Пред.
След.
Макеты страниц
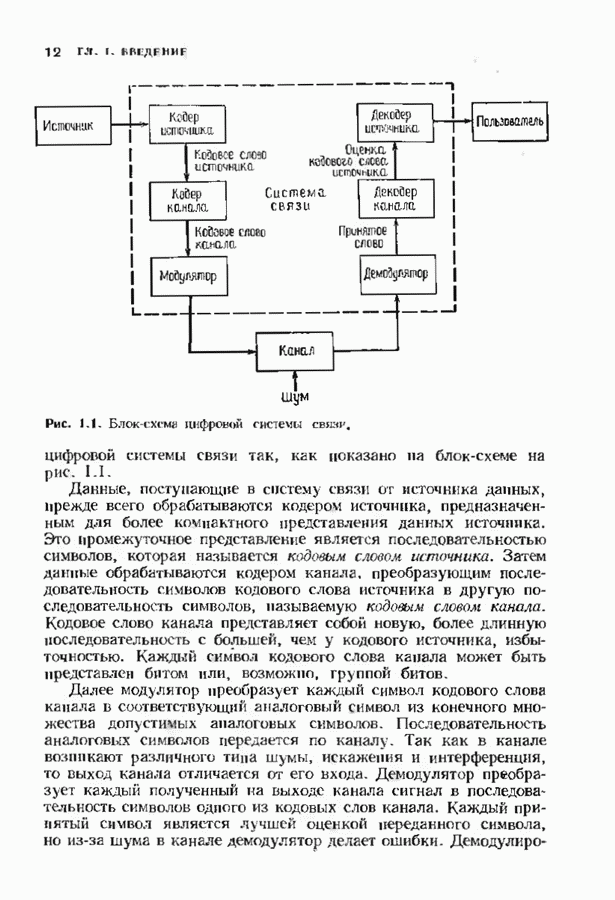
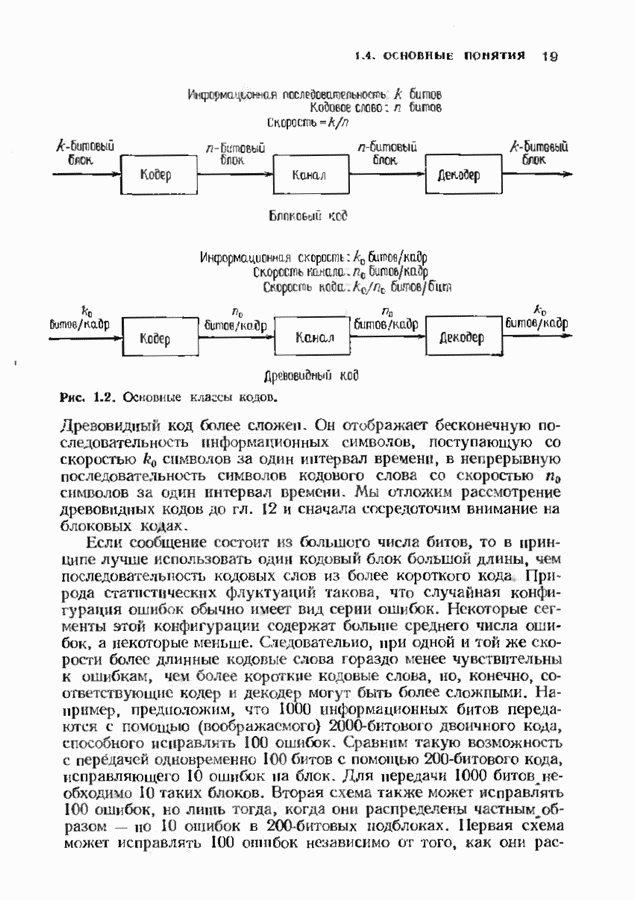
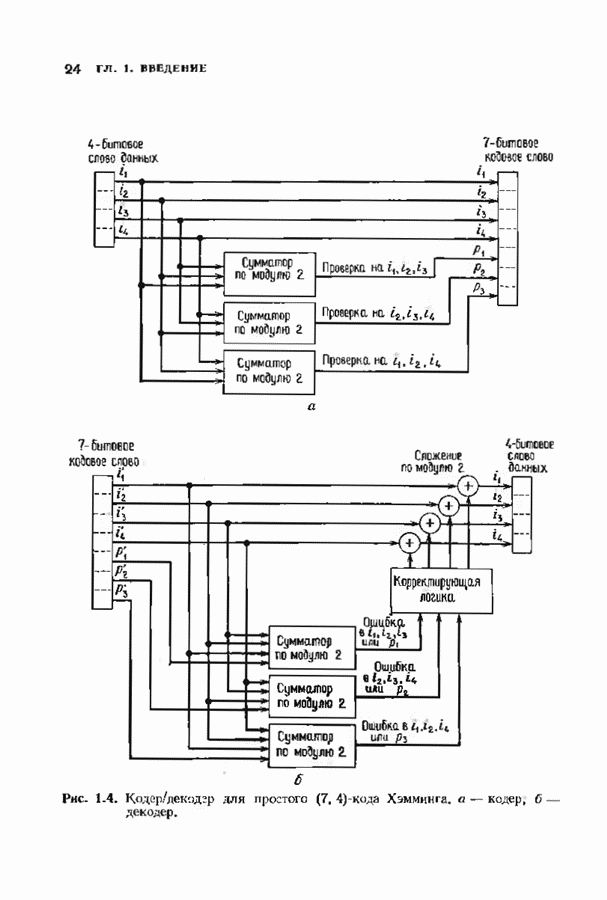
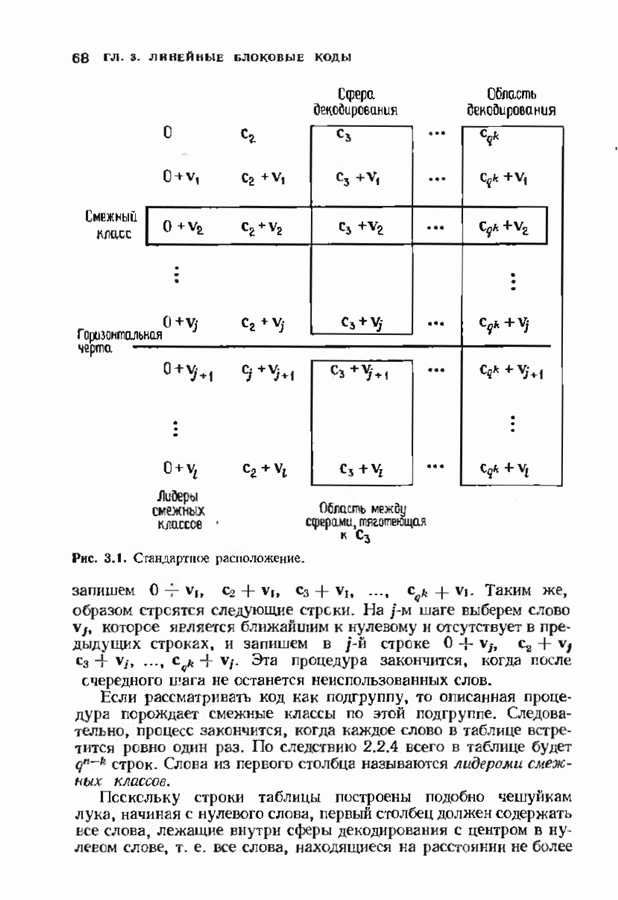
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.7. КОДЫ РИДА—МАЛЛЕРАКоды Рида-Маллера представляют собой класс линейных кодов над Код Рида-Маллера является линейным кодом. Мы определим этот код через порождающую матрицу; эту матрицу будем строить в удобной для декодирования несистематической форме. Прежде всего определим покомпонентное произведение деух векторов
то их произведение равно вектору
Порождающая матрица кода Рида-Маллера
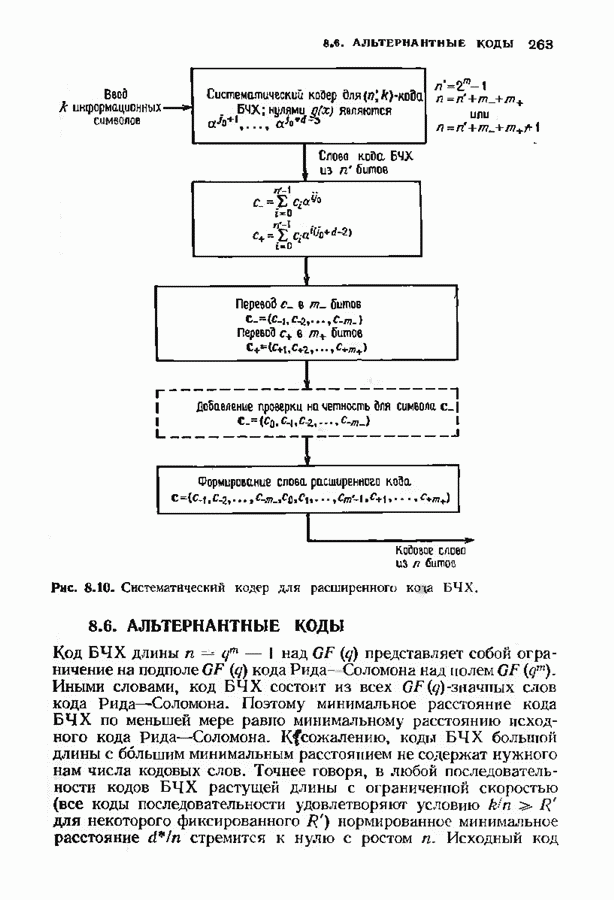
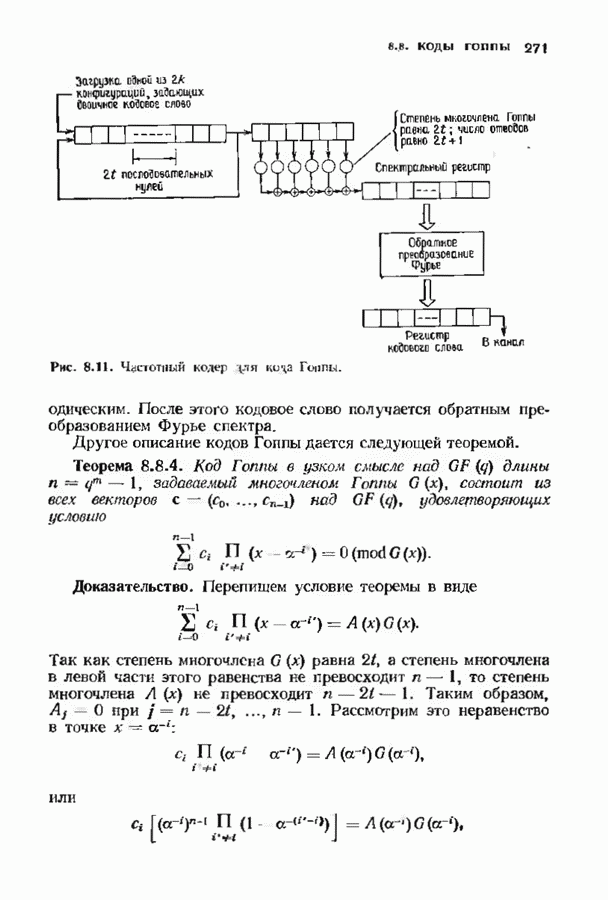
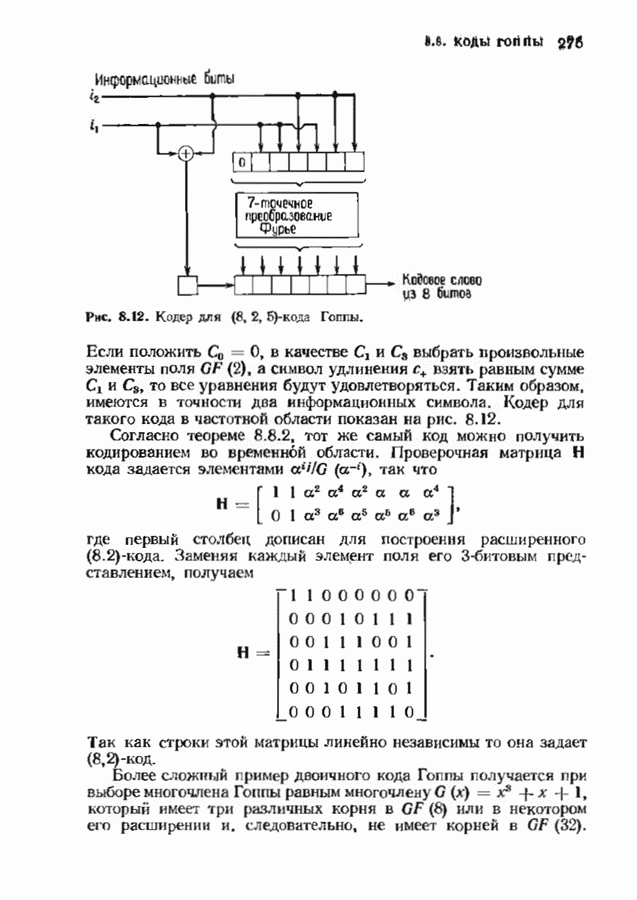
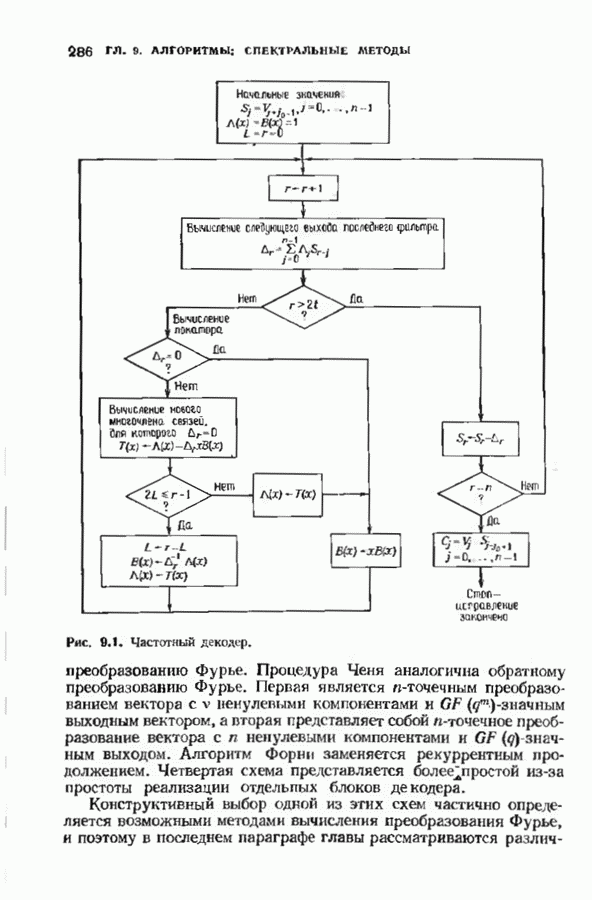
где Поскольку существует всего
что обеспечивается линейной независимостью строк в матрице В качестве примера положим
Поскольку
а матрица
Таким образом порождающая матрица кода Рида-Маллера третьего порядка длины 16 является
Эта порождающая матрица задает
и задает Из определения порождающей матрицы ясно, что код Рида—Маллера Каждая строка матрицы Мы должны доказать, что строки Алгоритм Рида был разработан специально для кодов Рида-Маллера. Можно, конечно, использовать процедуру синдромного декодирования, описанную в § 3.3, но в данном случае осуществить ее довольно сложно. Алгоритм Рида отличается от большинства алгоритмов декодирования тем, что позволяет восстановить информационные символы прямо из принятого слова и при этом не дает точного значения самой ошибки. В этом алгоритме не используются также промежуточные переменные, например синдром. Предположим, что у нас имеется декодер для кода Рида-Маллера Удобно разбить информационный вектор на
Предположим, что информационная последовательность разбита на сегменты следующим образом: каждому сегменту соответствует один из Принятое слово запишем в виде
Алгоритм декодирования сначала по вектору
которая является искаженным кодовым словом кода Рида-Маллера Прежде всего рассмотрим декодирование информационного бита Первая проверочная сумма представляет собой сумму по модулю 2 первых 2 битов принятого слова, вторая — сумму по модулю 2 вторых ошибок. Таким образом, мажоритарное голосование проверочных сумм дает правильное значение Для построенного ранее
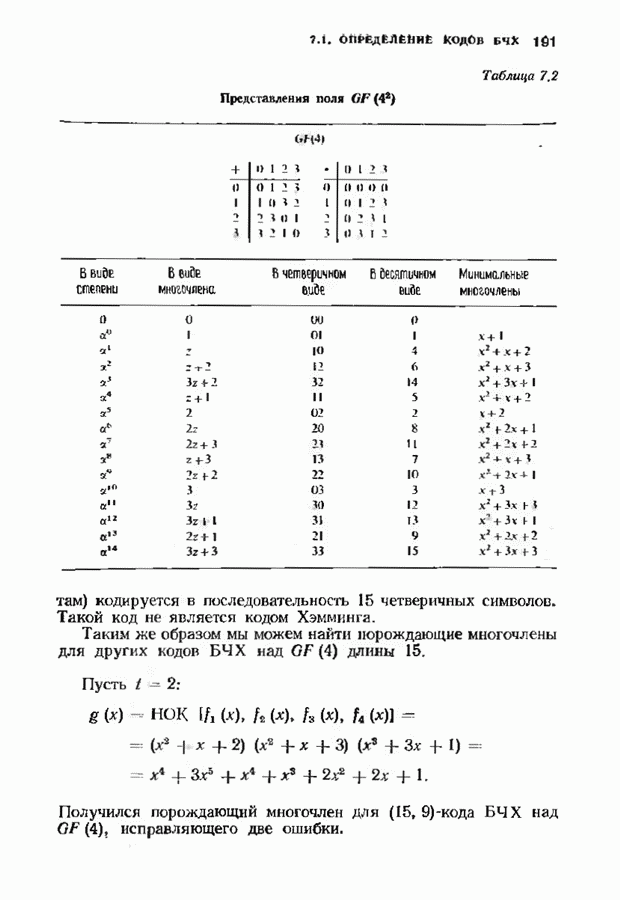
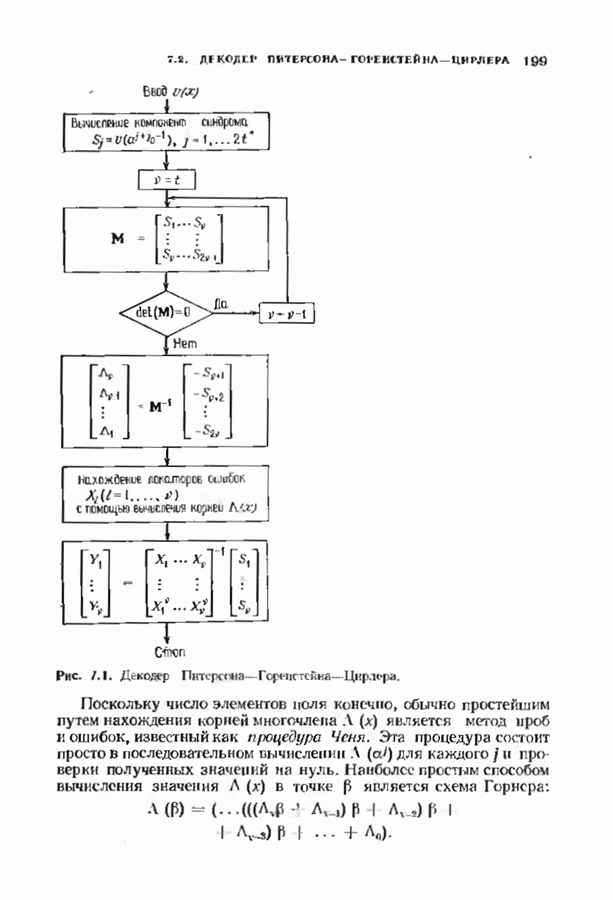
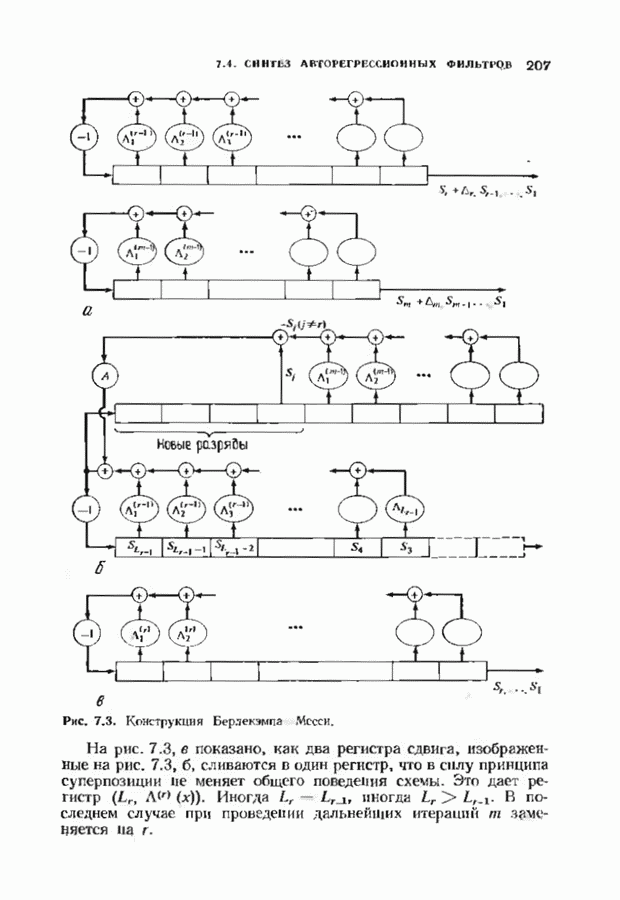
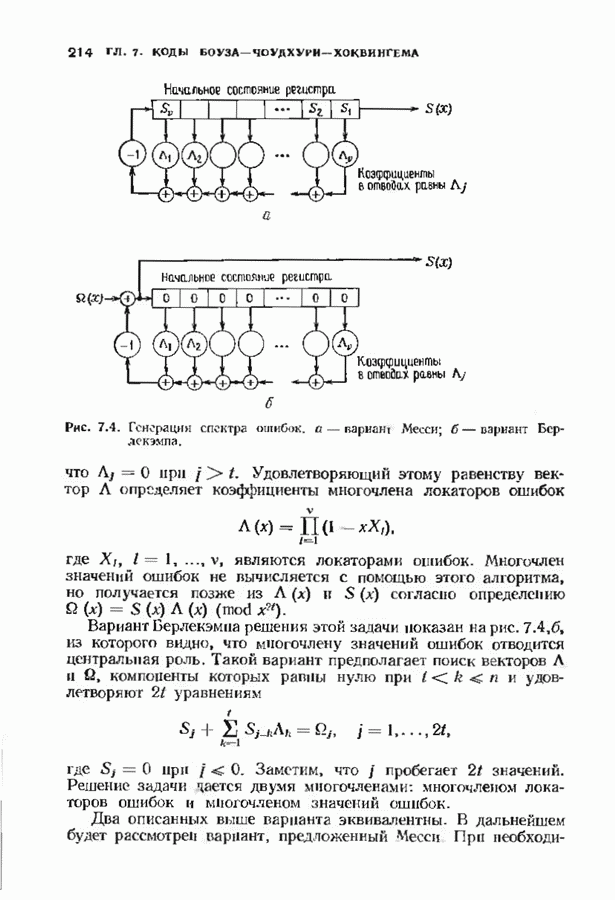
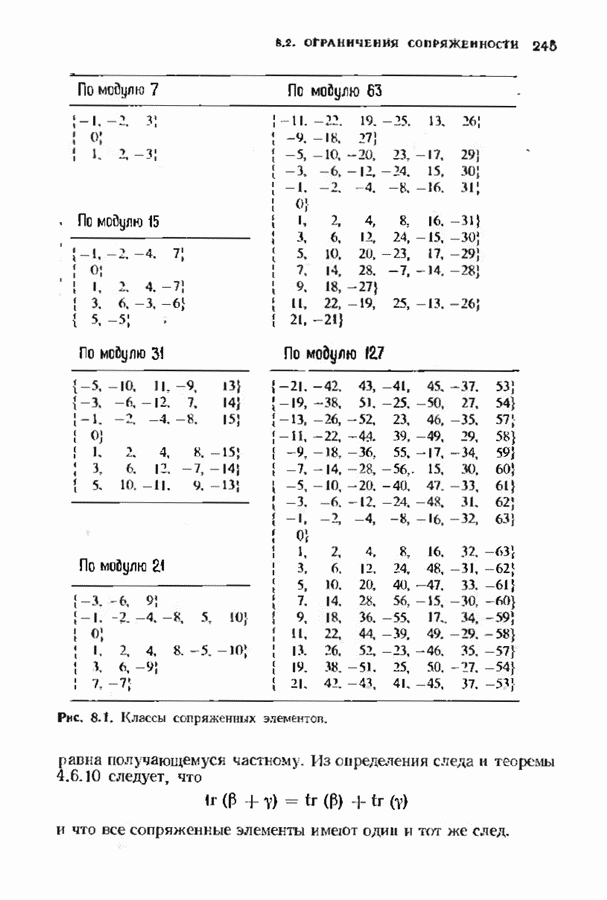
Если произошла только одна ошибка, то одна из оценок, даваемых проверочными суммами, будет неверна; мажоритарное решение дает значение Аналогично может быть продекодирован любой информационный символ, который умножается на одну из строк матрицы После того как эти информационные символы найдены, их вклад в кодовое слово вычитается из принятого слова. Это эквивалентно тому, что мы получаем слово кода Рида — Маллера Этот процесс повторяется до тех пор, пока не будут найдены все информационные биты. ЗАДАЧИ(см. скан) (см. скан) (см. скан) ЗАМЕЧАНИЯИзучение линейных кодов восходит к ранним работам Хэмминга [1950] и Голея 119491. Большинство положений, используемых в настоящее время при изучении линейных колов, заложено Слепяном [1956, 1960]: первые три параграфа тесно связаны с этими работами. Еще до этого Киксу 119537 обратил внимание на связь между линейными кодами и подпространствами векторных пространств. Коды с максимальным расстоянием впервые изучал Синглтон Двоичные коды Хэмминга как коды, исправляющие ошибки, впервые рассматривал Хэмминг, хотя подобные комбнпаторные структуры, рацее встречались в задачах статистики. Недвоичные коды Хэмминга были получены Голсем [1958] и Коком [1959]. Понятие совершенного кода впервые истречается у Голея, хотя он не пользовался таким термином. Делалось много попыток найти новые совершенные коды, но лишь отдельные из них увенчались успехом. В ряде работ Тиотявяйнен и Ван Лиит (работы завершились в 1974 и 1975 гг. соответственно) доказали, что не существует линейных (нетривиальных) совершенных кодов, отличных от кодов Хэмминга или Голея, и не существует нелинейных (нетривиальных) кодов, за исключением кодоп Васильева [1962] и Шёнхейма [1968]. Коды Рида-Маллера были получены Маллером [1954], и в этом же году Рид разработал алгоритм их декодирования. Этот алгоритм необычем тем, что принимает решение, основанное «а мажоритарной логике. Коды Рида-Маллера являются предшественниками обширных семейств мажоритарно декодируемых кодов, с которыми мы встретимся в следующих главах.
|
 |
Оглавление
|




















































































































































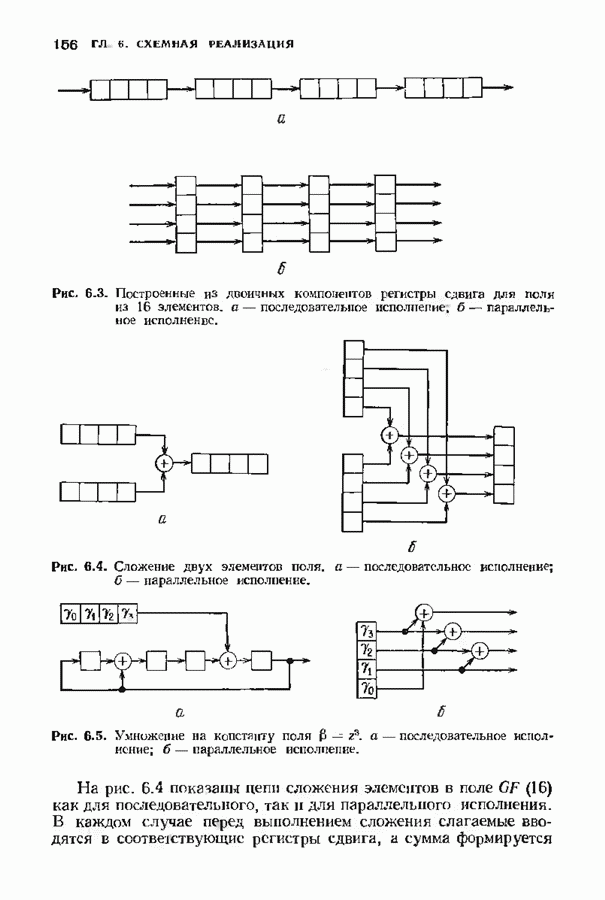




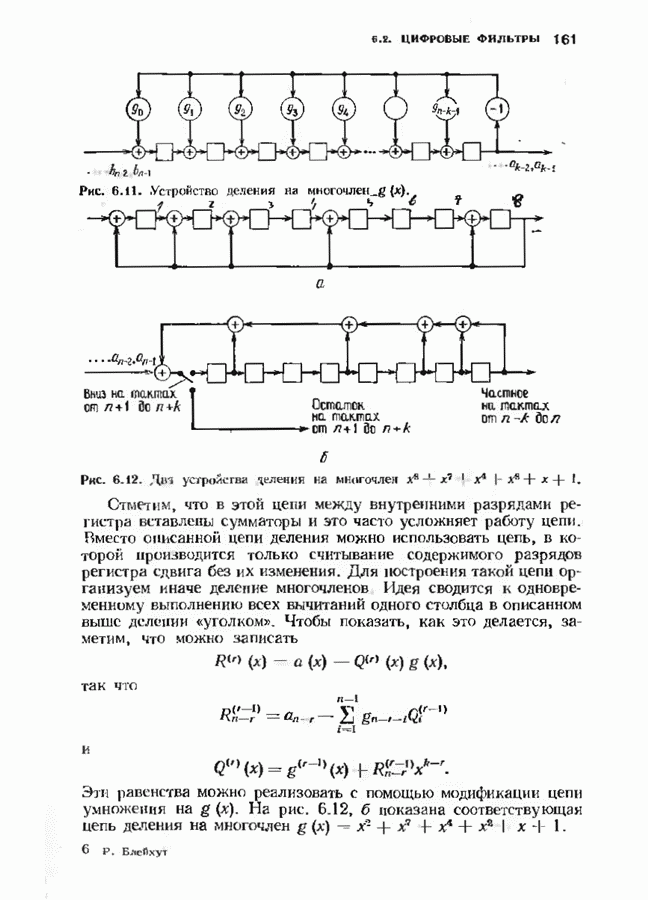

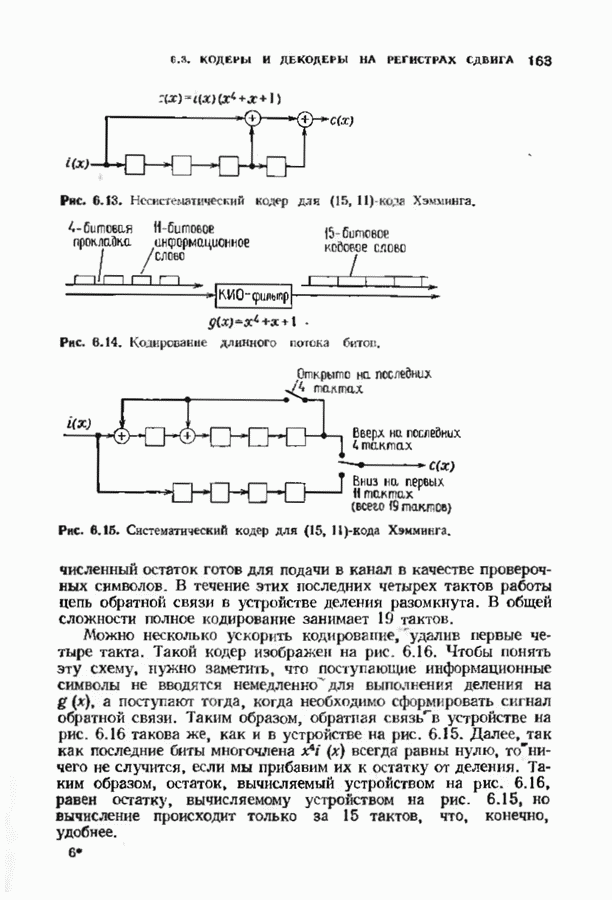
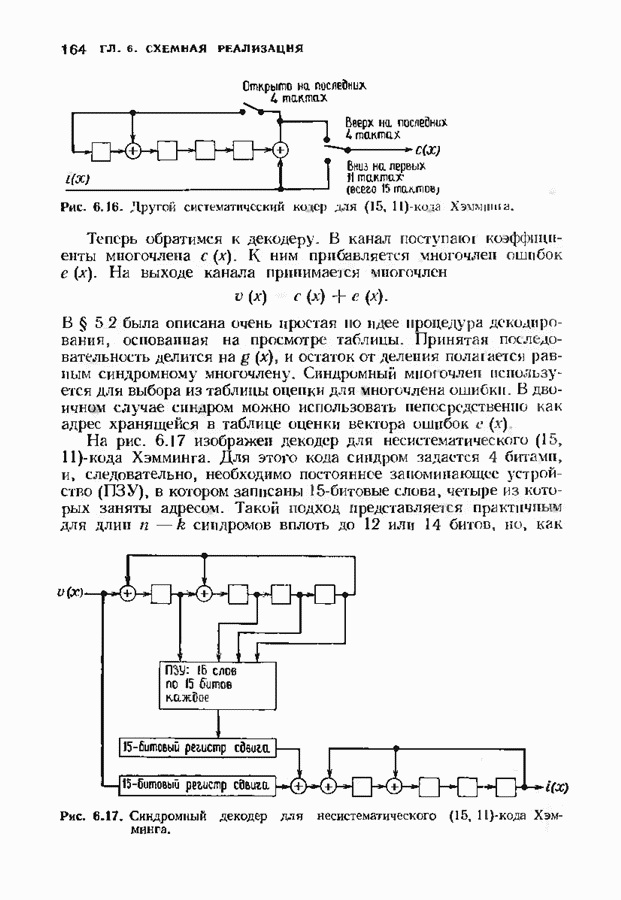








































































































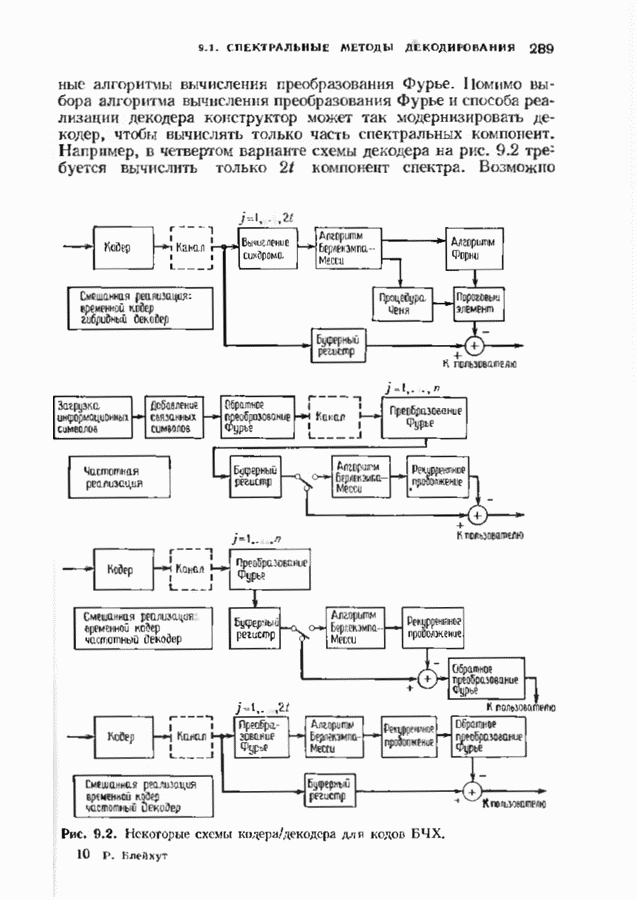



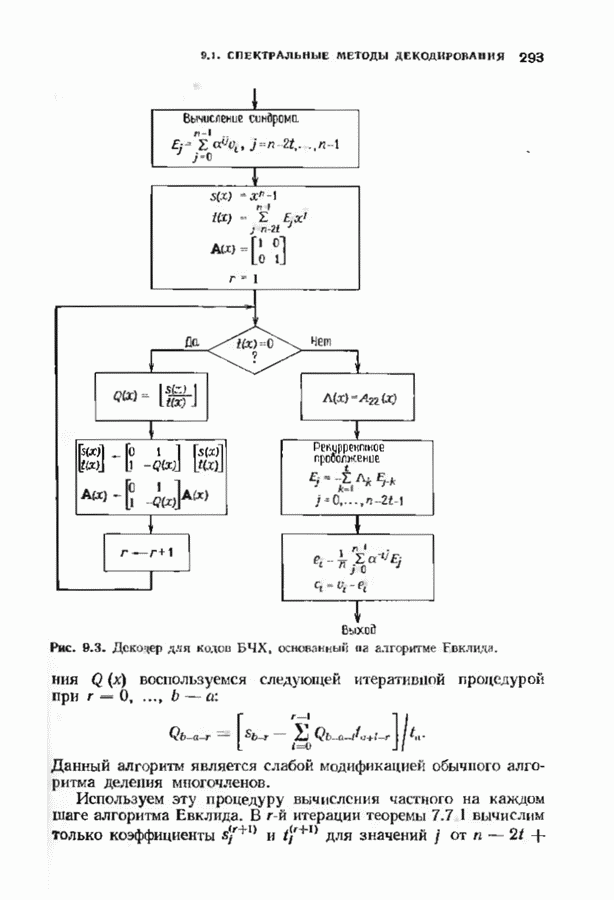





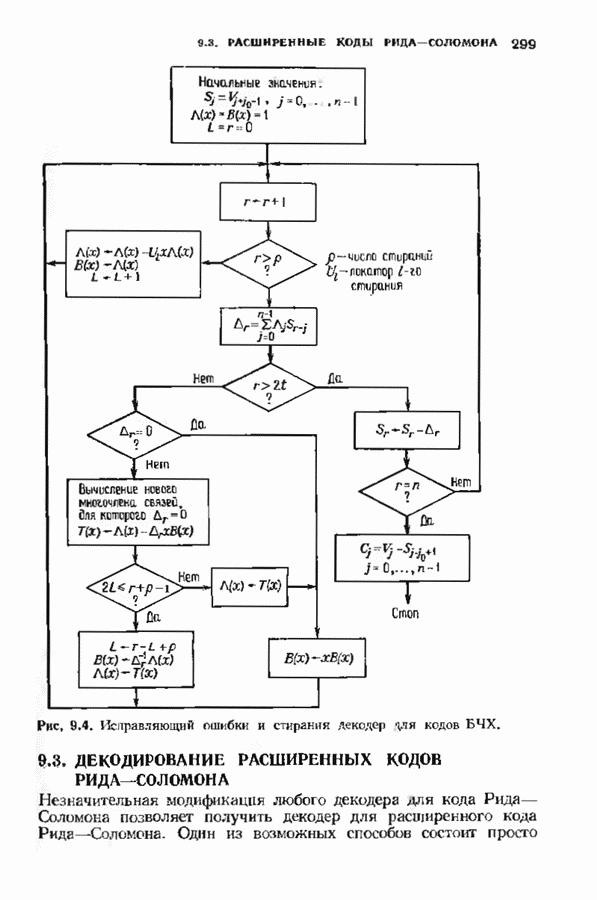


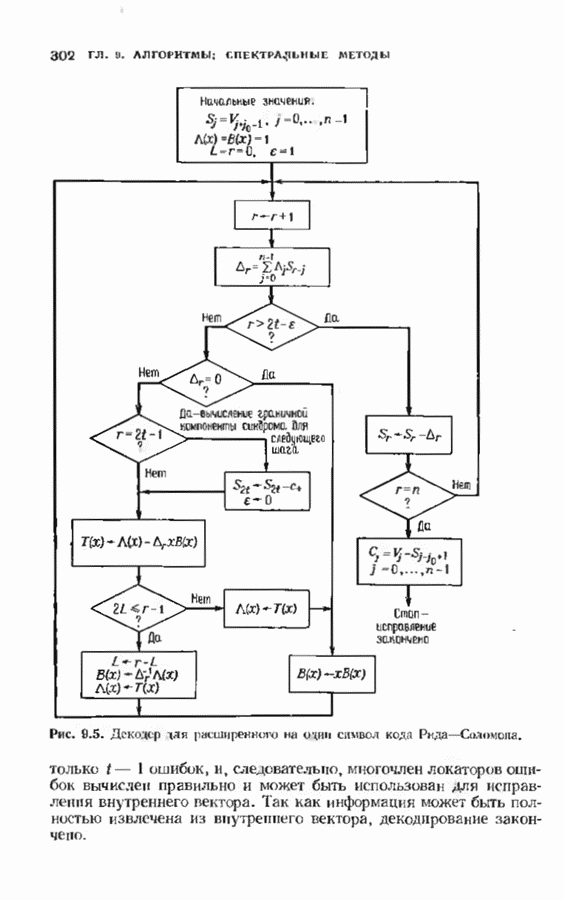



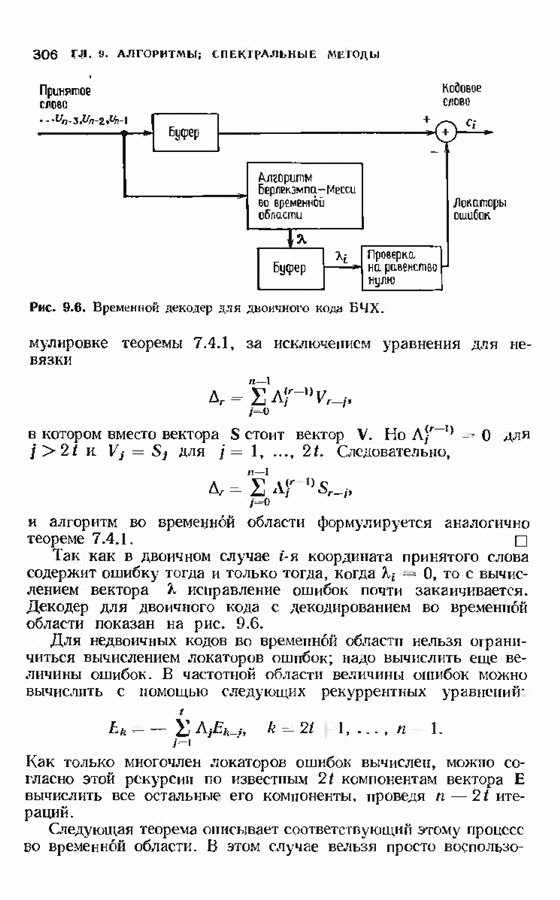

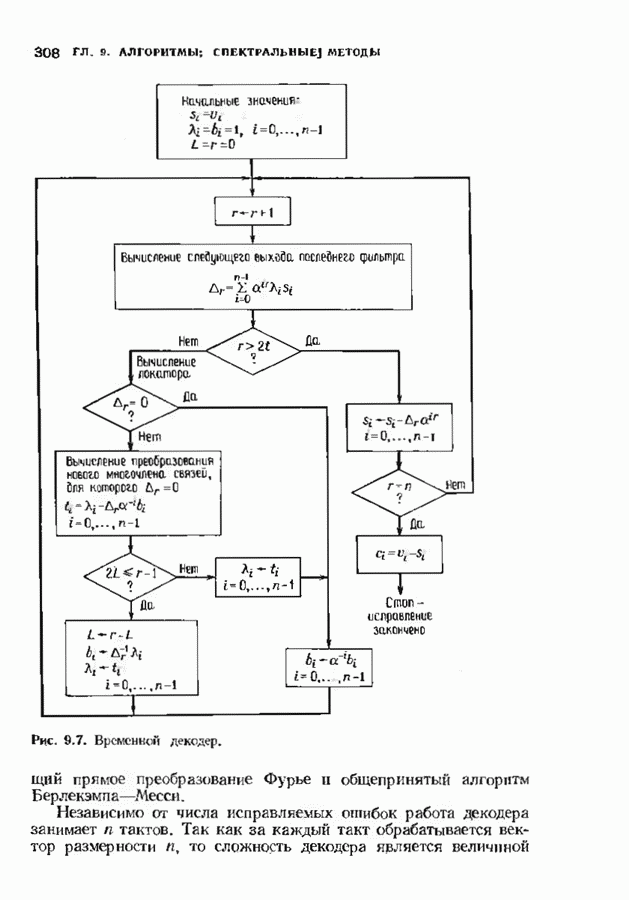







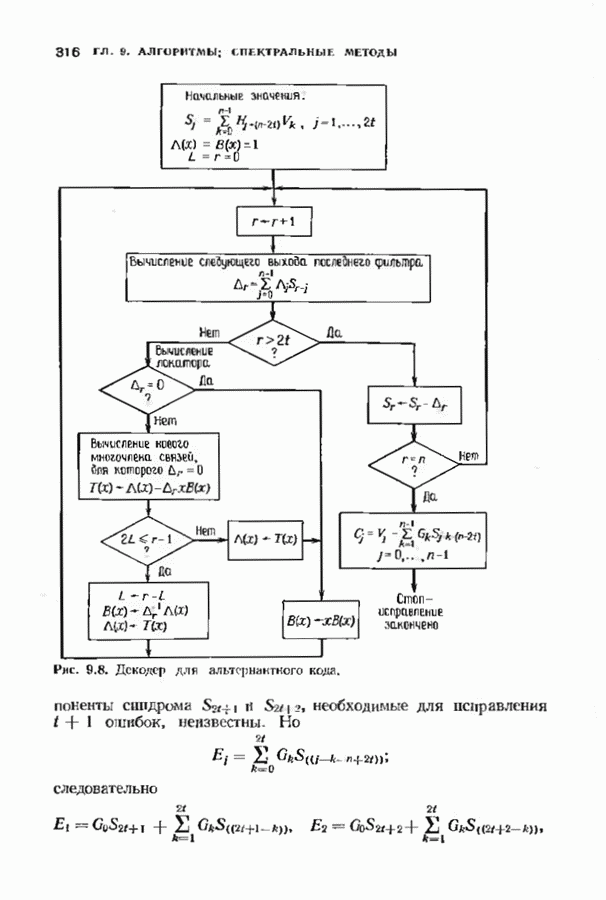

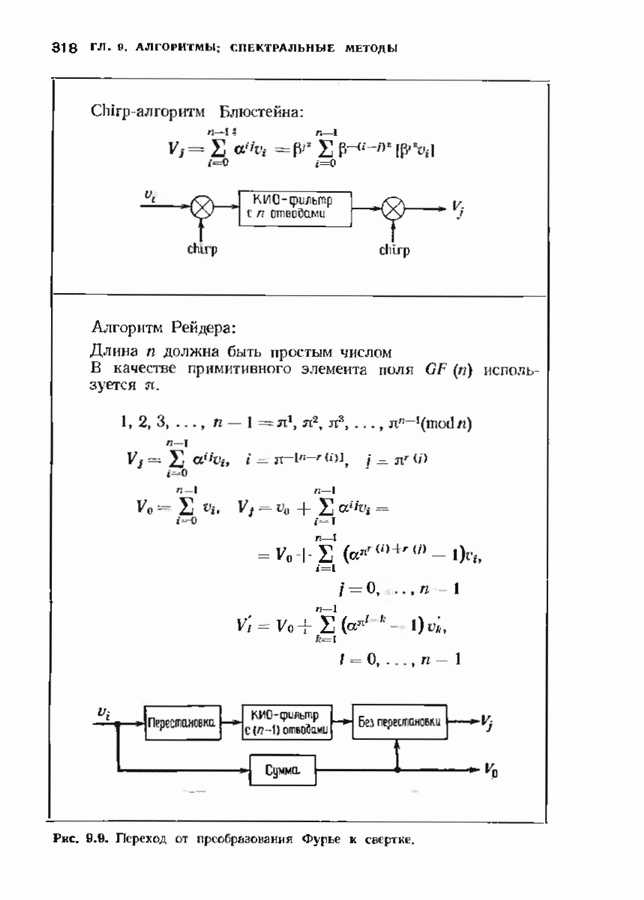


















































































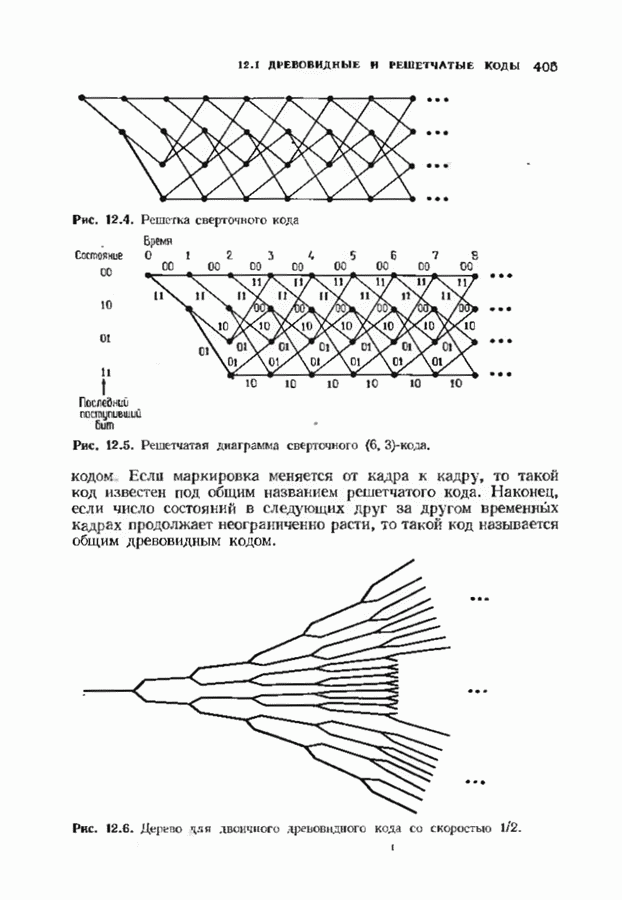

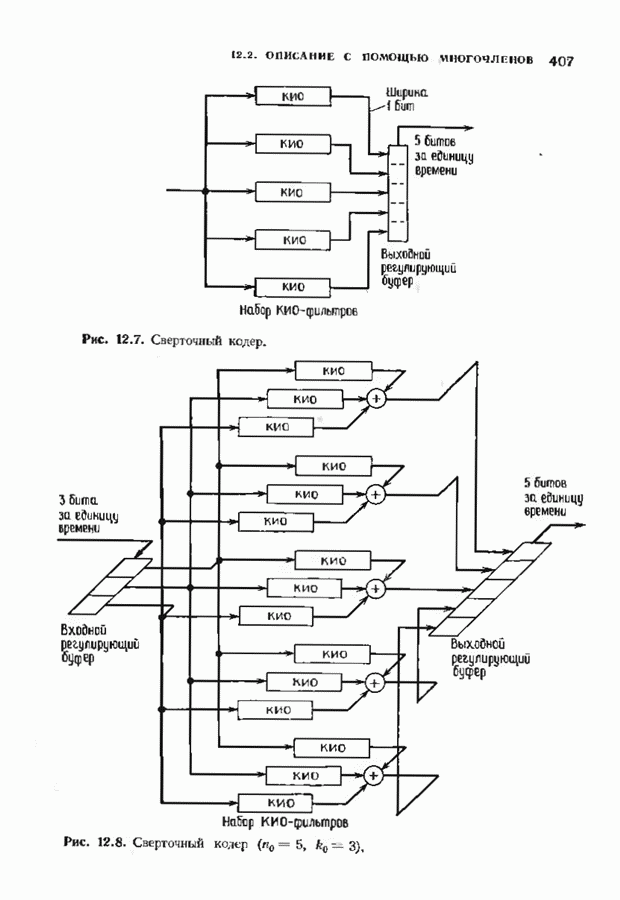




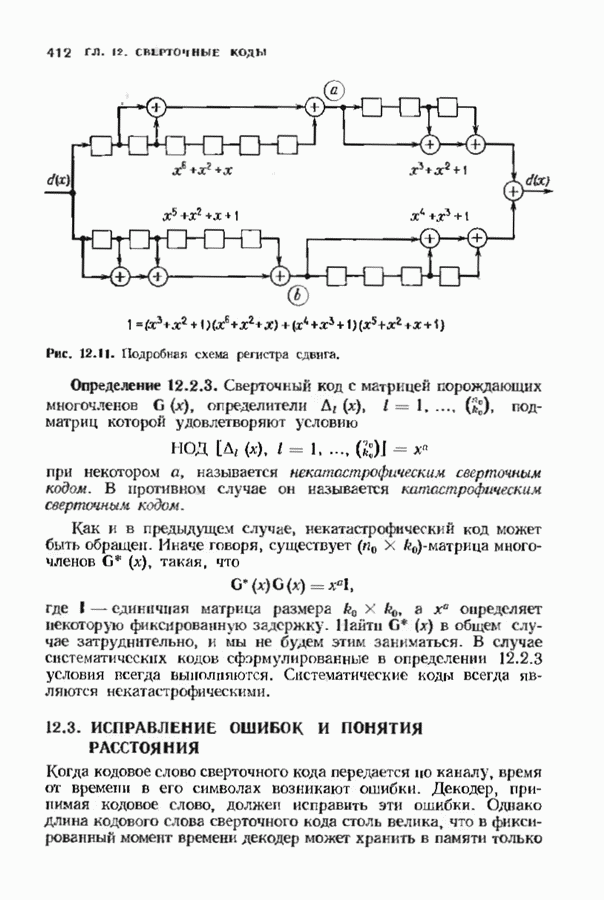




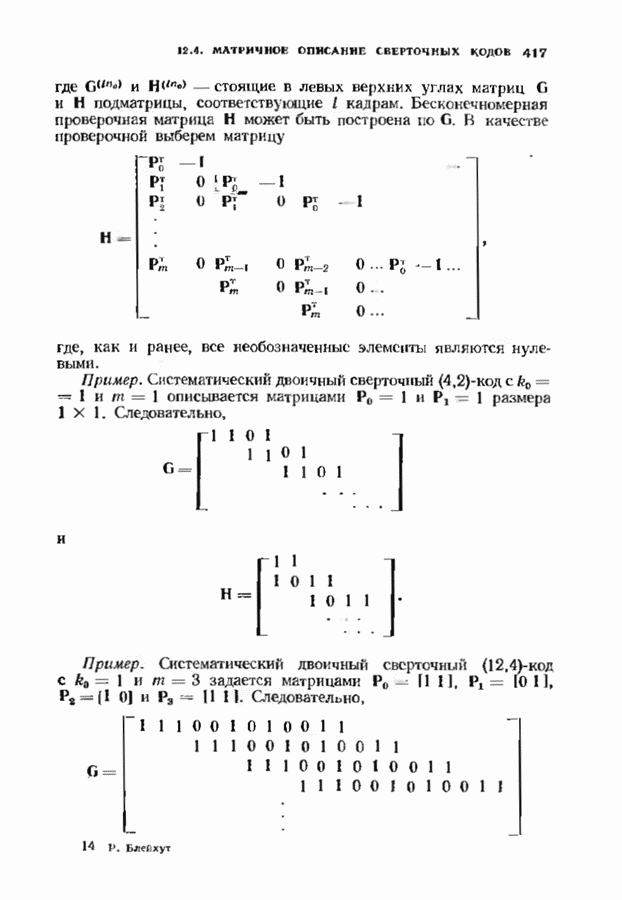


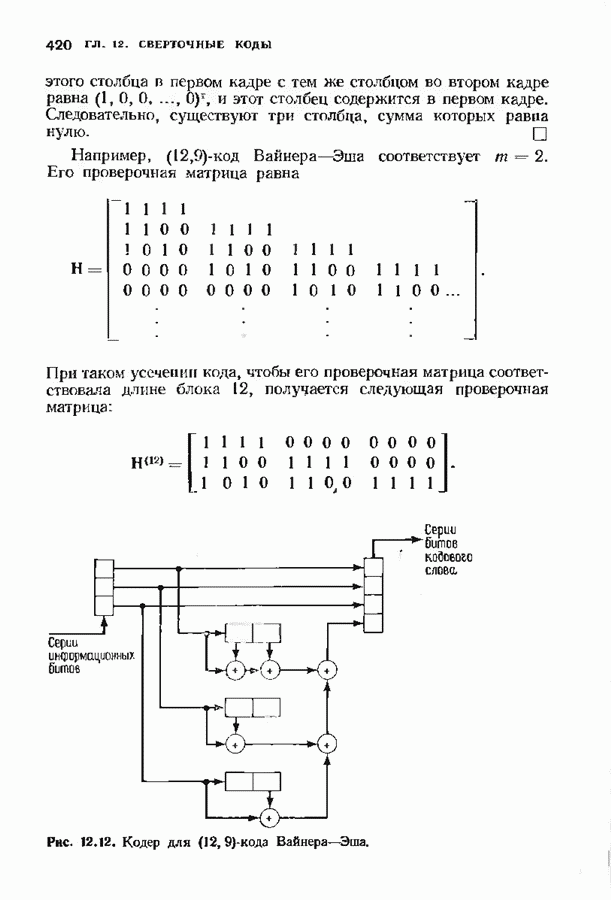
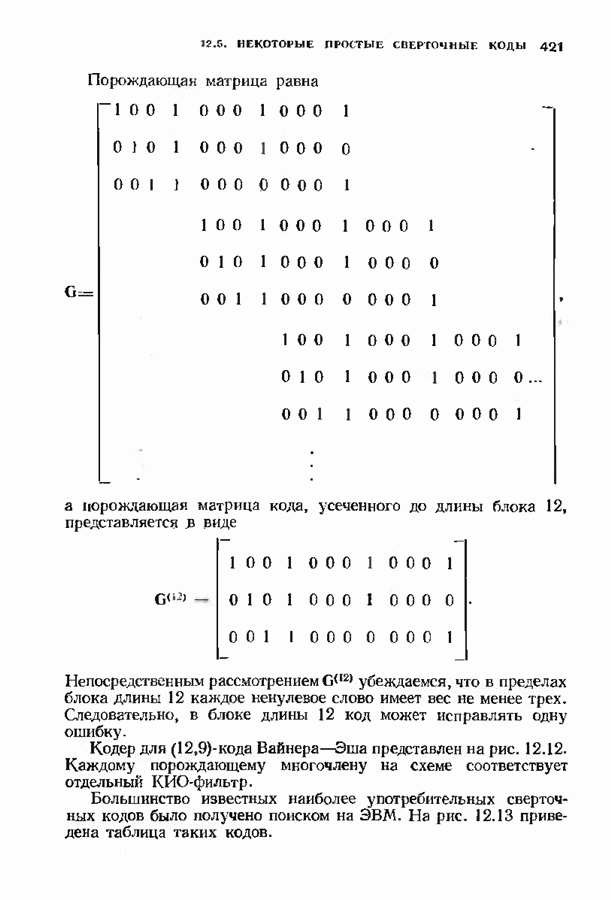


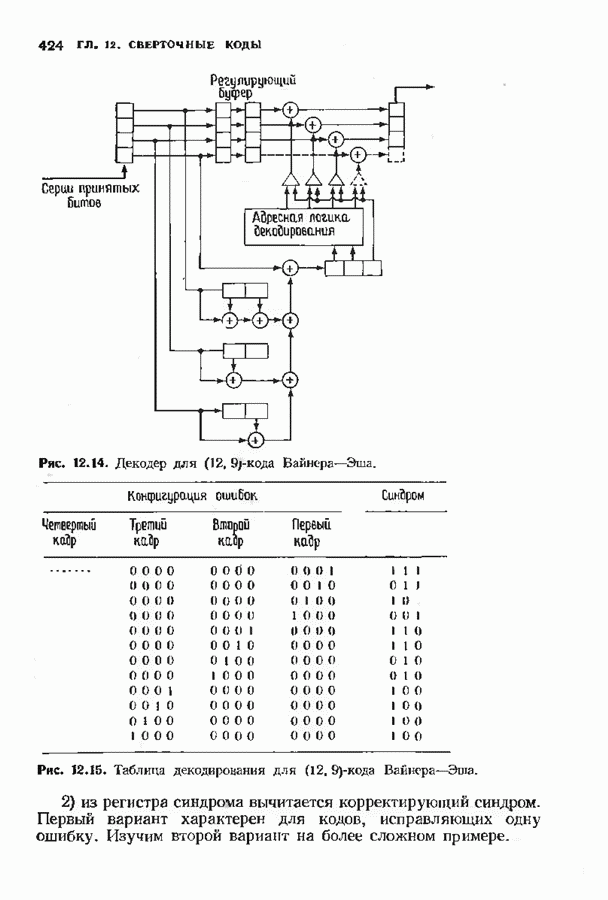
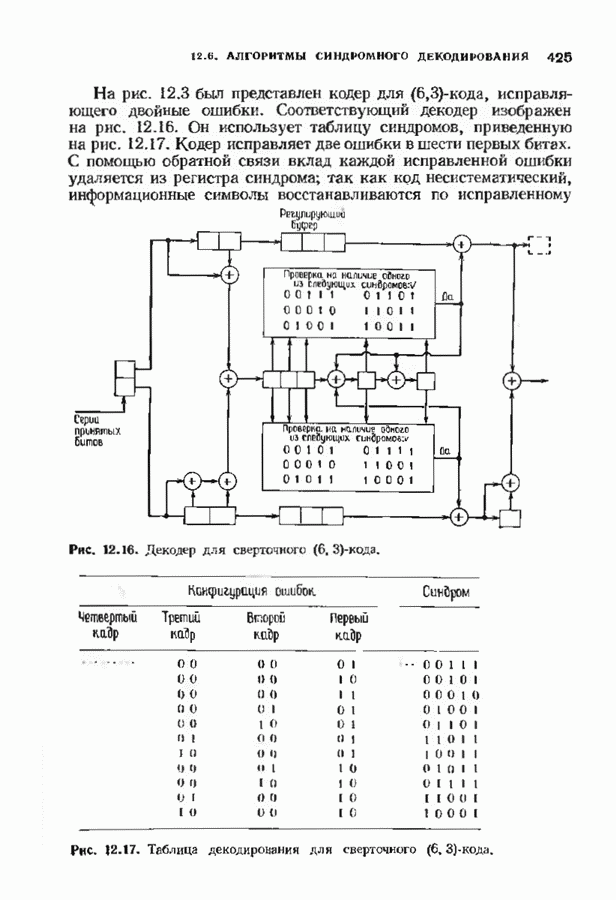











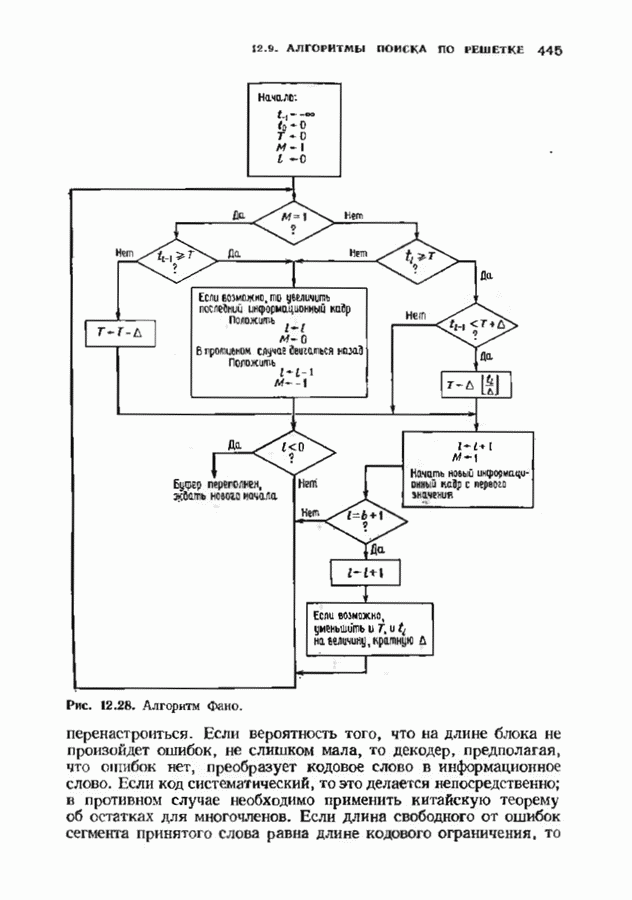



















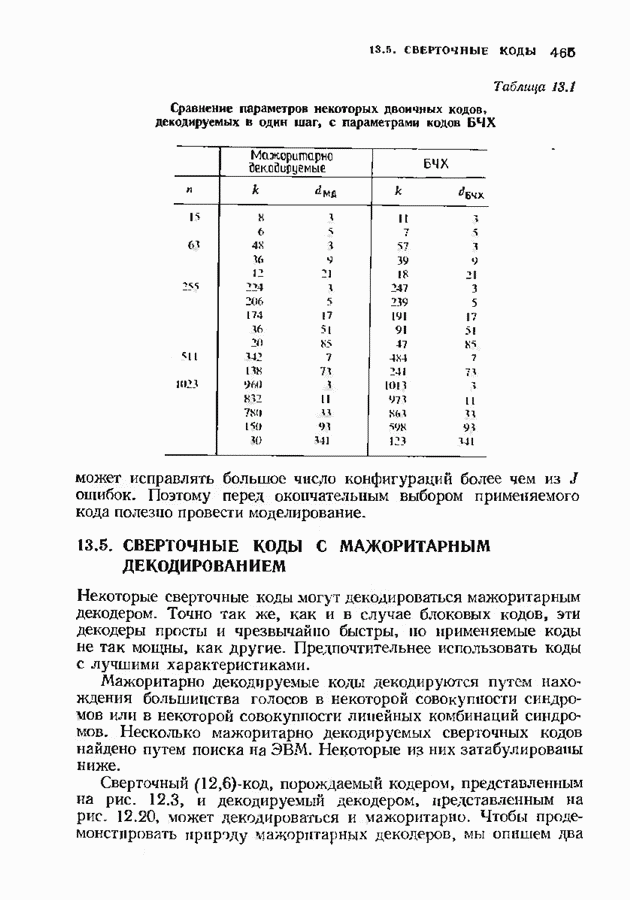
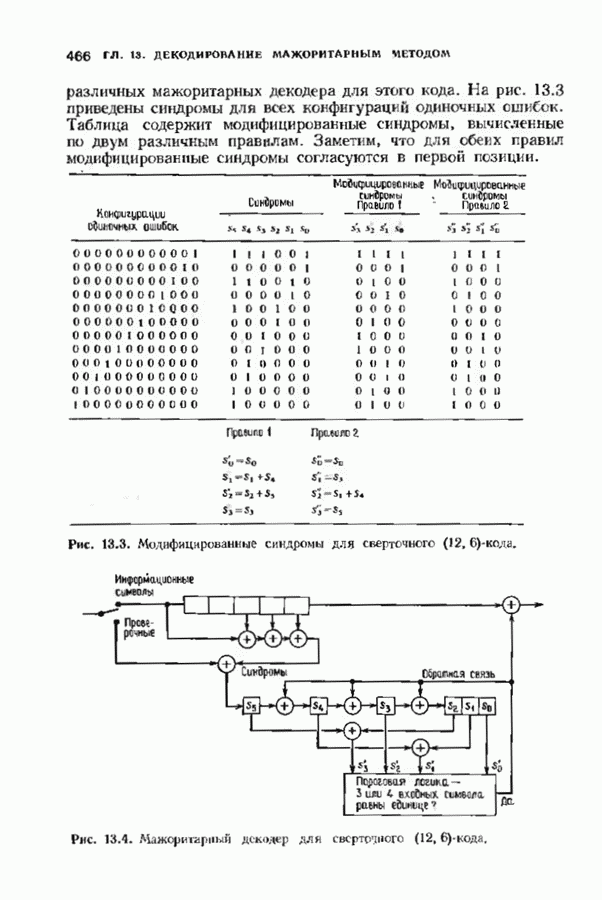
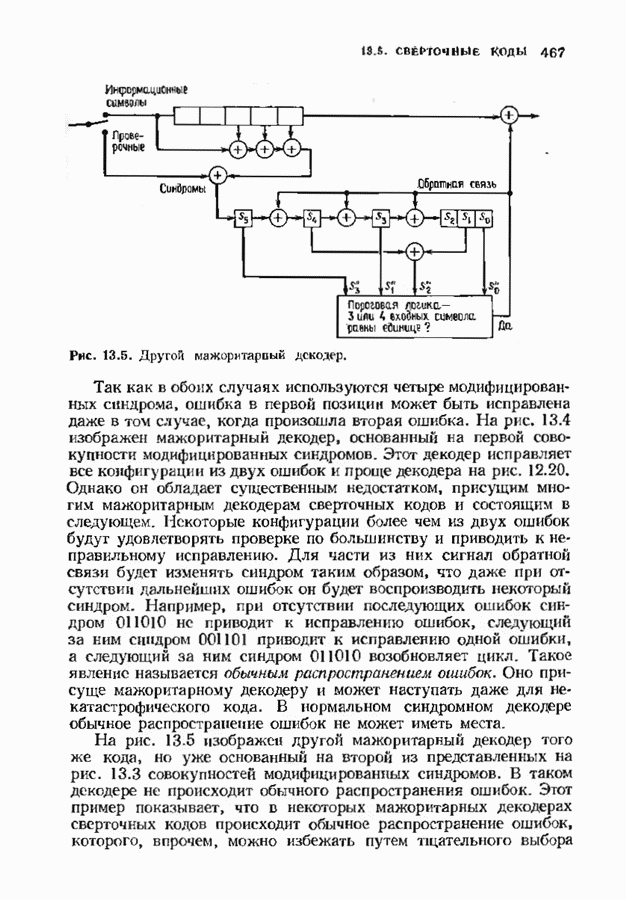





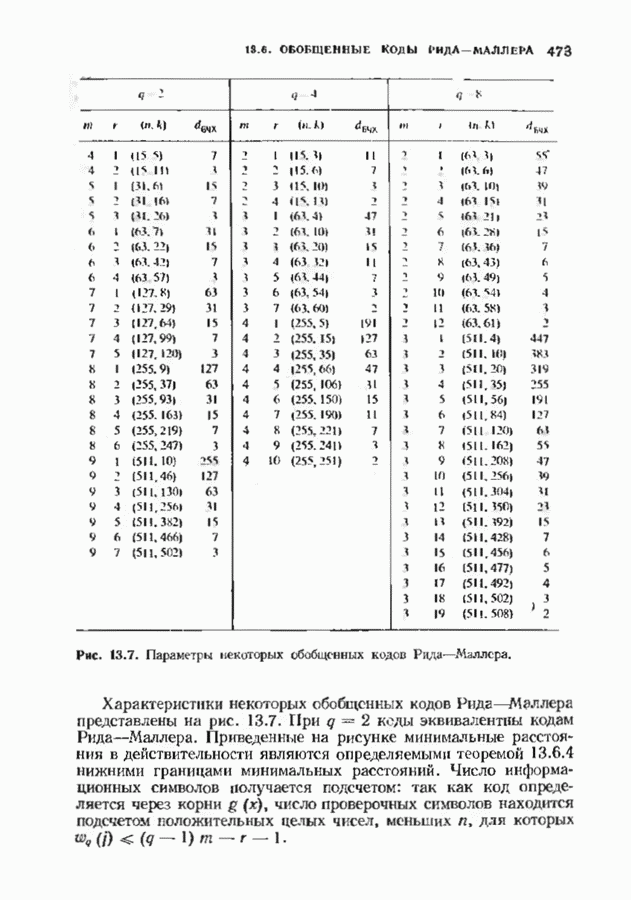
































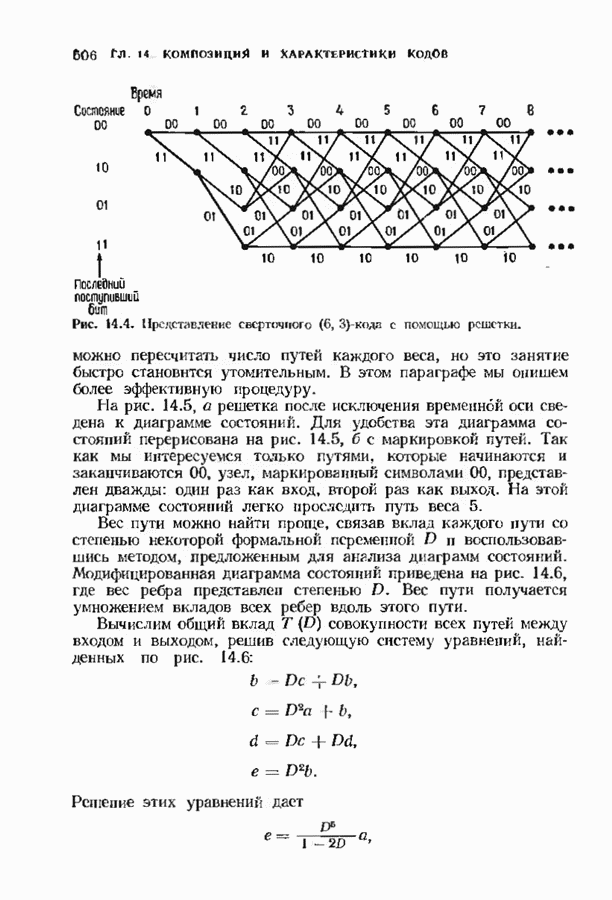
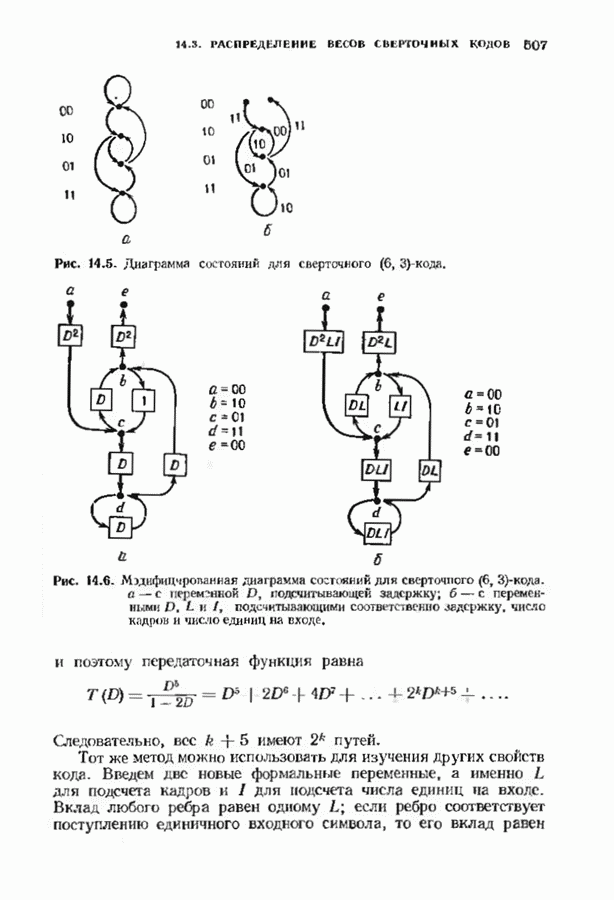




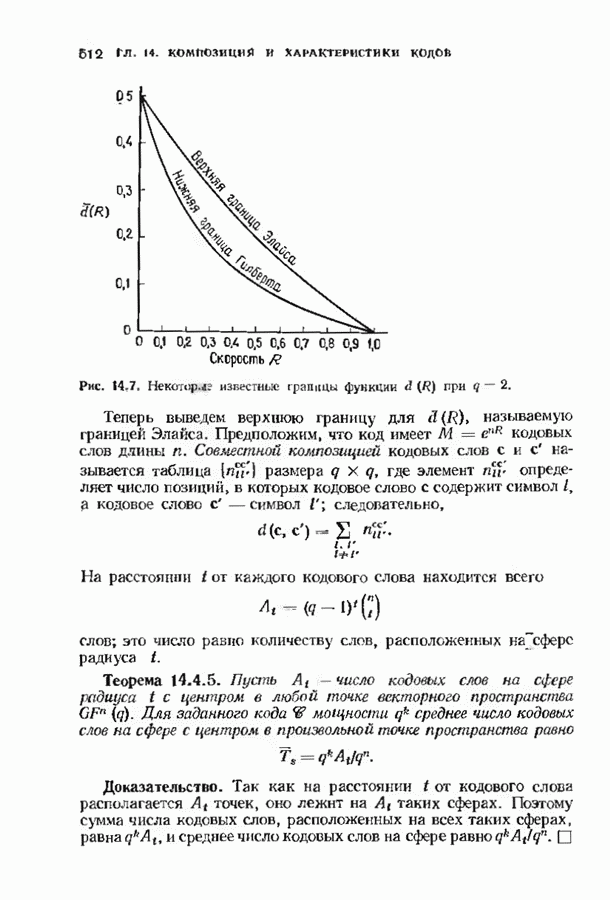




















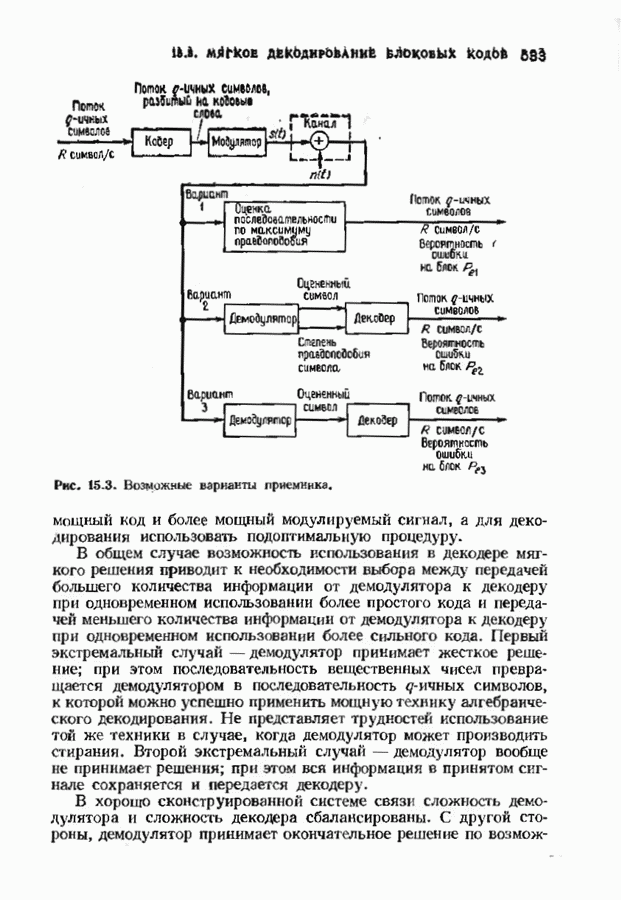








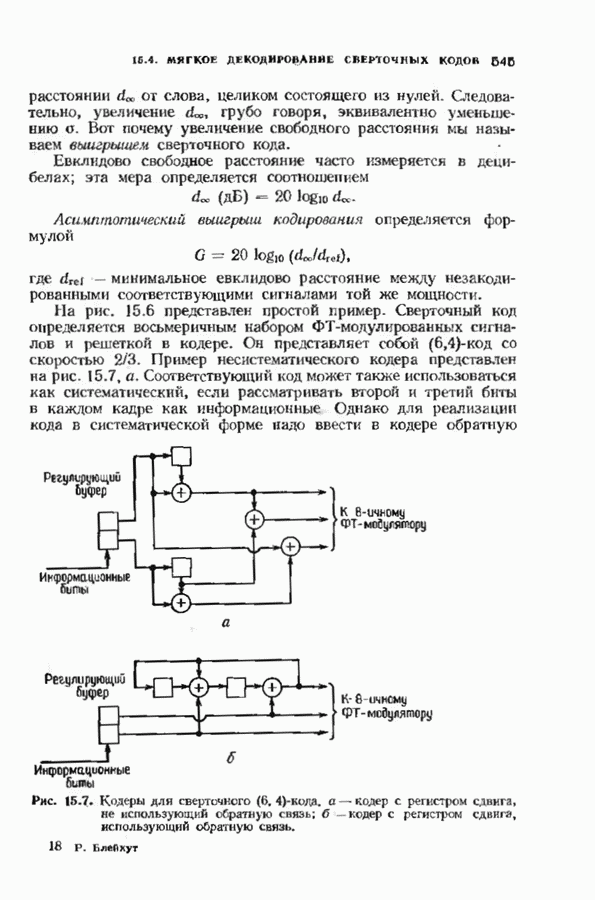
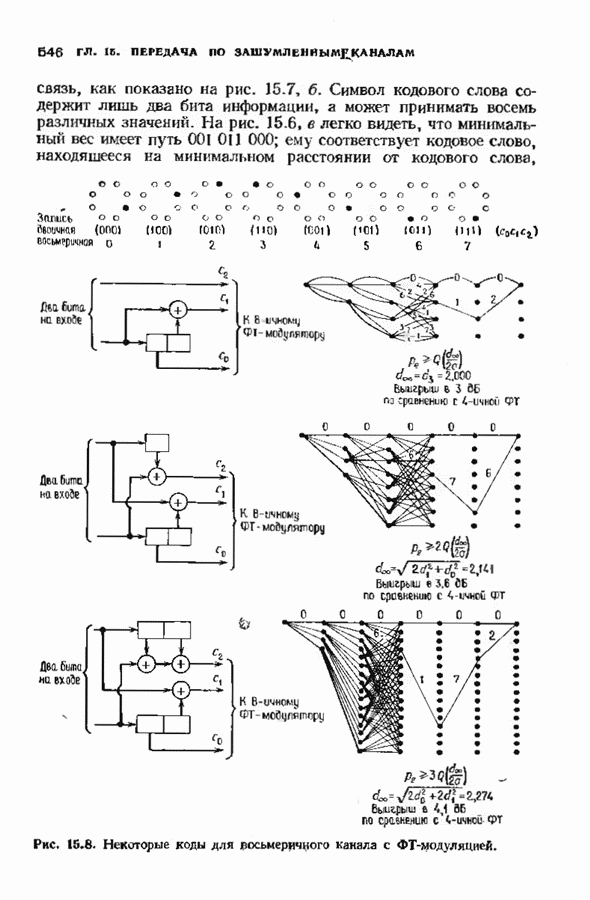


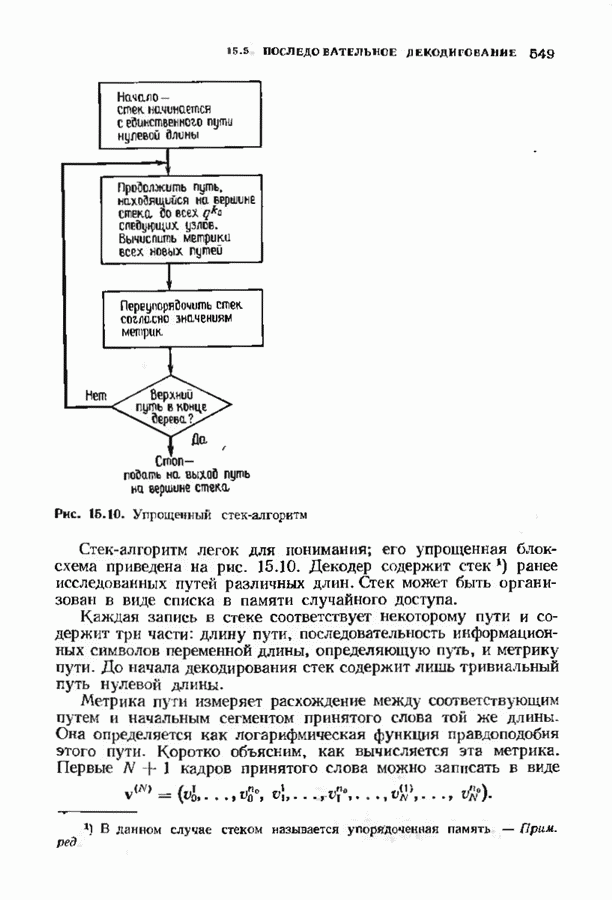














 с простым описанием и декодированием, осуществляемым методом простого голосования. По этим причинам коды Рида-Маллера играют важную роль в кодировании, хотя если судить об этих кодах по минимальному расстоянию, то, за некоторыми исключениями, они не заслуживают особого внимания. Для любых целых
с простым описанием и декодированием, осуществляемым методом простого голосования. По этим причинам коды Рида-Маллера играют важную роль в кодировании, хотя если судить об этих кодах по минимальному расстоянию, то, за некоторыми исключениями, они не заслуживают особого внимания. Для любых целых  существует код Рида Маллера длины
существует код Рида Маллера длины  который называется кодом Рида-Маллера
который называется кодом Рида-Маллера  -го порядка длины
-го порядка длины 
 если
если


 -го порядка длиной
-го порядка длиной  определяется как совокупность блоков
определяется как совокупность блоков

 вектор размерности
вектор размерности  состоящий из одних единиц;
состоящий из одних единиц;  есть
есть  -матрица, содержащая в качестве столбцов все двоичные
-матрица, содержащая в качестве столбцов все двоичные  -последовательности; строки матрицы
-последовательности; строки матрицы  получаются из строк матрицы
получаются из строк матрицы  как все возможные произведения I строк из
как все возможные произведения I строк из  Для определенности будем считать, что первый столбец в
Для определенности будем считать, что первый столбец в  состоит из одних нулей, последний — из одних единиц, а остальные
состоит из одних нулей, последний — из одних единиц, а остальные  -последовательности в
-последовательности в  расположены в порядке возрастания, считая, что младший бит расположен в нижней строке.
расположены в порядке возрастания, считая, что младший бит расположен в нижней строке.
 способов выбора
способов выбора  строк, входящих в произведение, то матрица
строк, входящих в произведение, то матрица  имеет размер
имеет размер  Ясно, что для кода Рида-Маллера порядка
Ясно, что для кода Рида-Маллера порядка 

 Код Рида-Маллера нулевого порядка является
Код Рида-Маллера нулевого порядка является  -кодом. Это просто код с повторением, который тривиально декодируется с помощью мажоритарного метода. Минимальное расстояние такого кода равно
-кодом. Это просто код с повторением, который тривиально декодируется с помощью мажоритарного метода. Минимальное расстояние такого кода равно 
 Тогда
Тогда

 имеет 4 строки, матрица
имеет 4 строки, матрица  имеет (2) строк:
имеет (2) строк:

 имеет
имеет  строк:
строк:

 -матрицей вида
-матрицей вида 

 -код над
-код над  (на самом деле это просто код с проверкой на четность) Другой код Рида-Маллера может быть получен с использованием этих матриц, если мы положим
(на самом деле это просто код с проверкой на четность) Другой код Рида-Маллера может быть получен с использованием этих матриц, если мы положим  этом случае порождающая матрица имеет вид
этом случае порождающая матрица имеет вид

 -код над GF (2). (В действительности это
-код над GF (2). (В действительности это  -код Хэмминга, расширенный с помощью проверки на четность.)
-код Хэмминга, расширенный с помощью проверки на четность.)
 порядка может быть получен пополнением кода Рида-Маллера
порядка может быть получен пополнением кода Рида-Маллера  -го порядка, а код Рида-Маллера
-го порядка, а код Рида-Маллера  -го порядка получается из кода
-го порядка получается из кода  порядка с помощью выбрасывания. Поскольку код Рида-Маллера
порядка с помощью выбрасывания. Поскольку код Рида-Маллера  -го порядка содержит код
-го порядка содержит код  порядка, ясно что его минимальное расстояние не может быть больше минимального расстояния кода
порядка, ясно что его минимальное расстояние не может быть больше минимального расстояния кода  порядка. В дальнейшем мы докажем, что код Рида-Маллера
порядка. В дальнейшем мы докажем, что код Рида-Маллера  -го порядка имеет минимальное расстояние
-го порядка имеет минимальное расстояние 
 имеет вес
имеет вес  Таким образом, любая строка матрицы
Таким образом, любая строка матрицы  имеет четный вес, а сумма двух двоичных векторов четного веса также имеет четный вес (см. задачу 3.11). Следовательно, все линейные комбинации строк матрицы
имеет четный вес, а сумма двух двоичных векторов четного веса также имеет четный вес (см. задачу 3.11). Следовательно, все линейные комбинации строк матрицы  имеют четный вес, а это означает, что все кодовые слова имеют четный вес. Матрица
имеют четный вес, а это означает, что все кодовые слова имеют четный вес. Матрица  содержит строки весом
содержит строки весом  следовательно, минимальный вес кода не превосходит
следовательно, минимальный вес кода не превосходит 
 линейно независимы, и найти минимальный вес кода. Мы докажем, что код имеет минимальный вес
линейно независимы, и найти минимальный вес кода. Мы докажем, что код имеет минимальный вес  и строки в матрице
и строки в матрице  линейно независимы. Для этого мы построим алгоритм декодирования — алгоритм Рида, который позволяет исправлять
линейно независимы. Для этого мы построим алгоритм декодирования — алгоритм Рида, который позволяет исправлять  ошибок и восстанавливать к информационных символов. Отсюда следует, что минимальное расстояние будет не меньше
ошибок и восстанавливать к информационных символов. Отсюда следует, что минимальное расстояние будет не меньше  но оно должно быть четным и поэтому будет не меньше
но оно должно быть четным и поэтому будет не меньше 
 -го порядка, исправляющего
-го порядка, исправляющего  ошибок. Мы построим декодер для кода Рида-Маллера
ошибок. Мы построим декодер для кода Рида-Маллера  -го порядка, исправляющего
-го порядка, исправляющего  ошибку, сведя этот случай к предыдущему. Поскольку мы уже знаем, что код Рида-Маллера нулевого порядка может быть декодирован с помощью мажоритарного метода, мы по индукции получим метод декодирования дня кодов высших порядков.
ошибку, сведя этот случай к предыдущему. Поскольку мы уже знаем, что код Рида-Маллера нулевого порядка может быть декодирован с помощью мажоритарного метода, мы по индукции получим метод декодирования дня кодов высших порядков.
 сегмент, положив
сегмент, положив  где сегмент 1,- содержит информационных битов. Каждый
где сегмент 1,- содержит информационных битов. Каждый  мент будет умножаться на один блок матрицы
мент будет умножаться на один блок матрицы  Кодирование можно представить поблочным умножением вектора на матрицу:
Кодирование можно представить поблочным умножением вектора на матрицу:

 блоков порождающей матрицы, который при кодировании умножается на этот сегмент. Если мы сможем восстановить информационные биты в
блоков порождающей матрицы, который при кодировании умножается на этот сегмент. Если мы сможем восстановить информационные биты в  сегменте, то затем сможем вычислить их вклад в принятое слово и вычесть его из принятого слова. Тогда задача сведется к декодированию кода Рида-Маллера
сегменте, то затем сможем вычислить их вклад в принятое слово и вычесть его из принятого слова. Тогда задача сведется к декодированию кода Рида-Маллера  -го порядка. Процедура декодирования представляет собой последовательность мажоритарных декодирований и начинается с нахождения мажоритарным методом информационных символов в сегменте с номером
-го порядка. Процедура декодирования представляет собой последовательность мажоритарных декодирований и начинается с нахождения мажоритарным методом информационных символов в сегменте с номером 

 восстанавливает
восстанавливает  затем вычисляется разность
затем вычисляется разность

 -го порядка.
-го порядка.
 который умножается на последнюю строку матрицы
который умножается на последнюю строку матрицы  Декодируем этот бит, вычисляя
Декодируем этот бит, вычисляя  проверочных сумм по 2 бит из
проверочных сумм по 2 бит из  бит принятого слова, так что каждый принятый бит входит лишь в одну сумму. Проверочные суммы строятся таким образом, что символ вносит вклад только в один бит, а все другие информационные символы вносят вклад в четное число битов в каждой проверочной сумме. Таким образом, при отсутствии ошибок все проверочные суммы равны Но, даже если имеется не более
бит принятого слова, так что каждый принятый бит входит лишь в одну сумму. Проверочные суммы строятся таким образом, что символ вносит вклад только в один бит, а все другие информационные символы вносят вклад в четное число битов в каждой проверочной сумме. Таким образом, при отсутствии ошибок все проверочные суммы равны Но, даже если имеется не более  сшибок, большинство проверочных сумм по-прежнему будет равняться
сшибок, большинство проверочных сумм по-прежнему будет равняться
 битов принятого слова и
битов принятого слова и  Всего получается
Всего получается  проверочных сумм и но предположению имеется
проверочных сумм и но предположению имеется 
 -кода Рида-Маллера эти четыре суммы выглядят следующим образом:
-кода Рида-Маллера эти четыре суммы выглядят следующим образом:

 Если произошло две ошибки, то ни одно значение проверочных сумм не встречается чаще других и обнаруживается даойная ошибка.
Если произошло две ошибки, то ни одно значение проверочных сумм не встречается чаще других и обнаруживается даойная ошибка.
 Это происходит потому, что любая строка матрицы
Это происходит потому, что любая строка матрицы  ничем не выделяется среди остальных. Перестановкой столбцов мы можем добиться того, что любая строка будет выглядеть так же, как последняя строка матрицы
ничем не выделяется среди остальных. Перестановкой столбцов мы можем добиться того, что любая строка будет выглядеть так же, как последняя строка матрицы  Следовательно, можно использовать те же самые проверочные суммы, соответственно переставив индексы у символов, входящих в эти суммы. После построения
Следовательно, можно использовать те же самые проверочные суммы, соответственно переставив индексы у символов, входящих в эти суммы. После построения  проверочных сумм каждый бит декодируется мажоритарным методом.
проверочных сумм каждый бит декодируется мажоритарным методом.
 порядка. В свою очередь его последний сегмент информационных битов вычисляется с помощью тон же самой процедуры.
порядка. В свою очередь его последний сегмент информационных битов вычисляется с помощью тон же самой процедуры.