Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
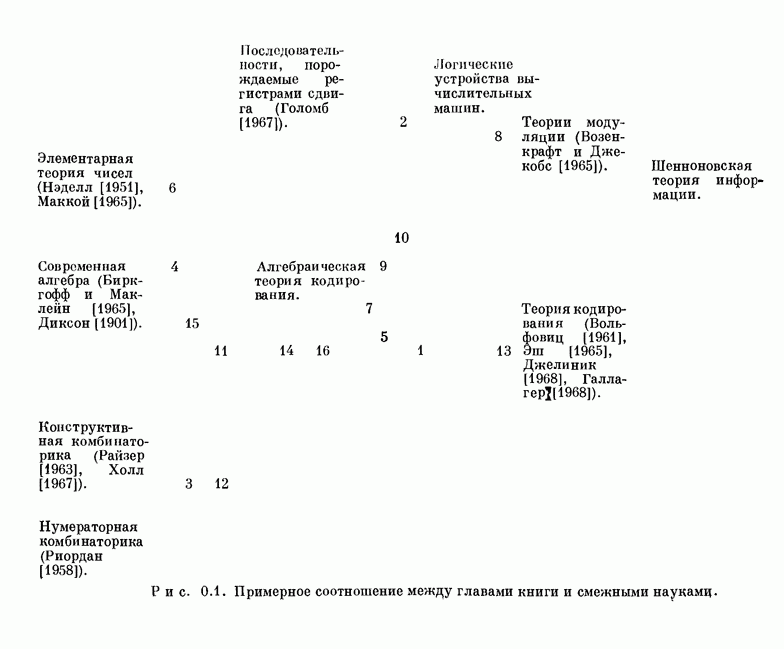
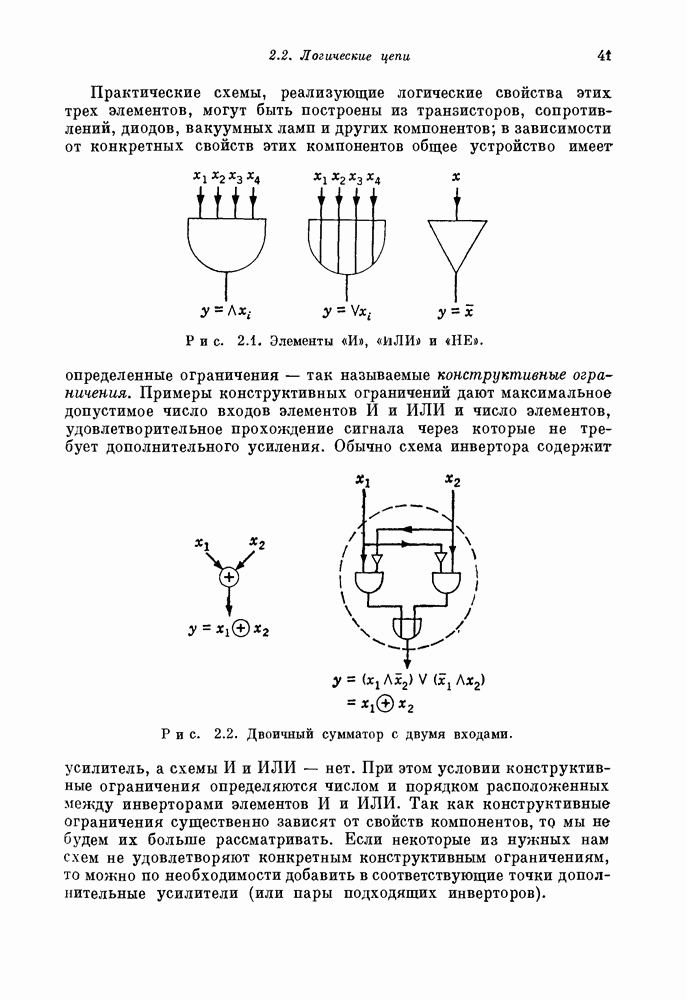
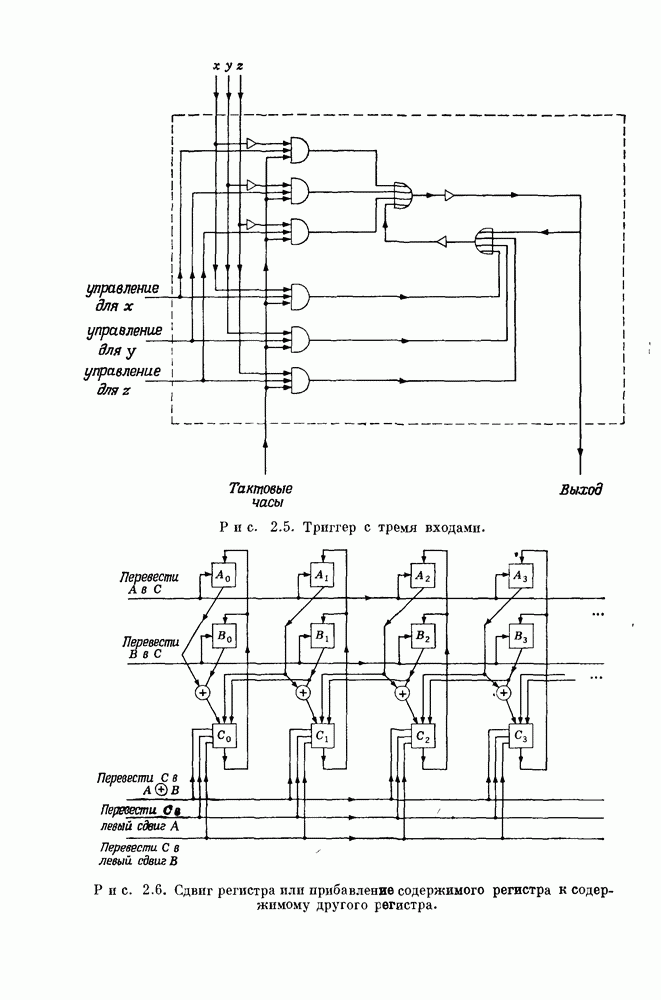
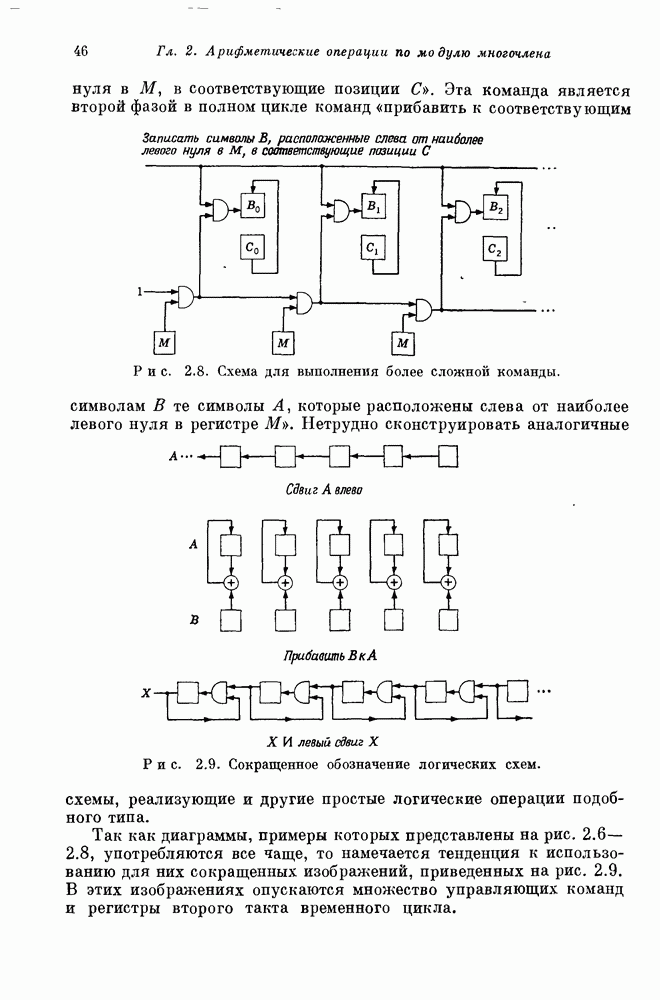
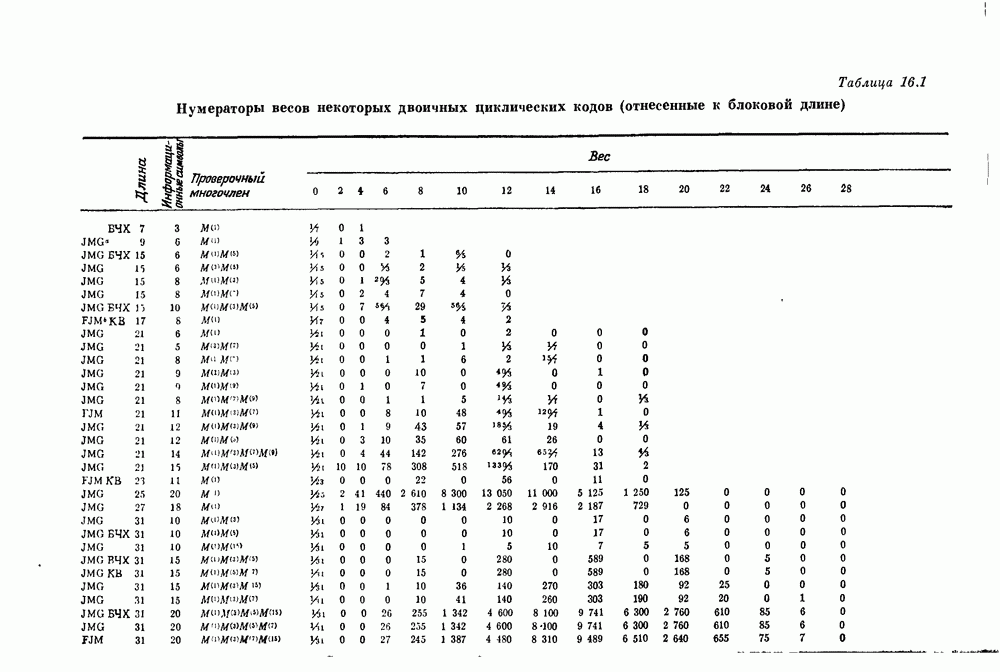
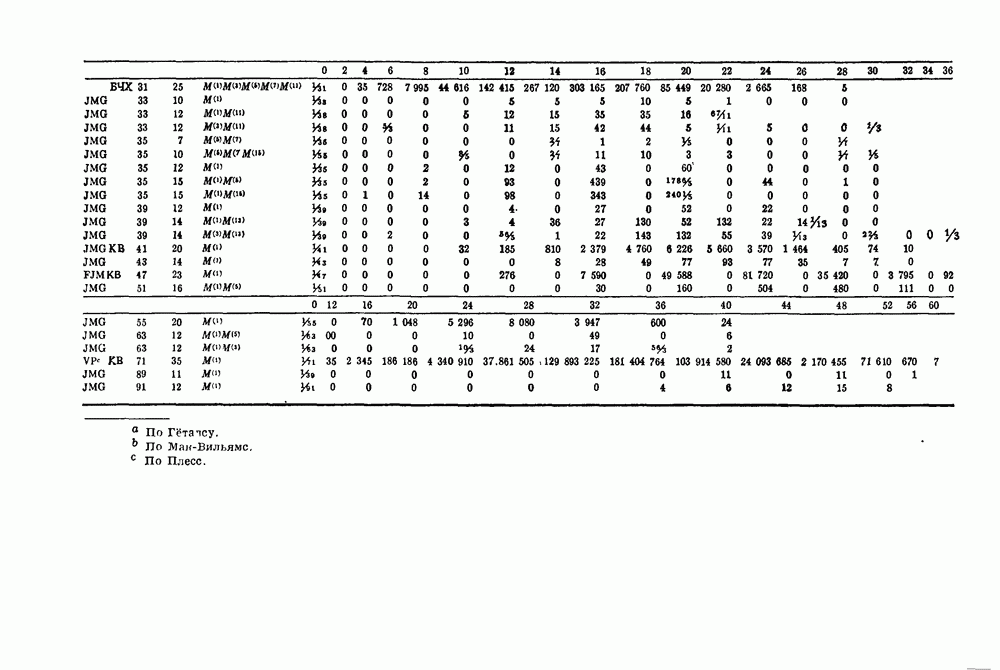
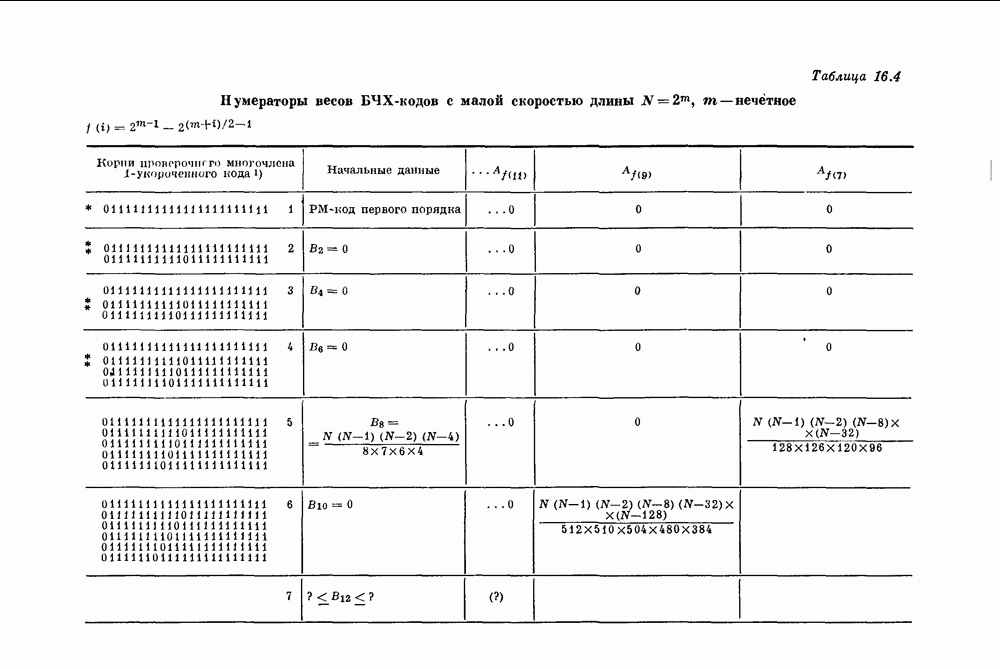
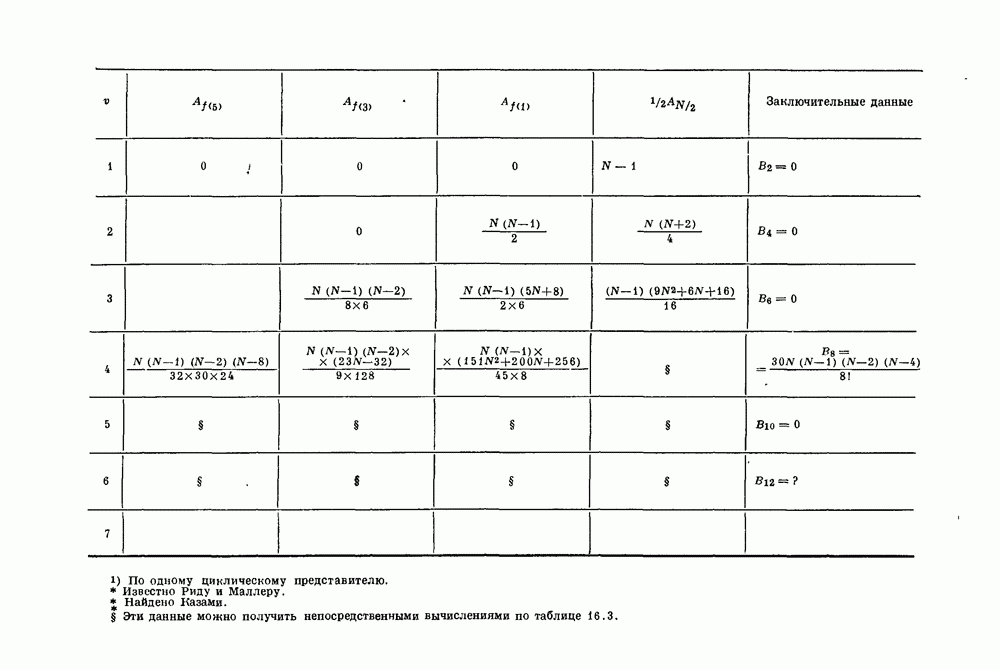
Глава 1. Основные двоичные коды1.1. Коды с повторением и коды с одной проверкой на четностьПредположим, что по каналу с шумом передается последовательность двоичных цифр. Иногда воздействие шума в канале приводит к тому, что переданная единица ошибочно интерпретируется как нуль или переданный нуль ошибочно интерпретируется как единица. Хотя мы не можем предотвратить подобные ошибки в канале, использование кодирования позволяет ограничить их нежелательное воздействие. Основная идея проста. Выберем множество из к двоичных символов сообщения, подлежащих передаче, припишем к ним Для произвольно заданной последовательности из к символов сообщения передатчик должен иметь некоторое правило выбора Если канал достаточно зашумлен, то независимо от передававшегося кодового слова на выходе может быть получена любая из Одним из простейших примеров двоичных кодов являются коды с повторением с следующее правило. Подсчитывается число нулей и число единиц в полученной последовательности. Если нулей получено больше, чем единиц, то выносится решение, что передаваемое кодовое слово состояло из нулей; если единиц получено больше, чем нулей, то выносится решение, что передаваемое кодовое слово состояло из единиц. Если число нулей оказывается равным числу единиц, то решение не принимается. Ясно, что это правило декодирования позволяет декодировать правильно во всех случаях, когда шум в канале искажает меньше половины символов в каждом блоке. Если шум канала искажает точно половину символов некоторого блока, то декодер фиксирует отказ от декодирования: он не может декодировать полученное слово ни в одно из возможно передававшихся сообщений В наших рассмотрениях отказ от декодирования предпочтительнее ошибки декодирования, а правильное декодирование предпочтительнее обеих этих возможностей. Конечно, модифицируя алгоритм декодирования, часто можно изменить соотношения между отказами и ошибками декодирования. Например, рассмотрим код с повторением с блоковой длиной В некоторых приложениях ошибка декодирования равносильна катастрофе, например при получении неправильной команды на ракете или межпланетном корабле. Отказ от декодирования, напротив, может привести лишь к игнорированию команды. Эту небольшую неприятность можно ликвидировать простым повторением команды. В такого рода приложениях предпочтительным является алгоритм со значительной неполнотой декодирования, который умышленно отказывается от декодирования любого достаточно сомнительного полученного слова. Однако существуют другие приложения, в которых нет возможности повторять недекодированные сообщения. В таких случаях отказ от декодирования столь же катастрофичен, как и ошибка декодирования. В приложениях подобного типа желательна максимальная вероятность правильного декодирования. Алгоритм полного декодирования не допускает отказа от декодирования принятого слова, даже если оно весьма сомнительно. Независимо от того, какая последовательность получена, принимается некоторое решение о переданном кодовом слове, Даже если это решение — всего лишь тонкая догадка. Для многих кодов очень трудно продолжить известные алгоритмы неполного декодирования до алгоритмов полного декодирования. Наоборот, обычно бывает очень легко получить хорошие алгоритмы неполного декодирования из алгоритмов полного декодирования. Мы видели, что формулировка алгоритма полного декодирования для кодов с повторением не вызывает трудностей. Если блоковая длина достаточно велика, то вероятность ошибки декодирования при этом очень мала. Однако эти коды имеют очень низкую скорость передачи информации, Замечательным примером таких высокоскоростных кодов являются коды с одной проверкой на четность, содержащие только один проверочный символ. Этот проверочный символ является суммой по модулю два Два рассмотренных примера, коды с повторением и коды с проверкой на четность, представляют собой предельные относительно простые случаи двоичных кодов. Коды с повторением имеют огромную корректирующую способность, но на каждый блок приходится только один информационный символ. Коды с одной проверкой на четность обладают очень высокой скоростью передачи, но так как в каждый блок входит только один проверочный символ, то они не обеспечивают ничего, кроме обнаружения нечетного числа ошибок. Для того чтобы построить коды с приемлемыми скоростями и приемлемыми корректирующими возможностями, лежащие между этими двумя предельными классами кодов, рассмотрим более общий класс линейных кодов, к которому эти коды принадлежат.
|
 |
Оглавление
|


























































































































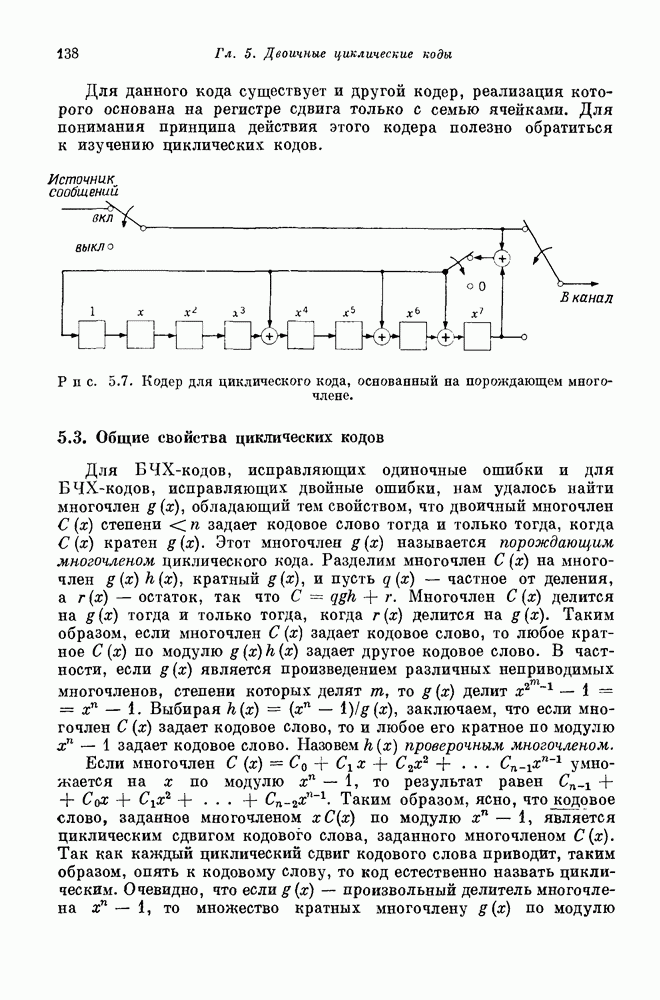


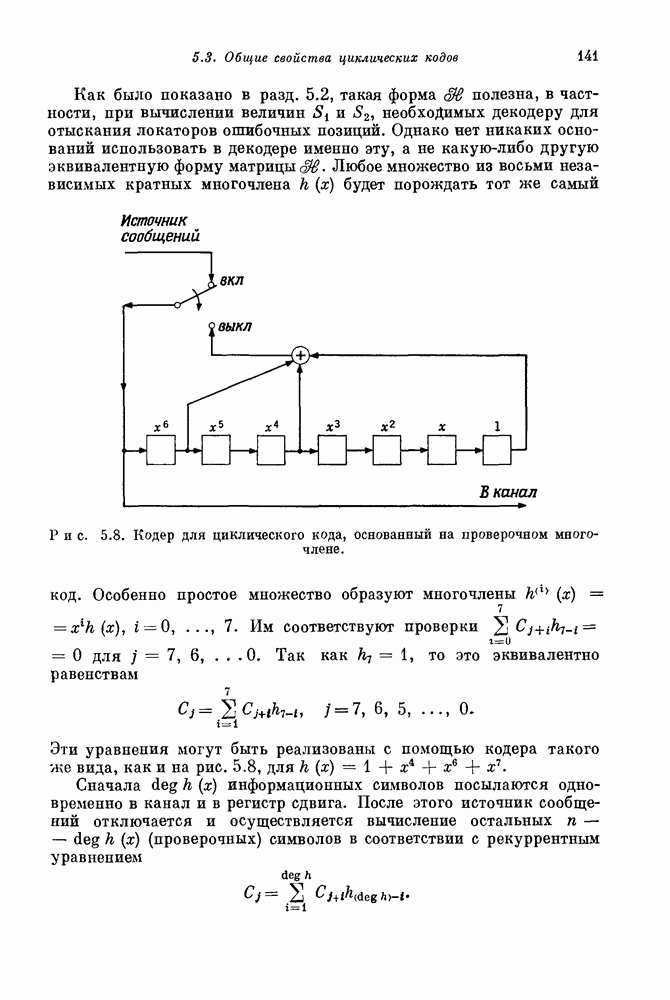

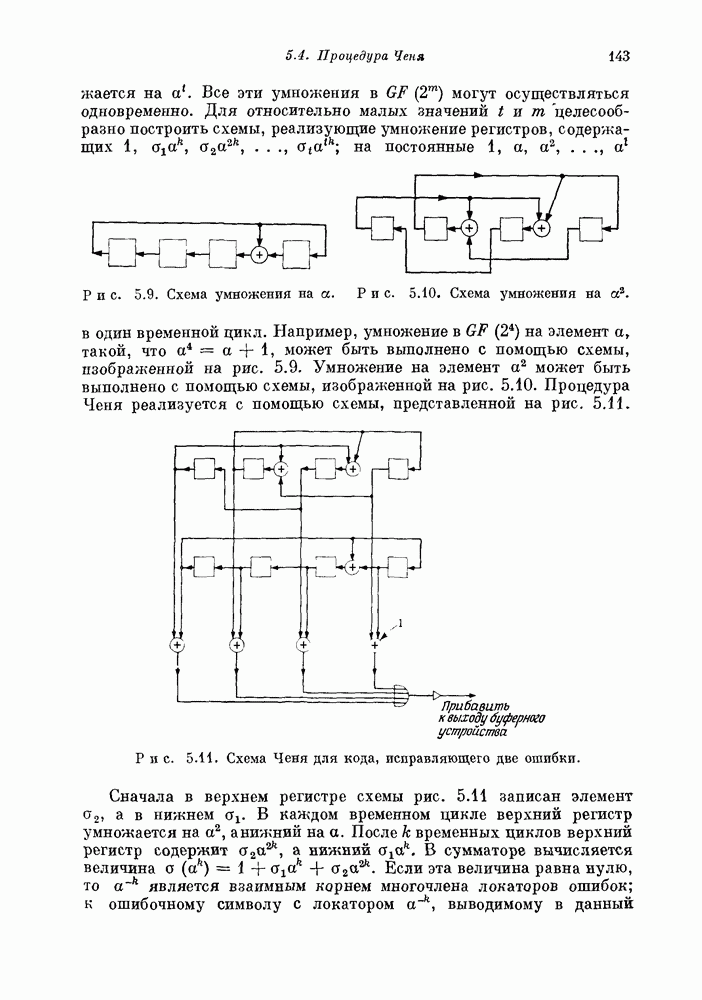
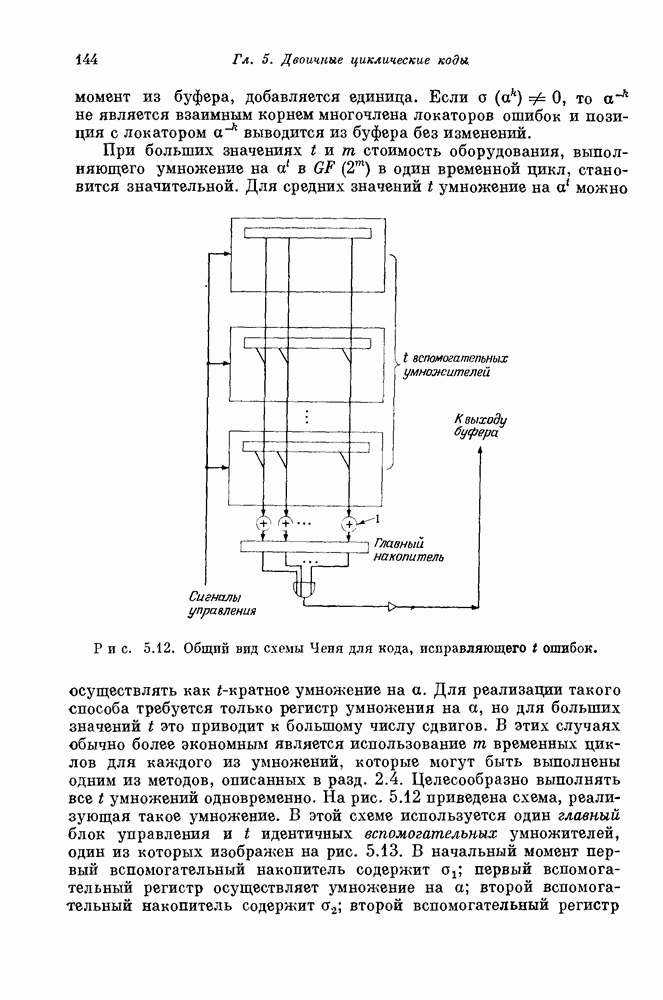
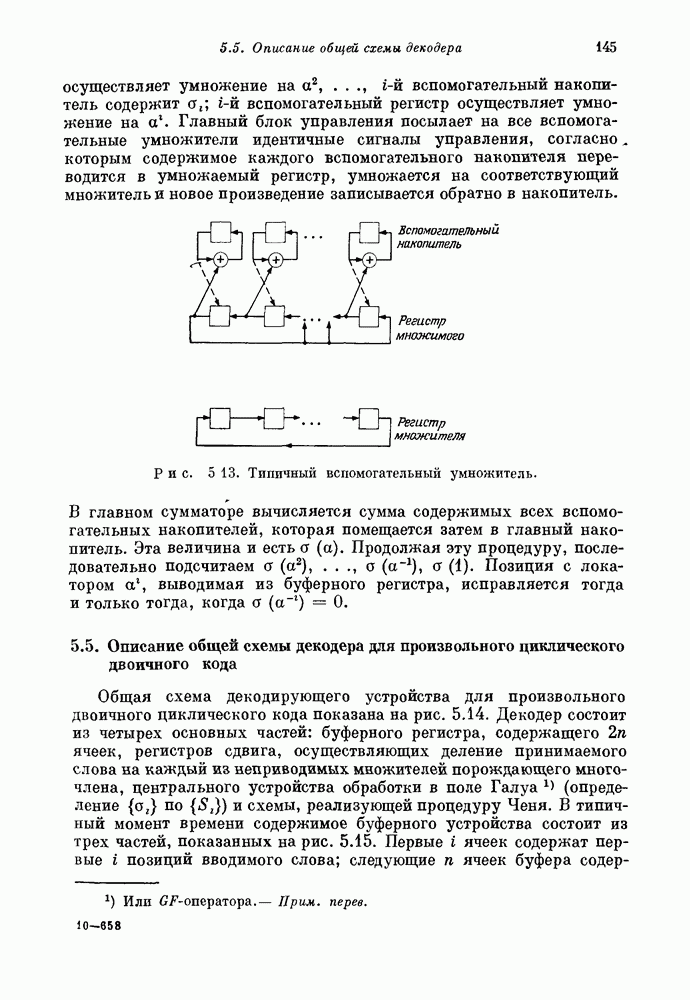
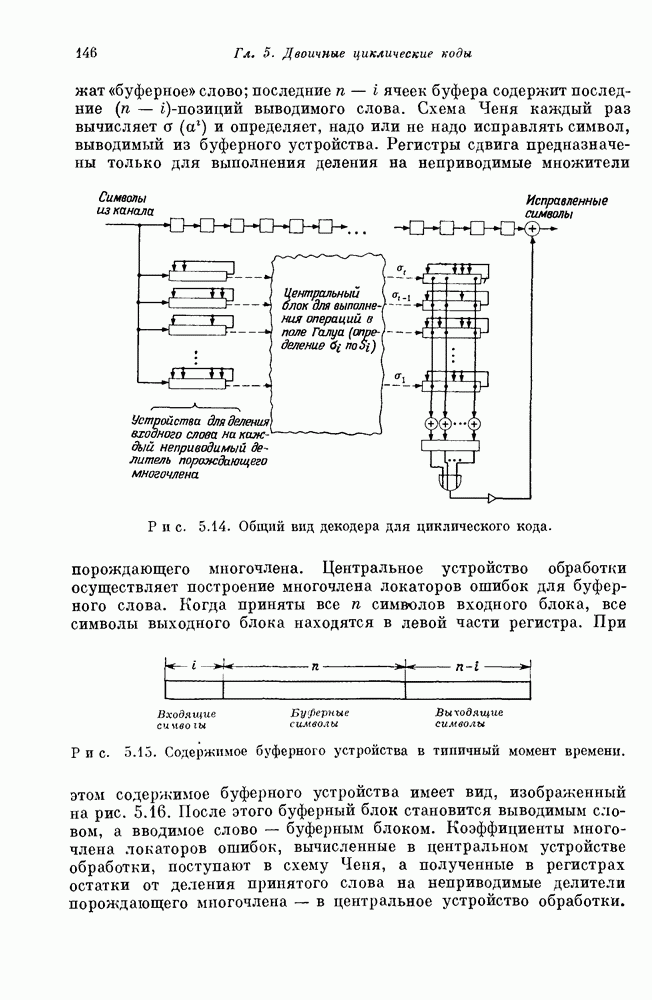

























































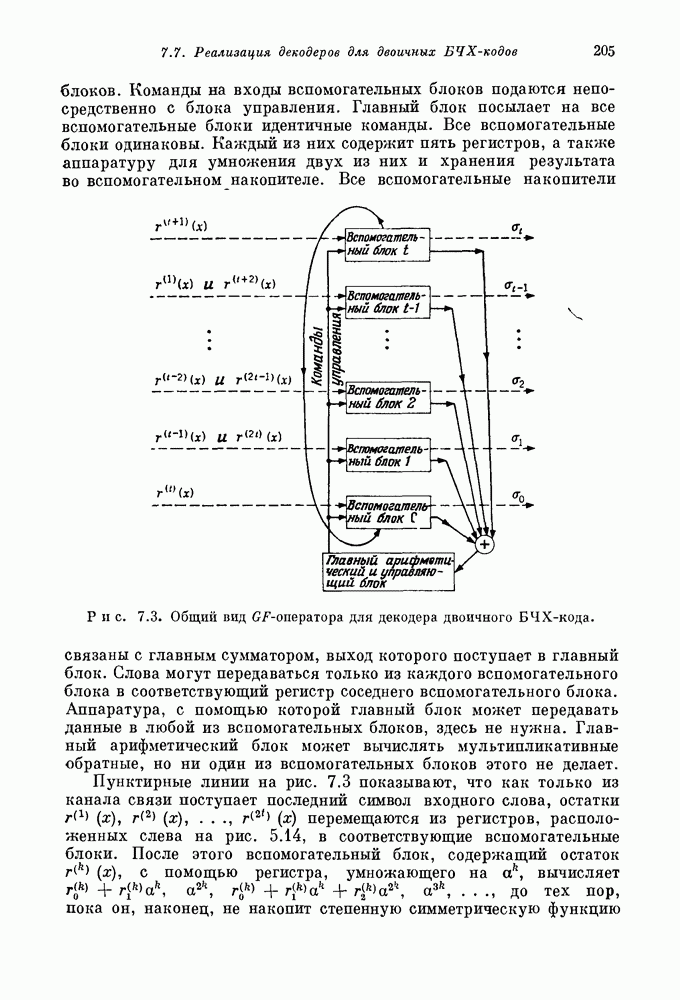































































































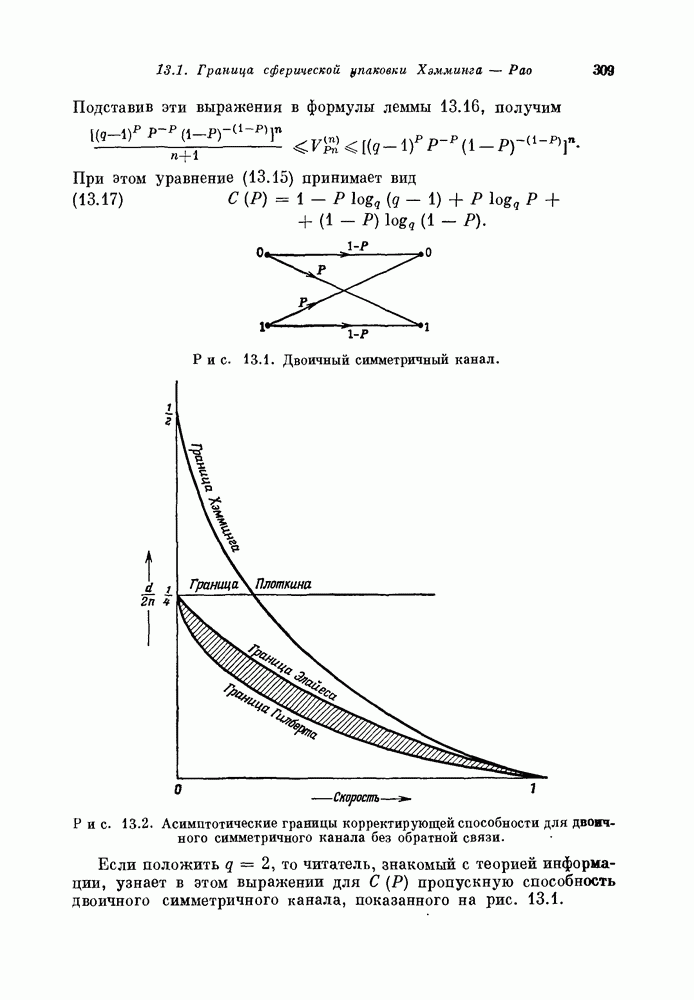

























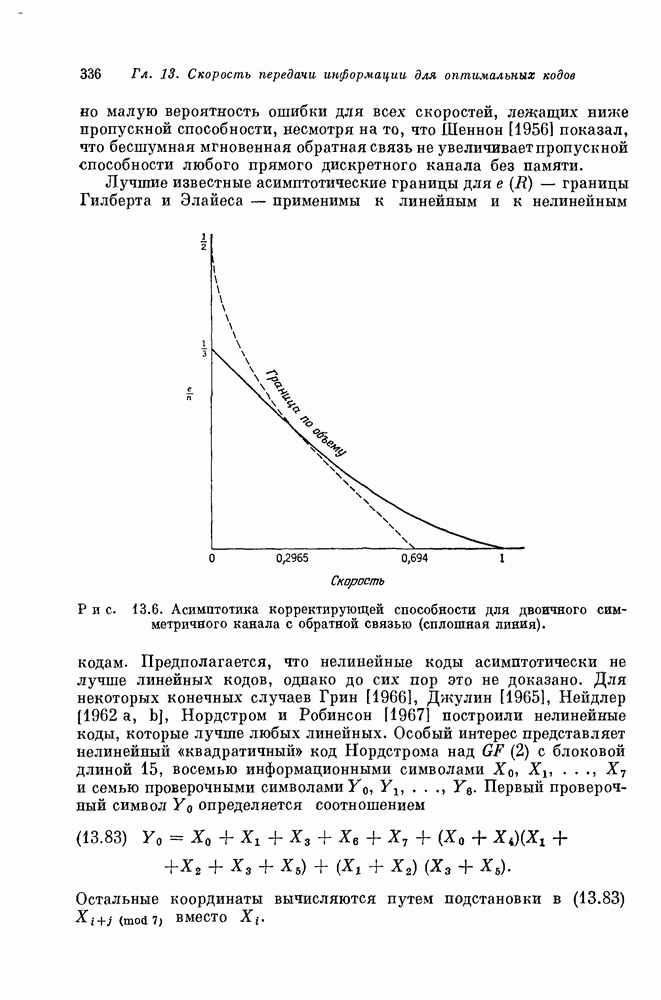


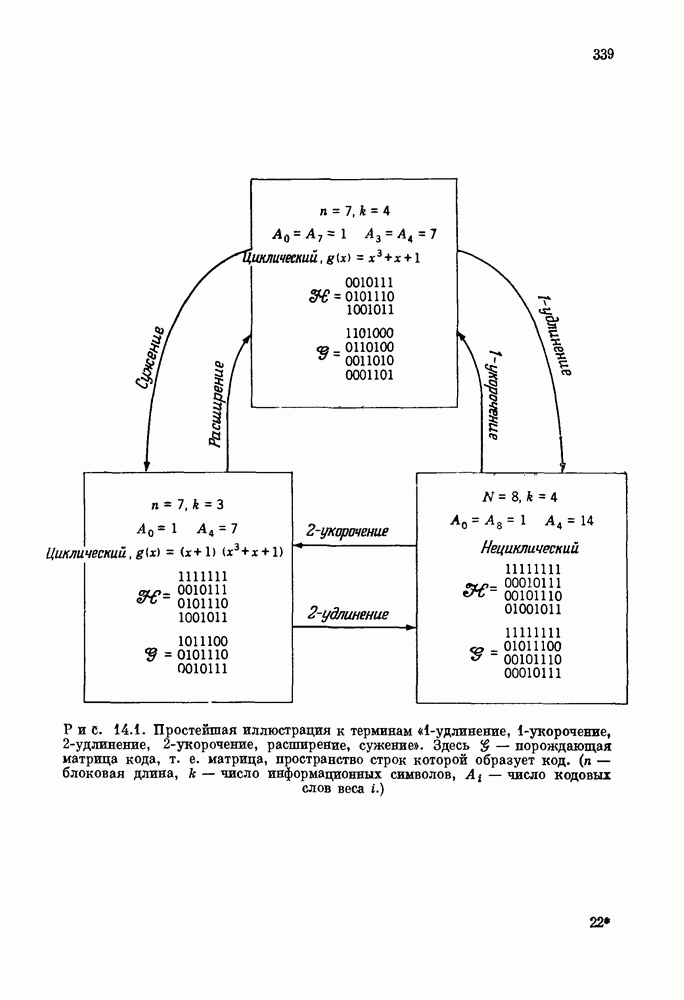

































































































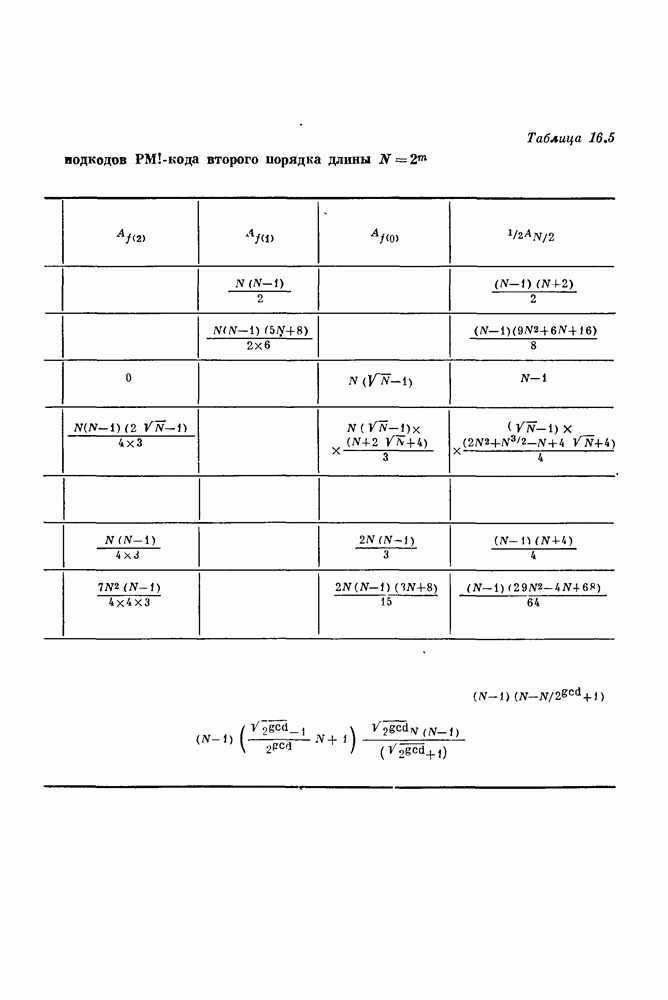













 проверочных символов и передадим входной блок из
проверочных символов и передадим входной блок из  канальных символов. Если шум в канале искажает достаточно малую долю из этих
канальных символов. Если шум в канале искажает достаточно малую долю из этих  передаваемых канальных символов, то
передаваемых канальных символов, то  проверочных символов дают приемнику достаточную информацию, позволяющую ему обнаружить и исправить ошибки, происшедшие в канале.
проверочных символов дают приемнику достаточную информацию, позволяющую ему обнаружить и исправить ошибки, происшедшие в канале.
 проверочных символов. Построение такого правила является задачей кодирования. Любая конкретная последовательность, которая может быть передана кодером, называется кодовым словом. Хотя всего существует
проверочных символов. Построение такого правила является задачей кодирования. Любая конкретная последовательность, которая может быть передана кодером, называется кодовым словом. Хотя всего существует  различных двоичных последовательностей длины
различных двоичных последовательностей длины  только
только  из них являются кодовыми словами, так как
из них являются кодовыми словами, так как  проверочных символов любого кодового слова полностью определяются к символами сообщения. Множество, состоящее из
проверочных символов любого кодового слова полностью определяются к символами сообщения. Множество, состоящее из  кодовых слов длины
кодовых слов длины  называется кодом.
называется кодом.
 двоичных последовательностей длины
двоичных последовательностей длины  По полученным
По полученным  символам декодер должен попытаться решить, какое из
символам декодер должен попытаться решить, какое из  возможных кодовых слов передавалось.
возможных кодовых слов передавалось.
 произвольным
произвольным  Код содержит два кодовых слова: последовательность из
Код содержит два кодовых слова: последовательность из  нулей и последовательность из
нулей и последовательность из  единиц. Первый символ слова можно назвать информационным, а остальные
единиц. Первый символ слова можно назвать информационным, а остальные  проверочными. Значение каждого проверочного символа (0 или 1) в коде с повторением совпадает со значением информационного символа. Декодер может использовать
проверочными. Значение каждого проверочного символа (0 или 1) в коде с повторением совпадает со значением информационного символа. Декодер может использовать
 Если шум в канале искажает более половины символов некоторого блока, то в декодере произойдет ошибка декодирования: он неверно декодирует полученное слово. При редких ошибках в канале вероятность отказа или ошибки декодирования для кода с повторением с большой блоковой длиной, очевидно, очень мала.
Если шум в канале искажает более половины символов некоторого блока, то в декодере произойдет ошибка декодирования: он неверно декодирует полученное слово. При редких ошибках в канале вероятность отказа или ошибки декодирования для кода с повторением с большой блоковой длиной, очевидно, очень мала.
 Сначала предположим, что если полученная последовательность содержит не более двух единиц, то она декодируется как нулевое кодовое слово. В противном случае она декодируется как единичное кодовое слово. Этот алгоритм декодирует каждое возможное полученное слово в одно из возможных кодовых слов; такое декодирование называется полным. В полных алгоритмах декодирования отказ от декодирования невозможен. Однако для того же кода с повторением с блоковой длиной
Сначала предположим, что если полученная последовательность содержит не более двух единиц, то она декодируется как нулевое кодовое слово. В противном случае она декодируется как единичное кодовое слово. Этот алгоритм декодирует каждое возможное полученное слово в одно из возможных кодовых слов; такое декодирование называется полным. В полных алгоритмах декодирования отказ от декодирования невозможен. Однако для того же кода с повторением с блоковой длиной  можно использовать и альтернативный алгоритм неполного декодирования. Например, можно декодировать все полученные последовательности, содержащие 0 или 1 единиц как нулевое кодовое слово, а все полученные последовательности, содержащие 4 или 5 единиц, как единичное кодовое слово. Этот алгоритм декодирования не действует при декодировании последовательностей, содержащих 2 или 3 единицы. Хотя этот алгоритм неполного декодирования имеет положительную вероятность отказа от декодирования, он имеет значительно меньшую вероятность ошибки декодирования, чем полный алгоритм.
можно использовать и альтернативный алгоритм неполного декодирования. Например, можно декодировать все полученные последовательности, содержащие 0 или 1 единиц как нулевое кодовое слово, а все полученные последовательности, содержащие 4 или 5 единиц, как единичное кодовое слово. Этот алгоритм декодирования не действует при декодировании последовательностей, содержащих 2 или 3 единицы. Хотя этот алгоритм неполного декодирования имеет положительную вероятность отказа от декодирования, он имеет значительно меньшую вероятность ошибки декодирования, чем полный алгоритм.
 так как все позиции, кроме одной, являются проверочными. Мы же обычно заинтересованы в кодах, обеспечивающих большие скорости передачи информации.
так как все позиции, кроме одной, являются проверочными. Мы же обычно заинтересованы в кодах, обеспечивающих большие скорости передачи информации.
 информационных символов. Информационные символы складываются в соответствии с двоичными правилами:
информационных символов. Информационные символы складываются в соответствии с двоичными правилами:  Двоичная сумма некоторого числа двоичных цифр равна 0 или 1 в соответствии с четностью или нечетностью числа единиц среди складываемых двоичных цифр. Поэтому общее число единиц (включая проверочный символ) в каждом кодовом слове кода с одной проверкой на четность всегда четно. Если полученное слово содержит четное число единиц, то декодер должен декодировать его без изменений, а в противном случае слово не декодируется. Это правило неполного декодирования позволяет правильно декодировать только тогда, когда канал не исказил ни одного символа передаваемого блока. Одиночные ошибки (или любое нечетное число ошибок) приводят к отказу от декодирования и тем самым обнаруживаются. Любое ненулевое четное число ошибок приводит к ошибке декодирования.
Двоичная сумма некоторого числа двоичных цифр равна 0 или 1 в соответствии с четностью или нечетностью числа единиц среди складываемых двоичных цифр. Поэтому общее число единиц (включая проверочный символ) в каждом кодовом слове кода с одной проверкой на четность всегда четно. Если полученное слово содержит четное число единиц, то декодер должен декодировать его без изменений, а в противном случае слово не декодируется. Это правило неполного декодирования позволяет правильно декодировать только тогда, когда канал не исказил ни одного символа передаваемого блока. Одиночные ошибки (или любое нечетное число ошибок) приводят к отказу от декодирования и тем самым обнаруживаются. Любое ненулевое четное число ошибок приводит к ошибке декодирования.