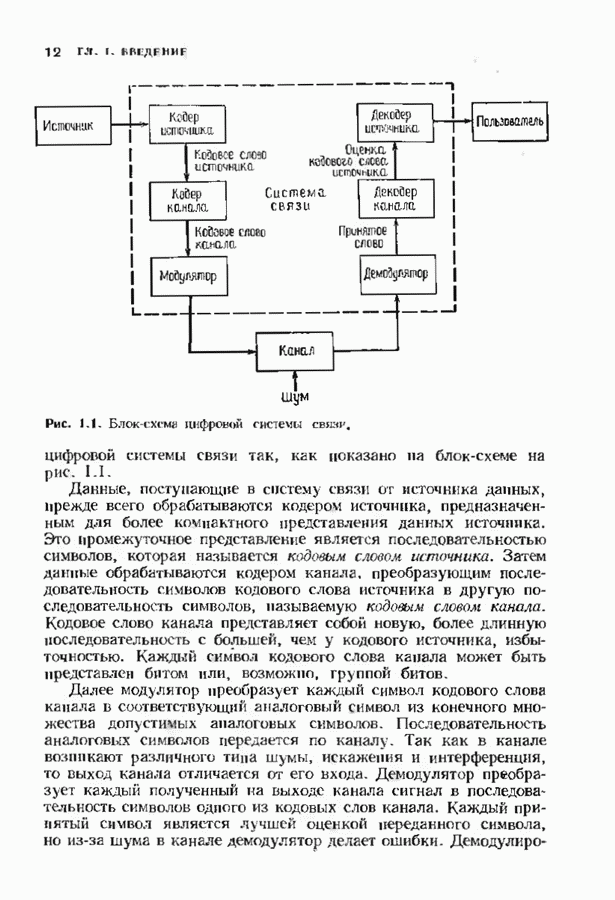
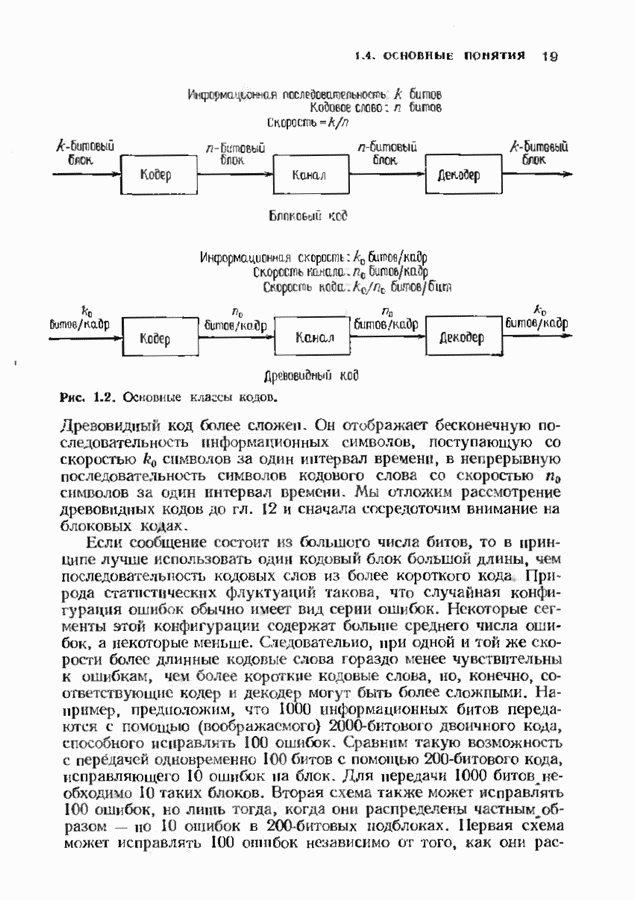
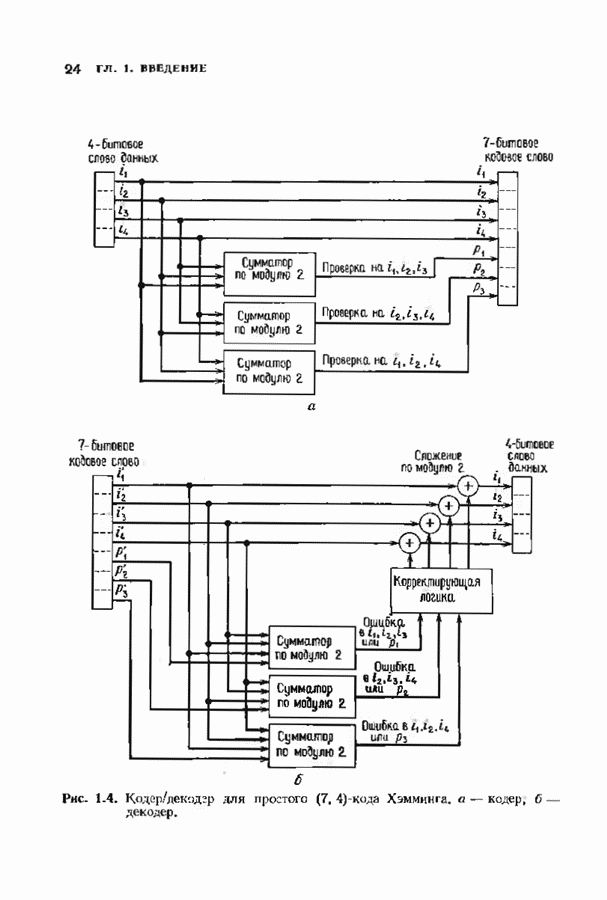
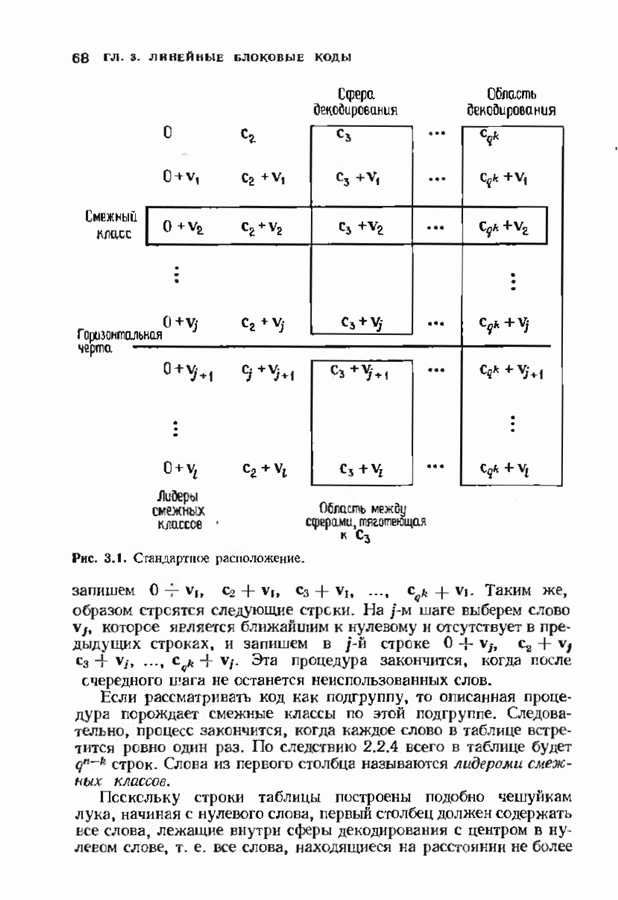
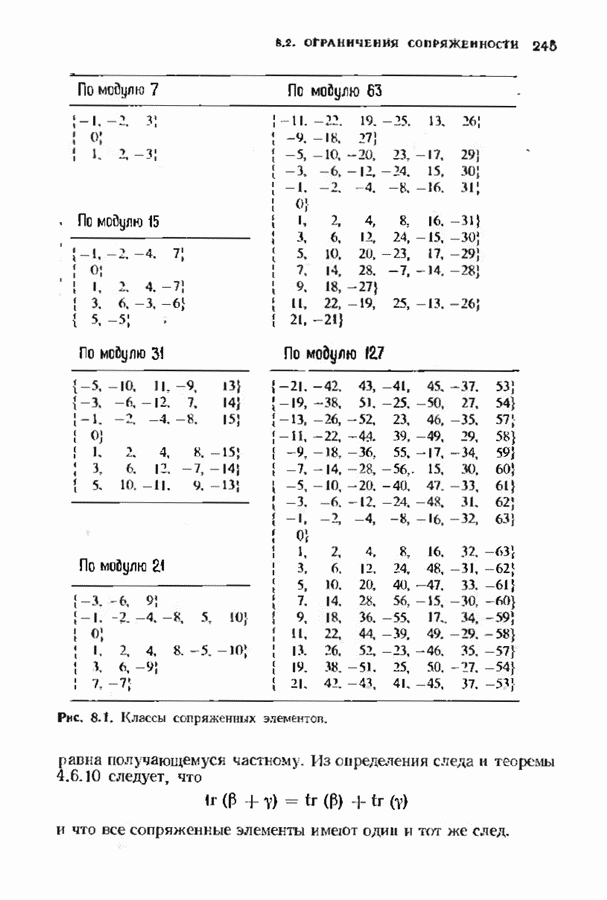
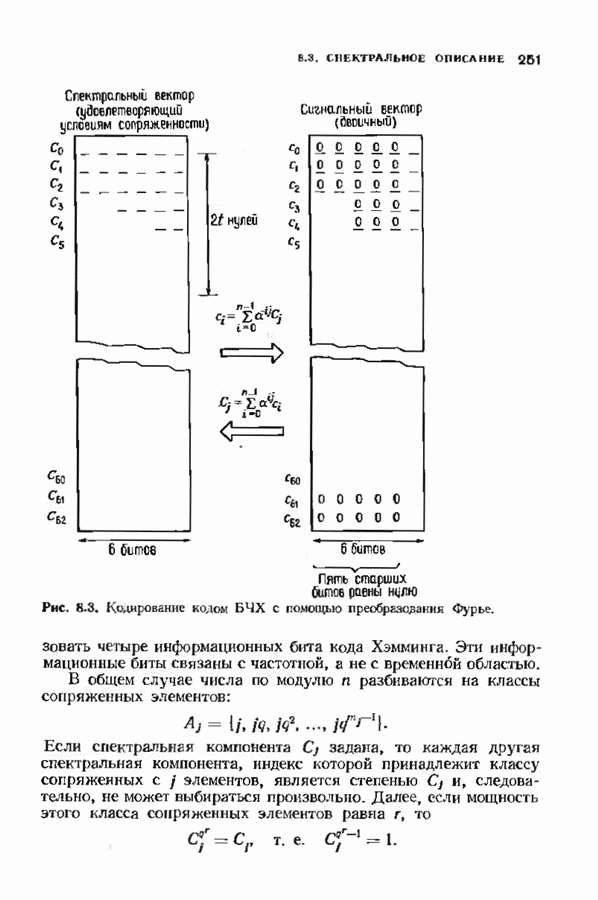
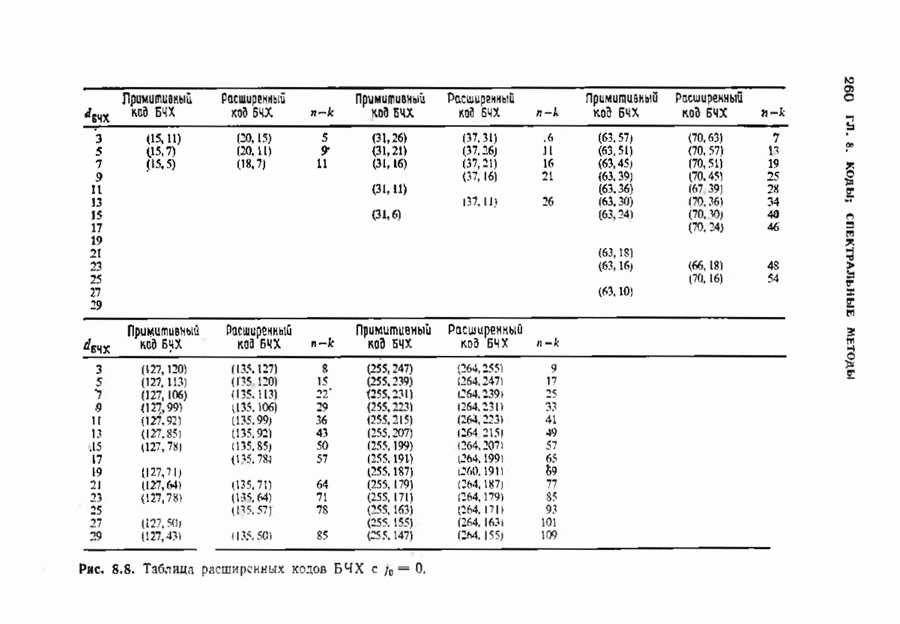
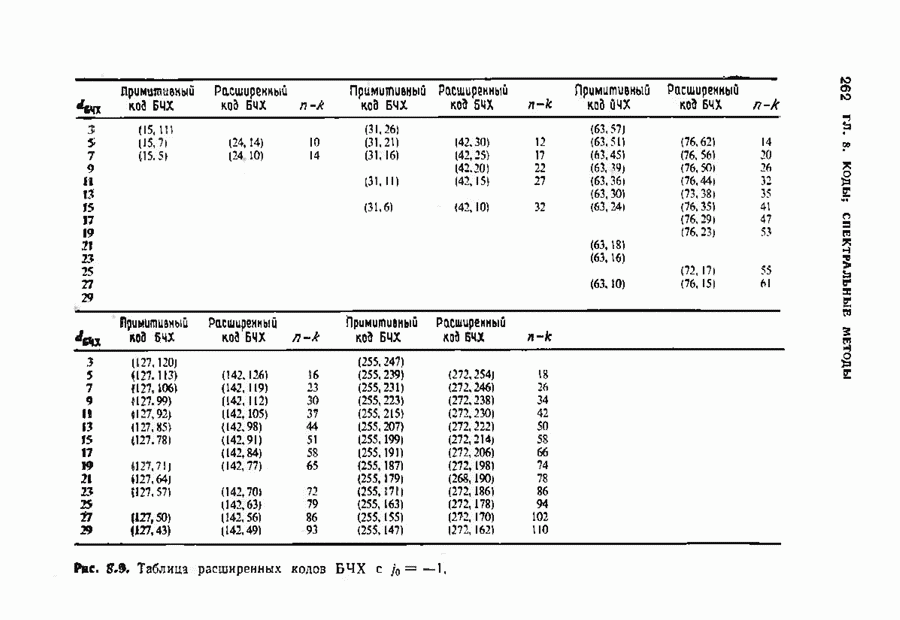
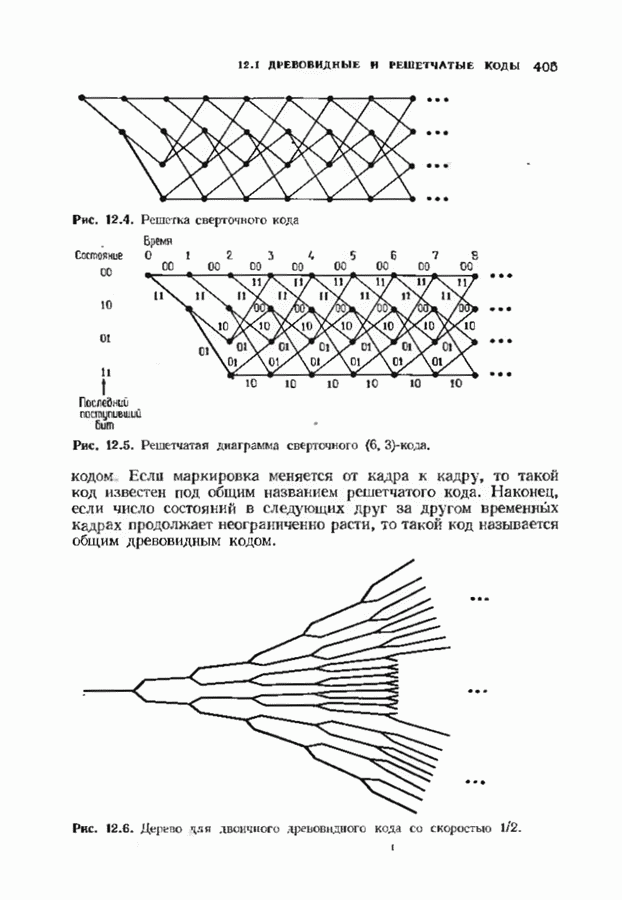
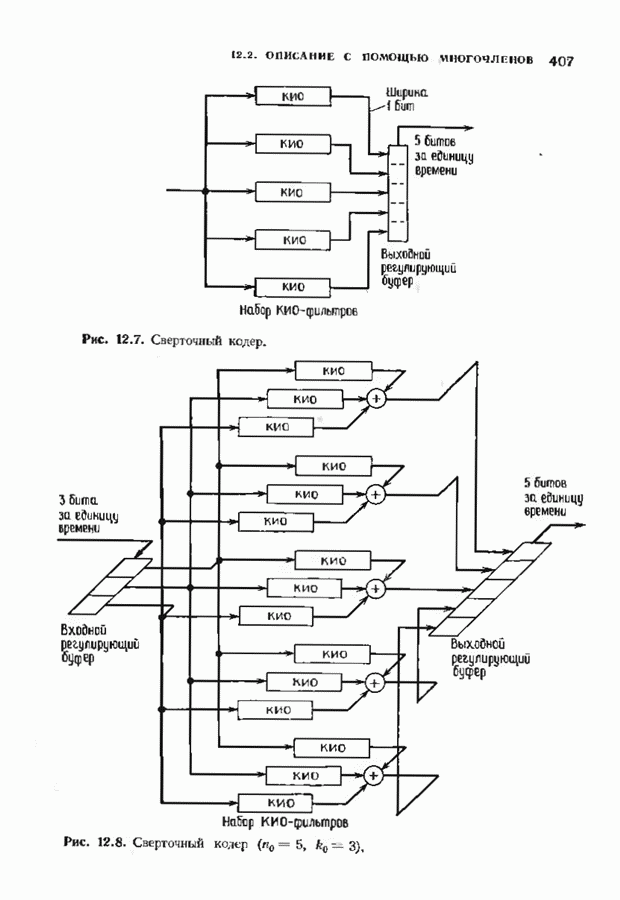
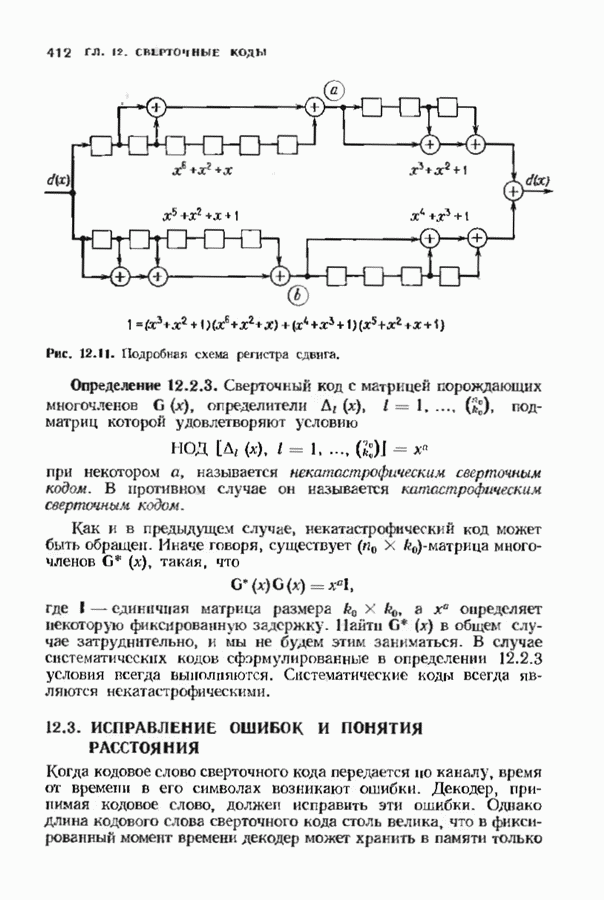
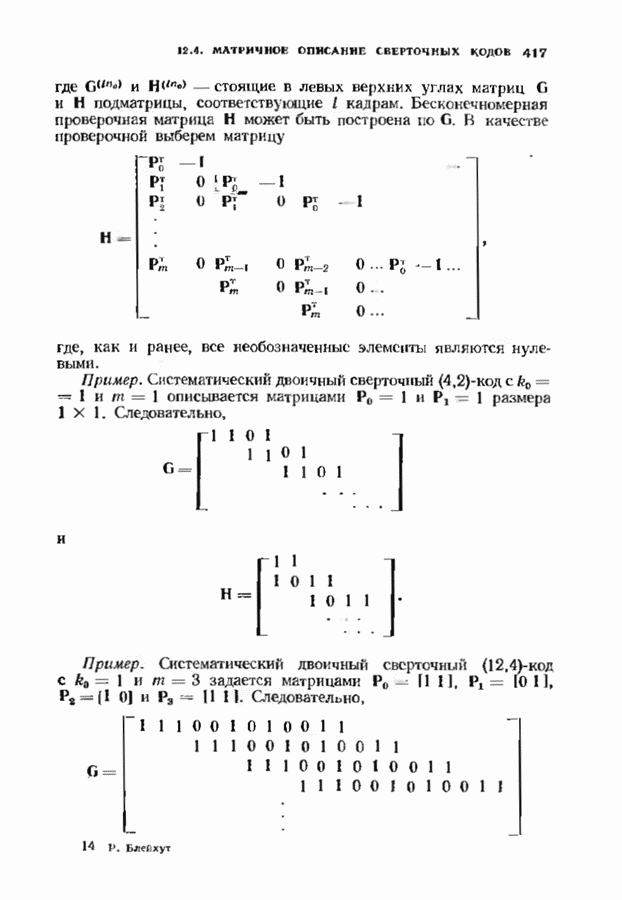
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
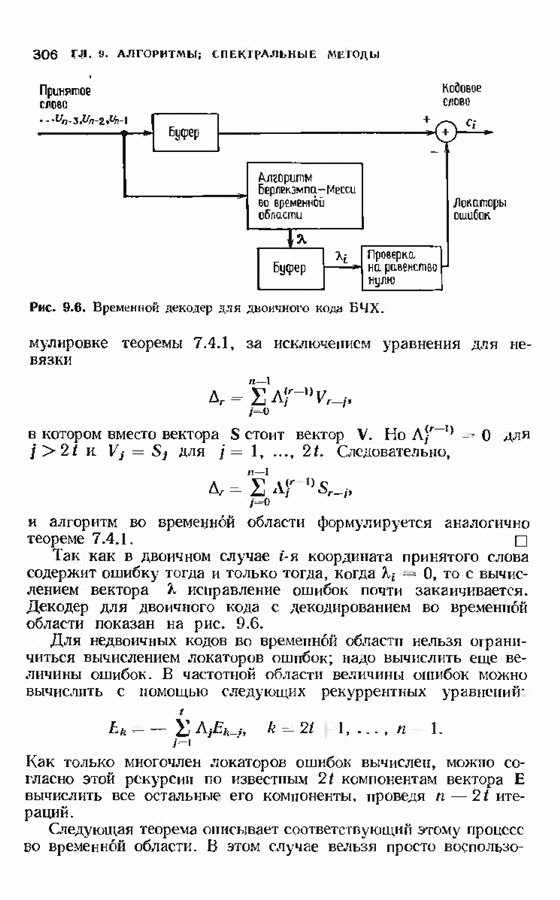
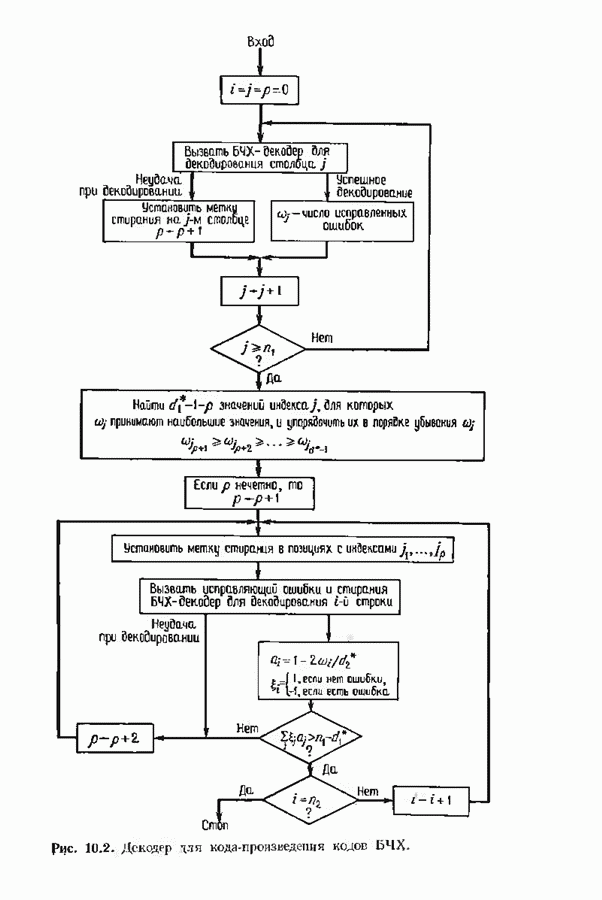
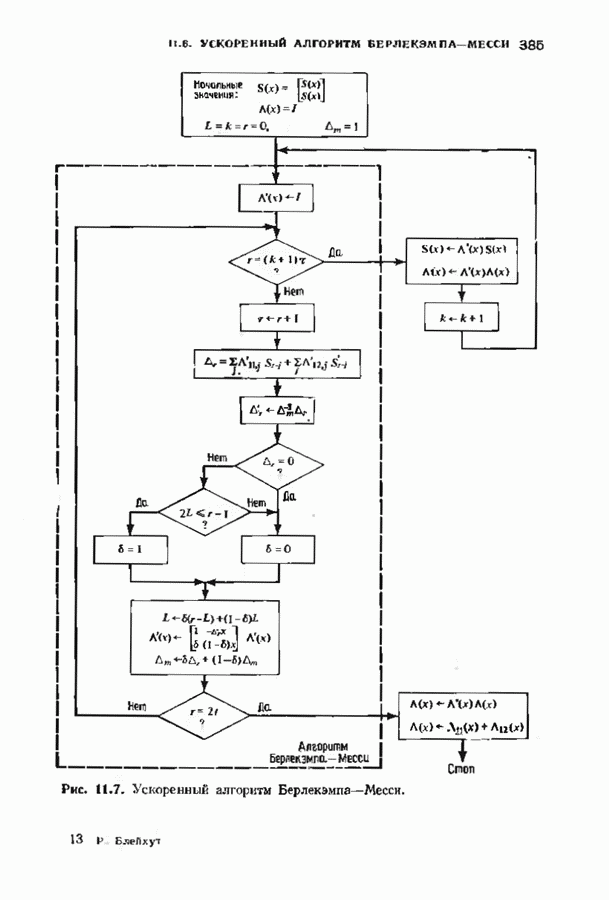
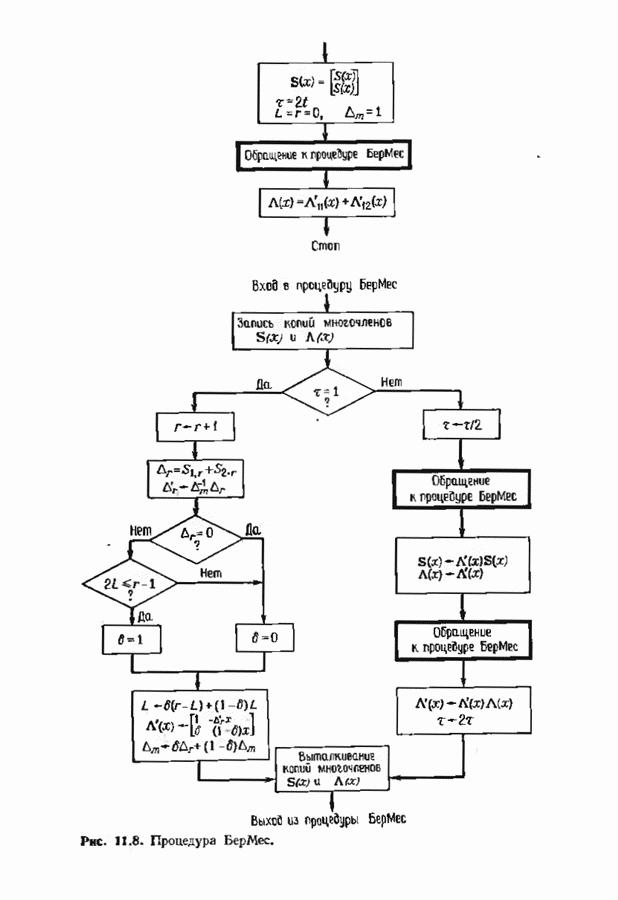
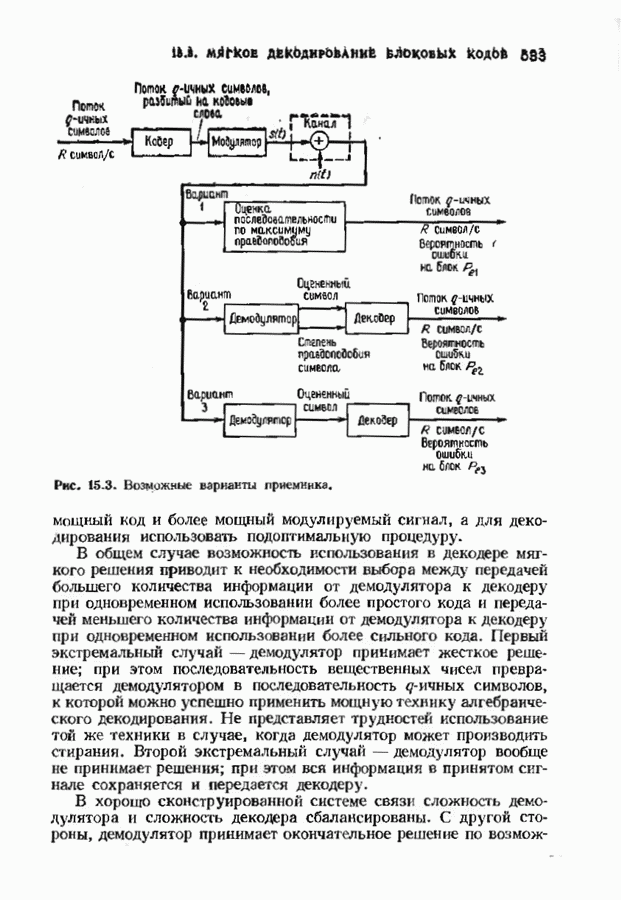
15.3. МЯГКОЕ ДЕКОДИРОВАНИЕ БЛОКОВЫХ КОДОВВероятность ошибки декодирования минимизируется одновременным выбором демодуляции и декодирования. Модулятор отображает Выходной сигнал канале Плотность распределения вероятностей вектора
причем предполагается, что отсчеты шума представляют собой независимые одинаково распределенные гауссовские случайные величины с дисперсией Однако поскольку шум предполагается гауссовским, приемник максимального правдоподобия идентичен приемнику минимального евклидова расстояния. Этот приемник находит значение
минимально, и объявляет, что было передано Далее, если энергия
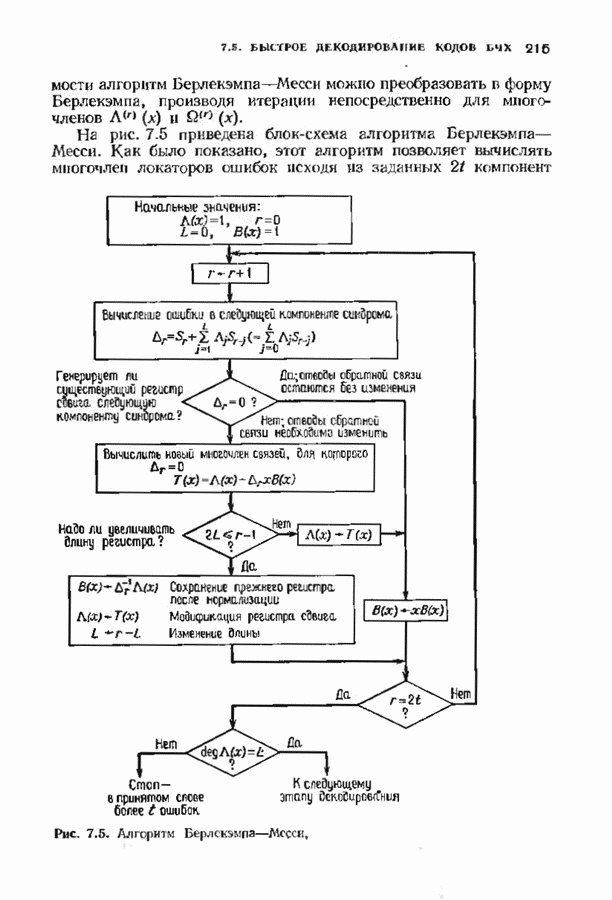
и затем принимает решение в пользу того кодовою слова На рис. 15.3 предлагается несколько вариантов приемника. Если модулятор и кодер фиксированы, то выбор самого верхнего варианта приводит к наименьшей частоте ошибок на символ, а самого нижнего — к наибольшей. Может создаться впечатление, что по мере возможности всегда желательпо реализовать нриемник максимального правдоподобия. Но это, вообще говоря, не так Часто целесообразнее затратить имеющиеся ресурсы на более
Рис. 15.3. Возможные варианты приемника. мощный код и более мощный модулируемый сигнал, а для декодирования использовать подоптимальную процедуру. В общем случае возможность использования в декодере мягкого решения приводит к необходимости выбора между передачей большего количества информации от демодулятора к декодеру при одновременном использовании более простого кода и передачей меньшего количества информации от демодулятора к декодеру при одновременном использовании более сильного кода. Первый экстремальный случай — демодулятор принимает жесткое решение; при этом последовательность вещественных чисел превращается демодулятором в последовательность В хорошо сконструированной системе связи сложность демодулятора и сложность декодера сбалансированы. С другой стороны, демодулятор принимает окончательное решение по возможности на уровне символов; с другой стороны, он передает декодеру достаточно информации, чтобы качественные характеристики системы оставались достаточно высокими. Сохраняется также возможность использования каскадных кодов. Тогда соотношения между сложностью и качеством можно рассматривать на трех уровнях обработки в демодуляторе и на двух уровнях декодера. Используя мягкое решение в сочетании с малой длиной кода во внутреннем декодере и жесткое решение с исправлением ошибок и стираний во внешнем декодере, корректирующем оставшиеся ошибки и отказы внутреннего декодера, можно получить отличное соотношение между сложностью и качеством декодирования. Изучим частный случай декодера мягкого решения, использующий алгоритм обобщенного минимального расстояния (ОМР-алгоритм). Этот алгоритм мы опишем дважды: сначала для двоичных кодов, используя некоторые геометрические построения, а затем для кодов над произвольным полем Галуа. В первом случае в демодулятор поступает последовательность двоичных чисел на фоне шумов. Принимаемый демодулятором Мы уже рассмотрели два частных случая. Если величины на выходе демодулятора принимают значения ±1, то демодулятор является демодулятором жесткого решения, а декодер исправляет лишь ошибки. Если на выходе демодулятора величины После обработки принятого сигнала демодулятором на его выход поступает принятый вектор
Если в канале не произошло ошибок и демодулятор приписал максимальный доверительный уровень каждому биту, то символы принятого вектора равны — 1 в тех позициях, в которых символы переданного кодового слова Пусть с
Это выражение описывает отображение кодовых слов из
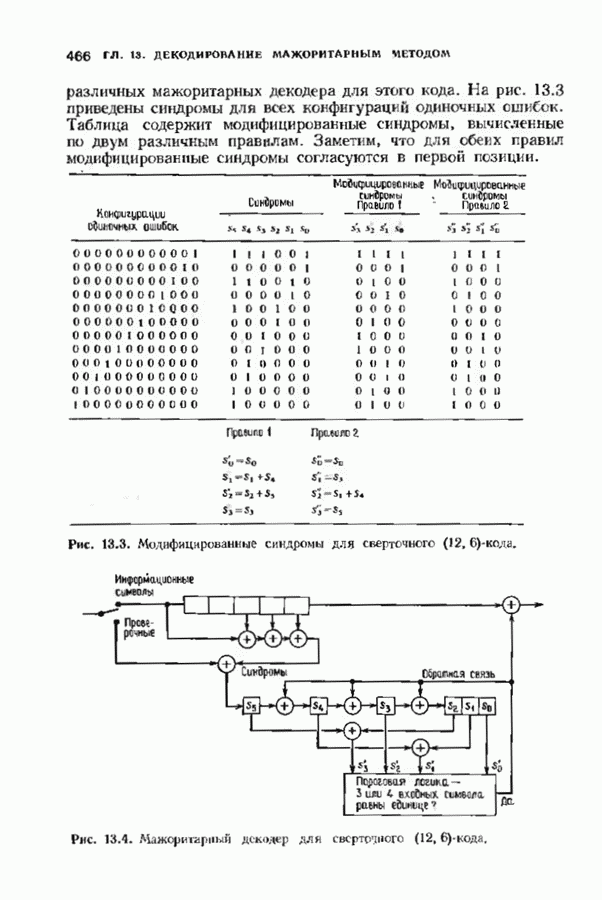
Если
где компоненты вектора
Минимальное евклидово расстояние кода и минимальное хэммингово расстояние
Опишем ОМР-декодер с помощью скалярного произведения
Для фчксированного Декодеру, исправляющему только ошибки, предшествует демодулятор. который принимает лишь жесткие решения. При этом
удовлетворяет не более одного кодового слова
Наконец, так как
и не более чем одно кодовое слово удовлетворяет неравенству
где
если такое кодовое слово существует. Возможно, что решения не существует и декодер не в состоянии найти кодовое слово. Такой декодер неполон, но он будет указывать, что соответствующие конфигурации ошибок являются неисправляемыми. Если действия демодулятора сводятся к жесткому решению или стиранию,
если такое кодовое слово существует. Как и ранее, соответствующий декодер полон. Следующая теорема утверждает, что те же условия существования справедливы и при мягком решении. Теорема 15.3.1. Каков бы ни был вектор
Доказательство. Пусть
тогда
Но величина
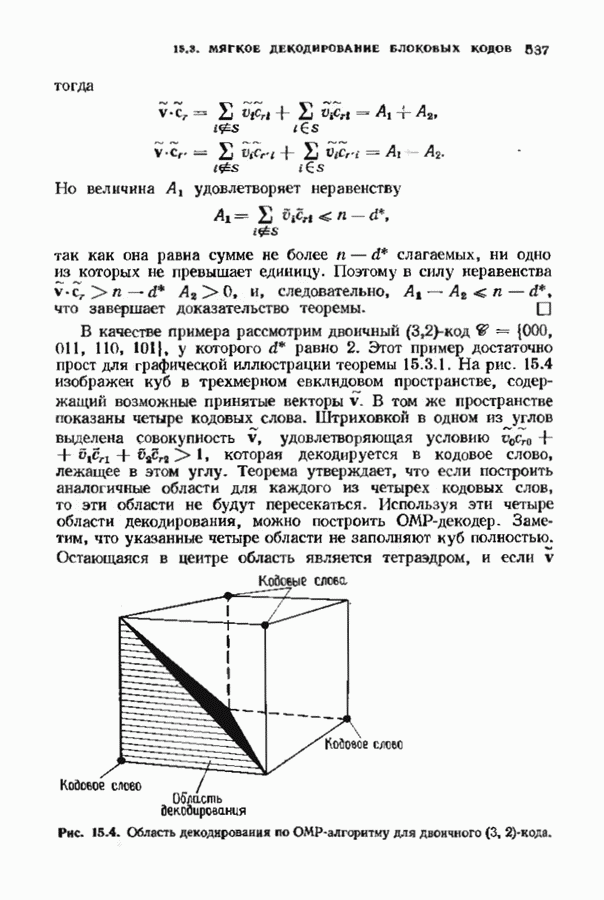
так как она равна сумме не более В качестве примера рассмотрим двоичный
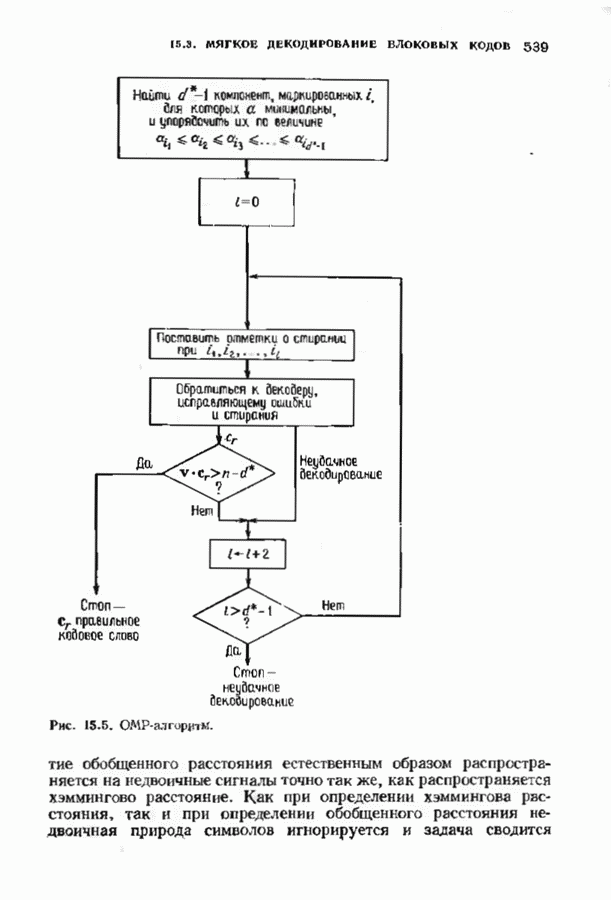
Рис. 15.4. Область декодирования попадает в этот тетраэдр, то декодирование объявляется неудачным. Декодер является неполным, и его области декодирования лежат в евклидовом пространстве. ОМР-декодер находит единственное кодовое слово, удовлетворяющее теореме 15.3.1, если опо существует; в противном случае декодирование объявляется неудачным. Конечно, находить это кодовое слово, вычисляя все Мы уже знаем, как построить декодеры, исправляющие ошибки и стирания, полученные в результате жестких решений. Любой декодер, исправляющий ошибки и стирания, можно дополнить внешней петлей обработки данных. Основываясь на информации мягкого решения, этот модернизированный декодер вычисляет последовательность пробных векторов жесткого решения со стиранием. Для каждого I от 0 до Декодируем На рис. 15.5 представлен ОМР-алгоритм в недвоичном случае. Теоремы 15.3.2 и 15.3 4 утверждают, что ОМР-алгоритм, представленный на рис. 15.5, в самом деле декодирует в единственное ОМР-кодовое слово. Заметим, что алгоритм, изображенный на рисунке, проверяет неравенство лишь при четных Теорема 15.3.2. Если
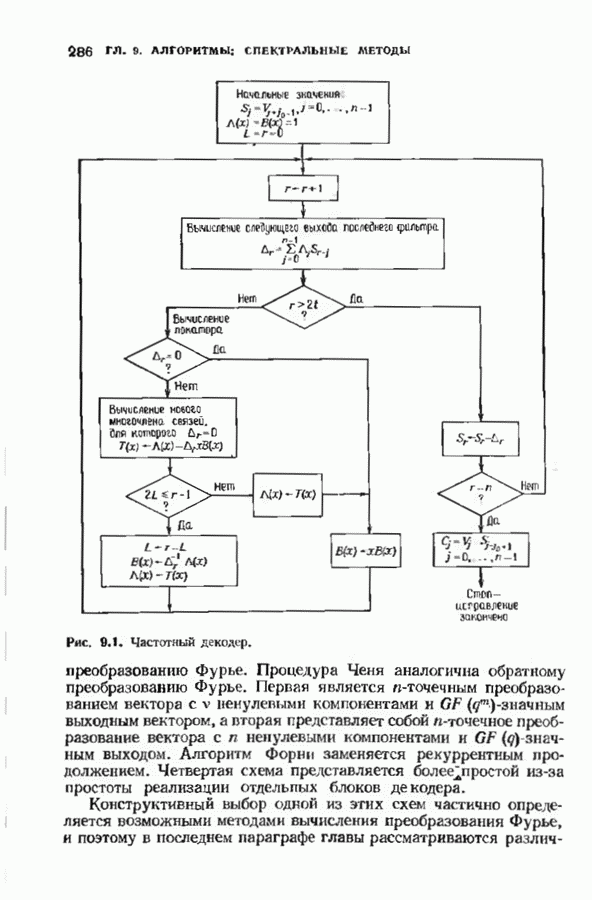
Доказательство следует из доказательства теоремы 15.3.4, являющейся более общей формой нашей теоремы. Теперь обобщим ОМР-декодеры на недвоичные коды. Сложность ОМР-декодера приблизительно в Рис. 15.5. (см. скан) ОМР-алгоритм Понятие обобщенного расстояния естественным образом распространяется на недвоичные сигналы точно так же, как распространяется хэммингово расстояние. Как при определении хэммингова расстояния, так и при определении обобщенного расстояния недвоичная природа символов игнорируется и задача сводится к двоичной, при которой лишь учитывается, совпадают или нет два символа, а их величины не принимаются во внимание. ОМР-декодер в недвоичном случае почти не меняется. На выход демодулятора поступают Как и в двоичном случае, для алгоритма декодирования не важно, какое правило демодулятор использует для нахождения В двоичном случае мы смогли дать геометрическую интерпретацию декодирования, используя знак а для обозначения оценки переданного двоичного символа. В
Затем определим произведение
использование которого позволяет доказать Теорема 15.3.3. В коде над
Доказательство аналогично доказательству теоремы 15.3.1. Алгоритм декодирования в недвоичном случае таков же, как и в двоичном. Для любого I из интервала ОMP-декодированным кодовым словом. Если оно не удовлетворяется, т. е. если 1-е декодирование оказывается неудачным, то увеличим Теорема 15.3.4. Если для кодового слова
Доказательство. Достаточно доказать теорему для I, пробегающих значения от 0 до
и
Тогда
и поэтому
Допустим, что
что противоречит предположению теоремы. Поэтому теорема доказана.
|
 |
Оглавление
|




















































































































































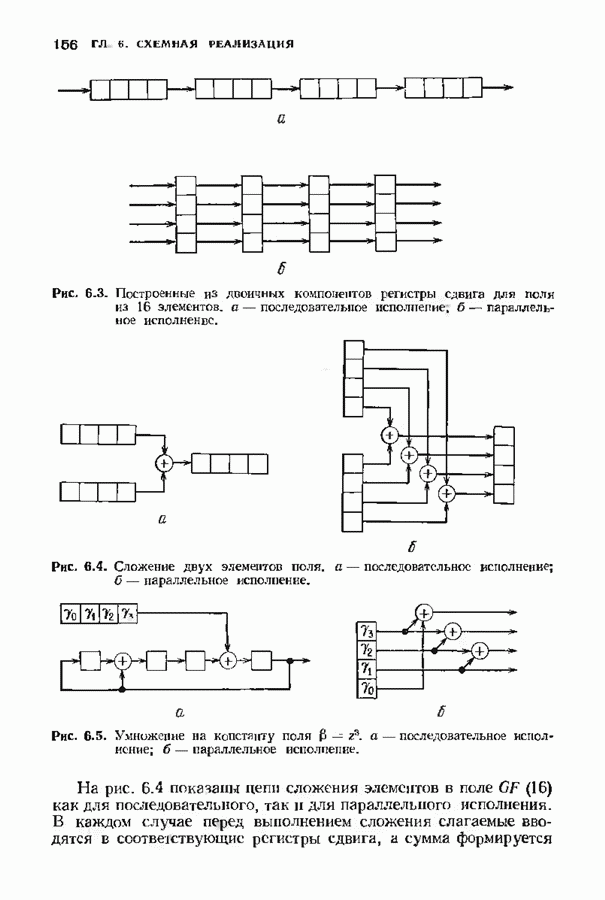



























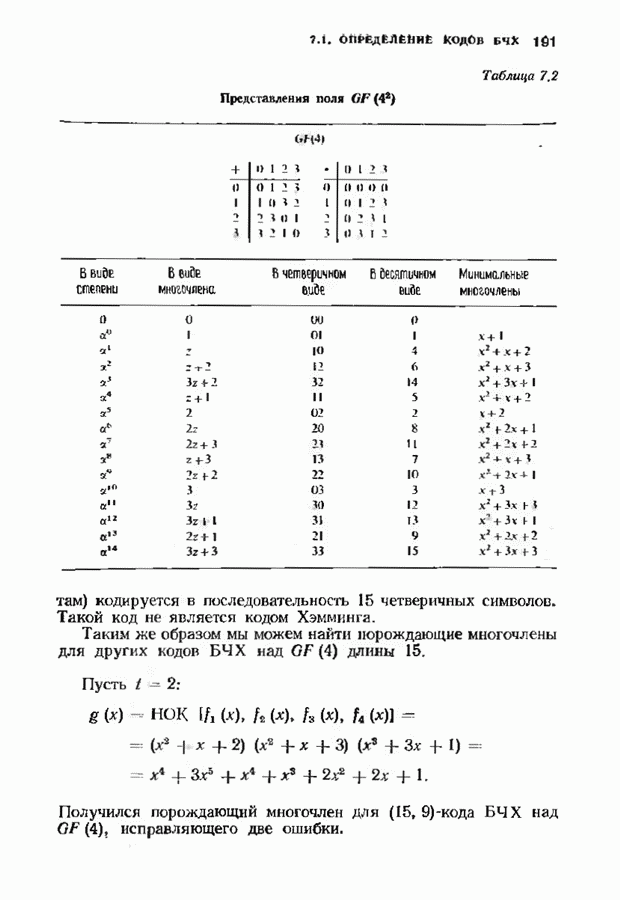







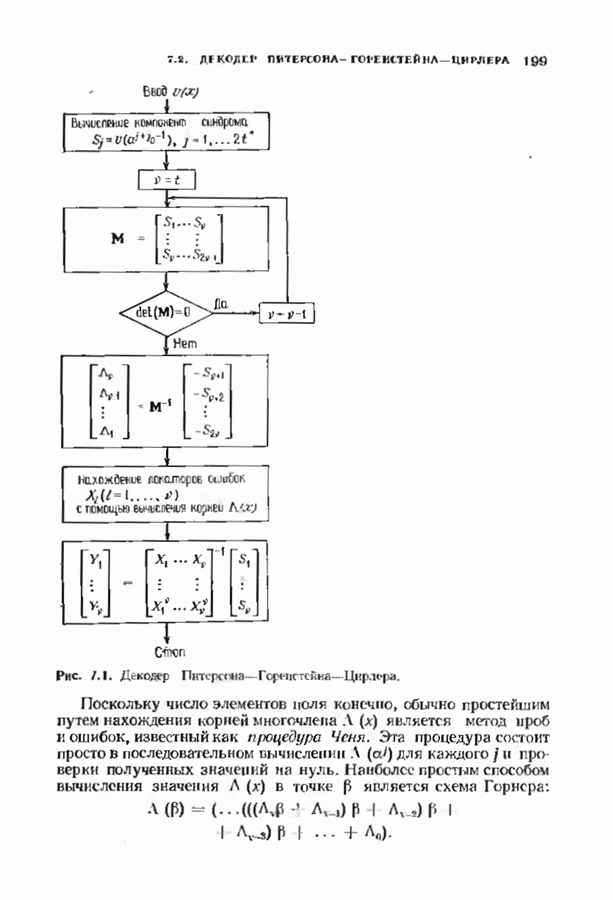







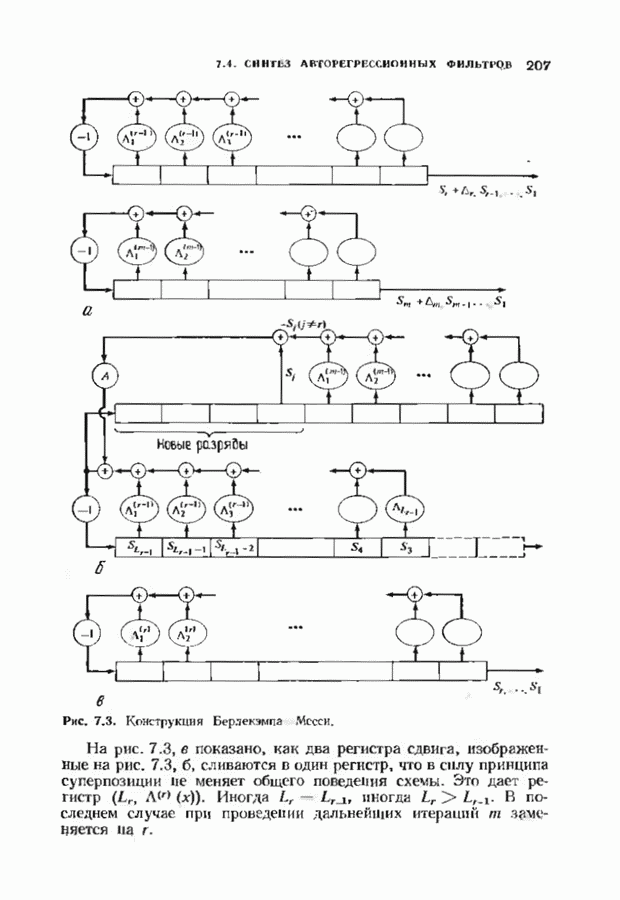






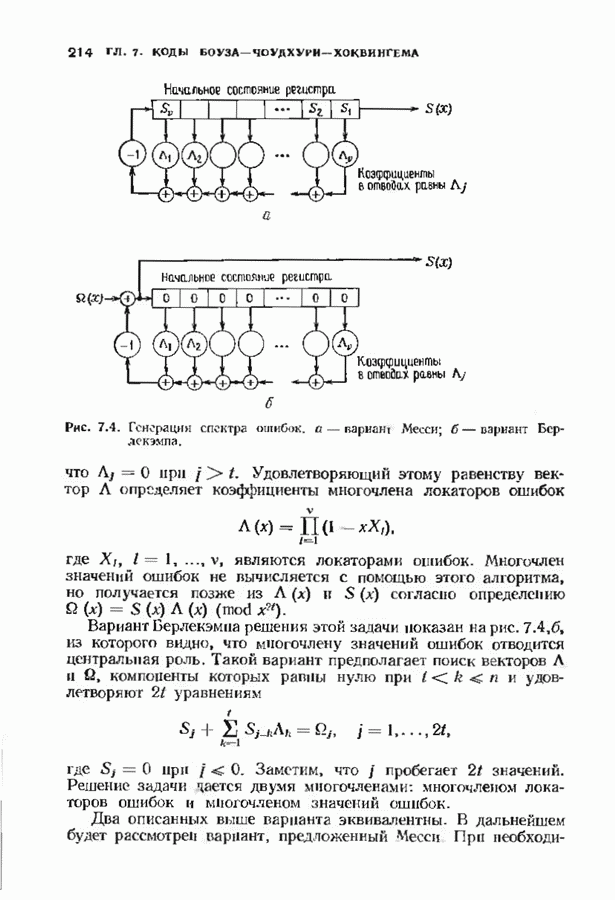






























































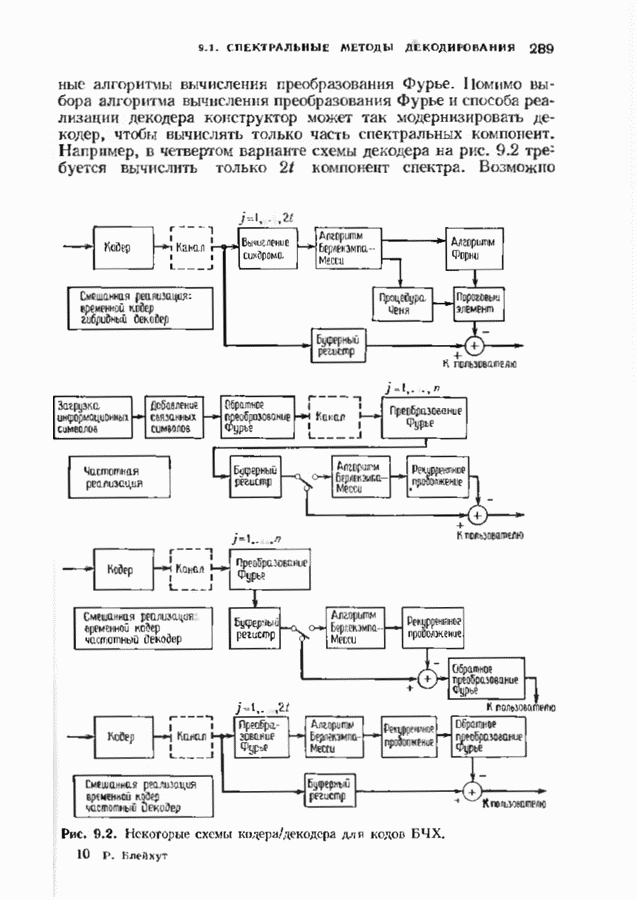





















































































































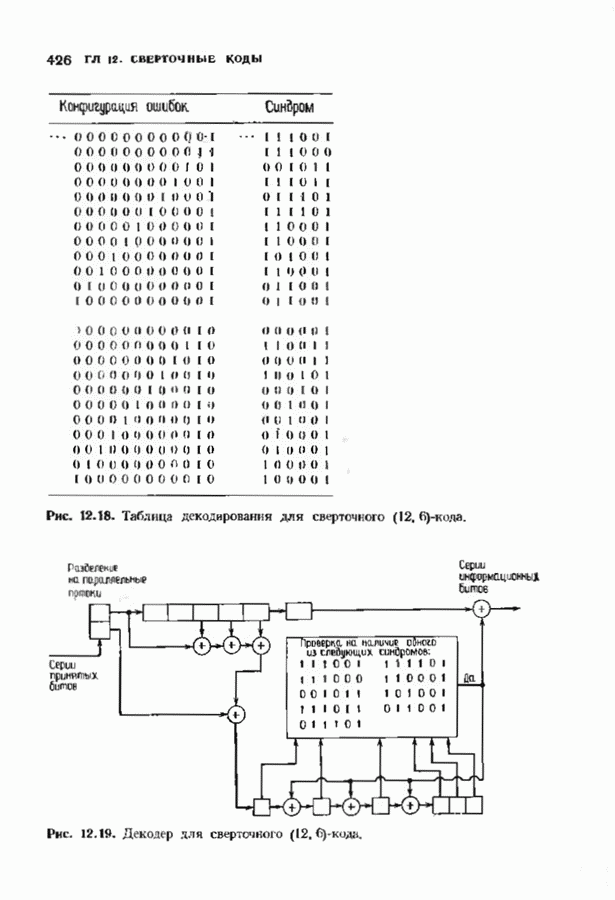
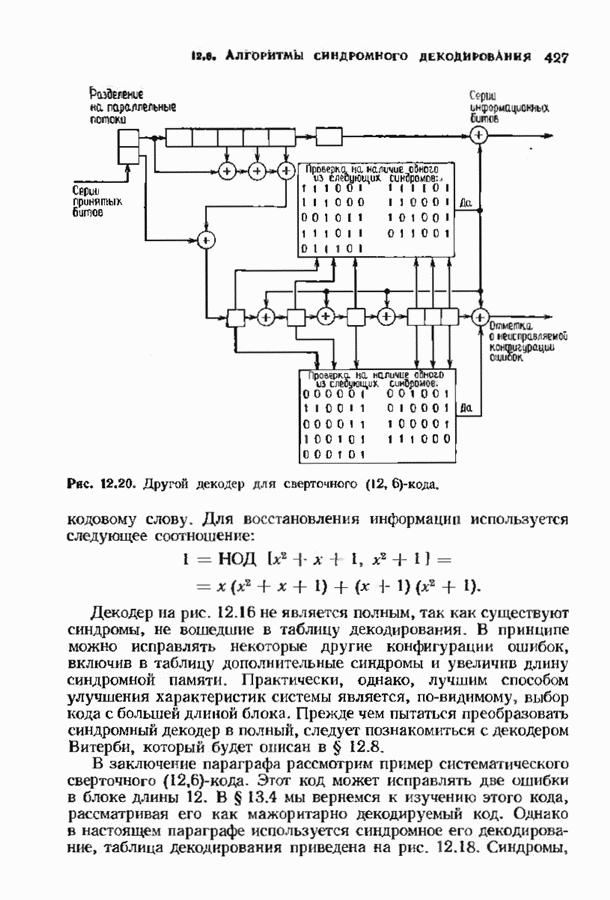



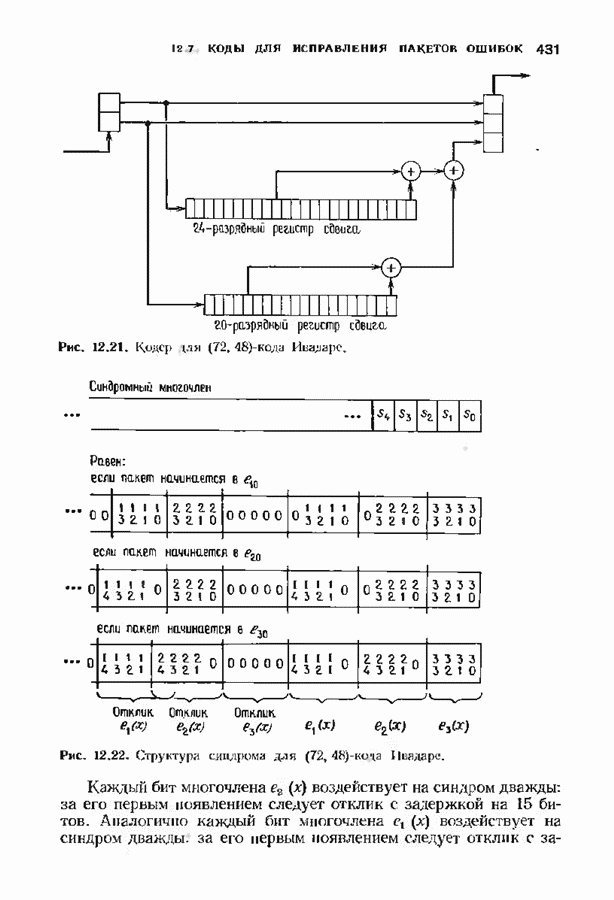
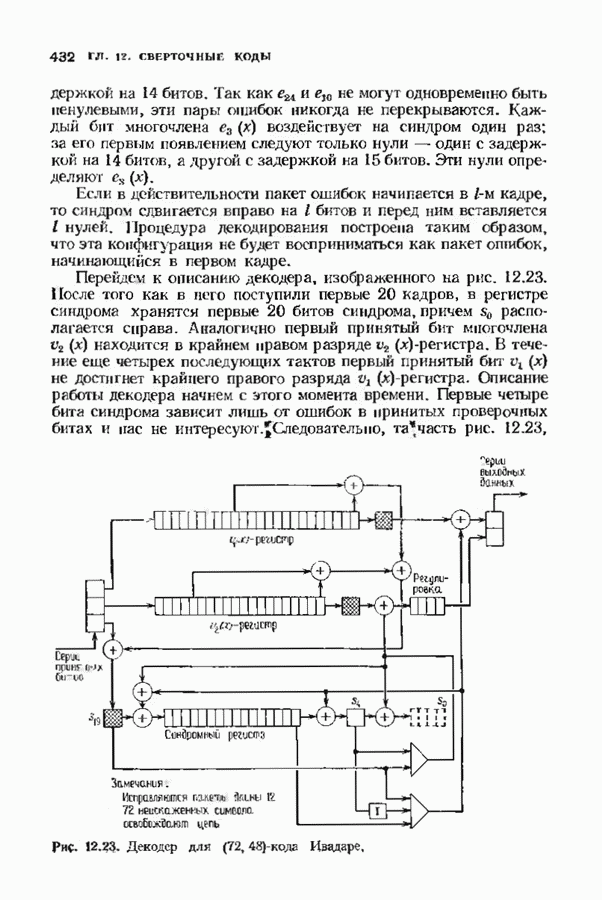
































































































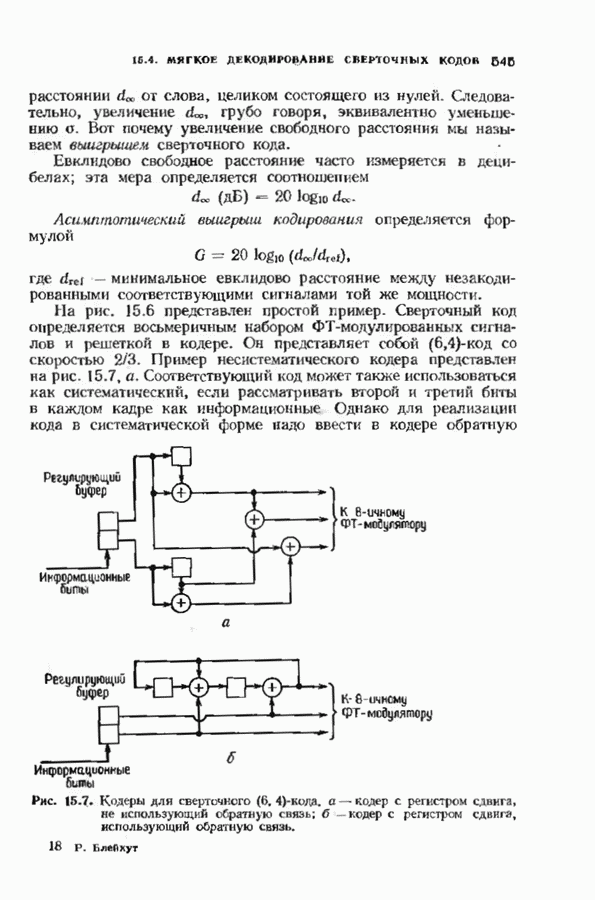
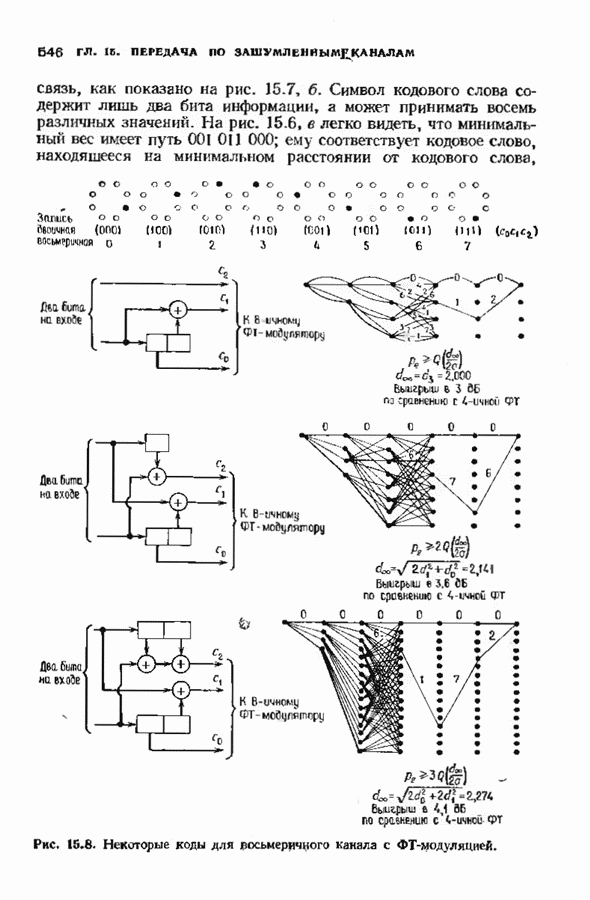


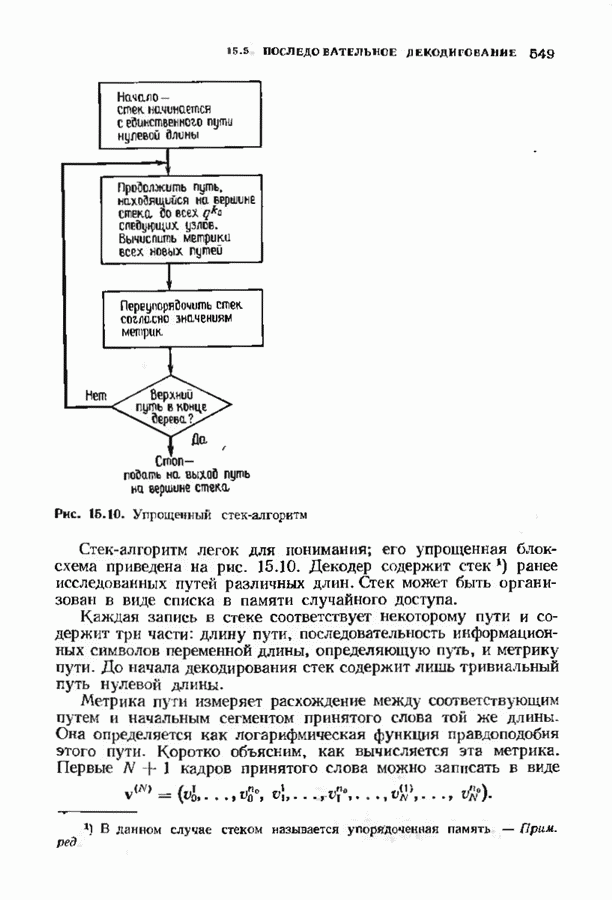














 кодовых слов в
кодовых слов в  сигналов
сигналов  где
где 
 где
где  Передаваемый сигнал,
Передаваемый сигнал,  реализация шума, представляется своими отсчетами
реализация шума, представляется своими отсчетами  при
при  По этим отсчетам демодулятор и декодер должны восстановить кодовое слово, а затем и информационные символы.
По этим отсчетам демодулятор и декодер должны восстановить кодовое слово, а затем и информационные символы.
 при условии, что передан сигнал
при условии, что передан сигнал  дается выражением
дается выражением

 По принятому сигналу
По принятому сигналу  приемник максимального правдоподобия определяет значение
приемник максимального правдоподобия определяет значение  при котором
при котором  максимально, и объявляет, что было передано
максимально, и объявляет, что было передано  сообщение.
сообщение.
 при котором евклидово расстояние
при котором евклидово расстояние

 сообщение.
сообщение.
 одинакова для всех
одинакова для всех  то приемник минимального евклидова расстояния может быть заменен корреляционным приемником. Он вычисляет совокупность
то приемник минимального евклидова расстояния может быть заменен корреляционным приемником. Он вычисляет совокупность  коэффициентов корреляции
коэффициентов корреляции

 у которого
у которого  при всех
при всех  После этого по
После этого по  восстанавливаются информационные символы. Поскольку
восстанавливаются информационные символы. Поскольку  очень велико, обычно даже этот приемник довольно непрактичен и поэтому переходят к более компактным схемам, схемам меньшей сложности.
очень велико, обычно даже этот приемник довольно непрактичен и поэтому переходят к более компактным схемам, схемам меньшей сложности.

 -ичных символов, к которой можно успешно применить мощную технику алгебраического декодирования. Не представляет трудностей использование той же техники в случае, когда демодулятор может производить стирания. Второй экстремальный случай — демодулятор вообще не принимает решения; при этом вся информация в принятом сигнале сохраняется и передается декодеру.
-ичных символов, к которой можно успешно применить мощную технику алгебраического декодирования. Не представляет трудностей использование той же техники в случае, когда демодулятор может производить стирания. Второй экстремальный случай — демодулятор вообще не принимает решения; при этом вся информация в принятом сигнале сохраняется и передается декодеру.
 двоичный бит описывается вещественным числом
двоичный бит описывается вещественным числом  представляющим оценку принятого символа в сочетании с доверительным уровнем. Если
представляющим оценку принятого символа в сочетании с доверительным уровнем. Если  равно —1, то
равно —1, то  принятый бит равен 0 с максимальным доверительным уровнем; если
принятый бит равен 0 с максимальным доверительным уровнем; если  то
то  принятый бит равен единице с максимальным доверительным уровнем. Если 5; представлено в виде числа, характеризуемого знаком и величиной, то можно считать, что его знак представляет оценку
принятый бит равен единице с максимальным доверительным уровнем. Если 5; представлено в виде числа, характеризуемого знаком и величиной, то можно считать, что его знак представляет оценку  бита на выходе демодулятора, а абсолютная величина - доверительный уровень оценки.
бита на выходе демодулятора, а абсолютная величина - доверительный уровень оценки.
 принимают лишь значения ±1 или 0, то демодулятор является демодулятором жесткого решения со стиранием, а декодер исправляет ошибки и стирания. В данном параграфе мы рассмотрим ОМР-алгоритм, который оперирует с величинами
принимают лишь значения ±1 или 0, то демодулятор является демодулятором жесткого решения со стиранием, а декодер исправляет ошибки и стирания. В данном параграфе мы рассмотрим ОМР-алгоритм, который оперирует с величинами  принимающими любое значение между
принимающими любое значение между  Этот алгоритм декодирования может использоваться с любым демодулятором, выходные символы которого
Этот алгоритм декодирования может использоваться с любым демодулятором, выходные символы которого  лежат в интервале
лежат в интервале 

 равны нулю, и равны
равны нулю, и равны  в тех позициях, в которых символы
в тех позициях, в которых символы  равны единице.
равны единице.
 вектор в
вектор в  -мерном евклидовом пространстве, такой, что его компоненты определяются выражением
-мерном евклидовом пространстве, такой, что его компоненты определяются выражением

 Сохраним за
Сохраним за  название кодового слова. Евклидово расстояние между принятым словом
название кодового слова. Евклидово расстояние между принятым словом  и кодовым словом
и кодовым словом  равно
равно 

 состоит лишь из символов жесткого решения
состоит лишь из символов жесткого решения  то евклидово расстояние связано с хэмминговым расстоянием соотношением
то евклидово расстояние связано с хэмминговым расстоянием соотношением

 равны 0, если
равны 0, если  и равны 1, если
и равны 1, если  частности, для любых двух кодовых слов
частности, для любых двух кодовых слов

 связаны соотношением
связаны соотношением

 предварительно выразив евклидово расстояние кода через скалярное произведение. Мы можем переписать его в виде
предварительно выразив евклидово расстояние кода через скалярное произведение. Мы можем переписать его в виде

 минимизация
минимизация  по
по  эквивалентна максимизации скалярного произведения
эквивалентна максимизации скалярного произведения  по
по  поскольку
поскольку  не зависит от
не зависит от  равно
равно  для любого кодового слова. Минимизация евклидова расстояния интуитивно понятнее, но при вычислениях лучше максимизировать скалярное произведение.
для любого кодового слова. Минимизация евклидова расстояния интуитивно понятнее, но при вычислениях лучше максимизировать скалярное произведение.
 Следовательно, нахождение
Следовательно, нахождение  на минимальном евклидовом расстоянии от
на минимальном евклидовом расстоянии от  эквивалентно нахождению
эквивалентно нахождению  на минимальном хэмминговом расстоянии от
на минимальном хэмминговом расстоянии от  Неравенству
Неравенству

 Следовательно, не более чем одно кодовое слово с, удовлетворяет неравенству
Следовательно, не более чем одно кодовое слово с, удовлетворяет неравенству

 равно
равно  в случае демодулятора с жестким решением, то
в случае демодулятора с жестким решением, то


 минимальное хэммингово расстояние кода. Декодирование с исправлением только ошибок эквивалентно нахождению того единственного кодового слова
минимальное хэммингово расстояние кода. Декодирование с исправлением только ошибок эквивалентно нахождению того единственного кодового слова  для которого
для которого

 или 0. По тем же причинам, что и выше, декодирование с исправлением ошибок и стираний эквивалентно нахождению того единственного кодового слова
или 0. По тем же причинам, что и выше, декодирование с исправлением ошибок и стираний эквивалентно нахождению того единственного кодового слова  для которого
для которого

 с компонентами, лежащими в интервале
с компонентами, лежащими в интервале  в двоичном коде с длиной
в двоичном коде с длиной  и минимальным хэмминговым расстоянием
и минимальным хэмминговым расстоянием  существует не более одного кодового слова
существует не более одного кодового слова  для которого
для которого

 — некоторое кодовое слово, удовлетворяющее приведенному выше неравенству, и пусть
— некоторое кодовое слово, удовлетворяющее приведенному выше неравенству, и пусть  любое другое кодовое слово. Тогда
любое другое кодовое слово. Тогда  отличается от с, по меньшей мере в
отличается от с, по меньшей мере в  позициях. Пусть
позициях. Пусть


 удовлетворяет неравенству
удовлетворяет неравенству

 слагаемых, ни одно из которых не превышает единицу. Поэтому в силу неравенства
слагаемых, ни одно из которых не превышает единицу. Поэтому в силу неравенства  следовательно,
следовательно,  что завершает доказательство теоремы.
что завершает доказательство теоремы. 
 -код
-код  у которого
у которого  равно 2. Этот пример достаточно прост для графической иллюстрации теоремы 15.3.1. На рис. 15.4 изображен куб в трехмерном евклидовом пространстве, содержащий возможные принятые векторы
равно 2. Этот пример достаточно прост для графической иллюстрации теоремы 15.3.1. На рис. 15.4 изображен куб в трехмерном евклидовом пространстве, содержащий возможные принятые векторы  В том же пространстве показаны четыре кодовых слова. Штриховкой в одном из углов выделена совокупность
В том же пространстве показаны четыре кодовых слова. Штриховкой в одном из углов выделена совокупность  удовлетворяющая условию
удовлетворяющая условию  которая декодируется в кодовое слово, лежащее в этом углу. Теорема утверждает, что если построить аналогичные области для каждого из четырех кодовых слов, то эти области не будут пересекаться. Используя эти четыре области декодирования, можно построить ОМР-декодер - Заметим, что указанные четыре области не заполняют куб полностью. Остающаяся в центре область является тетраэдром, и если
которая декодируется в кодовое слово, лежащее в этом углу. Теорема утверждает, что если построить аналогичные области для каждого из четырех кодовых слов, то эти области не будут пересекаться. Используя эти четыре области декодирования, можно построить ОМР-декодер - Заметим, что указанные четыре области не заполняют куб полностью. Остающаяся в центре область является тетраэдром, и если 

 ОМР-алгоритму для двоичного
ОМР-алгоритму для двоичного  -кода.
-кода.
 скалярных произведений, непрактично. Опишем практический способ нахождения этого кодового слова. Идея состоит в следующем.
скалярных произведений, непрактично. Опишем практический способ нахождения этого кодового слова. Идея состоит в следующем.
 он стирает I компонент, для которых
он стирает I компонент, для которых  минимальны. (Если для некоторых
минимальны. (Если для некоторых  в силу равенства нескольких компонент выбор этих I компонент неоднозначен, то соответствующее I опускается.) Совокупность нестертых компонент отображается в нули или единицы в зависимости от знака При этом над
в силу равенства нескольких компонент выбор этих I компонент неоднозначен, то соответствующее I опускается.) Совокупность нестертых компонент отображается в нули или единицы в зависимости от знака При этом над  формируется вектор
формируется вектор  со стираниями.
со стираниями.
 используя декодер, исправляющий ошибки и стирания. Если декодирование дало кодовое слово
используя декодер, исправляющий ошибки и стирания. Если декодирование дало кодовое слово  то проверим выполнение неравенства
то проверим выполнение неравенства  Если это неравенство выполняется, то
Если это неравенство выполняется, то  объявляется ОМР-декодированным кодовым словом. В противном случае I увеличивается и процедура повторяется до тех пор, пока I не превзойдет
объявляется ОМР-декодированным кодовым словом. В противном случае I увеличивается и процедура повторяется до тех пор, пока I не превзойдет  ; в последнем случае декодирование объявляется неудачным.
; в последнем случае декодирование объявляется неудачным.
 Этого достаточно, так как при изменении числа стираний на два число ошибок, которые можно исправить, изменяется на единицу.
Этого достаточно, так как при изменении числа стираний на два число ошибок, которые можно исправить, изменяется на единицу.
 то хотя бы одно слово
то хотя бы одно слово  удовлетворяет неравенству
удовлетворяет неравенству


 раз выше, чем декодера для кода, исправляющего ошибки и стирания.
раз выше, чем декодера для кода, исправляющего ошибки и стирания.
 -ичные символы, каждый из которых характеризуется своей оценкой
-ичные символы, каждый из которых характеризуется своей оценкой  элементом
элементом  н доверительным уровнем
н доверительным уровнем  измеряющим надежность оценки. Если
измеряющим надежность оценки. Если  равно единице, то принятый символ равен
равно единице, то принятый символ равен  с максимальным доверительным уровнем; если
с максимальным доверительным уровнем; если  равно 0, принятый символ равен
равно 0, принятый символ равен  с минимальным доверительным уровнем.
с минимальным доверительным уровнем.
 Он даже может всегда полагать
Он даже может всегда полагать  равным единице — в этом случае он является демодулятором с жестким решением; он может полагать
равным единице — в этом случае он является демодулятором с жестким решением; он может полагать  равным 0 или 1 — в этом случае он является демодулятором с жестким решением и со стиранием. Возможно также использование для нахождения
равным 0 или 1 — в этом случае он является демодулятором с жестким решением и со стиранием. Возможно также использование для нахождения  более сложной доверительной меры.
более сложной доверительной меры.
 -ичном случае такой геометрической интерпретации не существует. Для определения скалярного произведения введем обозначение для любого
-ичном случае такой геометрической интерпретации не существует. Для определения скалярного произведения введем обозначение для любого 


 -ичный вариант теоремы 15.3.1. Это определение
-ичный вариант теоремы 15.3.1. Это определение  удобно, но неточно, поскольку
удобно, но неточно, поскольку  зависит и от а.
зависит и от а.
 с длиной
с длиной  и минимальным, расстоянием
и минимальным, расстоянием  существует хотя бы одно кодовое слово
существует хотя бы одно кодовое слово  для которого
для которого

 сотрем компоненты, для которых
сотрем компоненты, для которых  минимальны. При этом получим над
минимальны. При этом получим над  слово
слово  со стираниями. Начиная с I, равного 0, декодируем
со стираниями. Начиная с I, равного 0, декодируем  используя декодер, исправляющий ошибки и стирания. Для декодирования
используя декодер, исправляющий ошибки и стирания. Для декодирования  в с, проверяется неравенство
в с, проверяется неравенство  Если оно удовлетворяется, то
Если оно удовлетворяется, то  , объявляется
, объявляется
 будем повторять процедуру до тех пор, пока I не превысит
будем повторять процедуру до тех пор, пока I не превысит  в этом последнем случае декодирование объявляется неудачным. Следующая теорема обосновывает эту процедуру.
в этом последнем случае декодирование объявляется неудачным. Следующая теорема обосновывает эту процедуру.
 выполняется неравенство
выполняется неравенство  то хотя бы одно слово
то хотя бы одно слово  удовлетворяет неравенству
удовлетворяет неравенству

 поскольку ясно, что утверждение теоремы не может выполняться при
поскольку ясно, что утверждение теоремы не может выполняться при  Упорядочим
Упорядочим  по их величине. Пусть
по их величине. Пусть


 так что вектор К ведет себя как вероятностное распределение. Более того,
так что вектор К ведет себя как вероятностное распределение. Более того,


 при всех
при всех  Тогда
Тогда
