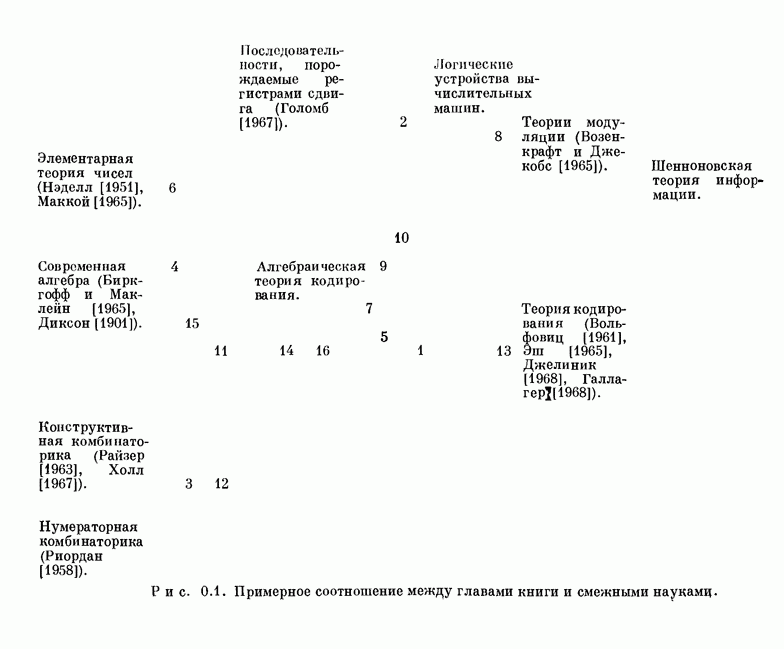
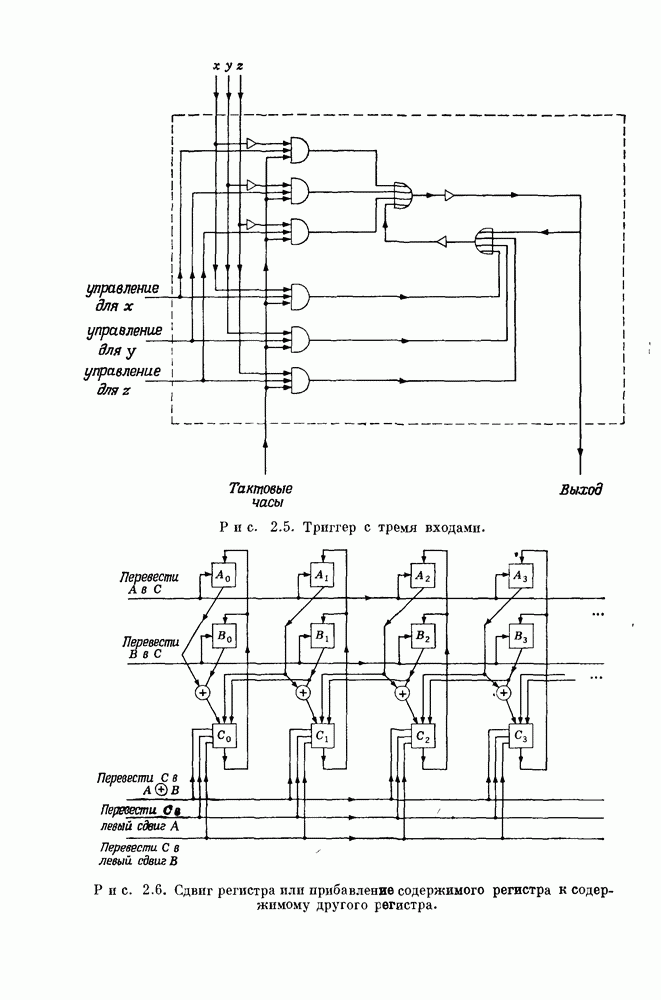
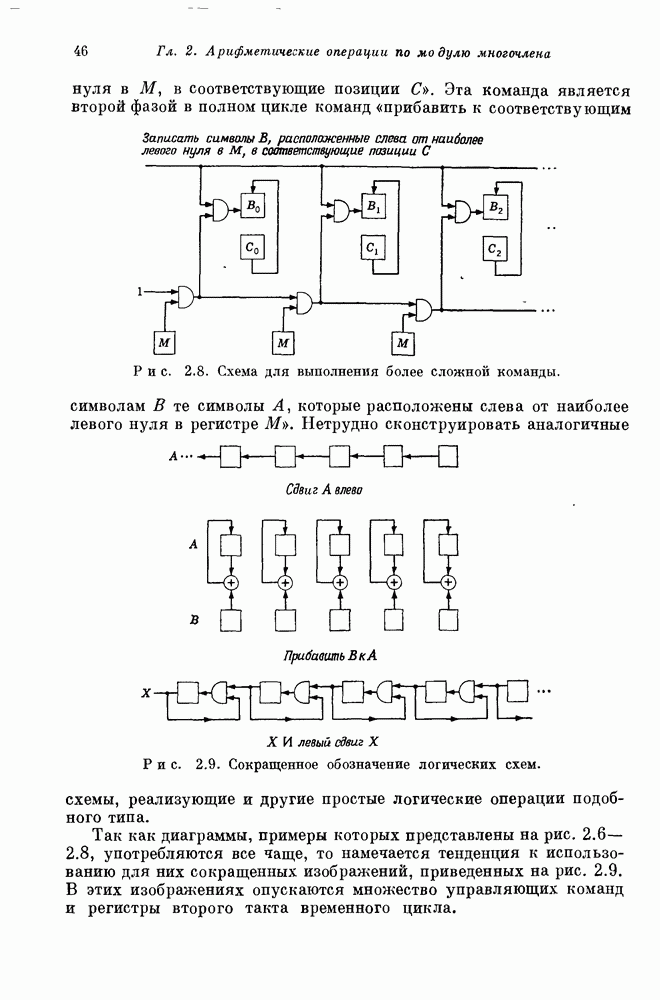
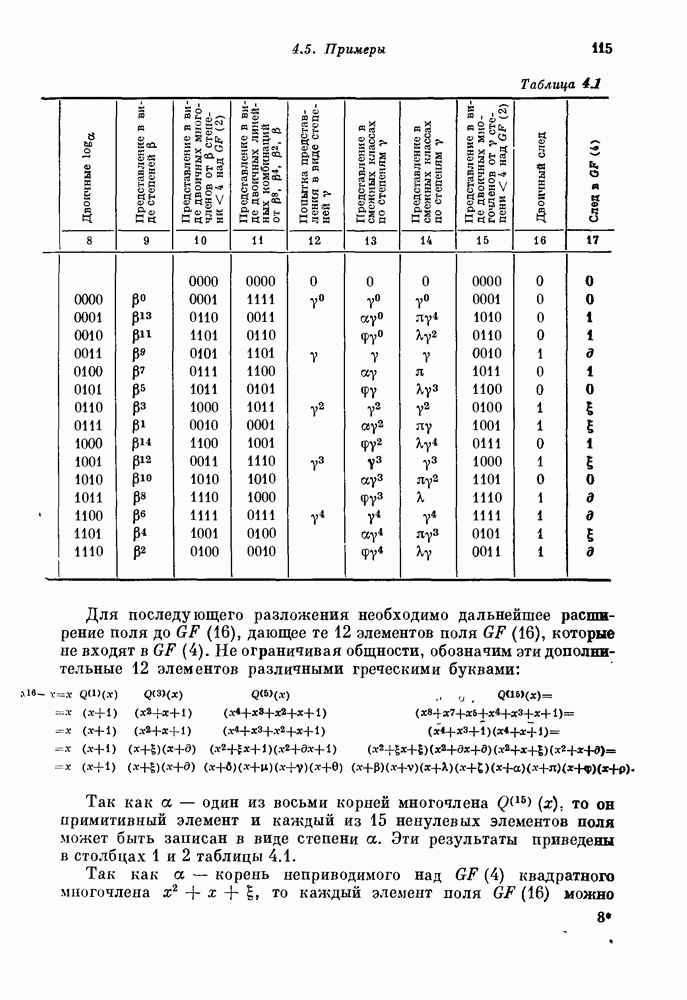
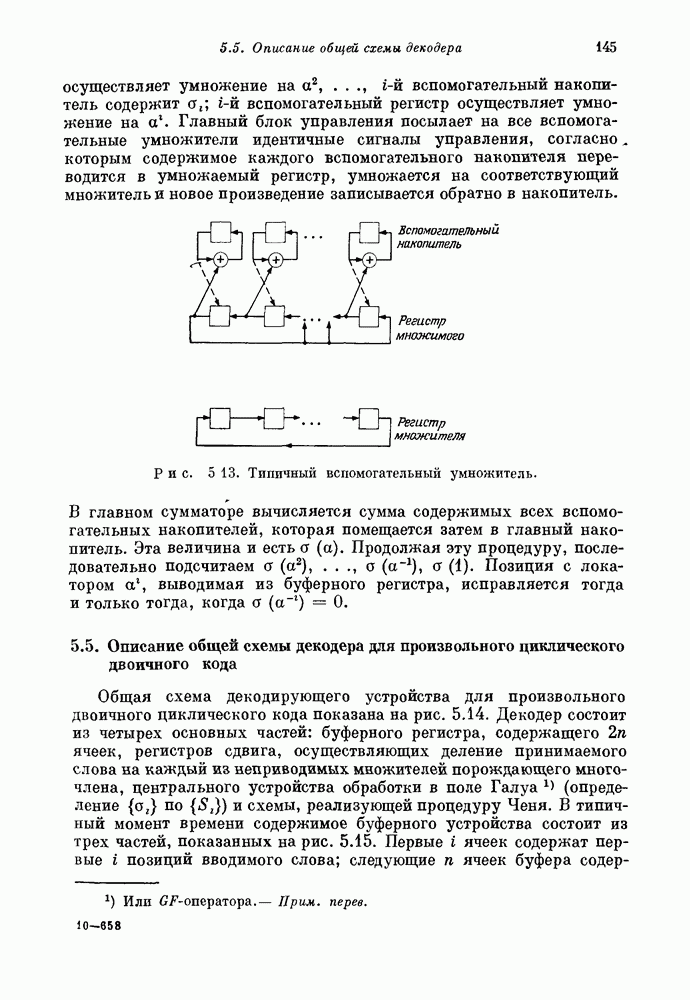
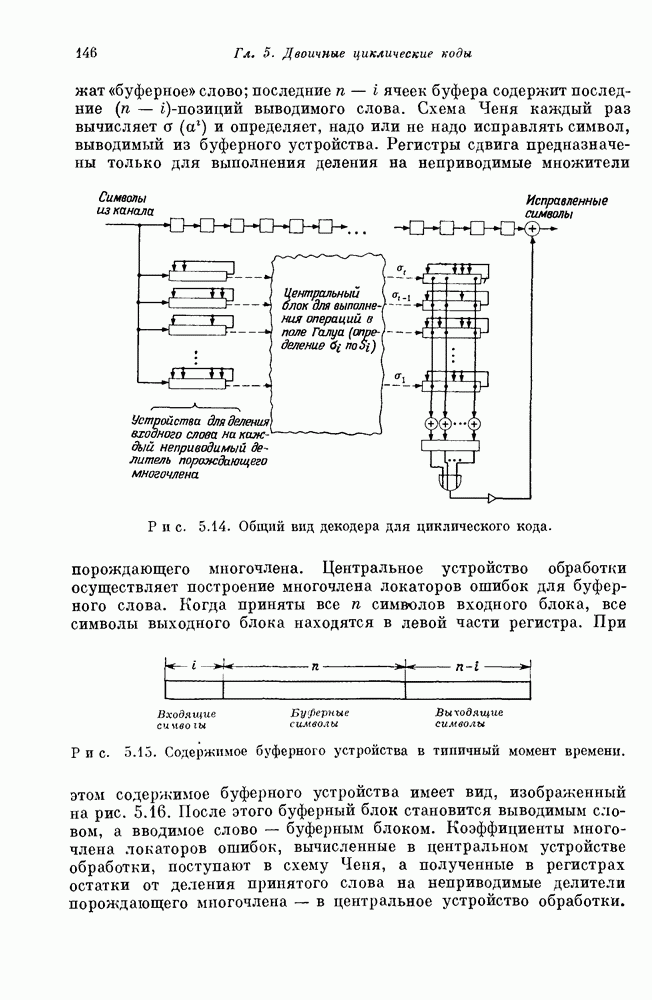
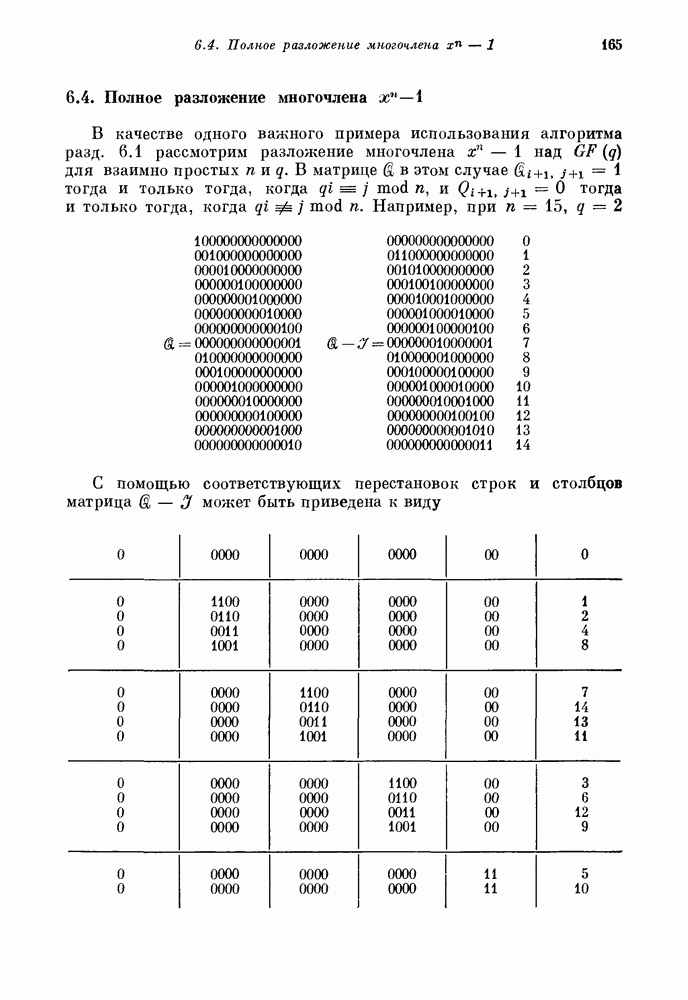
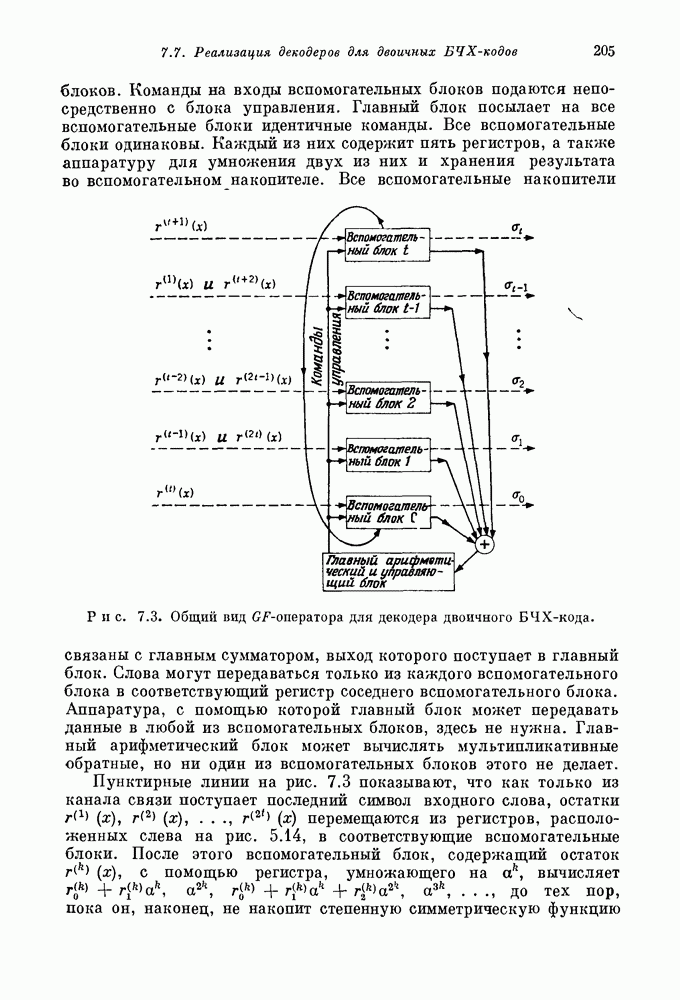
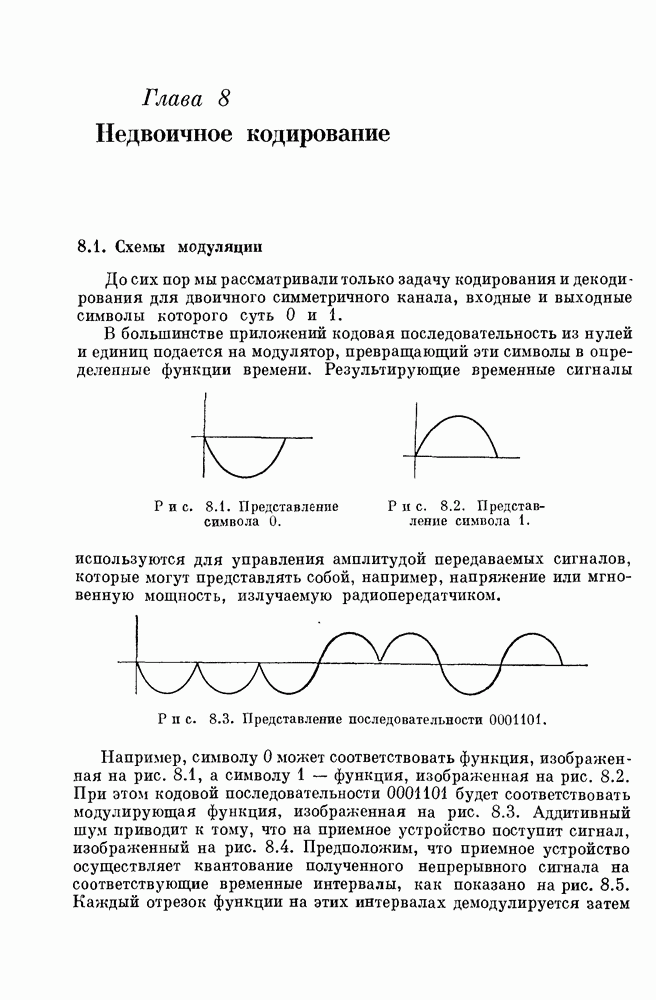
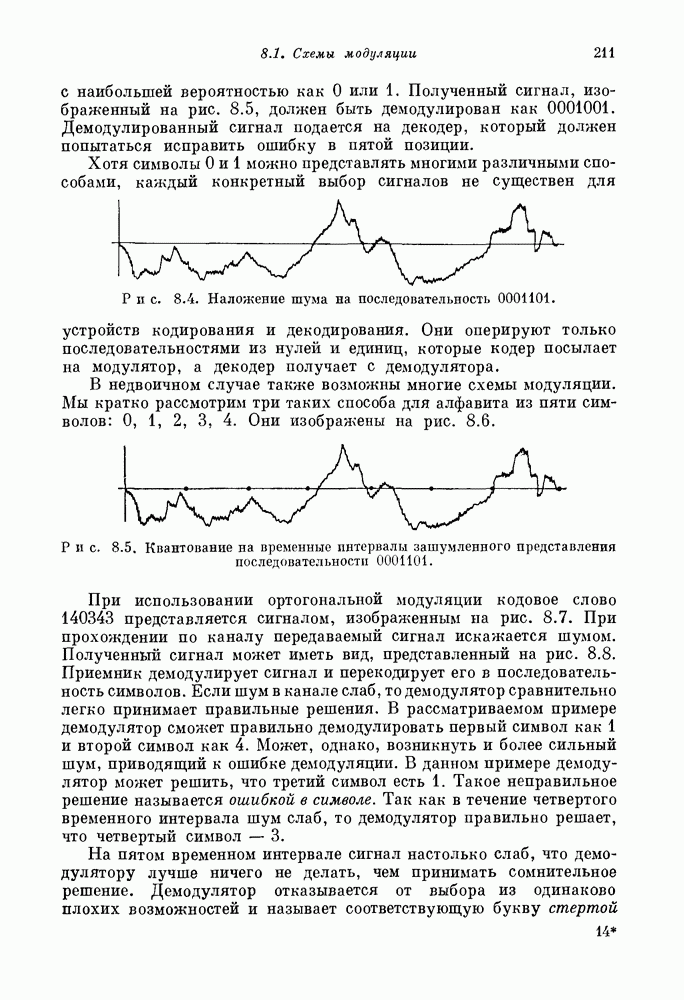
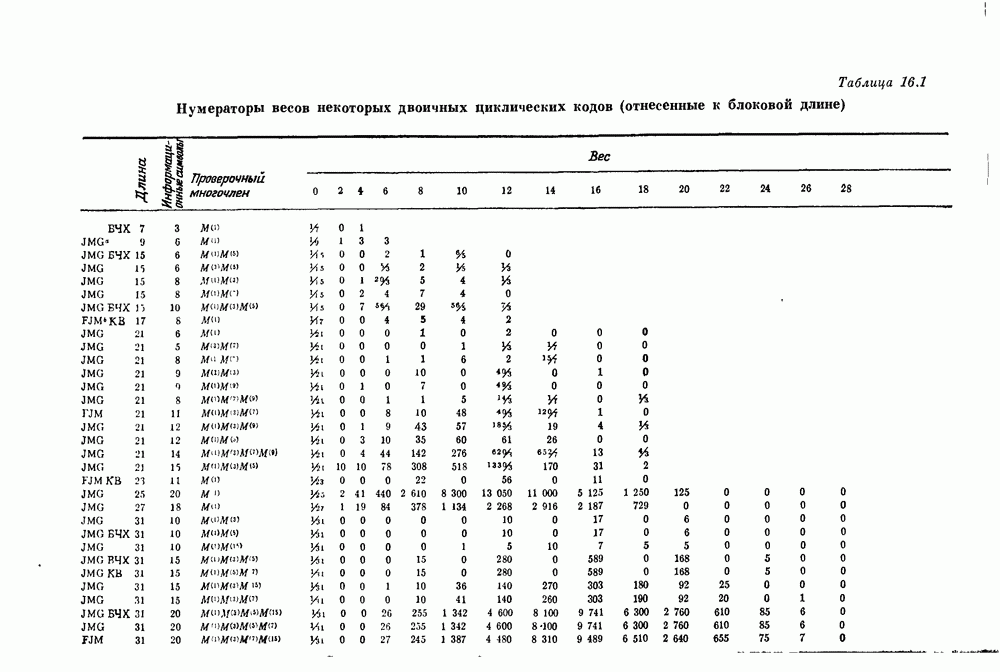
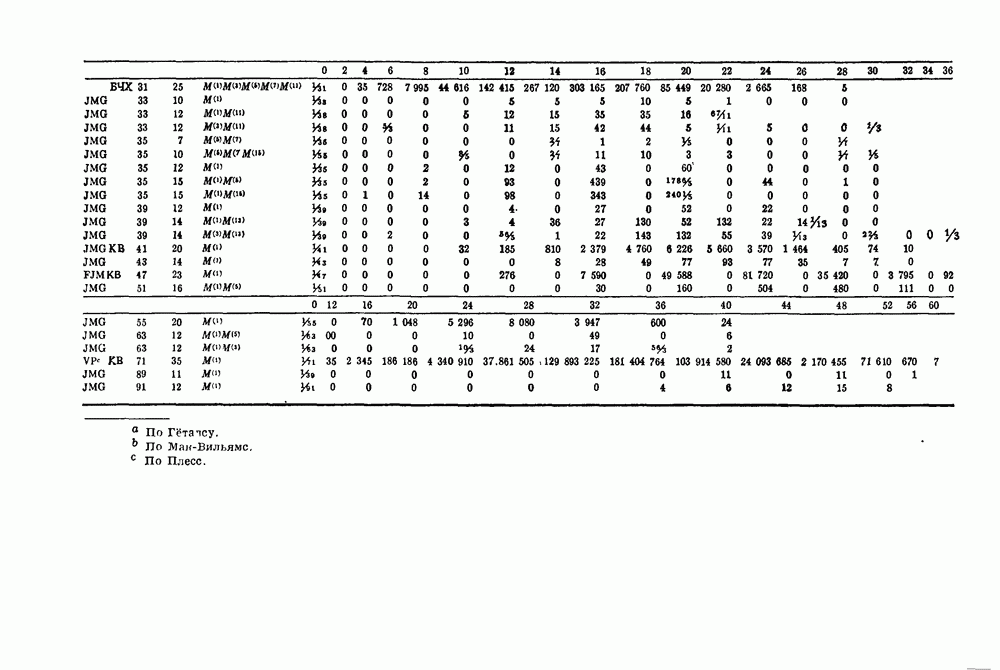
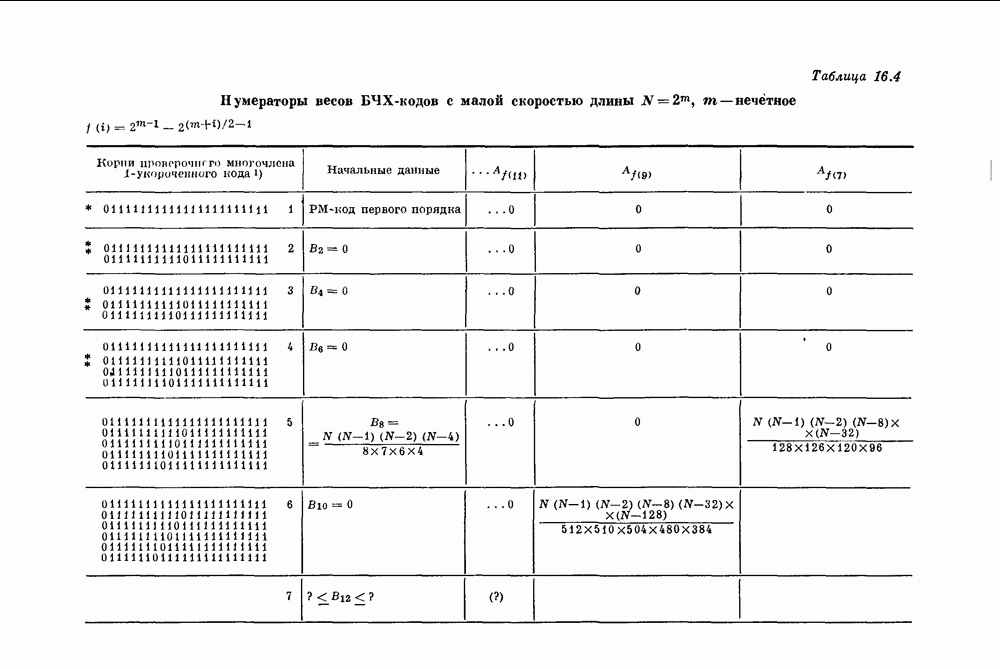
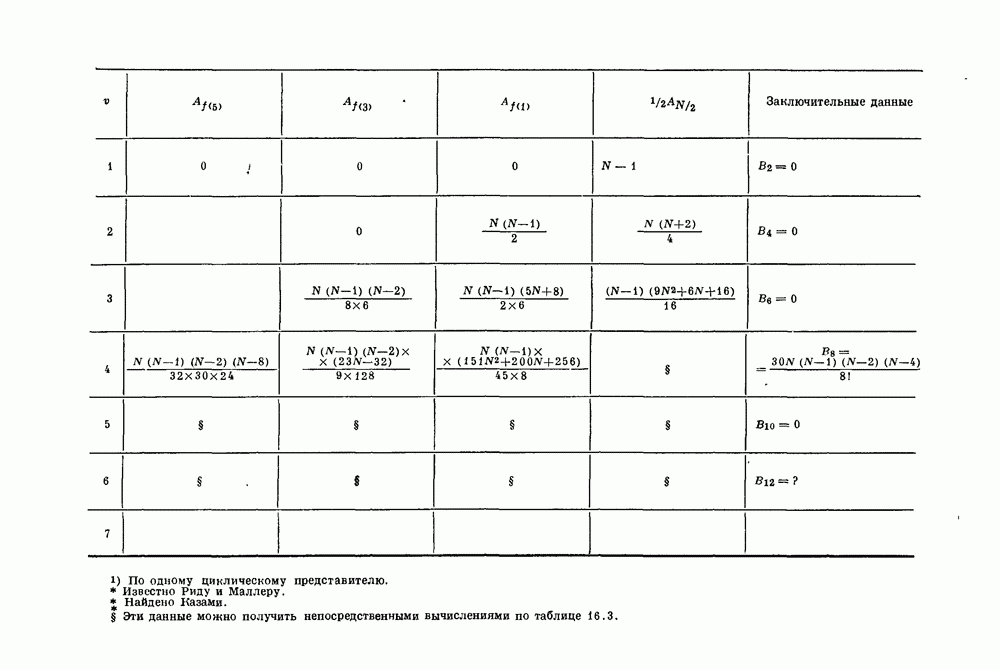
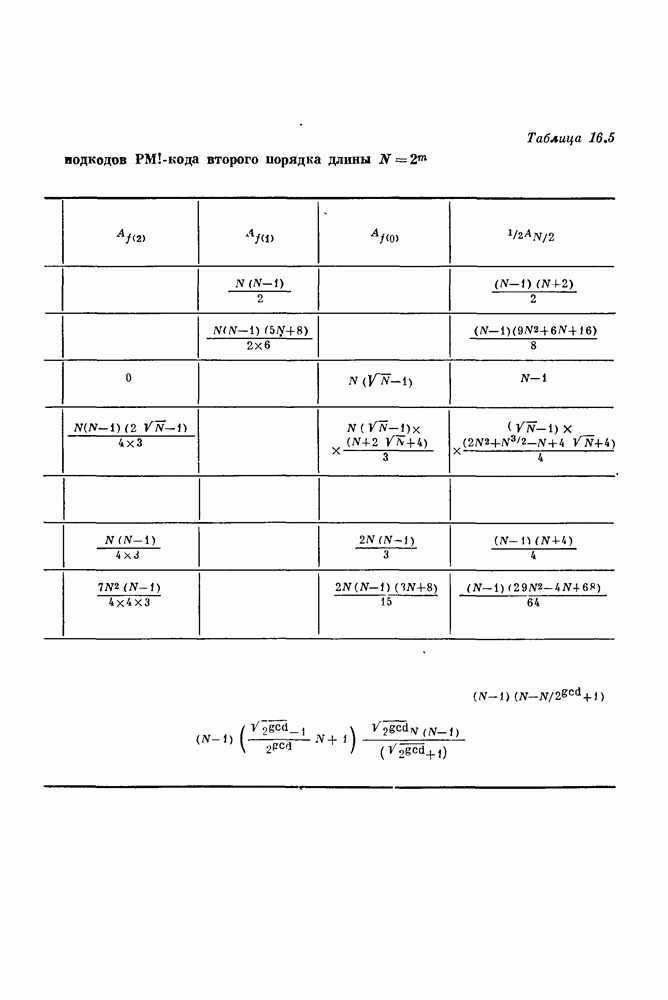
15.4. Пороговое декодирование — лучший из известных алгоритмов декодирования некоторых кодов
Так как кодовые слова РМ-кодов образуют подмножество множества кодовых слов БЧХ-кода, то к РМ-кодам применимы алгебраические алгоритмы декодирования БЧХ-кодов. Однако к РМ-кодам с малыми скоростями применим и более простой алгоритм, известный под названием порогового декодирования. Впервые один из вариантов порогового декодирования для кодов Рида — Маллера был описан Ридом [1954]. Для некоторых других классов блоковых кодов процедуры порогового декодирования были впервые введены Месси [1963].
Метод порогового декодирования мы объясним на последовательности примеров.
15.41. Двоичные коды длины  повторением. Начнем с простейшего случая
повторением. Начнем с простейшего случая  -укороченного РМ-кода нулевого порядка, представляющего собой двоичный код с повторением. При декодировании для этого кода достаточно подсчитывать число единиц среди
-укороченного РМ-кода нулевого порядка, представляющего собой двоичный код с повторением. При декодировании для этого кода достаточно подсчитывать число единиц среди  полученных символов.
полученных символов.

Рис. 15.4. Декодер для  -укороченного РМ-кода нулевого порядка.
-укороченного РМ-кода нулевого порядка.
Если получено более  единиц, то принимается решение, что передавалось единичное кодовое слово; если получено меньше
единиц, то принимается решение, что передавалось единичное кодовое слово; если получено меньше  единиц, то принимается решение, что передавалось нулевое кодовое слово. Непосредственный метод реализации этого решающего правила представлен на рис. 15.4. Декодер содержит
единиц, то принимается решение, что передавалось нулевое кодовое слово. Непосредственный метод реализации этого решающего правила представлен на рис. 15.4. Декодер содержит  -разрядный счетчик и
-разрядный счетчик и  -ячеечный регистр сдвига с обратной связью
-ячеечный регистр сдвига с обратной связью  . В начальном состоянии счетчик установлен на нуль, а
. В начальном состоянии счетчик установлен на нуль, а  содержит
содержит  Символы, поступающие из канала связи, складываются в счетчике. Переход
Символы, поступающие из канала связи, складываются в счетчике. Переход  снова в состояние
снова в состояние  означает, что все
означает, что все  символов
символов
приняты. Наивысший разряд счетчика равен 1 тогда и только тогда, когда среди принятых символов содержалось не менее  единиц. Наивысший разряд счетчика выдается на выход, а сам он устанавливается в нулевое положение, чтобы приготовиться к приему следующего блока из
единиц. Наивысший разряд счетчика выдается на выход, а сам он устанавливается в нулевое положение, чтобы приготовиться к приему следующего блока из  символов.
символов.
Двоичный код с повторением описывается следующими проверочными соотношениями:

Каждое из этих проверочных уравнений связывает  и один из других символов. Более того, никакая пара проверочных соотношений не содержит общих символов, за исключением
и один из других символов. Более того, никакая пара проверочных соотношений не содержит общих символов, за исключением  Поэтому каждое из уравнений определяет независимое значение
Поэтому каждое из уравнений определяет независимое значение 

Если не более половины координат вектора шума  равны 1, то решение о
равны 1, то решение о  можно принять «по большинству голосов» для
можно принять «по большинству голосов» для 
Уравнения (15.42) представляют собой простейший пример системы ортогональных проверок. В общем случае имеет место следующее определение:
15.43. Определение. Множество проверочных уравнений называется ортогональным на множестве позиций  тогда и только тогда, когда
тогда и только тогда, когда
1)  входит во все проверочные уравнения множества для любого
входит во все проверочные уравнения множества для любого  ;
;
2)  входит не более чем в одно проверочное уравнение множества для любого
входит не более чем в одно проверочное уравнение множества для любого  .
.
15.44. ОСР-коды максимальной длины. Рассмотрим далее  -укороченные РМ-коды первого порядка, совпадающие с ОСР-кодами максимальной длины. Так как совершенные коды Хэмминга, исправляющие одну ошибку, дуальны к этим кодам, то такой код удовлетворяет проверочному уравнению
-укороченные РМ-коды первого порядка, совпадающие с ОСР-кодами максимальной длины. Так как совершенные коды Хэмминга, исправляющие одну ошибку, дуальны к этим кодам, то такой код удовлетворяет проверочному уравнению  тогда и только тогда, когда
тогда и только тогда, когда  . В частности, для любой заданной пары позиций
. В частности, для любой заданной пары позиций  код содержит проверочные соотношения
код содержит проверочные соотношения
 веса 3, связывающие эти символы, где
веса 3, связывающие эти символы, где  Следовательно, для любой заданной позиции можно выбрать
Следовательно, для любой заданной позиции можно выбрать  проверочных соотношений веса 3, ортогональных на зтой позиции. Например, предположим, что
проверочных соотношений веса 3, ортогональных на зтой позиции. Например, предположим, что  Тогда ортогональными на нулевой позиции будут следующие семь проверочных множеств:
Тогда ортогональными на нулевой позиции будут следующие семь проверочных множеств:  Если в канале произошло не более трех ошибок, то
Если в канале произошло не более трех ошибок, то  может быть определено «по большинству голосов» из следующих восьми равенств:
может быть определено «по большинству голосов» из следующих восьми равенств:

Если не менее пяти из этих величин совпадут, то «голосование» обеспечит наиболее вероятное значение  Если четыре из этих равенств дадут
Если четыре из этих равенств дадут  а остальные четыре —
а остальные четыре —  то пороговая процедура приведет к нарушению декодирования, что позволит обнаружить четыре или более ошибок в канале.
то пороговая процедура приведет к нарушению декодирования, что позволит обнаружить четыре или более ошибок в канале.
Для того чтобы избежать зтой «пробки», рассмотрим вероятности различных оценок (15.45). В двоичном симметричном канале вероятностью ошибки  имеем
имеем

Если  то
то  так что значение
так что значение  имеет большую вероятность, чем все остальные. На зтой основе можно построить более тонкий пороговый декодер, который при делении голосов «четыре на четыре» дает оценке
имеет большую вероятность, чем все остальные. На зтой основе можно построить более тонкий пороговый декодер, который при делении голосов «четыре на четыре» дает оценке  дополнительный голос.
дополнительный голос.
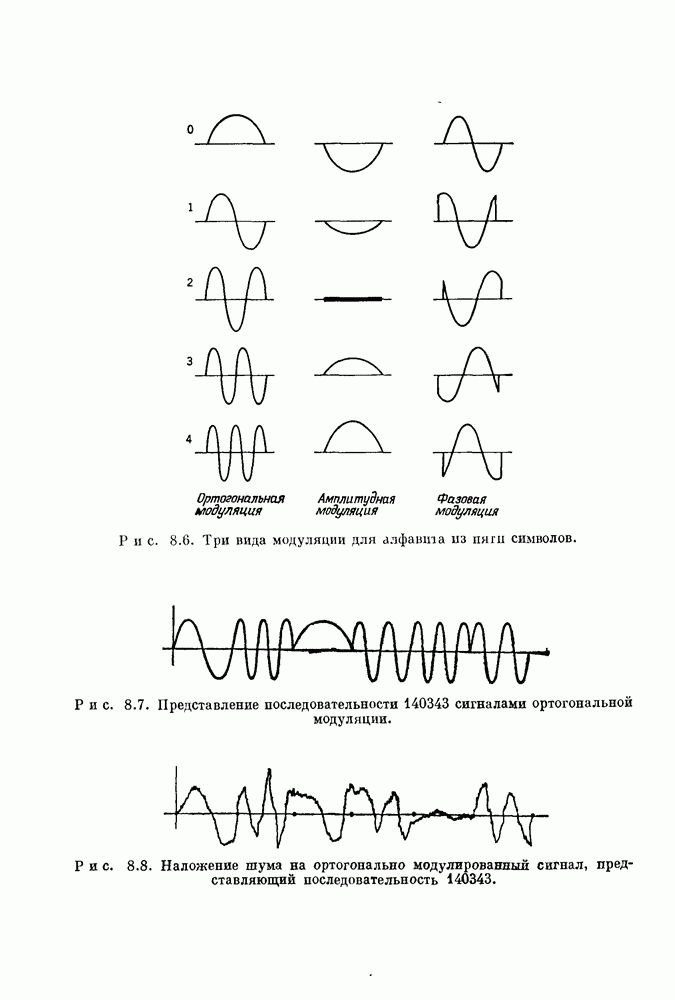
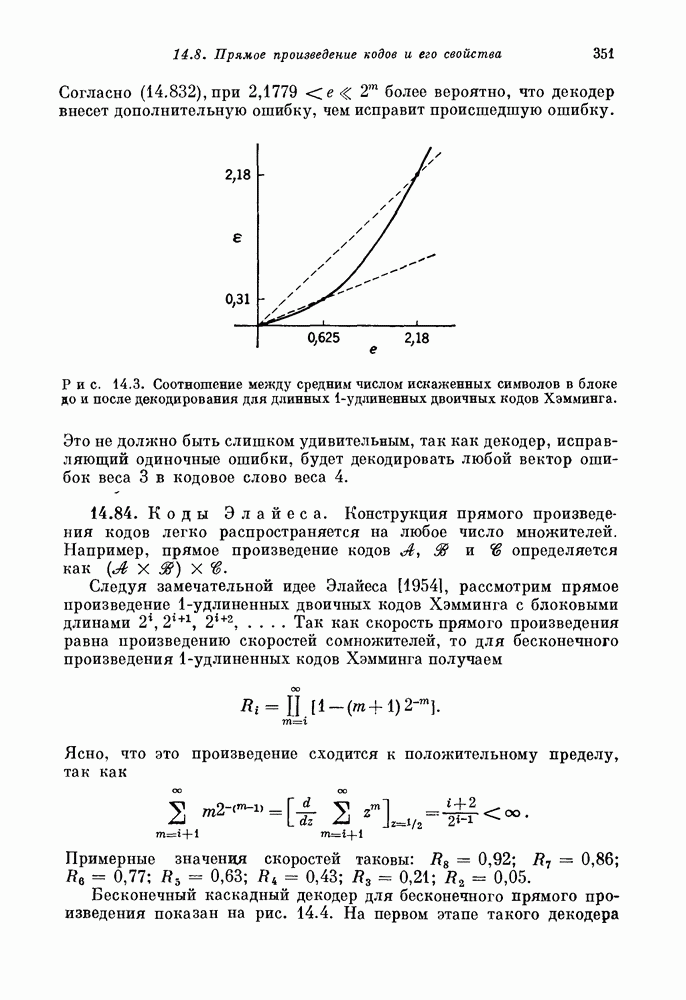
Декодер на рис. 15.5 вычисляет согласно 15.45 все восемь оценок. Сначала к нулевому состоянию счетчика добавляется  Затем вычисляется величина
Затем вычисляется величина  и складывается с содержимым счетчика. После зтого кодовое слово подвергается подстановке
и складывается с содержимым счетчика. После зтого кодовое слово подвергается подстановке  показанной на рис. 15.3. Эта подстановка не трогает позиции 0, но переставляет 2-ю и 8-ю позиции соответственно с 1-й и 4-й. Затем вычисляется новая проверочная сумма и добавляется к содержимому счетчика. После вычисления всех восьми величин по большинству голосов» определяется
показанной на рис. 15.3. Эта подстановка не трогает позиции 0, но переставляет 2-ю и 8-ю позиции соответственно с 1-й и 4-й. Затем вычисляется новая проверочная сумма и добавляется к содержимому счетчика. После вычисления всех восьми величин по большинству голосов» определяется  Далее осуществляется циклический
Далее осуществляется циклический
сдвиг кодового слова и процесс повторяется для определения 
Хотя схема декодирования рис. 15.5 использует только один сумматор полученных символов, для декодирования с ее помощью одного символа слова требуется осуществить 7 перестановок.

Рис. 15.5. Перестановочно-пороговый декодер для ОСР-кода, 
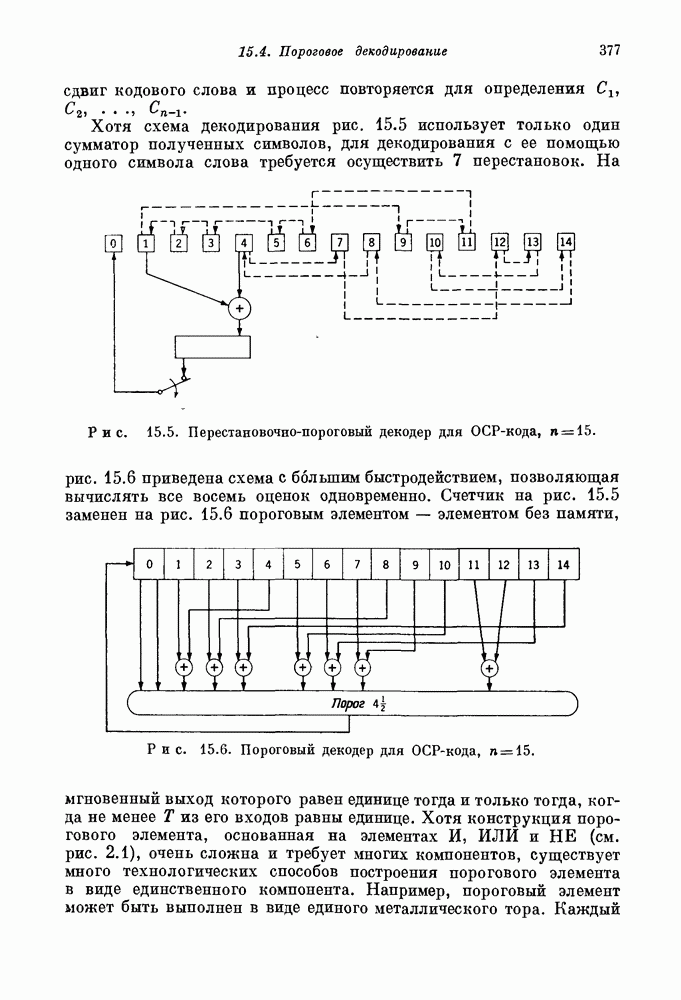
На рис. 15.6 приведена схема с большим быстродействием, позволяющая вычислять все восемь оценок одновременно.

Рис. 15.6. Пороговый декодер для ОСР-кода, 
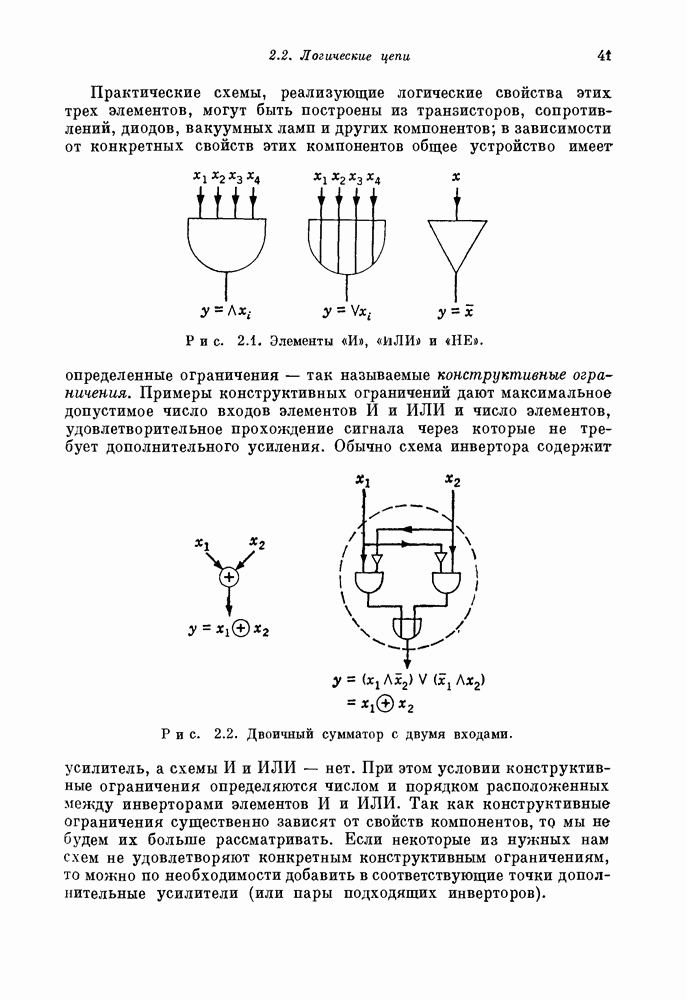
Счетчик на рис. 15.5 заменен на рис. 15.6 пороговым элементом — элементом без памяти, мгновенный выход которого равен единице тогда и только тогда, когда не менее  из его входов равны единице. Хотя конструкция порогового элемента, основанная на элементах И, ИЛИ и НЕ (см. рис. 2.1), очень сложна и требует многих компонентов, существует много технологических способов построения порогового элемента в виде единственного компонента. Например, пороговый элемент может быть выполнен в виде единого металлического тора. Каждый
из его входов равны единице. Хотя конструкция порогового элемента, основанная на элементах И, ИЛИ и НЕ (см. рис. 2.1), очень сложна и требует многих компонентов, существует много технологических способов построения порогового элемента в виде единственного компонента. Например, пороговый элемент может быть выполнен в виде единого металлического тора. Каждый
вход выполняется в виде проволоки, обернутой вокруг тора определенное число раз. Ток проходит по каждому входному проводу (во всех проводах в одном направлении) тогда и только тогда, когда соответствующий ему вход равен 1. Дополнительный провод имеет в  раз больше витков, чем каждый из входных. По нему всегда проходит ток в противоположном направлении. Выход порогового элемента определяется направлением потока в торе.
раз больше витков, чем каждый из входных. По нему всегда проходит ток в противоположном направлении. Выход порогового элемента определяется направлением потока в торе.
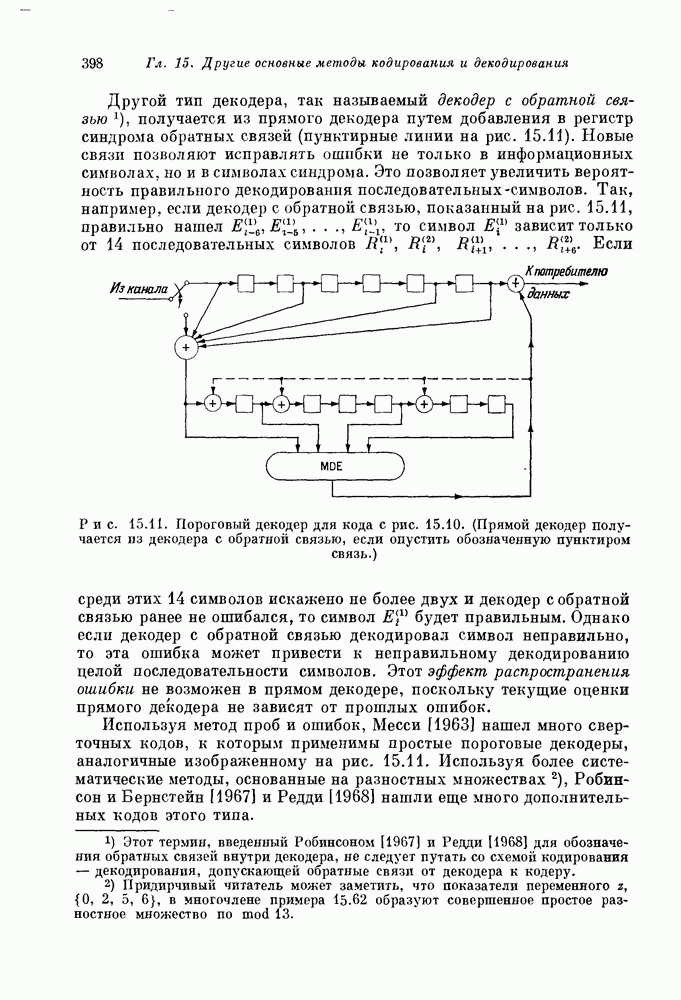
Декодер рис. 15.7 отличается от декодера рис. 15.6 тем, что пороговый элемент с девятью входами заменен на несколько дополнительных сумматоров и пороговый элемент с семью входами, выход которого равен 1 тогда и только тогда, когда не менее пяти из его входов равны 1.

Рис. 15.7. Синдромно-пороговый декодер для ОСР-кода,  .
.
Декодер, изображенный на рис. 15.7, называется синдромным пороговым декодером, так как входы порогового элемента представляют собой символы синдрома  значения которых равны соответственно
значения которых равны соответственно  Выход порогового элемента равен принимаемой величине символа
Выход порогового элемента равен принимаемой величине символа 
Алгоритмы декодирования с исправлением  ошибок (рис. 15.4-15.7) используют существование 21 проверочных соотношений, ортогональных на декодируемой позиции. Для большинства кодов, исправляющих
ошибок (рис. 15.4-15.7) используют существование 21 проверочных соотношений, ортогональных на декодируемой позиции. Для большинства кодов, исправляющих  ошибок, не существует 21 проверочных уравнений, ортогональных на любой заданной позиции. Однако, как показывает следующий пример, иногда мажоритарное решение позволяет определить вектор ошибок, если использовать в декодере многоступенчатую процедуру.
ошибок, не существует 21 проверочных уравнений, ортогональных на любой заданной позиции. Однако, как показывает следующий пример, иногда мажоритарное решение позволяет определить вектор ошибок, если использовать в декодере многоступенчатую процедуру.
15.46. Двухступенчатое пороговое декодирование  -кода. Рассмотрим
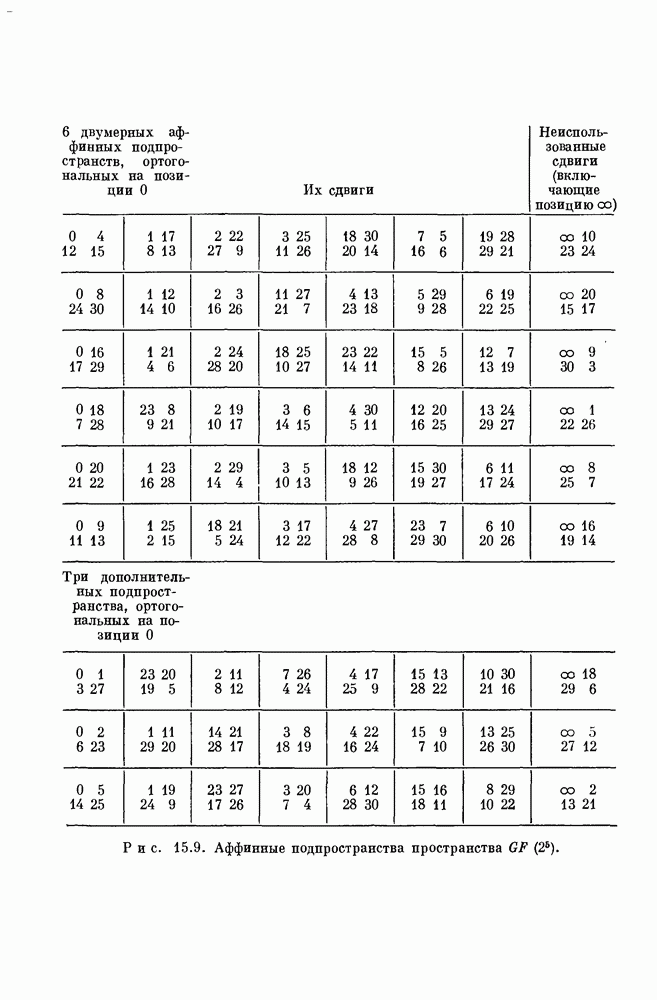
-кода. Рассмотрим  -укороченный код второго порядка с блоковой длиной 31, исправляющий 3 ошибки. Мы покажем, что этот код можно декодировать с помощью синдромного порогового декодера рис. 15.8, где связи внутри «цепей суммирования» могут быть определены из рис. 15.9 способом, который будет объяснен ниже.
-укороченный код второго порядка с блоковой длиной 31, исправляющий 3 ошибки. Мы покажем, что этот код можно декодировать с помощью синдромного порогового декодера рис. 15.8, где связи внутри «цепей суммирования» могут быть определены из рис. 15.9 способом, который будет объяснен ниже.
Задачей всех цепей на рис. 15.8 является получение величины символа  вектора шума. Как только это будет сделано, символ в нулевой позиции может быть исправлен, и, используя циклический сдвиг, на той же схеме можно будет получить величины
вектора шума. Как только это будет сделано, символ в нулевой позиции может быть исправлен, и, используя циклический сдвиг, на той же схеме можно будет получить величины 
Величина  получается как выход оконечного порогового элемента с шестью входами. Каждый вход этого оконечного порогового элемента равен двоичной сумме четырех символов вектора ошибки, соответствующих одному из множеств, указанных в крайнем левом столбце верхней таблицы на рис. 15.9.
получается как выход оконечного порогового элемента с шестью входами. Каждый вход этого оконечного порогового элемента равен двоичной сумме четырех символов вектора ошибки, соответствующих одному из множеств, указанных в крайнем левом столбце верхней таблицы на рис. 15.9.

Рис. 15.8. Двухступенчатый декодер для 
На первый вход подается величина  второй
второй  на шестой
на шестой 
Каждая из четверок на рис. 15.9 определяет аффинное подпространство в  Любые две четверки из одной и той же строки могут быть переведены друг в друга. Следовательно, объединение любых двух четверок из одной и той же строки на рис. 15. 9 определяет трехмерное аффинное подпространство в
Любые две четверки из одной и той же строки могут быть переведены друг в друга. Следовательно, объединение любых двух четверок из одной и той же строки на рис. 15. 9 определяет трехмерное аффинное подпространство в  Например, объединение первых двух четверок на рис. 15.9 дает
Например, объединение первых двух четверок на рис. 15.9 дает  что соответствует трехмерному аффинному подпространству
что соответствует трехмерному аффинному подпространству

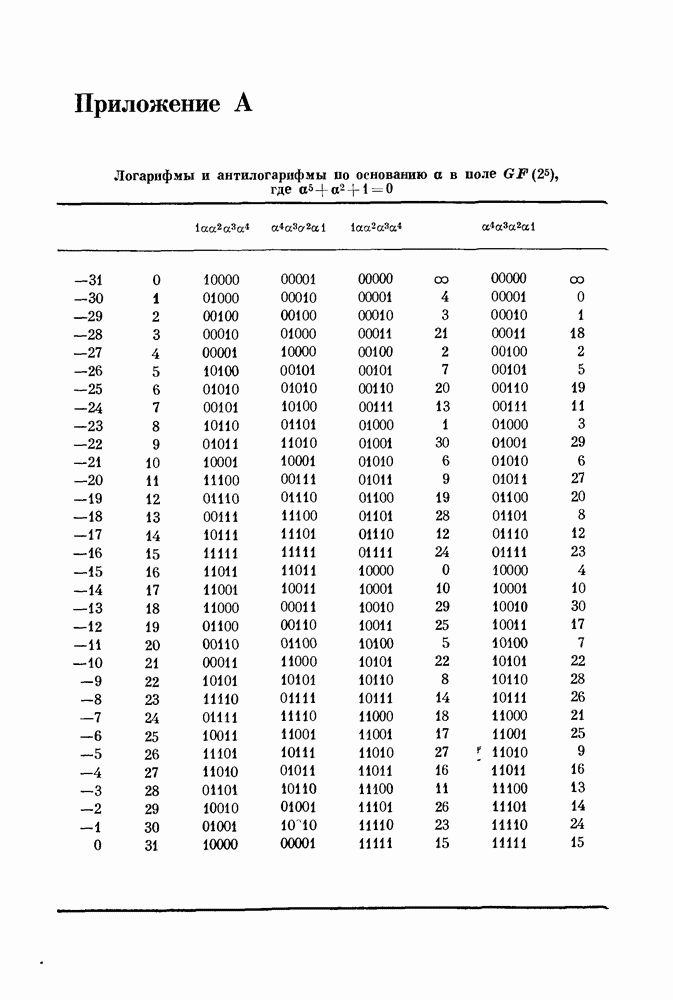
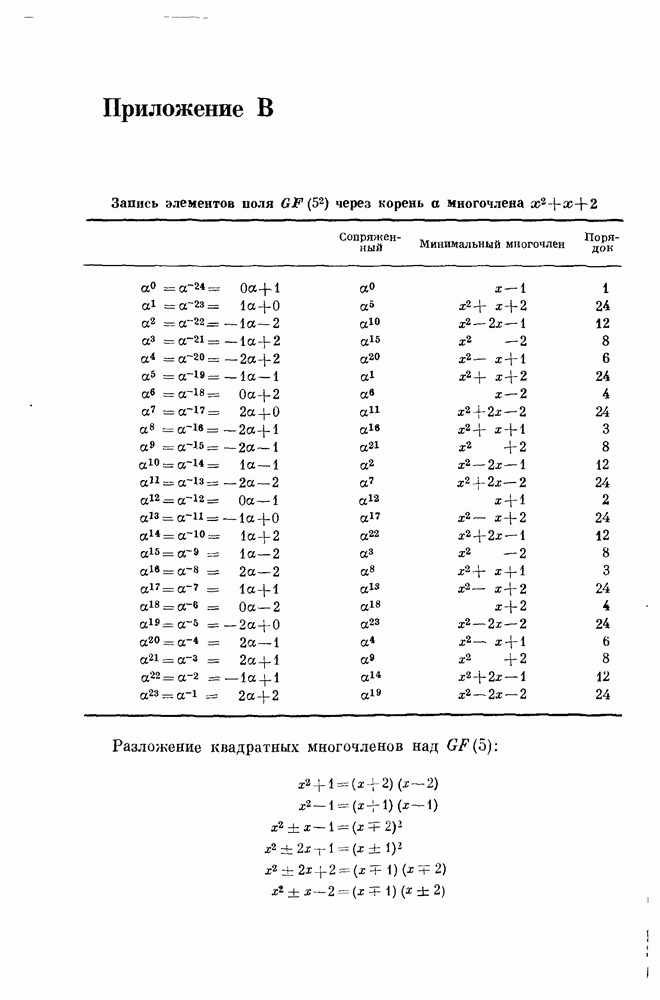
Используя приложение А, читатель может проверить, что это действительно аффинное подпространство. Согласно теоремам 15.323 и 15.329, код удовлетворяет проверочному соотношению, которое определяется любым трехмерным аффинным подпространством, не содержащим  Иными словами, декодер может вычислять символы
Иными словами, декодер может вычислять символы

(кликните для просмотра скана)
синдрома

как суммы

Аналогично может быть вычислена двоичная сумма ошибочных символов в позициях  Так как эти шесть проверочных соотношений ортогональны на
Так как эти шесть проверочных соотношений ортогональны на  то при условии, что в канале произошло не более трех ошибок, выход первого предварительного порогового элемента равен
то при условии, что в канале произошло не более трех ошибок, выход первого предварительного порогового элемента равен 
Каждый из шести предварительных пороговых элементов определяет соответственно величину двоичной суммы ошибочных символов, указанных в крайнем левом столбце верхней таблицы рис. 15.9. Если в канале произошло не более трех ошибок, то каждая из этих величин правильна и выход оконечного порогового элемента дает правильное значение символа  Если в канале произошло четыре или более ошибок, то декодер рис. 15.8 может произвести как правильное, так и ошибочное декодирование (см. задачу 15.5).
Если в канале произошло четыре или более ошибок, то декодер рис. 15.8 может произвести как правильное, так и ошибочное декодирование (см. задачу 15.5).
Декодер рис. 15.8 осуществляет двуступенчатое пороговое декодирование, так как рассматриваемый код ортогонализируем в два шага в соответствии со следующим определением.
15.47. Определение. Линейный код, исправляющий  ошибок, называется ортогонализируемым в 1 шаг, если для него существует 21 проверочных уравнений, ортогональных на каждой позиции
ошибок, называется ортогонализируемым в 1 шаг, если для него существует 21 проверочных уравнений, ортогональных на каждой позиции 
Код называется ортогонализируемым в  шагов, если существуют множества позиций
шагов, если существуют множества позиций  такие, что:
такие, что:
1) для всех  код имеет 21 проверок, ортогональных на
код имеет 21 проверок, ортогональных на 
2) подкод исходного кода, удовлетворяющий этим проверкам  Для всех
Для всех  ортогонализируем в
ортогонализируем в  шаг.
шаг.
Для РМ-кода порядка  и длины
и длины  исправляющего
исправляющего  ошибок, в качестве множеств
ошибок, в качестве множеств  могут быть выбраны
могут быть выбраны  -мерные аффинные подпространства пространства
-мерные аффинные подпространства пространства  Подкод, удовлетворяющий проверкам
Подкод, удовлетворяющий проверкам  для всех
для всех  является РМ-кодом порядка
является РМ-кодом порядка  Отсюда непосредственно (индукция по
Отсюда непосредственно (индукция по  ) вытекает следующее утверждение:
) вытекает следующее утверждение:
15.48. Теорема. РМ-код порядка  с длиной
с длиной  исправляющий
исправляющий  ошибок, и
ошибок, и  -укороченный РМ-код порядка
-укороченный РМ-код порядка  с длиной
с длиной  исправляющий
исправляющий  ошибок, ортогонализируемы в
ошибок, ортогонализируемы в  шагов;
шагов;  -укороченный РМ-код порядка
-укороченный РМ-код порядка  с длиной
с длиной  исправляющий
исправляющий  ошибок, ортогонализируем в
ошибок, ортогонализируем в  шагов.
шагов.
Как видно из примера 15.46, некоторые РМ-коды порядка  ортогонализируемы меньше чем в
ортогонализируемы меньше чем в  шагов. Однако ни один из
шагов. Однако ни один из  -укороченных РМ-кодов при
-укороченных РМ-кодов при  не допускает ортогонализацию в один шаг.
не допускает ортогонализацию в один шаг.
Для некоторых кодов, исправляющих несколько ошибок и допускающих ортогонализацию в несколько шагов, пороговое декодирование хуже алгебраических процедур декодирования. Например, коды Хэмминга являются  -укороченными РМ-кодами, и поэтому к ним применимо пороговое декодирование. Однако такие декодеры оказываются сложнее, чем декодер, схема которого представлена на рис. 5.3.
-укороченными РМ-кодами, и поэтому к ним применимо пороговое декодирование. Однако такие декодеры оказываются сложнее, чем декодер, схема которого представлена на рис. 5.3.
С другой стороны, для многих легко ортогонализируемых кодов с исправлением  ошибок пороговые декодеры значительно проще реализуемы, чем алгебраические. К сожалению, для большинства кодов легкая ортогонализация неосуществима, а у тех кодов, которые легко ортогонализируемы, минимальное расстояние значительно хуже минимального расстояния сравнимых БЧХ-кодов. Во многих случаях, однако, эти недостатки порогового декодирования окупаются преимуществами легкой реализации. В случаях, когда помимо всех ошибок веса
ошибок пороговые декодеры значительно проще реализуемы, чем алгебраические. К сожалению, для большинства кодов легкая ортогонализация неосуществима, а у тех кодов, которые легко ортогонализируемы, минимальное расстояние значительно хуже минимального расстояния сравнимых БЧХ-кодов. Во многих случаях, однако, эти недостатки порогового декодирования окупаются преимуществами легкой реализации. В случаях, когда помимо всех ошибок веса  необходимо исправлять многие ошибки более высокого веса, преимущества порогового декодирования еще больше. Как отмечалось в разд. 10.5, алгебраические алгоритмы декодирования требуют в этих случаях введения дополнительных остроумных правил. Пороговые алгоритмы позволяют исправлять многие ошибки веса
необходимо исправлять многие ошибки более высокого веса, преимущества порогового декодирования еще больше. Как отмечалось в разд. 10.5, алгебраические алгоритмы декодирования требуют в этих случаях введения дополнительных остроумных правил. Пороговые алгоритмы позволяют исправлять многие ошибки веса  автоматически.
автоматически.