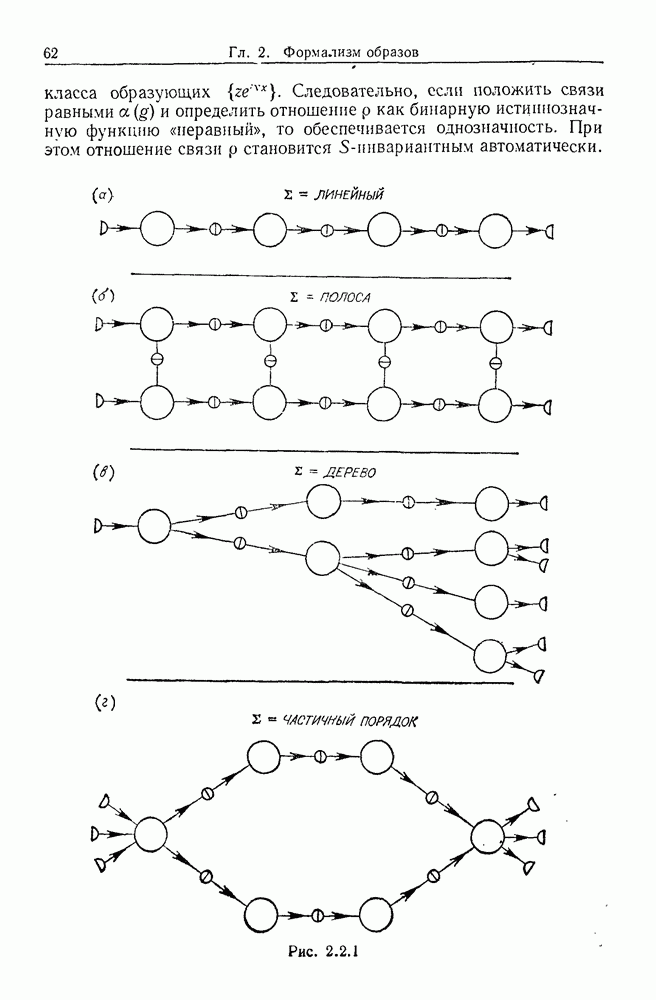
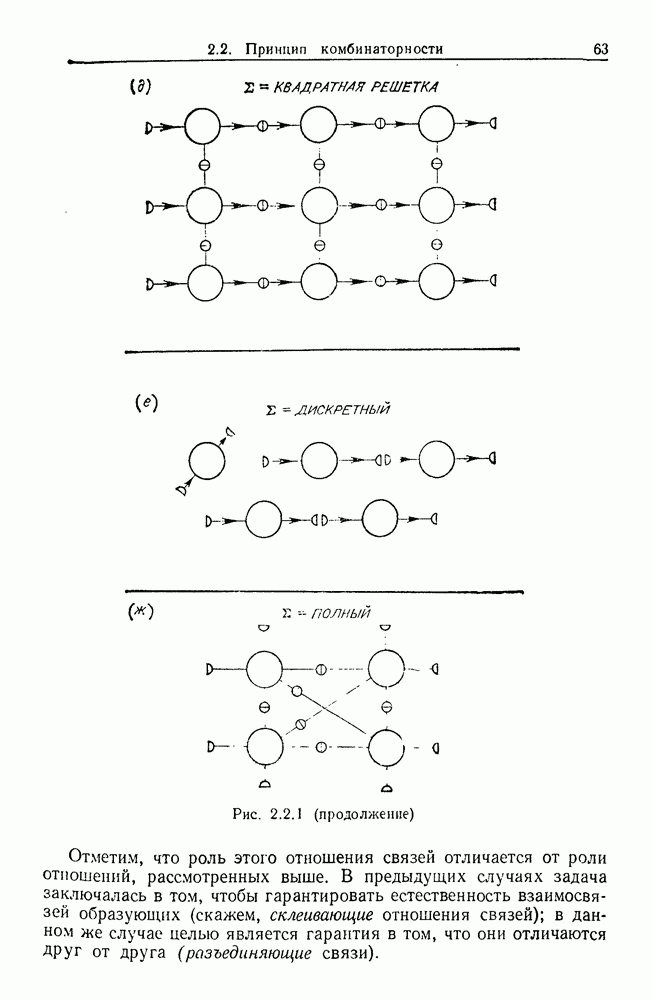
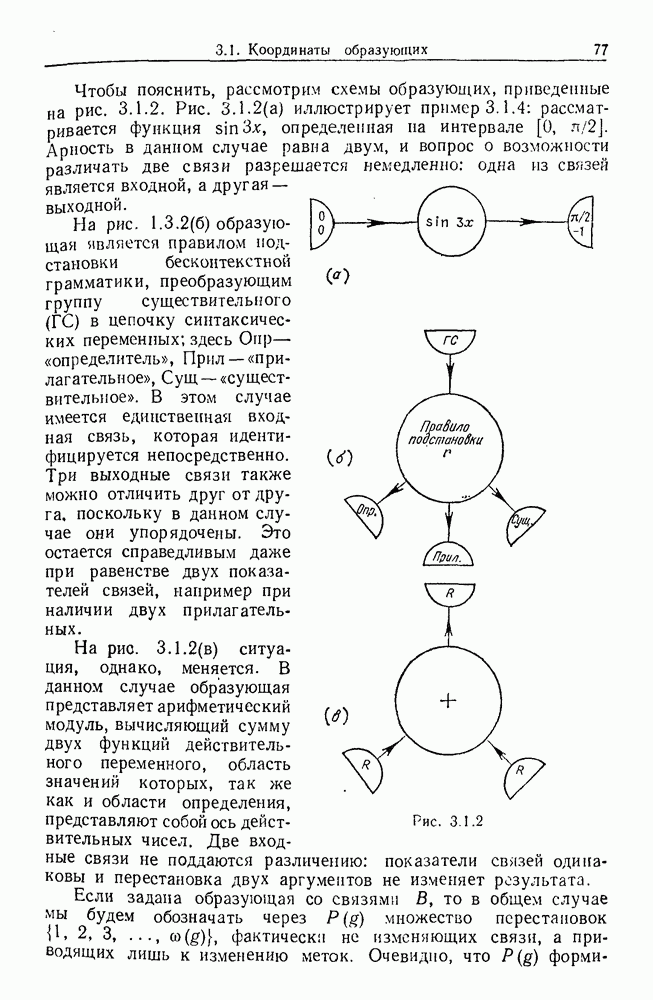
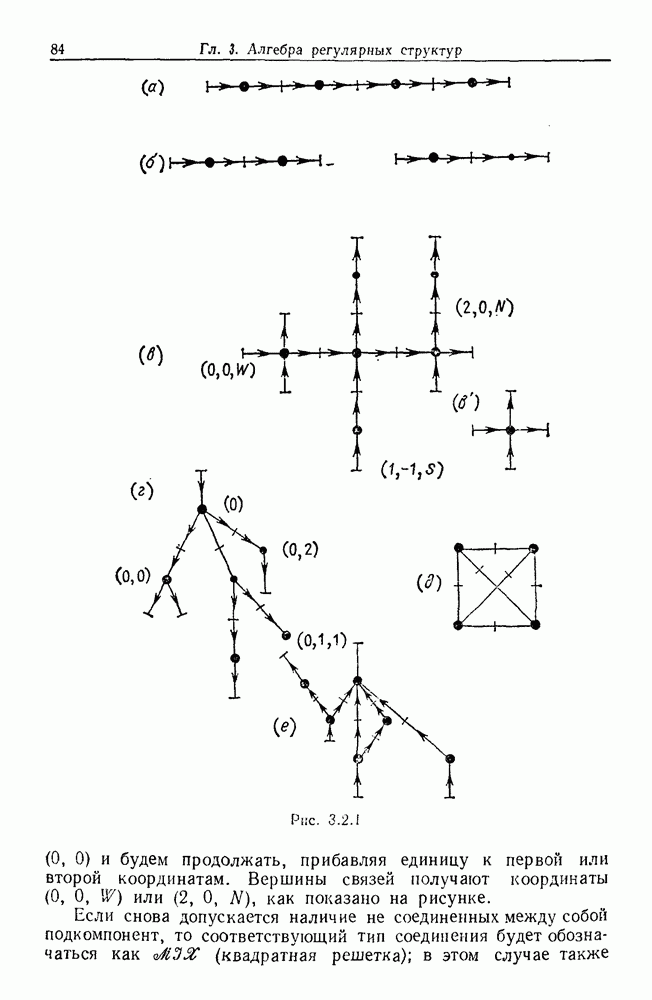
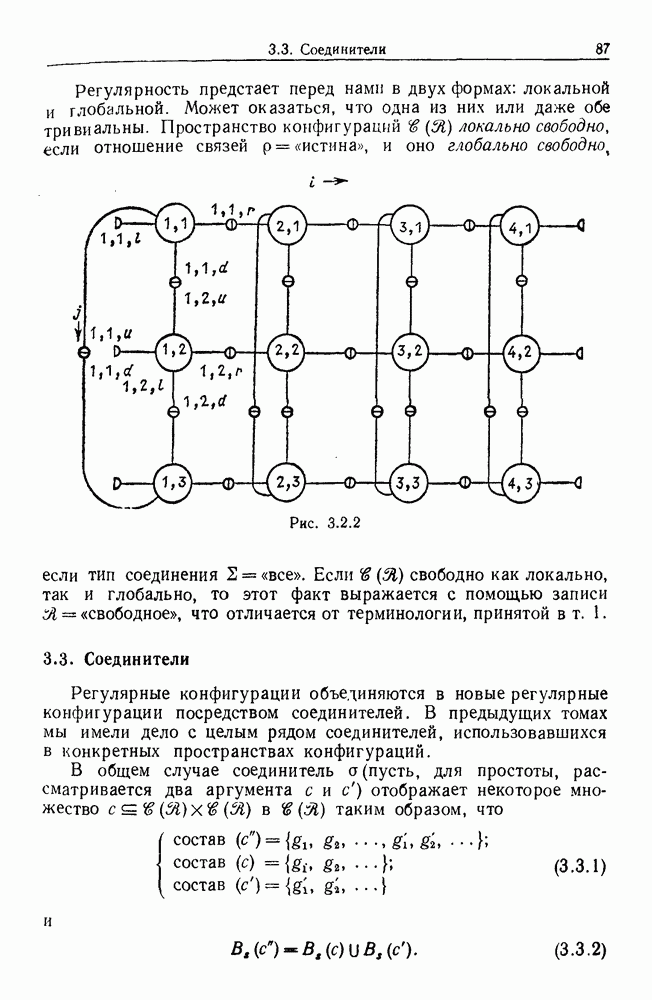
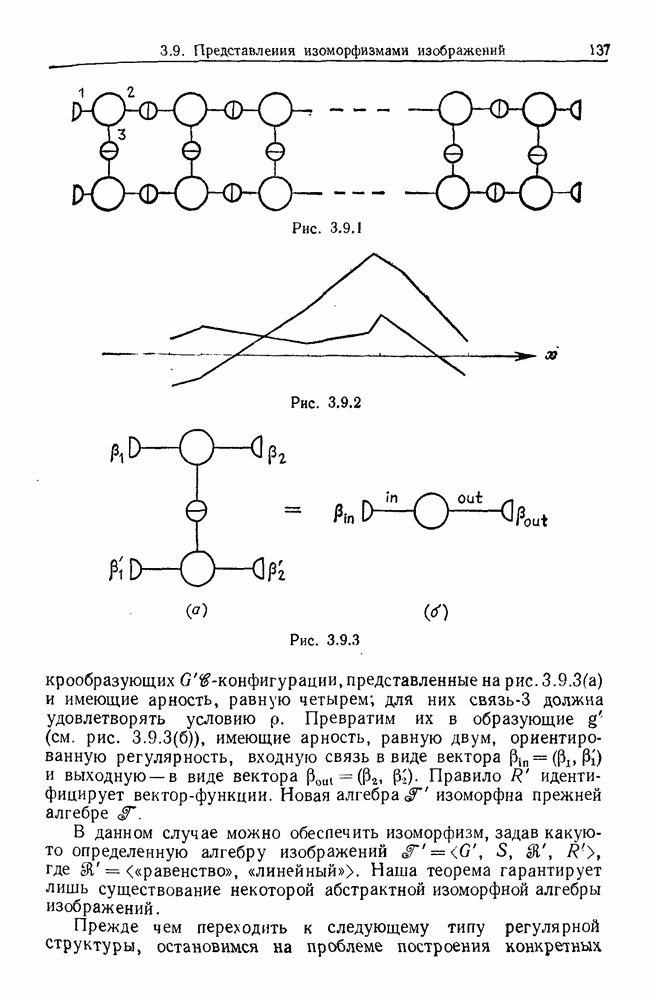
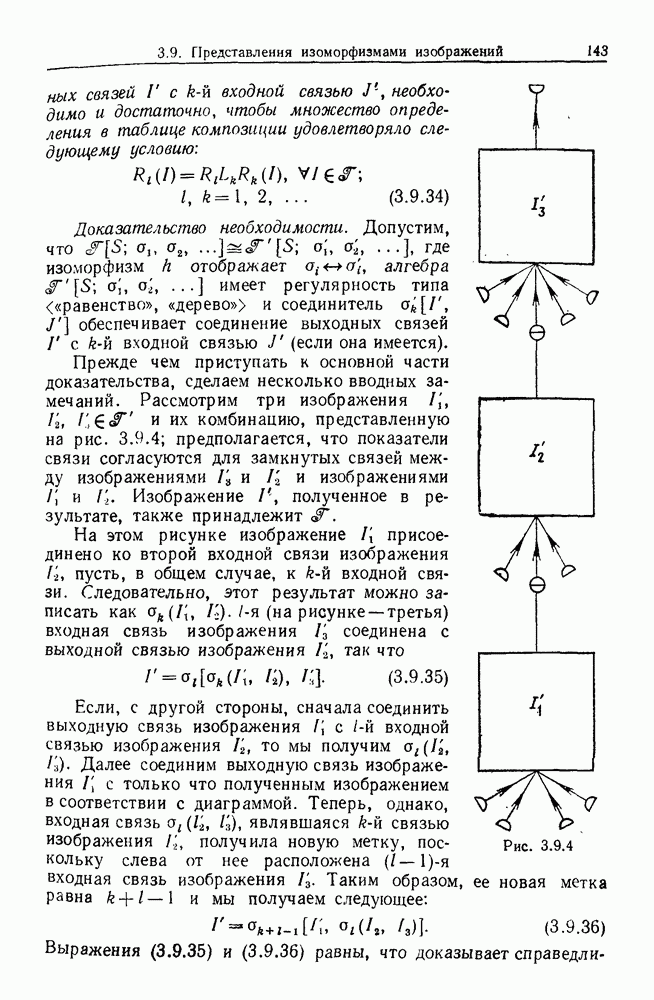
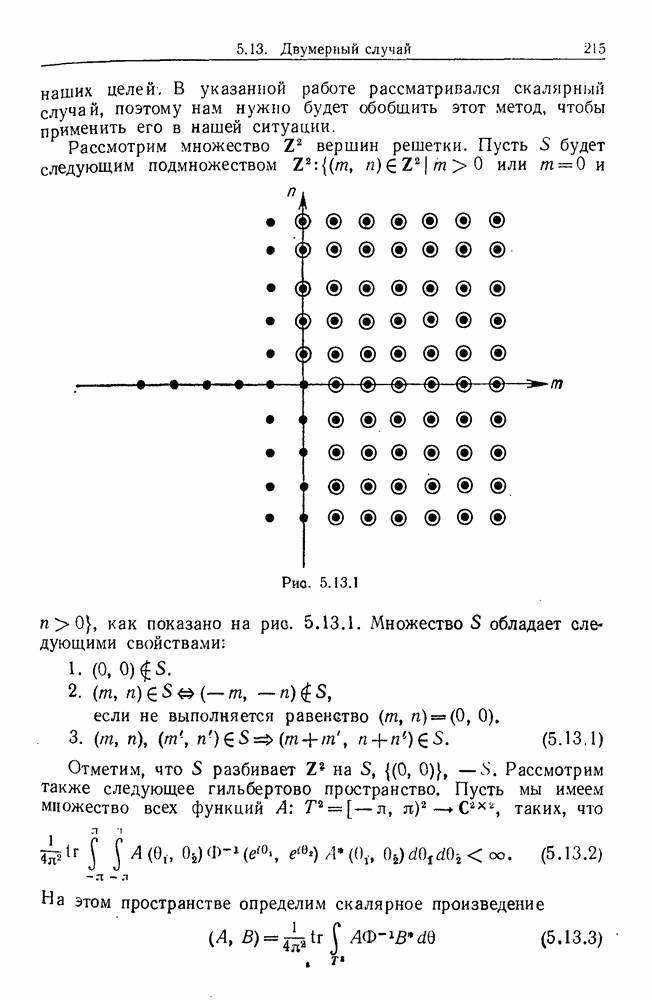
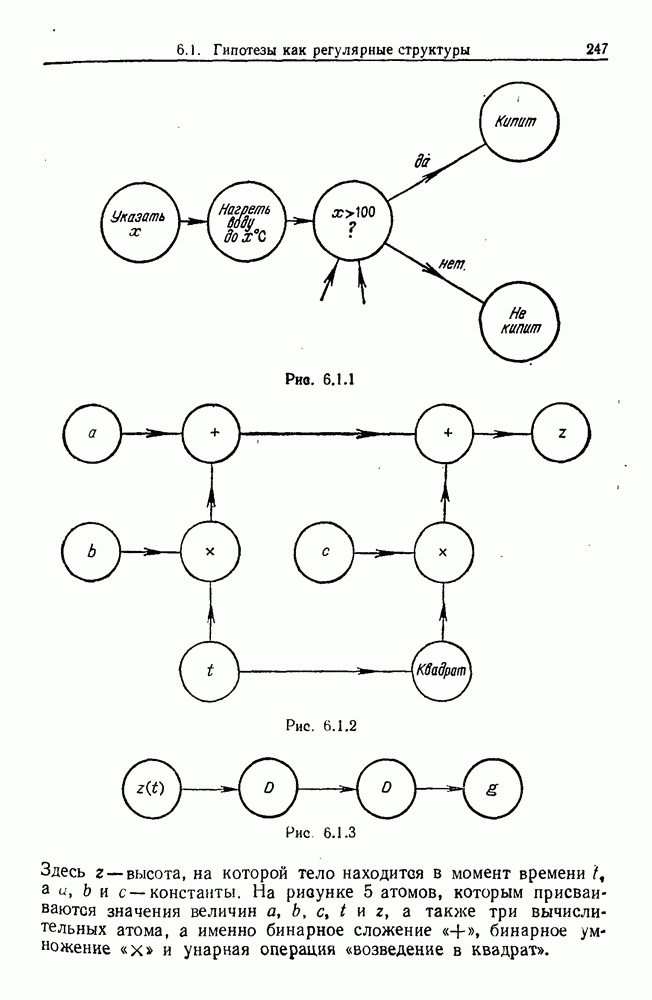
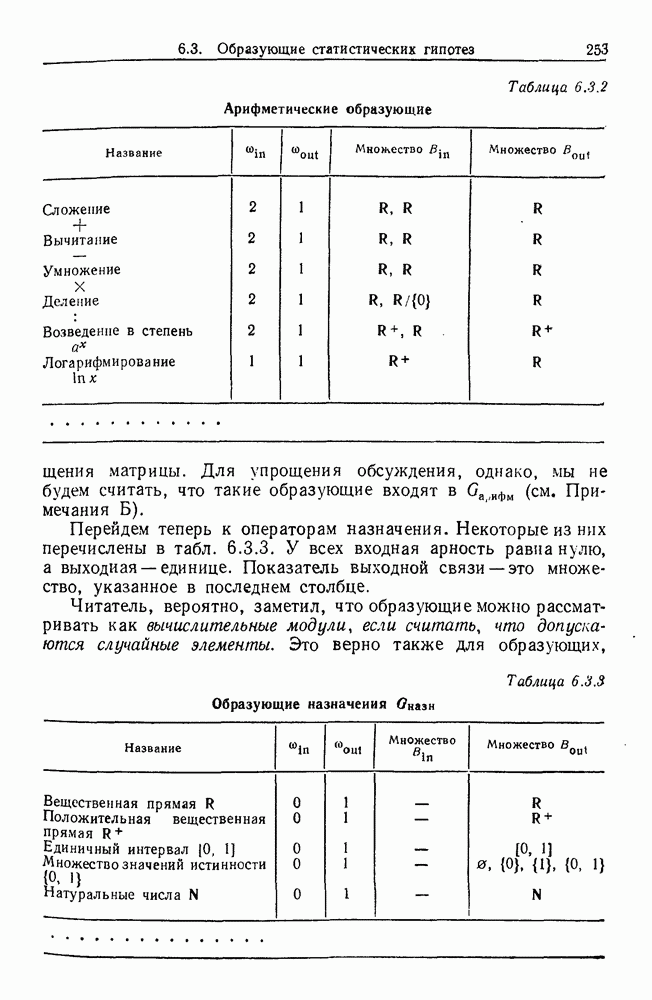
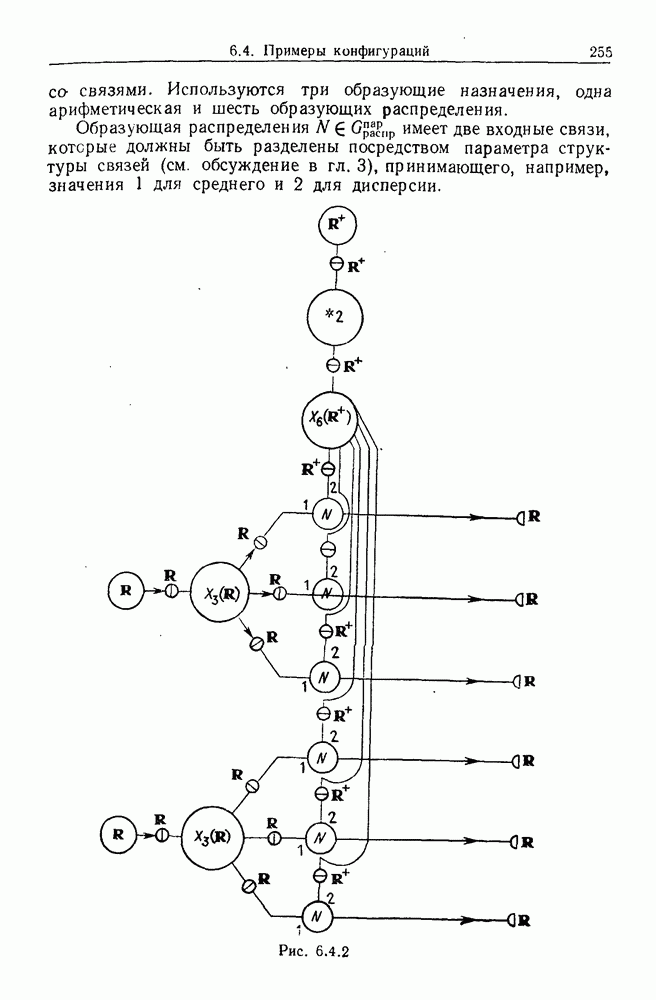
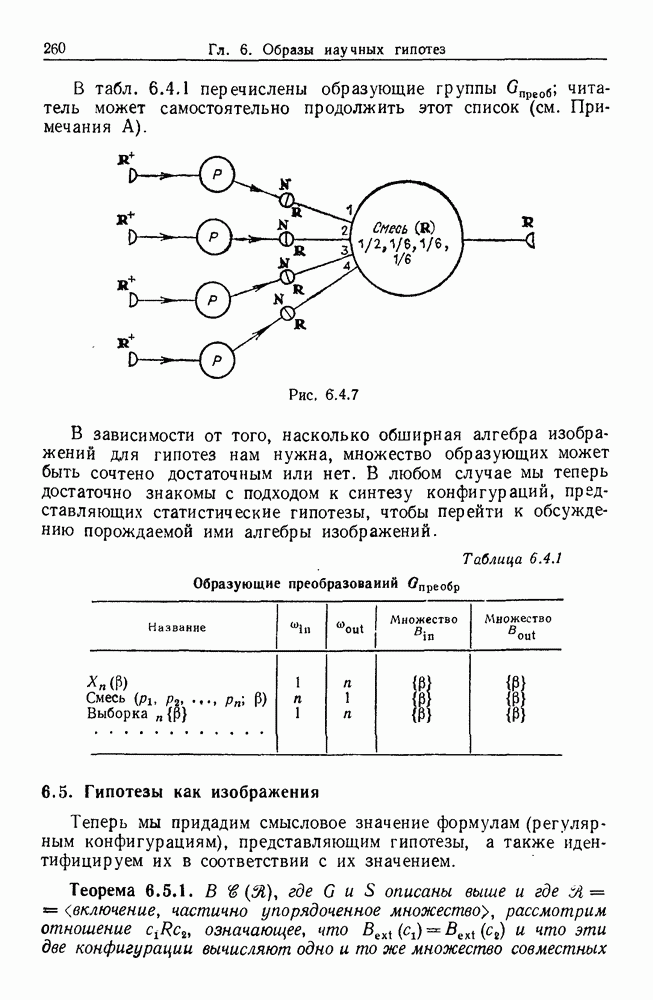
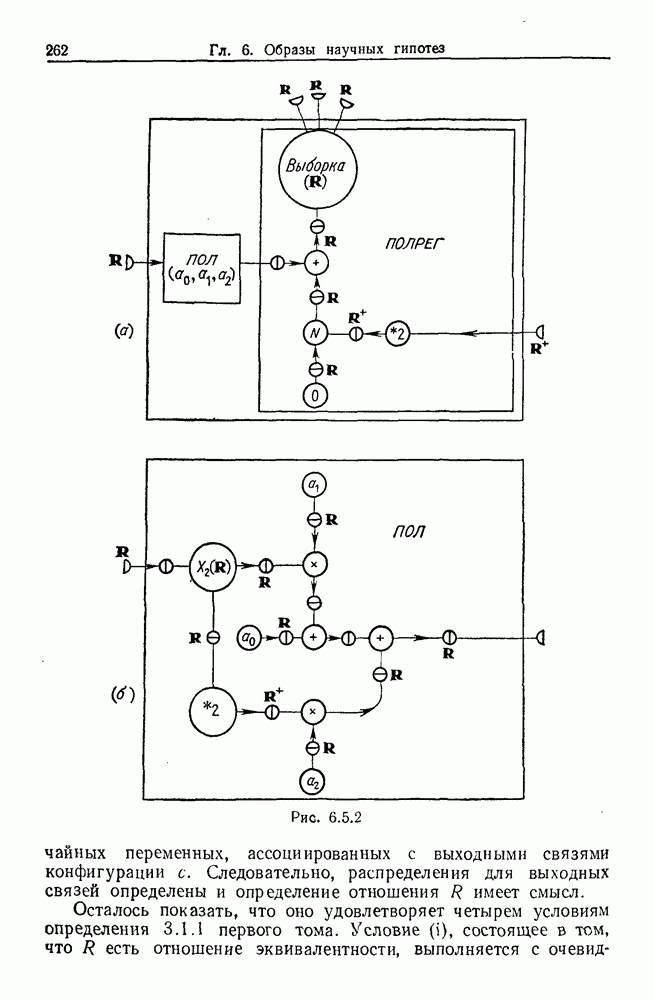
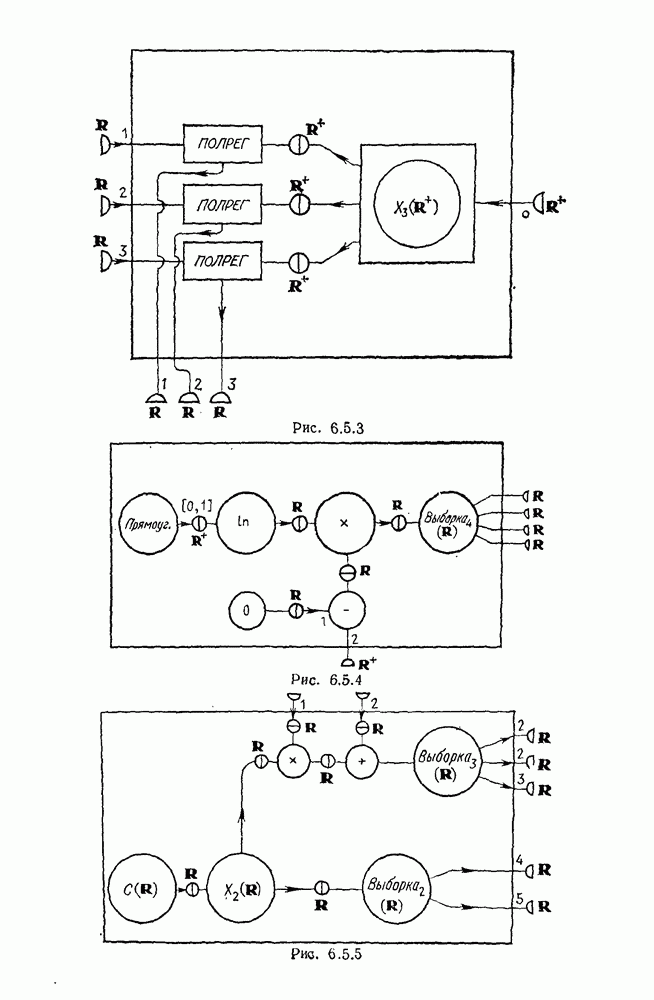
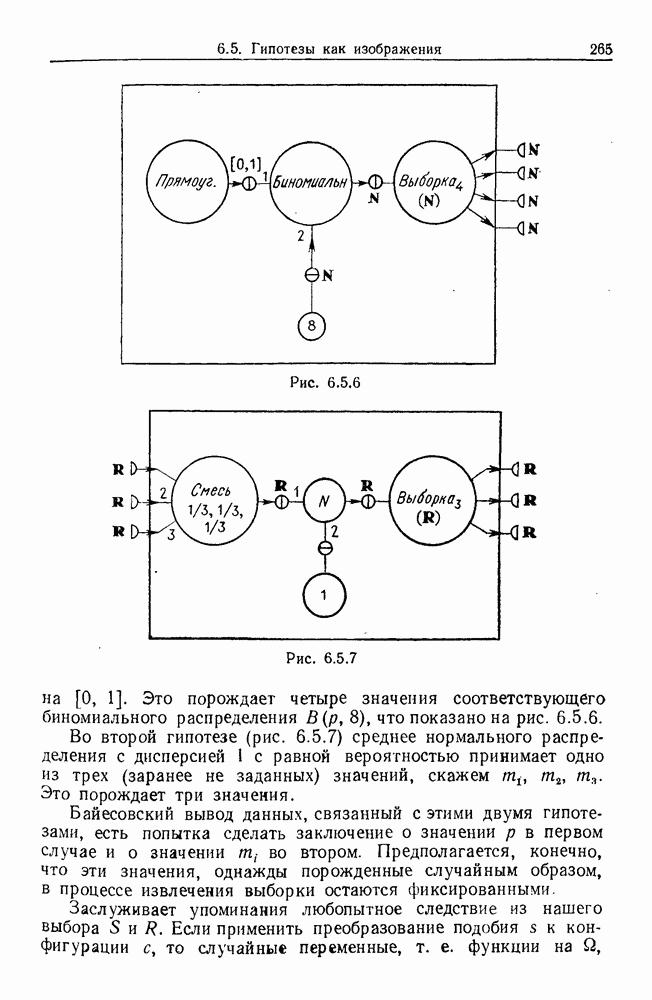
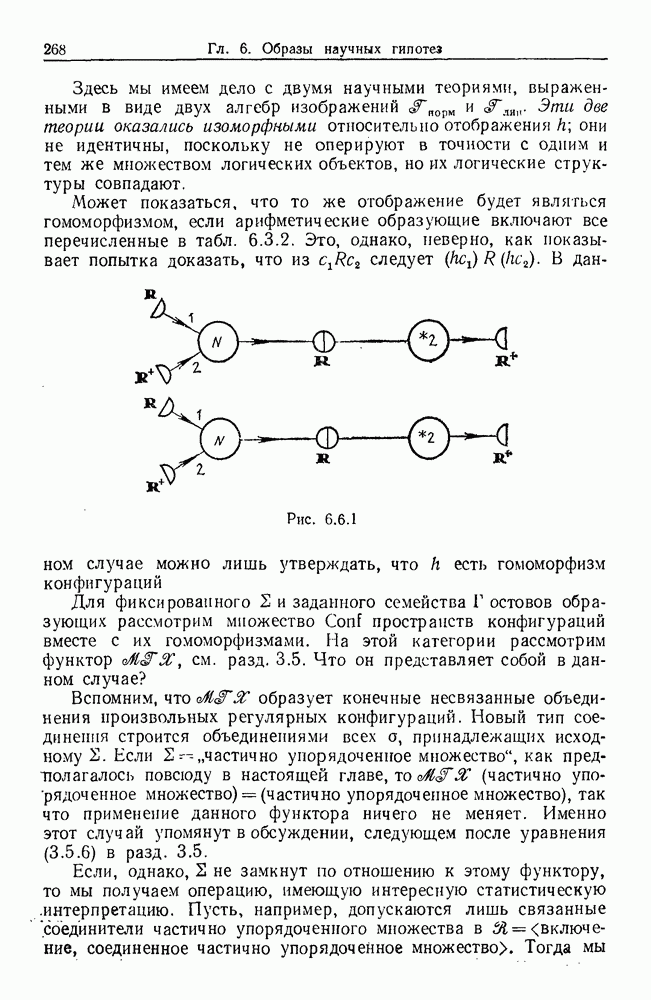
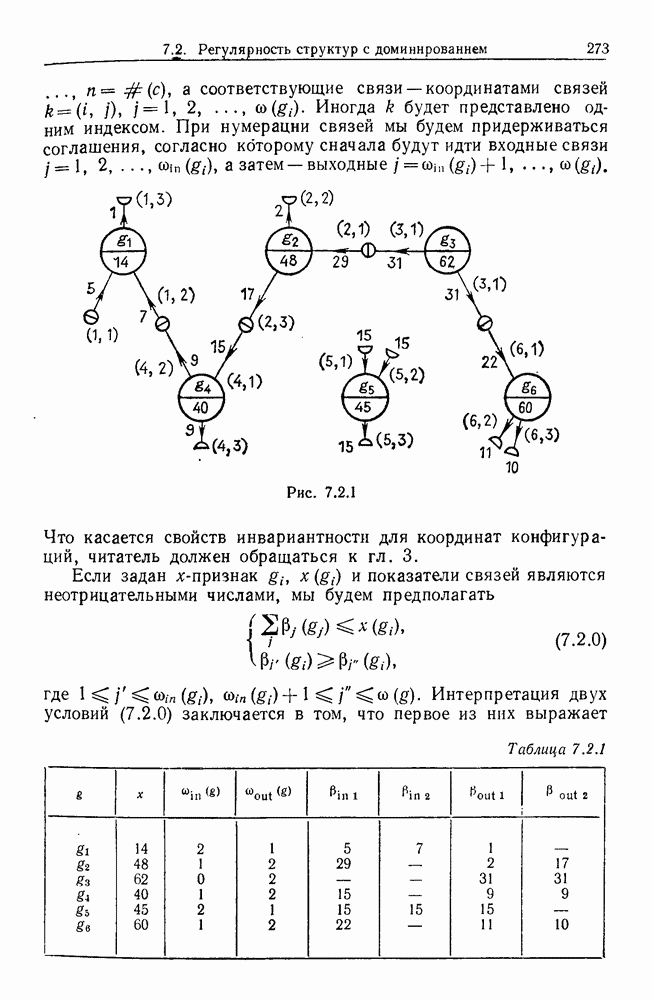
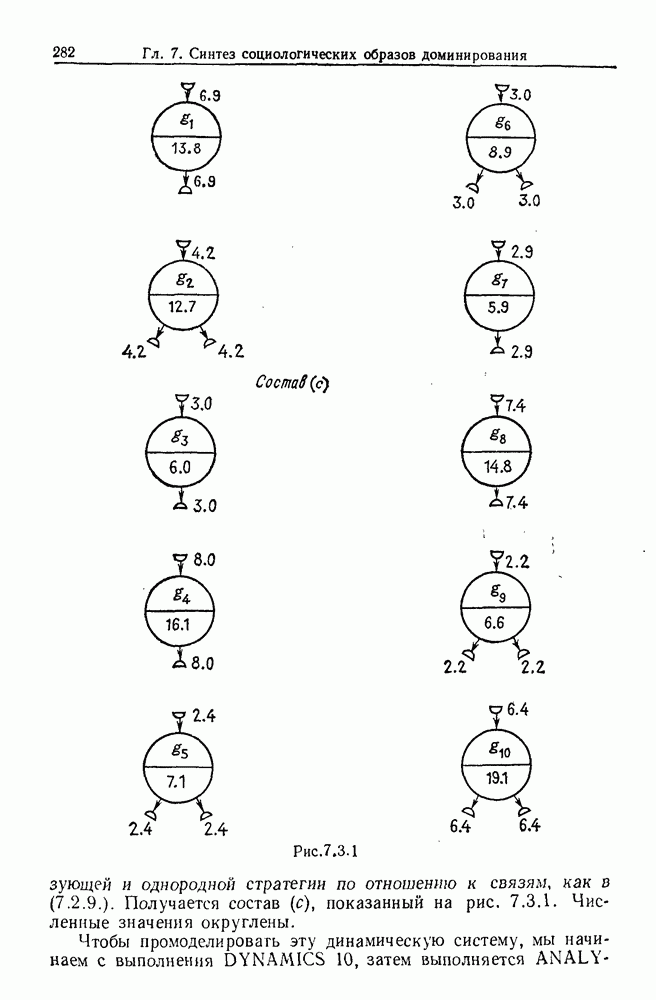
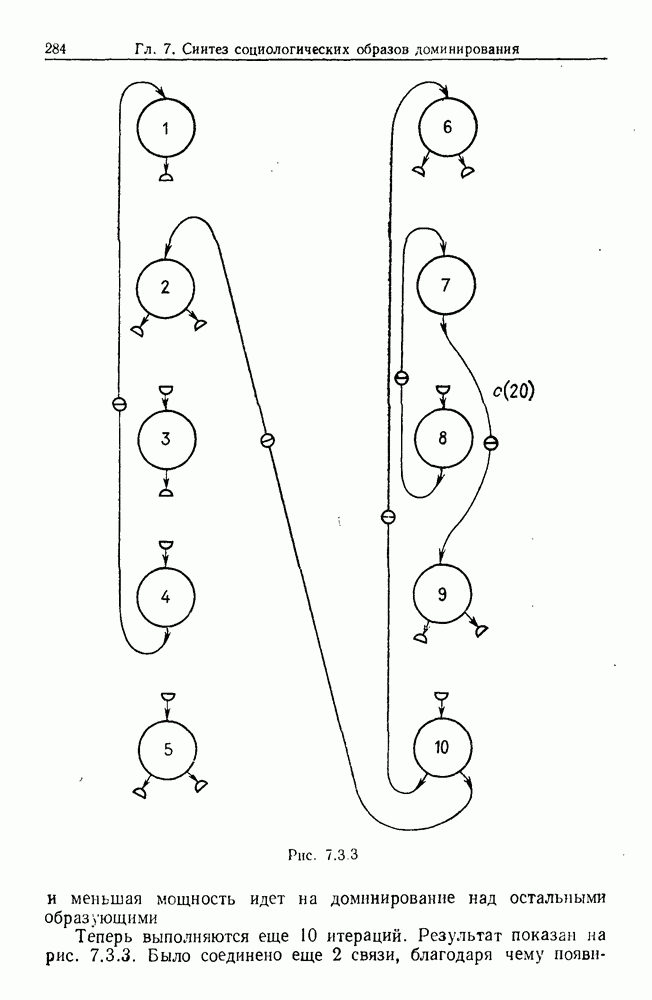
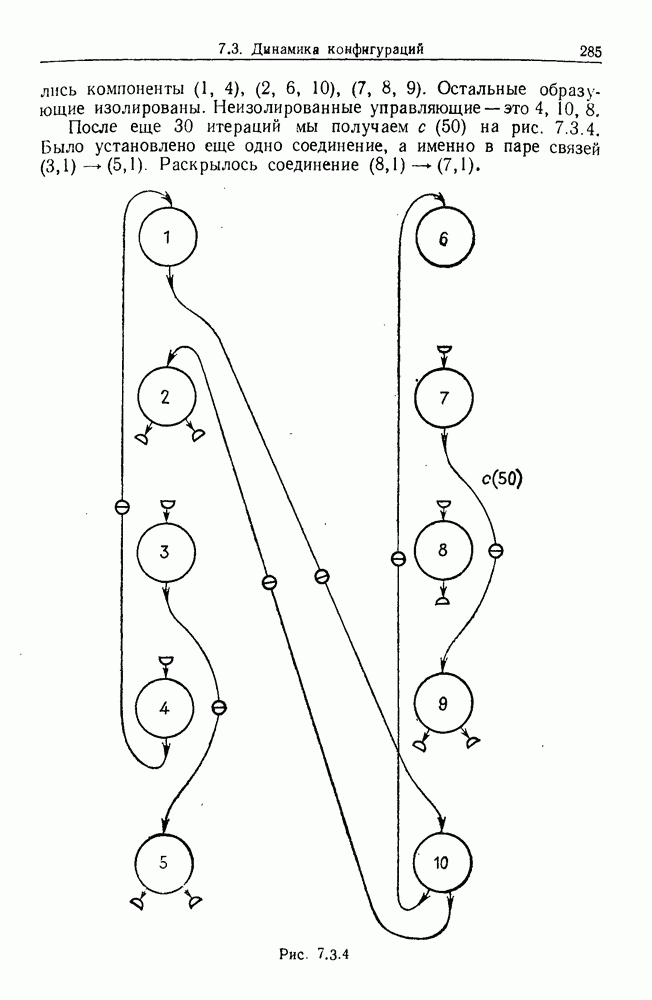
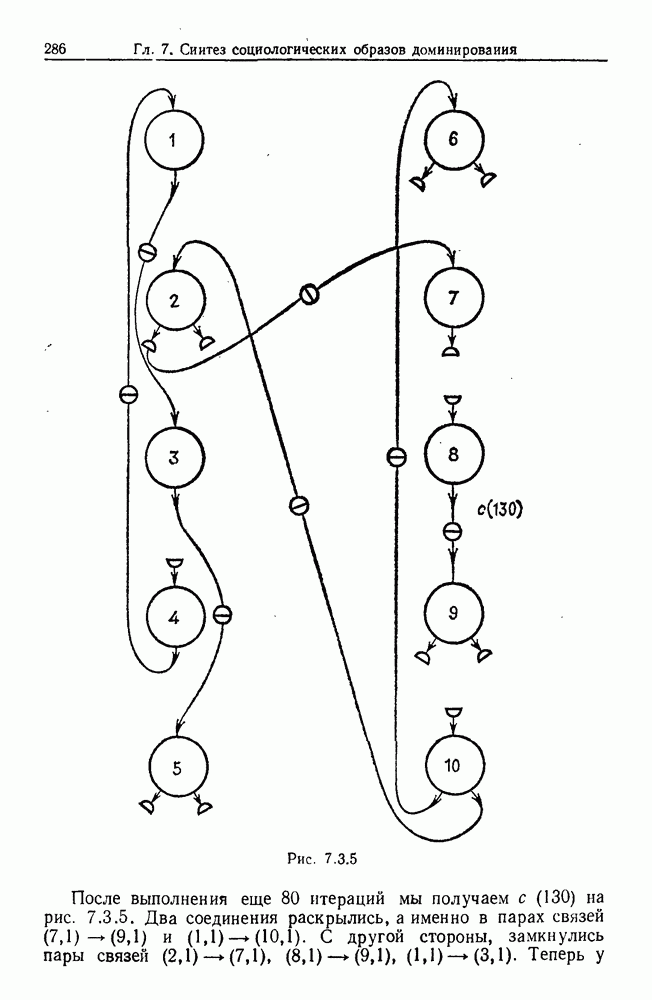
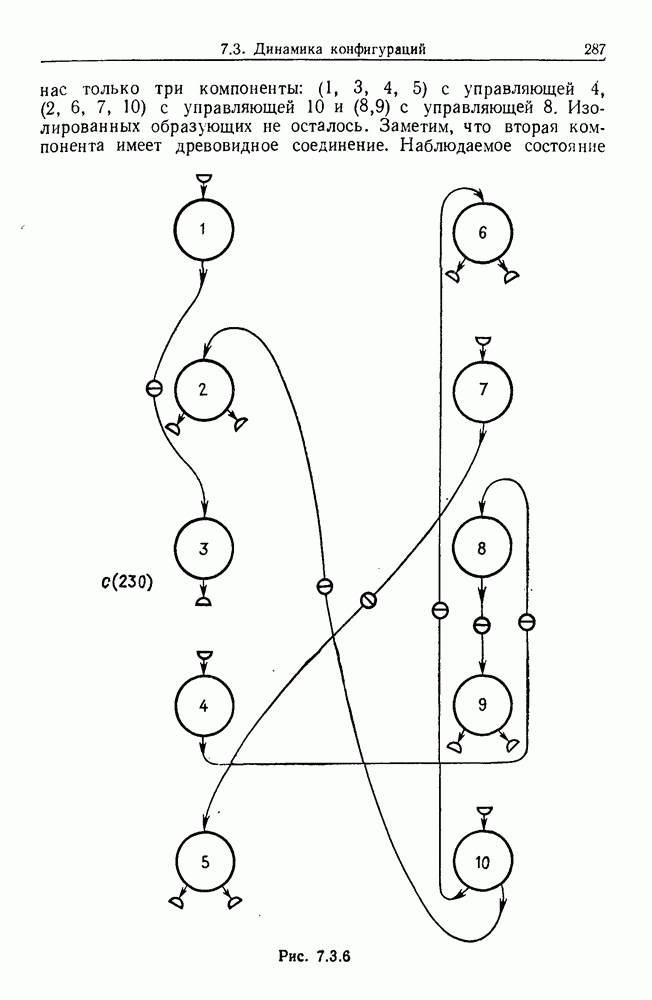
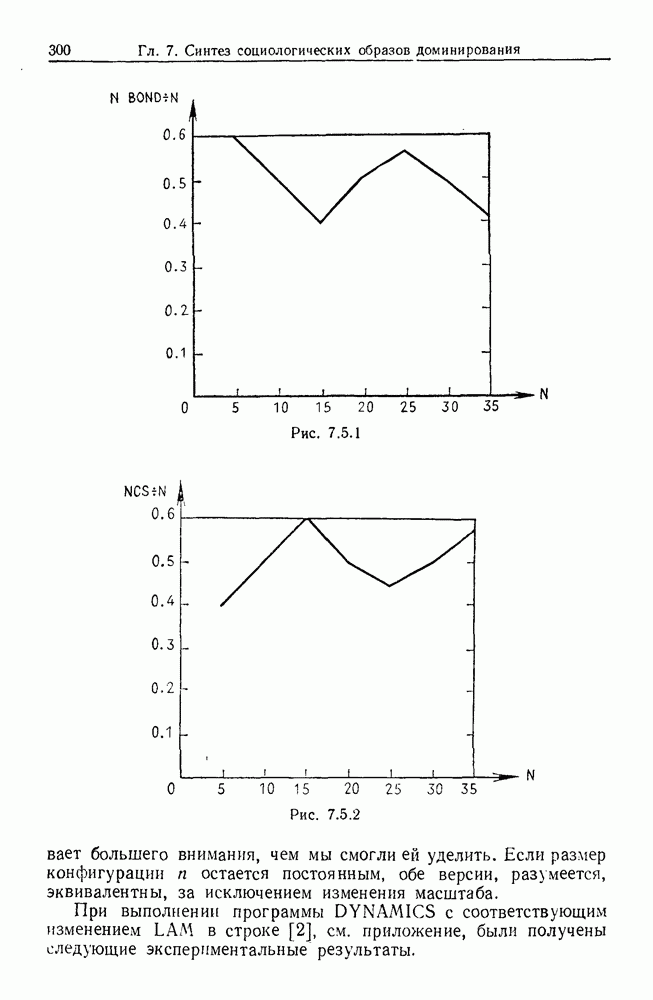
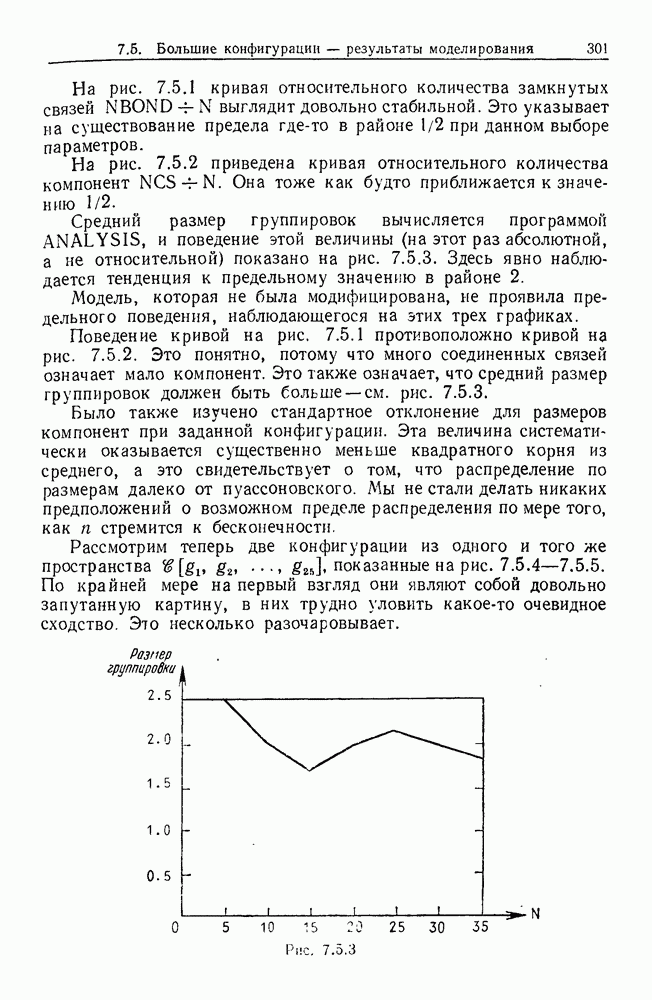
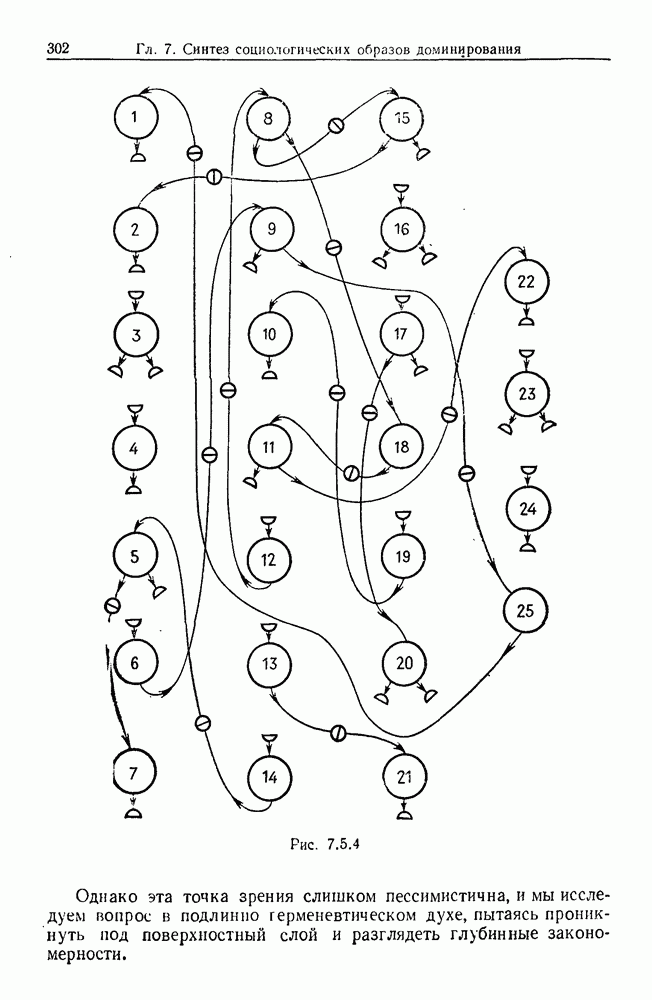
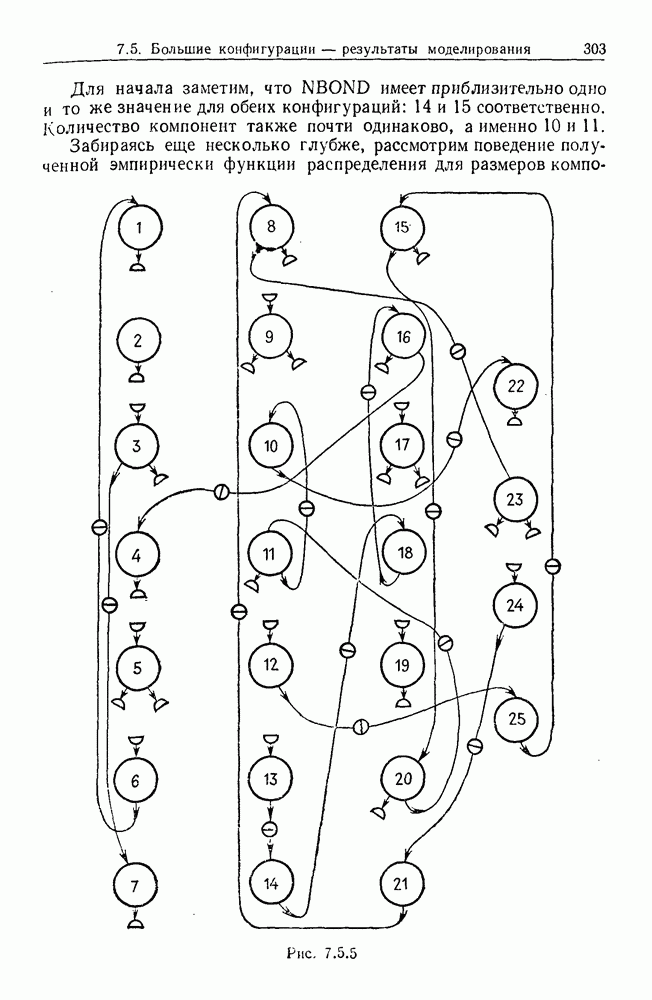
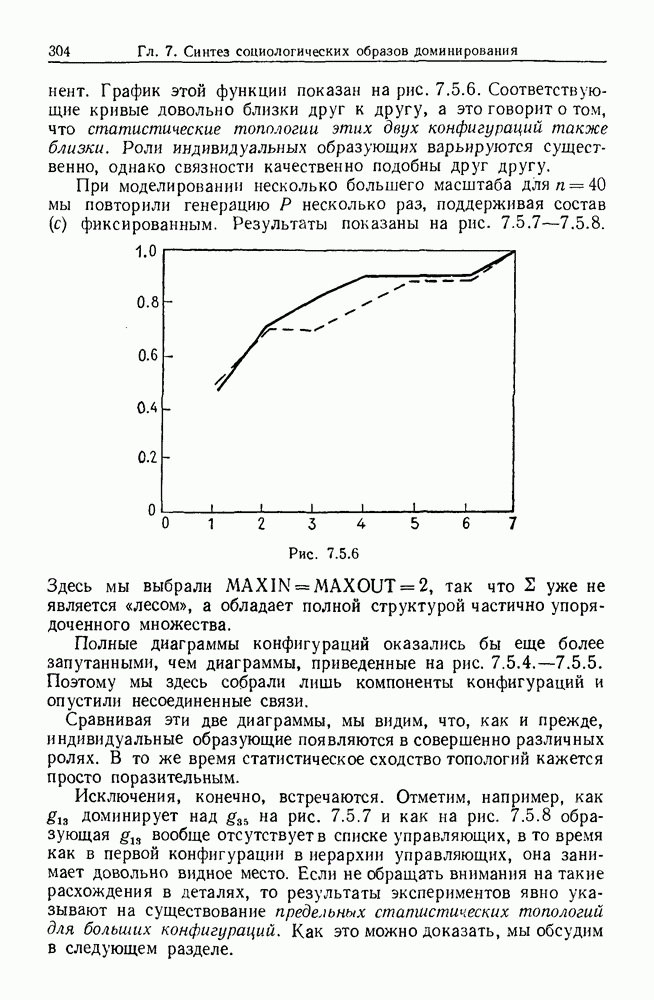
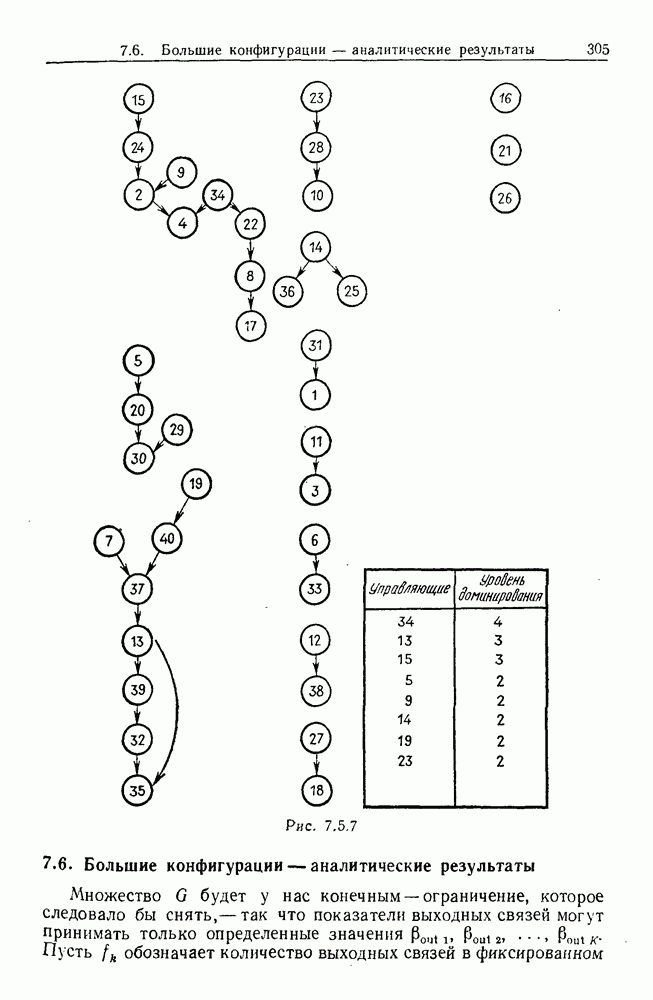
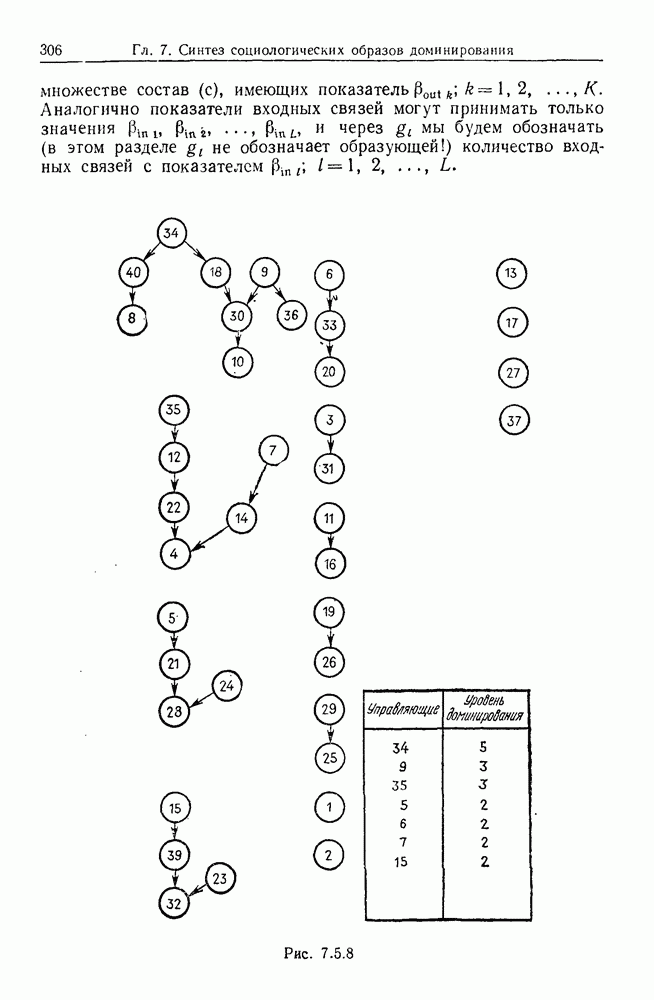
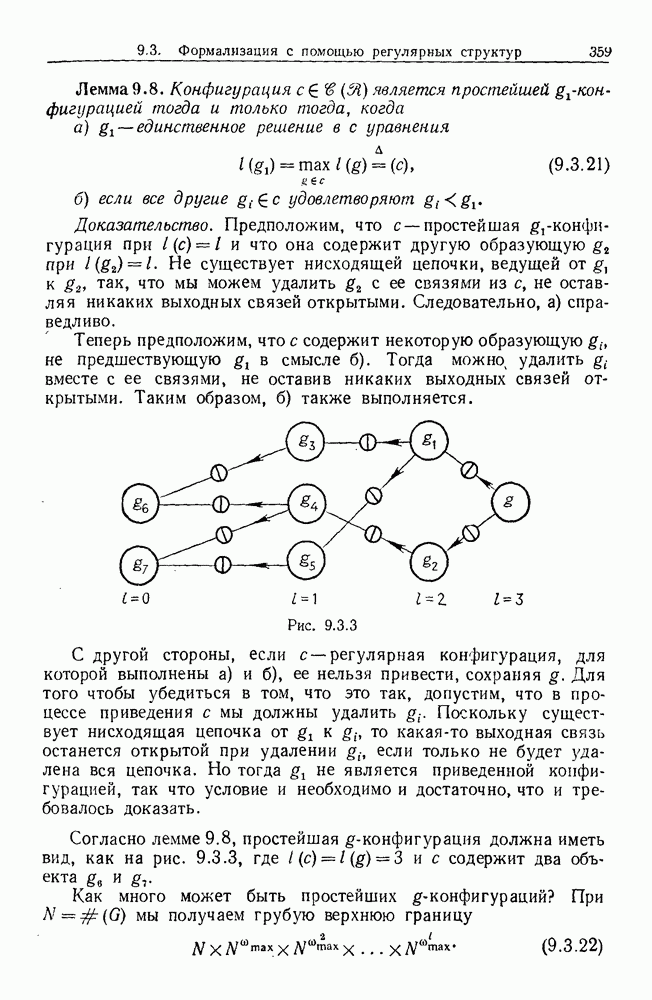
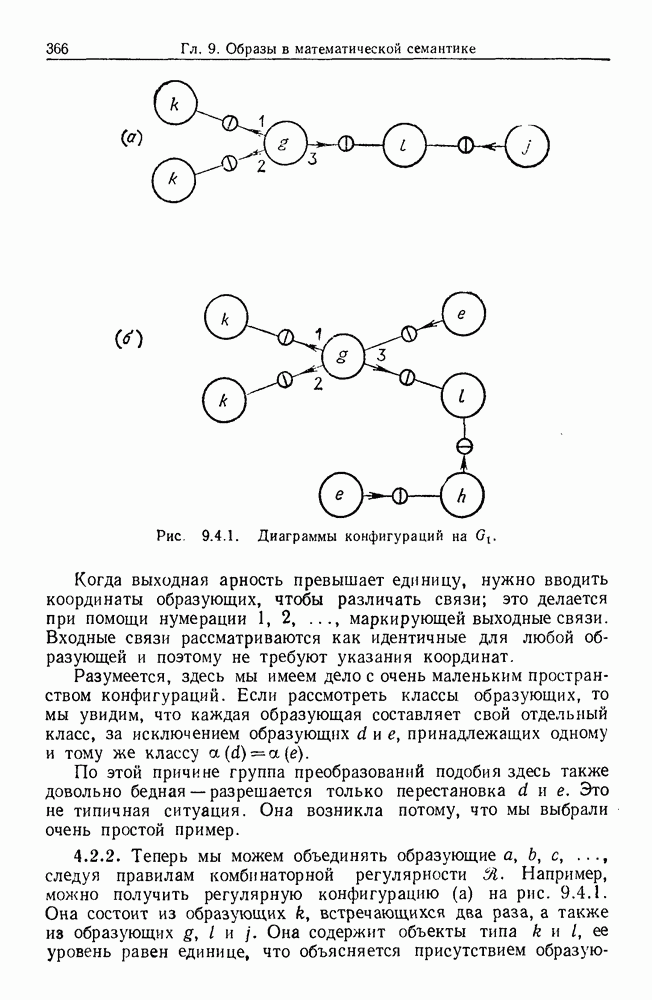
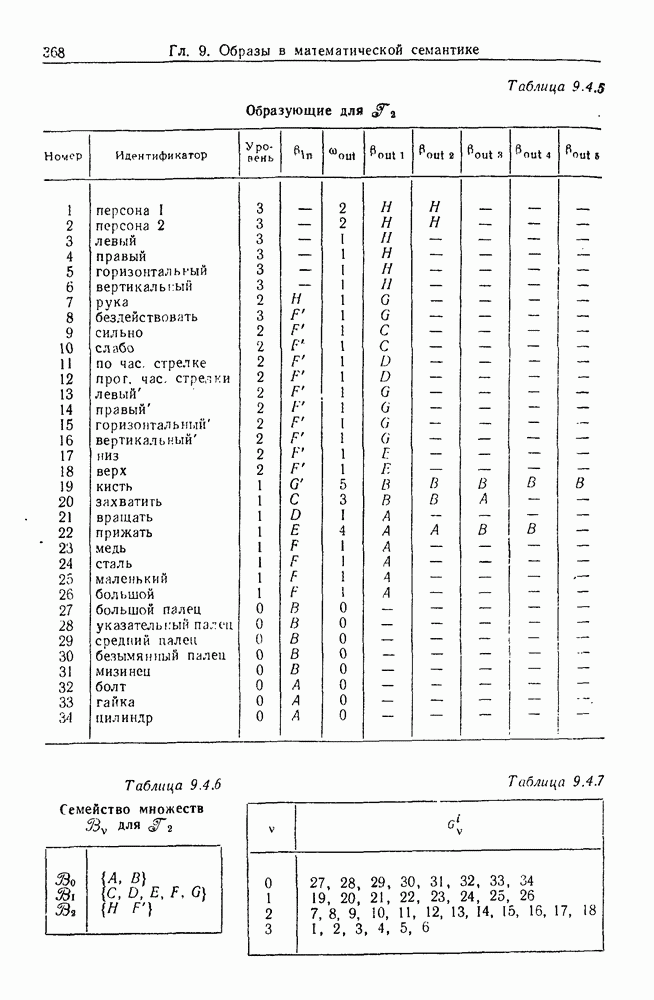
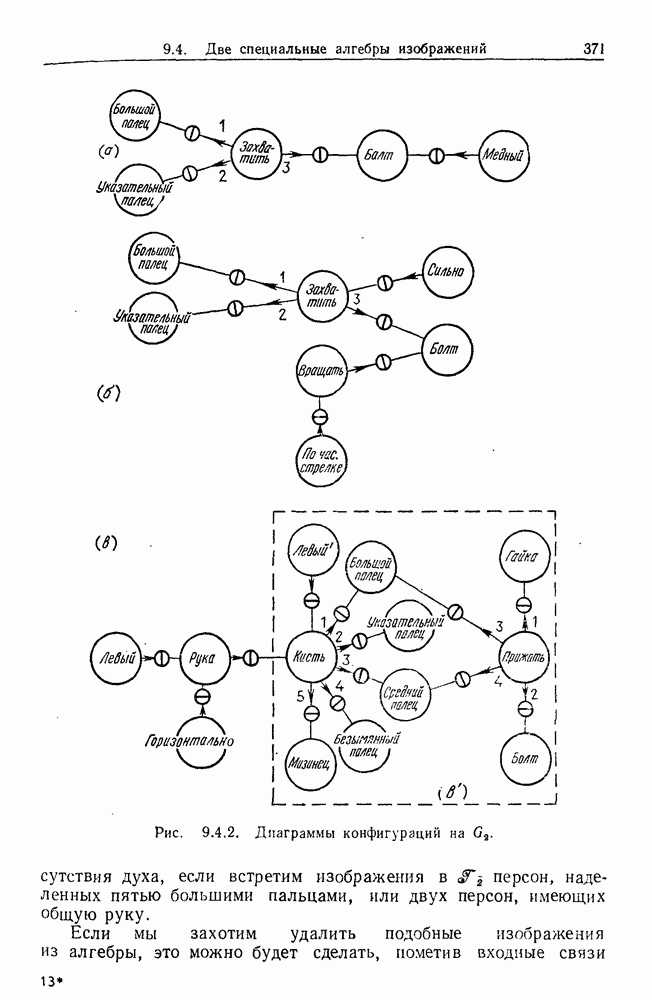
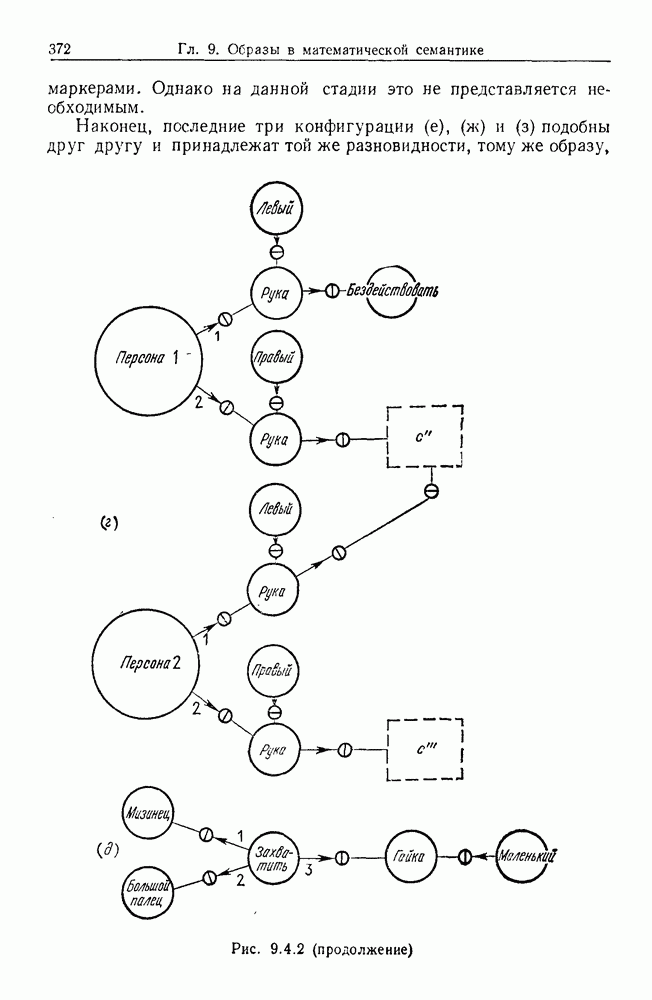
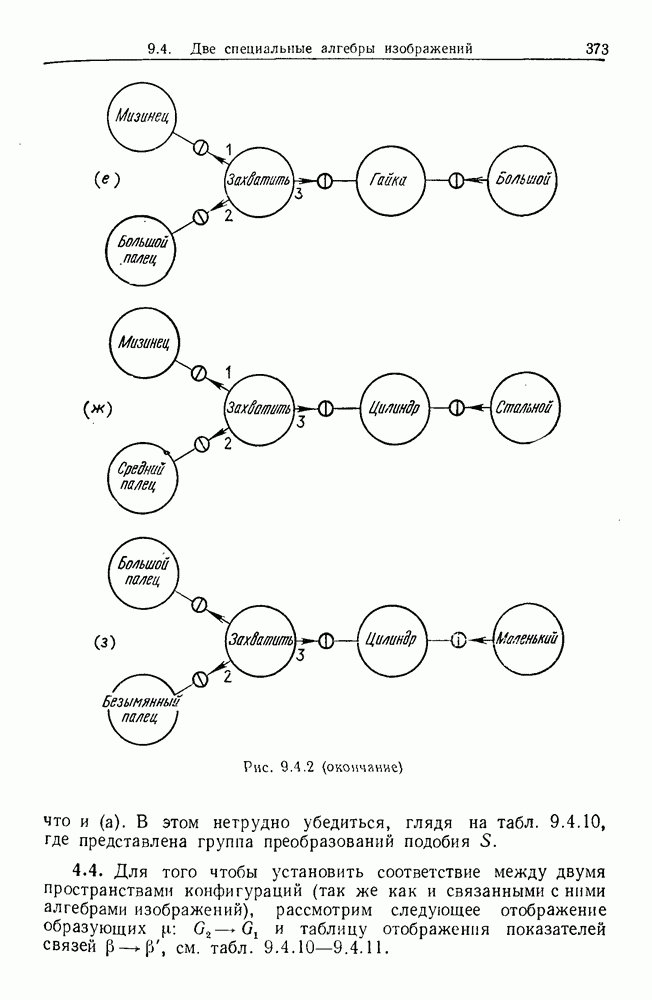
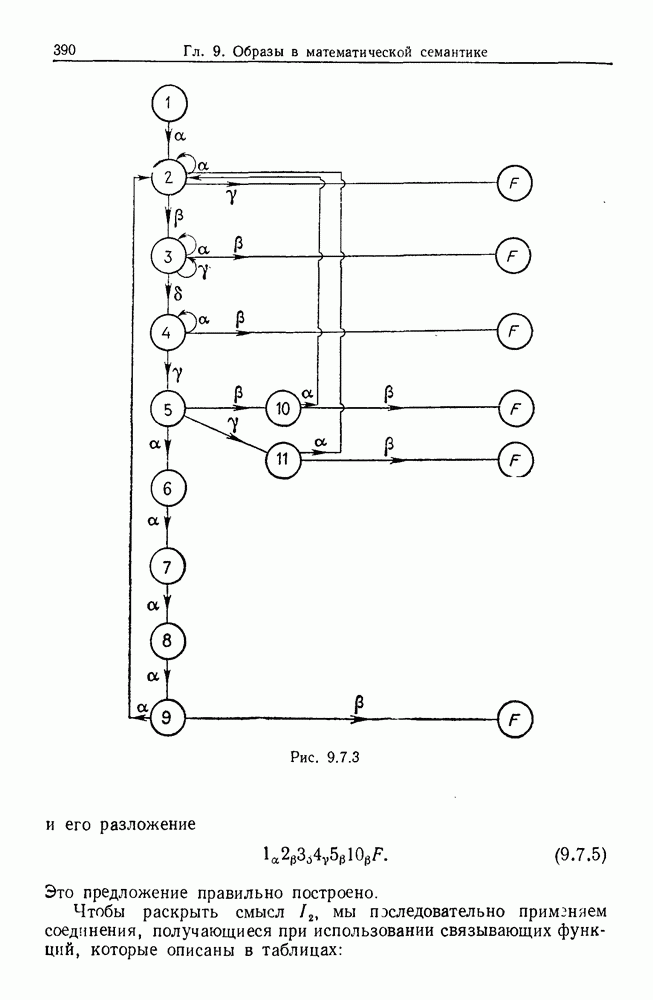
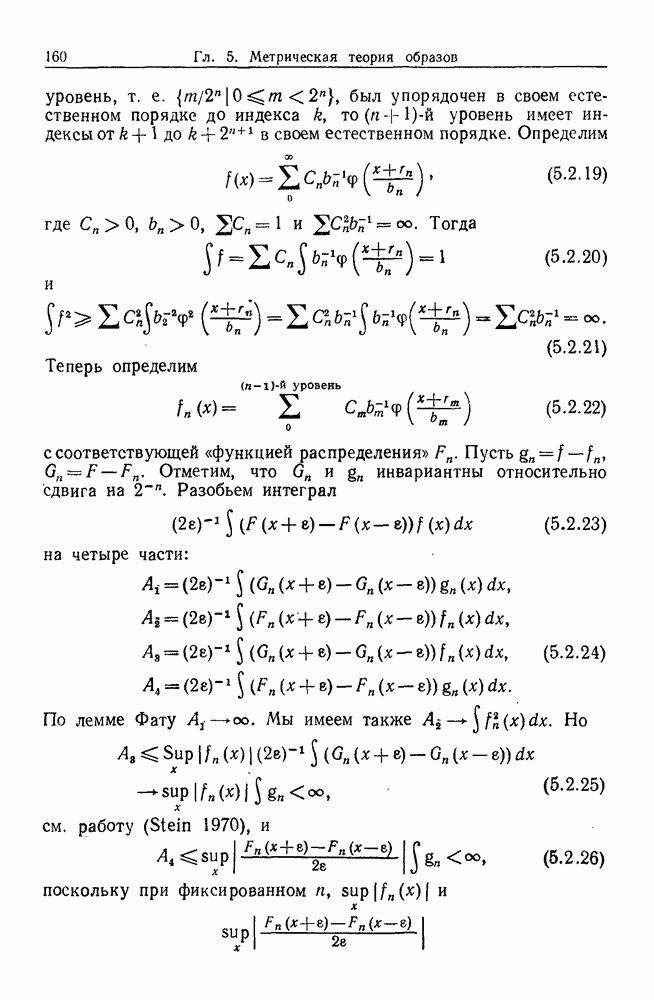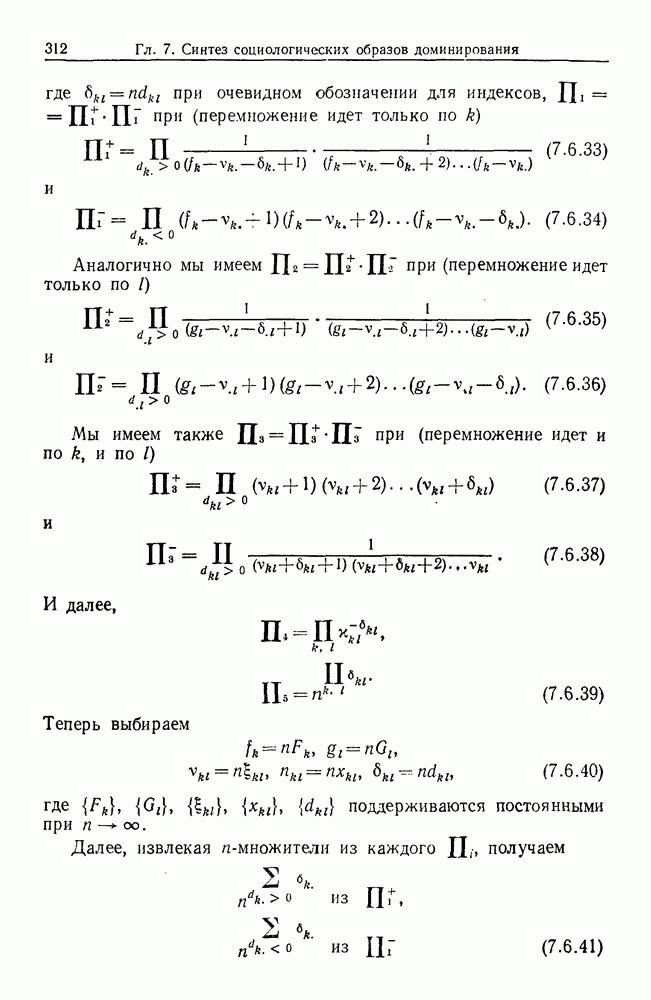9.8. Обучение семантике
Предположим, что мы имеем дело с некоторым фиксированным, но неизвестным семантическим отображением, обратно направленным и выражаемым, как в предыдущем разделе:

Как можно его выявить на основании конечного опыта? Точнее говоря, как можно выявить  при наблюдении последовательности пар изображений
при наблюдении последовательности пар изображений

где  Последовательность представляет наш конечный опыт, и мы опускаем синтаксически корректные, но не имеющие смысла предложения, которые могли нам встретиться.
Последовательность представляет наш конечный опыт, и мы опускаем синтаксически корректные, но не имеющие смысла предложения, которые могли нам встретиться.
Каждое изображение  можно выразить путем перечисления образующих и соединений в одной из конфигураций, из которых состоит изображение. Аналогично каждое предложение
можно выразить путем перечисления образующих и соединений в одной из конфигураций, из которых состоит изображение. Аналогично каждое предложение  можно выразить в виде разложения на последовательность продукций
можно выразить в виде разложения на последовательность продукций
 Мы будем искать отображение из множества продукций во множество образующих — соединений.
Мы будем искать отображение из множества продукций во множество образующих — соединений.
Множество продукций уже задано и оно конечно. Множество элементарных связок может быть бесконечным. Мы ограничим его, предположив, что максимальная задержка конечна. В таком случае мы будем иметь дело с отображениями между двумя конечными множествами. Рассмотрим два конечных множества  у которых
у которых  Неизвестное отображение
Неизвестное отображение  мы должны установить на основании пар множеств
мы должны установить на основании пар множеств  :
:

Разумеется,  обозначает множество всех значений у, полученных отображением а, которое применяется ко всем элементам
обозначает множество всех значений у, полученных отображением а, которое применяется ко всем элементам 
Ничего не было сказано о том, как была порождена последовательность  . В последующем будем предполагать, что она была получена как независимая одинаково распределенная выборка по отношению к заданной вероятностной мере на
. В последующем будем предполагать, что она была получена как независимая одинаково распределенная выборка по отношению к заданной вероятностной мере на  . В качестве такой меры можно было бы принять, например, одну из синтаксически управляемых мер для контекстно-свободных языков, изучавшихся в томе I, или какую-нибудь другую меру, представляющую интерес.
. В качестве такой меры можно было бы принять, например, одну из синтаксически управляемых мер для контекстно-свободных языков, изучавшихся в томе I, или какую-нибудь другую меру, представляющую интерес.
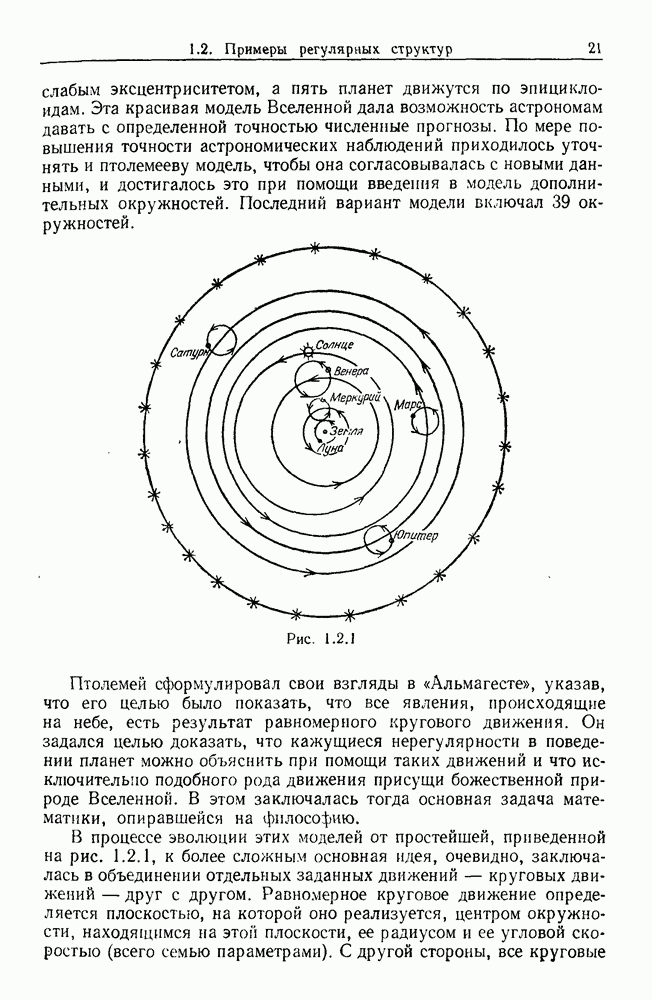
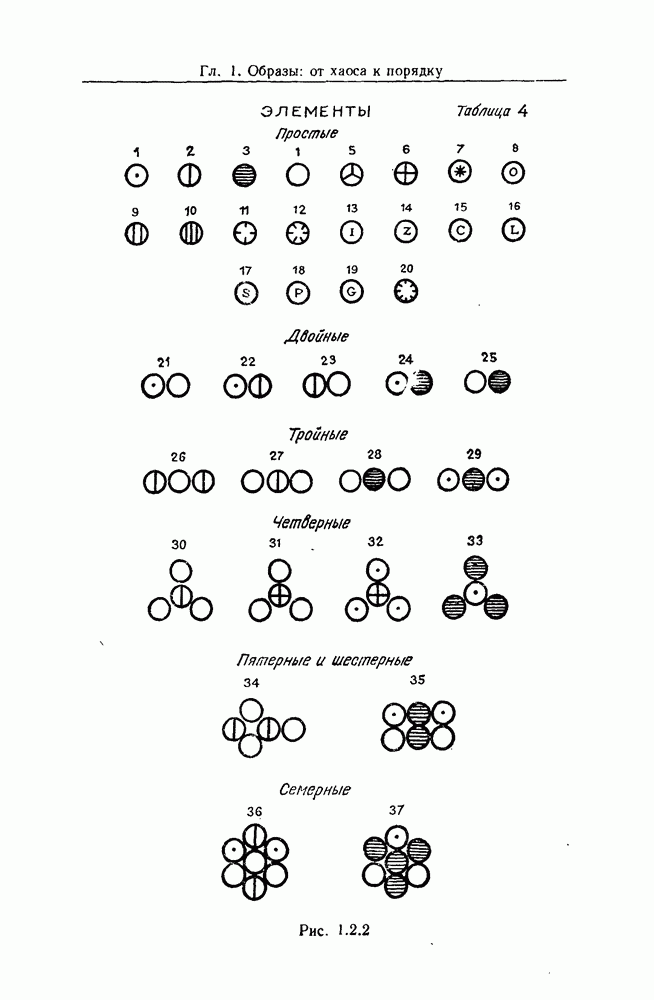
Важно понимать то, что наша проблема была сведена к оцениванию функции, обозначенной здесь через а, когда наблюдаться могут только множества. Похоже на то, что эта задача не изучалась в статистической литературе, поэтому нам придется начать с разработки соответствующих методов.
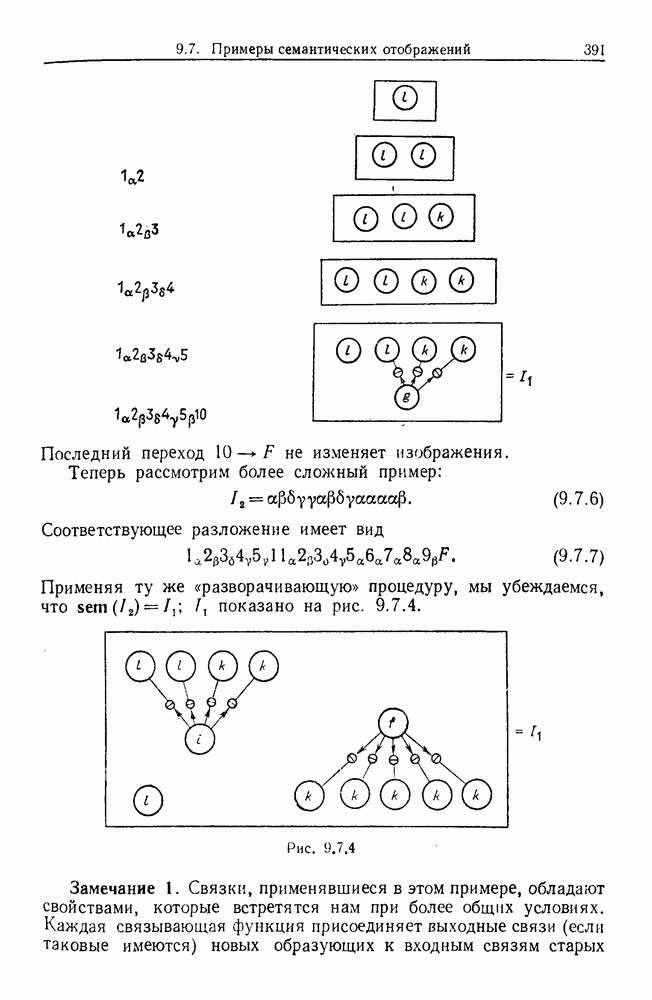
Прежде чем этим заняться, скажем несколько слов о следующем возможном расширении нашей задачи. Когда у нас есть разложение изображения для  оно состоит из цепочки продукций. Мы будем извлекать из этой последовательности информацию таким образом, чтобы оставалось только [множество продукций, встречающихся в цепочке. Конечно, при этом происходит потеря информации. Например, цепочка (1, 2, 2, 7, 14, 11, 7, 2) сводится к множеству {1, 2, 7, 11, 14}.
оно состоит из цепочки продукций. Мы будем извлекать из этой последовательности информацию таким образом, чтобы оставалось только [множество продукций, встречающихся в цепочке. Конечно, при этом происходит потеря информации. Например, цепочка (1, 2, 2, 7, 14, 11, 7, 2) сводится к множеству {1, 2, 7, 11, 14}.
Можно было бы сохранить больше информации, если бы мы также подсчитывали количество вхождений в цепочке. Например, вместо того, чтобы сказать лишь, что  встречалось», мы сказали бы, что
встречалось», мы сказали бы, что  встречалось дважды» и т. д. Другими словами, мы рассматривали бы
встречалось дважды» и т. д. Другими словами, мы рассматривали бы  в (9.8.3) не просто как множество, а как мультимножество, аналогично и для
в (9.8.3) не просто как множество, а как мультимножество, аналогично и для 
Еще лучше было бы считать цепочку упорядоченной, тогда мы бы не теряли информации. Аналогичным образом можно рассматривать вхождения образующих — соединений в  , (31) как частично упорядоченное множество.
, (31) как частично упорядоченное множество.
Теперь мы подготовлены к тому, чтобы работать с этими двумя более информативными версиями задачи, и надеемся, что другие исследователи эту работу проделают.
Возвращаясь к первой версии, снова задаемся вопросом: как оценить а? Будет поучительно проделать это, сначала предположив, что

Позже мы увидим, что происходит при более общих условиях. А теперь можно сразу доказать одно несложное утверждение.
Лемма 9.8.1. Из наблюдений следует, что

где  состоит из
состоит из  элемента
элемента  записана как индикаторная функция. Это самое сильное из возможных утверждений.
записана как индикаторная функция. Это самое сильное из возможных утверждений.
Доказательство. Рассмотрим множество

Очевидно, что  поскольку оба множителя в (9.8.6) имеют в нем 1-й элемент для всех
поскольку оба множителя в (9.8.6) имеют в нем 1-й элемент для всех  Но тогда а
Но тогда а  и, пользуясь тем фактом, что а — гомоморфизм для операций над множествами, так как оно биективно, мы получаем а
и, пользуясь тем фактом, что а — гомоморфизм для операций над множествами, так как оно биективно, мы получаем а 
Усилить (9.8.5) мы не можем. В самом деле, пусть отображение а удовлетворяет (9.8.5). Если  то а
то а  полностью определено. Если
полностью определено. Если  то
то  содержит два различных элемента, скажем
содержит два различных элемента, скажем  причем
причем  Мы утверждаем, что два множества
Мы утверждаем, что два множества  либо идентичны, либо они не пересекаются. Пересечение
либо идентичны, либо они не пересекаются. Пересечение  и
и  можно записать как
можно записать как

где

Ясно, что если  имеют общий элемент, то пересечение (9.8.7) пусто. Но если
имеют общий элемент, то пересечение (9.8.7) пусто. Но если  исключают друг друга, поскольку
исключают друг друга, поскольку  то должно выполняться
то должно выполняться  Это означает.
Это означает.
что

Тогда для заданного  должно быть либо
должно быть либо  либо одна из частей равна 1. В последнем случае (9.8.9) означает, что они обе должны быть равны 1. Поэтому для любого
либо одна из частей равна 1. В последнем случае (9.8.9) означает, что они обе должны быть равны 1. Поэтому для любого  мы имеем
мы имеем  Всномнив определение (9.8.6), мы видим, что
Всномнив определение (9.8.6), мы видим, что  Следовательно,
Следовательно,  представляет собой разбиение
представляет собой разбиение  Введем новое отображение а, которое идентично а, за исключением того, что оно переставляет
Введем новое отображение а, которое идентично а, за исключением того, что оно переставляет  Заметим, что а отображает множества
Заметим, что а отображает множества  так что построение возможно. Но а не противоречит наблюдениям, поэтому (9.8.5) — это наиболее сильное утверждение, основанное на наблюдениях, что и требовалось доказать.
так что построение возможно. Но а не противоречит наблюдениям, поэтому (9.8.5) — это наиболее сильное утверждение, основанное на наблюдениях, что и требовалось доказать.
Замечание 1. В доказательстве несколько раз используется свойство гомоморфизма. Это основано на том предположении, что а биективно.
Для заданной последовательности множеств мы будем говорить, что она полная, если  для любого
для любого 
Теорема 9.8.1. При  мы сможем обучиться а состоятельно (с вероятностью 1) тогда и только тогда, когда носитель
мы сможем обучиться а состоятельно (с вероятностью 1) тогда и только тогда, когда носитель  образует полное можество.
образует полное можество.
Доказательство. Предположим, что носитель  — полное множество. Тогда с вероятностью 1 бесконечная одинаково распределенная выборка будет содержать каждый элемент носителя. Тогда по лемме 9.8.1 мы однозначно получаем а.
— полное множество. Тогда с вероятностью 1 бесконечная одинаково распределенная выборка будет содержать каждый элемент носителя. Тогда по лемме 9.8.1 мы однозначно получаем а.
С другой стороны, чтобы при  с вероятностью 1 (а это требуется в лемме), мы должны рассуждать следующим образом. По мере роста
с вероятностью 1 (а это требуется в лемме), мы должны рассуждать следующим образом. По мере роста  мы будем получать все больше сомножителей в пересечении, в правой части (9.8.6). Последовательность множеств монотонна и, стало быть, имеет предел, почти наверное равный
мы будем получать все больше сомножителей в пересечении, в правой части (9.8.6). Последовательность множеств монотонна и, стало быть, имеет предел, почти наверное равный

где  носитель
носитель  Однако
Однако  , тогда и только тогда, когда
, тогда и только тогда, когда  образует полное множество, что и требовалось доказать.
образует полное множество, что и требовалось доказать.
Для заданного множества  можно указать алгоритм, который позволит определить, полное оно или нет. Это можно проделать при помощи ортогонализации Грама—Шмидта (последовательно) или непосредственно.
можно указать алгоритм, который позволит определить, полное оно или нет. Это можно проделать при помощи ортогонализации Грама—Шмидта (последовательно) или непосредственно.
Случай, когда Р, очевидно, обладает полнотой — это носитель  все множества встречаются с положительной вероятностью.
все множества встречаются с положительной вероятностью.
Теперь обратимся к несколько более сложному вопросу: какова скорость обучения? Чтобы обеспечить полноту, предположим, что мы имеем дело с только что упомянутой ситуацией, когда носитель  Например, все множества
Например, все множества  могут иметь одну и ту же вероятность
могут иметь одну и ту же вероятность  равномерное распределение на
равномерное распределение на  На этот вопрос дает ответ следующий результат (см. Примечания А).
На этот вопрос дает ответ следующий результат (см. Примечания А).
Теорема 9.8.2. Если носитель  то вероятность того, что мы узнаем а полностью после
то вероятность того, что мы узнаем а полностью после  испытаний, удовлетворяет соотношению
испытаний, удовлетворяет соотношению

где

 есть количество
есть количество  реализующих максимум.
реализующих максимум.
Доказательство. Чтобы определить вероятность того,  полна,
полна,  введем для
введем для  событие
событие  с индикаторной функцией
с индикаторной функцией

Тогда событие  «система полна» можно выразить так:
«система полна» можно выразить так:

Но в этом случае

где мы упорядочили все пары  и рассматриваем только
и рассматриваем только  суммировании.
суммировании.
При  используя свойство независимости и одинаковой распределенности, получаем
используя свойство независимости и одинаковой распределенности, получаем

где

Отсюда следует, что асимптотически значимые члены первой суммы в (9.8.15) вместе дают вклад  и остается показать, что прочими членами можно пренебречь. Рассмотрим член (9.8.15) вида
и остается показать, что прочими членами можно пренебречь. Рассмотрим член (9.8.15) вида

где  Сначала предположим, что все четыре индекса различны. Тогда для вероятности (9.8.18) имеем
Сначала предположим, что все четыре индекса различны. Тогда для вероятности (9.8.18) имеем

где

при

Если  томы имеем
томы имеем  так что
так что  однако
однако

не является тавтологией; это выражение имеет значение «ложь», например, когда  Поэтому
Поэтому  и
и

и соответствующие члены в (9.8.15) асимптотически пренебрежимо малы.
Теперь предположим, что  отличается от
отличается от  и от
и от  Тогда (9.8.19) следует заменить иа
Тогда (9.8.19) следует заменить иа

где

при

Те же рассуждения, что и выше, приводят к булевой функции

которая принимает значение «ложь», например, когда 
Оставшиеся члены рассматриваются аналогично. Таким образом, теорема доказана.
Замечание 1. При заданном уровне  мы можем ожидать полной системы наблюдений, если
мы можем ожидать полной системы наблюдений, если  по меньшей мере (заметьте,
по меньшей мере (заметьте,
что  ) равно
) равно

В частном случае, когда Р равномерно распределена на  мы имеем
мы имеем  при всех
при всех  так что
так что  Если основание логарифма в (9.8.28) равно 2, то мы получаем
Если основание логарифма в (9.8.28) равно 2, то мы получаем

Здесь множитель 2 кажется противоестественным!
В небольшом математическом эксперименте Р было принято равномерным и выборка на  продолжалась до получения полной системы. Для проверки полноты была написана программа на языке
продолжалась до получения полной системы. Для проверки полноты была написана программа на языке  Наблюдались следующие размеры выборки Т:
Наблюдались следующие размеры выборки Т:
(см. скан)
Поведение, предсказанное в (9.8.29), по-видимому, согласуется с наблюдаемым достаточно хорошо для больших значений 
Замечание 2. Старший член  не обладает устойчивостью. В самом деле, можно изменить Р на произвольно маленькую величину, такую, что
не обладает устойчивостью. В самом деле, можно изменить Р на произвольно маленькую величину, такую, что  не изменится, однако
не изменится, однако  изменится
изменится 
Замечание 3. В связи с выражением (9.8.11) естественно определить асимптотическую скорость обучения как

В рассматриваемом случае  Худшие случаи имеют место, когда
Худшие случаи имеют место, когда  в (9.8.12) велико, так что для некоторой пары
в (9.8.12) велико, так что для некоторой пары  близко к 1. Обучение происходит быстро, если все значения
близко к 1. Обучение происходит быстро, если все значения  малы, и возникает вопрос: каково минимальное значение
малы, и возникает вопрос: каково минимальное значение  когда
когда  фиксировано? Здесь ситуация менее ясна, чем в противоположном крайнем случае, и ответ дает теорема 9.8.3.
фиксировано? Здесь ситуация менее ясна, чем в противоположном крайнем случае, и ответ дает теорема 9.8.3.
Теорема 9.8.3. При заданном  справедливо соотношение
справедливо соотношение

где квадратные скобки означают целую часть и минимум берется по всем Р.
Доказательство. Введем индикаторную функцию

и заметим, что

так что

Возводя в квадрат  в (9.8.34) и замечая, что
в (9.8.34) и замечая, что  мы можем записать
мы можем записать

при  Этот квадратный трехчлен достигает минимума при
Этот квадратный трехчлен достигает минимума при 
У нас  — случайная переменная, принимающая всевозможные значения из
— случайная переменная, принимающая всевозможные значения из  . При четном
. При четном  мы получаем неравенство прямым вычислением (квадратные скобки опять обозначают целую часть величины)
мы получаем неравенство прямым вычислением (квадратные скобки опять обозначают целую часть величины)

При нечетном  поскольку
поскольку  может принимать только целые значения; мы вместо этого получаем лишь
может принимать только целые значения; мы вместо этого получаем лишь

Следовательно, (9.8.36) и (9.8.37) дают

Однако

Отсюда, как и утверждалось,

Из метода доказательства ясно, что для выполнения равенства в (9.8.40) мы должны иметь для четных значений 

и для нечетных 

Чтобы показать, что граница (9.8.40) достигается, выберем вектор  в котором число единиц равно
в котором число единиц равно  если
если  четно, и
четно, и  если
если  нечетно. Применим к
нечетно. Применим к  все перестановки и определим Р так, чтобы каждая из них имела одну и ту же вероятность
все перестановки и определим Р так, чтобы каждая из них имела одну и ту же вероятность  Тогда Р симметрична, так что все
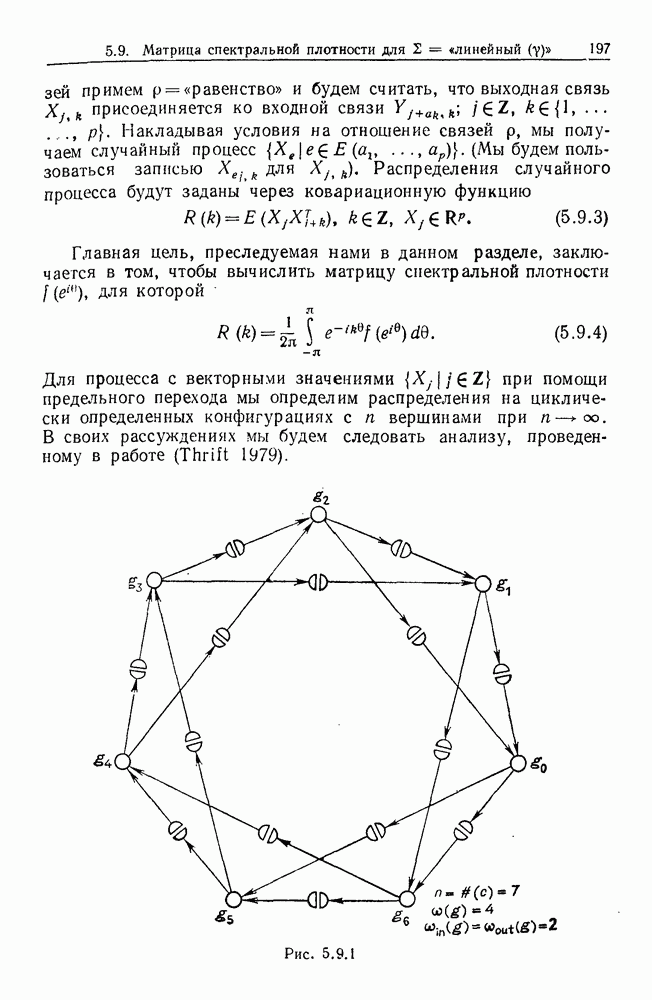
Тогда Р симметрична, так что все  равны между собой. Но поскольку
равны между собой. Но поскольку  удовлетворяет (9.8.41) или (9.8.42), то это общее значение
удовлетворяет (9.8.41) или (9.8.42), то это общее значение  должно удовлетворять
должно удовлетворять

и граница в (9.9.40) достигается, что и требовалось доказать.
Оценка а в (9.8.5) будет называться алгоритмом пересечения, чтобы отличить его от других алгоритмов, с которыми мы познакомимся ниже. Согласно теореме 9.8.1, если носитель Р образует полное множество, алгоритм пересечения с границей сходится к правильному отображению. Более того, нам известна асимптотическая скорость сходимости, которую дает теорема 9.8.2, и асимптотическая скорость обучения равна  при
при  определенном в (9.8.12).
определенном в (9.8.12).
Отсюда следует, что если Р не очень неравномерна на 2, то естественно ожидать, что отображение  будет найдено быстро. Если же Р очень неравномерна, то не приходится ожидать ничего хорошего. Крайний случай имеет место, когда Р дает нулевую вероятность многим подмножествам X, так что носитель оказывается неполным. В такой ситуации мы не можем надеяться, что процесс сойдется к правильному
будет найдено быстро. Если же Р очень неравномерна, то не приходится ожидать ничего хорошего. Крайний случай имеет место, когда Р дает нулевую вероятность многим подмножествам X, так что носитель оказывается неполным. В такой ситуации мы не можем надеяться, что процесс сойдется к правильному 
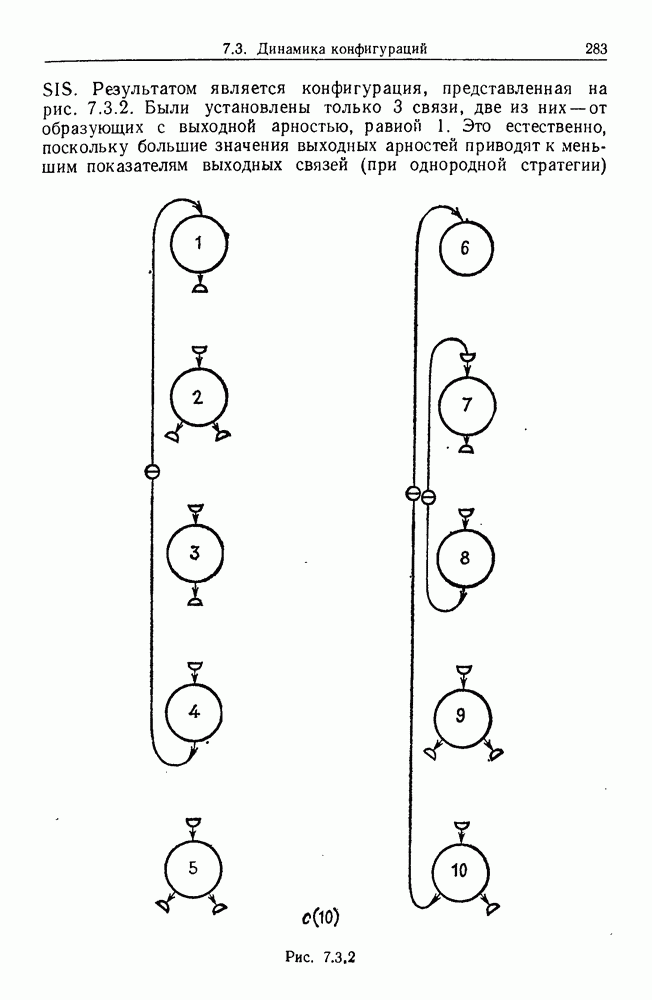
Оценка совершенно другого типа была предложена С. Джеманом. Случайный алгоритм начинает итерационный процесс при
 с произвольно выбранного
с произвольно выбранного  назовем его
назовем его  После наблюдения пары множеств
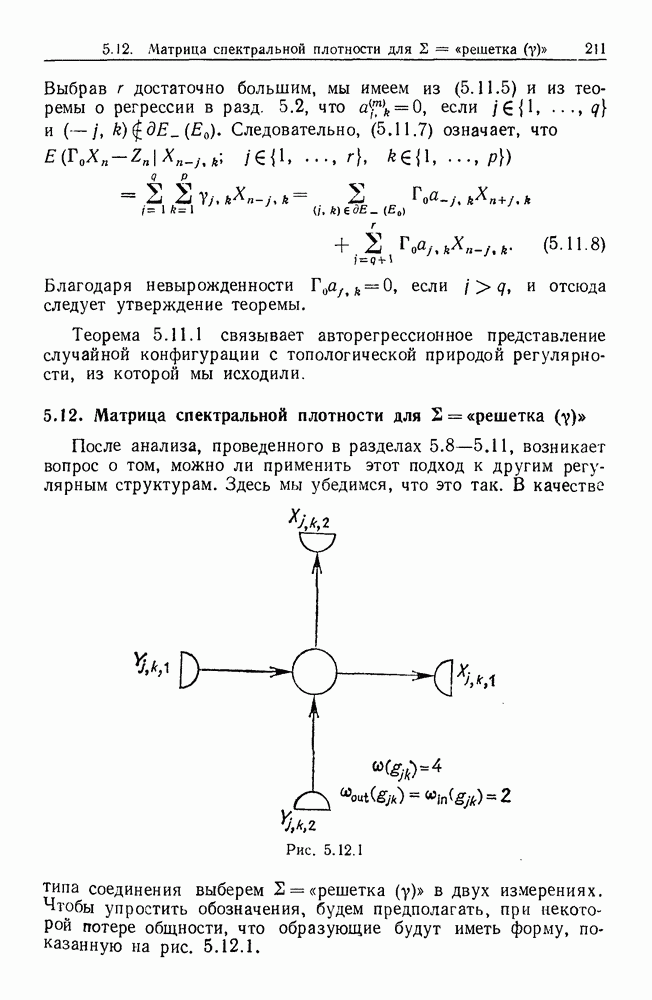
После наблюдения пары множеств  мы не изменяем тех компонент
мы не изменяем тех компонент  которые находятся в согласии с нашей информацией.
которые находятся в согласии с нашей информацией.
Компонента, которая ей противоречит, изменяется случайным образом.

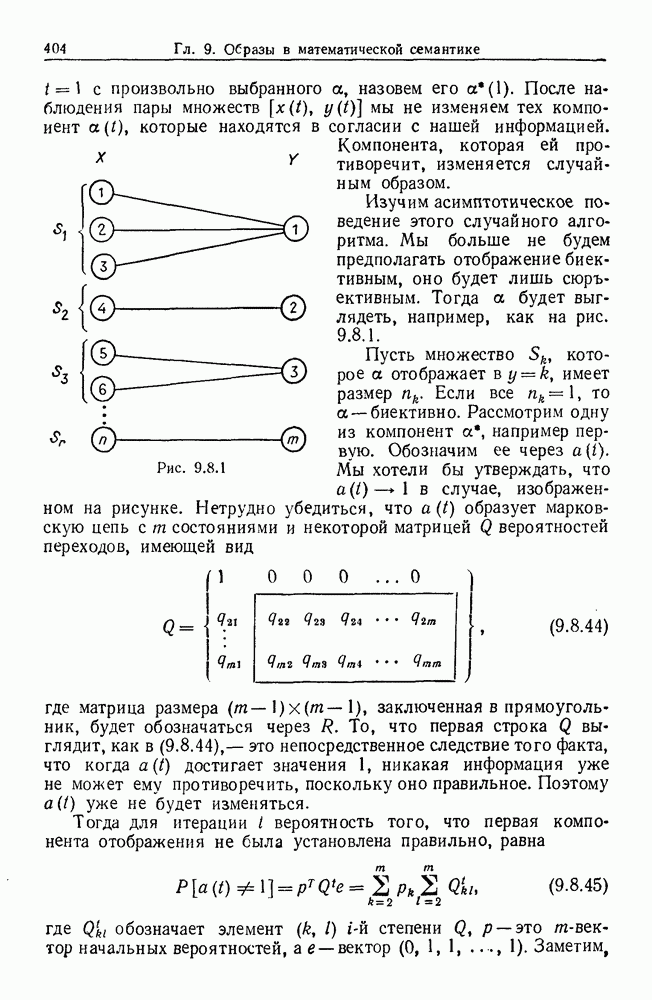
Рис. 9.8.1
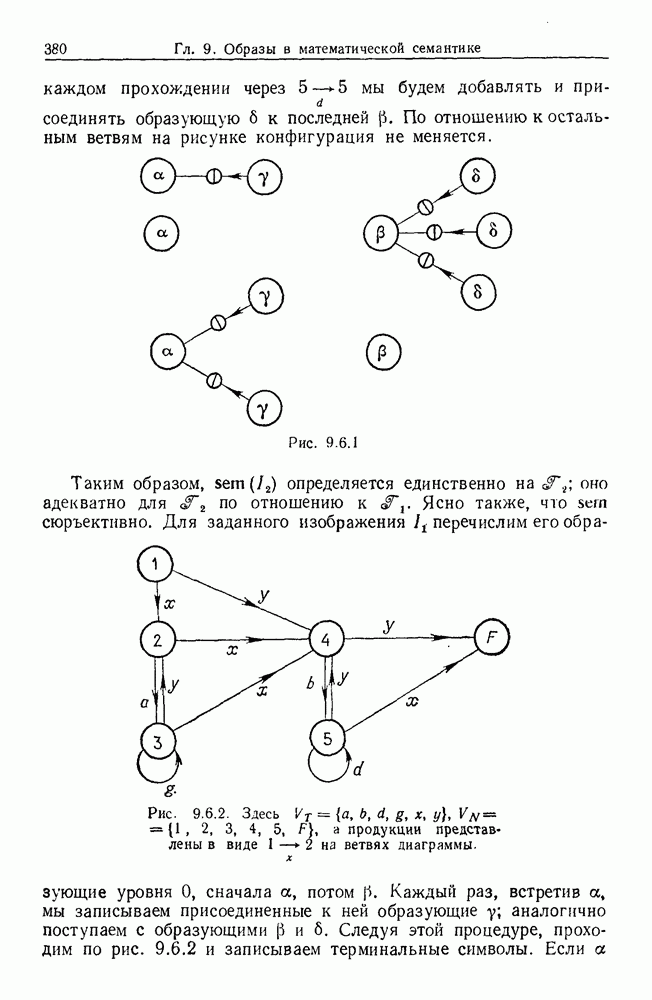
Изучим асимптотическое поведение этого случайного алгоритма. Мы больше не будем предполагать отображение биективным, оно будет лишь сюръективным. Тогда  будет выглядеть, например, как на рис. 9.8.1.
будет выглядеть, например, как на рис. 9.8.1.
Пусть множество  которое а отображает в
которое а отображает в  имеет размер
имеет размер  Если все
Если все  то
то  биективно. Рассмотрим одну из компонент а, например первую. Обозначим ее через
биективно. Рассмотрим одну из компонент а, например первую. Обозначим ее через  Мы хотели бы утверждать, что
Мы хотели бы утверждать, что  в случае, изображенном на рисунке. Нетрудно убедиться, что
в случае, изображенном на рисунке. Нетрудно убедиться, что  образует марковскую цепь с
образует марковскую цепь с  состояниями и некоторой матрицей
состояниями и некоторой матрицей  вероятностей переходов, имеющей вид
вероятностей переходов, имеющей вид

где матрица размера  заключенная в прямоугольник, будет обозначаться через
заключенная в прямоугольник, будет обозначаться через  То, что первая строка
То, что первая строка  выглядит, как в
выглядит, как в  это непосредственное следствие того факта, что когда
это непосредственное следствие того факта, что когда  достигает значения 1, никакая информация уже не может ему противоречить, поскольку оно правильное. Поэтому
достигает значения 1, никакая информация уже не может ему противоречить, поскольку оно правильное. Поэтому  уже не будет изменяться.
уже не будет изменяться.
Тогда для итерации I вероятность того, что первая компонента отображения не была установлена правильно, равна

где  обозначает элемент
обозначает элемент  степени
степени  это
это  -вектор начальных вероятностей,
-вектор начальных вероятностей,  вектор (
вектор ( Заметим,
Заметим,
что только значения элементов  принадлежащих матрице
принадлежащих матрице  появляются в сумме (9.8.45).
появляются в сумме (9.8.45).
Чтобы получить асимптотическую оценку для (9.8.45), рассмотрим  при
при  Это условная вероятность
Это условная вероятность

и чтобы событие  в (9.8.46) имело место, когда
в (9.8.46) имело место, когда  мы должны иметь
мы должны иметь

Чтобы найти вероятность того, что (9.8.47) имеет место, посмотрим на рис. 9.8.1 и допустим, например, что  Чтобы получить информацию, согласно которой мы изменим
Чтобы получить информацию, согласно которой мы изменим  на
на  мы должны иметь вхождение
мы должны иметь вхождение  но не иметь вхождений
но не иметь вхождений  в
в  . Затем мы выберем 1 с вероятностью
. Затем мы выберем 1 с вероятностью  где
где  обозначает индикаторную функцию по крайней мере одного встречающегося
обозначает индикаторную функцию по крайней мере одного встречающегося  Это так, поскольку мы выбираем новое значение с равными вероятностями из множества с размером
Это так, поскольку мы выбираем новое значение с равными вероятностями из множества с размером  Объединение этих вероятностей дает
Объединение этих вероятностей дает

Воспользовавшись неравенством между средним арифметическим и средним геометрическим, приводим (9.8.48) к неравенству

Было бы нетрудно усилить полученное неравенство, но мы здесь не будем этого делать. Вместо этого отметим, что (9.8.49) влечет за собой

при  приводит нас к грубой оценке
приводит нас к грубой оценке

Возвращаясь к (9.8.45), мы видим, что вероятность ошибки для первой компоненты ограничена геометрической прогрессией по мере увеличения количества итераций

Например, если  опять биективно,
опять биективно,  мы видим, что для больших
мы видим, что для больших  достаточно потребовать, чтобы
достаточно потребовать, чтобы  значительно превосходило
значительно превосходило  и мы будем уверены в сходимости любой заданной компоненты оценочного отображения а
и мы будем уверены в сходимости любой заданной компоненты оценочного отображения а  Хотя случайный алгоритм обучается значительно медленнее, чем алгоритм пересечений, он демонстрирует вполне приемлемое поведение при обучении биективным отображениям. Если
Хотя случайный алгоритм обучается значительно медленнее, чем алгоритм пересечений, он демонстрирует вполне приемлемое поведение при обучении биективным отображениям. Если  существенно неинъективно, так что
существенно неинъективно, так что  велико, то поведение этого алгоритма ухудшается.
велико, то поведение этого алгоритма ухудшается.
Для семантического отображения отсутствие инъективности означает, что несколько продукций языка соответствуют одной и той же связывающей функции в  Если
Если  содержит образующие с высоким уровнем, то, как показывает наш эмпирический опыт, часто случается так, что много продукций означают одну и ту же связывающую функцию: а далеко не биективно (см. Примечания Б). Это приводит к более медленной абдукции семантического отображения.
содержит образующие с высоким уровнем, то, как показывает наш эмпирический опыт, часто случается так, что много продукций означают одну и ту же связывающую функцию: а далеко не биективно (см. Примечания Б). Это приводит к более медленной абдукции семантического отображения.