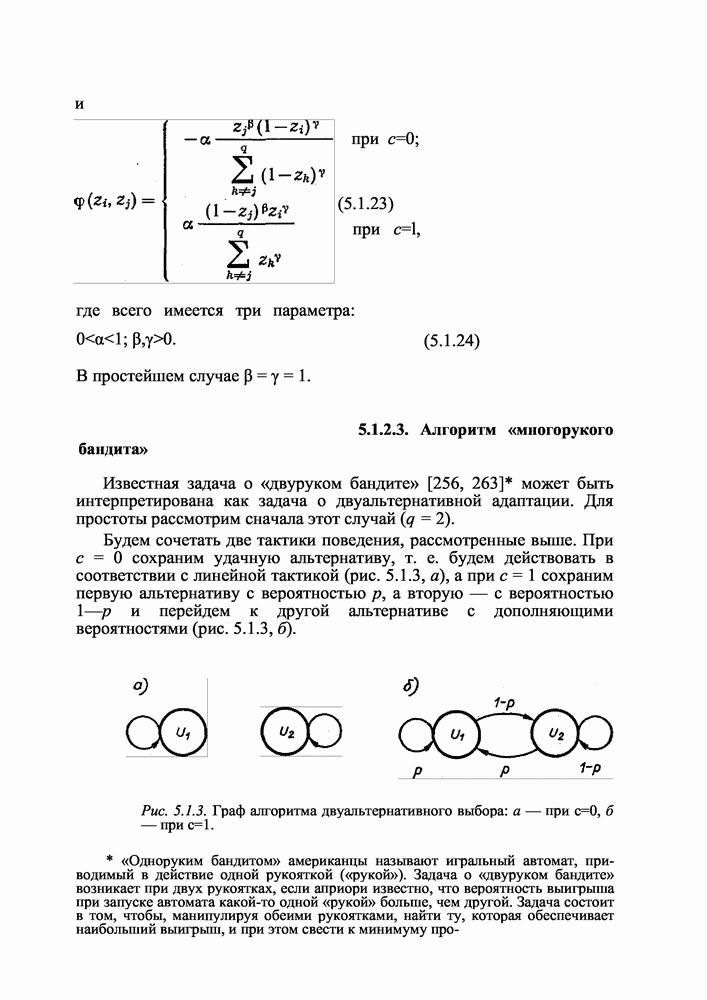
6.3.3. Адаптивное распределение памяти в сети ЭВМ
Естественной адаптивной мерой образования памяти ЭВМ в сети является сохранение наиболее часто используемых блоков информации. Сделать это можно следующим образом.
Пусть первоначальное распределение блоков по ЭВМ было произвольным (например, случайным):

где  — начальное множество номеров блоков информации, расположенное в памяти i-й ЭВМ. На это множество наложено ограничение по объему (6.3.2) в виде
— начальное множество номеров блоков информации, расположенное в памяти i-й ЭВМ. На это множество наложено ограничение по объему (6.3.2) в виде

Заявка (задача) представляет собой множество V номеров блоков информации, требуемых для ее обслуживания (решения). Представим  виде двоичных
виде двоичных  -мерных векторов:
-мерных векторов:

где

На двоичных векторах (6.3.14) введем функцию, определяющую число запрошенных  заявкой блоков информации, не обеспеченных содержимым памяти
заявкой блоков информации, не обеспеченных содержимым памяти  ЭВМ:
ЭВМ:

где верхней чертой обозначено логическое отрицание. Каждая  заявка сопровождается вектором
заявка сопровождается вектором

и направляется на обслуживание в ту  для которой
для которой  минимально, т. е. требует минимальных затрат обращения к банку данных:
минимально, т. е. требует минимальных затрат обращения к банку данных:

Если  очередь превышает величину
очередь превышает величину  то заявка переправляется к другой машине, для которой
то заявка переправляется к другой машине, для которой  минимально (исключая
минимально (исключая  Там заявка принимается на обслуживание, если очередь к ней не превышает
Там заявка принимается на обслуживание, если очередь к ней не превышает  . В противном случае заявка направляется к другой ЭВМ и т. д.
. В противном случае заявка направляется к другой ЭВМ и т. д.
Таким образом, в дисциплину обслуживания входит, вектор предельных длин очередей

который также может адаптироваться (но уже параметрическим образом).
Адаптация памяти каждой ЭВМ происходит после обслуживания очередной заявки. Здесь задача состоит в том, чтобы определить новое состояние памяти  по предыдущему
по предыдущему
 и множеству новых номеров
и множеству новых номеров  блоков, полученных в данный момент из банка данных. Очевидно, что
блоков, полученных в данный момент из банка данных. Очевидно, что

т. е. эти множества не пересекаются. При этом  должно удовлетворять ограничению
должно удовлетворять ограничению

Следовательно, работу алгоритма адаптивного изменения памяти можно представить в виде преобразования:

где  — алгоритм адаптации.
— алгоритм адаптации.
В качестве такого алгоритма могут быть использованы известные алгоритмы замещения [3], предложенные для обмена между основной и вспомогательной памятью ЭВМ:
1. Алгоритм случайного замещения формирует из двух множеств  одно случайное, удовлетворяющее условию (6.3.20), таким образом, чтобы не осталось ни одного блока, ко торый можно было бы разместить в памяти, не нарушив условия (6.3.20).
одно случайное, удовлетворяющее условию (6.3.20), таким образом, чтобы не осталось ни одного блока, ко торый можно было бы разместить в памяти, не нарушив условия (6.3.20).
2. Алгоритм «первый пришел — первый обслужен», в соответ ствии с которым из памяти удаляются (замещаются) те блоки, которые дольше находились в ней.
3. Алгоритм замещения наименее используемых блоков. В этом случае из памяти удаляются блоки, которые дольше всех не запрашивались при работе данной ЭВМ.
4. Многоуровневые алгоритмы замещения [3], которые  дятся к организации на каждом шаге приоритетных списков и принятию решения на их базе. Эти алгоритмы обобщают преды дущие.
дятся к организации на каждом шаге приоритетных списков и принятию решения на их базе. Эти алгоритмы обобщают преды дущие.
Хотя перечисленные алгоритмы вполне работоспособны, они не используют идей адаптации.
Предложим новый рандомизированный алгоритм  Пусть каждому
Пусть каждому  блоку информации, находящемуся в памяти любой ЭВМ сети, соответствует число
блоку информации, находящемуся в памяти любой ЭВМ сети, соответствует число  выражающее уровень приоритета этого
выражающее уровень приоритета этого  блока в момент
блока в момент  (индекс
(индекс  номера ЭВМ здесь можно снять, так как алгоритм одинаков для всех ЭВМ сети).
номера ЭВМ здесь можно снять, так как алгоритм одинаков для всех ЭВМ сети).
Введем монотонно возрастающую функцию  такую, что
такую, что

где  — число блоков, претендующих на сохранение в памяти ЭВМ. Значение этой функции можно рассматривать как вероятность сохранения соответствующего блока в памяти.
— число блоков, претендующих на сохранение в памяти ЭВМ. Значение этой функции можно рассматривать как вероятность сохранения соответствующего блока в памяти.

Рис. 6.3.1. График функции 
Итак, задача адаптации сводится к формированию такой функции  и преобразованию значения весов
и преобразованию значения весов  Естественно воспользоваться следующей рекуррентной формулой:
Естественно воспользоваться следующей рекуррентной формулой:

где  — параметры;
— параметры;

Видно, что при постоянном использовании  блока
блока  , а при неиспользовании
, а при неиспользовании 
Функцию  (рис. 6.3.1) удобно представить в виде
(рис. 6.3.1) удобно представить в виде

Ее параметрами являются  Завершает определение алгоритма
Завершает определение алгоритма  задание начального значения параметра
задание начального значения параметра  для веса новых блоков:
для веса новых блоков:

Таким образом, алгоритм  адаптации памяти ЭВМ в сети рандомизирован и однозначно определяется набором из пяти неотрицательных параметров
адаптации памяти ЭВМ в сети рандомизирован и однозначно определяется набором из пяти неотрицательных параметров

изменяемых в очевидных пределах

С помощью этих параметров оптимизируется работа ЭВМ: минимизируется ее обращаемость к банку данных в процессе решения задач.
Как видно, описанный алгоритм адаптивного распределения памяти по сети ЭВМ имеет ярко выраженную иерархическую
структуру. На первом (нижнем) уровне иерархии производится адаптивное образование памяти каждой ЭВМ и адаптация этого процесса

по критерию  — обращаемости данной
— обращаемости данной  к банку данных. На втором уровне производится адаптация параметров
к банку данных. На втором уровне производится адаптация параметров  порогов каждой ЭВМ, т. е. решается задача
порогов каждой ЭВМ, т. е. решается задача

где 3 — выбранный критерий функционирования всей сети, например среднее время решения одной задачи в сети и т. 
— множество допустимых порогов:

Таким образом, эффективность алгоритма эволюционной адаптации памяти каждой ЭВМ сети и сети в целом зависит от набора параметров (6.3.26) и (6.3.18), которые следует адаптировать параметрическим образом.
Эксперименты по эволюционной адаптации такого рода показали работоспособность и эффективность данного подхода даже без параметрической адаптации [143, 144, 211, 282—284].