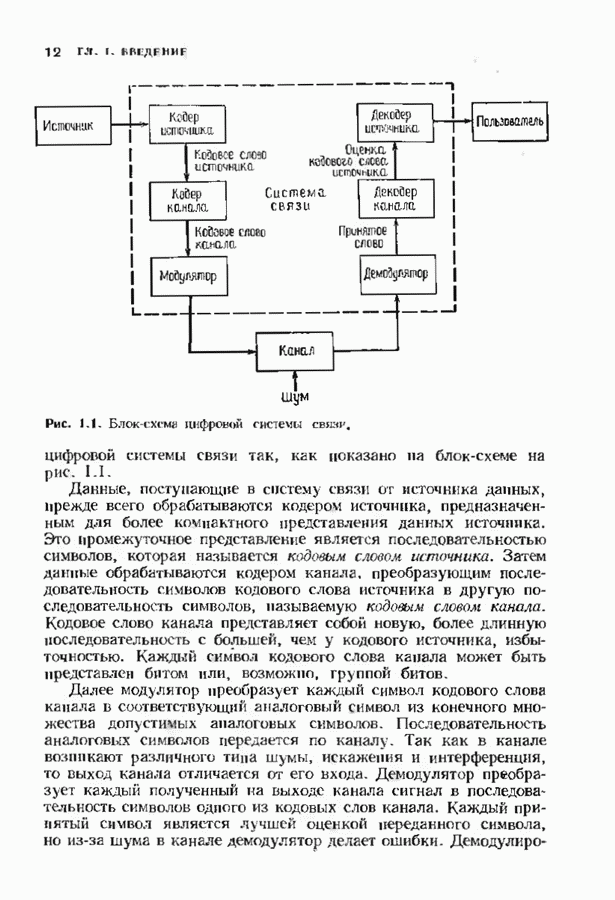
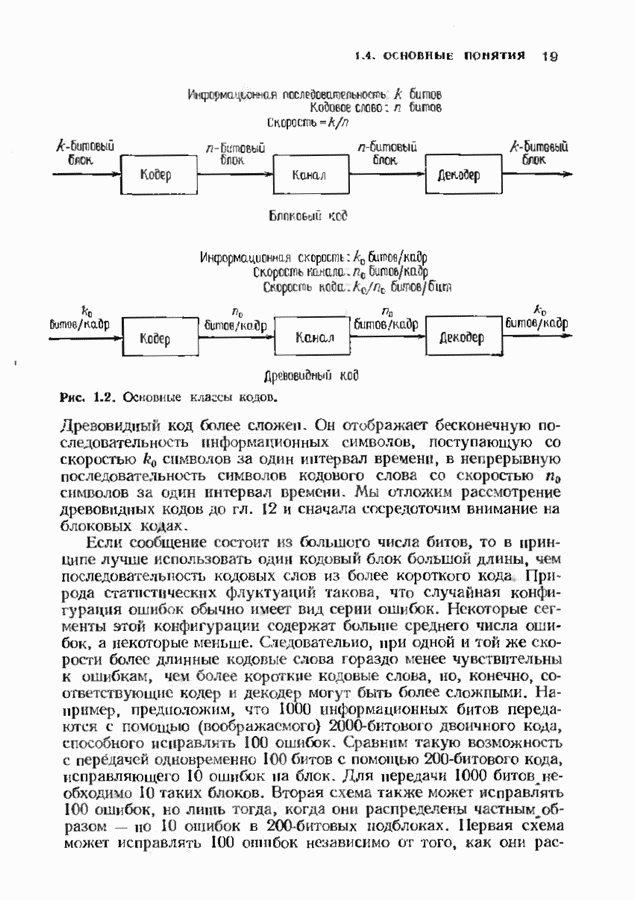
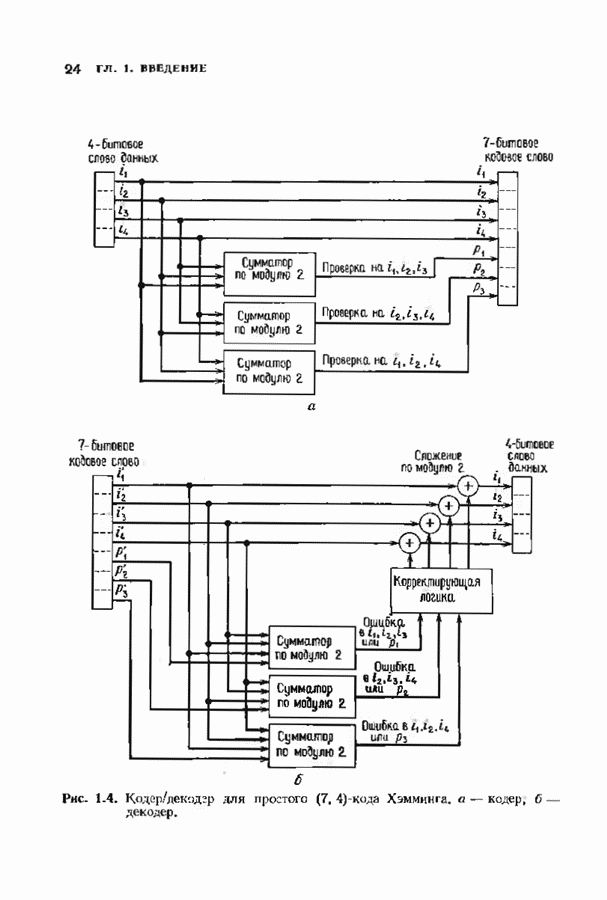
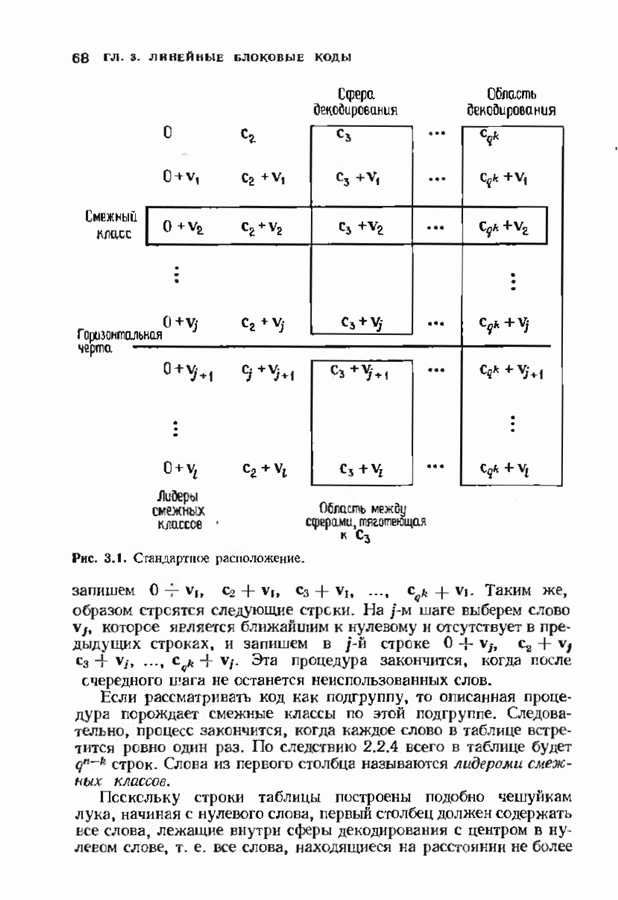
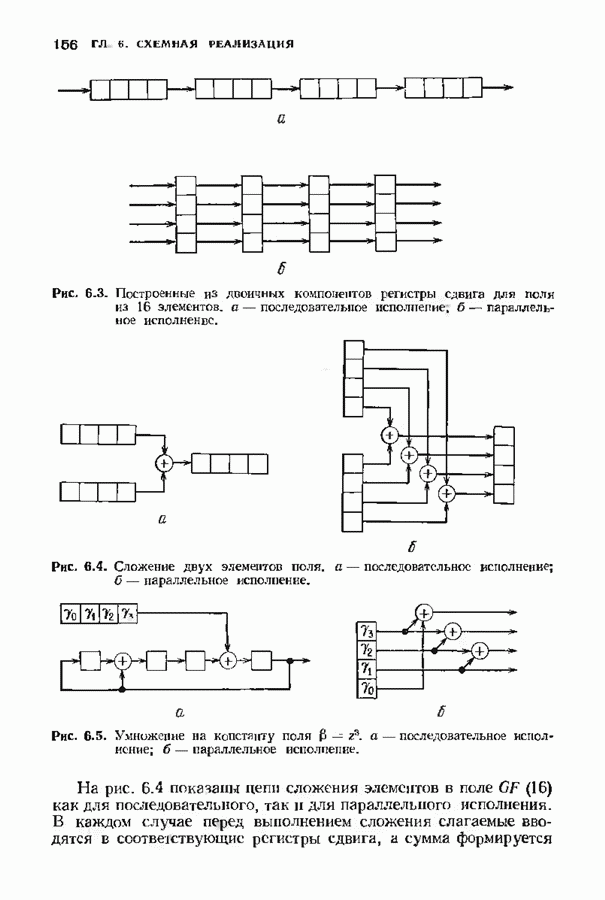
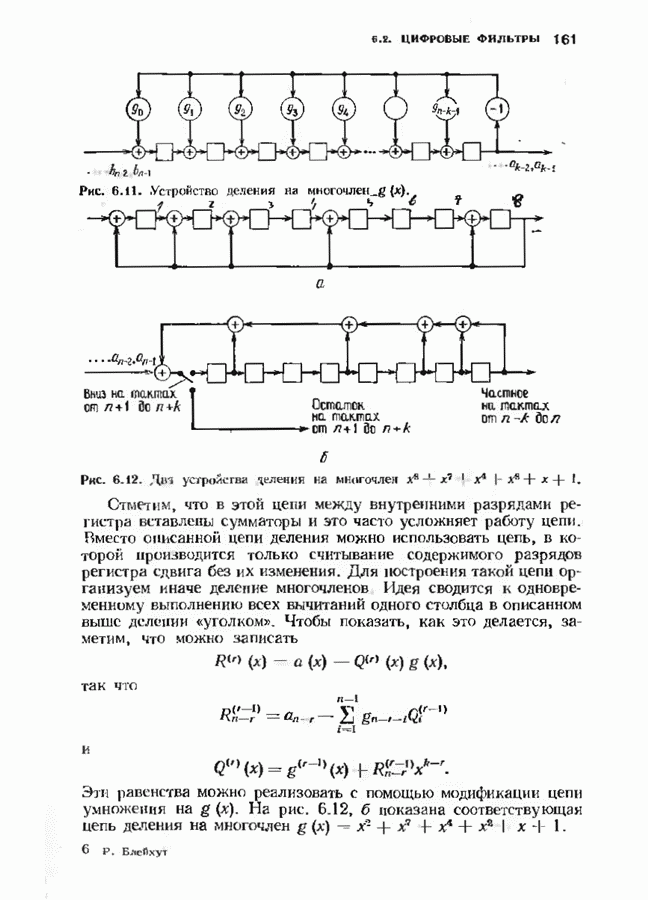
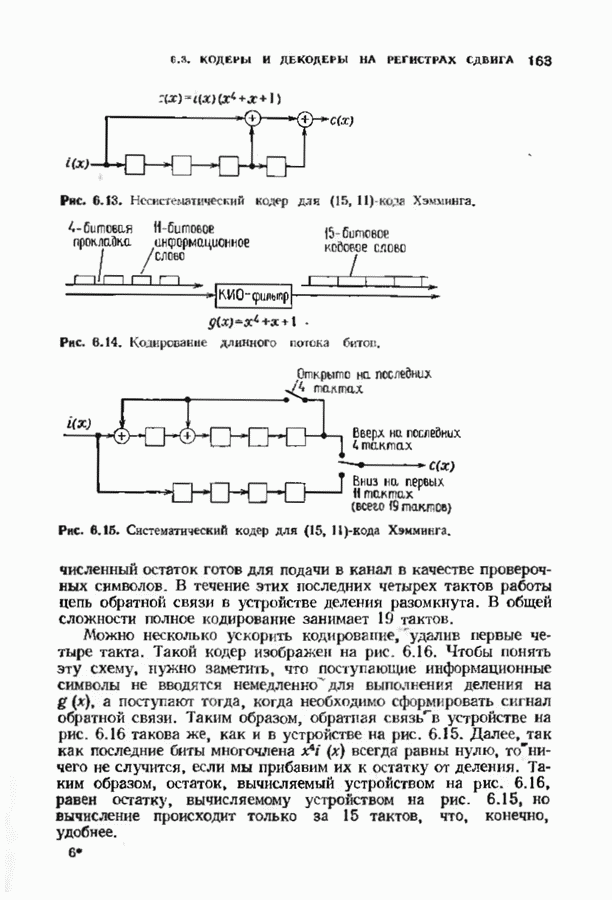
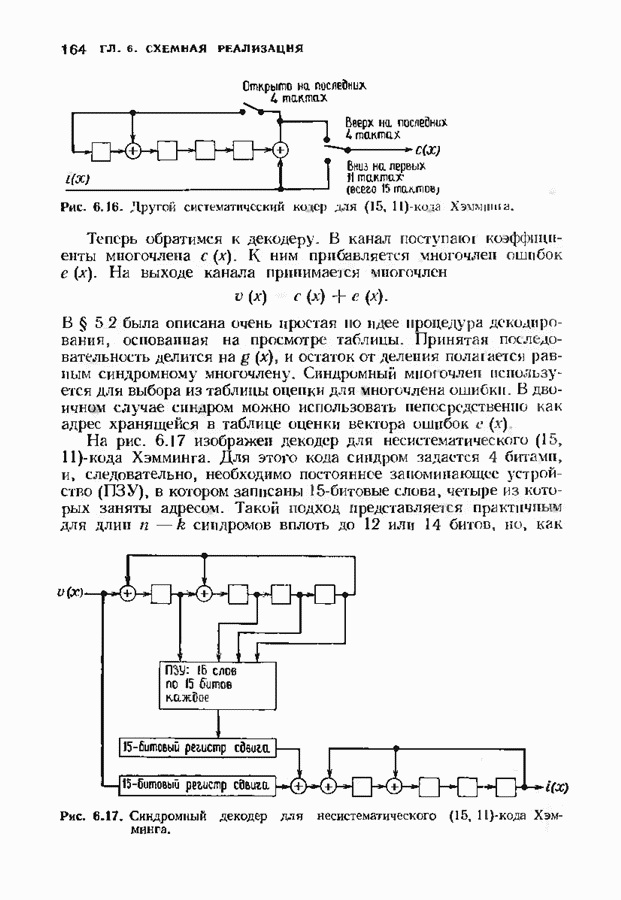
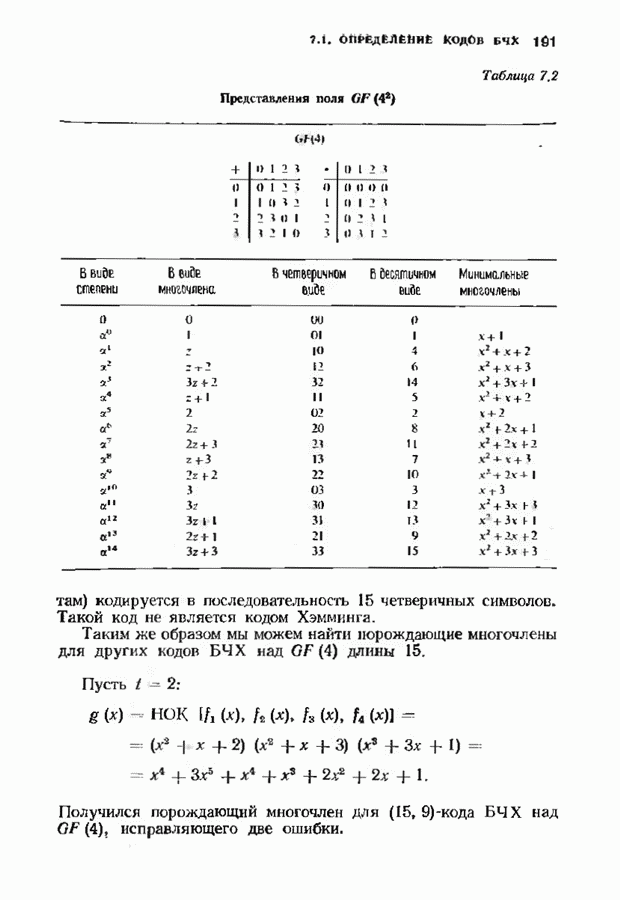
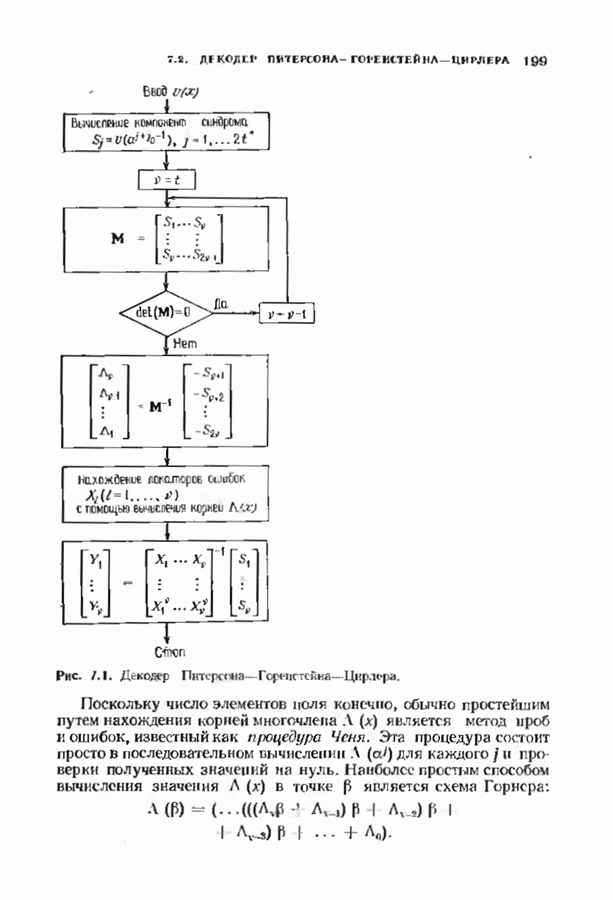
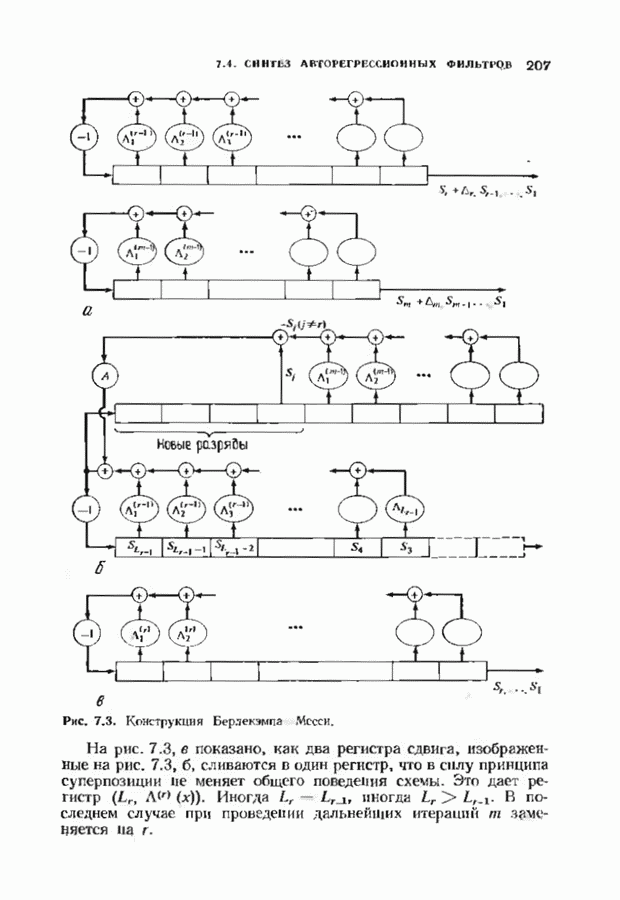
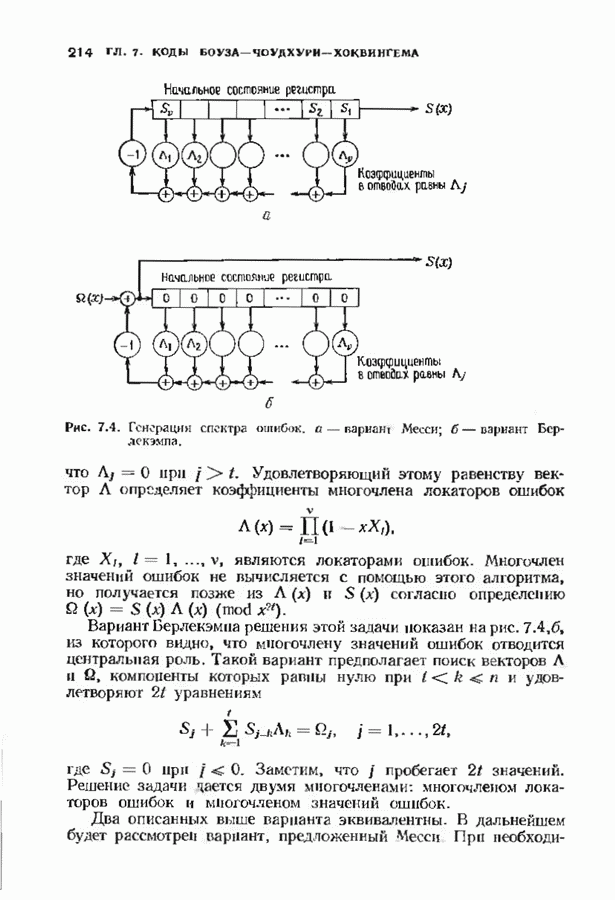
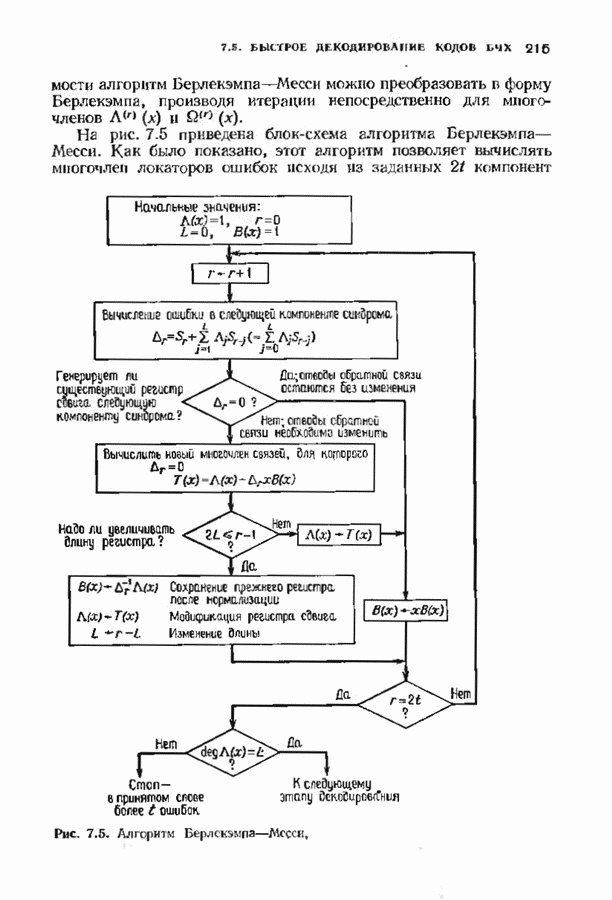
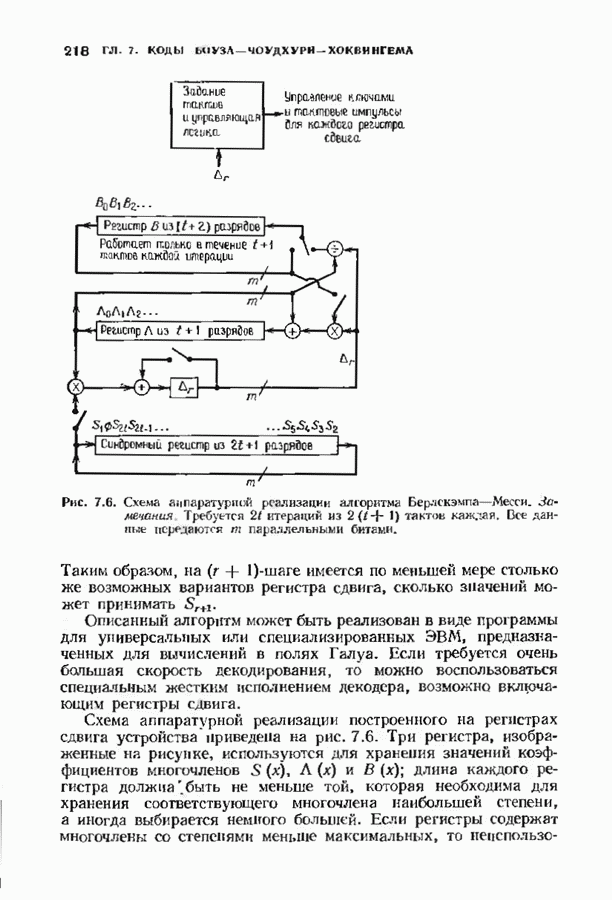
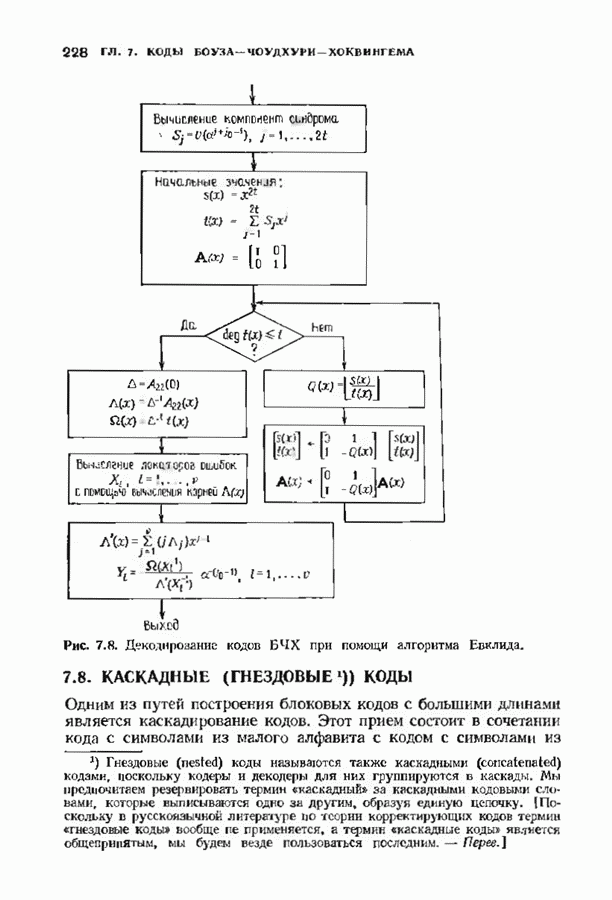
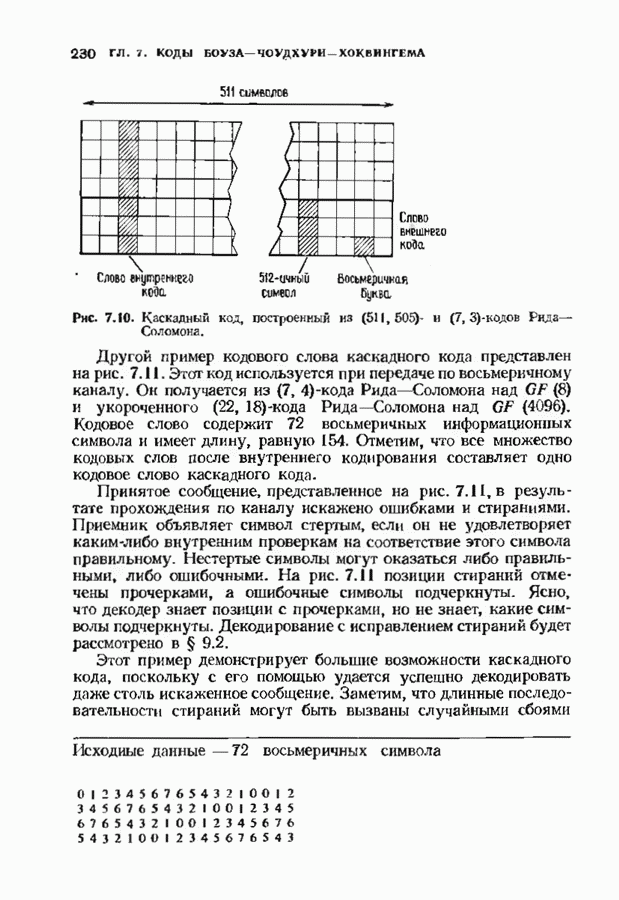
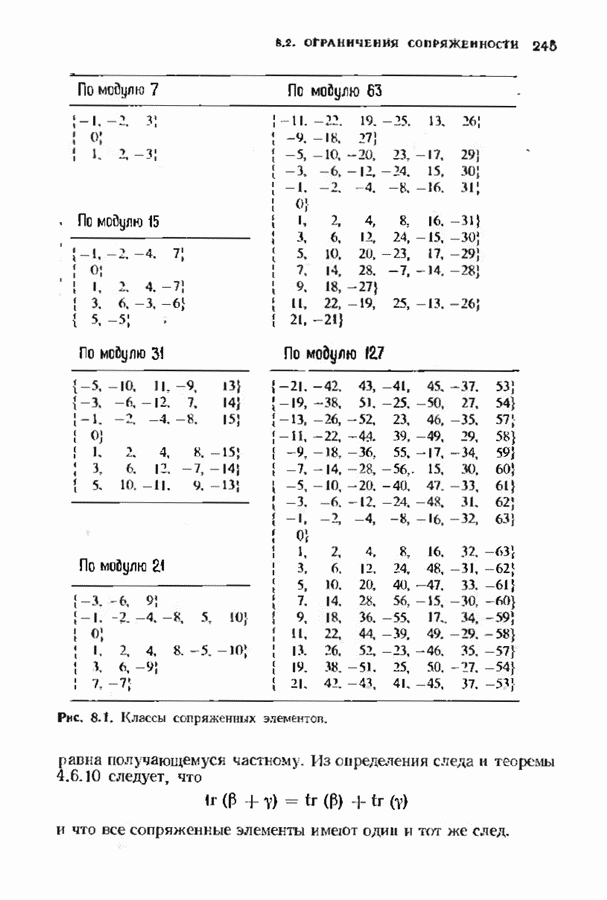
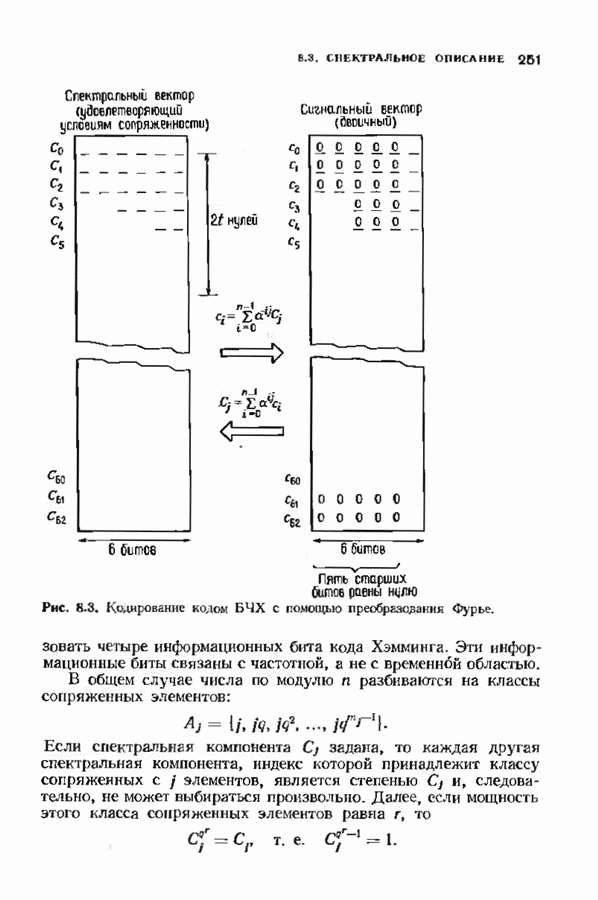
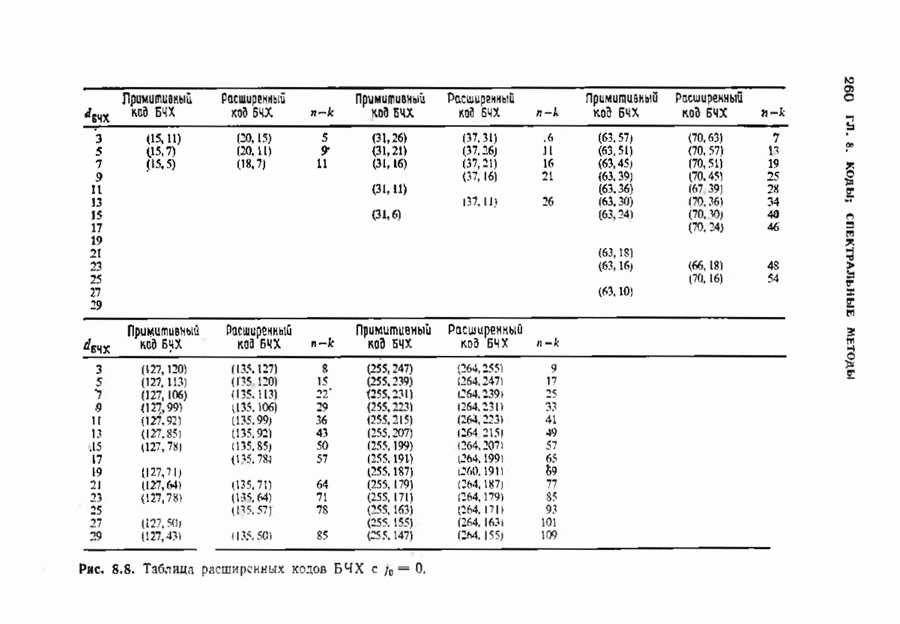
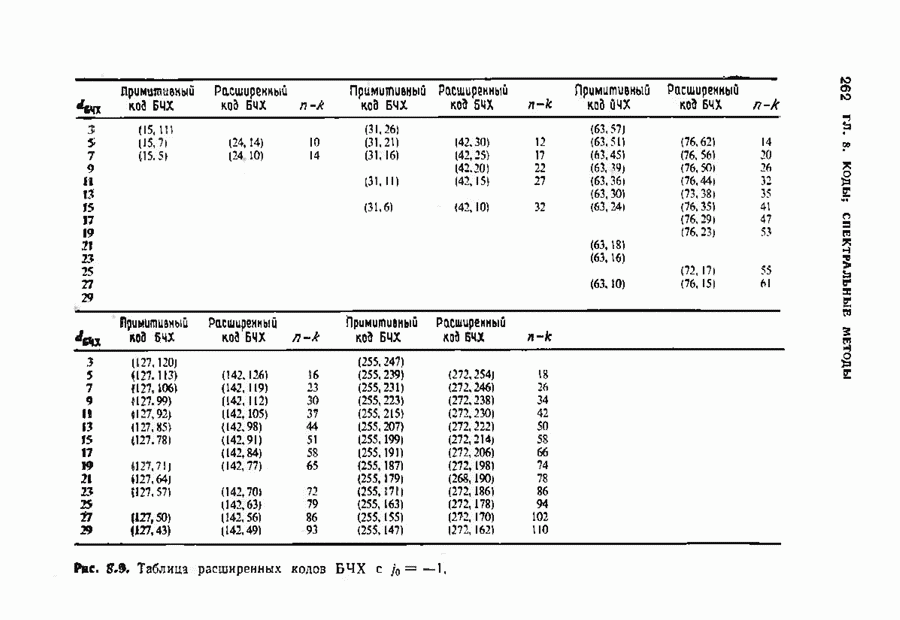
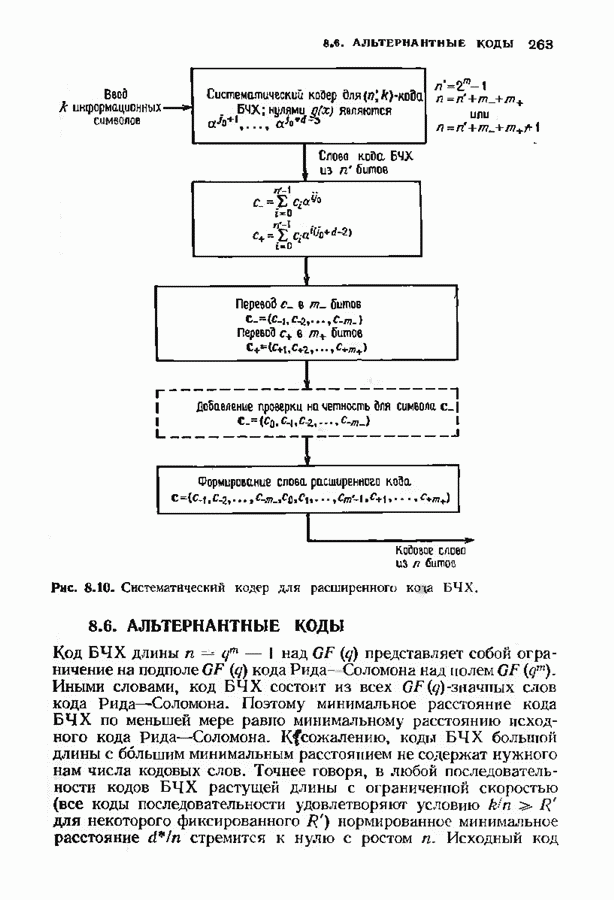
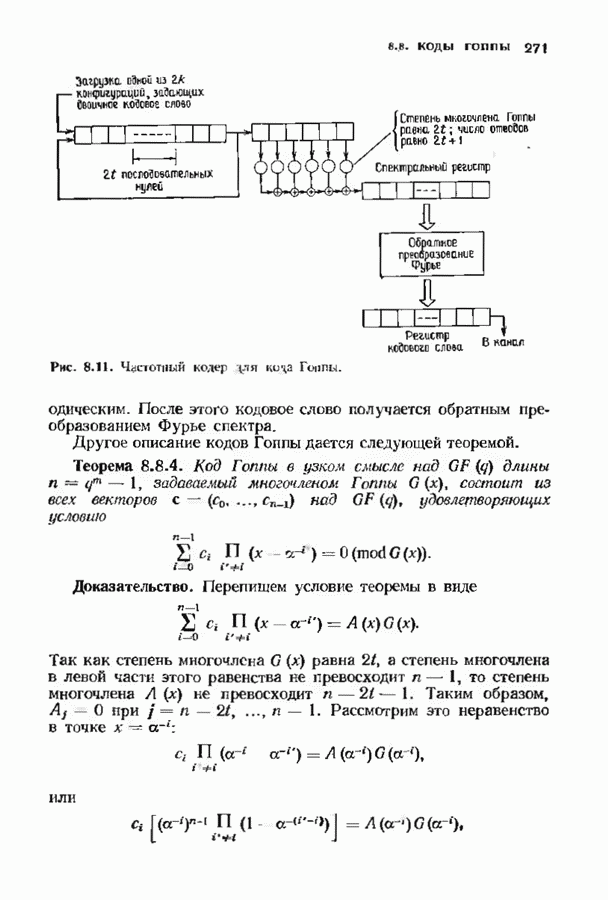
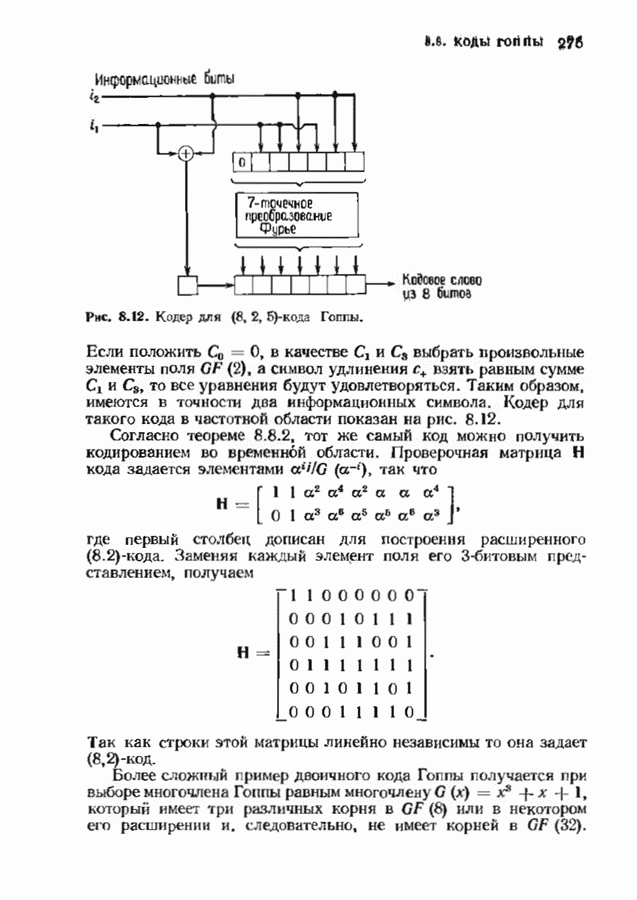
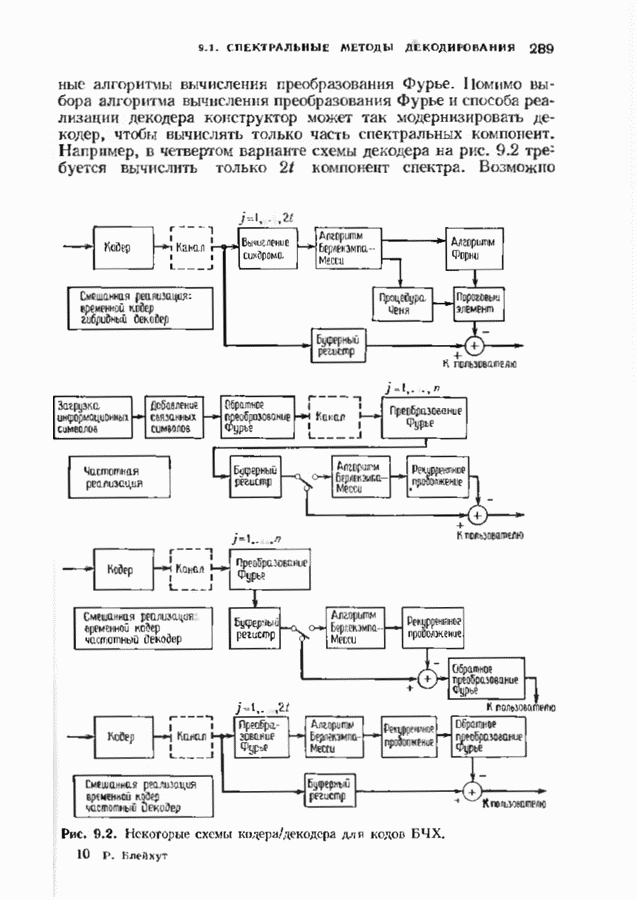
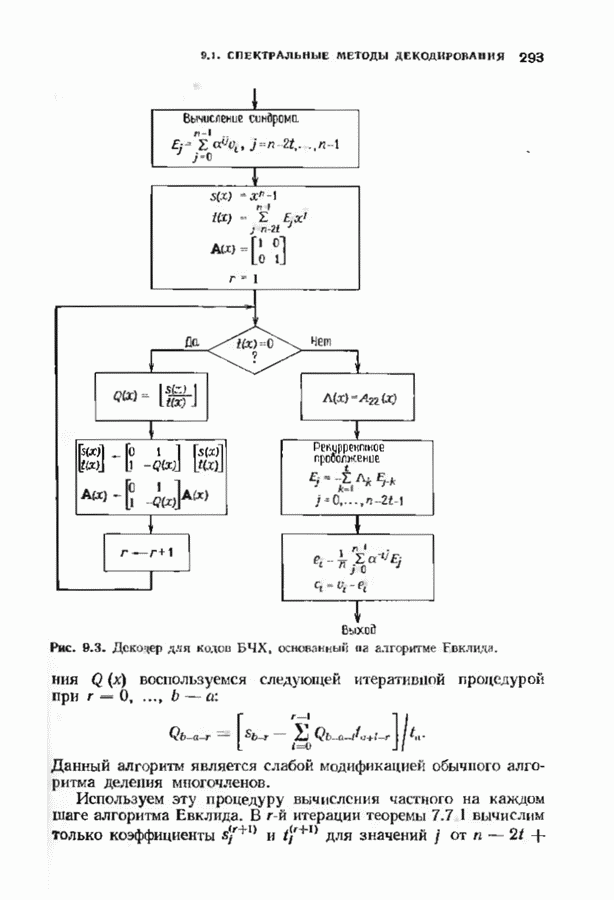
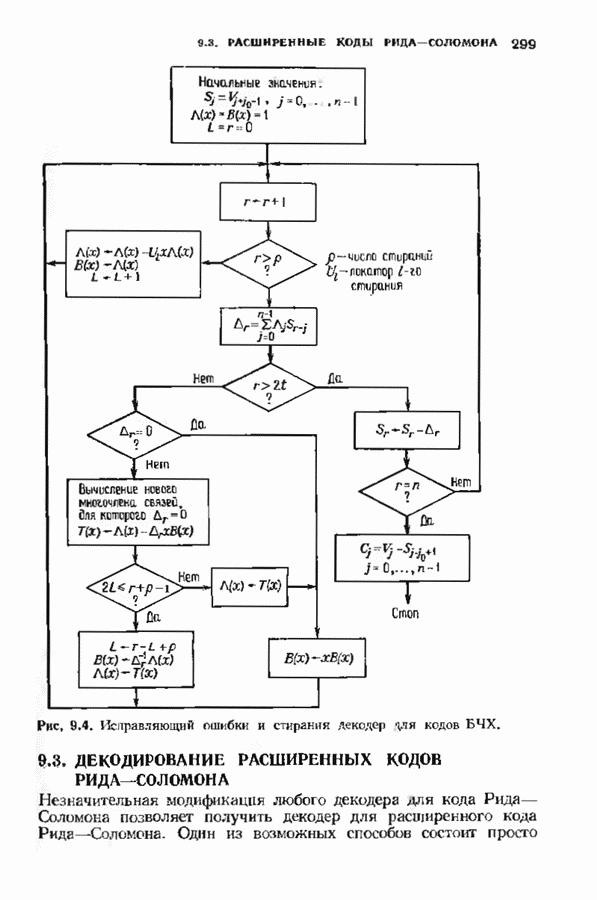
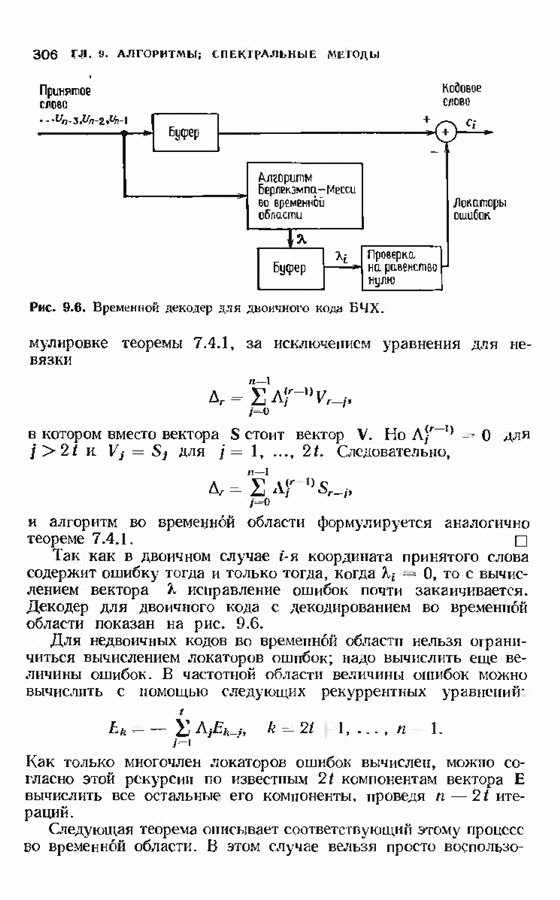
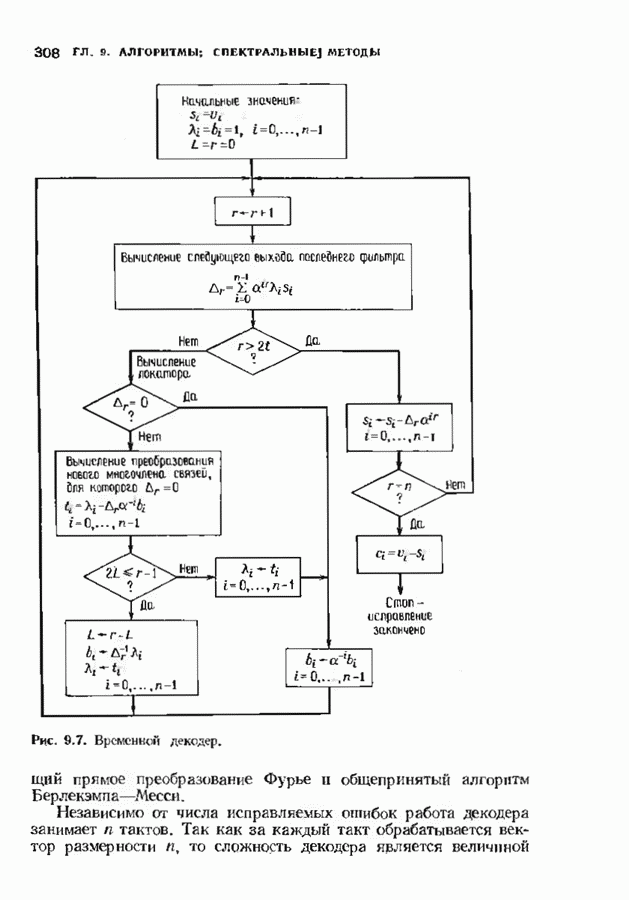
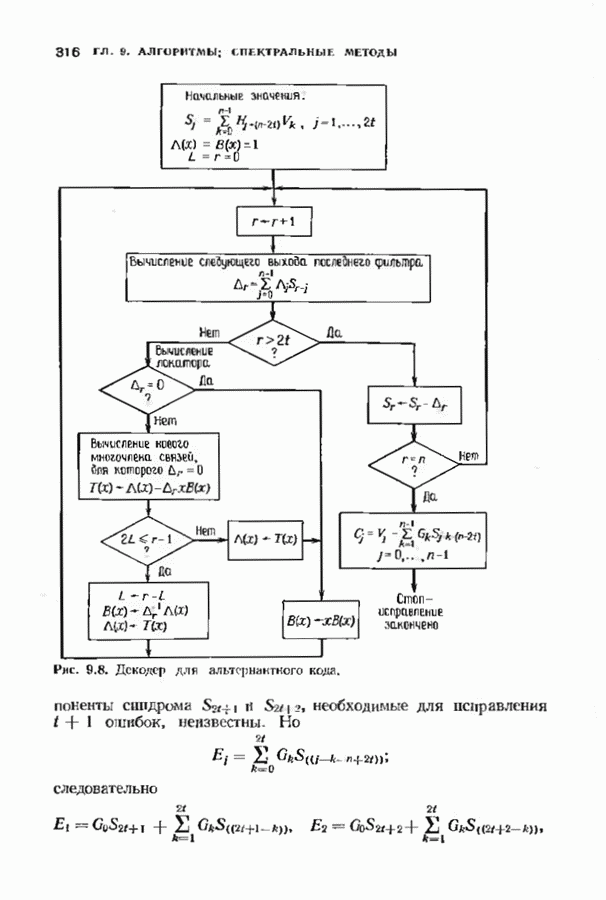
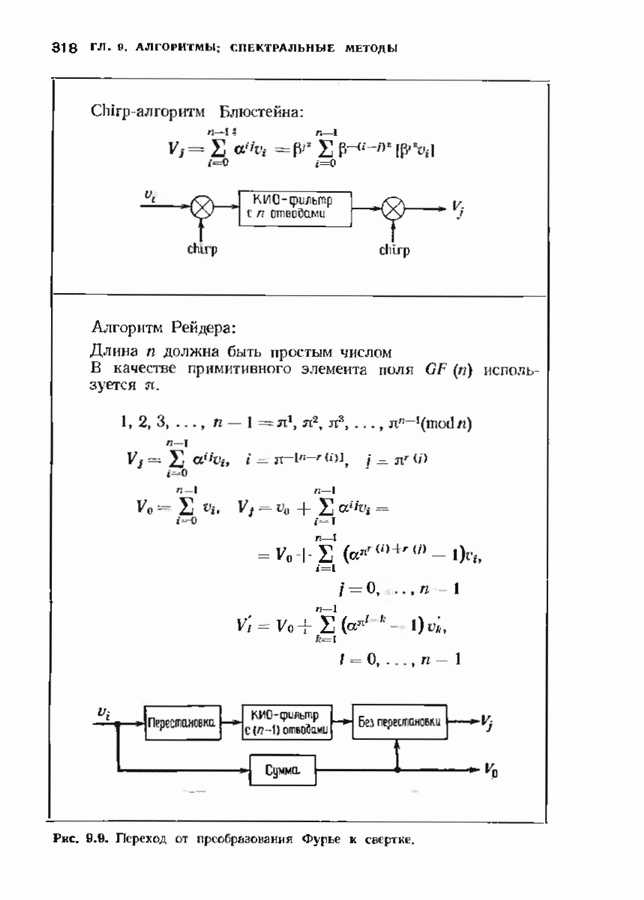
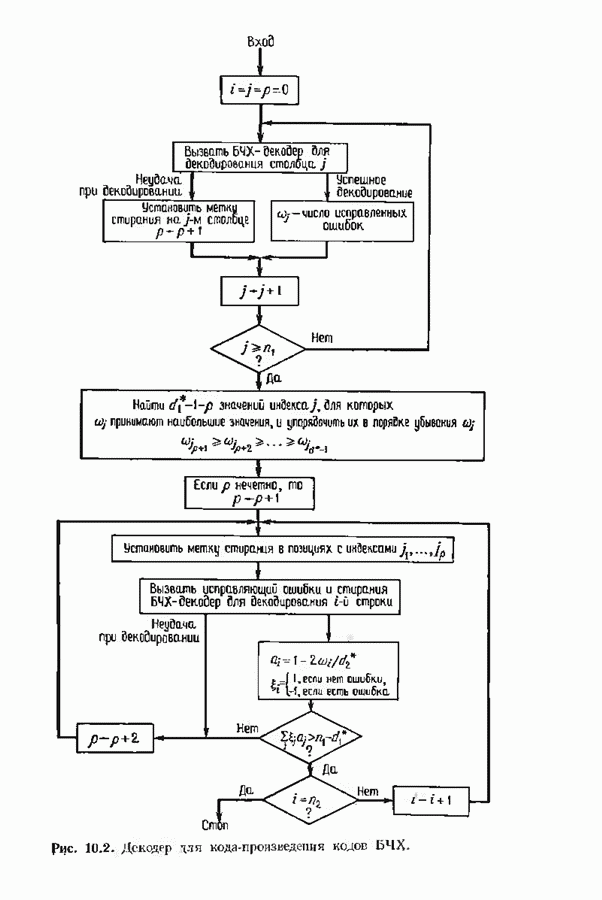
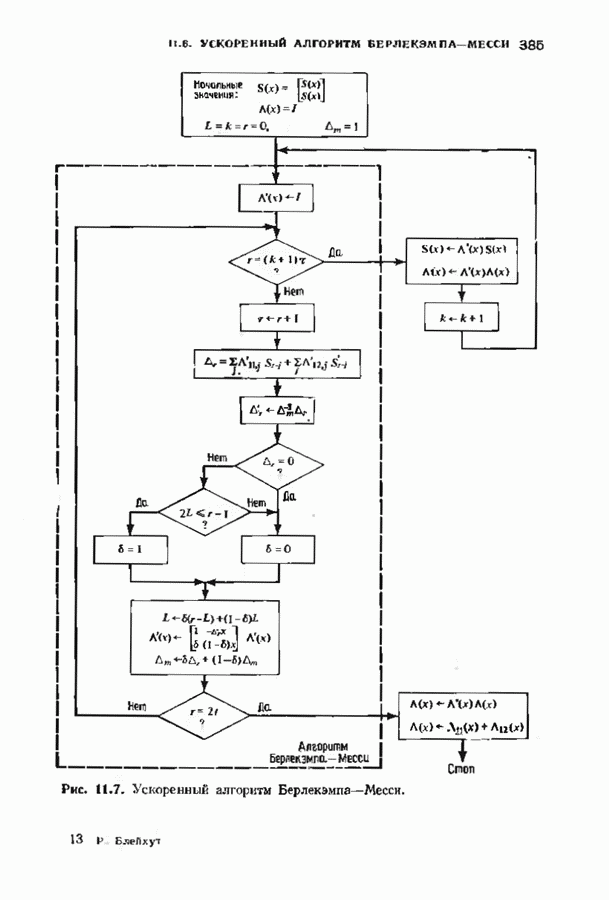
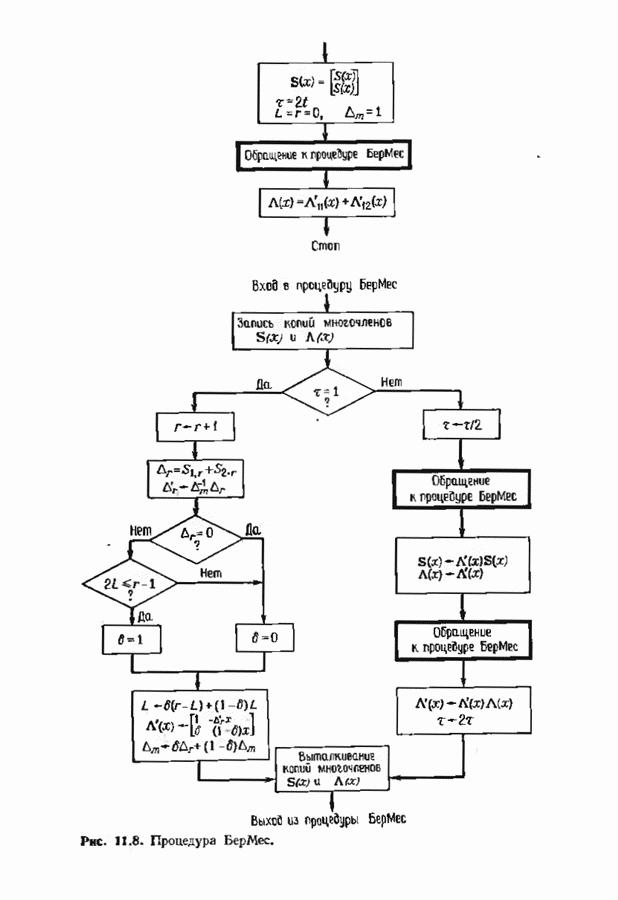
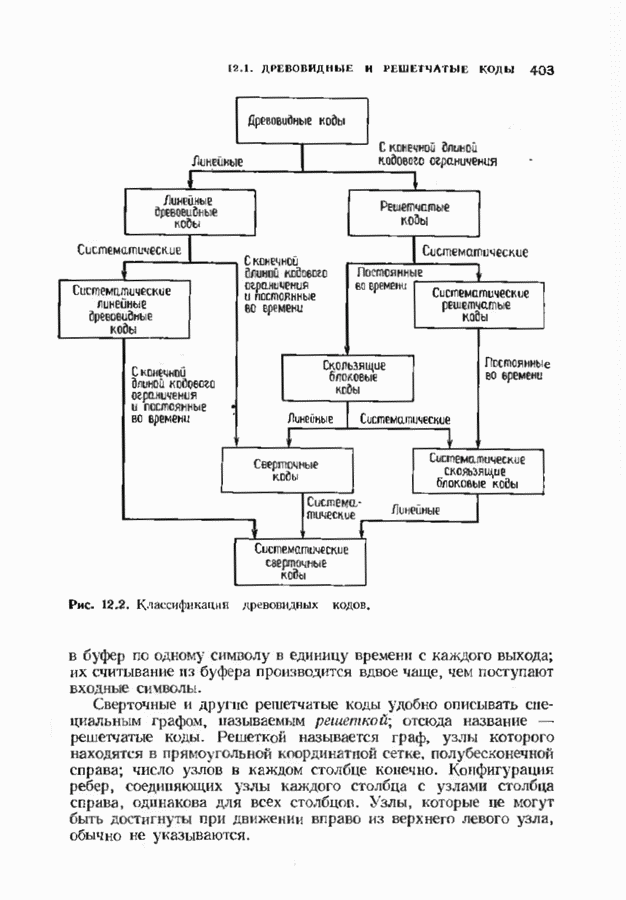
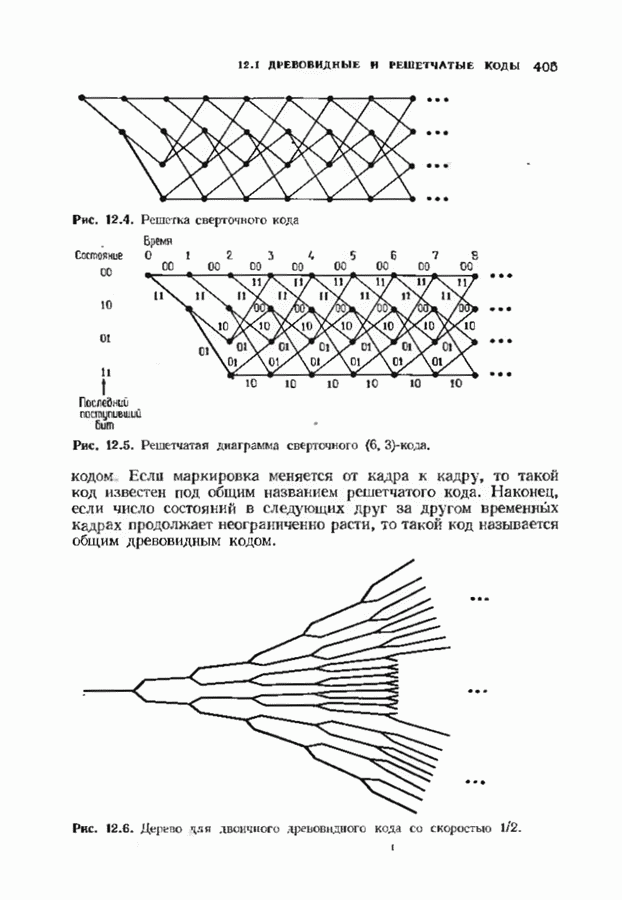
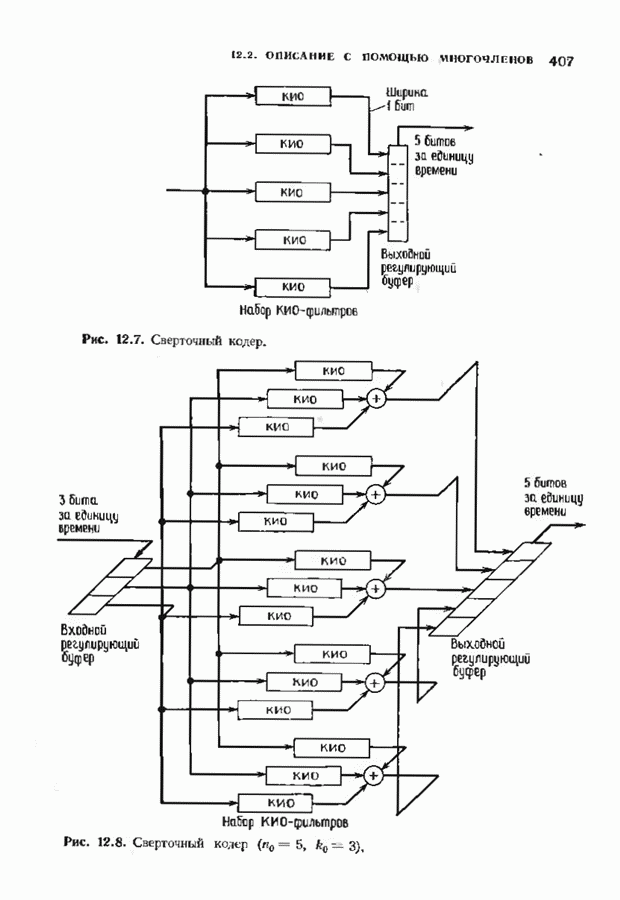
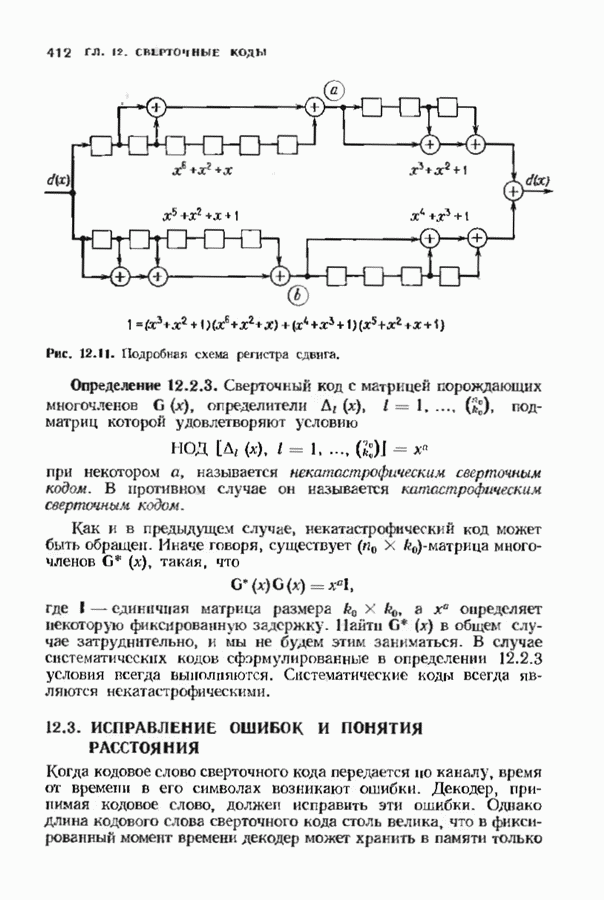
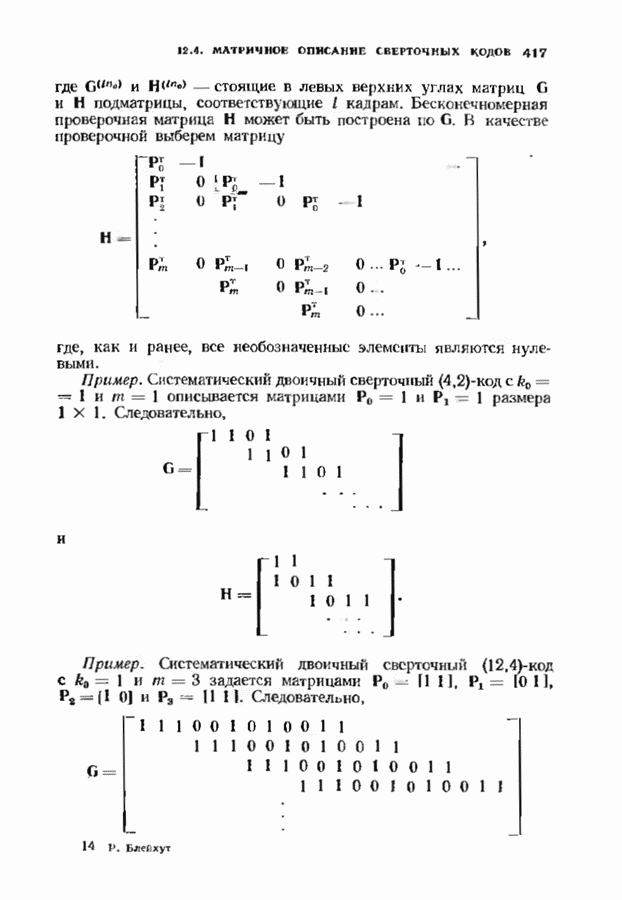
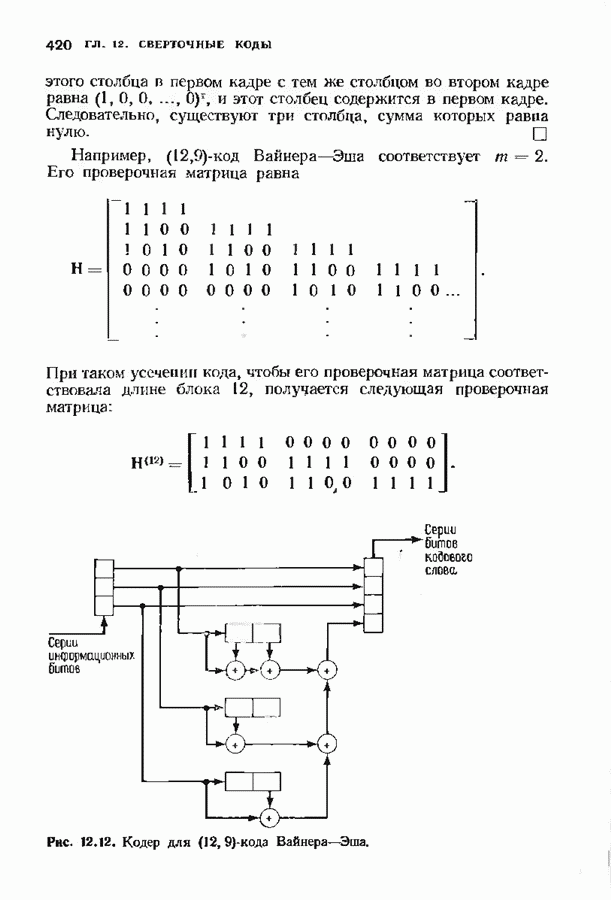
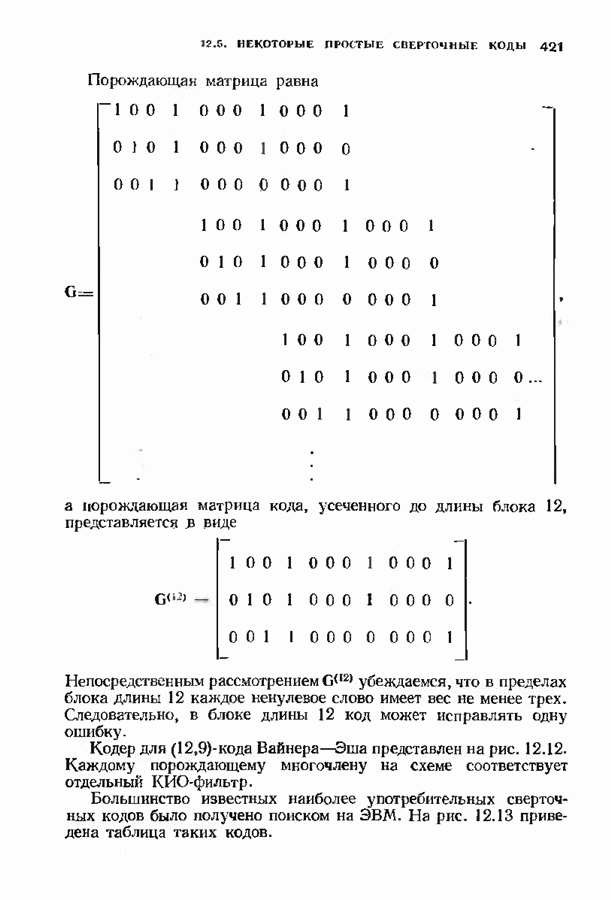
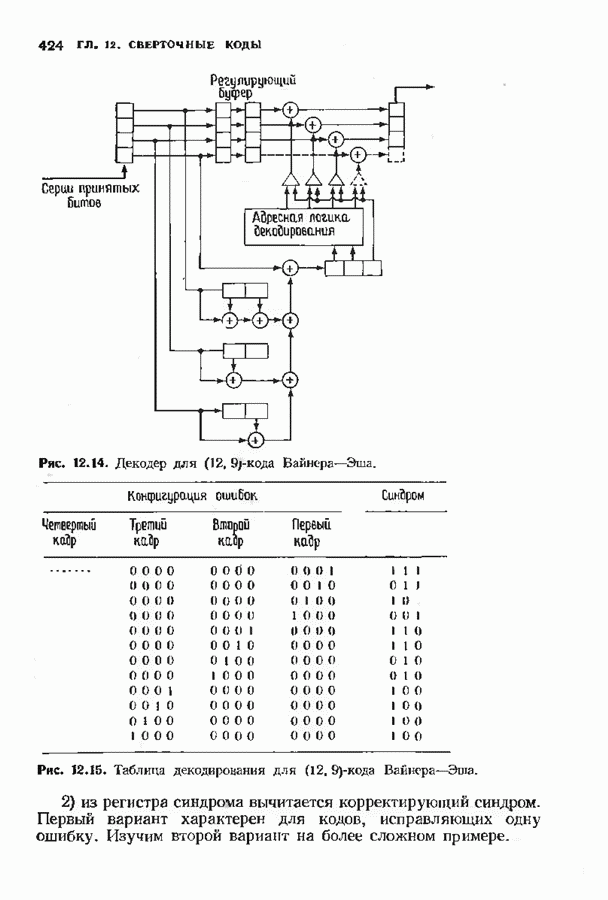
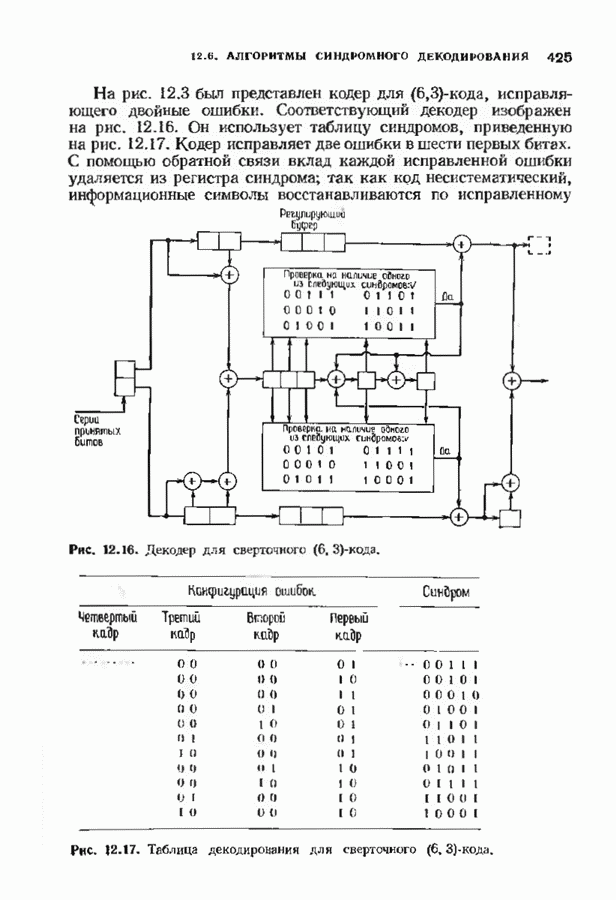
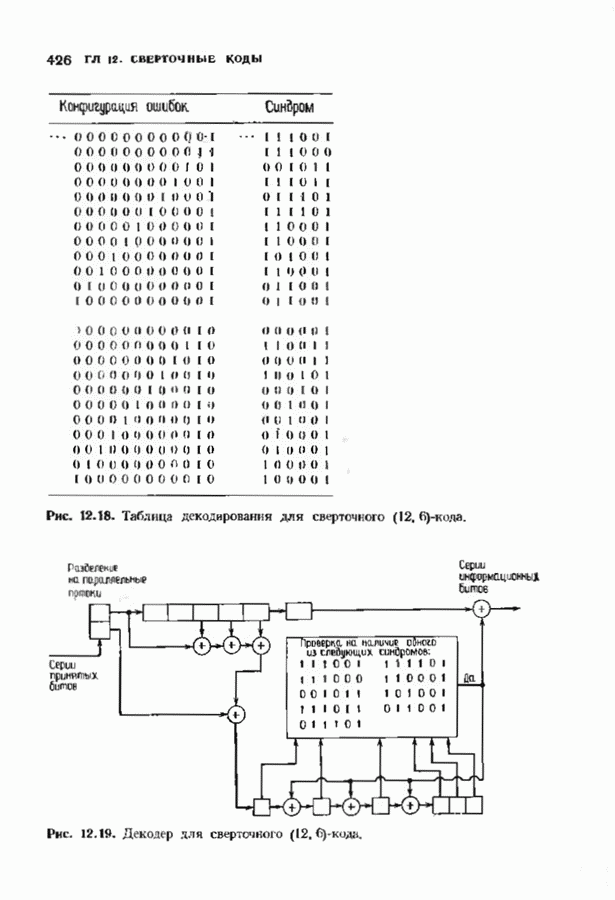
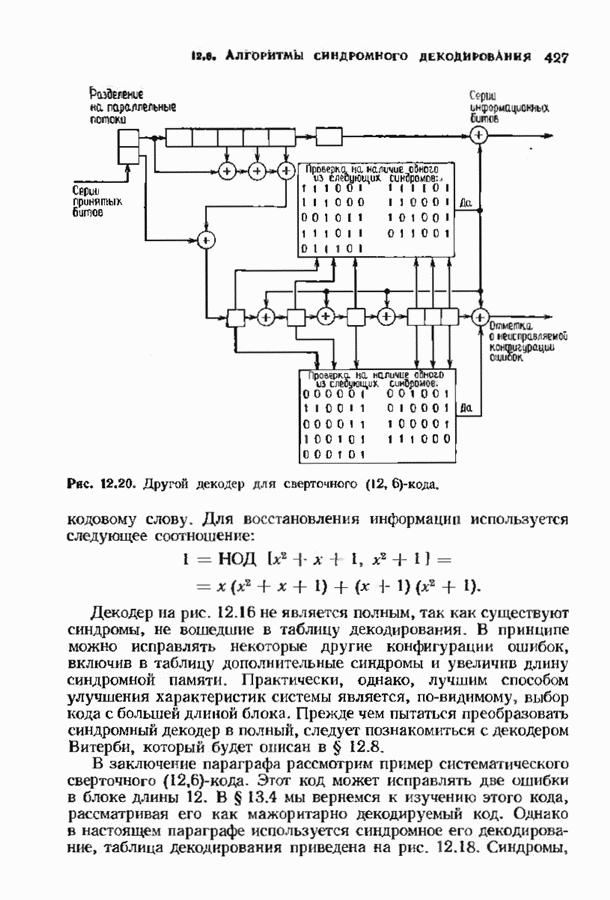
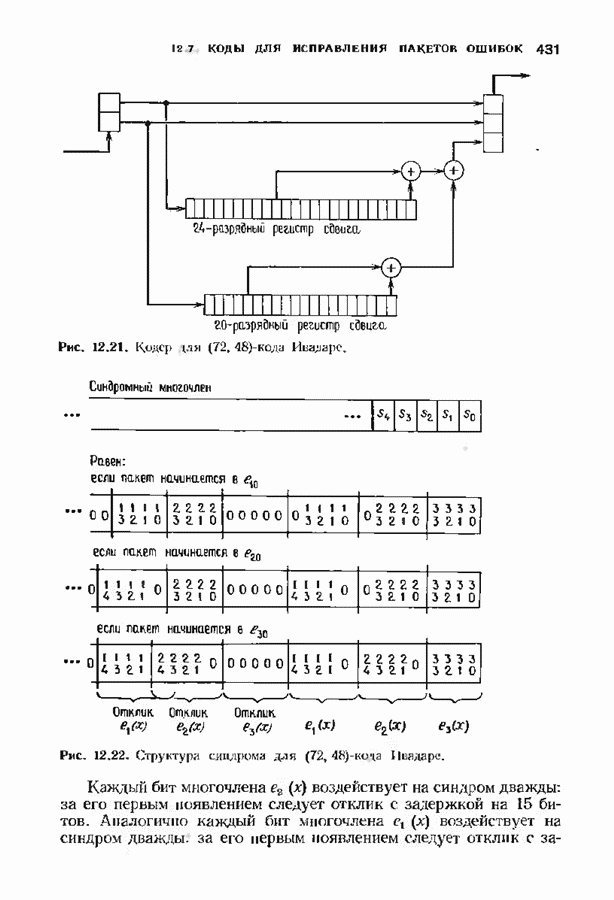
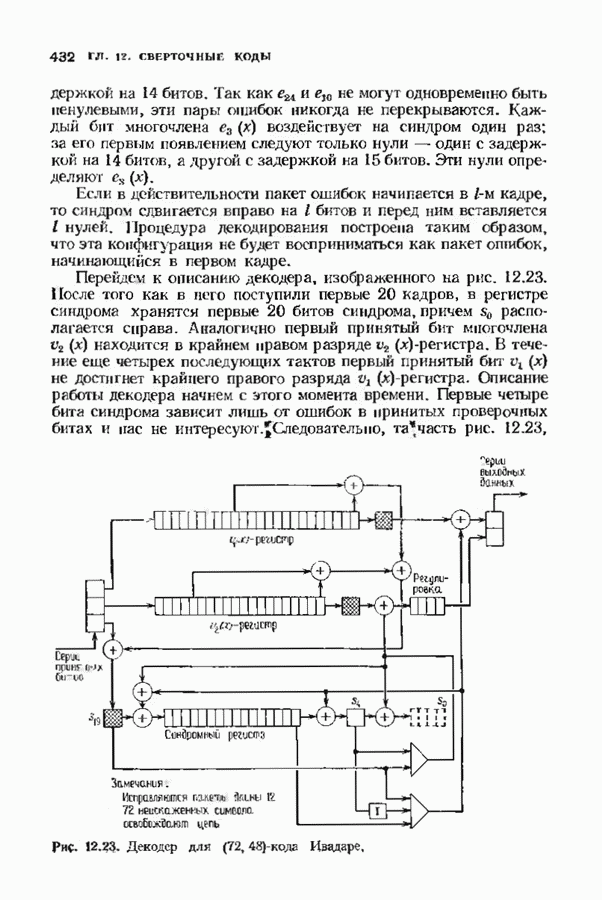
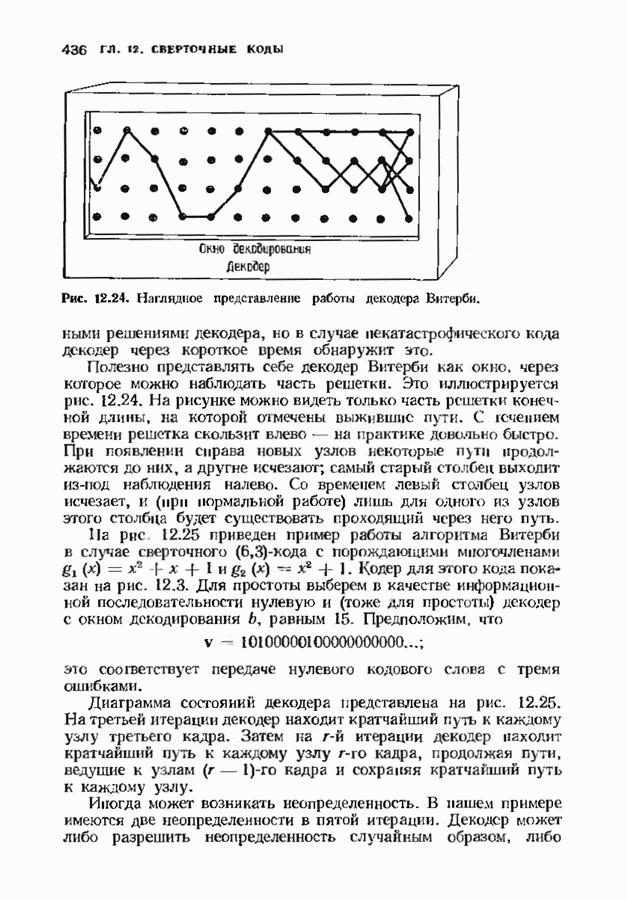
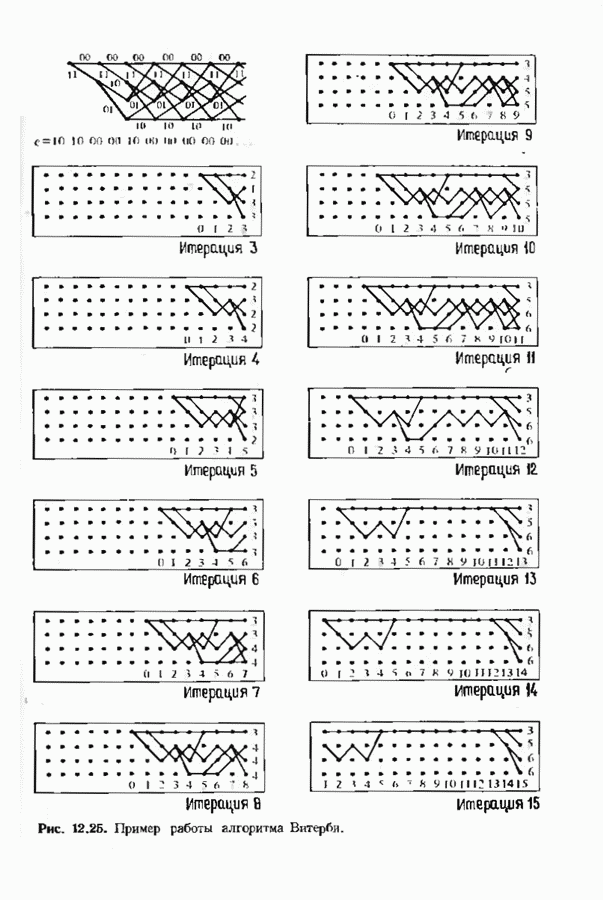
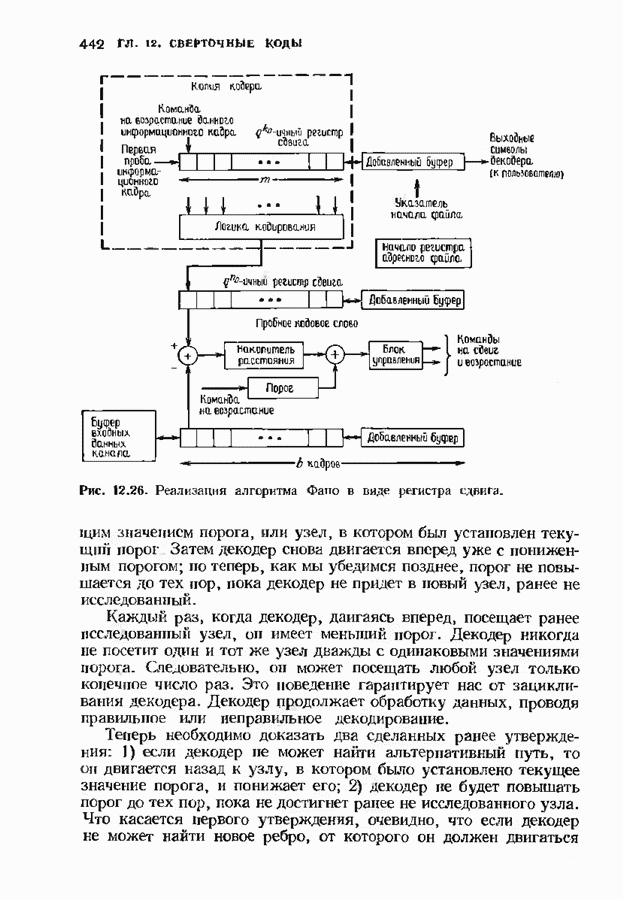
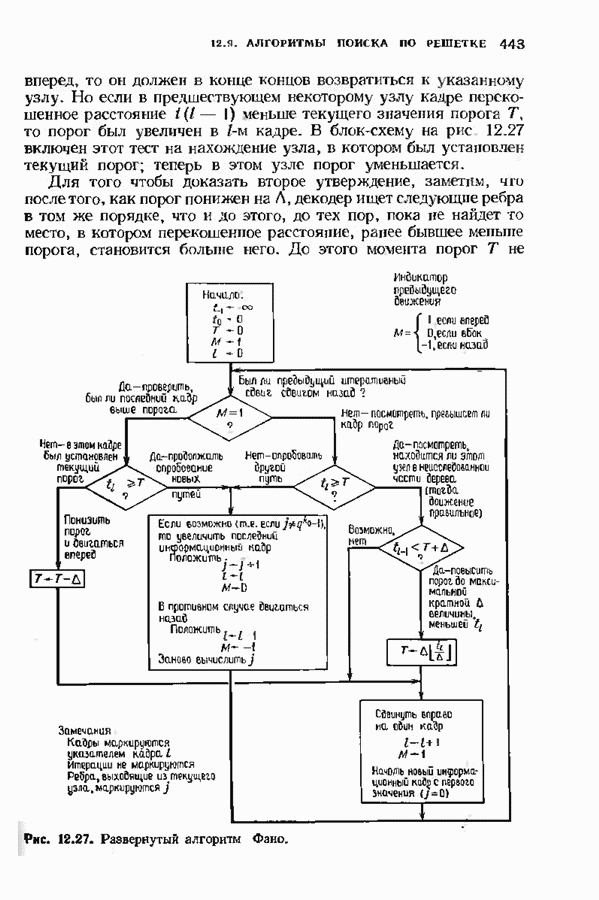
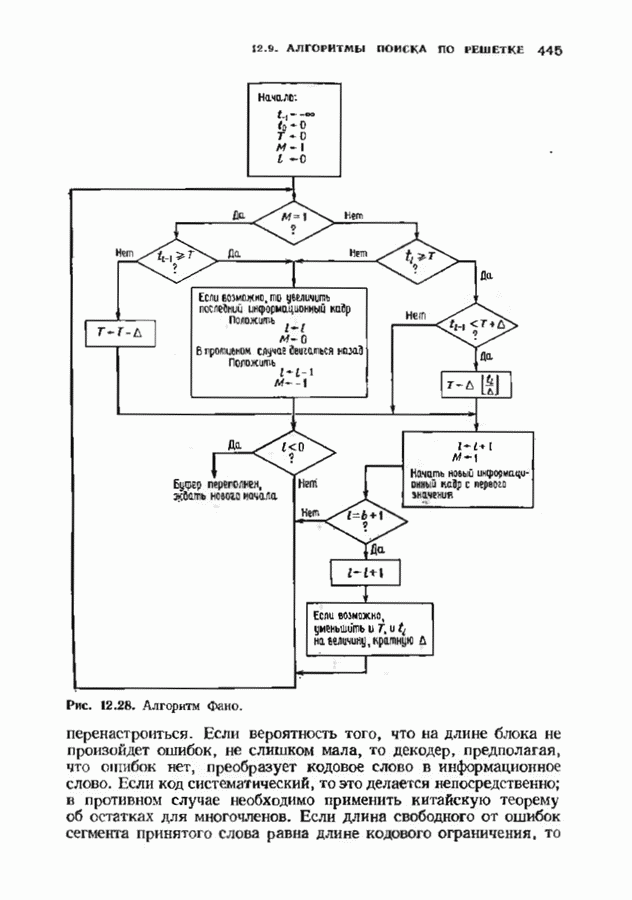
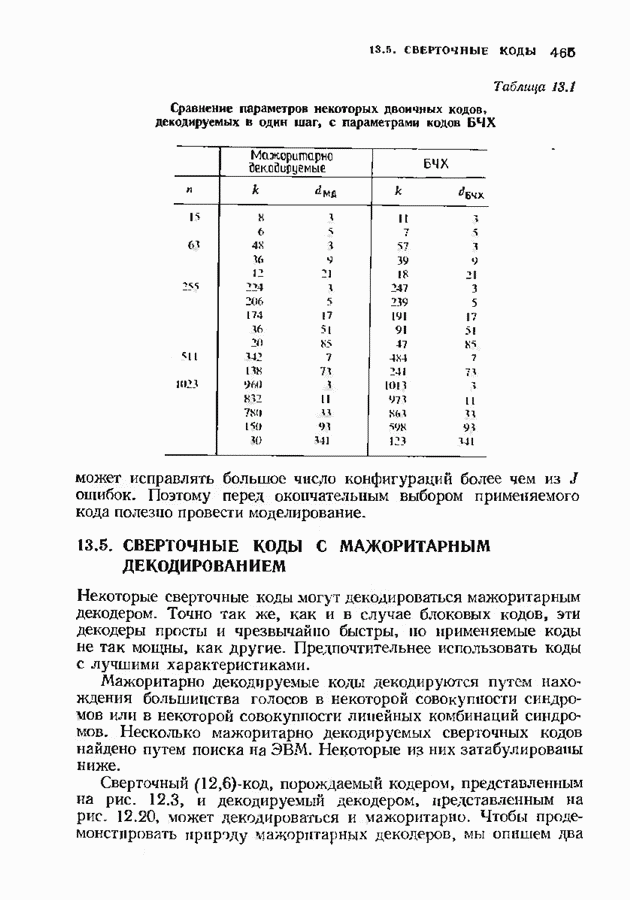
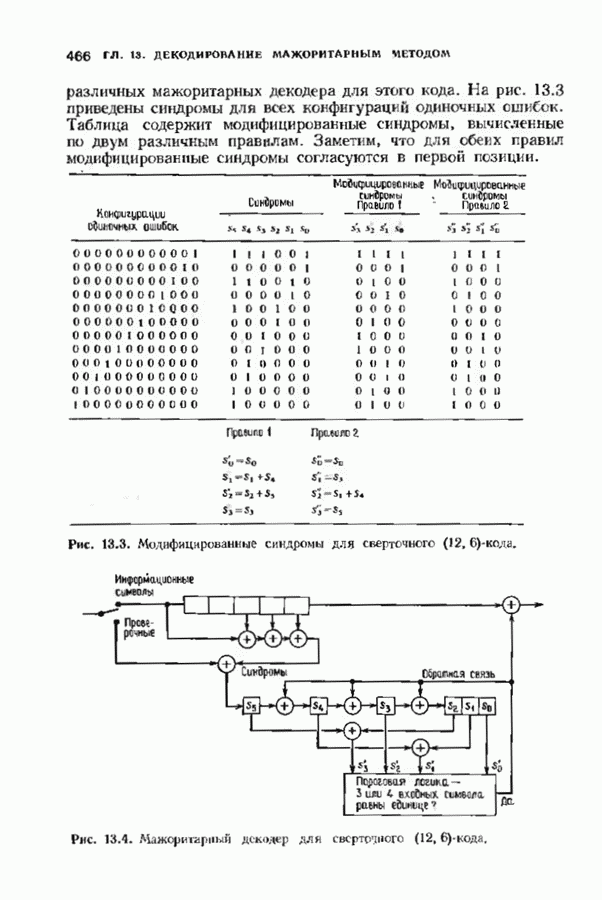
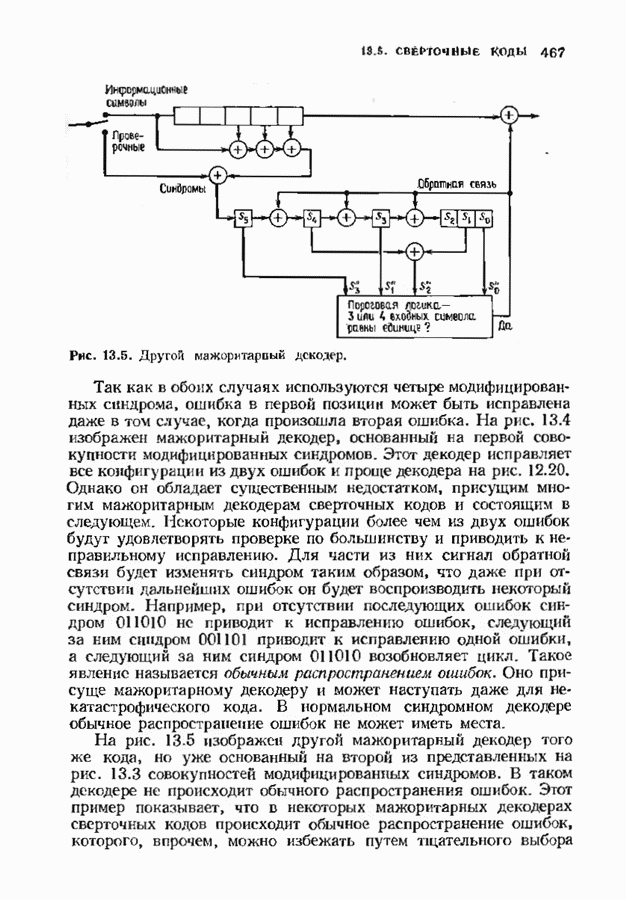
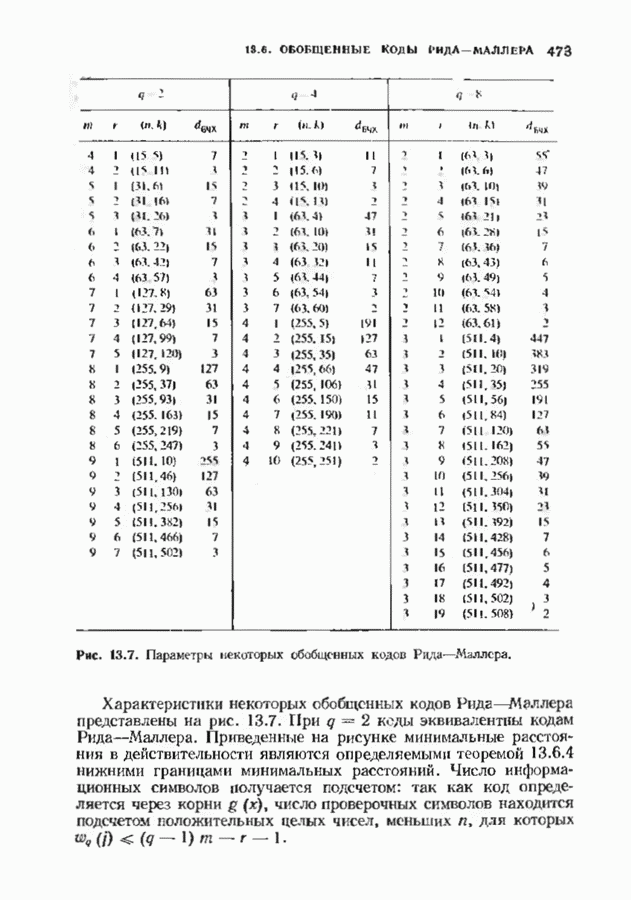
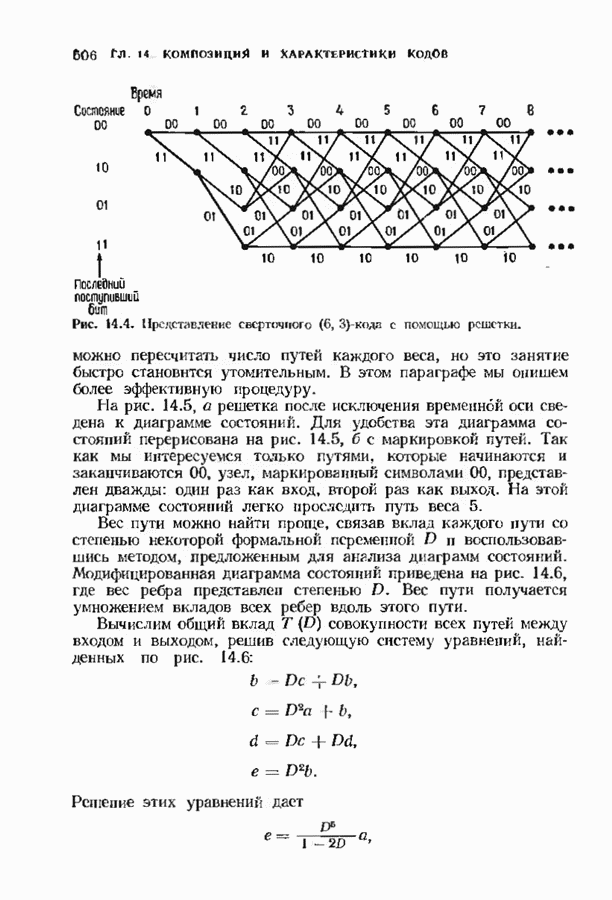
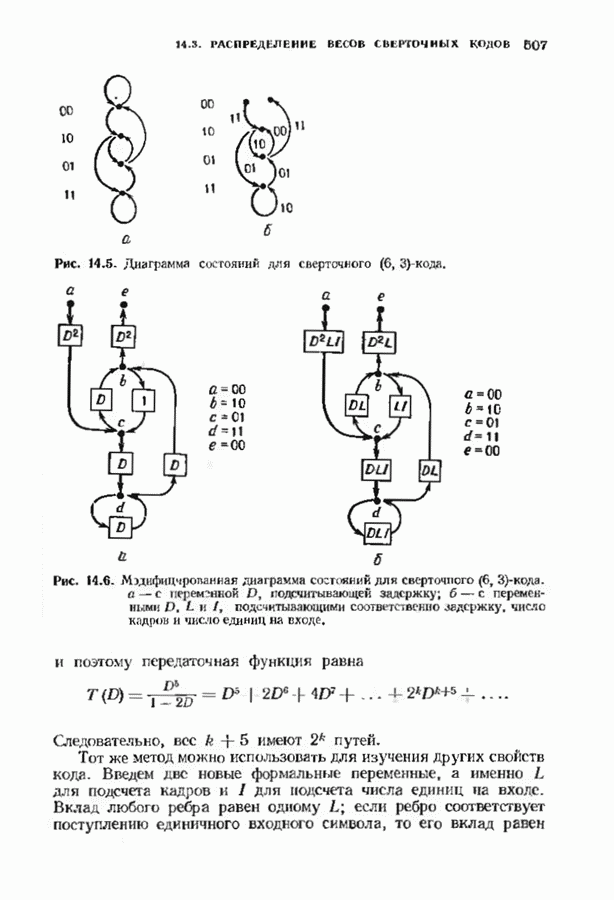
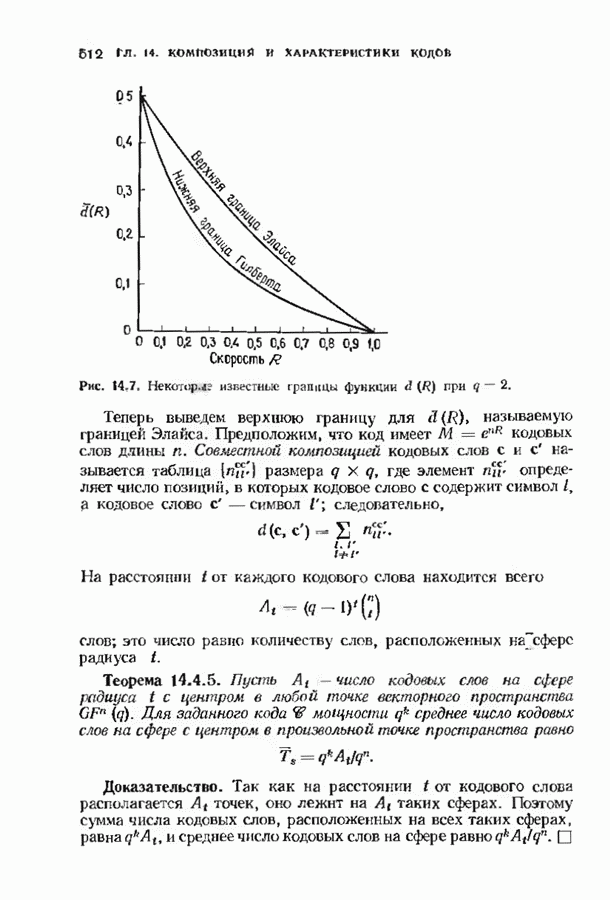
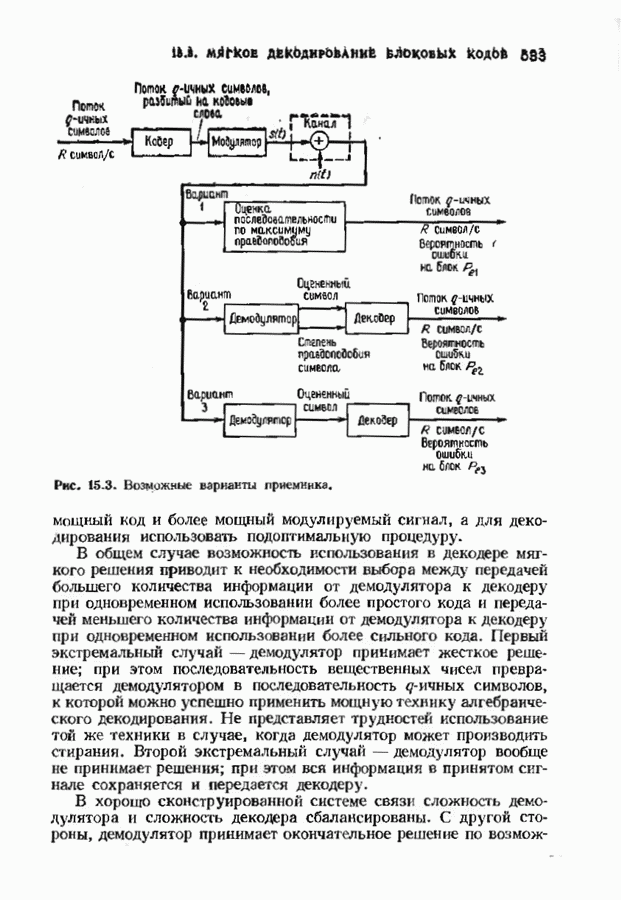
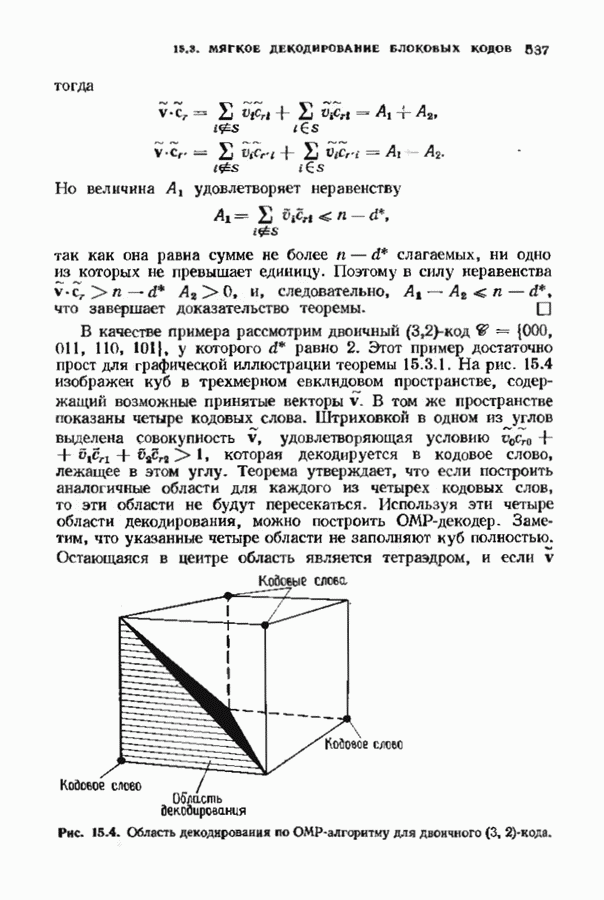
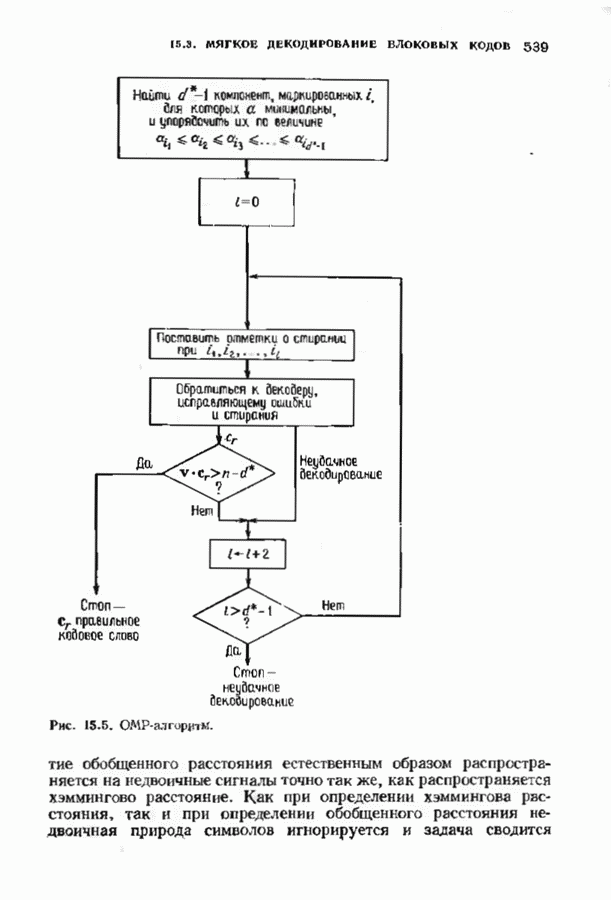
9.3. ДЕКОДИРОВАНИЕ РАСШИРЕННЫХ КОДОВ РИДА—СОЛОМОНА
Незначительная модификация любого декодера для кода Рида-Соломона позволяет получить декодер для расширенного кода Рида-Соломона. Один из возможных способов состоит просто
в переборе всех  возможных значений ошибок в двух символах расширении и последующих попытках декодирования для каждой пары. Если такая попытка приводит к кодовому слову при
возможных значений ошибок в двух символах расширении и последующих попытках декодирования для каждой пары. Если такая попытка приводит к кодовому слову при  или менее исправлениях, то результат правилен, так как только одно кодовое слово находится на расстоянии
или менее исправлениях, то результат правилен, так как только одно кодовое слово находится на расстоянии  принятого слова.
принятого слова.
Лучше, однако, отдельно рассматривать два случая возможных конфигураций ошибок: в первом случае искажен хотя бы один из символов расширения, а во втором ошибок в символах расширении нет. Сообщение при этом декодируется дважды (для каждого из случаев но отдельности). Пусть  . при
. при  и пусть
и пусть  и
и  если
если  не искажены. В первом случае во внутреннем векторе происходит не более
не искажены. В первом случае во внутреннем векторе происходит не более  ошибок и поэтому 21—2 компонент синдрома
ошибок и поэтому 21—2 компонент синдрома  достаточно для того, чтобы правильно восстановить внутренний спектр конфигурации ошибок. Эти
достаточно для того, чтобы правильно восстановить внутренний спектр конфигурации ошибок. Эти  компонент синдрома можно рекурреитио продолжить до
компонент синдрома можно рекурреитио продолжить до  компонент спектра конфигурации ошибок, так как
компонент спектра конфигурации ошибок, так как  втором случае все ошибки лежат во внутреннем векторе, но их не более
втором случае все ошибки лежат во внутреннем векторе, но их не более  и поэтому для восстановления спектра конфигурации ошибок компонент достаточно
и поэтому для восстановления спектра конфигурации ошибок компонент достаточно  компонент
компонент  Вообще говоря, одной попытки декодирования недостаточно и приходится делать обе попытки но так как
Вообще говоря, одной попытки декодирования недостаточно и приходится делать обе попытки но так как  нимапьнсе расстояние кода равно
нимапьнсе расстояние кода равно  может быть найдена только одна конфигурация не более чем из
может быть найдена только одна конфигурация не более чем из  ошибок.
ошибок.
Чтобы не удваивать сложность декодера дублированием декодеров, опишем вариант разделения вычислений, который дает лишь незначительное увеличение сложности. В этом параграфе мы опишем модификацию алгоритма Берлекэмпа-Месси для декодирования расширенных кодов Рида-Соломона, а в следующем сделаем то же самое для расширенных кодов БЧХ. Ограничимся вычислением многочлена локаторов ошибок, так как остальные шаги алгоритма нам уже известны.
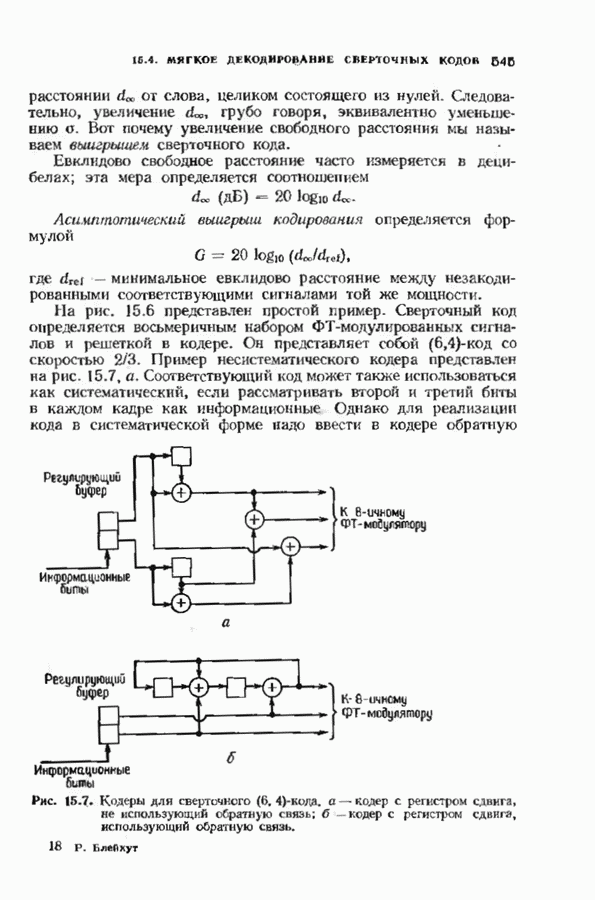
Наиболее важными расширениями кодов Рида-Соломона являются расширения на один символ, так как среди них содержатся коды длины  а во многих приложениях в качестве длины кода используется именно степень двойки. Мы начнем с этого случая, так как он претставляет практический интерес из-за простоты декодера и так как его лет ко объяспить.
а во многих приложениях в качестве длины кода используется именно степень двойки. Мы начнем с этого случая, так как он претставляет практический интерес из-за простоты декодера и так как его лет ко объяспить.
В рассматриваемом коде спектральные компоненты  равны нулю и единственную проверку на четность дает символ
равны нулю и единственную проверку на четность дает символ  Равенство нулю
Равенство нулю  компонент гарантирует, что минимальное расстояние в коде равно
компонент гарантирует, что минимальное расстояние в коде равно  , и поэтому код позволяет исправлять
, и поэтому код позволяет исправлять  и обнаруживать I ошибок. Блок
и обнаруживать I ошибок. Блок
из  компонент синдрома начинается с компоненты равной
компонент синдрома начинается с компоненты равной  и заканчивается компонентой
и заканчивается компонентой  равной
равной  Предположим, что произошло не более
Предположим, что произошло не более  ошибок, и проведем итерации алгоритма Берлекэмпа-Месси от
ошибок, и проведем итерации алгоритма Берлекэмпа-Месси от  до Если
до Если  и невязка
и невязка  равна нулю, то, согласно теореме 7.5.3, во внутреннем векторе произошло не более
равна нулю, то, согласно теореме 7.5.3, во внутреннем векторе произошло не более  ошибок и вычисленное значение многочлена локаторов ошибок правильно. В противном случае во внутреннем векторе произошло
ошибок и вычисленное значение многочлена локаторов ошибок правильно. В противном случае во внутреннем векторе произошло  ошибок, и, следовательно, символ
ошибок, и, следовательно, символ  правилен. Дополнительная компонуй
правилен. Дополнительная компонуй  синдрома
синдрома  позволяет продолжить алгоритм Берлекэмпа-Месси еще на один шаг, так что полное число итераций равно
позволяет продолжить алгоритм Берлекэмпа-Месси еще на один шаг, так что полное число итераций равно  , и поэтому найден многочлен локаторов
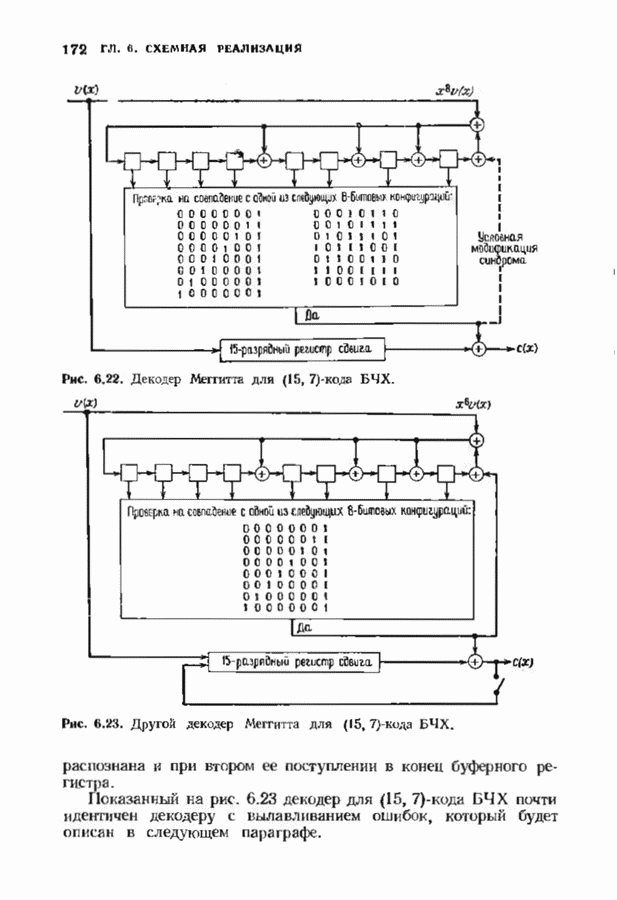
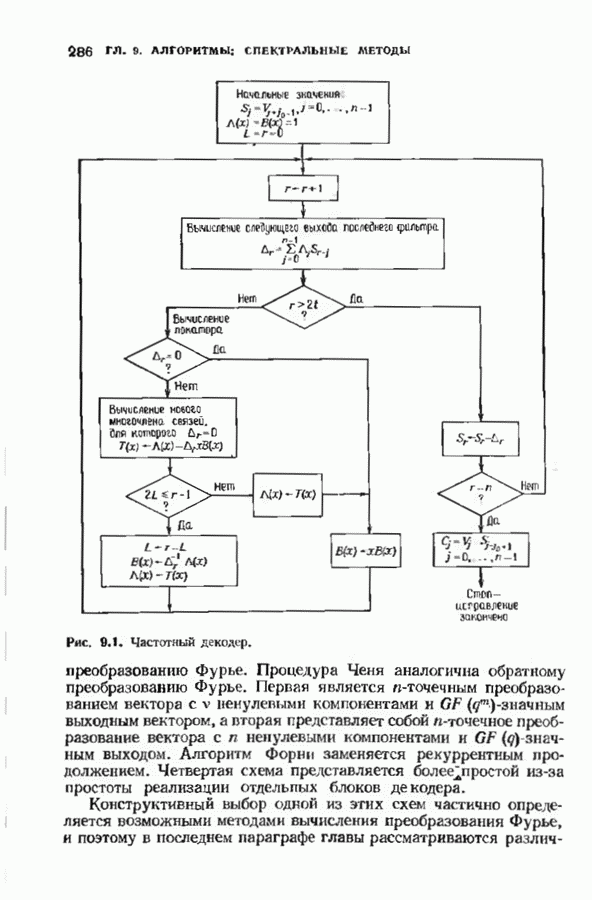
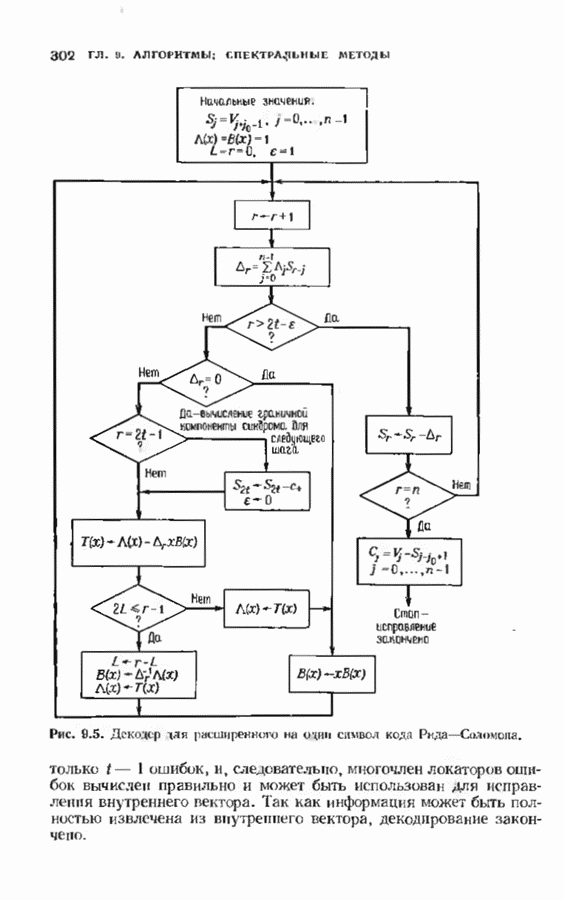
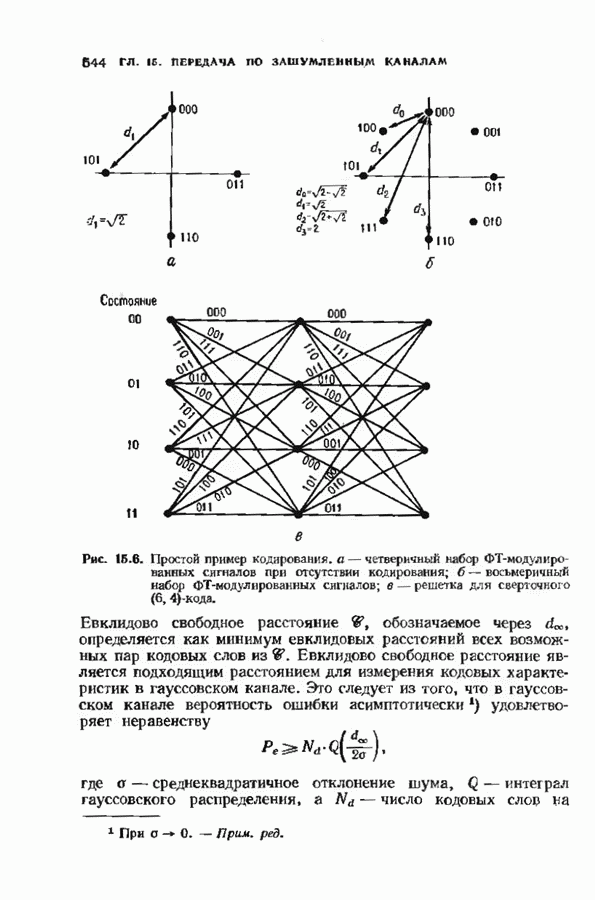
, и поэтому найден многочлен локаторов  ошибок. Декодер для расширенного на одну позицию кода Рида-Соломона показан на рис. 9.5.
ошибок. Декодер для расширенного на одну позицию кода Рида-Соломона показан на рис. 9.5.
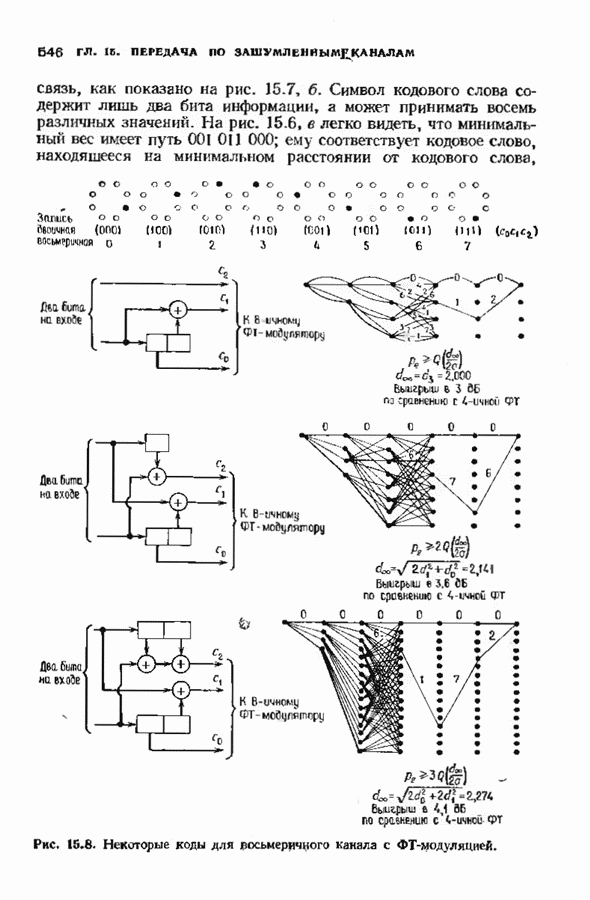
Декодер для расширенного на два символа кода Рида-Соломона более сложен и описать его труднее. Предположим, что произошло не более  ошибок. В нашем распоряжении имеются
ошибок. В нашем распоряжении имеются  компонент внутреннего синдрома, начиная с компоненты
компонент внутреннего синдрома, начиная с компоненты  равной
равной  Согласно теореме 7.5.3, воспользуемся ими для исправления
Согласно теореме 7.5.3, воспользуемся ими для исправления  ошибок во внутреннем векторе и обнаружения
ошибок во внутреннем векторе и обнаружения  ошибок. Иначе говоря, начиная с
ошибок. Иначе говоря, начиная с  и выполняя
и выполняя  итераций алгоритма Берлекэмпа-Месси, найдем многочлен локаторов ошибок. Если
итераций алгоритма Берлекэмпа-Месси, найдем многочлен локаторов ошибок. Если  то сделаем еще две итерации и остановимся, если хотя бы одна из невязок
то сделаем еще две итерации и остановимся, если хотя бы одна из невязок  или
или  отлична от нуля. Если обе невязки равны нулю, то во внутреннем векторе произошло не более
отлична от нуля. Если обе невязки равны нулю, то во внутреннем векторе произошло не более  ошибок. В этом случае многочлен локаторов ошибок вычислен правильпо и может быть использован для дальнейшего исправления ошибок во внутреннем векторе. Так как полезная информация может быть полностью выделена из внутреннего вектора, то декодирование закончено. В противном случае внутренний вектор содержит
ошибок. В этом случае многочлен локаторов ошибок вычислен правильпо и может быть использован для дальнейшего исправления ошибок во внутреннем векторе. Так как полезная информация может быть полностью выделена из внутреннего вектора, то декодирование закончено. В противном случае внутренний вектор содержит  или
или  ошибок, и поэтому искажено не более одного граничного символа. Следовательно, хотя бы одна из компонент
ошибок, и поэтому искажено не более одного граничного символа. Следовательно, хотя бы одна из компонент  и синдрома правильна, а если все ошибки произошли во внутреннем векторе, то они правильны обе. Присоединяя сначала одну, а затем вторую из них к остальным компонентам синдрома, получим два блока по
и синдрома правильна, а если все ошибки произошли во внутреннем векторе, то они правильны обе. Присоединяя сначала одну, а затем вторую из них к остальным компонентам синдрома, получим два блока по  символов, хотя бы один из которых содержит
символов, хотя бы один из которых содержит  правильных компонент синдрома.
правильных компонент синдрома.
Теперь дважды применим алгоритм Берлекэмпа-Месси, сначала к одному из этих блоков (от  до
до  ), а затем к другому (от до
), а затем к другому (от до  ). Каждый раз будем исправлять
). Каждый раз будем исправлять  обнаруживать
обнаруживать  ошибок. Если все
ошибок. Если все  ошибок расположены во внутреннем векторе, то обе попытки позволят обнаружить
ошибок расположены во внутреннем векторе, то обе попытки позволят обнаружить  ошибок во внутреннем векторе, и, следовательно, оба символа расширения являются правильными. Если при одной или при обеих попытках не обнаруживается
ошибок во внутреннем векторе, и, следовательно, оба символа расширения являются правильными. Если при одной или при обеих попытках не обнаруживается  ошибок, то во внутреннем векторе произошло
ошибок, то во внутреннем векторе произошло
Рис. 9.5. (см. скан) Декодер для расширенного на один символ кода Рида-Соломона.
только  ошибок, и, следовательно, многочлен локаторов ошибок вычислен правильно и может быть использован для исправления внутреннего вектора. Так как информация может быть полностью извлечена из внутреннего вектора, декодирование закончено.
ошибок, и, следовательно, многочлен локаторов ошибок вычислен правильно и может быть использован для исправления внутреннего вектора. Так как информация может быть полностью извлечена из внутреннего вектора, декодирование закончено.
Наконец, если во внутреннем векторе обнаружено  ошибок, то оба граничных символа правильны. Следовательно, и обе граничные компоненты синдрома также правильны, и в нашем распоряжении имеется 21 правильных компонент синдрома, позволяющих исправить
ошибок, то оба граничных символа правильны. Следовательно, и обе граничные компоненты синдрома также правильны, и в нашем распоряжении имеется 21 правильных компонент синдрома, позволяющих исправить  ошибок во внутреннем векторе.
ошибок во внутреннем векторе.
Описанная процедура декодирования все же дважды обращается к алгоритму Берлекэмпа-Месси. Такое описание выбрано из соображений простоты объяснения; процедуру можно сделать более компактной.