Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
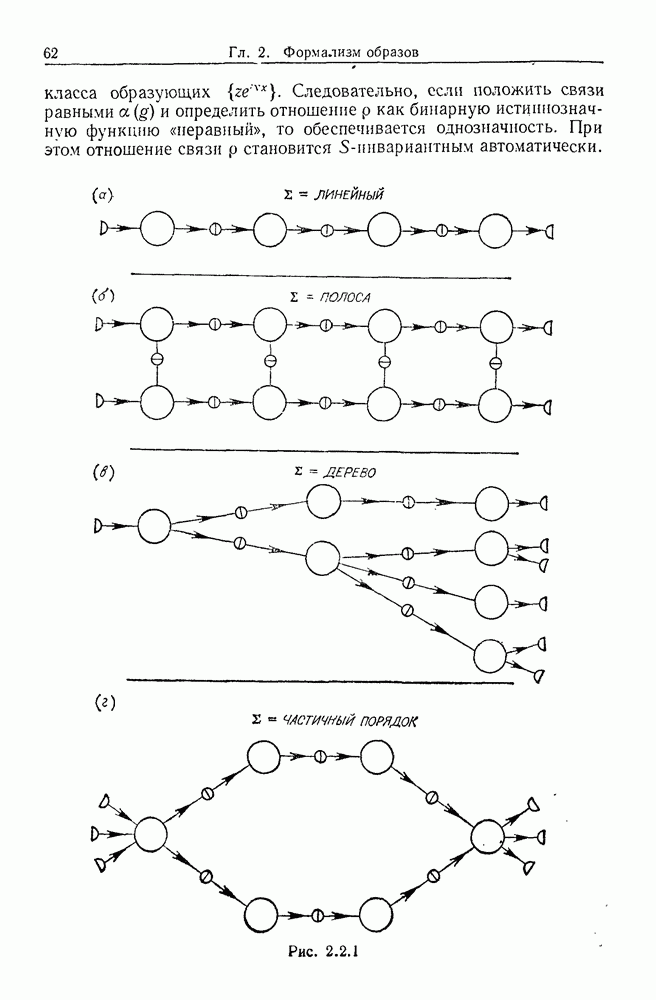
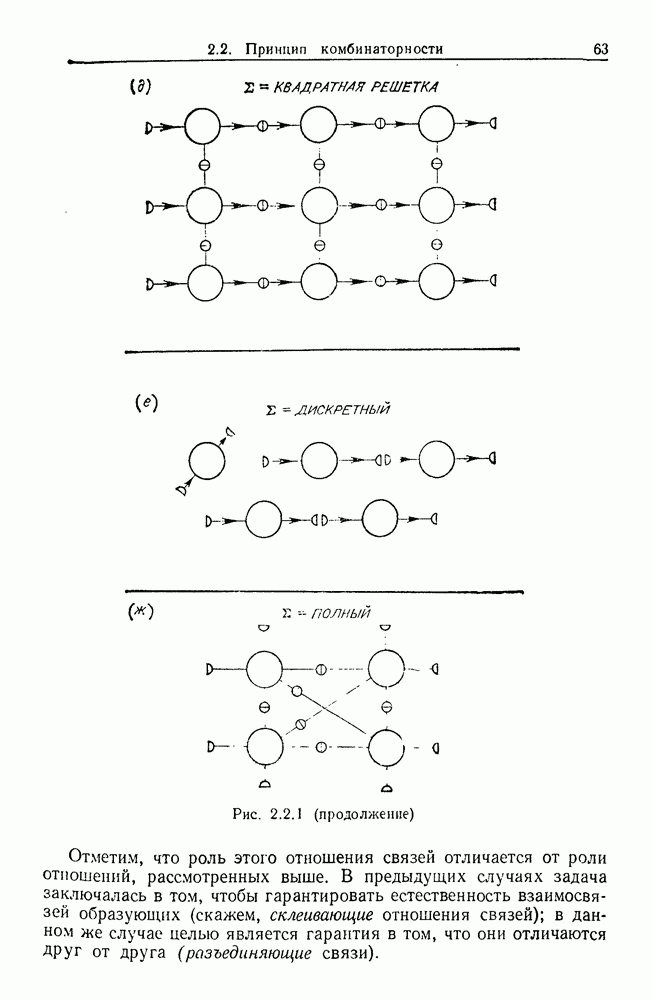
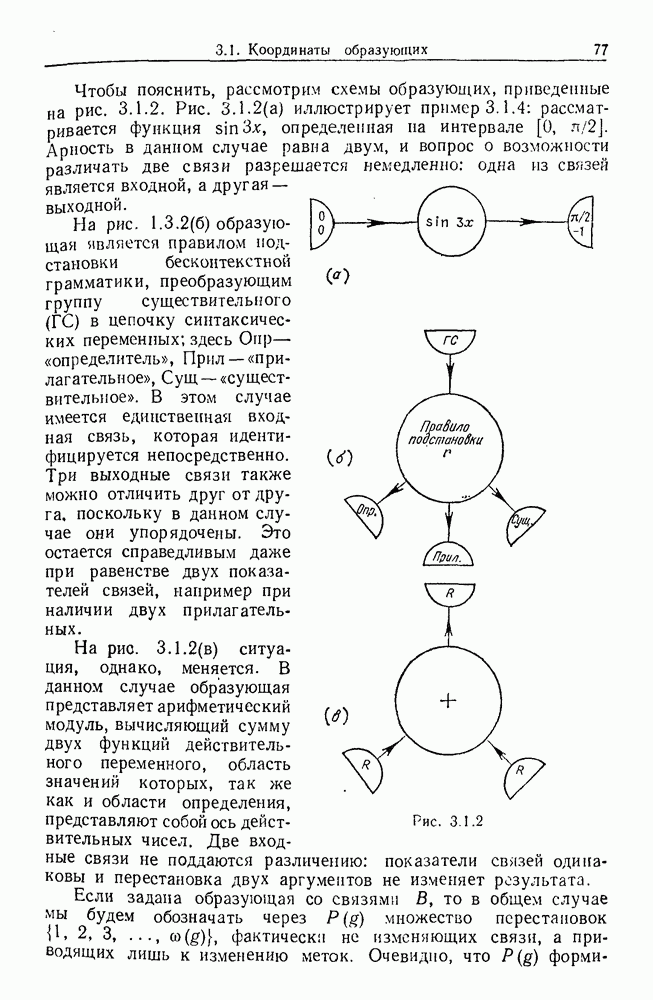
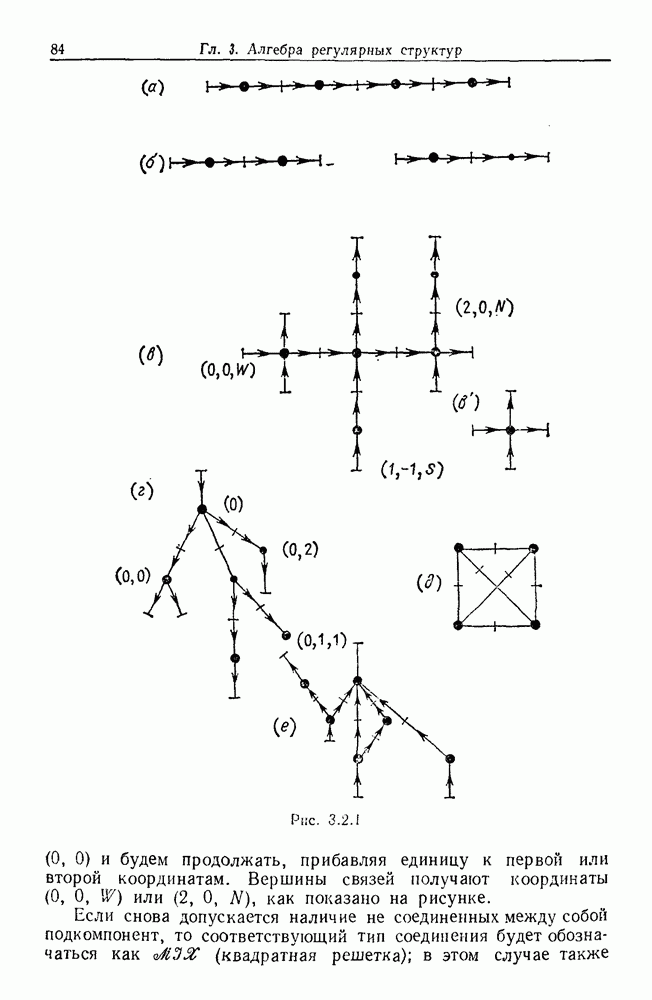
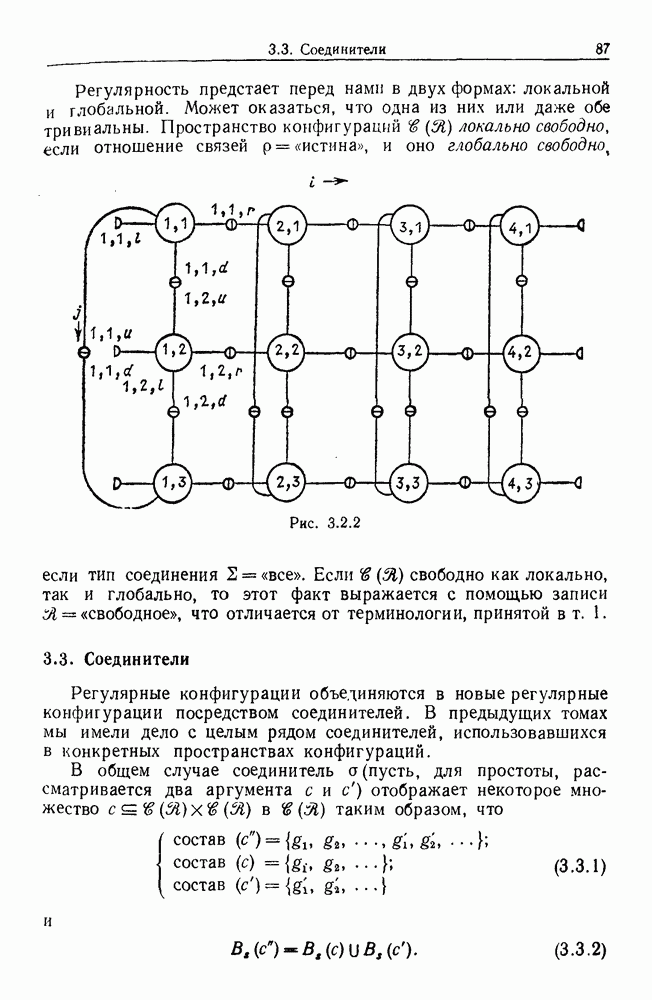
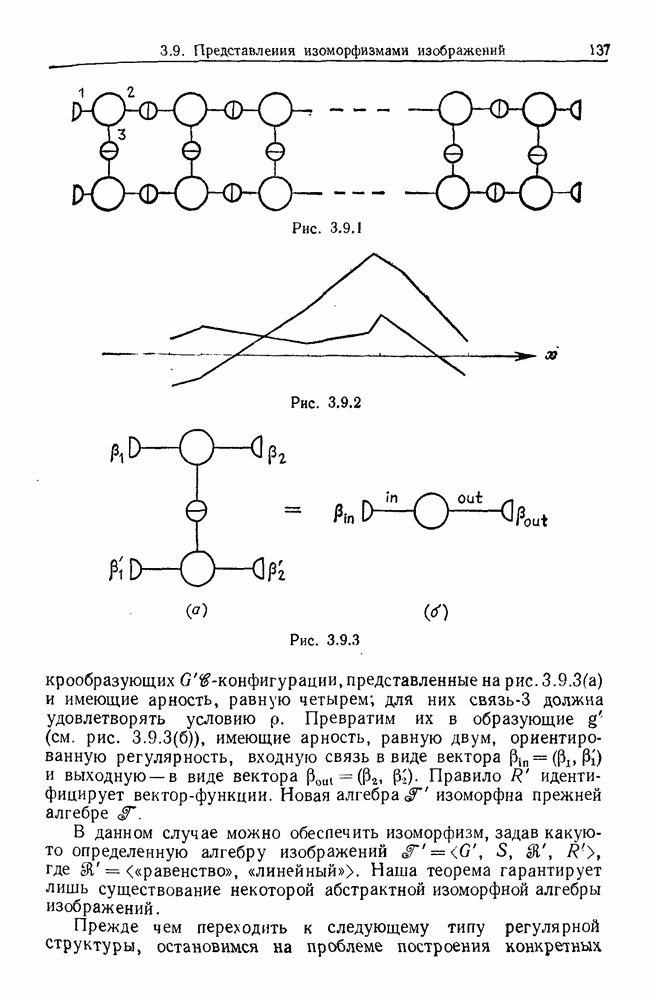
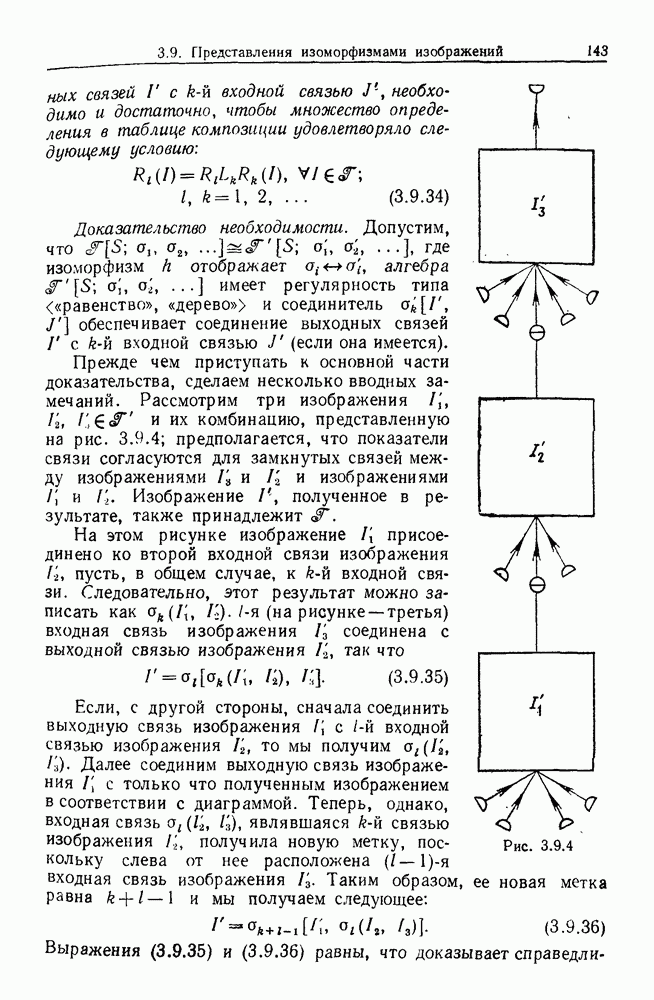
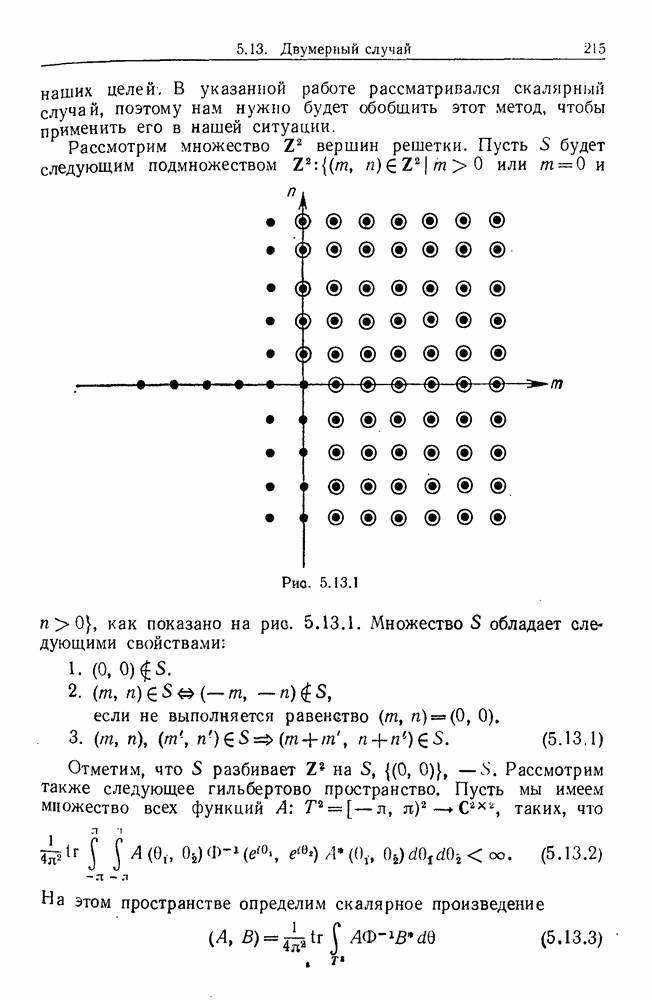
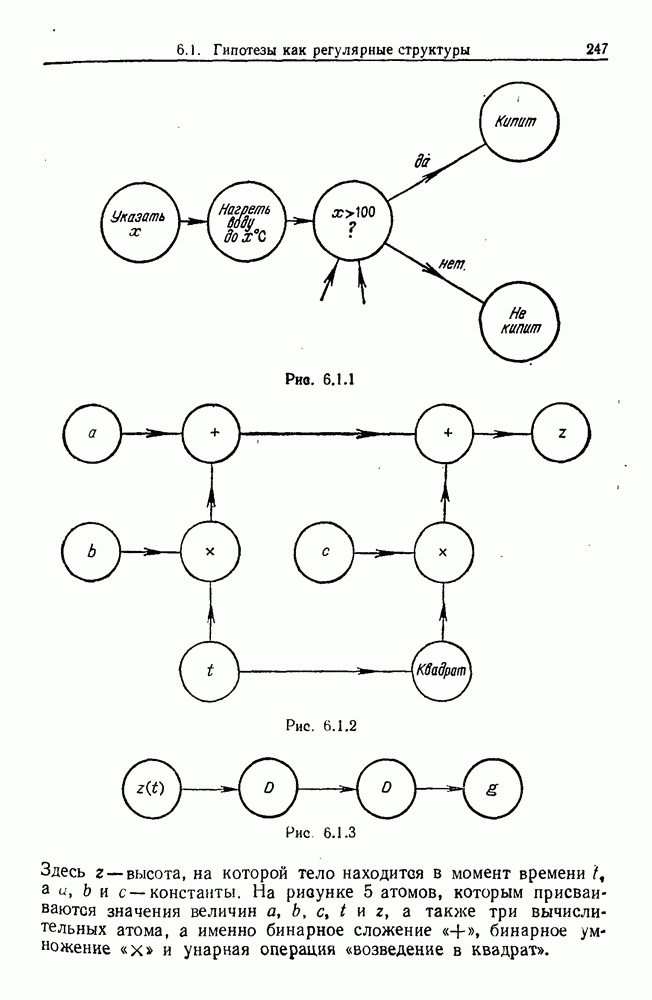
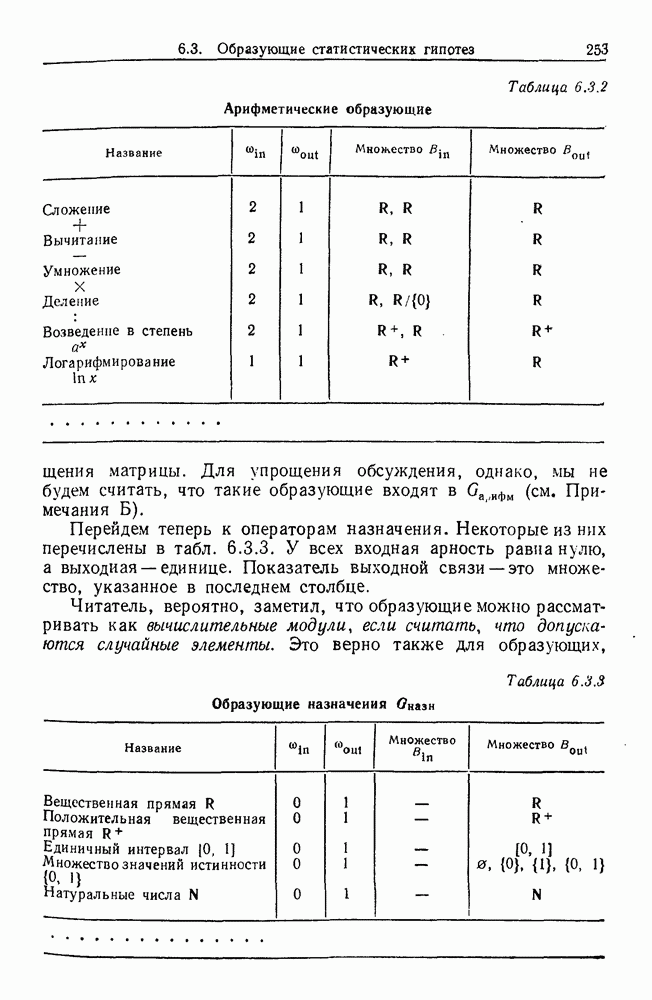
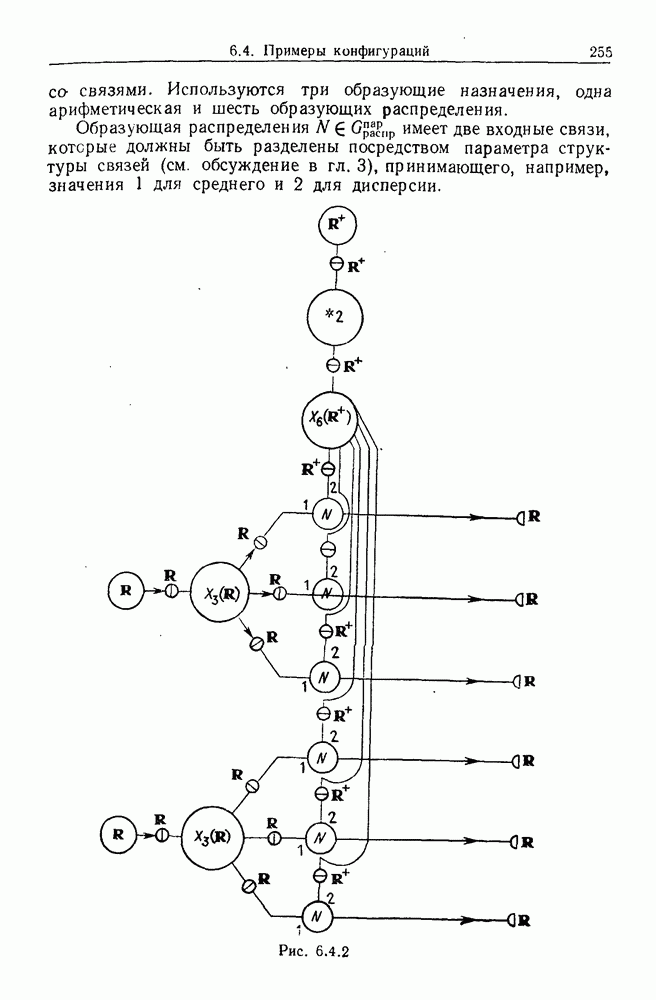
Глава 8. Таксономические образы8.1. Логика таксономических образовКогда Карл Линней писал, что основная работа таксономиста состоит в разделении и обозначении — т. е. в разбиении на классы, семейства, порядки и присваивании им названий — он подчеркивал различие или несходство особей. В абстрактной формулировке, если особи представлены элементами Вопрос о том, как построить такие разбиения опорного пространства X, приобретает смысл, только когда мы задаем логическую структуру, посредством которой разбиения можно определить и проанализировать. Один из способов сделать это — задать множество Естественно, что такие описания, т. е. В, обычно стремятся сделать простыми. Например, мы можем потребовать, чтобы В состояли только из конъюнкций некоторых
где Это и есть логика признаков, введенная автором. Она позволяет построить математическую основу для анализа таких понятий, как кластеризация, размер кластера, разделенность кластеров. Она позволяет также придать точный смысл такому понятию, как «наиболее эффективная кластеризация для заданной вероятностной меры», т. е. сформулировать критерий эффективности так: «какое множество Е для заданного размера кластера обладает максимальной вероятностью?» Это задача об изопериметрической кластеризации, заслуживающая тщательного изучения. Мы не будем здесь этого делать, лишь выскажем следующую догадку. Мы думаем, что в примере, приведенном выше, если Перейдем теперь к иной, дополняющей предыдущую точке зрения: вместо разделения X на очень несхожие множества попытаемся установить связи между очень сходными элементами
Рис. 8.1.1 Для этого необходима, конечно, какая-то мера сходства между х и у, но в общем случае задать глобальную меру сходства нелегко. Чтобы найти подход к этой проблеме, рассмотрим ситуацию, изображенную на рис. 8.1.1, где для простоты мы выбрали Другими словами, мы устанавливаем родственность особей (объектов) цепным рассуждением. Цепь состоит из набора объектов, линейно упорядоченных и таких, что последовательные расстояния равны, самое большее, Этот тип цепного рассуждения основан на допущении о том, что «природа не делает скачков», т. е. вид состоит из особей, связанных друг с другом непрерывно, без скачкообразных переходов. Если отсутствуют надежные филогенетические данные, то некоторый принцип такого сорта представляется необходимым. Если
Рис. 8.1.2 Если X отлично от Следует заметить, что можно начать с пространства признаков очень высокой размерности и заменить его проекцией в пространство более низкой размерности, содержащее только существенные признаки, скажем определенные линейные комбинации исходных признаков. Такое сведение иногда можно получить анализом главных компонент. Во всяком случае, далее мы будем предполагать, что такое сведение уже сделано. Предположим теперь, что в X (пусть для простоты это опять будет вероятности этого события в качестве меры отсутствия родственности между и и Рассматривая различные пути, соединяющие и и
|
 |
Оглавление
|

















































































































































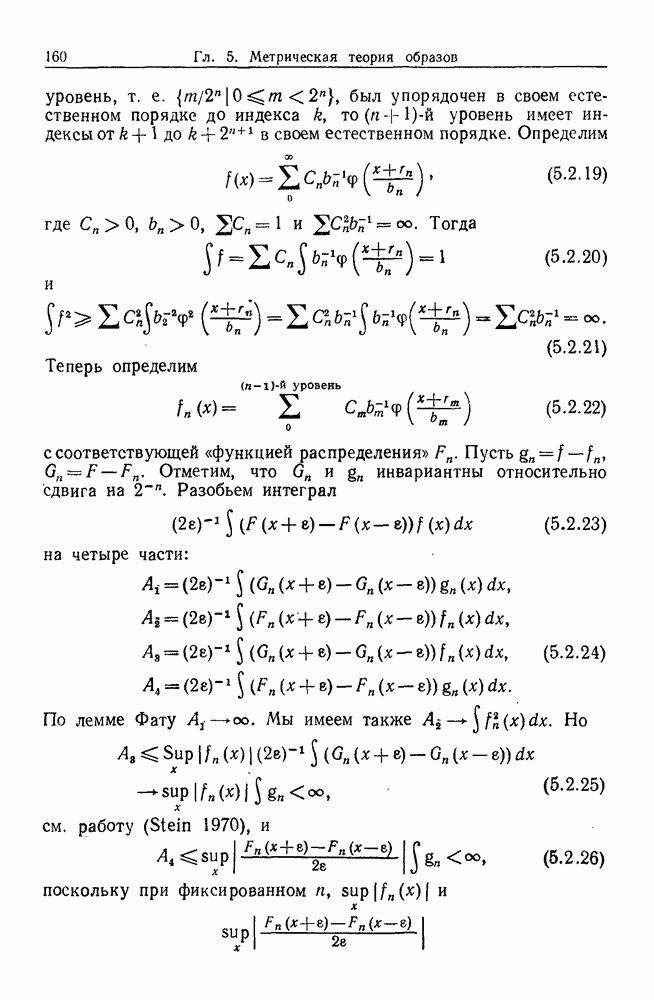

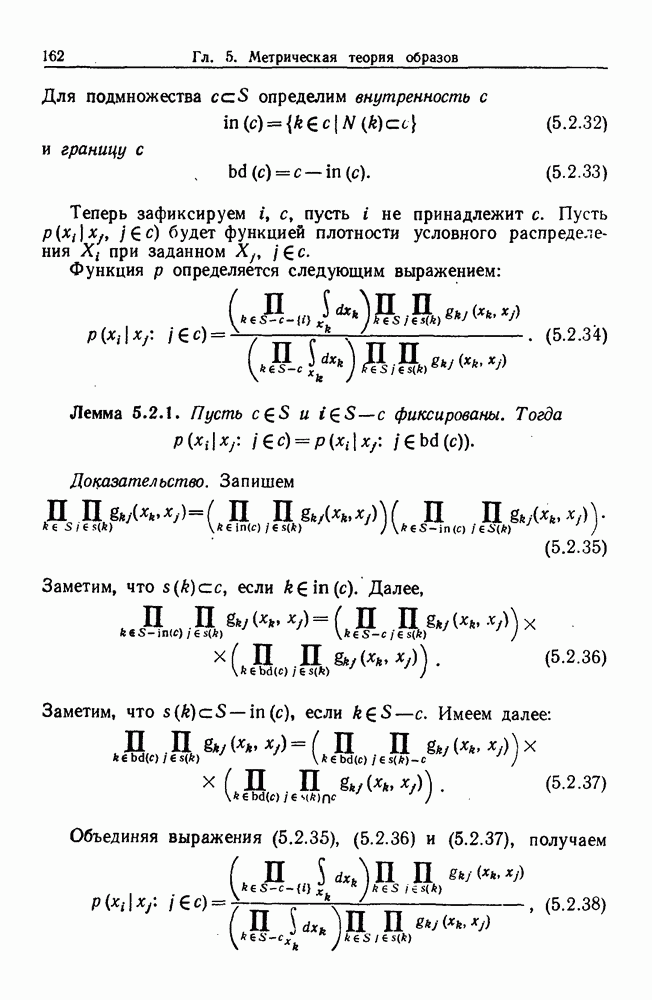












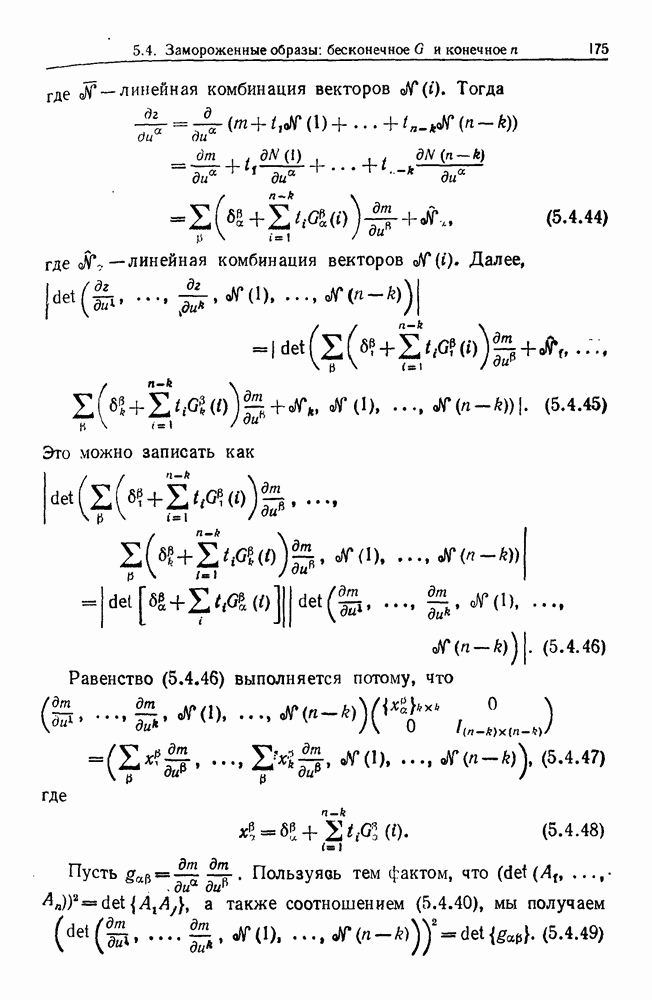





















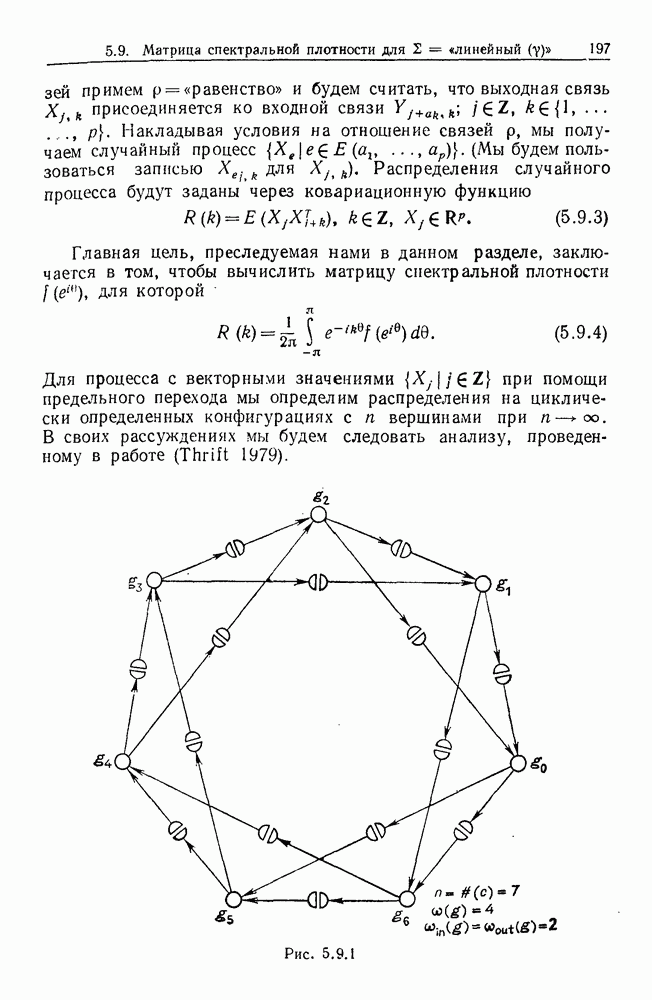













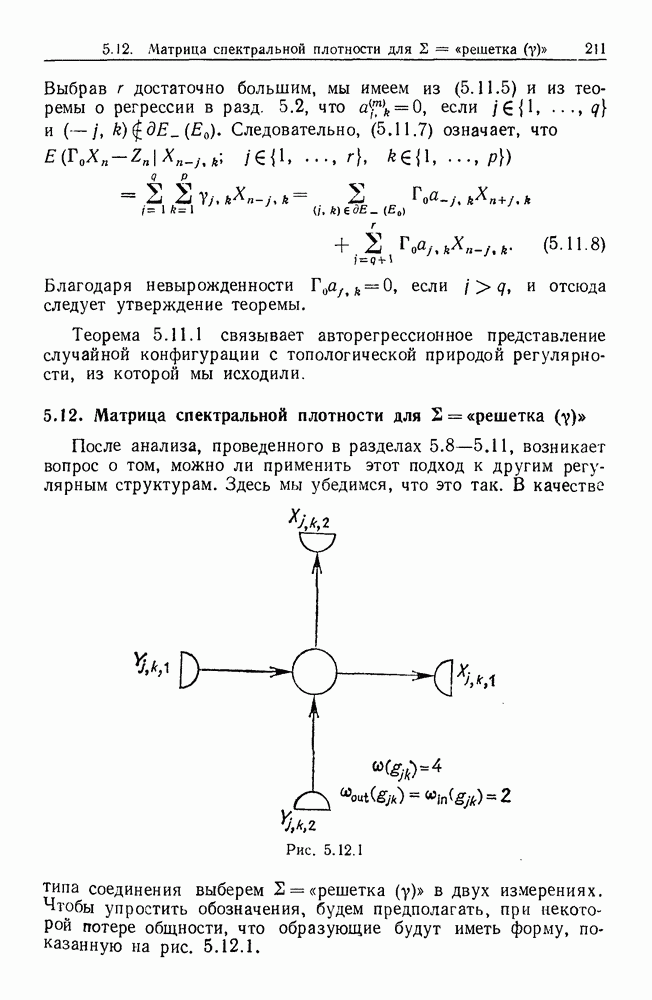








































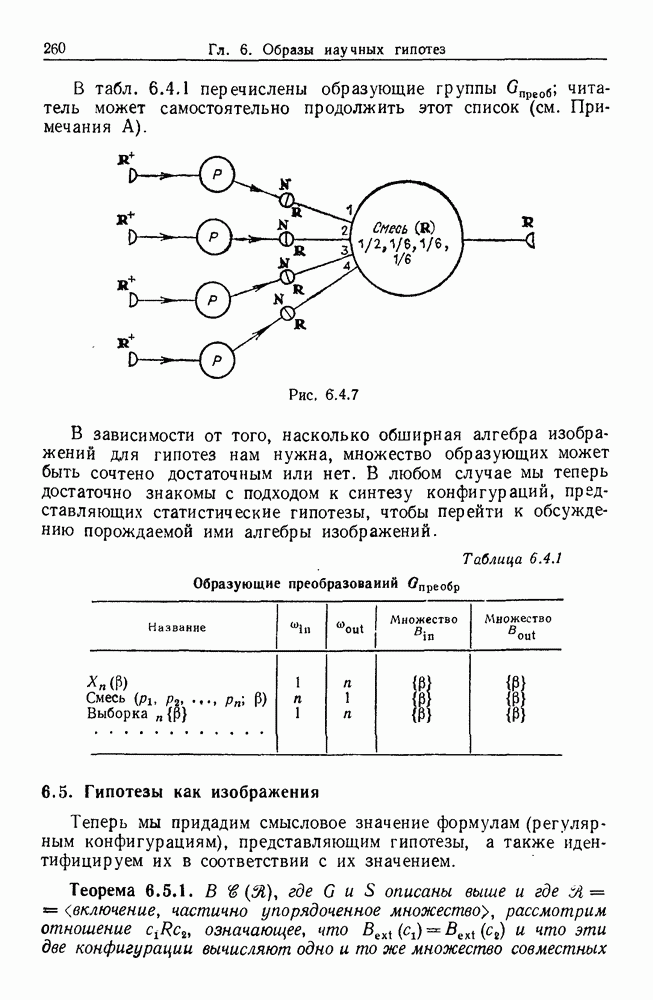




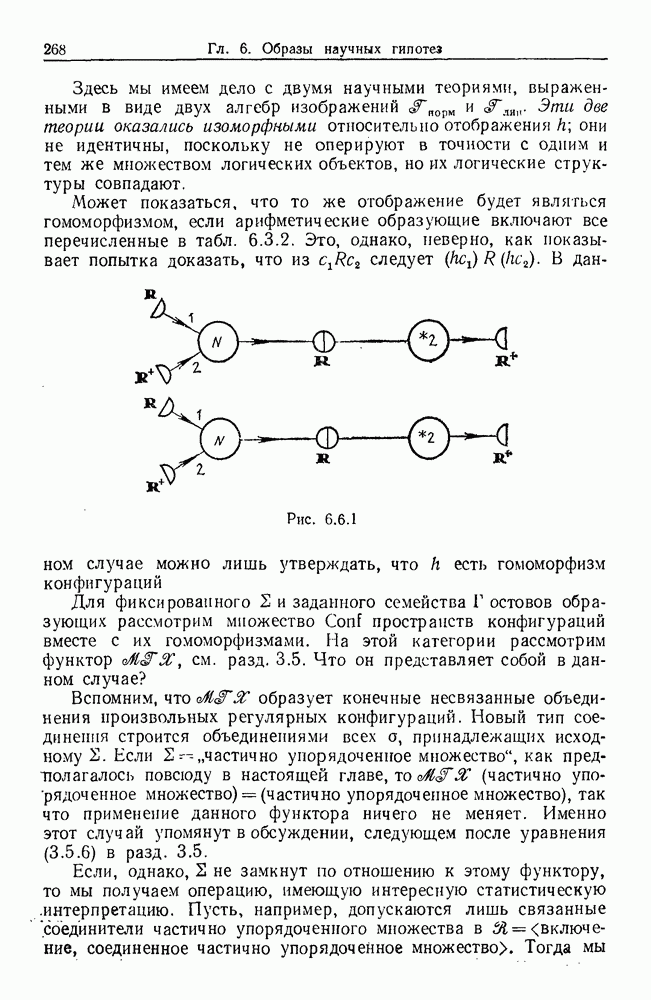




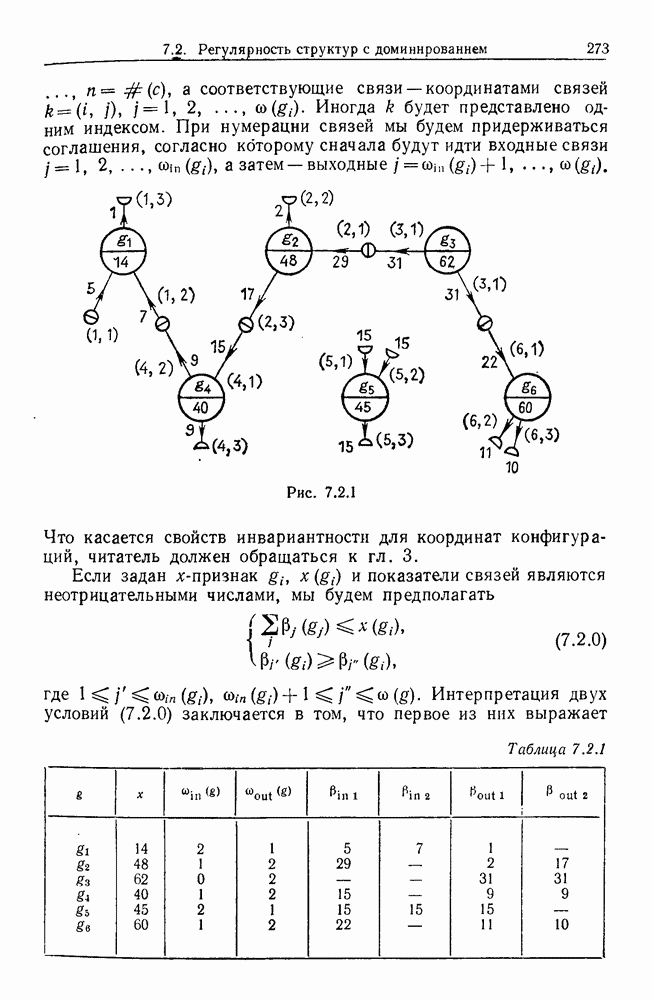








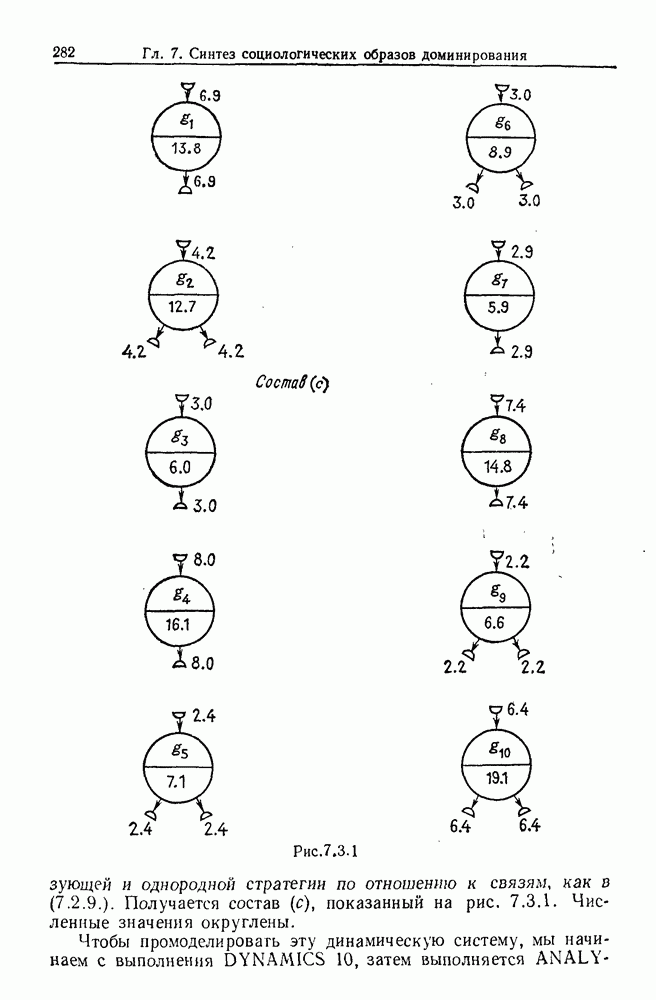
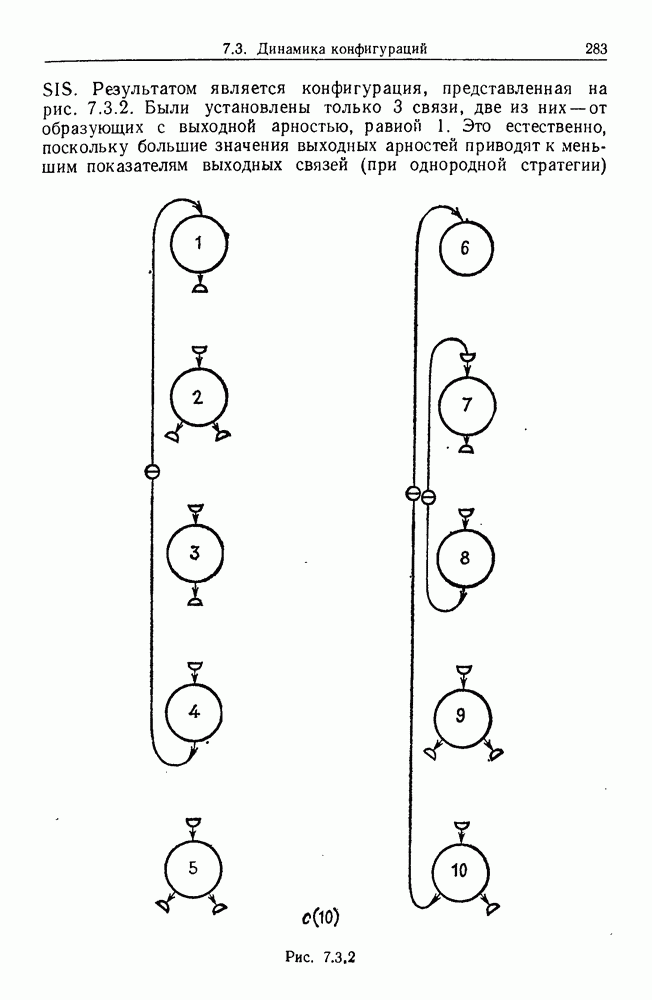
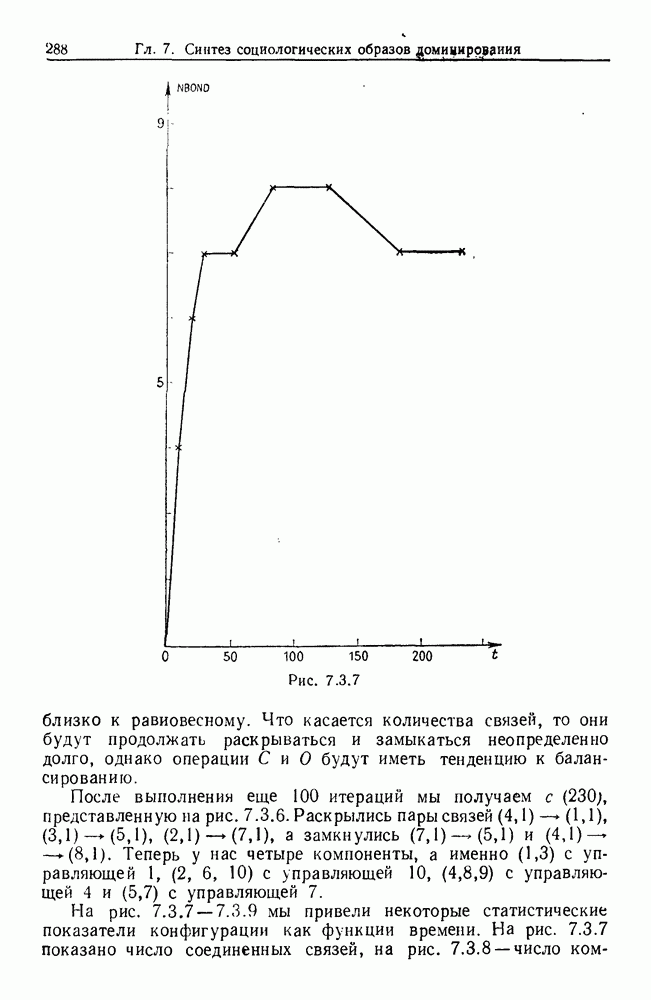
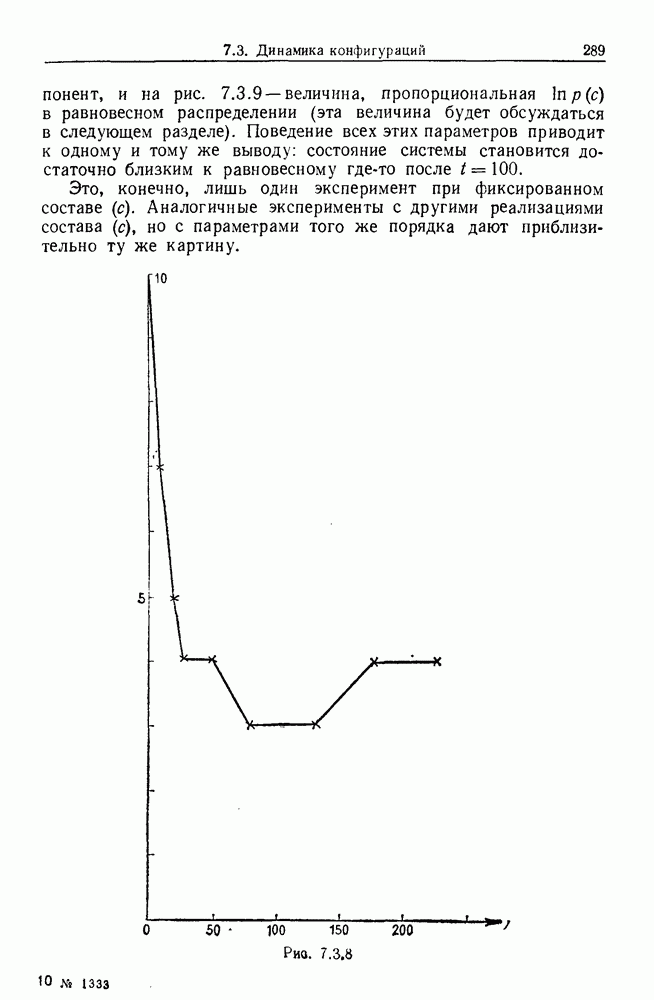
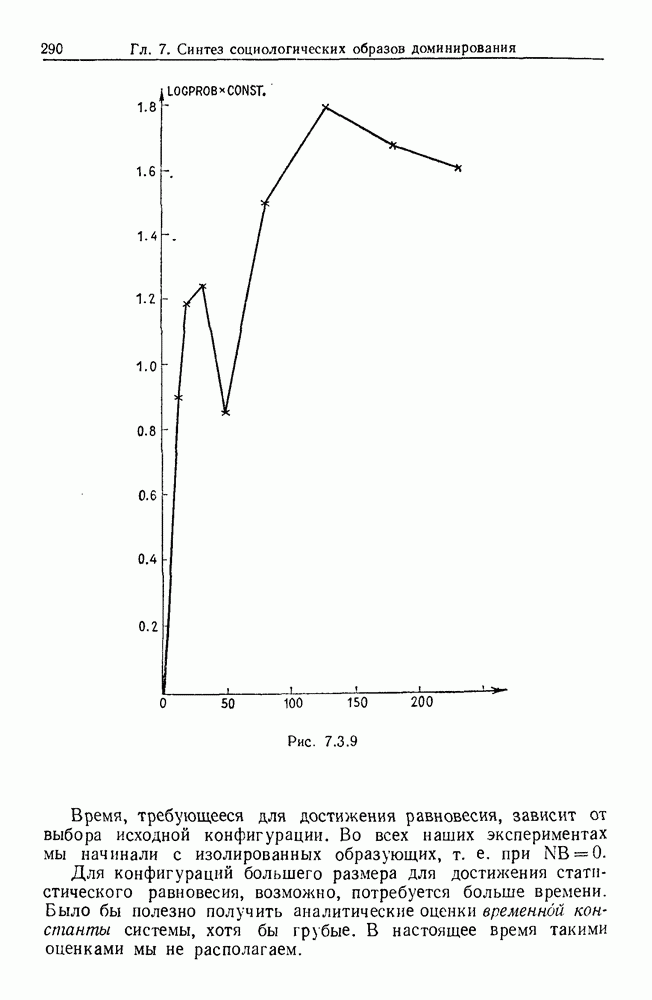






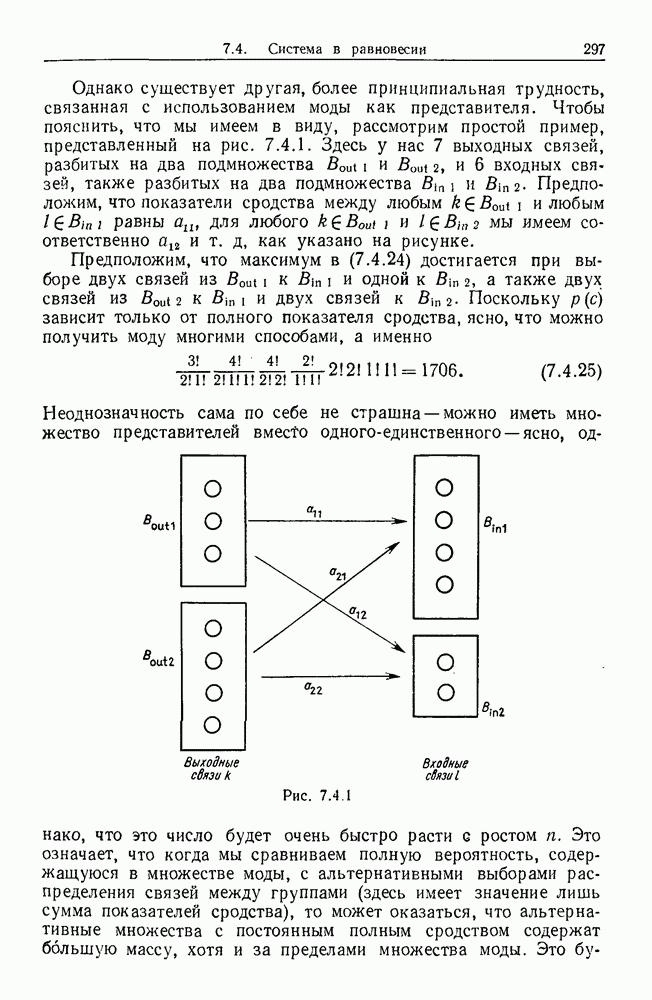


























































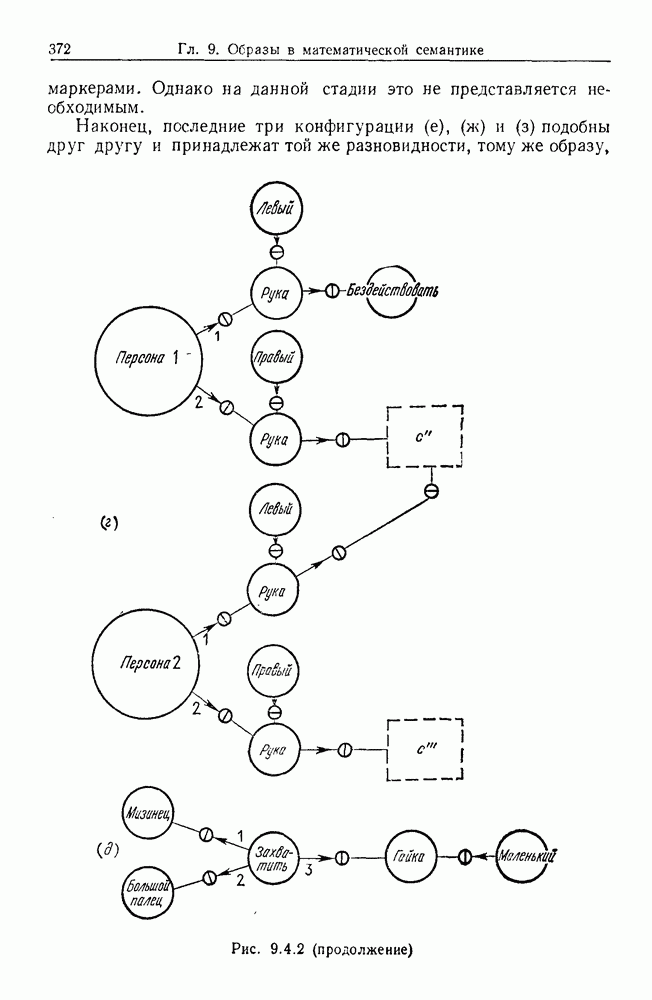
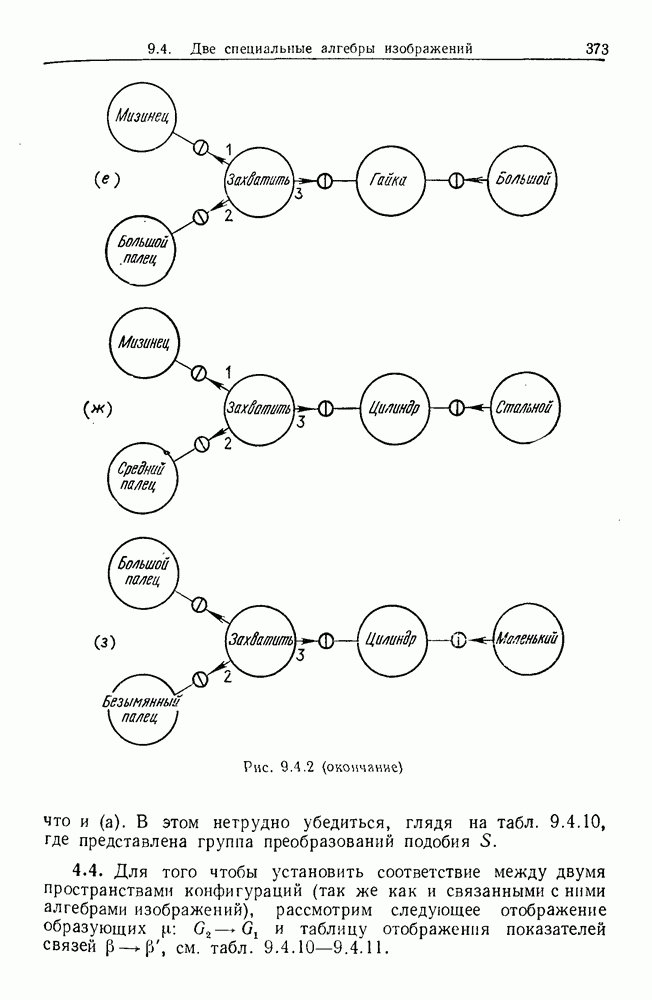


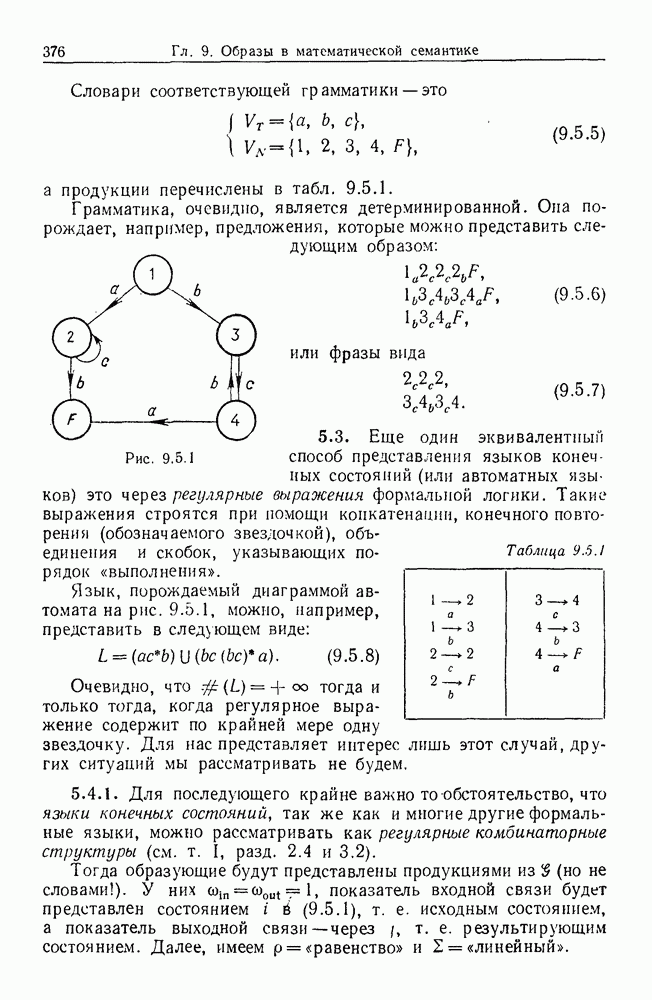



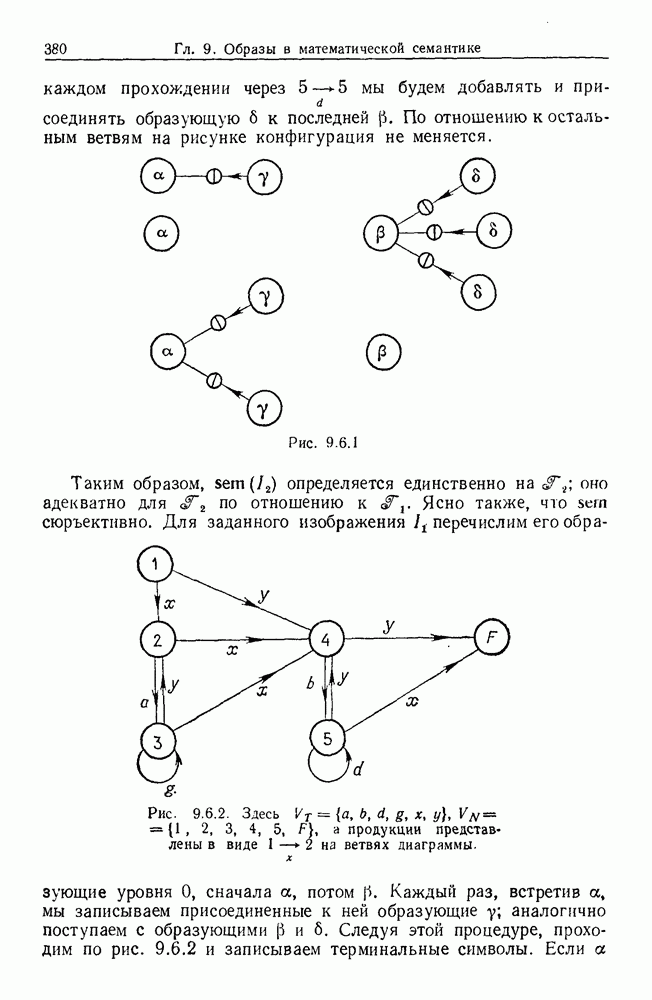









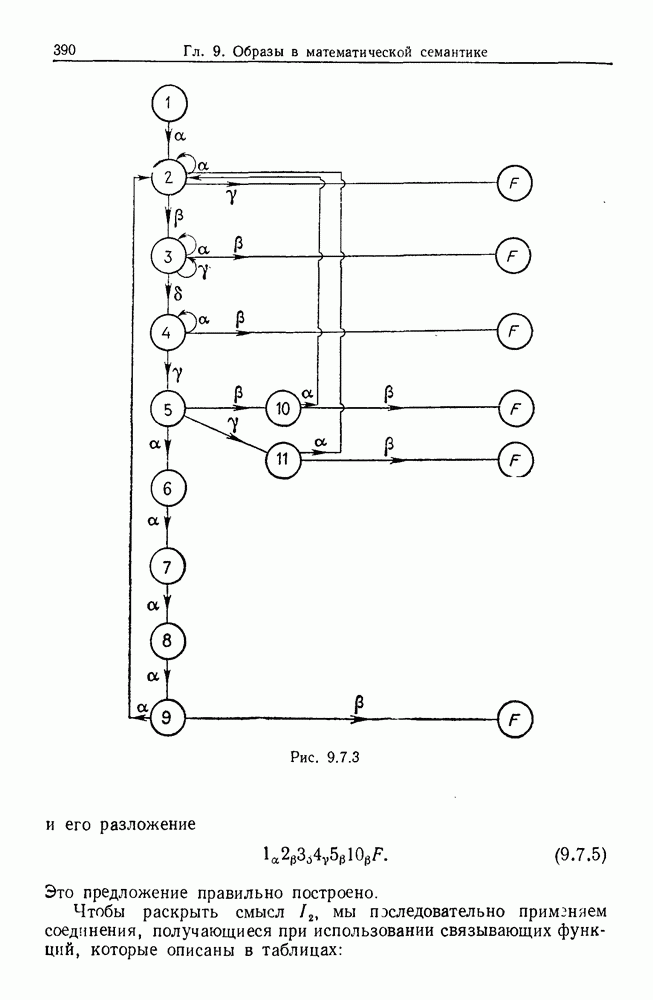
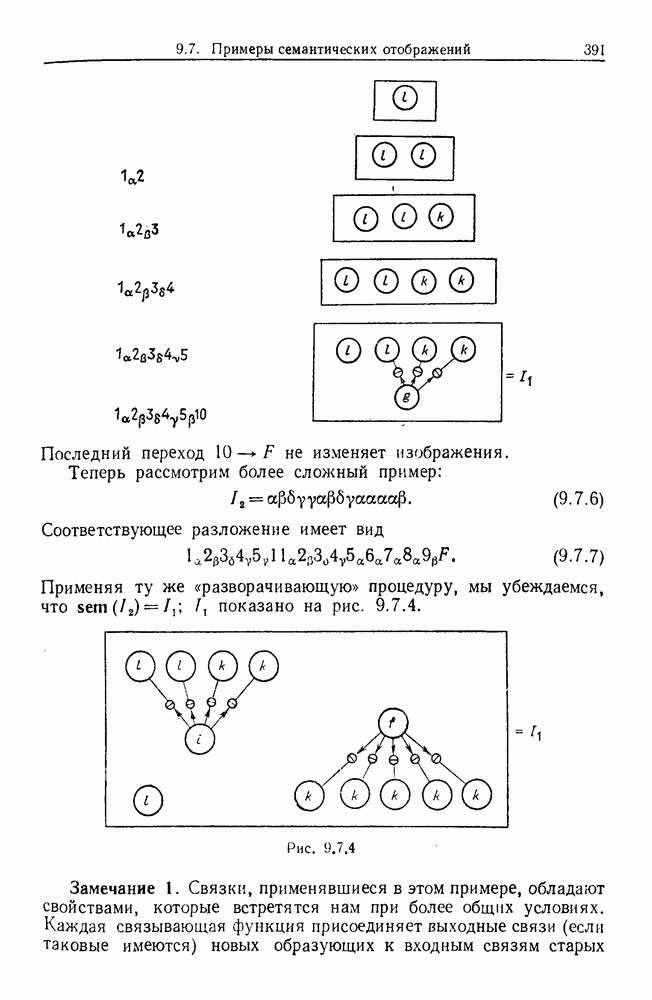



























 некоего пространства
некоего пространства  мы ищем такой способ разбиения X на подмножества
мы ищем такой способ разбиения X на подмножества  что элементы
что элементы  совершенно отличны от элементов
совершенно отличны от элементов  если (см. Примечания А).
если (см. Примечания А).
 двоичных признаков
двоичных признаков  и допустить только такие разбиения, которые можно описать некоторыми булевыми функциями от этих признаков.
и допустить только такие разбиения, которые можно описать некоторыми булевыми функциями от этих признаков.
 и их отрицаний, так что в нормальной конъюнктивной форме В должны иметь вид
и их отрицаний, так что в нормальной конъюнктивной форме В должны иметь вид

 Можно, с другой стороны, потребовать, чтобы логические множители в (8.1.1) были конъюнкциями, самое большее, двух признаков и их конъюнкций и так далее.
Можно, с другой стороны, потребовать, чтобы логические множители в (8.1.1) были конъюнкциями, самое большее, двух признаков и их конъюнкций и так далее.
 то изопериметрические множества отличаются тем свойством, что кривизна на границе пропорциональна плотности вероятностной меры.
то изопериметрические множества отличаются тем свойством, что кривизна на границе пропорциональна плотности вероятностной меры.
 .
.

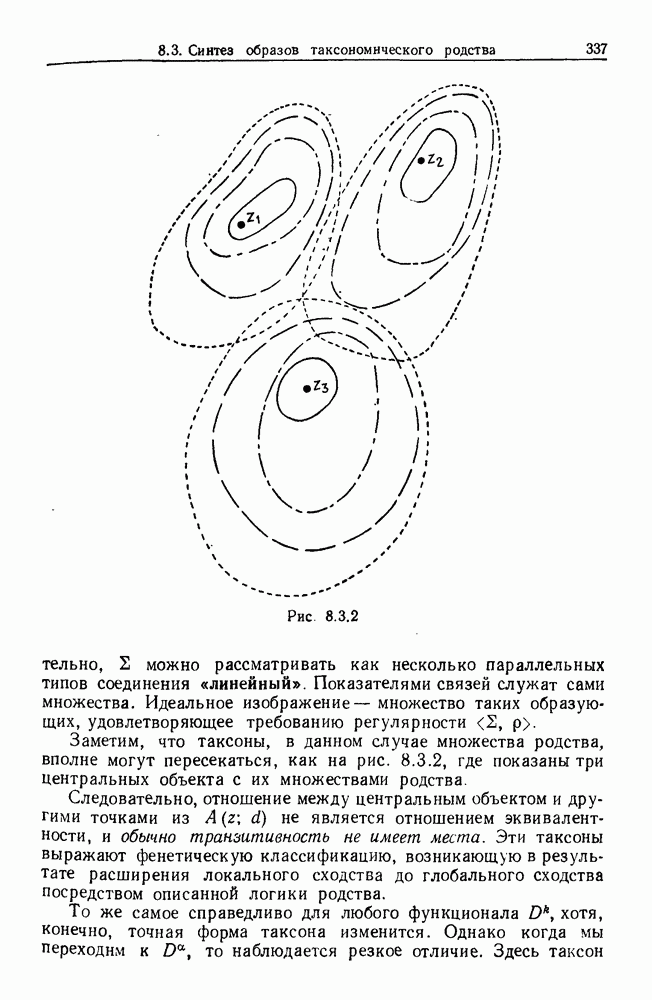
 Каждая точка представляет наблюдаемый объект, и мы связываем два объекта отрезком прямой, если расстояние между ними не превышает заданного
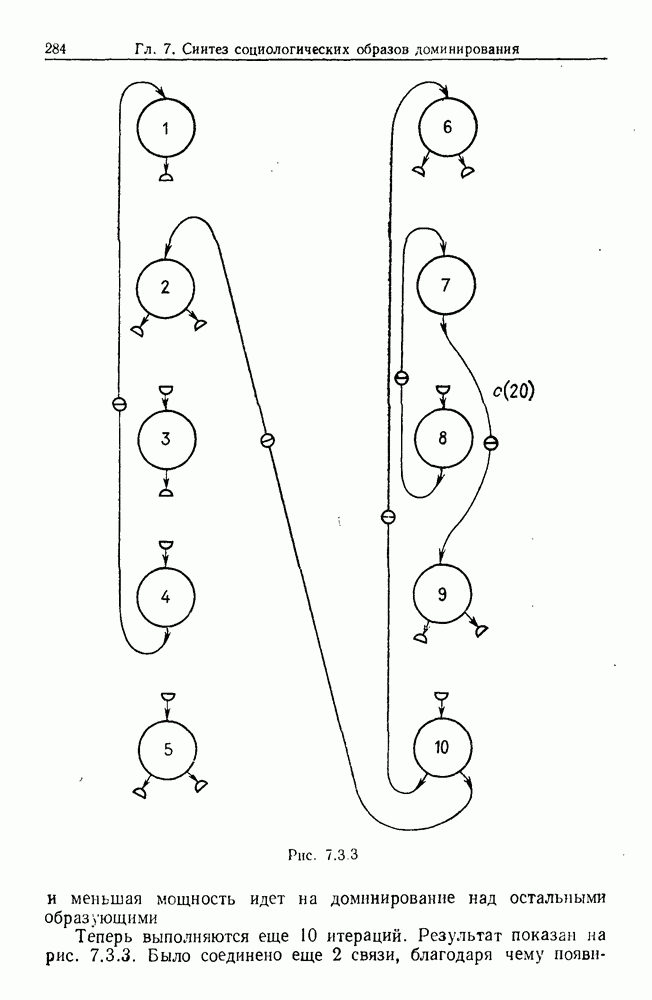
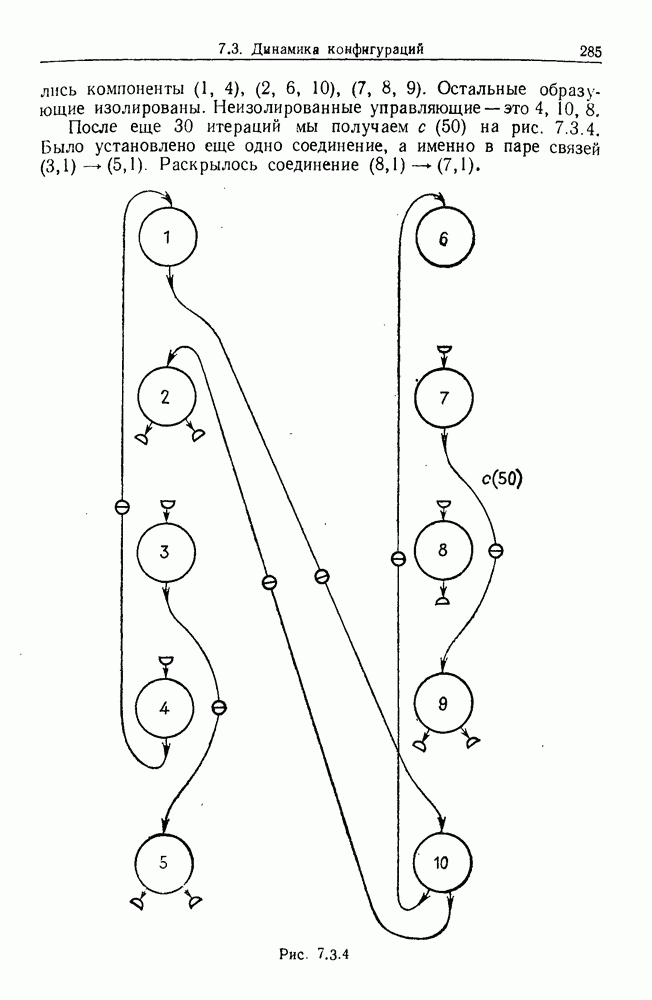
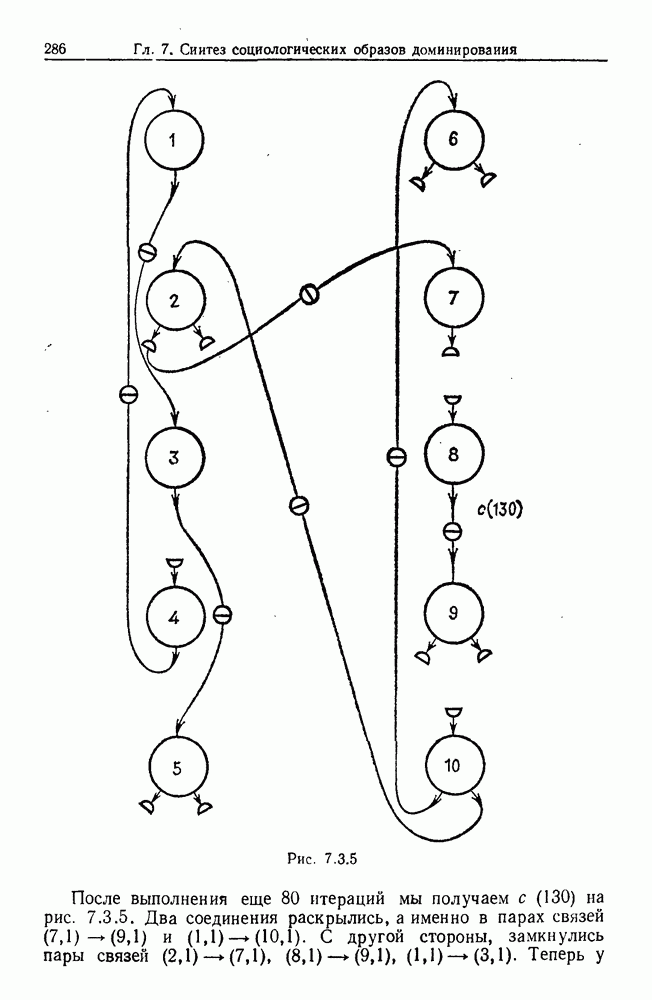
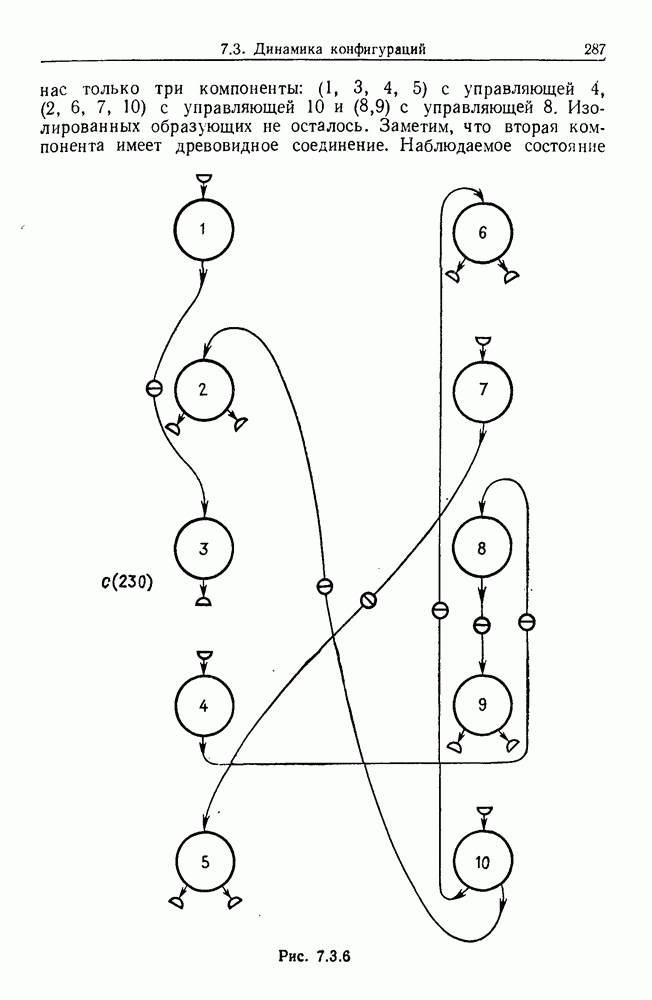
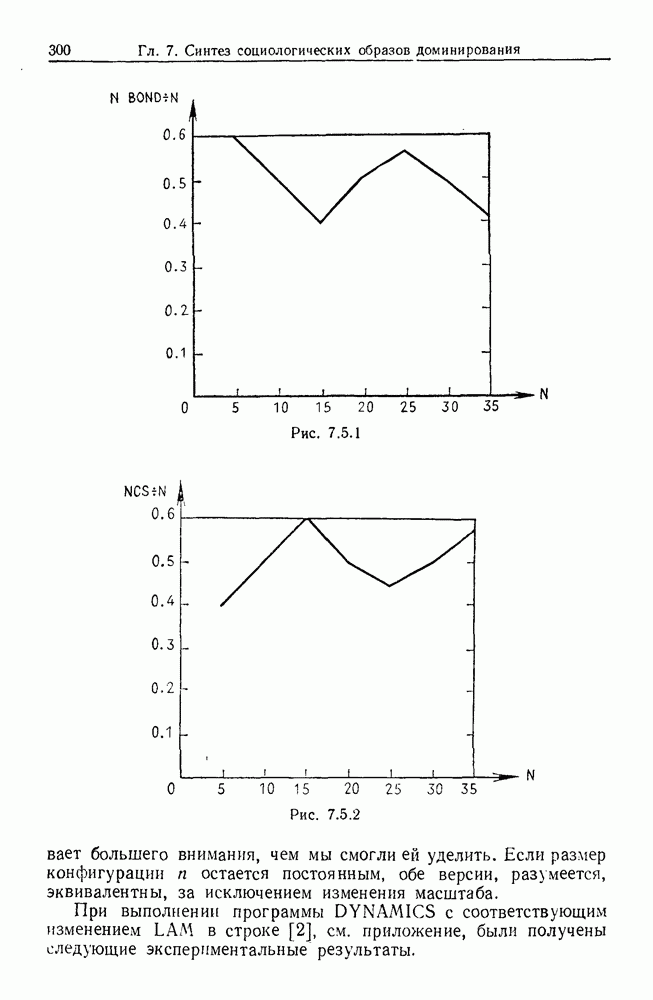
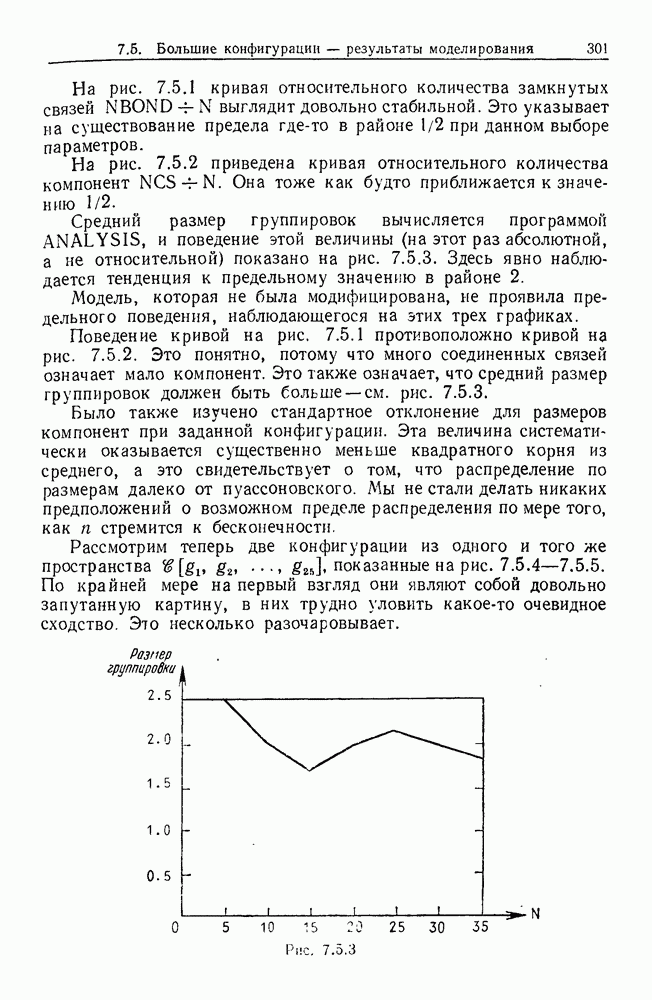
Каждая точка представляет наблюдаемый объект, и мы связываем два объекта отрезком прямой, если расстояние между ними не превышает заданного  Этим способом мы получаем граф, который на рисунке содержит 5 связных компонент.
Этим способом мы получаем граф, который на рисунке содержит 5 связных компонент.
 (см. рис. 8.1.2). Иначе говоря, для данного объекта
(см. рис. 8.1.2). Иначе говоря, для данного объекта  мы ищем соседние элементы, т. е. принадлежащие к пробному множеству
мы ищем соседние элементы, т. е. принадлежащие к пробному множеству  «диск радиуса
«диск радиуса  с центром в
с центром в  Разумеется, мы не обязаны пользоваться дисками, основанными на заданной локальной метрике, а можем применять критерии соседства более общего вида. Это до некоторой степени вопрос удобства вычислений.
Разумеется, мы не обязаны пользоваться дисками, основанными на заданной локальной метрике, а можем применять критерии соседства более общего вида. Это до некоторой степени вопрос удобства вычислений.
 есть заданная группа преобразований подобия на X, то естественно начать с пробного множества
есть заданная группа преобразований подобия на X, то естественно начать с пробного множества  положение которого зафиксировано, и затем образовать все
положение которого зафиксировано, и затем образовать все  .
.

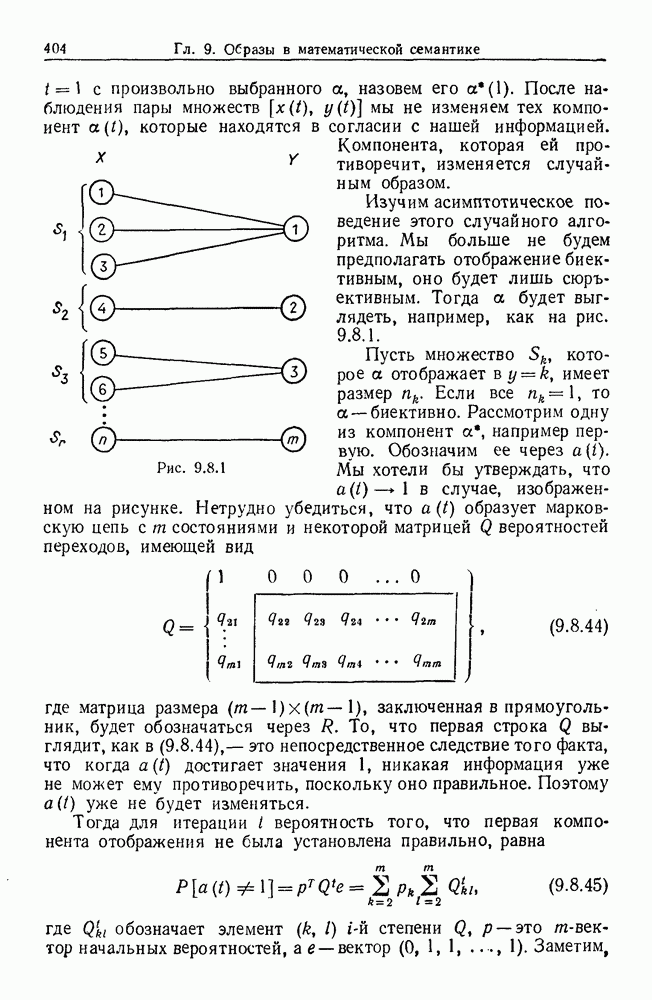
 то описанную выше процедуру необходимо видоизменить. Для
то описанную выше процедуру необходимо видоизменить. Для  очевидно, как это сделать. Далее, если
очевидно, как это сделать. Далее, если  это вектор признаков,
это вектор признаков,  из которых — вещественные числа, а остальные признаки двоичные или по крайней мере принимают конечное число значений, то X состоит из ряда листов, каждый из которых есть
из которых — вещественные числа, а остальные признаки двоичные или по крайней мере принимают конечное число значений, то X состоит из ряда листов, каждый из которых есть  наложенных один на другой. Нам нужен также критерий соседства, связывающий некоторые из этих листов.
наложенных один на другой. Нам нужен также критерий соседства, связывающий некоторые из этих листов.
 задана функция плотности
задана функция плотности  (ее не следует смешивать с признаками). Эту функцию можно рассматривать как интенсивность неравномерного пуассоновского случайного процесса или как плотность распределения. Можем ли мы соединить
(ее не следует смешивать с признаками). Эту функцию можно рассматривать как интенсивность неравномерного пуассоновского случайного процесса или как плотность распределения. Можем ли мы соединить  на рис. 8.1.2 цепочкой «малых» шагов? Чтобы это было возможно, среди наблюдаемых элементов не должно существовать промежутка размером больше
на рис. 8.1.2 цепочкой «малых» шагов? Чтобы это было возможно, среди наблюдаемых элементов не должно существовать промежутка размером больше  в полосе около пути Г. Примем взятую с обратным знаком величину логарифма
в полосе около пути Г. Примем взятую с обратным знаком величину логарифма
 Основания для такого выбора станут ясны ниже.
Основания для такого выбора станут ясны ниже.
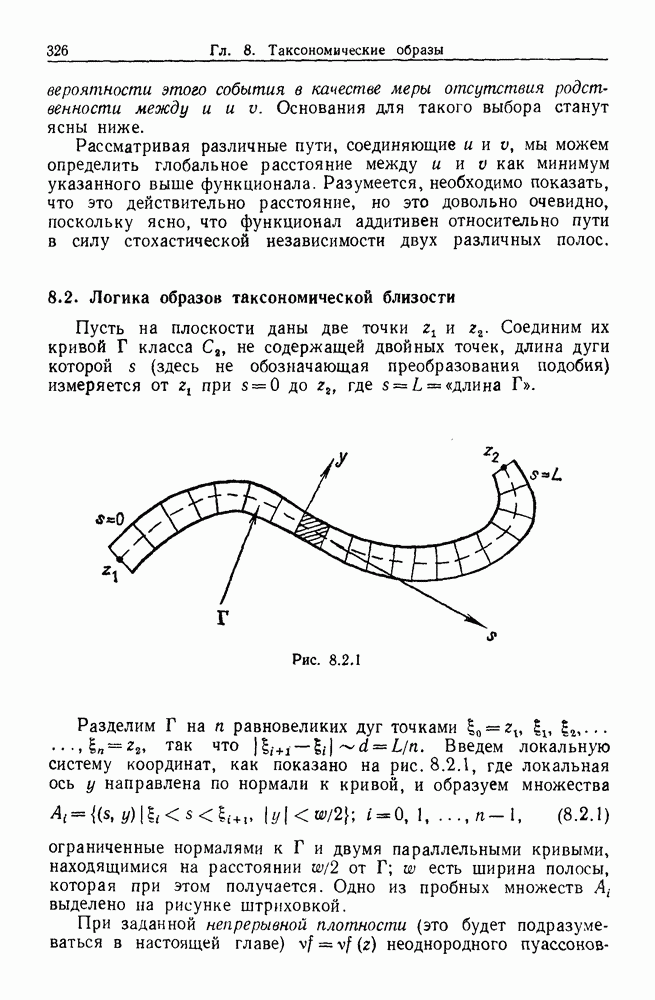
 мы можем определить глобальное расстояние между и и а как минимум указанного выше функционала. Разумеется, необходимо показать, что это действительно расстояние, но это довольно очевидно, поскольку ясно, что функционал аддитивен относительно пути в силу стохастической независимости двух различных полос.
мы можем определить глобальное расстояние между и и а как минимум указанного выше функционала. Разумеется, необходимо показать, что это действительно расстояние, но это довольно очевидно, поскольку ясно, что функционал аддитивен относительно пути в силу стохастической независимости двух различных полос.