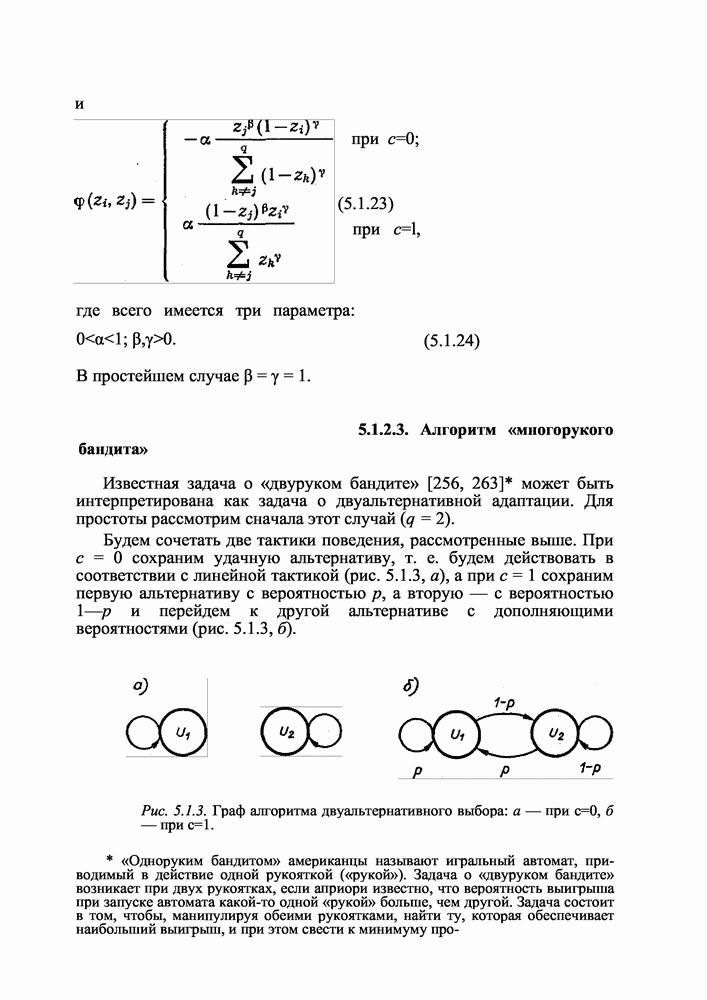
6.3.2. Сведение задачи распределения памяти к задаче математического программирования
Формализуем задачу. Пусть  — двоичная переменная, выражающая наличие
— двоичная переменная, выражающая наличие  или отсутствие
или отсутствие  в памяти i-й ЭВМ 7-го блока информации. Очевидно, что имеет место следующее ограничение, связанное с ограниченностью объема памяти каждой ЭВМ:
в памяти i-й ЭВМ 7-го блока информации. Очевидно, что имеет место следующее ограничение, связанное с ограниченностью объема памяти каждой ЭВМ:

Пусть поток задач, решаемых сетью, образуется из к различных потоков, каждый из которых характеризуется определенным распределением вероятностей использования блоков информации (6.3.1):

где  вероятность того, что при решении задачи
вероятность того, что при решении задачи  потока требуется
потока требуется  блок информации. Будем для удобства считать эти вероятности нормированными, т. е.
блок информации. Будем для удобства считать эти вероятности нормированными, т. е.

(хотя это и необязательно, так как для решения задачи обычно необходимо несколько блоков).
Определим вероятность попадания задачи  потока на
потока на  при следующей дисциплине обслуживания: «направлять задачу туда, где больше необходимой информации». Эта вероятность
при следующей дисциплине обслуживания: «направлять задачу туда, где больше необходимой информации». Эта вероятность

Аналогично можно определить вероятность того, что задача  потока, направленная на
потока, направленная на  найдем там необходимую для решения информацию, т. е. не придется обращаться к банку данных. Пусть эта вероятность
найдем там необходимую для решения информацию, т. е. не придется обращаться к банку данных. Пусть эта вероятность

Теперь, располагая интенсивностями потоков решаемых задач (естественно их считать пуассоновскими)

и интенсивностями решения задач каждой ЭВМ (их можно считать экспоненциальными)

можно сформулировать простейшую задачу определения оптимального расположения блоков информации (6.3.1) на ЭВМ сети, минимизирующего обращаемость к банку данных в процессе функционирования сети:

где

Здесь  — двоичный вектор, характеризующий распределение блоков памяти по сети:
— двоичный вектор, характеризующий распределение блоков памяти по сети:

 — интенсивность обращения к банку данных всех ЭВМ сети; первые ограничения (6.3.10) связаны с ограниченностью пропускной способности каждой ЭВМ: при нарушении хотя бы одного из них образуется бесконечная очередь заявок; вторые ограничения в (6.3.10) совпадают с (6.3.2).
— интенсивность обращения к банку данных всех ЭВМ сети; первые ограничения (6.3.10) связаны с ограниченностью пропускной способности каждой ЭВМ: при нарушении хотя бы одного из них образуется бесконечная очередь заявок; вторые ограничения в (6.3.10) совпадают с (6.3.2).
Полученная задача (6.3.9) является задачей стохастического программирования с булевыми переменными (6.3.11) большой размерности пт. Для ее решения прежде всего необходимо иметь информацию о вероятной структуре (6.3.3) потоков решаемых задач, интенсивности (6.3.7) этих потоков и интенсивности (6.3.8) решения задач в сети. Но именно эту информацию труднее всего выявить. Более того — и поток задач, и интенсивности обслуживания могут изменяться во времени непредсказуемым образом [274].
Следовательно, задачу распределения памяти по сети следует решать адаптивным способом. Воспользуемся для этого методами эволюционной адаптации.