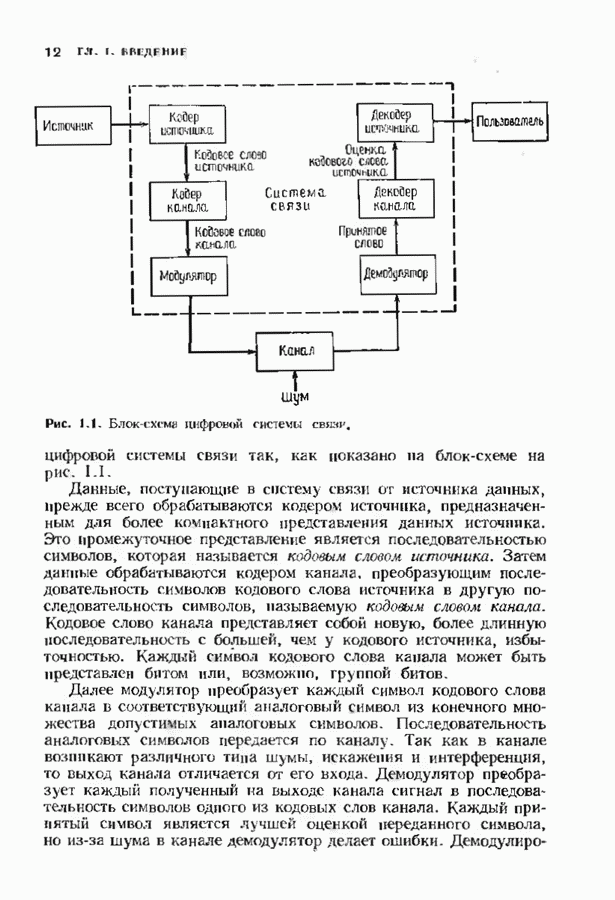
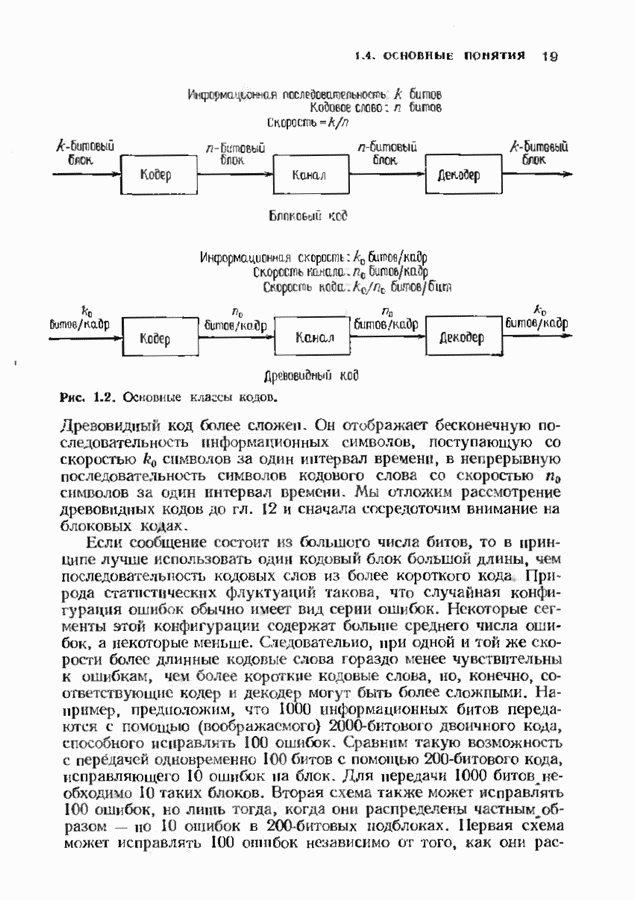
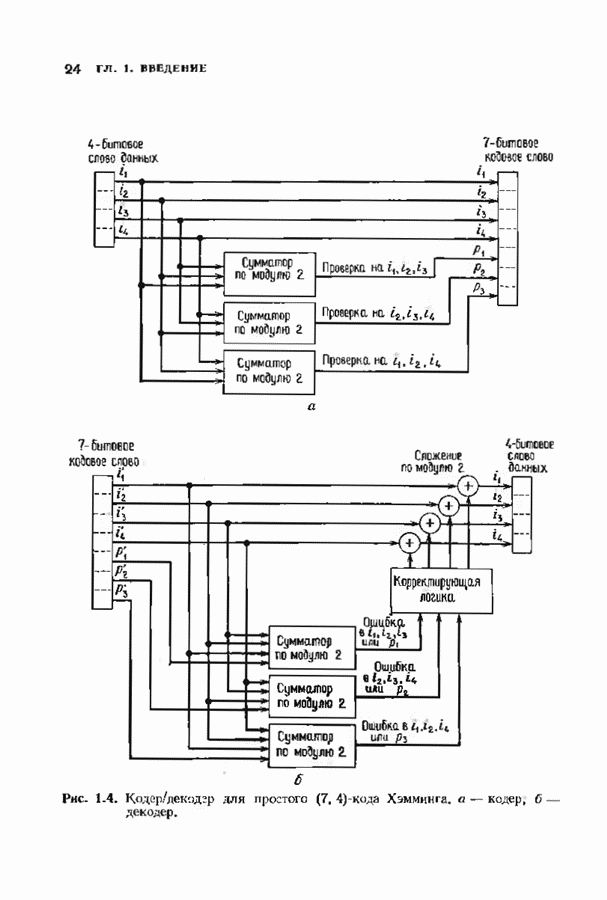
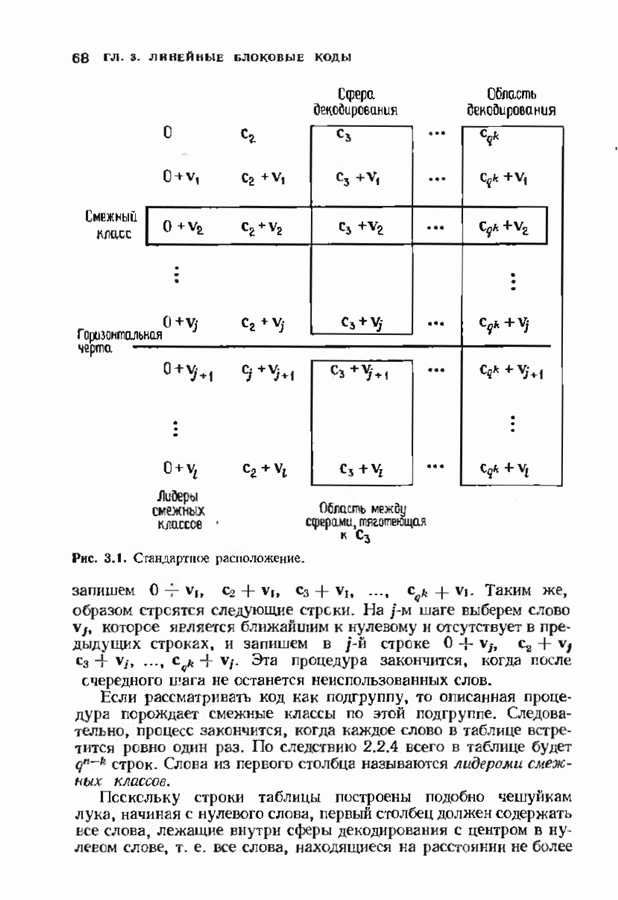
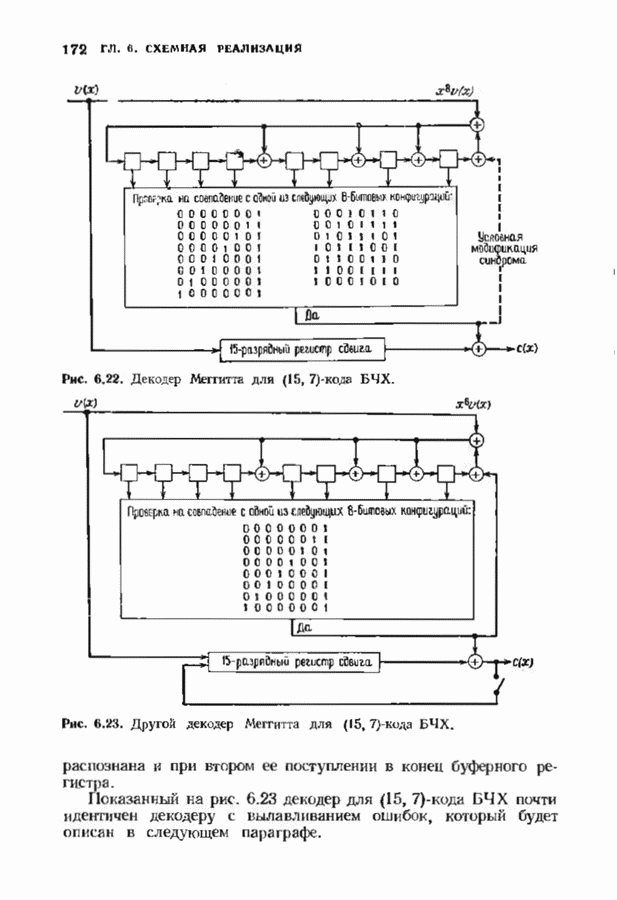
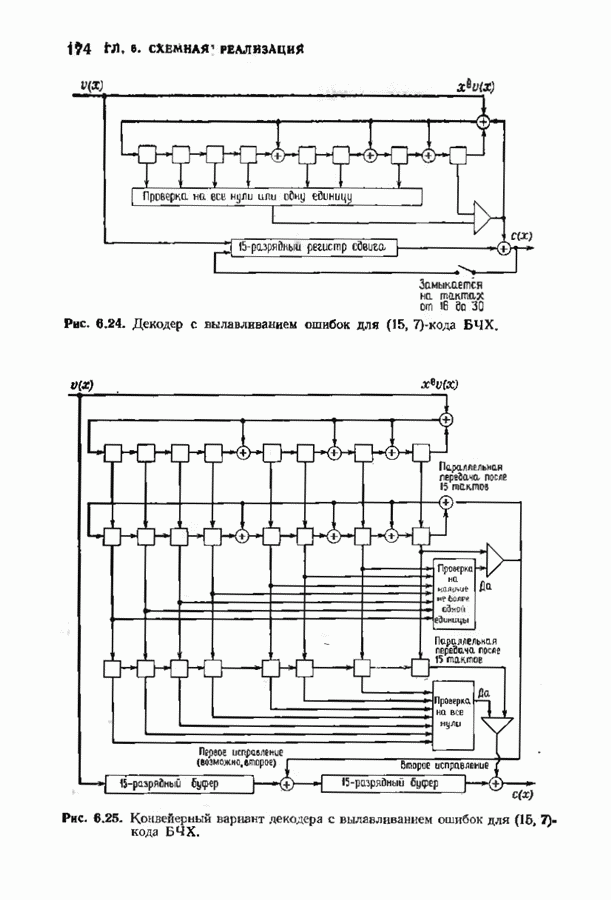
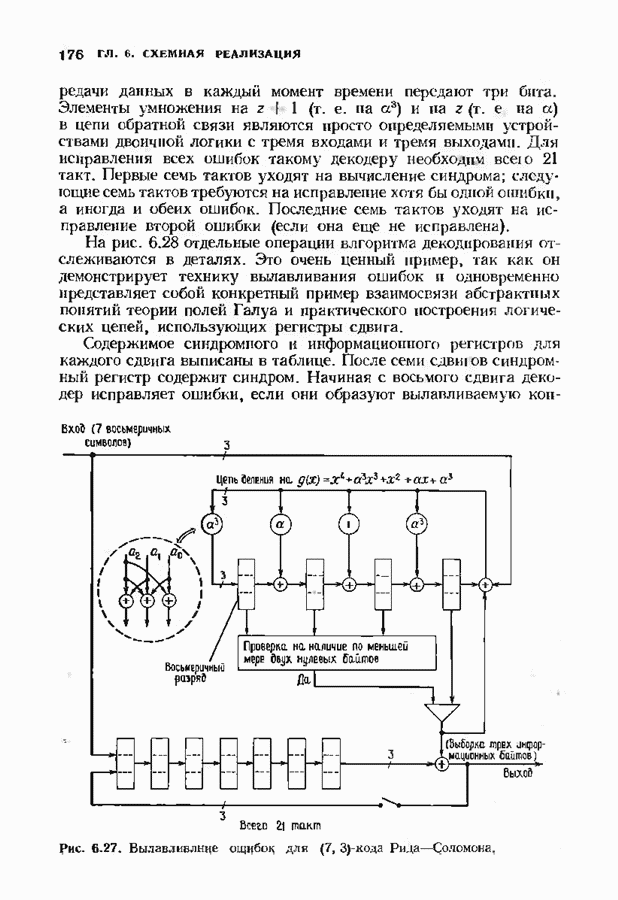
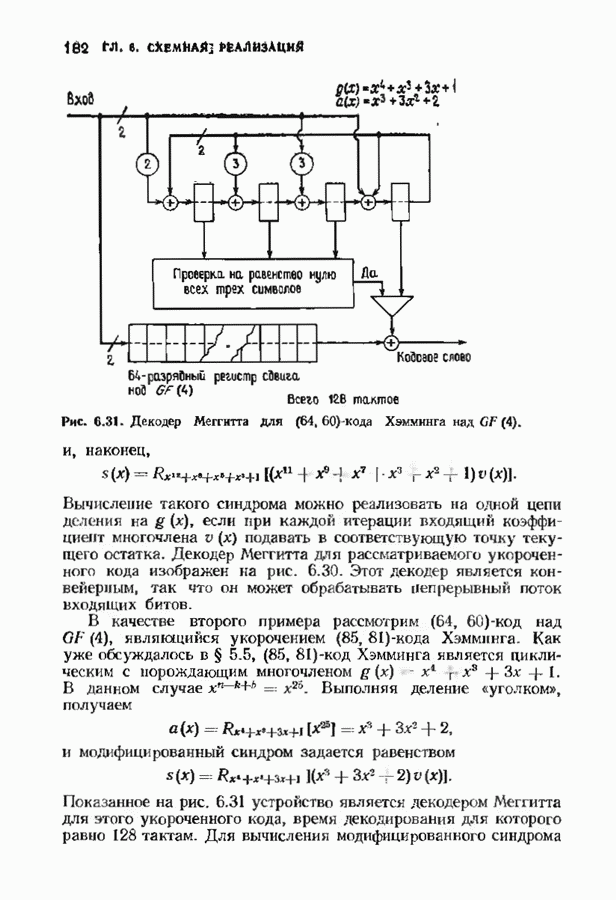
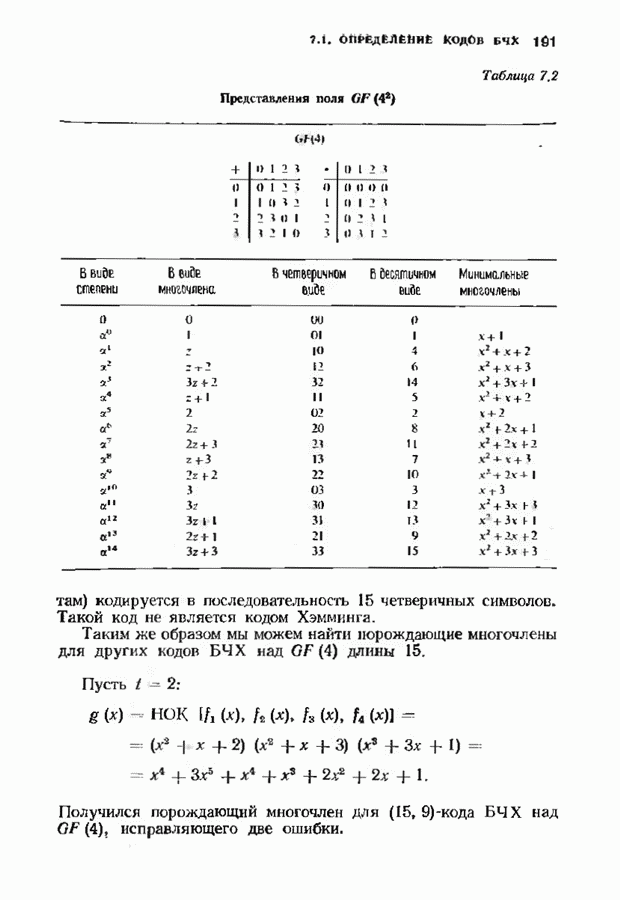
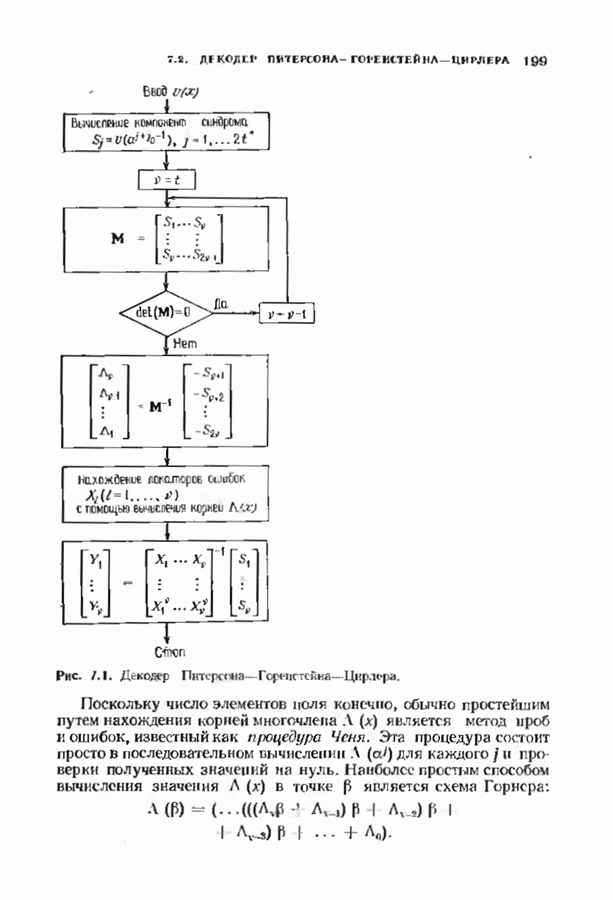
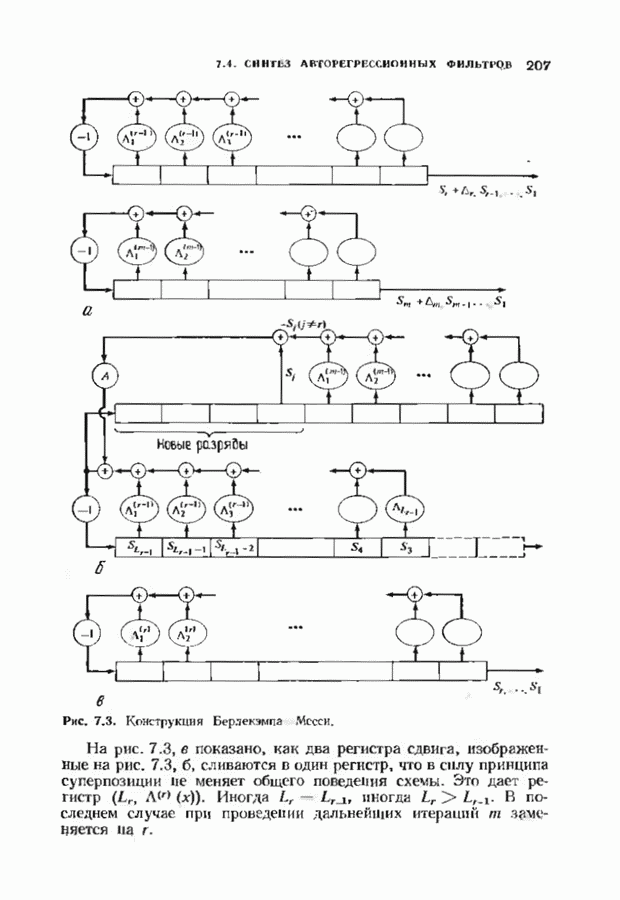
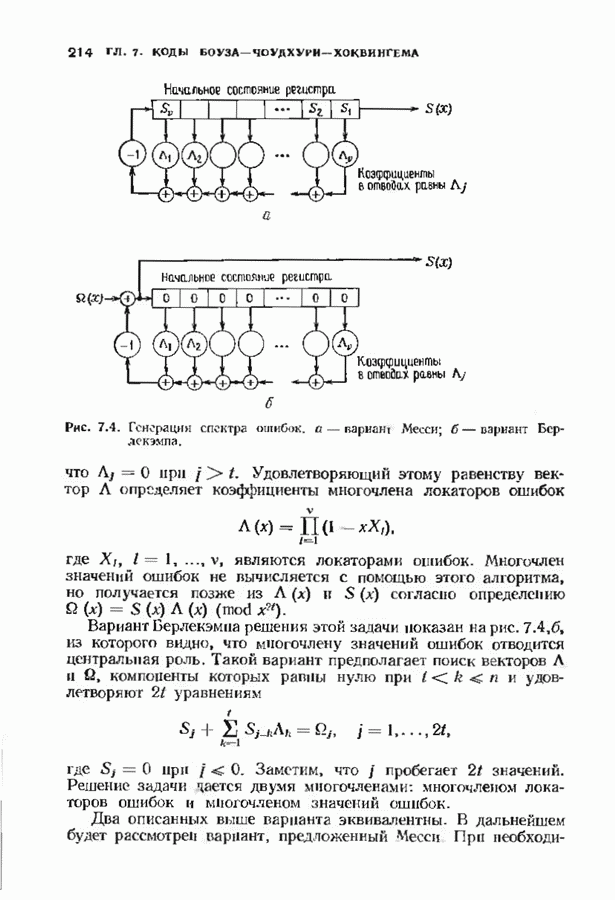
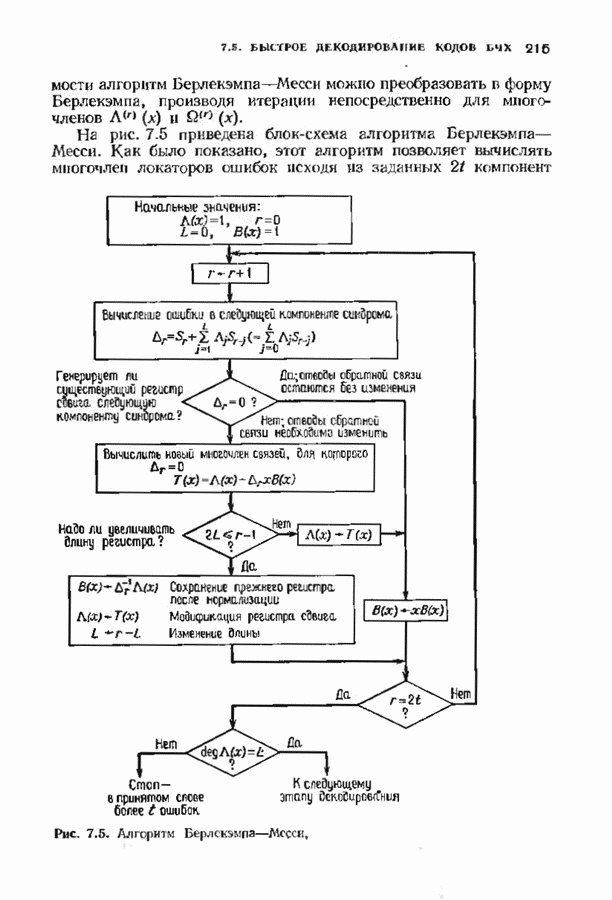
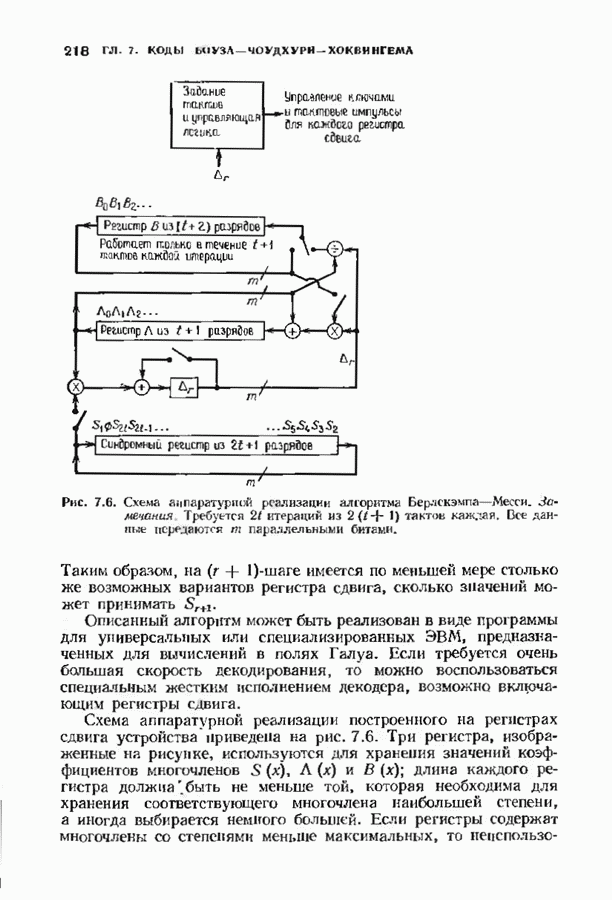
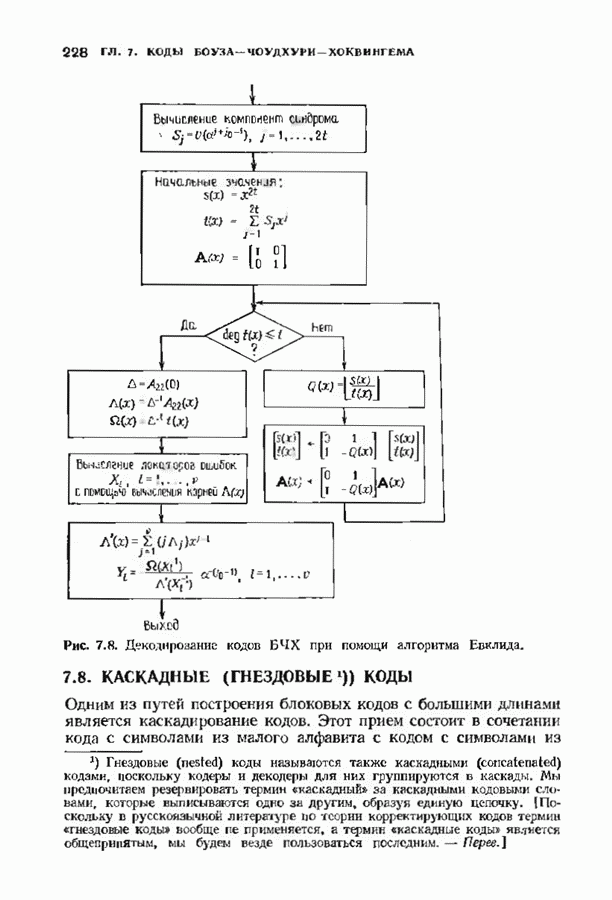
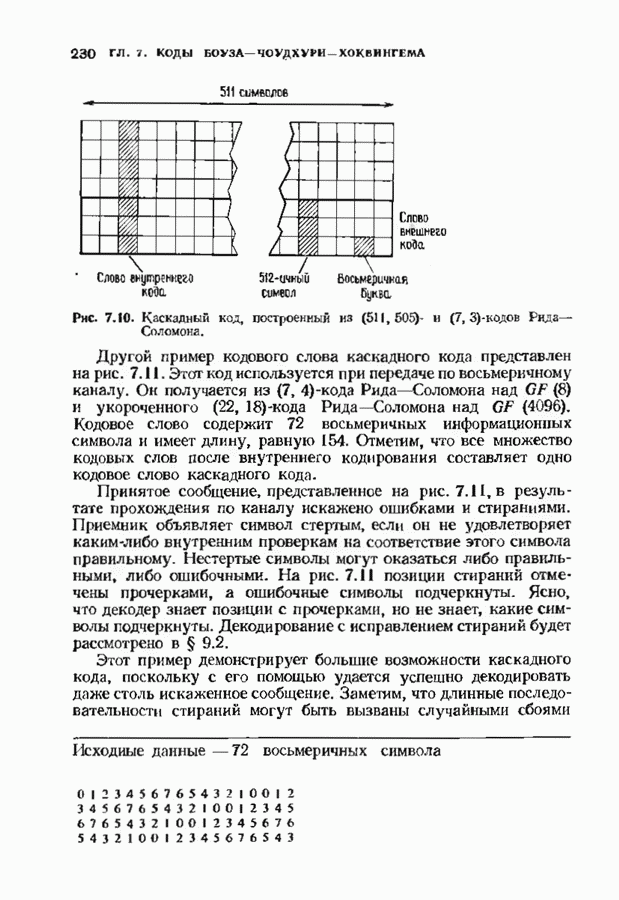
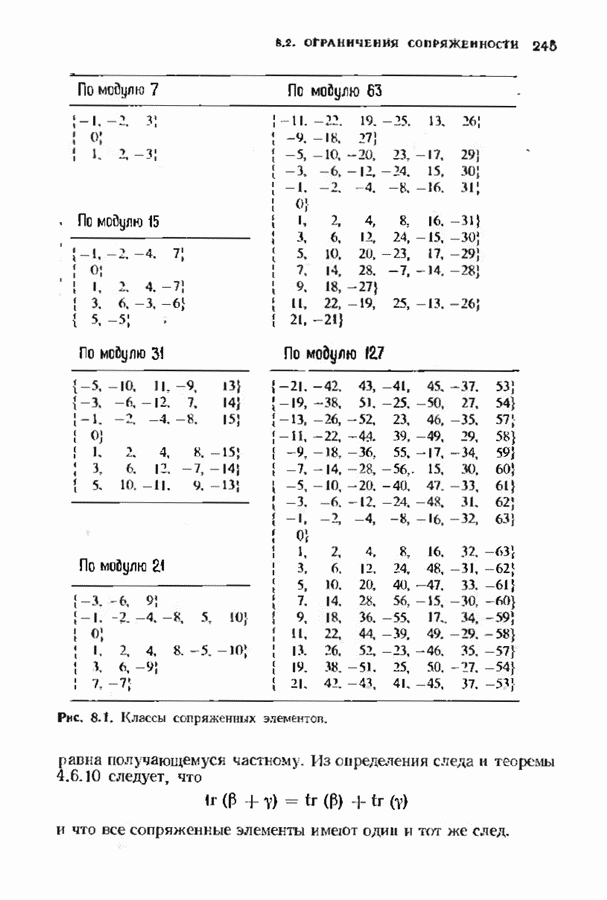
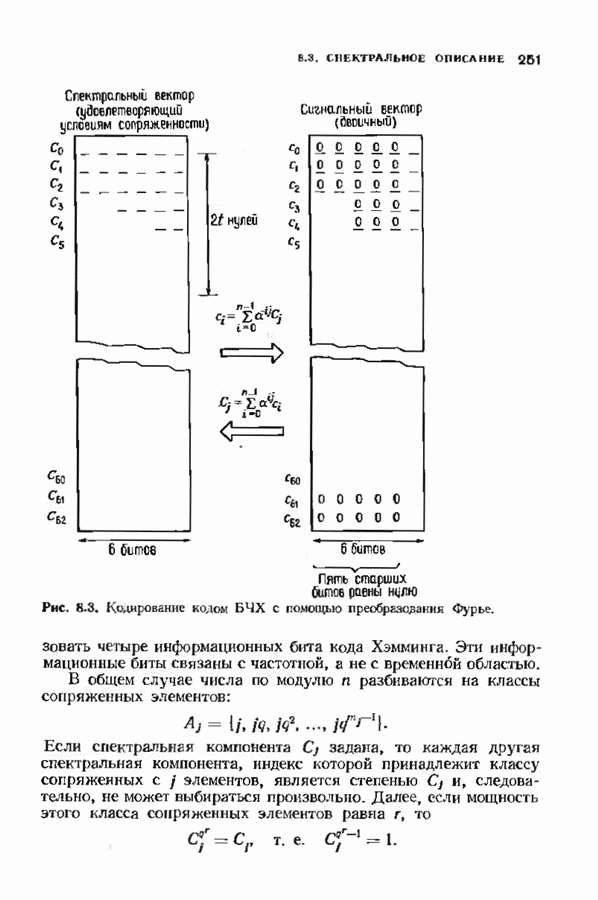
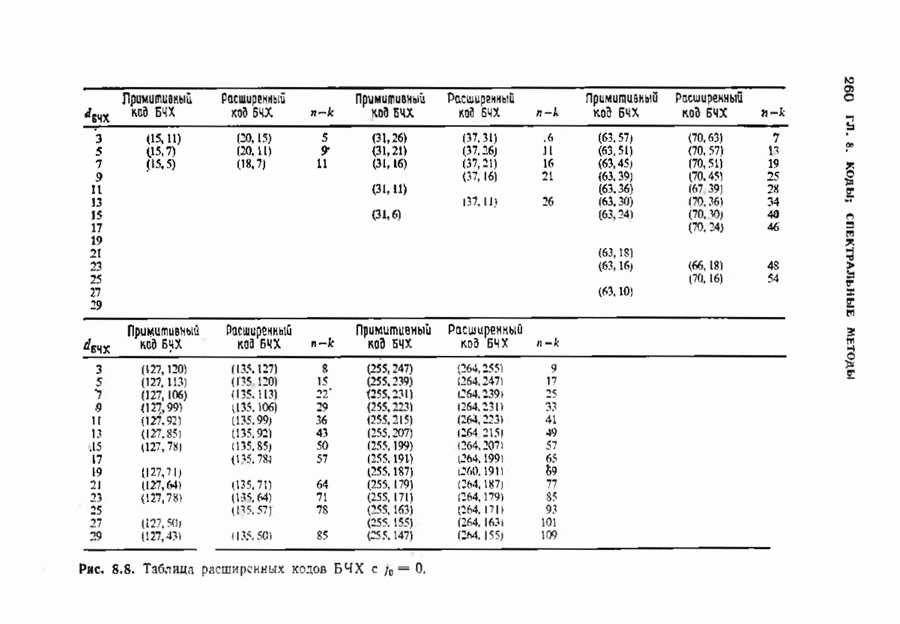
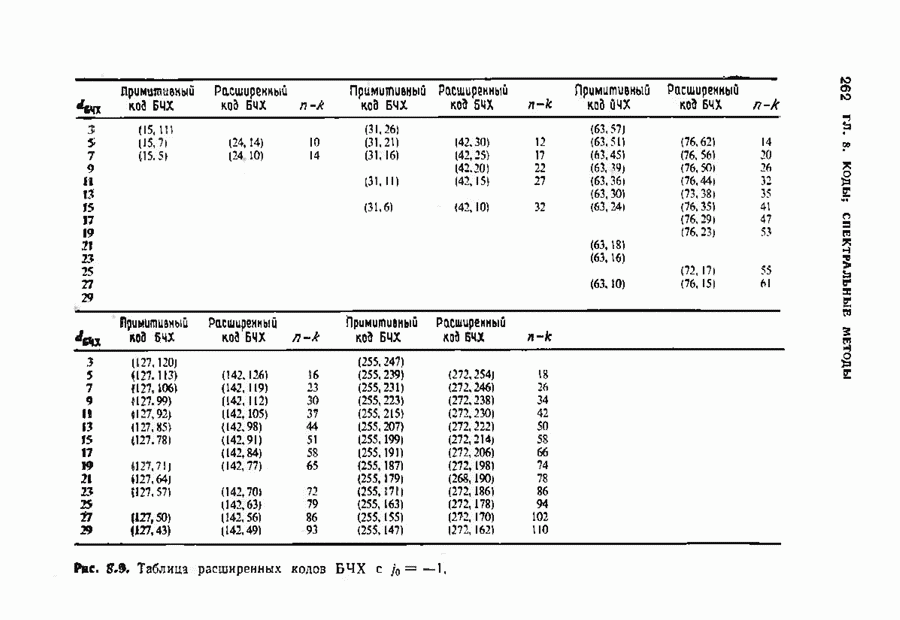
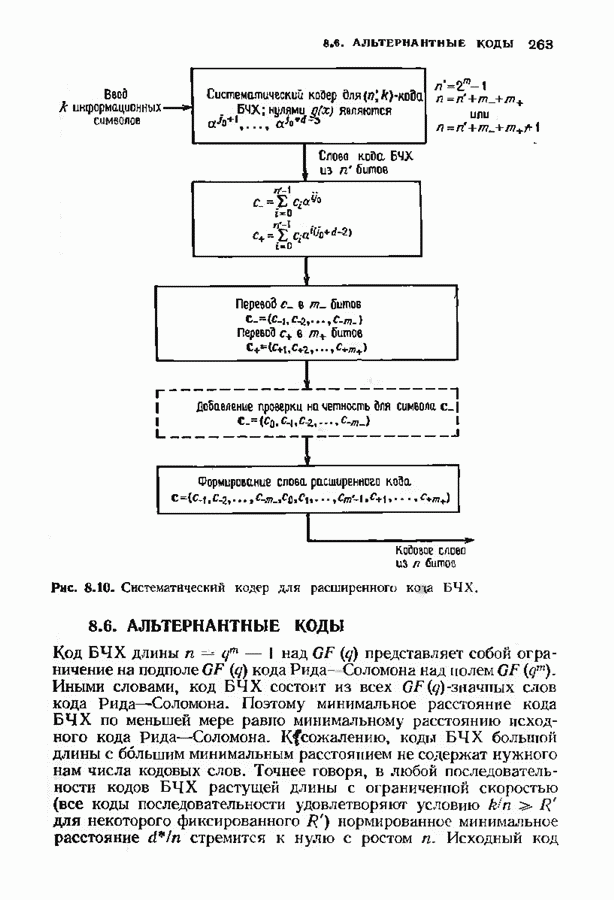
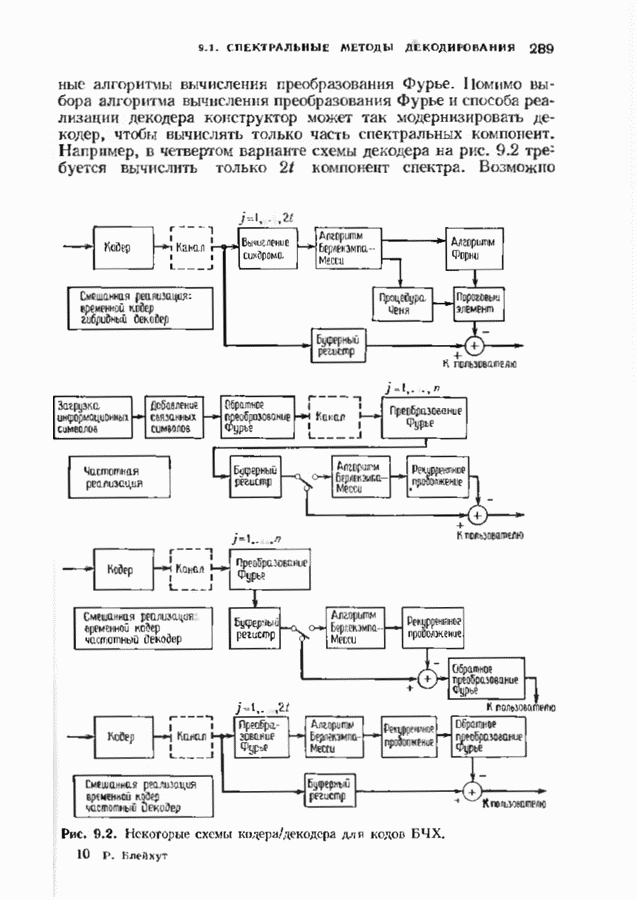
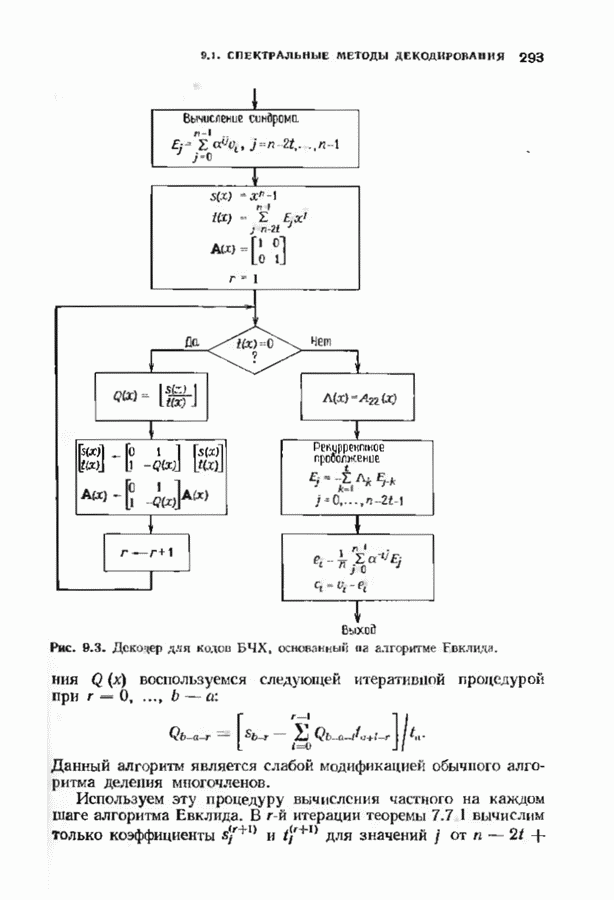
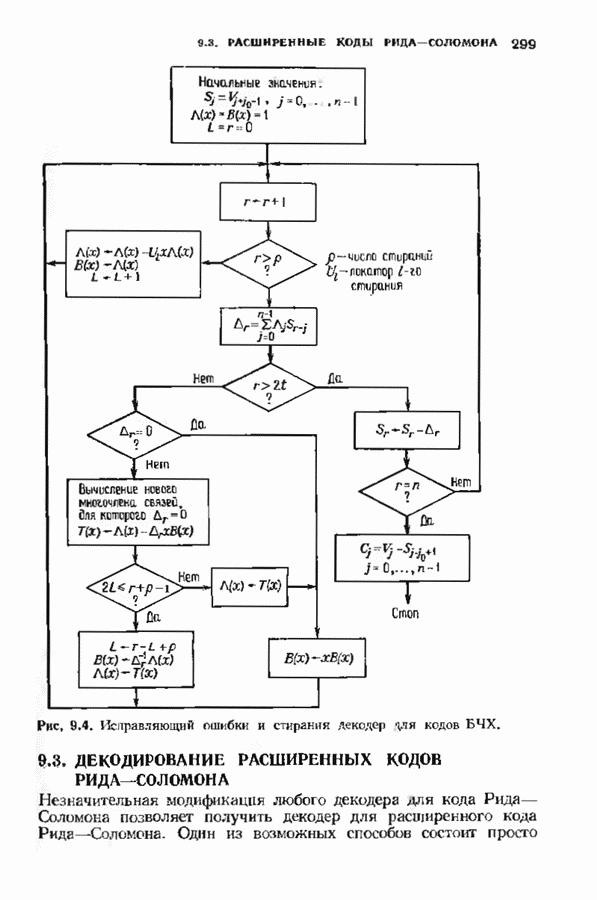
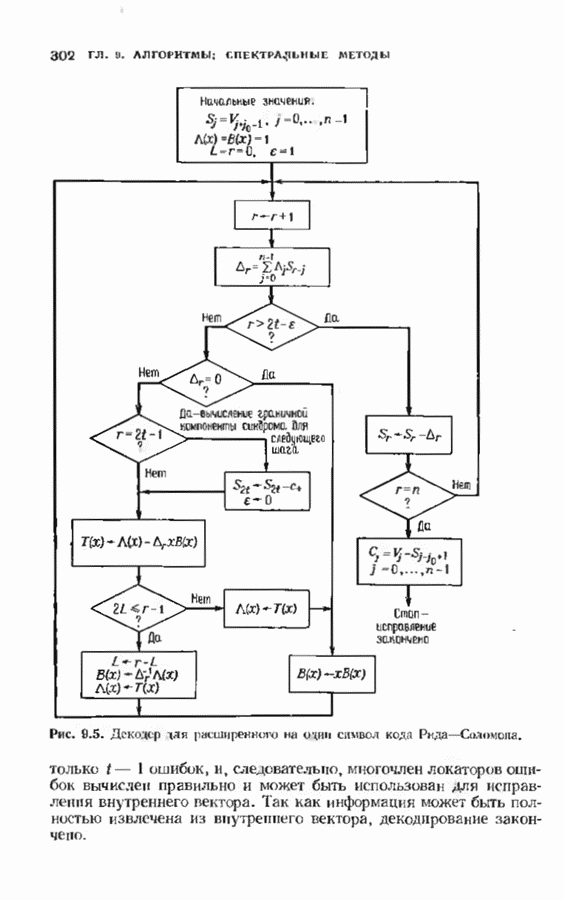
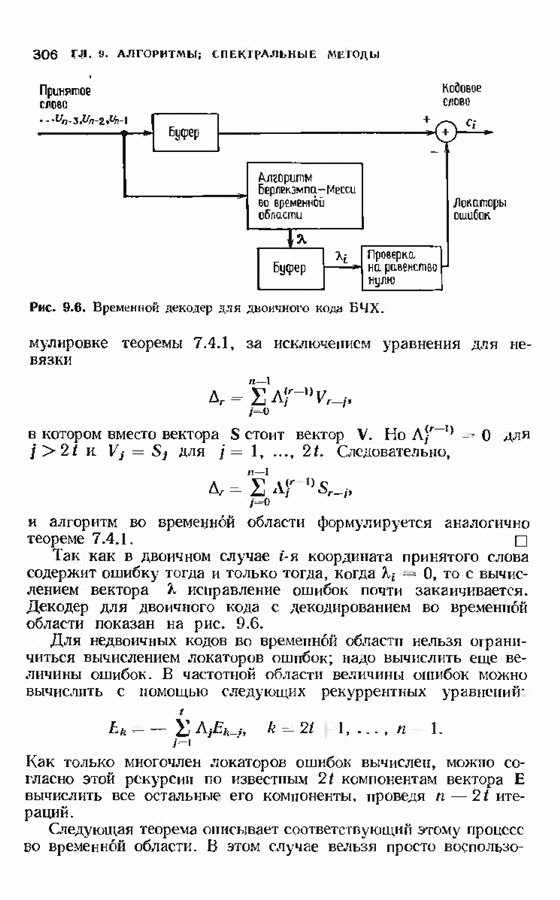
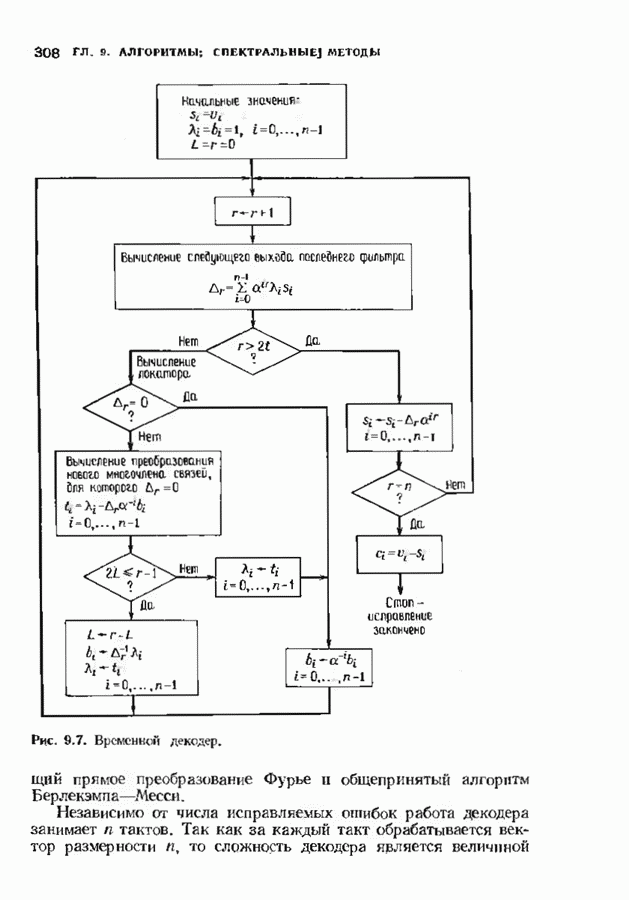
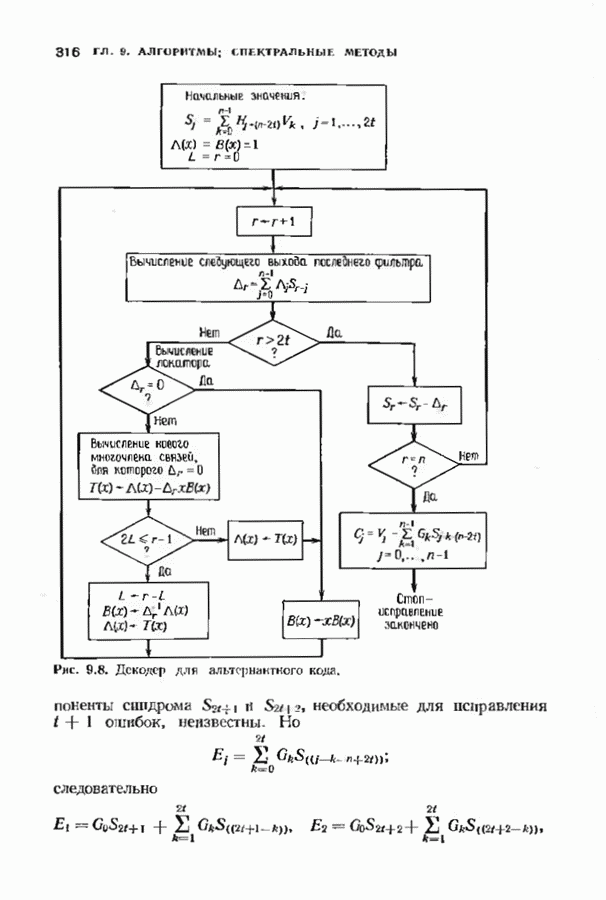
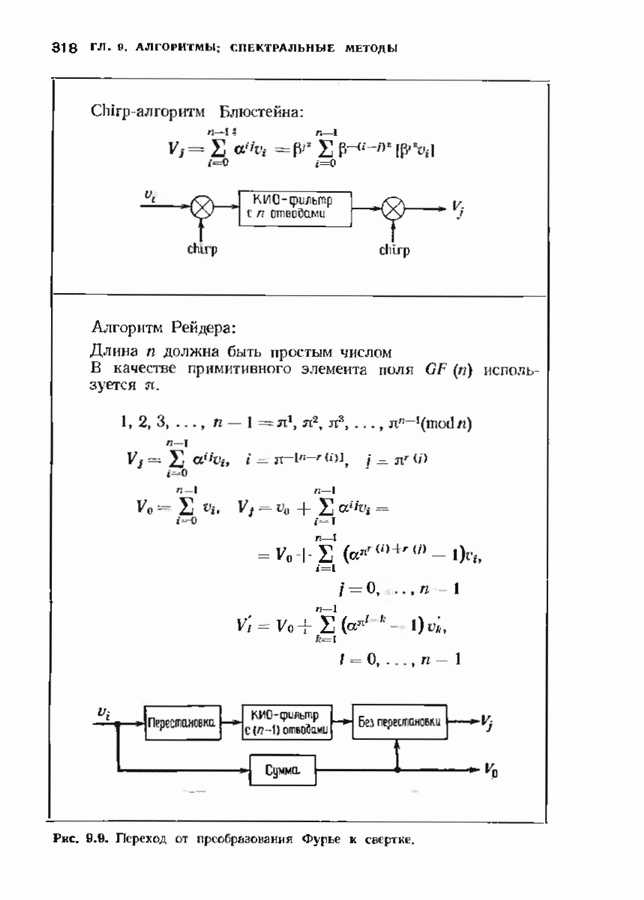
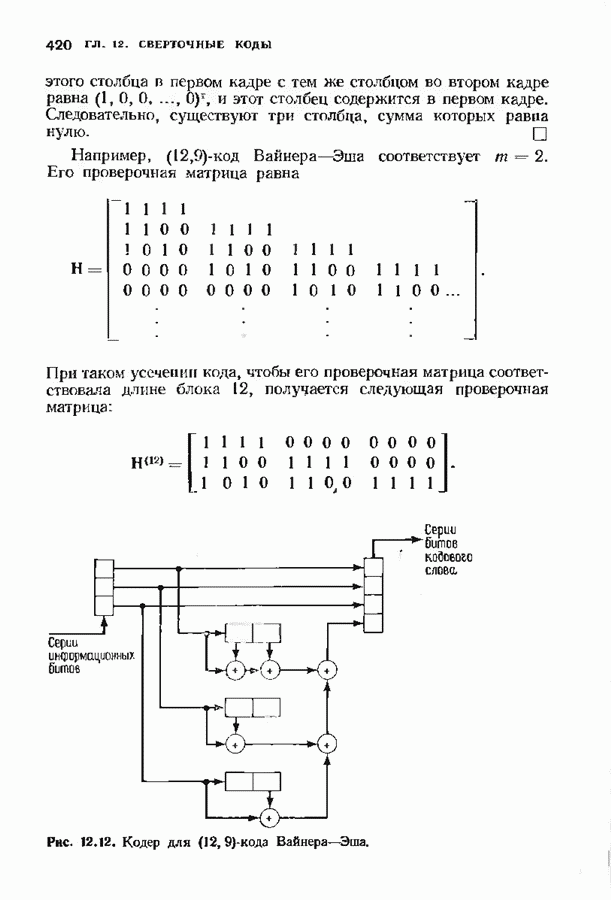
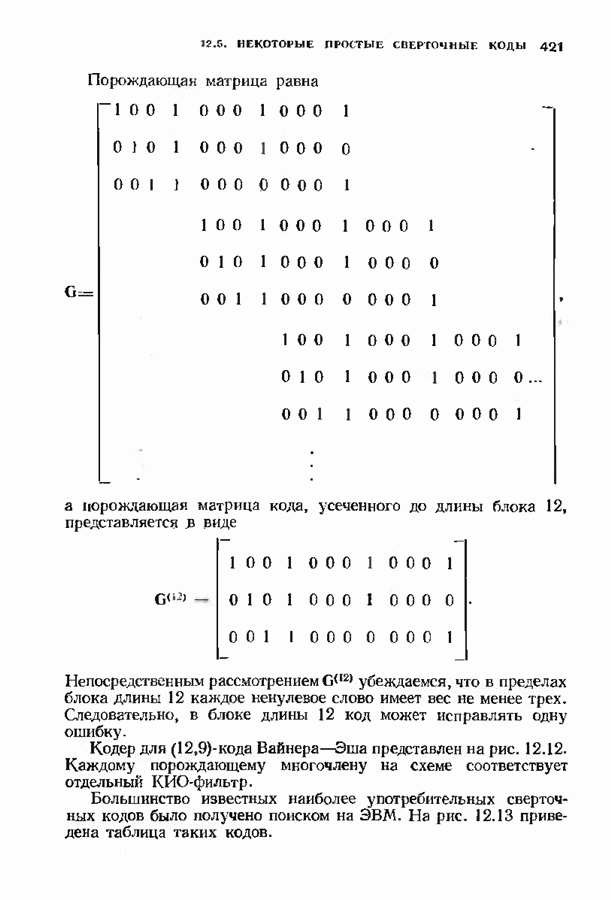
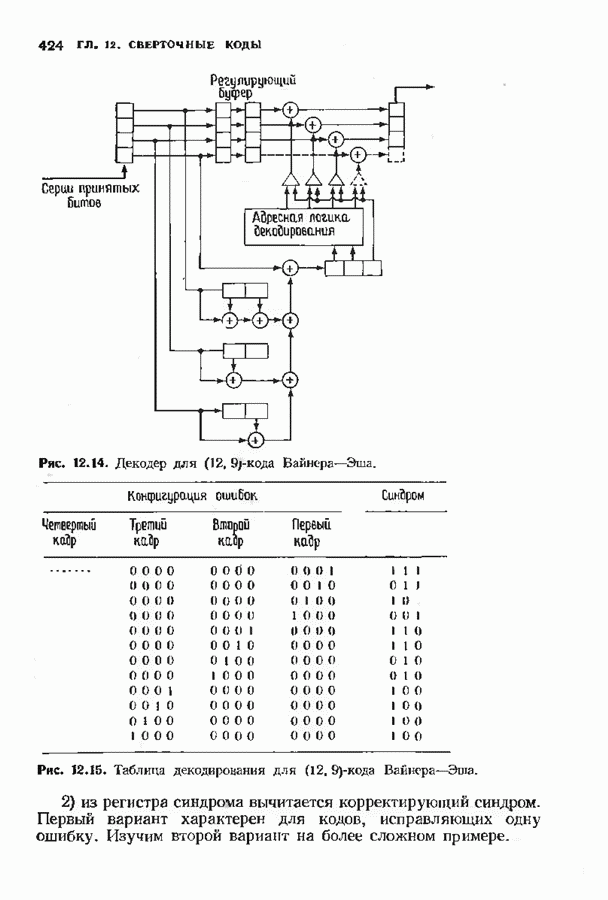
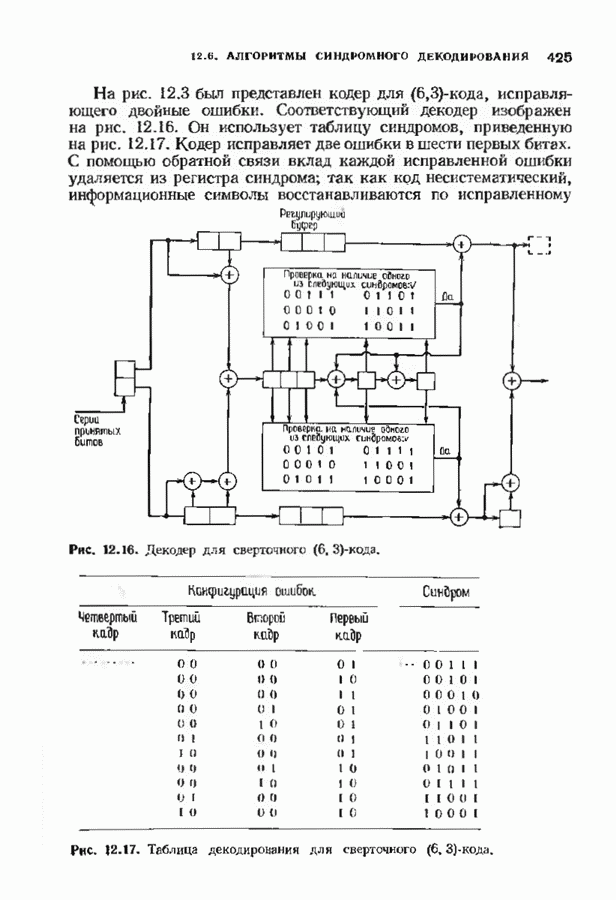
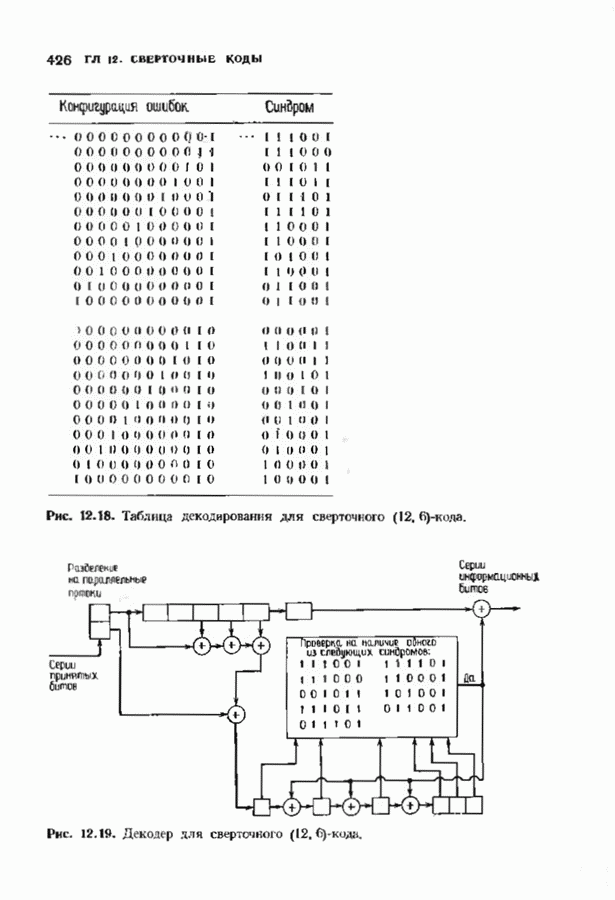
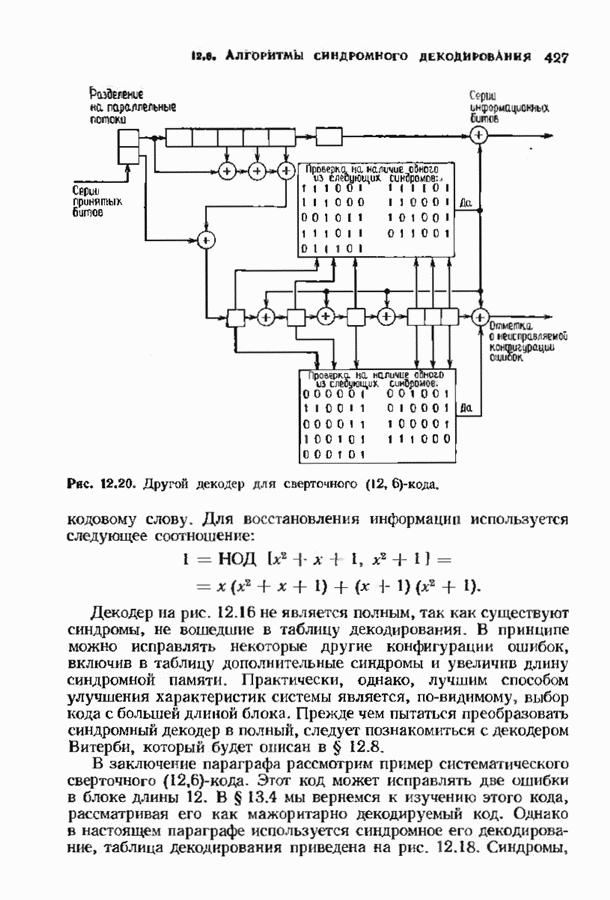
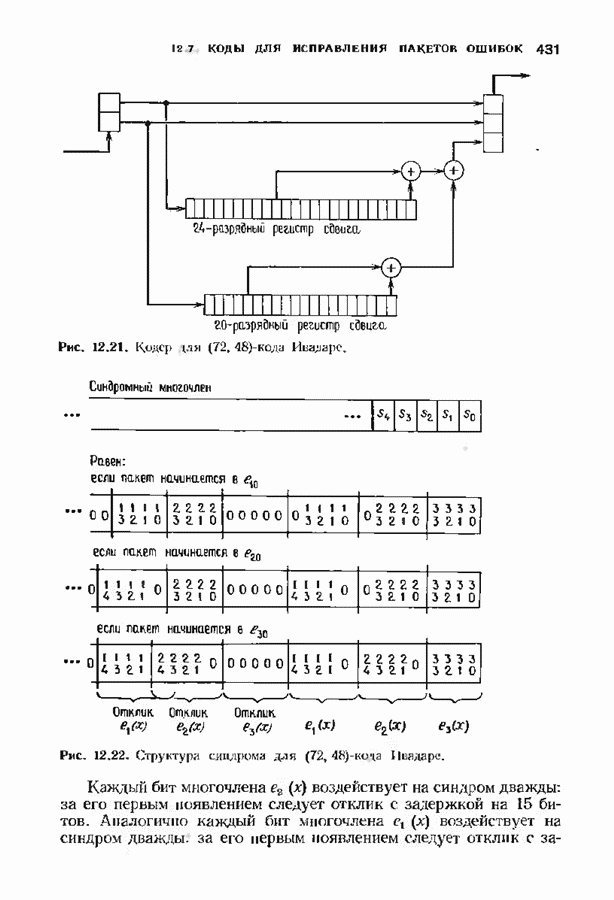
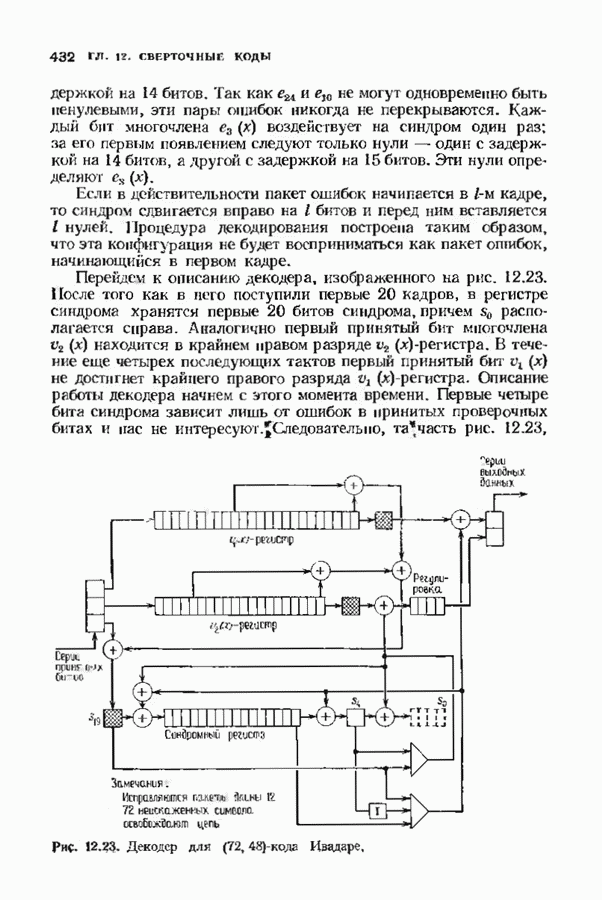
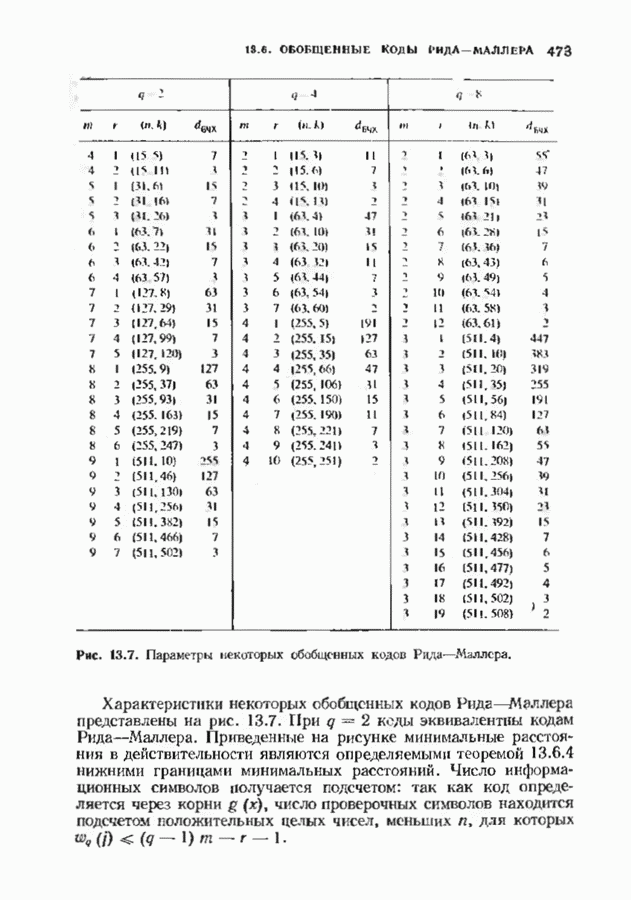
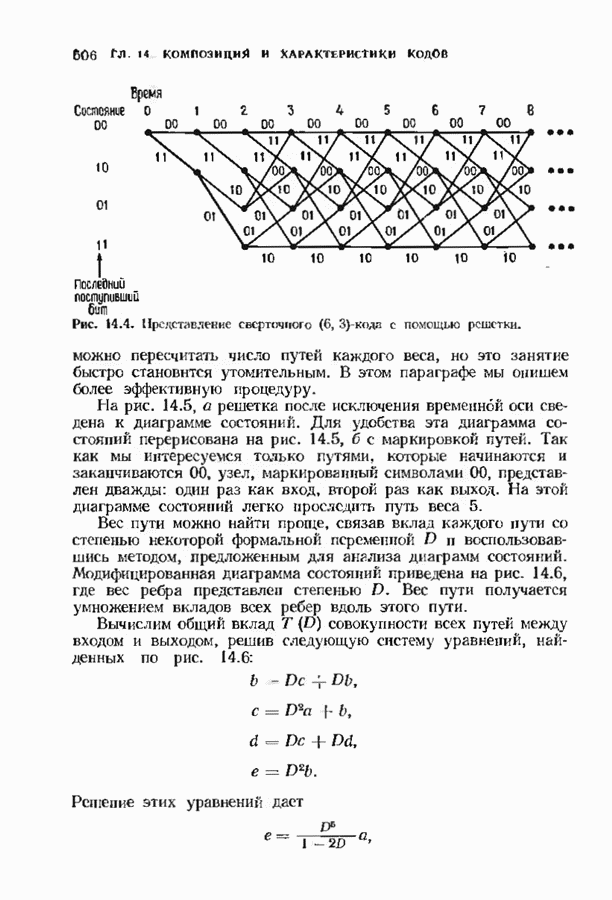
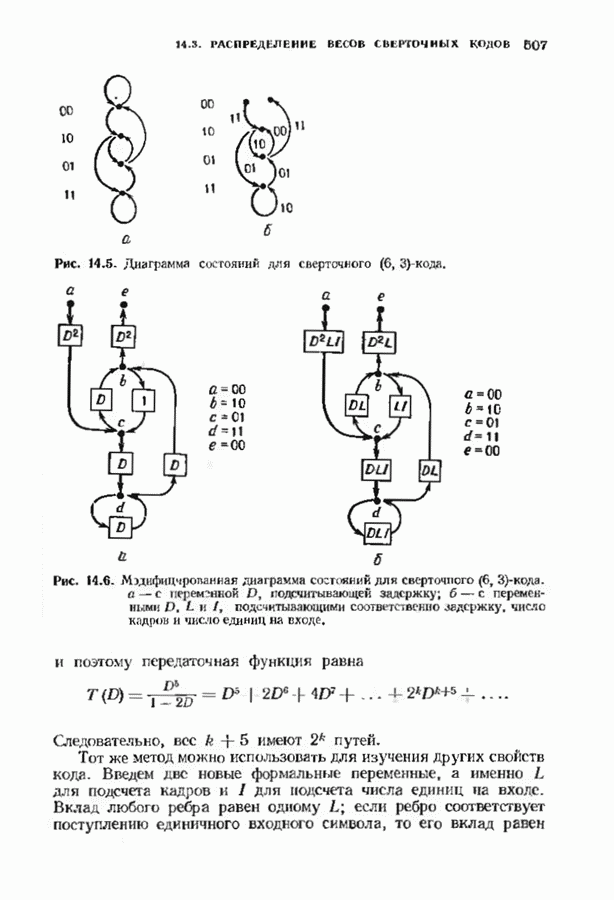
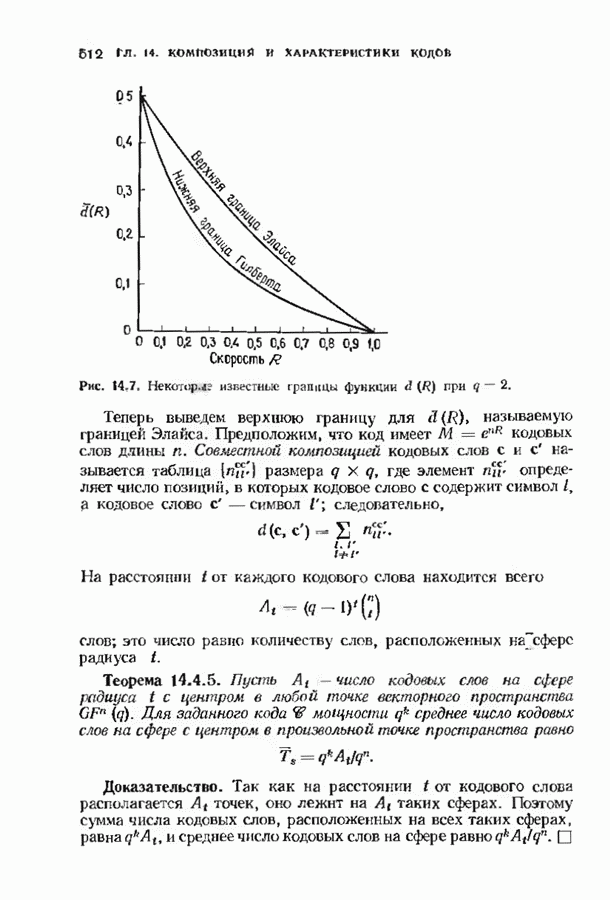
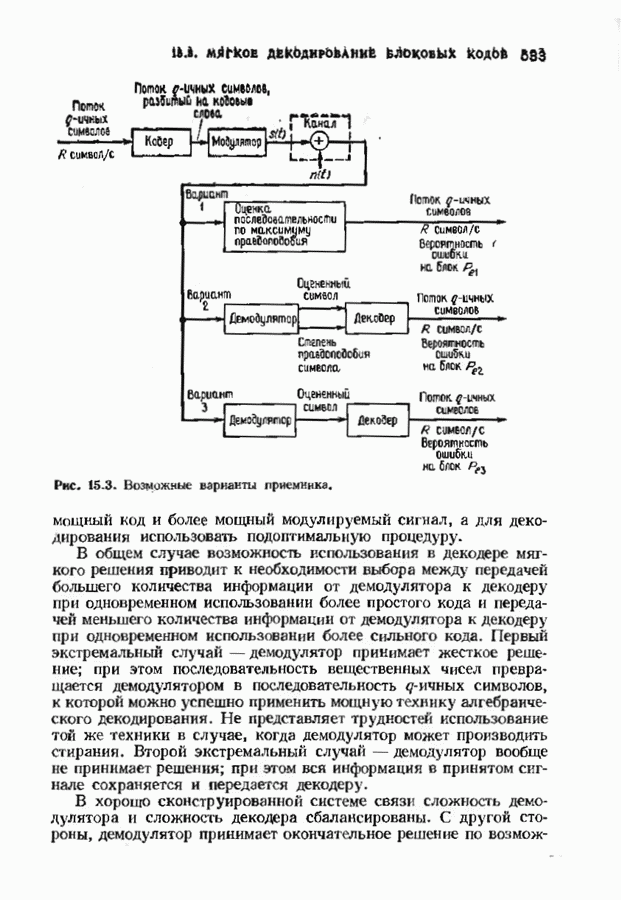
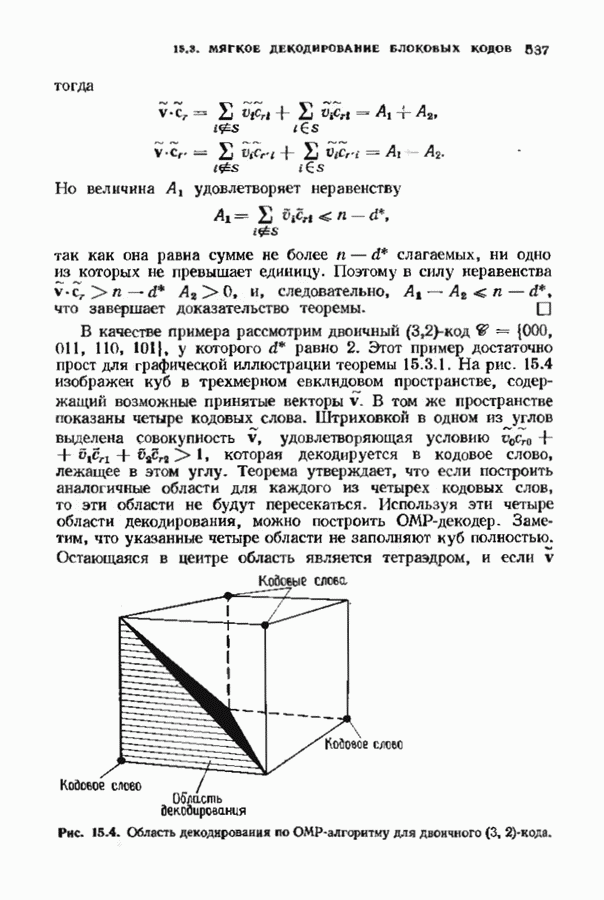
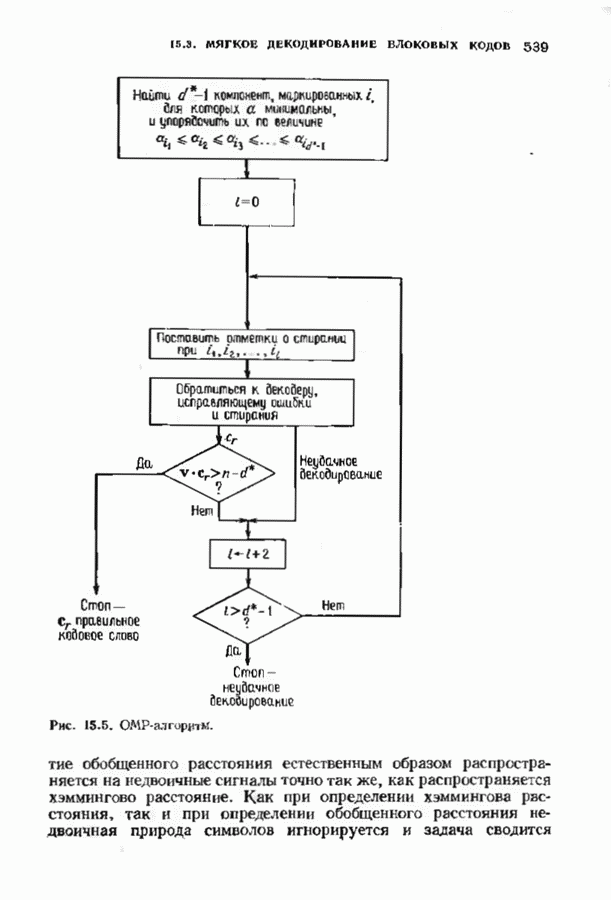
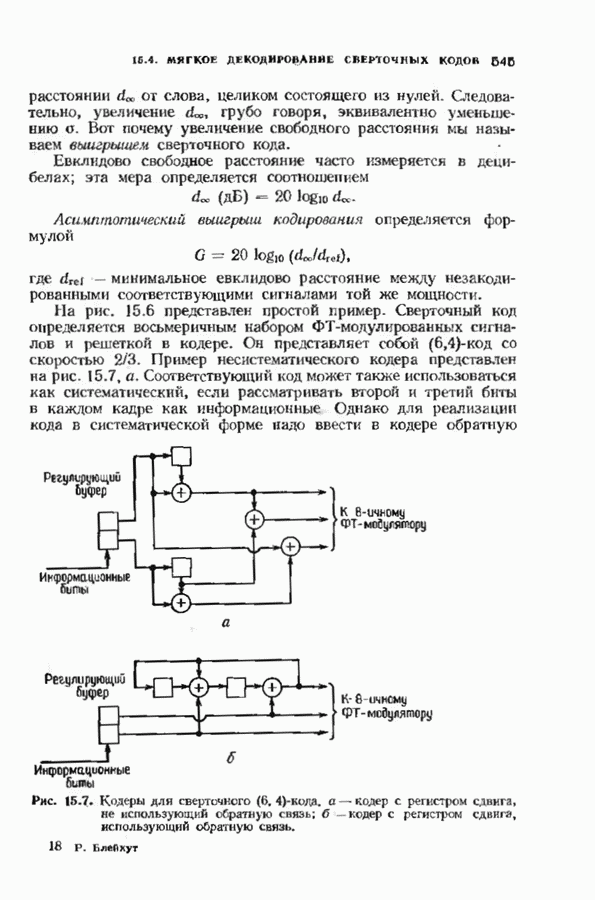
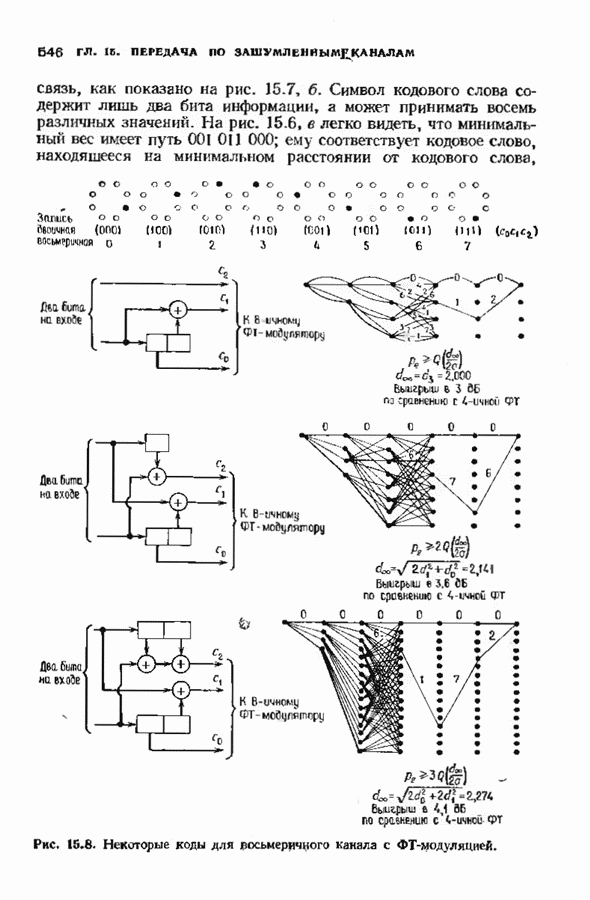
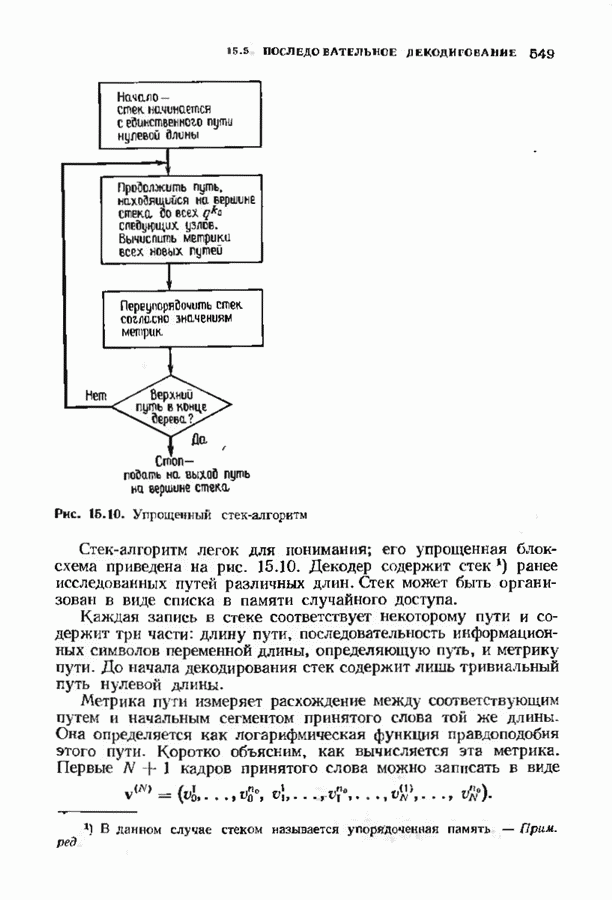
10.3. ДЕКОДИРОВАНИЕ КОДА-ПРОИЗВЕДЕНИЯ
Если  то код-произведение способен исправлять
то код-произведение способен исправлять  ошибок. Такая теоретическая корректирующая способность кода, однако, мало что дает без практических алгоритмов декодирования. В данном параграфе описывается такой алгоритм декодирования, основанный на исправляющем только ошибки под-алгоритме для одного кода-сомножителя и на исправляющем ошибки и стирания подал гор итме для другого кода-сомножителя. Такие декодеры были описаны только для кодов БЧХ, и, следовательно, мы будем говоригь только о произведениях кодов БЧХ.
ошибок. Такая теоретическая корректирующая способность кода, однако, мало что дает без практических алгоритмов декодирования. В данном параграфе описывается такой алгоритм декодирования, основанный на исправляющем только ошибки под-алгоритме для одного кода-сомножителя и на исправляющем ошибки и стирания подал гор итме для другого кода-сомножителя. Такие декодеры были описаны только для кодов БЧХ, и, следовательно, мы будем говоригь только о произведениях кодов БЧХ.
Рассмотрим случай, когда нечетно, и без ограничения общности предположим, что  Задача декодера, исправляющего в произведении кодов БЧХ только случайные ошибки, состоит в вычислении некоторого кодового слова, находящегося от принятого слова не далее радиуса упаковки
Задача декодера, исправляющего в произведении кодов БЧХ только случайные ошибки, состоит в вычислении некоторого кодового слова, находящегося от принятого слова не далее радиуса упаковки  так как такое слово единственно. Декодер состоит из внутреннего декодера для кода БЧХ и внешней цепи обработки, содержащей произвольный подходящий декодер для кода БЧХ, исправляющий ошибки и стирания. Сначача опишем упрощенный вариант декодера, потом улучшим его, а затем докажем, что он выполняет нужные исправления.
так как такое слово единственно. Декодер состоит из внутреннего декодера для кода БЧХ и внешней цепи обработки, содержащей произвольный подходящий декодер для кода БЧХ, исправляющий ошибки и стирания. Сначача опишем упрощенный вариант декодера, потом улучшим его, а затем докажем, что он выполняет нужные исправления.
Сначала декодер должен «исправлять» каждый столбец. Для алгоритма декодирования безразлично, передается ли кодовое слово по строкам или по столбцам, но при обсуждении этого алгоритма удобнее предполагать, что кодовое слово передается но столбцам, и воспринимать столбец как отдельно декодируемый
подблок. Позже, при декодировании строк, неправильные подблоки будут выявлены и исправлены.
Пусть в  столбце принятого слова произошло у ошибок; тогда
столбце принятого слова произошло у ошибок; тогда

Первый шаг состоит в использовании БЧХ-декодера для исправления каждого столбца. Для каждого  исправленного столбца указывается число и, сделанных исправлений. Это число представляет собой вес оценки
исправленного столбца указывается число и, сделанных исправлений. Это число представляет собой вес оценки  вектора-столбца ошибки и равно
вектора-столбца ошибки и равно  если декодирование произведено правильно. Если обнаружена неисправляемая ошибка, то столбец стирается. Пестертые столбцы с наибольшими значениями чисел
если декодирование произведено правильно. Если обнаружена неисправляемая ошибка, то столбец стирается. Пестертые столбцы с наибольшими значениями чисел  рассматриваются строчным декодером как наименее надежные.
рассматриваются строчным декодером как наименее надежные.
Затем исправляющий ошибки и стирания БЧХ-декодер применяется для исправления каждой строки. Теперь, однако, имеется сторонияя информация, которую можно использовать для правомерного стирания дополнительных столбцов. Спачала, игнорируя эту стороннюю информацию, декодируем, как удастся, все строки, начиная с первой. Строчный декодер может потерпеть неудачу и может внести ненулевую конфигурацию ошибок. Любой из этих случаев означает, что некоторые столбцы были декодированы неправильно. Требуется какое-то правило, указывающее, что нужно делать: принять декодированную строку или стереть наименее надежный столбец и попытаться декодировать строку сначала.
Основную теорему мы докажем сначала в предположении, что столбцовый декодер не производит никаких стираний. Впоследствии эта теорема будет использована и при наличии стираний с помощью простого уменьшения числа  на число стертых столбцов. Рассматриваемые методы доказательства будут использованы в гл. 15, когда мы будем изучать декодирование с мягким решением.
на число стертых столбцов. Рассматриваемые методы доказательства будут использованы в гл. 15, когда мы будем изучать декодирование с мягким решением.
Что можно сказать о строчном декодере, если дано, что код-произведение может исправлять  ошибок и что столбцовый декодер уже исправил
ошибок и что столбцовый декодер уже исправил  ошибок в
ошибок в  столбце? Предположим, что 1-й строка декодирована и для нее вычислена оценка
столбце? Предположим, что 1-й строка декодирована и для нее вычислена оценка  вектора-строки ошибки. Обозначим через
вектора-строки ошибки. Обозначим через  множество индексов
множество индексов  для которых
для которых  отлично от нуля. Если
отлично от нуля. Если  принадлежит множеству
принадлежит множеству  то
то  столбец продекодирован неправильно; в
столбец продекодирован неправильно; в  столбце имеется но меньшей мере
столбце имеется но меньшей мере  ошибок, среди которых
ошибок, среди которых  могли быть внесены столбцовым декодером, причем
могли быть внесены столбцовым декодером, причем  меньше
меньше  Следовательно, если строчному декодеру удастся правильно найти конфигурацию ошибок, то в исходном принятом слове в
Следовательно, если строчному декодеру удастся правильно найти конфигурацию ошибок, то в исходном принятом слове в 
столбце содержалось по меньшей мере  ошибок для каждого
ошибок для каждого  из множества
из множества  как уже известно, ошибок для каждого
как уже известно, ошибок для каждого  не принадлежащего множеству
не принадлежащего множеству  Таким образом, разумное условие принятия результата декодирования
Таким образом, разумное условие принятия результата декодирования  строки дается следующим неравенством:
строки дается следующим неравенством:

В приведенной ниже теореме доказываемся,  это неравенство является необходимым и достаточным условием правильности декодирования
это неравенство является необходимым и достаточным условием правильности декодирования  строки. Сначала перепишем это неравенство в форме скалярного произведения, удобной для использования в доказательстве теоремы. Для этою представим его в виде
строки. Сначала перепишем это неравенство в форме скалярного произведения, удобной для использования в доказательстве теоремы. Для этою представим его в виде

Тогда

Пусть  равно —1, если
равно —1, если  принадлежит
принадлежит  в противном случае. Тогда
в противном случае. Тогда

Если, наконец,  то неравенство приводится к виду
то неравенство приводится к виду

Теперь все готово для доказательства теоремы.
Теорема 10.3.1. Пусть  «пело позиций, в которых
«пело позиций, в которых  столбец исправленной столбцовым декодером таблицы отличается от принятого слова. Для каждого
столбец исправленной столбцовым декодером таблицы отличается от принятого слова. Для каждого  существует в точности одно слово строчного кода, удовлетворяющее неравенству
существует в точности одно слово строчного кода, удовлетворяющее неравенству

Здесь  мн тество номеров
мн тество номеров  позиций, в которых комшненты
позиций, в которых комшненты  строки кодового слова отличаются от компонент этой строки в исправленной столбцовым декодером таблице.
строки кодового слова отличаются от компонент этой строки в исправленной столбцовым декодером таблице.
Доказательство. На первом шаге мы докажем, что правильное слово строчного кода в  строке удовлетворяет выписанному неравенству. На втором
строке удовлетворяет выписанному неравенству. На втором  мы докажем единственность такого слова.
мы докажем единственность такого слова.
Шаг 1. Пусть  число неправильно декодированных столбцов,
число неправильно декодированных столбцов,  пусть
пусть  множество индексов этих столбцов. Тогда
множество индексов этих столбцов. Тогда  столбцов декодированы правильно. Но
столбцов декодированы правильно. Но

и число  произошедших в
произошедших в  столбце принятого слова ошибок удовлетворяет равенству
столбце принятого слова ошибок удовлетворяет равенству  если
если  столбец декодирован правильно, и неравенству
столбец декодирован правильно, и неравенству  сслч
сслч  столбец декодирован неправильно. Множество
столбец декодирован неправильно. Множество  декодированных столбцов, содержащих в
декодированных столбцов, содержащих в  строке ошибку, удовлетворяет включению
строке ошибку, удовлетворяет включению  следовательно,
следовательно,

а это и доказывает, что для каждой строки кодовое слово удовлетворяет данному неравенству.
Шаг 2. Рассмотрим  строку. Предположим, что
строку. Предположим, что  являются словами строчного кода, и обозначим
являются словами строчного кода, и обозначим  строку после «исправления» столбцов через
строку после «исправления» столбцов через  Пусть равно 1, если с, совпадает с
Пусть равно 1, если с, совпадает с  компоненте, и —1 в противном случае. Пусть обозначает аналогичную величину для кодового слова
компоненте, и —1 в противном случае. Пусть обозначает аналогичную величину для кодового слова  Определим множества
Определим множества

Каждый индекс  принадлежит одному из этих трех мцожеств; тогда
принадлежит одному из этих трех мцожеств; тогда

где величины  определены очевидным образом. Число элементов в
определены очевидным образом. Число элементов в  не превосходит
не превосходит  Если с, удовлетворяет условиям теоремы, то
Если с, удовлетворяет условиям теоремы, то

и, следовательно, 
Теперь рассмотрим кодовое слово  Мы имеем
Мы имеем

где величина  определена очевидным образом и на множестве V выполняется равенство
определена очевидным образом и на множестве V выполняется равенство  Но
Но  как мы видели,
как мы видели,  Следовательно,
Следовательно,

так что  не удовлетворяет неравенству.
не удовлетворяет неравенству.
Опишем теперь практический способ вычисления такого кодового слова. Мы уже знаем, как строить декодеры для исправления ошибок и стираний с жестким решением. К любому из таких декодеров присоединим внешнюю цепь обработки. По имеющейся таблице декодированных столбцов для  строки построим пробную цепочку векторов, полученных при жестком декодировании ошибок и стираний. Индексы упорядочим следующим образом:
строки построим пробную цепочку векторов, полученных при жестком декодировании ошибок и стираний. Индексы упорядочим следующим образом:  или
или  Для каждого I из интервала от 0 до — 1 будем стирать ! компонент с наибольшими значениями
Для каждого I из интервала от 0 до — 1 будем стирать ! компонент с наибольшими значениями  Такое построение принедет к вектору
Такое построение принедет к вектору  со стираниями. Декодируем этот вектор декодером для исправления ошибок и стираний и проверим результат декодирования
со стираниями. Декодируем этот вектор декодером для исправления ошибок и стираний и проверим результат декодирования  на соответствие условию, даваемому теоремой 10.3.1. Если он удовлетворяет этому условию, то
на соответствие условию, даваемому теоремой 10.3.1. Если он удовлетворяет этому условию, то  будет кодовым словом для данной строки; в противном случае увеличим
будет кодовым словом для данной строки; в противном случае увеличим  и повторим процедуру. Следующая теорема доказывает, что описанная процедура всегда приводит к кодовому слову.
и повторим процедуру. Следующая теорема доказывает, что описанная процедура всегда приводит к кодовому слову.
Теорема 10.3.2. Если кодовое слово  удовлетворяет неравенству
удовлетворяет неравенству

то хотя бы для одного  выполняется условие
выполняется условие

где

и, следовательно,  представляет собой единственное кодовое слово, вычисляемое исправляющим ошибки и стирания декодером.
представляет собой единственное кодовое слово, вычисляемое исправляющим ошибки и стирания декодером.
Доказательство. Доказательство достаточно провести для всех I от 0 до 1, так как при  утверждение теоремы, очевидно, не может выполняться
утверждение теоремы, очевидно, не может выполняться

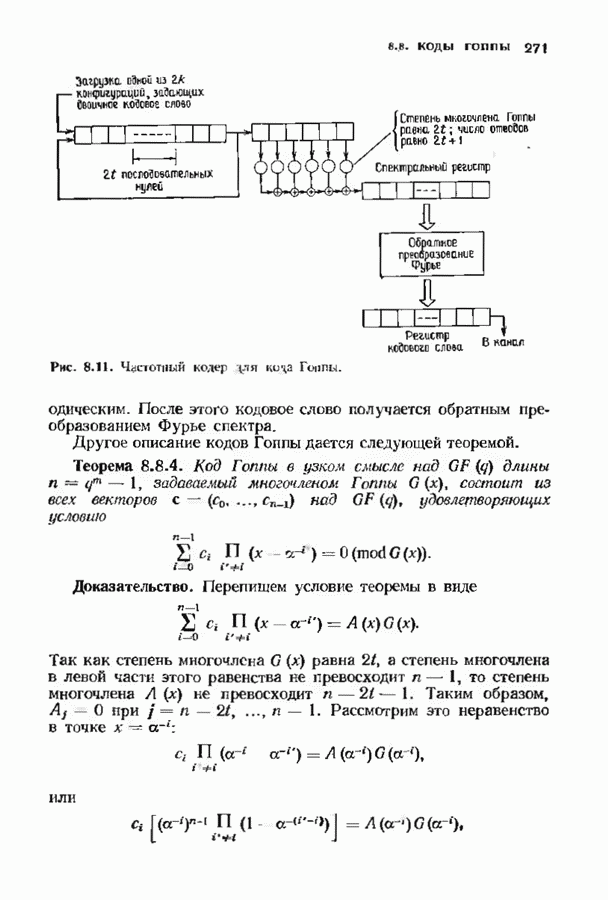
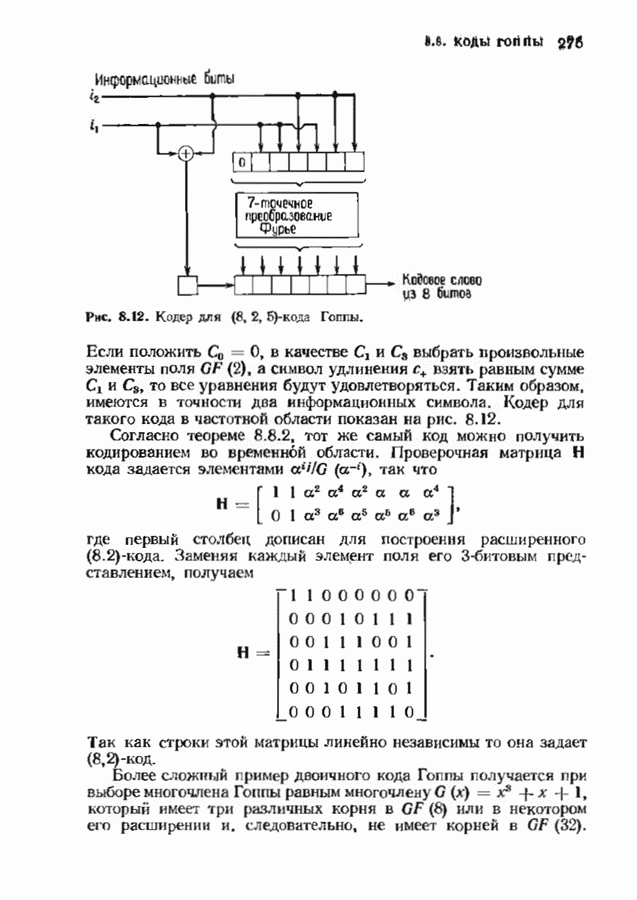
(кликните для просмотра скана)
Идея доказательства состоит в том, что  принадлежит выпуклой оболочке множества векторов
принадлежит выпуклой оболочке множества векторов  Пусть
Пусть

откуда следует, что 0 с  Кроме того,
Кроме того,

Предположим теперь, что для всех 

Тогда

что противоречит предположению теоремы. Следовательно, теорема доказана.
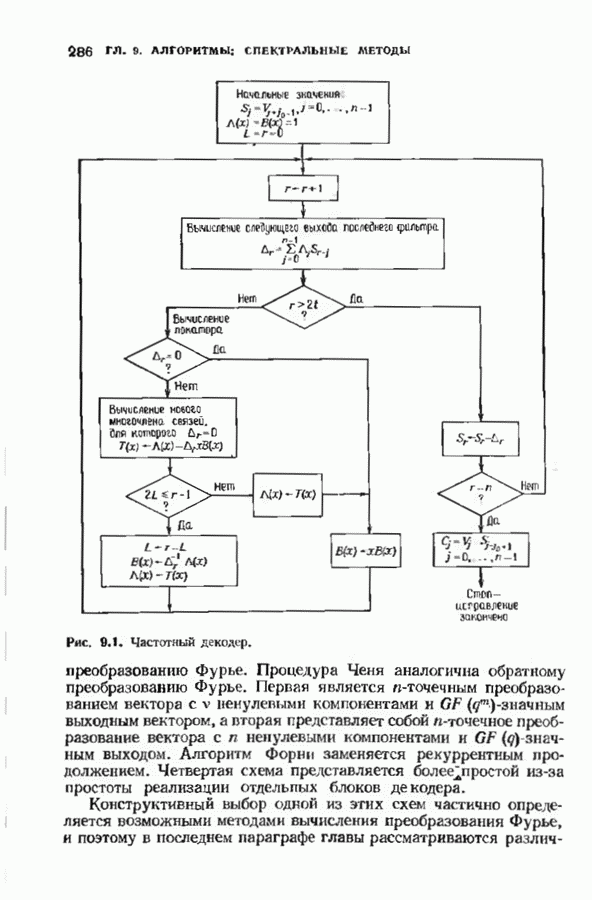
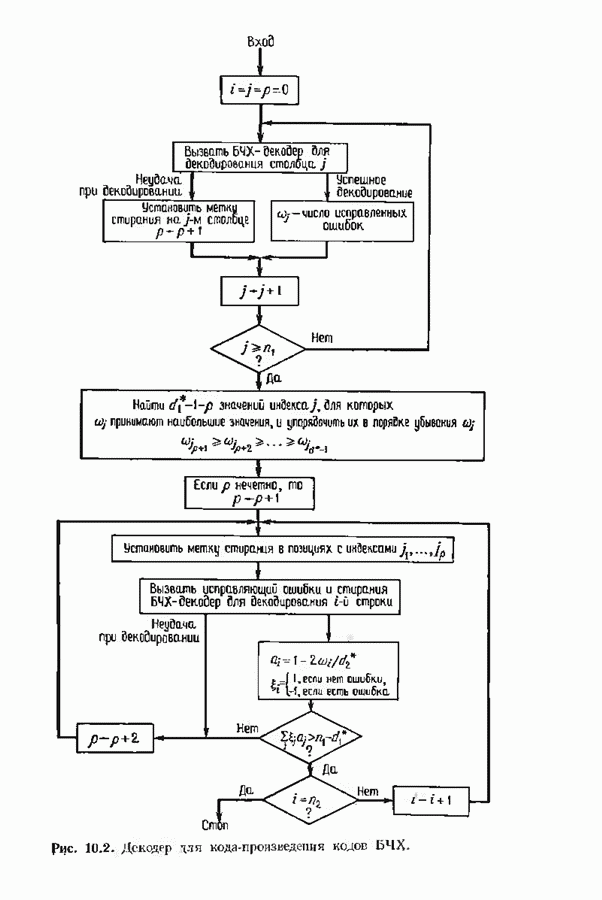
Изображенный на рис. 10.2 декодер основан на двух предыдущих теоремах. Если при декодировании  строки некоторые столбцы уже стерты, то используется та же самая процедура декодирования, но без учета стертых столбцов и при уменьшении
строки некоторые столбцы уже стерты, то используется та же самая процедура декодирования, но без учета стертых столбцов и при уменьшении  на число стертых столбцов. Далее, если при декодировании
на число стертых столбцов. Далее, если при декодировании  строки некоторые столбцы были стерты или отмечены как содержащие ошибку, то при декодировании всех последующих сгрок они остаются стертыми. В случае когда необходимо стереть только один столбец, декодер всегда стирает два, так что число стертых столбцов всегда четно. Это не уменьшает корректирующих способностей процедуры, по сводит число необходимых итераций не более чем к
строки некоторые столбцы были стерты или отмечены как содержащие ошибку, то при декодировании всех последующих сгрок они остаются стертыми. В случае когда необходимо стереть только один столбец, декодер всегда стирает два, так что число стертых столбцов всегда четно. Это не уменьшает корректирующих способностей процедуры, по сводит число необходимых итераций не более чем к