Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
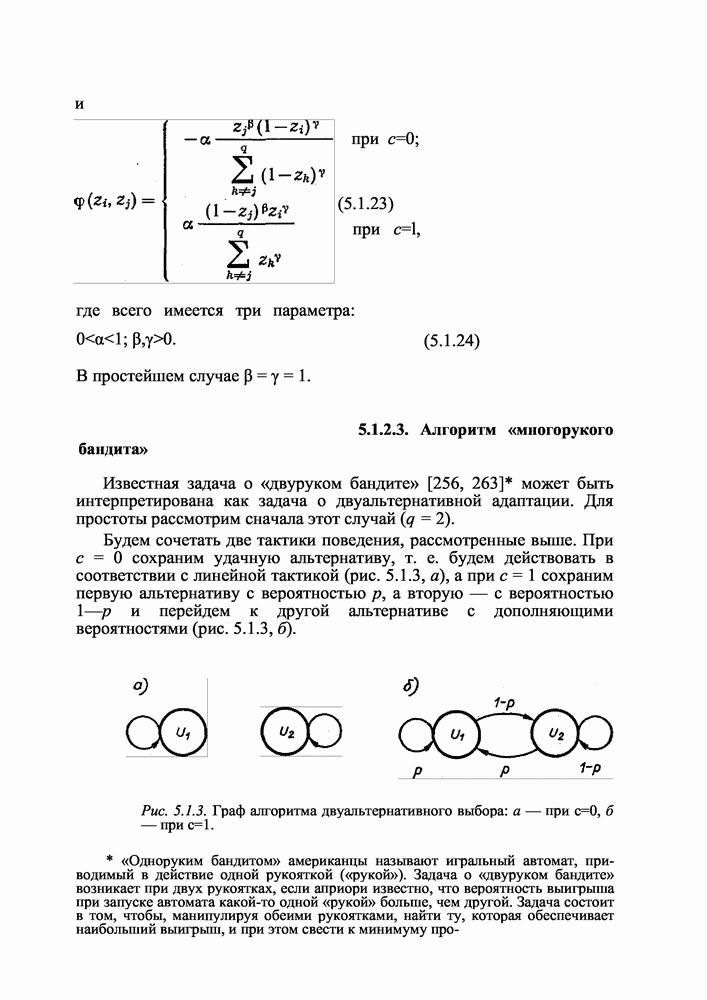
3.5.2. Параметрическая адаптация алгоритмов случайного поискаОсновными параметрами алгоритма случайного поиска являются величина рабочего шага Это качество выгодно отличает случайный поиск от регулярных алгоритмов, не имеющих такого «рычага управления» процессом поиска. Рассмотрим адаптацию по каждому из указанных факторов отдельно. 3.5.2.1. Адаптация величины рабочего шагаТакая адаптация связана с необходимостью уменьшить величину шага по мере приближения к положению экстремума
не учитывают складывающуюся в процессе оптимизации ситуацию и поэтому, как показал опыт, неэффективны при решении практических задач. Очевидно, что в процессе поиска необходимо и увеличивать, и уменьшать рабочий шаг. Очень плодотворной оказалась следующая эвристическая процедура: уменьшить шаг а при неудачном случайном шаге и увеличить — при удачном. В основе такой эвристики лежат естественные соображения: неудачный шаг, как правило, свидетельствует о том, что цель где-то близко и искать ее следует более мелкими шагами, а удачный — о том, что до цели далеко и следует увеличить шаг. Конечно, эти соображения не более чем эвристика, но они дали возможность построить очень эффективный алгоритм адаптации рабочего шага случайного поиска [184]:
где в соответствии с указанными соображениями Зададим вопрос: какими должны быть значения
где величина алгоритма, что позволяет значительно ускорить решение задачи оптимизации. Однако условие (3.5.2) получено теоретически для довольно частного случая объекта оптимизации. В реальных задачах оптимизации это соотношение иное и различно для каждого конкретного объекта. Очевидно, что необходимо определять параметры 3.5.2.2. Адаптация распределения случайного шагаЭтот вид адаптации заключается в том, что получаемая на каждом шаге поиска информация об успехе или неуспехе случайного шага используется для такой деформации распределения случайного шага, при которой эффективность процесса поиска возрастает. Пусть
откуда получаем Вектор Деформация распределения Здесь помогает довольно очевидная эвристика: направление следует формировать как взвешенную сумму случайных шагов, причем удачные шаги весами, а неудачные — с отрицательными. Предпочтение должно отдаваться более свежей информации. Эта эвристика реализуется, например, такой простой рекуррентной формулой изменения
где Легко показать, что такая организация изменения В общем случае взаимодействие векторов Можно показать, что в неизменной ситуации направление вектора Как видно, вектор
Рис. 3.5.1. Образование плотности распределения случайного шага со сносом. а — исходное распределение без сноса, б — взаимодействие вектора сноса со случайным вектором, в — результирующее распределение со сносом.
Рис. 3.5.2. Корреляция вектора предыстории при удачном (а) и неудачном (б) шагах поиска, а Чтобы такая адаптация была успешной, ситуация, которая складывается в процессе оптимизации, не должна изменяться слиш-. ком быстро, иначе она станет «неуловимой» для адаптации. Поэтому введение адаптации такого рода (часто называемой самообучением) не всегда улучшает процесс поиска, но зато и не ухудшает его. Здесь следует отметить, что параметры величины рабочего шага Более полное изложение методов параметрической адаптации случайного поиска имеется в монографии [135].
|
 |
Оглавление
|


































































































































































































































































































































































































 (см. формулы (3.3.12), (3.3.20) и (3.3.23)) и параметры плотности распределения
(см. формулы (3.3.12), (3.3.20) и (3.3.23)) и параметры плотности распределения  случайного шага Заметим, что случайный поиск отличается от любого, детерминированного метода именно наличием такого распределения, изменение которого позволяет адаптировать случайный поиск.
случайного шага Заметим, что случайный поиск отличается от любого, детерминированного метода именно наличием такого распределения, изменение которого позволяет адаптировать случайный поиск.
 Программные алгоритмы изменения рабочего шага (типа условий Дворецкого:
Программные алгоритмы изменения рабочего шага (типа условий Дворецкого:


 Элементарный анализ показывает, что при
Элементарный анализ показывает, что при  величина шага будет уменьшаться по мере приближения к экстремуму.
величина шага будет уменьшаться по мере приближения к экстремуму.
 и
и  , чтобы как можно, скорее попасть в точку экстремума
, чтобы как можно, скорее попасть в точку экстремума  или хотя бы в ее достаточно малую окрестность? Это зависит от вероятности того, что случайный шаг будет удачен, т. е. от вероятности события
или хотя бы в ее достаточно малую окрестность? Это зависит от вероятности того, что случайный шаг будет удачен, т. е. от вероятности события  . В процессе адаптации следует стремиться к тому значению шага, при котором приближение к цели
. В процессе адаптации следует стремиться к тому значению шага, при котором приближение к цели  будет наибольшим. Пусть вероятность удачного случайного шага при такой оптимальной величине равна
будет наибольшим. Пусть вероятность удачного случайного шага при такой оптимальной величине равна  Тогда оптимальные значения
Тогда оптимальные значения  связаны следующим соотношением [212]:
связаны следующим соотношением [212]:

 с ростом
с ростом  стремится к 0,27. Используя это выражение, можно добиться оптимального режима адаптации
стремится к 0,27. Используя это выражение, можно добиться оптимального режима адаптации
 не заранее, а в процессе поиска, т. е. надо их адаптировать. Следовательно, необходимо создать второй контур адаптации, адаптирующий первый. Эта проблема еще не решена, здесь нужны идеи. Ясно одно: без решения этой задачи не может быть эффективной адаптации величины рабочего шага при оптимизации достаточно сложных систем.
не заранее, а в процессе поиска, т. е. надо их адаптировать. Следовательно, необходимо создать второй контур адаптации, адаптирующий первый. Эта проблема еще не решена, здесь нужны идеи. Ясно одно: без решения этой задачи не может быть эффективной адаптации величины рабочего шага при оптимизации достаточно сложных систем.
 — плотность распределения случайного шага Основной характеристикой всякого распределения является его математическое ожидание Изменяя можно эффективно воздействовать на процесс поиска. Практически это сведется к прибавлению вектора
— плотность распределения случайного шага Основной характеристикой всякого распределения является его математическое ожидание Изменяя можно эффективно воздействовать на процесс поиска. Практически это сведется к прибавлению вектора  к — случайному вектору с нулевым математическим ожиданием:
к — случайному вектору с нулевым математическим ожиданием:


 как видно, определяет «снос» случайного блуждания в процессе поиска. Естественно, что этот снос должен быть направлен в сторону цели, т. е. искомого положения экстремума
как видно, определяет «снос» случайного блуждания в процессе поиска. Естественно, что этот снос должен быть направлен в сторону цели, т. е. искомого положения экстремума  Вектор
Вектор  должен отражать предысторию работы поиска и выявлять перспективное направление движения при оптимизации.
должен отражать предысторию работы поиска и выявлять перспективное направление движения при оптимизации.
 представлена на рис. 3.5.1. Исходное равномерное по всем направлениям распределение случайного вектора (рис. 3.5.1, а) взаимодействует по (3.5.3) с вектором памяти
представлена на рис. 3.5.1. Исходное равномерное по всем направлениям распределение случайного вектора (рис. 3.5.1, а) взаимодействует по (3.5.3) с вектором памяти  (рис. 3.5.1, б), в результате чего полученное распределение
(рис. 3.5.1, б), в результате чего полученное распределение  имеет явную тенденцию (снос) в сторону
имеет явную тенденцию (снос) в сторону  (рис. 3.5.1, в). Как видно, все сводится к разумной организации вектора
(рис. 3.5.1, в). Как видно, все сводится к разумной организации вектора  и его оперативному изменению.
и его оперативному изменению.
 следует брать с положительными
следует брать с положительными
 в процессе поиска:
в процессе поиска:

 — коэффициент забывания, а
— коэффициент забывания, а  — коэффициент интенсивности учета новой информации. Это и есть алгоритм адаптации распределения.
— коэффициент интенсивности учета новой информации. Это и есть алгоритм адаптации распределения.
 отражает требования, предъявляемые к этому вектору. Сначала рассмотрим крайние случаи. При отсутствии новой информации, т. е. при
отражает требования, предъявляемые к этому вектору. Сначала рассмотрим крайние случаи. При отсутствии новой информации, т. е. при  в силу
в силу  вектор 0, т. е. поиск становится равновероятным, что естественно в данных условиях. Если «забыть» всю предысторию
вектор 0, т. е. поиск становится равновероятным, что естественно в данных условиях. Если «забыть» всю предысторию  то
то  т. е. снос будет происходить либо в направлении предыдущего удачного шага, либо противоположно неудачному, что также вполне разумно.
т. е. снос будет происходить либо в направлении предыдущего удачного шага, либо противоположно неудачному, что также вполне разумно.
 будет таким, что при удаче
будет таким, что при удаче  будет разворачиваться в сторону удачного шага, а при неудаче — в сторону, противоположную неудачному.
будет разворачиваться в сторону удачного шага, а при неудаче — в сторону, противоположную неудачному.
 будет стремиться к антиградиенту, т. е. в сторону наиболее интенсивного уменьшения показателя качества. Происходит это по стандартным законам сложения векторных величин (рис. 3.5.2).
будет стремиться к антиградиенту, т. е. в сторону наиболее интенсивного уменьшения показателя качества. Происходит это по стандартным законам сложения векторных величин (рис. 3.5.2).
 интегрально отражает предысторию поиска, и поэтому его часто называют вектором предыстории. Случайный поиск, снабженный адаптацией вероятностных свойств, обладает, как правило, повышенным быстродействием.
интегрально отражает предысторию поиска, и поэтому его часто называют вектором предыстории. Случайный поиск, снабженный адаптацией вероятностных свойств, обладает, как правило, повышенным быстродействием.



 забывания
забывания  и запоминания (5) взаимосвязаны и для эффективной адаптации должны определяться в зависимости от специфики ситуации, сложившейся при оптимизации. Так возникает задача адаптации параметров адаптации, т. е. адаптация следующего уровня. Плодотворных подходов к ее решению пока нет, но совершенно ясно, что ее необходимо решать, т. е. нужно построить алгоритм изменения параметров
и запоминания (5) взаимосвязаны и для эффективной адаптации должны определяться в зависимости от специфики ситуации, сложившейся при оптимизации. Так возникает задача адаптации параметров адаптации, т. е. адаптация следующего уровня. Плодотворных подходов к ее решению пока нет, но совершенно ясно, что ее необходимо решать, т. е. нужно построить алгоритм изменения параметров  , с тем чтобы процесс оптимизации протекал наилучшим образом.
, с тем чтобы процесс оптимизации протекал наилучшим образом.