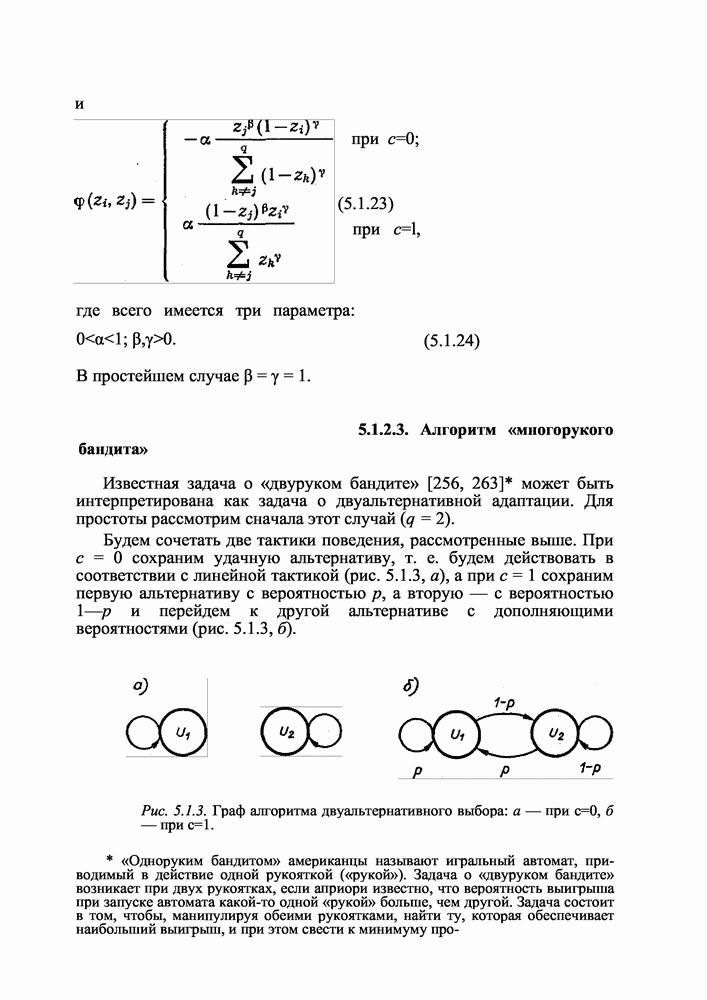
3.7.2. Поведенческие алгоритмы
Многие алгоритмы случайного поиска моделируют поведение живых организмов в неизвестной среде. В данном случае моделируется присущая живым организмам способность стремиться к комфортным ситуациям и уклоняться от некомфортных. Эта способность, выработанная эволюцией, глубоко рациональна и широко используется в процессах управления. Используется она и в случайном поиске. Назовем прежде всего алгоритм с линейной тактикой, рассмотренный в § 3.3 (3.3.12). Этот алгоритм моделирует поведение живого существа в среде, состояния которой могут быть для него комфортными и некомфортными. Попадая в такого рода среду, животное и человек обучаются: у них появляется стремление к комфортным ситуациям, в чем и состоит линейность их поведения. (Линейность поведения широко используют при дрессировке животных и при... воспитании. Поощрение в процессах воспитания дает результат именно благодаря этому свойству человеческого поведения.)
Рассмотрим модель поведения мыши в Т-образном лабиринте (рис. 3.7.1). Подобные эксперименты неоднократно проводились в различных лабораториях. Мышь здесь должна выбрать одно из двух направлений. Пусть  — вероятность ее поворота влево в
— вероятность ее поворота влево в  эксперименте. Легко представить результаты такого рода
эксперименте. Легко представить результаты такого рода

Рис. 3.7.1. Варианты экспериментов по выработке определенного поведения: а — с поощрением, б — с наказанием, в — сочетание поощрения с наказанием.
экспериментов. В первом эксперименте (рис. 3.7.1, а) зверек обучится устойчиво поворачивать влево  в результате поощрения, получаемого при нужной реакции (кусочек сала). Динамика такого обучения выражается следующей рекуррентной формулой [39]:
в результате поощрения, получаемого при нужной реакции (кусочек сала). Динамика такого обучения выражается следующей рекуррентной формулой [39]:

Вероятность поворотов влево на каждом шаге будет увеличиваться на  где
где  — параметр обучения при поощрении. Чем больше а, тем быстрее обучается зверек. Если же изменить положение приманки, то процесс обучения будет описываться несколько иначе:
— параметр обучения при поощрении. Чем больше а, тем быстрее обучается зверек. Если же изменить положение приманки, то процесс обучения будет описываться несколько иначе:

т. е. вероятность будет уменьшаться, так как 
Совершенно иначе построен второй эксперимент (рис. 3.7.1, б), в котором для обучения используется наказание (удар тока). Мышь и здесь обучится поворачивать влево, причем процесс ее обучения можно представить аналогичной формулой  где
где  — также параметр обучения, который, вообще говоря, не совпадает с а.
— также параметр обучения, который, вообще говоря, не совпадает с а.
И, наконец, тот же результат будет получен при обучении по «принципу кнута и пряника» (рис. 3.7.1, в), но с иным параметром обучения у.
Как видно, одного и того же поведения — поворота влево — можно добиться от животного разными способами — поощрением, наказанием и их, сочетанием.
Все эти биологические модели могут быть использованы при организации случайного поиска следующим образом. Пусть  — вероятность положительного смещения вдоль
— вероятность положительного смещения вдоль  координаты на
координаты на  шаге поиска:
шаге поиска:

(пусть величина смещения будет равна единице, т. е.  Естественно эту вероятность изменять так, чтобы увеличить число удачных шагов, для которых
Естественно эту вероятность изменять так, чтобы увеличить число удачных шагов, для которых 
Здесь можно применить все три рассмотренные выше схемы обучения:
1. Обучение только поощрением (только при 

где

Хорошо видно, что эта вероятность увеличивается, если шаг  оказался удачным, и уменьшается в обратном случае, что вполне логично. В случае неудачи
оказался удачным, и уменьшается в обратном случае, что вполне логично. В случае неудачи  т. е. вероятности, естественно, не изменяются. При оптимизации алгоритмом поиска
т. е. вероятности, естественно, не изменяются. При оптимизации алгоритмом поиска

процесс поиска будет иметь выраженный глобальный характер. Его будет «нести» в направлении первого же удачного шага, пока не будет сделан другой удачный, изменяющий направление «сноса», и т. д.
2. Обучение только наказанием (при  ):
):

При удаче  вероятности не изменяются.
вероятности не изменяются.
Легко видеть, что в этом случае поиск имеет локальный характер, что приводит к устойчивым блужданиям в районе ближайшего локального экстремума.
3. Обучение поощрением и наказанием можно построить  яко. Величину поощрения и наказания можно сделать одинаковой, что приводит к следующей схеме обучения:
яко. Величину поощрения и наказания можно сделать одинаковой, что приводит к следующей схеме обучения:

Однако более гибка и интересна другая схема, объединяющая обучение по формуле (3.7.8) при  и по формуле (3.7.9) при
и по формуле (3.7.9) при  Уровень поощрения и наказания может быть различным (при
Уровень поощрения и наказания может быть различным (при  эта схема вырождается в (3.7.11)). Здесь, варьируя величины
эта схема вырождается в (3.7.11)). Здесь, варьируя величины  можно придать различный характер поведению алгоритма случайного поиска (3.7.9), моделируя при этом различные способы обучения (точнее — дрессировки).
можно придать различный характер поведению алгоритма случайного поиска (3.7.9), моделируя при этом различные способы обучения (точнее — дрессировки).
Любопытно, что при  т. е. при более интенсивном поощрении, поиск напоминает поведение любознательного зверька: он ищет в более широкой области, чем при
т. е. при более интенсивном поощрении, поиск напоминает поведение любознательного зверька: он ищет в более широкой области, чем при  когда поиск имеет локальный характер. Сильное наказание сужает область поиска зоной ближайшего локального экстремума.
когда поиск имеет локальный характер. Сильное наказание сужает область поиска зоной ближайшего локального экстремума.
Как видно, анализ и моделирование поведения живых существ в процессе их обучения дают возможность построить новые эффективные алгоритмы случайного поиска.