Пред.
След.
Макеты страниц
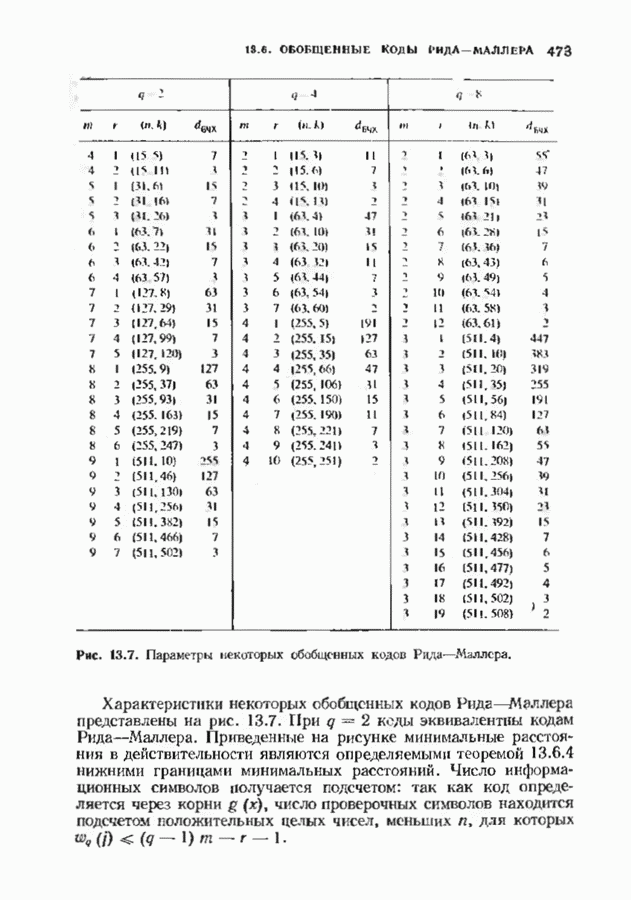
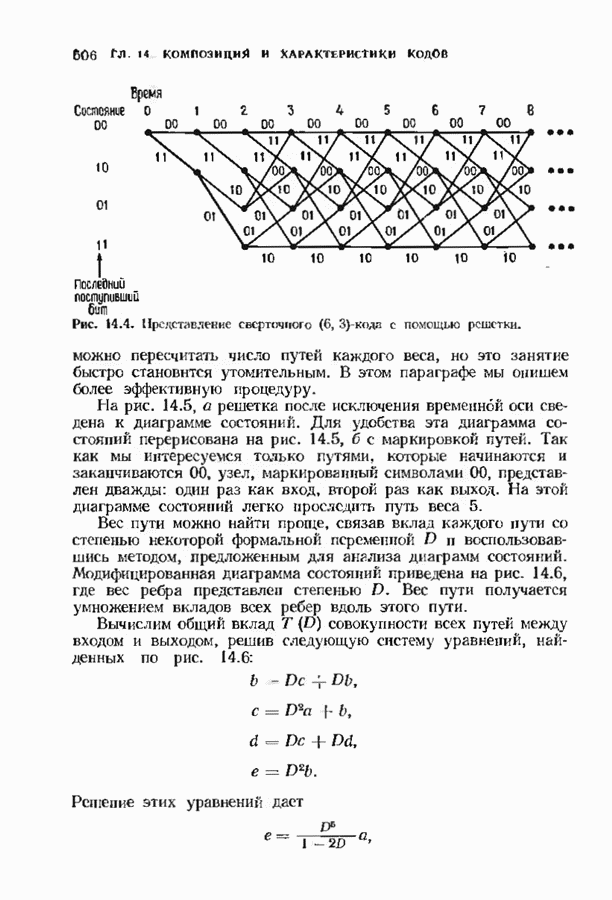
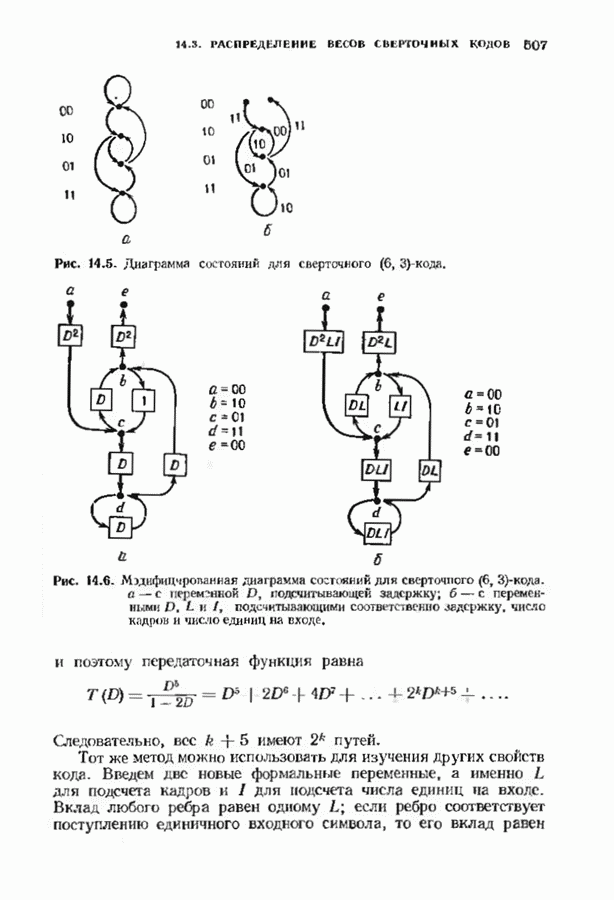
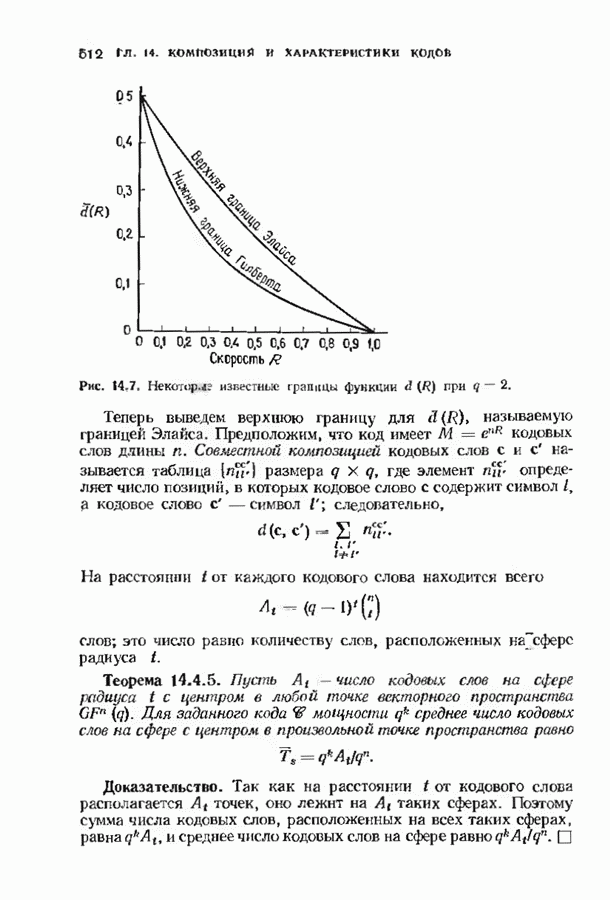
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
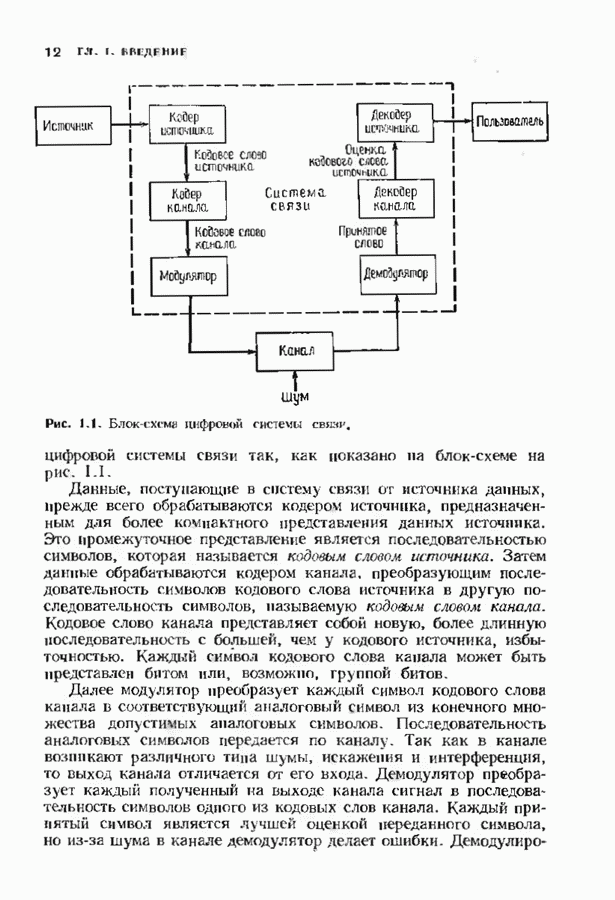
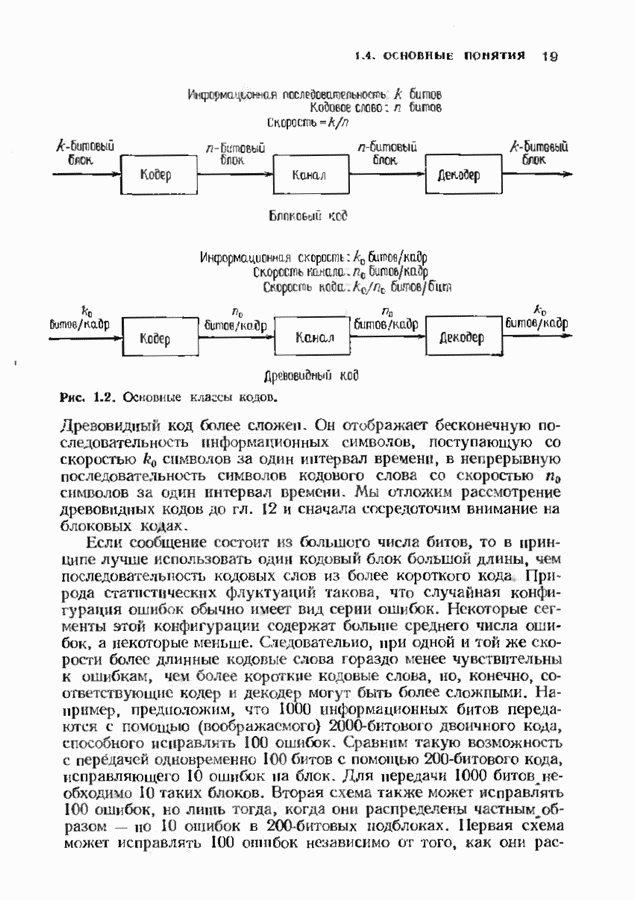
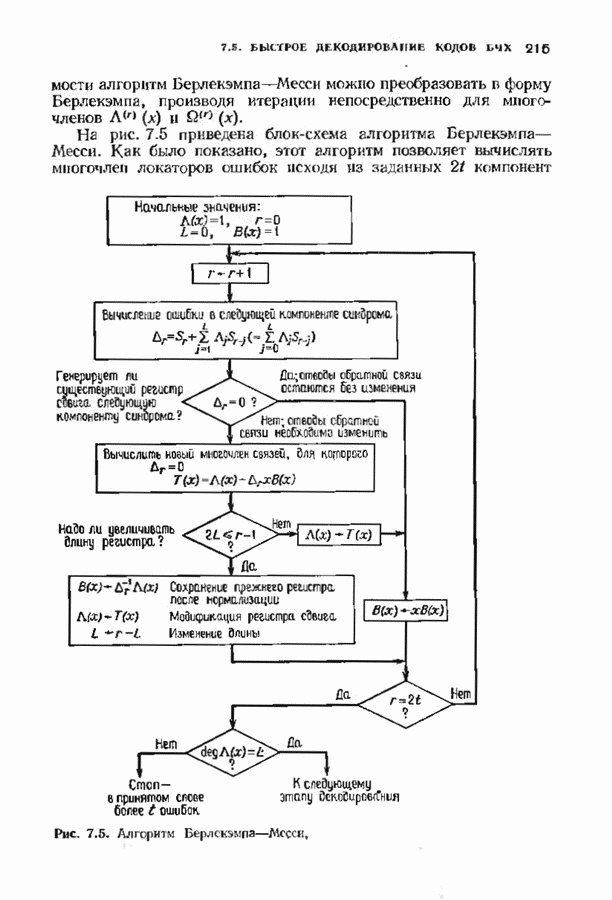
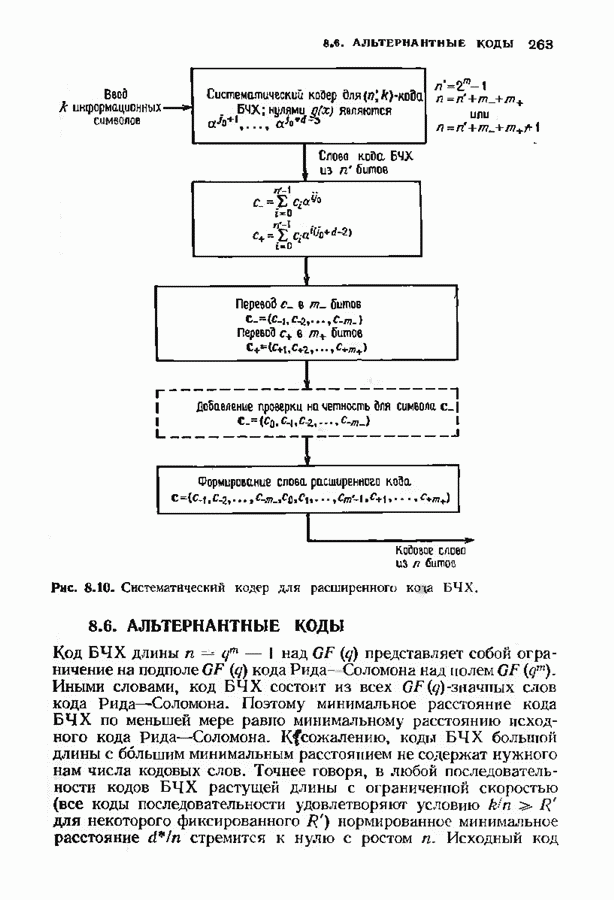
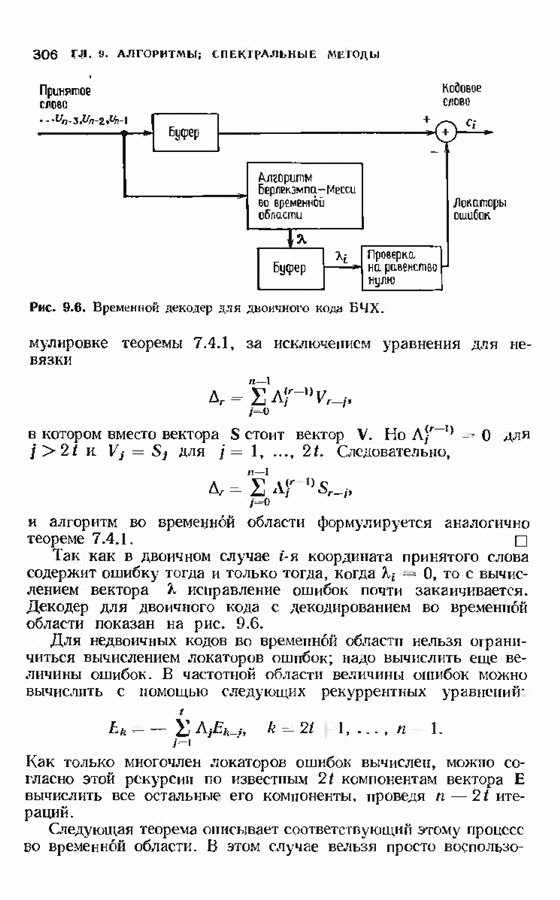
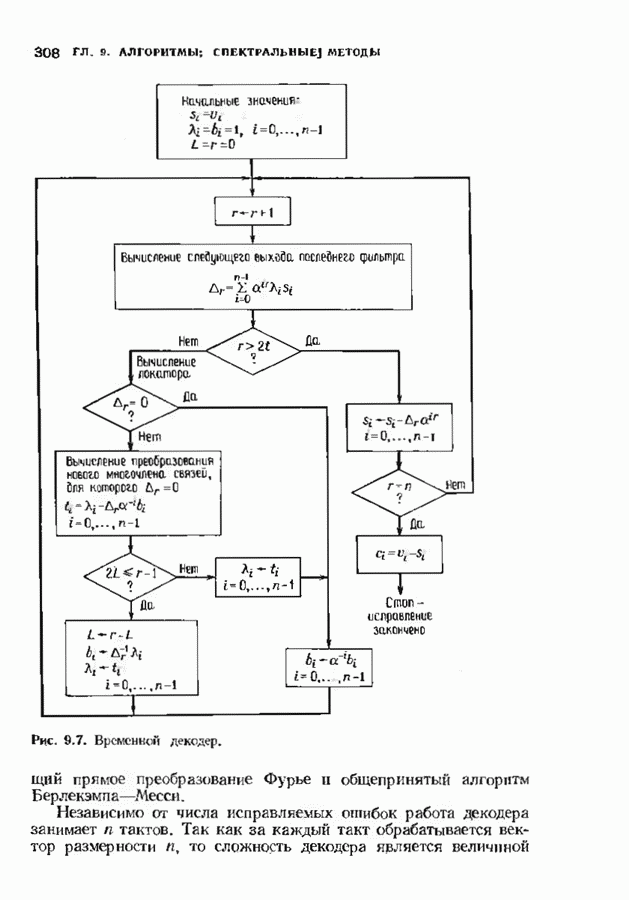
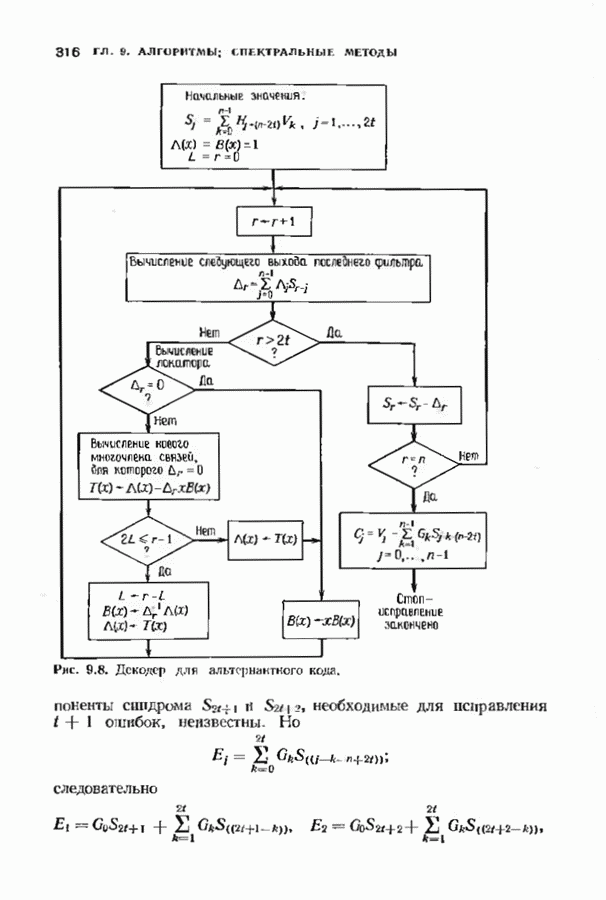
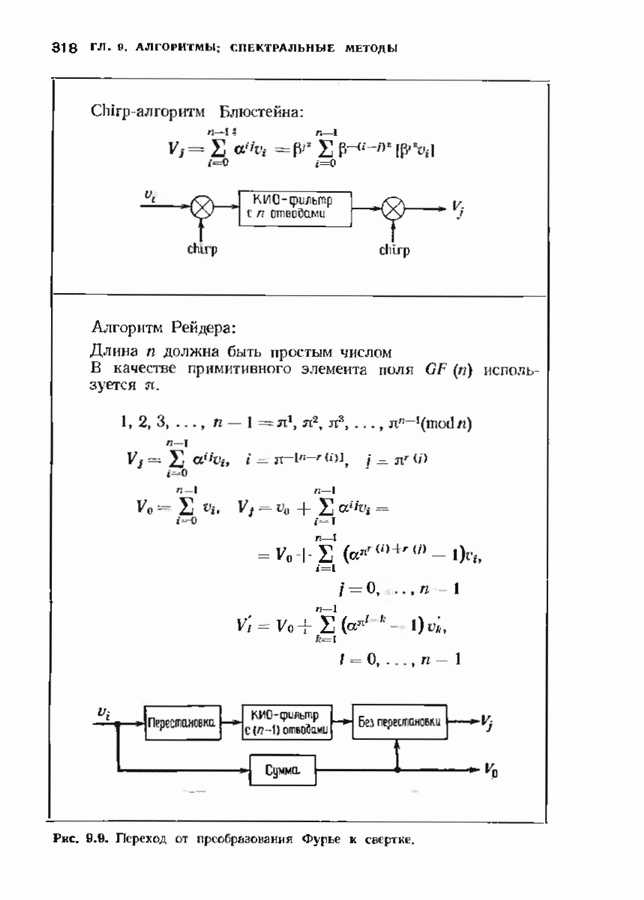
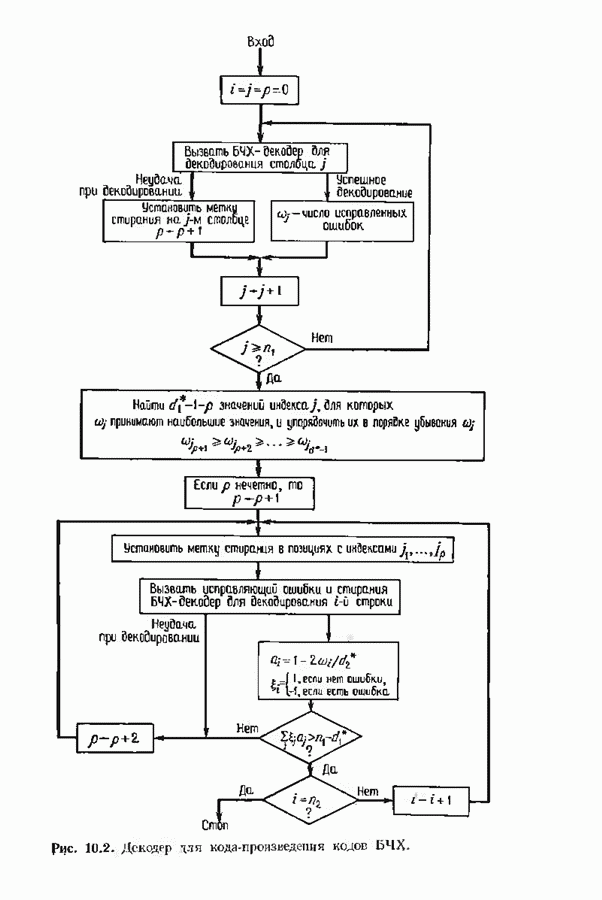
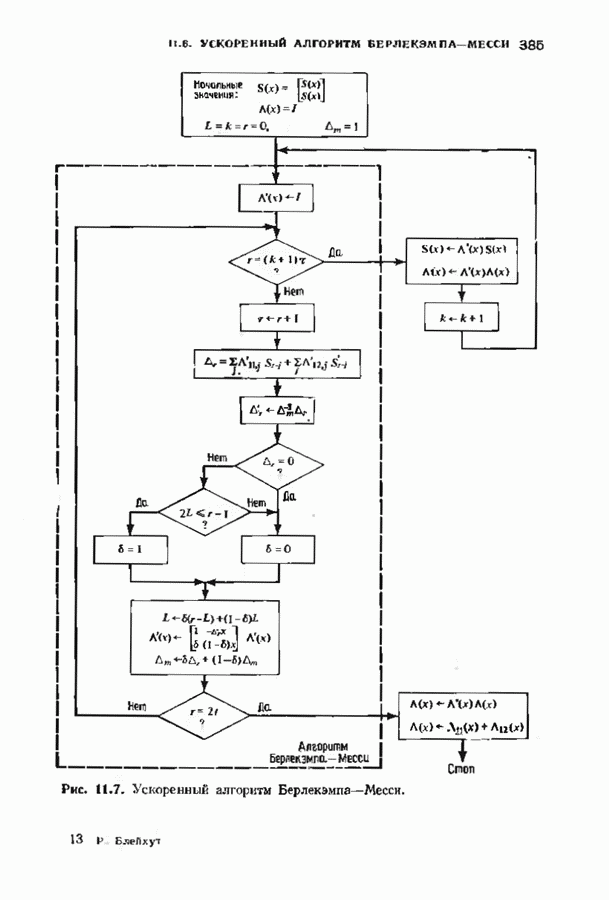
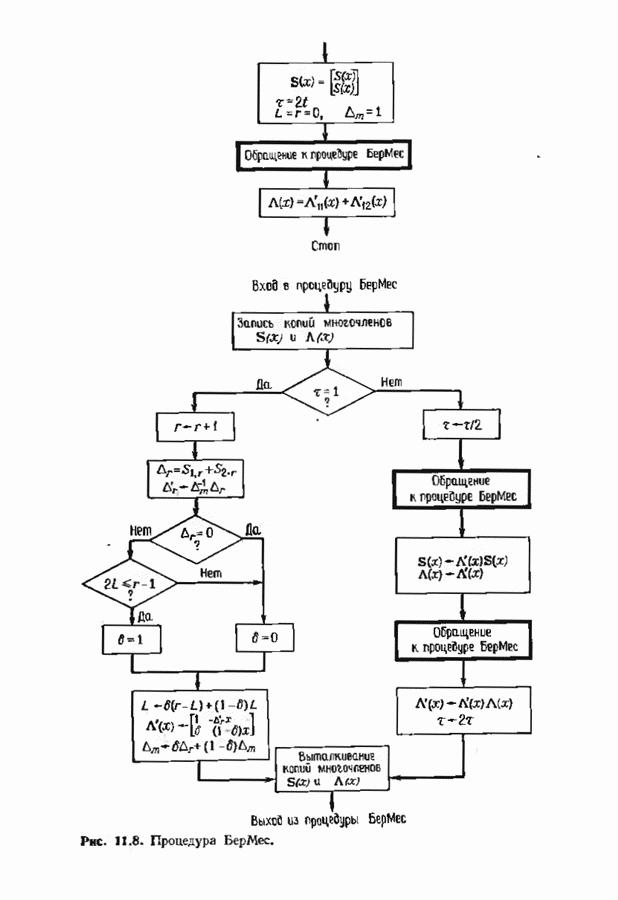
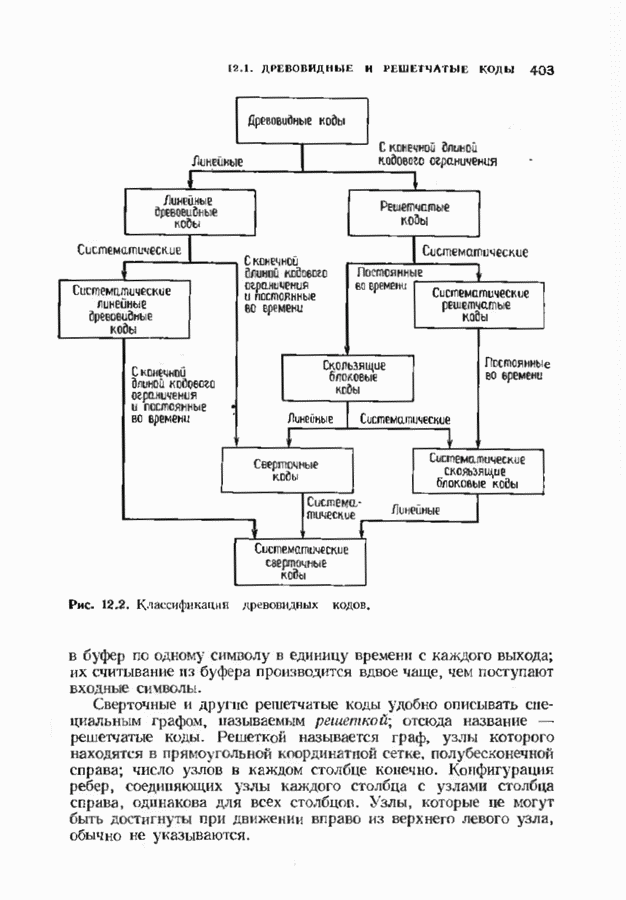
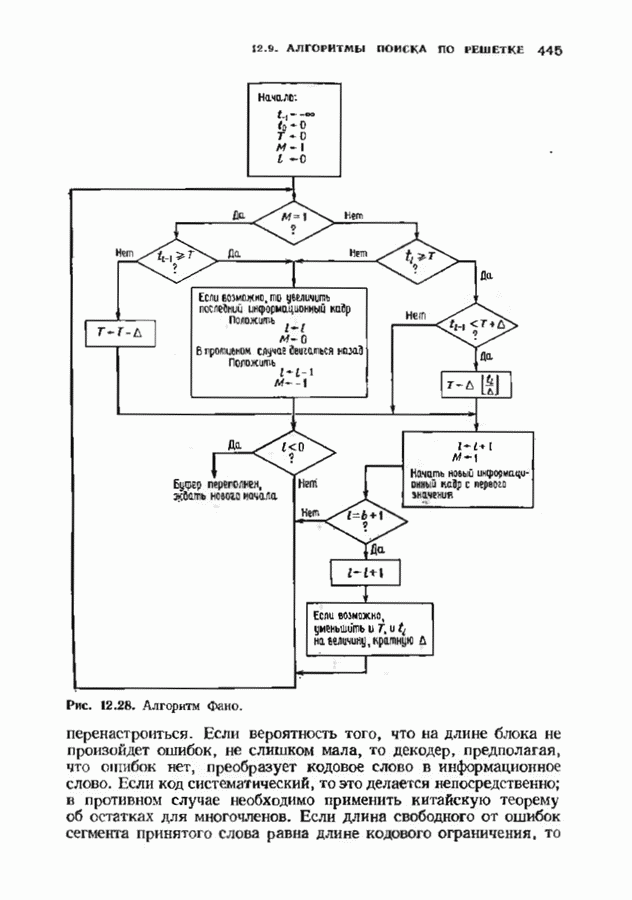
12.6. АЛГОРИТМЫ СИНДРОМНОГО ДЕКОДИРОВАНИЯПредположим, что принята бесконечная последовательность
Точно так же, как и в случае блоковых кодов, можно вычислить синдром:
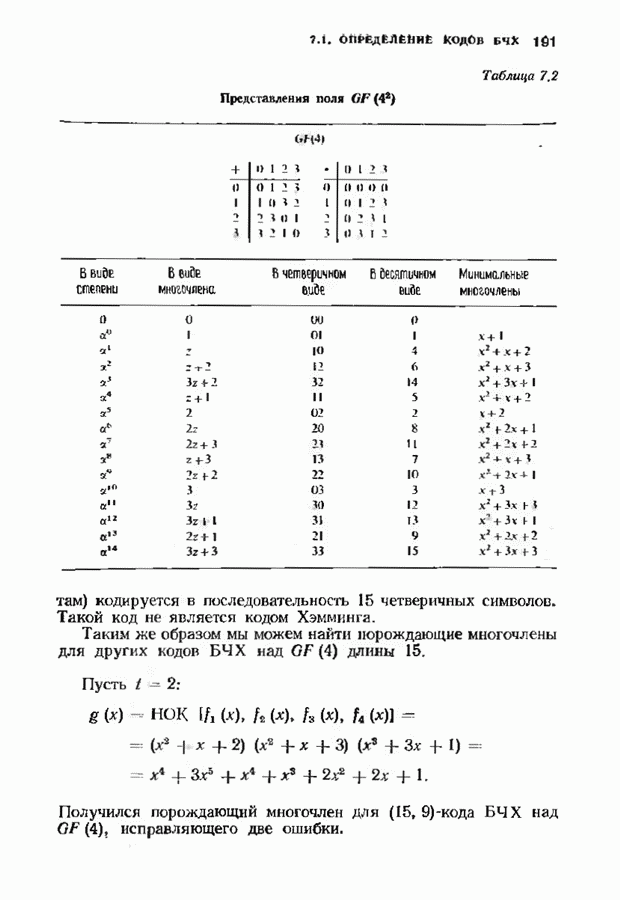
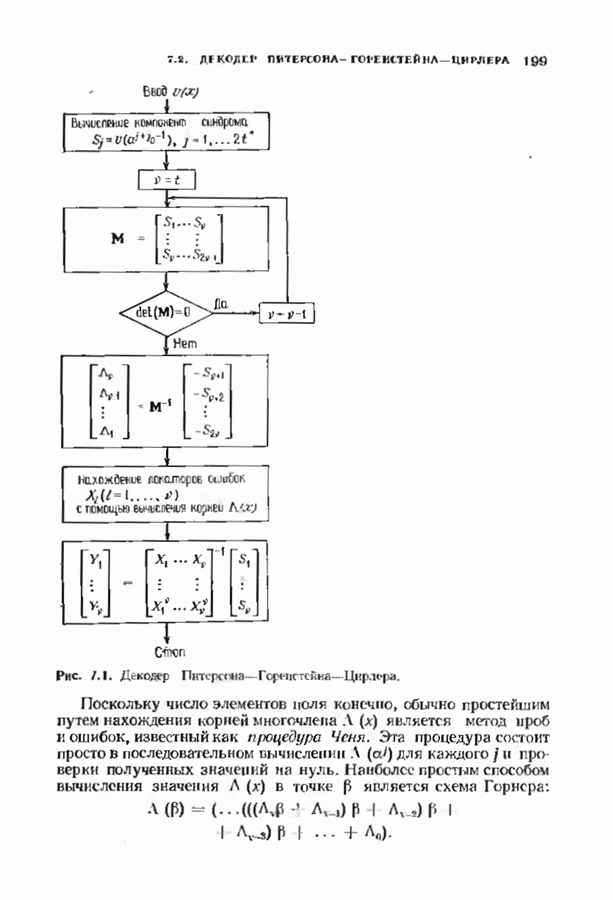
однако в этом случае синдром имеет бесконечную длину. Декодер не просматривает весь синдром однократно. Он работает с конца, вычисляя компоненты Приведем примеры различных синдромных декодеров. Начнем с декодера для Элементы, изображенные на рис. 12.14 штриховыми линиями, могут быть включены в декодер для восстановления кодовых слов, содержащих проверочные биты. Если такой необходимости нет, то эти элементы могут быть исключеиы. Необходимо рассмотреть еще одну задачу. После исправления первого кадра нужно изменить синдром таким образом, чтобы он не вызывал ошибочного исправления в следующем кадре. Это можно сделать несколькими способами, и хотя все они пригодны для данного кода, в случае более мощного кода они ведут себя совершенно по-разному. Возможны два варианта: 1) после каждого испрааления ошибки устанавливается нулевое состояние регистра синдрома;
Рис. 12.14. Декодер для
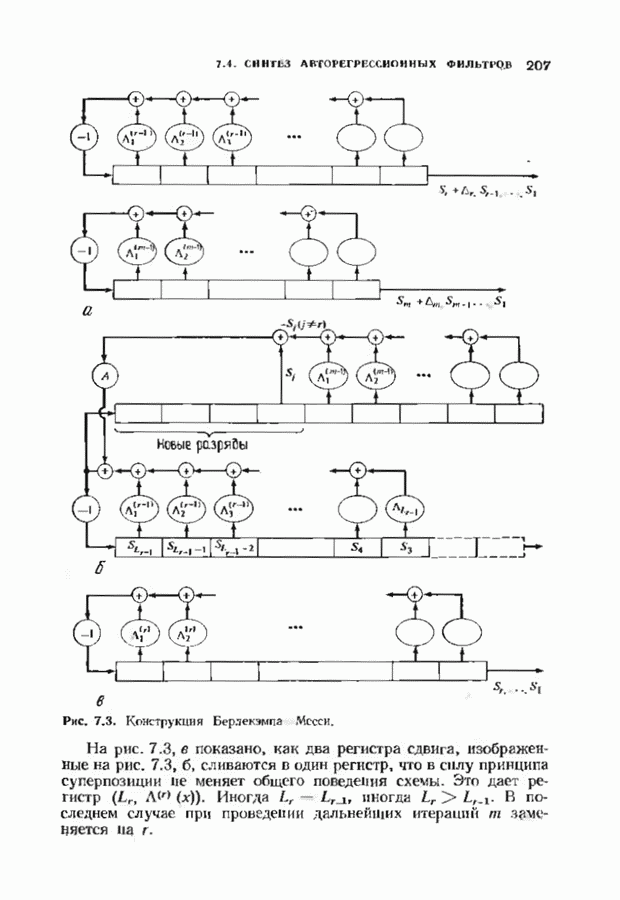
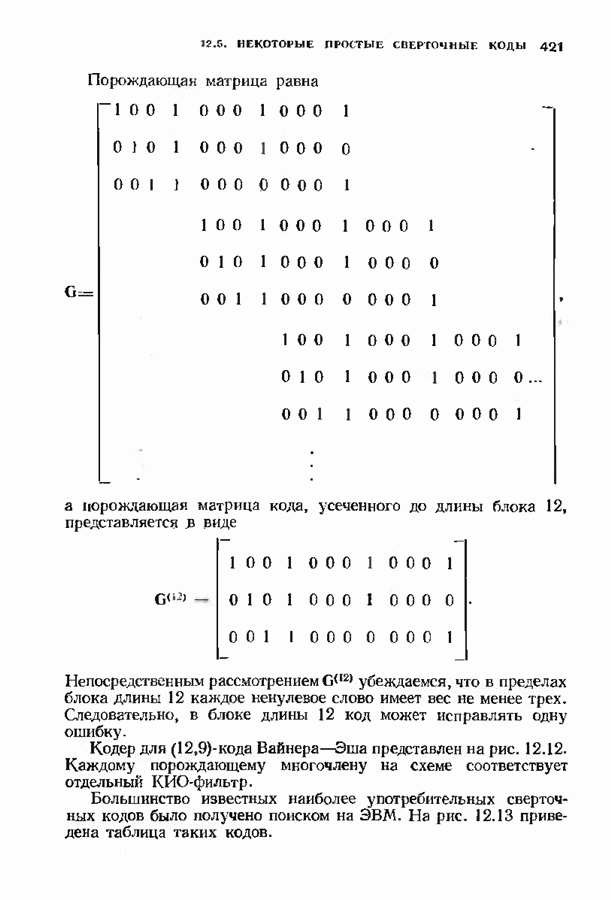
Рис. 12.15. Таблица декодирования для 2) из регистра синдрома вычитается корректирующий синдром. Первый вариант характерен для кодов, исправляющих одну ошибку. Изучим второй вариант на более сложном примере. На рис. 12.3 был представлен кодер для
Рис. 12.16. Декодер для сверточного
Рис. 12.17. Таблица декодирования для сверточного
(кликните для просмотра скана)
Рис. 12.20. Другой декодер для сверточного кодовому слову. Для восстановления информации используется следующее соотношение:
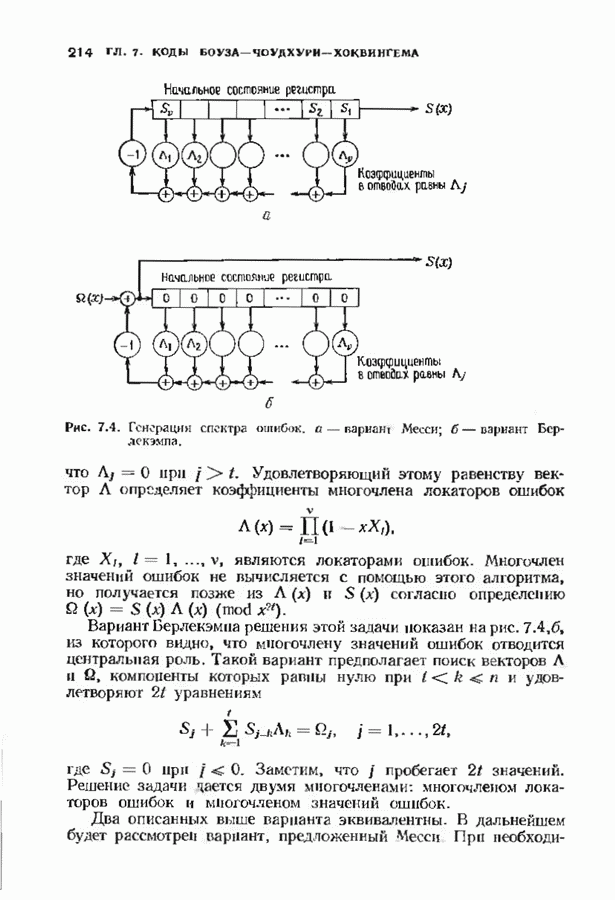
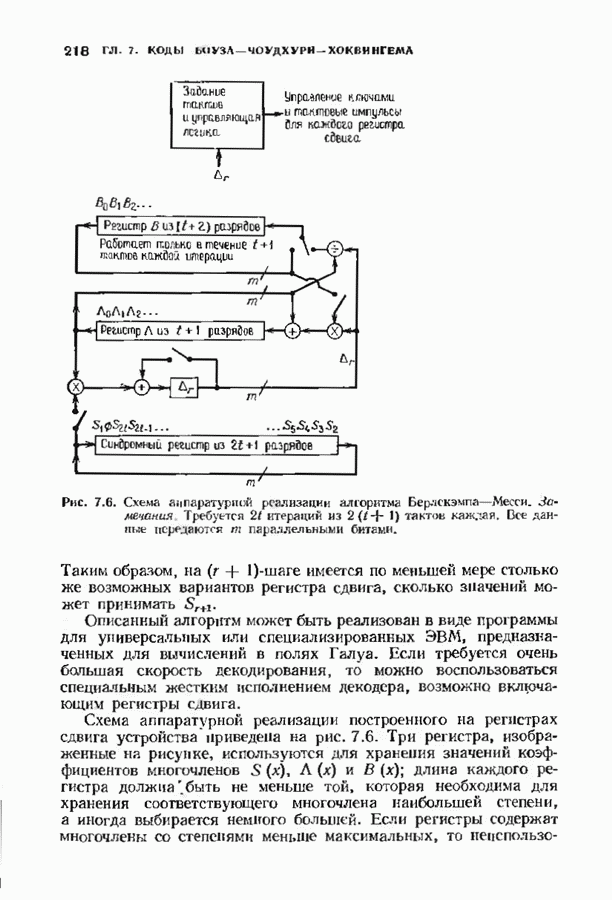
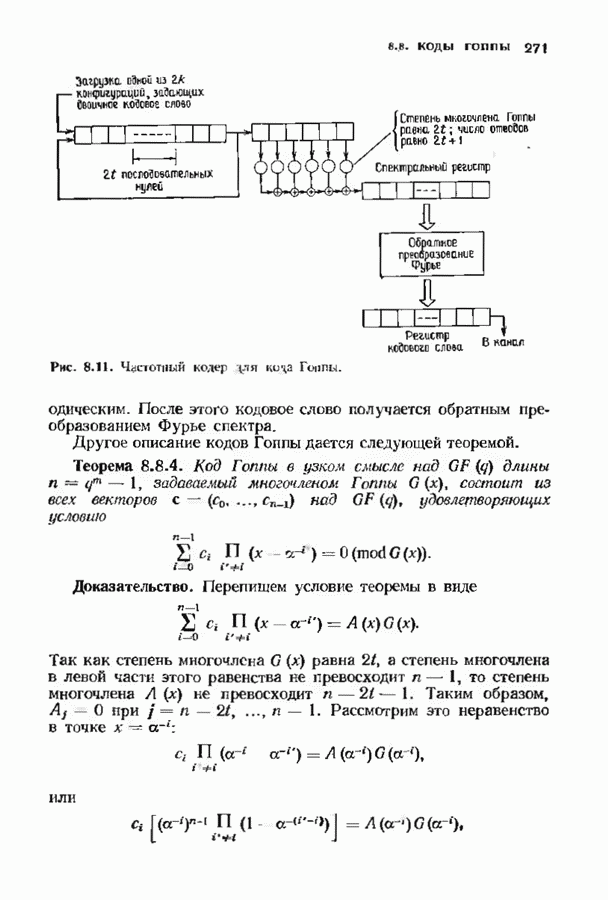
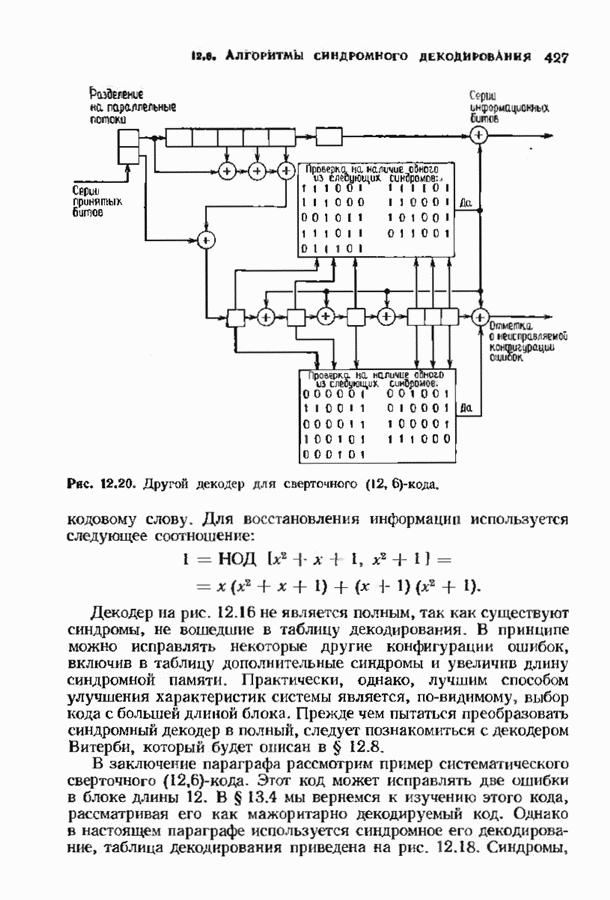
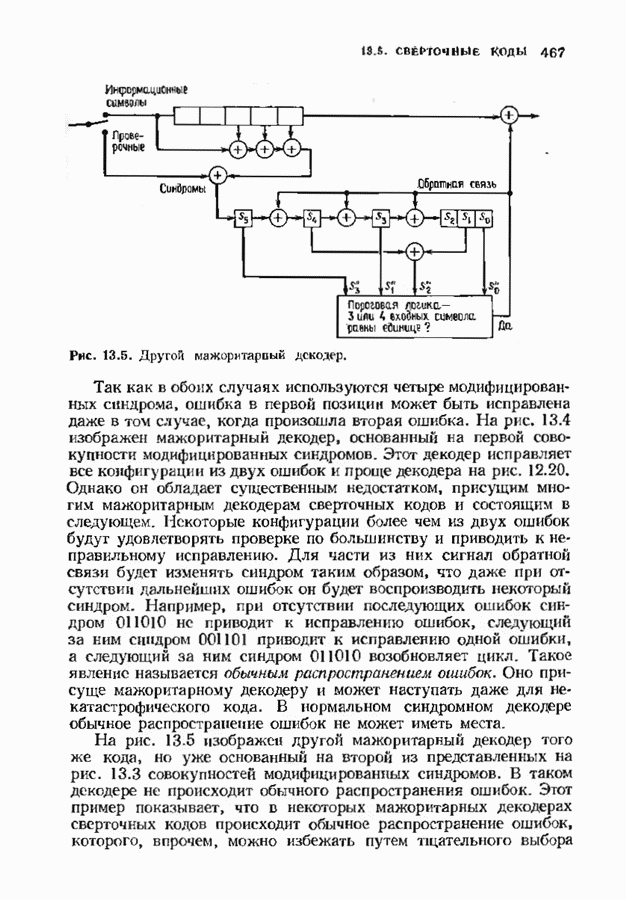
Декодер на рис. 12.16 не является полным, так как существуют синдромы, не вошедшие в таблицу декодирования. В принципе можно исправлять некоторые другие конфигурации ошибок, включив в таблицу дополнительные синдромы и увеличив длину синдромной памяти. Практически, однако, лучшим способом улучшения характеристик системы является, по-видимому, выбор кода с большей длиной блока. Прежде чем пытаться преобразовать синдромный декодер в полный, следует познакомиться с декодером Витерби, который будет описан в § 12.8. В заключение параграфа рассмотрим пример систематического сверточного расположенные выше пробела, соответствуют конфигурациям ошибок, содержащим, ошибку в правом информационном бите, а синдромы, расположенные ниже пробела, соответствуют конфигурациям ошибок, содержащим ошибку в правом проверочном бите, но не содержащем ошибок в правом информационном бите. Декодер, представленный на рис. 12.19, проверяет лишь синдромы, расположенные выше пробела, и поэтому позволяет исправлять информационные биты лишь при условии, что конфигурация ошибок лежит в пределах конструктивных возможностей декодера. Однако такой декодер не находит неисправляемых, но обнаруживаемых конфигураций ошибок. Чтобы найти такие конфигурации, в конструкции декодера надо предусмотреть проверку синдромов, расположенных ниже пробела. Такой декодер, обеспечивающий обнаружение ошибок, представлен на рис. 12.20.
|
 |
Оглавление
|





















































































































































































































































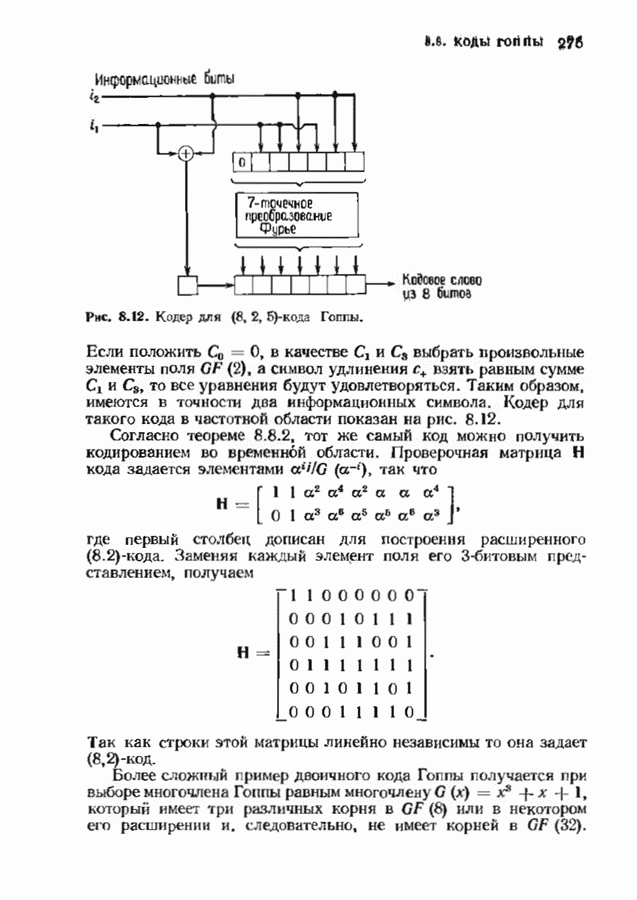












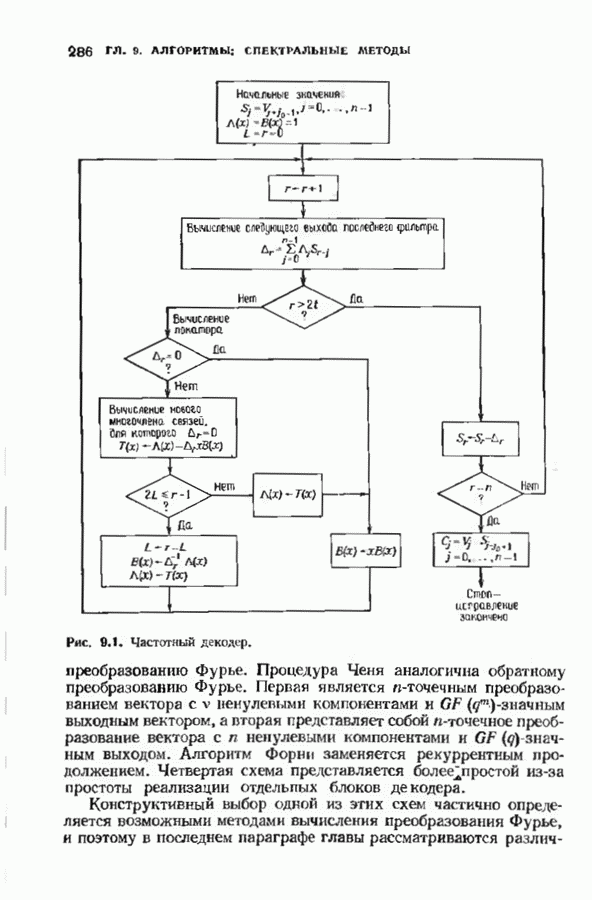
























































































































































































































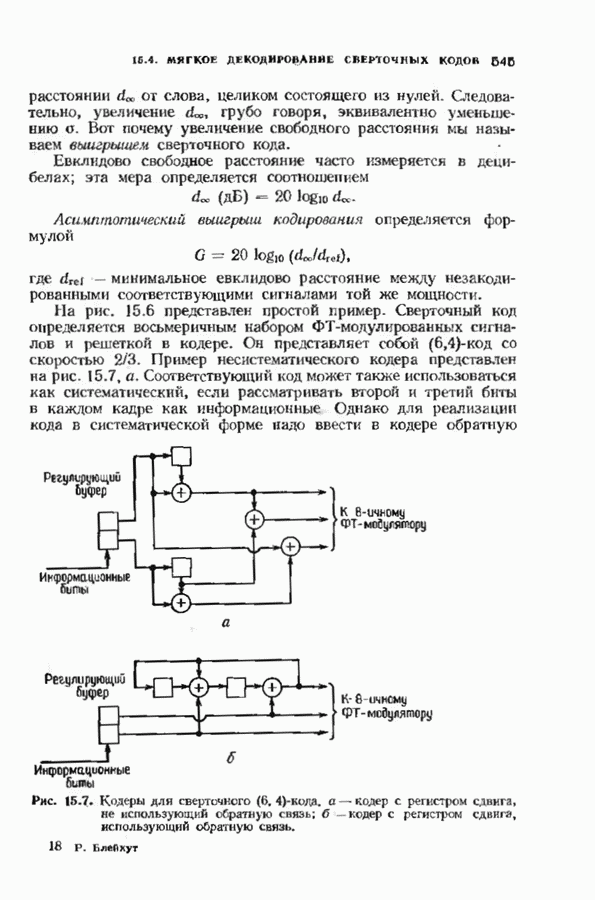
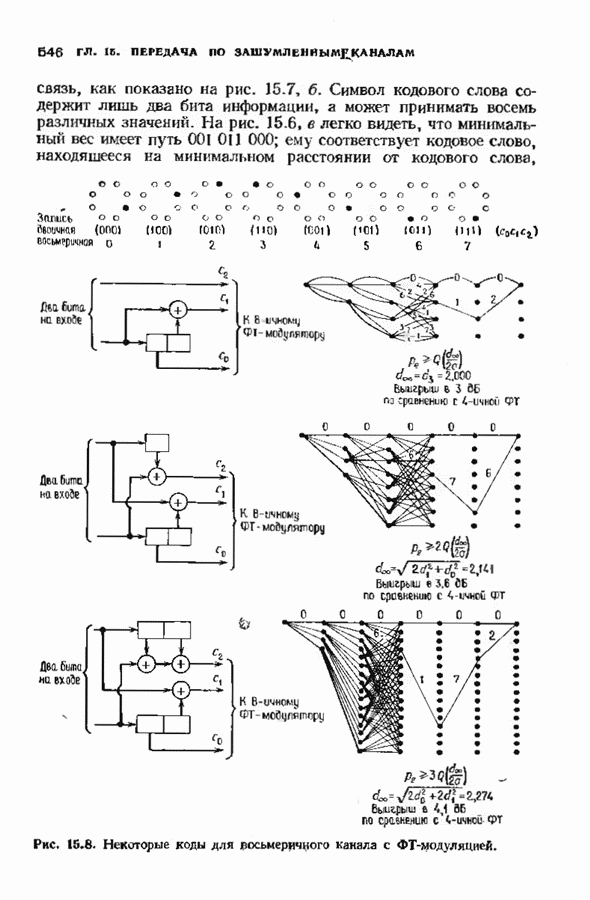


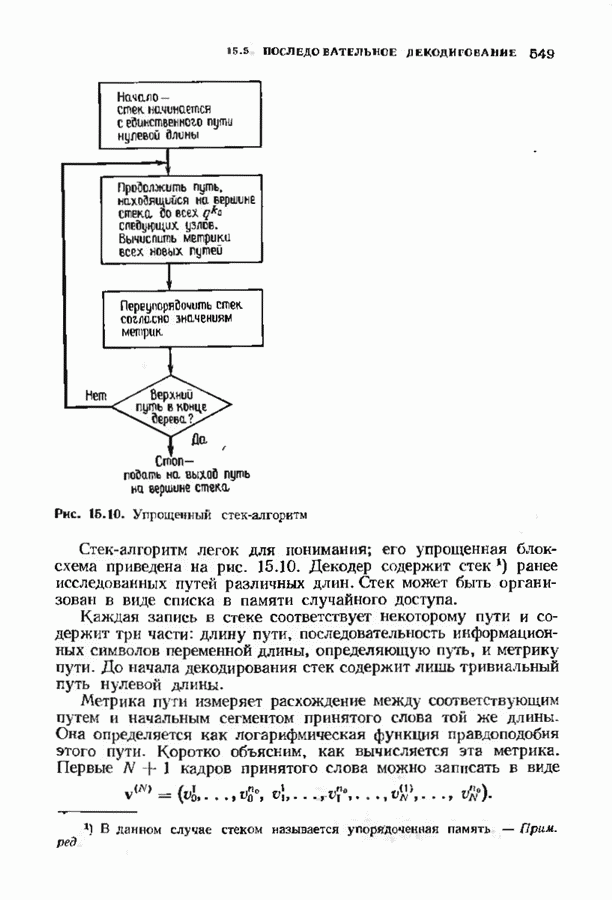














 состоящая из слова сверточного кода и шума:
состоящая из слова сверточного кода и шума:


 по мере их поступления, исправляя ошибки, и сбрасывая те компоненты 8, которые вычислены давно. Декодер содержит таблицу сегментов синдромов и сегментов конфигураций шума, которые приводят к данным
по мере их поступления, исправляя ошибки, и сбрасывая те компоненты 8, которые вычислены давно. Декодер содержит таблицу сегментов синдромов и сегментов конфигураций шума, которые приводят к данным  ментам синдрома. Когда декодер находит в таблице полученный сегмент синдрома, он исправляет начальный сегмент кодовою слова.
ментам синдрома. Когда декодер находит в таблице полученный сегмент синдрома, он исправляет начальный сегмент кодовою слова.
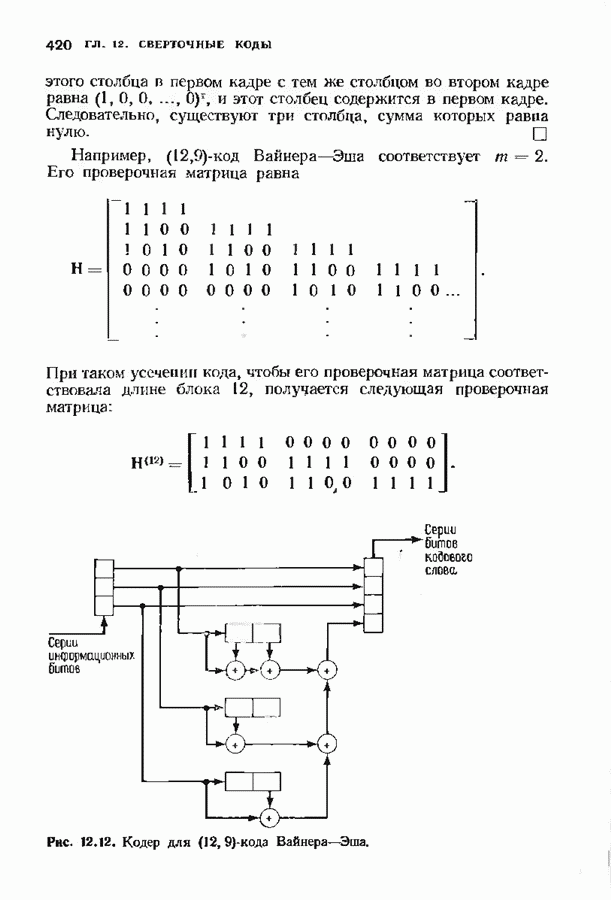
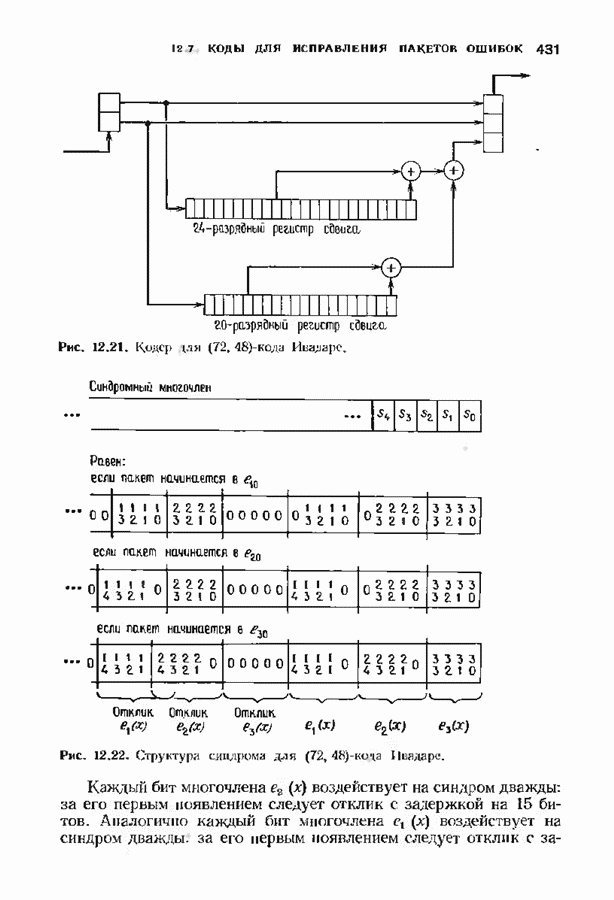
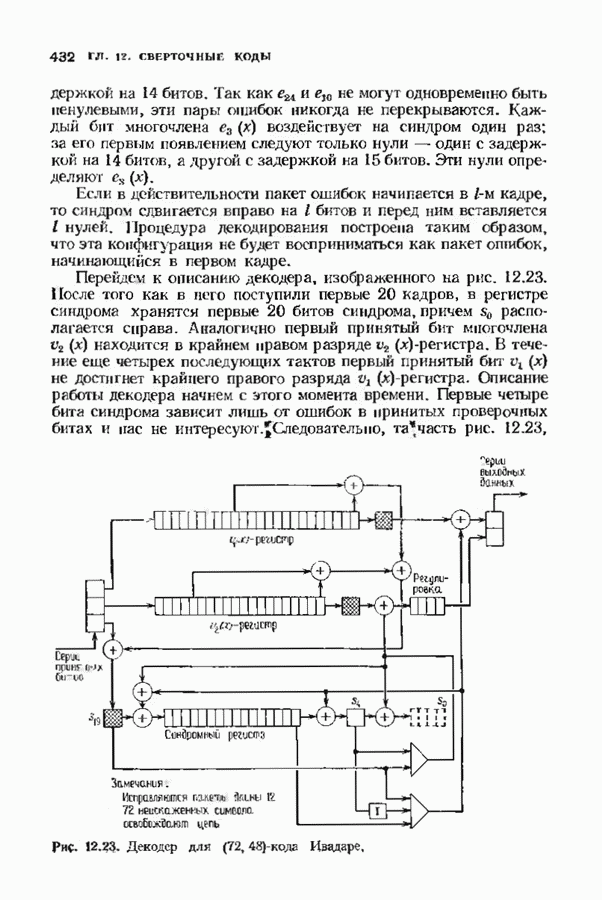
 -кода Вайнера-Эша. Он показан на рис. 12.14. Входящий поток битов поступает на
-кода Вайнера-Эша. Он показан на рис. 12.14. Входящий поток битов поступает на  параллельных линий; синдром вычисляется путем нахождения проверочного бита по принятым информационным битам и его сравнения с принятым проверочным битом. Необходимо вычислить лишь столько синдромных битов, сколько их требуется для исправления одиночной ошибки в первом кадре. Возможные конфигурации одиночных ошибок в первых трех кадрах и соответствующие первые три бита синдрома приведены в виде таблицы на рис. 12.15. Заметим, что правый бит равен единице тогда и только тогда, когда в первом кадре имеется ошибка. В этом случае два других бита синдрома точно определяют местонахождение ошибки в первом кадре.
параллельных линий; синдром вычисляется путем нахождения проверочного бита по принятым информационным битам и его сравнения с принятым проверочным битом. Необходимо вычислить лишь столько синдромных битов, сколько их требуется для исправления одиночной ошибки в первом кадре. Возможные конфигурации одиночных ошибок в первых трех кадрах и соответствующие первые три бита синдрома приведены в виде таблицы на рис. 12.15. Заметим, что правый бит равен единице тогда и только тогда, когда в первом кадре имеется ошибка. В этом случае два других бита синдрома точно определяют местонахождение ошибки в первом кадре.

 -кода Вайнера-Эша
-кода Вайнера-Эша

 -кода Вайкера-Эша.
-кода Вайкера-Эша.
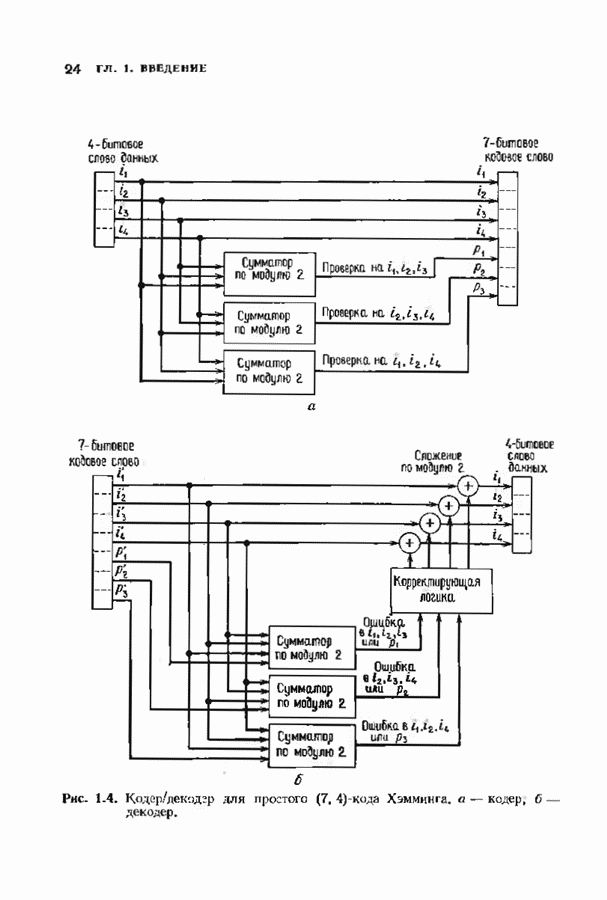
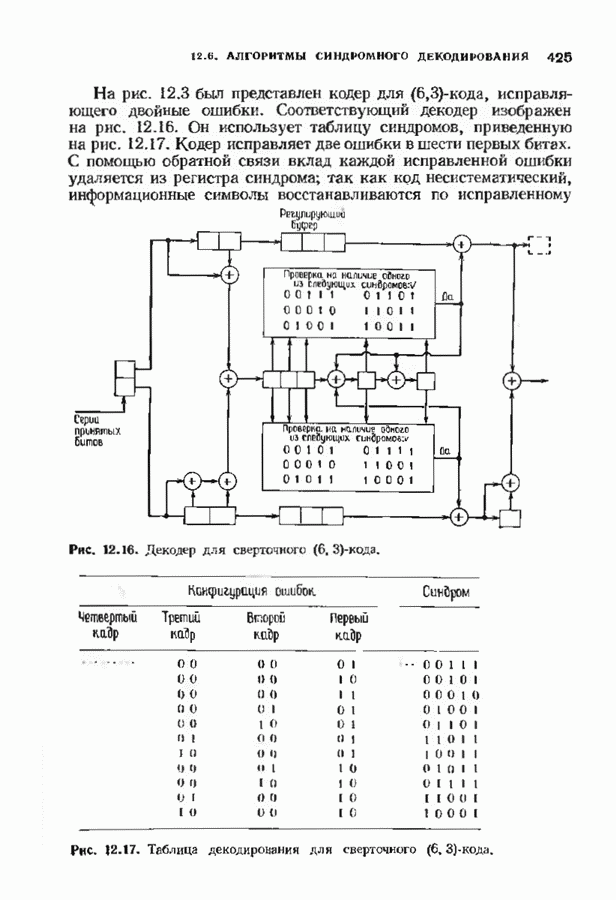
 -кода, исправляющего двойные ошибки. Соответствующий декодер изображен на рис. 12.16. Он использует таблицу синдромов, приведенную на рис. 12.17. Кодер исправляет две ошибки в шести первых битах. С помощью обратной связи вклад каждой исправленной ошибки удаляется из регистра синдрома; так как код несистематический, информационные символы восстанавливаются по исправленному
-кода, исправляющего двойные ошибки. Соответствующий декодер изображен на рис. 12.16. Он использует таблицу синдромов, приведенную на рис. 12.17. Кодер исправляет две ошибки в шести первых битах. С помощью обратной связи вклад каждой исправленной ошибки удаляется из регистра синдрома; так как код несистематический, информационные символы восстанавливаются по исправленному

 -кода.
-кода.

 -кода.
-кода.


 -кода.
-кода.

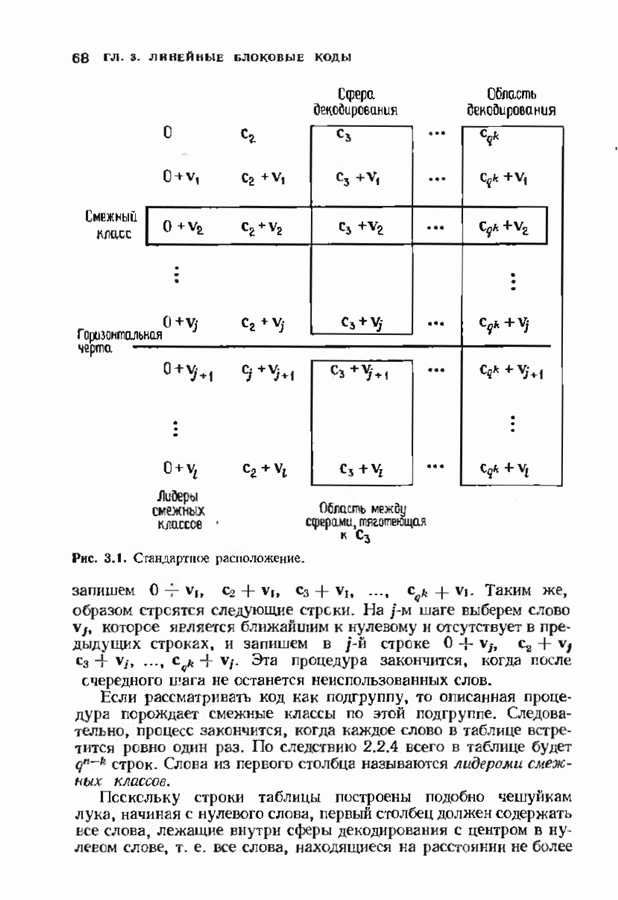
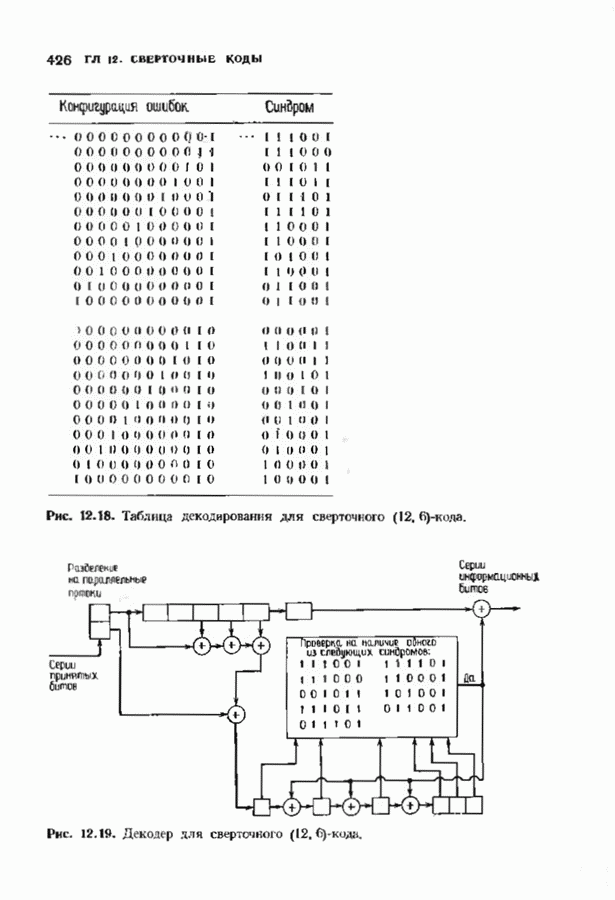
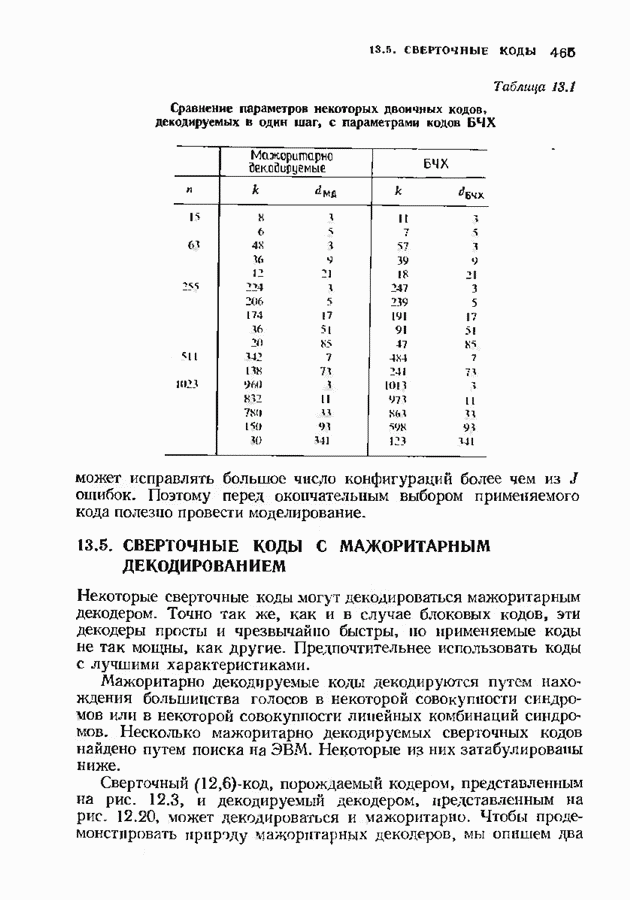
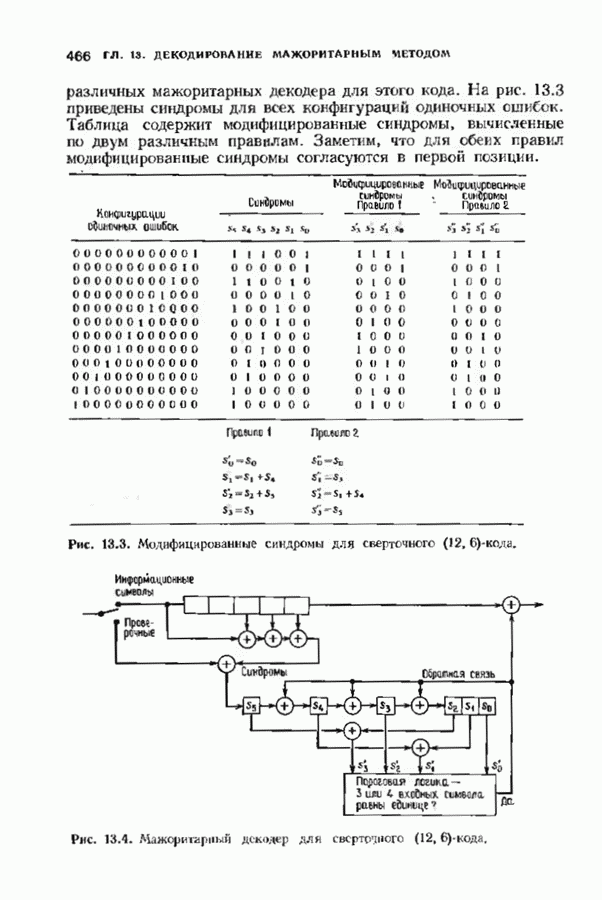
 -кода. Этот код может исправлять две ошибки в блоке длины 12. В § 13.4 мы вернемся к изучению этого кода, рассматривая его как мажоритарно декодируемый код. Однако в настоящем параграфе используется сивдромное его декодирование, таблица декодирования приведена на рис. 12.18. Синдромы,
-кода. Этот код может исправлять две ошибки в блоке длины 12. В § 13.4 мы вернемся к изучению этого кода, рассматривая его как мажоритарно декодируемый код. Однако в настоящем параграфе используется сивдромное его декодирование, таблица декодирования приведена на рис. 12.18. Синдромы,