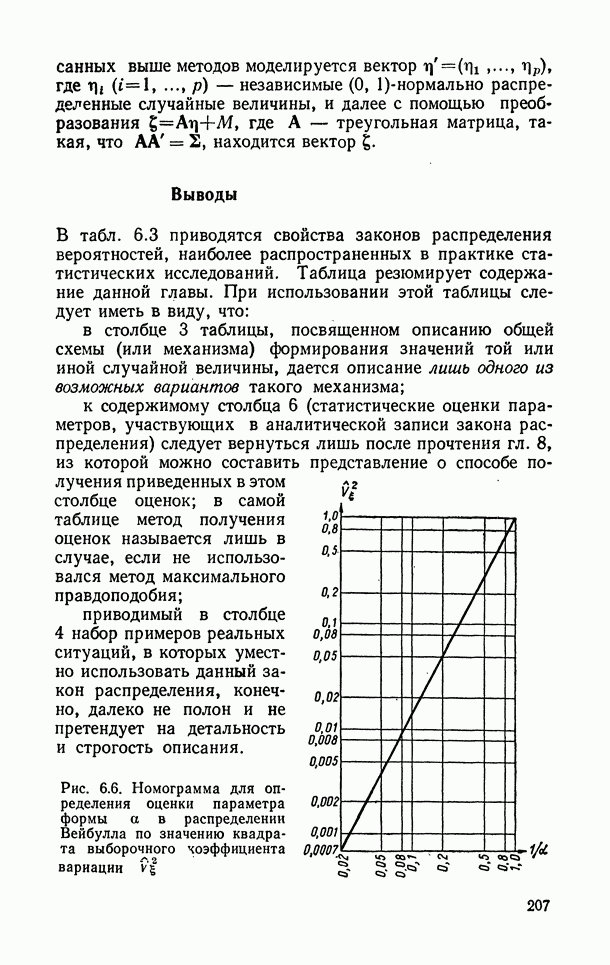
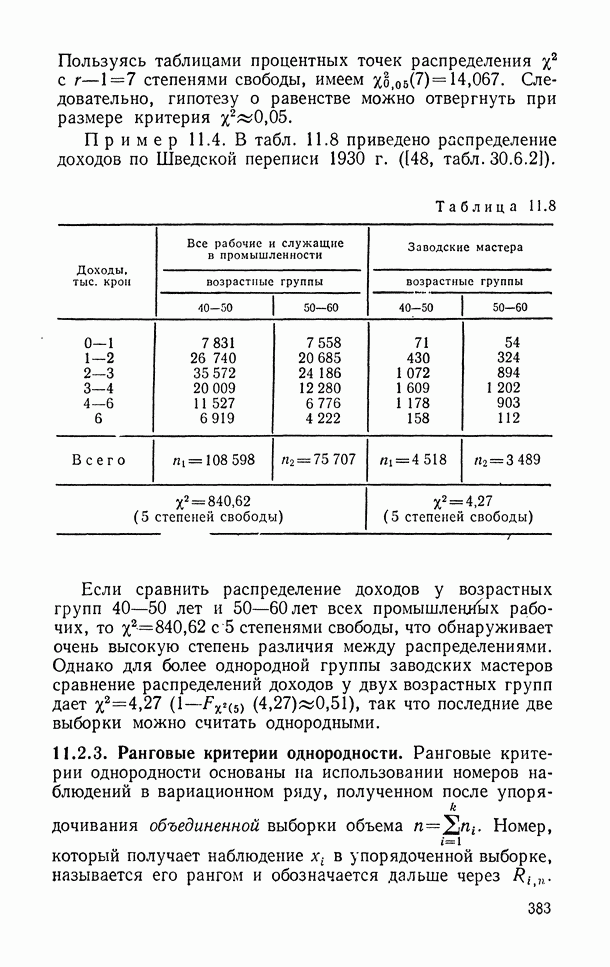
10.1.3. Просмотр данных.
Очень существенно, чтобы собранные в статистическом исследовании данные были тщательно просмотрены и отредактированы прежде, чем к ним будет применена основная статистическая техника.
Ошибки в данных могут привести к неожиданным результатам, иногда интерпретируемым, иногда нет, но всегда неверным.
Просмотр данных преследует следующие цели:
1) обнаружение грубых ошибок в словаре исследования, а также ошибок, допущенных при кодировании, перфорации и вводе данных в ЭВМ;
2) указание возможных выбросов или аномальных, т. е. резко выделяющихся по своей величине наблюдений, которые могут быть нерепрезентативными для изучаемой популяции (более подробно см. § 11.5);
3) получение первого, грубого представления об одномерных и, частично, двумерных распределениях.
Укажем некоторые приемы, облегчающие проведение просмотра данных, или, как иногда говорят, скрининга.
Распечатка введенных в ЭВМ данных в табличной форме по объектам, иногда с их предварительной сортировкой по величине какого-либо признака. При этом проверяются наличие грубых ошибок при задании формата данных, правильность и удобочитаемость названия исследования и имен переменных, полнота введенного материала и отсутствие лишних данных, а также попадание численных значений переменных или их кодов в предусмотренный диапазон. Просмотр расположенных по столбцам переменных позволяет обычно сразу же выделить грубые ошибки. При желании столбцы можно просмотреть и на экране дисплея. Однако хорошо оформленная бумажная распечатка является удобным справочным документом и по другим вопросам, которые могут возникнуть на последующих стадиях анализа.
Построение одномерных распределений. Если ЭВМ строит гистограмму (см. § 10.3), то ее столбцьгудобно заполнять номерами наблюдений. В крайнем случае если наблюдений слишком много, то указывать отдельно номера наблюдений, вышедших за 5 %- и 95 %-ные квантили.
Указание номеров наблюдений удобно использовать и при построении двумерных распечаток. Если в одну точку попадает несколько наблюдений, на графике ставится специальный знак, а номера наблюдений печатаются ниже. Двумерные широкоформатные распечатки очень удобны для формирования предварительных содержательных гипотез о связи переменных. Математические вопросы построения эмпирических распределений рассматриваются в § 10.3.