Пред.
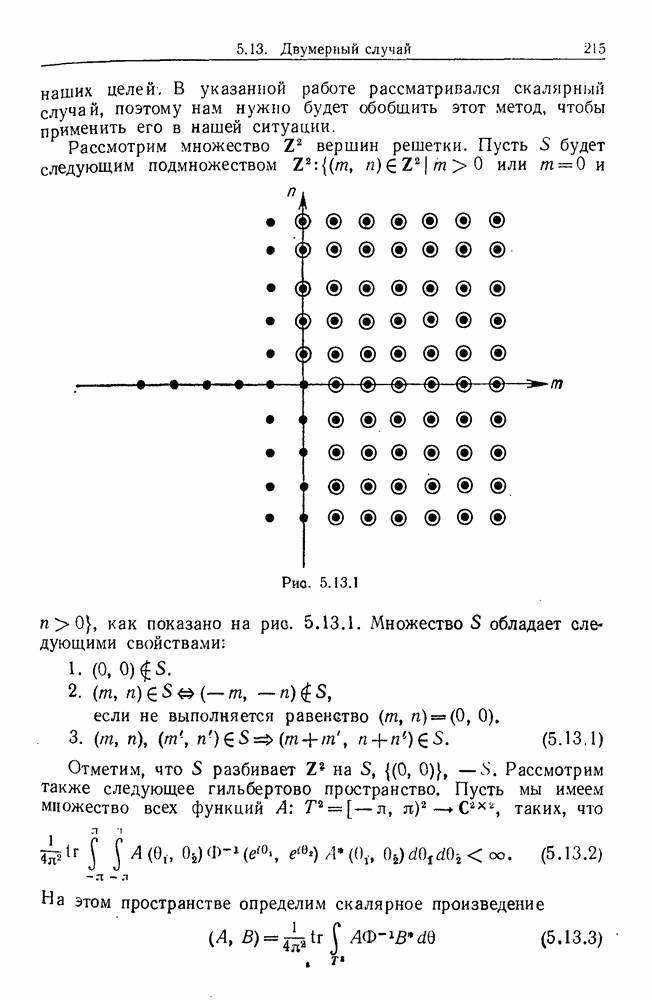
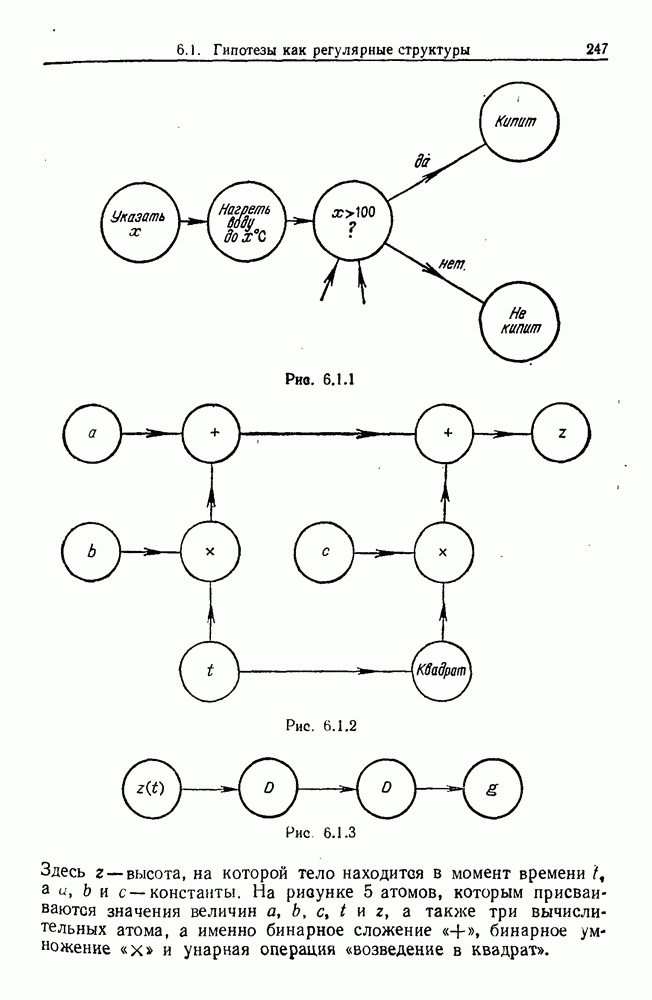
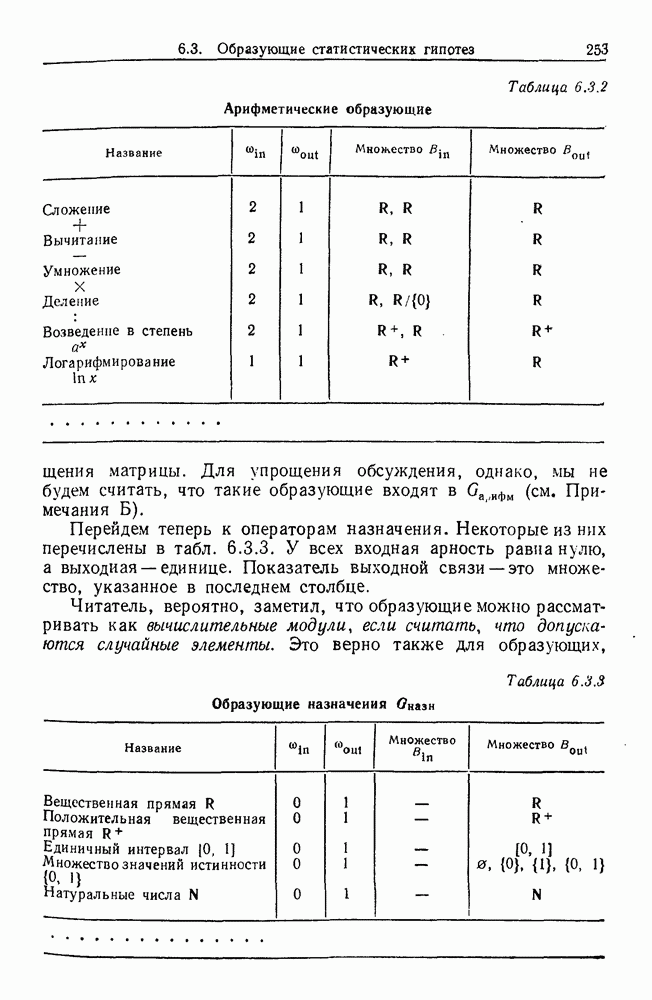
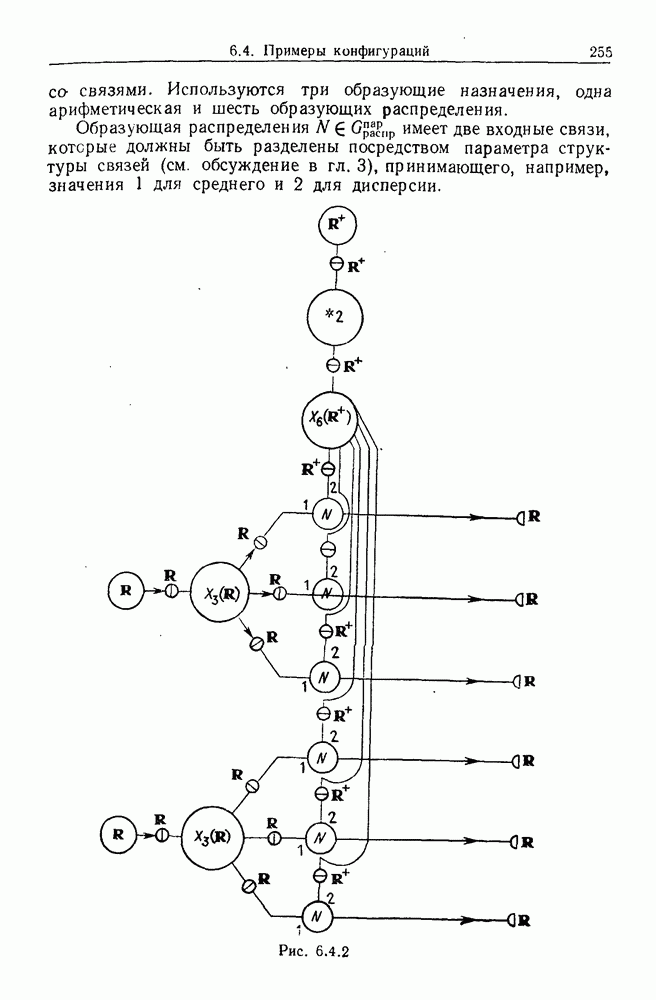
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
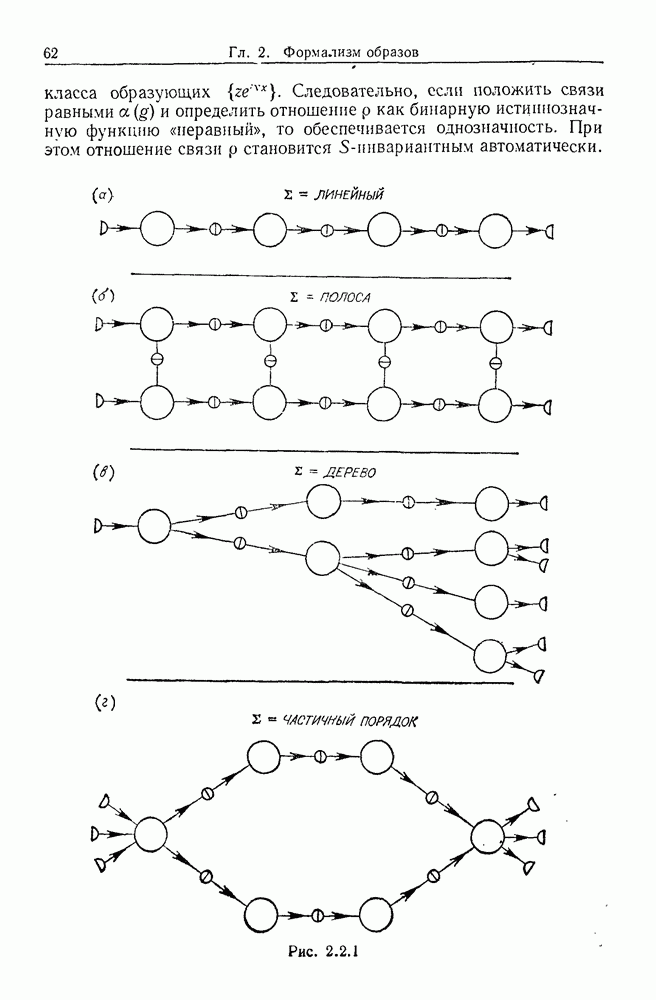
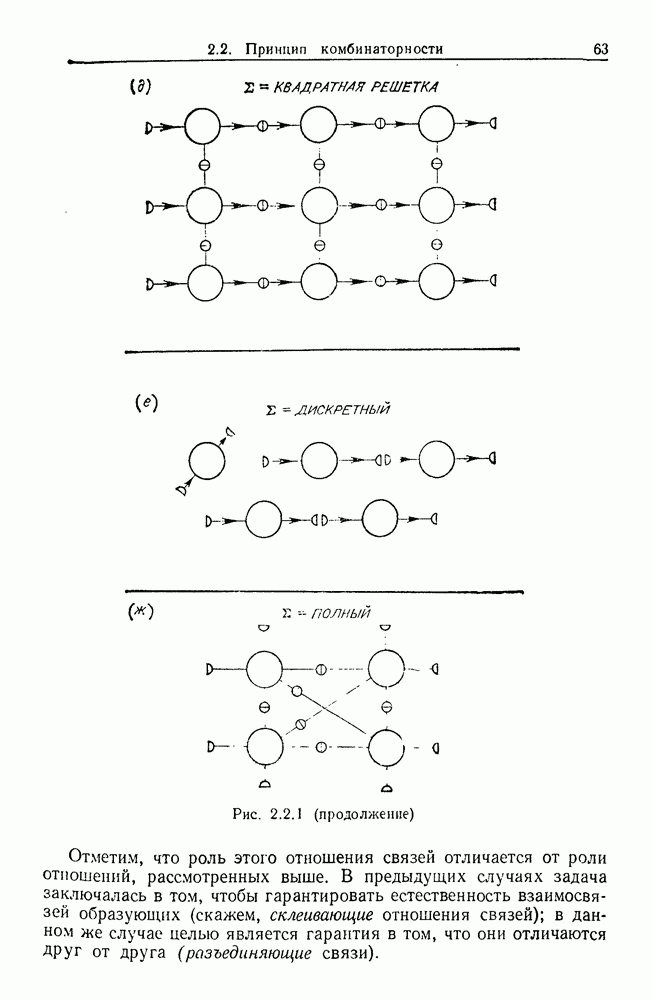
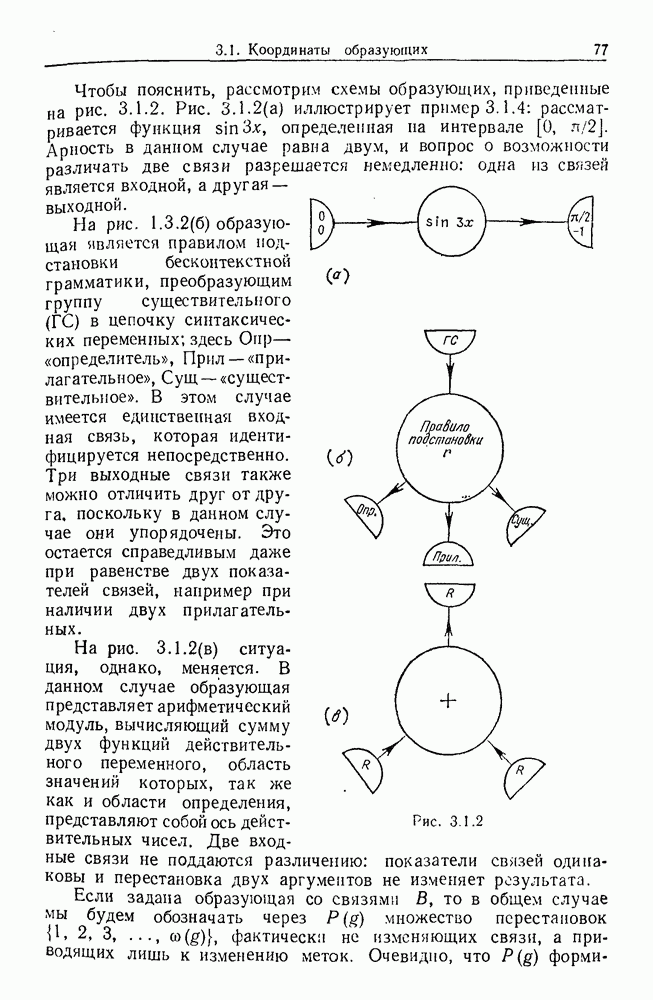
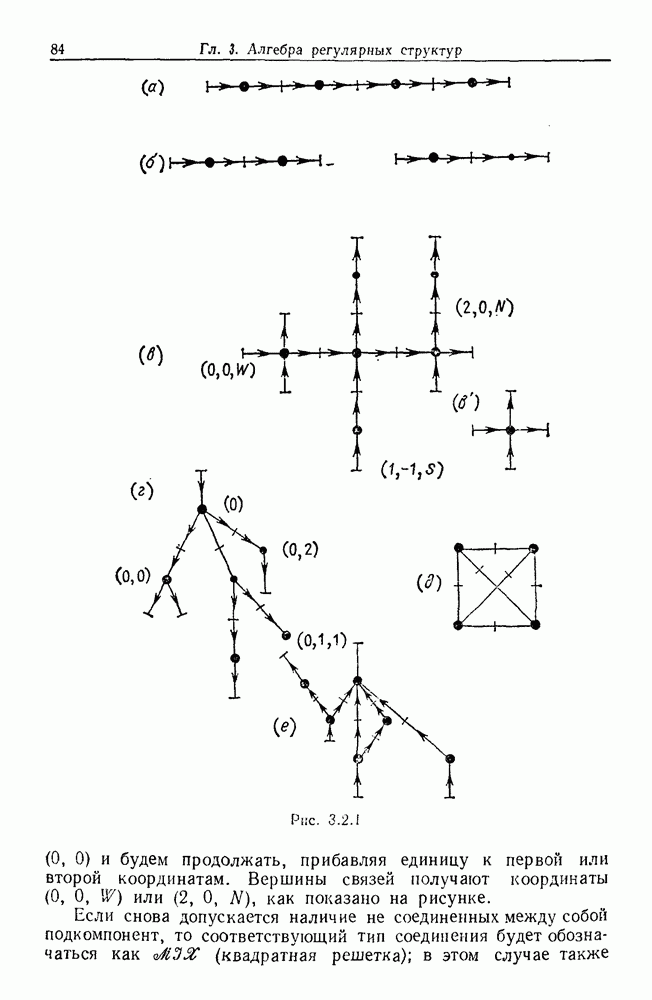
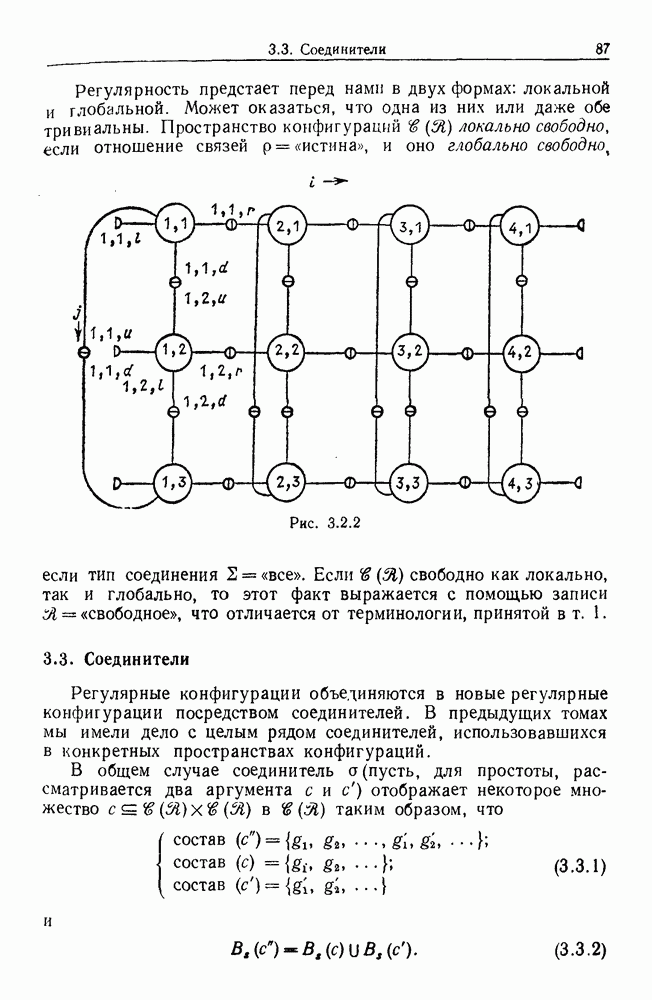
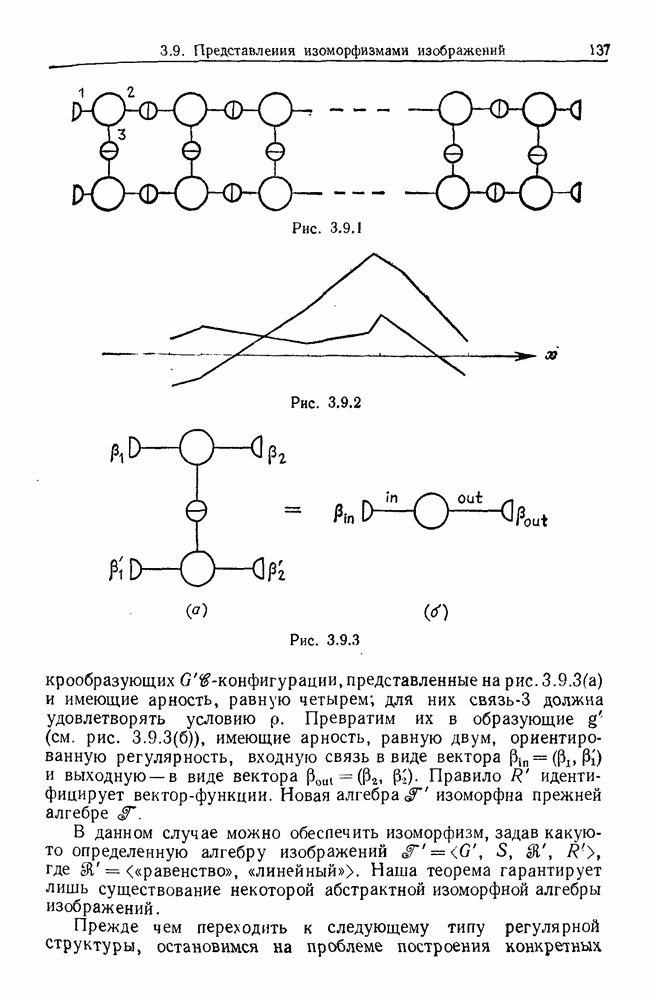
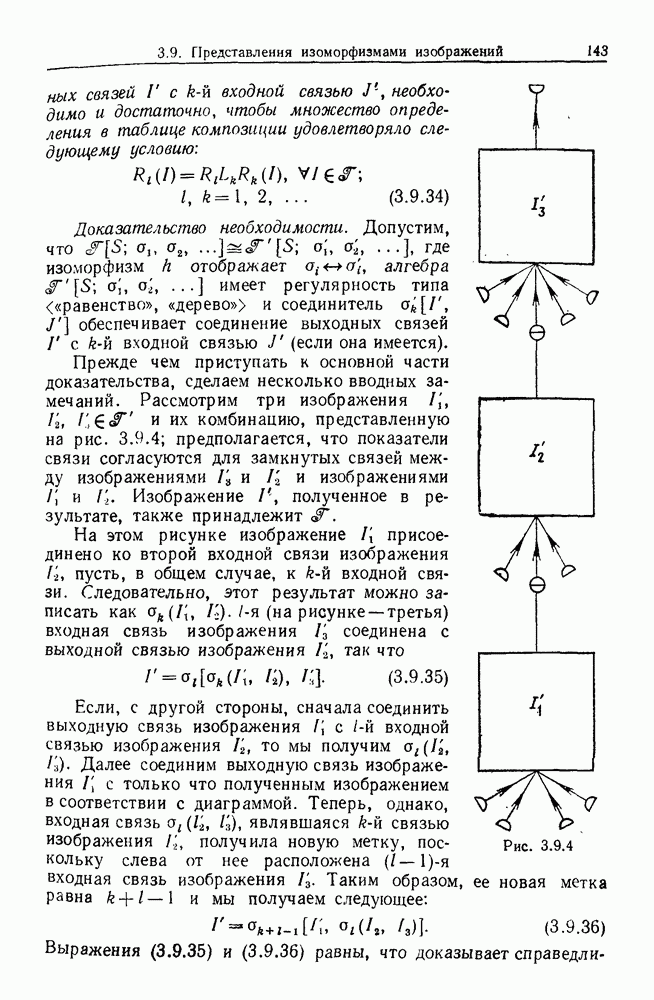
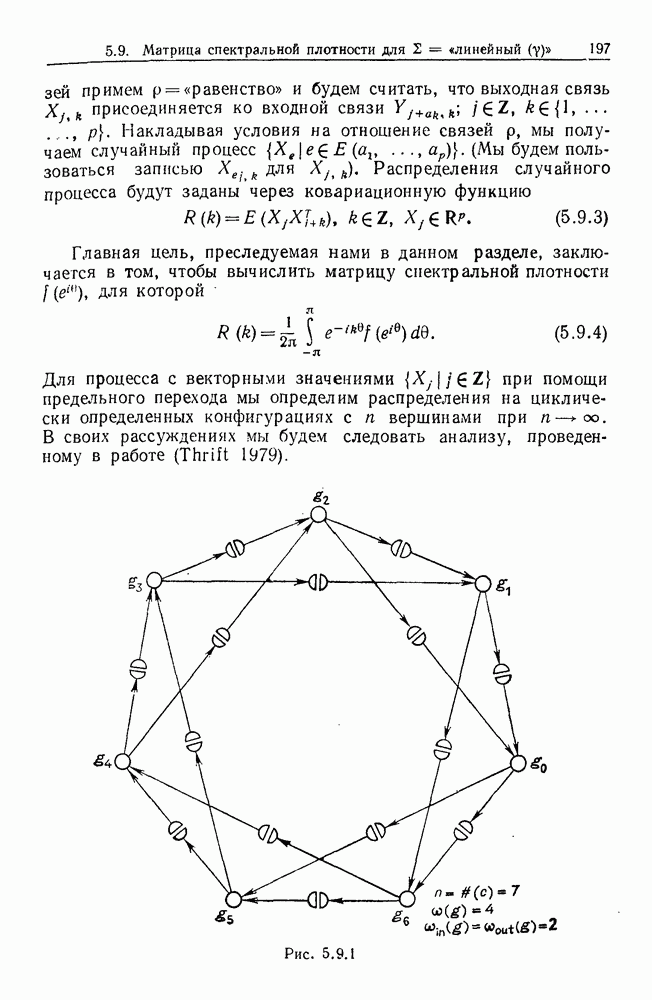
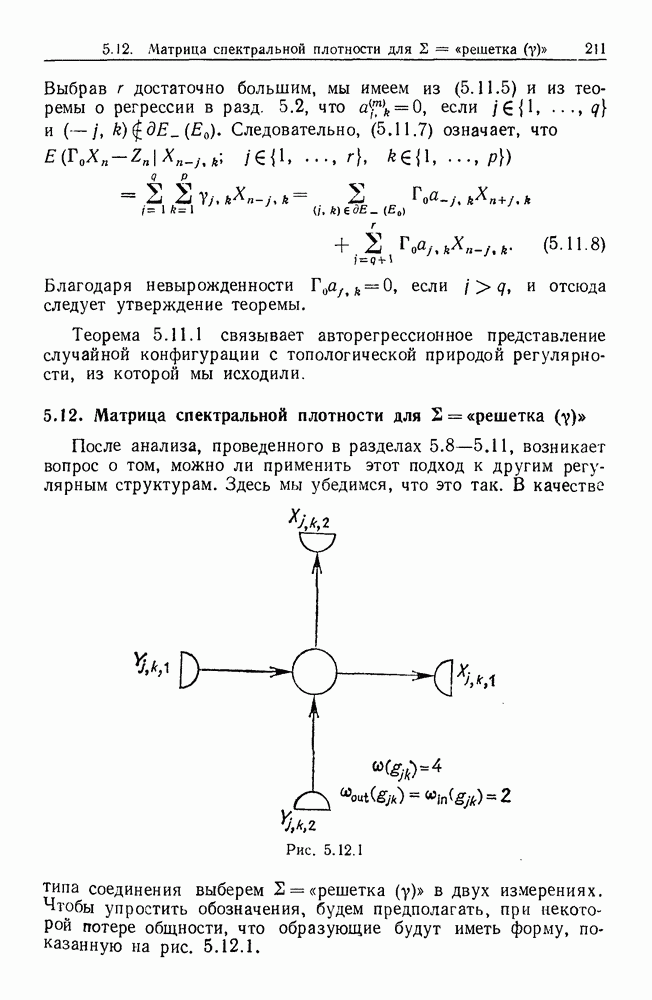
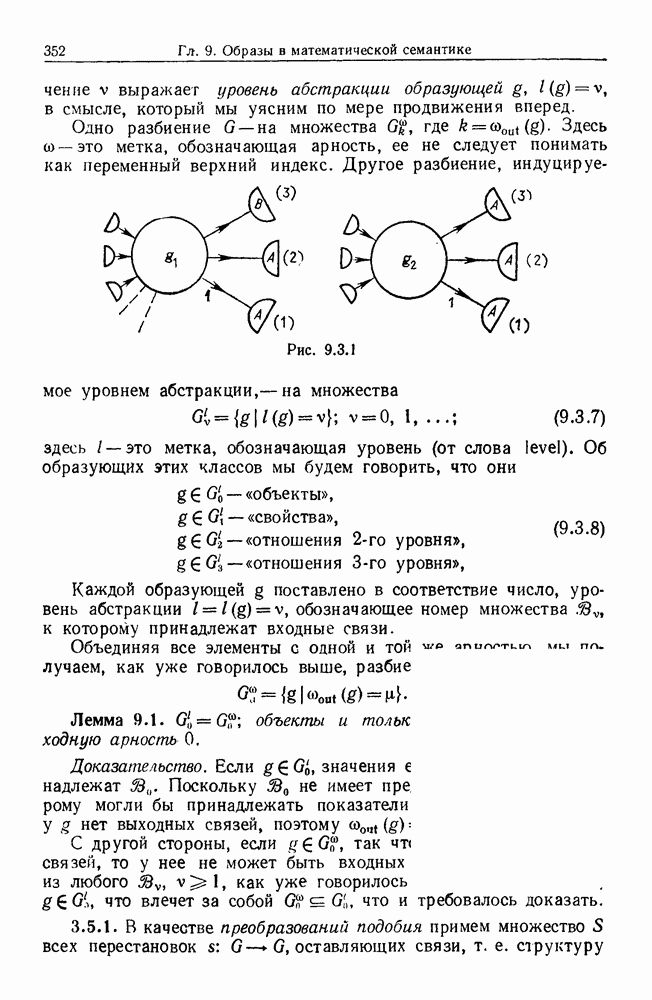
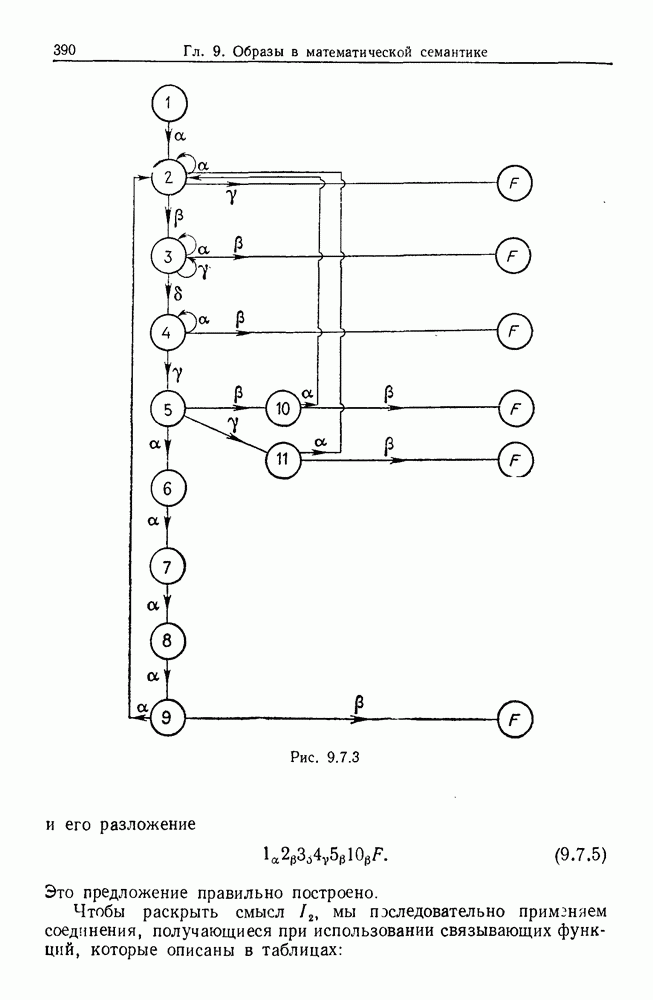
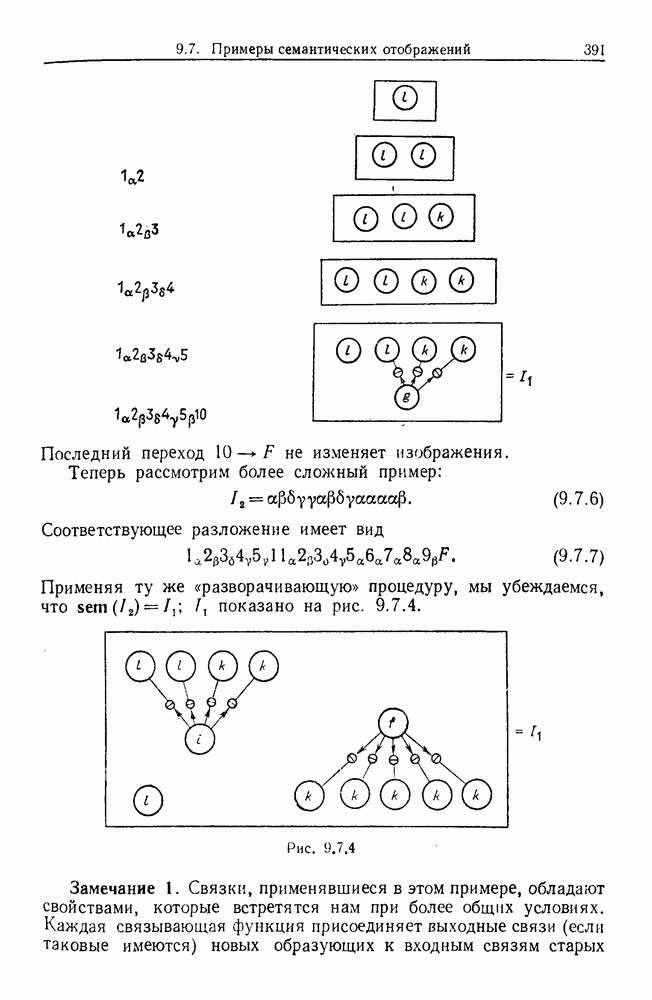
6.2. Образы статистических гипотезЧтобы синтезировать статистические гипотезы, нужно сначала выбрать атомы, или, в терминах теории образов, множество образующих Можно было бы начать с фундаментального уровня, скажем с исчисления предикатов, и строить дальнейшее на этом основании, но это не то, что мы имеем в виду. Нам нужен синтез образов, такой, чтобы основные особенности этих гипотез выражались наиболее близким к нашей интуиции способом. Следовательно, в данном случае образующими должны служить основные конструкции теории вероятности, такие, как случайные переменные, функции распределения и их плотности и т. д. Естественно начать с понятия случайной переменной. Пусть мы рассматриваем следующую статистическую гипотезу. Есть шесть независимых одно от другого наблюдений, три первых принадлежат совокупности с нормальным распределением и средним значением
Символы в (6.2.1) следует понимать обычно как случайные переменные и сложение случайных неременных. Общая гипотеза включает произвольные вещественные Можно было бы использовать в качестве образующих для (6.2.1) и других аналогичных систем арифметические операции вместе с некоторыми простыми случайными переменными. Однако случайная переменная, т. е. измеримая функция на некотором опорном пространстве, — это не то, что мы на самом деле хотим описать в типичной статистической гипотезе. Нас интересует не то, как эта функция выглядит, а только то, как распределены ее значения. Хотя образующие будут вводиться с помощью случайных переменных с заданными распределениями вероятностей, правило идентификации будет идентифицировать распределения, а не случайные переменные. Когда мы говорим, что образующая — это распределение вероятности (есть также и другие образующие), мы на самом деле имеем в виду случайную переменную Возвращаясь к (6.2.1), рассмотрим распределение Аналогичное верно для образующих назначения (см. т. 1, стр. 22). Они не обязательно должны полностью определять переменную, поэтому такие образующие могут определять переменную, ограничивая ее некоторым множеством. Но этого еще недостаточно; потребуются также весьма неожиданные образующие. Чтобы это показать, представим себе, что система (6.2.1) обобщена па случай выборок произвольного размера из двух совокупностей:
Мы по-прежнему можем синтезировать гипотезы посредством тех же образующих, пока Можно, конечно, избежать этой трудности, сказав, что гипотеза будет синтезирована многими конфигурациями, но на самом деле это было бы уходом от решения задачи. Вместо этого мы введем другую образующую, осуществляющую выборку из заданного распределения и имеющую один вход, а именно размер выборки. Это будет описано ниже более строго. По сходным причинам нам нужна еще одна образующая, которая копирует один объект и делает несколько идентичных копий. Например, если Показателем выходной связи образующей X служит пространство
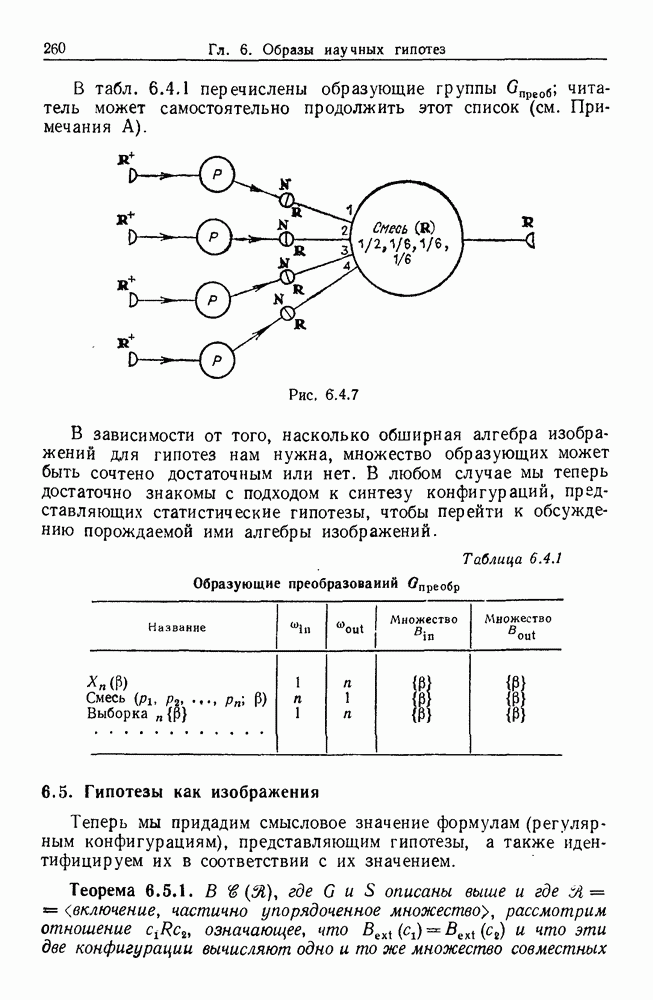
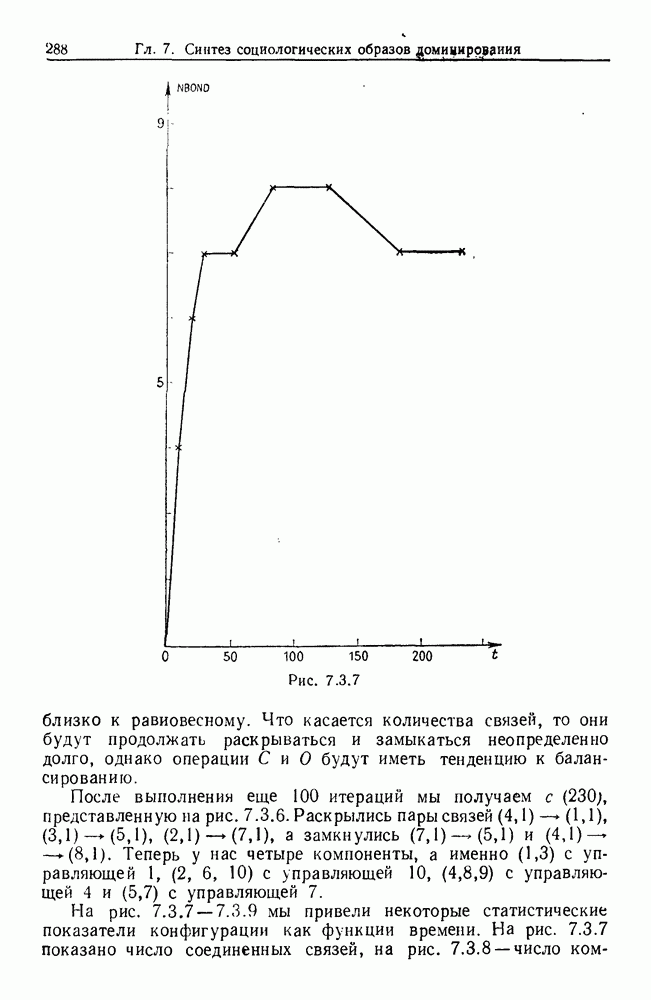
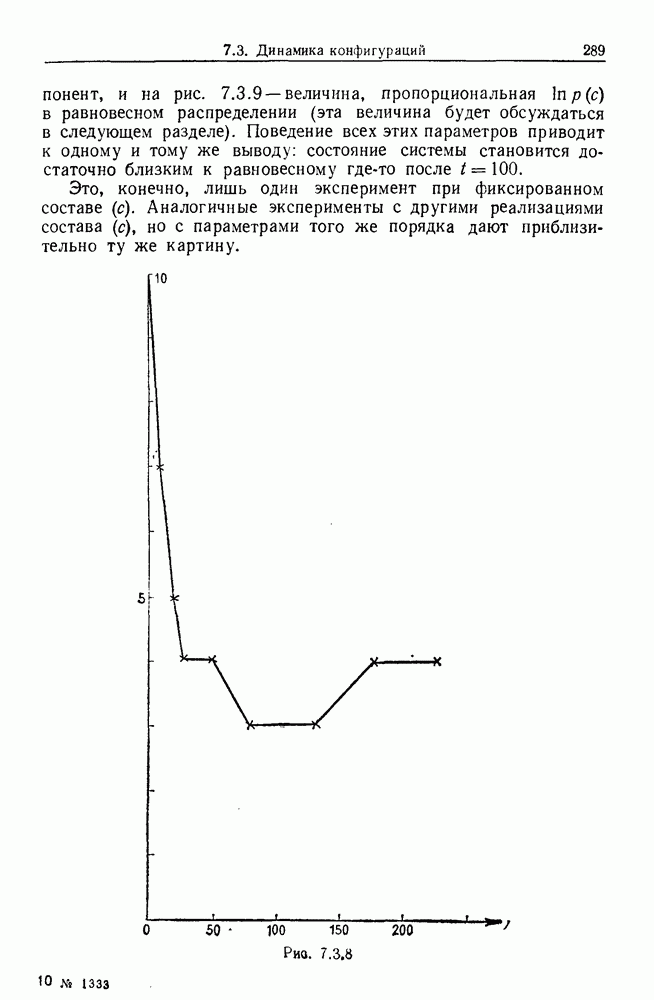
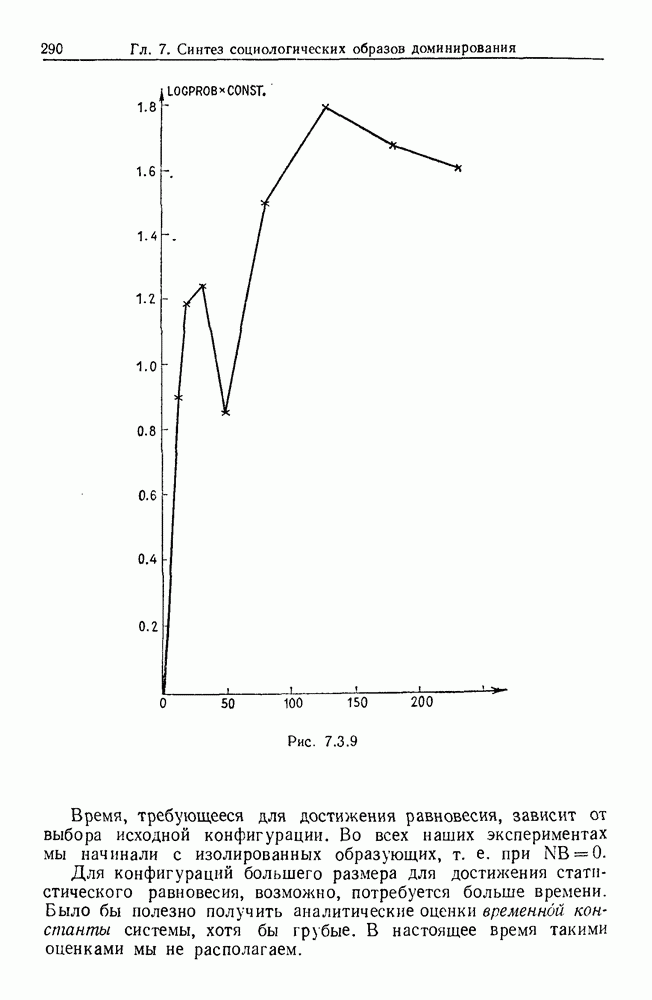
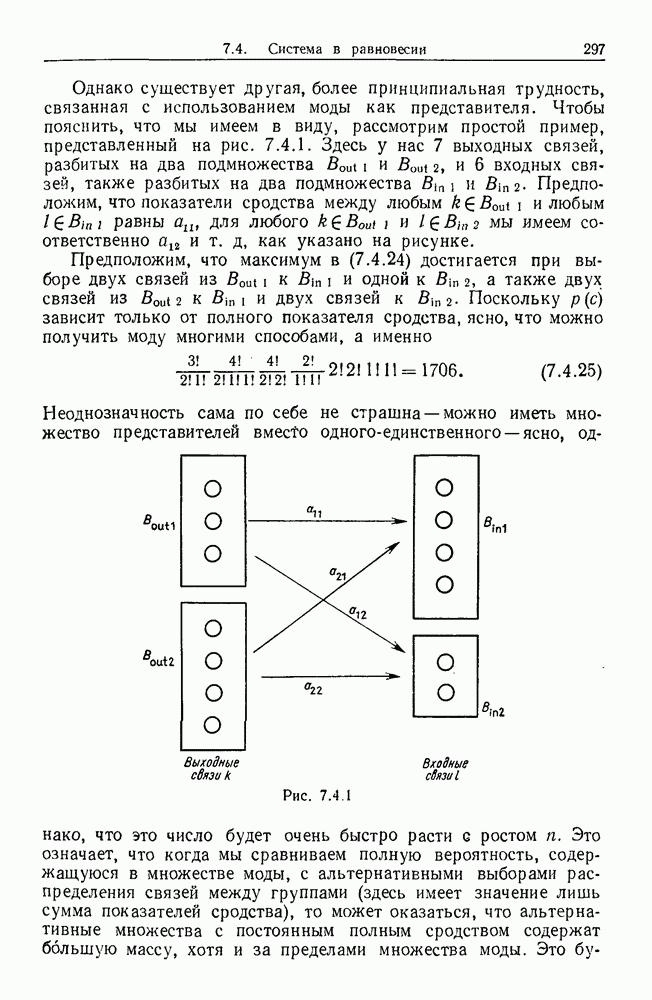
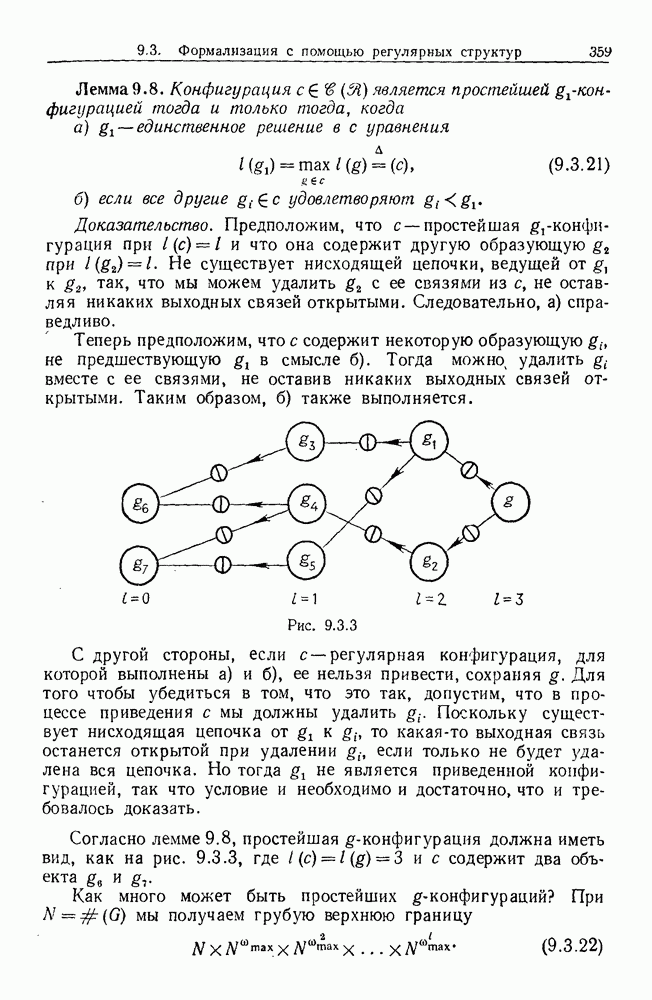
Рис. 6.2.1 В последующих разделах будет показано, что таких образующих достаточно для синтеза образов широкого класса статистических гипотез. Необходимо отметить, что последний не содержит гипотез последовательного конструировании (см. Примечания А), для которых необходимы также образующие «цикла». Завершив синтез образов, мы приходим к некоторой алгебре изображений. Чтобы конкретизировать сказанное выше, проделаем все этапы процедуры синтеза; смысл алгебры изображений, соответствующей обычным гипотезам, можно найти, в любом элементарном введении
|
 |
Оглавление
|

















































































































































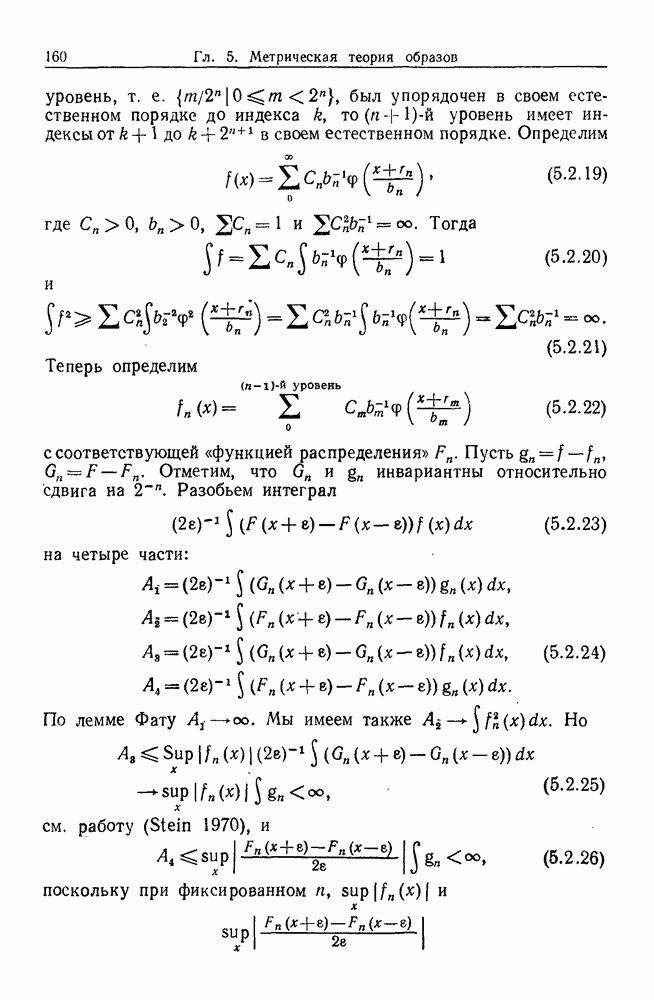

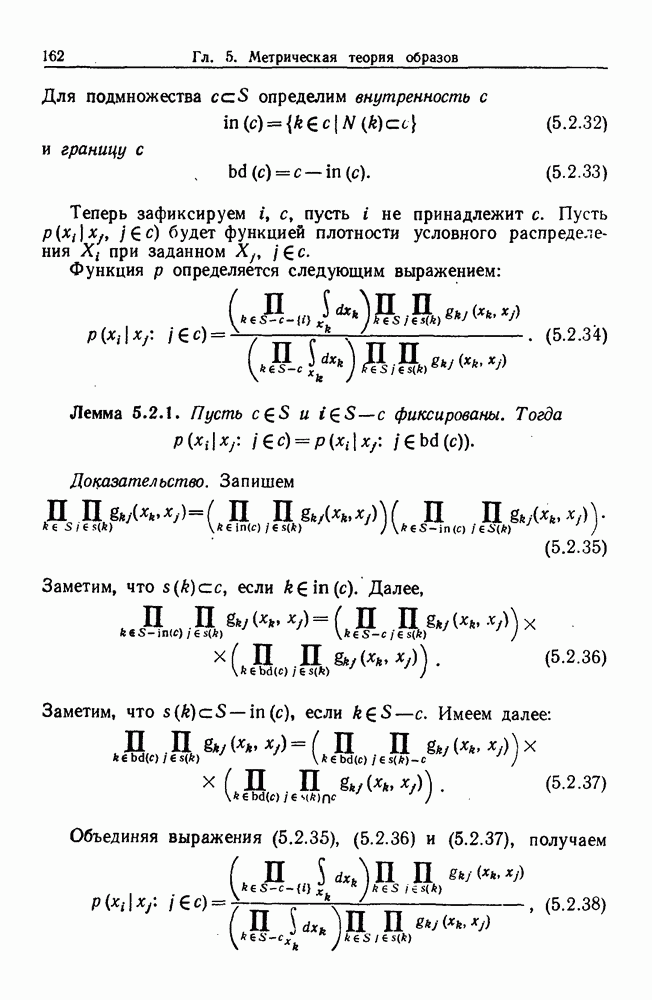












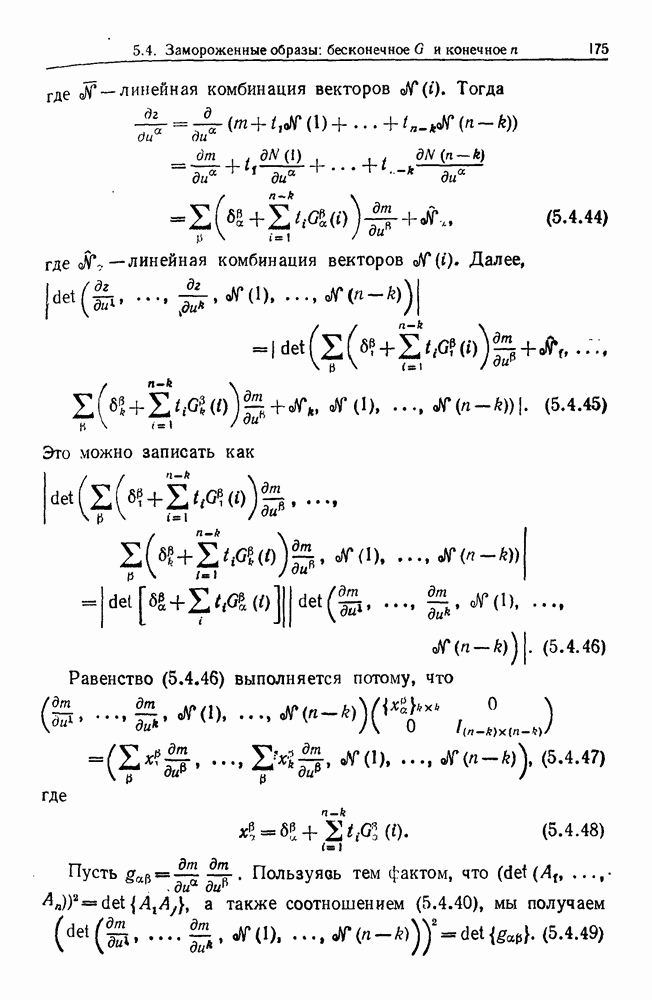










































































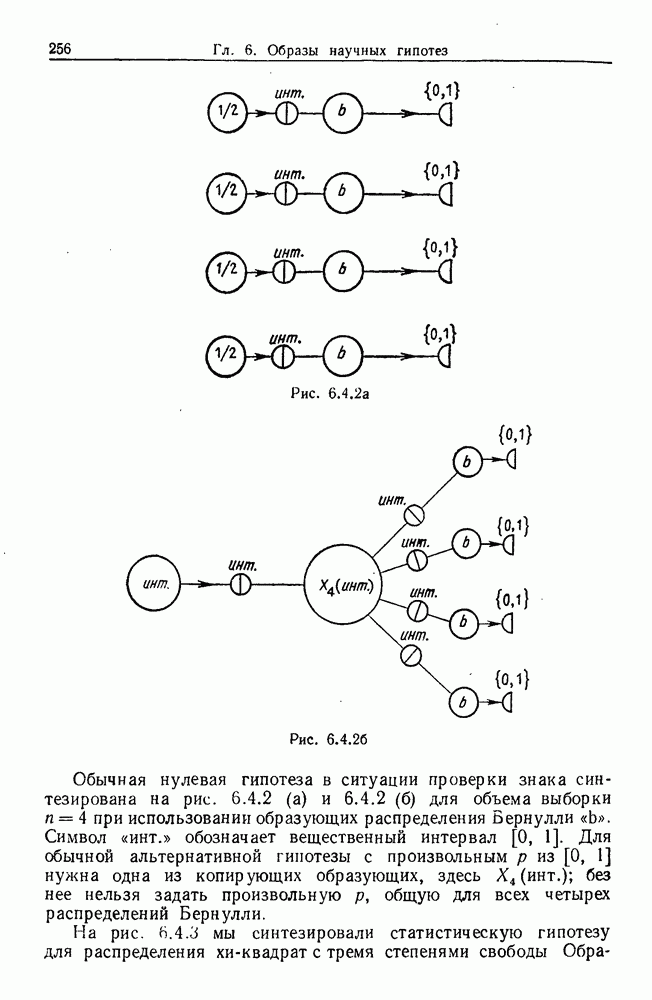
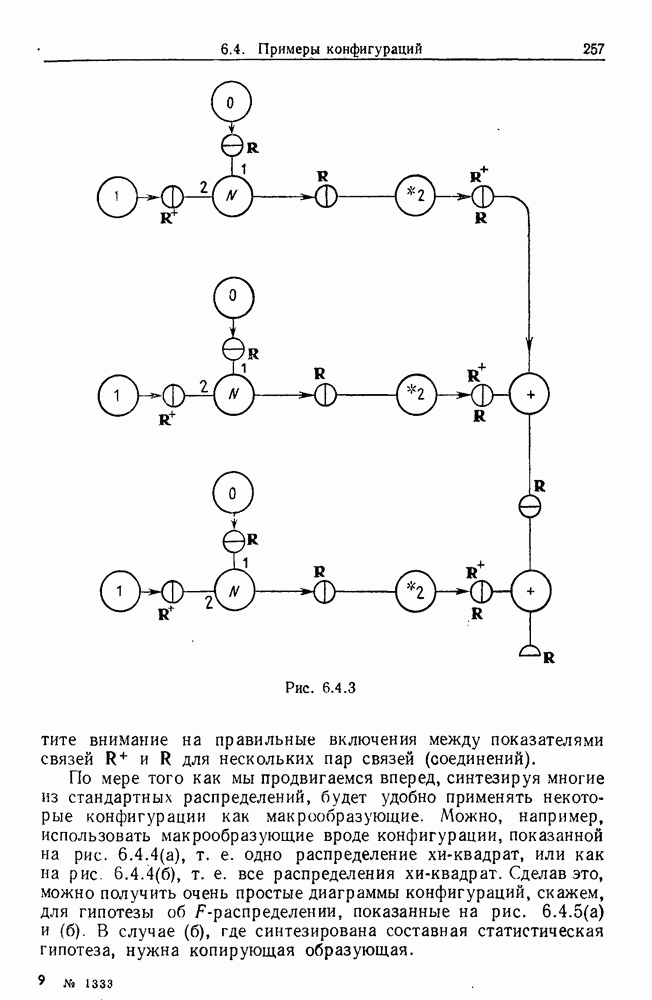
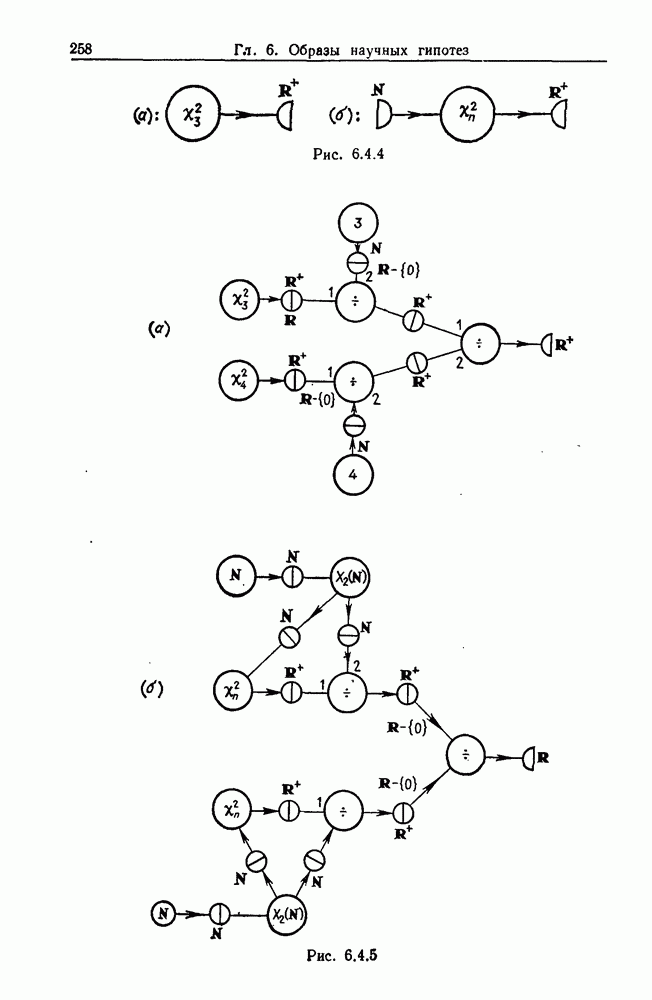
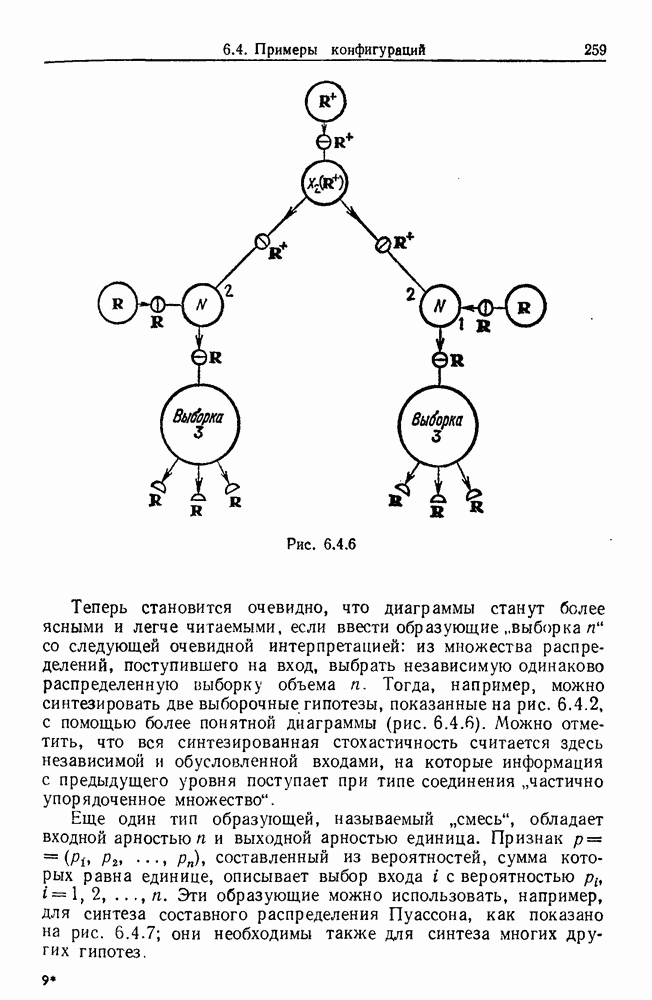




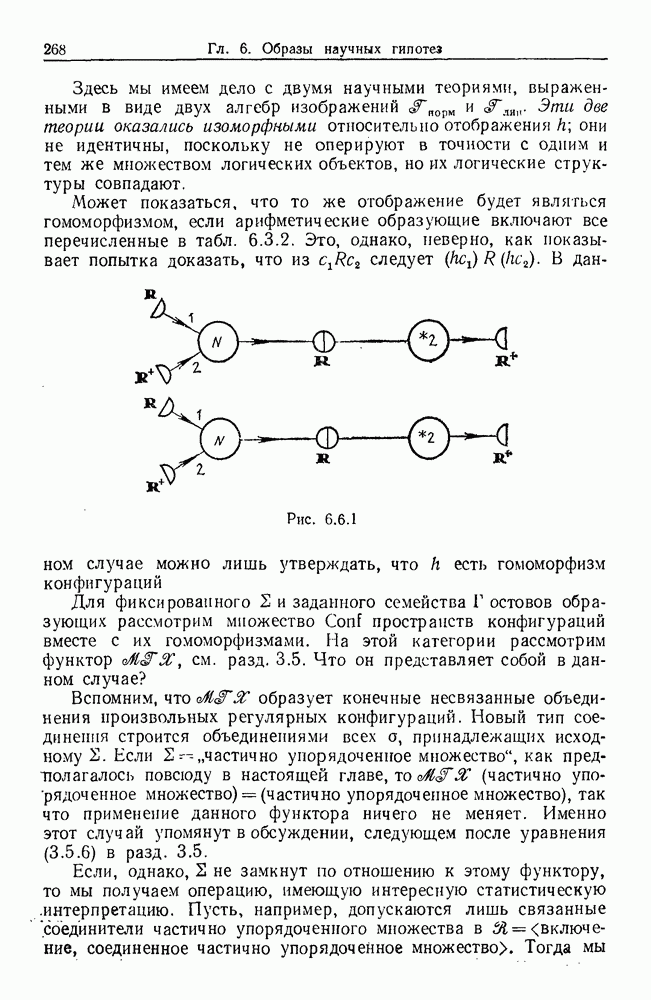




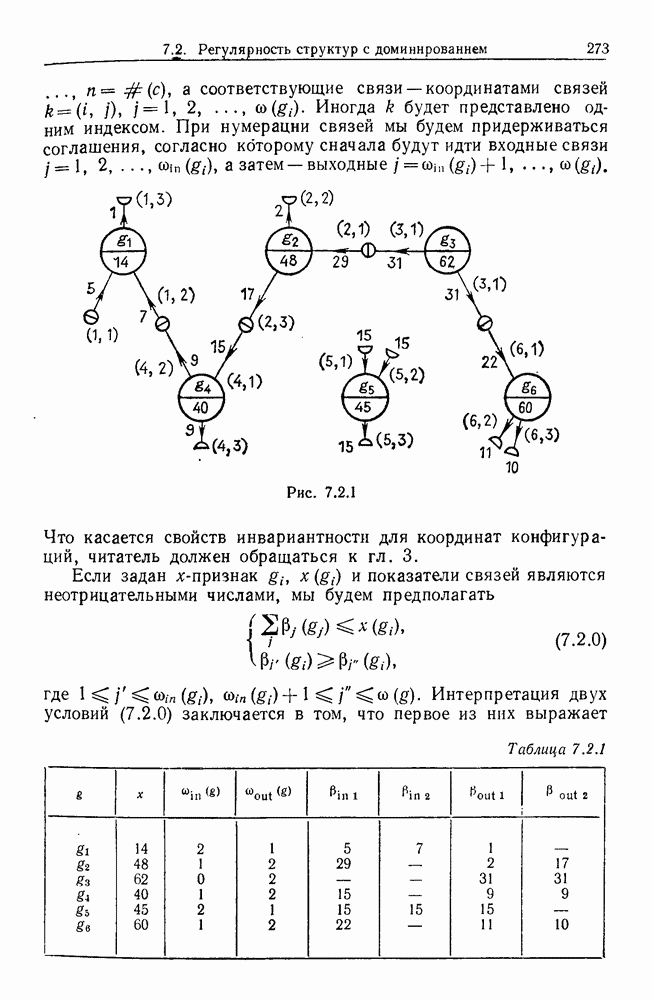








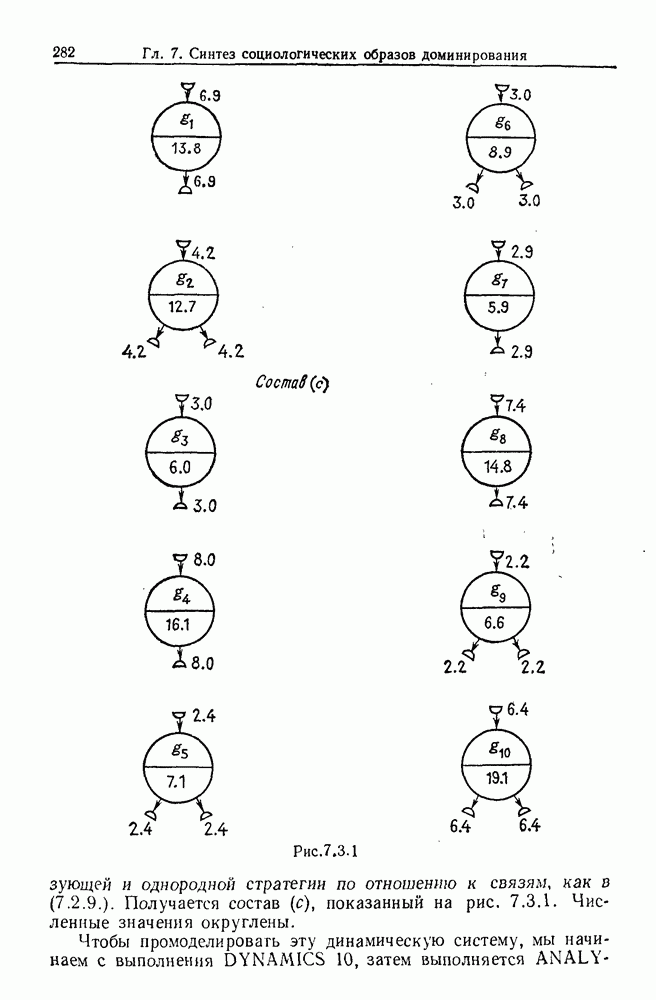
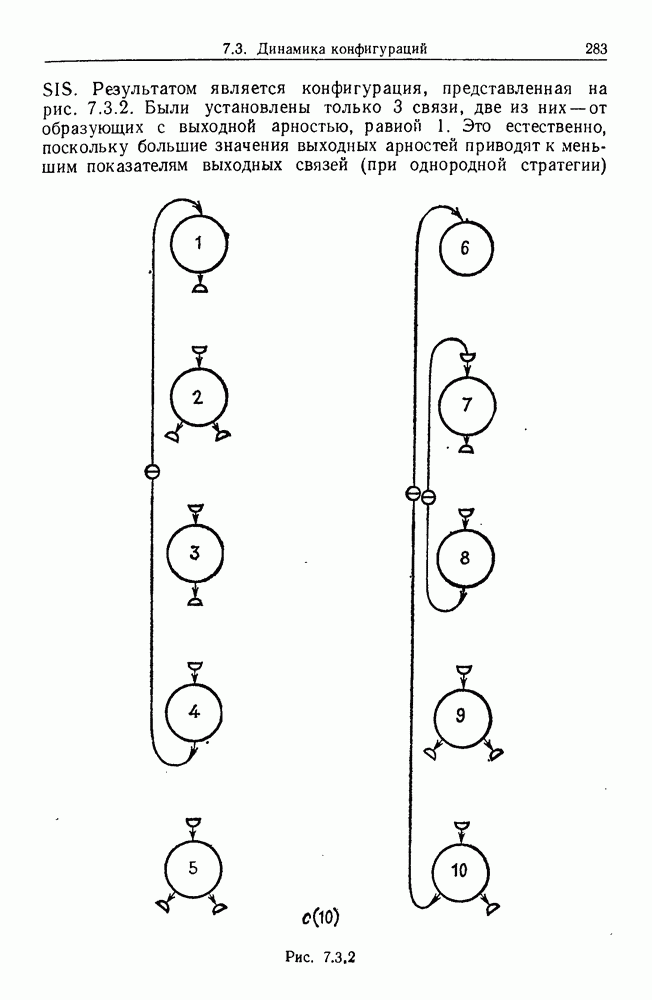
































































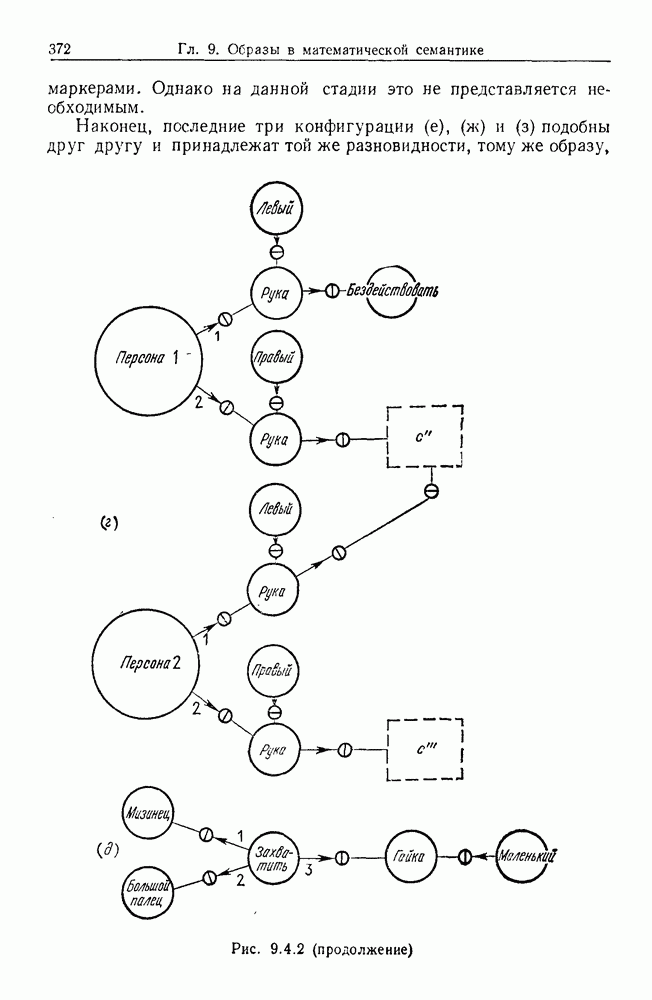
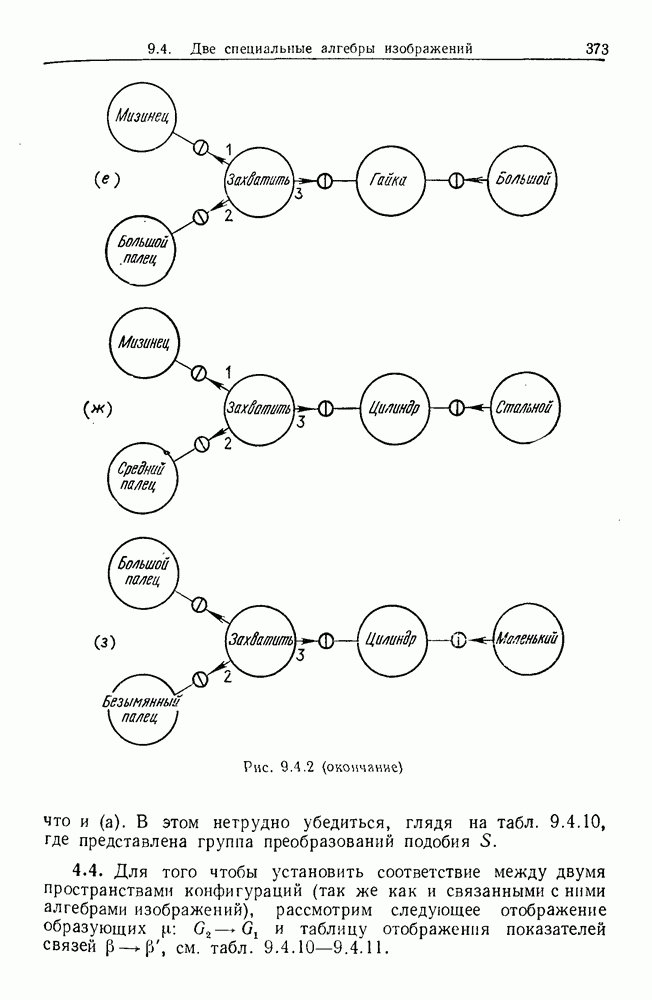


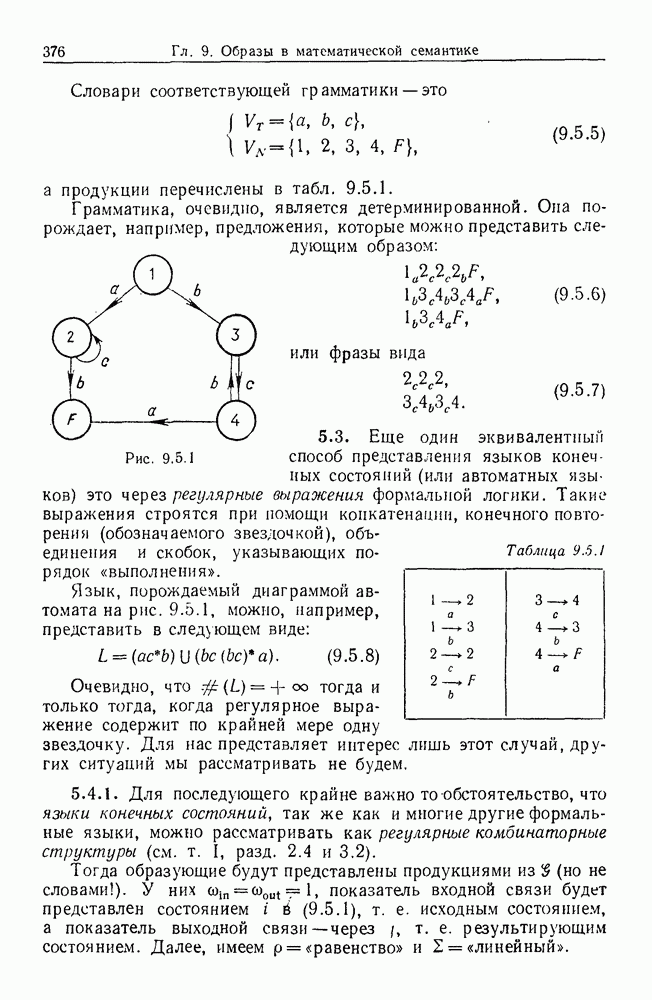



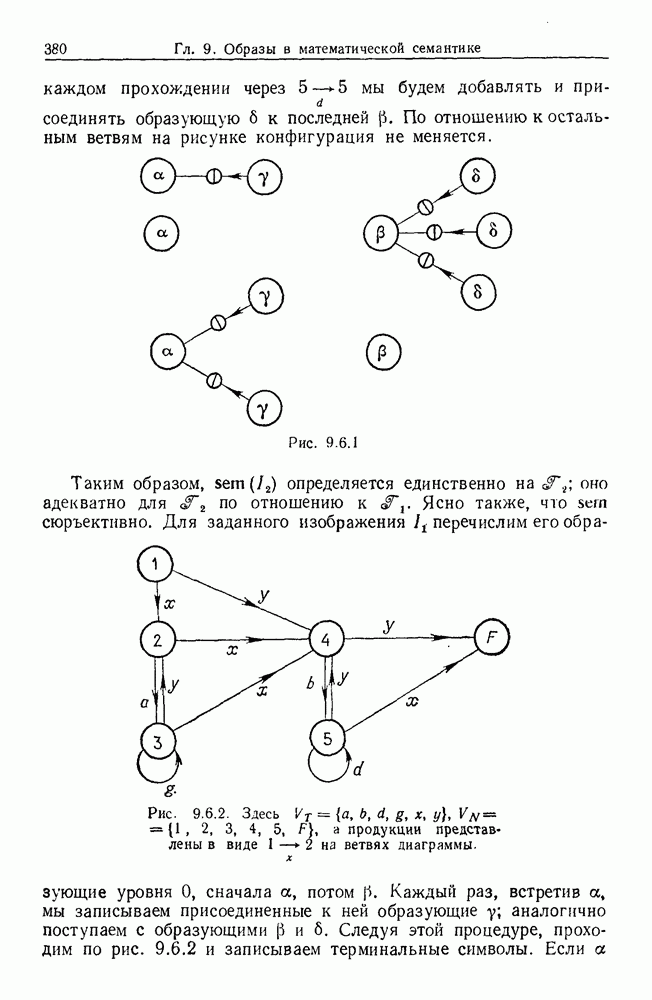




































 Какими они должны быть?
Какими они должны быть?
 а остальные — аналогичной совокупности со средним
а остальные — аналогичной совокупности со средним  . Или, более подробно,
. Или, более подробно,

 и произвольное положительное а, так что она содержит три независимых параметра. Нулевой гипотезой может служить ограничение общей гипотезы случаем
и произвольное положительное а, так что она содержит три независимых параметра. Нулевой гипотезой может служить ограничение общей гипотезы случаем  так что у нее два независимых параметра.
так что у нее два независимых параметра.
 т. е. измеримую функцию на некотором пространстве
т. е. измеримую функцию на некотором пространстве  имеющую заданное распределение. Далее это будет подразумеваться.
имеющую заданное распределение. Далее это будет подразумеваться.
 величин
величин  Заметим, что это не полностью определенное распределение: а является произвольным положительным числом. Эта ситуация весьма обычна для статистических гипотез, где часто встречаются составные гипотезы. Поэтому мы должны допустить, что такая образующая может состоять
Заметим, что это не полностью определенное распределение: а является произвольным положительным числом. Эта ситуация весьма обычна для статистических гипотез, где часто встречаются составные гипотезы. Поэтому мы должны допустить, что такая образующая может состоять  множества распределений вероятности (в действительности случайных переменных, представляющих эти распределения; см. выше).
множества распределений вероятности (в действительности случайных переменных, представляющих эти распределения; см. выше).

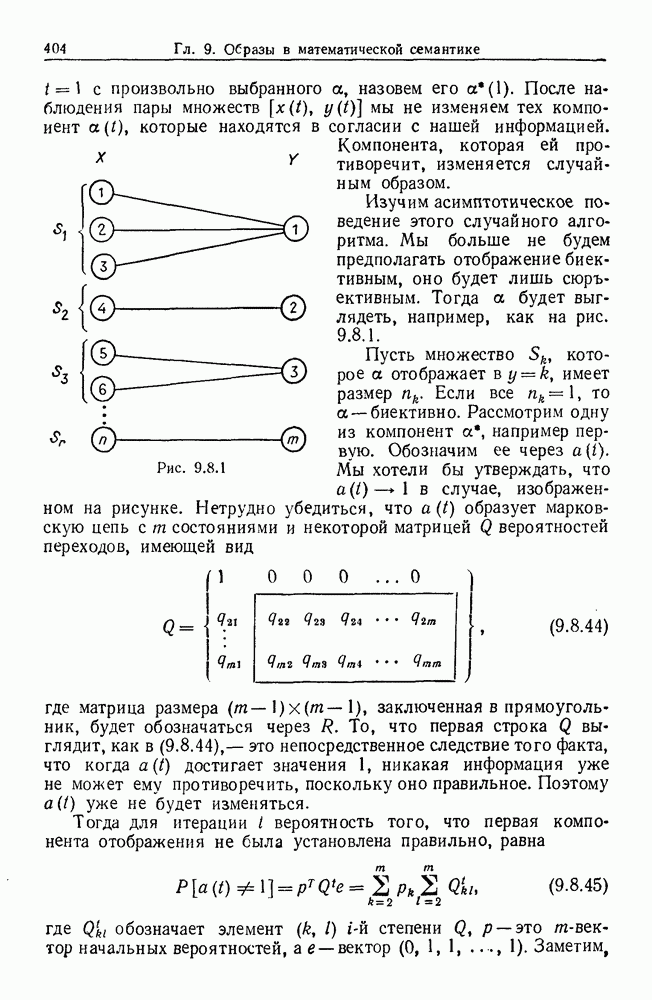
 суть фиксированные натуральные числа. Предположим, однако, что они не даны нам априори, а находятся из предварительного эксперимента или каким-либо иным способом. Тогда описанная выше процедура синтеза образов не срабатывает: число образующих в конфигурации не фиксировано.
суть фиксированные натуральные числа. Предположим, однако, что они не даны нам априори, а находятся из предварительного эксперимента или каким-либо иным способом. Тогда описанная выше процедура синтеза образов не срабатывает: число образующих в конфигурации не фиксировано.
 образующая с одним выходом, значением которого служит вещественное число (или множество вещественных чисел), то образующая X (это обозначение связано с названием копировальных аппаратов фирмы «Xerox») будет иметь своим выходным значением вектор, все
образующая с одним выходом, значением которого служит вещественное число (или множество вещественных чисел), то образующая X (это обозначение связано с названием копировальных аппаратов фирмы «Xerox») будет иметь своим выходным значением вектор, все  компонент которого равны выходному значению образующей
компонент которого равны выходному значению образующей  Это показано на диаграмме конфигурации (см. рис. 6.2.1)
Это показано на диаграмме конфигурации (см. рис. 6.2.1)
 -векторов, построенных в пространстве, представленном показателем входной связи этой образующей. Еще несколько образующих этого несколько необычного вида будут введены в разд. 6.3.
-векторов, построенных в пространстве, представленном показателем входной связи этой образующей. Еще несколько образующих этого несколько необычного вида будут введены в разд. 6.3.

 математическую статистику. Фактически мы рассмотрим несколько алгебр изображений такого тина и вкратце исследуем соотношения между ними.
математическую статистику. Фактически мы рассмотрим несколько алгебр изображений такого тина и вкратце исследуем соотношения между ними.