Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
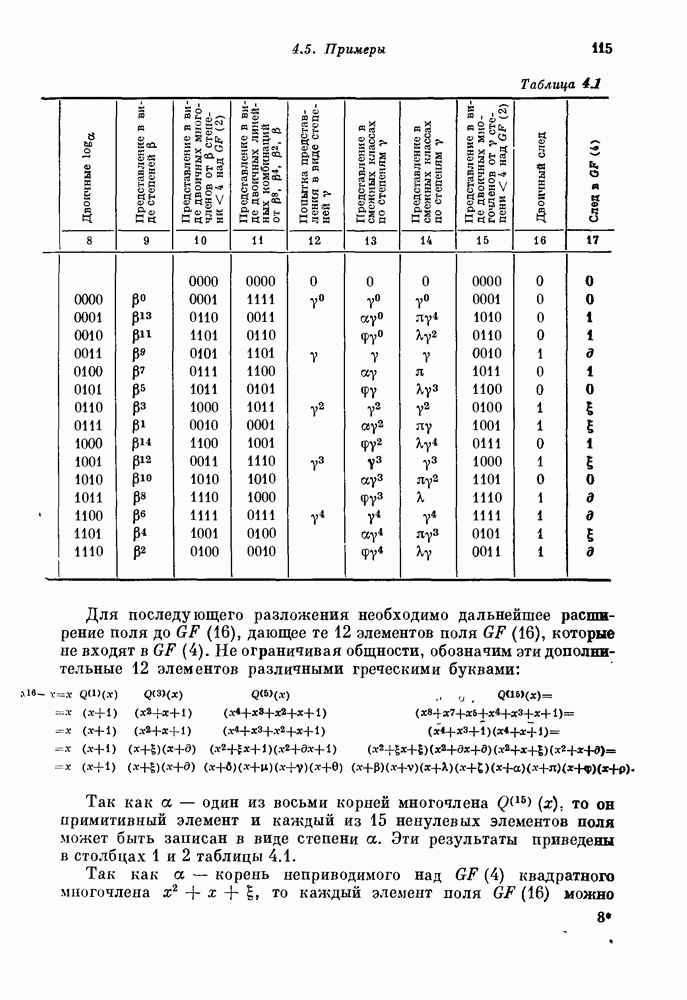
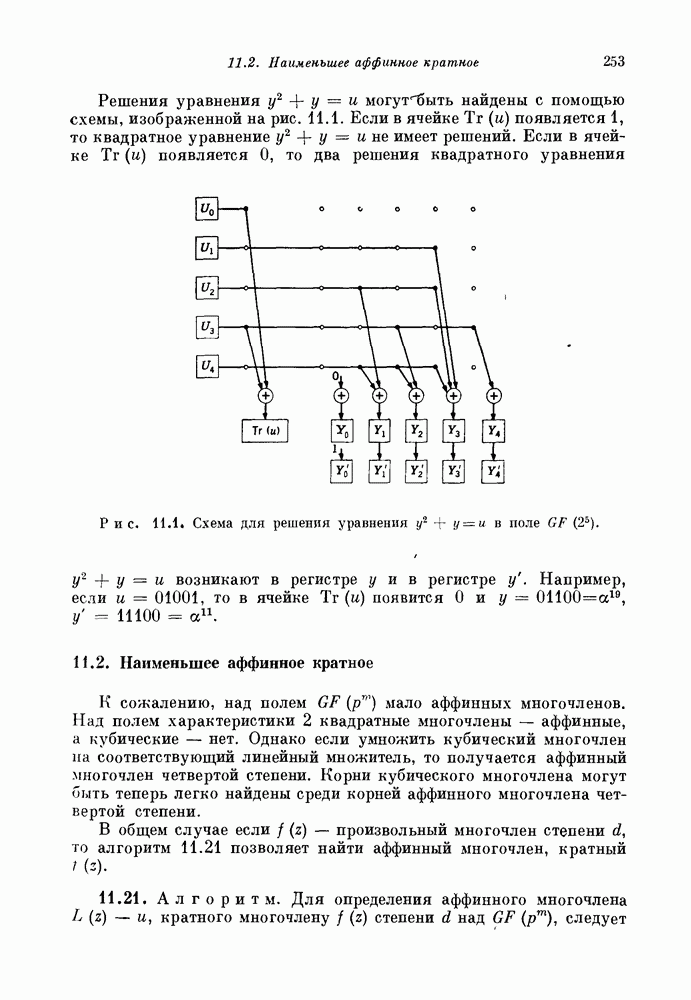
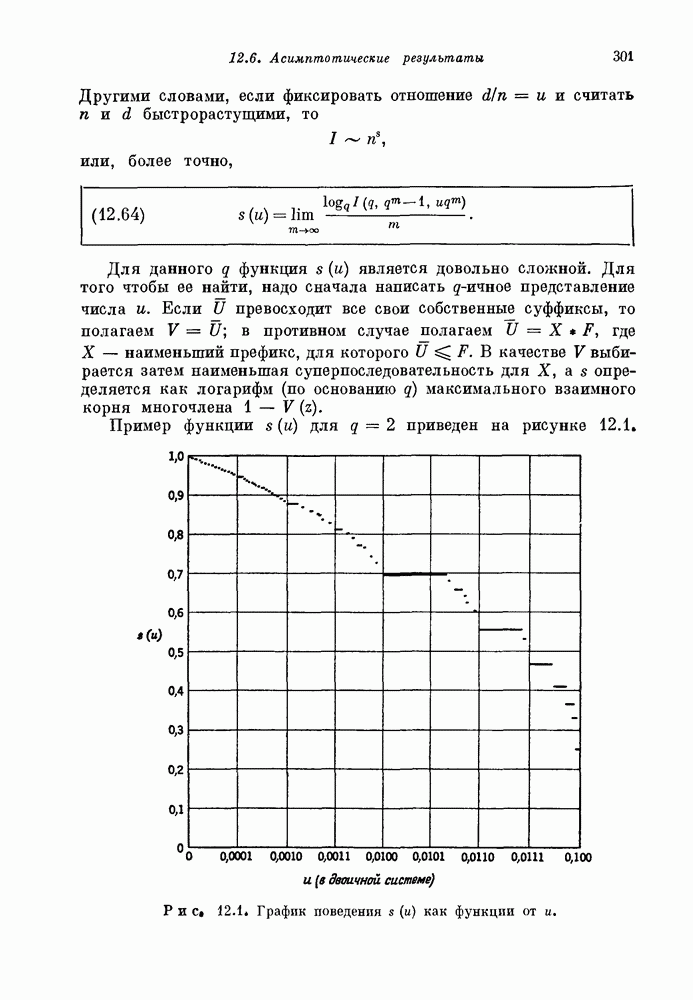
1.3. Коды ХэммингаПри очень малых или очень больших скоростях хорошие линейные коды строятся сравнительно легко. Интерполяцию между этими крайними случаями можно проводить одним из двух способов: (1) отталкиваясь от кодов с низкой скоростью передачи, постепенно увеличивать к, добавляя все новые и новые кодовые слова и пытаясь сохранить большие корректирующие возможности кода; (2) отталкиваясь от хороших кодов с большой скоростью передачи, постепенно увеличивать корректирующие возможности кода, пытаясь добавлять лишь малое число дополнительных проверочных ограничений. Исторически второй метод оказался более успешным. Мы также пойдем по этому пути. Начнем с построения одного специального класса кодов, исправляющих одиночные ошибки, — кодов Хэмминга. Синдром линейного кода связан с вектором ошибок уравнением
Таким образом, синдром является суммой тех столбцов матрицы 36, которым соответствуют ошибки в канале связи. Если некоторый столбец матрицы 36 нулевой, то ошибка в этой позиции не окажет на синдром никакого влияния. Код не позволяет даже обнаружить ошибку в такой позиции. Если два столбца матрицы 36 совпадают, то одиночные ошибки в каждой из этих позиций дают один и тот же синдром, т. е. векторы этих одиночных ошибок лежат в одном смежном классе. Так как только один из них можно выбрать в качестве лидера смежного класса, то только одна из ошибок может быть исправлена. Другая одиночная ошибка будет декодирована неправильно. Таким образом, если 36 содержит нулевые или совпадающие между собой столбцы, то соответствующий линейный код не позволяет исправлять все одиночные искажения в канале. Наоборот, предположим, что все столбцы матрицы 36 отличны от нулевого и друг от друга. Тогда одиночная ошибка в одной произвольной позиции приводит к синдрому, отличному от синдрома для ошибки в любой другой позиции. Каждый вектор одиночной ошибки является лидером смежного класса, и код позволяет исправлять все одиночные ошибки. 1.31. Теорема. Линейный код позволяет исправлять все одиночные ошибки тогда и только тогда, когда все столбцы его матрицы 36 отличны от нуля и друг от друга. Для декодирования одиночных ошибок декодер вычисляет синдром полученного слова. Если синдром равен нулю, то декодер полагает, что ошибок не произошло. Если синдром отличен от нуля и равен некоторому столбцу матрицы 36, то декодер полагает, что произошла ошибка в соответствующей позиции. Если синдром оказывается ненулевым и отличным от любого столбца матрицы 36, то фиксируется отказ от декодирования. Отказ или ошибка декодирования происходят только в том случае, когда в канале искажаются два или более символов. Например, предположим, что
Если принятое слово
и
Если же принятым словом является Зададимся теперь вопросом о наибольшей возможной блоковой длине кода, исправляющего одиночные ошибки и имеющего не более Для любого Для выявления конфигураций ошибок веса 2 к коду Хэмминга иногда добавляется еще одна общая проверка на четность. Результирующий код имеет блоковую длину
Присоединяя общую проверку на четность, получаем расширенный код Хэмминга с блоковой длиной 16, проверочная матрица которого имеет вид
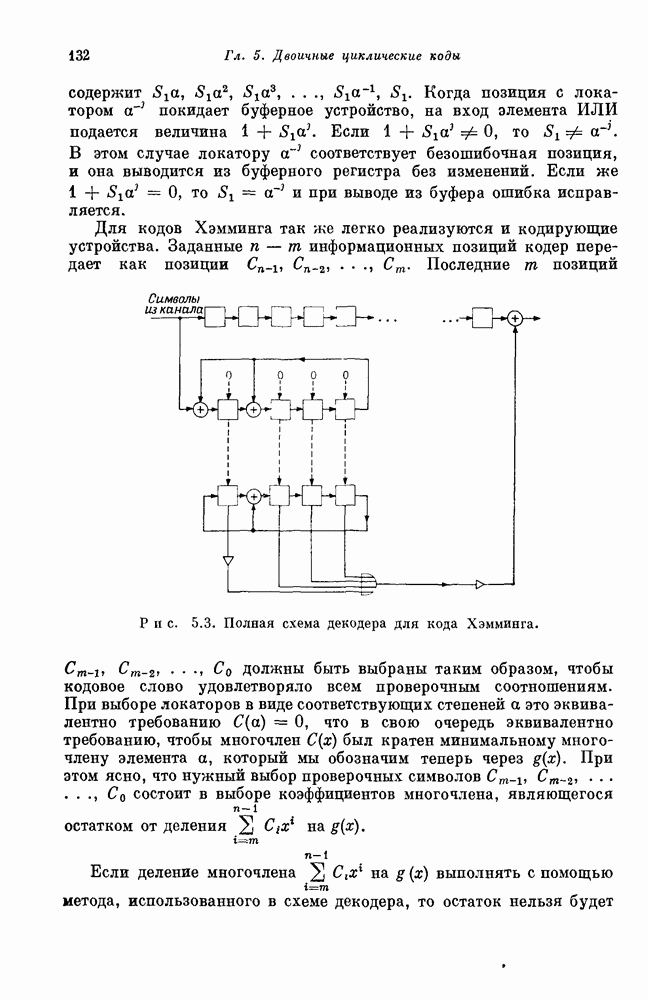
В первой строке проверочной матрицы расширенного кода Хэмминга стоят одни единицы, так что первая координата суммы любых двух столбцов всегда равна нулю. Поэтому синдром любого вектора ошибок веса 2 отличен от нуля и любого столбца матрицы Хотя столбцы проверочной матрицы кода Хэмминга могут быть упорядочены произвольным образом, некоторые способы упорядочивания приводят к значительно более простой реализации, чем другие. Поэтому все вопросы, связанные с реализацией кодов Хэмминга, мы откладываем до разд. 5.1. Код Хэмминга с блоковой длиной
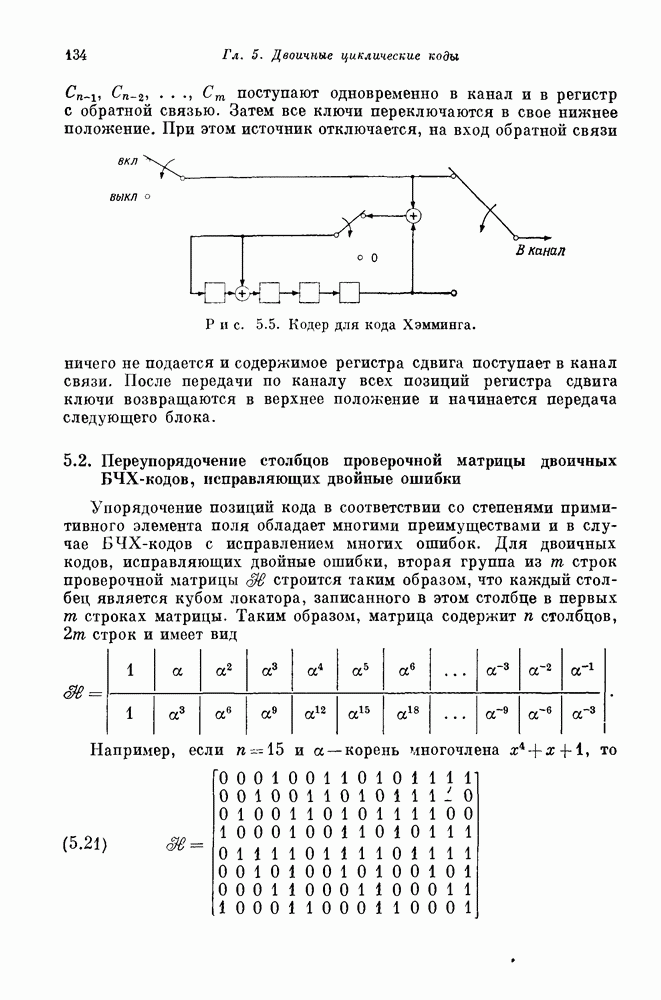
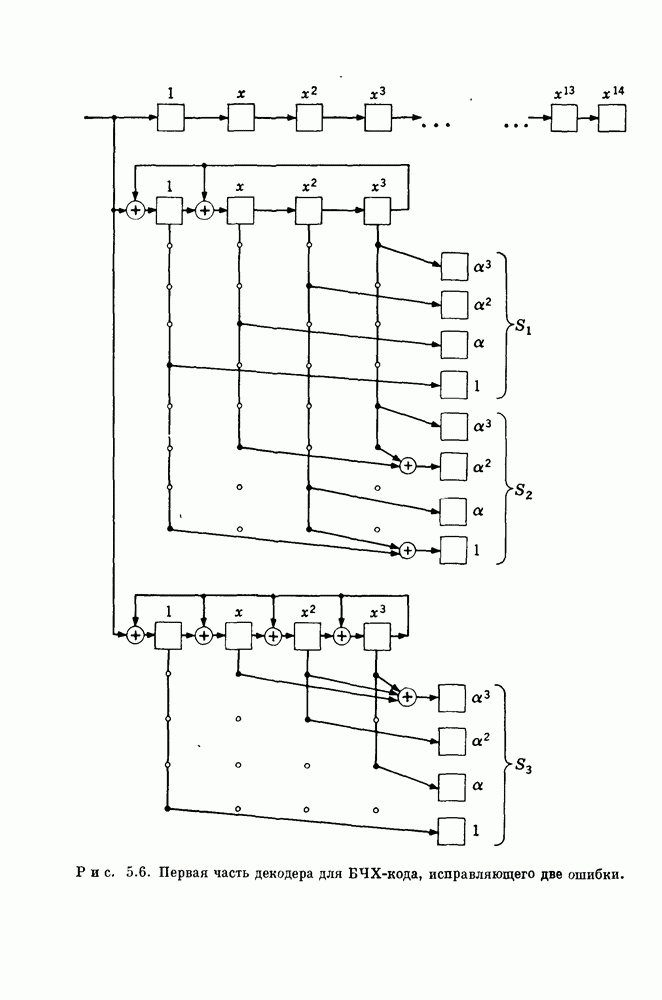
Можно строить коды Хэмминга все с большей и большей длиной; достаточно длинные коды обеспечивают скорость, близкую к 1. Таким образом, хотя коды Хэмминга существенно отличаются от кодов с одной проверкой на четность, они все еще образуют класс высокоскоростных кодов. Коды Хэмминга не позволяют исправлять ни одной конфигурации из двух или большего числа ошибок. Для того чтобы исправлять такие конфигурации ошибок, необходимо построить коды с большим числом проверочных позиций. Простота кодов Хэмминга резко контрастирует с относительной сложностью наиболее простых известных двоичных кодов, исправляющих двойные ошибки. Вслед за первой работой Хэмминга [1950] появилось большое число работ по конструктивной теории кодирования. Было предложено много новых кодов. Однако, за исключением нескольких важных случаев, предлагаемые конструкции носили узко специальный характер. Нерешенной оставалась даже следующая простейшая задача — построение двоичных кодов с приемлемой скоростью передачи, позволяющих исправлять любые двойные ошибки. Когда же, наконец, Боуз и Чоудхури в 1959 г. и Хоквингем в 1960 г. построили такие коды, то сразу же было предложено и их обобщение — коды с исправлением На самом деле интервал между открытием кодов Хэмминга в 1950 г. и БЧХ-кодов в 1960 г. составляет даже больше, чем десятилетие научных исследований, поскольку большинство результатов Хэмминга было опубликовано в несколько ином контексте еще в 1942 г. в работе Фишера, хорошо известной Боузу! Как бы то ни было, столь существенный интервал между открытием кодов Хэмминга и БЧХ-кодов с исправлением двойных ошибок является весьма примечательным. Поэтому мы рекомендуем начинающему читателю с особой тщательностью изучить следующий раздел, который, по нашему мнению, является весьма важным.
|
 |
Оглавление
|


























































































































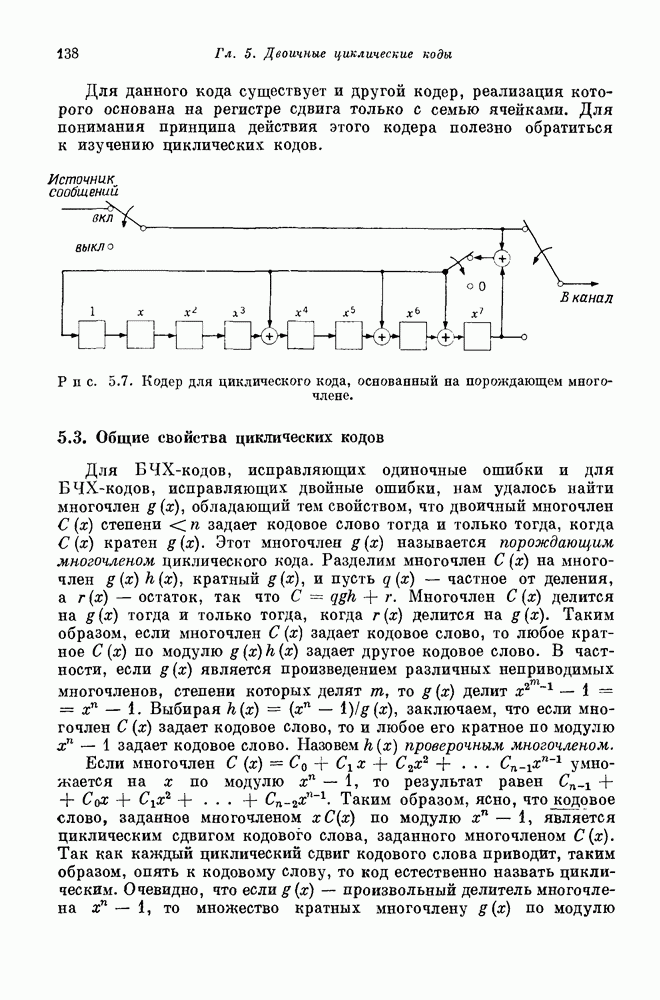


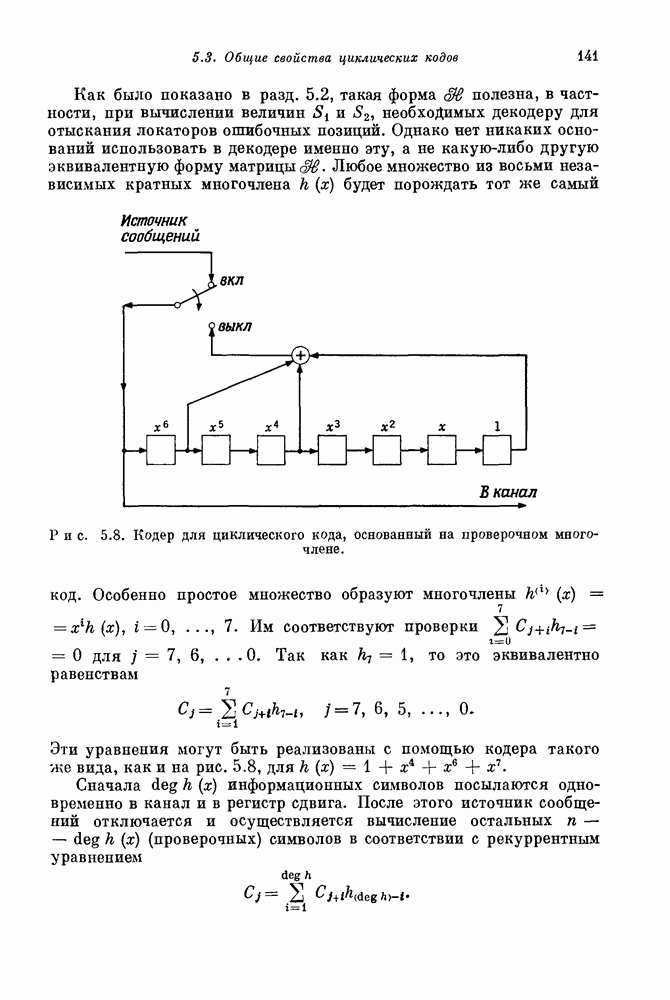

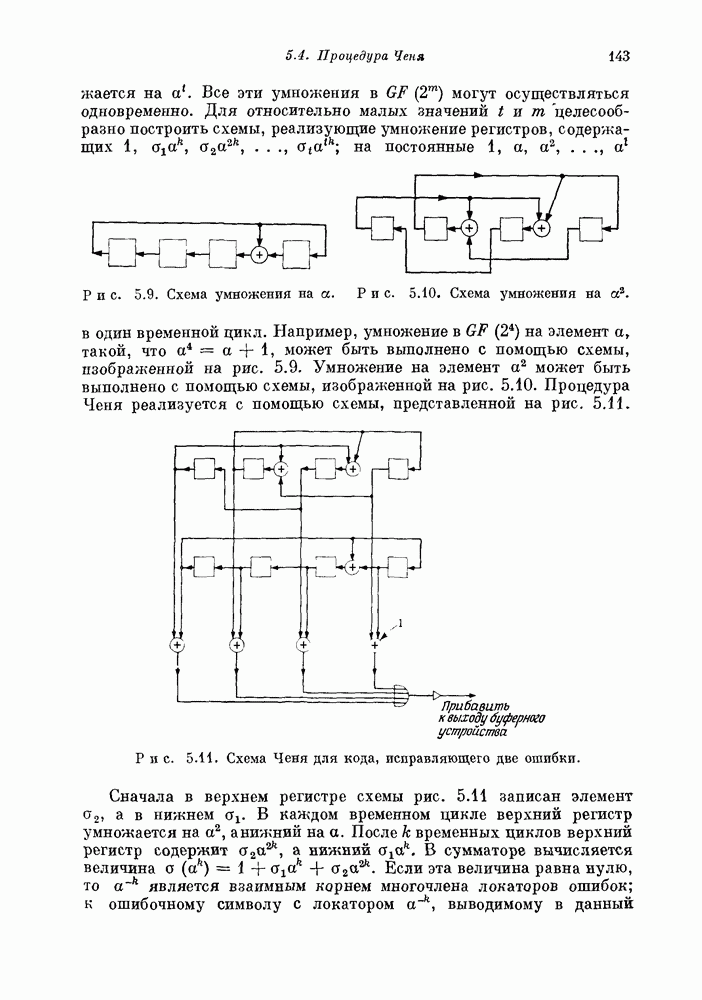
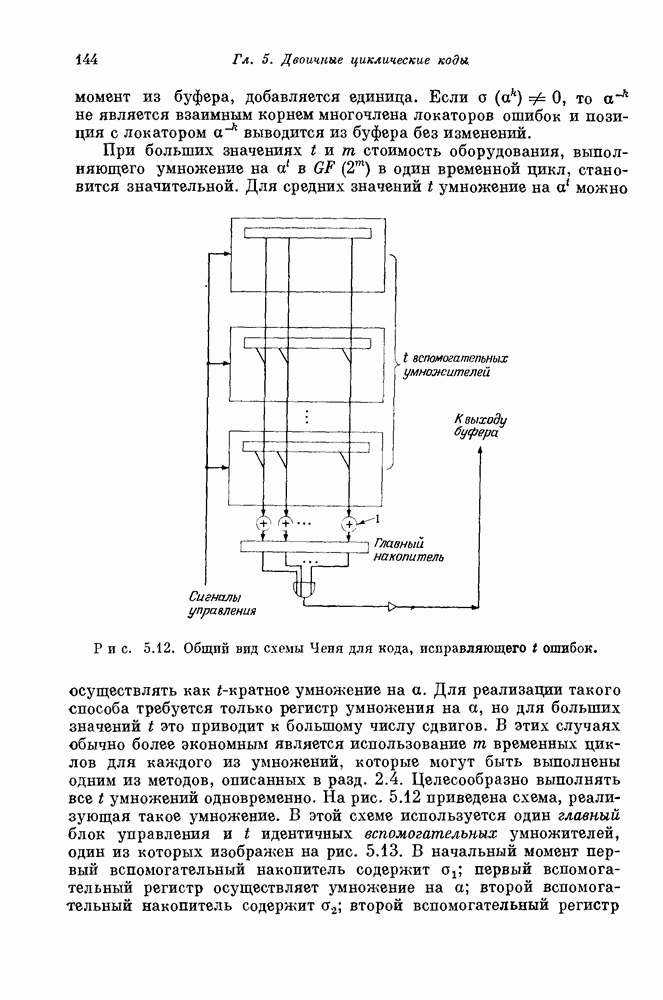
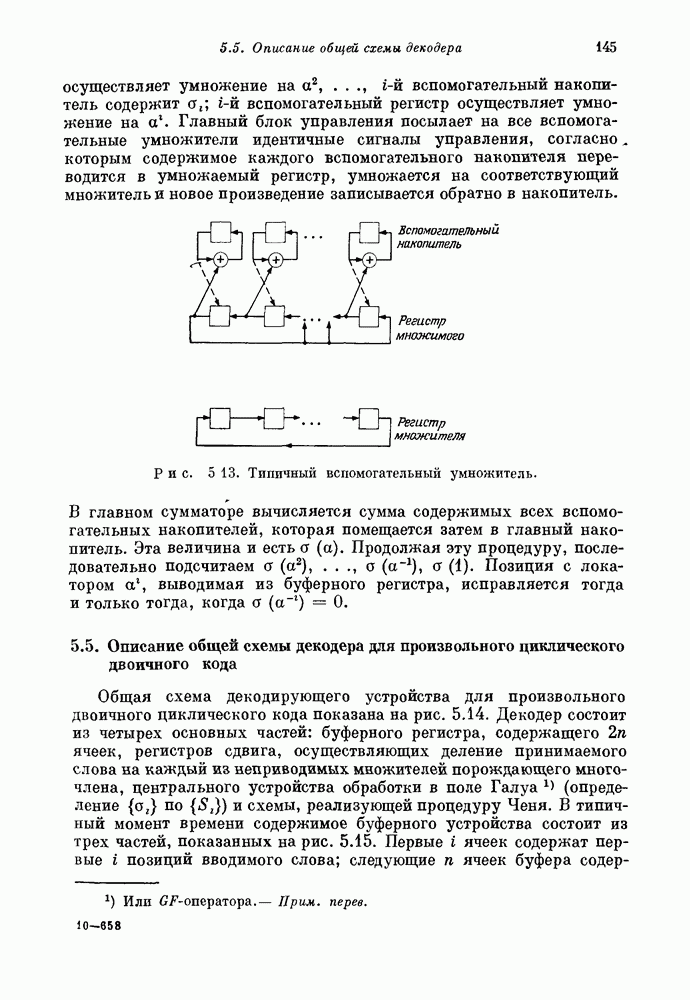
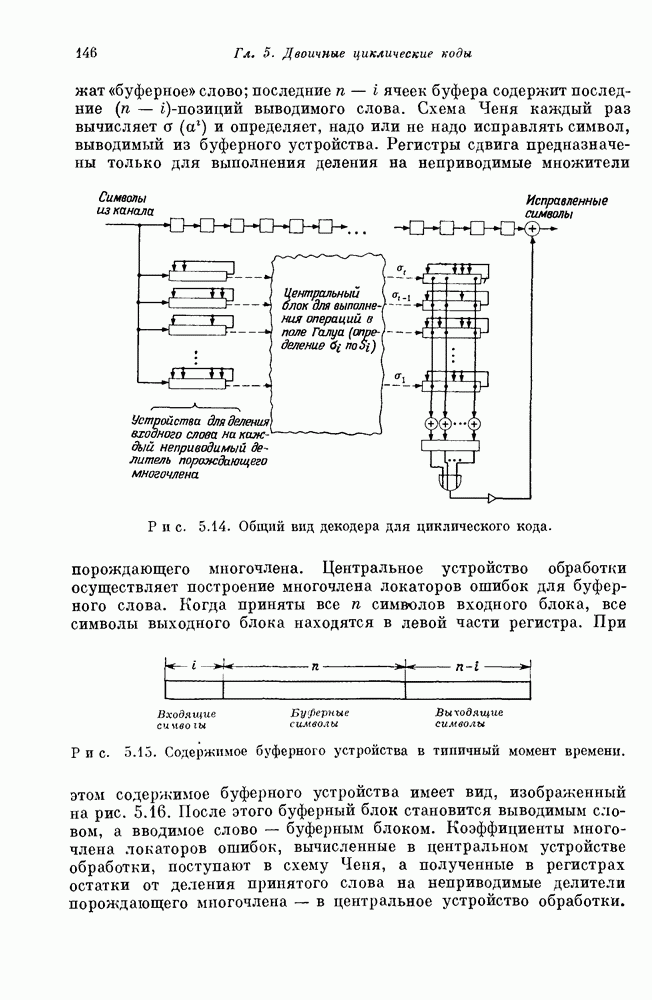


















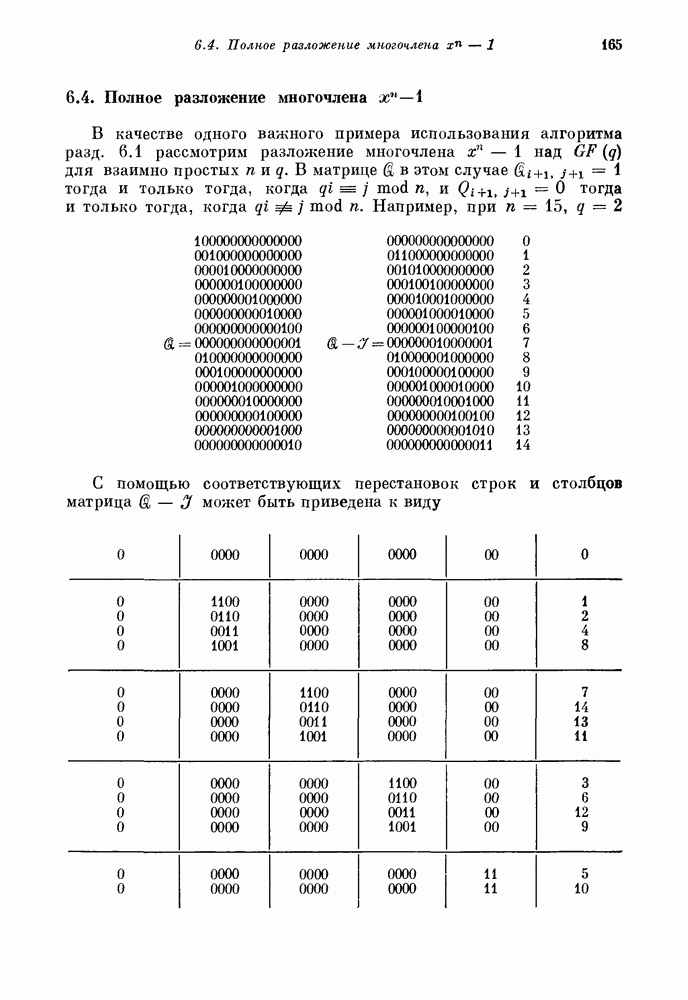







































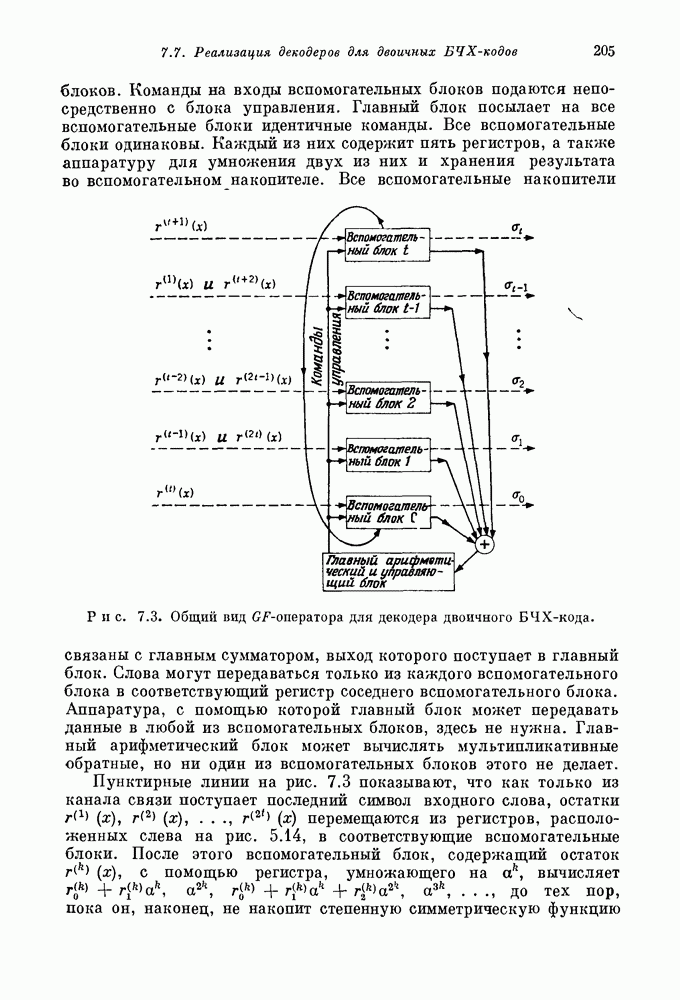
















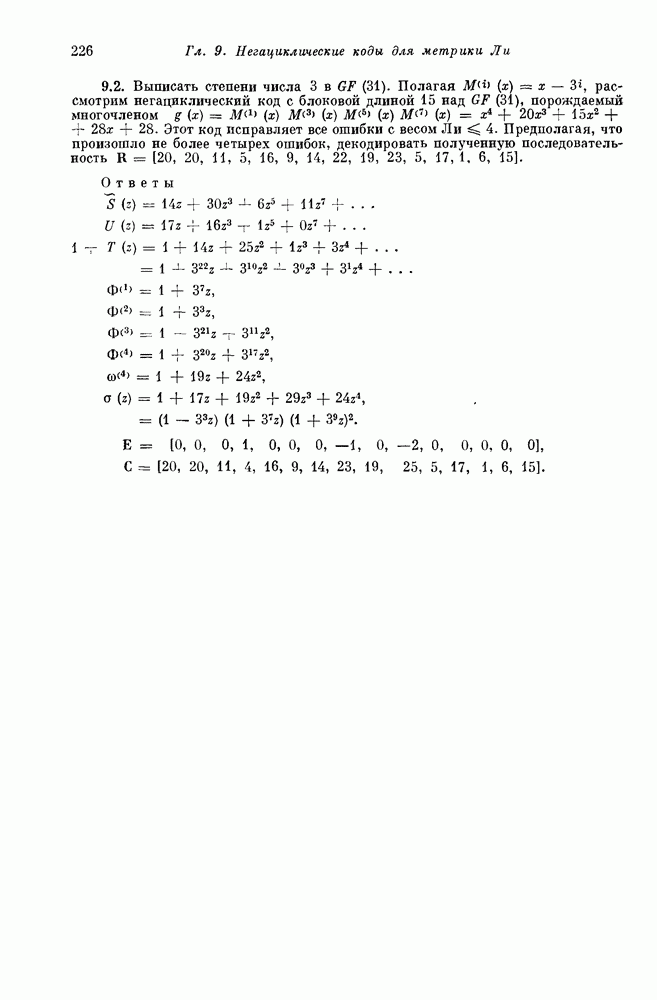
































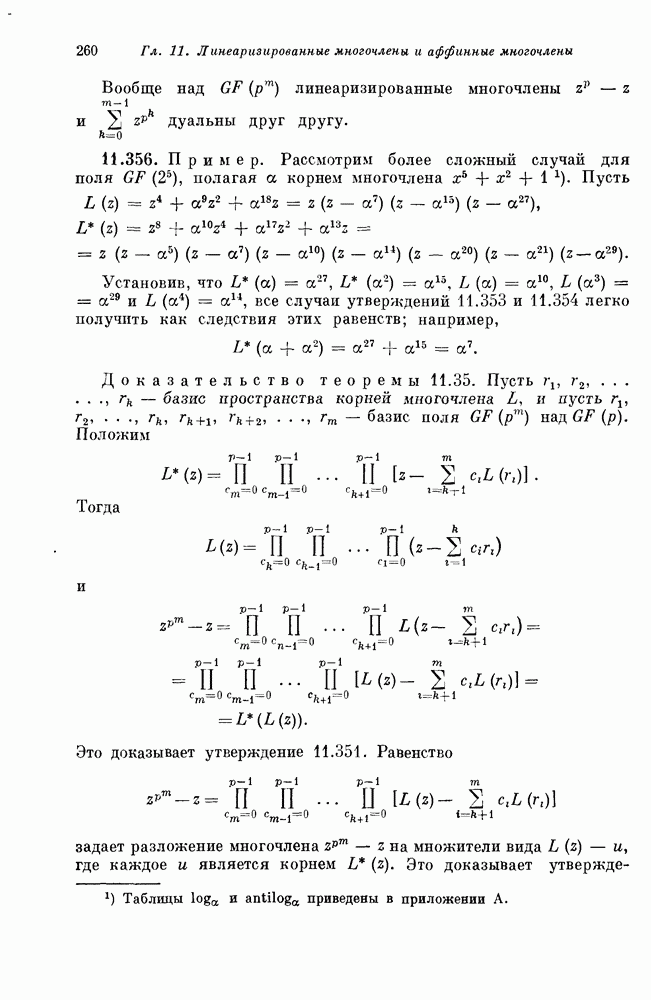
























































































































































































 Правая часть этого уравнения может быть записана в виде суммы, содержащей
Правая часть этого уравнения может быть записана в виде суммы, содержащей  раз первый столбец матрицы
раз первый столбец матрицы  раз второй столбец матрицы
раз второй столбец матрицы  раз третий столбец матрицы
раз третий столбец матрицы  Например, если
Например, если



 то синдром равен
то синдром равен  Так как
Так как  равен пятому столбцу матрицы
равен пятому столбцу матрицы  то заключаем, что
то заключаем, что


 , то
, то  . Так как
. Так как  не совпадает ни с одним из столбцов матрицы
не совпадает ни с одним из столбцов матрицы  то происходит отказ от декодирования, обнаруживающий две или более ошибок в канале.
то происходит отказ от декодирования, обнаруживающий две или более ошибок в канале.
 проверочных позиций. Так как число проверочных позиций равно числу линейно независимых строк матрицы
проверочных позиций. Так как число проверочных позиций равно числу линейно независимых строк матрицы  то этот вопрос равносилен вопросу о максимальном числе различных ненулевых столбцов двоичной матрицы, содержащей не более
то этот вопрос равносилен вопросу о максимальном числе различных ненулевых столбцов двоичной матрицы, содержащей не более  строк. Ответ очевиден:
строк. Ответ очевиден:  Столбцы матрицы
Столбцы матрицы  совпадают с
совпадают с  ненулевыми двоичными
ненулевыми двоичными  -мерными векторами, упорядоченными произвольным образом. Линейный код, определяемый такой матрицей, называется кодом Хэмминга.
-мерными векторами, упорядоченными произвольным образом. Линейный код, определяемый такой матрицей, называется кодом Хэмминга.
 существует двоичный код Хэмминга, содержащий
существует двоичный код Хэмминга, содержащий  проверочных позиций. Блоковая длина такого кода равна
проверочных позиций. Блоковая длина такого кода равна  , а число информационных позиций определяется равенством
, а число информационных позиций определяется равенством  Код позволяет исправлять одиночную ошибку в любой позиции. Более того, так как каждый возможный ненулевой синдром равен некоторому столбцу матрицы
Код позволяет исправлять одиночную ошибку в любой позиции. Более того, так как каждый возможный ненулевой синдром равен некоторому столбцу матрицы  то никогда не происходит отказа от декодирования. Процедура декодирования одиночных ошибок является полной. Вес лидера каждого смежного класса равен нулю или единице. Ни один вектор ошибок веса 2 не может быть обнаружен или исправлен.
то никогда не происходит отказа от декодирования. Процедура декодирования одиночных ошибок является полной. Вес лидера каждого смежного класса равен нулю или единице. Ни один вектор ошибок веса 2 не может быть обнаружен или исправлен.
 и содержит
и содержит  проверочных и
проверочных и  информационных символов. Например, код Хэмминга с блоковой длиной 15 описывается проверочной матрицей
информационных символов. Например, код Хэмминга с блоковой длиной 15 описывается проверочной матрицей


 Любая конфигурация двух ошибок в канале должна привести к отказу от декодирования. Таким образом, расширенный код Хэмминга исправляет все одиночные ошибки и обнаруживает все двойные ошибки.
Любая конфигурация двух ошибок в канале должна привести к отказу от декодирования. Таким образом, расширенный код Хэмминга исправляет все одиночные ошибки и обнаруживает все двойные ошибки.
 обеспечивает скорость передачи, равную
обеспечивает скорость передачи, равную

 ошибок для любого натурального
ошибок для любого натурального 