Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
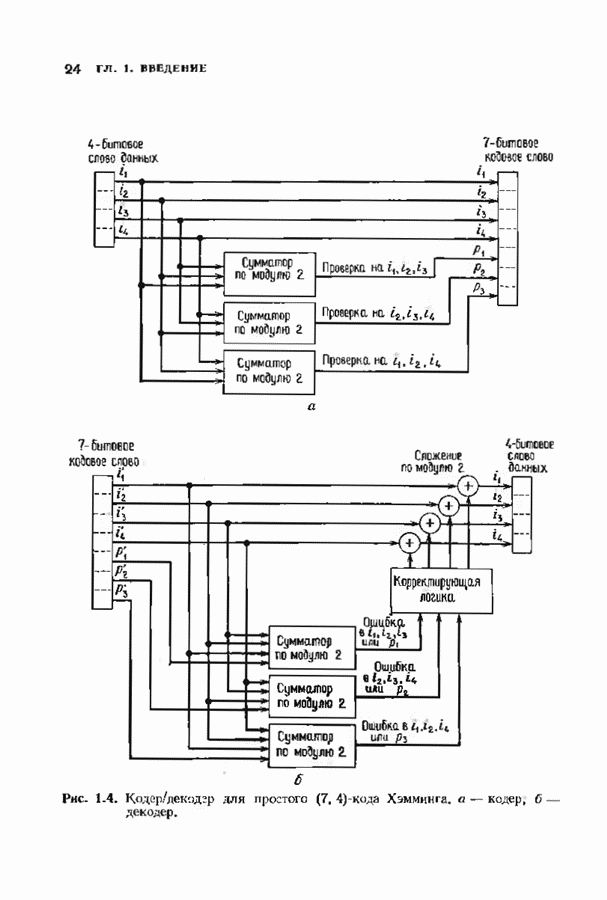
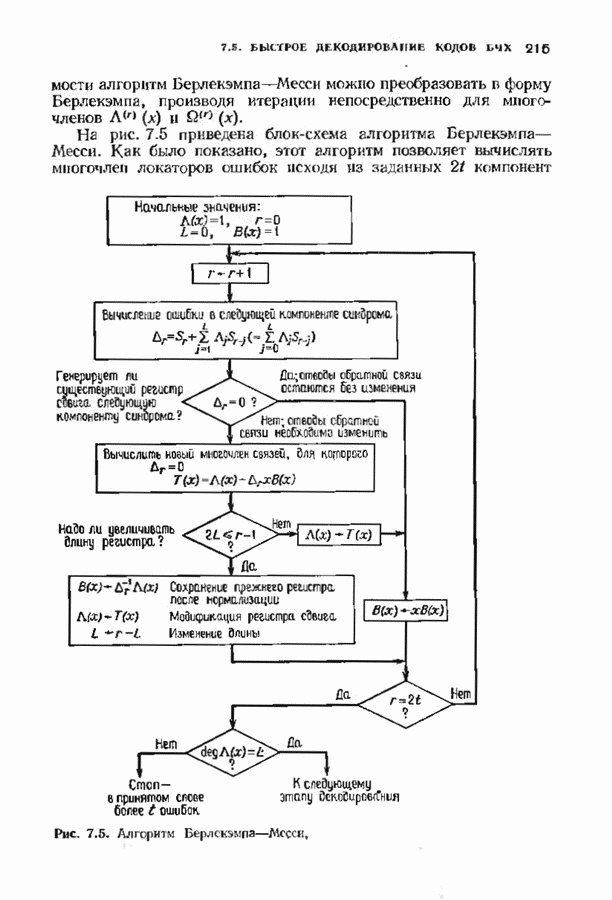
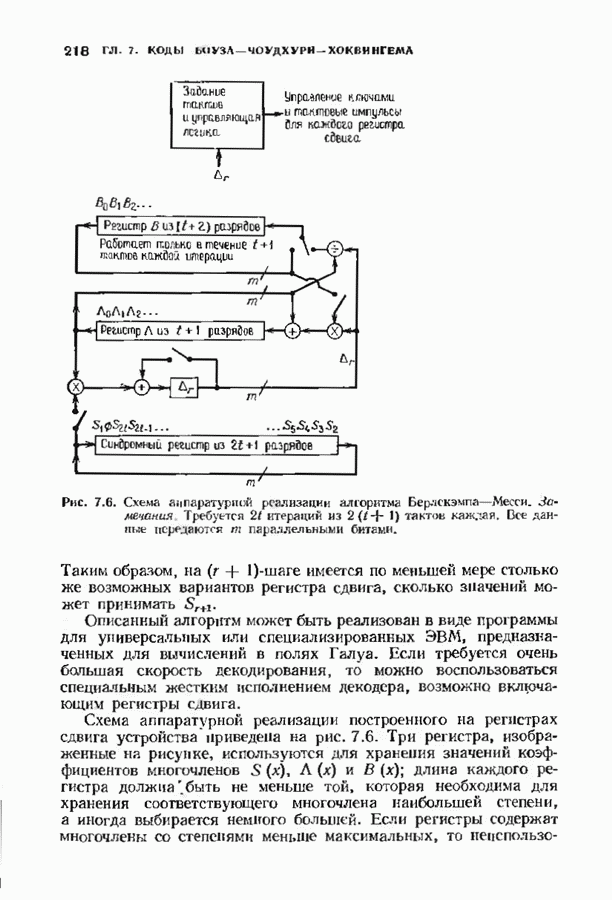
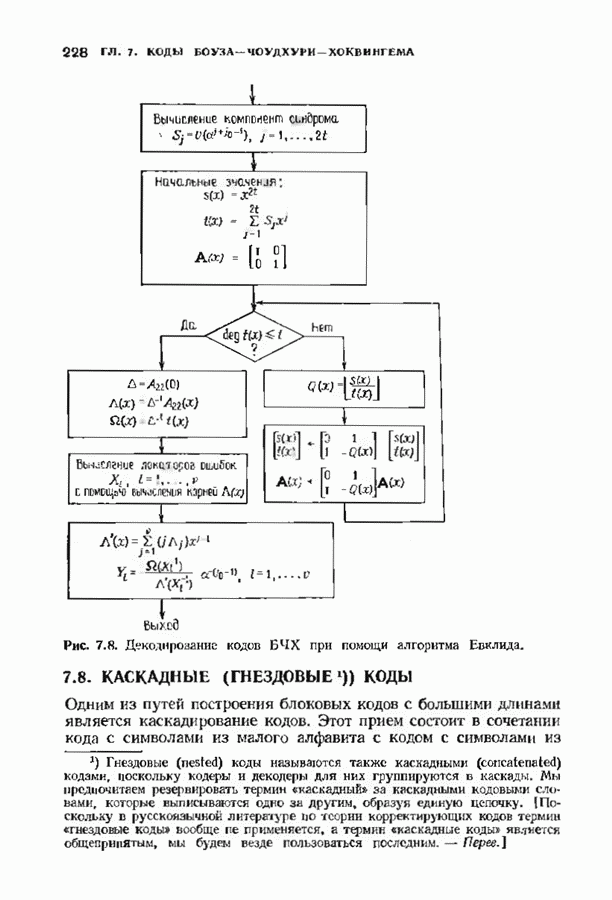
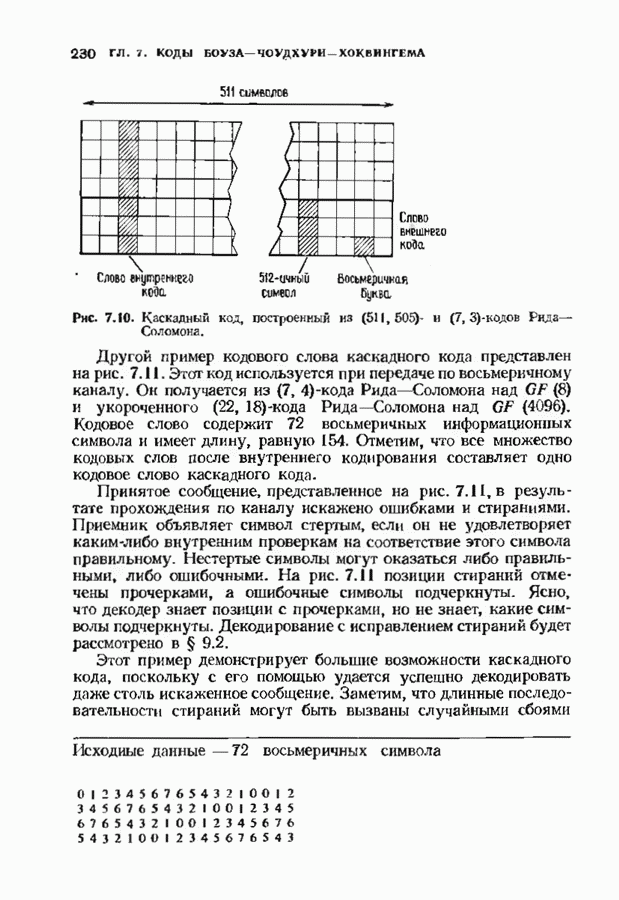
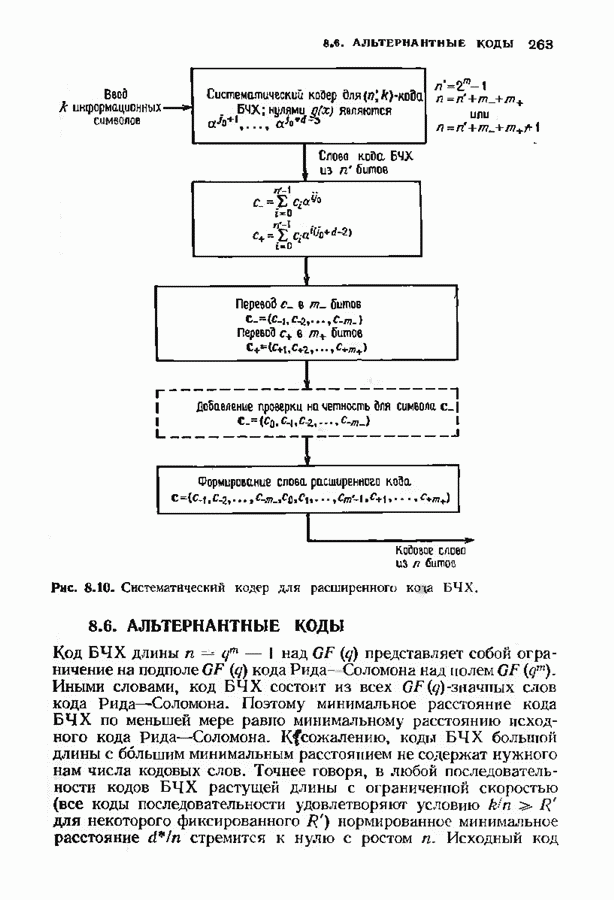
3.3. СТАНДАРТНОЕ РАСПОЛОЖЕНИЕПоскольку разность двух кодовых слов линейного кода является кодовым словом, нулевое слово всегда будет кодовым. Если мы знаем, какое множество принятых слов линейного кода лежит ближе всего к нулевому слову, то с помощью простого сдвига начала координат нетрудно выяснить, какие из принятых слов лежат ближе всего к любому другому кодовому слову. Пусть
Эта сфера содержит все принятые слова, которые декодируются в нулевое кодовое слово. Внутри сферы радиуса
тогда
Таким образом, мы можем выписать точки, лежащие внутри каждой сферы декодирования или (что эффективнее) внутри сферы декодирования с центром в нулевом слове, а точки, лежащие внутри других сфер получать но мере необходимости с помощью простого сдвига. Стандартное расположение представляет собой способ описания всех этих сфер. Пусть
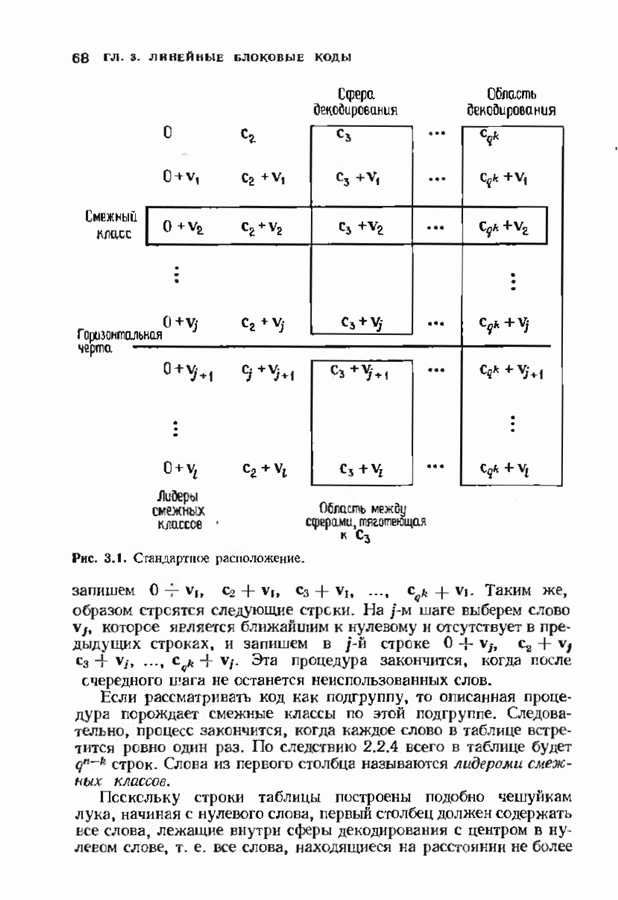
Рис. 3.1. Стандартное расположение. запишем Если рассматривать код как подгруппу, то описанная процедура порождает смежные классы по этой подгруппе. Следовательно, процесс закончится, когда каждое слово в таблице встретится ровно один раз. По следствию 2.2.4 всего в таблице будет Поскольку строки таблицы построены подобно чешуйкам лука, начиная с нулевого слова, первый столбец должен содержать все слова, лежащие внутри сферы декодирования с центром в нулевом слове, т. е. все слова, находящиеся на расстоянии не более
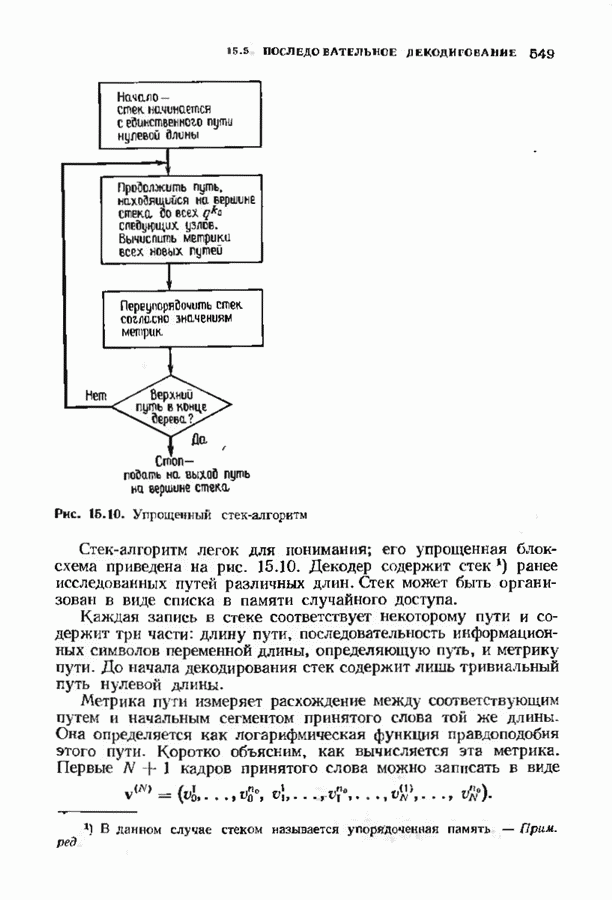
Существуют два основных класса декодеров, которые могут быть описаны с помощью стандартного расположения: полные декодеры и неполные декодеры. Полный декодер сопоставляет принятому слову ближайшее кодовое слово. Принятое слово необходимо найти в стандартном расположении, определить столбец, в котором оно находится, и декодировать его в кодовое слово в верхней позиции этого столйде. Неполный декодер сопоставляет каждому принятому слову кодовое слово, находящееся от него на расстоянии не более В качестве примера рассмотрим
Этот код позволяет исправлять одну ошибку. Стандартное расположение выглядит следующим образом:
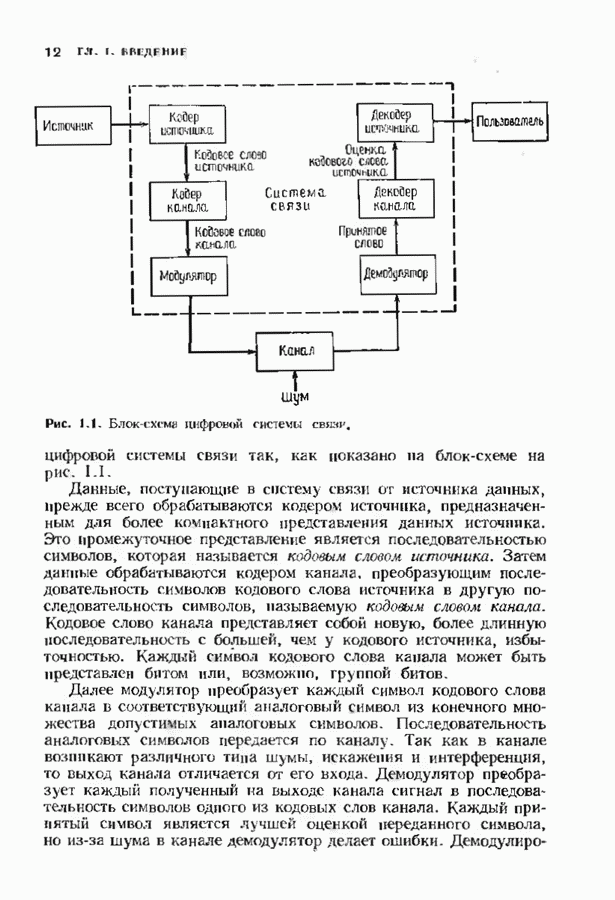
Сферы радиуса 1 не пересекаются. Имеются всего четыре сферы, шесть точек внутри каждой сферы и восемь точек вне каждой сферы. Очевидно, что ценность стандартного расположения относительна. Для больших Таблицу можно упростить, если мы сможем помнить только первый столбец и находить остальные столбцы по мере необходимости. Это можно сделать, введя понятие синдрома ошибок. Для любого принятого вектора
Теорема 3.3.1. Все векторы из одного смежного класса имеют одинаковый синдром, присущий только этому смежному классу. Доказательство. Если
и, следовательно, Любые два вектора из одного смежного класса имеют одинаковый синдром. Следовательно, нам необходимо только свести в таблицу синдромы и лидеры смежных классов. Затем мы можем производить декодирование следующим образом. По принятому вектору В примере, приведенном выше, проверочной матрицей будет
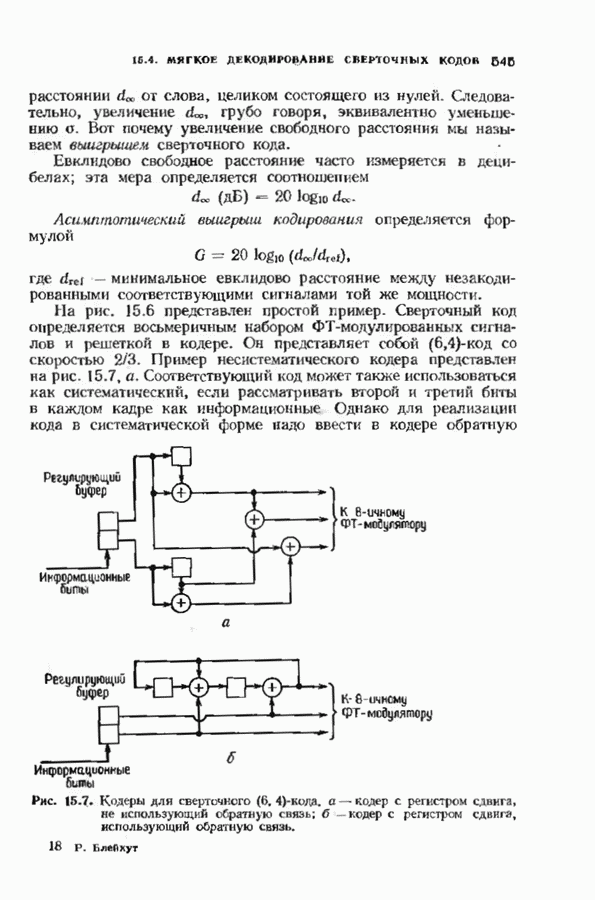
и новая таблица запишется в виде
Эта таблица проще, чем стандартное расположение. Предположим, что принят вектор
|
 |
Оглавление
|

























































































































































































































































































































































































































































































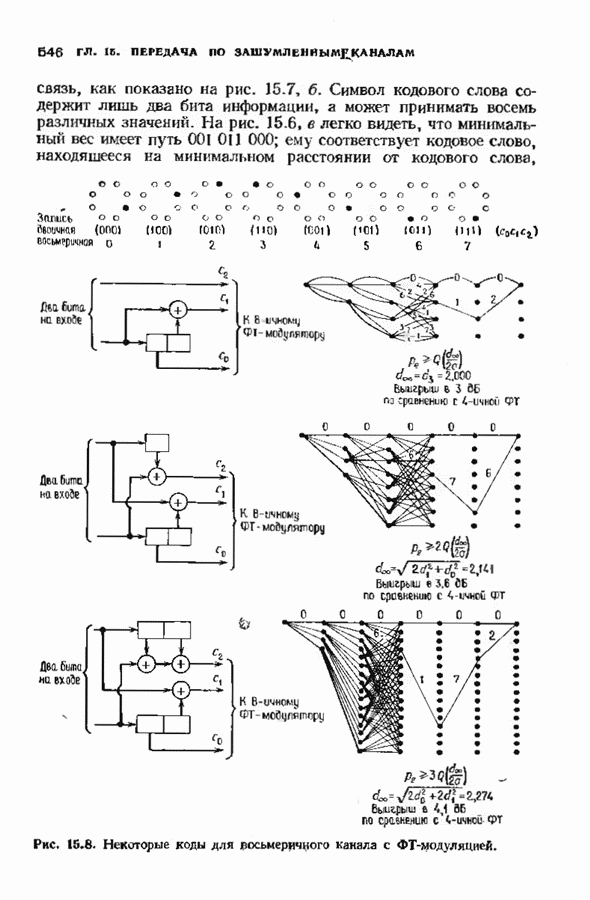
















 нечетно и
нечетно и  Внутри сферы радиуса
Внутри сферы радиуса  с центром в нулевом слове находится множество точек
с центром в нулевом слове находится множество точек

 с центром в кодовом слове с находится множество точек
с центром в кодовом слове с находится множество точек


 с суть
с суть  кодовых слов
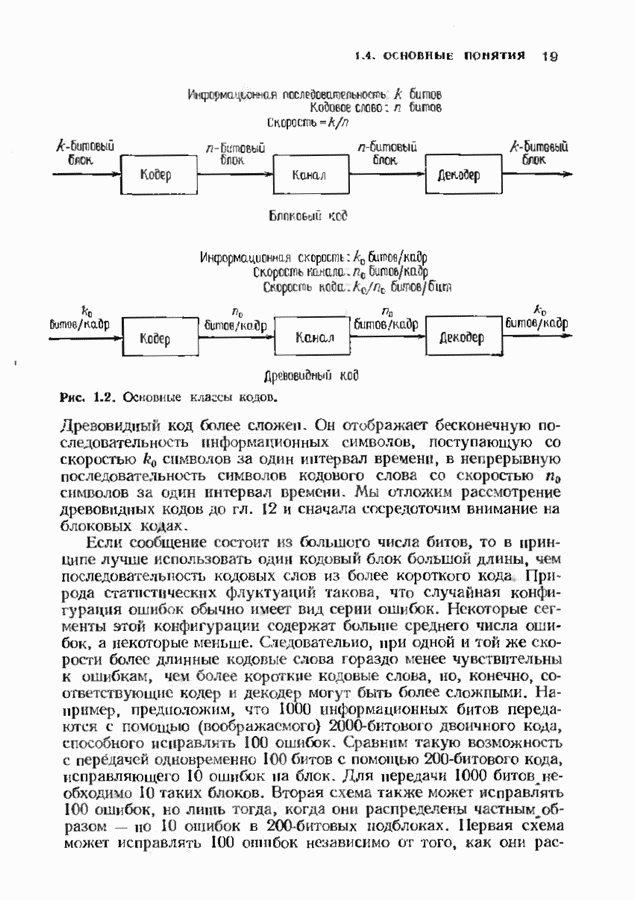
кодовых слов  -кода. Построим таблицу, изображенную на рис. 3.1. следующим образом. В первой строке выпишем все кодовые слова. Из оставшихся в
-кода. Построим таблицу, изображенную на рис. 3.1. следующим образом. В первой строке выпишем все кодовые слова. Из оставшихся в  слов, лежащих на расстоянии 1 от нулевого слова, выберем любое и обозначим его
слов, лежащих на расстоянии 1 от нулевого слова, выберем любое и обозначим его  Во второй строке
Во второй строке

 Таким же, образом строятся следующие строки. На
Таким же, образом строятся следующие строки. На  шаге выберем слово
шаге выберем слово  которое является ближайшим к нулевому и отсутствует в предыдущих строках, и запишем в
которое является ближайшим к нулевому и отсутствует в предыдущих строках, и запишем в  строке
строке  Эта процедура закончится, когда после очередного шага не останется неиспользованных слов.
Эта процедура закончится, когда после очередного шага не останется неиспользованных слов.
 строк. Слова из первого столбца называются лидерами смежных классов.
строк. Слова из первого столбца называются лидерами смежных классов.
 от нулевого. Когда чешуйки заполнят всю внутренность сферы радиуса
от нулевого. Когда чешуйки заполнят всю внутренность сферы радиуса  вокруг нулевого слова, проведем в таблице горизонтальную черту Могут остаться векторы, не занесепные в таблицу выше этой черты, и далее в стандартном расположении эти векторы будут сопоставляться ближайшим, но отчасти произвольным кодовым словам.
вокруг нулевого слова, проведем в таблице горизонтальную черту Могут остаться векторы, не занесепные в таблицу выше этой черты, и далее в стандартном расположении эти векторы будут сопоставляться ближайшим, но отчасти произвольным кодовым словам.
 если такое существует, в противном же случае отказывается от декодирования. Принятое слово необходимо найти в стандартном расположении. Если оно лежит выше горизонтальной черты, то декодируем его в кодовое слово в вершине столбца, в котором оказывается принятое слово. Если же оно лежит ниже горизонтальной черты, то помечаем принятое слово как не поддающееся декодированию. В таком слове имеется более
если такое существует, в противном же случае отказывается от декодирования. Принятое слово необходимо найти в стандартном расположении. Если оно лежит выше горизонтальной черты, то декодируем его в кодовое слово в вершине столбца, в котором оказывается принятое слово. Если же оно лежит ниже горизонтальной черты, то помечаем принятое слово как не поддающееся декодированию. В таком слове имеется более  ошибок.
ошибок.
 -код с порождающей матрицей
-код с порождающей матрицей


 составлять такую таблицу было бы не практично.
составлять такую таблицу было бы не практично.
 определим синдром равенством
определим синдром равенством

 лежат в одном смежном классе, то
лежат в одном смежном классе, то  у для некоторого у и кодовых слов
у для некоторого у и кодовых слов  Для любого кодового слова с выполняется равенство
Для любого кодового слова с выполняется равенство  Отсюда получаем
Отсюда получаем

 Обратно, допустим, что
Обратно, допустим, что  тогда
тогда  и поэтому разность
и поэтому разность  является кодовым словом. Следовательно,
является кодовым словом. Следовательно,  и V принадлежат одному смежному классу.
и V принадлежат одному смежному классу. 
 вычисляем синдром и находим соответствующий этому синдрому лидер смежного класса. Этот лидер является разностью между принятым словом и кодовым словом, которое одновременно является центром сферы кодирования. Таким образом, мы исправим ошибку, вычтя из слова
вычисляем синдром и находим соответствующий этому синдрому лидер смежного класса. Этот лидер является разностью между принятым словом и кодовым словом, которое одновременно является центром сферы кодирования. Таким образом, мы исправим ошибку, вычтя из слова  лидер смежного класса.
лидер смежного класса.


 Тогда
Тогда  Лидер смежного класса будет равен
Лидер смежного класса будет равен  Отсюда получим, что переданное слово равно
Отсюда получим, что переданное слово равно  а информационное слово равно II.
а информационное слово равно II.