Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.2. Линейные кодыВ кодах, содержащих несколько информационных и несколько проверочных символов, каждый проверочный символ является некоторой функцией от информационных символов. В простейшем случае кода с одной проверкой на четность единственный проверочный символ является двоичной суммой всех информационных символов. Если имеется несколько проверочных символов, то для задания кода представляется целесообразным каждый из них определить как двоичную сумму соответствующего подмножества информационных символов. Построим, например, двоичный код с блоковой длиной
или в матричных обозначениях
Полное кодовое слово содержит символы
или в матричной записи
где С — вектор-столбец, транспонированный к вектор-строке
О — нулевой вектор-столбец длины три,
После того как информационная последовательность закодирована в полное кодовое слово, оно передается по зашумленному каналу. Канал прибавляет к кодовому слову шумовое словог)
где
Полученное слою описывается последовательностью
где
Для данного примера это уравнение имеет вид
Так как символы синдрома также определяются проверочными уравнениями, то они выявляют картину искажений в переданном кодовом слове. Для того чтобы декодировать, декодер должен в конце концов ответить на вопрос: «Какое слово С передавалось?» Легче, однако, оказывается, ответить сначала на промежуточный вопрос: «Каков вектор Если же синдром, что и Предположим, например, что принятое слово является кодовым. Тогда Множество Таким образом, декодер может сразу исключить из рассмотрения все векторы ошибок, которые не лежат в одном смежном классе с принятым словом, т. е. векторы, которые имеют другие синдромы. Однако все векторы ошибок, лежащие в одном смежном классе с принятым словом, возможны. Ни одна из этих возможностей не может быть с полной определенностью исключена из рассмотрения. Но так как ошибки в канале относительно редки, то некоторые из векторов ошибок в пределах данного смежного класса гораздо менее вероятны, чем другие. Обычно более вероятно, что вектором ошибок будет вектор с малым числом единиц, чем вектор с большим числом единиц. Более точно, определим вес некоторого Наиболее вероятный вектор ошибок — это лидер смежного класса, содержащего принятое слово. Смежные классы для рассмотренного выше примера выписаны в виде строк таблицы 1.1. Первая строка есть смежный класс с Таблица 1.1. Стандартное расположение по Слепяну
нулевым синдромом, т. е. множество кодовых слов. Лидер каждого из последующих смежных классов выписан в первом столбце. Элемент, расположенный в Обычно используется терминология определений 1.21. 1.21. Определения. Код называется линейным или групповым, если он состоит из всех векторов С, удовлетворяющих уравнению Важные свойства линейных кодов дает следующая теорема: 1.22. Теорема. Если Сразу возникают две основные задачи: (1) как надо выбирать матрицу Для малых значений проблемы в общем случае не решены. Однако известно много «хороших» методов построения проверочных матриц и выбора лидеров смежных классов по заданному синдрому. В последующих главах книги мы приведем наиболее перспективные из этих методов. Самыми простыми примерами линейных кодов являются коды с повторением и коды с одной проверкой на четность, описанные в разд. 1.1. Проверочная матрица кода с одной проверкой имеет вид
а проверочная матрица кода с повторением —
|
 |
Оглавление
|





























































































































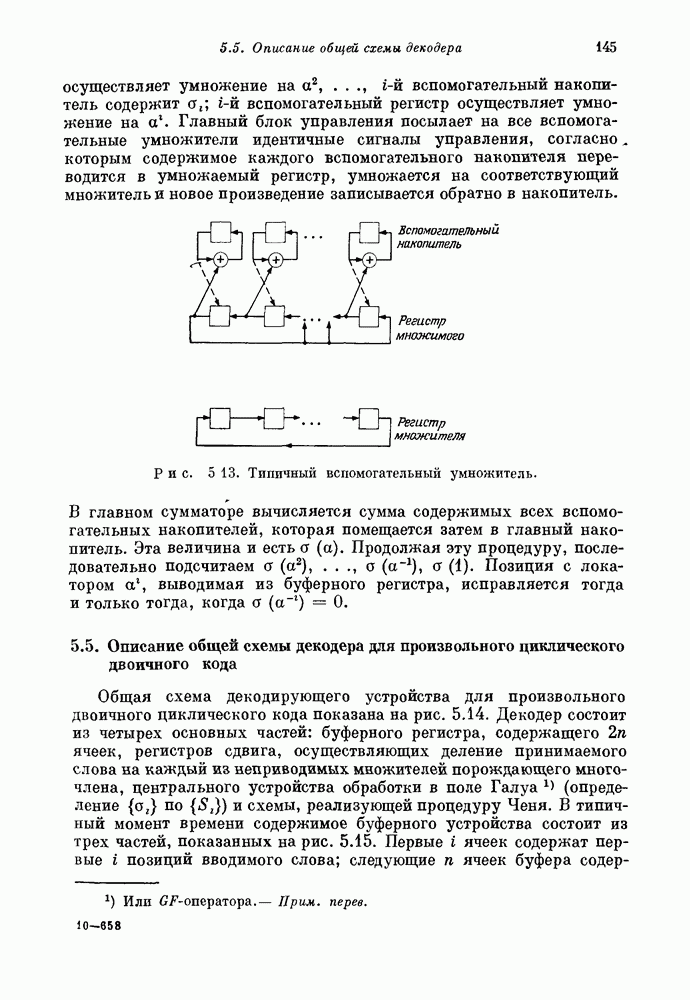
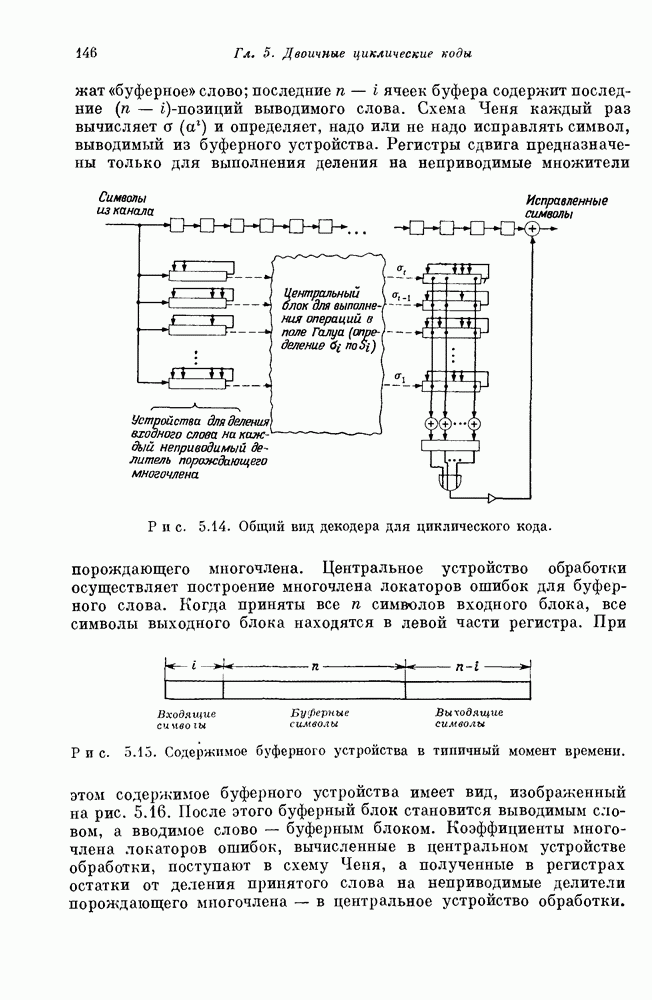


















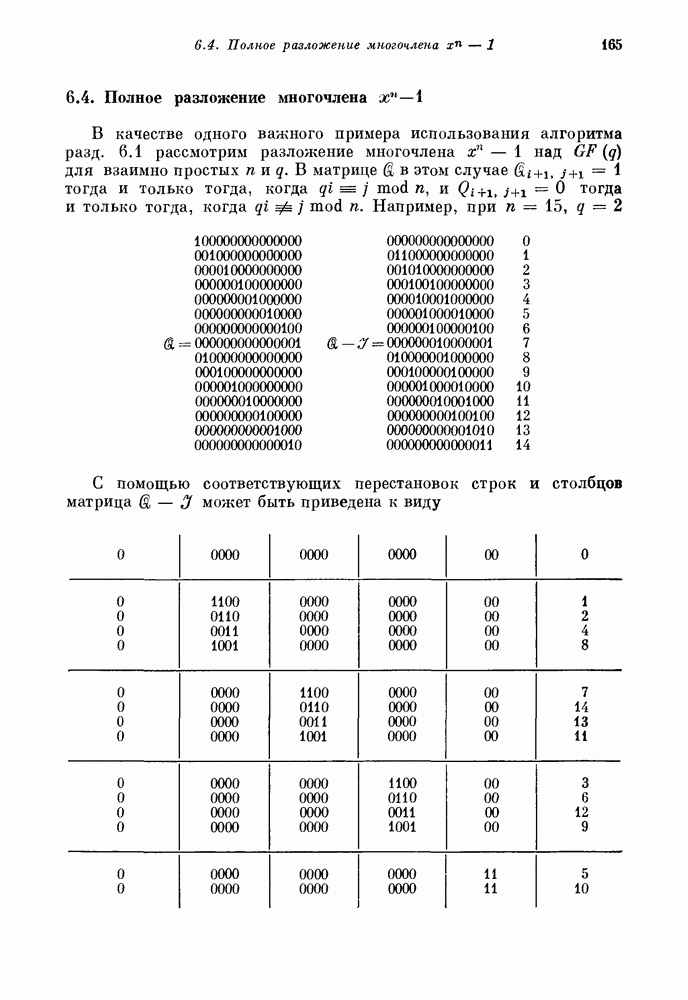







































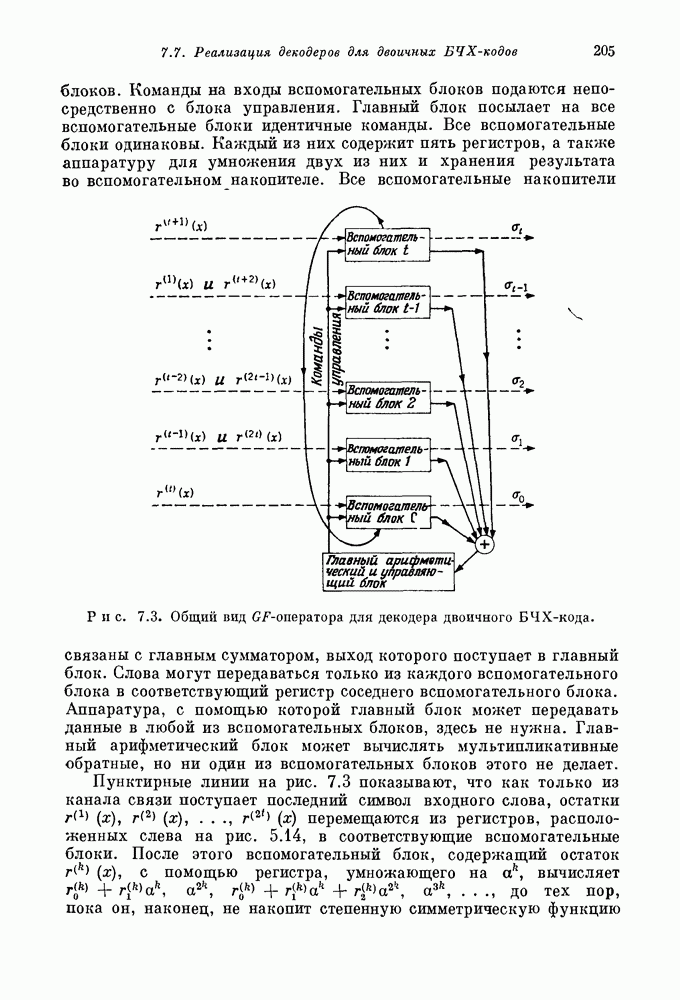
























































































































































































































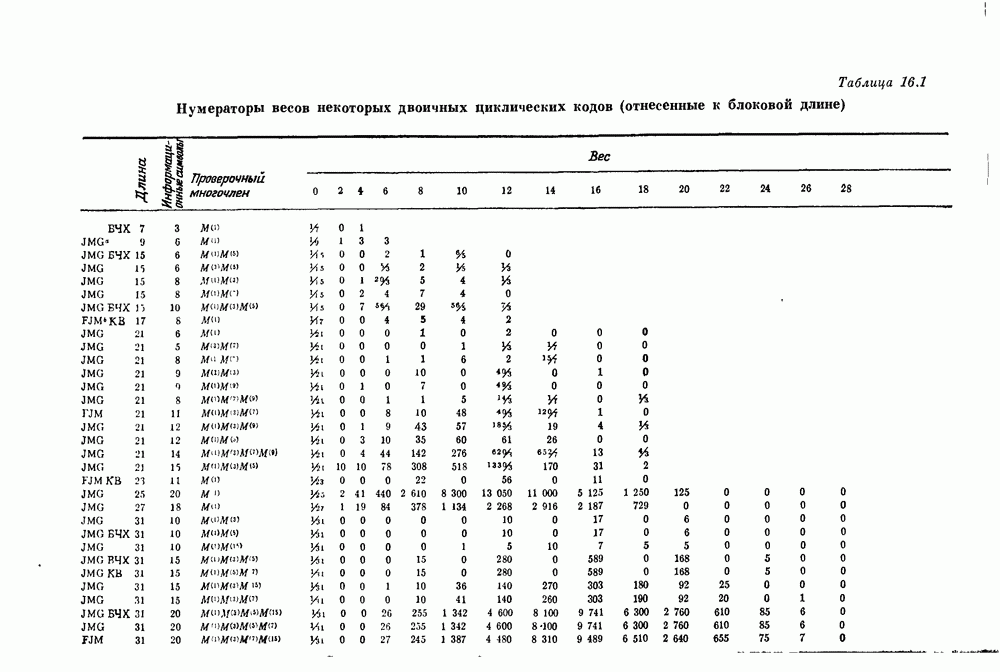
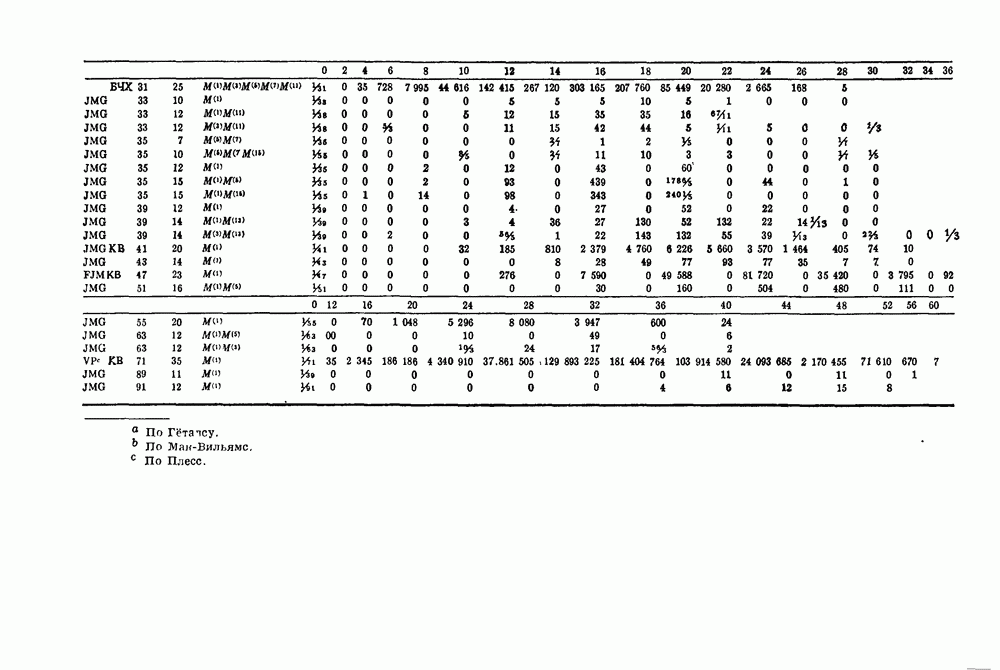


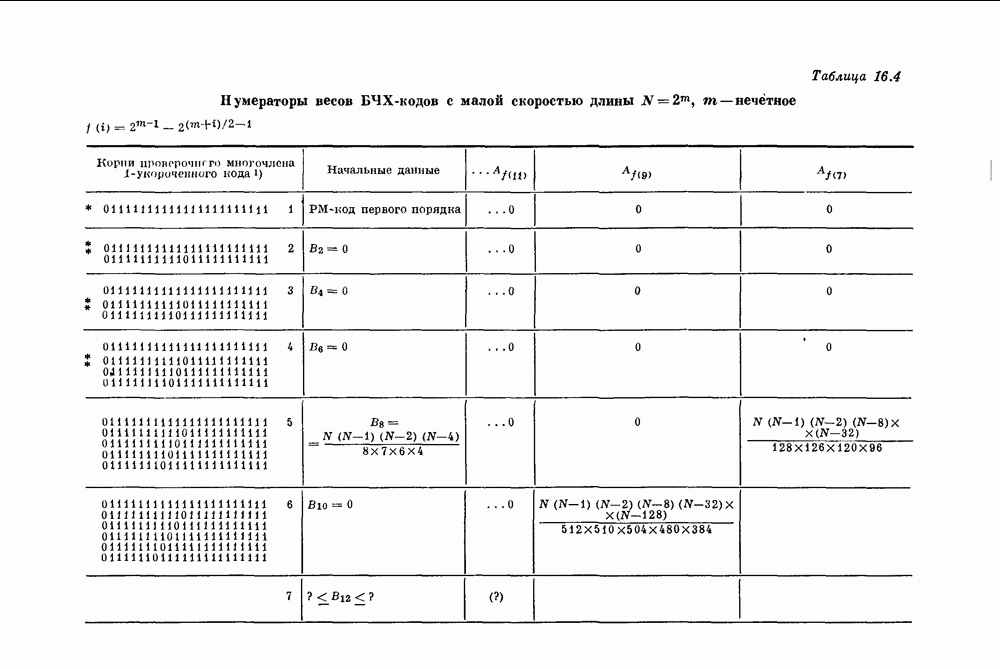
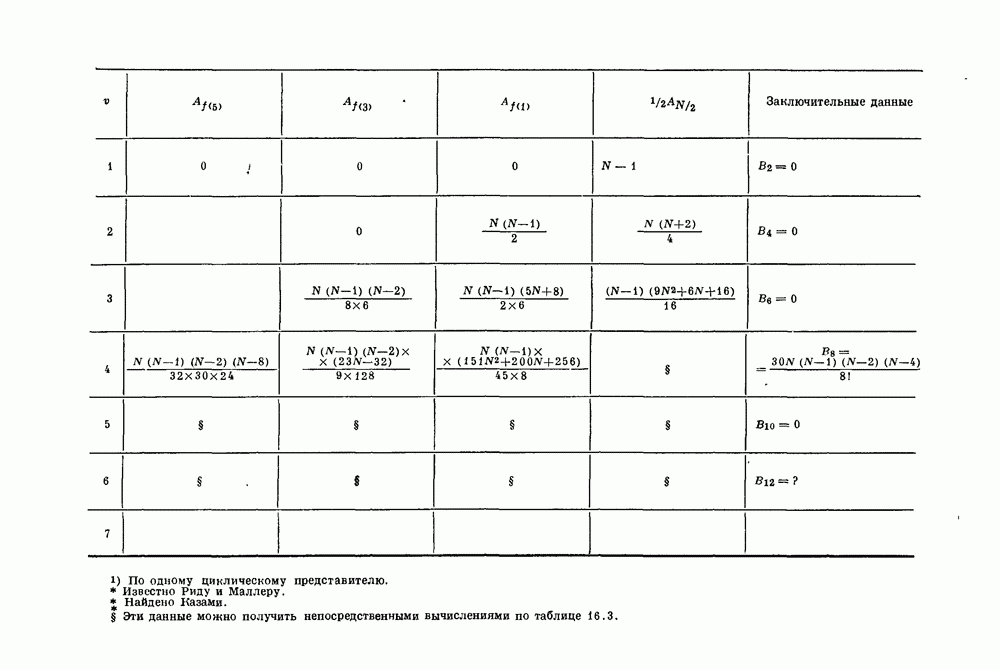














 имеющий
имеющий  информационных символов и
информационных символов и  проверочных символов. Обозначим через
проверочных символов. Обозначим через  информационные символы, а через
информационные символы, а через  и
и  проверочные символы, где
проверочные символы, где


 удовлетворяющие проверочным уравнениям
удовлетворяющие проверочным уравнениям



 проверочная матрица
проверочная матрица

 кодовых слов, очевидно, исчерпываются последовательностями
кодовых слов, очевидно, исчерпываются последовательностями




 или в векторной записи
или в векторной записи  Декодер начинает с вычисления символов синдрома, определяемого уравнением
Декодер начинает с вычисления символов синдрома, определяемого уравнением



 ошибок, происшедших в канале?» Если декодер сможет правильно определить вектор ошибок
ошибок, происшедших в канале?» Если декодер сможет правильно определить вектор ошибок  то С может быть найдено по формуле
то С может быть найдено по формуле  (В двоичном случае, конечно,
(В двоичном случае, конечно,  разность равна сумме и
разность равна сумме и  означает, что
означает, что 
 полученное слово, то множество возможных векторов ошибок в точности совпадает с множеством векторов, имеющих тот
полученное слово, то множество возможных векторов ошибок в точности совпадает с множеством векторов, имеющих тот
 Действительно, если
Действительно, если  то
то  так что
так что  не является переданным кодовым словом. Наоборот, если
не является переданным кодовым словом. Наоборот, если  то
то  и вектор ошибок может совпадать с
и вектор ошибок может совпадать с  если передавалось слово
если передавалось слово 
 так что вектор ошибок также должен быть кодовым словом.
так что вектор ошибок также должен быть кодовым словом.
 -мерных двоичных векторов с нулевым синдромом в точности совпадает с множеством кодовых слов. Если х и у — два кодовых слова,
-мерных двоичных векторов с нулевым синдромом в точности совпадает с множеством кодовых слов. Если х и у — два кодовых слова,  так что
так что  — также кодовое слово. Таким образом, разность любой пары кодовых слов является кодовым словом. Поэтому говорят, что множество кодовых слов образует линейный код, или групповой
— также кодовое слово. Таким образом, разность любой пары кодовых слов является кодовым словом. Поэтому говорят, что множество кодовых слов образует линейный код, или групповой  В общем случае, если х и у имеют один и тот же синдром (не обязательно нулевой), то
В общем случае, если х и у имеют один и тот же синдром (не обязательно нулевой), то  у является кодовым словом. Множество всех векторов, имеющих один и тот же синдром, называется смежным классом по подгруппе кодовых слов. Как только что показано, разность между любыми двумя векторами из одного и того же смежного класса является кодовым словом. Обратно, сумма некоторого вектора х и любого кодового слова лежит в том же смежном классе, что и х. Следовательно, число векторов в любом смежном классе равно числу
у является кодовым словом. Множество всех векторов, имеющих один и тот же синдром, называется смежным классом по подгруппе кодовых слов. Как только что показано, разность между любыми двумя векторами из одного и того же смежного класса является кодовым словом. Обратно, сумма некоторого вектора х и любого кодового слова лежит в том же смежном классе, что и х. Следовательно, число векторов в любом смежном классе равно числу  кодовых слов. Возможными векторами ошибок являются слова из того смежного класса, которому принадлежит полученное слово.
кодовых слов. Возможными векторами ошибок являются слова из того смежного класса, которому принадлежит полученное слово.
 -мерного двоичного вектора как число единиц в данном векторе. Вектор наименьшего веса в пределах данного смежного класса выберем в качестве лидера смежного класса.
-мерного двоичного вектора как число единиц в данном векторе. Вектор наименьшего веса в пределах данного смежного класса выберем в качестве лидера смежного класса.

 строке и
строке и  столбце, равен сумме
столбце, равен сумме  кодового слова и
кодового слова и  лидера.
лидера.
 Матрица
Матрица  называется проверочной матрицей. Блоковая длина
называется проверочной матрицей. Блоковая длина  кода равна числу столбцов матрицы
кода равна числу столбцов матрицы  Синдром
Синдром  любого слова
любого слова  определяется уравнением
определяется уравнением  Смежный класс состоит из всех слов с одним и тем же синдромом. Весом слова называется число его единичных координат. Слово наименьшего чеса в данном смежном классе называется его лидером.
Смежный класс состоит из всех слов с одним и тем же синдромом. Весом слова называется число его единичных координат. Слово наименьшего чеса в данном смежном классе называется его лидером.
 принятое слово, то множество возможных векторов ошибок совпадает со смежным классом, содержащим
принятое слово, то множество возможных векторов ошибок совпадает со смежным классом, содержащим  Наиболее вероятным вектором ошибок является лидер этого смежного класса. Линейный код может быть декодирован следующим образом: вычисляем синдром, находим лидер смежного класса, которому соответствует этот синдром, и, вычитая найденный лидер из принятого слова, получаем наиболее вероятное кодовое слово.
Наиболее вероятным вектором ошибок является лидер этого смежного класса. Линейный код может быть декодирован следующим образом: вычисляем синдром, находим лидер смежного класса, которому соответствует этот синдром, и, вычитая найденный лидер из принятого слова, получаем наиболее вероятное кодовое слово.
 и (2) как по заданному синдрому находить лидер смежного класса?
и (2) как по заданному синдрому находить лидер смежного класса?
 эти вопросы могут быть исследованы с помощью полного перебора. Для больших
эти вопросы могут быть исследованы с помощью полного перебора. Для больших  обе эти
обе эти

