Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 4.6. Адаптация алгоритмов распознаванияРешение проблемы повышения эффективности распознающих решающих правил в настоящее время затрудняется значительной априорной неопределенностью структуры решаемой задачи распознавания. Там, где эта структура проста, удается предложить весьма эффективные способы синтеза распознающих решающих правил [13, 30, 89, 90, 151]. Однако научно-техническая практика очень часто выдвигает такие сложные задачи, относительно структуры которых априори почти ничего нельзя сказать. Именно в этом случае со всей остротой встает проблема выбора структуры решающего правила. Интуиция исследователя, на которую обычно уповают [30], здесь дает крайне мало, а зачастую и ухудшает выбор ввиду влияния малосущественных факторов (мода, опыт исследователя, случай и т. д.). Действительно, успешному применению алгоритма должна предшествовать проверка некоторых условий его применимости. Примерами таких условий могли служить, например, гипотеза компактности в методе потенциальных функций [13], требование нормальности априорных распределений в статистических алгоритмах [89, 90], условие неразличимости признаков [90] и т. д. Проверка этих условий для сложных задач распознавания обычно невозможна [285]. Однако при синтезе алгоритмов необходимо прежде всего определять их структуру. Это можно сделать двояким образом. С одной стороны, можно пытаться создать метаструктуру объектов распознавания, обобщающую известные структуры. Примером такой метаструктуры являются всякого рода языки описания ситуаций, например двумерные грамматики при распознавании плоских изображений [241]. Этот путь требует чрезвычайно тщательного исследования и формализации рассматриваемого поля задач, что удается далеко не всегда и лишь для весьма узкого класса задач. Пожалуй, единственным примером такой формализации является создание уже упомянутых двумерных грамматик [241]. Именно поэтому для решения «сложных задач распознавания следует изыскивать другие подходы. В качестве одного из таких подходов можно предложить использовать структуры уже известных решающих правил. Это означает, что искомую структуру следует искать как некую комбинацию известных структур. Такой путь в сочетании с адаптацией оказался весьма плодотворным и получил название коллективного (по аналогии принятия коллективных экспертных решений). Рассмотрим его [177]. Пусть имеется
где
(для простоты рассматриваем случай дихотомии). Тогда коллективное решающее правило можно представить в виде
где функция
где
Рис. 4.6.1. Блок-схемы коллективных решений: а — голосование, б — гибрид, в — коллектив решающих правил. по указанной схеме принятия коллективного решения. Примерами таких методов являются алгоритмы статистических решений [45], некоторые локальные методы [239], корреляционные методы [230] и т. д. Такой подход можно улучшить, введя понятие взвешенного голосования. В этом случае решения каждого из членов коллектива взвешиваются и голосование производится с весами. Для этого достаточно в формуле (4.6.4) определить Гибридное решающее правило [79] является обобщением описанных алгоритмов голосования. Оно реализуется с помощью скалярной функции свертки
где функция Здесь Р — вид свертки (ее структура), а
при естественном нормирующем ограничении
где распознавания на обучающей выборке, т. е. решением оптимизационной задачи
Здесь
где
где
Для решения задачи (4.6.8) используются различные алгоритмы случайного поиска [166]. В случае большого числа к параметров оптимизация гибридного решающего правила осуществляется путем структурной оптимизации. Она реализуется последовательным добавлением к гибриду из Легко видеть, что гибридное решающее правило (4.6.3), полученное путем оптимизации (4.6.8), обладает очевидным свойством: оно не может быть хуже лучшего из решающих правил, входящих в этот гибрид. Практически же оно всегда оказывается значительно лучше. Указанное свойство гибридного решающего правила проиллюстрировано на нескольких примерах [79]. В одном из них гибрид был образован линейной сверткой (4.6.6) двух алгоритмов Фикса—Ходжеса с различными радиусами сфер сбора информации: Аналогичный результат был получен при эксперименте на гибридном решающем правиле, которое было образовано линейной сверткой трех алгоритмов распознавания: Фикса—Ходжеса, потенциальной функции и линейной дискриминантной функции: Нелинейная свертка (4.6.7) двух алгоритмов распознавания Фикса—Ходжеса с разными параметрами: Таким образом, синтез оптимальных гибридных решающих правил распознавания дает возможность получить правила, свойства которых превышают свойства исходных правил, входящих в гибрид. Процедура синтеза гибрида заключается в выборе исходных правил Однако гибрид обладает одним недостатком — неявной зависимостью решения от ситуации X. Это обстоятельство сужает возможности гибридных алгоритмов, хотя и упрощает их синтез. Рассмотрим теперь решающие правила с явной зависимостью решения от ситуации X. В отличие от (4.6.5) они имеют вид (см. рис. 4.6.1, в):
Здесь функция ее синтез значительно труднее, чем (4.6.5). Однако и возможностей при этом больше. Хорошие результаты при реализации (4.6.12) показала следующая эвристика, названная коллективом решающих правил [189—191]. Веса голосующих правил не детерминированы, а изменяются от ситуации к ситуации. Для этого все пространство ситуаций условно разбивается на области предпочтительности применения того или иного решающего правила и вводится зависимость веса
Здесь
Это означает, что решение коллектива в ситуации X определяется решением такого правила Как видно, предлагаемый подход представляет собой двухуровневую процедуру распознавания: на первом уровне осуществляется распознавание принадлежности ситуации X к той или иной области компетентности При подобной организации коллективного решения основной задачей является синтез алгоритма определения областей компетентности Один из алгоритмов синтеза коллектива основан на методе потенциальных функций, и его можно назвать алгоритмом восстановления потенциалов компетентности. Суммарный потенциал
Вообще говоря, правилом выбора алгоритма может стать любое, легко решающее многоклассовую задачу, — например, правило Байеса, ближайшей точки, Фикса—Ходжеса и т. д. Каждое из этих правил может быть успешно использовано для определения областей компетентности при распознавании методом коллектива. Надо отметить, что в результате выделения областей компетентности в коллективе наряду с компетентными правилами (у которых области компетентности велики) могут оказаться как малокомпетентные, так и некомпетентные решающие правила (область компетентности мала или вообще отсутствует). Естественно поставить задачу синтеза коллектива решающих правил, образованного компетентными правилами. Существует немало методов поиска оптимального коллектива алгоритмов распознавания. Одним из них является алгоритм селекции, рассмотренный в работе [189], согласно которому вводятся критерии эффективности решающих правил: 1. Средний вклад
где 2. Вероятность правильного распознавания
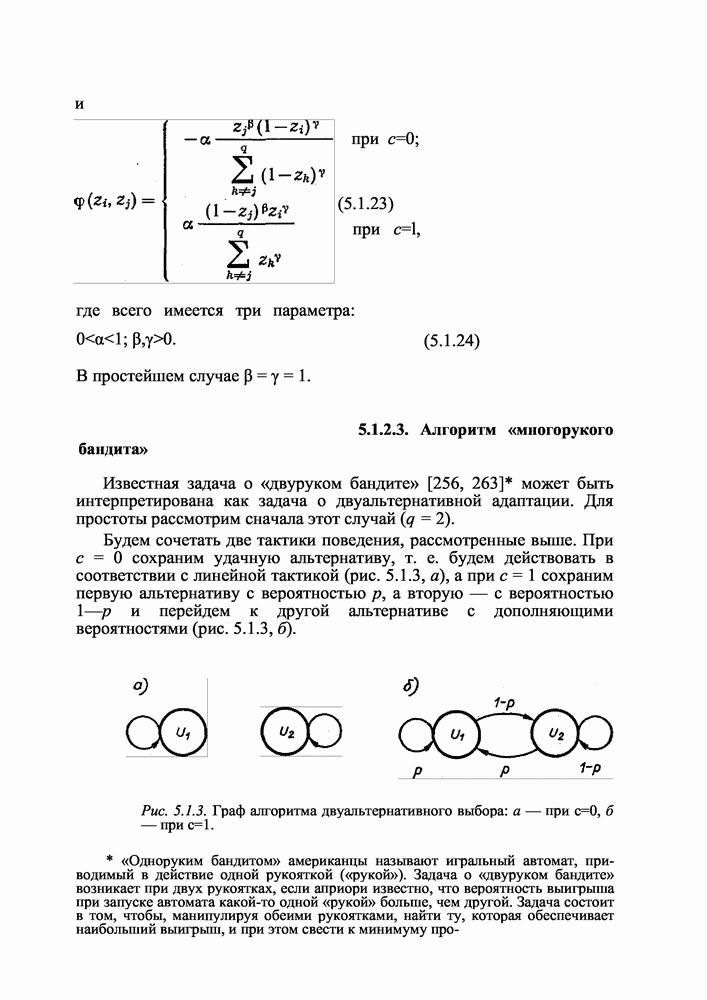
Тогда задача селекции, т. е. задача синтеза оптимального коллектива правил, формируется как многокритериальная задача с
где V — множество допустимых решающих правил, генерируемых для селекции. Поставленная многокритериальная задача может быть сведена к однокритериальной путем введения обобщенного критерия вероятности ошибки распознавания коллективом, которую, естественно, нужно минимизировать в процессе синтеза коллектива:
Указанный критерий оптимизируется путем применения эвристического алгоритма селекции. С помощью этого алгоритма генерирование новых членов и замена малокомпетентных и некомпетентных решающих правил новыми членами улучшает качество работы коллектива. Очевидно, что указанные в работе [189] алгоритмы селекции не исчерпывают все возможности выбора разумных приемов для достижения указанных целей. Другим методом синтеза оптимального коллектива алгоритмов распознавания является оптимизация параметров решающих правил — членов коллектива — с помощью алгоритмов поиска [190]. Здесь рассматривается коллектив алгоритмов, где каждое решающее правило задается с точностью до конечного числа параметров. Тогда, очевидно, свойства коллектива решающих правил определяются параметрами решающих правил, составляющих коллектив. В пространстве этих параметров, которое естественно называть пространством коллективов, каждый конкретный коллектив отображается в точку. Для оптимизации такого коллектива алгоритмов можно воспользоваться адаптивным глобальным алгоритмом случайного поиска [166] параметров решающих правил этого коллектива. Обозначив через
где Очевидно, что использование предложенного параметрического метода оптимизации коллектива эффективно лишь при малых Для решения этой задачи при большом числе параметров можно предложить прием структурной адаптации [78]. Его суть заключается в последовательном наращивании коллектива новыми членами — алгоритмами распознавания. Сначала коллектив состоит из одного решающего правила Эффективность предложенного способа структурной оптимизации, т. е. метода последовательного наращивания коллектива новыми членами, показана на модельной задаче [78]. В коллектив были объединены линейные дискриминантные функции, т. е. каждое из решающих правил задавалось Приведенные результаты экспериментов указывают на преимущество метода последовательной оптимизации по сравнению с одновременной оптимизацией всех параметров коллектива или случайной генерацией новых членов коллектива без оптимизации. Очевидно, что в коллектив кроме параметрических решающих правил могут быть объединены и непараметрические решающие правила, к которым относятся, например, алгоритм Байеса, «Кора» и др. Специфика работы с такими алгоритмами заключается в том, что ввиду отсутствия параметров они не могут быть оптимизированы параметрически. С другой стороны, параметры параметрических алгоритмов не всегда позволяют варьировать свойства этих алгоритмов в необходимых пределах. Эти обстоятельства заставляют искать новые пути создания оптимального разнообразия в коллективе таких алгоритмов. Для преодоления указанной трудности предлагается варьировать обучающую выборку [80]. Например, эту вариацию можно осуществить путем стохастического изменения принадлежности объектов к заданным классам или путем случайного изменения координат объектов обучающей выборки в пространстве признаков. В первом случае элементы обучающей выборки случайно заменяются другими элементами того же множества. Такие преобразования характеризуются стохастической матрицей:
где Надо отметить, что после применения того или иного метода оптимизации полученный коллектив должен обладать некоторым разнообразием, т. е. правила, составляющие коллектив, должны быть достаточно разнообразны по своей структуре. С другой стороны, слишком большое разнообразие снижает эффективность распознавания. Поэтому естественно рассмотреть задачу синтеза коллективных и гибридных решающих правил с оптимальным разнообразием исходного множества решающих правил [81]. Для параметрических алгоритмов распознавания каждый член исходного множества решающих правил в пространстве признаков отображается в точку, а сам коллектив и гибрид — в совокупность таких точек. В этом случае разнообразие вводится в виде среднего значения расстояния между этими точками [189]. Для коллектива и гибрида непараметрических алгоритмов распознавания такой подход непригоден из-за отсутствия параметров. Поэтому для них [80] вводится другая мера разнообразия — коэффициент варьирования обучающей выборки (например, среднеквадратичное отклонение). Показано [80], что такое варьирование обучающей выборки позволяет получить разнообразие как коллектива, так и гибридов непараметрических решающих правил, а оптимизацией этого параметра варьирования можно получить коллектив и гибрид с оптимальным разнообразием алгоритмов, который минимизирует вероятность ошибки распознавания с минимальным числом членов коллектива. В заключение отметим, что синтезированный указанным образом коллектив является весьма мощным средством распознавания ситуаций. Все перечисленные свойства коллектива и Рис. 4.6.2. (см. скан) Алгоритмическая блок-схема пакета программ для синтеза коллективных алгоритмов распознавания. гибридных решающих правил получены за счет введения процедуры оптимизации, что создает реальные предпосылки для разработки специального пакета оптимизируемых программ распознавания. Его алгоритмическая структура представлена на рис. 4.6.2. Основой пакета является библиотека алгоритмов распознавания и оптимизации. В библиотеке должны быть объединены как параметрические, так и непараметрические алгоритмы распознавания. Признаки объектов распознавания должны иметь возможность измеряться как в метрической шкале (количественные признаки), так и в шкале наименований (качественные признаки). Так как пока существует мало алгоритмов распознавания для объектов со смешанными признаками, то необходимо предусмотреть алгоритмические средства для сведения подобных задач только к качественным признакам (при большом числе таких признаков) или только к количественным (при малом числе качественных признаков). В последнем случае задача сводится к синтезу нескольких решающих правил, соответствующих различным значениям качественных признаков. В пакете необходимо предусмотреть возможность различных способов быстрой оценки критерия эффективности алгоритма, так как метод скользящего контроля [13] требует значительных затрат при большой обучающей выборке. На пользователя следует возложить функцию выбора: а) алгоритмов распознавания из библиотеки; б) структуры синтезируемого решающего правила (отдельный алгоритм, гибрид или коллектив); в) способа варьирования правил или оптимизации (варьиро вание обучающей выборки, параметров алгоритмов и их сверток или последовательное наращивание структуры коллектива). Сервисная часть пакета должна обеспечивать надежные оценки доверительных интервалов показателей, интересующих пользователя, и наглядное представление результатов на экране дисплея в интерактивной версии пакета.
|
 |
Оглавление
|


































































































































































































































































































































































































 различных алгоритмов распознавания
различных алгоритмов распознавания  каждый из которых имеет следующую структуру:
каждый из которых имеет следующую структуру:

 — решение, принимаемое
— решение, принимаемое  алгоритмом в ситуации X, а
алгоритмом в ситуации X, а


 реализует свертку индивидуальных решений в коллективное. Приведем очевидные примеры синтеза функции
реализует свертку индивидуальных решений в коллективное. Приведем очевидные примеры синтеза функции  Простейшим способом организации коллективного решения является равноправное голосование членов коллектива (рис. 4.6.1, а). Это означает, что принимается решение, собирающее большинство голосов, т. е.
Простейшим способом организации коллективного решения является равноправное голосование членов коллектива (рис. 4.6.1, а). Это означает, что принимается решение, собирающее большинство голосов, т. е.

 — число голосов, набранное
— число голосов, набранное  решением
решением  в ситуации X. При этом
в ситуации X. При этом  т. е. членам коллектива запрещается голосовать одновременно за два решения. Существует немало известных методов распознавания, которые работают
т. е. членам коллектива запрещается голосовать одновременно за два решения. Существует немало известных методов распознавания, которые работают

 где
где  — вес решающего правила
— вес решающего правила  — множество правил, голосовавших за
— множество правил, голосовавших за  решение. Вес
решение. Вес  может быть определен, например, как величина, обратная оценке ошибочности правила
может быть определен, например, как величина, обратная оценке ошибочности правила  Примерами использования такого взвешенного голосования являются известные перцептронные алгоритмы [64].
Примерами использования такого взвешенного голосования являются известные перцептронные алгоритмы [64].
 которая определяется не на множестве решений исходных решающих правил
которая определяется не на множестве решений исходных решающих правил  а на значениях
а на значениях  (см, рис. 4.6.1, б):
(см, рис. 4.6.1, б):

 определяющая гибрид, задается в виде
определяющая гибрид, задается в виде 
 — вектор параметров этой свертки. Например, в случае линейной свертки гибридное решающее правило имеет вид
— вектор параметров этой свертки. Например, в случае линейной свертки гибридное решающее правило имеет вид

 . В нелинейном случае
. В нелинейном случае  может быть представлена любой полиномиальной функцией
может быть представлена любой полиномиальной функцией  переменных:
переменных:

 , а k — число слагаемых. Выбор параметров а гибридных правил производится путем минимизации ошибок
, а k — число слагаемых. Выбор параметров а гибридных правил производится путем минимизации ошибок

 — функционал эффективности решающего правила
— функционал эффективности решающего правила  на обучающей выборке
на обучающей выборке 

 ситуация выборки,
ситуация выборки,  — ее принадлежность к классу
— ее принадлежность к классу  Функционал
Функционал  в простейшем случае может быть определен, например, как число ошибок правила
в простейшем случае может быть определен, например, как число ошибок правила  на обучающей выборке
на обучающей выборке  Однако наиболее интересна экстраполирующая способность правила
Однако наиболее интересна экстраполирующая способность правила  которая определяется в виде числа ошибок правила, обученного на различных вариантах
которая определяется в виде числа ошибок правила, обученного на различных вариантах  точки выборки [100], при проверке правила на оставшейся точке (метод скользящего контроля):
точки выборки [100], при проверке правила на оставшейся точке (метод скользящего контроля):

 — правило, обученное на выборке
— правило, обученное на выборке  полученной из
полученной из  усечением ее на один
усечением ее на один  элемент:
элемент:

 правил нового
правил нового  решающего правилами оптимизацией только тех параметров, которые связаны с решением
решающего правилами оптимизацией только тех параметров, которые связаны с решением  правила. Этим процесс оптимизации значительно упрощается, так как число оптимизируемых переменных резко сокращается. Так, для линейной свертки (4.6.6) при добавлении одного правила в свертку решение задачи оптимизации производится трлько по одному параметру (и лишь на первом шаге, когда
правила. Этим процесс оптимизации значительно упрощается, так как число оптимизируемых переменных резко сокращается. Так, для линейной свертки (4.6.6) при добавлении одного правила в свертку решение задачи оптимизации производится трлько по одному параметру (и лишь на первом шаге, когда  имеем двухпараметрическую оптимизацию по
имеем двухпараметрическую оптимизацию по 
 . В результате оптимизации по параметру свертки а получена минимальная вероятность ошибки распознавания гибридом:
. В результате оптимизации по параметру свертки а получена минимальная вероятность ошибки распознавания гибридом:  тогда как вероятности ошибки распознавания каждого алгоритма в отдельности были:
тогда как вероятности ошибки распознавания каждого алгоритма в отдельности были: 
 После оптимизации по параметрам свертки
После оптимизации по параметрам свертки  глобальным алгоритмом случайного поиска вероятность ошибки распознавания гибридного решающего правила была
глобальным алгоритмом случайного поиска вероятность ошибки распознавания гибридного решающего правила была  а вероятности ошибки распознавания каждого из алгоритмов, свернутых в гибрид, составляли соответственно:
а вероятности ошибки распознавания каждого из алгоритмов, свернутых в гибрид, составляли соответственно:  .
.
 дала вероятность ошибки распознавания оптимального гибрида
дала вероятность ошибки распознавания оптимального гибрида  тогда как каждый алгоритм в отдельности распознавал обучающую выборку со значительными ошибками:
тогда как каждый алгоритм в отдельности распознавал обучающую выборку со значительными ошибками:  . Отсюда следует, что гибрид всегда лучше, нежели лучшее из входящих в него правил, благодаря обязательному введению процедуры оптимизации параметров гибрида.
. Отсюда следует, что гибрид всегда лучше, нежели лучшее из входящих в него правил, благодаря обязательному введению процедуры оптимизации параметров гибрида.
 и минимизации критерия качества гибрида
и минимизации критерия качества гибрида  по параметрам свертки функции
по параметрам свертки функции  т. е. в решении задачи (4.6.8).
т. е. в решении задачи (4.6.8).

 имеет
имеет  аргументов
аргументов  и поэтому
и поэтому
 решающего правила от ситуации X в виде
решающего правила от ситуации X в виде  Весовые коэффициенты определяются следующим образом:
Весовые коэффициенты определяются следующим образом:

 область компетентности
область компетентности  решающего правила, которая определяется как область ситуаций
решающего правила, которая определяется как область ситуаций  где данное решающее правило имеет наилучшее качество по заданному критерию
где данное решающее правило имеет наилучшее качество по заданному критерию  т. е.
т. е.

 к области компетентности которого
к области компетентности которого  эта ситуация принадлежит, т. е.
эта ситуация принадлежит, т. е. 
 на втором — решение выделенного таким образом правила отождествляется с решением всего коллектива, т. е. (4.6.15)
на втором — решение выделенного таким образом правила отождествляется с решением всего коллектива, т. е. (4.6.15)
 решающих правил, входящих в коллектив. Естественно для членения пространства признаков на области компетентности воспользоваться методами распознавания — здесь решается
решающих правил, входящих в коллектив. Естественно для членения пространства признаков на области компетентности воспользоваться методами распознавания — здесь решается  -классовая задача.
-классовая задача.
 определяет потенциал компетентности
определяет потенциал компетентности  если
если 
 решающего правила, наводимый точками обучающей последовательности в произвольной точке X. Решение в точке X принимает правило с номером
решающего правила, наводимый точками обучающей последовательности в произвольной точке X. Решение в точке X принимает правило с номером  который определяется исходя из условия
который определяется исходя из условия

 решающего правила, т. е. доля объек тов, распознаваемых этим правилом как наиболее компетентным:
решающего правила, т. е. доля объек тов, распознаваемых этим правилом как наиболее компетентным:

 — число объектов контрольной последовательности, для которых
— число объектов контрольной последовательности, для которых  правило наиболее компетентно;
правило наиболее компетентно;  — объем этой последовательности.
— объем этой последовательности.
 правилом при условии, что оно является наиболее компетентным:
правилом при условии, что оно является наиболее компетентным:

 критериями:
критериями:


 — вектор параметров
— вектор параметров  решающего правила
решающего правила  задачу синтеза оптимального коллектива можно записать в виде
задачу синтеза оптимального коллектива можно записать в виде

 — критерий эффективности коллектива, например, по (4.6.10);
— критерий эффективности коллектива, например, по (4.6.10);  — вектор параметров коллектива размерностью
— вектор параметров коллектива размерностью  область определения этих параметров.
область определения этих параметров.

 и задача оптимизации (4.6.21) решается только по параметрам
и задача оптимизации (4.6.21) решается только по параметрам  этого правила. Далее образуется коллектив из двух правил путем добавления второго решающего правила
этого правила. Далее образуется коллектив из двух правил путем добавления второго решающего правила  с неизвестными параметрами
с неизвестными параметрами  которые определяются путем оптимизации коллектива решающих правил по параметрам
которые определяются путем оптимизации коллектива решающих правил по параметрам  Эта процедура продолжается до тех пор, пока вероятность ошибки распознавания коллективом алгоритмов не станет достаточно малой. Как видно, здесь на каждом этапе производится оптимизация по параметрам
Эта процедура продолжается до тех пор, пока вероятность ошибки распознавания коллективом алгоритмов не станет достаточно малой. Как видно, здесь на каждом этапе производится оптимизация по параметрам  лишь одного решающего правила
лишь одного решающего правила  что значительно упрощает задачу оптимизации.
что значительно упрощает задачу оптимизации.
 параметром линейной формы. Добавление членов коллектива осуществлялось до выполнения критерия останова
параметром линейной формы. Добавление членов коллектива осуществлялось до выполнения критерия останова  Во всех десяти экспериментах этот критерий достигался коллективом, составленным из
Во всех десяти экспериментах этот критерий достигался коллективом, составленным из  алгоритмов при
алгоритмов при  Для сравнения рассматривался случай наращивания коллектива случайными линейными правилами без оптимизации. В результате десятикратного эксперимента указанный критерий останова достигался, когда в коллектив были объединены в среднем одиннадцать линейных решающих правил. В другом примере на той же модельной задаче проводилась одновременная оптимизация параметров всех членов коллектива (т. е. решалась задача (4.6.21)). Значения критерия
Для сравнения рассматривался случай наращивания коллектива случайными линейными правилами без оптимизации. В результате десятикратного эксперимента указанный критерий останова достигался, когда в коллектив были объединены в среднем одиннадцать линейных решающих правил. В другом примере на той же модельной задаче проводилась одновременная оптимизация параметров всех членов коллектива (т. е. решалась задача (4.6.21)). Значения критерия  не удалось достигнуть ни в одном эксперименте.
не удалось достигнуть ни в одном эксперименте.

 — число классов, а
— число классов, а  — вероятность изменения принадлежности элемента к
— вероятность изменения принадлежности элемента к  классу на принадлежность к
классу на принадлежность к  Во втором случае производится случайное варьирование координат обучающей выборки в пространстве признаков. Затем стандартным методом обучения определяется решающее правило
Во втором случае производится случайное варьирование координат обучающей выборки в пространстве признаков. Затем стандартным методом обучения определяется решающее правило  Очевидно, что каждое варьирование обучающей выборки позволяет получить новый алгоритм распознавания, что необходимо при организации коллектива алгоритмов.
Очевидно, что каждое варьирование обучающей выборки позволяет получить новый алгоритм распознавания, что необходимо при организации коллектива алгоритмов.