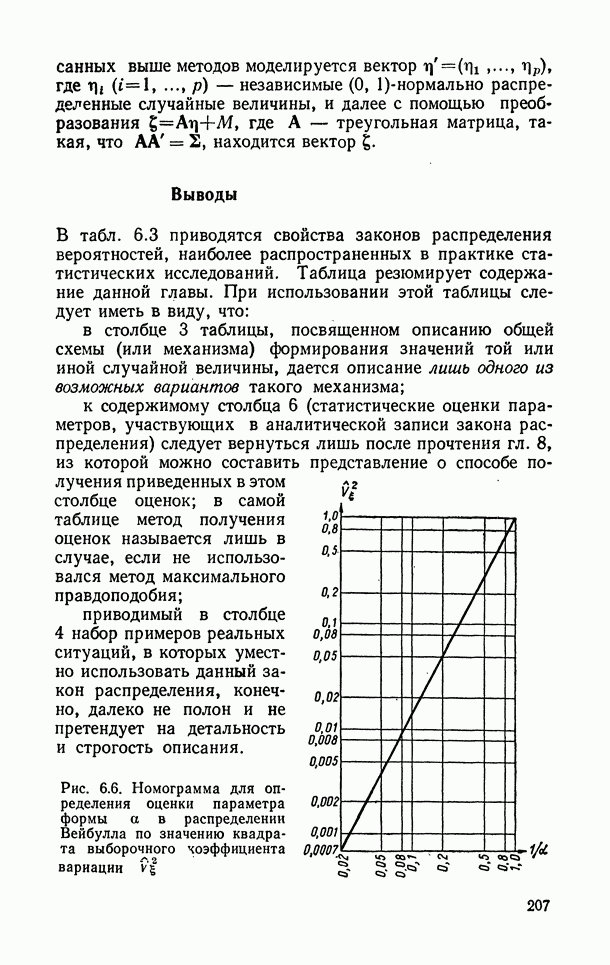
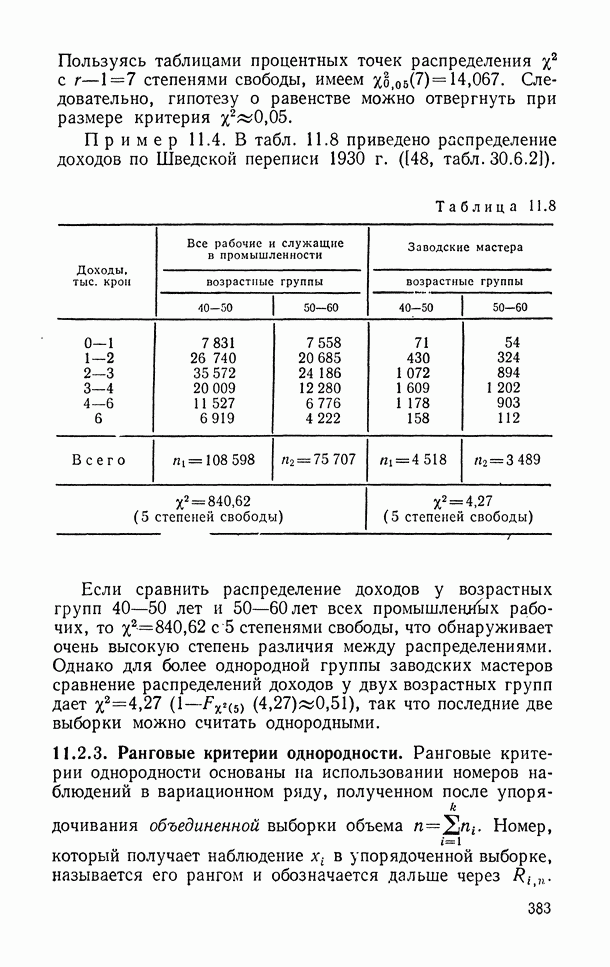
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
Прозрачное пояснение такой терминологии мы получаем в рамках дискретного вероятностного пространства, поскольку в этом случае речь идет о правиле распределения суммарной единичной вероятности (т. е. вероятности достоверного события) между отдельными возможностями 
Очевидно, задание закона распределения вероятностей, т. е. соответствий типа (5.2), может осуществляться с помощью таблиц и графиков (только в дискретном случае), а также с помощью функций и алгоритмически (об основных формах задания законов распределения и примерах их модельной, т. е. аналитической, записи см. гл. 6).
Приведем примеры табличного и графического задания законов распределения вероятностей.
Тщательный статистический анализ засоренности партий дефектными изделиями (пример 4.5) позволил построить следующее распределение вероятностей для случайной величины выражающей число дефектных изделий, обнаруженных при контроле партии, состоящей из N=30 изделий, случайно отобранных из продукции массового производства (табл. 5.2):
Таблица 5.2

Значения вероятностей, приведенные в табл. 5.2, даны с точностью до третьего десятичного знака, поэтому то, что суммирование представленных в таблице вероятностей дает 0,998 (вместо единицы), легко объяснимо: недостающие 0,002 как-то «размазаны» между возможными значениями 11, ..., 30, но на каждое отдельное возможное значение приходится вероятность, меньшая 0,0005.
Тот же закон распределения может быть представлен графически (рис. 5.2).
Геометрическое изображение закона распределения вероятностей дискретной случайной величины часто называют полигоном распределения или полигоном частот.

Рис. 5.2. Графическое задание закона распределения вероятностей для числа дефектных изделий, обнаруженных в наугад извлеченной партии, состоящей из 30 изделий массового производства

Рис. 5.3. Полигон двумерного распределения семей по качеству жилищных условий  и по уровню дохода
и по уровню дохода 

В рассматриваемом примере (см. табл. 5.3) частные распределения  подсчитаны по формулам (5.3) и (5.3) и задают соответственно распределение семей отдельно по качеству жилищных условий и по уровню дохода (они приведены соответственно в последней строке и в последнем столбце табл. 5.3).
подсчитаны по формулам (5.3) и (5.3) и задают соответственно распределение семей отдельно по качеству жилищных условий и по уровню дохода (они приведены соответственно в последней строке и в последнем столбце табл. 5.3).
Условный закон распределения
подвектора h анализируемой многомерной случайной величины  при условии, что значение другого подвектора
при условии, что значение другого подвектора  зафиксировано на уровне
зафиксировано на уровне  вычисляется по формуле
вычисляется по формуле

Аналогично

Формулы (5.4) и (5.4) получаются как простые следствия теоремы умножения вероятностей (4.11).
Так, например, если нас интересует условное распределение группы семей с высоким доходом по качеству жилищных условий, т. е. распределение  то вычисления по (5.4) на основе данных табл. 5.3 дают:
то вычисления по (5.4) на основе данных табл. 5.3 дают:

что означает, в частности, что из всей совокупности семей с высоким доходом 5 % проживает в плохих жилищных условиях, 10 % — в удовлетворительных, 5 % — в хороших и 50 % — в очень хороших.


































































































































































































































































































































































































































































 (и тем самым описать множество теоретически возможных значений анализируемой случайной величины). К этому необходимо добавить также: в дискретном случае — правило сопоставления с каждым возможным значением
(и тем самым описать множество теоретически возможных значений анализируемой случайной величины). К этому необходимо добавить также: в дискретном случае — правило сопоставления с каждым возможным значением  случайной величины
случайной величины  вероятности его появления
вероятности его появления  в непрерывном случае — правило сопоставления с каждой измеримой областью
в непрерывном случае — правило сопоставления с каждой измеримой областью  возможных значений случайной величины
возможных значений случайной величины  вероятности
вероятности  события, заключающегося в том, что в случайном эксперименте реализуется одно из возможных значений, принадлежащих заданной области АХ. Это правило, позволяющее устанавливать соответствия вида:
события, заключающегося в том, что в случайном эксперименте реализуется одно из возможных значений, принадлежащих заданной области АХ. Это правило, позволяющее устанавливать соответствия вида:

 .
.
 и среднедушевой доход
и среднедушевой доход  Еще более упростим рассматриваемую схему, перейдя от по существу непрерывной случайной величины
Еще более упростим рассматриваемую схему, перейдя от по существу непрерывной случайной величины  к ее дискретному аналогу
к ее дискретному аналогу  отказываясь от точного знания среднедушевого дохода каждой семьи и ограничиваясь лишь тремя возможными градациями: семья имеет низкий доход (градация
отказываясь от точного знания среднедушевого дохода каждой семьи и ограничиваясь лишь тремя возможными градациями: семья имеет низкий доход (градация  ), средний доход (градация
), средний доход (градация  ) и высокий доход (градация
) и высокий доход (градация  ). С учетом четырех градаций качества жилищных условий:
). С учетом четырех градаций качества жилищных условий:  — качество низкое
— качество низкое  — качество удовлетворительное;
— качество удовлетворительное;  — качество хорошее и
— качество хорошее и  — качество очень хорошее, и проведенного вероятностно-статистического анализа получаем следующий закон распределения вероятностей двумерной случайной величины
— качество очень хорошее, и проведенного вероятностно-статистического анализа получаем следующий закон распределения вероятностей двумерной случайной величины  (данные условные):
(данные условные):

 (
( см. (5.1)) анализируемого многомерного признака
см. (5.1)) анализируемого многомерного признака  дискретна и имеет конечное число
дискретна и имеет конечное число  всех возможных значений, то, очевидно, общее число возможных «значений» случайного вектора
всех возможных значений, то, очевидно, общее число возможных «значений» случайного вектора  будет
будет  .
.
 удобнее пользоваться
удобнее пользоваться  -мерной индексацией вида
-мерной индексацией вида  , где первый индекс i определяет номер возможного значения по первой компоненте, второй индекс j — по второй компоненте и т. д. Тогда
, где первый индекс i определяет номер возможного значения по первой компоненте, второй индекс j — по второй компоненте и т. д. Тогда  будет означать возможное значение
будет означать возможное значение  , полученное сочетанием
, полученное сочетанием  возможного значения компоненты
возможного значения компоненты  возможного значения компоненты
возможного значения компоненты  возможного значения компоненты
возможного значения компоненты  а вероятности
а вероятности  удобно обозначать
удобно обозначать  . Таким образом, в табл. 5.3 представлены вероятности
. Таким образом, в табл. 5.3 представлены вероятности

 , рассмотренная в табл. 5.1, естественно разбивается на два подвектора:
, рассмотренная в табл. 5.1, естественно разбивается на два подвектора:  описывающий социальнодемографические и экономическую характеристики семьи, и
описывающий социальнодемографические и экономическую характеристики семьи, и  описывающий структуру семейного потребления.
описывающий структуру семейного потребления.
 описывает распределение вероятностей признака в ситуации, когда на значения другой части компонент
описывает распределение вероятностей признака в ситуации, когда на значения другой части компонент  не накладывается никаких условий. В дискретном случае соответствующие вероятности определяются по формулам:
не накладывается никаких условий. В дискретном случае соответствующие вероятности определяются по формулам:

 возможные значения векторных признаков соответственно h и
возможные значения векторных признаков соответственно h и  .
.
 если принять во внимание следующие очевидные связи между интересующими нас событиями:
если принять во внимание следующие очевидные связи между интересующими нас событиями:

