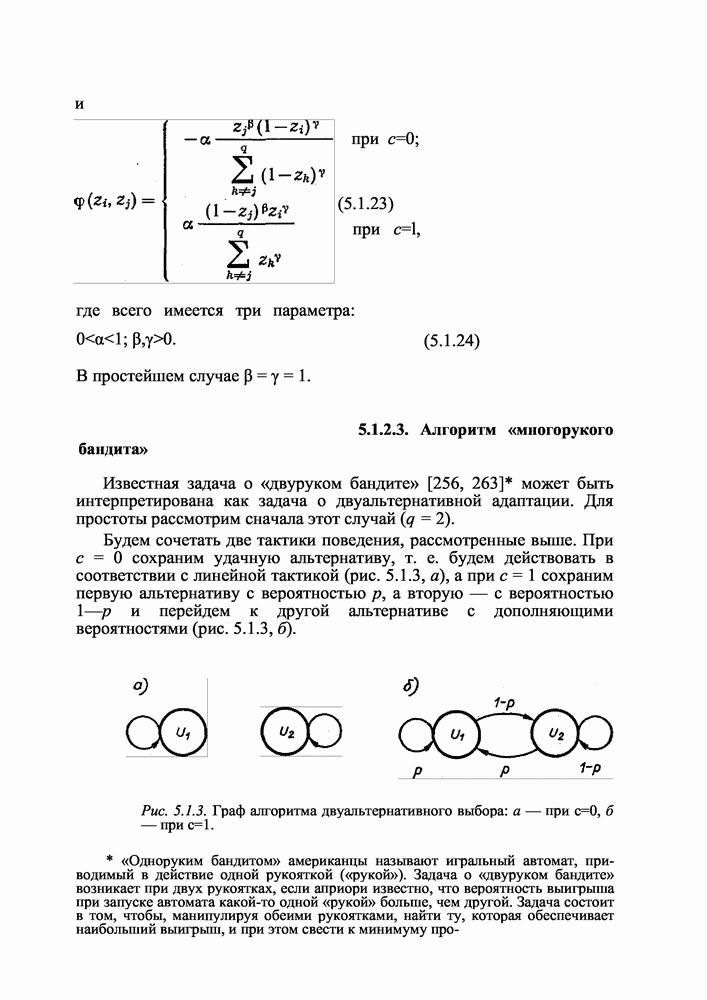
3.3.2.4. Метод стохастического градиента
Стохастический градиент оценивается по формуле [164]:

т. е. представляет собой сумму всех случайных векторов  с весами, равными приращениям минимизируемой функции в данных случайных направлениях.
с весами, равными приращениям минимизируемой функции в данных случайных направлениях.
Если в качестве взять орты, т.  то эта оценка при
то эта оценка при  как легко заметить из (3.3.22), дает точное значение градиента.
как легко заметить из (3.3.22), дает точное значение градиента.
Обе описанные оценки градиента могут эффективно применяться при любых значениях  в том числе и при
в том числе и при  что существенно отличает их от детерминированного способа оценивания (3.3.22), для которого строго
что существенно отличает их от детерминированного способа оценивания (3.3.22), для которого строго  Это же обстоятельство подтверждает, что детерминированные методы обобщаются случайными (см. конец подраздела 3.3.1). Приведем еще пример такого обобщения.
Это же обстоятельство подтверждает, что детерминированные методы обобщаются случайными (см. конец подраздела 3.3.1). Приведем еще пример такого обобщения.
Градиентный поиск (3.3.21) является частным случаем по крайней мере двух алгоритмов случайного поиска. Первый алгоритм:

где  — по-прежнему единичный случайный
— по-прежнему единичный случайный  -мерный вектор. Это известный градиентный алгоритм случайного поиска [145, 247]. Второй алгоритм имеет вид (3.3.23), но оценка градиента вычисляется по формуле
-мерный вектор. Это известный градиентный алгоритм случайного поиска [145, 247]. Второй алгоритм имеет вид (3.3.23), но оценка градиента вычисляется по формуле

При  как легко заметить, оба алгоритма вырождаются, в градиентный алгоритм поиска (3.3.21).
как легко заметить, оба алгоритма вырождаются, в градиентный алгоритм поиска (3.3.21).
Таким образом, случайный поиск является естественным расширением, продолжением и обобщением известных регулярных методов поиска.
Другой особенностью случайного поиска, которая открывает широкие возможности для его эффективного применения, является использование оператора случайного шага в качестве стохастической модели сложных регулярных операторов отыскания направлений поиска в пространстве оптимизируемых параметров 
Так, алгоритм случайного поиска с линейной тактикой (3.3.12) является стохастической моделью алгоритма наискорейшего спуска:

в которой случайный вектор  моделирует оценку градиента. Любопытно, что подобную «оценку» нельзя даже назвать грубой, так как ее стохастические свойства и не напоминают свойств оцениваемого градиента. Однако, как показано выше, алгоритм случайного поиска не только работоспособен, но в ряде случаев и более эффективен, чем алгоритм наискорейшего спуска. Здесь
моделирует оценку градиента. Любопытно, что подобную «оценку» нельзя даже назвать грубой, так как ее стохастические свойства и не напоминают свойств оцениваемого градиента. Однако, как показано выше, алгоритм случайного поиска не только работоспособен, но в ряде случаев и более эффективен, чем алгоритм наискорейшего спуска. Здесь
оператор случайного шага  заменяет громоздкий оператор оценки градиента, например, по формуле (3.3.22).
заменяет громоздкий оператор оценки градиента, например, по формуле (3.3.22).
Следующей особенностью случайного поиска, выгодно отличающей его от регулярных методов, является глобальность, проявляющаяся прежде всего в локальных алгоритмах случайного поиска, не предназначенных для отыскания глобального экстремума. Так, алгоритм случайного спуска может найти глобальный экстремум, а регулярный алгоритм наискорейшего спуска в принципе не допускает такой возможности, поскольку он построен для отыскания локального экстремума.
Следовательно, глобальность алгоритмов случайного поиска является как бы «премией» за использование случайности и чем-то вроде «бесплатного приложения» к алгоритму. Это обстоятельство особенно важно при оптимизации объектов с неизвестной структурой, когда нет полной уверенности в одноэкстремальности задачи и возможно (хотя и не ожидается) наличие нескольких экстремумов. Использование в таком случае методов глобального поиска было бы неразумной расточительностью. Методы локального случайного поиска здесь наиболее приемлемы, так как они эффективно решают локальную задачу и могут в принципе решить глобальную, если таковая будет иметь место. Это обеспечивает случайному поиску своеобразную психологическую надежность, которую очень ценят пользователи.
Алгоритмическая простота случайного поиска делает его привлекательным в первую очередь для потребителей [229]. Опыт показывает, что известные алгоритмы случайного поиска являются лишь «канвой», на которой пользователь в каждом конкретном случае «вышивает узоры» новых алгоритмов, отражающих не только его вкусы и наклонности (что нельзя не учитывать), но и специфику оптимизируемого объекта. Последнее создает благоприятную основу для реализации известного принципа, что алгоритм должен конструироваться «под объект». Наконец, алгоритмическая простота случайного поиска обусловливает простоту его аппаратурной реализации. Это не только дает возможность строить простые, компактные и надежные оптимизаторы с неограниченным числом оптимизируемых параметров [183], но и позволяет довольно просто организовать их оптимальный синтез на ЭВМ [142].