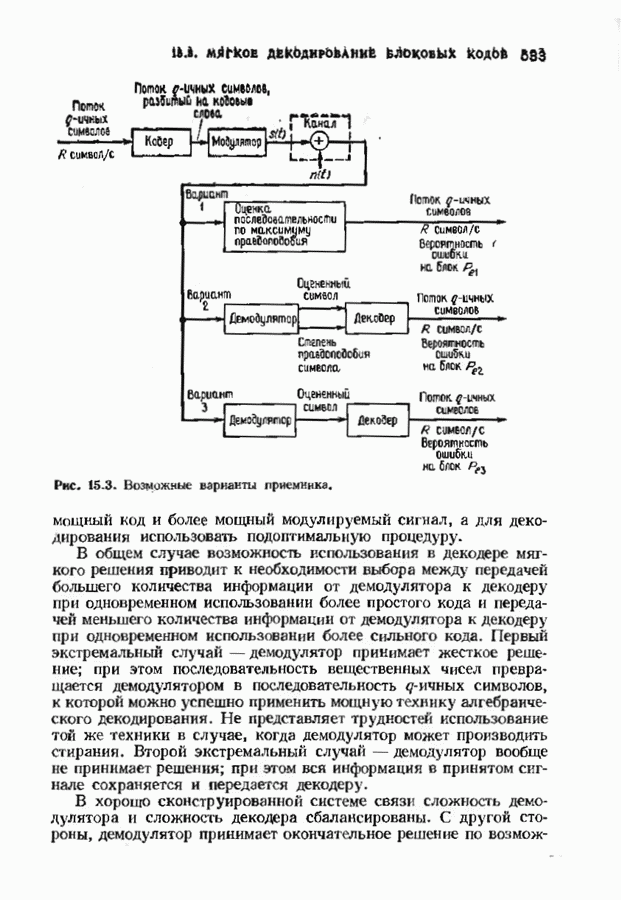
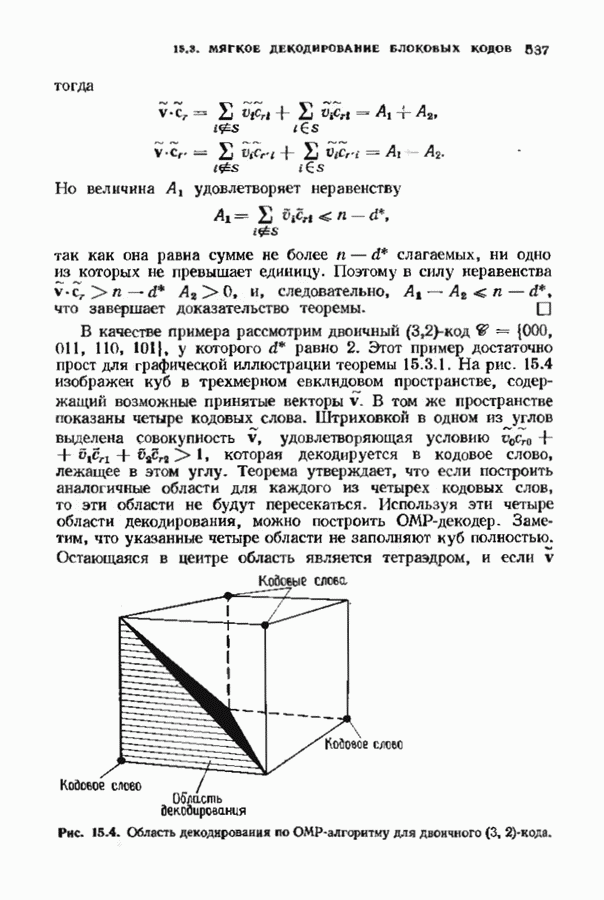
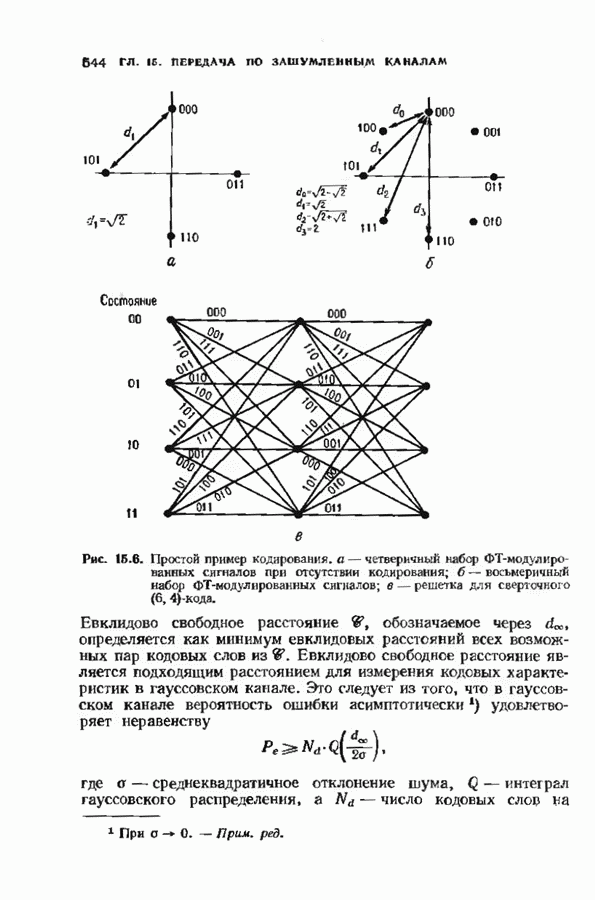
Пред.
След.
Макеты страниц
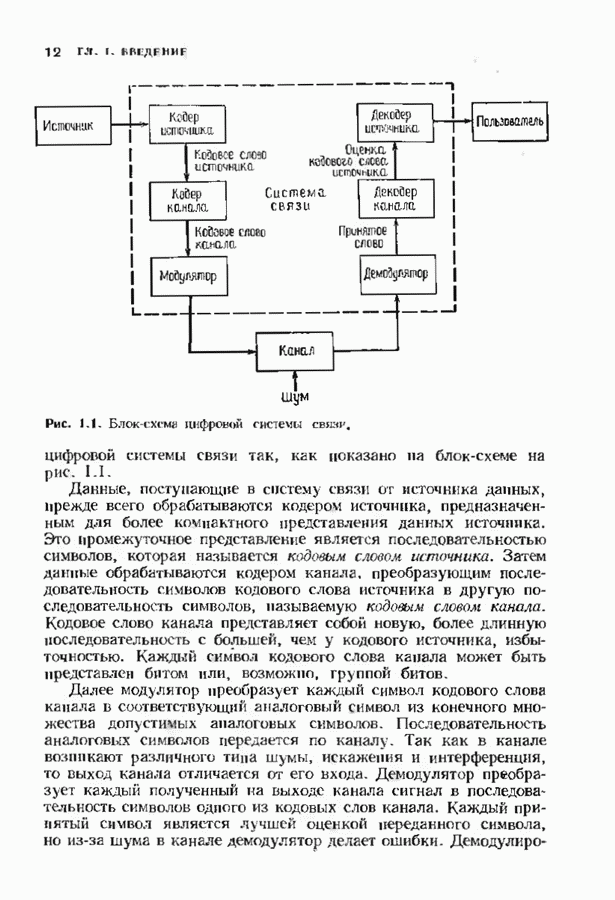
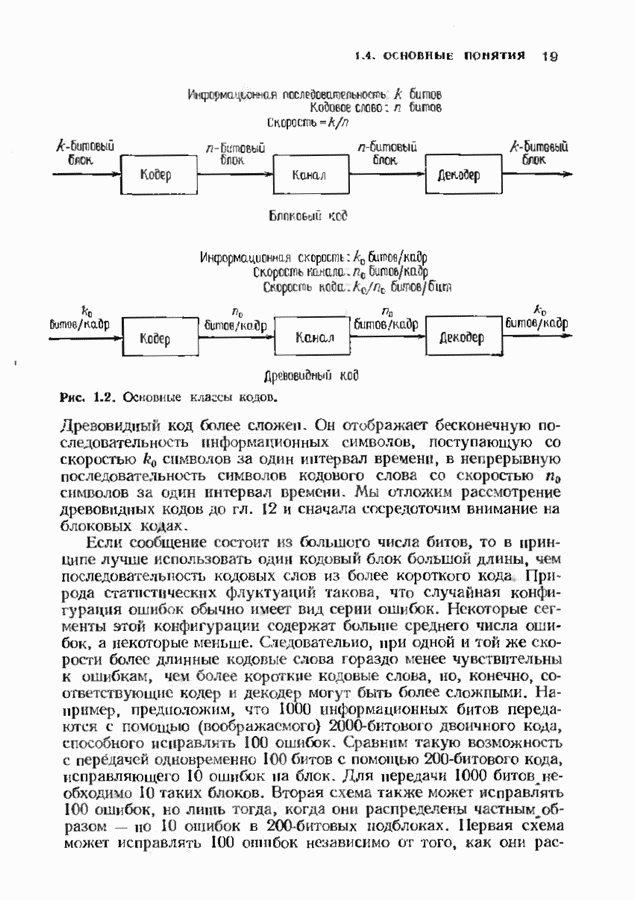
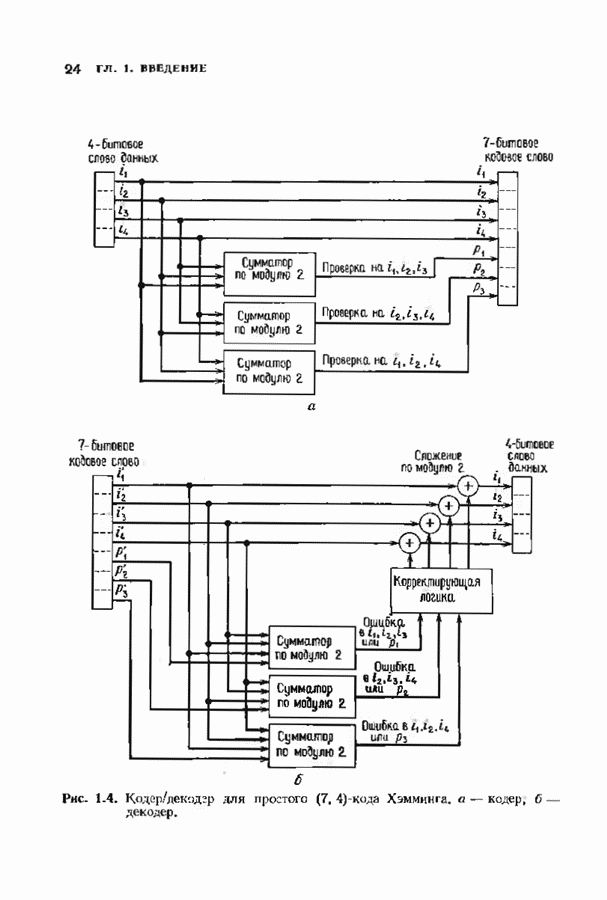
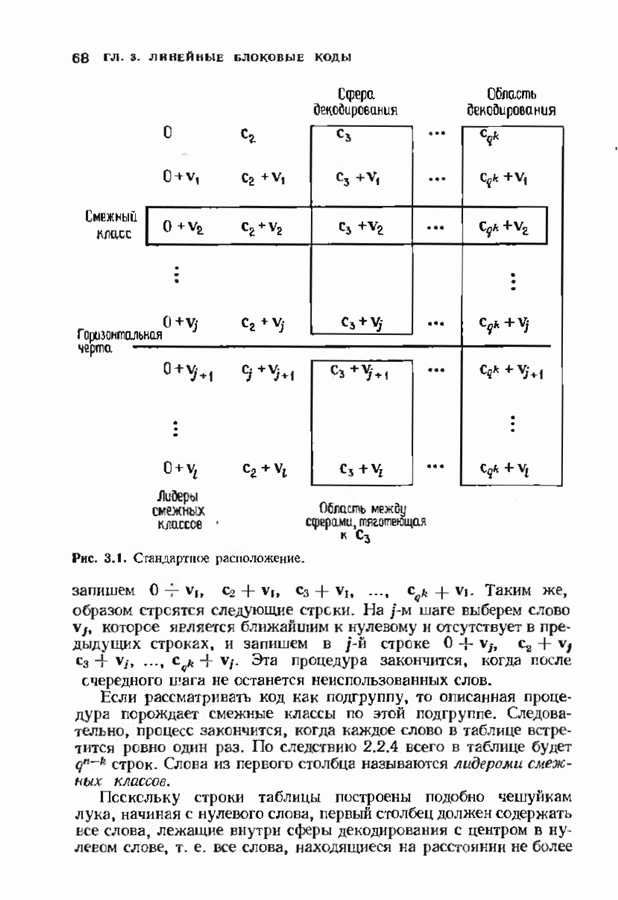
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
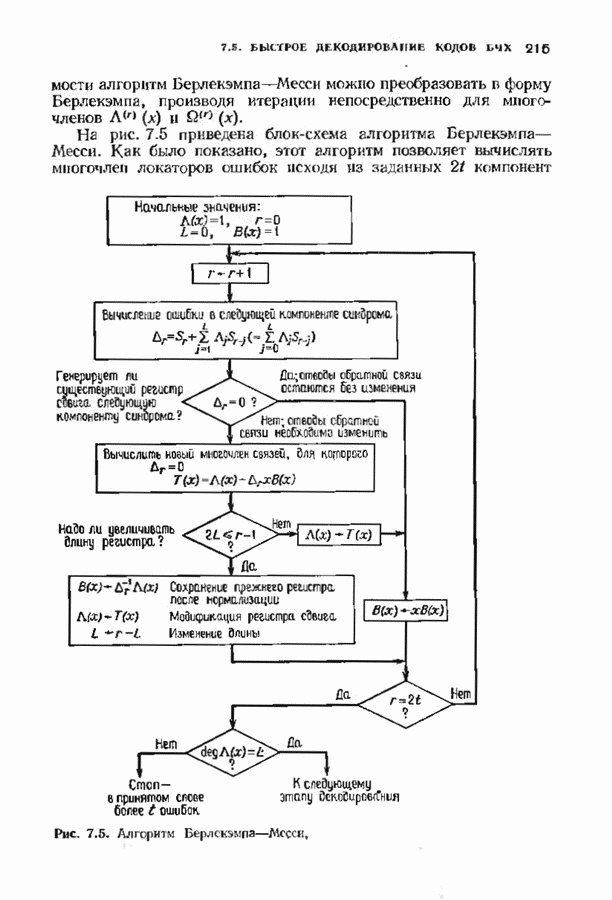
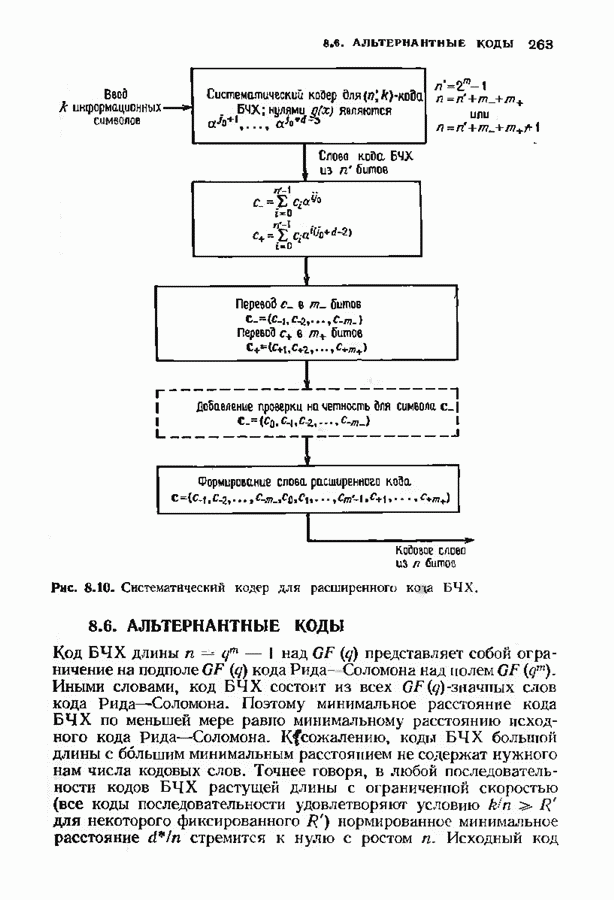
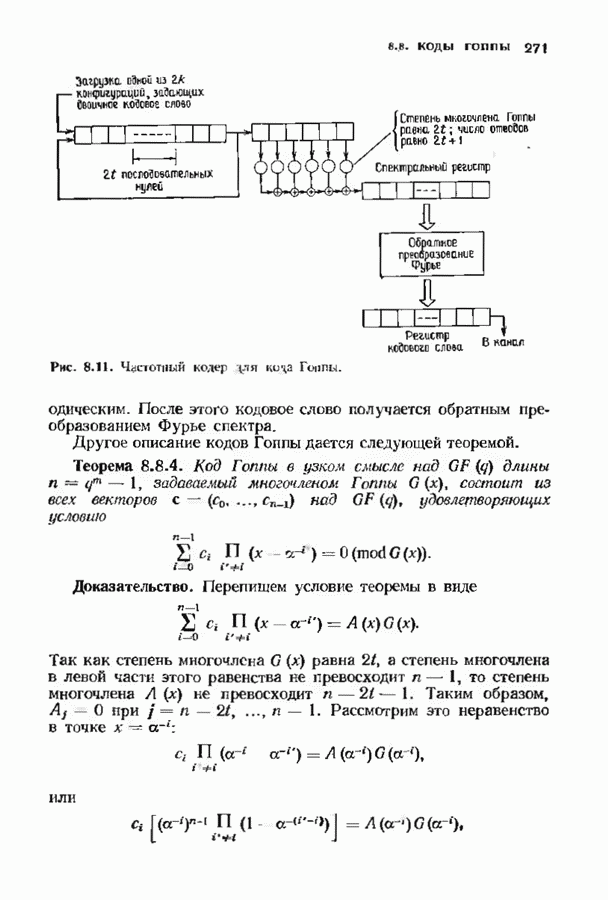
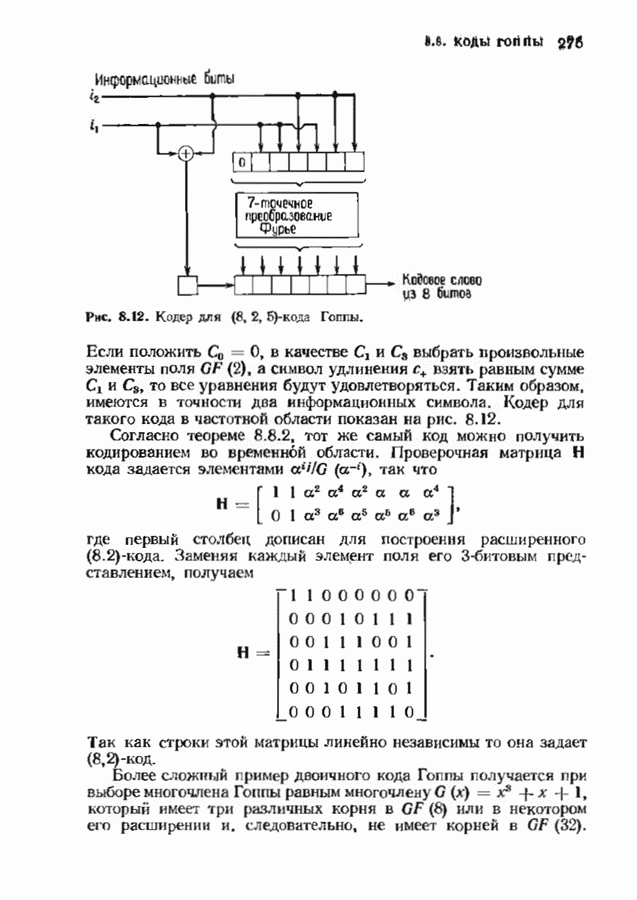
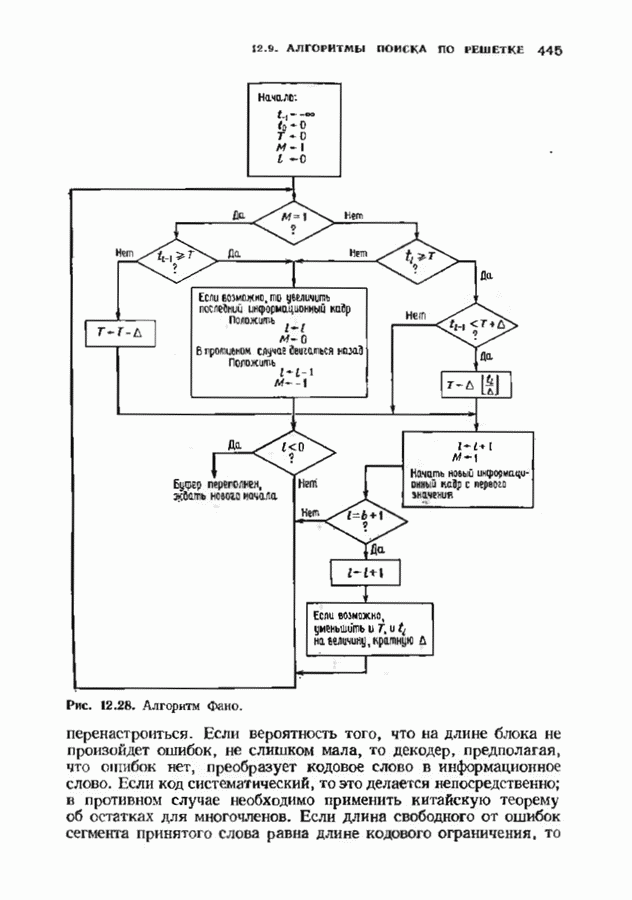
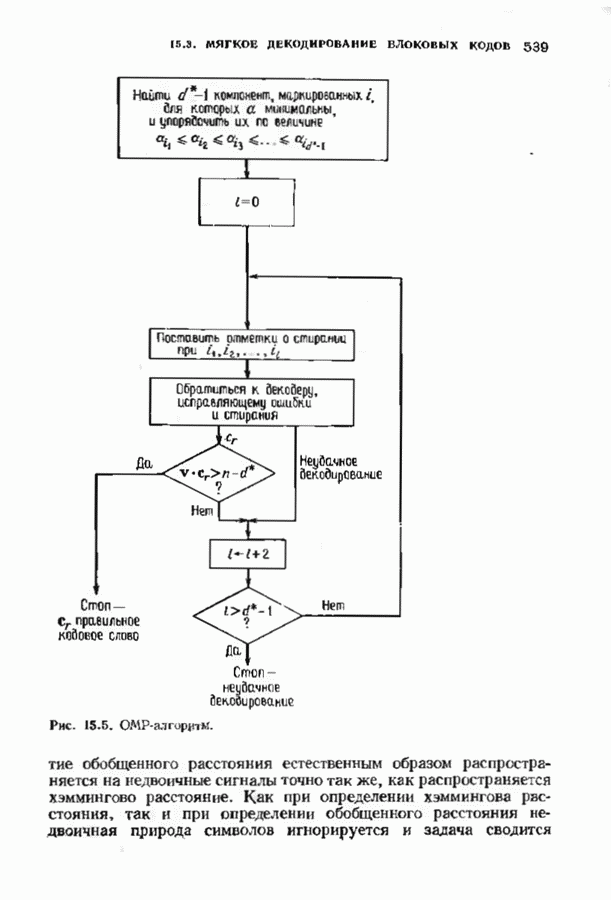
15.5. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕИспользуются два типа алгоритмов последовательного декодирования — алгоритм Фано, который уже изучался применительно к каналам с жестким решением, и стек-алгоритм. Они достаточно отличаются по структуре и аппаратурной реализации. Оба могут использоваться и в каналах с жестким решением, и в каналах с мягким решением. Относительные преимущества каждого из этих алгоритмов до сих пор обсуждаются. Начнем с обсуждения стек-алгоритма. Класс алгоритмов последовательного декодирования, носящий общее название стек-алгоритма, был предложен для уменьшения вычислительной работы по сравнению с алгоритмом Фано. Стек-алгоритм сохраняет информацию о всех путях, которые уже были исследованы. В этом состоит его отличие от алгоритма Фано, который может продвинуться из данного узла, а затем вернуться на то же расстояние назад лишь для того, чтобы повторить обследование из того же узла. Стек-алгоритм хранит информацию лучше, так что не нужно повторять ненужную работу. С другой стороны, стек-алгоритм требует значительно большей памяти.
Рис. 15.10. Упрощенный стек-алгоритм Стек-алгоритм легок для понимания; его упрощенная блок-схема приведена на рис. 15.10. Декодер содержит стек Каждая запись в стеке соответствует некоторому пути и содержит три части: длину пути, последовательность информационных символов переменной длины, определяющую путь, и метрику пути. До начала декодирования стек содержит лишь тривиальный путь нулевой длины. Метрика пути измеряет расхождение между соответствующим путем и начальным сегментом принятого слова той же длины. Ока определяется как логарифмическая функция правдоподобия этого пути. Коротко объясним, как вычисляется эта метрика. Первые
Первые
Мы хотим найти сегмент кодового слова, для которою
По предположению кодовые слова используются с одинаковой вероятностью; поэтому
Множитель
Правая часть распадается на две части: произведение условных вероятностей по
максимальна. Используемая нами в последовательном декодировании метрика пути, которая называется метрикой Фано, представляет собой логарифмическую функцию
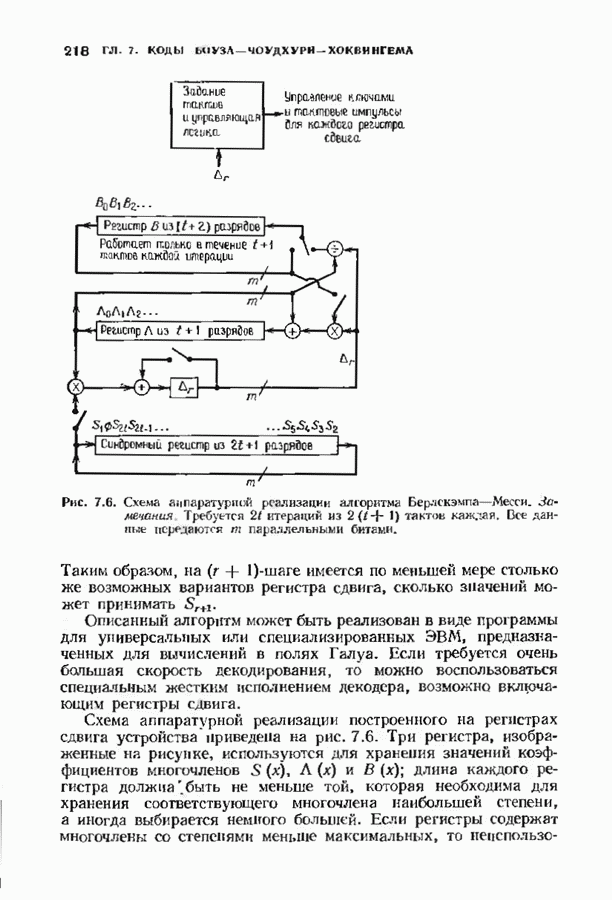
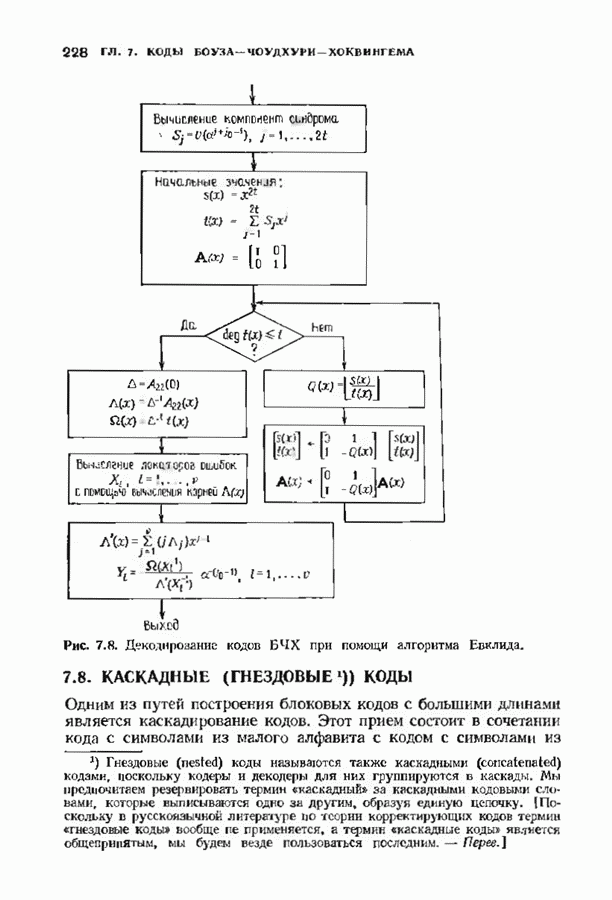
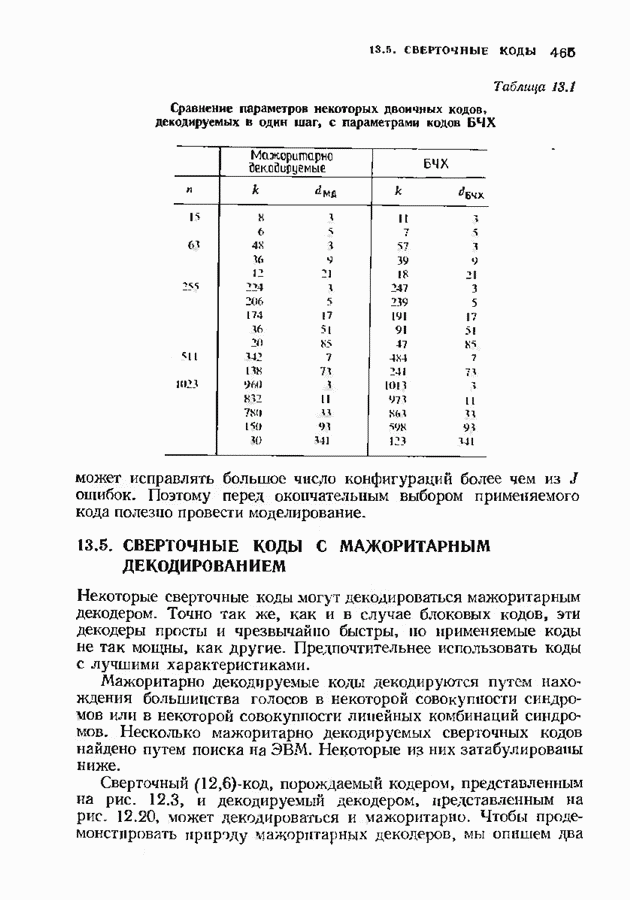
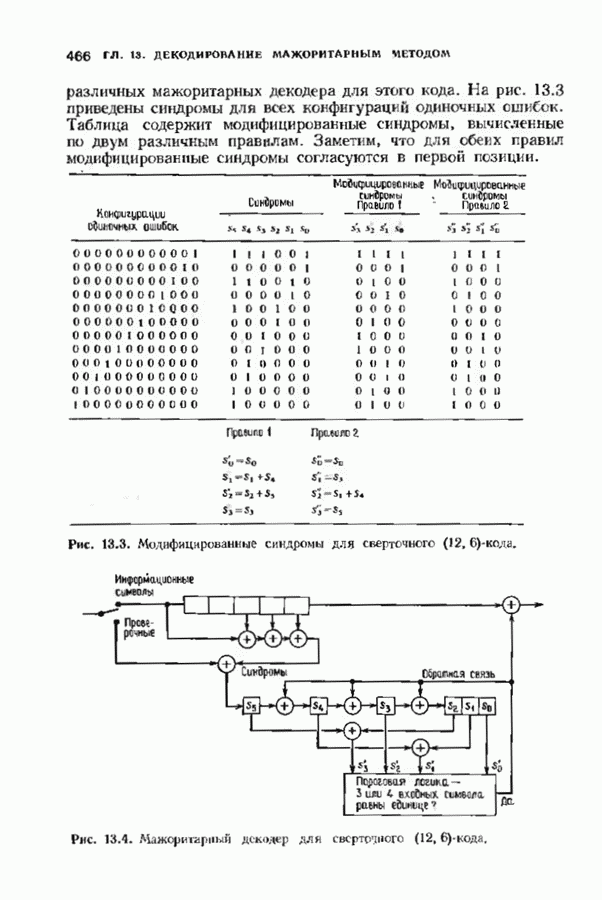
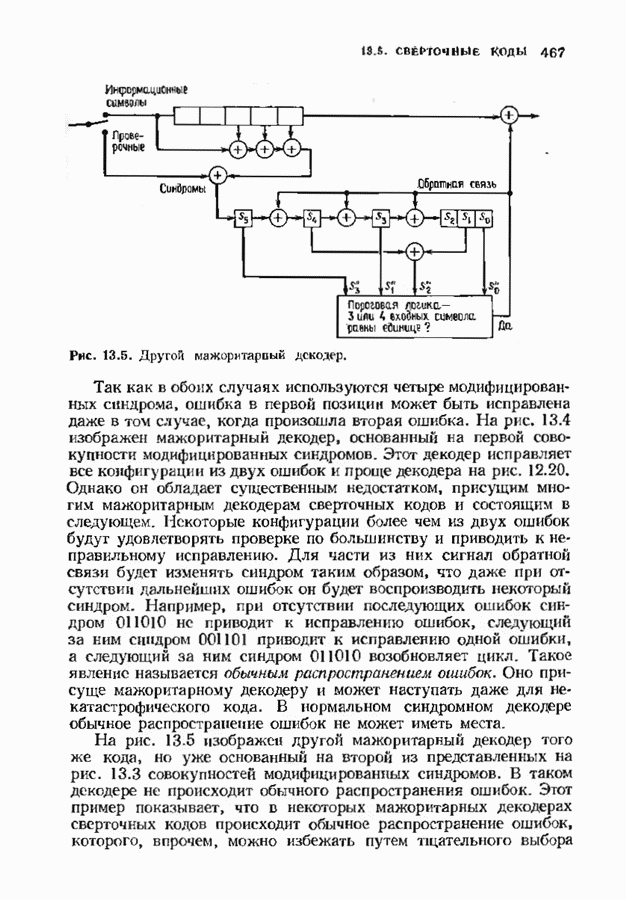
В квадратную скобку заключен вклад в метрику Фано, вносимый вычислять лишь этот член. Метрика пути Последовательное декодирование для жесткого решения, основанное на алгоритме Фано, уже обсуждалось в § 12.9; аналогичное обсуждение может быть проведено и для каналов с мягким решением. Единственно реальная разница между декодером для каналов с жестким решением и каналов с мягким решением состоит в используемой метрике пути. Соответствующая мягкому решению метрика пути — это метрика Фано. Единственное, что необходимо изменить в алгоритме Фано, описанном в § 12.9, — это ввести новую метрику. После такого изменения декодер Фано, описанный в § 12.9, станет пригодным и для каналов с мягким решением. Любой алгоритм последовательного декодирования обладает следующими свойствами: этот декодер производит по меньшей мере одно вычисление в каждом посещаемом им узле; ребра исследуются последовательно, так что в любом узле выбор декодером ребра среди ранее не исследованных ребер не зависит от тех принятых ребер, которые расположены глубже на дереве. Это второе условие — критическое; оно приводит к характерным особенностям поведения последовательного декодирования. Декодеры блоковых кодов и синдромные декодеры сверточных кодов могут использовать последующую информацию, чтобы принять более раннее решение, и поэтому ведут себя иначе. Число вычислений, производимых любым последовательным декодером для продвижения на один узел в глубь кодового дерева, является случайной величиной. Это обстоятельство в основном и влияет на сложность, требуемую для достижения заданного качественного уровня. Когда шум слаб, декодер обычно продвигается по правильному пути, используя лишь одно вычисление для продвижения в глубь кодового дерева на одно ребро. Однако когда шум становится сильным, декодер может проследовать вдоль неправильного пути, и прежде чем декодер найдет правильный путь, ему, возможно, потребуется произвести большое число вычислений. Непостоянство числа вычислений означает, что буферу входных данных может потребоваться большая намять. Использование любого конечного буфера при последовательном декодировании приводит к ненулевой вероятности переполнения; это обстоятельство должно приниматься во внимание при вычислениях характеристик декодера. ЗАДАЧИ(см. скан) ЗАМЕЧАНИЯВозможность использования декодирования с мягким решением для улучшения качества декодирования стала ясной почти с того момента, когда были построены первые коды, однако хорошие декодеры для них тогда не были найдены. По существу первая попытка построить алгоритмический декодер мягкого решения для блоковых кодов была сделана Форни [1966], который ввел понятие обобщенного минимального расстояния. Несколько отличающийся алгоритм был предложен Чейзом [1972], который дополнил внешней петлей декодер двоичных кодов с жестким решением, венравляющнй только ошибки. В работе Хартмана и Рудолфа [1976] предложен декодер мягкого решения совершенно Для сверточных кодов декодеры с мягким решением были введены легче и получили более широкое практическое распространение, чем для блоковых. Это произошло из-за того, что декодеры минимального расстояния, используемые для сверточных кодов, менее сложны, чем алгебраические декодеры, используемые для блоковых кодов, таких, как коды БЧХ. Хэммингово расстояние может быть заменено другими мерами разделения кодовых слов при весьма малом изменении структуры вычислений. Унгербек [1977, 1982] построил специально предназначенные для приемника мягкого решения кода, комбинируя выбор модуляции и выбор кода. Использование решетки для модуляции исследовали также Андерсон и Тейлор [1978], но вне связи с кодированием. Последовательное декодирование было предложено Возепкрафтом [1957] и опиевно Возенкрафтом и Рейффеном [1961]. Оно было развито далее в работах Фано [1963], Зигангирова [1966] и Джелинека [1969]. Прогрессу в данной области слособстаовкаи также обзорные работы Джелинена [1968 и Форни [1974] и последующие разработки Шевийя и Костелло [1978] Хаккоуна и Ферпосона [1975]. Нижпие границы распределения числа вычислений последовательного декодирования получили Джек обе и Берлекзми [1967], рассмотревшие также иллюстративный пример. Соответствующая верхняя грнница была найдем Севиджем [1966].
|
 |
Оглавление
|
































































































































































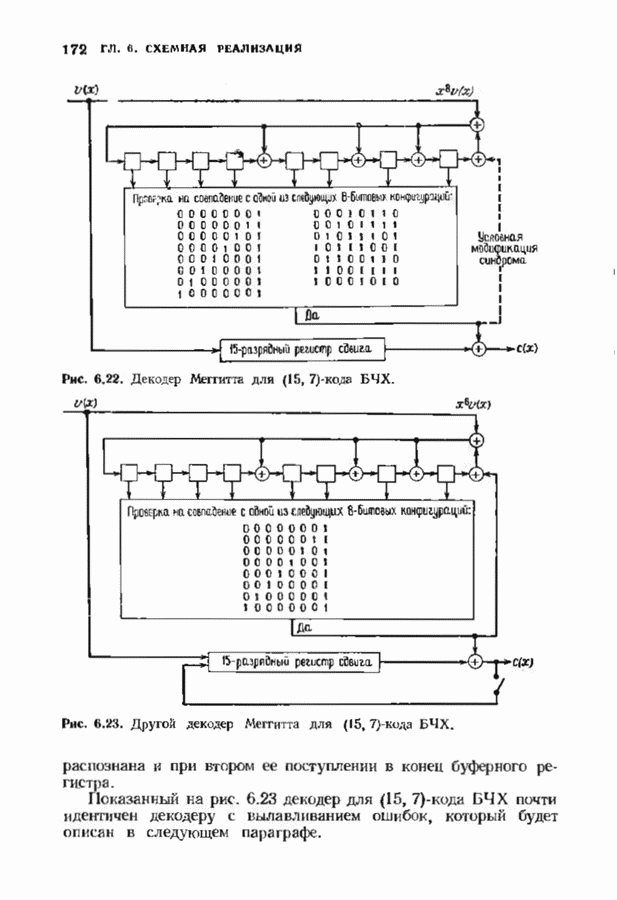

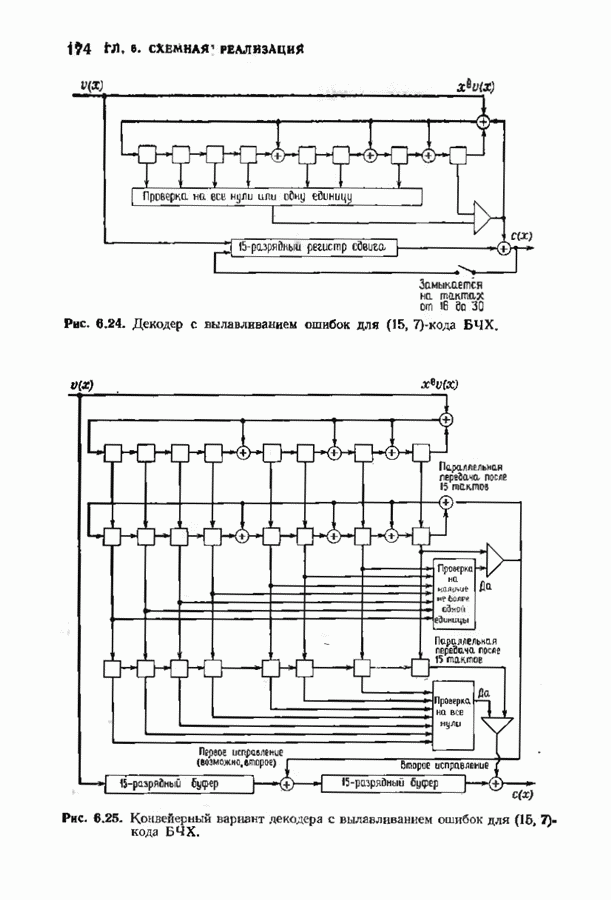

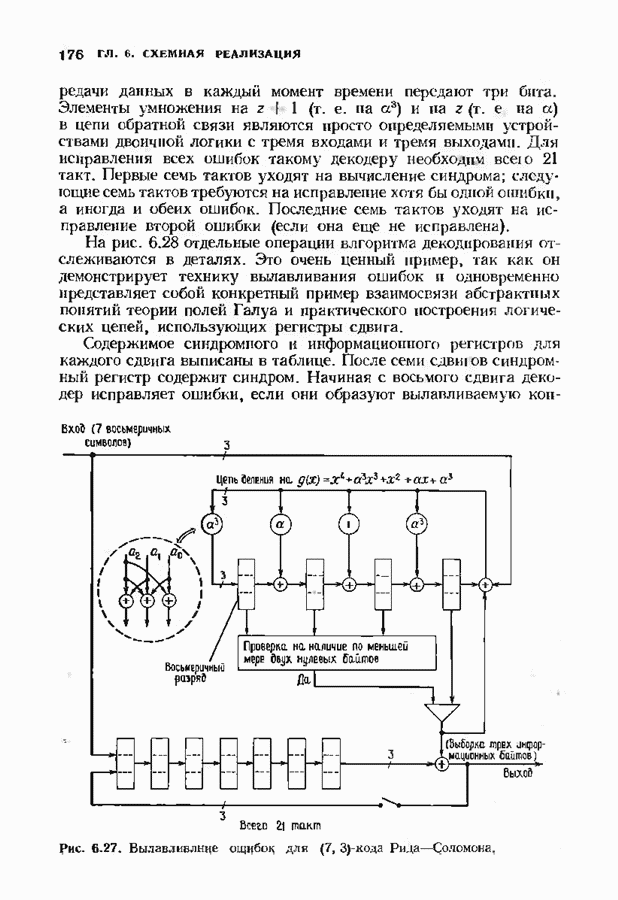





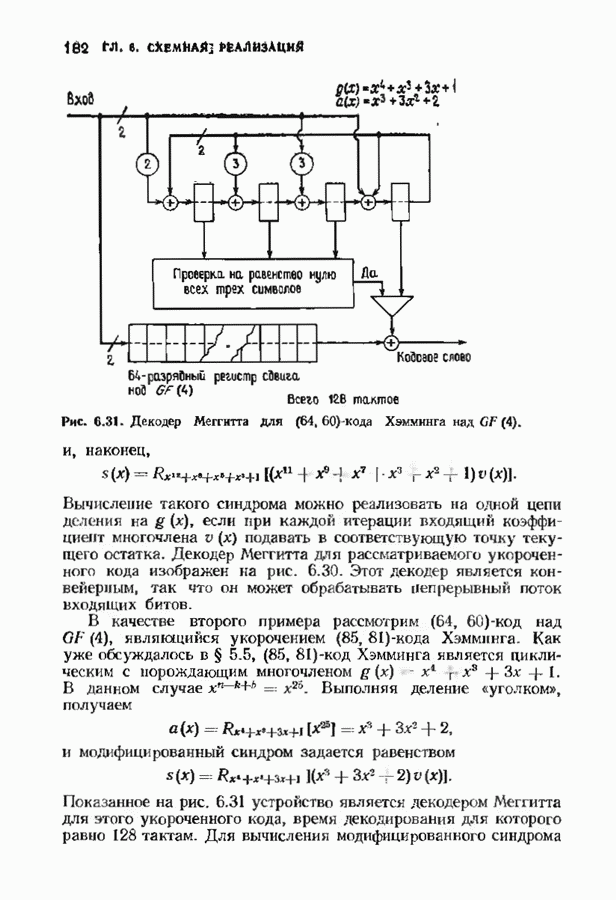


























































































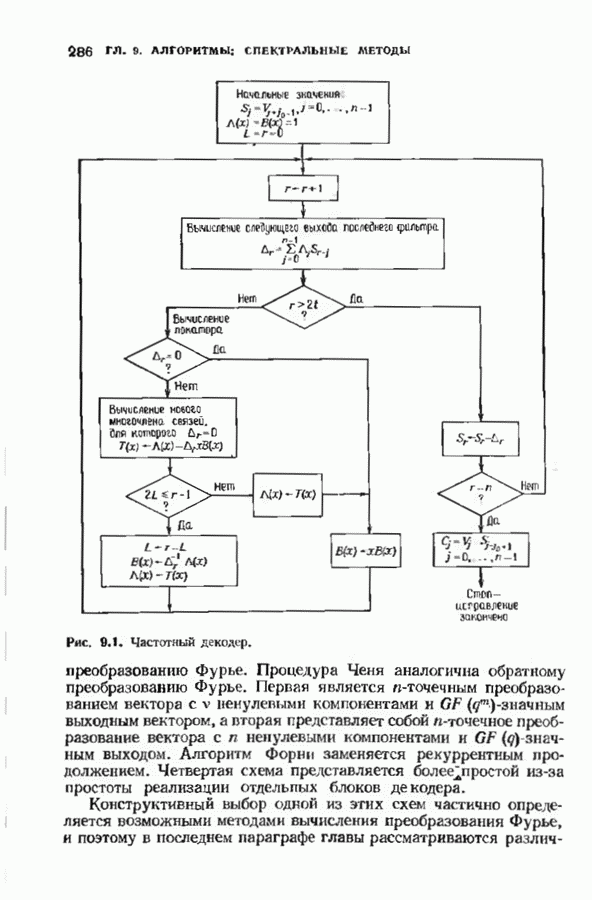
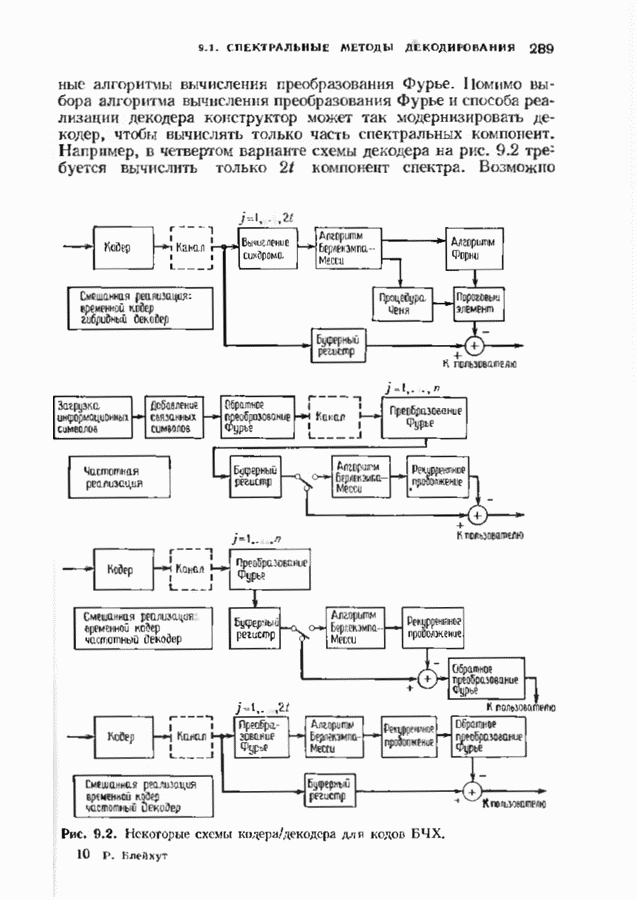



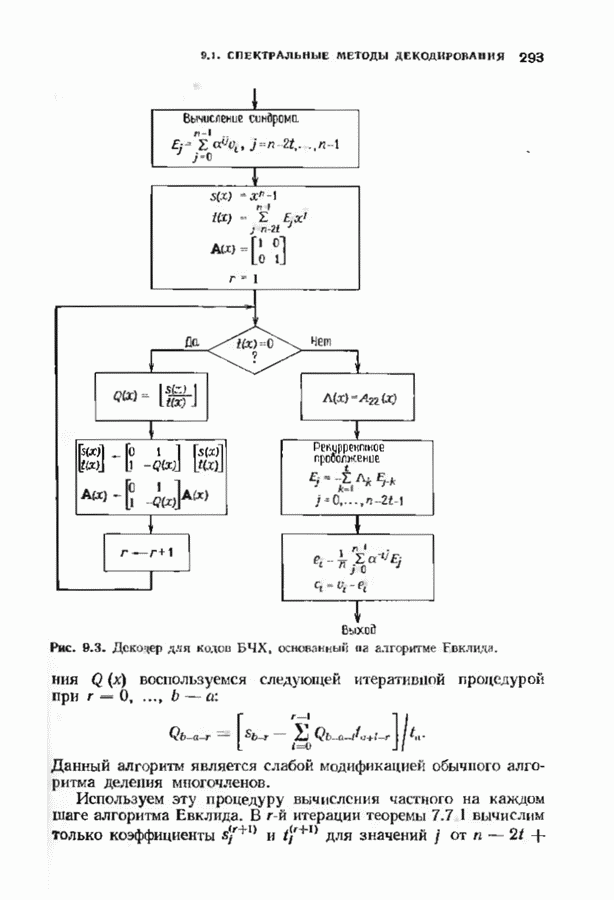





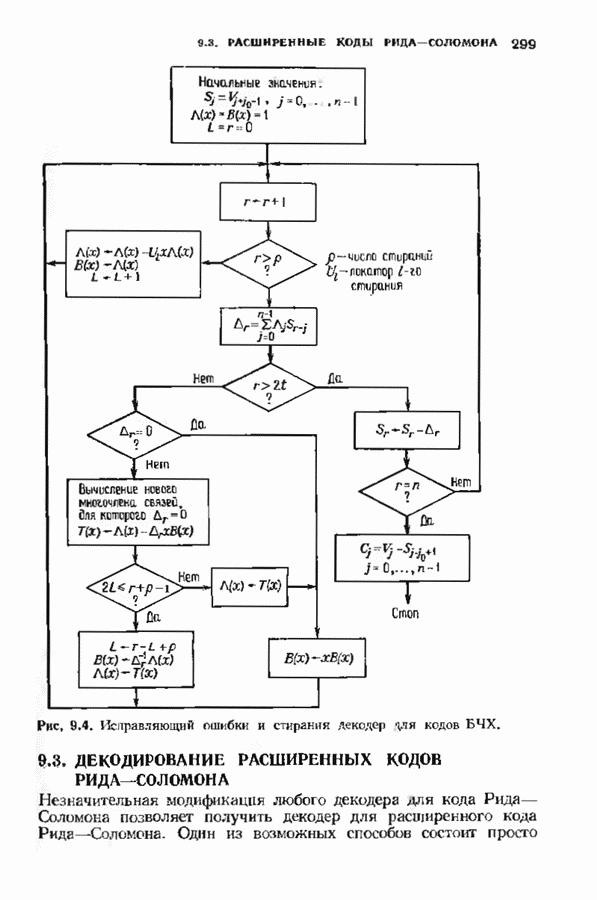


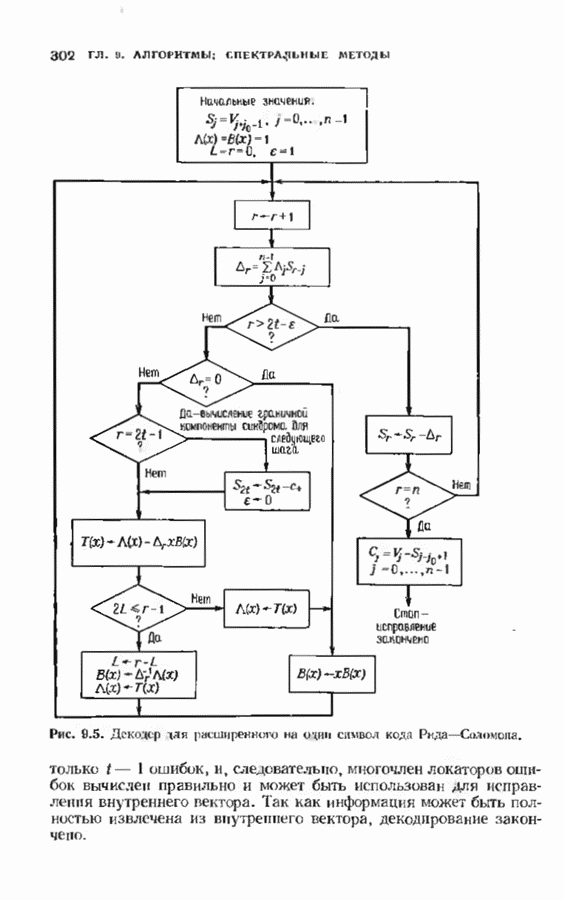






























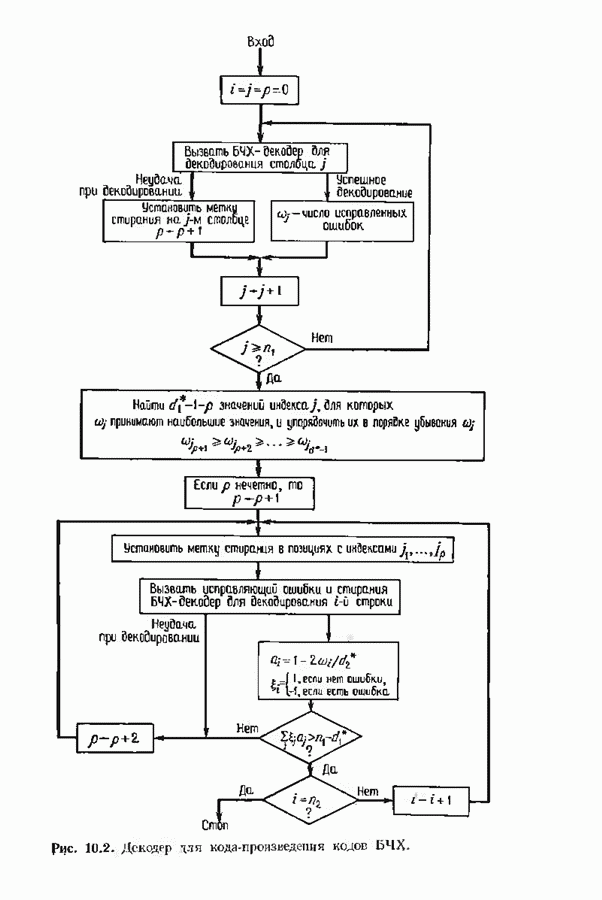











































































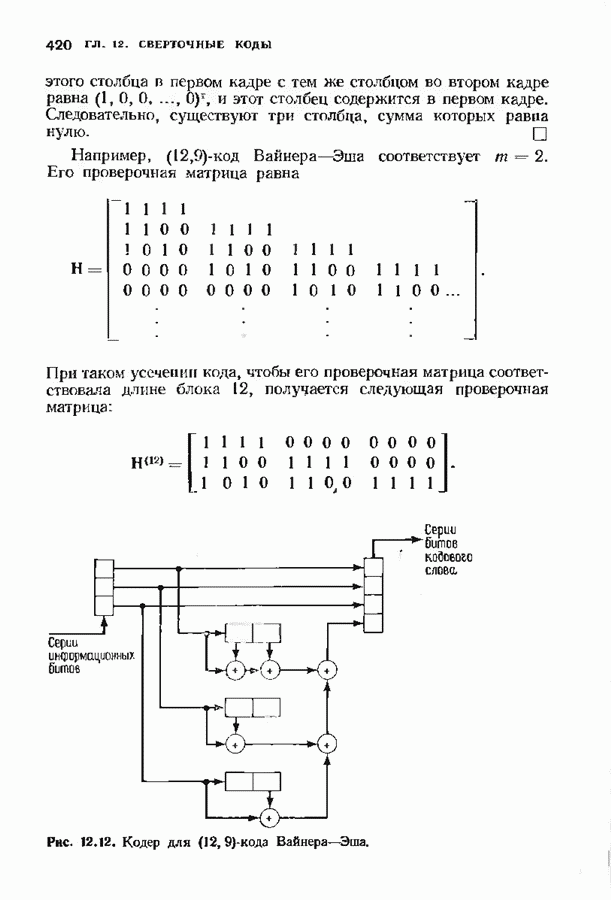
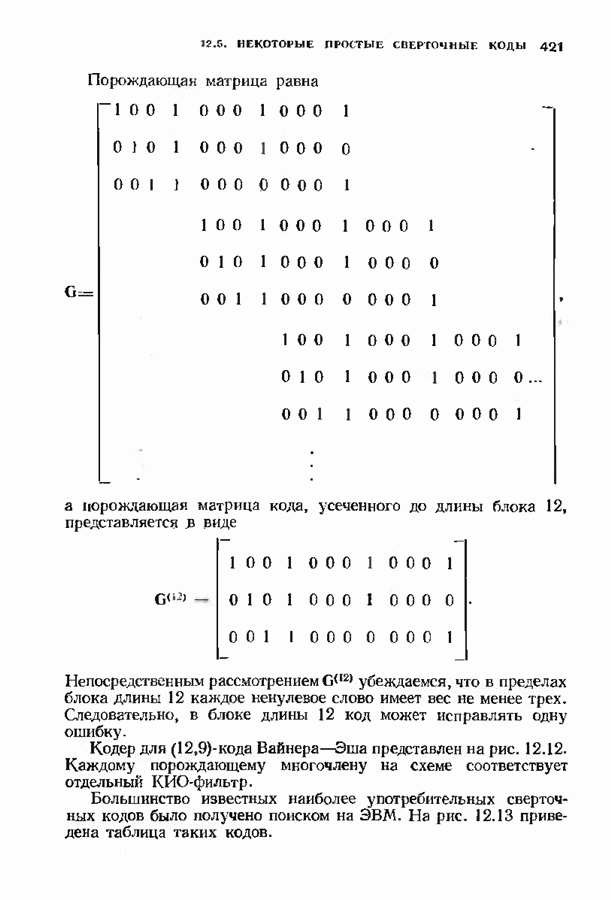


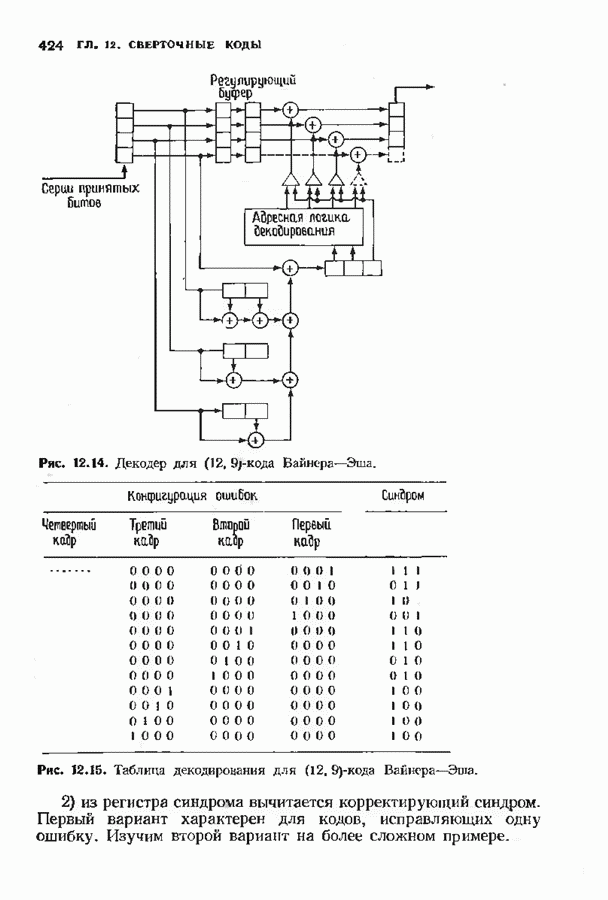
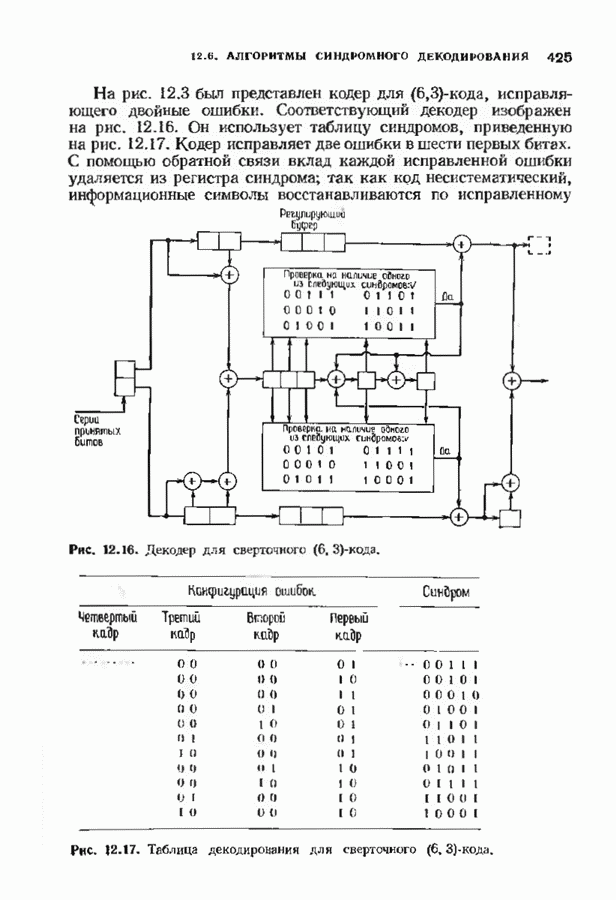





































































































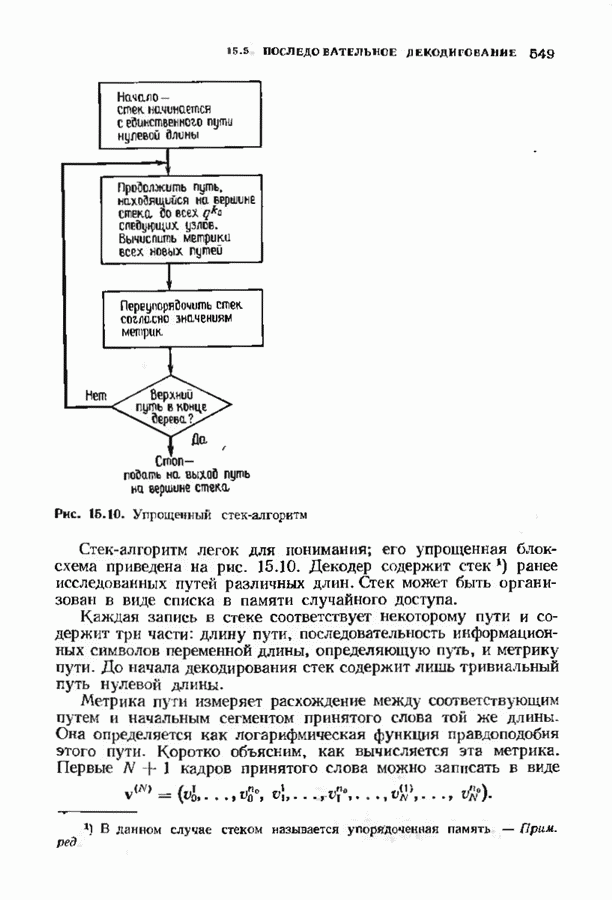















 ранее исследованных путей различных длин. Стек может быть организован в виде списка в памяти случайного доступа.
ранее исследованных путей различных длин. Стек может быть организован в виде списка в памяти случайного доступа.
 кадров принятого слова можно записать в виде
кадров принятого слова можно записать в виде

 кадров кодового слова с имеют вид
кадров кодового слова с имеют вид

 максимален. По определению последовательного декодера выбор начального
максимален. По определению последовательного декодера выбор начального  мента кодового слова длины
мента кодового слова длины  должен производиться без учета последующей структуры кодового дерева. Но по правилу Бейеса
должен производиться без учета последующей структуры кодового дерева. Но по правилу Бейеса


 можно переписать в виде
можно переписать в виде

 кадрам кодового слова и произведение безусловных вероятностей по тем кадрам, в которых кодовое слово еще не определено. Разбиение вероятности на две части, которое мы провели, приводит естественным образом к вероятностному описвнию последовательного декодирования. Задача сводится к нахождению пути, для которого величина
кадрам кодового слова и произведение безусловных вероятностей по тем кадрам, в которых кодовое слово еще не определено. Разбиение вероятности на две части, которое мы провели, приводит естественным образом к вероятностному описвнию последовательного декодирования. Задача сводится к нахождению пути, для которого величина


 кадром. В каждом кадре каждого кодового слова необходимо
кадром. В каждом кадре каждого кодового слова необходимо
 получается прибавлением соответствующего приращения к метрике Фано кодового слова, находившегося на вершине стека на предыдущей итерации.
получается прибавлением соответствующего приращения к метрике Фано кодового слова, находившегося на вершине стека на предыдущей итерации.