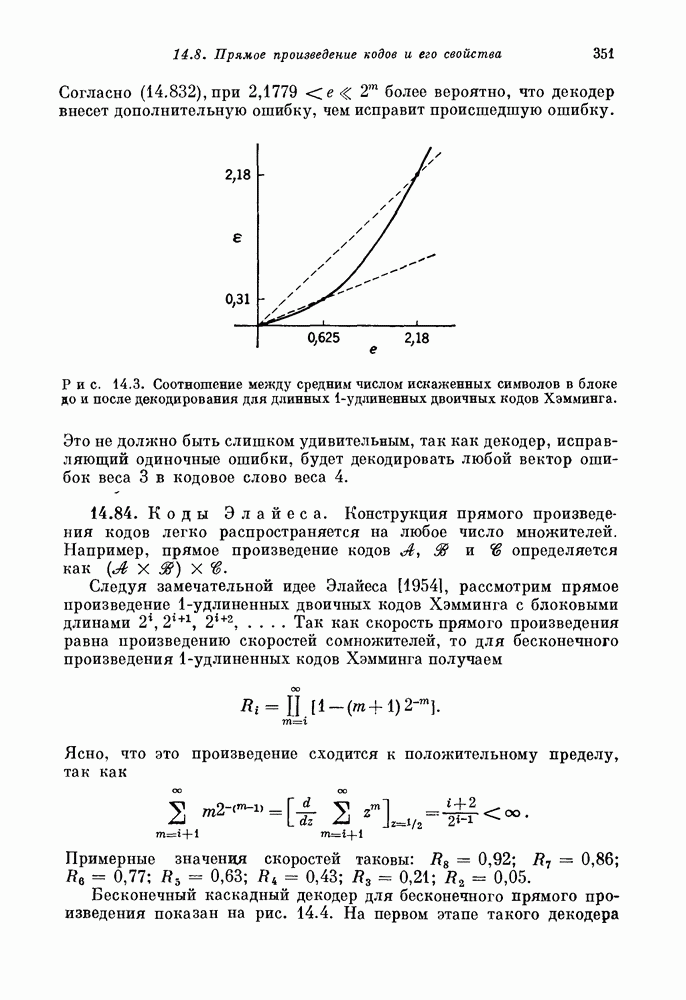
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
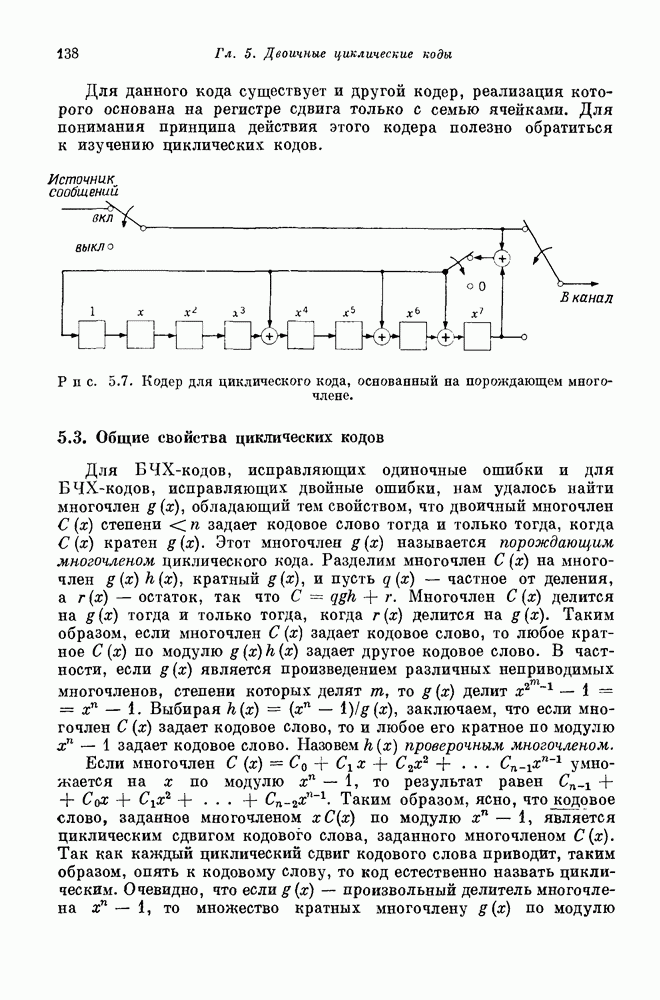
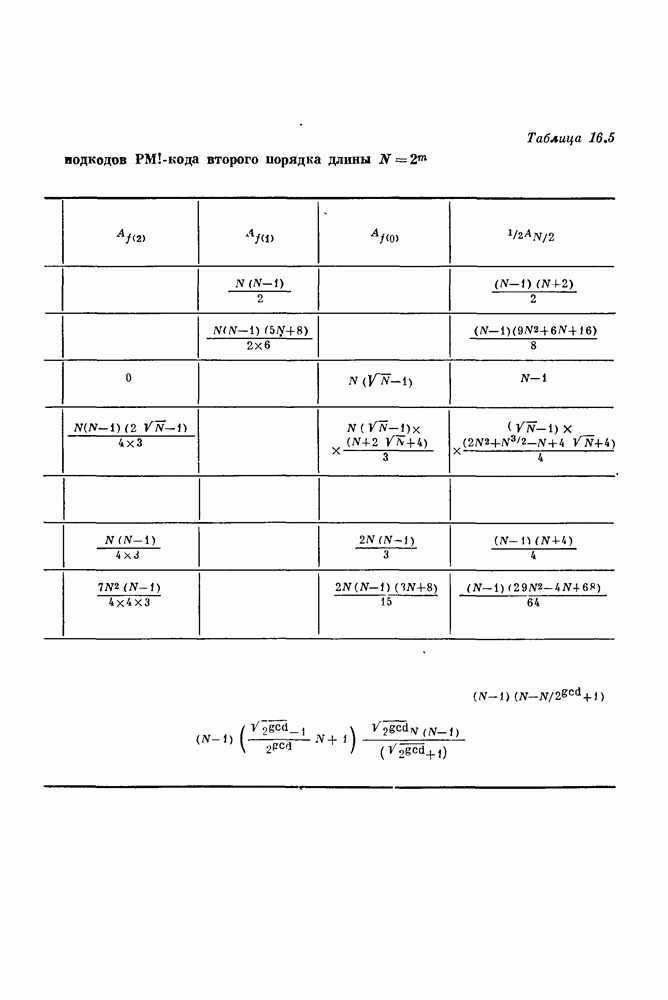
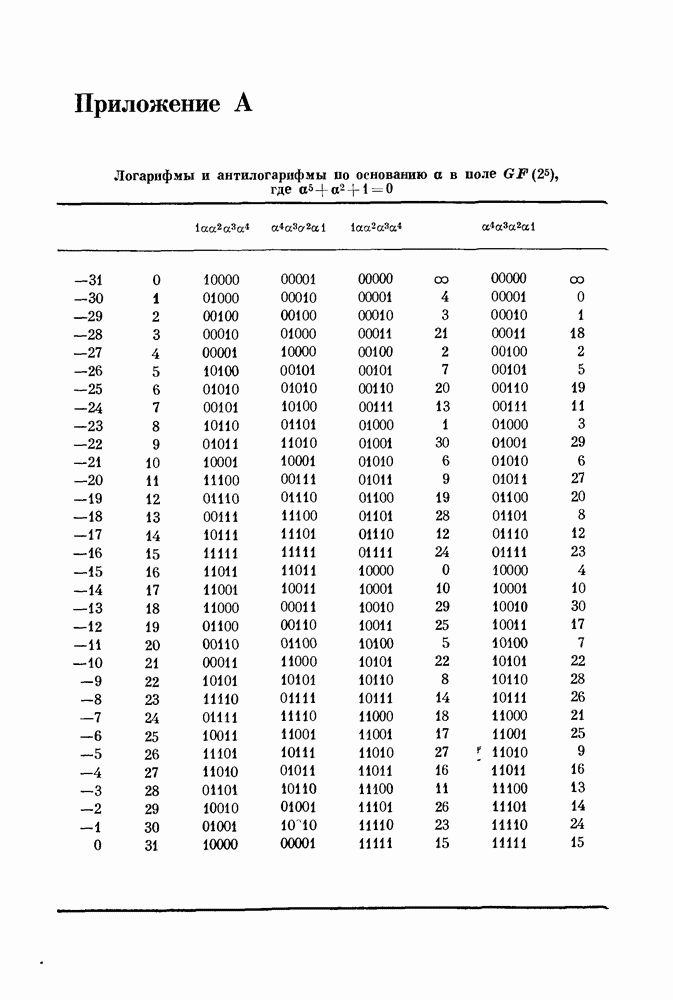
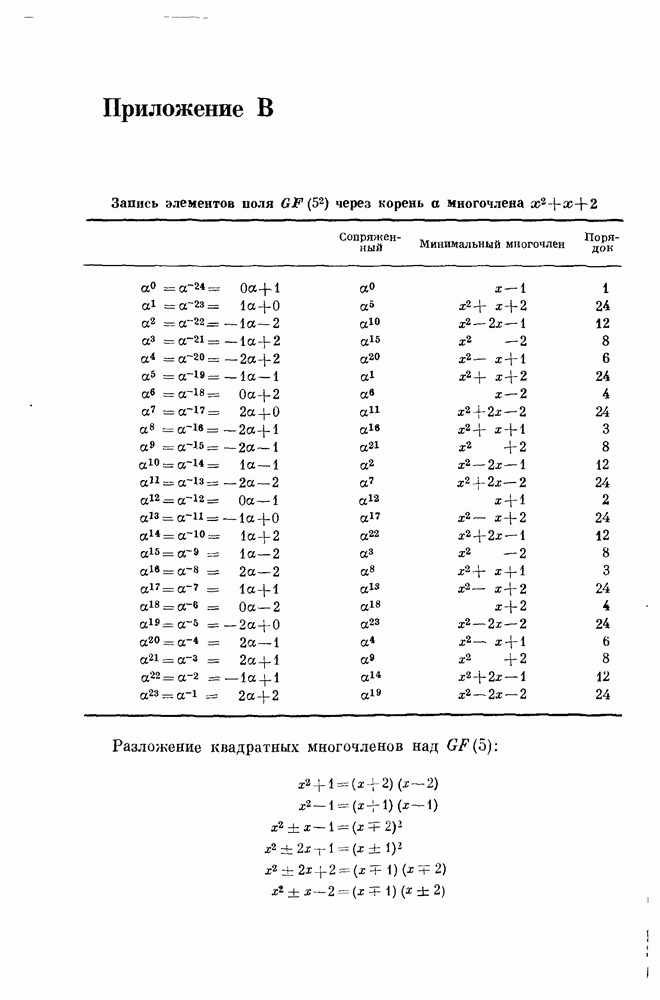
15.6. Сверточные коды — обзор15.61. Введение. Кодер блокового кода со скоростью передачи В кодере для кодов другого типа, так называемых сверточных или рекуррентных кодов, поступающие символы разбиваются на блоки большой (а не малой, как в предыдущем случае) длины к. После получения из источника к символов кодер передает
то выходом кодера является последовательность
где
(Предполагается, что
Ясно, что
Многочлены
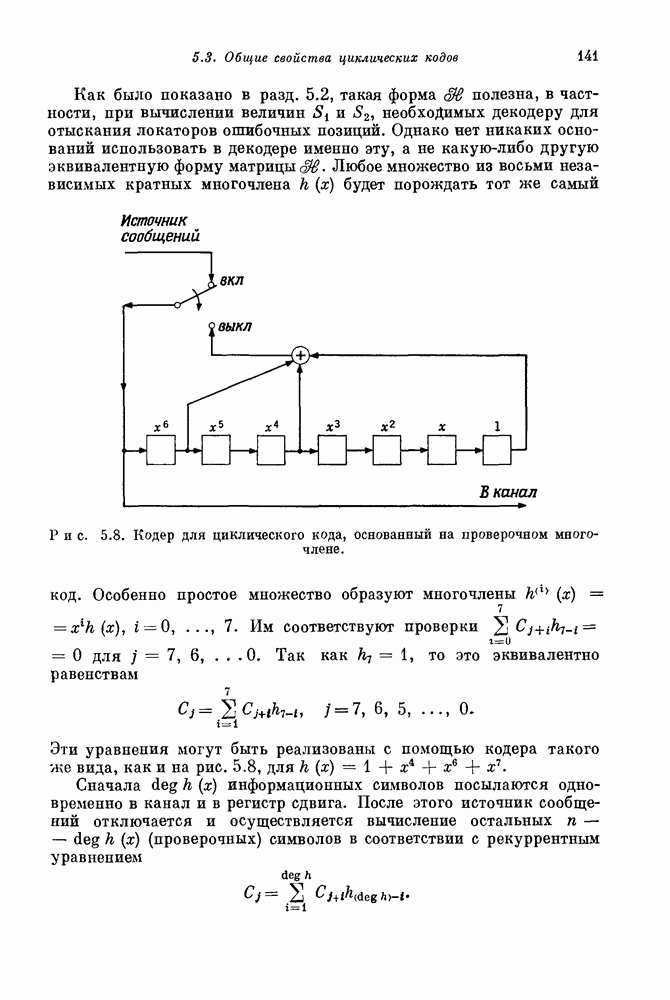
назовем проверочными многочленами кода. (Некоторые авторы называют их порождающими многочленами.) Память кодера равна Сверточные коды впервые рассматривались Элайесом [1955]. Кроме этого, их изучали Хегельбергер [1959], Месси [1963], Вайнер и Эш [1963], Саллайвен [1966], Редди [1968] и др. 15.62. Пример (Хегельбергер [1959]). Пусть шести блокам; кодовое ограничение равно 14. Кодер для этого кода показан на рис. 15.10.
Рис. 15.10. Кодер для сверточного кода. 15.63. Пороговое декодирование. Сравнение прямого декодирования и декодирования с обратной связью. Среди проверочных уравнений, которым удовлетворяет код предыдущего примера, содержатся уравнения
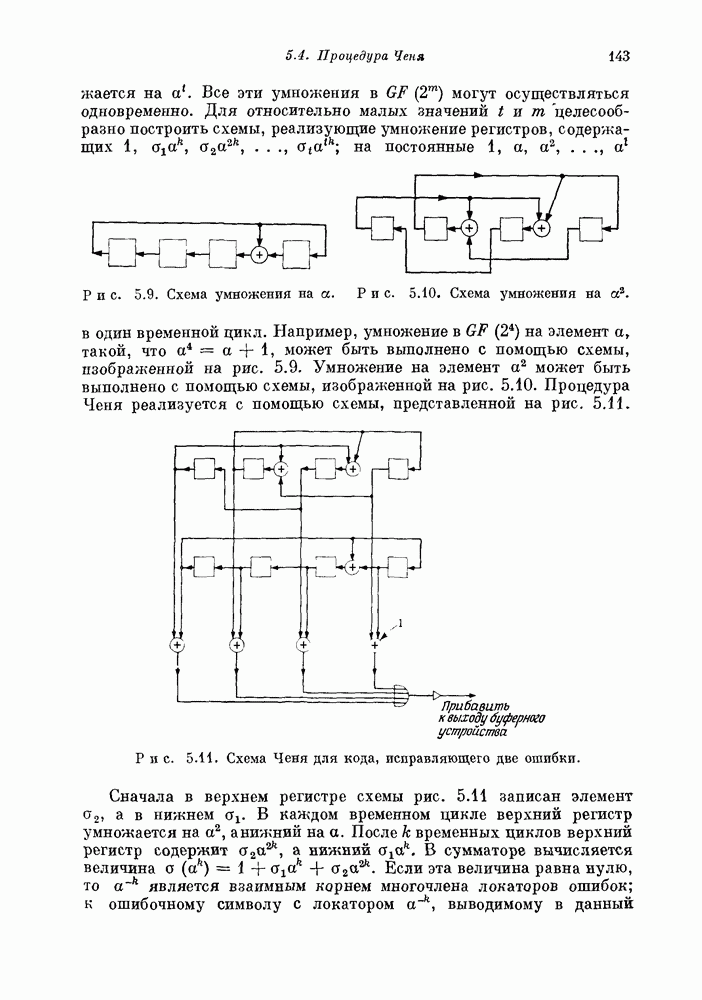
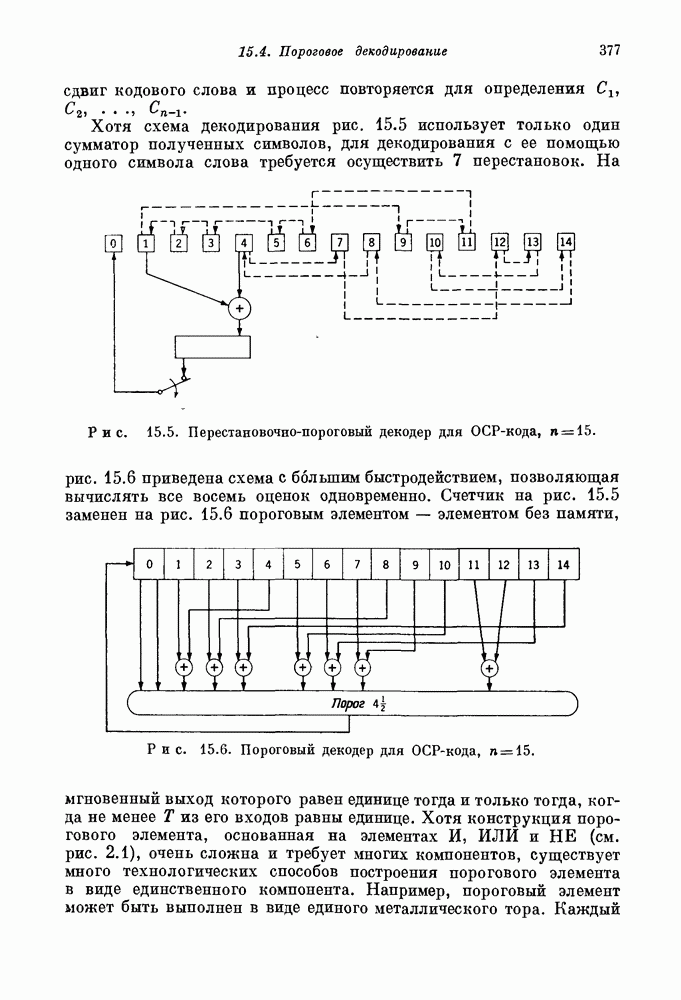
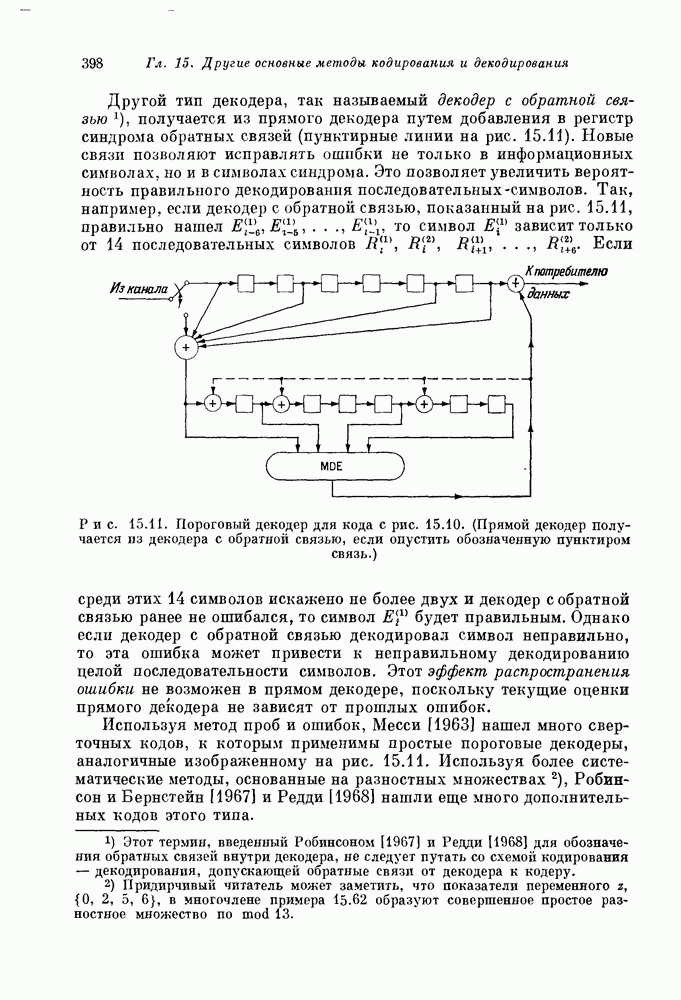
Так как эти проверочные уравнения ортогональны на Другой тип декодера, так называемый декодер с обратной связью, получается из прямого декодера путем добавления в регистр синдрома обратных связей (пунктирные линии на рис. 15.11). Новые связи позволяют исправлять ошибки не только в информационных символах, но и в символах синдрома. Это позволяет увеличить вероятность правильного декодирования последовательных символов. Так, например, если декодер с обратной связью, показанный на рис. 15.11, правильно нашел
Рис. 15.11. Пороговый декодер для кода с рис. 15.10. (Прямой декодер получается из декодера с обратной связью, если опустить обозначенную пунктиром связь.) Если среди этих 14 символов искажено не более двух и декодер с обратной связью ранее не ошибался, то символ Используя метод проб и ошибок, Месси [1963] нашел много сверточных кодов, к которым применимы простые пороговые декодеры, аналогичные изображенному на рис. 15.11. Используя более систематические методы, основанные на разностных множествах, Робинсон и Бернстейн [1967] и Редди [1968] нашли еще много дополнительных кодов этого типа. Хотя пороговое декодирование оказалось очень эффективным для декодирования многих частных кодов с малым и умеренным кодовым ограничением, оно представляет собой весьма слабый метод декодирования кодов с большим кодовым ограничением. Месси [1963] показал, что вероятность ошибки для лучших пороговых декодеров независимо от длины кодового ограничения отлична от нуля. 15.64. Отыскание «хороших» сверточных кодов. Все известные алгебраические процедуры декодирования для блоковых кодов основаны на ряде сведений о математической структуре этих кодов. К сожалению, среди известных сверточных кодов лишь очень немногие обладают известной структурой. Берлекэмп [1963] построил класс сверточных кодов с хорошо обозримой структурой, исправляющих пакеты стираний; однако эти коды не очень эффективны для каналов без памяти со случайными ошибками. Вайнер и Эш [1963] построили класс сверточных кодов, исправляющих одну ошибку при минимальном возможном защитном интервале. Эти коды аналогичны блоковым кодам Хэмминга, исправляющим одну ошибку. К сожалению, сверточные аналоги БЧХ-кодов, исправляющих несколько ошибок, пока не известны. Эпштейн [1958 b] и Бассгенг [1965] нашли «лучшие» двоичные сверточные коды для некоторых скоростей передачи и малых кодовых ограничений, однако для Несмотря на то что о методах построения «хороших» сверточных кодов почти ничего не известно, многое известно о «наилучших» сверточных кодах. Эти результаты получены на основе исследования случайно выбранных сверточных кодов. Элайес [1954] показал, что такие коды позволяют получать произвольно малую вероятность ошибки декодирования при всех скоростях, меньших пропускной способности канала. Месси [1963] показал, что для сверточных кодов справедлива граница, аналогичная границе Гилберта для блоковых кодов (см. разд. 13.7). Юдкин [1964] и Витерби [1967] получили точные границы вероятности ошибки для таких кодов. Результаты Витерби показывают, что вероятность ошибки для случайно выбранного сверточного кода с большой скоростью и кодовым ограничением 15.65. Последовательное декодирование. Помимо порогового декодирования и нескольких других конструктивных методов, к сверточным кодам применим важный метод декодирования, известный под названием последовательного декодирования. Введенный Возенкрафтом и Рейффеном [1961], этот алгоритм был вскоре модифицирован и улучшен Фано [1963]. Конструктивные методы декодирования всегда опираются на математическую структуру кода, а последовательное декодирование — вероятностный алгоритм, почти всегда пригодный для почти всех случайно выбранных сверточных кодов. Грубо говоря, при последовательном декодировании производится попытка принять решение для каждого полученного символа, но при этом учитываются ранее принятые решения. Если при декодировании последовательности символов на некотором шаге невозможно сделать разумный выбор, то декодер возвращается назад и изменяет некоторые из ранее принятых решений. Последовательный декодер Фано [1963] декодирует сверточный код с бесконечным кодовым ограничением. При этом с вероятностью единица любой данный символ будет в конце концов декодирован правильно и с некоторого момента будет оставаться неизменным. К сожалению, число операций, необходимых для декодирования любого данного символа, — случайная величина, зависящая от шума в канале. Полученные Джекобсом и Верлекэмпом [1967], а также Джелинеком [1968] границы показывают, что распределение этой случайной величины примерно описывается равенством
где Некоторые нежелательные свойства распределения числа вычислений при последовательном декодировании можно исключить с помощью гибридных схем декодирования, сочетающих сверточные коды и последовательное декодирование с другими способами кодирования и декодирования. Такие схемы были предложены Пинскером [1965] и Фэлконером [1967]. Подробное исследование последовательного декодирования можно найти у Возенкрафта и Джекобса [1965] или у Джелинека [1968]. 15.66. Сверточные коды для исправления пакетов ошибок. Хотя для канала без памяти со случайными ошибками не известны методы построения лучших сверточных кодов, предложены точные методы построения лучших сверточных кодов, исправляющих пакеты ошибок. При передаче информации по некоторым каналам связи наблюдаются длинные периоды, в течение которых сигнал замирает. Такой фединг приводит к стиранию последовательных символов, что называется пакетом стираний. После окончания пакета стираний опять наступает возможность передачи информации по каналу связи без ошибок и стираний до тех пор, пока следующий глубокий фединг не приведет к новому пакету стираний. Система кодирования для такого канала должна исправлять каждый пакет стираний до тех пор, пока не начнется новый пакет. Если за пакетом стираний из Первая попытка построения сверточных кодов, исправляющих пакеты ошибок, была сделана Хегельбергером [1959]. Вайнер и Эш [1963] больше математизировали задачу и для лучших сверточных кодов с данной скоростью вывели границы для минимальной величины защитного интервала между исправляемыми пакетами стираний. Берлекэмп [1964а] и Препарата [1964] построили затем класс кодов, достигающих границы Вайнера — Эша для пакетов с заданным фазовым расположением относительно блоков сверточного кода. Месси [1965] предложил простой алгоритм декодирования этих кодов. Экономи [1965] и Сю [1969] построили некоторые сверточные коды, исправляющие пакеты с меньшими фазовыми ограничениями по сравнению с кодами Берлекэмпа — Препараты. Однако общие методы построения фазово-независимых сверточных кодов, исправляющих пакеты ошибок и удовлетворяющих границе Вайнера — Эша, пока не найдены. Галлагер [1966] показал, что граница Вайнера — Эша применима не только к сверточным, но и к блоковым кодам. Он также построил класс сверточных кодов, исправляющих многие (но не все) пакеты заданной длины при значительно меньшем защитном интервале, чем требуется согласно границе Вайнера — Эша. Задачи(см. скан) (см. скан)
|
 |
Оглавление
|
















































































































































































































































































































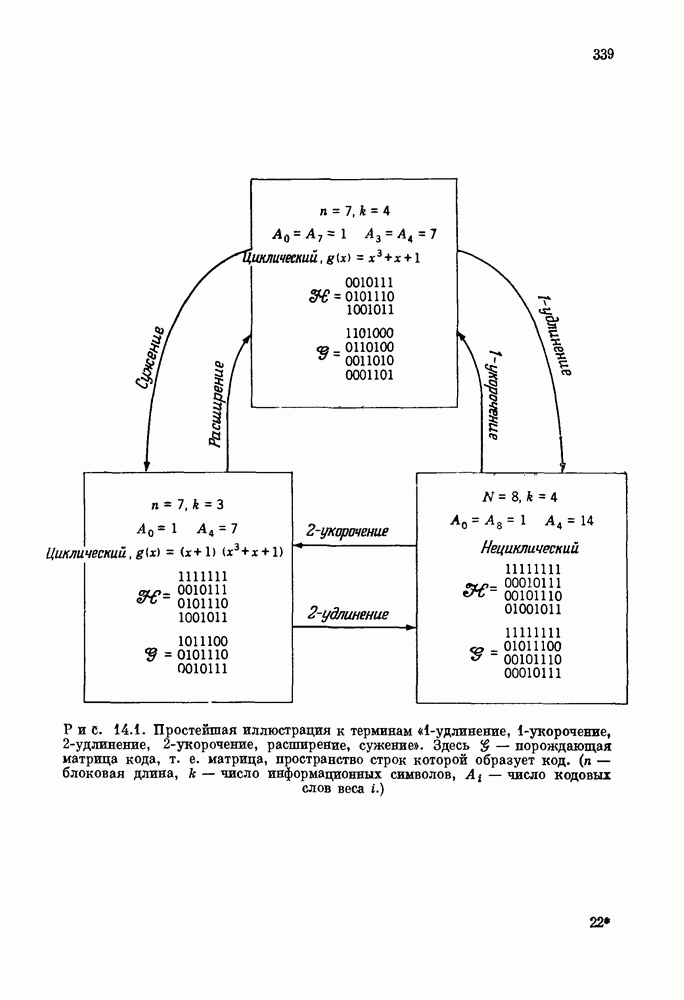






























































































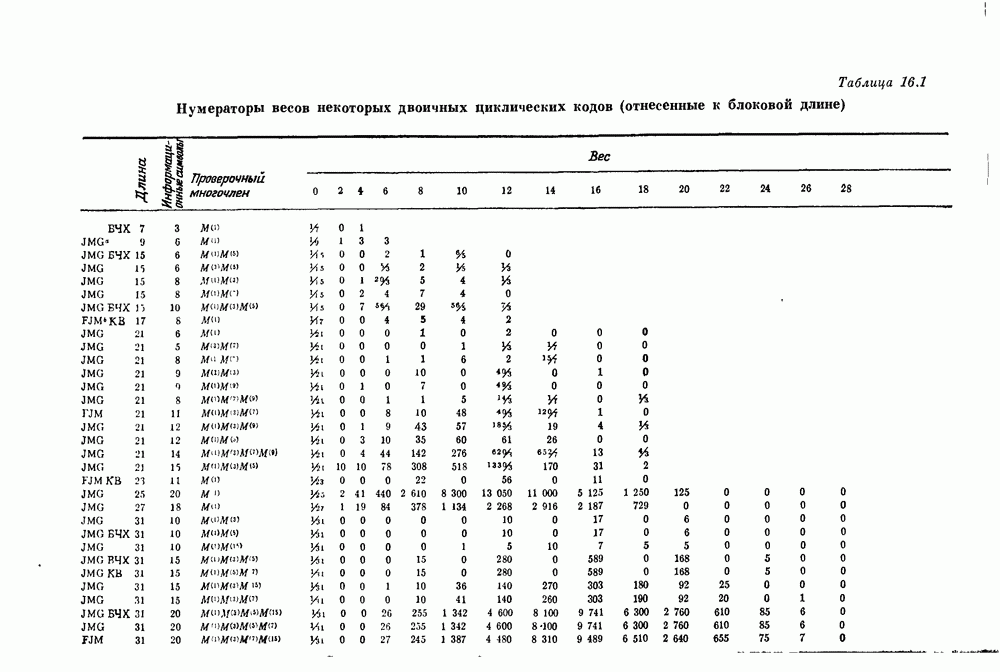
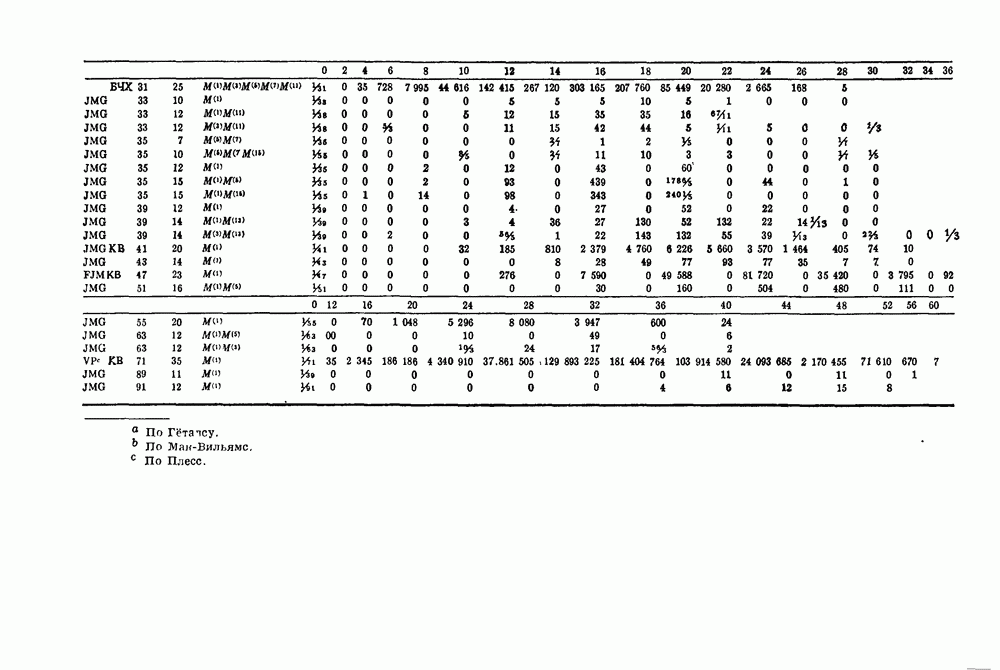


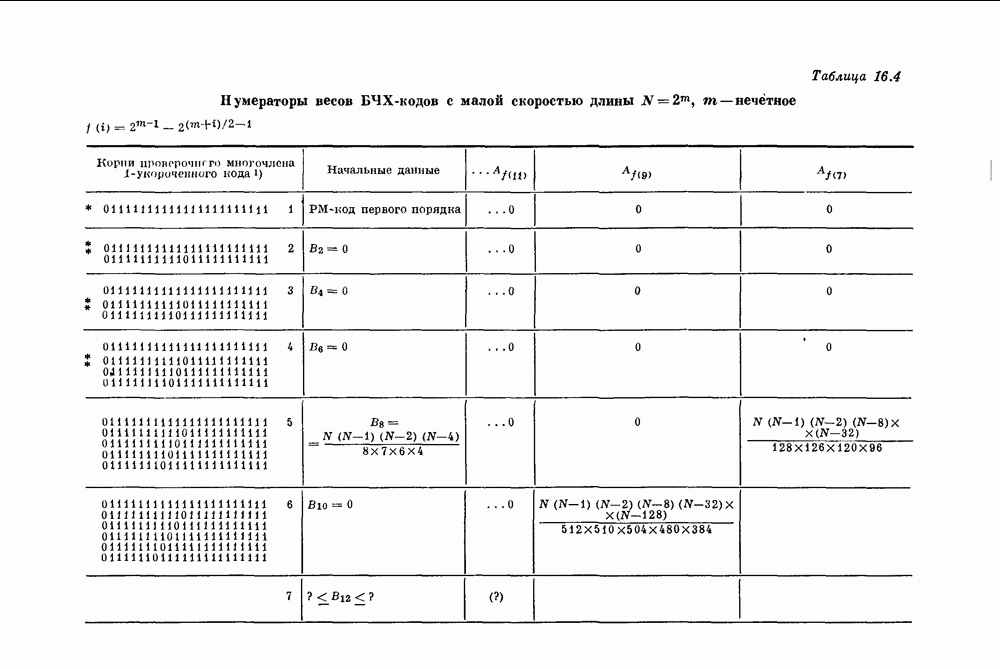
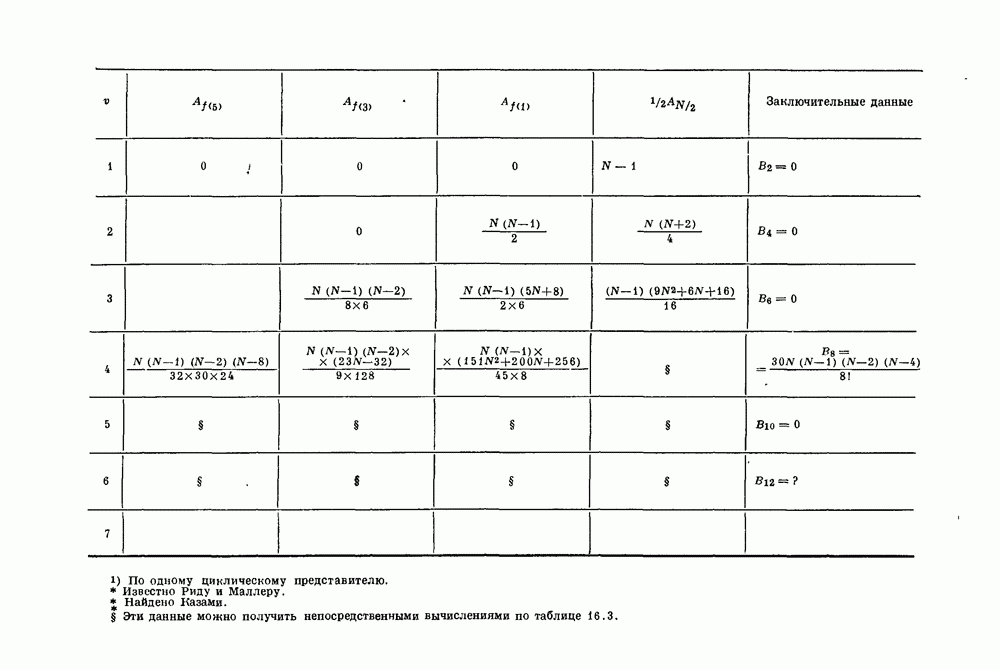














 и длиной
и длиной  разбивает поступающие из источника данных символы на блоки по
разбивает поступающие из источника данных символы на блоки по  символов. Каждый из блоков кодируется более длинным блоком из
символов. Каждый из блоков кодируется более длинным блоком из  символов и передается затем по зашумленному каналу.
символов и передается затем по зашумленному каналу.
 символов, которые зависят не только от этих к символов, но и от многих ранее полученных символов. Точнее, если входом кодера была последовательность данных
символов, которые зависят не только от этих к символов, но и от многих ранее полученных символов. Точнее, если входом кодера была последовательность данных 



 если
если  ) Как и в случае линейных блоковых кодов, будем обозначать через
) Как и в случае линейных блоковых кодов, будем обозначать через  полученные символы, а через
полученные символы, а через  ошибки в канале. Для
ошибки в канале. Для  определим символы синдрома с помощью равенств
определим символы синдрома с помощью равенств



 блокам; кодовым ограничением называется число
блокам; кодовым ограничением называется число  . Кодовое ограничение для сверточного кода, грубо говоря, играет ту же роль, что и блоковая длина для блокового кода.
. Кодовое ограничение для сверточного кода, грубо говоря, играет ту же роль, что и блоковая длина для блокового кода.
 Память равна
Память равна


 то этот код может быть декодирован с помощью порогового декодера, показанного на рис. 15.11. Полученный из канала информационный символ поступает в регистр сообщения. Поступающий из канала проверочный символ
то этот код может быть декодирован с помощью порогового декодера, показанного на рис. 15.11. Полученный из канала информационный символ поступает в регистр сообщения. Поступающий из канала проверочный символ  прибавляется к
прибавляется к  и запоминается в регистре синдрома. При подходе
и запоминается в регистре синдрома. При подходе  к выходу из буфера сообщения мажоритарный
к выходу из буфера сообщения мажоритарный  элемент выбирает символ Еголосованием по большинству среди символов синдрома
элемент выбирает символ Еголосованием по большинству среди символов синдрома  Если три или четыре из них равны 1, то и
Если три или четыре из них равны 1, то и  принимается равным 1; если менее чем два равны 1, то полагаем
принимается равным 1; если менее чем два равны 1, то полагаем  Декодер сможет правильно декодировать символ, если в 26 последовательных позициях
Декодер сможет правильно декодировать символ, если в 26 последовательных позициях  произойдет не более трех ошибок. Описанный декодер называется прямым, поскольку решение о символе
произойдет не более трех ошибок. Описанный декодер называется прямым, поскольку решение о символе  принимается в результате анализа полученной конечной последовательности символов без учета прошлой работы декодера.
принимается в результате анализа полученной конечной последовательности символов без учета прошлой работы декодера.
 то символ
то символ  зависит только от 14 последовательных символов
зависит только от 14 последовательных символов 

 будет правильным. Однако если декодер с обратной связью декодировал символ неправильно, то эта ошибка может привести к неправильному декодированию целой последовательности символов. Этот эффект распространения ошибки не возможен в прямом декодере, поскольку текущие оценки прямого декодера не зависят от прошлых ошибок.
будет правильным. Однако если декодер с обратной связью декодировал символ неправильно, то эта ошибка может привести к неправильному декодированию целой последовательности символов. Этот эффект распространения ошибки не возможен в прямом декодере, поскольку текущие оценки прямого декодера не зависят от прошлых ошибок.
 подобных результатов нет.
подобных результатов нет.
 существенно меньше, чем вероятность ошибки для лучших блоковых кодов с длиной
существенно меньше, чем вероятность ошибки для лучших блоковых кодов с длиной 

 функция от скорости передачи и статистики шума в канале. Если скорость достаточно мала, то
функция от скорости передачи и статистики шума в канале. Если скорость достаточно мала, то  и среднее число вычислений на декодируемый символ ограничено. Однако сама случайная величина может принимать бесконечные значения. Даже в случае конечной дисперсии число вычислений для декодирования данного символа часто бывает очень большим. Именно эта проблема вычислений, а не вероятность ошибки, ограничивает возможности последовательного декодирования.
и среднее число вычислений на декодируемый символ ограничено. Однако сама случайная величина может принимать бесконечные значения. Даже в случае конечной дисперсии число вычислений для декодирования данного символа часто бывает очень большим. Именно эта проблема вычислений, а не вероятность ошибки, ограничивает возможности последовательного декодирования.
 символов следует правильный отрезок сообщения из
символов следует правильный отрезок сообщения из  символов, то исправления будут не возможны, если число проверочных символов, входящих в защитный интервал, будет меньше числа стертых информационных символов. Отсюда следует, что скорость кода должна быть столь малой, чтобы выполнялось неравенство
символов, то исправления будут не возможны, если число проверочных символов, входящих в защитный интервал, будет меньше числа стертых информационных символов. Отсюда следует, что скорость кода должна быть столь малой, чтобы выполнялось неравенство  Берлекэмп [1963] показал, что для любого заданного
Берлекэмп [1963] показал, что для любого заданного  можно построить сверточный код с величинами
можно построить сверточный код с величинами  удовлетворяющими этому неравенству. В двоичном случае эта конструкция приводит к единственному коду с такими свойствами. Он допускает очень простой алгоритм декодирования, основанный на структуре кода. Оптимальные сверточные коды с исправлением пакетов стираний оптимальны также и для обнаружения пакетов ошибок максимально возможной длины.
удовлетворяющими этому неравенству. В двоичном случае эта конструкция приводит к единственному коду с такими свойствами. Он допускает очень простой алгоритм декодирования, основанный на структуре кода. Оптимальные сверточные коды с исправлением пакетов стираний оптимальны также и для обнаружения пакетов ошибок максимально возможной длины.