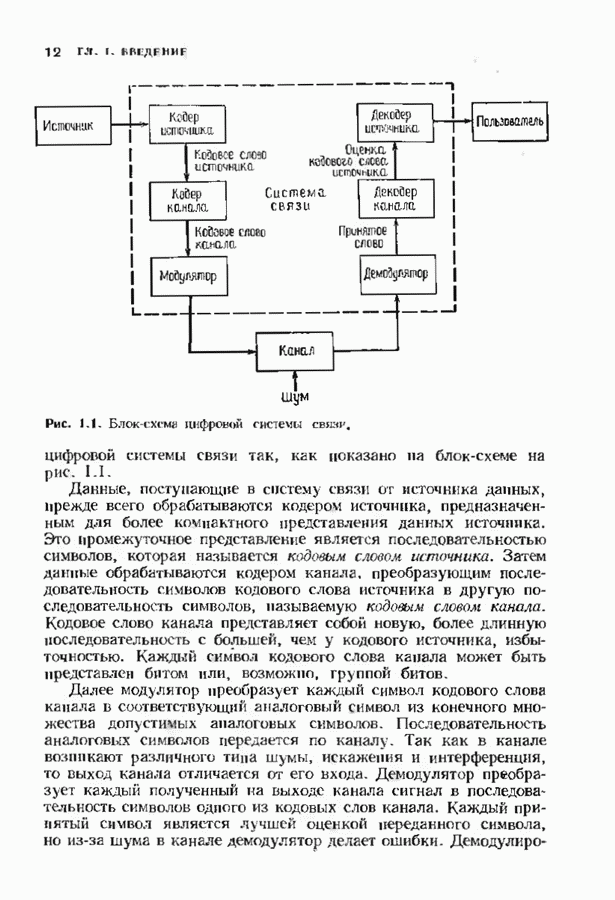
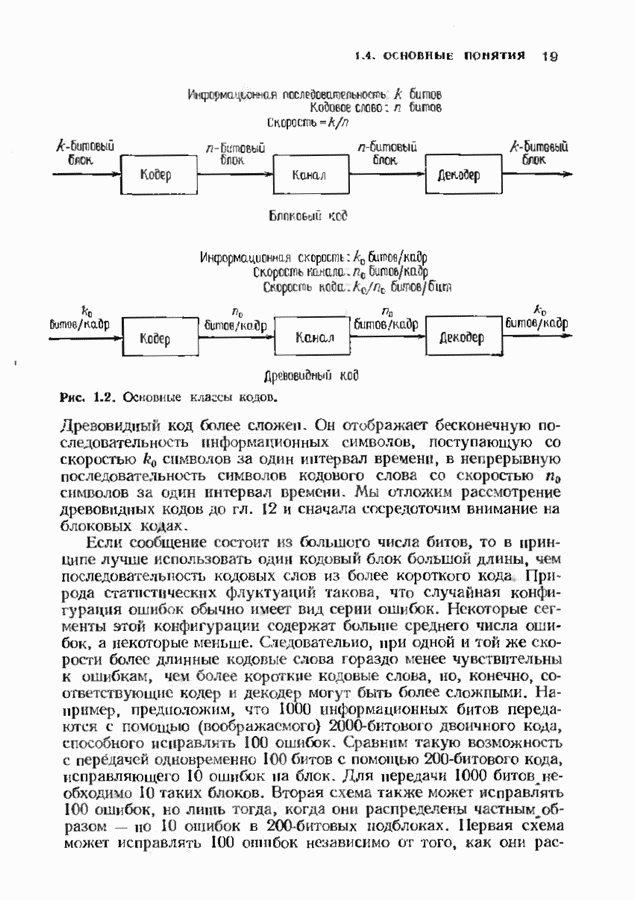
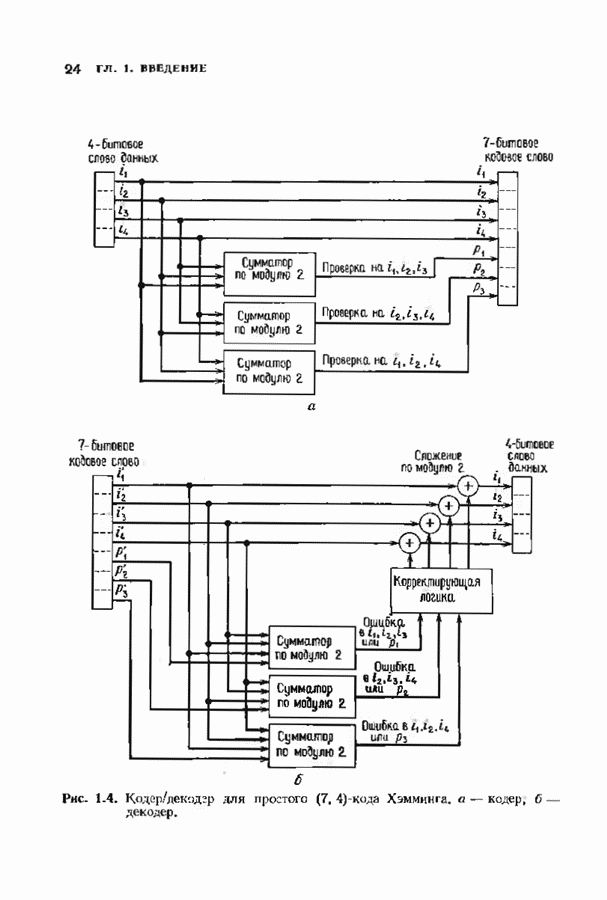
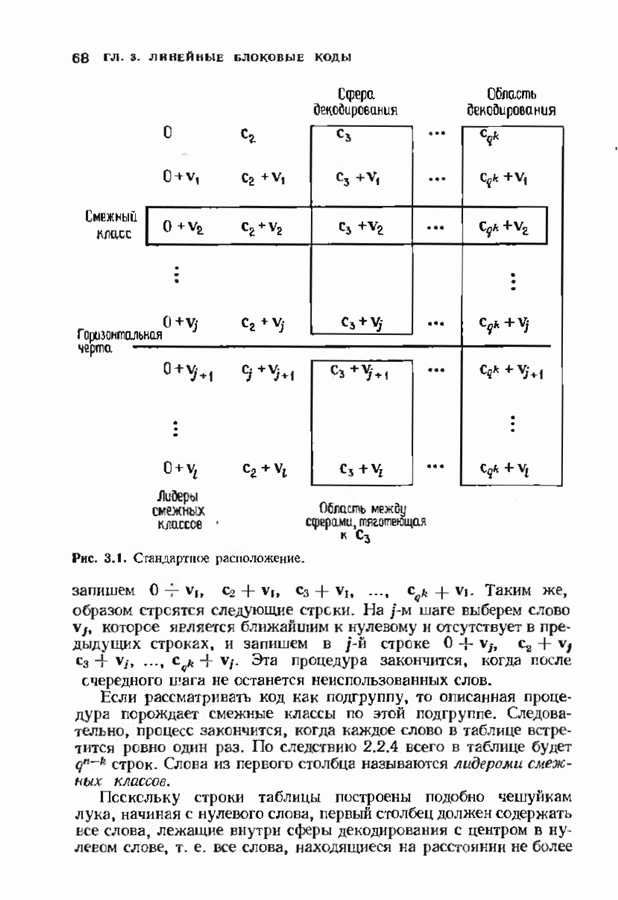
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
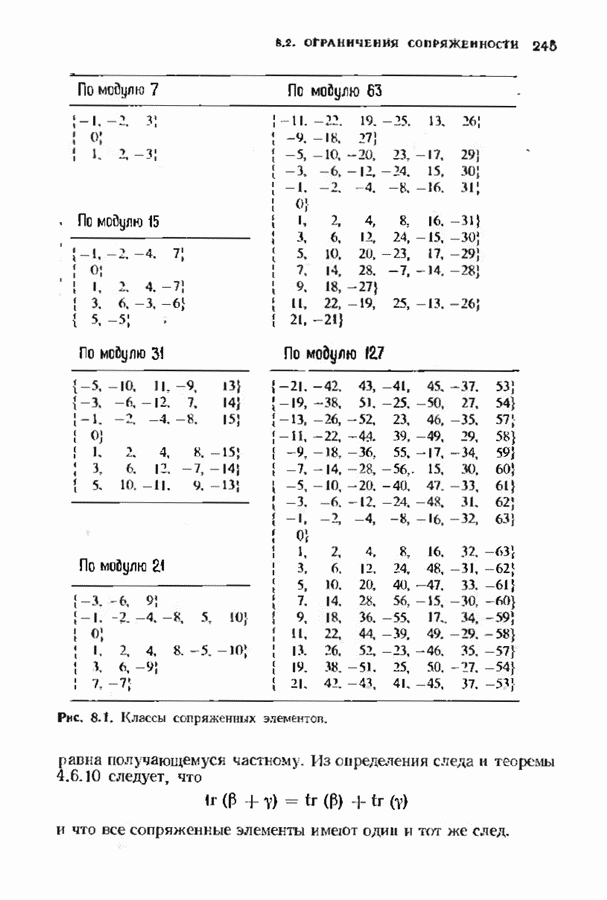
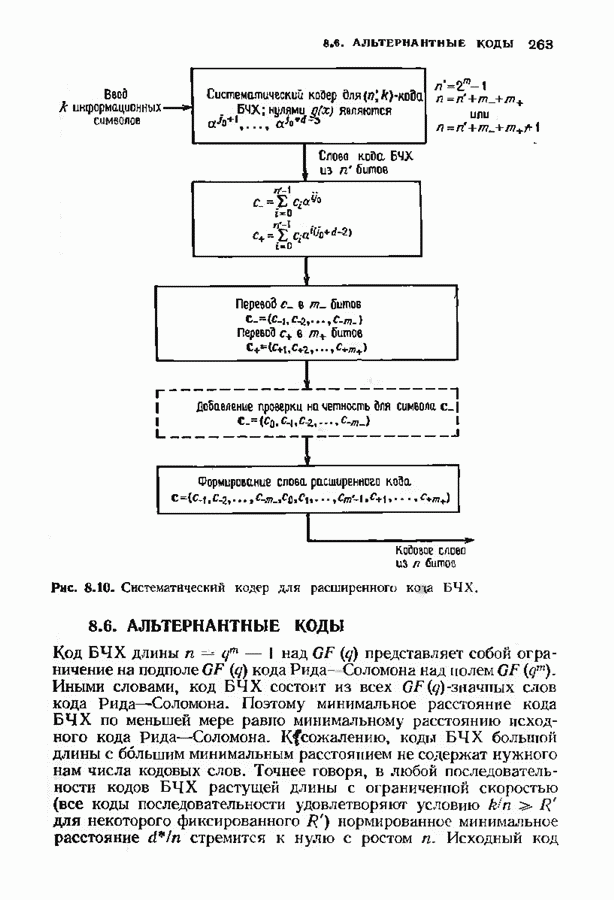
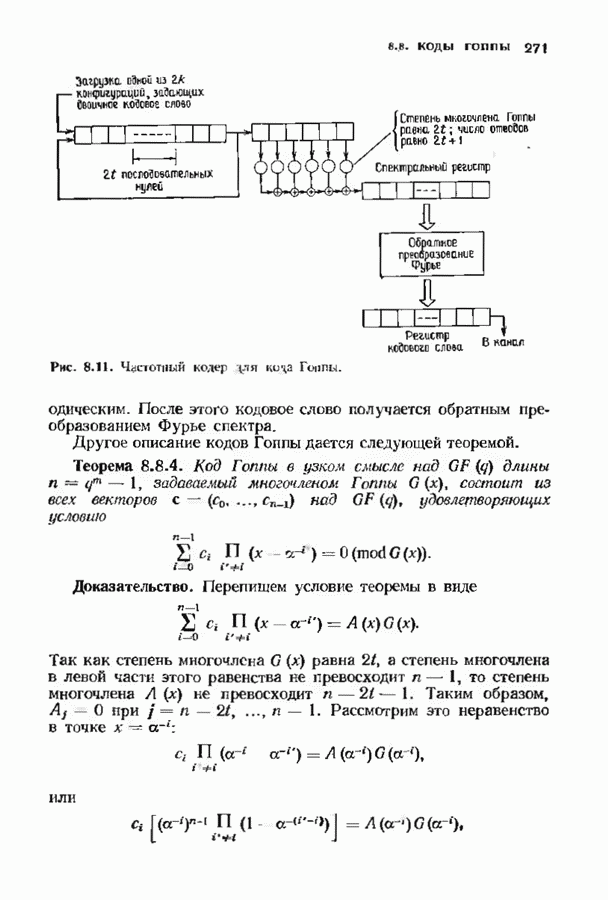
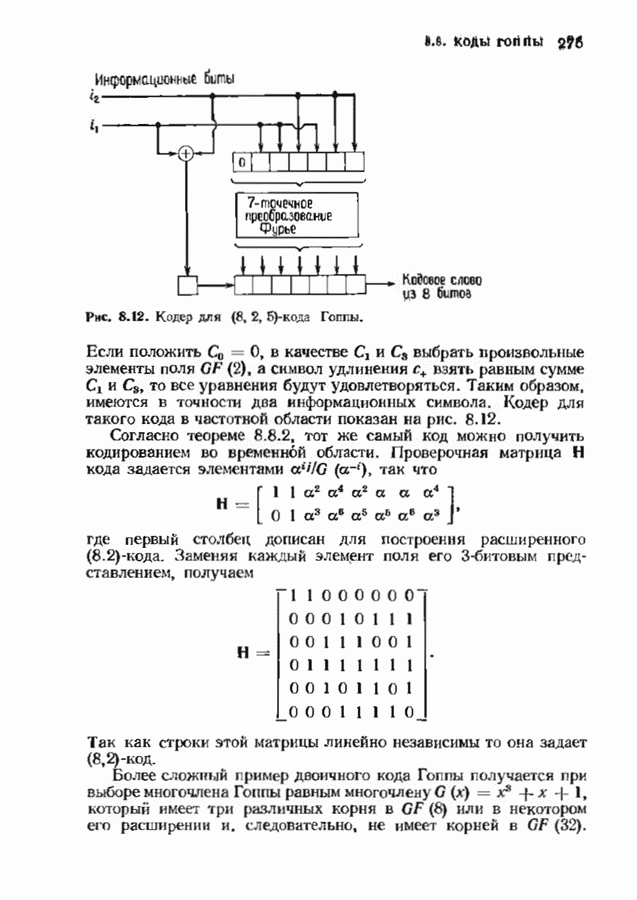
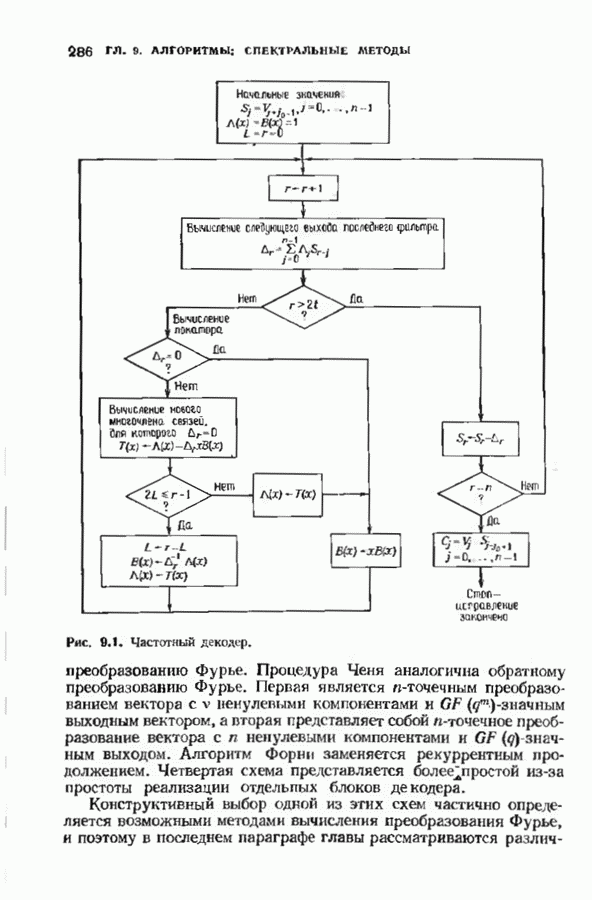
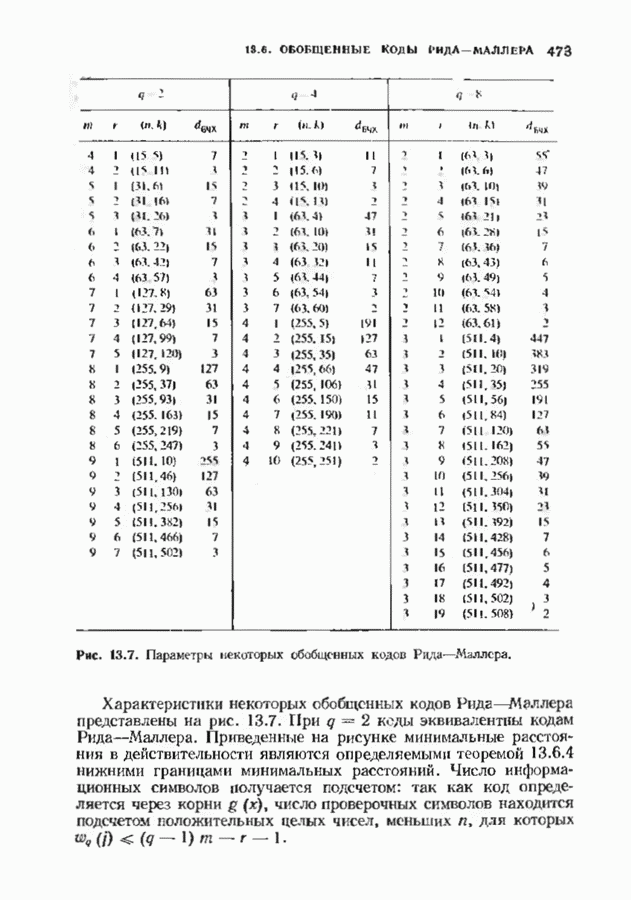
7.9. КОДЫ ЮСТЕСЕНАЛюбой код над полем Это «развертывание» представляет собой простой способ построения кода, исправляющего многократные пакеты ошибок. Если исходный код имел минимальное расстояние, равное 5, то в результате получится код, исправляющий одиночные пакеты Юстесен обнаружил, что если разумным образом дополнить эту конструкцию, то можно получить хорошие коды. В результате получился класс кодов, называемых кодами Юсгесена, содержащий, как будет показано ниже, некоторые очень хорошие коды. К сожалению, коды Юстесена хороши только при больших длинах и поэтому не представляют особого практического интереса. Эти коды могут служить примером построения хороших кодов с большой длиной. Алгоритмы декодирования кодов Юстесена еще не достаточно разработаны. Кодовое слово
Каждый элемент этой таблицы лежит в поле Прежде всего заметим, что указанная процедура приводит к линейному коду. Это важно, поскольку в этом случае для определения минимального расстояния кода достаточно найти значение минимального веса в коде. Остановимся теперь на той особенности конструкции Юстесена, благодаря которой она относится к классу хороших кодов. Поскольку слова кода Рида-Соломона имеют вес не менее Теорема 7.9.1. Для минимального расстояния
имеет место оценка Доказательство. Кодовое слово минимального веса содержит
существует столбец веса
Для того чтобы наилучшим образом использовать результат теоремы 7.9.1, требуется помощь ЭВМ. Но для больших значений Лемма 7.9.2. Для всех
Доказательство. Пусть — произвольное положительное число. Справедлива следующая цепочка неравенств:
Отсюдв получаем
Выберем теперь к
что доказывает лемму. Лемма 7.9.3. Для любого множества
где X — любое число в интервале (0, 1/2). Доказательство. В силу леммы 7.9.2 в рассматриваемом множестве для любого к из интервала (0, 1/2) число последовательностей длины
Таким образом, для каждого X существует не менее
Лемма доказана. Теорема 7.9.4. Пусть для каждого фиксированного
где Доказательство. Поскольку
Выберем
или
Полагая
приходим к утверждению теоремы. Из теоремы 7.9.4 следует важность кодов Юстесена. Эта теорема гласит, что для достаточно больших
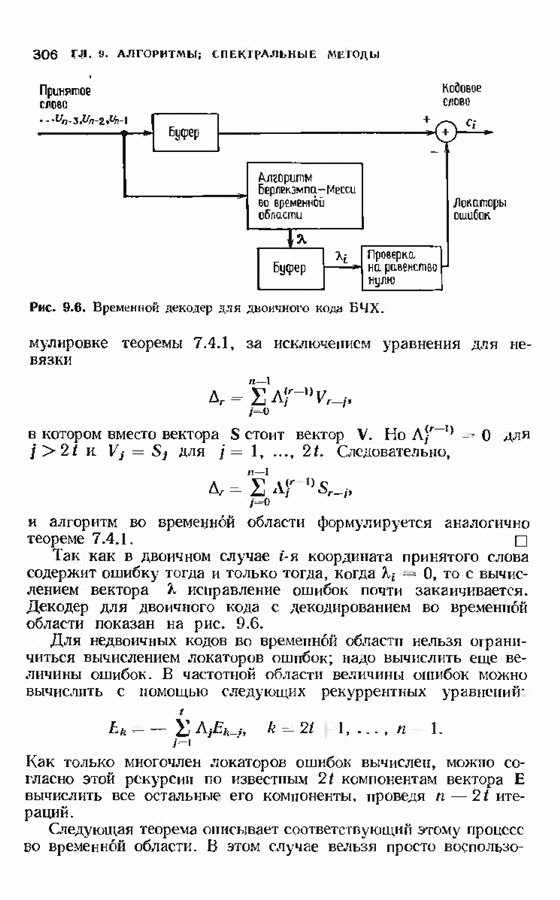
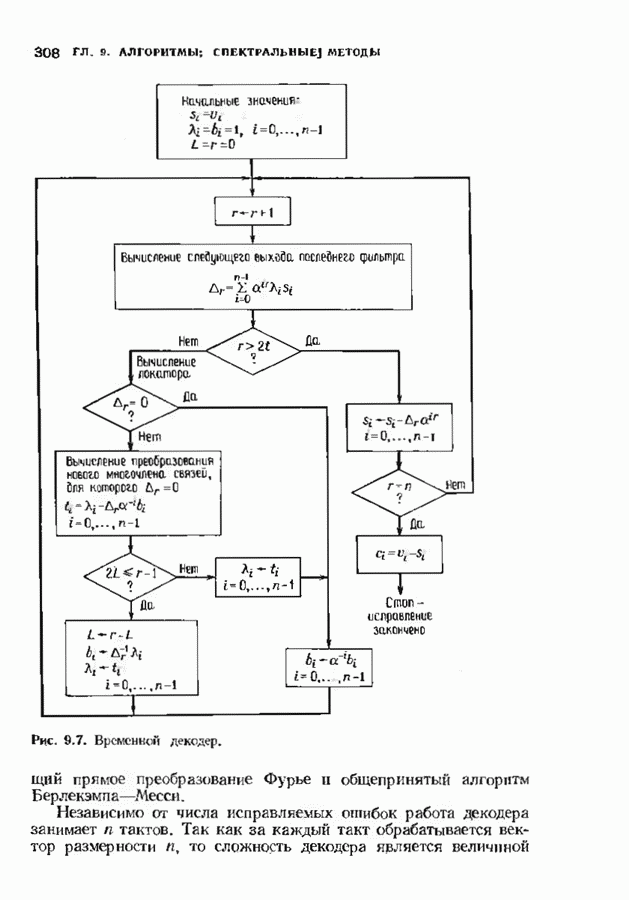
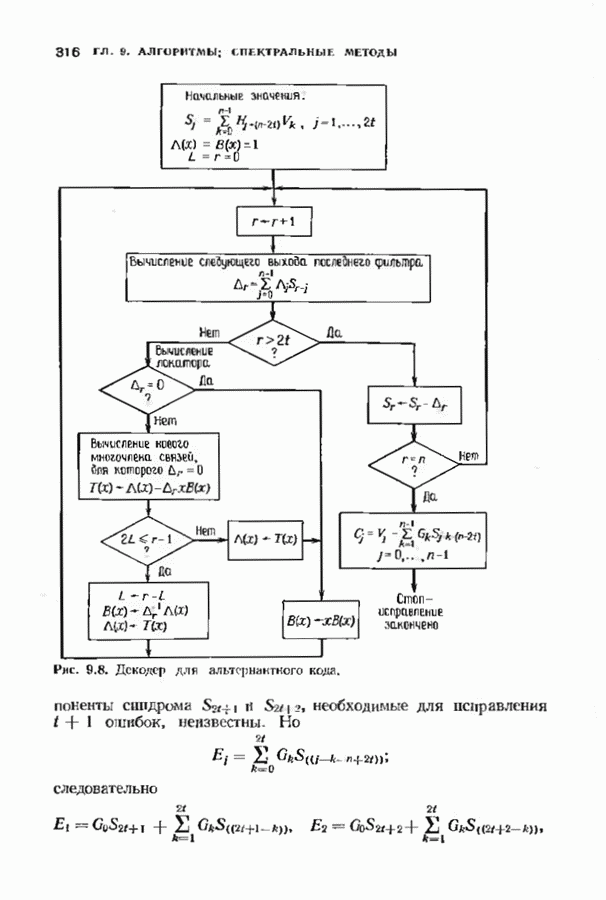
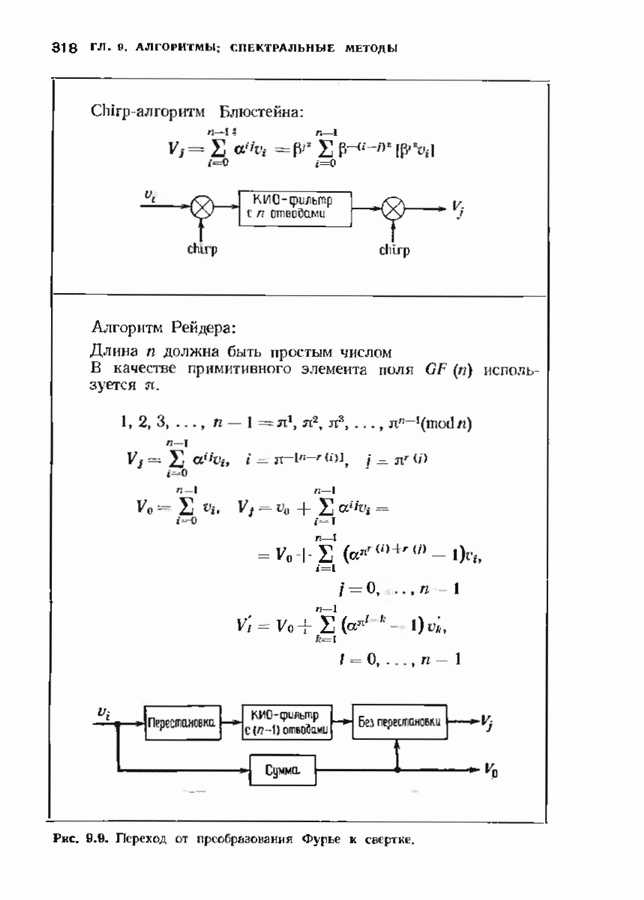
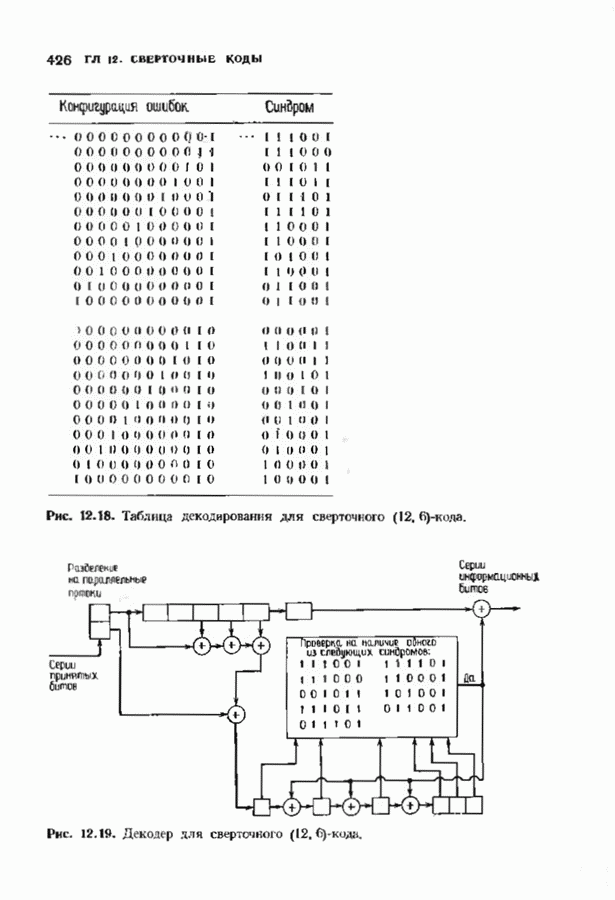
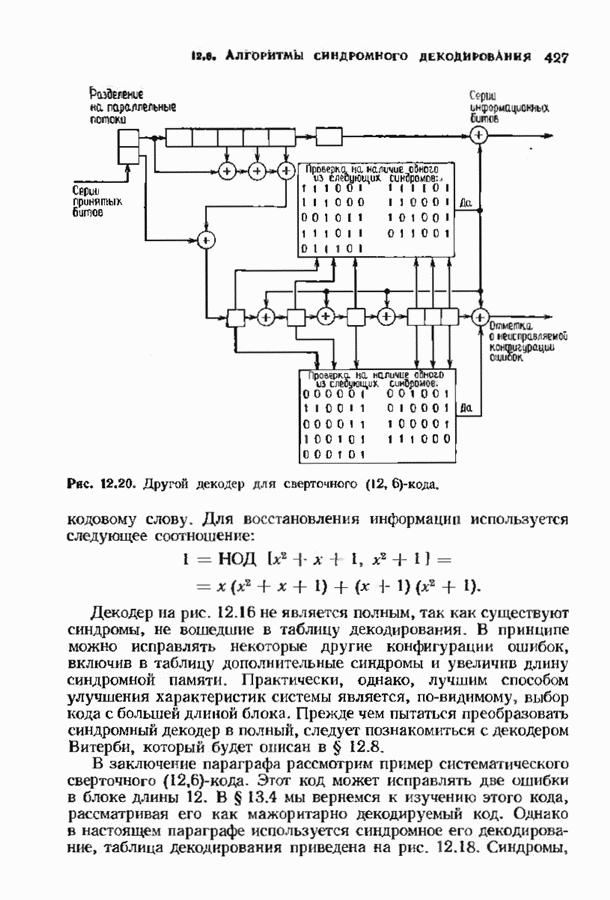
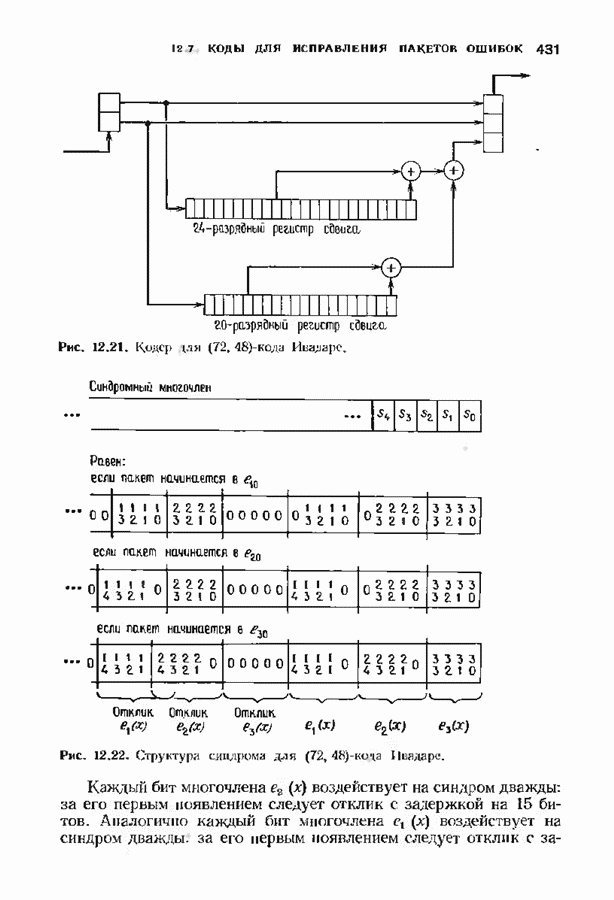
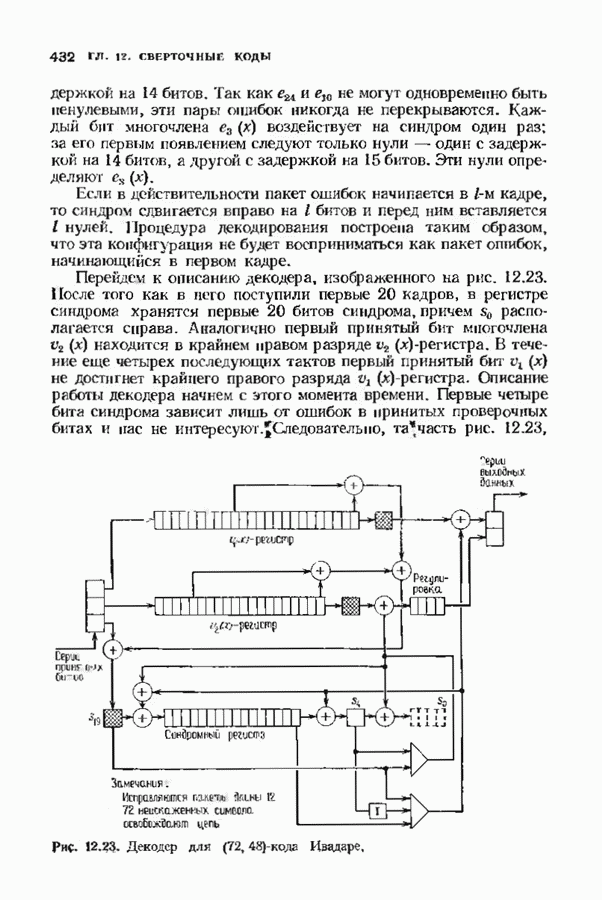
При фиксированном Коды Юстесена имеют скорость, меньшую 1/2. Коды с большей скоростью можно получить, выкалывая компоненты исходного кода. Получаемые таким образом коды также представляют только теоретический интерес как пример кодов, имеющих хорошие характеристики при очень больших длинах. ЗАДАЧИ(см. скан) (см. скан) (см. скан) ЗАМЕЧАНИЯКоды БЧХ независимо открыли Хоквингем [1959] и Боуз и Рой-Чоудхури [1960]. Вскоре Горенстейн и Цирлер [19611 установили, что открытые ранее Ридом и Соломоном [19601 коды являются частным случаем недвоичных кодов БЧХ. Поведение минимального расстояния и скорости кодов БЧХ большой длины исследовалось многими авторами на протяжении большого промежутка времени. Коды БЧХ длины Касами и Токура [1969] открыли бесконечный подкласс примитивных кодов БЧХ, для которых граница БЧХ строго меньше истинного минимвльного расстояния, первым примером такого кода был Впервые процедура исправления ошибок для двоичных кодов БЧХ была предложена Питерсоном [1960], а для кодов БЧХ с произвольным алфавитом — Горенстенном и Цирлером [1961]. Чень [1964] и Форни 11965] упростили эту процедуру. Итеративный алгоритм нахождения многочлена локаторов ошибок был предложен Берлекэмпом [1968]. Месси [1969] представил этот алгоритм в виде процедуры построения авторегрессиоиных фальтров. Бартон [1971] показьл, как осуществлть алгоритм Берлекэмпа-Месси. не используя деления, хотя для вычисления значений ошибок деление все равио необходимо. Сугияыа, Касахара, Хирасава и Намекава [1975] впервые предложили использовать при декодировании алгоритм Евклида. Велч и Шольц 119791 построили использующий разложение в непрерывную дробь декодер, совершенно эквивалентный декодеру, использующему алгоритм Евклида. Другой способ использования алгоритма Евклида при декодировании был предложен Мандельбаумом [19771 и будет рассмотрен в § 9.1
|
 |
Оглавление
|















































































































































































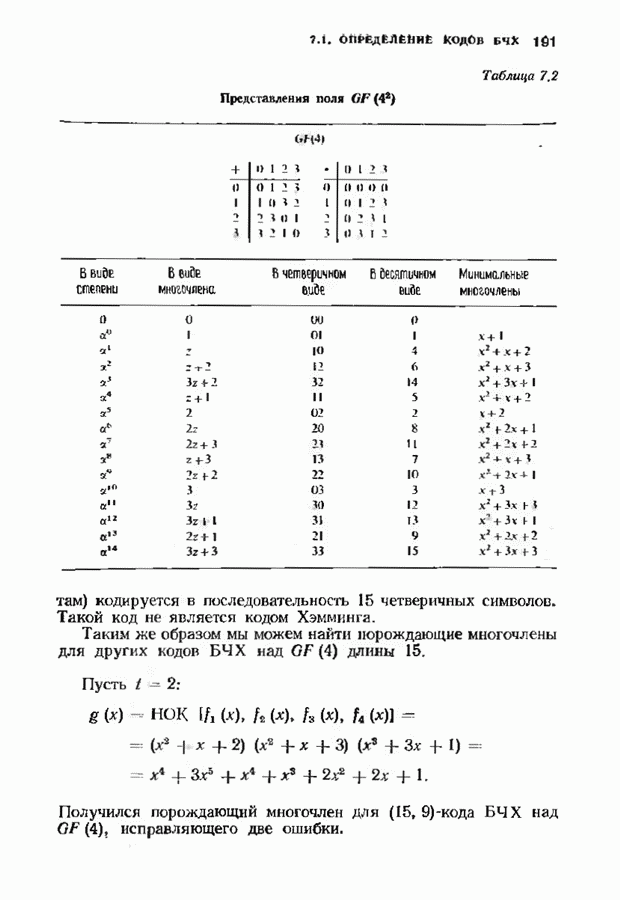







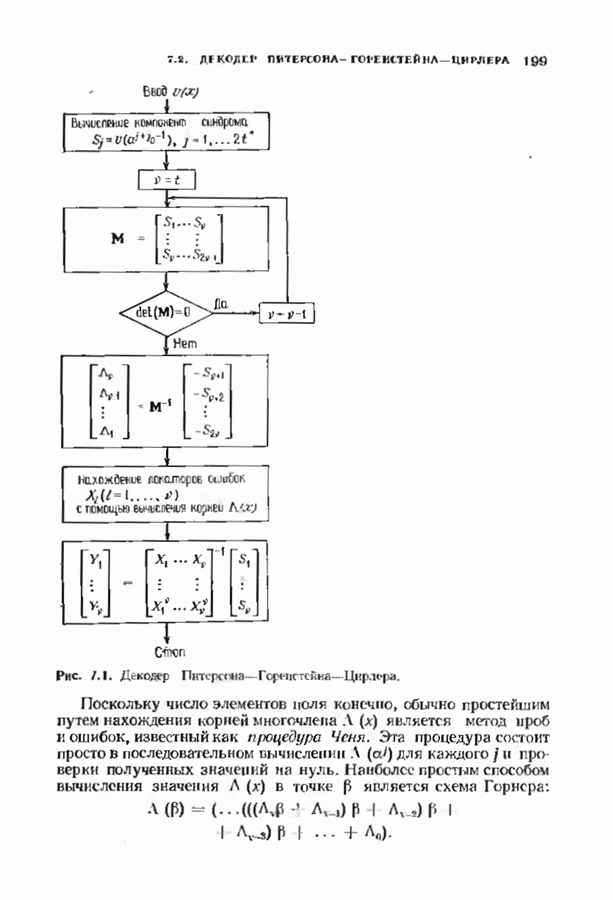







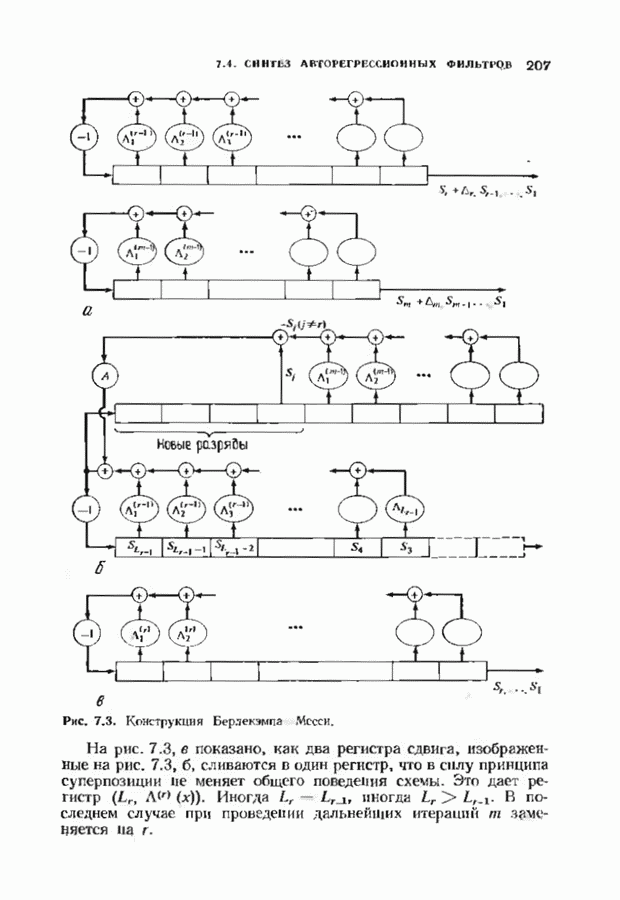






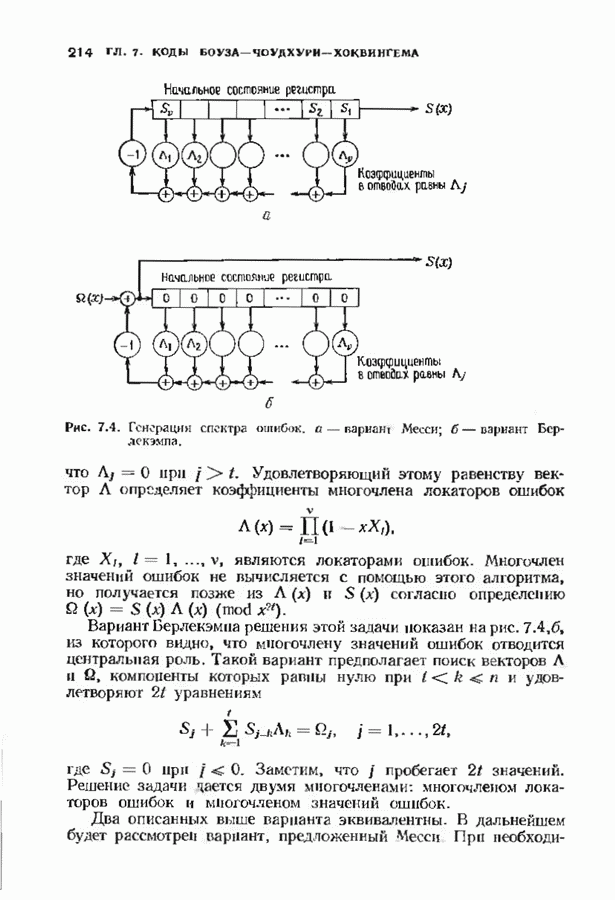































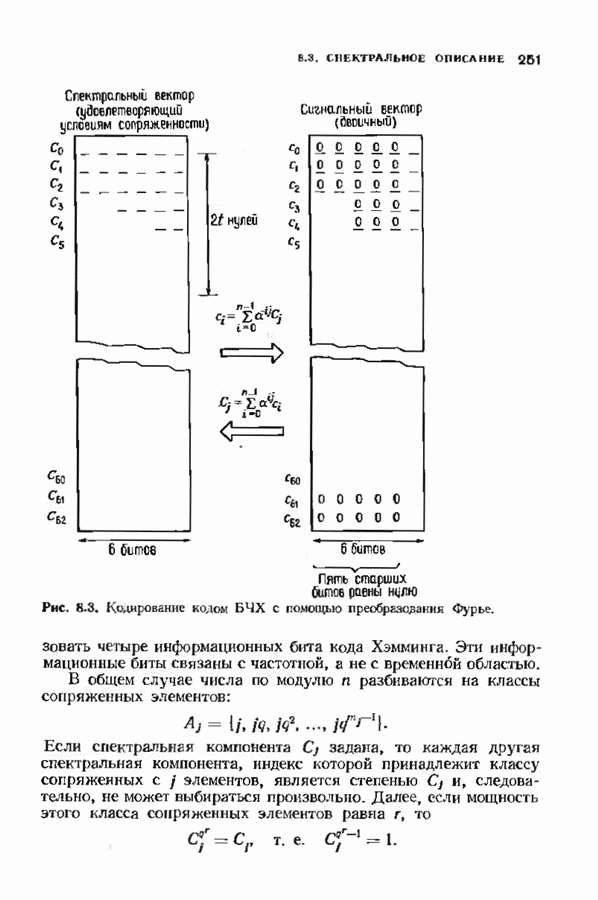































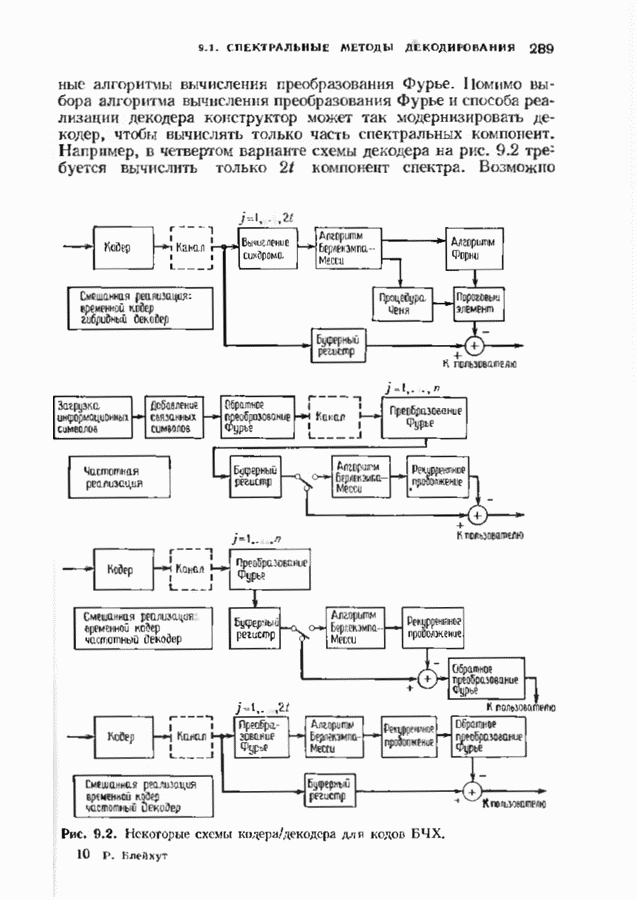



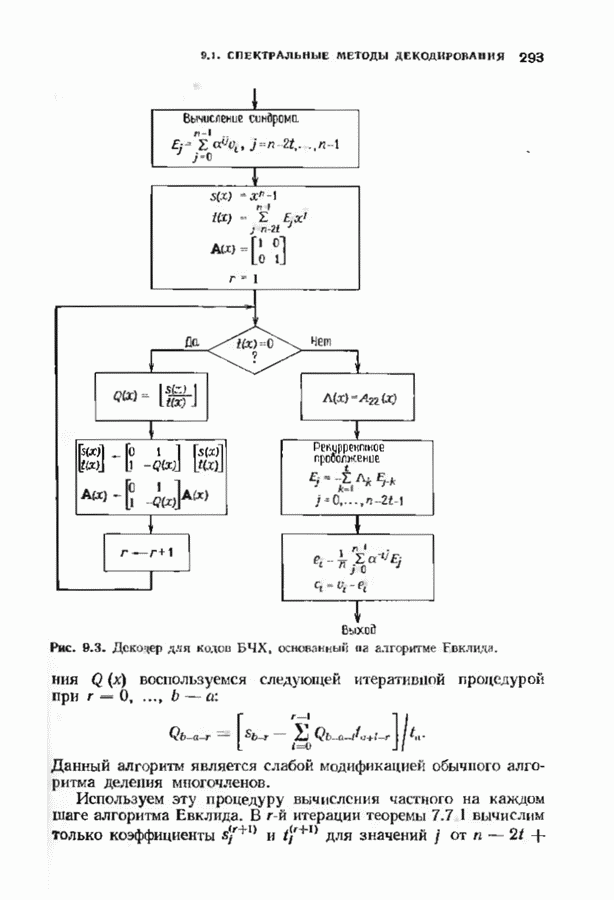





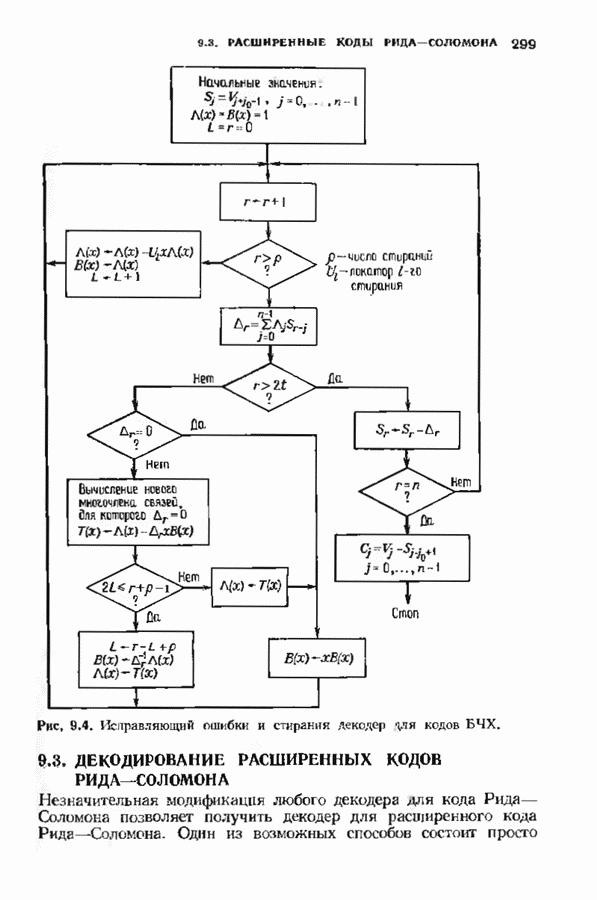


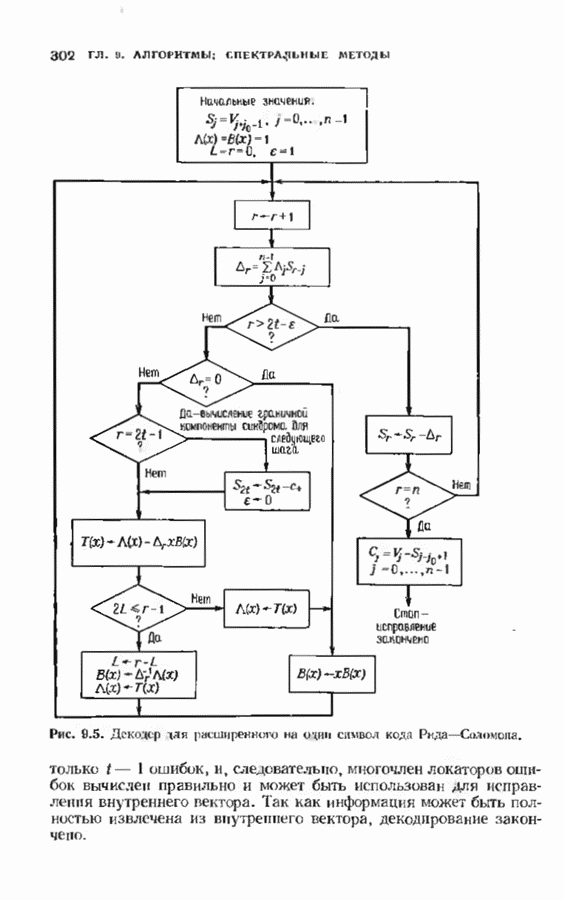









































































































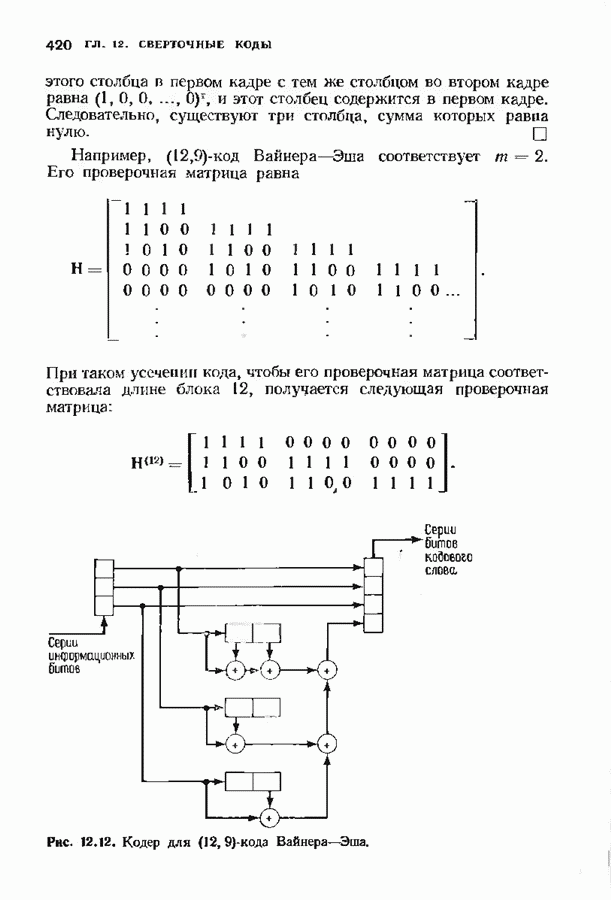
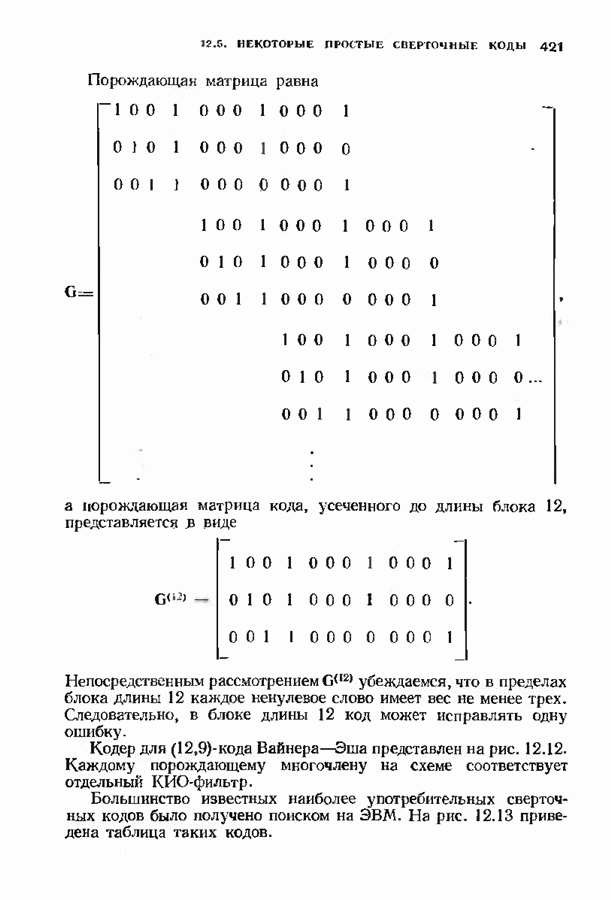


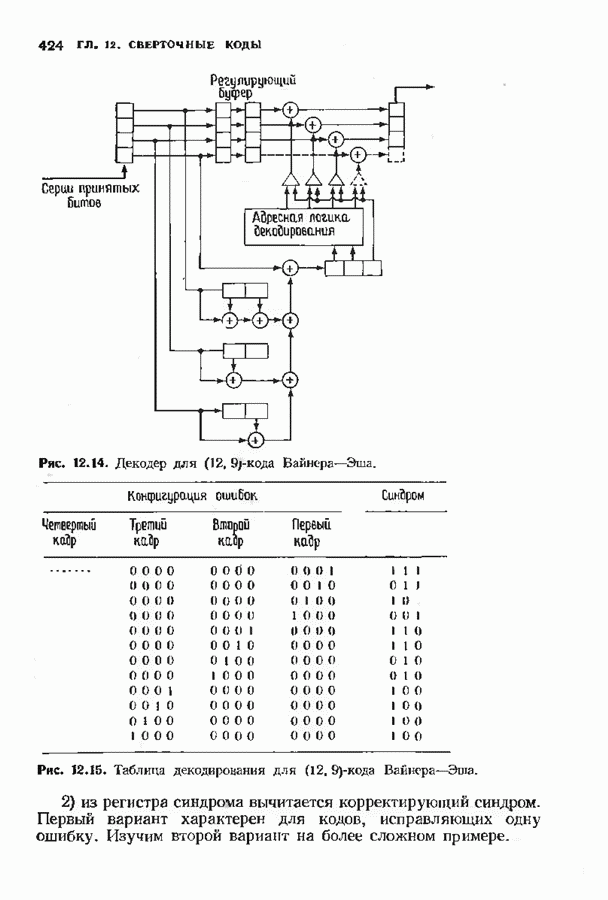
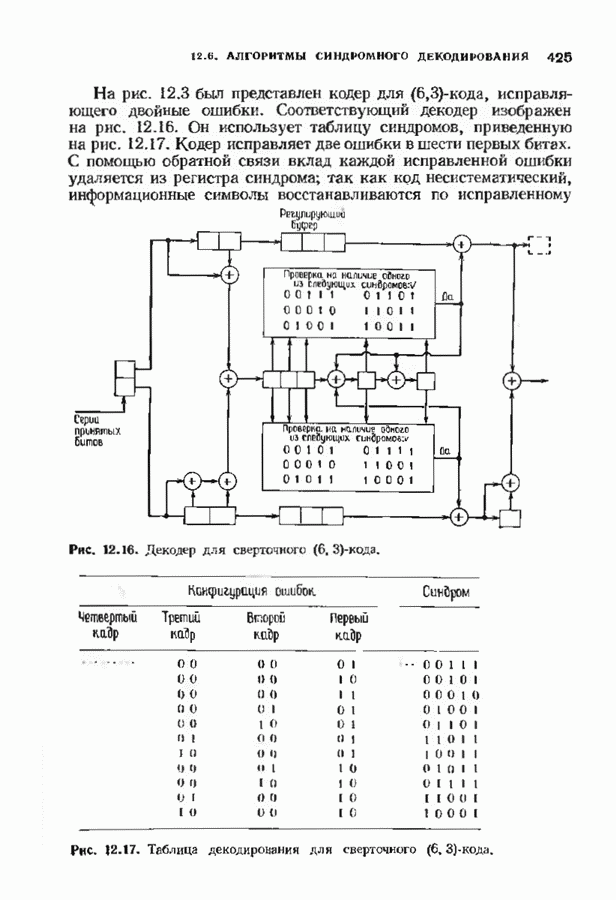



































































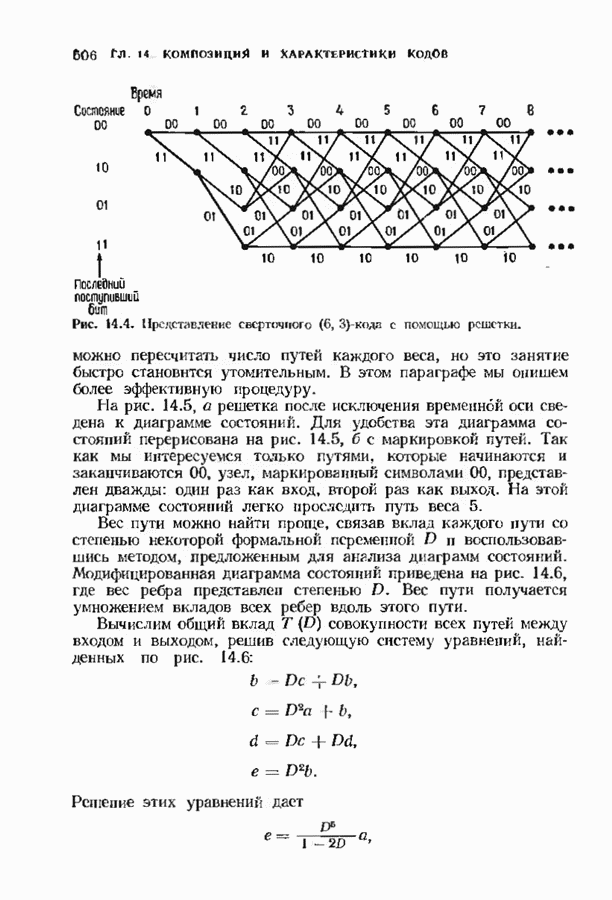
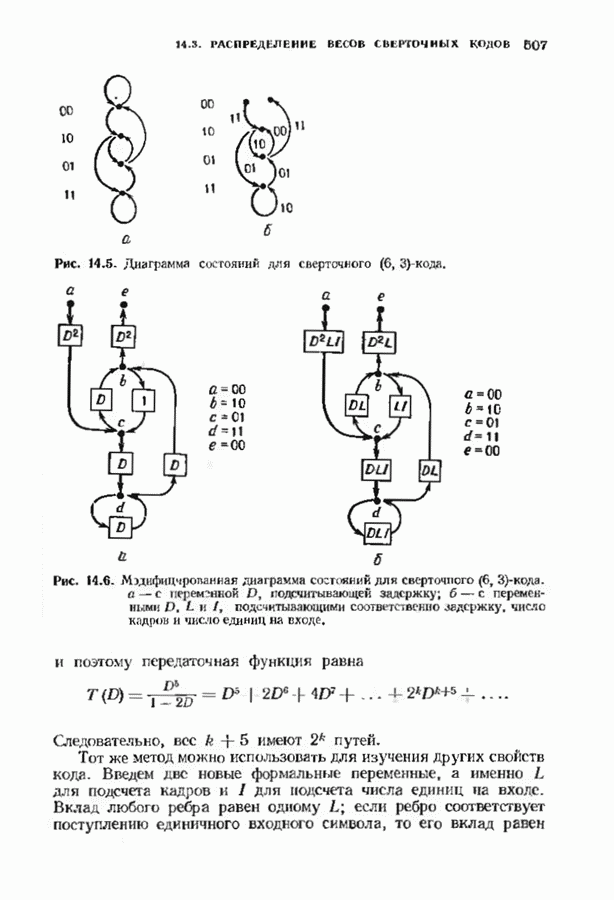




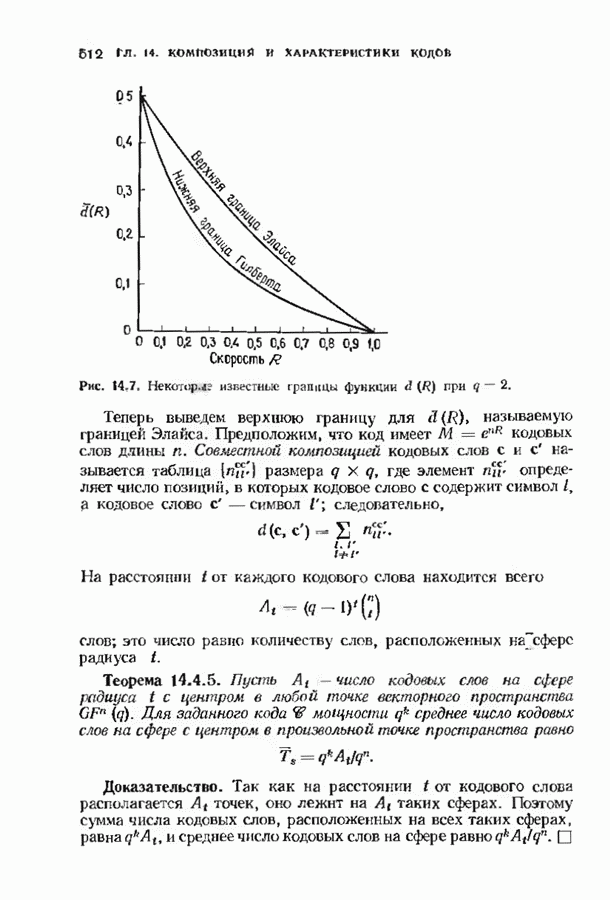












































 можно превратить в код над полем
можно превратить в код над полем  «развернув» каждый
«развернув» каждый  -ичпый символ исходного кода в последовательность
-ичпый символ исходного кода в последовательность  -ичных символов. В результате из линейного
-ичных символов. В результате из линейного  -кода над
-кода над  получится линейный
получится линейный  -код над
-код над  . В кодовом слове минимального веса
. В кодовом слове минимального веса  ненулевых символов запишутся в виде последовательности из
ненулевых символов запишутся в виде последовательности из  символов, из которых только часть будут ненулевыми. Скорость полученного кода будет такая же, как и у исходного кода, а минимальное расстояние будет составлять много меньшую долю длины.
символов, из которых только часть будут ненулевыми. Скорость полученного кода будет такая же, как и у исходного кода, а минимальное расстояние будет составлять много меньшую долю длины.
 -ичных ошибок длины
-ичных ошибок длины  и многие конфигурации из двух пакетов меньшей длины. Например,
и многие конфигурации из двух пакетов меньшей длины. Например,  код Рида-Соломона над
код Рида-Соломона над  развертывается в двоичный
развертывается в двоичный  -код, исправляющий многократные пакеты ошибок. Однако, как правило, такой код плохо исправляет случайные ошибки.
-код, исправляющий многократные пакеты ошибок. Однако, как правило, такой код плохо исправляет случайные ошибки.
 -кода Юстесена представляет собой
-кода Юстесена представляет собой  Ьтаблицу элементов поля
Ьтаблицу элементов поля  Построение кода Юстесена начинается с выбора фиксированного
Построение кода Юстесена начинается с выбора фиксированного  -кода Рида-Соломона, содержащего столько слов, сколько должно содержаться в конструируемом коде Юстесена. Прежде всего построим начинающуюся с кодового слова
-кода Рида-Соломона, содержащего столько слов, сколько должно содержаться в конструируемом коде Юстесена. Прежде всего построим начинающуюся с кодового слова  кода Рида-Соломона
кода Рида-Соломона  -таблицу над
-таблицу над 

 Заменим теперь каждый символ в таблице соответствующим
Заменим теперь каждый символ в таблице соответствующим  -мерным вектором-столбцом над
-мерным вектором-столбцом над  Получившаяся таблица элементов из
Получившаяся таблица элементов из  размера
размера  будет образовывать одно кодовое слово кода Юстесена. Эту таблицу можно любым удобным образом преобразовать в вектор. После повторения такой процедуры для каждого слова кода Рида-Соломона получится код Юстесена.
будет образовывать одно кодовое слово кода Юстесена. Эту таблицу можно любым удобным образом преобразовать в вектор. После повторения такой процедуры для каждого слова кода Рида-Соломона получится код Юстесена.
 каждая представляющая кодовое слово таблица содержит не менее
каждая представляющая кодовое слово таблица содержит не менее  ненулевых столбцов. Далее, если в двух столбцах таблицы совпадают
ненулевых столбцов. Далее, если в двух столбцах таблицы совпадают  верхних элементов, то в этих столбцах
верхних элементов, то в этих столбцах  нижних элементов обязательно будут различными. Таким образом, в таблице нетдвух одинаковых ненулевых столбцов. Чтобы оценить минимальный вес кодового слова, допустим, что все
нижних элементов обязательно будут различными. Таким образом, в таблице нетдвух одинаковых ненулевых столбцов. Чтобы оценить минимальный вес кодового слова, допустим, что все  ненулевых столбцов различны и имеют минимальный возможный вес. Искомая оценка получится суммированием весов
ненулевых столбцов различны и имеют минимальный возможный вес. Искомая оценка получится суммированием весов  -мерных векторов минимального веса.
-мерных векторов минимального веса.
 Юстесена, построенного из
Юстесена, построенного из  -кода Рида-Соломона, при каждом
-кода Рида-Соломона, при каждом  удовлетворяющем неравенству
удовлетворяющем неравенству


 различных ненулевых столбцов. Таким образом, вес этого слова не меньше веса слова, которое получится при записи в этих
различных ненулевых столбцов. Таким образом, вес этого слова не меньше веса слова, которое получится при записи в этих  столбцах
столбцах  различных последовательностей длины
различных последовательностей длины  имеющих минимальный вес. Существует способов выбора
имеющих минимальный вес. Существует способов выбора  ненулевых элементов в по следовательности длины
ненулевых элементов в по следовательности длины  а число таких ненулевых элементов равняется
а число таких ненулевых элементов равняется  Следовательно, при любом
Следовательно, при любом  удовлетворяющем неравенству
удовлетворяющем неравенству

 Минимальное расстояние кода будет не меньше суммы весов
Минимальное расстояние кода будет не меньше суммы весов

 вычисление биномиальных коэффициентов даже на ЭВМ оказывается весьма непростой задачей. Сейчас будет предложен другой подход к исследованию поведения кода при больших длинах. (Последующий текст не связан непосредственно с теорией кодирования и необходим лишь для описания асимптотического поведения кода при больших длинах
вычисление биномиальных коэффициентов даже на ЭВМ оказывается весьма непростой задачей. Сейчас будет предложен другой подход к исследованию поведения кода при больших длинах. (Последующий текст не связан непосредственно с теорией кодирования и необходим лишь для описания асимптотического поведения кода при больших длинах 
 удовлетворяющих условию
удовлетворяющих условию  причем
причем  - целое число, имеет место неравенство
- целое число, имеет место неравенство



 тогда
тогда

 различных ненулевых двоичных слов длины
различных ненулевых двоичных слов длины  сумма
сумма  весов слов удовлетворяет неравенству
весов слов удовлетворяет неравенству

 имеющих вес не более
имеющих вес не более  удовлетворяет неравенству
удовлетворяет неравенству

 слов веса более
слов веса более  Следовательно, сумма весов
Следовательно, сумма весов  слов множества удовлетворяет неравенству
слов множества удовлетворяет неравенству

 Тогда при каждом целом
Тогда при каждом целом  Юстесена
Юстесена  имеет скорость не менее
имеет скорость не менее  и минимальное расстояние, удовлетворяющее неравенству
и минимальное расстояние, удовлетворяющее неравенству

 функция от
функция от  стремящаяся к нулю при
стремящаяся к нулю при 
 и, следовательно, скорость кода
и, следовательно, скорость кода  превышает
превышает  Кодовое слово с содержит не менее
Кодовое слово с содержит не менее  различных ненулевых столбцов, т. е. не менее
различных ненулевых столбцов, т. е. не менее  различных ненулевых двоичных последовательностей длины
различных ненулевых двоичных последовательностей длины  Далее,
Далее,

 этих последовательностей длины
этих последовательностей длины  Тогда условия леммы 7.9.3 удовлетворяются, и из этой леммы следует оценка
Тогда условия леммы 7.9.3 удовлетворяются, и из этой леммы следует оценка



 выполняется неравенство
выполняется неравенство

 отношение
отношение  отделено от нуля при
отделено от нуля при  Коды Юстесена являются единственным известным классом кодов с заданной в явном виде конструкцией, для которых установлено это свойство
Коды Юстесена являются единственным известным классом кодов с заданной в явном виде конструкцией, для которых установлено это свойство
 становятся неудовлетворительными, когда эта длина оказывается много больше
становятся неудовлетворительными, когда эта длина оказывается много больше  Для умеренных длин кодов так происходит потому, что в случае двоичных кодов на каждую исправляемую ошибку приходится порядка
Для умеренных длин кодов так происходит потому, что в случае двоичных кодов на каждую исправляемую ошибку приходится порядка  проверочных символов, а в случае кода с
проверочных символов, а в случае кода с  порядка
порядка  проверочных символов. Асимптотическое поведение таких кодов несколько лучше, хотя все еще остается неудовлетворительным. Точное изложение
проверочных символов. Асимптотическое поведение таких кодов несколько лучше, хотя все еще остается неудовлетворительным. Точное изложение  вопросов потребовало бы значительных усилий.
вопросов потребовало бы значительных усилий.
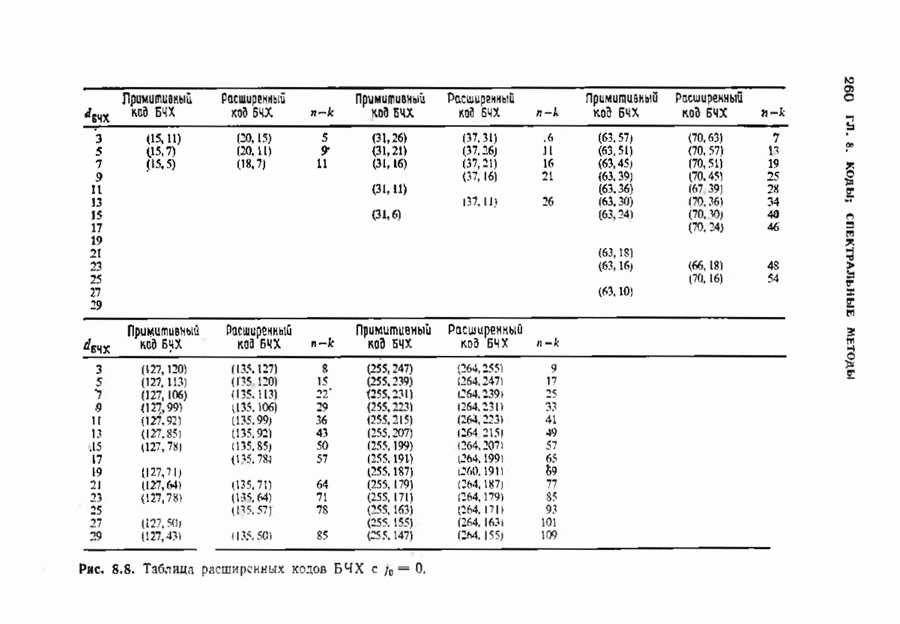
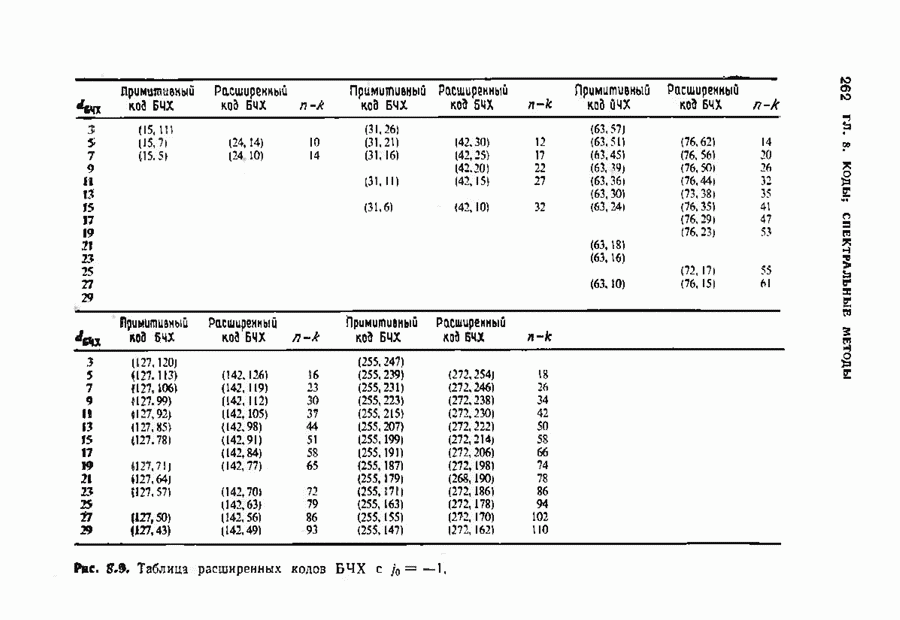
 -код БЧХ с
-код БЧХ с  . Чинь [1970] придумвл примеры циклических кодов, которые лучше кодов БЧХ; одним из таких примеров является циклический
. Чинь [1970] придумвл примеры циклических кодов, которые лучше кодов БЧХ; одним из таких примеров является циклический  -код.
-код.