Пред.
След.
Макеты страниц
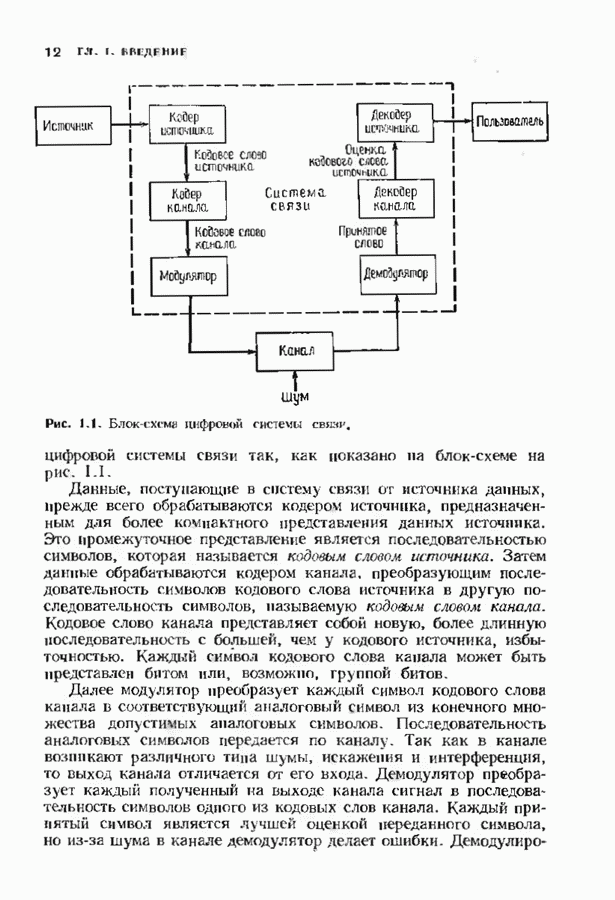
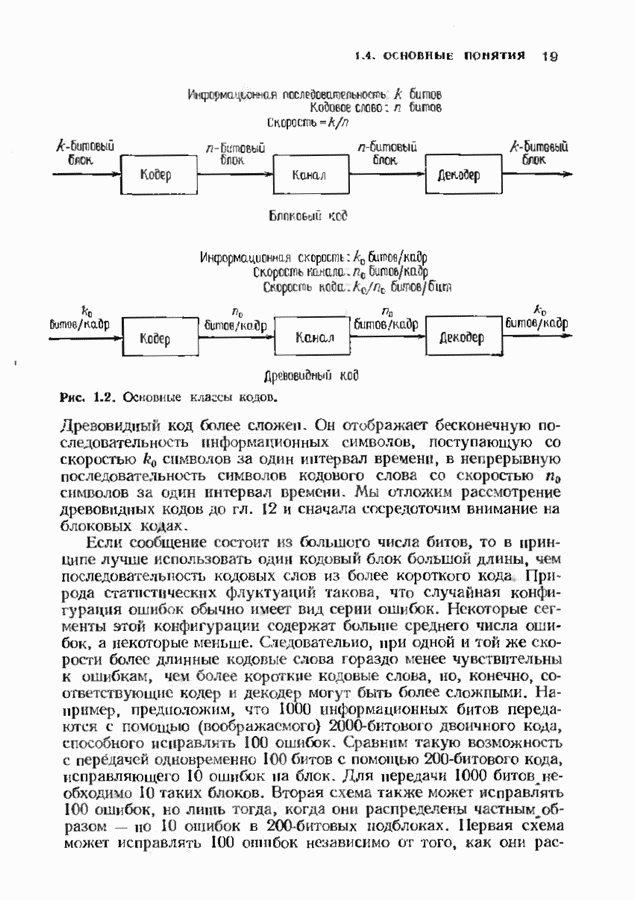
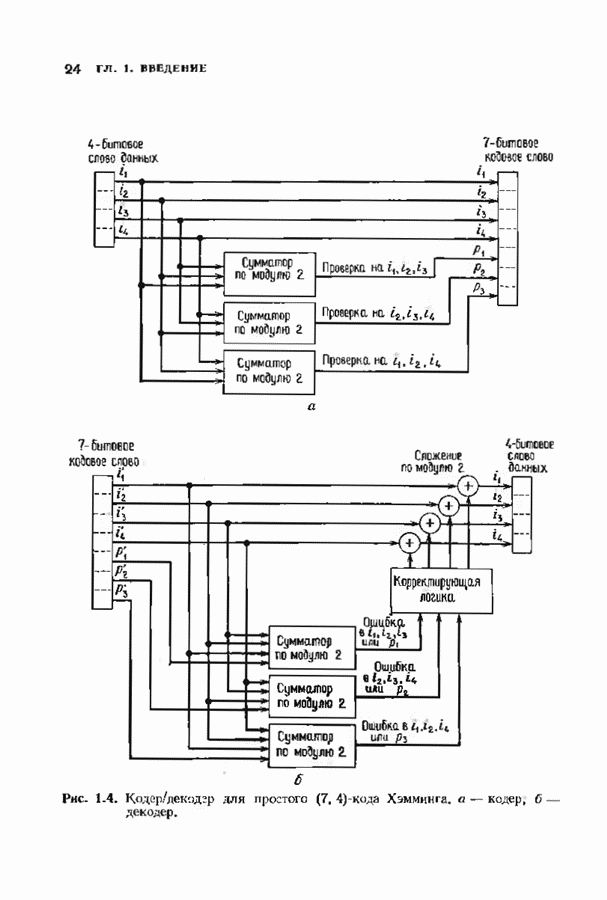
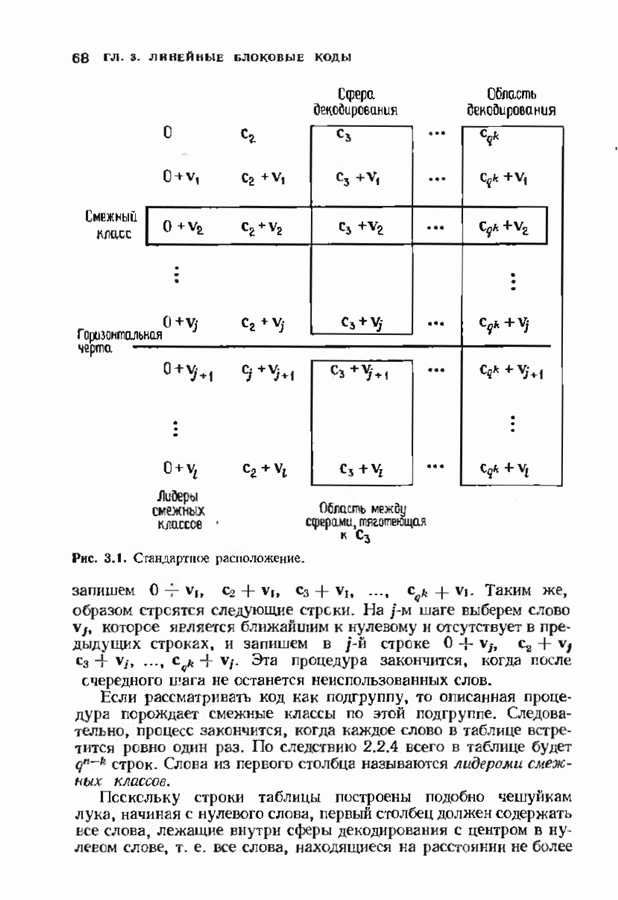
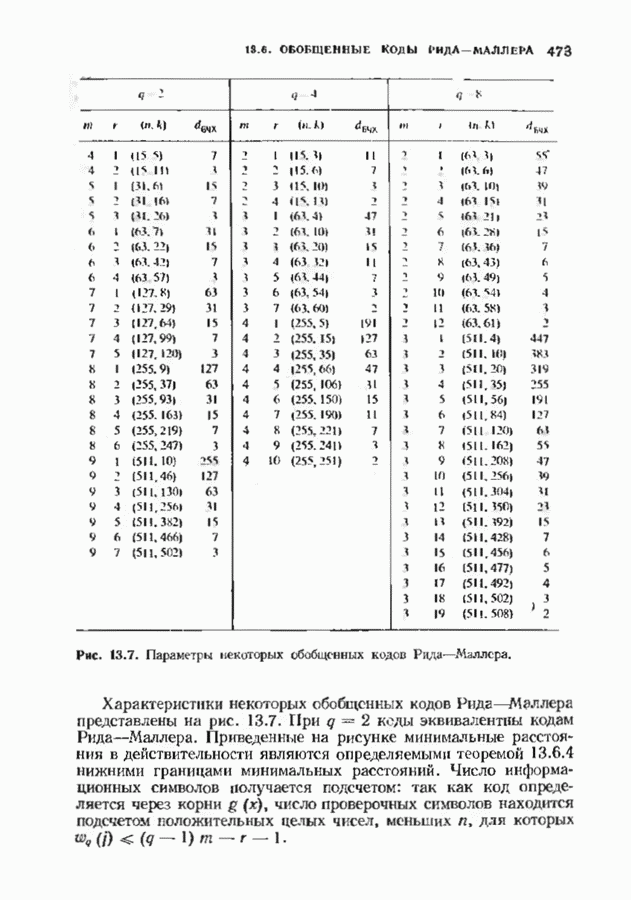
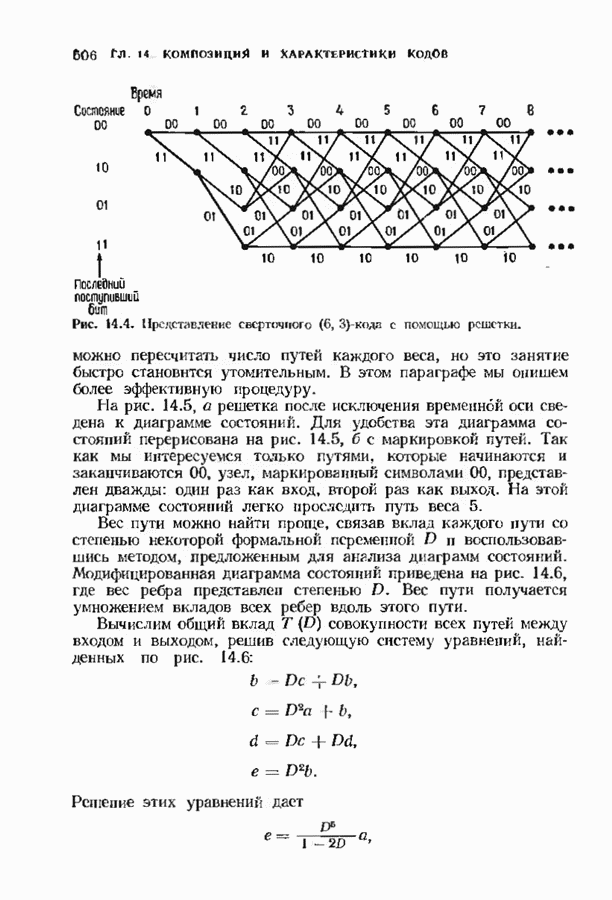
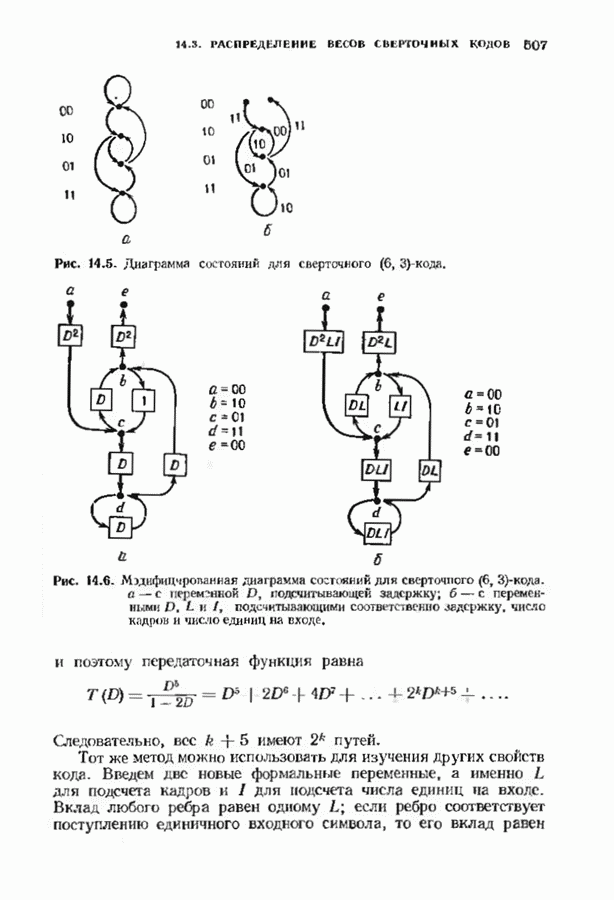
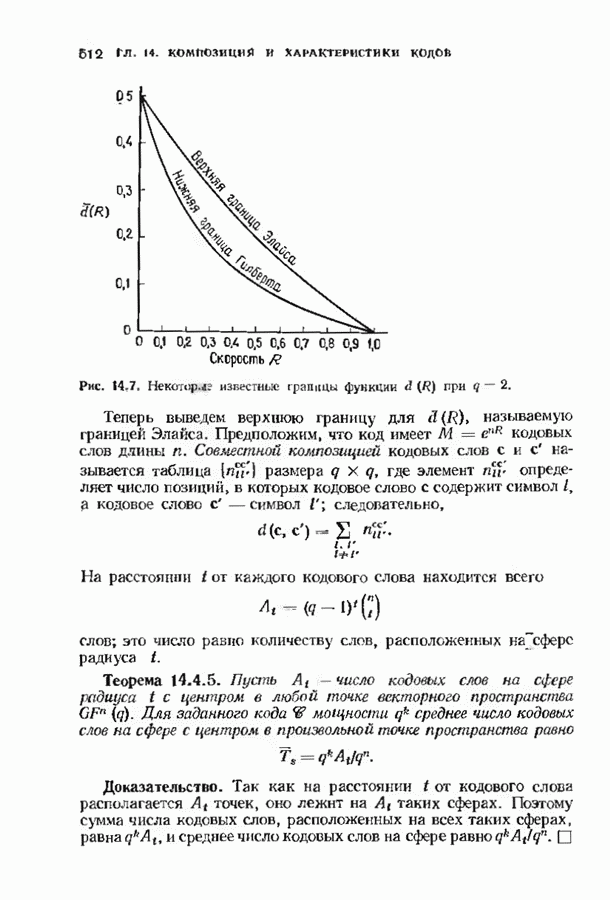
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
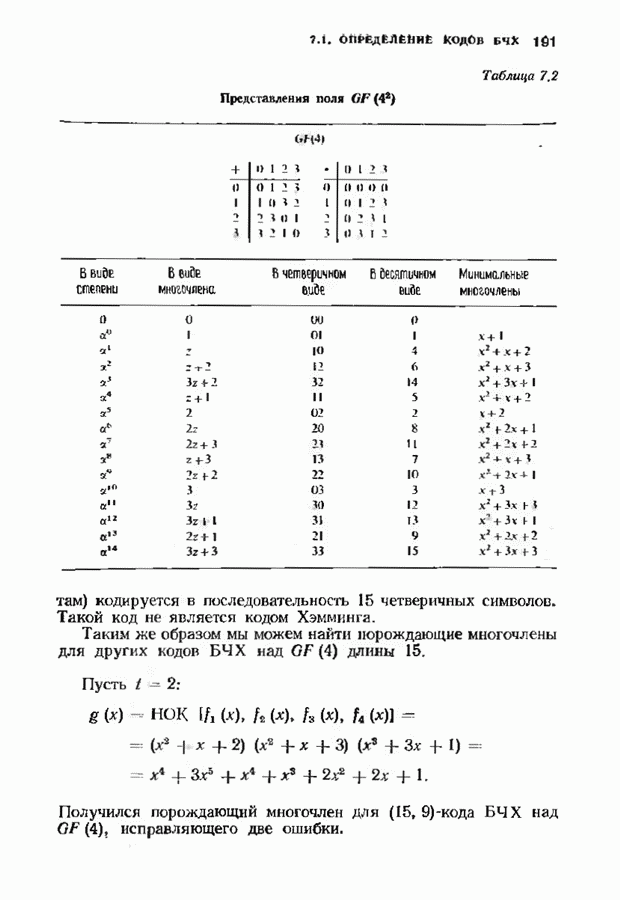
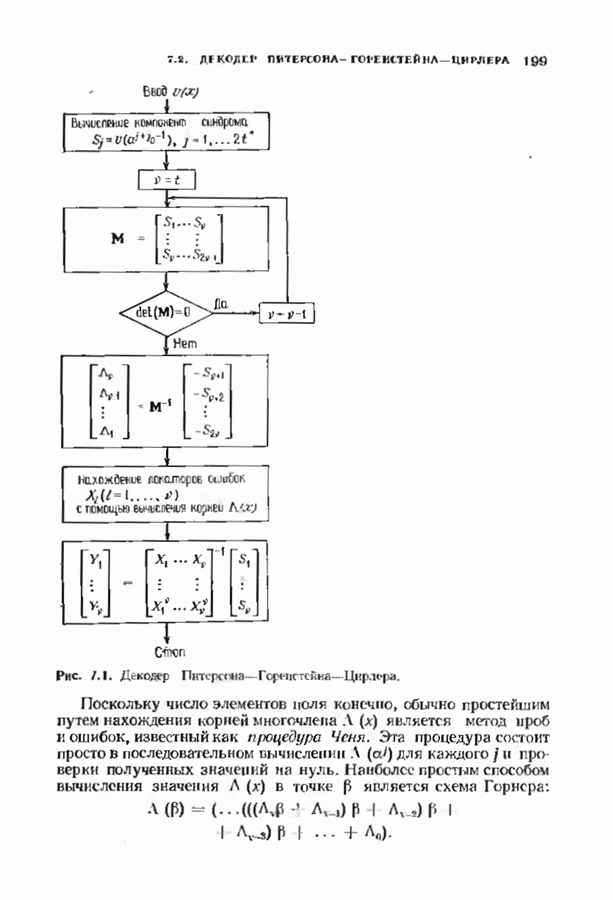
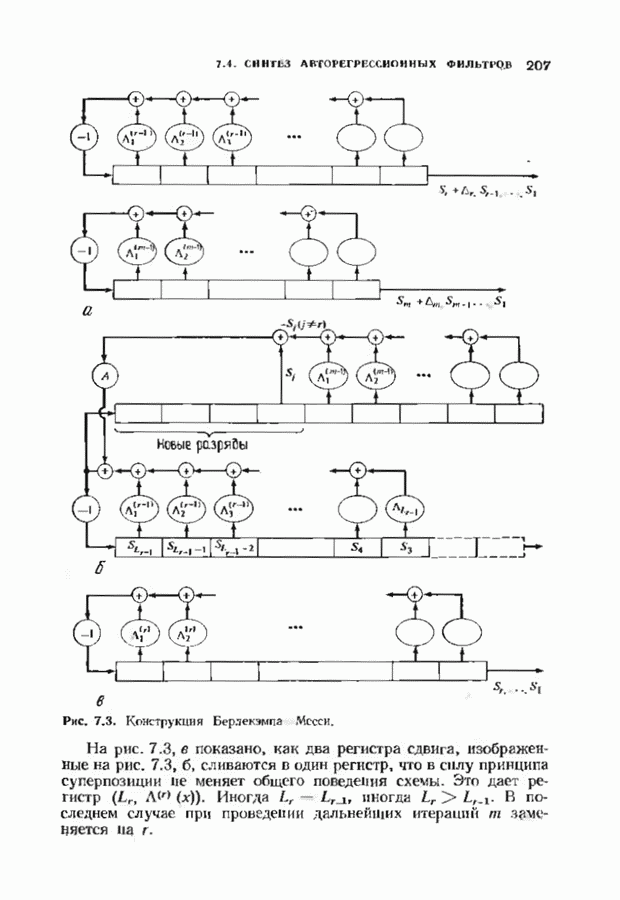
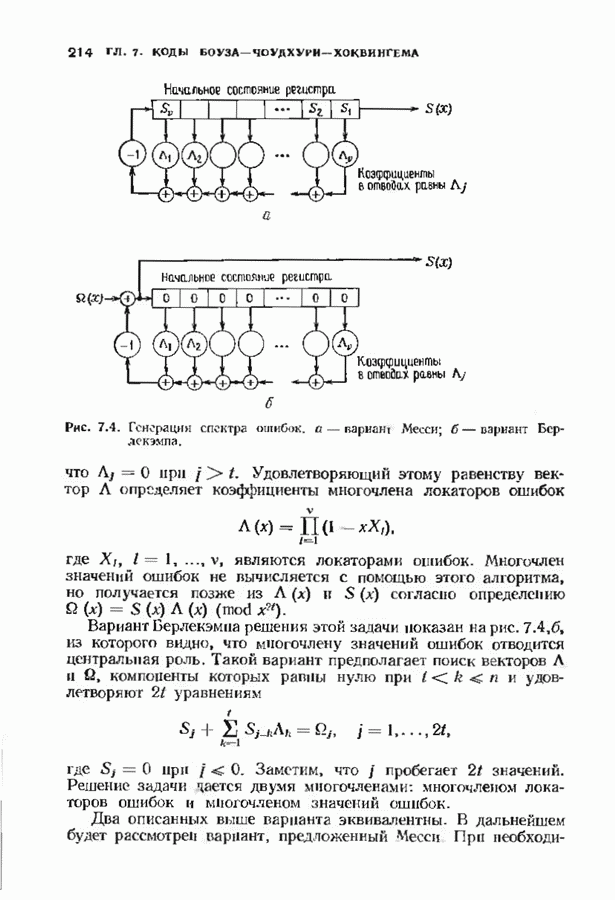
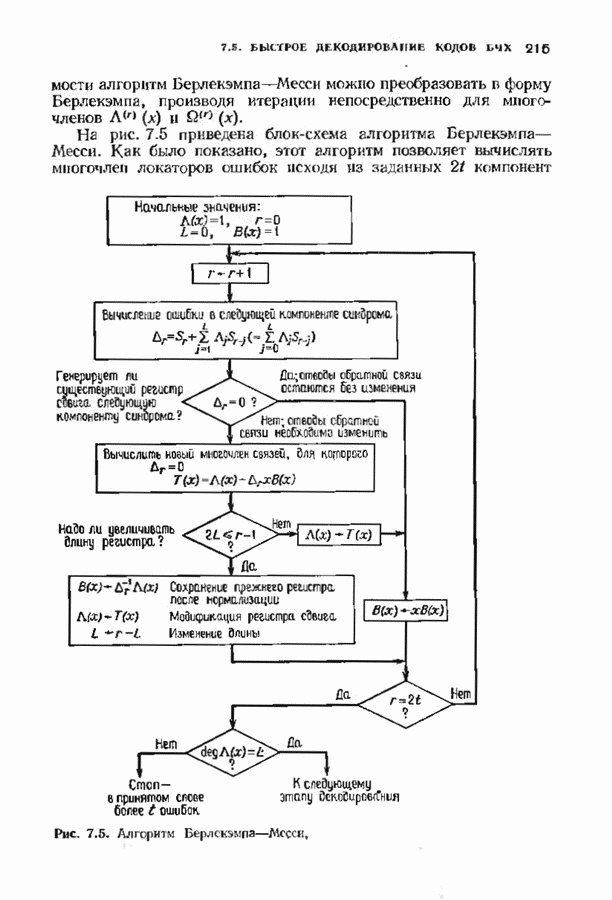
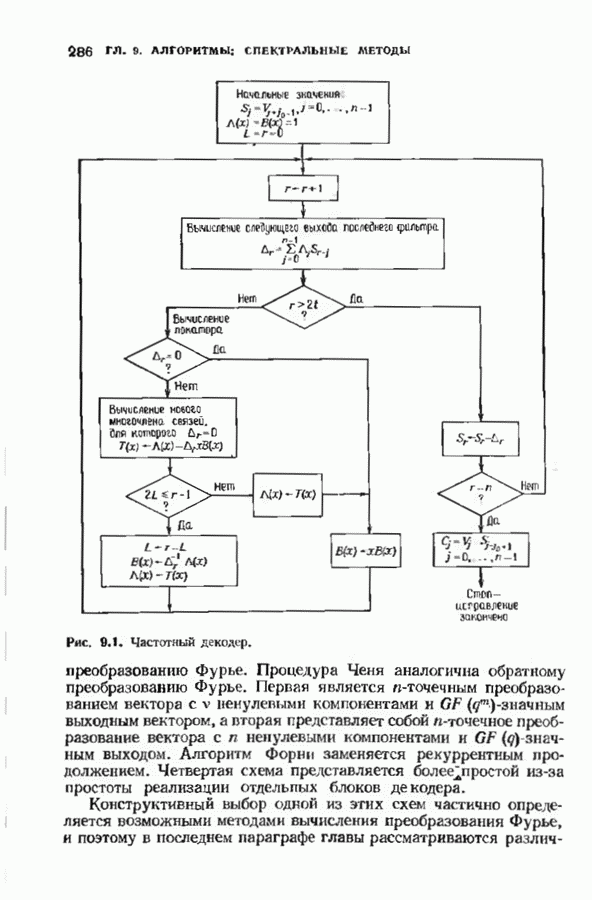
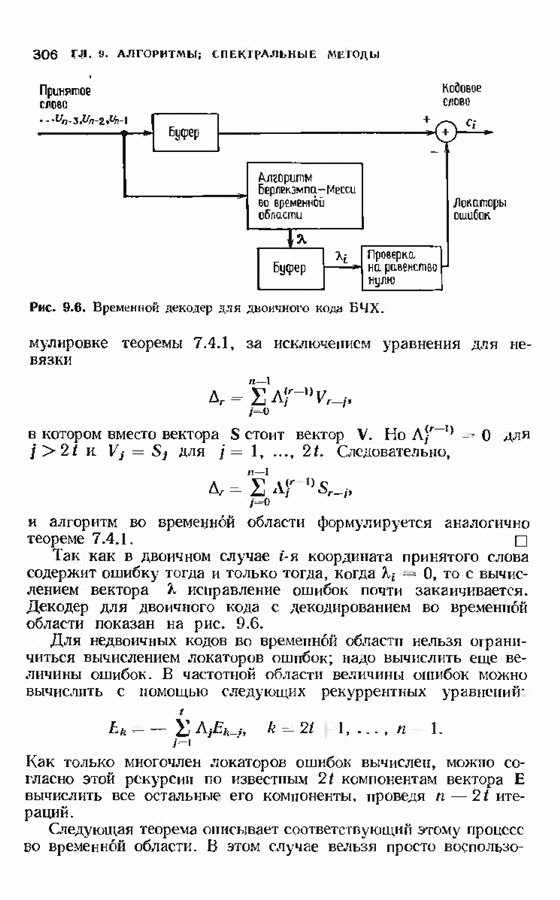
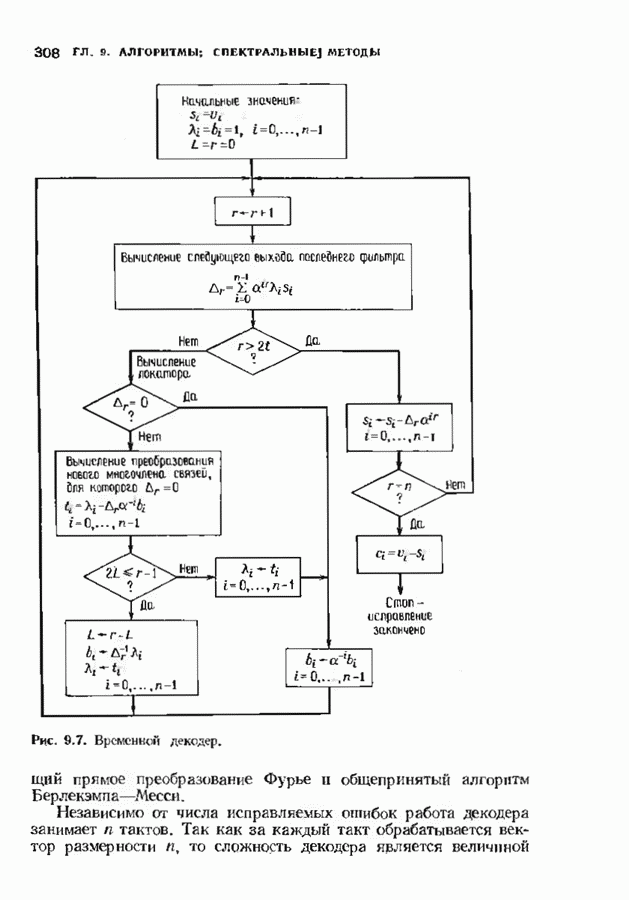
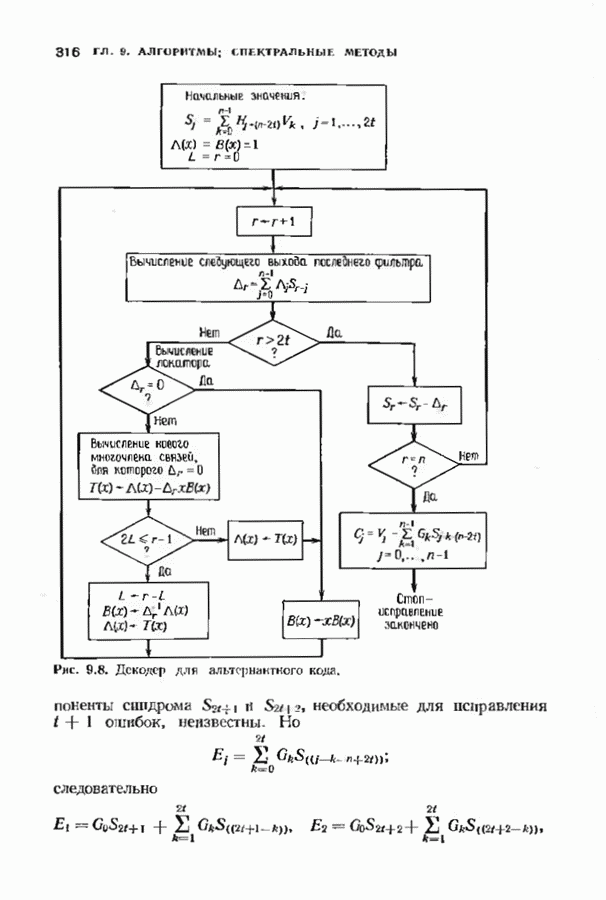
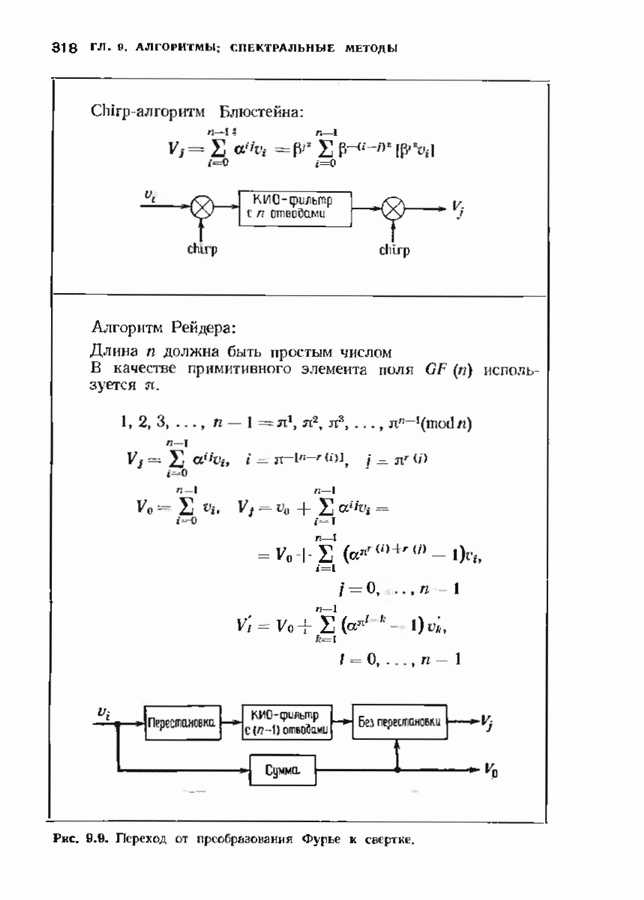
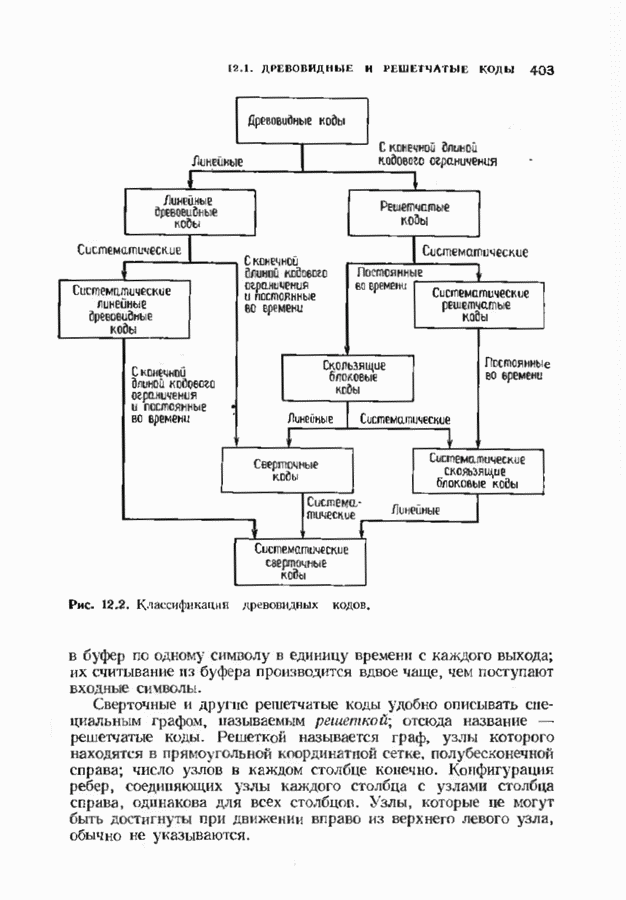
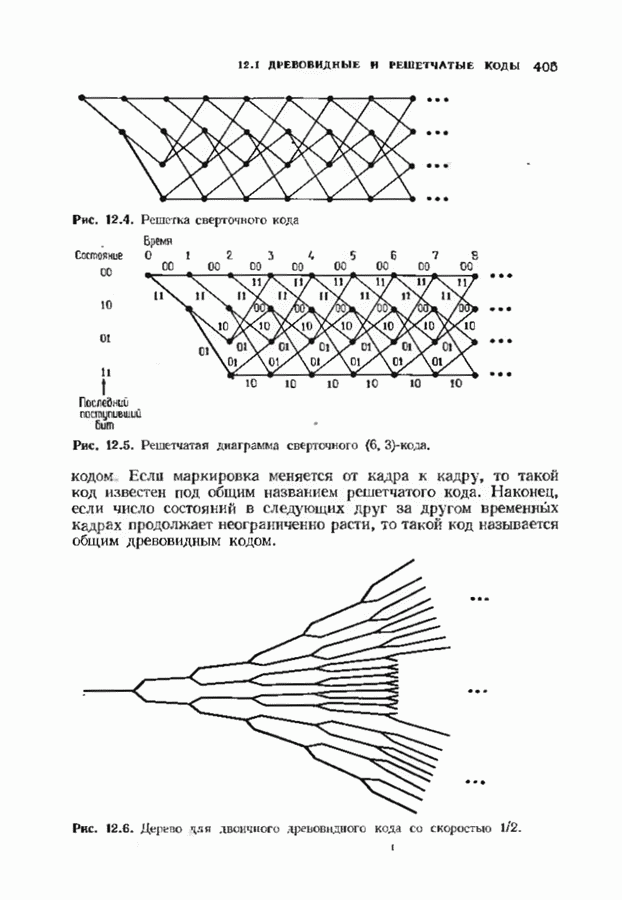
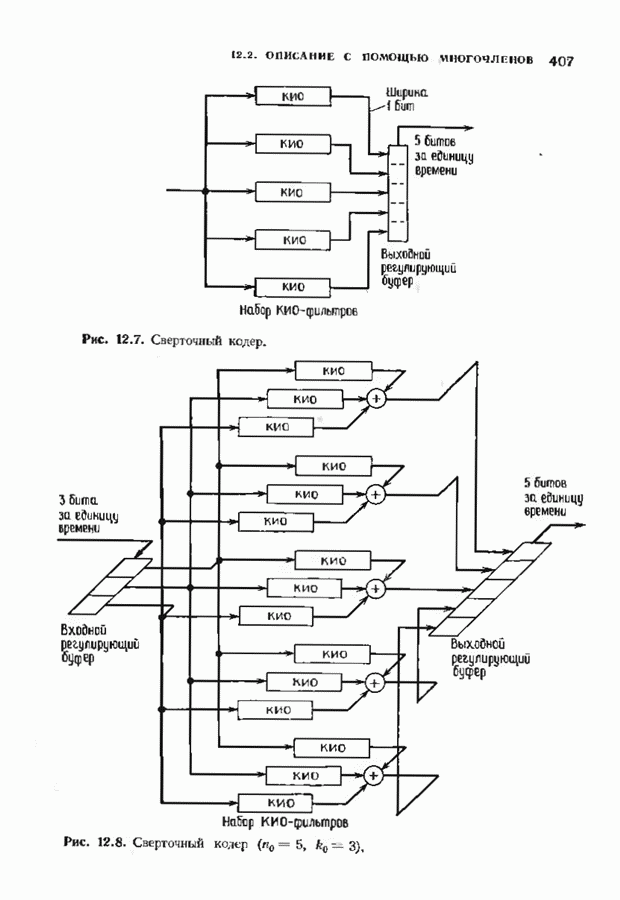
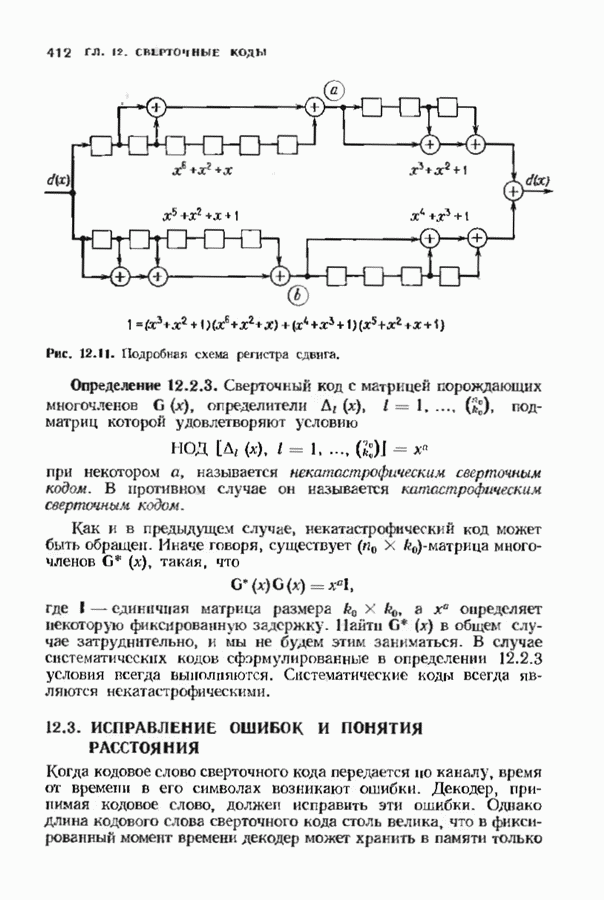
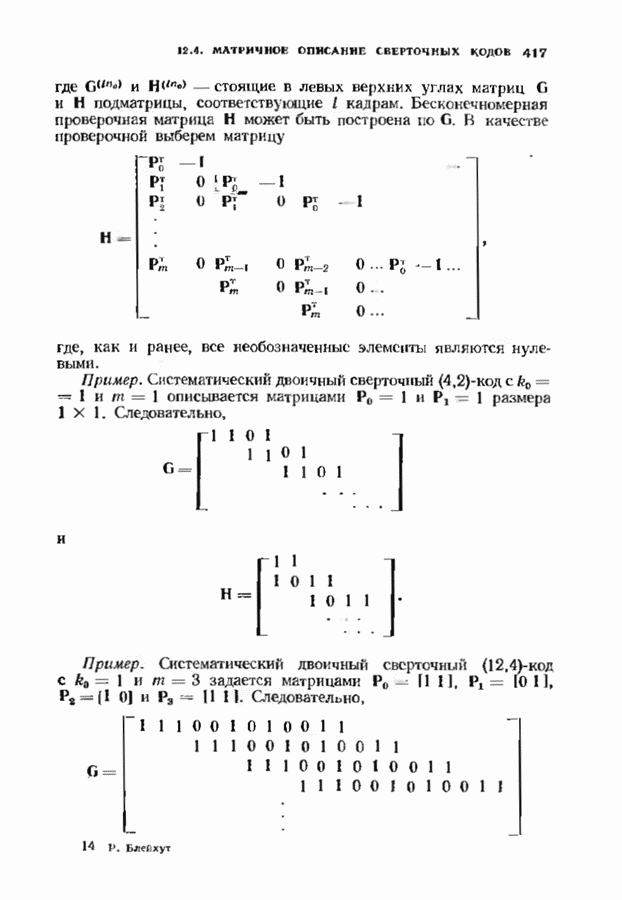
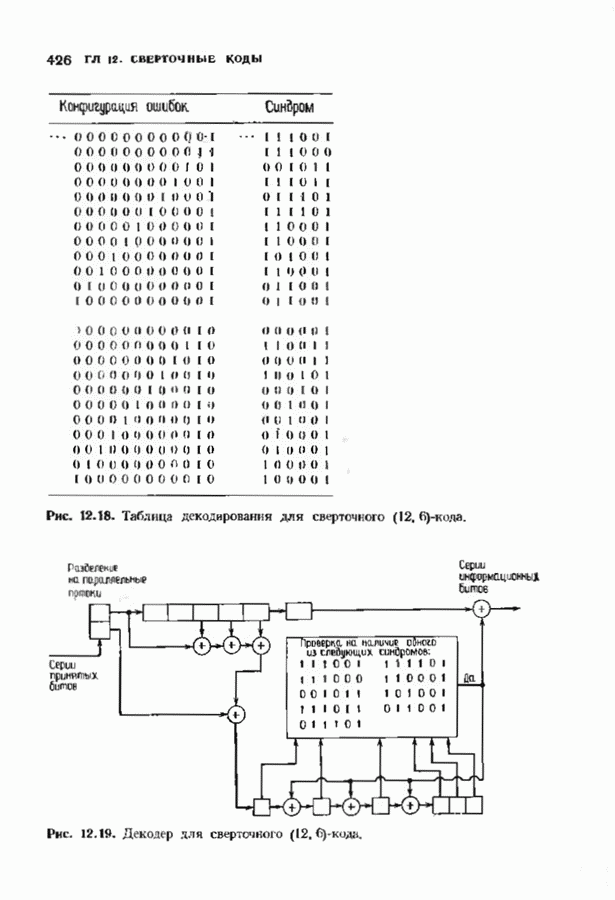
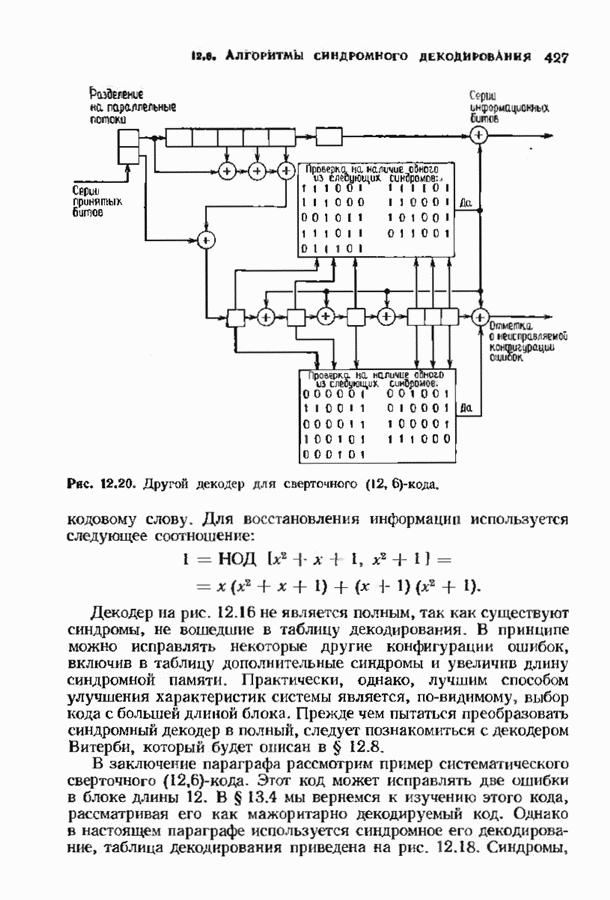
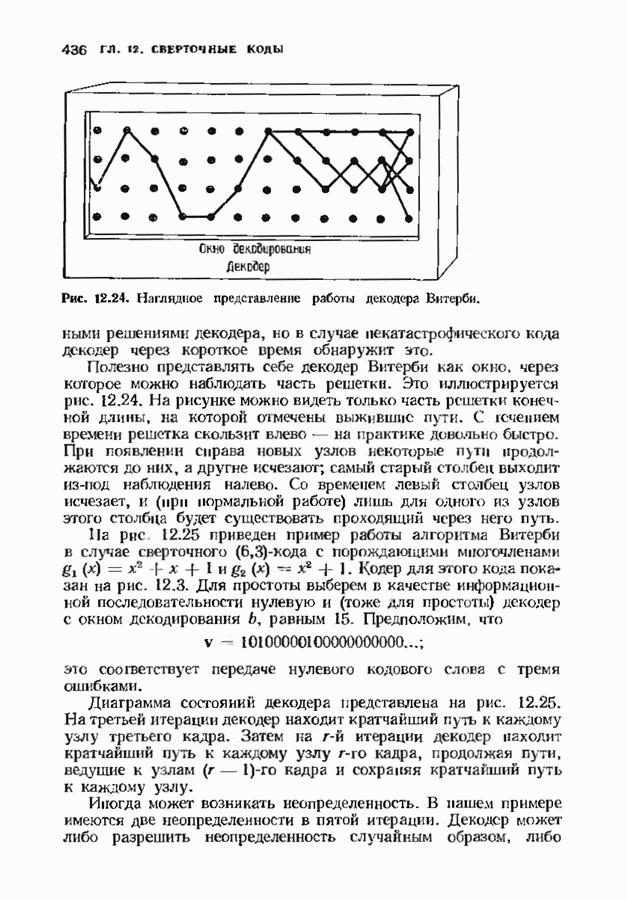
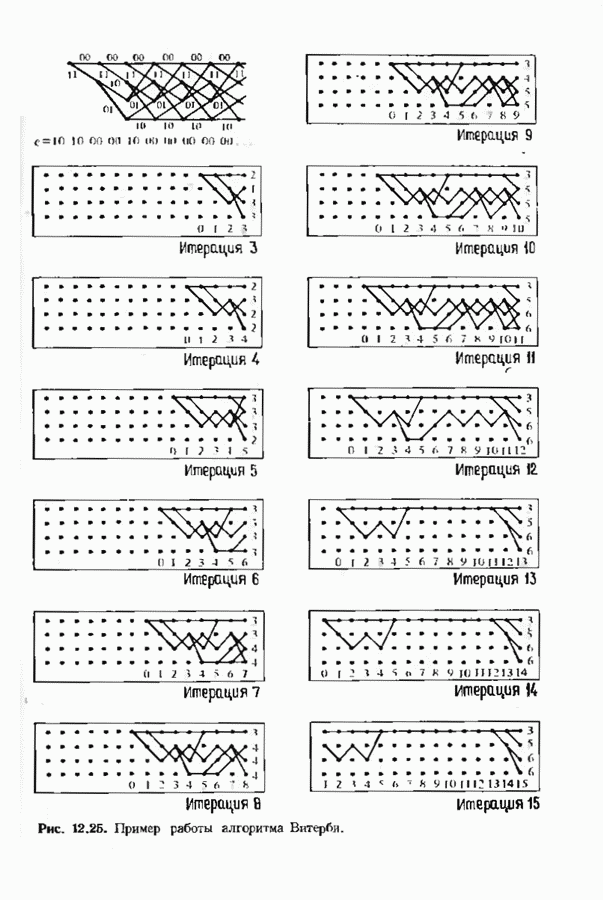
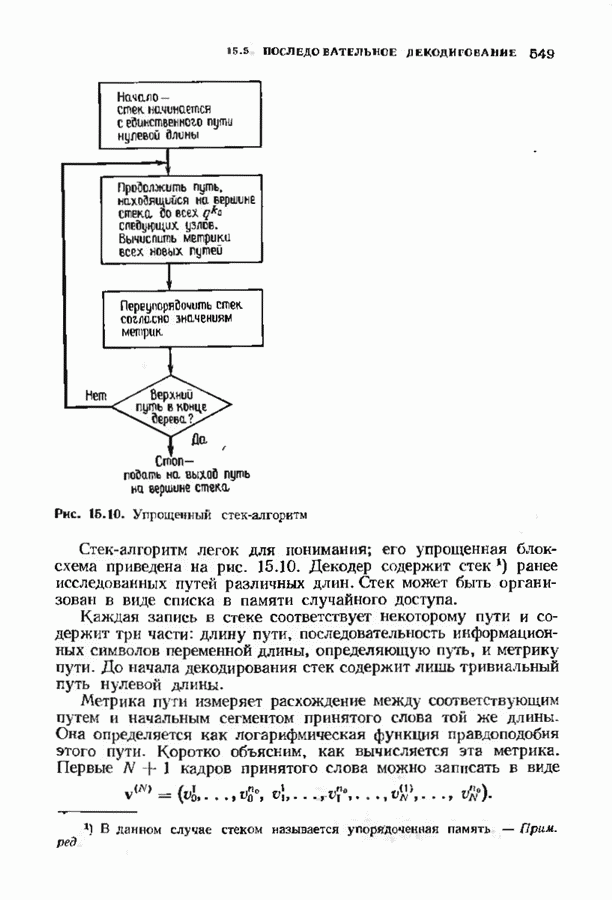
12.9. АЛГОРИТМЫ ПОИСКА ПО РЕШЕТКЕМожно улучшить характеристики сверточного кода, увеличив длину кодового ограничения. Декодер Витерби, однако, быстро становится непрактичным: при длине кодового ограничения 10 декодер двоичного кода уже должен помнить 1024 выживших путей. Для того чтобы ослабить влияние больших длин кодового ограничения, была разработана стратегия, игнорирующая маловероятные пути по решетке как только они становятся маловероятными. При такой стратегии не принимается решений о том, чтобы окончательно оставить данный путь. Время от времени декодер решает вернуться назад и продолжить оставленный ранее путь. Все такие стратегии поиска наиболее вероятного пути на решетке известны под общим названием последовательного декодирования. Последовательное декодирование носит довольно общий характер и может использоваться как в каналах, в которых принимаются жесткие решения (мы рассмотрим их в этом параграфе), так и в каналах, допускающих стирание или даже мягкие решения (мы изучим их в гл. 15). Представим себе решетку сверточного кода с большой длиной кодового ограничения, скажем равной 40. Для того чтобы найти решение, эту решетку нужно исследовать на нескольких сотнях уровней. Еще больше будет число узлов на каждом уровне. Всего таких узлов будет 210, или приблизительно В отличие от оптимальной процедуры алгоритма Витерби декодер, описание которого мы начинаем, просматривает только первый кадр, принимает решение и переходит в узел решетки на первом уровне. Затем он продолжает эту процедуру. На каждом уровне он находится в одном узле; он смотрит на следующий кадр, выбирая ребро, ближайшее к принятому кадру, и переходит в узел на следующем уровне. Если ошибок нет, то эта процедура работает превосходно, однако при наличии ошибок декодер может случайно выбрать неправильную ветвь. Если декодер продолжает следовать по ложному пути, он внезапно обнаружит, что происходит слишком много ошибок. Но это ошибка декодера, а не канала. Последовательный декодер вернется назад на несколько кадров и начнет исследовать альтернативные пути до тех пор, пока не найдется правдоподобный путь; затем он будет следовать вдоль этого альтернативного пути. Ниже будут кратко описаны правила, которыми он руководствуется при этом поиске. Характеристики декодера зависят от ширины относительно самого старого кадра, выводит соответствующие биты из окна и вдвигает в окно новый кадр. Мы можем считать, что последовательный декодер движется вдоль слова сверточного кода с переменной скоростью. Обычно он двигается равномерно, подавая на выход исправленные выходные биты. Иногда возникает небольшое затруднение, и движение на некоторое время замедляется. Реже возникают серьезные трудности, и продвижение декодера прекращается до тех пор, пока он не преодолеет этот сложный участок Разработаны подробные алгоритмы реализации такой процедуры. Наиболее популярным является алгоритм Фано, к описанию которого мы переходим. В этом алгоритме требуется знать вероятность
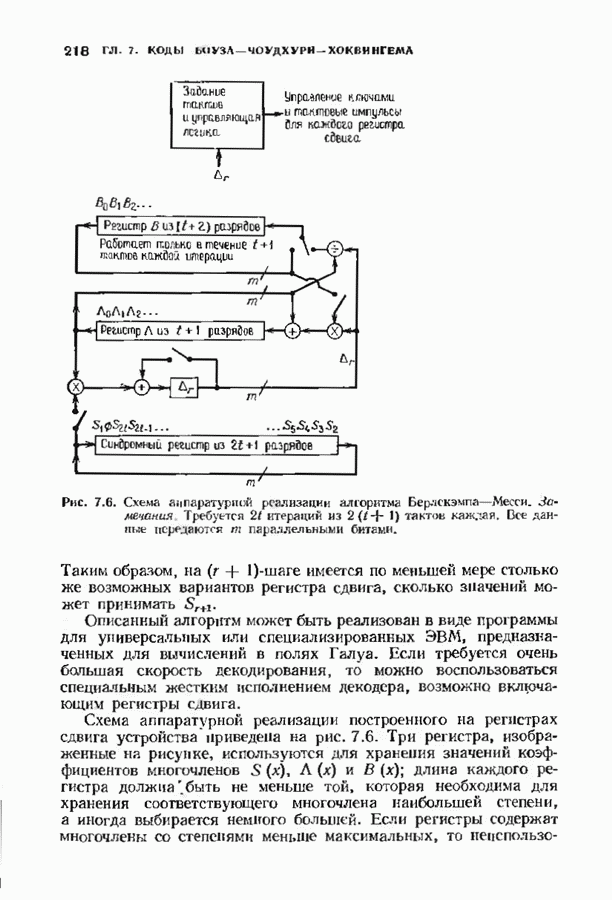
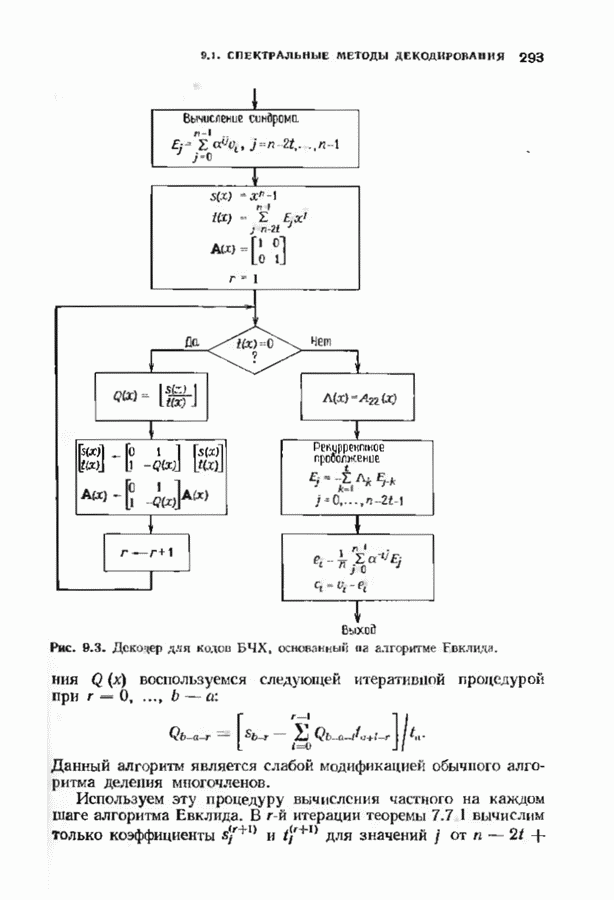
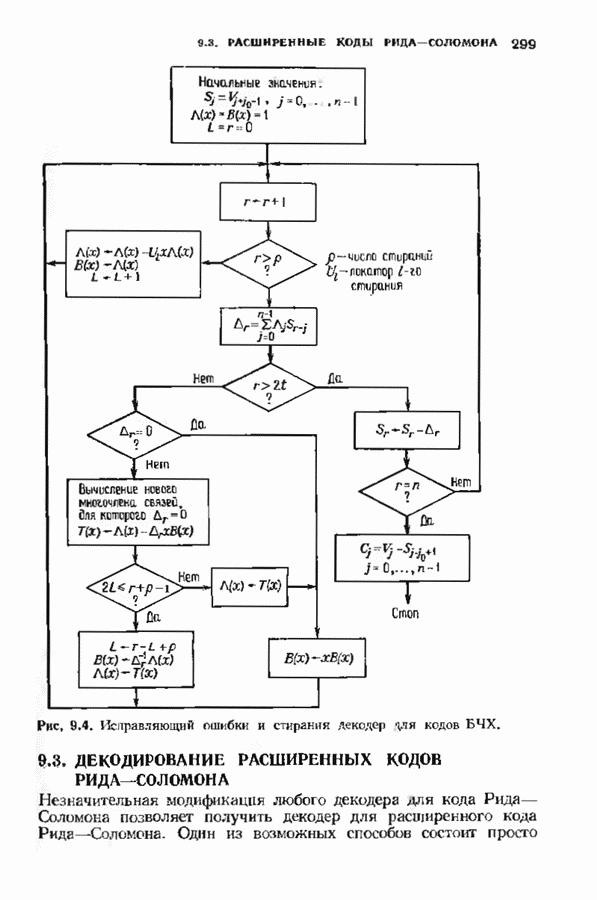
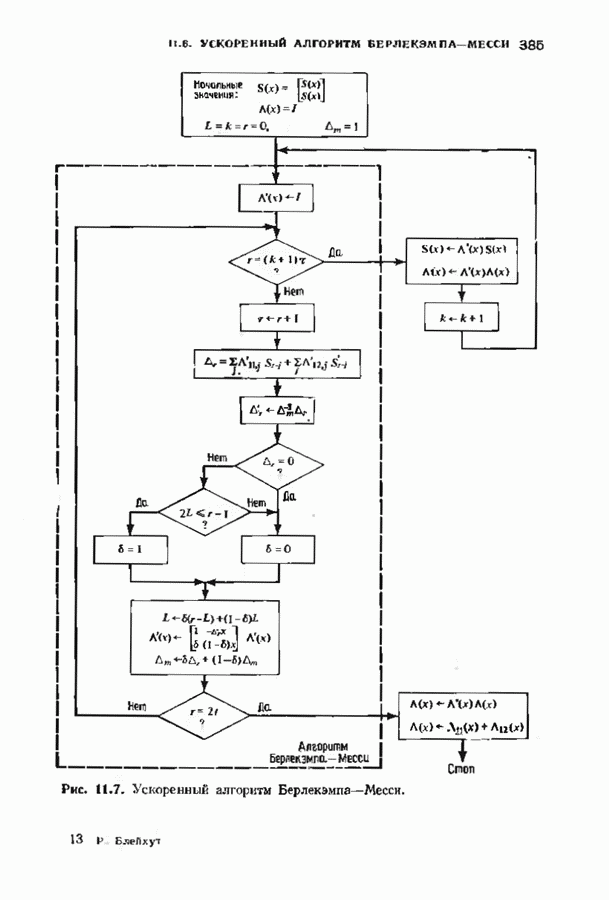
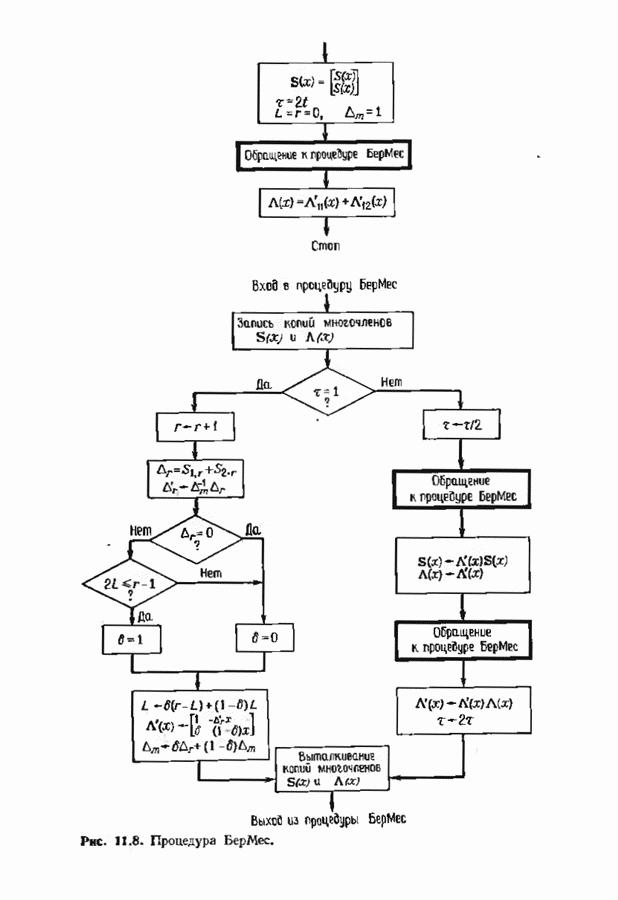
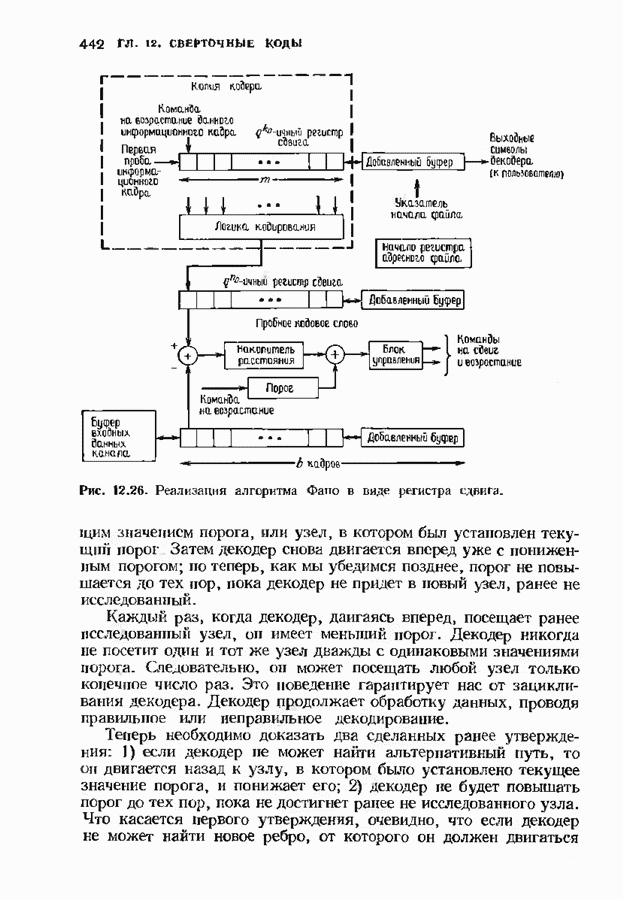
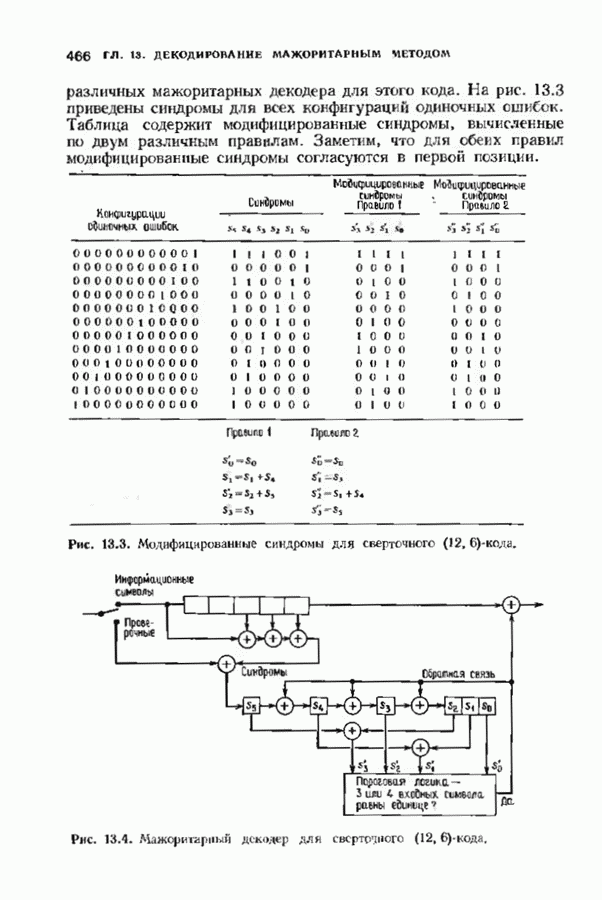
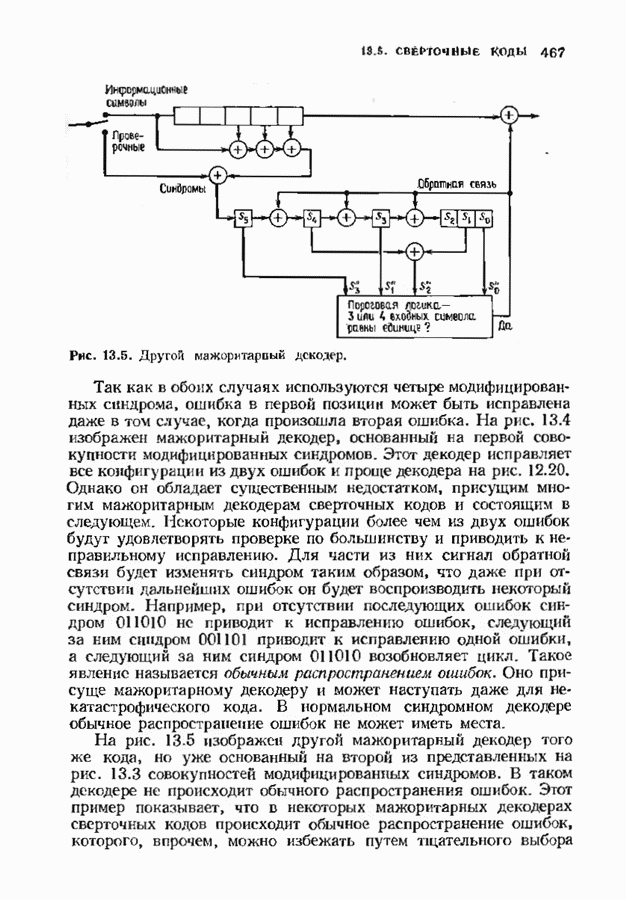
где В алгоритме Фано требуется, чтобы по которому при возвращении декодера в узел по ребру с известным индексом Реализация декодера в виде регистра сдвига, основанная на алгоритме Фано, приведена на рис. 12.26. Основой декодера является копия кодера с несколькими вспомогательными запоминающими регистрами. Декодер пытается подать символы в копию кодера таким образом, чтобы на его выходе появилось кодовое слово, достаточно близкое к принятому слову. После каждой итерации он может обратиться последнему кадру, поданному в копию кодера. Он может изменить информацию в этом кадре, вернуться к более раннему кадру или ввести новый кадр. Декодер решает, что делать, основываясь на сравнении величины перекошенного расстояния Алгоритм Фано, который контролирует декодер, упрощенно представлен на рис. 12.27. Практические детали, связанные с конечностью размеров буфера, временно игнорируются. Если шум в канвле мал и ошибки редки, то декодер будет циркулировать по правой петле рис. 12.27, каждый раз сдвигая все регистры рис. 12.26 на один кадр вправо. До тех пор пока Как мы увидим в дальнейшем, если декодер начал возвра щаться, то алгоритм заставит его двигаться назад до тех пор, пока он не найдет альтернативный путь, который находится над
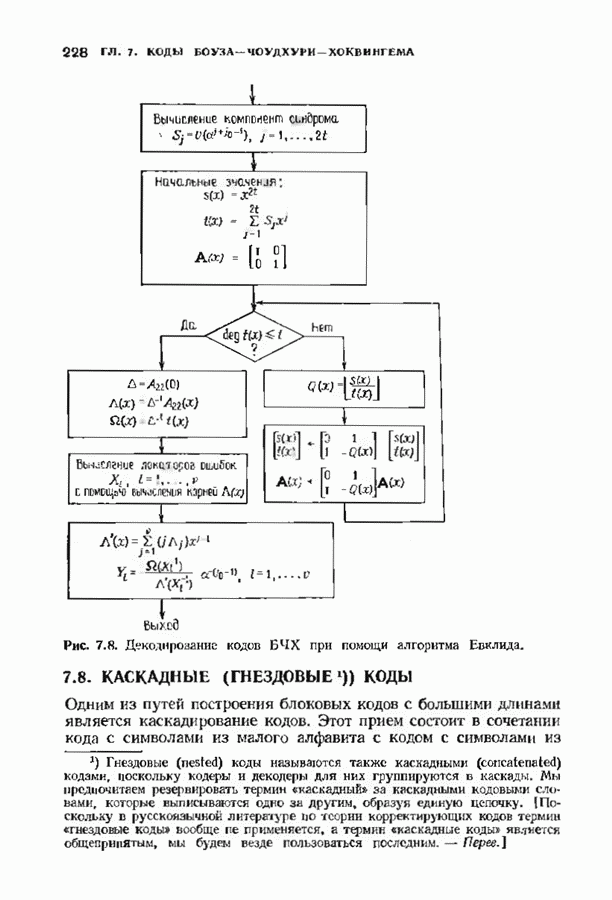
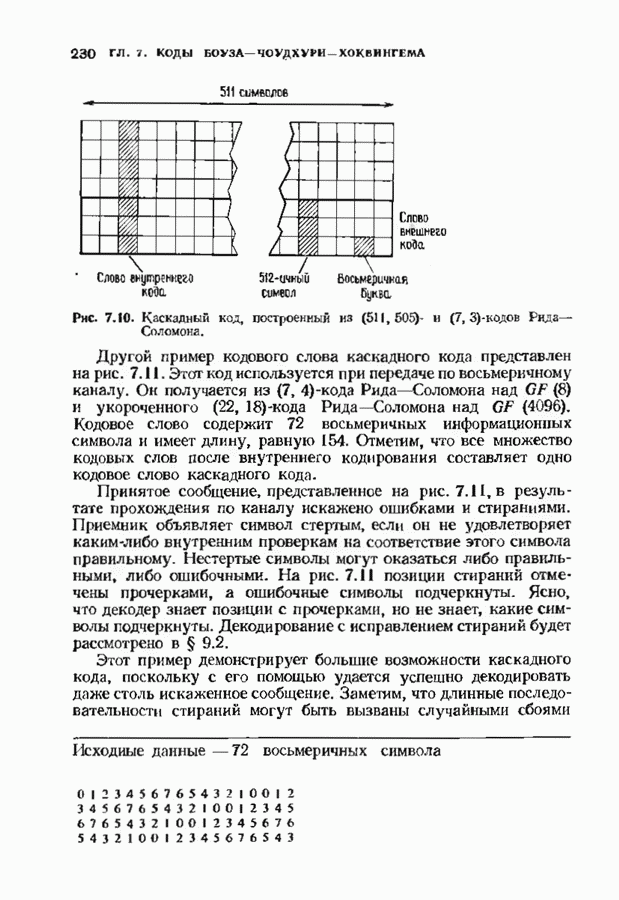
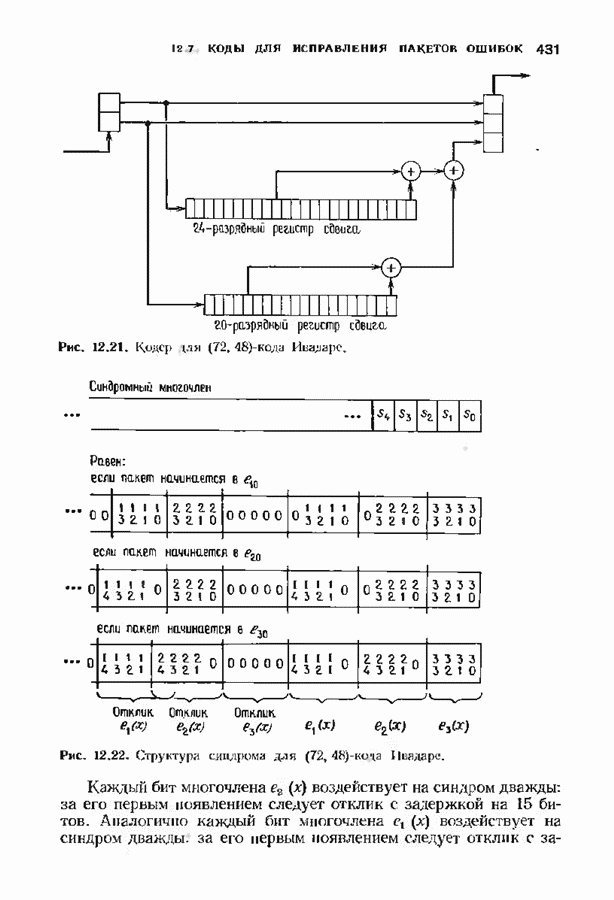
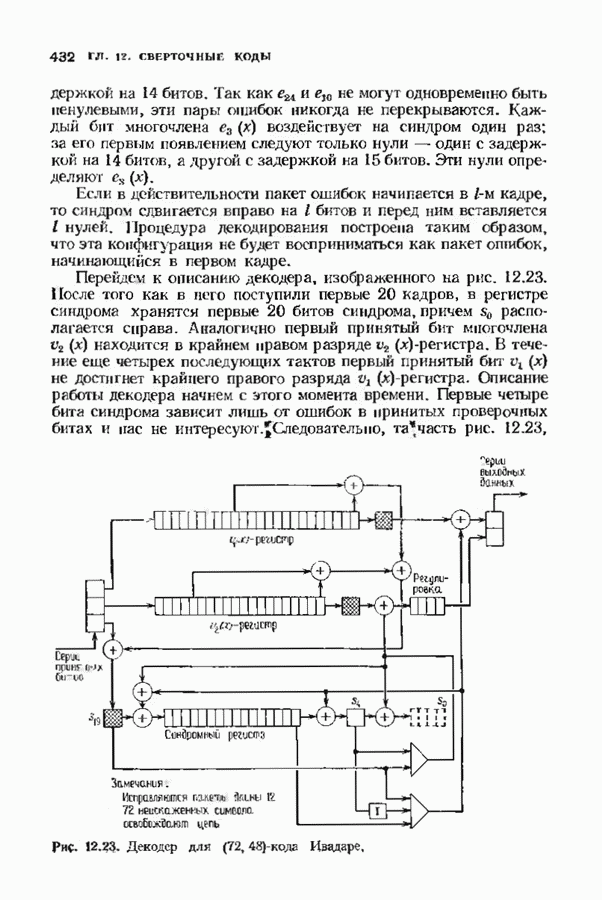
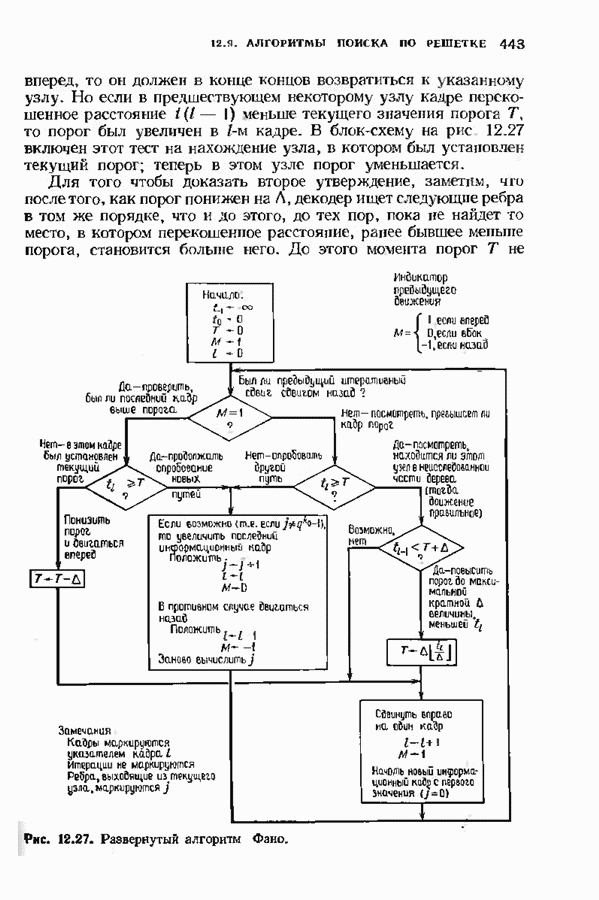
Рис. 12.26. Реализация алгоритма Фатго в виде регистра сдвига. текущим значением порога, или узел, в котором был установлен текущий порог Затем декодер снова двигается вперед уже с пониженным порогом; по теперь, как мы убедимся позднее, порог не повышается до тех пор, пока декодер не придет в новый узел, ранее не исследованный. Каждый раз, когда декодер, даигаясь вперед, посещает ранее исследованный узел, он имеет меньший порог. Декодер никогда не посетит один и тот же узел дважды с одинаковыми значениями порога. Следовательно, он может посещать любой узел только конечное число раз. Это поведение гарантирует нас от зацикливания декодера. Декодер продолжает обработку данных, проводя правильное или неправильное декодирование. Теперь необходимо доказать два сделанных ранее утверждения: I) если декодер не может найти альтернативный путь, то он двигается назад к узлу, в котором было установлено текущее значение порога, и понижает его; 2) декодер не будет повышать порог до тех пор, пока не достигнет ранее не исследованного узла. Что касается первого утверждения, очевидно, что если декодер не может найти новое ребро, от которого он должен двигаться вперед, то он должен в конце концов возвратиться к указанному узлу. Но если в предшествующем некоторому узлу кадре перекошенное расстояние Для того чтобы доказать второе утверждение, заметим, что после того, как порог понижен на Рис. 12.27. (см. скан) Развернутый алгоритм Фано. может изменяться. Это происходит из-за того, что после понижения порога на Алгоритм Фано зависит от двух параметров При практическом применении следует так же выбирать ширину Иногда последовательный декодер делает так много вычислений, что величина входного буфера становится недостаточной. Это явление называется переполнением буфера и является существенным ограничением для применения алгоритма Фано. Вероятность переполнения буфера с ростом размера буфера уменьшается очень медленно, и поэтому вне зависимости от того, насколько большим выбран буфер, эта проблема полностью не снимается. Существуют два способа управления переполнением буфера. Наиболее надежным является периодическая подача в кодер известной последовательности информационных символов (обычно последовательности нулей) с длиной, равной длине кодового ограничения сверточного кода. Если буфер переполнится, то декодер считает декодирование неудавшимся, ждет известного ему момента начала следующей последовательности и снова начинает декодирование. Все данные, поступившие между моментом переполнения буфера и следующим включением, теряются. Такой подход несколько уменьшает скорость кода и ставит при конструировании декодеров задачу синхронизации по времени. В случае когда длина кодового ограничения не слишком велика, вльтернативный путь состоит в движении указателя вперед. Если декодеру удастся найти правильный узел, то он может Рис. 12.28. (см. скан) Алгоритм Фано. перенастроиться. Если вероятность того, что на длине блока не произойдет ошибок, не слишком мала, то декодер, предполагая, что ошибок нет, преобразует кодовое слово в информационное слово. Если код систематический, то это делается непосредственно; в противном случае необходимо применить китайскую теорему об остатках для многочленов. Если длина свободного от ошибок сегмента принятого слова равна длине кодового ограничения, то декодер находит правильный узел и продолжает декодирование. Если ЗАДАЧИ(см. скан) (см. скан) ЗАМЕЧАНИЯПонятие сверточного кола было введено Элайсом [1954] и развито Возеп к рифтом [1957] Вайнср и Эш [1963] предложили для семейства сверточных кодов, исправляющих одну ошибку, общую конструкцию, родственную конструкции кодов Хэмминга. Класс сверточных кодов, исправляющих многократные ошибки, нашел Месси [1963] Коды Месси просты в декодировании, но в то же время имеют не слишком хорошие характеристики. Общего правила построения семейства быстродействующих высококачественных сверточных кодов, исправляющих многократные ошибки, не известно. Костелло [1969] предложил некоторые пути нахождения хороших сверточных кодов с умеренной длиной блока Основные используемые в настоящее время коды были найдены поиском на ЭВМ Бусаангом [1965], Оденвальдером [1970], Болом и Джелинеком [1971], Ларсеном [1973], Пааске [1974] и Йоханнессоном [1975]. Эти коды приведены на рис 12.13. Общее исследование влгебранчсской структуры сверточных кодов было проведено Месси и Сайном [1968], а также Форпи [1970], который впервые использовал решетки. Паше описание таких кодов с помощью многочленов основывается на этих статьях Костелло [1969] показал, что если в кодере введена обратная связь, то каждый сверточный код можно свести к систематическому Дополнительное обсуждение абстрактных структур может бьнь найдено у Линднера и Штайгера [1977]. Создание декодеров для сверточных кодов начали со сложных чекочеров с хорошими характеристиками, а затем постепенно перешли к простым декодерам с посредственными характеристиками, которые так популярны теперь. Алгоритм поиска на решетке принадлежит Фано [1963]. Наша формулировка алгоритма Фано следует Галлагеру [1968] и сильно отличается от первоначальной. Витерби [1967] предложил свой алгоритм скорее в учебных целях, чем в качестве серьезного алгоритма Вскоре после этого Хеллер [1968] указал, что алгоритм Витерби при не счишком больших длинах кодового ограничения вполне практичен. Общее обсуждение сверточных кодов можно найти в книге Витерби и Омуры [1970], а также в обзорных статьях Форни [1974] и Месси [1975].
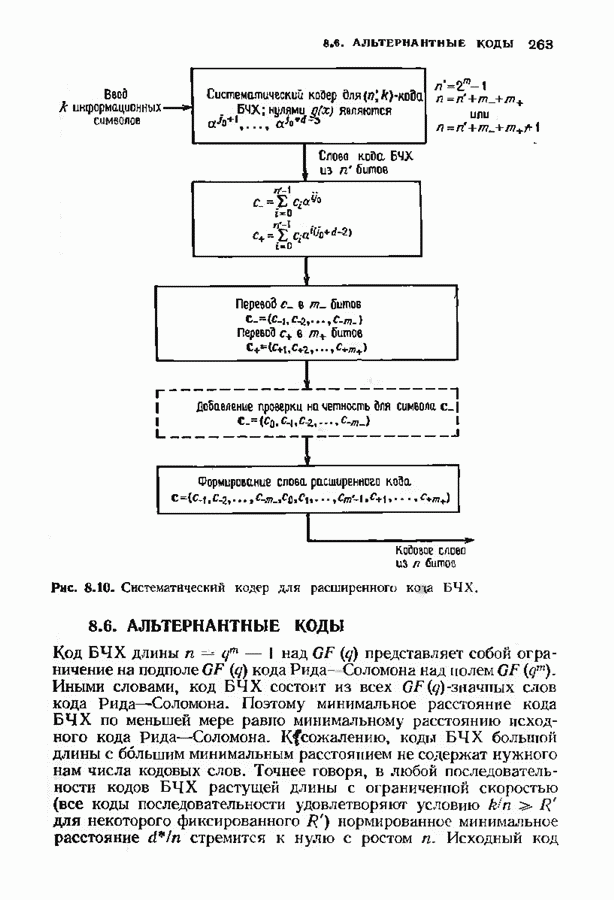
|
 |
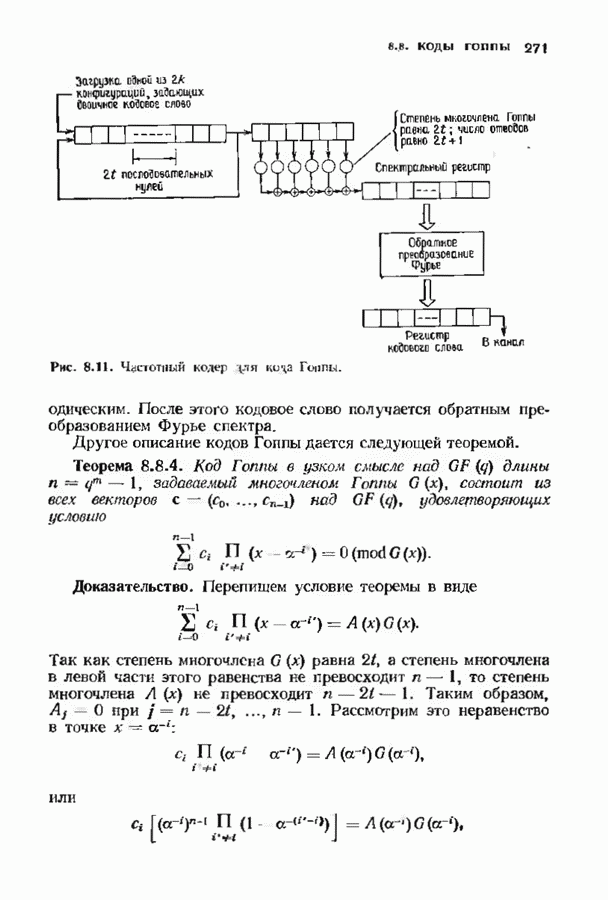
Оглавление
|
































































































































































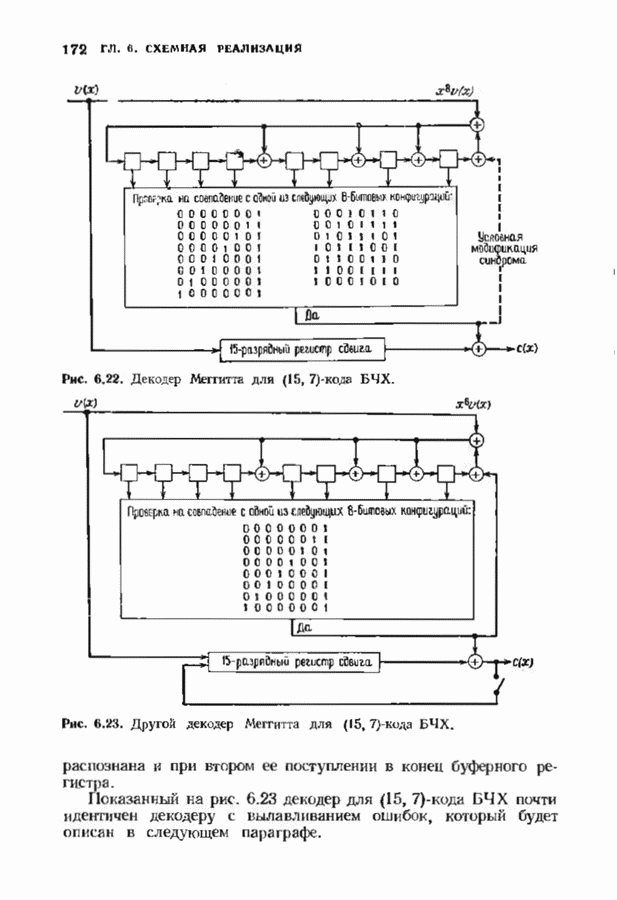

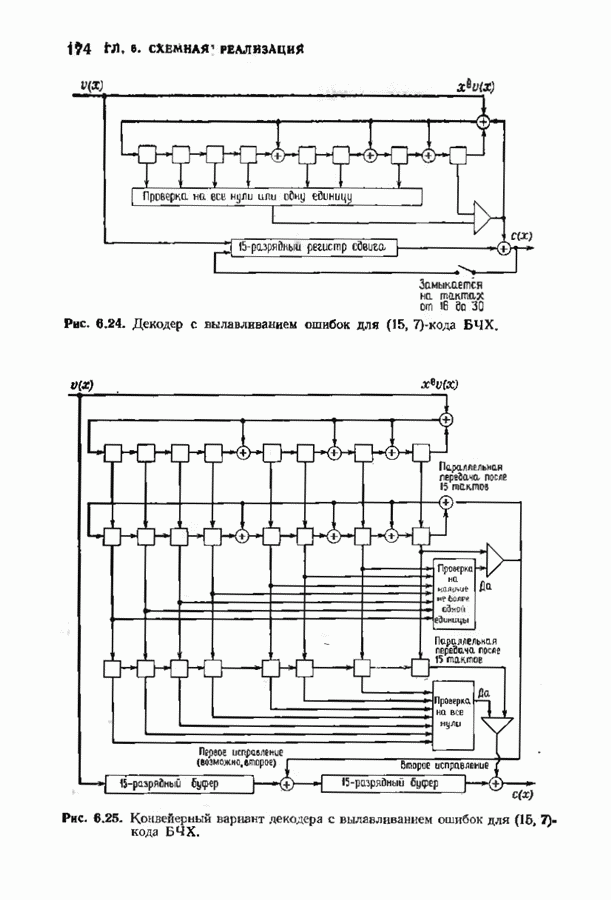

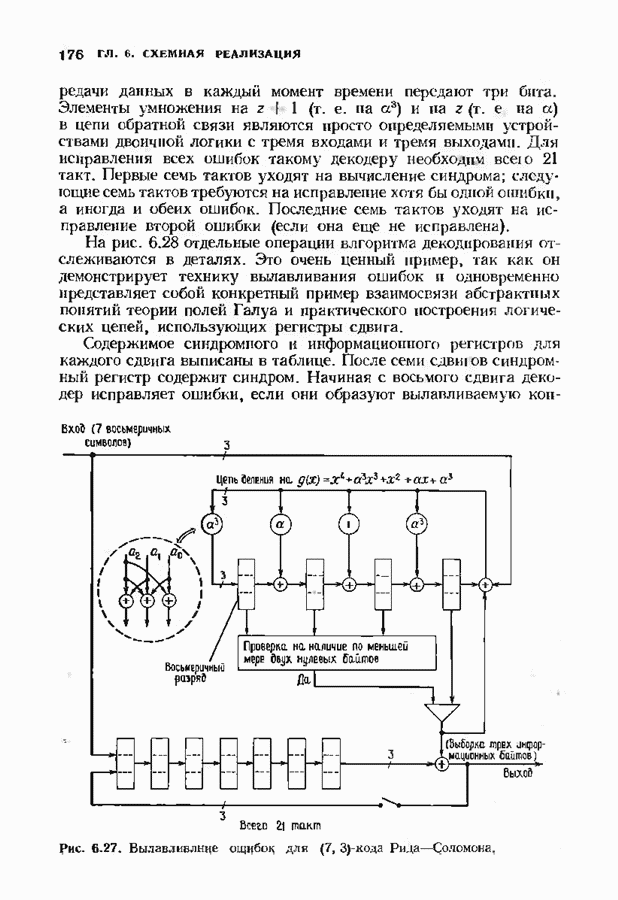





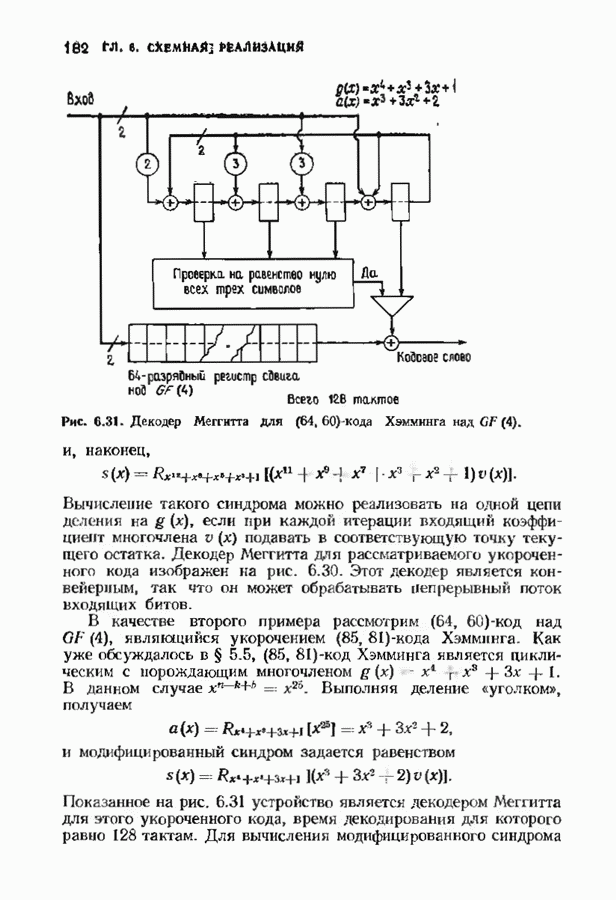






















































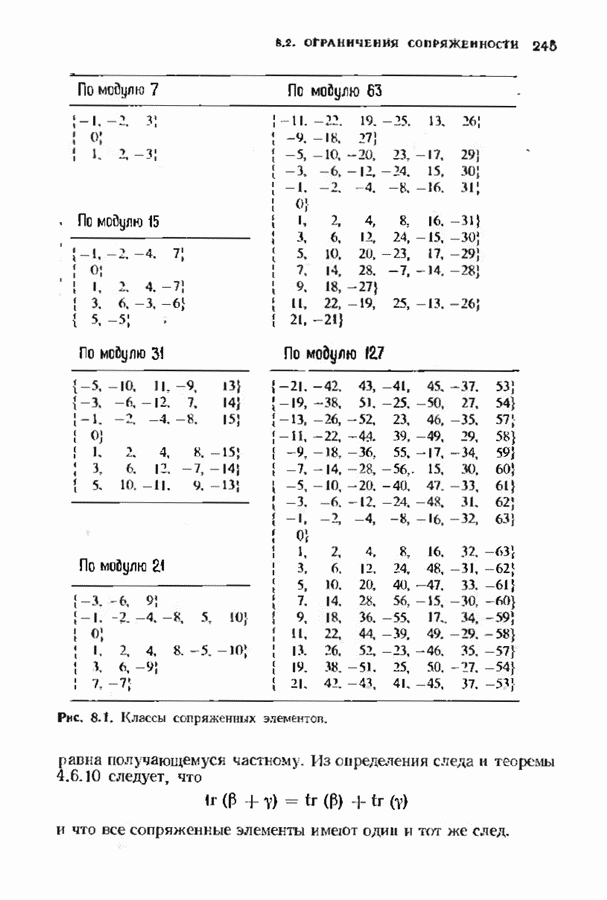





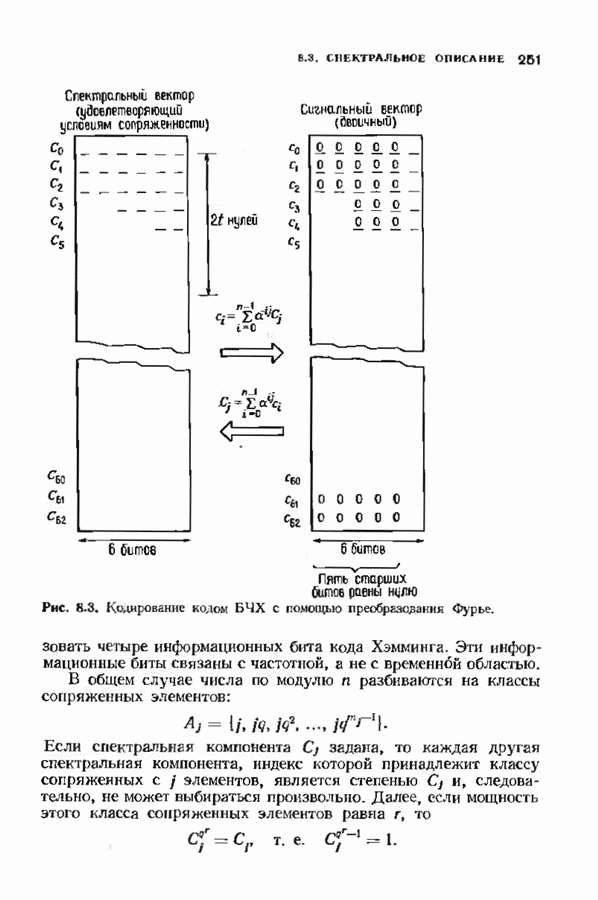








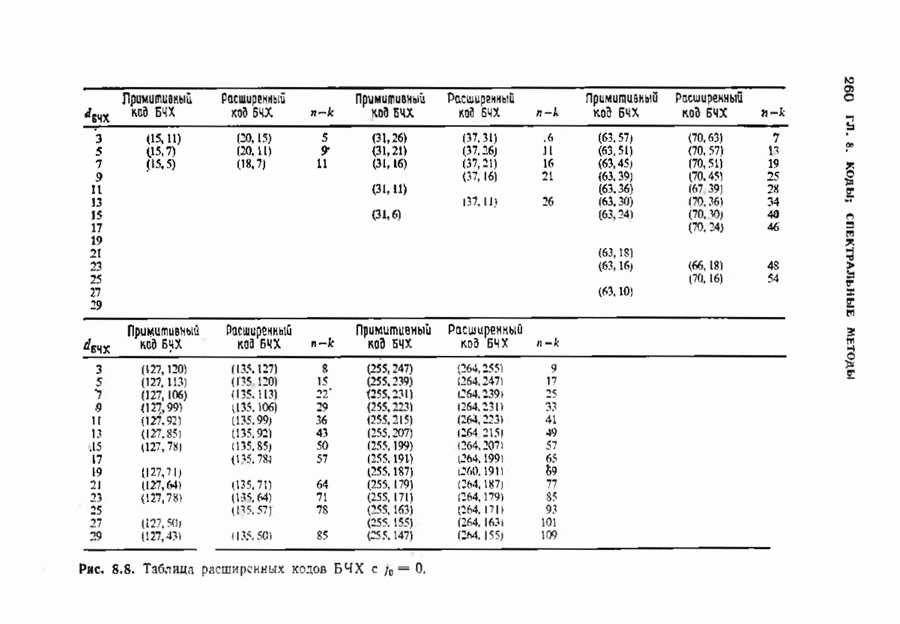

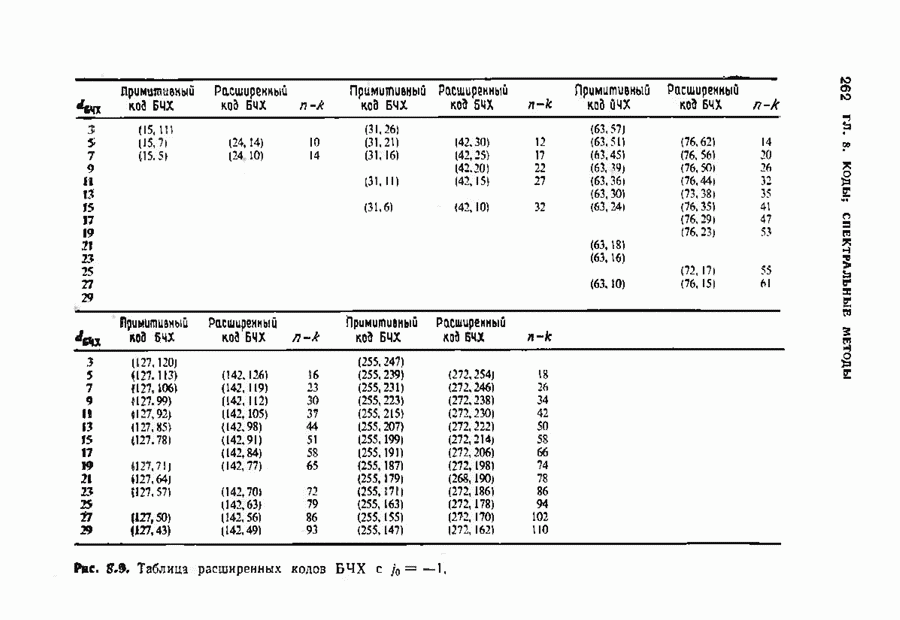










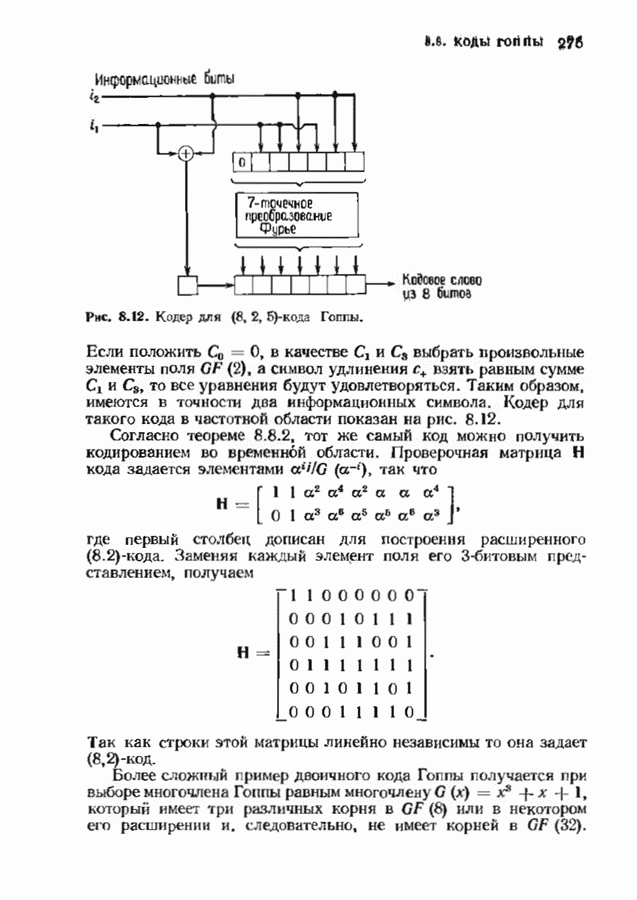












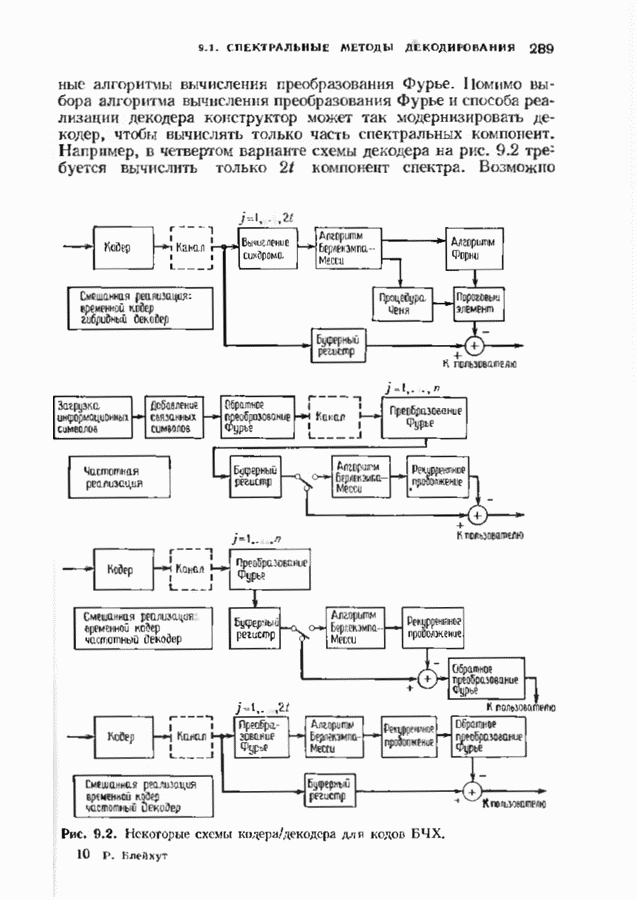








































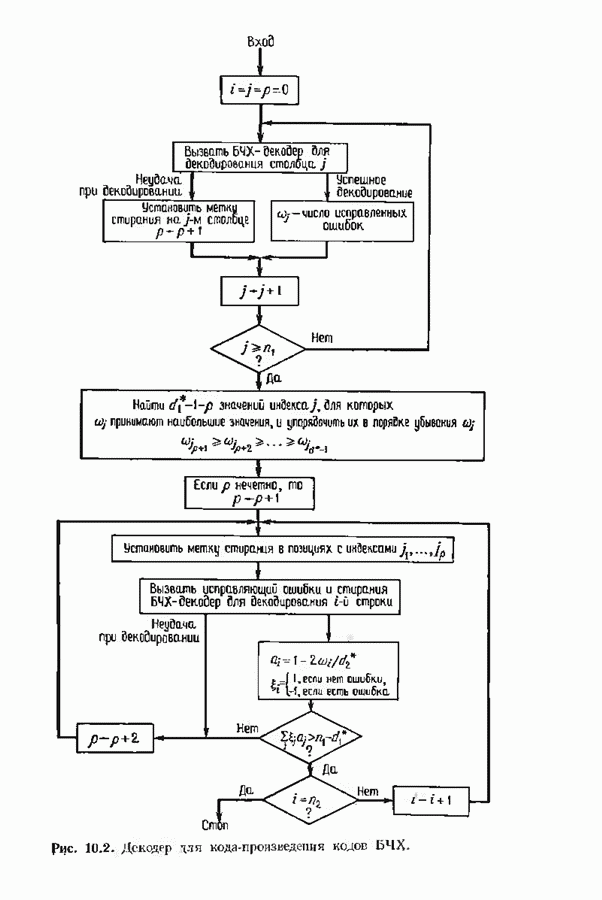











































































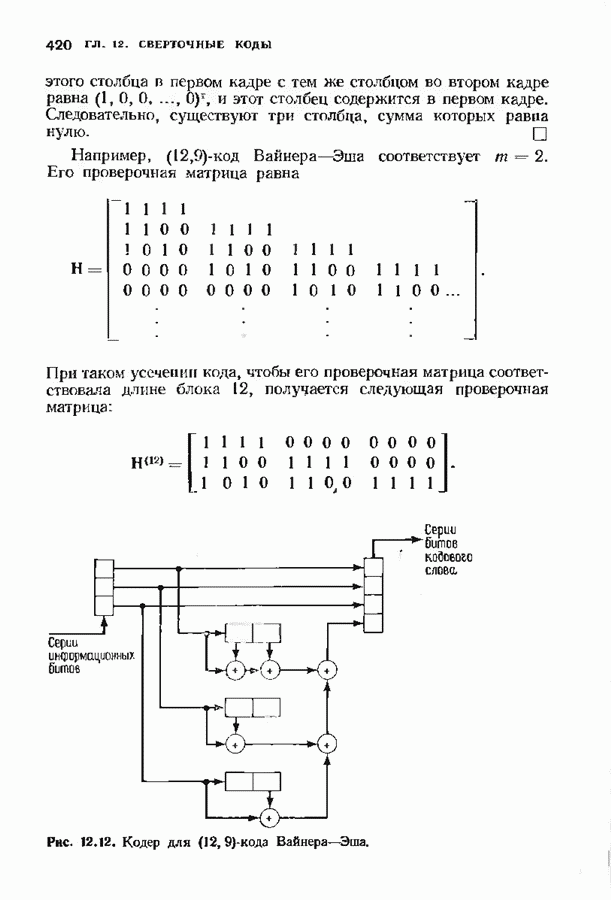
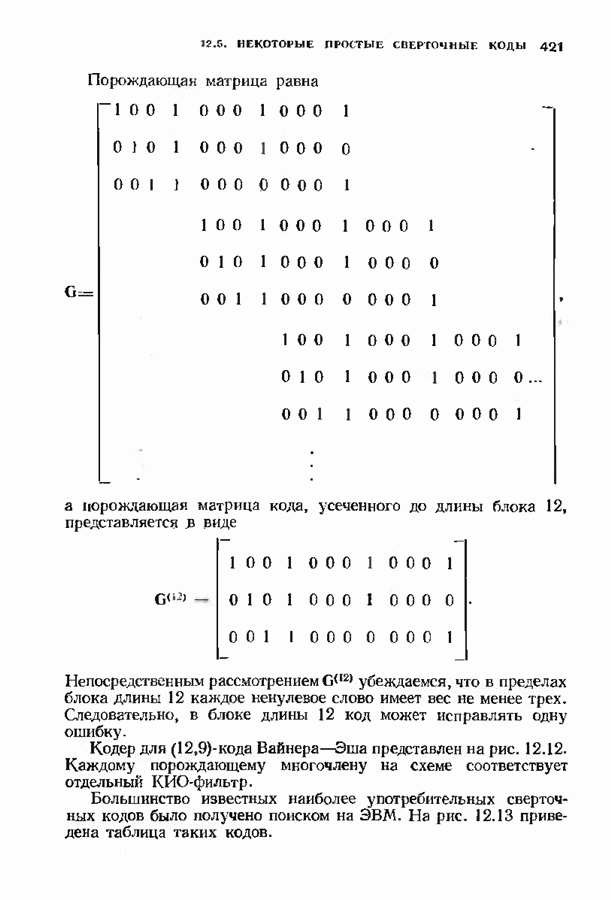


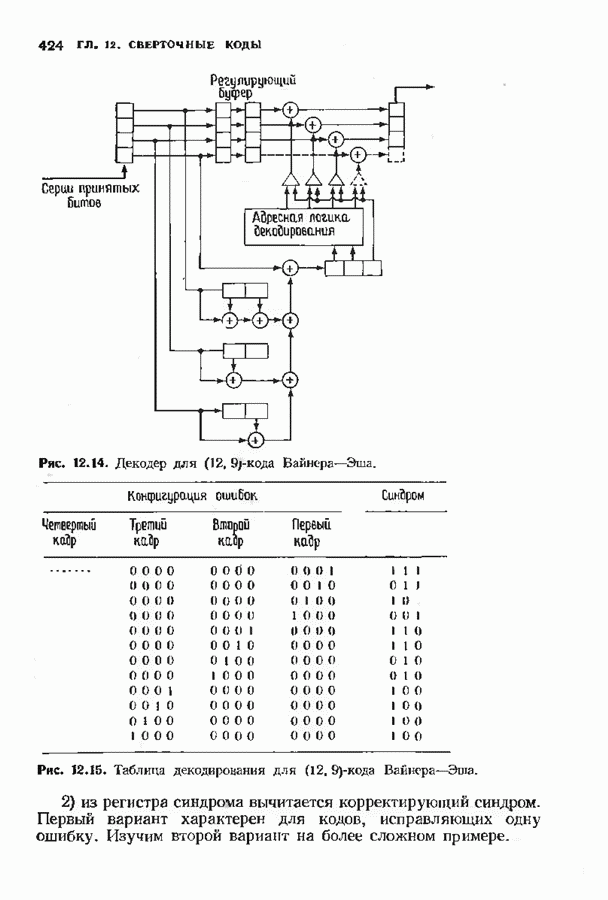
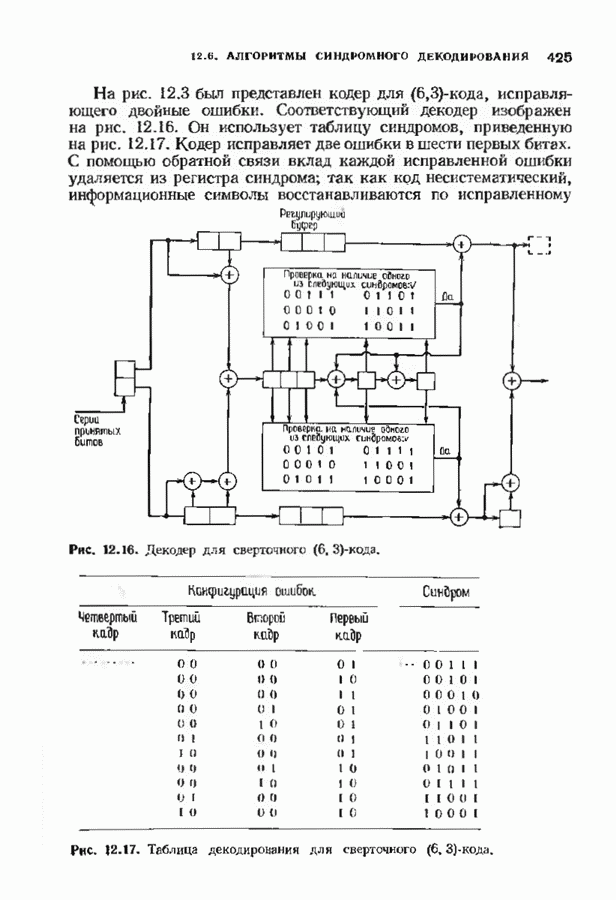



























































































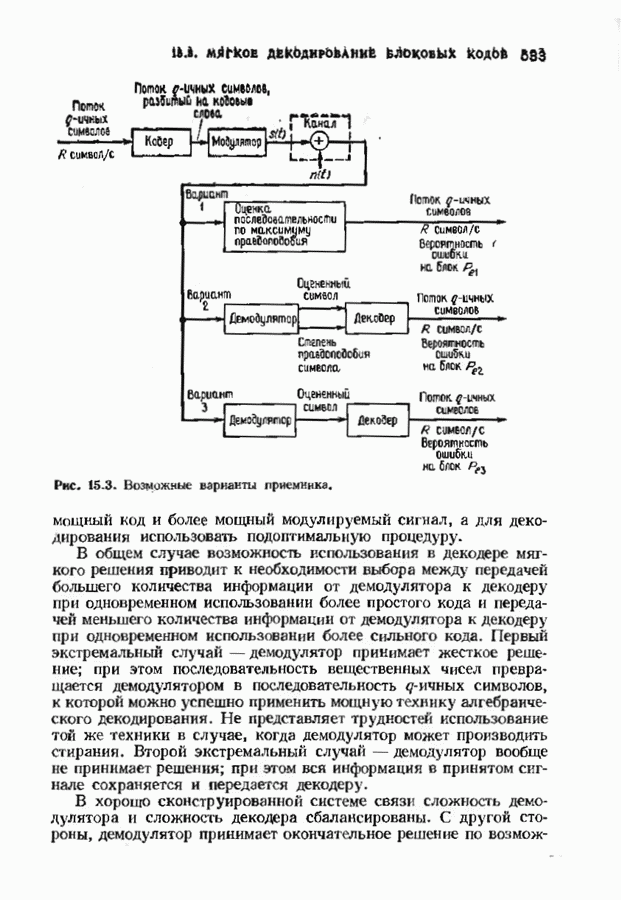



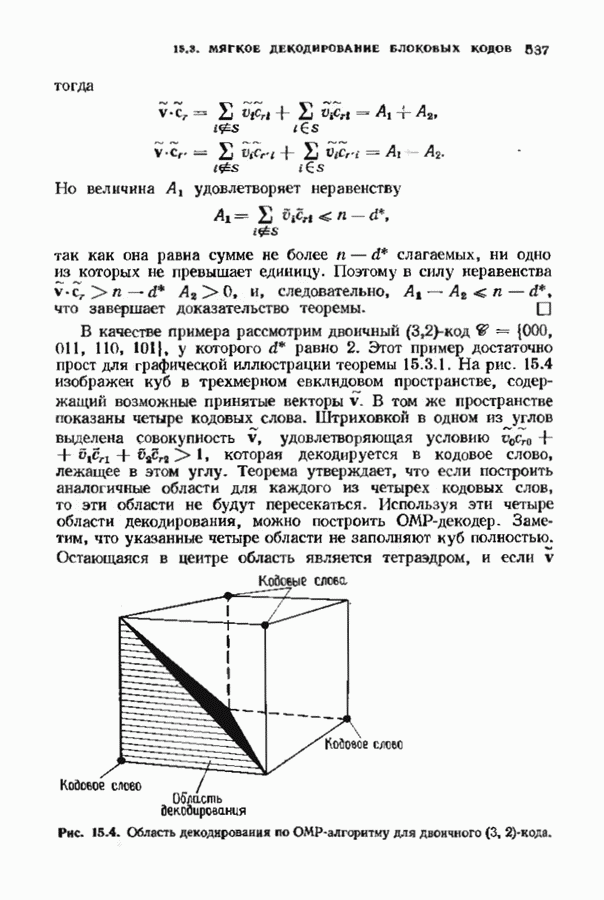

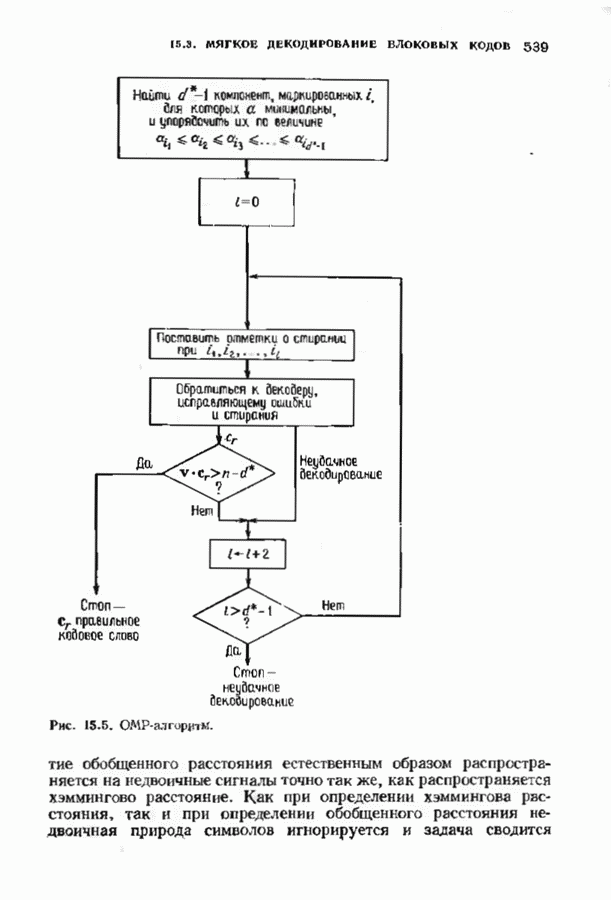




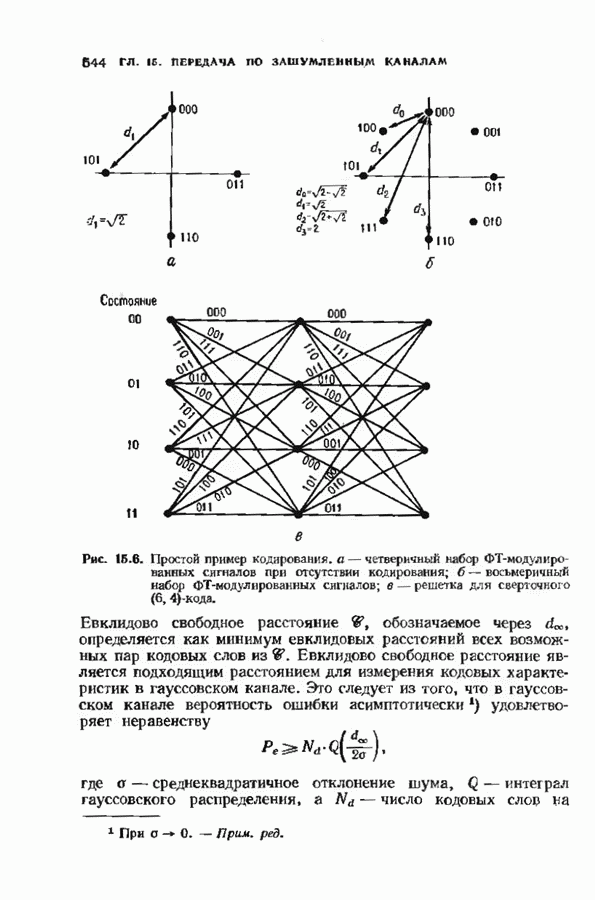
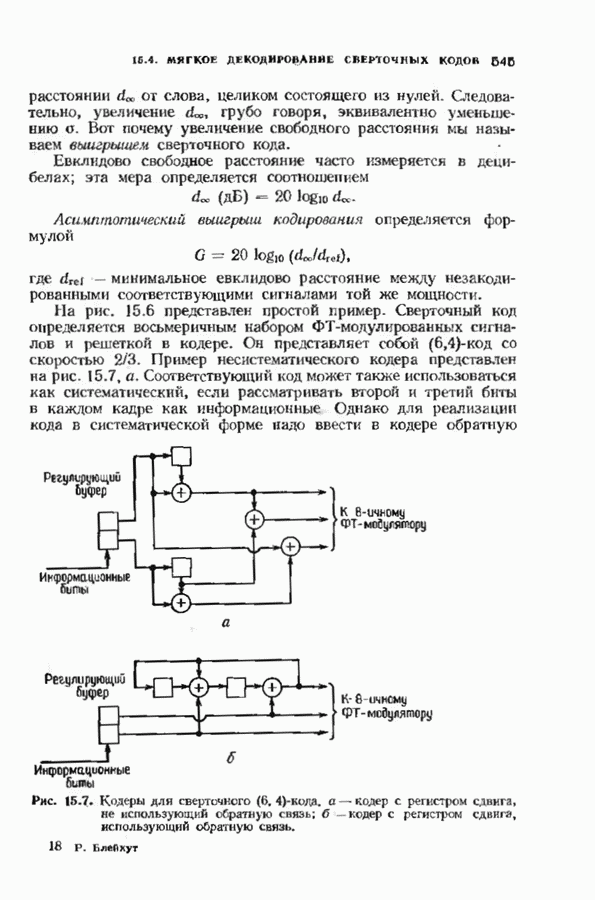
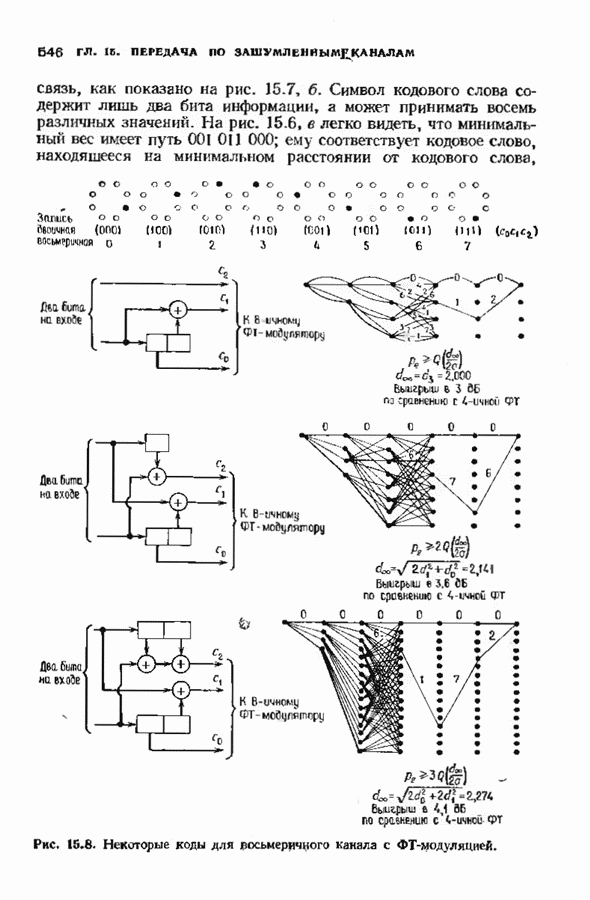
















 Декодер должен найти но этой решетке путь, наиболее близкий к принятому слову в смысле расстояния Хэммтиа по крайней мере он должен сделать это с очень высокой вероятностью, хотя время от времени ему дозволено отказываться от декодирования. Такой отказ является дополнительным видом ошибки, не существовавшим в декодере Витерби; декодер может отказаться от декодирования даже в том случае, когда декодирование по минимуму расстояния было бы верным.
Декодер должен найти но этой решетке путь, наиболее близкий к принятому слову в смысле расстояния Хэммтиа по крайней мере он должен сделать это с очень высокой вероятностью, хотя время от времени ему дозволено отказываться от декодирования. Такой отказ является дополнительным видом ошибки, не существовавшим в декодере Витерби; декодер может отказаться от декодирования даже в том случае, когда декодирование по минимуму расстояния было бы верным.
 окна декодирования, измеряемой числом кадров кодового слова. Если декодер нашел путь, проходящий через
окна декодирования, измеряемой числом кадров кодового слова. Если декодер нашел путь, проходящий через  кадров решетки, он принимает окончательное решение
кадров решетки, он принимает окончательное решение
 появления ошибочного символа в канале или хотя бы верхнюю границу для
появления ошибочного символа в канале или хотя бы верхнюю границу для  Пока декодер следует по правильному пути, вероитное число ошибок в первых
Пока декодер следует по правильному пути, вероитное число ошибок в первых  кадрах приблизительно равно
кадрах приблизительно равно  Декодер допускает несколько большее число ошибок, но если оно намного больше, то декодер сделает вывод, что он находится на ложном пути. Выберем (быть может, моделированием) некоторый параметр
Декодер допускает несколько большее число ошибок, но если оно намного больше, то декодер сделает вывод, что он находится на ложном пути. Выберем (быть может, моделированием) некоторый параметр  больший
больший  но меньший 1/2, и определим перекошенное расстояние формулой
но меньший 1/2, и определим перекошенное расстояние формулой

 расстояние Хэмминга между принятым словом и текущим путем по решетке. Для правильного пути
расстояние Хэмминга между принятым словом и текущим путем по решетке. Для правильного пути  приблизительно равно
приблизительно равно  положительно и возрастает. До тех пор пока
положительно и возрастает. До тех пор пока  возрастает, декодер продолжает следовать по пути на решетке. Если вдруг
возрастает, декодер продолжает следовать по пути на решетке. Если вдруг  станет уменьшаться, то декодер заключает, что в некотором узле он выбрал ошибочное ребро, и возвращается по решетке, проверяя другие пути. Он может найти лучший путь и проследовать по нему или может возвратиться к тому же самому узлу, но уже более уверенно и продолжить путь через него. Для того чтобы решить, когда
станет уменьшаться, то декодер заключает, что в некотором узле он выбрал ошибочное ребро, и возвращается по решетке, проверяя другие пути. Он может найти лучший путь и проследовать по нему или может возвратиться к тому же самому узлу, но уже более уверенно и продолжить путь через него. Для того чтобы решить, когда  начинает уменьшаться, декодер пользуется текущим порогом
начинает уменьшаться, декодер пользуется текущим порогом  который всегда кратен приращению
который всегда кратен приращению  порога. Пока декодер движется вперед, порог, оставаясь мепьшим
порога. Пока декодер движется вперед, порог, оставаясь мепьшим  и кратным приращению А, принимает максимально возможное при этих ограничениях значение. Благодаря тому что
и кратным приращению А, принимает максимально возможное при этих ограничениях значение. Благодаря тому что  квантуется, допускается небольшое убывание
квантуется, допускается небольшое убывание  без пересечения порога.
без пересечения порога.
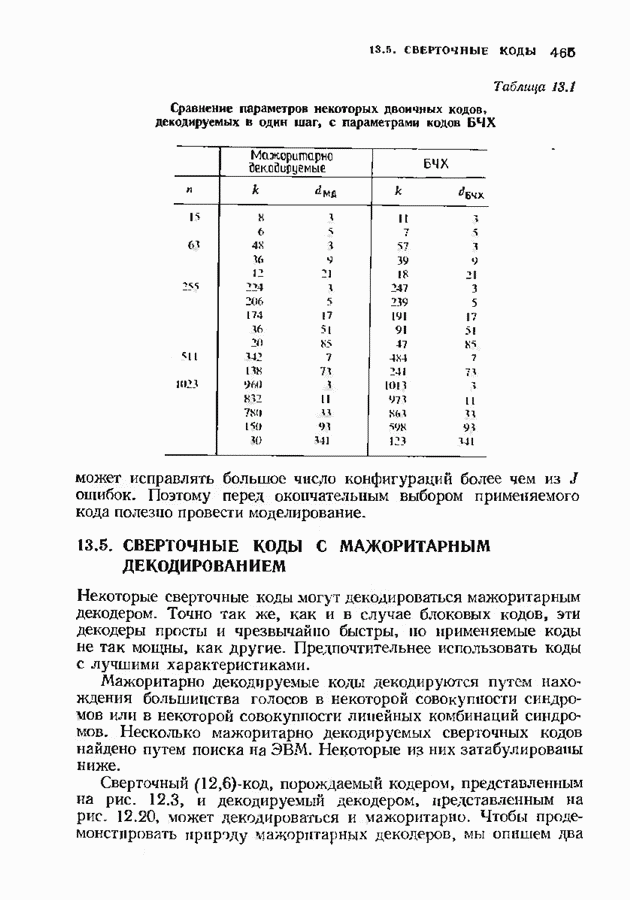
 ребер, выходящих из каждого узла, были перенумерованы согласно некоторому правилу упорядочения. Это правило ставит в соответствие каждому ребру индекс
ребер, выходящих из каждого узла, были перенумерованы согласно некоторому правилу упорядочения. Это правило ставит в соответствие каждому ребру индекс  Нет необходимости запомнить эти индексы в каждом ребре, достаточно знать правило,
Нет необходимости запомнить эти индексы в каждом ребре, достаточно знать правило,
 он мог переупорядочить ребра, найти ребро
он мог переупорядочить ребра, найти ребро  зная его, найти ребро
зная его, найти ребро  Наиболее общим правилом является правило минимума расстояния. Ребра упорядочиваются в соответствии с их расстояниями Хэмминга до соответствующего кадра принятого слова, а неопределенность разрешается по любому удобному подправил у. Алгоритм Фано будет нормально функционировать и в том случае, когда ребрам приписан любой фиксированный поридок; например, ребра могут быть упорядочены лексикографически в соответствии с их информационными символами. Это последнее правило упорядочения приводит к более длительному поиску назад — вперед, но освобождает от необходимости вычисления и перевычисления порядка при достижении каждого узла. Какоечправило упорядочения более просто в реализации, зависит от конструкции декодера. Для простоты понимания структуры алгоритма правило упорядочения лучше оставить несколько неопределенным; предположим лишь, что в каждом узле ребро, ближайшее к принятому ребру по расстоянию Хэмминга, считается первым. Декодер будет искать ребра из каждого узла в соответствии с этим правилом.
Наиболее общим правилом является правило минимума расстояния. Ребра упорядочиваются в соответствии с их расстояниями Хэмминга до соответствующего кадра принятого слова, а неопределенность разрешается по любому удобному подправил у. Алгоритм Фано будет нормально функционировать и в том случае, когда ребрам приписан любой фиксированный поридок; например, ребра могут быть упорядочены лексикографически в соответствии с их информационными символами. Это последнее правило упорядочения приводит к более длительному поиску назад — вперед, но освобождает от необходимости вычисления и перевычисления порядка при достижении каждого узла. Какоечправило упорядочения более просто в реализации, зависит от конструкции декодера. Для простоты понимания структуры алгоритма правило упорядочения лучше оставить несколько неопределенным; предположим лишь, что в каждом узле ребро, ближайшее к принятому ребру по расстоянию Хэмминга, считается первым. Декодер будет искать ребра из каждого узла в соответствии с этим правилом.
 и текущего значения порога
и текущего значения порога 
 остается выше порога, декодер продолжает сдвигаться вправо и повышать порог так, чтобы тот оставался близким к
остается выше порога, декодер продолжает сдвигаться вправо и повышать порог так, чтобы тот оставался близким к  Если
Если  опускается ниже порога, то декодер проверяет альтернативные ребра этого кадра, пытаясь найти то ребро, которое находится выше порога. Если он не может сделать этого, то возвращается назвд.
опускается ниже порога, то декодер проверяет альтернативные ребра этого кадра, пытаясь найти то ребро, которое находится выше порога. Если он не может сделать этого, то возвращается назвд.

 меньше текущего значения порога
меньше текущего значения порога  то порог был увеличен в
то порог был увеличен в  кадре. В блок-схему на рис 12.27 включен этот тест на нахождение узла, в котором был установлен текущий порог; теперь в этом узле порог уменьшается.
кадре. В блок-схему на рис 12.27 включен этот тест на нахождение узла, в котором был установлен текущий порог; теперь в этом узле порог уменьшается.
 декодер ищет следующие ребра в том же порядке, что и до этого, до тех пор, пока не найдет то место, в котором перекошенное расстояние, ранее бывшее меньше порога, становится больше него. До этого момента порог
декодер ищет следующие ребра в том же порядке, что и до этого, до тех пор, пока не найдет то место, в котором перекошенное расстояние, ранее бывшее меньше порога, становится больше него. До этого момента порог  не
не
 перекошенное расстояние в тех узлах, где оно превышало первоначальный порог, никогда не будет меньше
перекошенное расстояние в тех узлах, где оно превышало первоначальный порог, никогда не будет меньше  Когда декодер продвигается в новую часть дерева, он в конце концов достигает состояния, в котором
Когда декодер продвигается в новую часть дерева, он в конце концов достигает состояния, в котором  В этой точке порог повышается. Это и является тестом для определения того, новый ли узел был посещен, и нет необходимости помнить все посещенные ранее узлы. Такой тест включен в схему на рис. 12.27.
В этой точке порог повышается. Это и является тестом для определения того, новый ли узел был посещен, и нет необходимости помнить все посещенные ранее узлы. Такой тест включен в схему на рис. 12.27.
 которые могут быть выбраны при помощи моделирования на ЭВМ. На практике необходимо время от времени уменьшать
которые могут быть выбраны при помощи моделирования на ЭВМ. На практике необходимо время от времени уменьшать  так. чтобы эти числа не становились слишком большими. Вычитание из обеих функций некоторого числа, кратного
так. чтобы эти числа не становились слишком большими. Вычитание из обеих функций некоторого числа, кратного  не влияет на последующие вычисления.
не влияет на последующие вычисления.
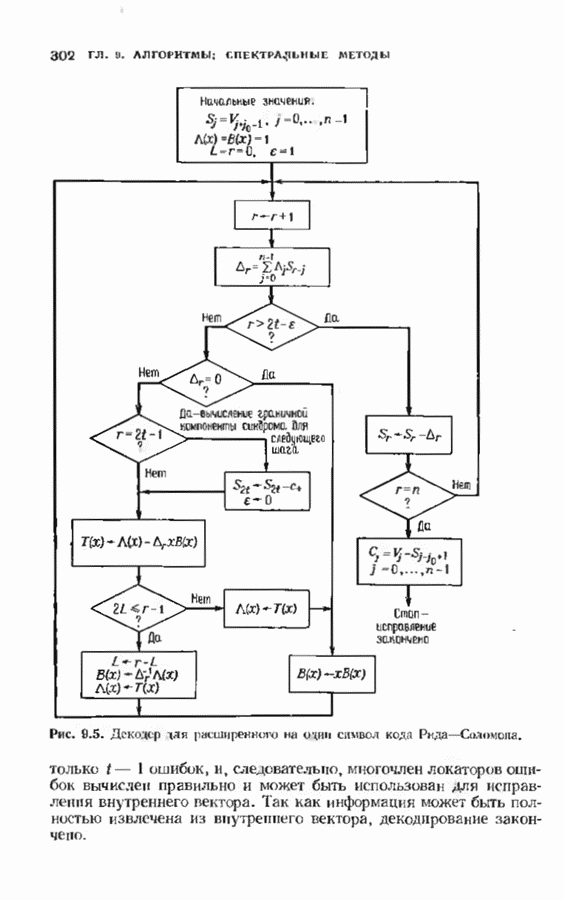
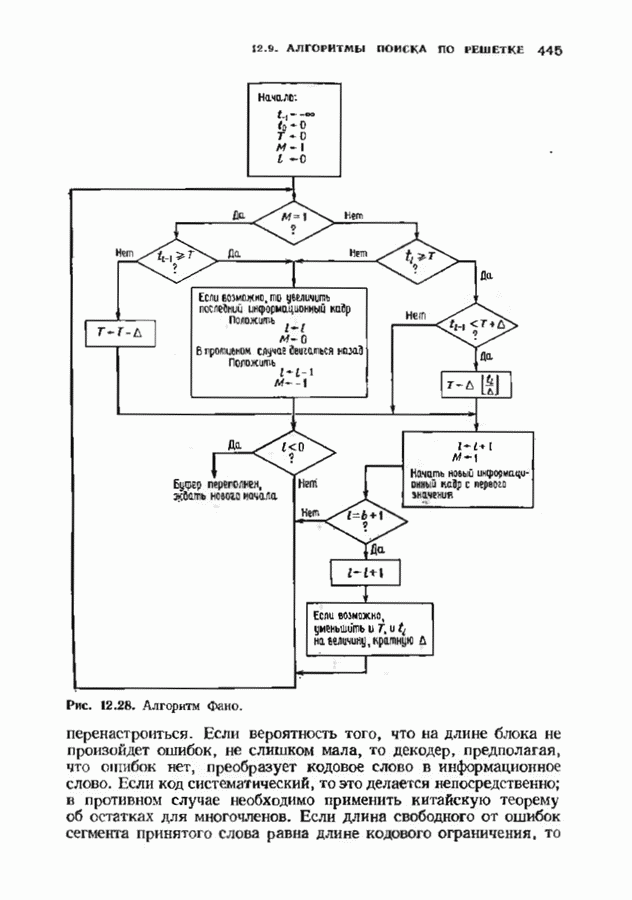
 окна декодирования в несколько раз больше длины блока. На рис. 12.28 приведена более полная блок-схема алгоритма фано, отражающая важную роль
окна декодирования в несколько раз больше длины блока. На рис. 12.28 приведена более полная блок-схема алгоритма фано, отражающая важную роль  Каждый раз, когда самый старый информационный кадр достигает конца буфера, что отмечается указателем кадра, он выходит из декодера, а указатель кадра уменьшается таким образом, чтобы всегда указывать на самый старый имеющийся кадр. В протнвном случае декодер может попытаться возвратиться к кадру, уже вышедшему из декодера.
Каждый раз, когда самый старый информационный кадр достигает конца буфера, что отмечается указателем кадра, он выходит из декодера, а указатель кадра уменьшается таким образом, чтобы всегда указывать на самый старый имеющийся кадр. В протнвном случае декодер может попытаться возвратиться к кадру, уже вышедшему из декодера.
 противоречии с нашим предположением появилась ошибка, то узел неправилен,
противоречии с нашим предположением появилась ошибка, то узел неправилен,  буфер скоро снова переполнится. Этот процесс продвижения декодера вперед продолжается до тех пор, пока не будет получено правильное декодирование.
буфер скоро снова переполнится. Этот процесс продвижения декодера вперед продолжается до тех пор, пока не будет получено правильное декодирование.