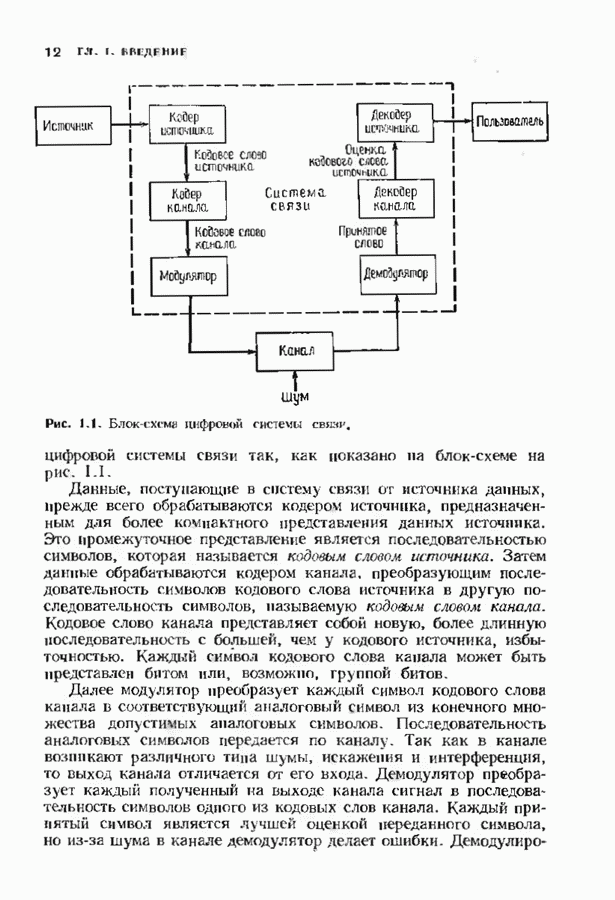
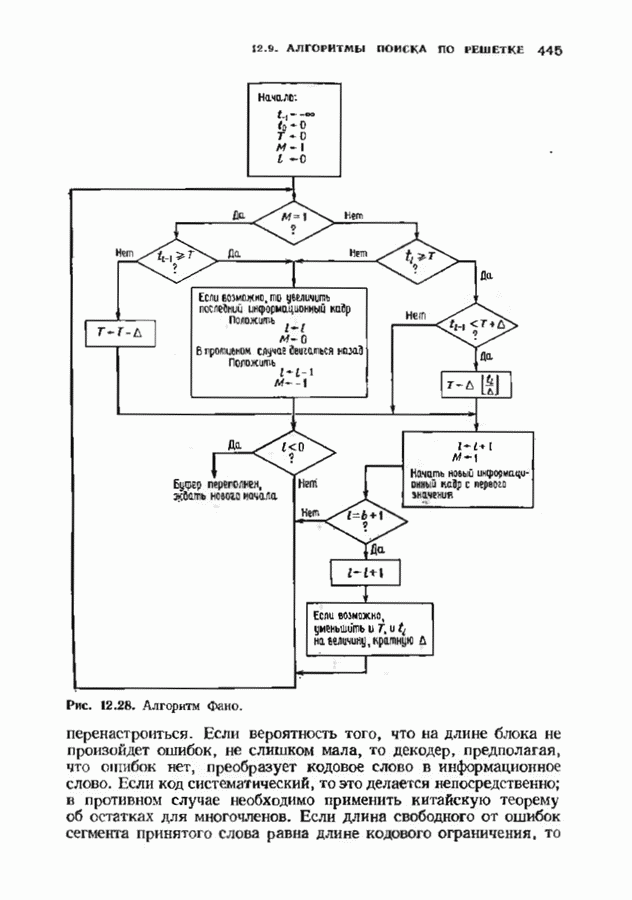
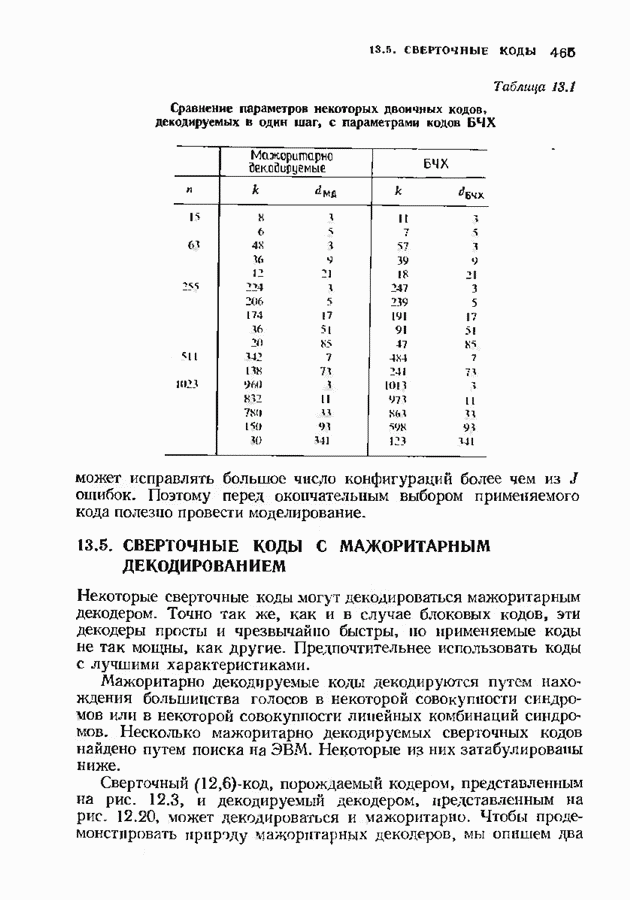
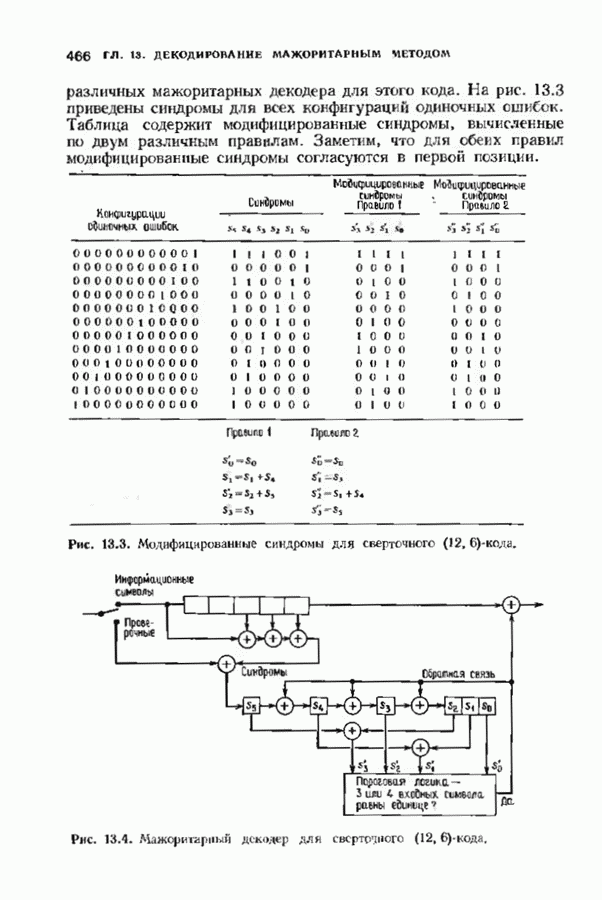
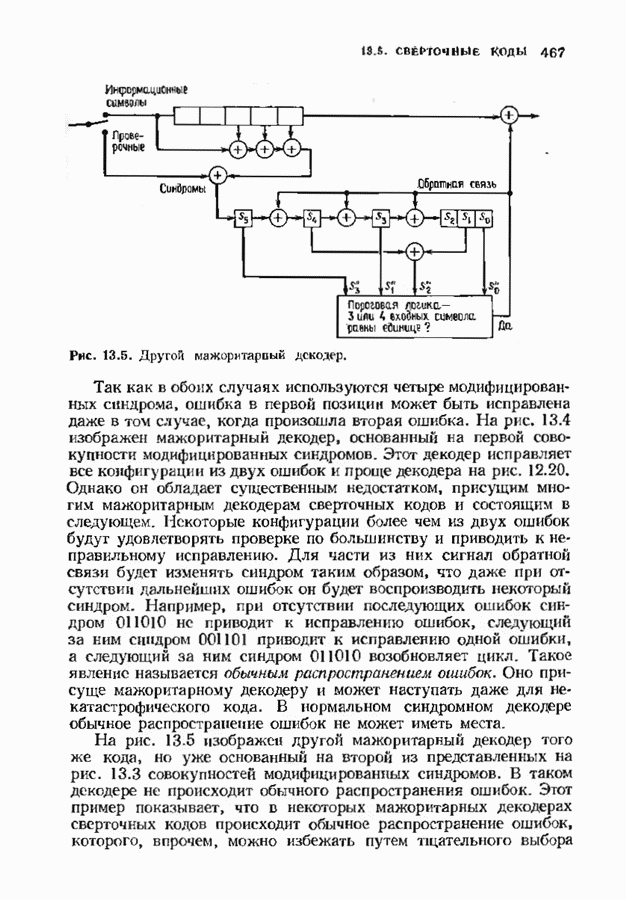
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
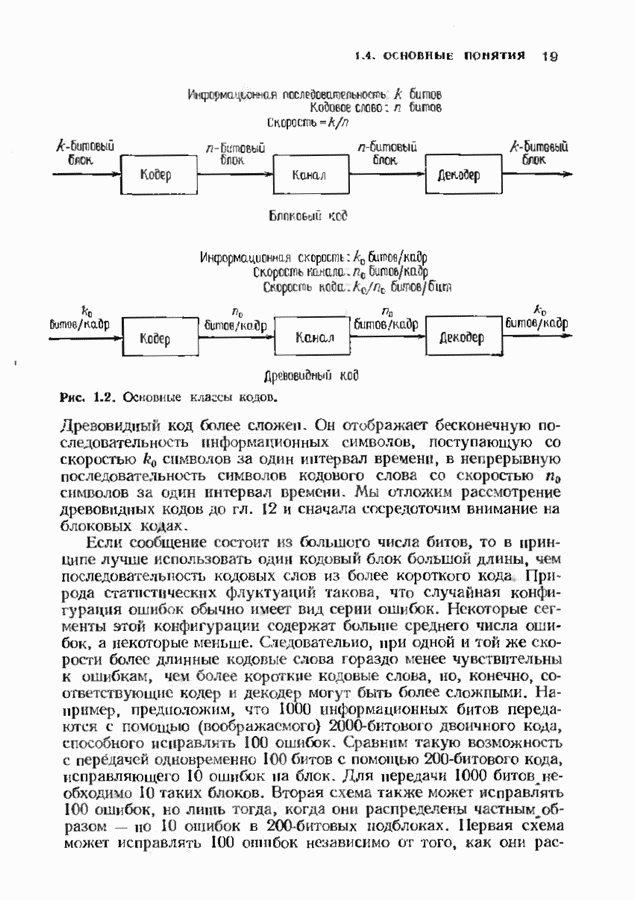
ZADANIA.TO
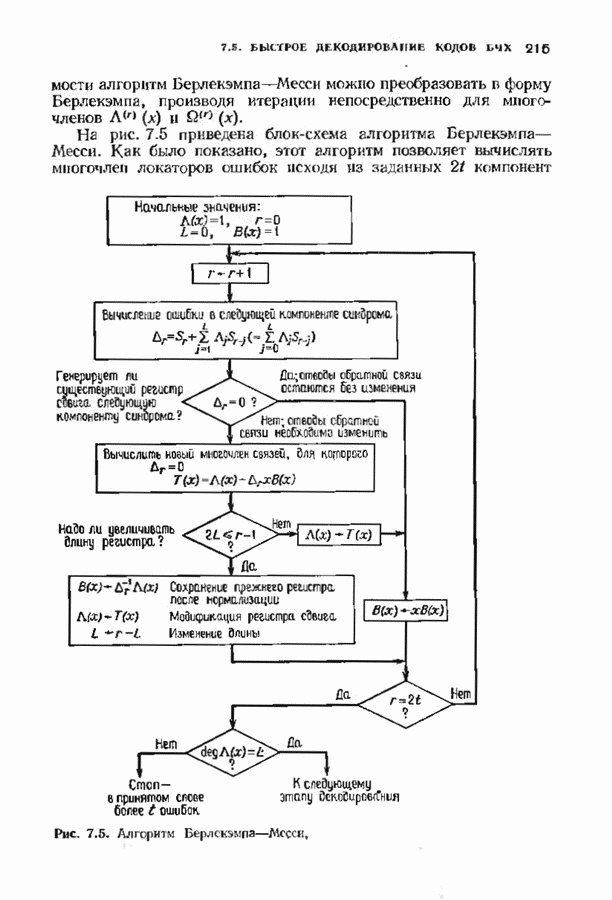
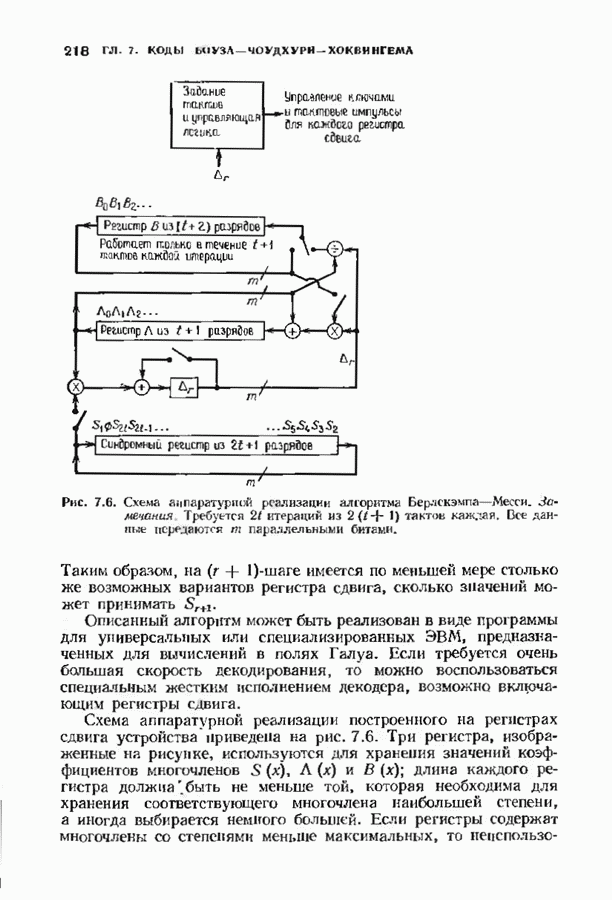
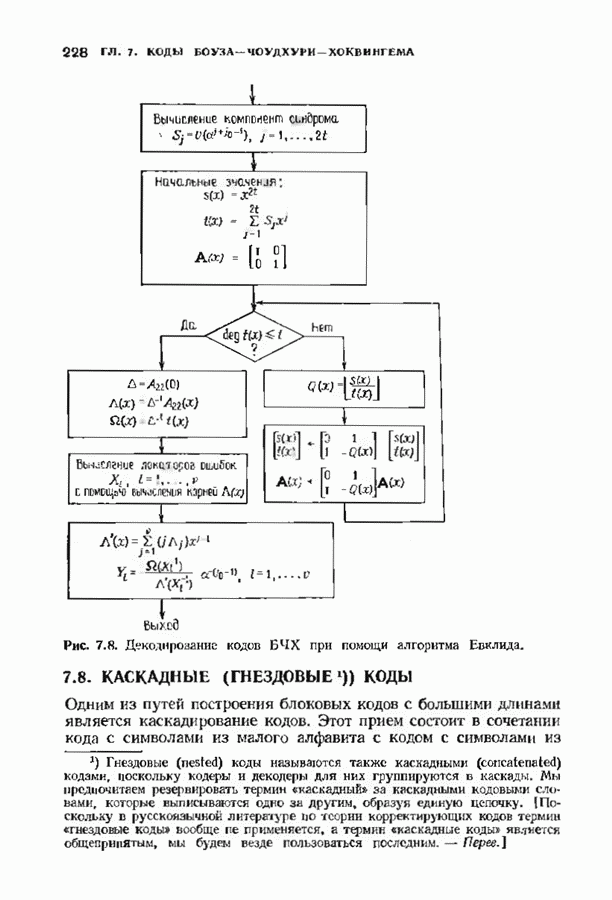
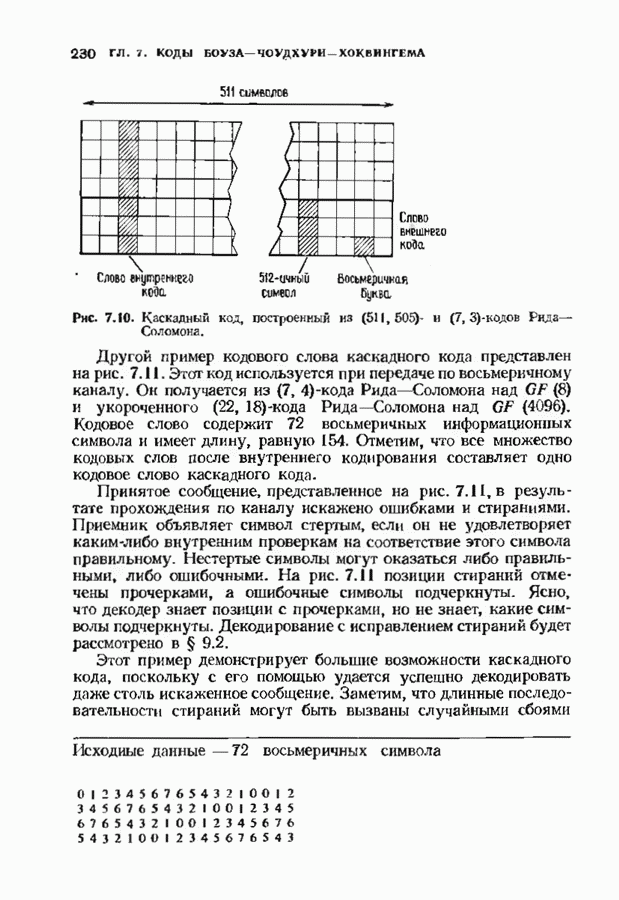
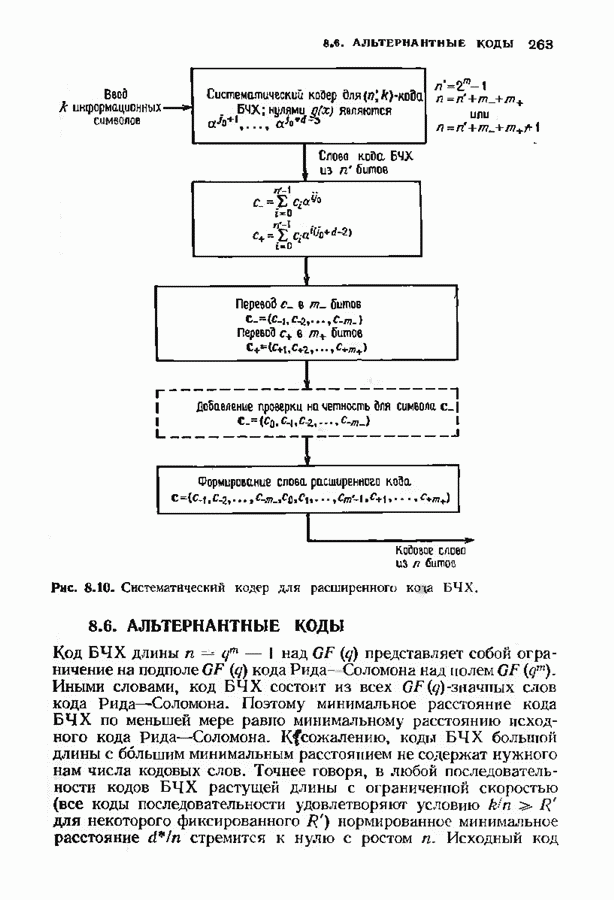
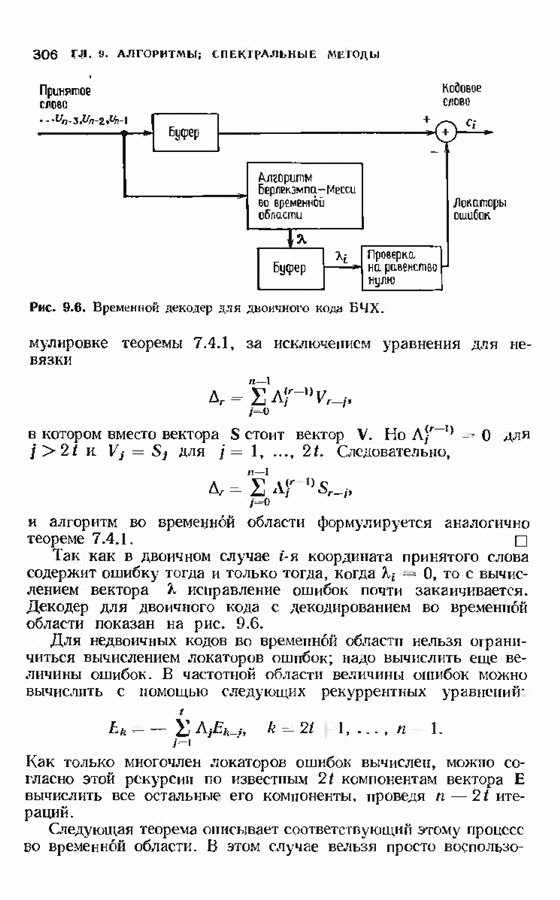
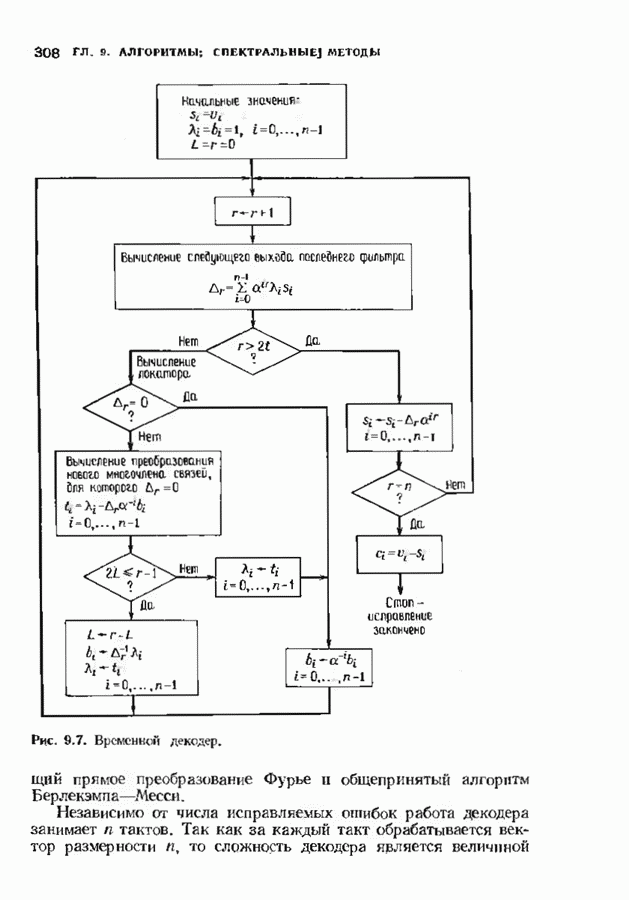
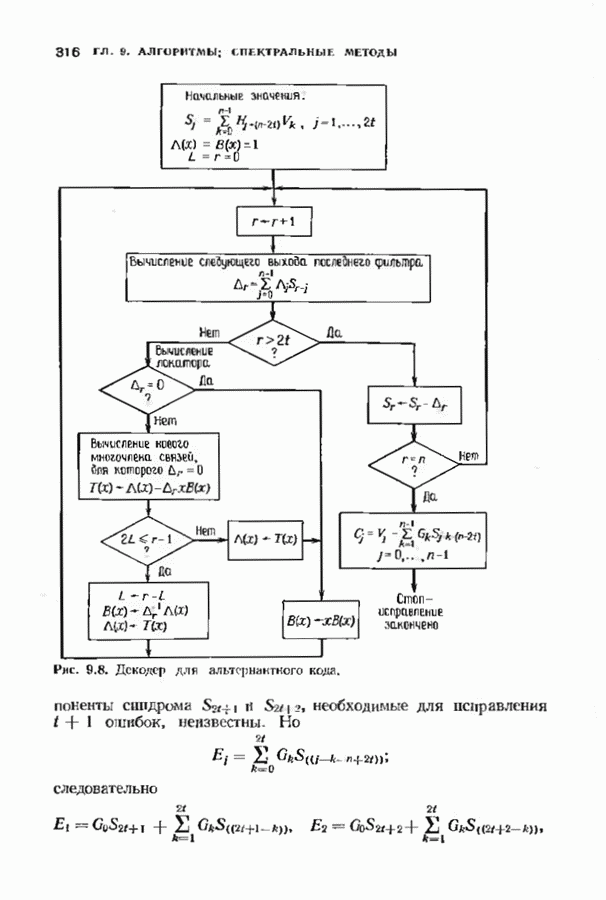
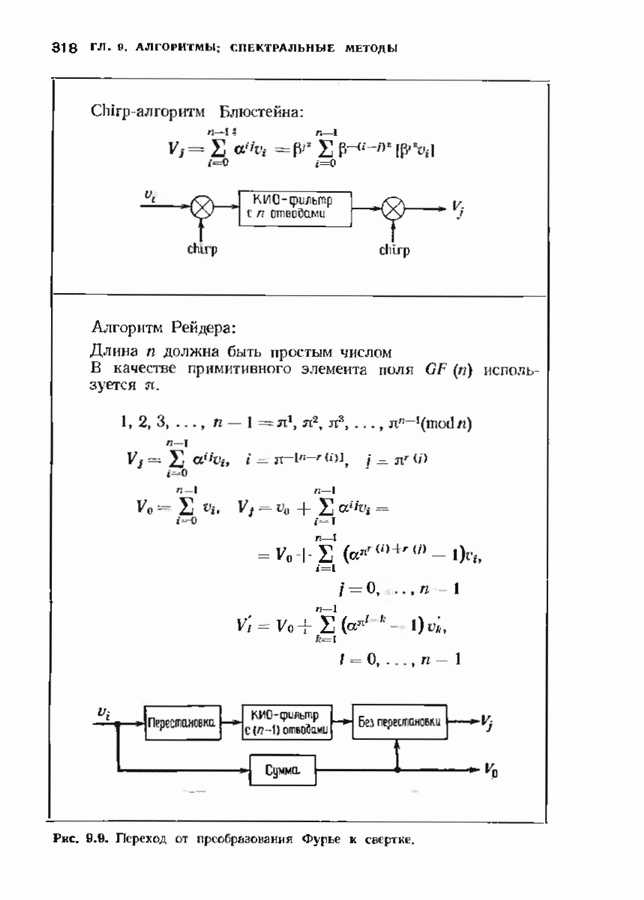
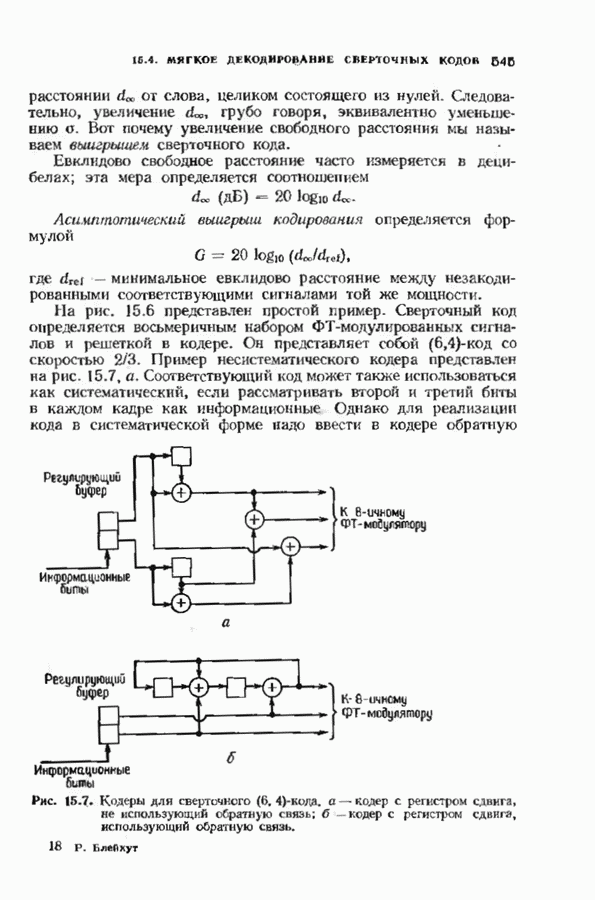
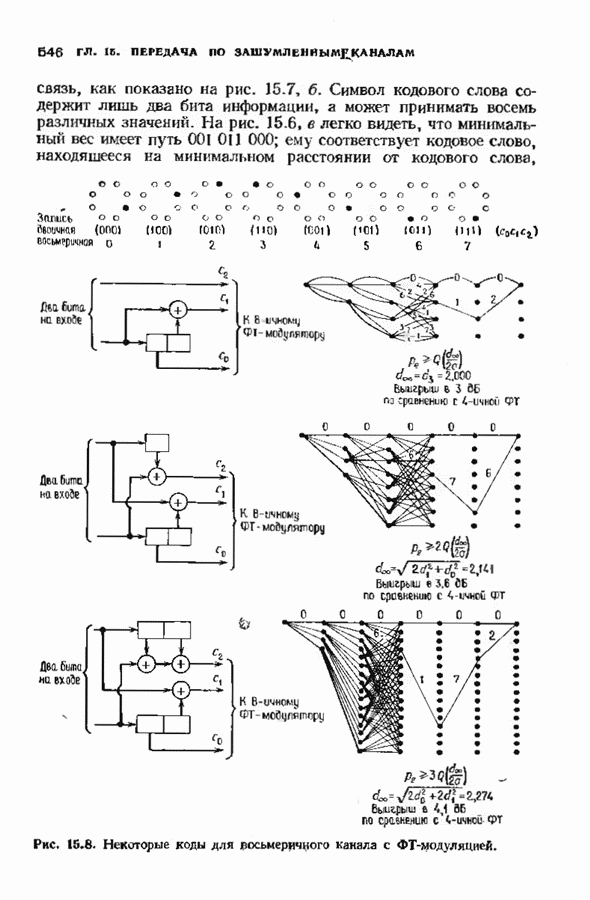
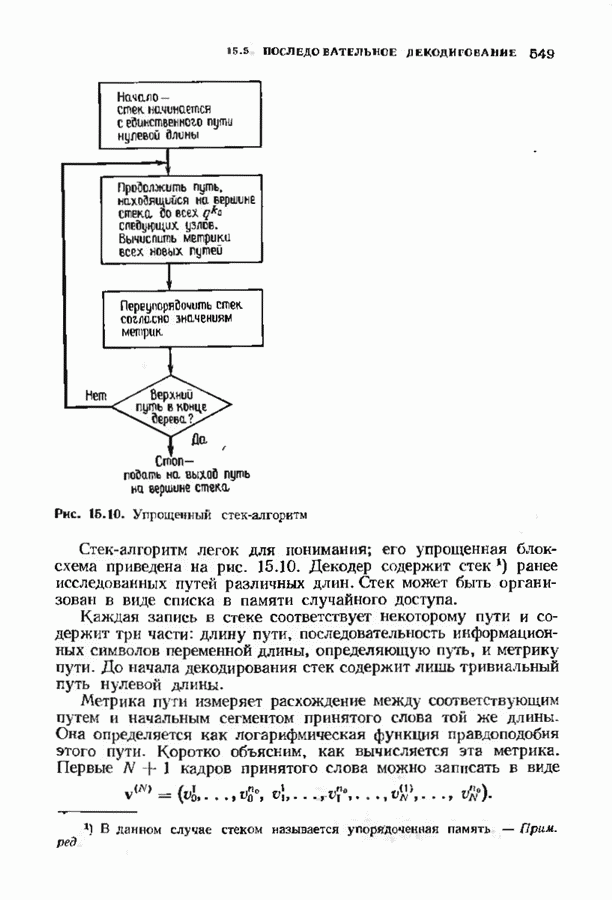
11.6. УСКОРЕННЫЙ АЛГОРИТМ БЕРЛЕКЭМПА—МЕССИВ описанном в § 7.4 алгоритме Берлекэмпа-Месси требуемое число умножений на Ускоренный алгоритм обосновывается следующим образом. На начальных итерациях алгоритм Берлекэмпа-Месси в частотной области содержит умеренное число умножений порядка степени миоючлена Построение начнем с более компактной организации алгоритма Берлекэмпа-Месси. Заменим многочлены
Для обозначения элементов матрицы Напомним, что вычисления алгоритма Берлекэмпа-Месси основываются на двух равенствах:
и
Второе равенство можно записать в виде
Определим матрицу
Через эту матрицу можно выразить многочлены
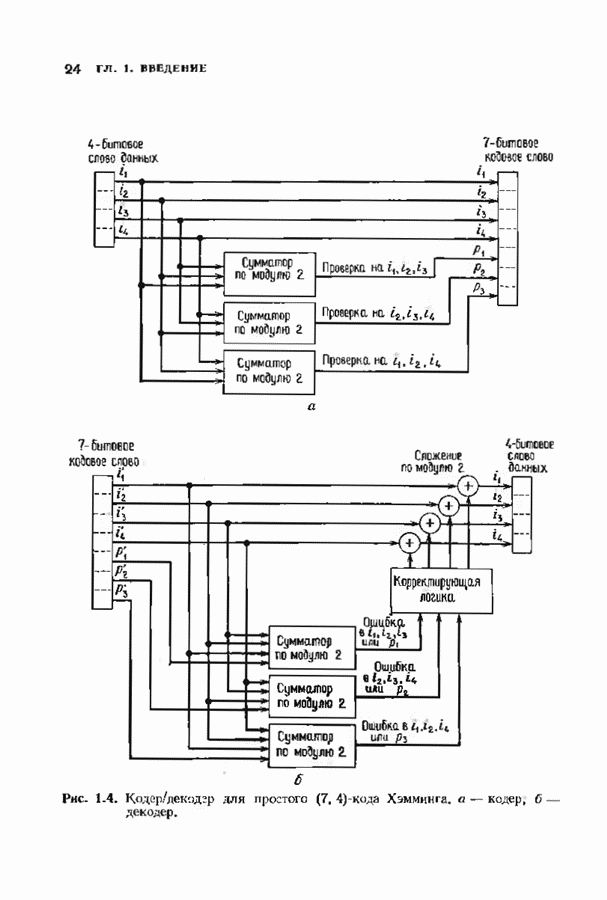
Полученное равенство может быть использовано как для вычисления В перестроенном виде алгоритм Берлекэмпа-Месси основывается на двух уравнениях, а именно на уравнениях
и
Теперь мы хотим уменьшить число вычислений, группируя итерации в пакеты. Определим матрицу
так что
Это произведение должно вычисляться последовательно по одному члену, начиная справа, так как Определим следующие частичные произведения рассматриваемых матриц:
тогда
Определим также вектор модифицированных синдромных многочленов
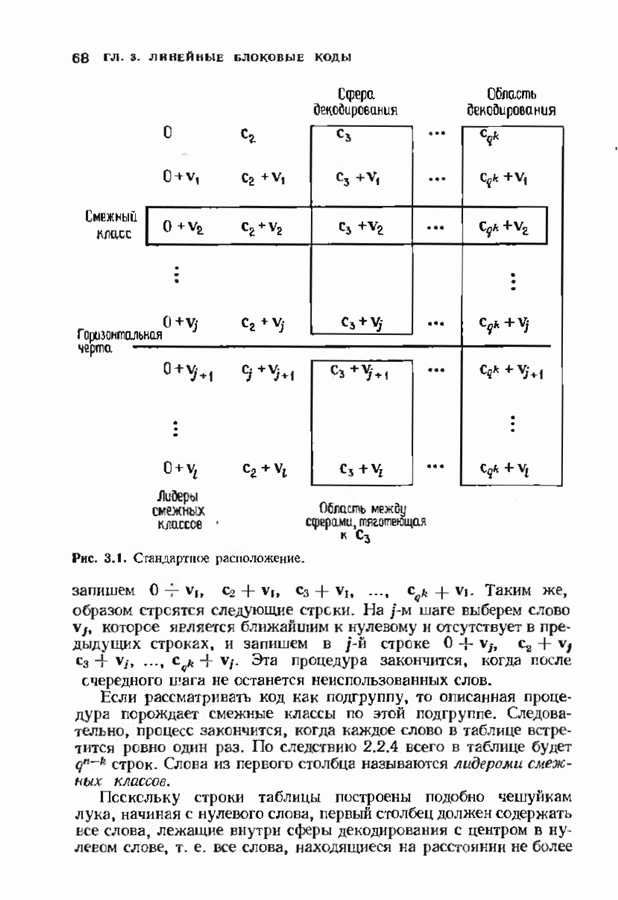
Невязка
становится равной
Группируя члены, получаем
Стоящие в квадратных скобках многочлены являются компонентами вектора
где
На
где
В конце
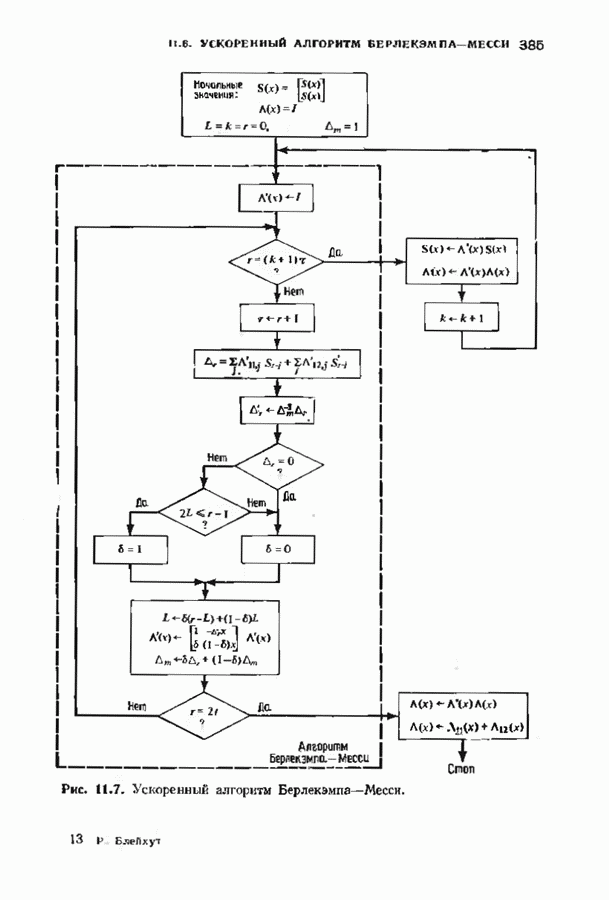
где На рис. 11.7 приведена блок-схема ускоренного алгоритма Берлекэмпа-Месси с некоторыми очевидными сокращениями. В левой части рисунка приведен стандартный алгоритм, расписанный для
(кликните для просмотра скана) Расширенный (4096, 2048)-код Рида-Соломона над Подсчитаем число операций для несколько видоизмененного варианта ускоренного алгоритма Берлекэмпа Месси. Вместо того чтобы формировать пакеты одинакового объема, делая разветвления алгоритма через каждые В течение каждой итерации требующееся для выполнения вычислений, показанных слева на рис. 11.7, число умножений примерно вчетверо больше степени многочлена После каждою ответвления надо вычислять член вида Продолжая таким образом, всего получим 168 обращений к алгоритму циклической свертки, что в итоге дает 480 480 умножений. После выполнения каждого пакета из 128 итераций необходимо также вычислить матричное произведение Полное число умножений, необходимых для рассматриваемого декодирования (4096, 2048)-кода Рида-Соломона, получается сложением этих трех величин. Всего получаем 1 462 768 умножений против 2 097 152 необходимых при непосредственном использовании алгоритма Берлекэмпа-Месси.
|
 |
Оглавление
|









































































































































































































































































































































































































































































































 итерации примерно равно удвоенной степени многочлена
итерации примерно равно удвоенной степени многочлена  Так как степень многочлена
Так как степень многочлена  имеет порядок
имеет порядок  и в типичном случае равна
и в типичном случае равна  а алгоритм содержит
а алгоритм содержит  итераций, то для его выполнения необходимо
итераций, то для его выполнения необходимо  умножений и примерно столько же сложений. Это квадратичная функция
умножений и примерно столько же сложений. Это квадратичная функция  Кратко говорят, что алгоритм Берлекэмпа-Месси содержит число умножений порядка
Кратко говорят, что алгоритм Берлекэмпа-Месси содержит число умножений порядка  или, формально,
или, формально,  умножений. Для очень длинных кодов и большого
умножений. Для очень длинных кодов и большого  число умножений в алгоритме может стать обременительным. В настоящем параграфе рассматривается метод уменьшения вычислительной сложности алгоритма для длинных кодов при большом числе
число умножений в алгоритме может стать обременительным. В настоящем параграфе рассматривается метод уменьшения вычислительной сложности алгоритма для длинных кодов при большом числе  исправляемых ошибок.
исправляемых ошибок.
 Но степень многочлена
Но степень многочлена  возрастает до существенной доли длины
возрастает до существенной доли длины  таким образом, среднее число умножений на итерацию имеет поридок
таким образом, среднее число умножений на итерацию имеет поридок  Преимущества ускоренного алгоритма связаны попросту с тем, что на ранних шагах несколько итераций в частотной области выполняются одновременно. После такого пакетного выполнения нескольких итераций полученный промежуточный результат используется для модификации синдрома путем ввода в него вычисленных в этом пакете многочленов
Преимущества ускоренного алгоритма связаны попросту с тем, что на ранних шагах несколько итераций в частотной области выполняются одновременно. После такого пакетного выполнения нескольких итераций полученный промежуточный результат используется для модификации синдрома путем ввода в него вычисленных в этом пакете многочленов  и
и  Следующий пакет итераций начинает выполнение алгоритма Берлекэмпа-Месси, сначала используя в качестве синдрома вычисленный модифицированный синдром и полагая в начальный момент
Следующий пакет итераций начинает выполнение алгоритма Берлекэмпа-Месси, сначала используя в качестве синдрома вычисленный модифицированный синдром и полагая в начальный момент  равным 1. Ускоренный декодер эффективен для декодирования длинных, но все еще практически применяемых кодов. В следующем параграфе будут рассмотрены другие, даже более эффективные декодеры.
равным 1. Ускоренный декодер эффективен для декодирования длинных, но все еще практически применяемых кодов. В следующем параграфе будут рассмотрены другие, даже более эффективные декодеры.
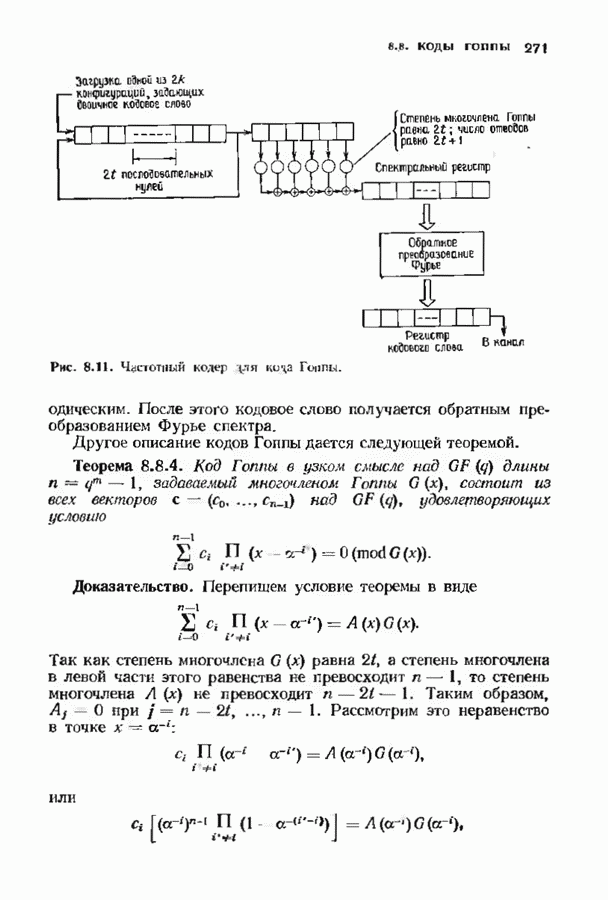
 -матрицей из многочленов
-матрицей из многочленов

 нам понадобится несколько индексов; символ
нам понадобится несколько индексов; символ  будет означать
будет означать  коэффициент многочлена, стоящего на пересечении строки а и столбца
коэффициент многочлена, стоящего на пересечении строки а и столбца  итерации.
итерации.



 равенством
равенством



 так и для вычисления многочленов
так и для вычисления многочленов  Непосредственное вычисление матрицы
Непосредственное вычисление матрицы  содержит вдвое больше умножений, так как вместо двух элементов в вычислениях участвуют четыре. Поэтому замена итераций многочленов
содержит вдвое больше умножений, так как вместо двух элементов в вычислениях участвуют четыре. Поэтому замена итераций многочленов  итерациями матрицы
итерациями матрицы  удваивает необходимое число умножений. Это ухудшение будет затем устранено реорганизацией вычислений.
удваивает необходимое число умножений. Это ухудшение будет затем устранено реорганизацией вычислений.




 нельзя вычислить до тех пор, пока не вычислена
нельзя вычислить до тех пор, пока не вычислена 





 члену свертки и может быть записана через многочлены:
члену свертки и может быть записана через многочлены:


 модифицированных синдромпых многочленов. Следовательно, выражение для невязки можно переписать в виде
модифицированных синдромпых многочленов. Следовательно, выражение для невязки можно переписать в виде

 и
и  обозначают соответственно
обозначают соответственно  коэффициенты многочленов в первой и второй компонентах вектора
коэффициенты многочленов в первой и второй компонентах вектора  Для ускорения алгоритма Берлекэмпа-Месси сформируем пакеты по
Для ускорения алгоритма Берлекэмпа-Месси сформируем пакеты по  итераций в каждом. Если
итераций в каждом. Если  делит
делит  то обращение к каждому из
то обращение к каждому из  пакетов одинаково В противном случае последний пакет содержит меньше
пакетов одинаково В противном случае последний пакет содержит меньше  итераций, но мы полагаем его таким же. Индекс
итераций, но мы полагаем его таким же. Индекс  теперь пробегает значения
теперь пробегает значения

 итерации
итерации  пакета модифицированный алгоритм Берлекэмпа-Месси вычисляет
пакета модифицированный алгоритм Берлекэмпа-Месси вычисляет  согласно равенству
согласно равенству

 вычисляется по формуле
вычисляется по формуле

 пакета, когда
пакета, когда  равно
равно  матрица локаторов ошибок и вектор модифицированных синдромных многочленов даются соответственно равенствами
матрица локаторов ошибок и вектор модифицированных синдромных многочленов даются соответственно равенствами

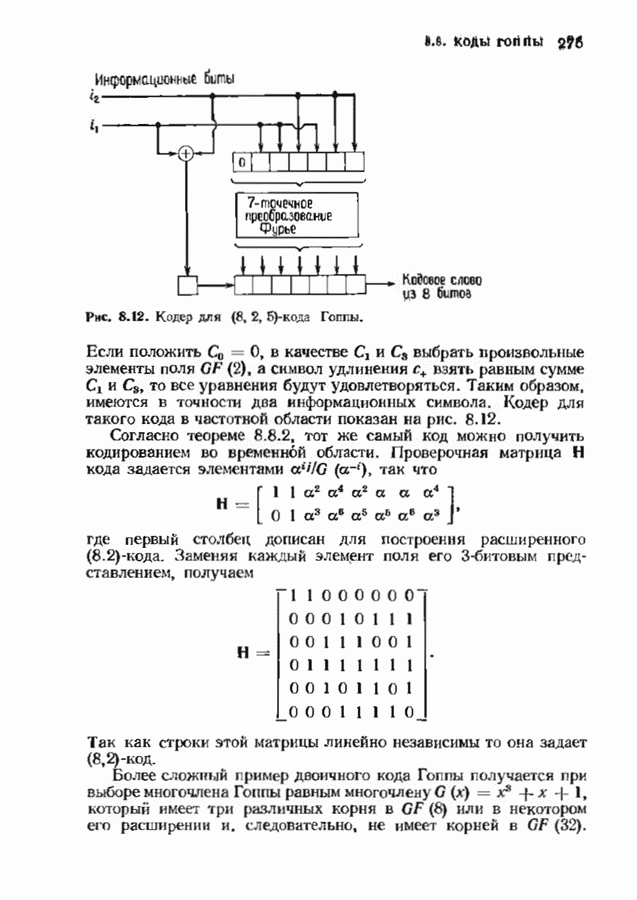
 Теперь ускоренный алгоритм готов начать
Теперь ускоренный алгоритм готов начать  пакет.
пакет.
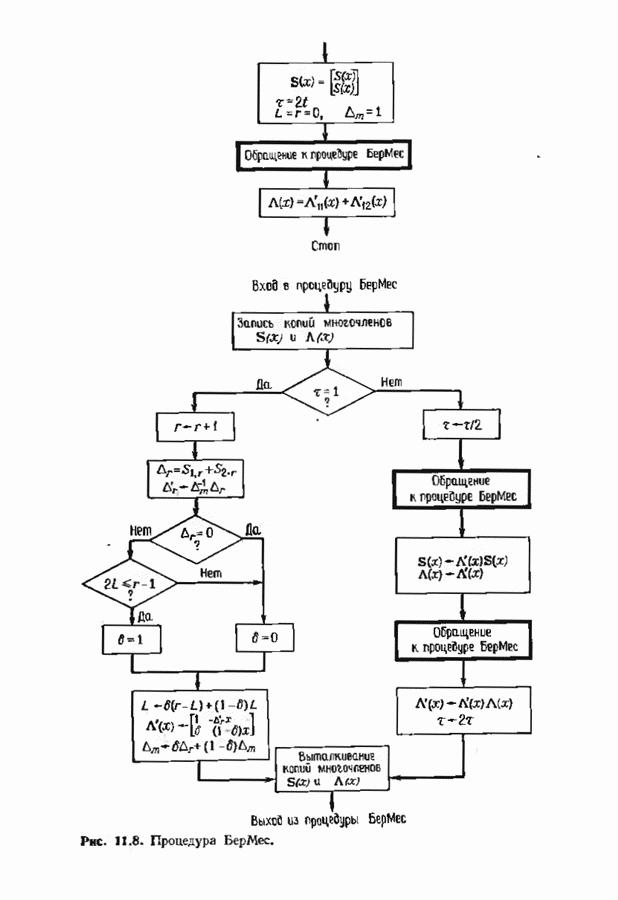
 итераций, а в правой показаны блоки, осуществляющие связку пакетов по
итераций, а в правой показаны блоки, осуществляющие связку пакетов по  итераций каждый. Если правая часть алгоритма выполняется так, как она выписана, то мы не получаем никакой экономии вычислений. Однако умножения многочленов в блоках правой части эквивалентны сверткам, которые могут быть эффективно вычислены с помощью описанных в § 11.1 и 11.3 методов или с помощью быстрого преобразования Фурье и теоремы о свертке. Некоторые возможности иллюстрируются следующим примером.
итераций каждый. Если правая часть алгоритма выполняется так, как она выписана, то мы не получаем никакой экономии вычислений. Однако умножения многочленов в блоках правой части эквивалентны сверткам, которые могут быть эффективно вычислены с помощью описанных в § 11.1 и 11.3 методов или с помощью быстрого преобразования Фурье и теоремы о свертке. Некоторые возможности иллюстрируются следующим примером.

 имеет скорость, равную
имеет скорость, равную  позволяет исправлять все конфигурации ошибок из
позволяет исправлять все конфигурации ошибок из  -битовых байтов. В типичных случаях алгоритм Берлекэмпа-Месси содержит
-битовых байтов. В типичных случаях алгоритм Берлекэмпа-Месси содержит  умножений
умножений  -битовых чисел поля
-битовых чисел поля  а для наихудших конфигураций ошибок это число может возрасти в 1,5 раза. Ускоренный алгоритм позволяет провести вычисления лучше.
а для наихудших конфигураций ошибок это число может возрасти в 1,5 раза. Ускоренный алгоритм позволяет провести вычисления лучше.
 итераций, будем строить разветвления в те моменты, когда степень многочлена
итераций, будем строить разветвления в те моменты, когда степень многочлена  достигнет предписанного предела. А именно будем формировать новую ветвь алгоритма тогда, когда степень одного из многочленов, входящих в матрицу
достигнет предписанного предела. А именно будем формировать новую ветвь алгоритма тогда, когда степень одного из многочленов, входящих в матрицу  станет равной 128, и закончим процесс формирования ветвей после 2048 итераций. В случае когда происходит точно 1024 ошибки, алгоритм будет содержать восемь разветвлений, каждое из которых будет выполнять 128 итераций. Именно этот случай мы сейчас проанализируем.
станет равной 128, и закончим процесс формирования ветвей после 2048 итераций. В случае когда происходит точно 1024 ошибки, алгоритм будет содержать восемь разветвлений, каждое из которых будет выполнять 128 итераций. Именно этот случай мы сейчас проанализируем.
 вычисляемого при этой итерации. Это вдвое больше числа умножений, необходимых в исходном варианте алгоритма Берлекэмпа-Месси. Следовательно, в каждом ответвлении алгоритма имеется примерно
вычисляемого при этой итерации. Это вдвое больше числа умножений, необходимых в исходном варианте алгоритма Берлекэмпа-Месси. Следовательно, в каждом ответвлении алгоритма имеется примерно  итераций, выполняющих вычисления, указанные на левой части рис. 11.7. Всего имеется восемь ветвей, и
итераций, выполняющих вычисления, указанные на левой части рис. 11.7. Всего имеется восемь ветвей, и  равно 128; таким образом, выполнение всех ветвей алгоритма содержит 524 228 умножений. К этому надо прибавить число умножений, необходимых для вычисления указанных в правой части рис. 11.7 сверток, объединяющих вычисленные пакеты. Для вычисления этих линейных сверток воспользуемся алгоритмом
равно 128; таким образом, выполнение всех ветвей алгоритма содержит 524 228 умножений. К этому надо прибавить число умножений, необходимых для вычисления указанных в правой части рис. 11.7 сверток, объединяющих вычисленные пакеты. Для вычисления этих линейных сверток воспользуемся алгоритмом  -точечпой циклической свертки, содержащим 2470 умножений. Этот алгоритм представляет собой алгоритм Агарвала-Кули вычисления свертки, построенной из трех алгоритмов вычисления коротких сверток, длины которых соответственно равны пяти, семи и девяти.
-точечпой циклической свертки, содержащим 2470 умножений. Этот алгоритм представляет собой алгоритм Агарвала-Кули вычисления свертки, построенной из трех алгоритмов вычисления коротких сверток, длины которых соответственно равны пяти, семи и девяти.
 где степень многочлена
где степень многочлена  равна
равна  а степень многочлена
а степень многочлена  равна 128. Воспользуемся методом перекрытия с накомплением и алгоритмом
равна 128. Воспользуемся методом перекрытия с накомплением и алгоритмом  -точечпой циклической свертки. Это даст нам
-точечпой циклической свертки. Это даст нам  правильных выходных точек линейной свертки
правильных выходных точек линейной свертки  Для вычисления 2048 — 256 точек алгоритм циклической свертки придется применить 10 раз. Так как
Для вычисления 2048 — 256 точек алгоритм циклической свертки придется применить 10 раз. Так как  содержит четыре линейные свертки, всего потребуется 40 обращений к алгоритму циклической свертки.
содержит четыре линейные свертки, всего потребуется 40 обращений к алгоритму циклической свертки.
 Разбивая в матричном произведении длинные свертки на короткие и проводя вычисления, аналогичные проделанным, приходим к 216-кратному обращению к алгоритму 315-точечной циклической свертки.
Разбивая в матричном произведении длинные свертки на короткие и проводя вычисления, аналогичные проделанным, приходим к 216-кратному обращению к алгоритму 315-точечной циклической свертки.