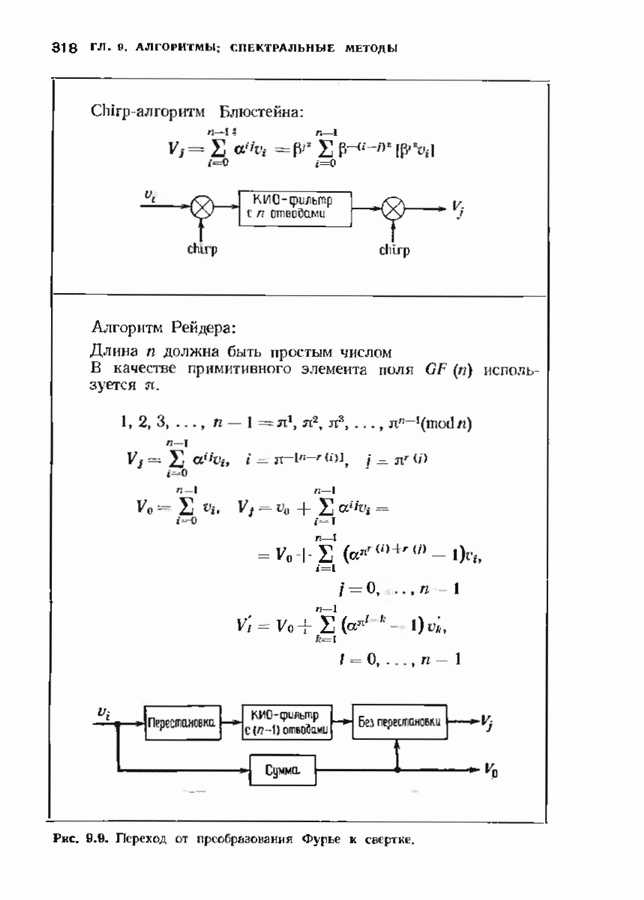
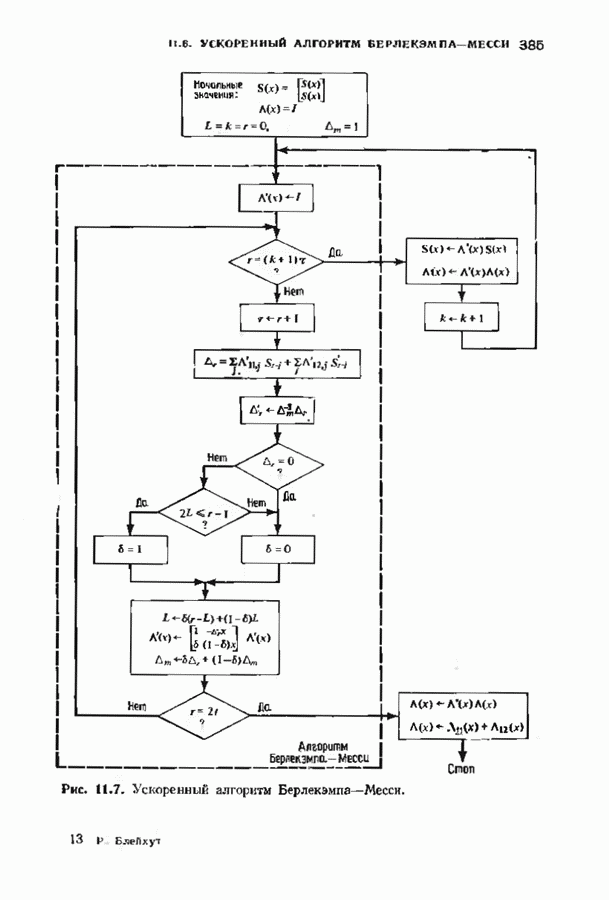
11.7. РЕКУРРЕНТНЫЙ АЛГОРИТМ БЕРЛЕКЭМПА—МЕССИ
Можно построить декодер, еще более эффективный, чем рассмотренный в предыдущем параграфе. Такой улучшенный декодер представляет не только практический, но и теоретический интерес, так как позволяет доказать, что асимптотическая сложность декодирования кодов Рида-Соломона не превосходит величины  (и очень близка к величине
(и очень близка к величине  Этот алгоритм не только обладает хорошими асимптотическими свойствами, но и практически пригоден для кодов с умеренной длиной.
Этот алгоритм не только обладает хорошими асимптотическими свойствами, но и практически пригоден для кодов с умеренной длиной.
Для простоты в основном будем рассматривать случай, когда  равно степени двух. Пусть длина
равно степени двух. Пусть длина  Рекуррентный алгоритм сводит задачу длины
Рекуррентный алгоритм сводит задачу длины  к двум задачам длины
к двум задачам длины  -которые сочленяются с помощью алгоритма
-которые сочленяются с помощью алгоритма  -точечной свертки. Каждая из этих двух подзадач в свою очередь расщепляется на две подзадачи. Это продолжается до тех пор, пока не получается задача, состоящая из одной итерации. Если каждая подзадача аналогична исходной задаче, то алгоритм допускает рекуррентную реализацию.
-точечной свертки. Каждая из этих двух подзадач в свою очередь расщепляется на две подзадачи. Это продолжается до тех пор, пока не получается задача, состоящая из одной итерации. Если каждая подзадача аналогична исходной задаче, то алгоритм допускает рекуррентную реализацию.
В случае, когда  не является степенью двух, имеется несколько способов модификации процедуры. Один
не является степенью двух, имеется несколько способов модификации процедуры. Один  них состоит в представлении числа
них состоит в представлении числа  в виде произведения простых множителей. Если
в виде произведения простых множителей. Если  представляет собой 1-й множитель, то на
представляет собой 1-й множитель, то на  уровне задача подразделяется на
уровне задача подразделяется на  подзадач вместо двух. В остальном алгоритм не меняется.
подзадач вместо двух. В остальном алгоритм не меняется.
Второй способ состоит в замене числа итераций наименьшей степенью двух, превосходящей число  и разбиении задачи на каждом уровне пополам. В каждый момент обращения к процедуре проверяется, превысил ли счетчик общего числа операций величину
и разбиении задачи на каждом уровне пополам. В каждый момент обращения к процедуре проверяется, превысил ли счетчик общего числа операций величину  . Если превысил, то итерация не выполняется и
. Если превысил, то итерация не выполняется и
алгоритм декодирования переходит к своему следующему шагу. В остальном алгоритм не изменяется.
Формулировка шага рекуррентной процедуры становится очевидной, если заметить, что описанные в предыдущем параграфе вычисления величин  по величине
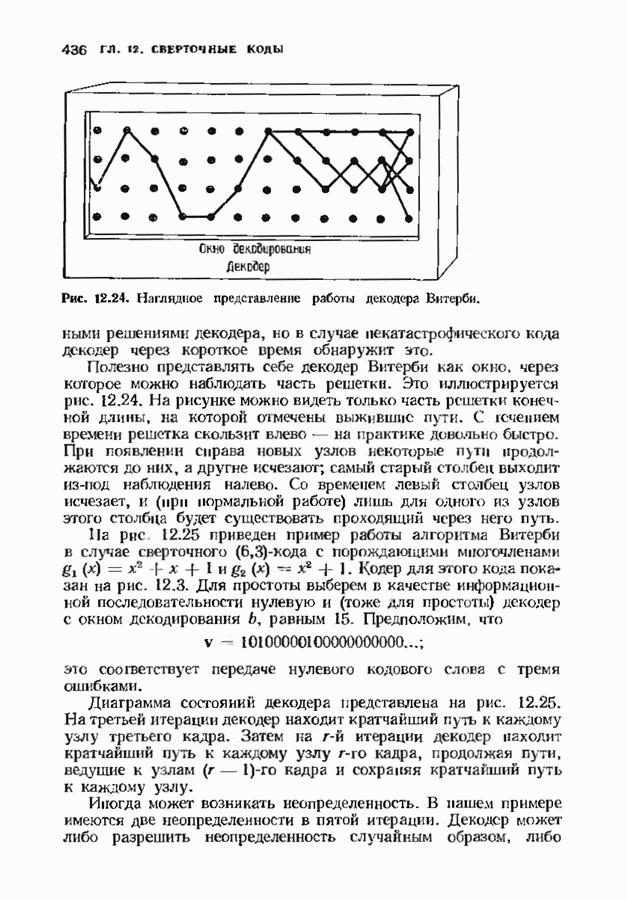
по величине  в точности совпадают с процедурой теоремы 7.4.1 с заменой
в точности совпадают с процедурой теоремы 7.4.1 с заменой  на
на  на
на  и вектора синдромных многочленов
и вектора синдромных многочленов  на
на  Следовательно, для вычисления
Следовательно, для вычисления  можно воспользоваться тем же алгоритмом, что
можно воспользоваться тем же алгоритмом, что  для вычисления
для вычисления 
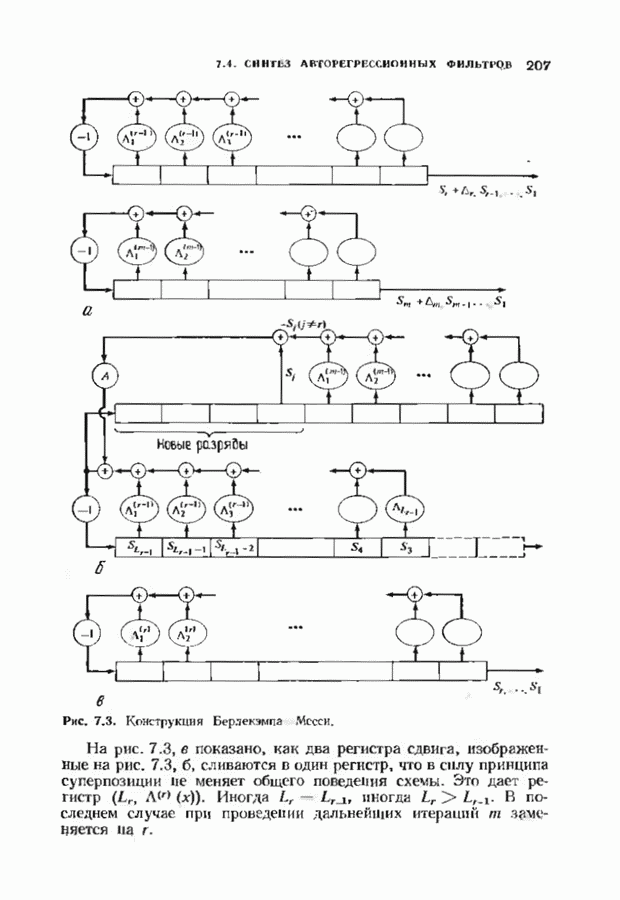
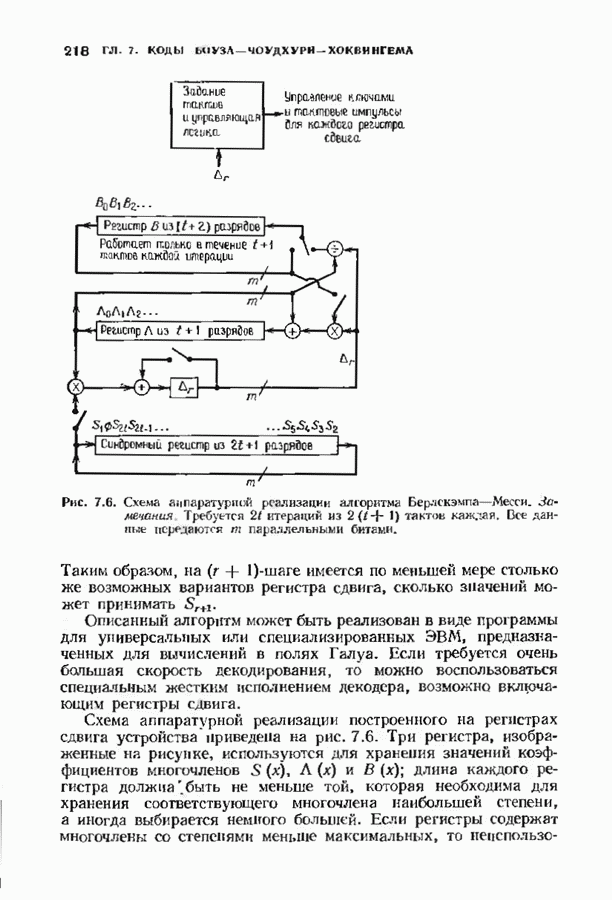
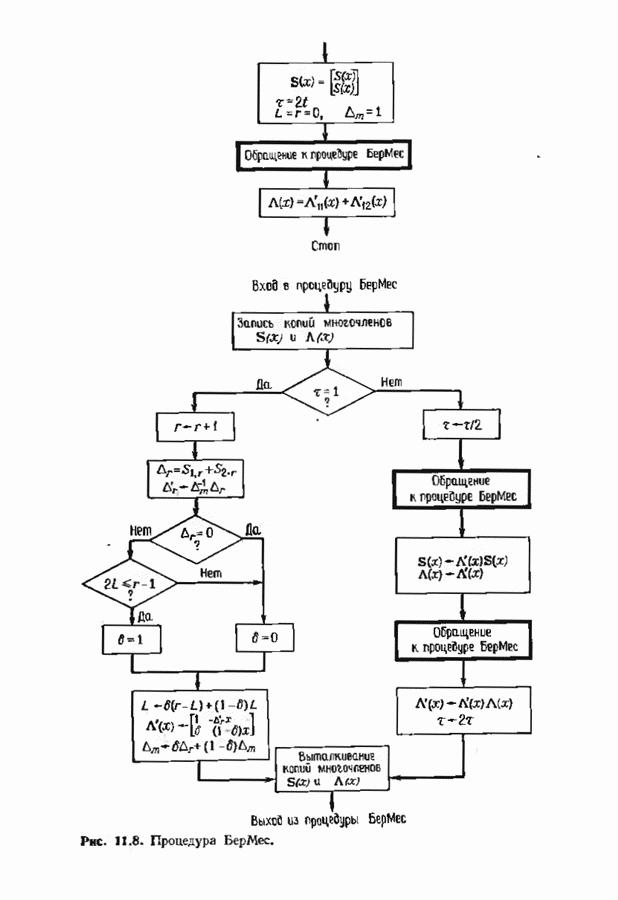
Этот рекуррентный алгоритм, названный процедурой БерМес, приведен на рис. 11.8. Процедура использует самое себя. Она содержит стековую память 1), в которой при переходе с одного уровня на другой временно запоминаются данные одного уровня. Поведение алгоритма на следующем уровне ничем не отличается от его поведения на предыдущем уровне, но в стеке записываются другие данные. В конце концов задача сводится только к одной итерации, и ее уже нельзя разделить пополам. Тогда процедура БерМес состоит просто в выполнении этой итерации и алгоритм возвращается в надлежащую точку.
Каждый раз при обращении процедуры БерМес к самой себе необходимо запоминание локальных переменных в стеке. Пели в начале алгоритма решение задвчи требует  итераций, то глубина рекурсии равна
итераций, то глубина рекурсии равна  имеется
имеется  уровней рекуррентного алгоритма. Объем стека должен быть достаточно велик для того, чтобы содержать все временные множества переменных.
уровней рекуррентного алгоритма. Объем стека должен быть достаточно велик для того, чтобы содержать все временные множества переменных.
Алгоритм проходит  уровень
уровень  раз: нулевой уровень — один раз, первый уровень — два раза и
раз: нулевой уровень — один раз, первый уровень — два раза и  последний уровень проходится
последний уровень проходится  раз. Выполняемое на
раз. Выполняемое на  уровне вычисление
уровне вычисление  содержит четыре умножения многочленов. Степень многочленов
содержит четыре умножения многочленов. Степень многочленов  равна примерно
равна примерно  и они умножаются на многочлены степени
и они умножаются на многочлены степени  Необходимо правильно вычислить только
Необходимо правильно вычислить только  коэффициентов произведения многочленов, а именно коэффициенты, стоящие при степенях переменной от
коэффициентов произведения многочленов, а именно коэффициенты, стоящие при степенях переменной от  до
до  так как только эти коэффициенты входят в вектор
так как только эти коэффициенты входят в вектор  используемый при втором обращении к процедуре БерМес. На
используемый при втором обращении к процедуре БерМес. На  уровне вычисляется также матричное произведение
уровне вычисляется также матричное произведение  которое содержит произведения многочленов степеии
которое содержит произведения многочленов степеии  каждый.
каждый.
Число умножений в процедуре БерМес почти полностью определяется свертками, так как итерации алгоритма

(кликните для просмотра скана)

Рис. 11.9. Подсчет числа умножений в процедуре БерМес.
Берлекэмпа-Месси
фактически выполняются только на конечном шаге, на котором все подалгоритмы алгоритма содержат по одной итерации и только по одному умножению (на  ), которым при подсчете общего числа умножений можно пренебречь. Вычислительная сложность процедуры БерМес определяется непосредственно вычислительной сложностью алгоритмов свертки. Успех ее использования предполагает наличие хорошего набора алгоритмов свертки.
), которым при подсчете общего числа умножений можно пренебречь. Вычислительная сложность процедуры БерМес определяется непосредственно вычислительной сложностью алгоритмов свертки. Успех ее использования предполагает наличие хорошего набора алгоритмов свертки.
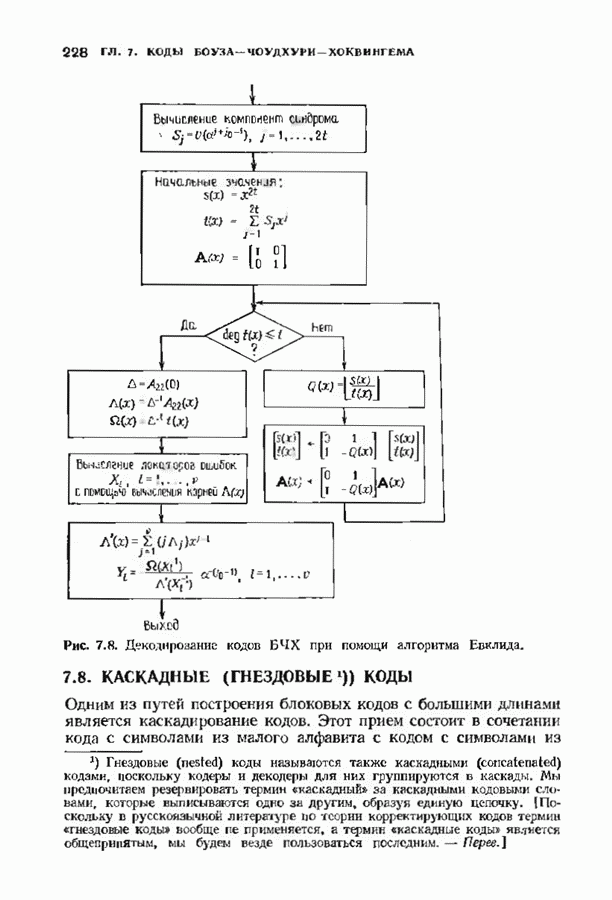
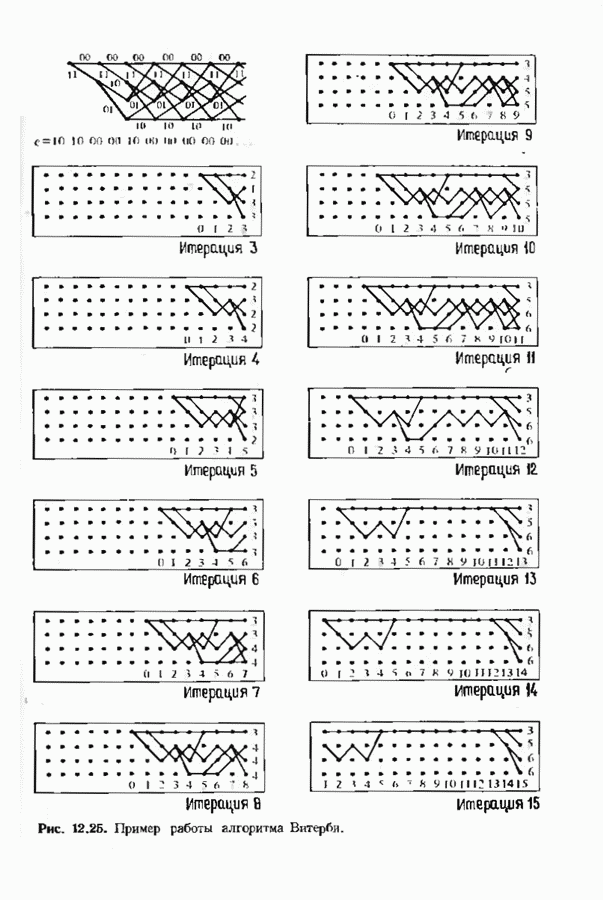
На рис. 11.9 приведены результаты подсчета числа умножений в рекуррентном алгоритме декодирования применительно к тому же  -коду Рида-Соломона, который был рассмотрен в предыдущем параграфе. Для вычисления циклических сверток в обеих половинах использовались метод перекрытия с накоплением и одна из коротких сверток, приведенных на рис. 11.5. Выписанные на рис. 11.9 детали расчетов являются убедительным свидетельством сложности структуры рассматриваемого алгоритма. Эта структура, однако, позволяет разумно использовать вычислительные ресурсы при программной и аппаратурной реализации отдельных фрагментов. По мере необходимости она вызывает алгоритмы свертки из библиотеки таких алгоритмов.
-коду Рида-Соломона, который был рассмотрен в предыдущем параграфе. Для вычисления циклических сверток в обеих половинах использовались метод перекрытия с накоплением и одна из коротких сверток, приведенных на рис. 11.5. Выписанные на рис. 11.9 детали расчетов являются убедительным свидетельством сложности структуры рассматриваемого алгоритма. Эта структура, однако, позволяет разумно использовать вычислительные ресурсы при программной и аппаратурной реализации отдельных фрагментов. По мере необходимости она вызывает алгоритмы свертки из библиотеки таких алгоритмов.
В общем случае алгоритм Берлекэмпа-Месси, содержащий  итераций, имеет измеряемую числом умножений вычислительную сложность порядка
итераций, имеет измеряемую числом умножений вычислительную сложность порядка  где
где  число умножений, необходимое для вычисления свертки двух многочленов степени
число умножений, необходимое для вычисления свертки двух многочленов степени  Это объясняется тем, что к
Это объясняется тем, что к  уровню алгоритм обращается 2 раз, причем длина выполняемой на
уровню алгоритм обращается 2 раз, причем длина выполняемой на  уровне свертки равна
уровне свертки равна  Сложность вычисления 2 сверток длины
Сложность вычисления 2 сверток длины  каждая
каждая
Принимает наибольшее значение при  , равном нулю для всех
, равном нулю для всех  значений.
значений.
Граница асимптотической сложности алгоритма зависит от асимптотической сложности вычисления свертки в полях Галуа. Напомним, что в алгоритме Винограда вычисления свертки требуется по возможности наличие простых делителей над полем  Для минимизации числа умножений показатели степени этих делителей надо выбирать малыми. Но если
Для минимизации числа умножений показатели степени этих делителей надо выбирать малыми. Но если  велико, то может не оказаться достаточного числа многочленов малой степени и будет необходимо воспользоваться многочленами степени порядка
велико, то может не оказаться достаточного числа многочленов малой степени и будет необходимо воспользоваться многочленами степени порядка  Это приведет к замене свертки длины
Это приведет к замене свертки длины  некоторым количеством сверток, наибольшая длина которых имеет порядок
некоторым количеством сверток, наибольшая длина которых имеет порядок  Этот же процесс приведет к замене свертки длины
Этот же процесс приведет к замене свертки длины  и некоторым количеством сверток меньшей длины, самая длинная из которых имеет порядок длины, равный
и некоторым количеством сверток меньшей длины, самая длинная из которых имеет порядок длины, равный  Формализуя это рассуждение, можно сказать, что асимптотическая сложность вычисления свертки в поле Галуа равна величине
Формализуя это рассуждение, можно сказать, что асимптотическая сложность вычисления свертки в поле Галуа равна величине  где
где  — число, показывающее, сколько раз надо последовательно проинтегрировать логарифм по основанию 2, начиная с
— число, показывающее, сколько раз надо последовательно проинтегрировать логарифм по основанию 2, начиная с  для того, чтобы получить число, не превосходящее единицы. Таким образом
для того, чтобы получить число, не превосходящее единицы. Таким образом

и число шагов в этом итеративном процессе равно  Величина
Величина  стремится к бесконечности медленнее, чем итерированный любое число раз логарифм.
стремится к бесконечности медленнее, чем итерированный любое число раз логарифм.
Лучшая известная граница числа  имеет вид
имеет вид  следовательно, сложность рекуррентного алгоритма Берлекэмпа-Месси оценивается величиной
следовательно, сложность рекуррентного алгоритма Берлекэмпа-Месси оценивается величиной  Таким образом, сложность рекуррентного алгоритма Берлекэмпа-Месси больше, чем
Таким образом, сложность рекуррентного алгоритма Берлекэмпа-Месси больше, чем  но очень близка к этой границе.
но очень близка к этой границе.