Пред.
След.
Макеты страниц
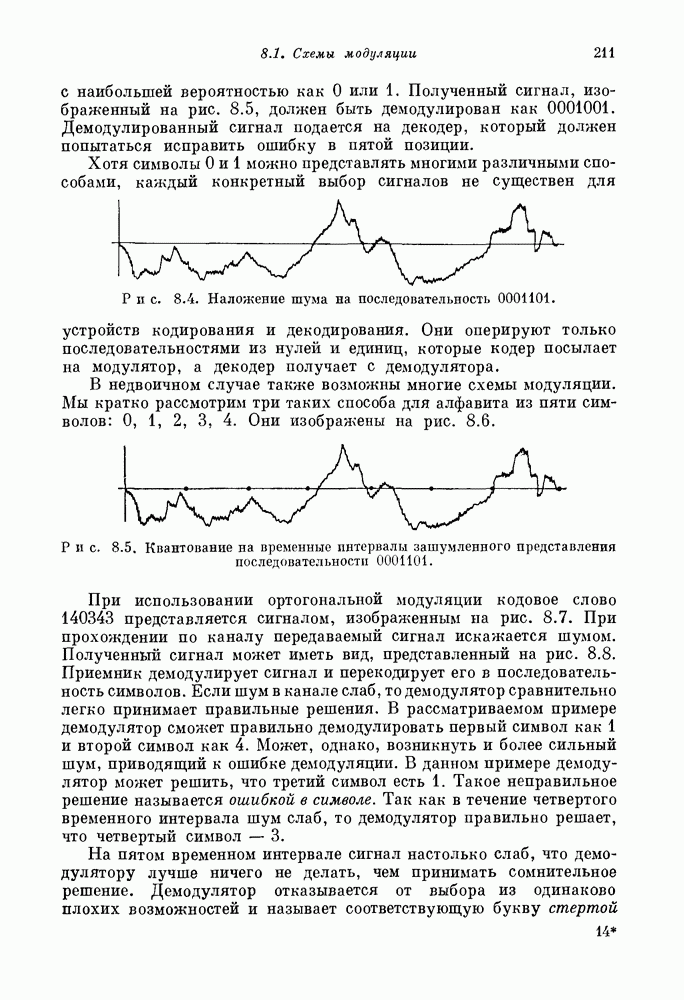
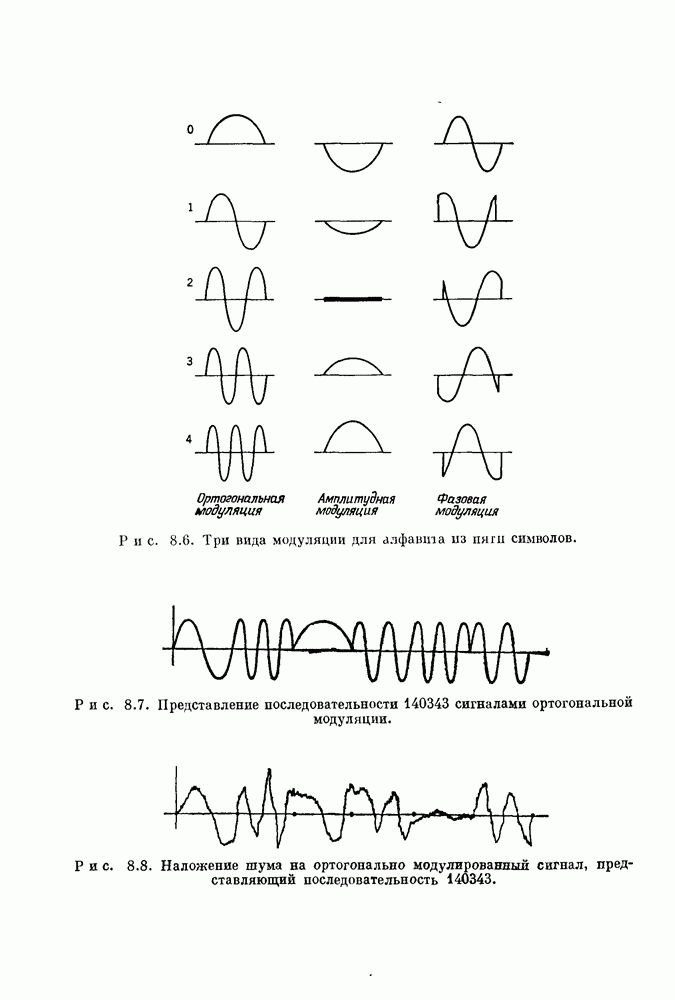
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
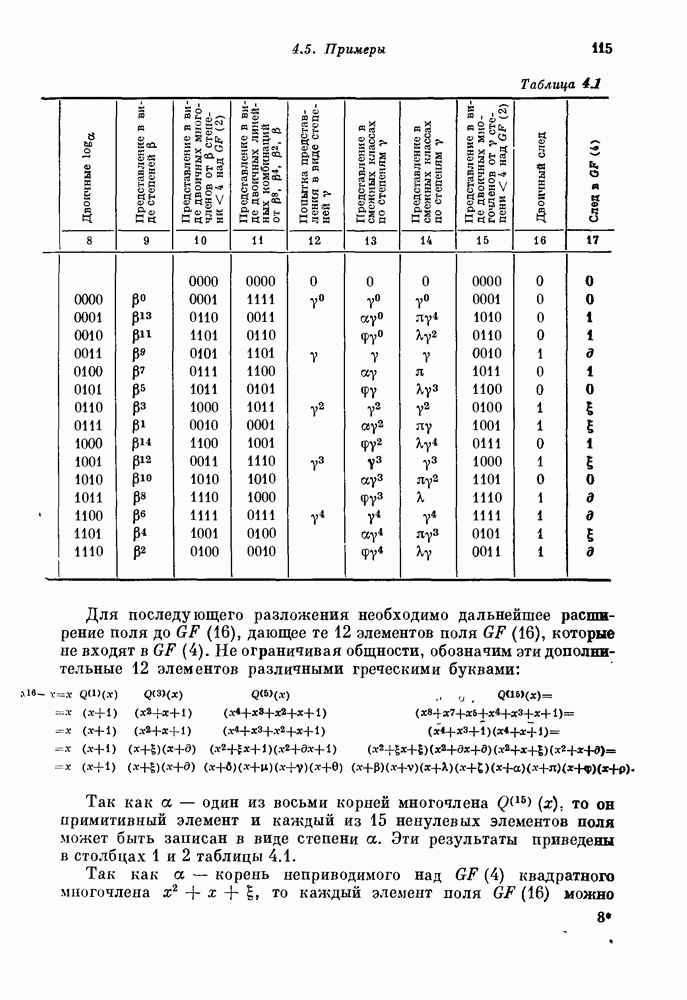
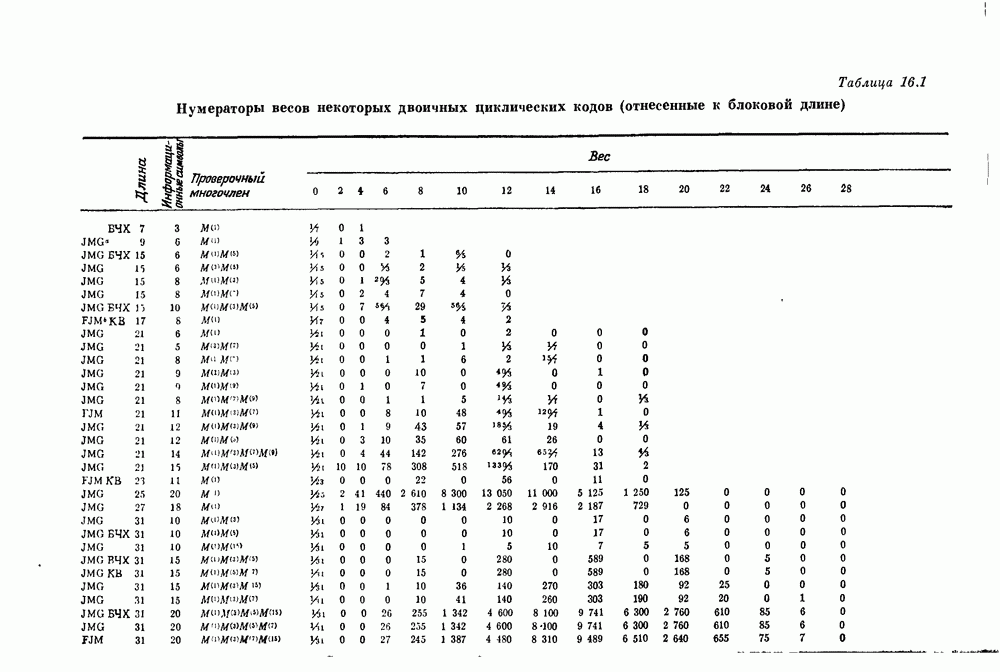
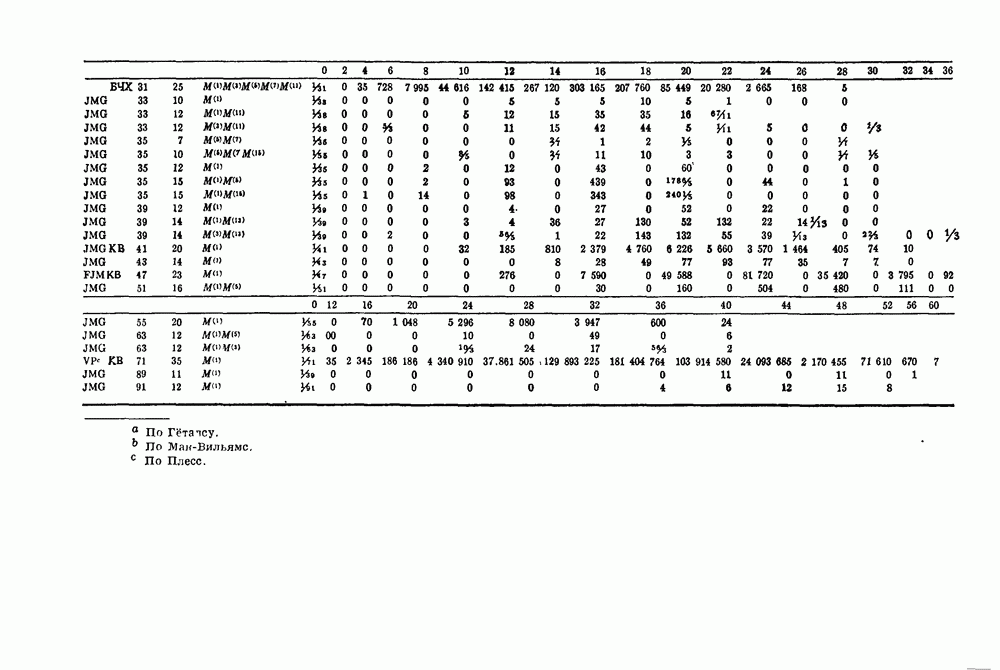
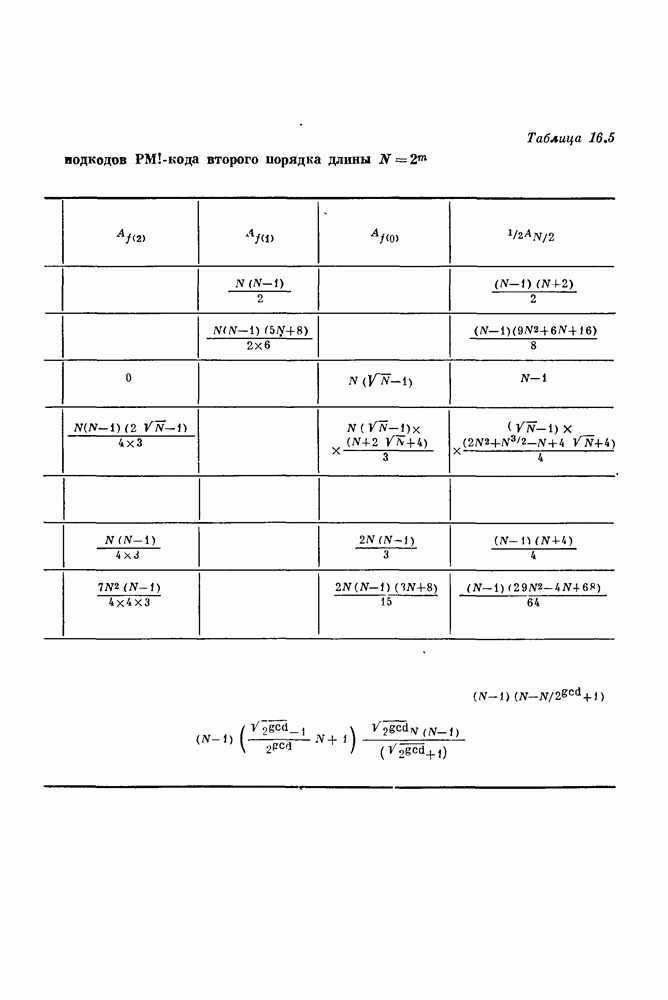
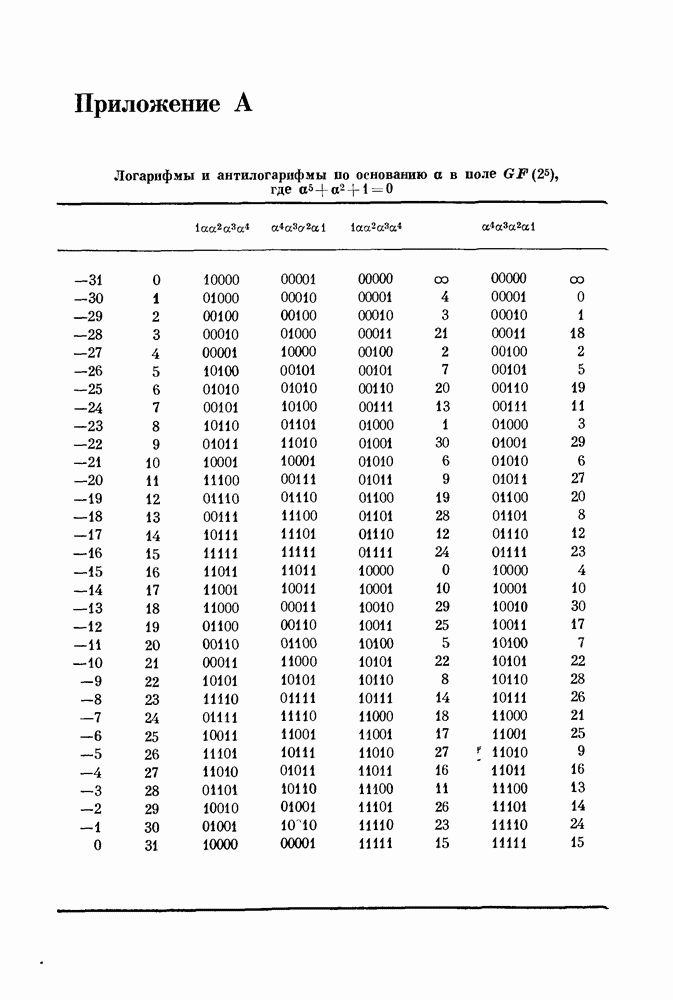
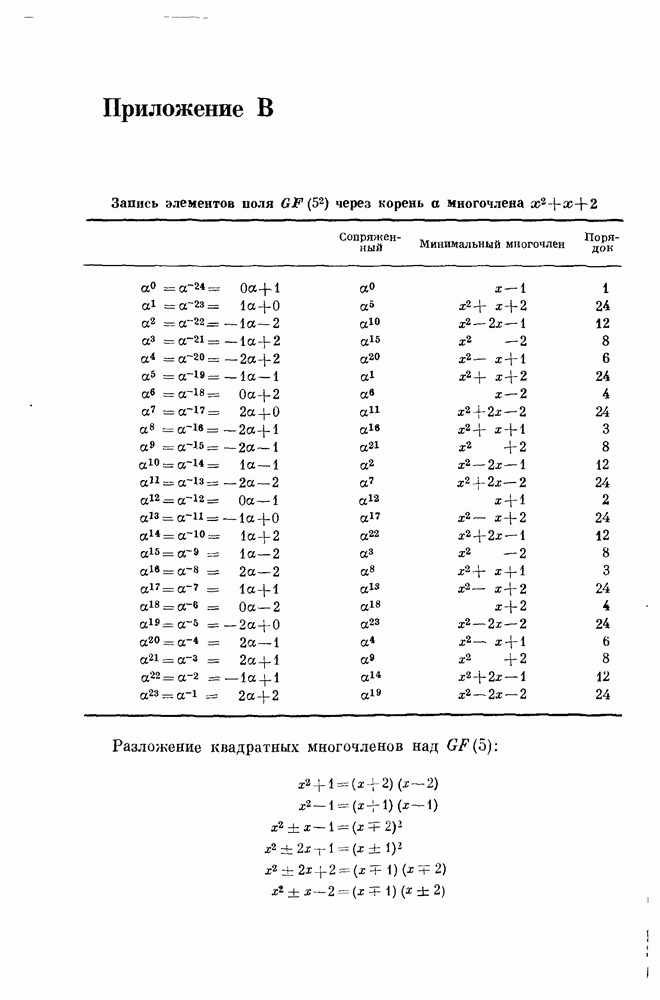
14.8. Прямое произведение кодов и его свойства14.81. Прямое произведение кодов. В большинстве случаев координаты кодового слова длины
Если символы этого кодового слова должны передаваться последовательно, то одномерная природа времени заставляет нас перевести эту двумерную матрицу в одномерную строку. Для отождествления упорядочение имеет вид
Циклическое упорядочение, рассмотренное Бартоном и Велдоном [1965], определяется условиями
Например, если
Если и Среди двумерных кодов наиболее интенсивно изучалось введенное Элайесом [1954] прямое произведение кодов. 14.812. Определение. Пусть
Не представляет труда проверить следующие два свойства прямого произведения кодов 1):
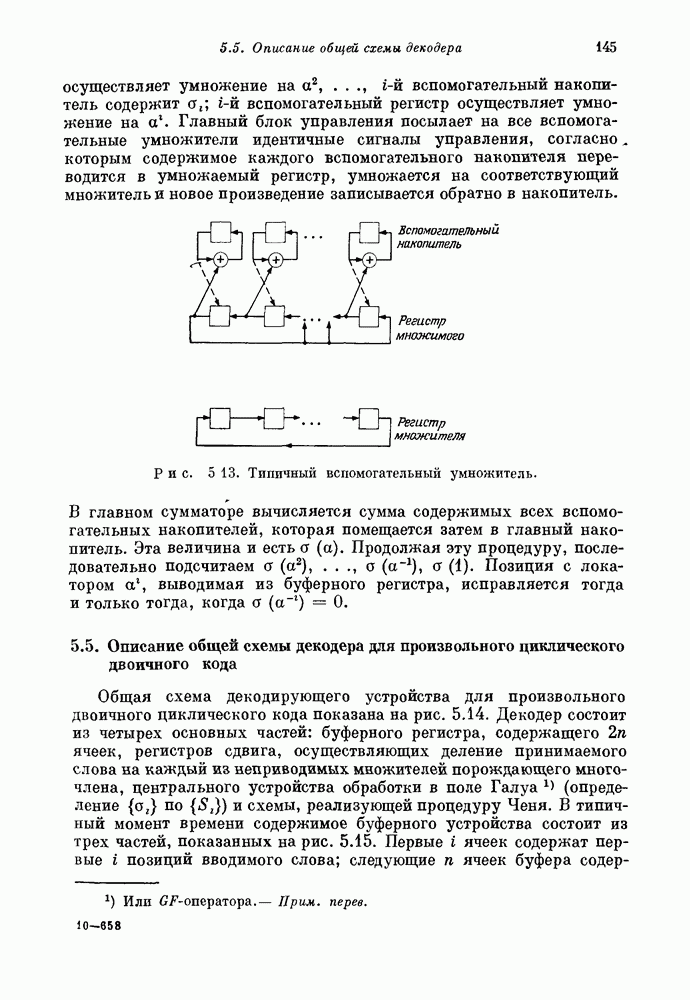
Наиболее естественным способом декодирования канонически упорядоченного прямого произведения является представленное на рис. 14.2 каскадное декодирование. На первом этапе каскадного декодера используется декодер для кода 1, а на втором — декодер для кода линией, состоящей из Эта простая процедура декодирования в каналах без памяти оставляет желать лучшего. Она приводит к отказу от декодирования при многих ошибках, которые код может исправлять
Рис. 14.2. Каскадный декодер для прямого произведения кодов, передаваемого в каноническом виде. Если составляющие коды имеют нечетные минимальные расстояния Однако процедура каскадного декодирования прямого произведения кодов дает эффективный метод построения реализуемых систем связи для каналов с группирующимися ошибками, так как такие искажения не могут поражать слишком много строк кода. Если прямое произведение передается в циклическом порядке, то пакеты ошибок будут поражать и строки и столбцы. В силу этого обстоятельства циклическое упорядочение часто бывает предпочтительней канонического. Другое интересное свойство циклического упорядочения описывается в разд. 14.82. 14.82. Циклическое произведение кодов. В общем случае прямое произведение двух циклических кодов не является циклическим кодом. Но если блоковые длины исходных кодов взаимно просты, а символы прямого произведения упорядочены согласно правилам (14.811), то такое произведение будет циклическим. Это составляет содержание теоремы 14.821. 14.821. Теорема (Бартон — Велдон ([1965]). Если
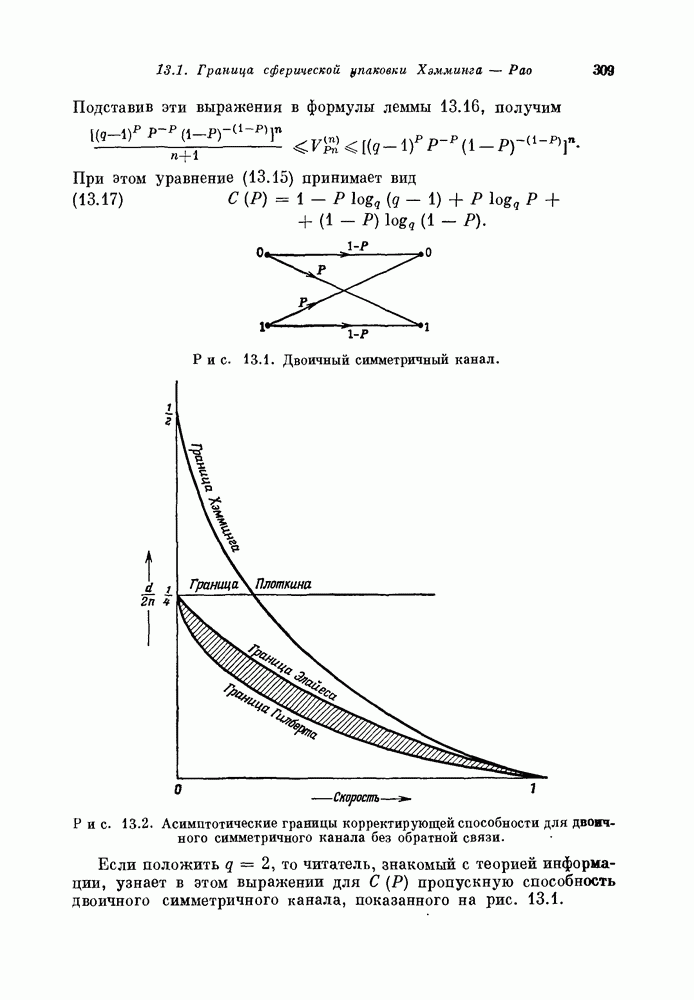
Доказательство. Согласно Элспасу [1968], компоненты двумерного кодового слова С можно представить как коэффициенты многочлена от двух переменных:
С другой стороны, компоненты С можно рассматривать как коэффициенты многочлена от одной переменной:
где Пусть а — примитивный корень (тцга-й степени из единицы;
Эквивалентность утверждений 14.822 и 14.823 следует из определения 14.812. Утверждения 14.823 и 14.824 эквивалентны потому, что каждый корень многочлена Если I определено соотношениями (14.811), то
Имеем
Таким образом,
Согласно определению
Эквивалентность утверждений 14.824 и 14.825 следует из равенств (14.827) и (14.828). Наконец, эквивалентность утверждений 14.825 и 14.826 вытекает из того факта, что каждый корень многочлена 14.829. Следствие. В условиях теоремы 14.821
где
Доказательство.
Пусть
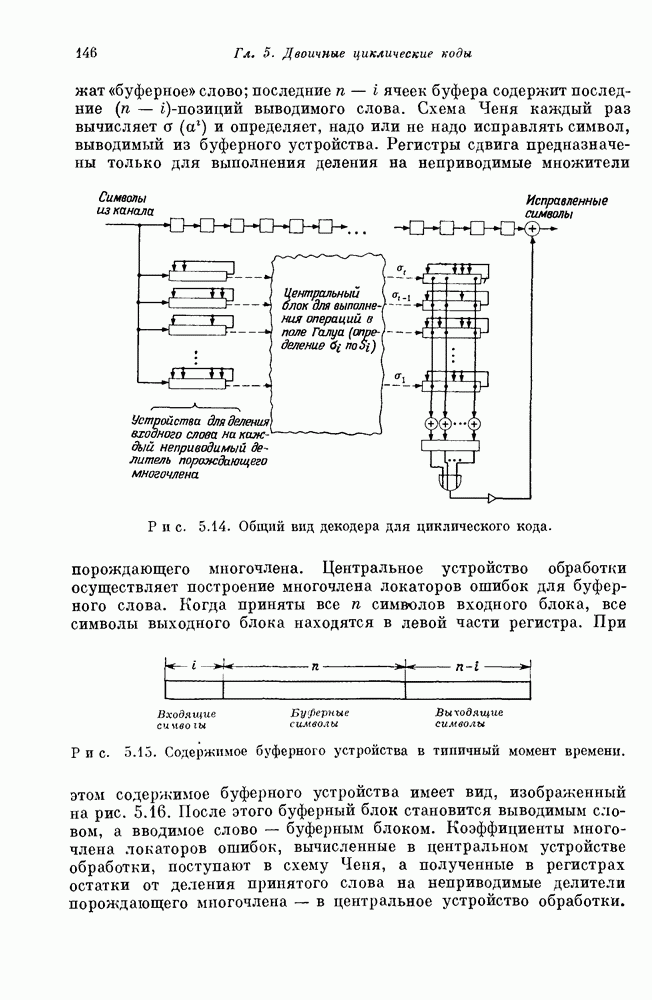
Поскольку циклическое упорядочение отличается от канонического, то декодер для циклического произведения кодов несколько отличается от каскадного декодера, изображенного на рис. 14.2. Так как из канала связи символы поступают в последовательности С ось Теорема 14.821 и следствие 14.829 позволяют определить, можно ли заданный код с блоковой длиной 14.83. Среднее число ошибочно декодируемых символов в коде Хэмминга. Чтобы рассчитать характеристики прямого произведения кода Хэмминга и некоторого другого кода, полезно прежде найти среднее число ошибочно декодируемых символов в ной Если в канале искажается четное число символов блока длины Обозначим через Если вероятность ошибки в канале равна
где Формула для Функциональное соотношение между
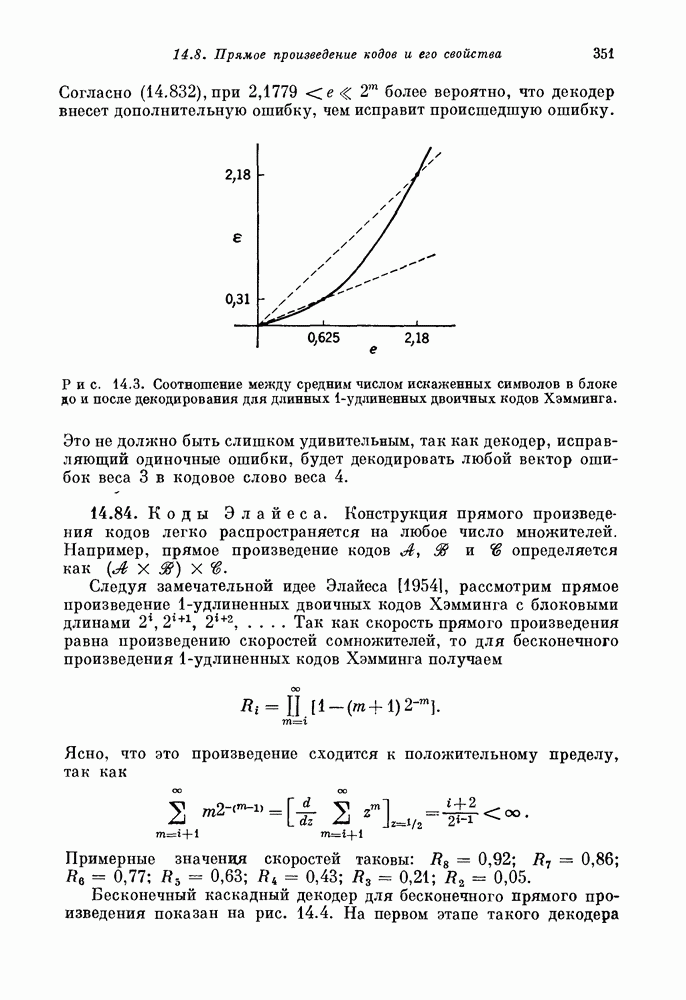
Согласно (14.832), при
Рис. 14.3. Соотношение между средним числом искаженных символов в блоке до и после декодирования для длинных Это не должно быть слишком удивительным, так как декодер, исправляющий одиночные ошибки, будет декодировать любой вектор ошибок веса 3 в кодовое слово веса 4. 14.84. Коды Элайеса. Конструкция прямого произведения кодов легко распространяется на любое число множителей. Например, прямое произведение кодов А, 38 и определяется как Следуя замечательной идее Элайеса [1954], рассмотрим прямое произведение
Ясно, что это произведение сходится к положительному пределу, так как
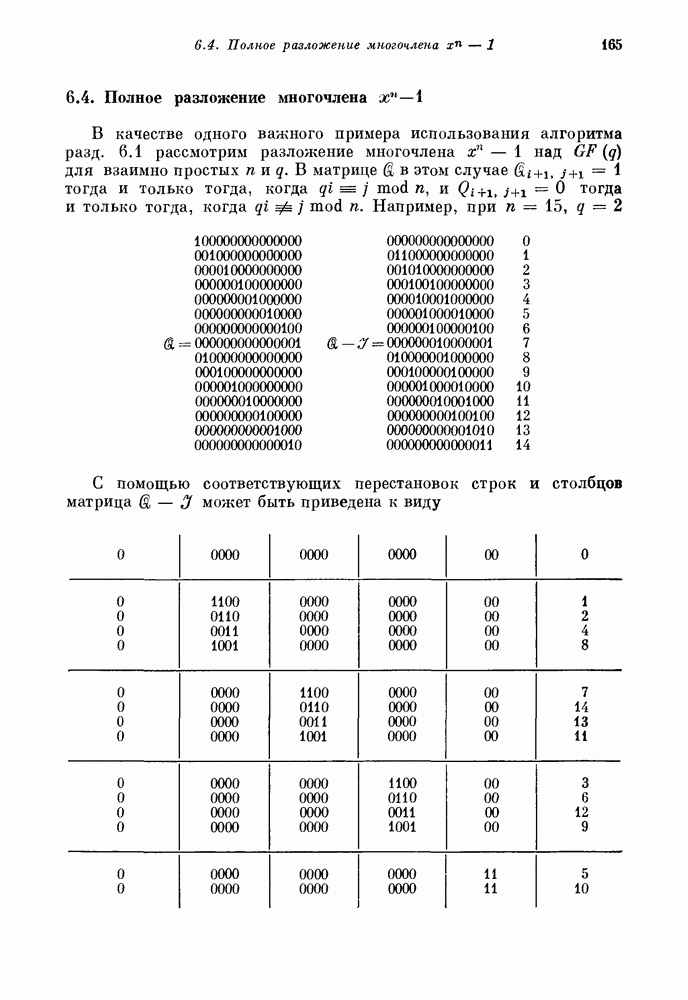
Примерные значения скоростей таковы: Бесконечный каскадный декодер для бесконечного прямого произведения показан на рис. 14.4. На первом этапе такого декодера используется декодер для Пусть
Рис. 14.4. Каскадный декодер для кода Элайеса. Следовательно, ошибки, расположенные внутри блока из В силу свойства (14.833) заключаем, что если
Как видно из этой таблицы, каскадный декодер для бесконечного прямого произведения Коды Элайеса — единственный известный класс кодов, обеспечивающих безошибочное кодирование в одностороннем двоичном симметричном канале с положительной скоростью передачи. 14.85. Тензорное произведение кодов. Любая проверочная матрица из Если Если длина и избыточность кода
Хотя для односторонних каналов связи без памяти использование тензорного произведения не представляется особо привлекательным, Вулф [1965 а] показал, что некоторые коды такого сорта позволяют исправлять кратные пакеты ошибок. Элспас и Вулф [1963] и Вулф [1965 Ь] построили тензорные произведения кодов, которые могут быть использованы для локализации искаженных подблоков. При использовании таких кодов в двухпутевых каналах связи приемник может запрашивать передатчик о ретрансляции только искаженных подблоков. 14.86. Прямая сумма к одхо в. Если Хотя прямая сумма кодов мало схожа с прямым произведением кодов, вместе эти два понятия употребляются очень часто. Код 3 называется разложимым, если после некоторой перестановки координат он может быть записан в виде прямой суммы
|
 |
Оглавление
|


























































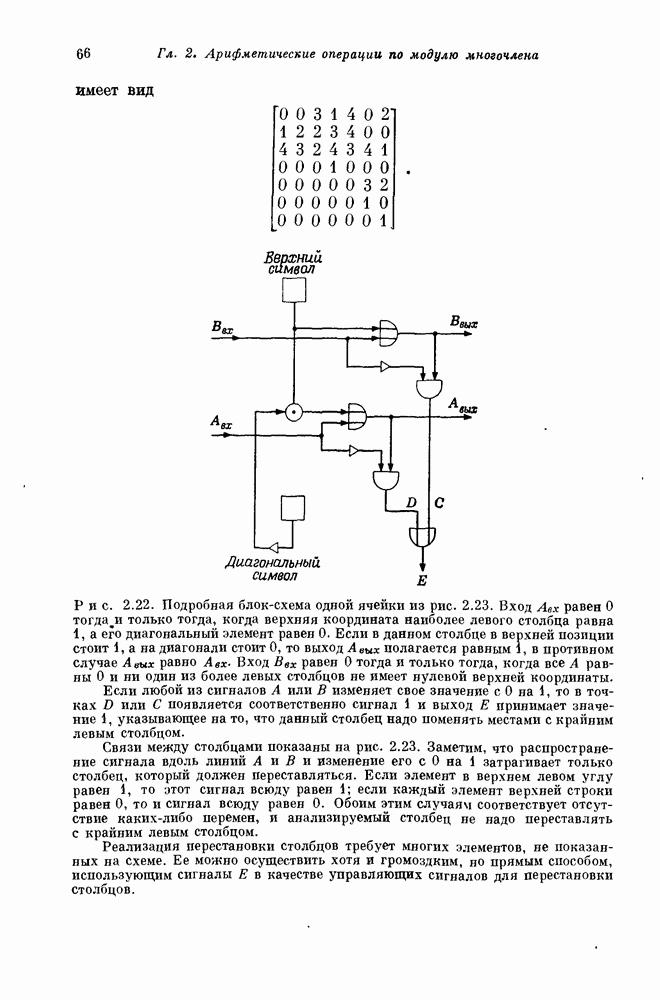
































































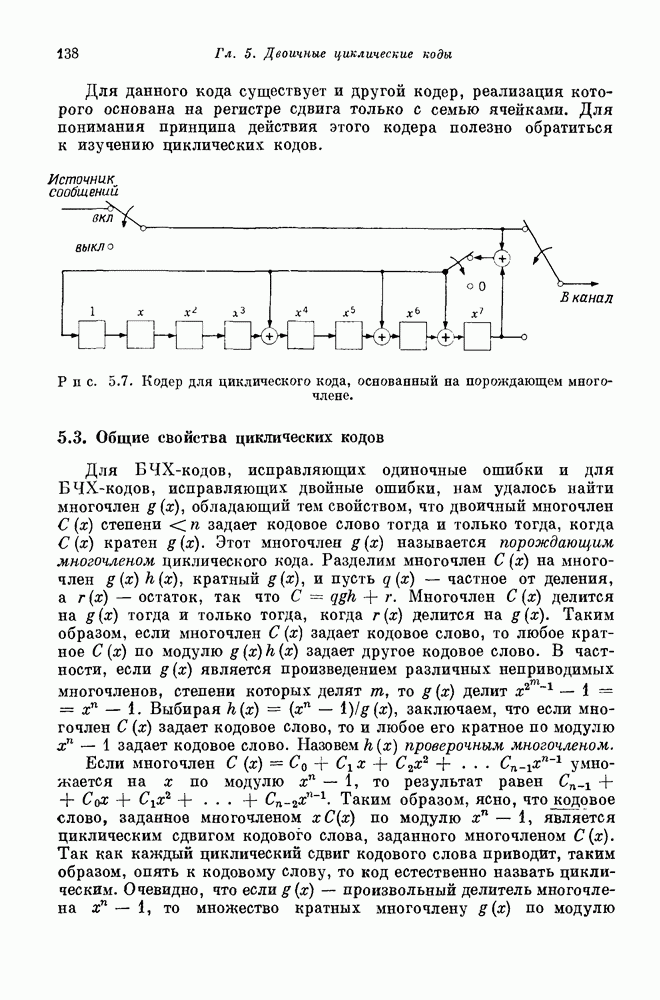


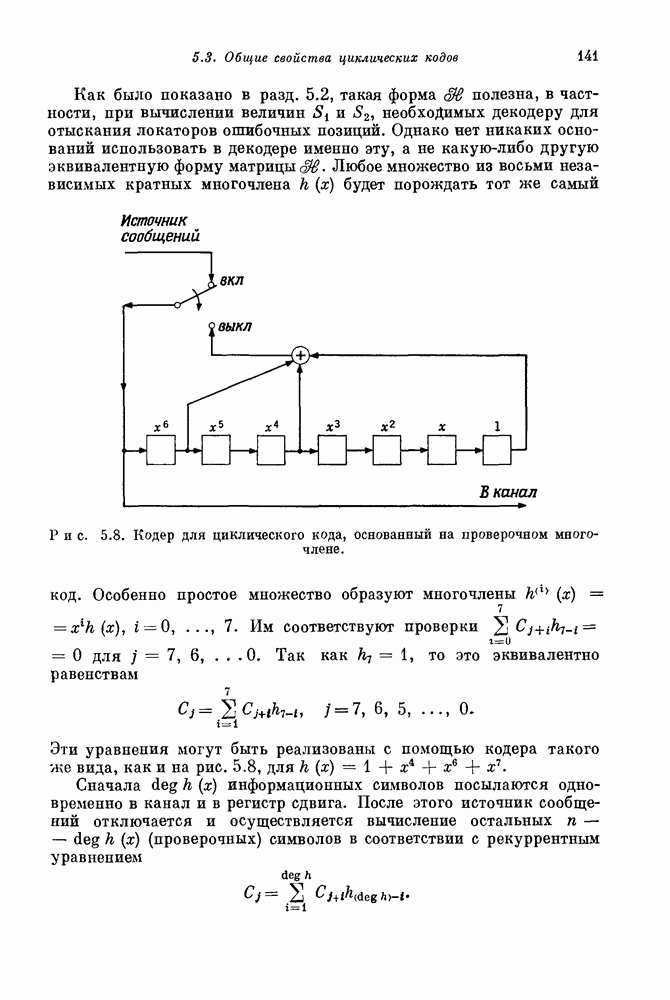

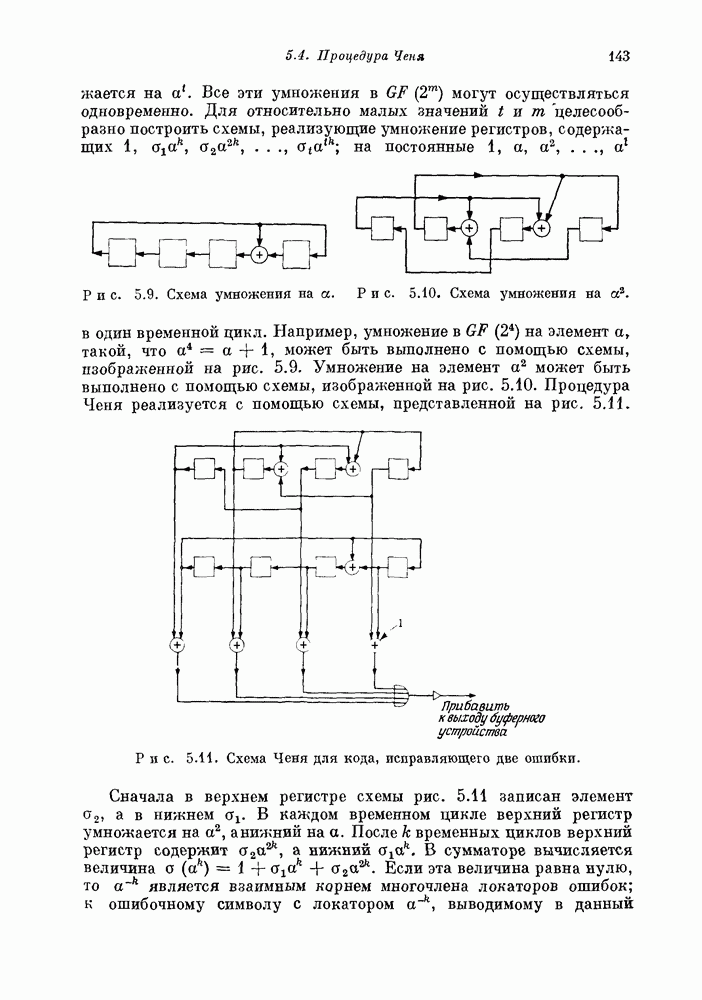
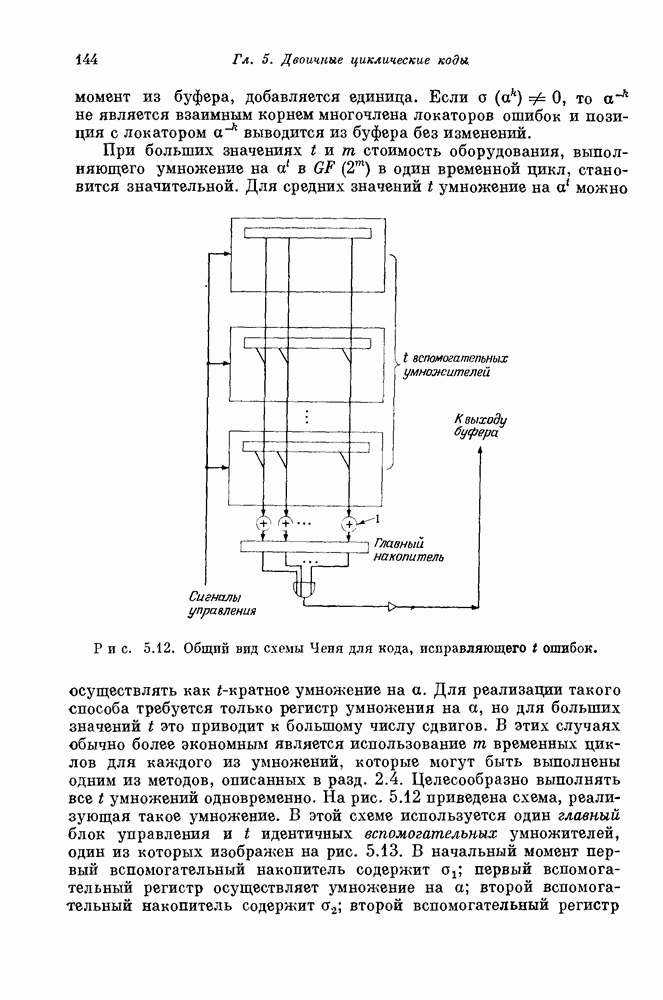

































































































































































































































































































 удобно записывать в виде
удобно записывать в виде  . Однако, если
. Однако, если  составное число, то иногда удобнее записывать кодовое слово С в виде
составное число, то иногда удобнее записывать кодовое слово С в виде  -мерной матрицы
-мерной матрицы

 надо определить! и
надо определить! и  как функции от
как функции от  Это можно сделать различными способами. Каноническое упорядочение получается при выборе в качестве
Это можно сделать различными способами. Каноническое упорядочение получается при выборе в качестве  частного и остатка от деления I на
частного и остатка от деления I на  Это
Это


 то
то

 взаимно просты, то, согласно китайской теореме об остатках 2.16, при
взаимно просты, то, согласно китайской теореме об остатках 2.16, при  циклическое упорядочение устанавливает взаимно однозначное соответствие между числами
циклическое упорядочение устанавливает взаимно однозначное соответствие между числами  и парами
и парами  где
где  Для не взаимно простых и
Для не взаимно простых и  циклическое упорядочение не имеет смысла.
циклическое упорядочение не имеет смысла.
 линейный код с длиной
линейный код с длиной  линейный код с длиной
линейный код с длиной  Прямое произведение кодов
Прямое произведение кодов  обозначается через
обозначается через  и представляет собой «двумерный» код, состоящий из всех кодовых слов длины
и представляет собой «двумерный» код, состоящий из всех кодовых слов длины  , удовлетворяющих следующим условиям:
, удовлетворяющих следующим условиям:


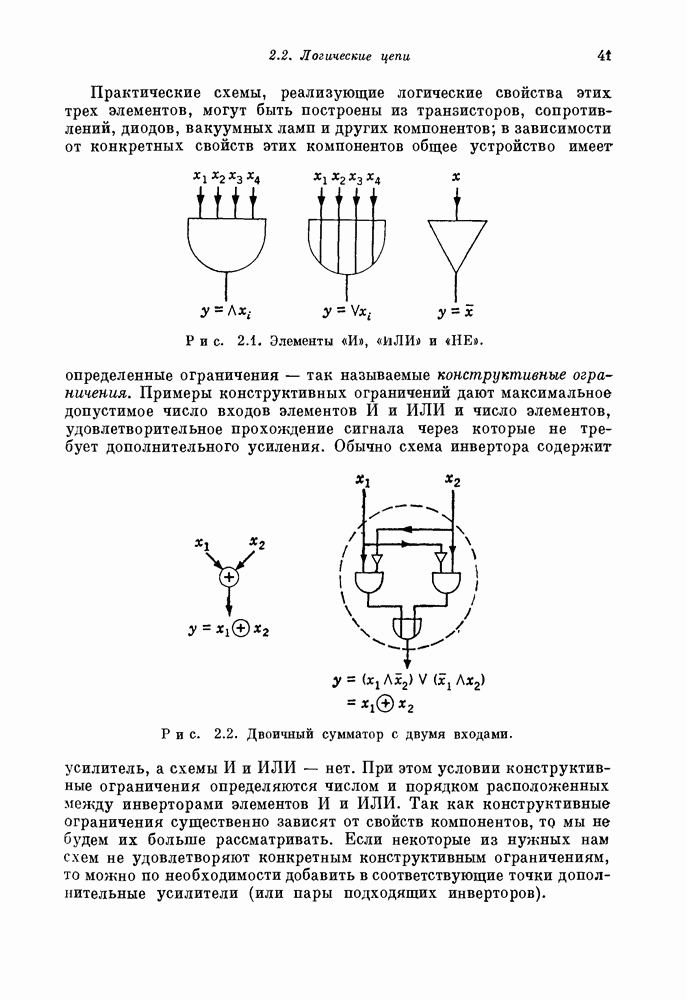
 в котором каждый элемент единичной задержки заменен
в котором каждый элемент единичной задержки заменен
 элементов единичной задержки. Последнее позволяет декодировать все
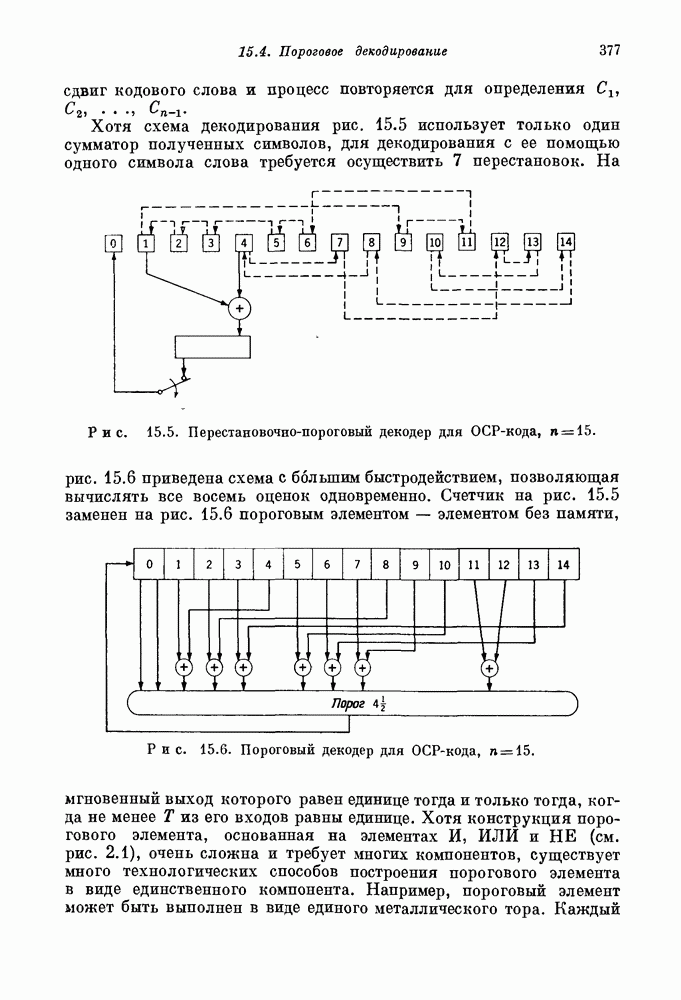
элементов единичной задержки. Последнее позволяет декодировать все  столбцов синфазно. Все элементы, появляющиеся на выходе второго декодера в фиксированный момент времени, принадлежат одному и тому же столбцу кода. На первом этапе декодируется каждая строка кода; а на втором этапе — каждый столбец кода. Если даже среди поступающих на первый декодер символов содержится много искаженных, то от первого декодера ко второму (к счастью) передается уже значительно меньше ошибок, а информация, поступающая на выход декодера, по существу вообще не содержит ошибок.
столбцов синфазно. Все элементы, появляющиеся на выходе второго декодера в фиксированный момент времени, принадлежат одному и тому же столбцу кода. На первом этапе декодируется каждая строка кода; а на втором этапе — каждый столбец кода. Если даже среди поступающих на первый декодер символов содержится много искаженных, то от первого декодера ко второму (к счастью) передается уже значительно меньше ошибок, а информация, поступающая на выход декодера, по существу вообще не содержит ошибок.

 , то имеются векторы шума веса
, то имеются векторы шума веса  которые данной процедурой декодируются неверно, хотя код может исправлять все ошибки веса
которые данной процедурой декодируются неверно, хотя код может исправлять все ошибки веса  и меньше.
и меньше.

 циклический код с длиной
циклический код с длиной  и порождающим многочленом
и порождающим многочленом  — циклический код с длиной
— циклический код с длиной  и порождающим многочленом
и порождающим многочленом  то циклически упорядоченное прямое произведение кодов
то циклически упорядоченное прямое произведение кодов  является циклическим кодом с длиной
является циклическим кодом с длиной  и порождающим многочленом
и порождающим многочленом



 связаны правилами (14.811) циклического упорядочения.
связаны правилами (14.811) циклического упорядочения.
 Тогда эквивалентны следующие утверждения:
Тогда эквивалентны следующие утверждения:

 является степенью
является степенью  а каждый корень многочлена
а каждый корень многочлена  есть степень у.
есть степень у.





 является корнем
является корнем  степени из единицы, а каждый корень
степени из единицы, а каждый корень  степени из единицы может быть записан в виде где
степени из единицы может быть записан в виде где  подходящим образом подобранные целые числа.
подходящим образом подобранные целые числа. 



 циклические коды с порождающими многочленами
циклические коды с порождающими многочленами  Согласно результатам разд.
Согласно результатам разд.  и являются перестановками
и являются перестановками  следовательно,
следовательно,

 то, как заметил Эбрамсон [1968], на первом этапе каскадного декодера должен использоваться декодер для кода
то, как заметил Эбрамсон [1968], на первом этапе каскадного декодера должен использоваться декодер для кода  в котором единичные элементы задержки заменены линиями задержки из элементов, а на втором этапе каскадного декодера — декодер для кода
в котором единичные элементы задержки заменены линиями задержки из элементов, а на втором этапе каскадного декодера — декодер для кода  в котором каждая единичная задержка заменена линией задержки из
в котором каждая единичная задержка заменена линией задержки из  элементов.
элементов.
 представить в виде произведения двух циклических кодов с длинами
представить в виде произведения двух циклических кодов с длинами  Для этого надо выписать все корни исходного порождающего многочлена в виде набора пар
Для этого надо выписать все корни исходного порождающего многочлена в виде набора пар  и проверить выполнение условий теоремы 14.821 и следствия 14.829. Многие неразложимые коды являются подкодами больших кодов, которые разложимы в произведение циклических кодов. Эта задача о разложении изучалась с более абстрактной точки зрения Гёталсом [1967].
и проверить выполнение условий теоремы 14.821 и следствия 14.829. Многие неразложимые коды являются подкодами больших кодов, которые разложимы в произведение циклических кодов. Эта задача о разложении изучалась с более абстрактной точки зрения Гёталсом [1967].
 -удлиненном коде Хэмминга с блоковой
-удлиненном коде Хэмминга с блоковой 
 при передаче по двоичному симметричному каналу без памяти с вероятностью
при передаче по двоичному симметричному каналу без памяти с вероятностью  ошибки в одном символе.
ошибки в одном символе.
 то декодер для кода Хэмминга не изменяет принятого вектора; если число ошибок нечетно, то декодер изменяет один символ на противоположный. Если в канале произошла только одна ошибка, то она будет исправлена. Однако, если ошибок несколько, то декодер либо исправит одну из них, либо внесет новую ошибку. Декодер исправит ошибку тогда и только тогда, когда вес вектора ошибок равен
то декодер для кода Хэмминга не изменяет принятого вектора; если число ошибок нечетно, то декодер изменяет один символ на противоположный. Если в канале произошла только одна ошибка, то она будет исправлена. Однако, если ошибок несколько, то декодер либо исправит одну из них, либо внесет новую ошибку. Декодер исправит ошибку тогда и только тогда, когда вес вектора ошибок равен  и он находится на расстоянии 1 от кодового слова веса
и он находится на расстоянии 1 от кодового слова веса  декодер внесет дополнительную ошибку тогда и только тогда, когда вес вектора ошибок равен
декодер внесет дополнительную ошибку тогда и только тогда, когда вес вектора ошибок равен  и вектор находится на расстоянии 1 от кодового слова веса
и вектор находится на расстоянии 1 от кодового слова веса 
 число кодовых слов веса
число кодовых слов веса  в
в  -удлиненном коде Хэмминга с длиной
-удлиненном коде Хэмминга с длиной  и пусть
и пусть  Среди
Среди  слов, расположенных на расстоянии 1 от данного кодового слова веса
слов, расположенных на расстоянии 1 от данного кодового слова веса  точно
точно  слов имеют вес
слов имеют вес  и точно
и точно  слов имеют вес
слов имеют вес  Следовательно, нумератор ошибок, приводящих декодер к дополнительной ошибке, равен
Следовательно, нумератор ошибок, приводящих декодер к дополнительной ошибке, равен  а нумератор исправляемых декодером ошибок равен
а нумератор исправляемых декодером ошибок равен 
 то среднее число ошибок равно
то среднее число ошибок равно  Вероятность того, что декодер внесет дополнительную ошибку, равна
Вероятность того, что декодер внесет дополнительную ошибку, равна  где
где  . Аналогично, вероятность исправления ошибки равна
. Аналогично, вероятность исправления ошибки равна  Используя эти вероятности, можно вычислить
Используя эти вероятности, можно вычислить  среднее число искаженных символов в принятом блоке. Соответствующая формула имеет вид
среднее число искаженных символов в принятом блоке. Соответствующая формула имеет вид


 будет выведена в разд. 16.2. Мы не приводим здесь этого вывода, поскольку не хотим отвлекать читателя громоздкими деталями доказательства.
будет выведена в разд. 16.2. Мы не приводим здесь этого вывода, поскольку не хотим отвлекать читателя громоздкими деталями доказательства.
 зависит от
зависит от  при
при  существует предельное соотношение, график которого изображен на рис. 14.3. Две точки этой кривой заслуживают особого внимания:
существует предельное соотношение, график которого изображен на рис. 14.3. Две точки этой кривой заслуживают особого внимания:

 более вероятно, что декодер внесет дополнительную ошибку, чем исправит происшедшую ошибку.
более вероятно, что декодер внесет дополнительную ошибку, чем исправит происшедшую ошибку.

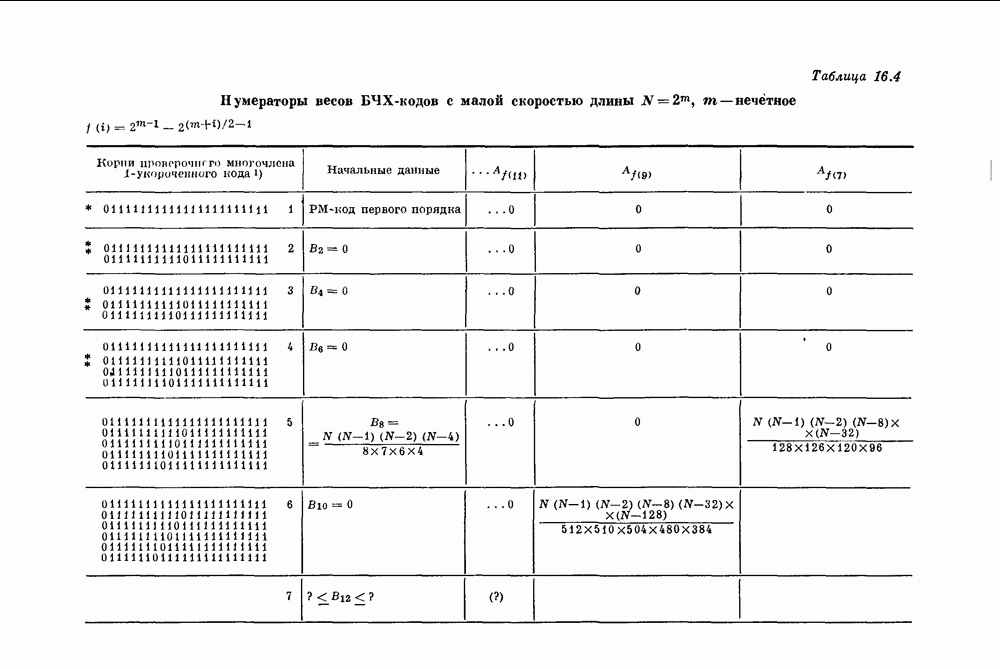
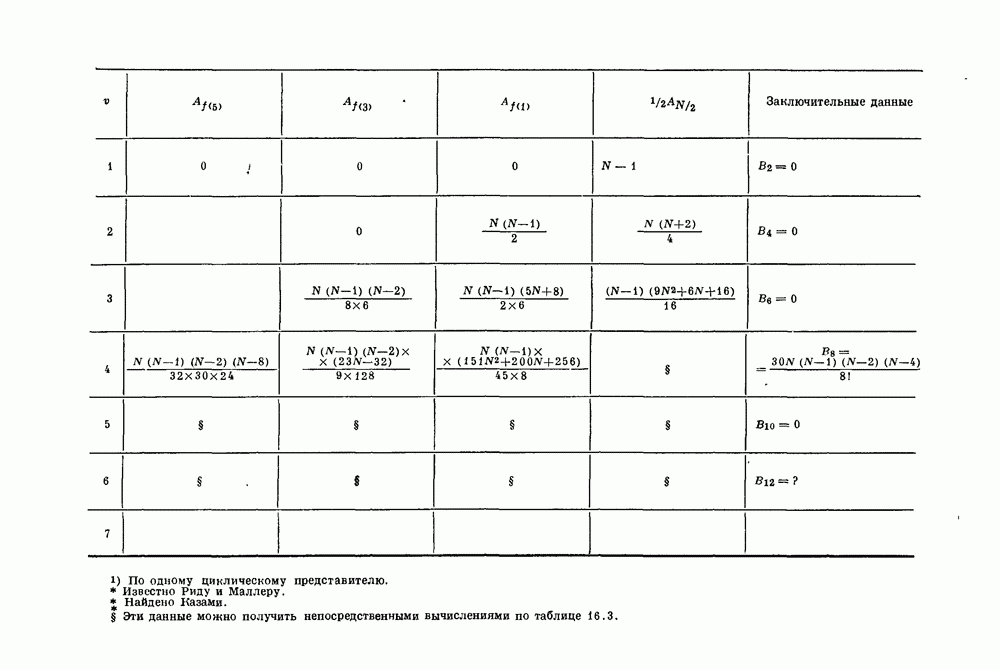
 -удлиненных двоичных кодов Хэмминга.
-удлиненных двоичных кодов Хэмминга.

 -удлиненных двоичных кодов Хэмминга с блоковыми длинами
-удлиненных двоичных кодов Хэмминга с блоковыми длинами  Так как скорость прямого произведения равна произведению скоростей сомножителей, то для бесконечного произведения
Так как скорость прямого произведения равна произведению скоростей сомножителей, то для бесконечного произведения  -удлиненных кодов Хэмминга получаем
-удлиненных кодов Хэмминга получаем



 -удлиненного кода Хэмминга с блоковой длиной
-удлиненного кода Хэмминга с блоковой длиной  на втором этапе — декодер для
на втором этапе — декодер для  -удлиненного кода Хэмминга с блоковой длиной
-удлиненного кода Хэмминга с блоковой длиной 
 среднее число искаженных символов в блоке, поступающем на вход декодера для кода Хэмминга с длиной
среднее число искаженных символов в блоке, поступающем на вход декодера для кода Хэмминга с длиной  Тогда вероятность ошибки в символе равна
Тогда вероятность ошибки в символе равна  и среднее число ошибок в блоке длины
и среднее число ошибок в блоке длины  равно
равно  Эти ошибки не являются статистически независимыми, так как в пределах любого блока
Эти ошибки не являются статистически независимыми, так как в пределах любого блока  -удлиненного блока кода Хэмминга с длиной
-удлиненного блока кода Хэмминга с длиной  содержится четное число искаженных символов. Более того, иногда эти ошибки образуют кодовые слова. Однако ошибки внутри одного блока статистически независимы от ошибок, расположенных внутри другого блока кода.
содержится четное число искаженных символов. Более того, иногда эти ошибки образуют кодовые слова. Однако ошибки внутри одного блока статистически независимы от ошибок, расположенных внутри другого блока кода.

 символов, поступающего на вход декодера следующего кода Хэмминга, статистически независимы. Это позволяет использовать равенство (14.831) для расчета вероятности ошибки в символе на каждом этапе каскадного декодера.
символов, поступающего на вход декодера следующего кода Хэмминга, статистически независимы. Это позволяет использовать равенство (14.831) для расчета вероятности ошибки в символе на каждом этапе каскадного декодера.
 для любого достаточно большого
для любого достаточно большого  то
то  . В этом случае среднее число ошибок на декодируемый блок уменьшается на каждом этапе каскадного кода не менее чем в 2 раза. Поэтому хотя блоковый «объем» соответствующих кодов Хэмминга увеличивается, среднее число ошибок на блок стремится к нулю. С другой стороны, если
. В этом случае среднее число ошибок на декодируемый блок уменьшается на каждом этапе каскадного кода не менее чем в 2 раза. Поэтому хотя блоковый «объем» соответствующих кодов Хэмминга увеличивается, среднее число ошибок на блок стремится к нулю. С другой стороны, если  для достаточно большого
для достаточно большого  то
то  . В конце концов мы найдем такое к, что
. В конце концов мы найдем такое к, что  После этого любые дальнейшие попытки декодирования будут приводить лишь к увеличению среднего числа ошибок в блоке. Таким образом, для достаточно больших
После этого любые дальнейшие попытки декодирования будут приводить лишь к увеличению среднего числа ошибок в блоке. Таким образом, для достаточно больших  величина 0,6246 является критической точкой для
величина 0,6246 является критической точкой для  На основе равенства (14.831) с помощью вычислительного устройства нами получены следующие критические значения:
На основе равенства (14.831) с помощью вычислительного устройства нами получены следующие критические значения:

 -удлиненных кодов Хэмминга длин
-удлиненных кодов Хэмминга длин  обеспечивает безошибочное декодирование, если вероятность ошибки в символе в канале не превосходит 0,0402. Если
обеспечивает безошибочное декодирование, если вероятность ошибки в символе в канале не превосходит 0,0402. Если  то вероятность ошибки в каждом символе после соответствующего блока каскадного декодера становится равной
то вероятность ошибки в каждом символе после соответствующего блока каскадного декодера становится равной 
 строк и
строк и  столбцов над
столбцов над  может быть продолжена до проверочной матрицы из
может быть продолжена до проверочной матрицы из  строк и
строк и  столбцов над
столбцов над  как это сделано в примере (5.21) на стр. 134 для
как это сделано в примере (5.21) на стр. 134 для  Соответствующий код над
Соответствующий код над  будем называть продолжением кода над
будем называть продолжением кода над  а код над
а код над  будем называть сжатием кода над
будем называть сжатием кода над  Каждый код над
Каждый код над  имеет единственное продолжение, но некоторые коды над
имеет единственное продолжение, но некоторые коды над  имеют несколько сжатий на
имеют несколько сжатий на  в частности, если избыточность кода над
в частности, если избыточность кода над  не кратна
не кратна 
 — коды над
— коды над  и
и  — продолжение кода
— продолжение кода  над
над  то тензорным произведением
то тензорным произведением  называется продолжение кода, дуального к прямому произведению дуальных к
называется продолжение кода, дуального к прямому произведению дуальных к  кодов.
кодов.
 равны
равны  а длина и избыточность кода
а длина и избыточность кода  равны
равны  то длина и избыточность кода равны
то длина и избыточность кода равны  Практически часто для кода
Практически часто для кода  полагают
полагают  а в качестве А выбирается код Рида — Соломона. В декодере сначала декодируется код А, причем
а в качестве А выбирается код Рида — Соломона. В декодере сначала декодируется код А, причем  символов синдрома над
символов синдрома над  рассматриваются как
рассматриваются как  символов синдрома над
символов синдрома над  а полученные «значения ошибок» лежат в
а полученные «значения ошибок» лежат в  Каждое из этих «значений ошибок» рассматривается затем как
Каждое из этих «значений ошибок» рассматривается затем как  -символьный синдром над
-символьный синдром над
 и используется для декодирования кодовых слов длины
и используется для декодирования кодовых слов длины  кода
кода 
 — коды над одним и тем же полем, то прямой суммой
— коды над одним и тем же полем, то прямой суммой  называется код, состоящий из всех слов вида а
называется код, состоящий из всех слов вида а  где
где  а обозначает композицию
а обозначает композицию  Длина кода
Длина кода  равна сумме длин кодов
равна сумме длин кодов  его размерность — сумме размерностей этих кодов; минимальное расстояние кода
его размерность — сумме размерностей этих кодов; минимальное расстояние кода  равно наименьшему из минимальных расстояний кодов
равно наименьшему из минимальных расстояний кодов  .
.
 Слепян [1960] показал, что ни один разложимый линейный код не имеет большее минимальное расстояние или меньшую вероятность ошибки, чем лучший неразложимый линейный код с той же скоростью и блоковой длиной.
Слепян [1960] показал, что ни один разложимый линейный код не имеет большее минимальное расстояние или меньшую вероятность ошибки, чем лучший неразложимый линейный код с той же скоростью и блоковой длиной.