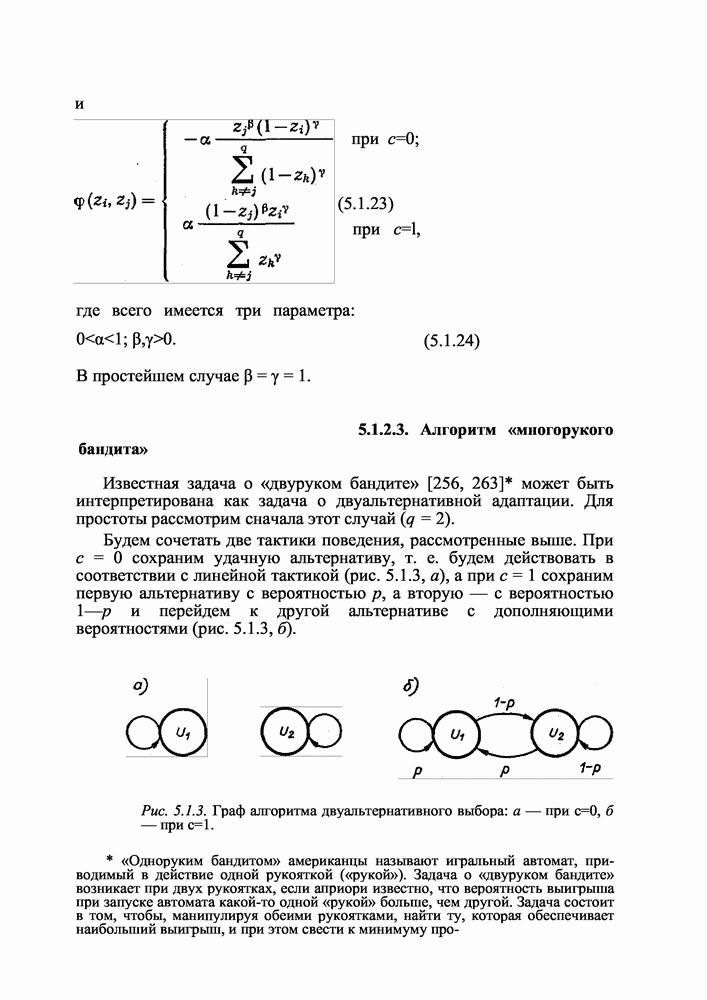
6.4.4. Модельные эксперименты
Адаптация структуры перцептрона методом случайного поиска исследовалась на примере распознавания двух классов объектов, образованных следующим образом [60].
В соответствии с выражениями (6.4.17) и (6.4.18), в которых  задавались два эталонных объекта, и для каждого из них был образован свой класс объектов. Полученные таким образом 100 объектов были затем дополнительно разбиты случайным образом на два класса по 50 объектов.
задавались два эталонных объекта, и для каждого из них был образован свой класс объектов. Полученные таким образом 100 объектов были затем дополнительно разбиты случайным образом на два класса по 50 объектов.
Для решения данной задачи на ЭВМ моделировался трехслойный перцептрон с сетчаткой из 64 рецепторов  и числом А-элементов, равным 100 и 25. Каждый А-элемент имел пять входов: два входа для тормозящих и три — для возбуждающих связей с сетчаткой. Порог 0 каждого А-элемента был принят равным 1. Исходная структура связей выбиралась случайным образом.
и числом А-элементов, равным 100 и 25. Каждый А-элемент имел пять входов: два входа для тормозящих и три — для возбуждающих связей с сетчаткой. Порог 0 каждого А-элемента был принят равным 1. Исходная структура связей выбиралась случайным образом.
Полученная случайная обучающая последовательность имела случайные признаки, и для ее распознавания было проведено семь независимых экспериментов. В каждом эксперименте объекты этой обучающей последовательности заново разбивались на два класса случайным образом и проводилось обучение перцептронов с 25 и 100 А-элементами по двум алгоритмам: 1) алгоритм I:  -система подкрепления с коррекцией ошибок (6.4.11); 2) алгоритм II:
-система подкрепления с коррекцией ошибок (6.4.11); 2) алгоритм II:  -система подкрепления с коррекцией ошибок в комбинации с описанным алгоритмом адаптации структуры (6.4.13).
-система подкрепления с коррекцией ошибок в комбинации с описанным алгоритмом адаптации структуры (6.4.13).
В качестве показателя качества каждого А-элемента принималось число неправильных реакций А-элемента на объекты обучающей последовательности, и для каждой последовательности задавался ряд значений порога 
В случае перцептрона со 100 А-элементами оказалось достаточным применить только первый алгоритм обучения, для того чтобы по окончании процесса обучения безошибочно распознать объекты обучающей последовательности во всех семи экспериментах, т. е. для решения задачи распознавания использовалась только процедура (6.4.11).
В случае перцептрона с 25 А-элементами использования для обучения только  -системы подкрепления с коррекцией ошибок оказалось недостаточным для обеспечения безошибочной классификации объектов обучающей последовательности. Здесь обучение проводилось по второму алгоритму, т. е. использовалась процедура (6.4.6). Результаты обучения, осредненные по семи экспериментам, а также доверительные интервалы, соответствующие доверительной вероятности 0,92, приведены на рис. 6.4.3. Видно, что полученные при решении такой модельной задачи экспериментальные результаты хорошо согласуются с приведенными выше теоретическими.
-системы подкрепления с коррекцией ошибок оказалось недостаточным для обеспечения безошибочной классификации объектов обучающей последовательности. Здесь обучение проводилось по второму алгоритму, т. е. использовалась процедура (6.4.6). Результаты обучения, осредненные по семи экспериментам, а также доверительные интервалы, соответствующие доверительной вероятности 0,92, приведены на рис. 6.4.3. Видно, что полученные при решении такой модельной задачи экспериментальные результаты хорошо согласуются с приведенными выше теоретическими.
Кроме того, проводилось сравнение перцептрона с адаптивной структурой и алгоритма «Кора» [42] на примере решения

Рис. 6.4.3. Результаты экспериментов по обучению обычного перцептрона (алгоритм I) и перцептрона с адаптивной структурой (алгоритм II).  — надежность классификации (доля правильных ответов перцептрона,
— надежность классификации (доля правильных ответов перцептрона,  — доля
— доля  правильных реакций Л-элемента на объекты обучающей последовательности.
правильных реакций Л-элемента на объекты обучающей последовательности.
следующей задачи. В соответствии с выражениями (6.4.17) и (6.4.18), в которых принималось:  задавались два класса объектов. Из общего числа 96 объектов случайным образом выбирались четыре различные обучающие последовательности, в которые входило по 32 объекта из каждого класса, а оставшиеся 32 объекта использовались только для экзамена.
задавались два класса объектов. Из общего числа 96 объектов случайным образом выбирались четыре различные обучающие последовательности, в которые входило по 32 объекта из каждого класса, а оставшиеся 32 объекта использовались только для экзамена.
Для решения этой задачи на ЭВМ «Минск-32» моделировались алгоритм «Кора» и трехслойный перцептрон с адаптивной структурой связей А-элементов с сетчаткой. Число А-элементов  в перцептроне было принято равным 100 и 25, каждый А-элемент имел два входа для тормозящих и три — для возбуждающих связей с сетчаткой
в перцептроне было принято равным 100 и 25, каждый А-элемент имел два входа для тормозящих и три — для возбуждающих связей с сетчаткой  порог в каждого А-элемента был принят равным единице. В качестве признаков в алгоритме «Кора» рассматривались конъюнкции не выше третьего ранга. Количество отбираемых признаков принималось равным 10 и 30, а значения заданного минимального числа объектов одного класса в обучающей последовательности, для которых данная конъюнкция истинна, задавались равными 7 и 12 соответственно.
порог в каждого А-элемента был принят равным единице. В качестве признаков в алгоритме «Кора» рассматривались конъюнкции не выше третьего ранга. Количество отбираемых признаков принималось равным 10 и 30, а значения заданного минимального числа объектов одного класса в обучающей последовательности, для которых данная конъюнкция истинна, задавались равными 7 и 12 соответственно.
Результаты экзамена, осредненные по четырем независимым экспериментам, а также время обучения приведены в табл. 6.4.1.
Таблица 6.4.1

Эти результаты показывают, что введение в перцептрон процедуры адаптации структуры методами случайного поиска позволяет достичь того же эффекта гораздо быстрее, чем с помощью алгоритма «Кора», использующего метод перебора признаков (как видно из таблицы, в одном случае имеем выигрыш времени более чем на порядок).