Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
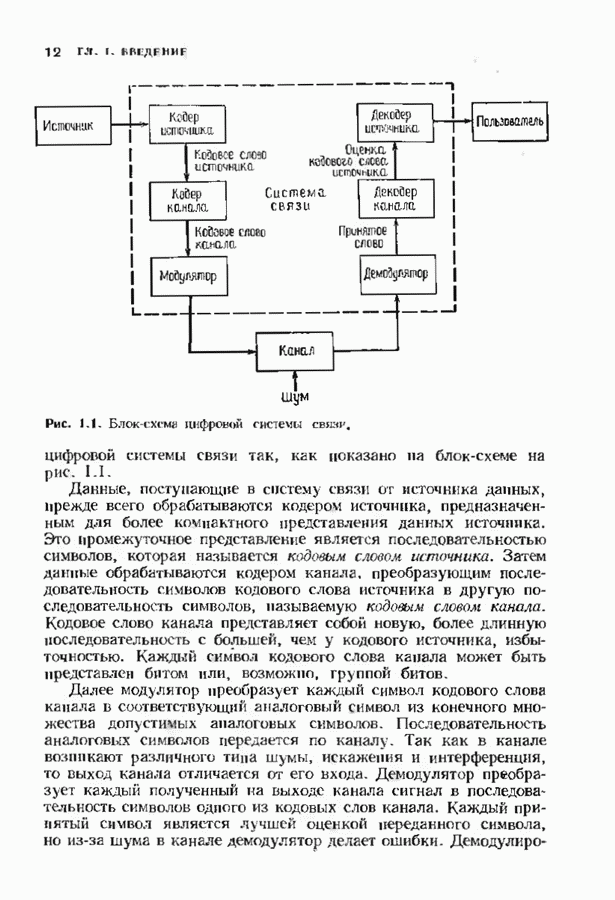
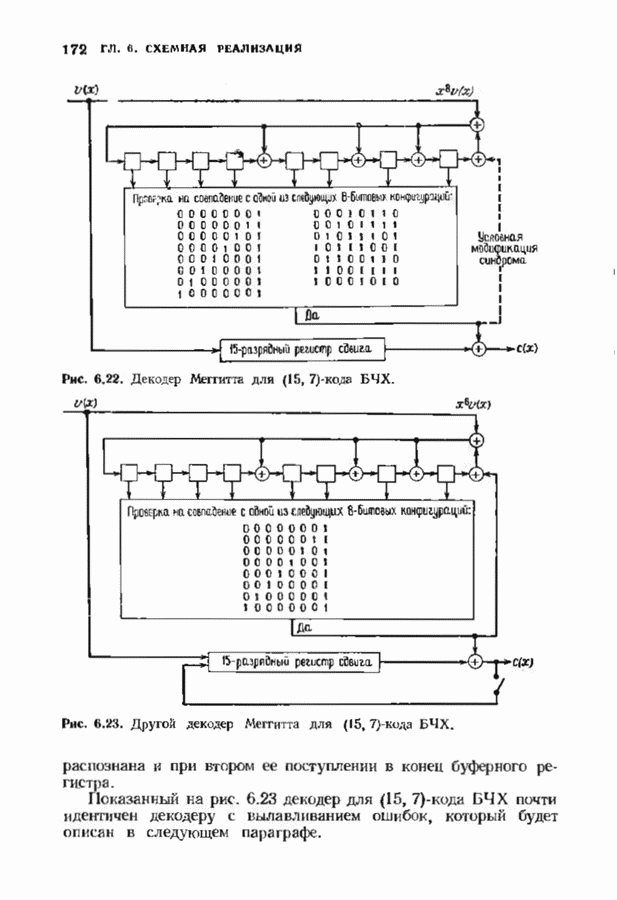
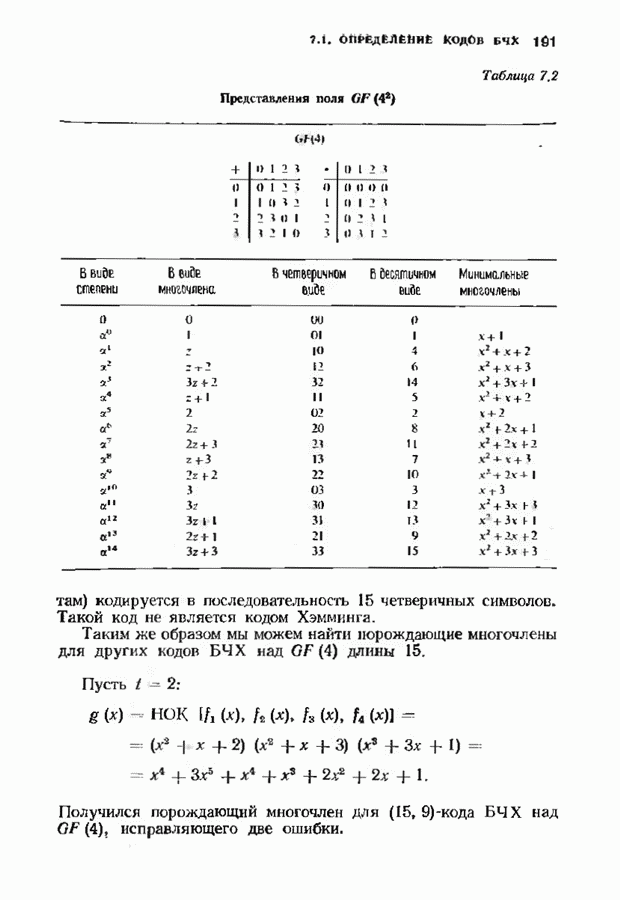
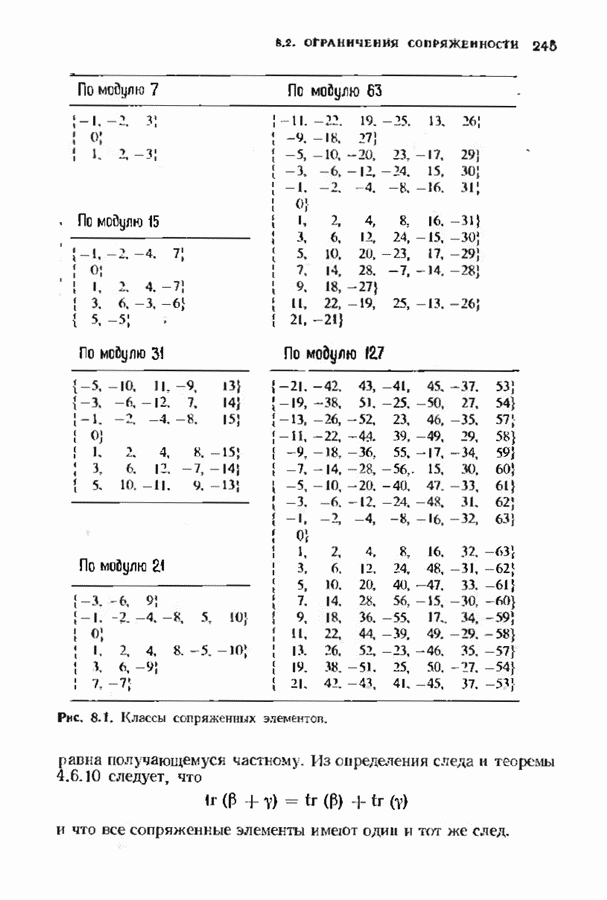
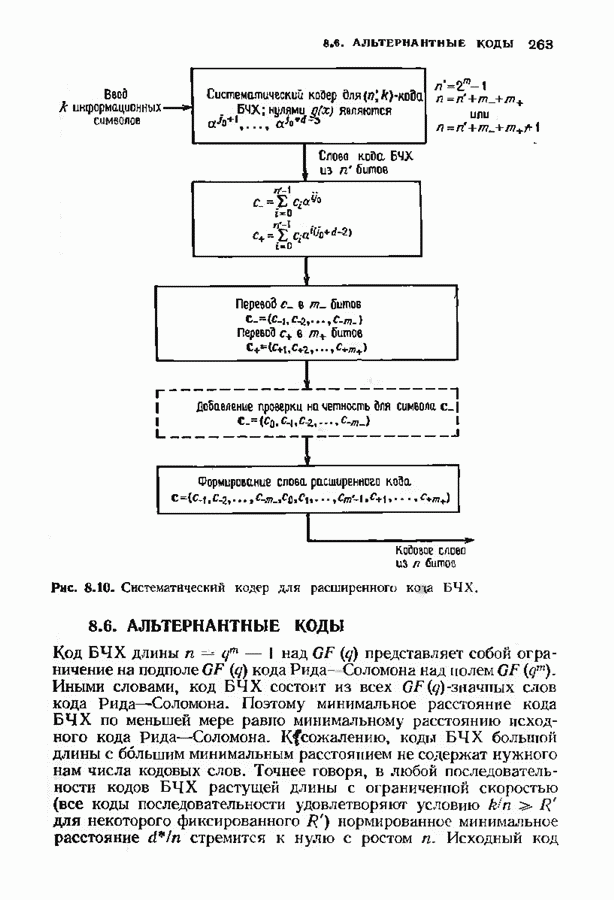
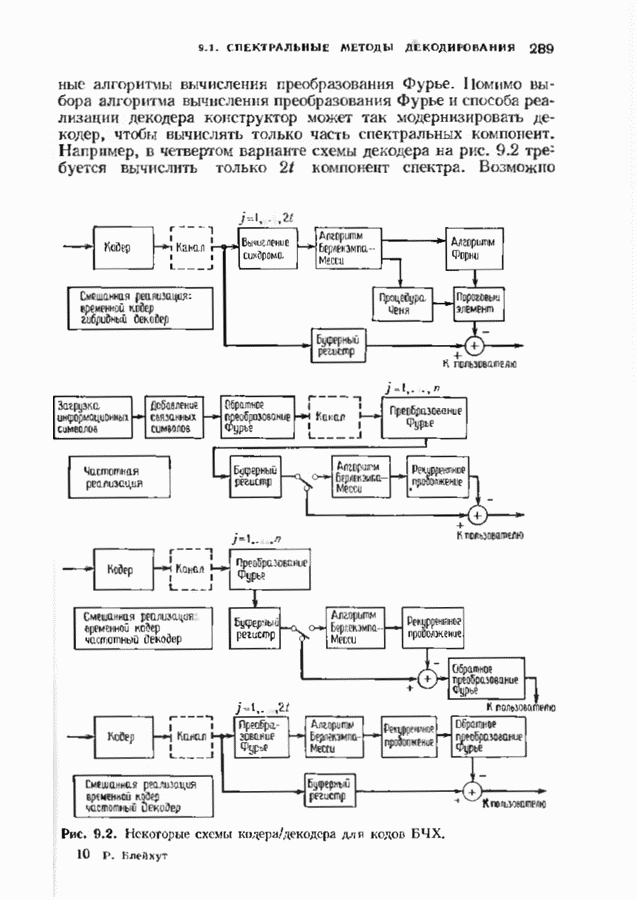
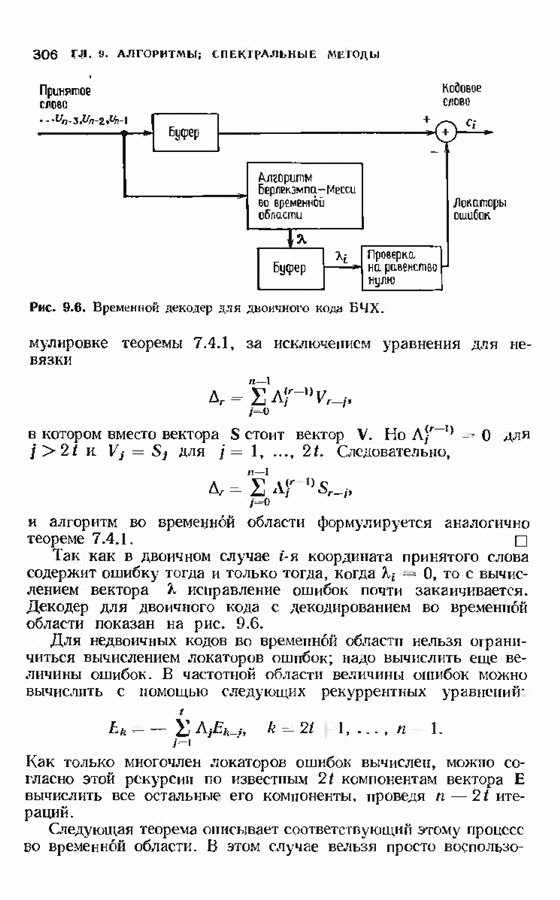
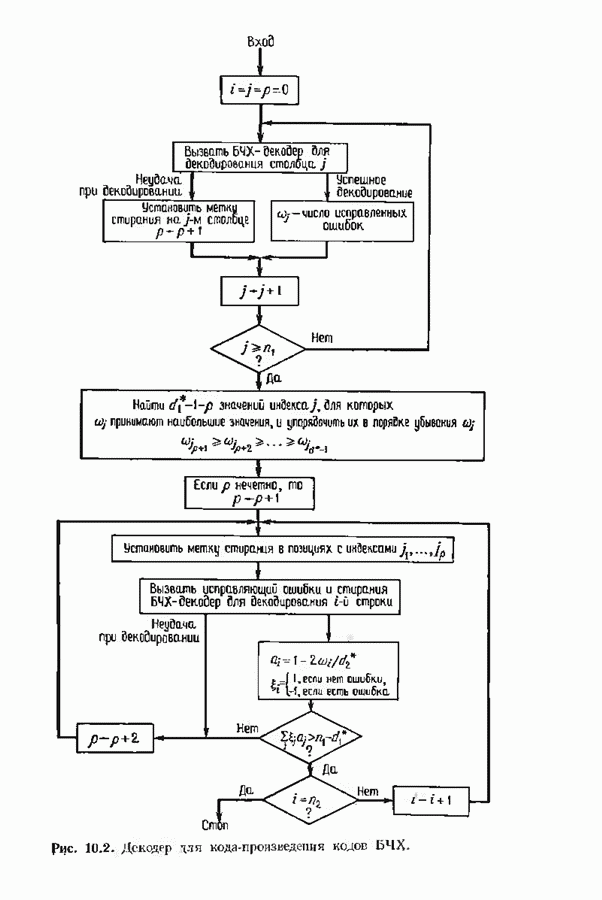
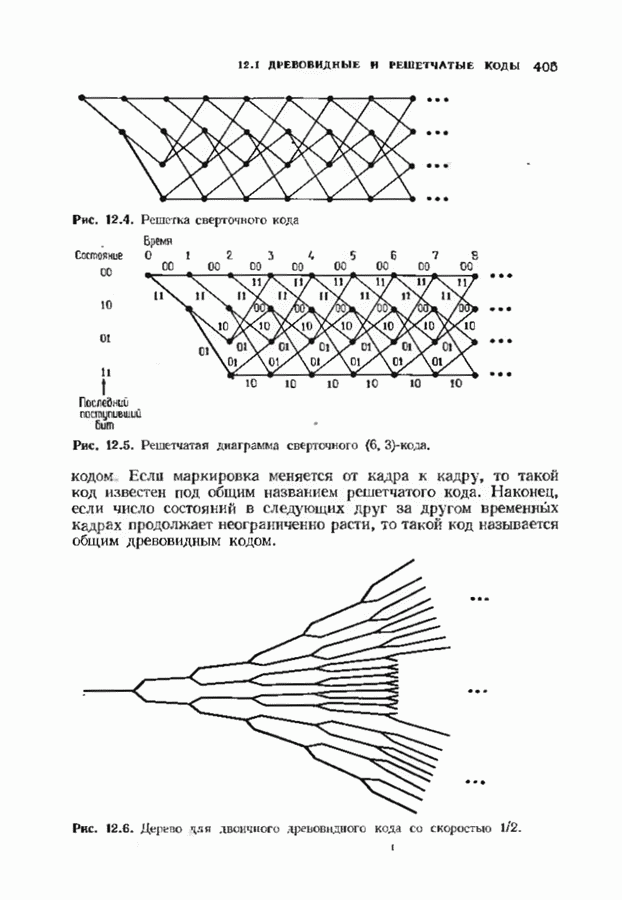
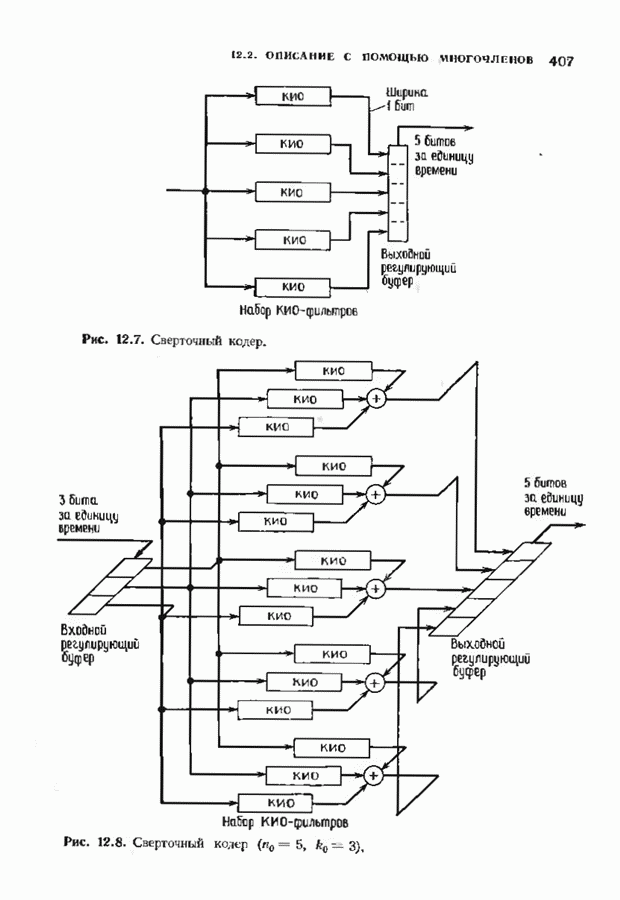
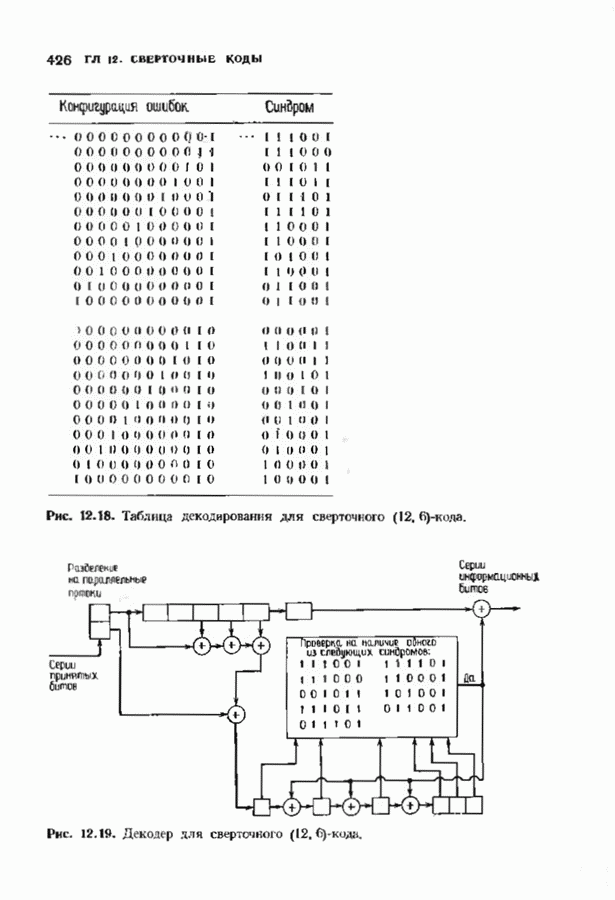
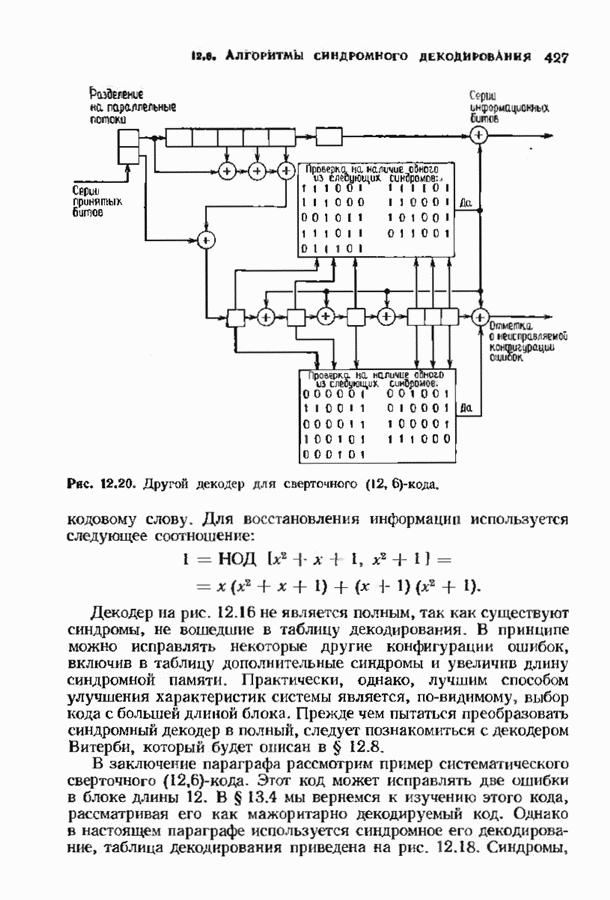
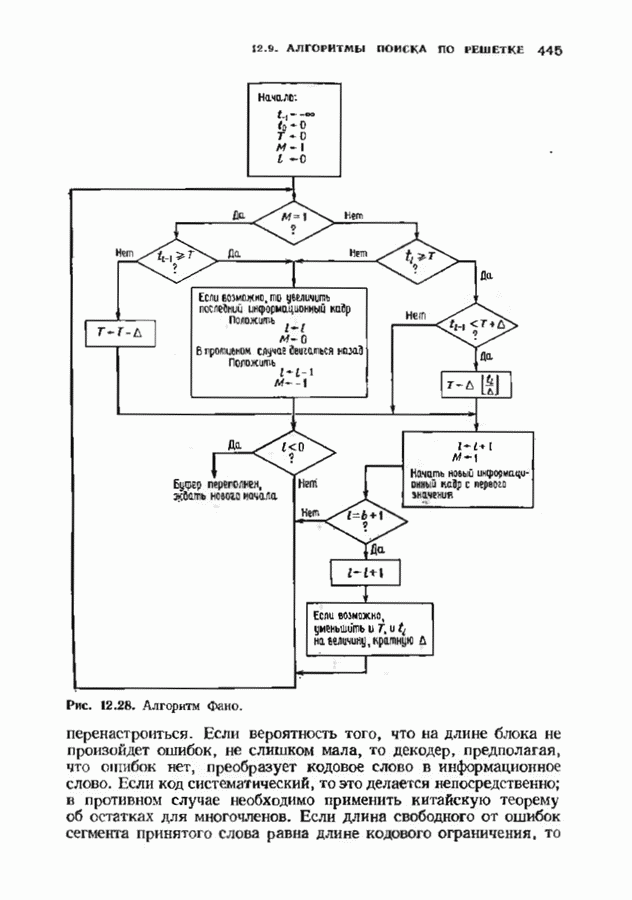
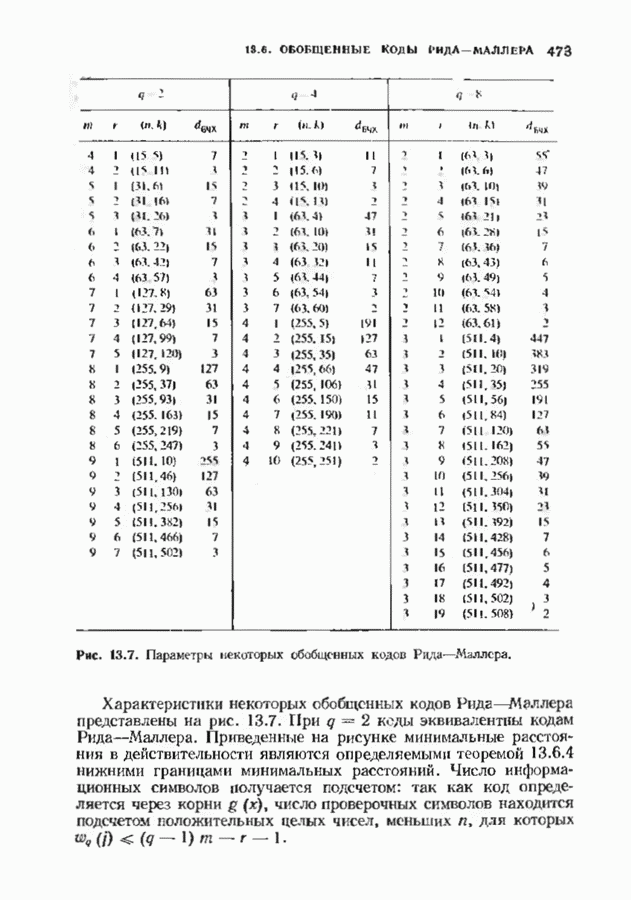
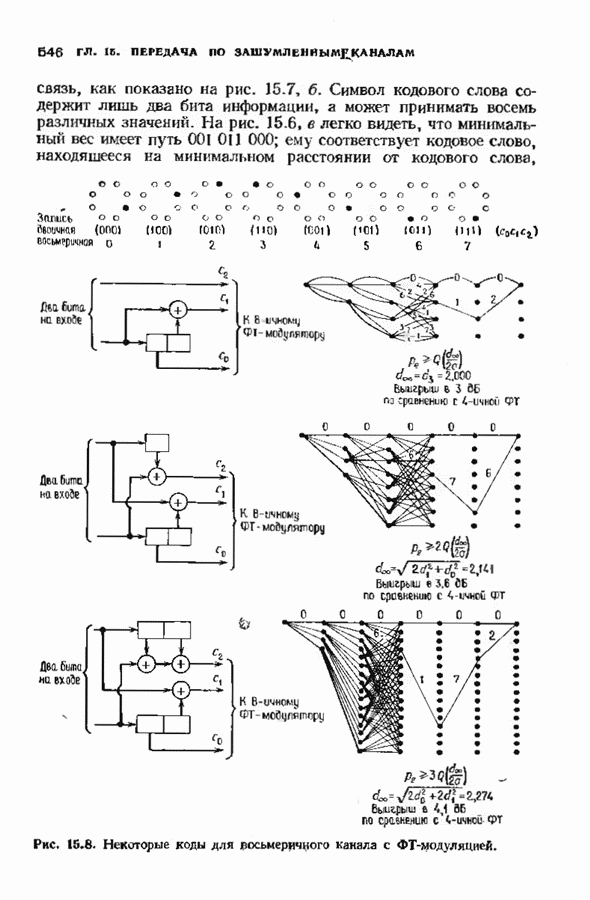
7.5. БЫСТРОЕ ДЕКОДИРОВАНИЕ КОДОВ БЧХУяснение работы декодера Пнтерсоиа-Горенстейна-Цирлера - лучший путь к пониманию процесса декодирования кодов БЧХ. Но при построении декодера приходится жертвовать концептуальной ясностью во имя вычислительной эффективности. Опи санный в § 7.2 декодер Питерсона-Горенстейна-Цирлера предполагает обращение двух матриц размера Для описания алгоритма Форни нам понадобится многочлен локаторов ошибок
имеющий корни
Определим синдромный многочлен
и многочлен значений ошибок
Многочлен значений ошибок будет иногда использоваться в дальнейших рассуждениях. Его связь с локаторами и значениями ошибок устанавливается следующей теоремой. Теорема 7.5.1. Многочлен значений ошибок можно записать в следующем виде:
Доказательство. Из определения сомножителей, входящих в равенство для
Выражение в квадратных скобках является разложением для
Последнее выражение, взятое по модулю Теперь все готово для того, чтобы выписать выражение для значений ошибок, которое намного проще аналотнчного выражения, использующего обращение матрицы. Теорема 7.5.2 (алгоритм Форни). Значения ошибок получаются из равенства
Доказательство. Используя равенство из утверждения теоремы 7.5.1 при
откуда вытекает первая часть теоремы. С другой стороны, производная многочлена
и таким образом,
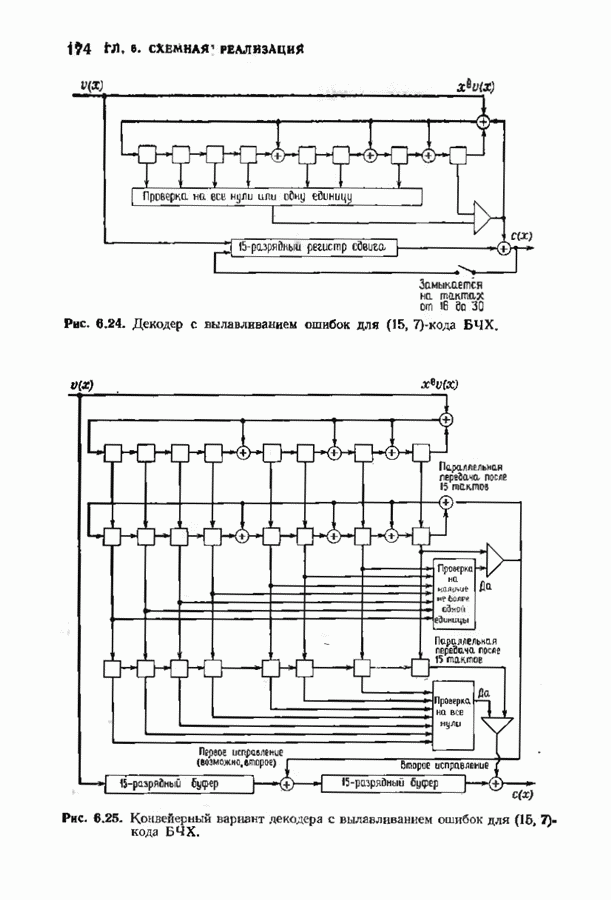
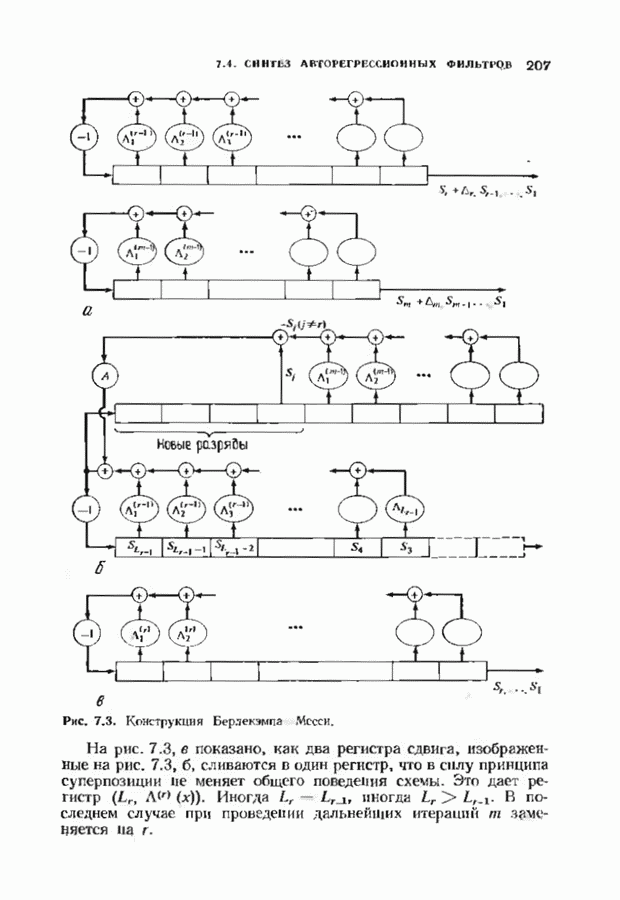
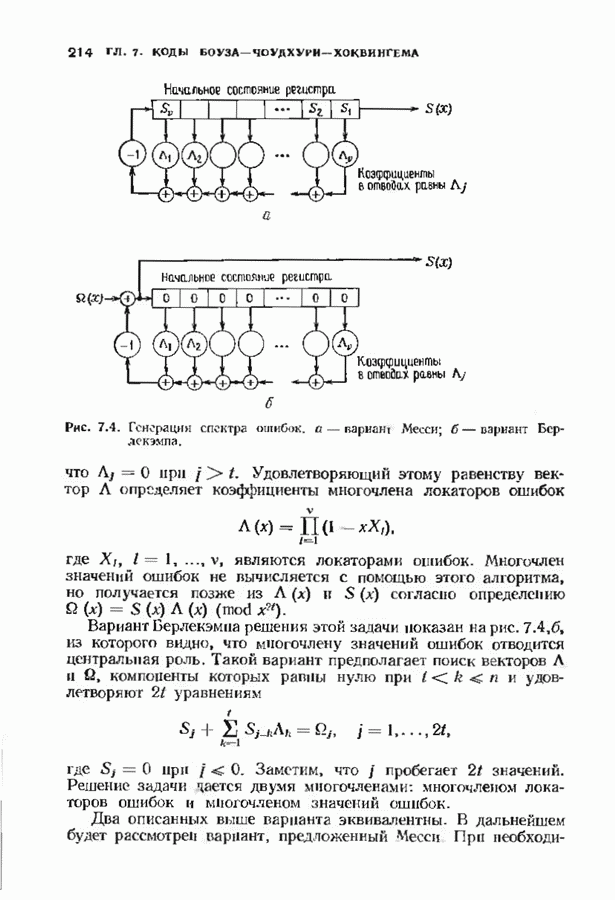
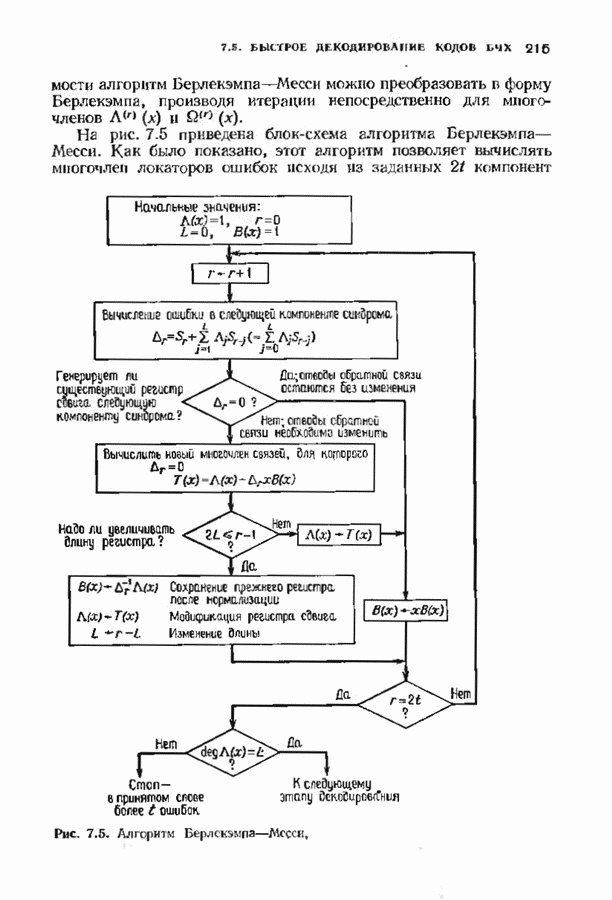
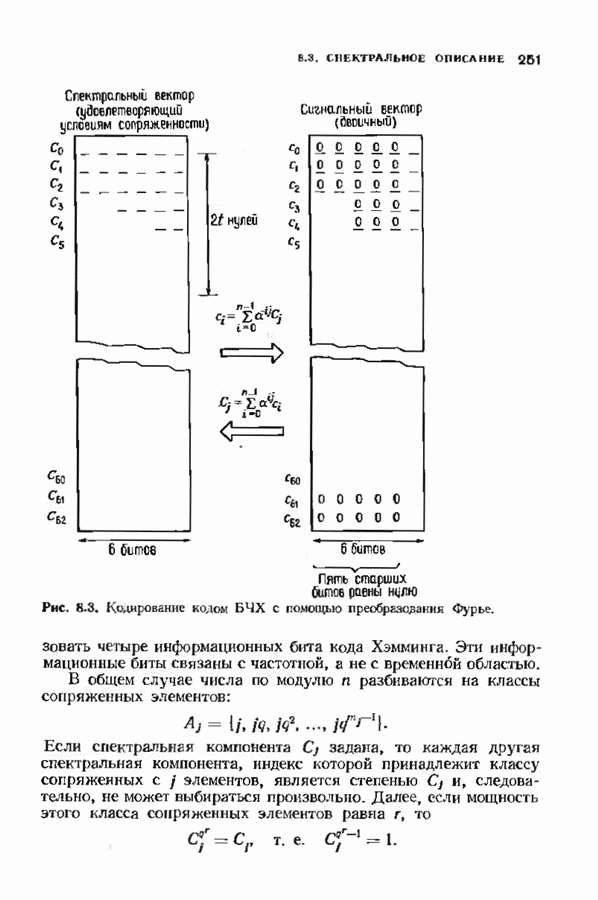
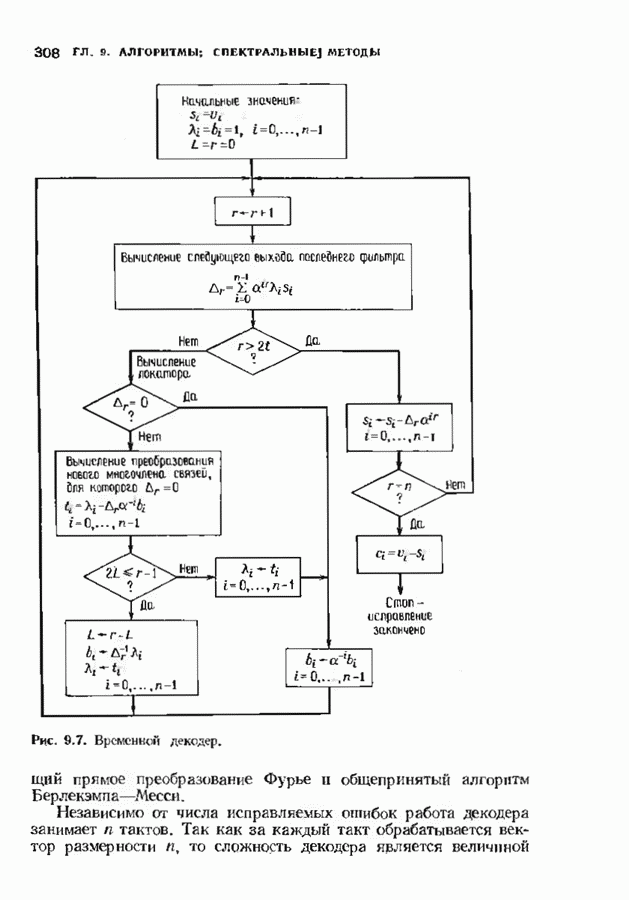
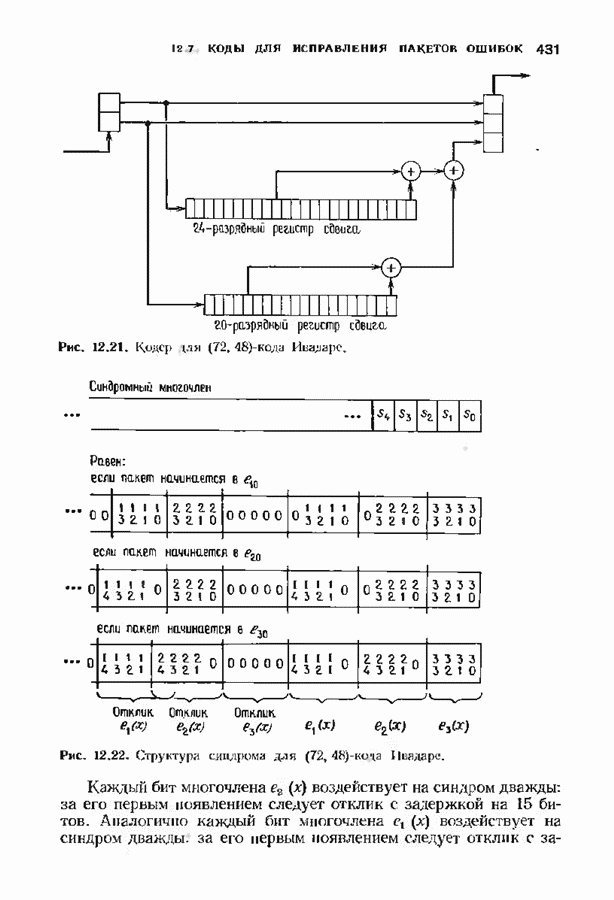
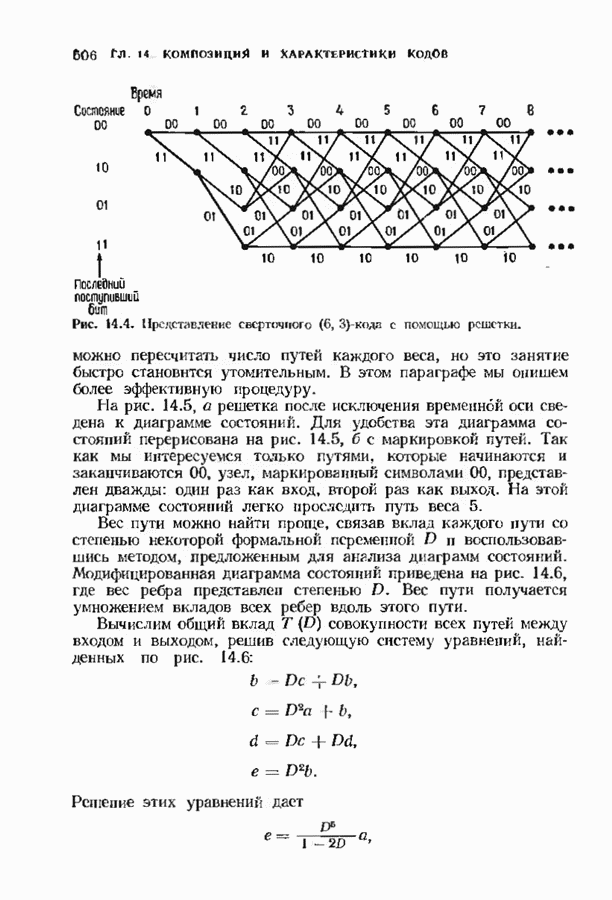
откуда сразу следует утверждение теоремы. Алгоритм Форни обладает существенным преимуществом перед обращением матрицы, но использует деление. В гл. 9 будет предложено другое решение, не использующее деление. Теперь вернемся к вычислению многочлена локаторов ошибок, использующему алгоритм Берлекэмпа-Месси теоремы 7.4.1. Предложенный Месси вариант решения этой задачи показан на рис. 7.4, а. По заданным
Это означает, что требуется по заданным 21 компонентам вектора
Рис. 7.4. Генерации спектра ошибок, а — вариант Месси; б - вариант Берлекэмпа. что
где Вариант Берлекэмна решения этой задачи показан на рис. 7.4.6, из которого видно, что многочлену значений ошибок отводится центральная роль. Такой вариант предполагает поиск векторов
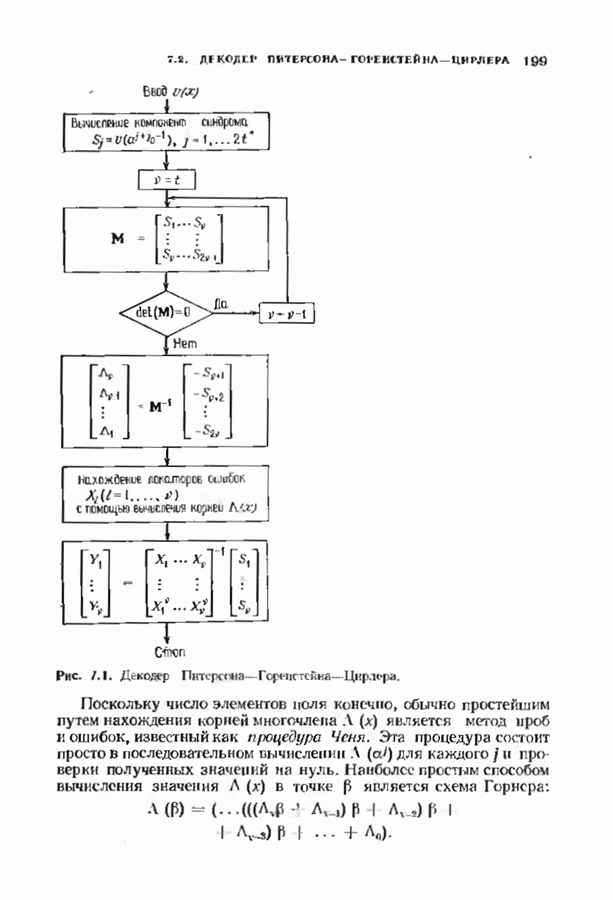
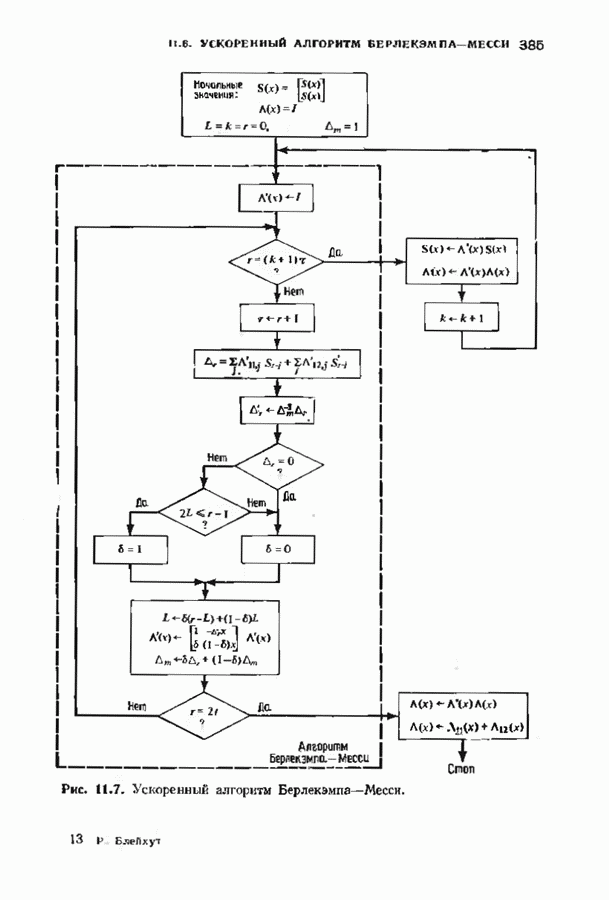
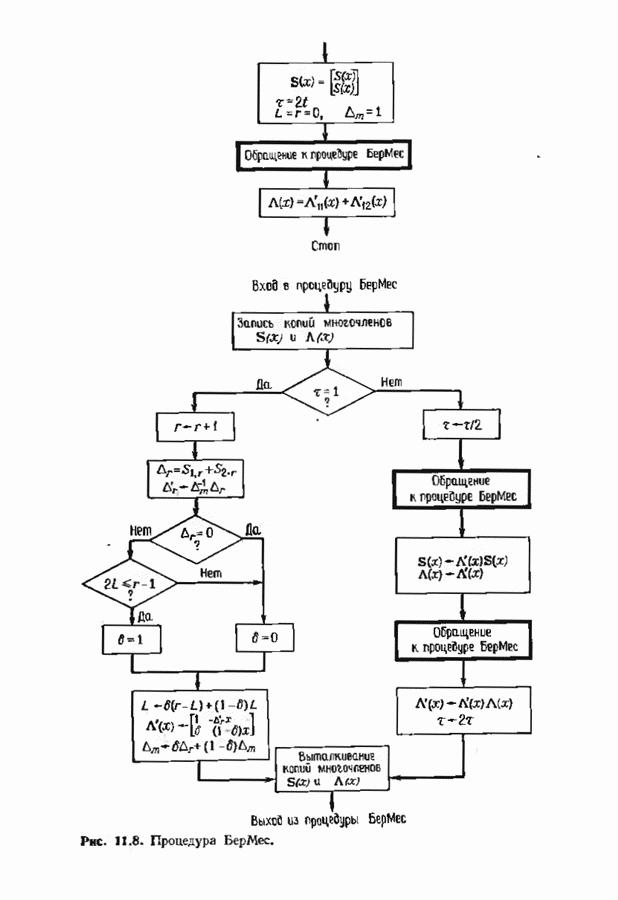
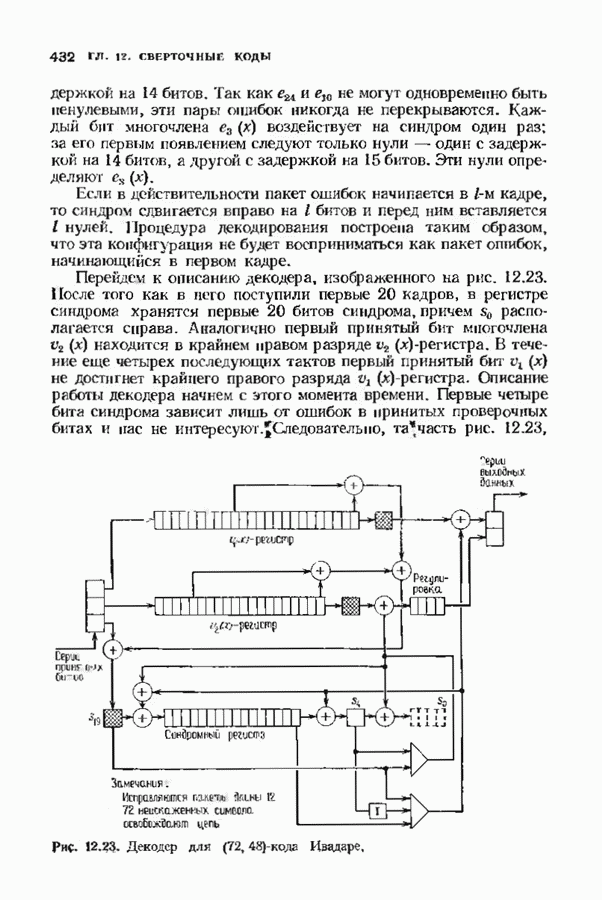
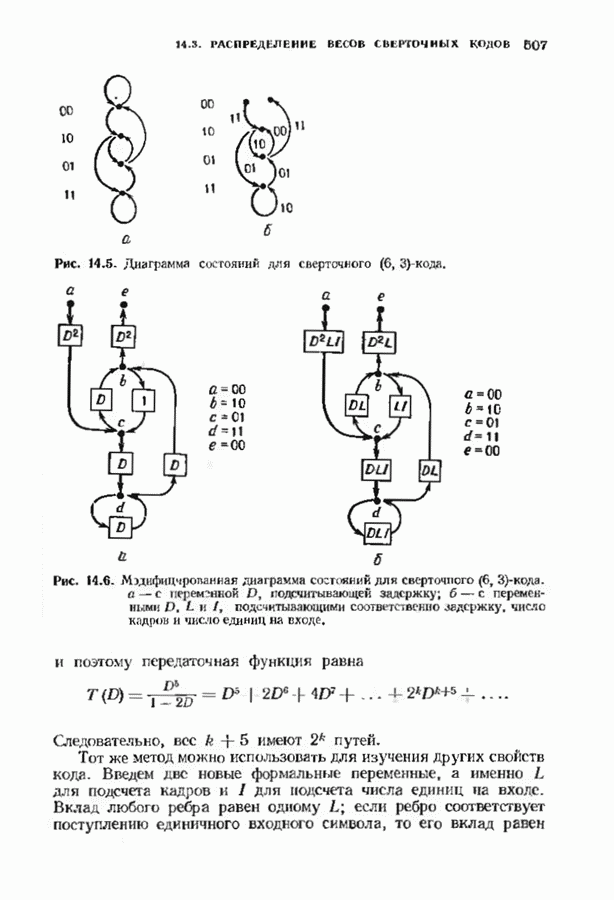
где Два описанных выше варианта эквивалентны. В дальнейшем будет рассмотрен варнант, предложенный Мессн При необходимости алгоритм Берлекэмпа-Месси можно преобразовать в форму Берлекэмпа, производя итерации непосредственно для многочленов На рис. 7.5 приведена блок-схема алгоритма Берлекэмпа— Месси. Как было показано, этот алгоритм позволяет вычислять многочлен локаторов ошибок исходя из заданных Рис. 7.5. (см. скан) Алгоритм Берлекэмпа-Месси, синдрома Этот алгоритм и его обоснование будут понятнее, если во всех деталях проследить работу алгоритма по схеме на рис. 7.5 для конкретных примеров. В табл. 7.3 приведены необходимые вычисления для Внутренняя логика работы алгоритма Берлекэмпа-Месси может показаться несколько загадочной. Возможно, ответы на Таблица 7.3 (см. скан) Алгоритм Берлекэмпа-Месси для Таблица 7.4 (см. скан) Алгоритм Берлекэмпа-Месси для возникшие вопросы помогут найти следующие соображения. На некоторых итерациях, скажем на
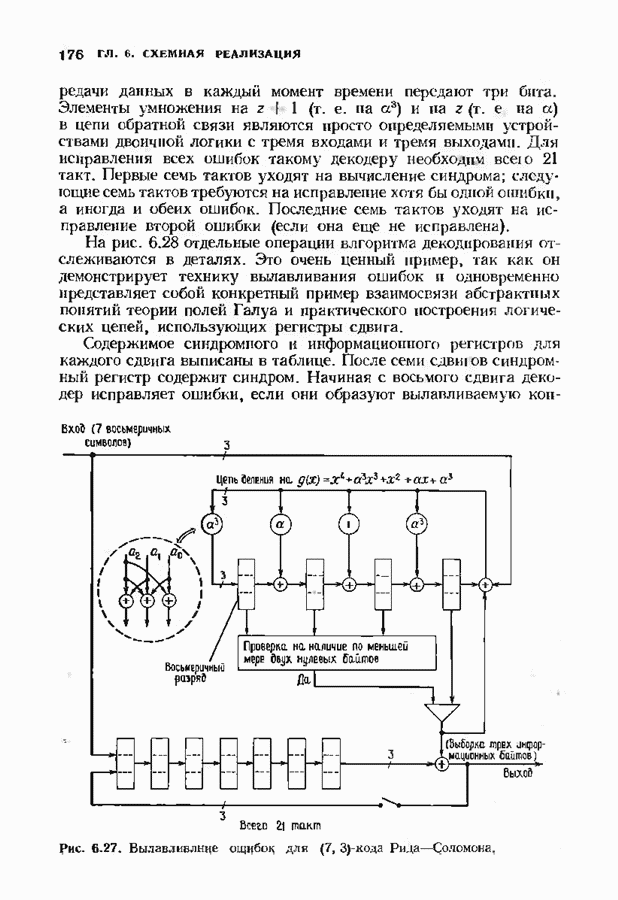
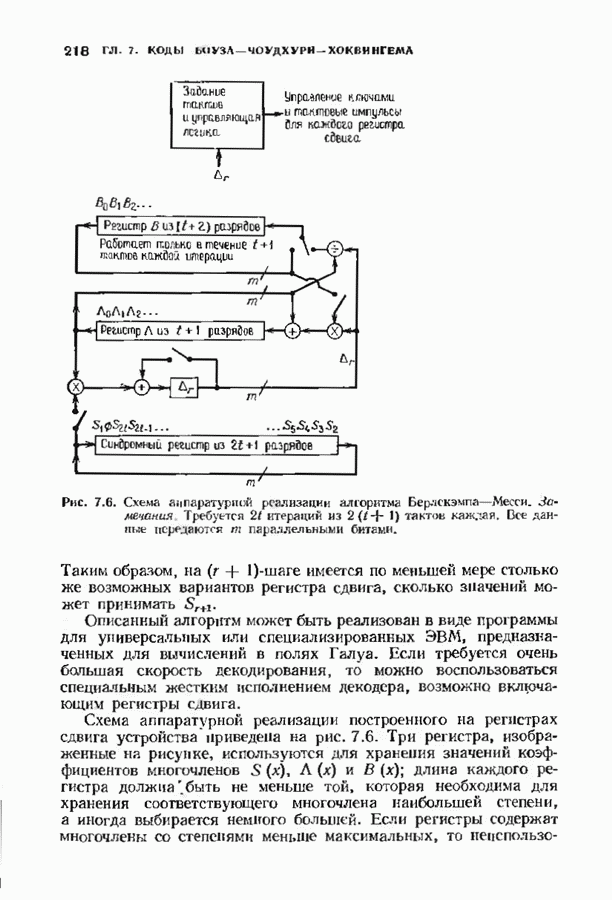
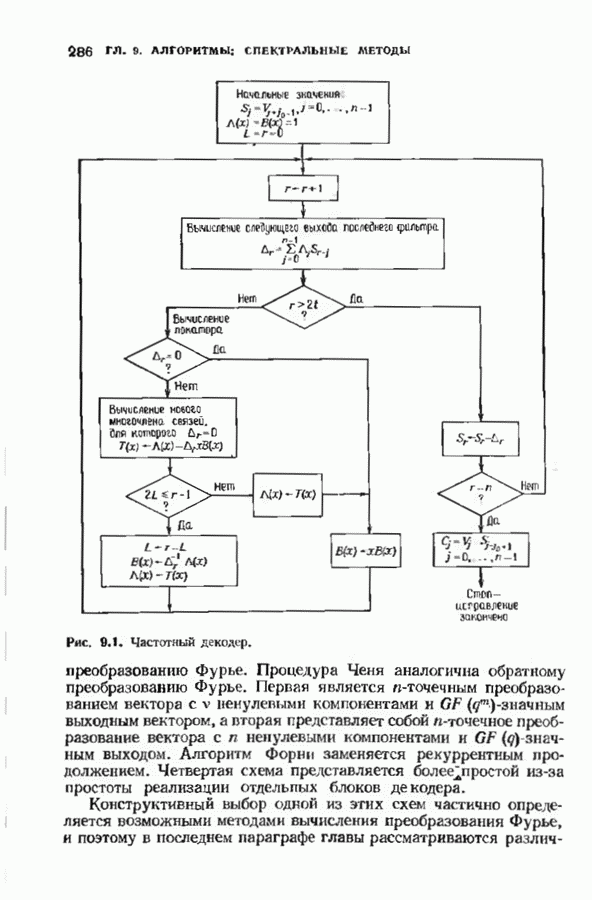
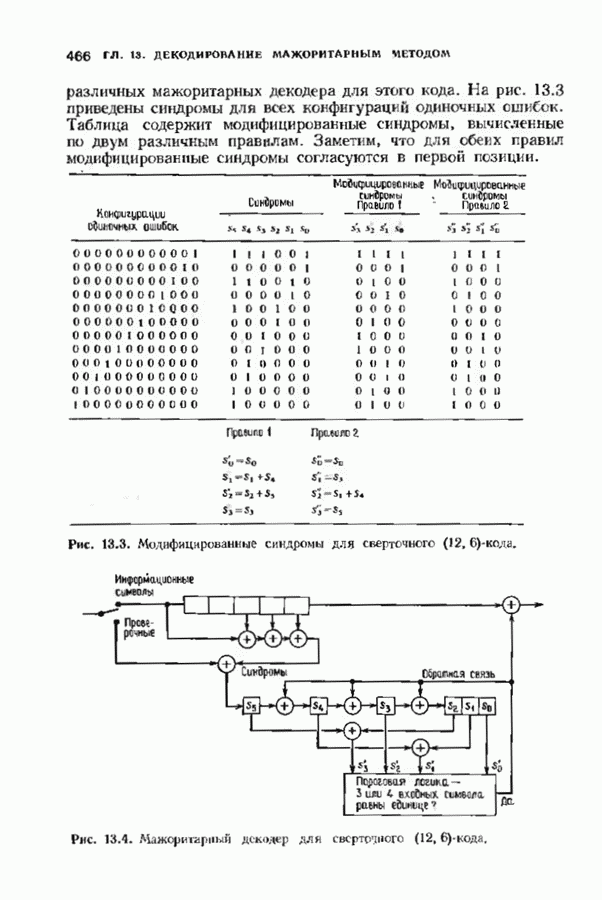
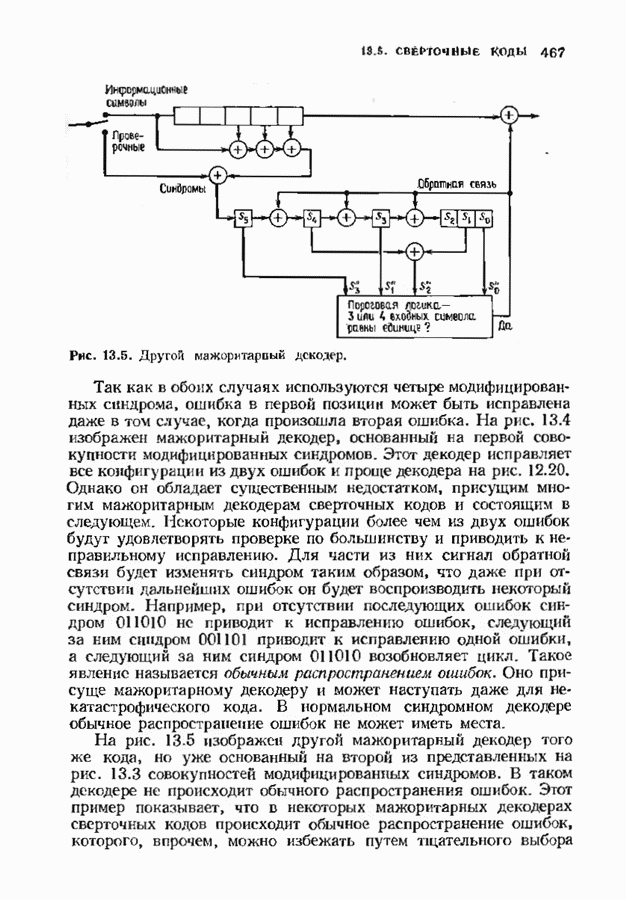
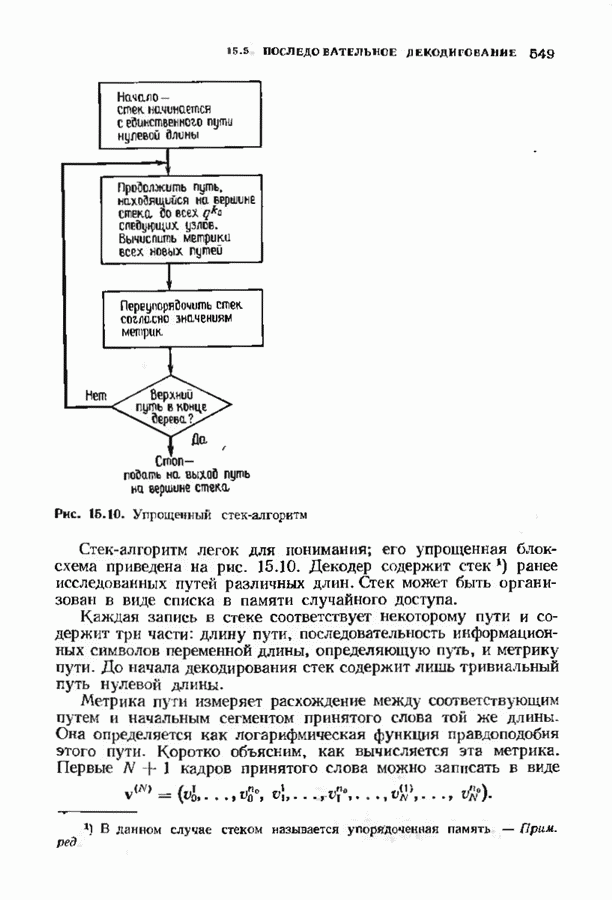
Рис. 7.6. Схема аппаратурной реализации алгоритма Берлекэмпа-Месси. Замечания Требуется 21 итераций из Таким образом, на Описанный алгоритм может быть реализован в виде программы для универсальных или специализированных ЭВМ, предназначенных для вычислений в полях Галуа. Если требуется очень большая скорость декодирования, то можно воспользоваться специальным жестким исполнением декодера, возможно включающим регистры сдвига. Схема аппаратурной реализации построенного на регистрах сдвига устройства приведена на рис. 7.6. Три регистра, изображенные на рисунке, используются для хранения значений коэффициентов многочленов неиспользованные разряды заполняются нулями. Регистры Такой выбор длин регистров вместе с выбором числа тактов работы каждого из регистров в течение одной итерации приводит к тому, что в результате каждой итерации коэффициенты многочленов сдвигаются от своего первоначального положения на одну позицию. Это обеспечивает умножение На рис. 7.7 представлена последовательность вычислений, производимых декодером, использующим алгоритм Берлекэмпа—Месси и алгоритм Форни. В случае когда произошло не более
Рис. 7.7. Быстрое декодирование кодов БЧХ. ошибок, такой декодер выдаст правильное выражение для многочлена локаторов ошибок. В случае когда произойдет более 1) число различных лежащих в 2) значения ошибок не лежат в поле символов кода. При декодировании сначала осуществляется проверка многочлена локаторов ошибок. Если он удовлетворяет требуемым условиям, то декодер приступает к вычислению многочлена значений ошибок. Может случиться, что значения ошибок не будут лежать в поле символов кодовых слов, если последнее меньше поля локаторов ошибок. Такой символ не может быть внесен каналом, и, следовательно, его наличие указывает на то, что вектор ошибок содержит более В § 9.6 будут рассмотрены способы декодирования кодов БЧХ с исправлением некоторых конфигураций более чем Для уменьшения вероятности неправильного декодирования число исправляемых декодером ошибок можно ограничить числом
поскольку для перехода кодового слова в неправильную сферу декодирования должно произойти не менее В таком декодере хорошо применять алгоритм Берлекэмпа-Месси. Для вычисления итераций Правомерность описанной процедуры доказывается следующей теоремой. Теорема 7.5.3. Пусть произошло не более
причем Доказательство. В условии теоремы заданы компоненты синдрома
а это противоречит предположению о том, что произошло не более
|
 |
Оглавление
|




















































































































































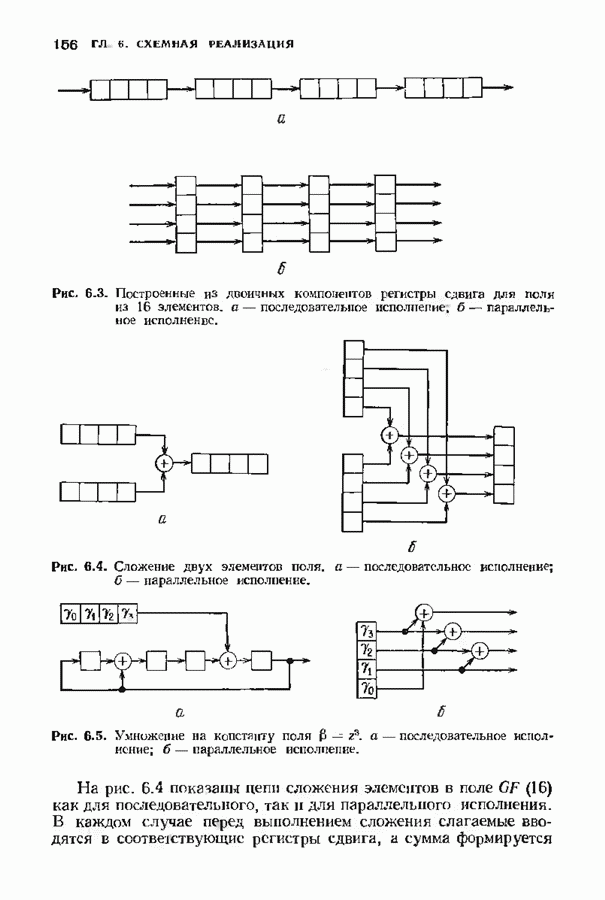




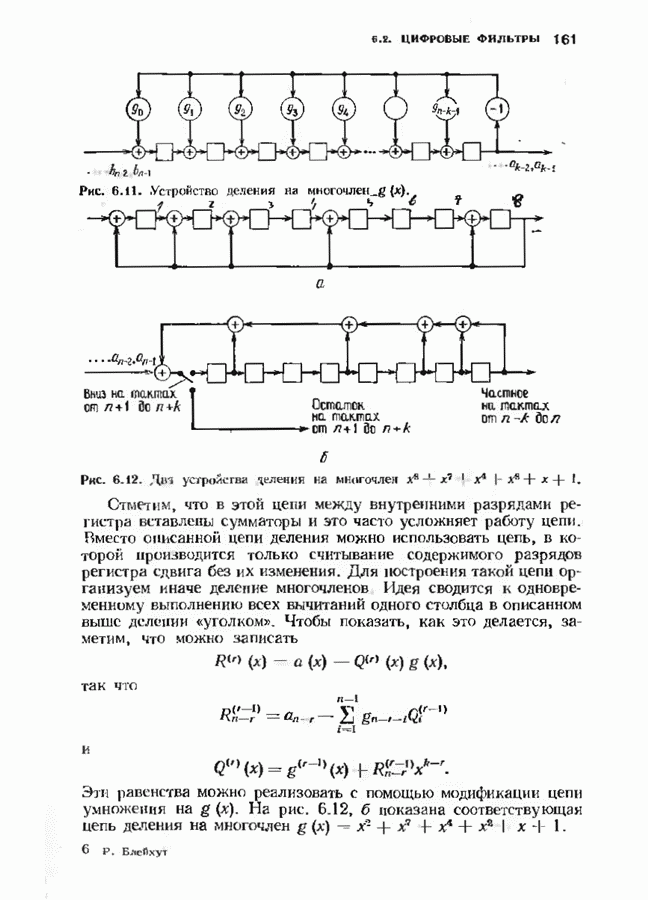

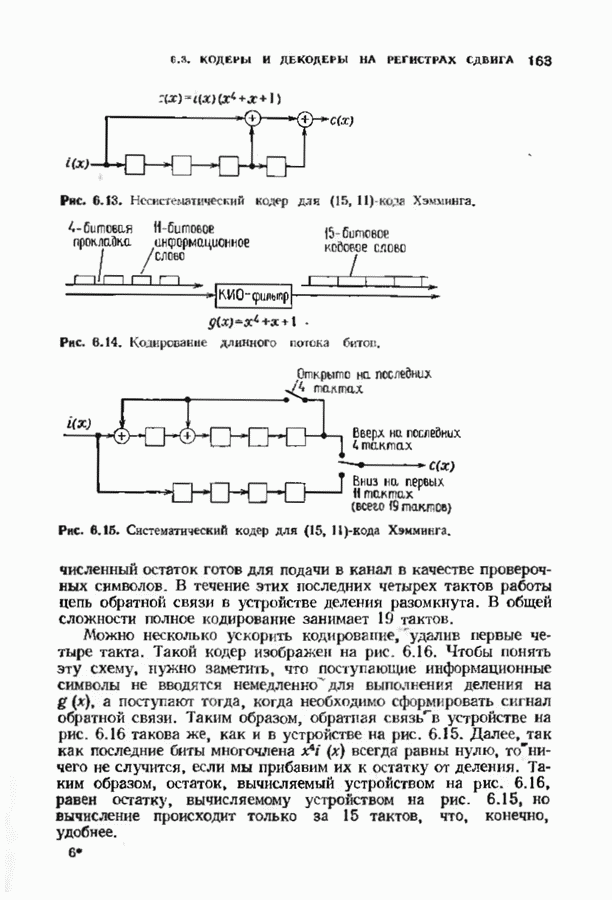
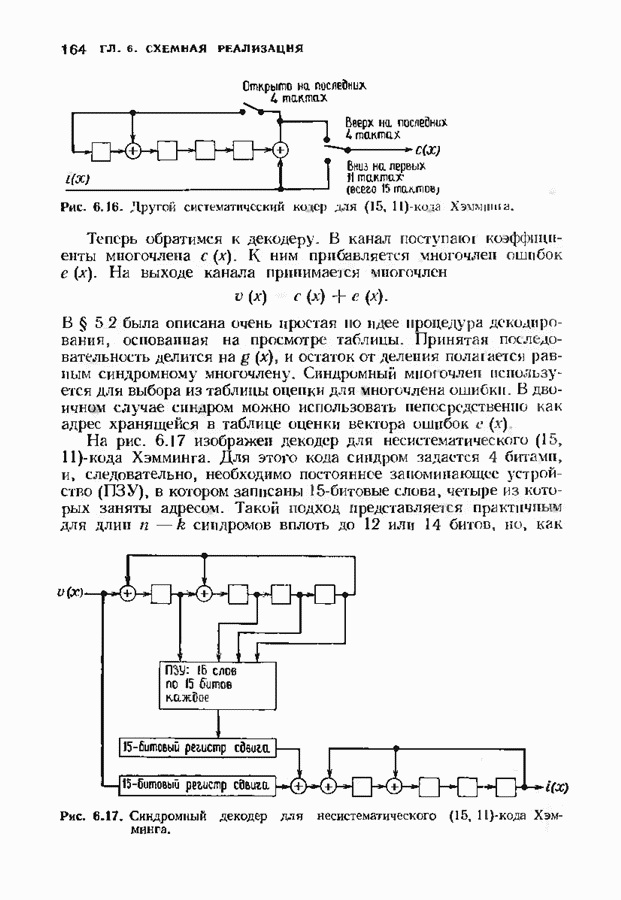














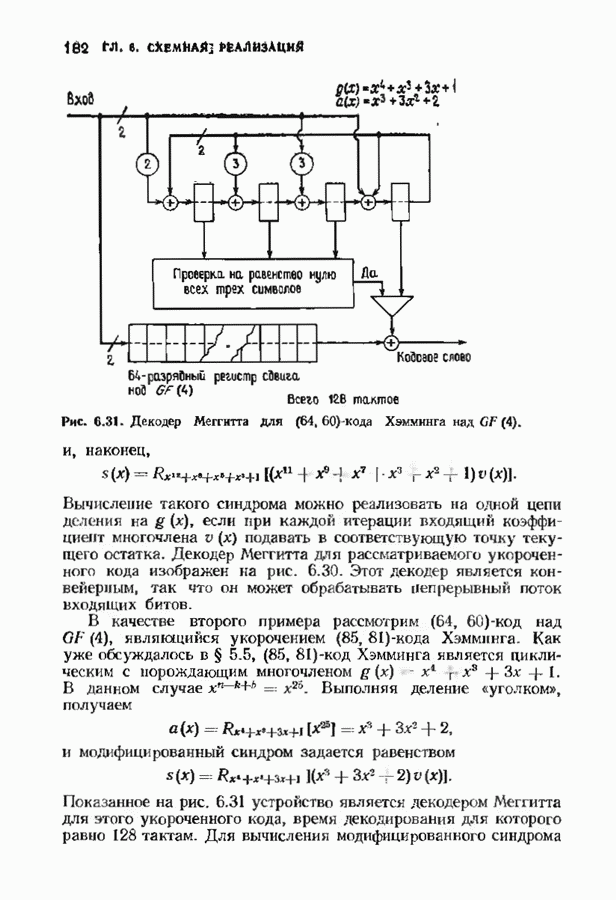







































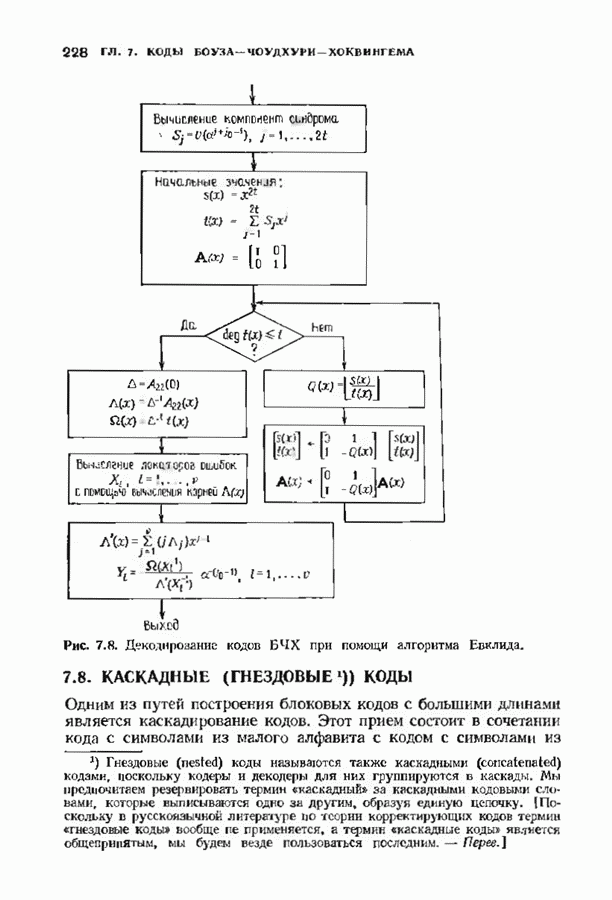






















































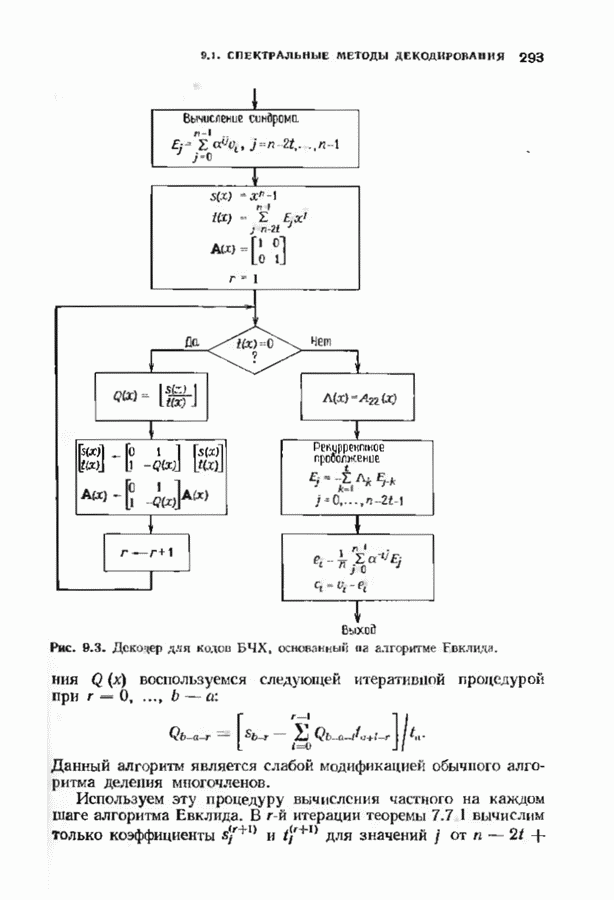





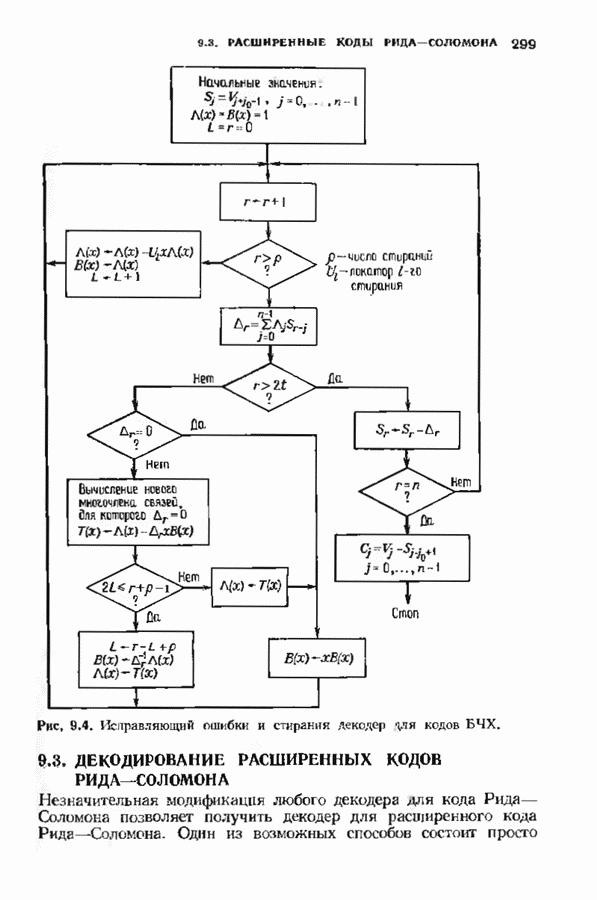


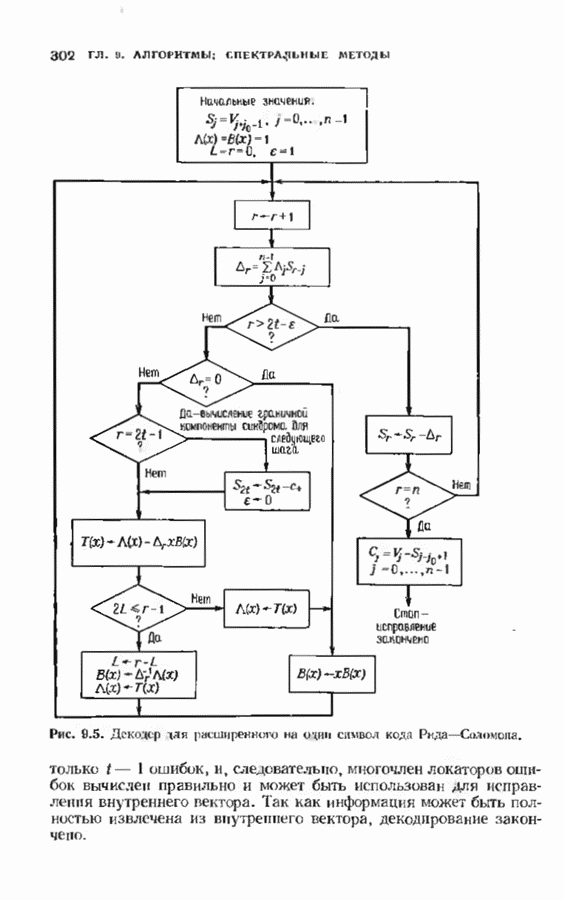












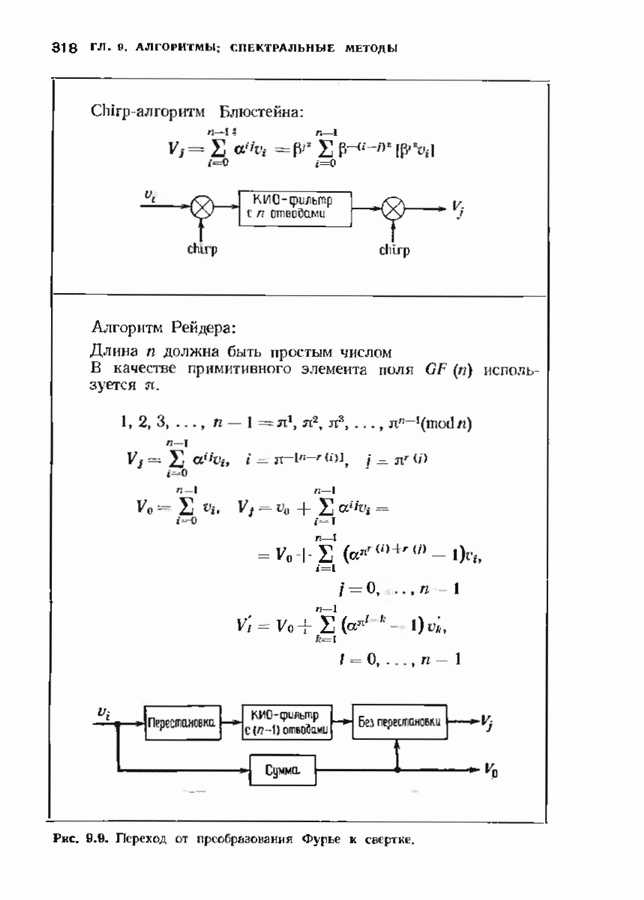























































































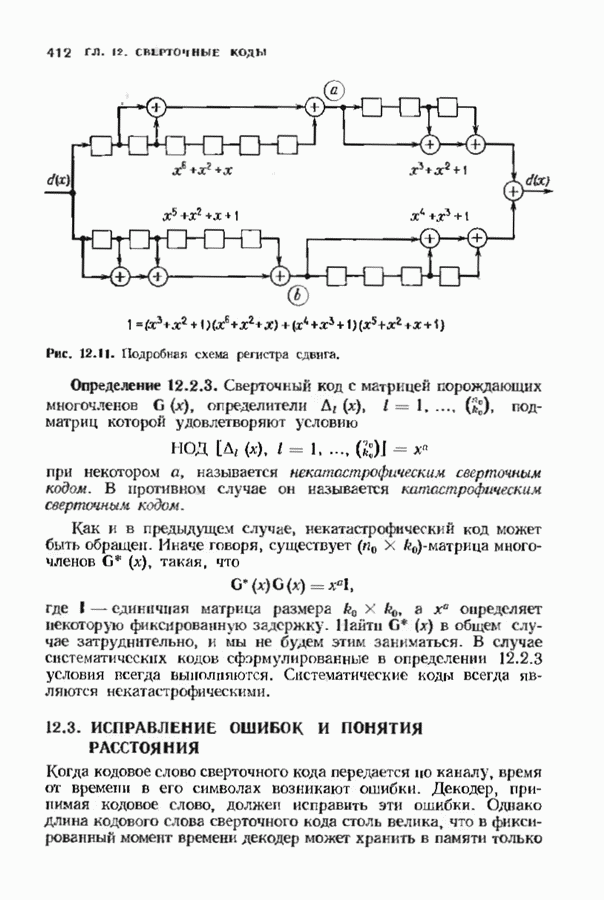




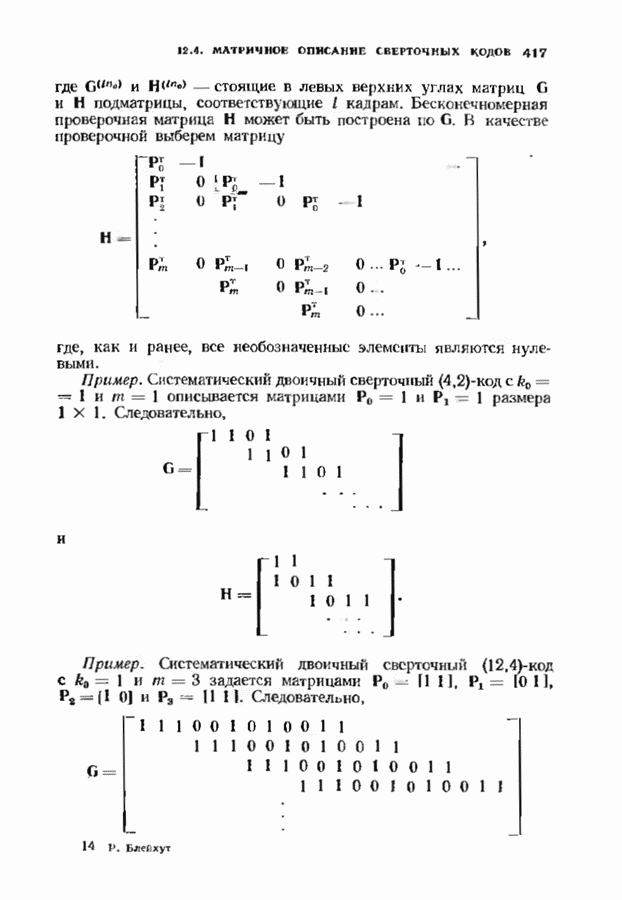


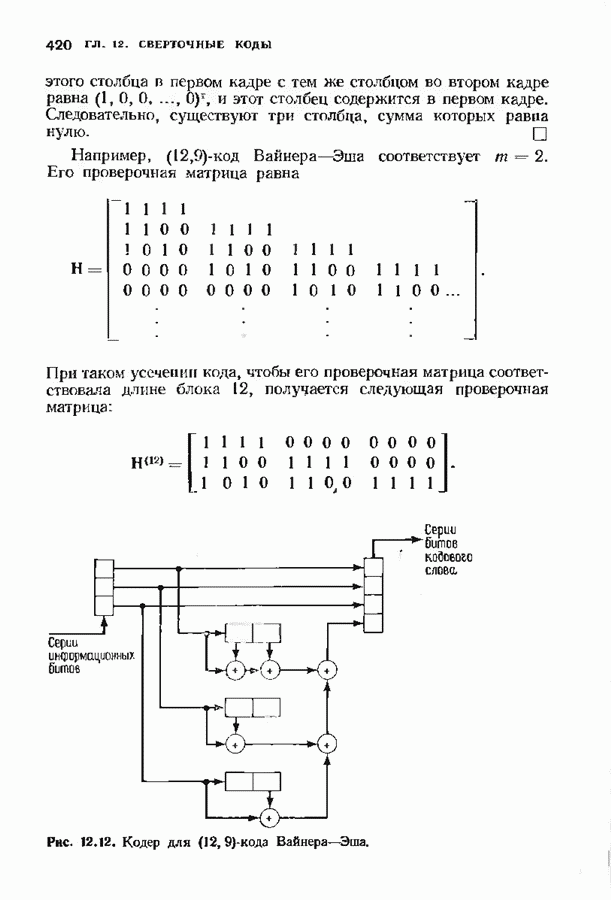
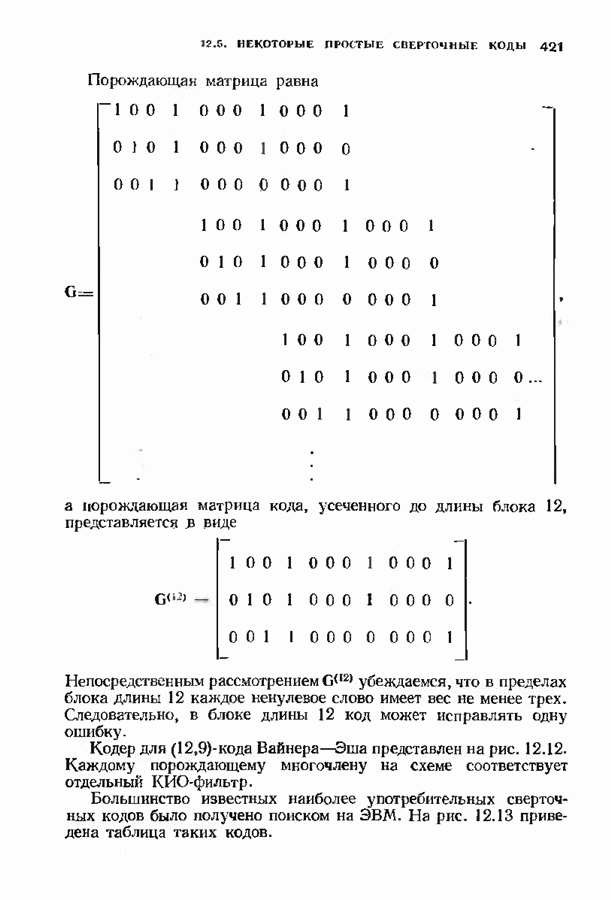


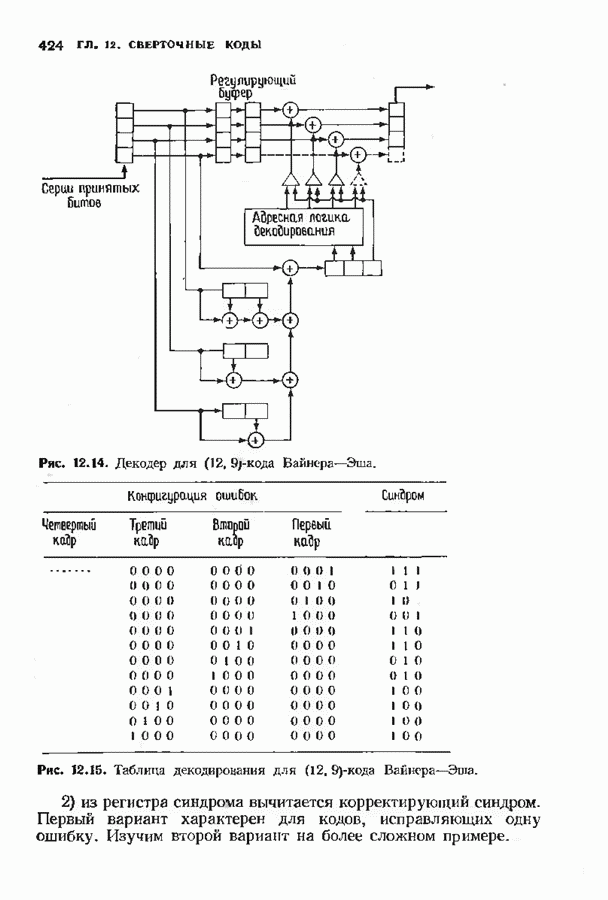
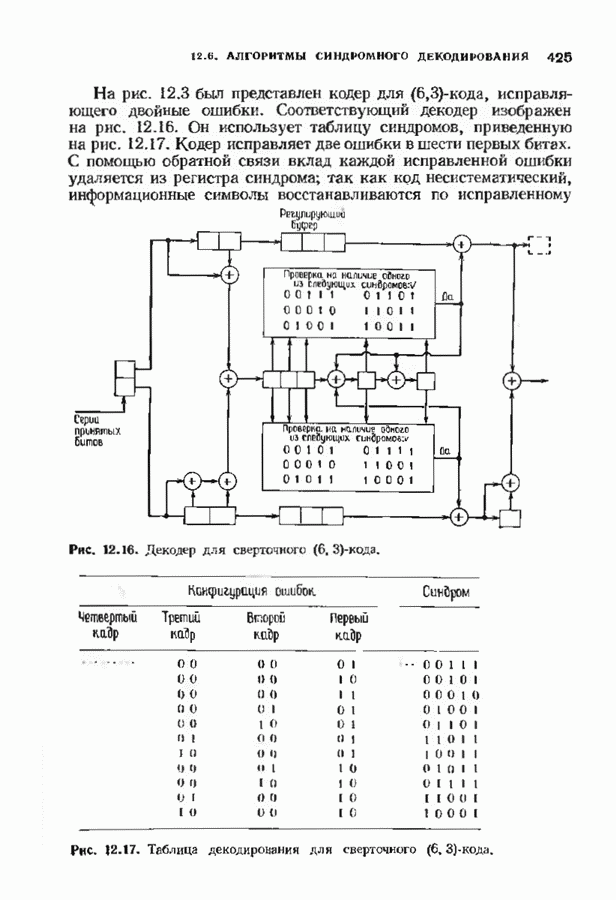



























































































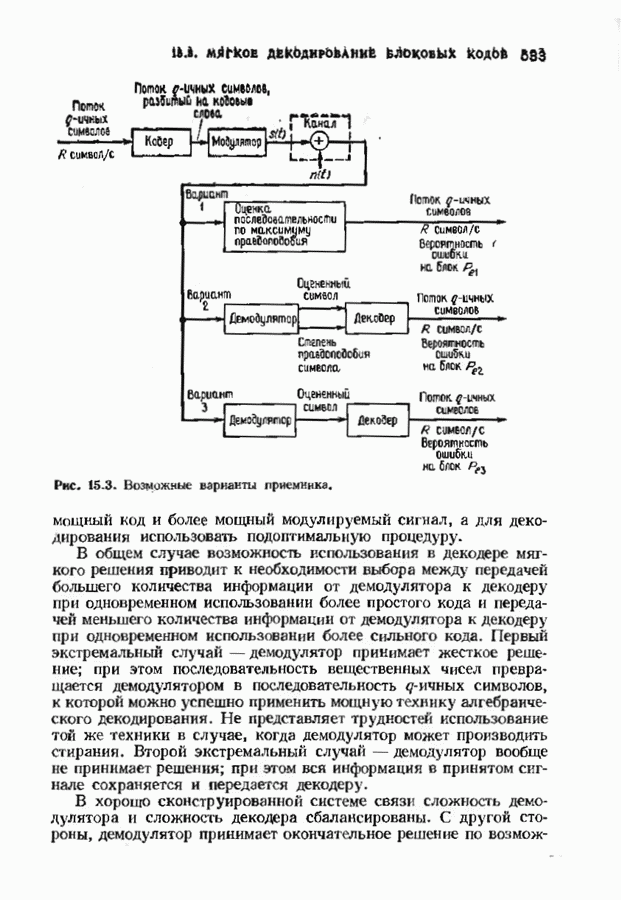



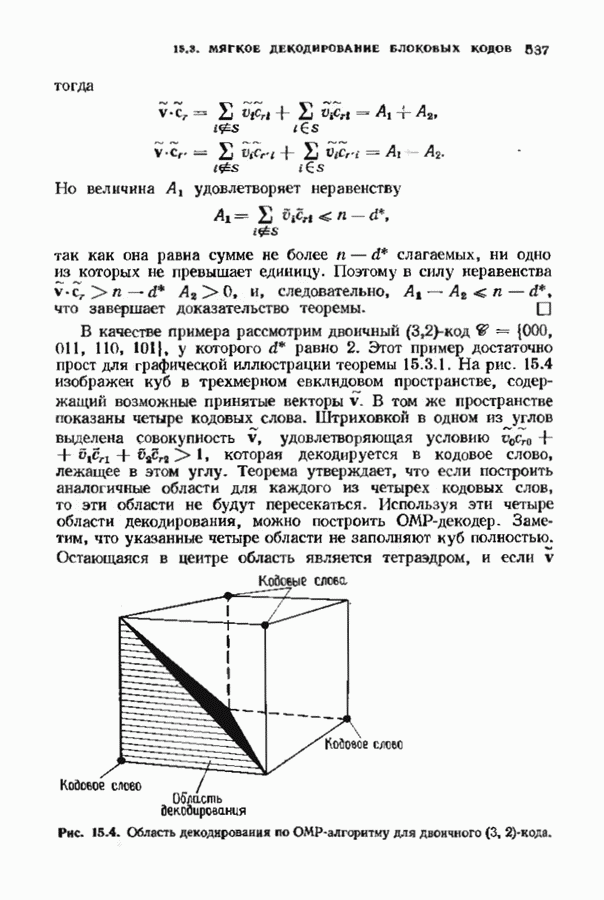

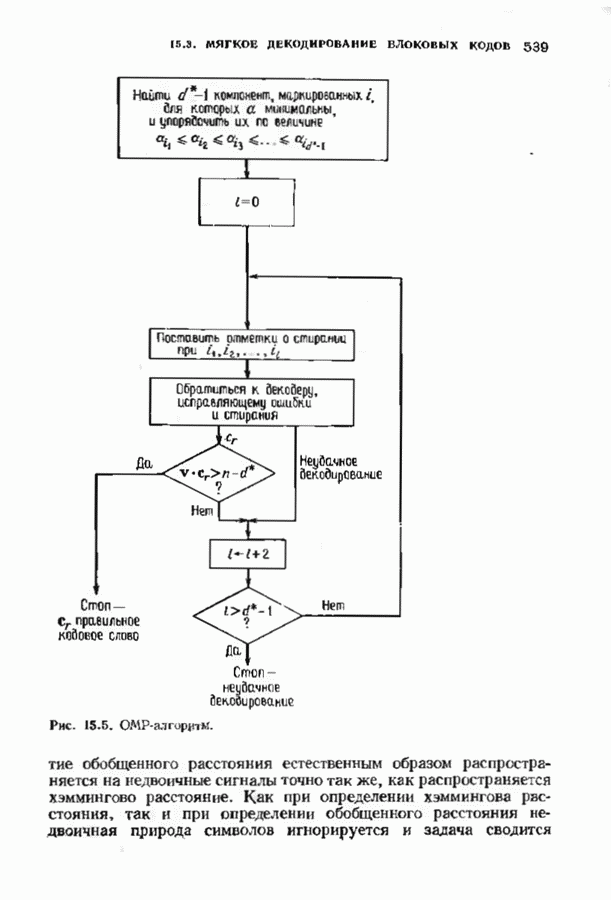




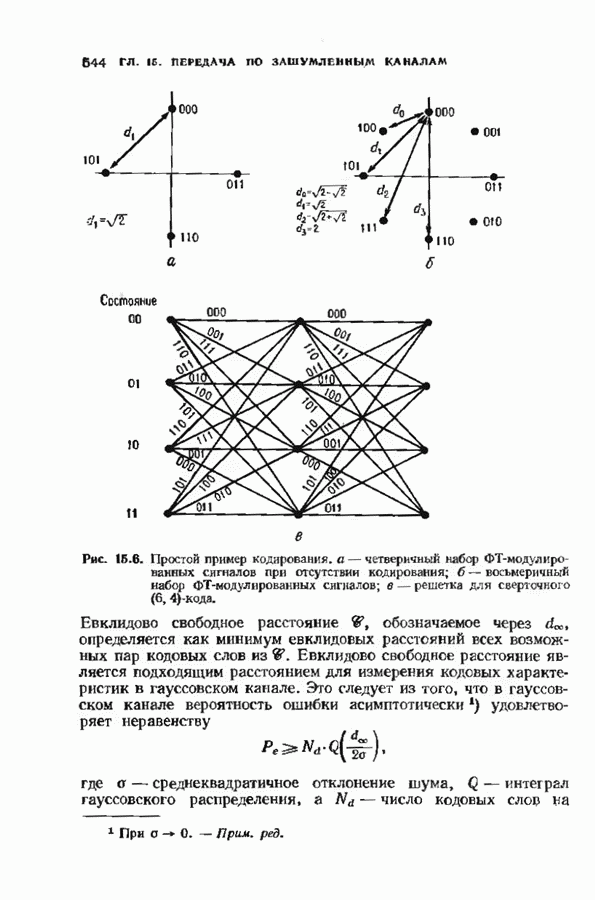
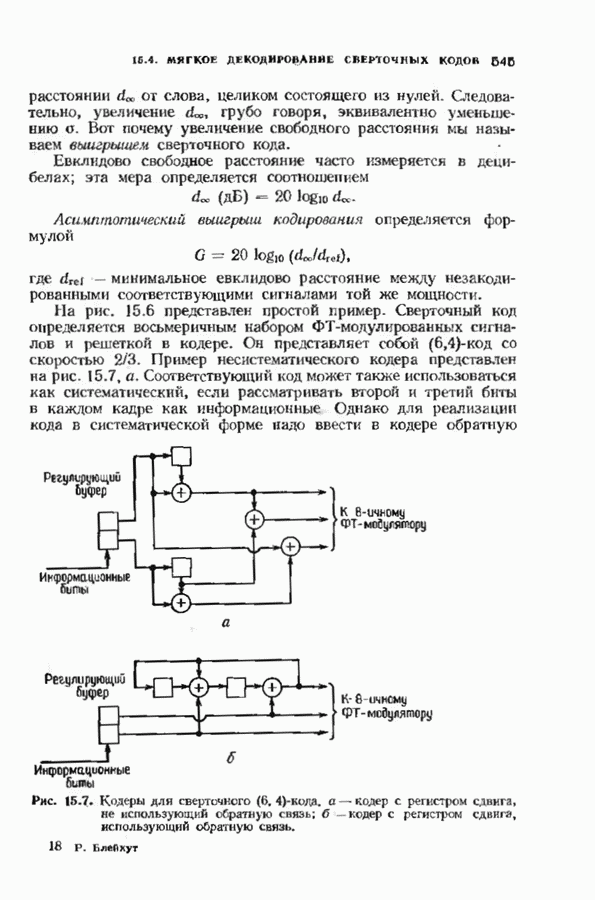
















 Хотя обращение матрицы в конечном поле не приводит к ошибкам округления, вычислительная работа, особенно для больших значений
Хотя обращение матрицы в конечном поле не приводит к ошибкам округления, вычислительная работа, особенно для больших значений  может оказаться чрезмерно большой. В то же время обращения обеих матриц можно избежать. Обращение первой матрицы, необходимое для вычисления многочлена локаторов сшибок, можно обойти, используя алгоритм Берлекэмпа-Месси. Обращение второй матрицы, необходимое для вычисления значений ошибок, можно обойти, воспользовавшись процедурой, носящей название алгоритма Форнн. Этот параграф начнется с описания алгоритма Форни, а затем будет продолжено рассмотрение алгоритма Берлекэмпа-Месси.
может оказаться чрезмерно большой. В то же время обращения обеих матриц можно избежать. Обращение первой матрицы, необходимое для вычисления многочлена локаторов сшибок, можно обойти, используя алгоритм Берлекэмпа-Месси. Обращение второй матрицы, необходимое для вычисления значений ошибок, можно обойти, воспользовавшись процедурой, носящей название алгоритма Форнн. Этот параграф начнется с описания алгоритма Форни, а затем будет продолжено рассмотрение алгоритма Берлекэмпа-Месси.







 получаем
получаем

 Таким образом,
Таким образом,

 совпадает с выражением, которое требуется доказать. Тем самым теорема доказана.
совпадает с выражением, которое требуется доказать. Тем самым теорема доказана.

 получим
получим

 равна
равна


 находится вектор
находится вектор  минимальной длины, удовлетворяющий
минимальной длины, удовлетворяющий  уравнениям
уравнениям

 из свертки вычислить вектор А, если априори известно,
из свертки вычислить вектор А, если априори известно,

 Удовлетворяющий этому равенству вектор
Удовлетворяющий этому равенству вектор  определяет коэффициенты многочлена локаторов ошибок
определяет коэффициенты многочлена локаторов ошибок

 являются локаторами ошибок. Многочлен значений ошибок не вычисляется с помощью этого алгоритма, но получается позже из
являются локаторами ошибок. Многочлен значений ошибок не вычисляется с помощью этого алгоритма, но получается позже из  и
и  согласно определению
согласно определению 
 компоненты которых рапиы нулю при К.
компоненты которых рапиы нулю при К.  и удовлетворяют 11 уравнениям
и удовлетворяют 11 уравнениям

 при
при  . Заметим, что
. Заметим, что  пробегает
пробегает  значений. Решение задачи чается двумя многочленами: многочленом локаторов ошибок и многочленом значений ошибок.
значений. Решение задачи чается двумя многочленами: многочленом локаторов ошибок и многочленом значений ошибок.

 компонент
компонент
 Если
Если  в коде отлично от 1, то определим
в коде отлично от 1, то определим  Эти компоненты синдрома участвуют в вычислениях точно так же, как и прежние компоненты. Сам алгоритм при этом не претерпевает никаких изменений, и дело сводится лишь к соответствующему изменению индексов внутренних переменных в алгоритме.
Эти компоненты синдрома участвуют в вычислениях точно так же, как и прежние компоненты. Сам алгоритм при этом не претерпевает никаких изменений, и дело сводится лишь к соответствующему изменению индексов внутренних переменных в алгоритме.
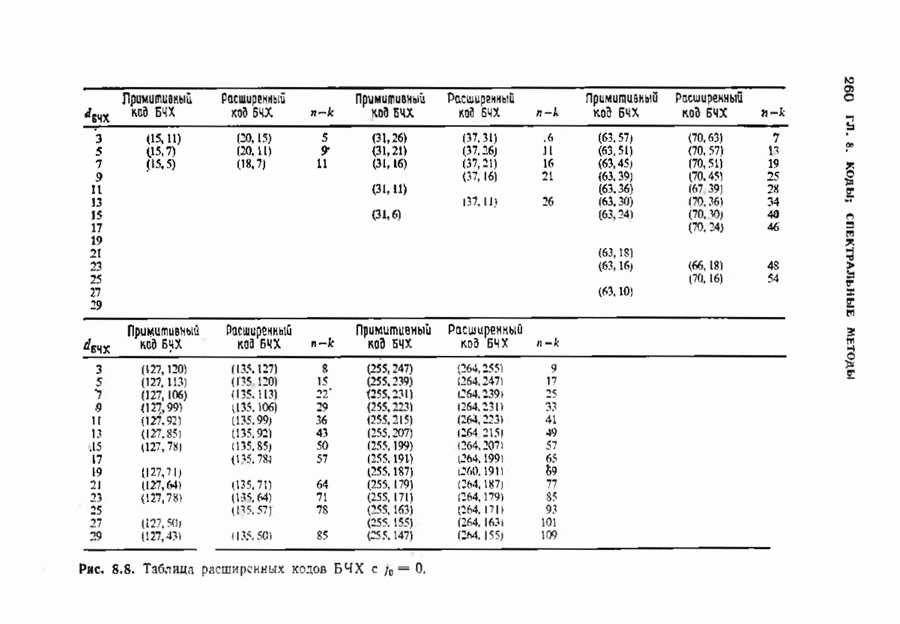
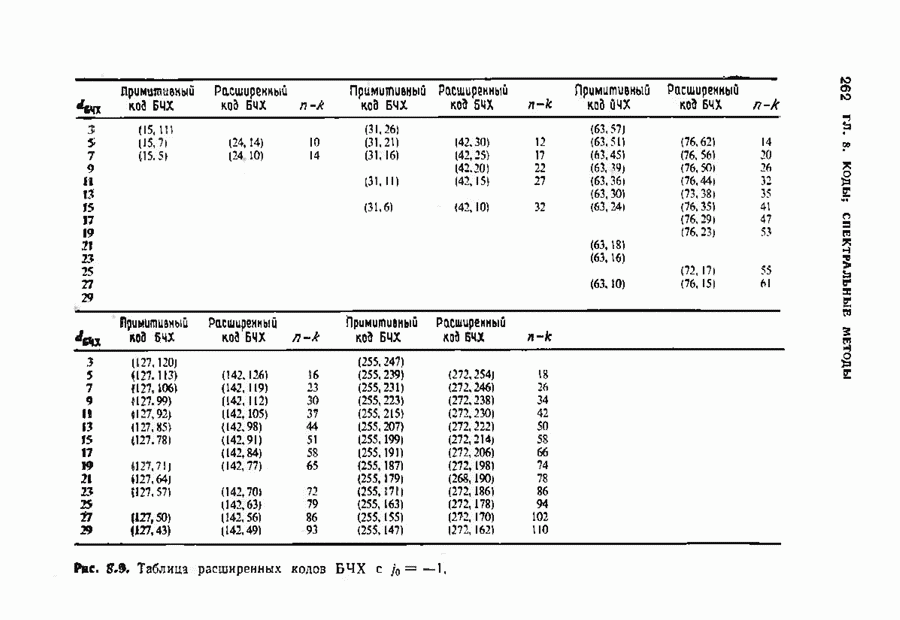
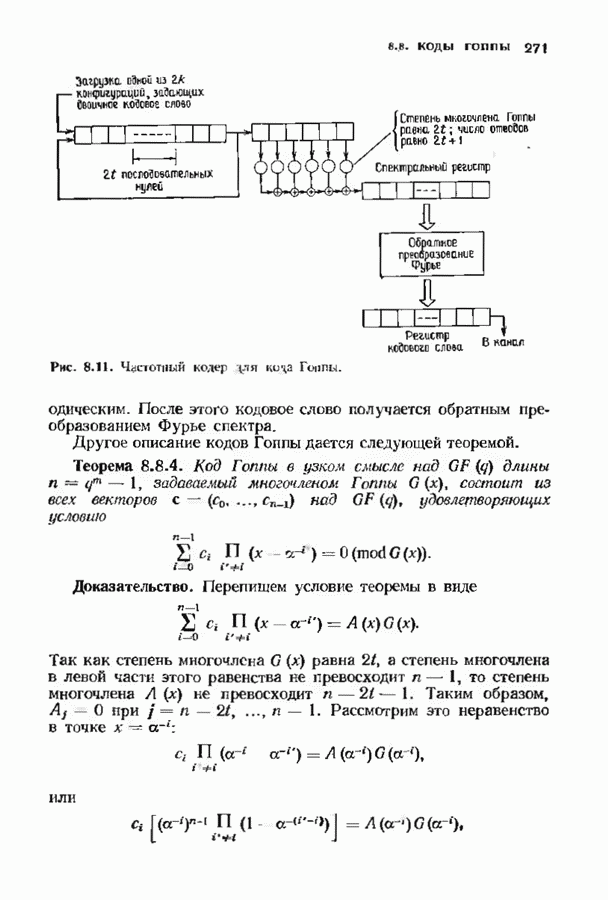
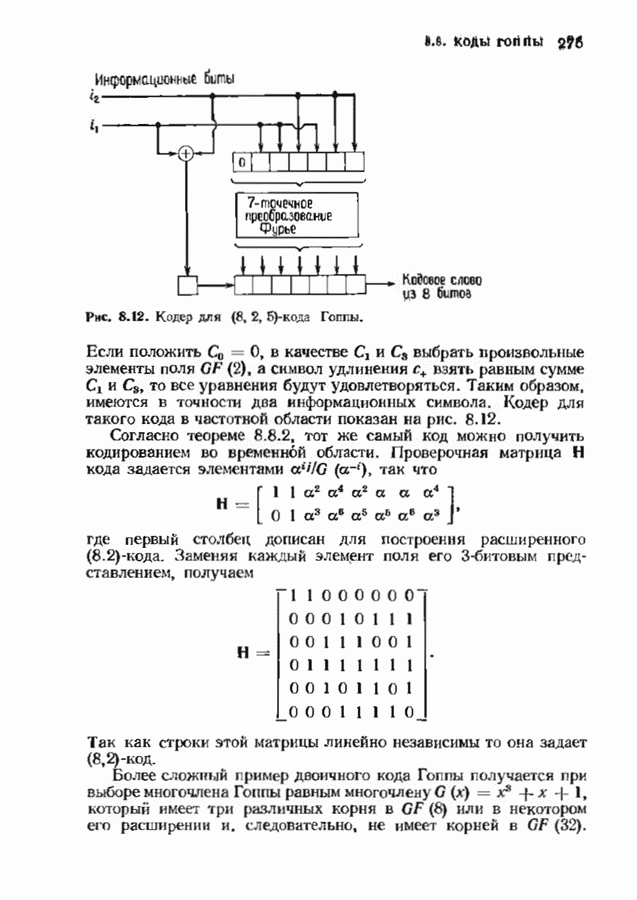
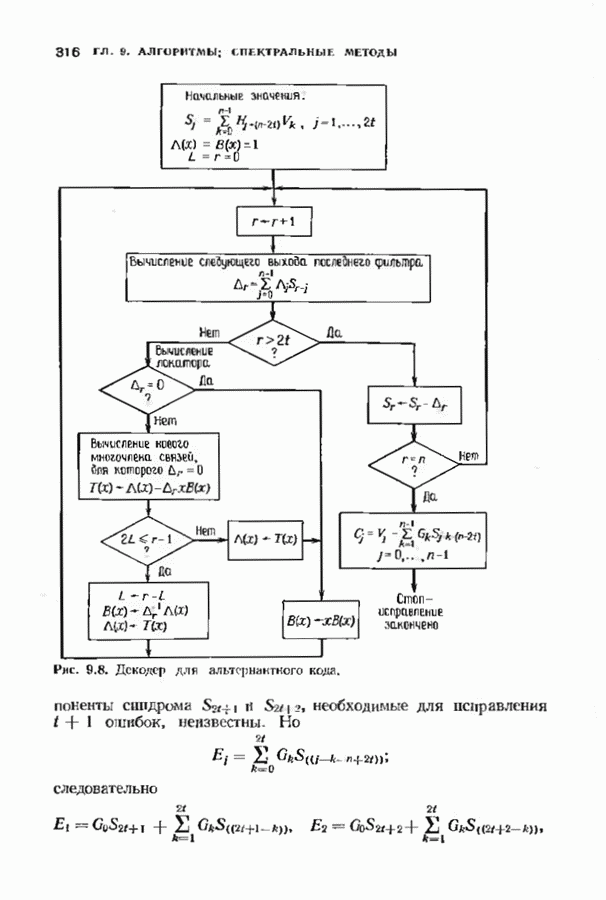
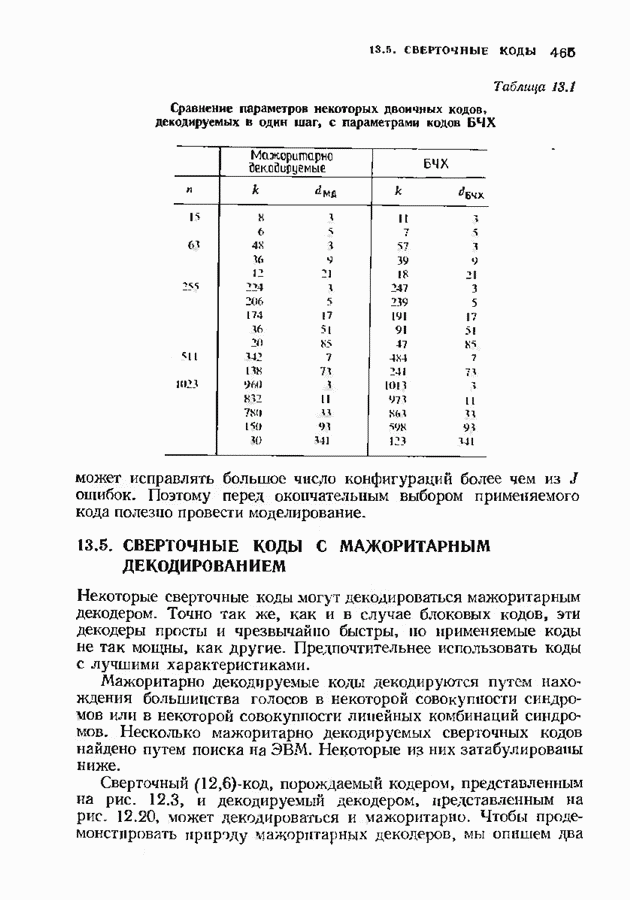
 -кода Рида-Соломона, исправляющего тройные ошибки. В достоверности приведенных вычислений можно убедиться, проделав шесть итераций по изображенной на рис. 7.5 схеме. Табл. 7.4 содержит анвлогичные вычисления для исправляющего тройные ошибки
-кода Рида-Соломона, исправляющего тройные ошибки. В достоверности приведенных вычислений можно убедиться, проделав шесть итераций по изображенной на рис. 7.5 схеме. Табл. 7.4 содержит анвлогичные вычисления для исправляющего тройные ошибки  -кода БЧХ.
-кода БЧХ.
 -кода Рида-Соломона, исправляющего тройные ошибки
-кода Рида-Соломона, исправляющего тройные ошибки
 -кода БЧХ, исправляющего тройные ошибки
-кода БЧХ, исправляющего тройные ошибки
 итерации, наравне с выбранным по алгоритму Берлекэмпа-Месси регистром с линейной обратной связью могут существовать другие регистры минимальной длины с линейной обратной связью, генерирующие требуемые символы. Все эти регистры будут генерировать одну и ту же требуемую последовательность
итерации, наравне с выбранным по алгоритму Берлекэмпа-Месси регистром с линейной обратной связью могут существовать другие регистры минимальной длины с линейной обратной связью, генерирующие требуемые символы. Все эти регистры будут генерировать одну и ту же требуемую последовательность  компонент синдрома; в то же время последующие компоненты, не входящие в
компонент синдрома; в то же время последующие компоненты, не входящие в  итерацию, у них будут различны. Каждый раз, когда это возможно, на следующей итерации выбирается регистр сдвига с линейной обратной связью с прежней длиной, генерирующий следующую требуемую компоненту синдрома; если такого регистра не оказывается, то длину регистра приходится увеличивать. Однако при решении вопроса о необходимости увеличения длины регистра никак не учитывается значение следующей компоненты синдрома (проверяется лишь выполнение соотношения
итерацию, у них будут различны. Каждый раз, когда это возможно, на следующей итерации выбирается регистр сдвига с линейной обратной связью с прежней длиной, генерирующий следующую требуемую компоненту синдрома; если такого регистра не оказывается, то длину регистра приходится увеличивать. Однако при решении вопроса о необходимости увеличения длины регистра никак не учитывается значение следующей компоненты синдрома (проверяется лишь выполнение соотношения 

 тактов каждая. Все данные передаются
тактов каждая. Все данные передаются  параллельными битами.
параллельными битами.
 -шаге имеется по меньшей мере столько же возможных вариантов регистра сдвига, сколько значений может принимать
-шаге имеется по меньшей мере столько же возможных вариантов регистра сдвига, сколько значений может принимать 
 длина каждого регистра должнабыть не меньше той, которая необходима для хранения соответствующего многочлена наибольшей степени, а иногда выбирается немного большей. Если регистры содержат многочлены со степенями меньше максимальных, то
длина каждого регистра должнабыть не меньше той, которая необходима для хранения соответствующего многочлена наибольшей степени, а иногда выбирается немного большей. Если регистры содержат многочлены со степенями меньше максимальных, то
 и
и  имеют на один разряд больше, чем необходимо для хранения многочленов максимальной степени; отметим наличие дополнительного разряда в регистре
имеют на один разряд больше, чем необходимо для хранения многочленов максимальной степени; отметим наличие дополнительного разряда в регистре 
 на х и такую переиндексацию компонент
на х и такую переиндексацию компонент  чтобы получились компоненты
чтобы получились компоненты  входящие в выражение для
входящие в выражение для  Чтобы понять это, снова обратимся к рис. 7.6, на котором регистр
Чтобы понять это, снова обратимся к рис. 7.6, на котором регистр  показан в своем исходном состоянии. В результате каждой итерации содержимое этого регистра сдвигается на одну позицию вправо, что позволяет в следующей итерации правильно произвести умножение соответствующих коэффициентов многочленов
показан в своем исходном состоянии. В результате каждой итерации содержимое этого регистра сдвигается на одну позицию вправо, что позволяет в следующей итерации правильно произвести умножение соответствующих коэффициентов многочленов  и
и  Регистр
Регистр  в течение одной итерации сдвигается на полную длину дважды: когда вычисляется
в течение одной итерации сдвигается на полную длину дважды: когда вычисляется  и когда в этот регистр вводится новое значение
и когда в этот регистр вводится новое значение 


 ошибок, декодирование будет неудачным и получится либо многочлен, не удовлетворяющий условиям, которым должен удовлетворять многочлен локаторов ошибок, либо допустимый, но неправильный многочлен. В первом случае декодер может обнаружить ошибку и пометить сообщение как не поддающееся декодированию. Решение об обнаружении неисправляемой конфигурации ошибок принимается тогда, когда выполняется хотя бы одно из двух условий:
ошибок, декодирование будет неудачным и получится либо многочлен, не удовлетворяющий условиям, которым должен удовлетворять многочлен локаторов ошибок, либо допустимый, но неправильный многочлен. В первом случае декодер может обнаружить ошибку и пометить сообщение как не поддающееся декодированию. Решение об обнаружении неисправляемой конфигурации ошибок принимается тогда, когда выполняется хотя бы одно из двух условий:
 корней
корней  отлично от
отлично от 
 искаженных позиций.
искаженных позиций.
 ошибок; здесь же мы обсудим противоположный случай, когда число исправляемых ошибок ограничивается конструктивным расстоянием. На практике такое декодирование используется для значительного уменьшения вероятности ошибки декодирования, платой за которое является увеличение вероятности отказа от декодирования
ошибок; здесь же мы обсудим противоположный случай, когда число исправляемых ошибок ограничивается конструктивным расстоянием. На практике такое декодирование используется для значительного уменьшения вероятности ошибки декодирования, платой за которое является увеличение вероятности отказа от декодирования
 таким, что
таким, что  будет строго меньше
будет строго меньше  (при четном
(при четном  это выполняется всегда). В этом случае декодер всегда будет обнаруживать неисправляемую конфигурацию ошибок при условии, что число
это выполняется всегда). В этом случае декодер всегда будет обнаруживать неисправляемую конфигурацию ошибок при условии, что число  действительно случившихся ошибок удовлетворяет неравенству
действительно случившихся ошибок удовлетворяет неравенству

 ошибок.
ошибок.
 необходимо сделать 21 итераций по алгоритму Берлекэмпа — Месси. Остальные
необходимо сделать 21 итераций по алгоритму Берлекэмпа — Месси. Остальные  итераций,
итераций,  требуются для проверки равенства нулю невязок
требуются для проверки равенства нулю невязок  Если хотя бы при одной из этих дополнительных
Если хотя бы при одной из этих дополнительных
 не равняется нулю, то принятое слово объявляется словом, в котором произошло более
не равняется нулю, то принятое слово объявляется словом, в котором произошло более  ошибок.
ошибок.
 ошибок и заданы
ошибок и заданы  при
при  Пусть, далее,
Пусть, далее,  регистр сдвига с линейной обратной связью, генерирующий последовательность
регистр сдвига с линейной обратной связью, генерирующий последовательность  и
и

 равняются нулю при
равняются нулю при  Тогда произошло не более
Тогда произошло не более  ошибок и
ошибок и  будет являться правильным многочленом локаторов ошибок.
будет являться правильным многочленом локаторов ошибок.
 для
для  Если бы имелись еще
Если бы имелись еще  компонент синдрома
компонент синдрома  то можно было бы исправлять
то можно было бы исправлять  ошибок, т. е. любую конфигурацию предполагаемых ошибок. Вообразим на минуту, что эти дополнительные компоненты сообщены нам добрым волшебником или переданы по неведомому добавочному каналу. Тогда, используя алгоритм Берлекэмпа-Месси, можно найти многочлен локаторов ошибок, степень которого равна числу ошибок. Но при
ошибок, т. е. любую конфигурацию предполагаемых ошибок. Вообразим на минуту, что эти дополнительные компоненты сообщены нам добрым волшебником или переданы по неведомому добавочному каналу. Тогда, используя алгоритм Берлекэмпа-Месси, можно найти многочлен локаторов ошибок, степень которого равна числу ошибок. Но при  итерации
итерации  и по предположению
и по предположению  равняется нулю при
равняется нулю при  Поэтому значение
Поэтому значение  не будет меняться до итерации с номером
не будет меняться до итерации с номером  и, следовательно, но правилу изменения
и, следовательно, но правилу изменения 

 ошибок.
ошибок.