Пред.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Раздел I. ПРИКЛАДНАЯ СТАТИСТИКА: ЕЕ СУЩНОСТЬ И НАЗНАЧЕНИЕ (общие методические принципы)Глава 1. ПРИКЛАДНАЯ СТАТИСТИКА КАК САМОСТОЯТЕЛЬНАЯ НАУЧНАЯ ДИСЦИПЛИНА1.1. Связь прикладной статистики с другими статистическими дисциплинами и основные этапы статистического исследования1.1.1. Определение прикладной статистики.Нужно ли использовать этот термин или можно ограничиться более привычным понятием «математическая статистика»? Как соотносится прикладная статистика с другими статистическими дисциплинами, такими, как «математическая статистика», «анализ данных», «экономическая статистика» и т. д.? Для обоснования правомерности и целесообразности рассмотрения прикладной статистики как самостоятельной научной дисциплины следует упомянуть, как минимум, о двух моментах. Во-первых, до сих пор развитие теории, методологии и практики статистической обработки анализируемых данных шло, по существу, в двух параллельных направлениях. Одно из них представлено методами, предусматривающими возможность вероятностной интерпретации обрабатываемых данных и полученных в результате обработки статистических выводов. Именно эти методы (и только они!) и составляют содержание подавляющего большинства монографий и руководств по математической статистике. Другими словами, под методами математической статистики принято понимать лишь те методы статистической обработки исходных данных, разработка и использование которых апеллируют к вероятностной природе этих данных. При этом развиваемый в рамках второго направления весьма широкий и актуальный класс методов статистической переработки исходной информации, а именно о вся совокупность тех методов, которые априори не опираются на вероятностную природу обрабатываемых данных (представителями методов такого типа являются, например, разнообразные методы кластер-анализа, многомерного шкалирования, теории измерений и др.), остается за общепринятыми рамками научной дисциплины «математическая статистика» Во-вторых, специалисты, занимающиеся разработкой и конкретными применениями методов статистической обработки исходной информации, не могут игнорировать ту внушительную дистанцию, которая разделяет момент успешного завершения разработки собственно математического метода и момент получения результата от использования этого метода в решении конкретной практической задачи. В процессе прохождения этой трудной дистанции математику-прикладнику приходится: глубоко вникать в содержательную сущность задачи, адекватно «прилаживать» исходные модельные допущения (на которых строится любой математический метод) к выясненной сущности реальной задачи; решать (в некоторых специальных случаях) весьма трудную задачу преобразования имеющейся исходной информации, представленной, например, в виде физических сигналов, радиолокационных разверток, геологических срезов и т. п., к стандартной (унифицированной) форме обрабатываемых статистических данных (см. (1.4), и разрабатывать практически реализуемые вычислительные алгоритмы и программное обеспечение с учетом специфики обрабатываемой статистической информации и возможностей имеющейся вычислительной техники; организовать достаточно удобный и эффективный режим общения с электронно-вычислительной машиной (ЭВМ) в процессе решения задачи. Понятийный аппарат, методы и результаты, позволяющие проходить эту дистанцию, вместе с этапом «прилаживания» и доработки необходимого математического инструментария и составляют главное содержание прикладной статистики. Таким образом, мы приходим к определению прикладной статистики как самостоятельной научной дисциплины, разрабатывающей и систематизирующей понятия, приемы, математические методы и модели, предназначенные для организации сбора, стандартной записи, систематизации и обработки (в том числе — с помощью ЭВМ) статистических данных с целью их удобного представления, интерпретации и получения научных и практических выводов. Для определения той же самой системы понятий, приемов, математических методов и моделей некоторые специалисты используют термин «анализ данных», понимаемый в расширительном толковании. 1.1.2. Два варианта интерпретации исходных данных и два подхода к их статистической обработке. Рассмотрим два примера. Цель статистического анализа в первом примере — исследование возможностей массового производства по исходным данным, представляющим результаты контроля (по альтернативному признаку) ограниченного ряда изделий, случайно отобранных из продукции этого производства. Если было проконтролировано
где результат контроля В этом случае саму выборку мы рассматриваем как составную часть, как представителя «стоящей за ней» бесконечной совокупности, т. е. всего массового производства, а ее основные статистические характеристики, например ее среднюю арифметическую, являющуюся, как легко видеть, долей брака дефектных изделий в ней, — как некое приближение к истинной доле брака, характеризующей все производство. В подобных ситуациях имеется принципиальная возможность, хотя бы мысленно реально представимая, многократного повторения нашего наблюдения (или эксперимента) в рамках одного и того же реального комплекса условий, включающего в себя «мешающее» влияние большого числа не поддающихся учету случайных факторов (которые и являются причиной стохастического, т. е. не предопределенного заранее, результата каждого отдельного наблюдения). Такие ситуации могут быть описаны в рамках той или иной вероятностной модели (см. § 1.2 и 1.3). Соответственно ряд наблюдений (1.1) интерпретируется как случайная выборка из некоторой генеральной совокупности, т. е. как экспериментальные (или наблюденные) значения анализируемой случайной величины, и для его статистической обработки применяются классические математико-статистические методы (методы статистического оценивания неизвестных параметров, методы проверки статистических гипотез и т. п., см. разд. III) При подобной (вероятностной) интерпретации исходных статистических данных в поле зрения исследователя одновременно попадают две совокупности объектов: реально наблюдаемая, статистически представленная рядом наблюдений типа (1.1) (т. е. выборка), и теоретически домысливаемая (так называемая генеральная совокупность). Основные свойства и характеристики выборки, называемые эмпирическими (или выборочными), могут быть проанализированы и вычислены по имеющимся статистическим данным (1.1). Основные свойства и характеристики генеральной совокупности, называемые теоретическими, не известны исследователю, но назначение математико-статистических методов как раз в том и состоит, чтобы с их помощью получить как можно более точное представление об этих теоретических свойствах и характеристиках по соответствующим свойствам и характеристикам выборок. Для демонстрации второго возможного варианта интерпретации исходных статистических данных рассмотрим следующий пример (упрощенный вариант задачи, приведенной в [8, с. 223]). Была статистически обследована совокупность из 74 средних городов РСФСР (с численностью населения от 100 до 500 тыс. чел.). По каждому городу регистрировались значения 32 признаков
где результат обследования
компоненты которого определяют числовые значения анализируемых признаков по данному городу. Цель статистического анализа исходных данных (1.2) — выявление числа и состава различных типов городов, где под типом понимается класс городов обследованной совокупности, однородных (сходных) по структуре уровня образования их жителей, половозрастному составу и характеру занятости. Если допустить, что геометрическая близость двух точек — городов интерпретации исходных статистических данных (1.2) в качестве выборки из некоторой (теоретически домысливаемой) генеральной совокупности; использовании вероятностных моделей для построения и выбора наилучших методов статистической обработки; вероятностной интерпретации выводов, основанных на статистическом анализе исходных данных. В этом и заключается главное различие двух возможных подходов к статистическому анализу исходных данных. Однако и в том и в другом подходе выбор наилучшего из всех возможных методов обработки данных производится в соответствии с некоторым функционалом качества метода. Различие описываемых подходов проявляется здесь в способе обоснования выбора этого функционала качества метода, а также в интерпретации самого функционала и получаемых статистических выводов: в первом случае исследователь основывает свой выбор на допущениях о вероятностной природе исходных данных и использует эти же допущения при вероятностной интерпретации своих выводов; во втором случае исследователь не располагает никакими априорными сведениями о вероятностной природе исходных данных и при обосновании выбора оптимизируемого критерия качества опирается на соображения содержательного (физического) плана — как именно и для чего получены обрабатываемые данные. Но после того, как выбор конкретного вида оптимизируемого критерия качества метода осуществлен, математические средства решения задачи статистической обработки данных оказываются общими для обоих подходов: и в том, и в другом случае исследователь использует методы решения экстремальных задач. Правда, на заключительном этапе — на этапе осмысления и интерпретации полученных статистических выводов — каждый из подходов снова имеет свою специфику. Таким образом, общим для обоих описываемых подходов является наличие исходной статистической информации на «входе» задачи и необходимость наилучшей (в смысле оптимизации некоторого функционала качества метода) статистической обработки этой информации с целью получения научных или практических выводов «на выходе». Итак, принимаясь за статистический анализ исходных данных, исследователь должен прежде всего определить, в рамках какой из двух описанных выше схем следует проводить этот анализ. Другими словами, он должен сделать принципиальный выбор типа модели. И с этой точки зрения предостережения некоторых авторов (см. [10], [80]) по поводу вреда от чрезмерного (а порой бездумного) использования вероятностно-статистических методов в качестве главного инструмента статистической обработки исходных данных нам представляются уместными и полезными. Однако нельзя отбивать всякую охоту пользоваться этими методами: именно такую цель, похоже, ставил перед собой автор [10] и именно к такому выводу (о прикладной никчемности и неэффективности вероятностно-статистических методов) пришли многие читатели работы [80], хотел того ее автор или нет. В действительности же приходится исходить из следующей ситуации. Будем отправляться от момента, когда исследователь уже располагает исходными статистическими данными, характеризующими те или иные стороны интересующего его процесса или явления. Вопрос состоит в том, как наилучшим (в определенном смысле) образом обработать эту информацию с целью получить из нее научные или практические выводы определенного характера об исследуемом явлении. Для того чтобы уточнить понятие «наилучшим образом», исследователь должен формализовать задачу, выбрать модель. Всякая модель является упрощенным (математическим) представлением изучаемой действительности (см. § 3.1). Очевидно, мера адекватности выбранной модели и изучаемой действительности является решающим фактором, определяющим эффективность и действенность используемых затем методов статистической обработки. Поскольку ни одна из жестко определенных моделей не может на практике идеально соответствовать изучаемой реальной действительности, то можно только приветствовать желание исследователя многократно обработать свои исходные данные, проводя каждую новую статистическую обработку в рамках несколько измененного варианта модели (см. развитие этого тезиса в § 1.2). 1.1.3. Основные этапы статистической обработки исходных данных. Попытаемся теперь описать общую логическую схему статистического анализа исходных данных. Для пояснения роли и места основных приемов статистического моделирования и методов первичной статистической обработки исходных данных удобно разложить эту схему на основные этапы исследования. Подобное разложение носит, конечно, условный характер. В частности, оно не означает, что этапы осуществляются в строгой хронологической последовательности один за другим. Более того, многие из этапов (например, этапы 4, 5 и 6) находятся, в плане хронологическом, в соотношении итерационного взаимодействия: результаты реализации более поздних этапов могут содержать выводы о необходимости повторной «прогонки» (с учетом новой информации) предыдущих этапов. Этап 1: исходный (предварительный) анализ исследуемой реальной системы. В результате этого анализа определяются: а) основные цели исследования на неформализованном, содержательном уровне; б) совокупность единиц, представляющая предмет статистического исследования; в) перечень е) моменты, требующие предварительной проверки перед составлением детального плана исследования (например, не всегда априори ясна возможность идентификации единиц наблюдения, в медицинских исследованиях не всегда может быть получено согласие больного следовать определенным рекомендациям медперсонала и т. п.); ж) формализованная постановка задачи, по возможности включающая вероятностную модель изучаемого явления, и природа статистических выводов, к которым должен (или может) прийти исследователь в результате переработки массива исходных данных; з) формы, используемые для сбора первичной информации и для введения ее в ЭВМ. По затратам сил наиболее квалифицированного персонала, участвующего в работе, трудоемкость первого этапа работы весьма значительна и бывает даже сравнима с суммарной трудоемкостью всех остальных этапов при условии, что обработка проводится с помощью подходящего пакета программ. Поэтому максимального развития заслуживают методы машинного ассистирования в проведении этой части работы. Оно может заключаться в подсказке (с одновременной оценкой) форм документации для сбора первичной информации, методов построения контрольной или «псевдоконтрольной» групп при изучении какого-либо воздействия (что особенно актуально для медицинских приложений), подходящих моделей, в ведении тезауруса исследования и т. п. Этап 2: составление детального плана сбора исходной статистической информации. При составлении этого плана необходимо, по возможности, учитывать полную схему дальнейшего статистического анализа, о чем часто забывают. Априорное представление о том, как и для чего данные будут анализироваться, может оказать существенное влияние на их сбор. При планировании особого внимания заслуживают случаи, когда: а) используется аппарат общей теории выборочных обследований (см., например, [43]), т. е. определяется, какой должна быть выборка — случайной, пропорциональной, расслоенной и т. п.; б) производится расчет «разрешающей силы» исследования заданного объема и продолжительности (см., например, [127], где оценивается сверху число возможных статистически значимых ассоциацйй между риск-факторами и частотой заболеваний, или [102], где предлагается простейшая модель для феноменологического описания действия лечебного фактора); в) хотя бы для части входных переменных эксперимент носит активный характер: переменные допускают фиксацию в каждом конкретном наблюдении на определенном уровне, и выбор плана обследования осуществляется с привлечением методов планирования (регрессионных) экспериментов (см., например,(81)). В некоторых руководствах по общей теории статистики (см., например, [64, с. 274]) этот этап называют этапом «организационно-методической подготовки». Как уже сказано выше, вопросы разработки методологии определения априорной системы показателей, характеризующих исследуемый объект или процесс, вынесены за рамки описываемых здесь этапов и должны быть отнесены к области конкретно-содержательной статистики (экономической, медицинской и т. п.). Этап 3: сбор исходных статистических данных и их введение в ЭВМ. Одновременно в ЭВМ вносятся полные и краткие (для автоматизированного воспроизводства в таблицах) определения используемых терминов. В пакете должны быть предусмотрены специальдые меры, исключающие или резко уменьшающие возможность появления расчетов не с тем подмножеством данных или не для той подгруппы объектов. Таким образом, независимо от того, производится ли исследователем выбор метода и плана статистического обследования или он уже располагал результатами так называемого пассивного эксперимента, к моменту определения основного инструментария статистического исследования исследователь в общем случае располагает в качестве массива исходных статистических данных временной последовательностью матриц наблюдений вида
где
вектор, характеризующий то, как протекает В ряде ситуаций и в первую очередь в ситуациях, когда исходные статистические данные получают с помощью специальных опросов, анкет, экспертных оценок, возможны случаи, когда элементом первичного наблюдения является не состояние
Очевидно, что от формы запису (1.4) можно непосредственно перейти к (1.4) (при наличии заданной метрики в пространстве объектов и в пространстве признаков). Однозначный обратный переход от (1.4) к (1.4) без дополнительных предположений и специальных методов (скажем, многомерного шкалирования, см. [122]), в общем, невозможен. Возможны и другие формы представления геометрической структуры исходных данных, однако мы не будем здесь на них останавливаться. В целях упрощения обозначений в наших дальнейших рассуждениях, если специально не оговорено противное, мы будем рассматривать статический вариант схемы, т. е. ситуацию, в которой нас будет интересовать массив исходных данных (1.4) или (1.4), отнесенный лишь к одному какому-то фиксированному моменту времени Этап 4: первичная статистическая обработка данных. В ходе первичной статистической обработки данных обычно решаются следующие задачи: а) отображение переменных, описанных текстом, в номинальную (с предписанным числом градаций) или ординальную (порядковую) шкалу; б) статистическое описание исходных совокупностей с определением пределов варьирования переменных; в) анализ резко выделяющихся наблюдений; г) восстановление пропущенных наблюдений; д) проверка статистической независимости последовательности наблюдений, составляющих массив исходных данных; е) унификация типов переменных, когда с помощью различных приемов добиваются унифицированной записи всех переменных; ж) экспериментальный анализ закона распределения исследуемой генеральной совокупности и параметризация сведений о природе изучаемых распределений (иногда этот этап называют процессом составления сводки и группировки [64, с. 274—275]). Кроме того, этап 4 включает в себя вычислительную реализацию решения следующих вопросов: учет размерности и алгоритмической сложности задачи и одновременно возможностей используемой ЭВМ; формулировку задачи на входном языке пакета и т. п. (см. подробнее об этом в описании этапа 6). Остановимся на некоторых из затронутых вопросов подробнее. Анализ резко выделяющихся наблюдений.Часто даже беглый предварительный просмотр (визуальный или автоматизированный) исходных данных (1.4) или (1.4) может вызвать у исследователя сомнения в истинности (или правомерности) отдельных наблюдений, слишком резко выделяющихся на общем фоне. В этих случаях возникает вопрос: вправе ли мы объяснить обнаруженные резкие отклонения в исходных данных (аномальные выбросы) лишь обычными случайными колебаниями выборки (которые обусловлены природой анализируемой генеральной совокупности) или здесь дело в существенных искажениях стандартных условий сбора статистических данных, а возможно, и в прямых ошибках регистрации (записи)? В последних двух случаях «подозрительные» наблюдения, очевидно, следует исключить из дальнейшего рассмотрения. Единственным абсолютно надежным способом решения вопроса об исключении резко выделяющихся результатов наблюдений является тщательное рассмотрение условий, при которых эти наблюдения регистрировались. Однако во многих случаях проведение такого содержательного анализа объективно затруднительно или принципиально невозможно. Тогда необходимо обратиться к соответствующим формальным (статистическим) методам. Общая логическая схема этих методов следующая: отправляясь от исходных допущений о природе анализируемой совокупности данных, исследователь задается функцией
от всех имеющихся наблюдений X, характеризующей степень аномальности (меру удаленности от основной массы наблюдений) «подозрительных» наблюдений С различными вариантами методов анализа резко выделяющихся наблюдений читатель познакомится в § 11.5 (см. также [6], [76]). Восстановление пропущенных (стертых) наблюдений.В матрицах исходных статистических данных (1.4) или (1.4) по разным причинам (в том числе и в результате исключения резко выделяющихся наблюдений) могут быть пропуски отдельных элементов или каких-то частей строк или столбцов. Исключать по этой причине из дальнейшего рассмотрения весь объект (столбец, в котором обнаружены пропуски) или признак (строку, в которой обнаружены пропуски) слишком расточительно с точки зрения потери полезной информации. Поэтому возникает задача наилучшего в некотором смысле восстановления пропущенных (стертых) данных. Конкретизация критерия качества восстановления стертых данных производится в зависимости от характера последующей обработки исходных данных, т. е. в зависимости от окончательных целей исследования (см. § 11.4, а также [35], [66], [95]). Проверка однородности нескольких порций исходных данных.Объективные условия сбора исходных статистических данных, особенно в ситуациях пассивного эксперимента, могут быть такими, что общая Очевидно, перед тем как подвергать исходные данные основной статистической обработке (т. е. применять к ним те или иные методы прикладного статистического анализа, выбор которых обусловлен конечными целями исследования), исследователь должен ответить на вопрос: правомерно ли объединение имеющихся в его распоряжении порций (выборок) в один общий массив или же каждая из порций имеет свою специфику и, следовательно, и обрабатывать их надо по отдельности? В рамках математикостатистических моделей этот вопрос сводится к выяснению Проверка статистической независимости последовательности наблюдений, составляющих массив исходных данных.Применение многих статистических методов является правомерным лишь в ситуациях, когда справедливо допущение о статистической независимости обрабатываемого ряда наблюдений Унификация типа переменных.Одна из сложностей автоматизированного анализа информации заключается в том, что среди компонент В связи с этим возникает вопрос унификации записи единичного наблюдения, снятого с объекта i. В соответствии с одним из вариантов решения этого вопроса В качестве альтернативного подхода к способу унификации записи исходных данных может быть использована идея, прямо противоположная той, на основании которой построен только что описанный прием. В частности, руководствуясь некоторыми дополнительными соображениями (и допущениями), исследователь пытается преобразовать качественные и классификационные переменные в количественные, используя процесс так называемой «оцифровки», или шкалирования, неколичественных переменных, а также некоторые специальные модели (Терстоуна, Лазарсфельда и др.), см. § 10.2, а также [31], [57], [88], [134]. Экспериментальный анализ закона распределения исследуемой генеральной совокупности и вопрос ее подходящей параметризации.Эта часть предварительной статистической обработки исходного массива данных, представленных в виде (1.4), включает в себя вычисление основных числовых характеристик распределения: среднего значения, дисперсии, коэффициентов асимметрии и эксцесса, а в многомерном случае — и элементов выборочной ковариационной матрицы. Кроме того, исследователь проводит численный и графический анализ одномерных законов распределения рассматриваемых показателей, заключающийся в построении соответствующих полигонов частот, гистограмм, эмпирических функций распределения. Результаты этого экспериментального анализа, дополненные априорными сведениями о природе анализируемой генеральной совокупности, зачастую оказываются достаточными для формулировки одной или нескольких конкурирующих гипотез об общем (параметрическом) виде закона распределения вероятностей, задающего эту генеральную совокупность. Не следует пренебрегать такой возможностью, поскольку знание общего вида вероятностного распределения в исследуемой генеральной совокупности позволяет сделать наилучший выбор метода статистического оценивания параметров этого распределения, а также метода последующей основной статистической обработки массива исходных данных (из набора конкурирующих методов). Как известно, выяснение непротиворечивости высказанной исследователем гипотезы об общем виде распределения анализируемых наблюдений с природой и спецификой имеющихся в распоряжении исследователя конкретных исходных данных осуществляется с помощью тех или иных статистических критериев согласия (см. § 10.3 и 11.1). Этап 5: составление детального плана вычислительного анализа материала. Этап начинается с составления справки по собранному материалу и результатам предварительного анализа. Определяются основные группы, для которых будет проводиться дальнейший анализ. Пополняется и уточняется тезаурус содержательных понятий. Четко описывается блок-схема анализа с указанием привлекаемых методов. Формулируется оптимизационный критерий, на основании которого выбирается один из альтернативных методов (или одно из альтернативных семейств методов) основной статистической обработки исходных данных (см. § 1.2). Этап 6: вычислительная реализация основной части статистической обработки данных. Основная забота исследователя на этом этапе — эффективное управление вычислительным процессом путем формулировки задачи обработки и описания данных на входном языке пакета. Учитываются размерность задачи, алгоритмическая сложность вычислительного процесса, возможности используемой ЭВМ (длина слова, быстродействие, объем оперативной памяти, организация базы данных и т. п.) и, наконец, особенности данных (степень обусловленности используемых при реализации линейных процедур матриц, надежность априорных оценок параметров и т. п.). Этап 7: подведение итогов исследования. Этап начинается с построения формального статистического отчета о проведенном исследовании. При интерпретации результатов применения статистических процедур (оценка параметров, проверка гипотез, отображения в пространство меньшей размерности, классификация и т. п.) учитывается как место этих процедур в блок-схеме анализа, так и соотношение объемов используемых выборок, размерности пространства наблюдений, числа и значений параметров. Теоретически эти вопросы, несмотря на их крайнюю актуальность, разработаны довольно мало. Как исключение можно назвать работы [27], [58], [59]. В тех случаях, когда при интерпретации результатов вычислений нельзя опереться на теоретические утверждения, может оказаться полезным использование имитационного статистического моделирования (см. § 3.3 и 6.3). Затем результаты исследования, его основные выводы формулируются в содержательных терминах. Если исследование проводилось в рамках математико-статистических методов и моделей, то его выводы формулируются в терминах оценок неизвестных параметров анализируемой системы или в видеответа на вопрос о справедливости проверяемой статистической гипотезы и сопровождаются гарантируемыми количественными оценками степени их достоверности. Если же исследование осуществлялось средствами анализа данных (т. е. в рамках второго подхода), то его выводы не претендуют на вероятностную интерпретацию. В заключение проверяется, в какой мере достигнуты намеченные на этапе 1 содержательные цели работы, и, если достигнуты не все из них, то объясняется, почему. Работа завершается содержательной формулировкой новых задач, вытекающих из проведенного исследования. В некоторых руководствах по общей теории статистики (см., например, [64]) этапы 5, 6 и 7 объединены в одном этапе, названном «Обработка и анализ». Резюмируя описание общей логической схемы статистического анализа исходных данных, отметим, что основные приемы статистического моделирования и методы первичной статистической обработки являются главными в ходе реализации важнейших этапов 1, 4 и 7, а также по мере необходимости могут привлекаться при реализации этапов 3, 5 и 6.
|
 |
Оглавление
|



































































































































































































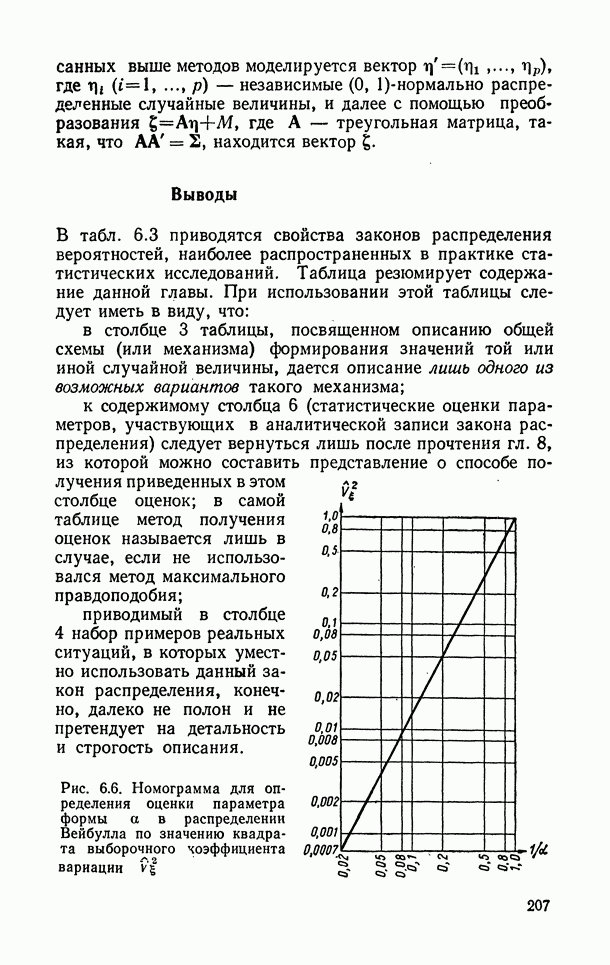















































































































































































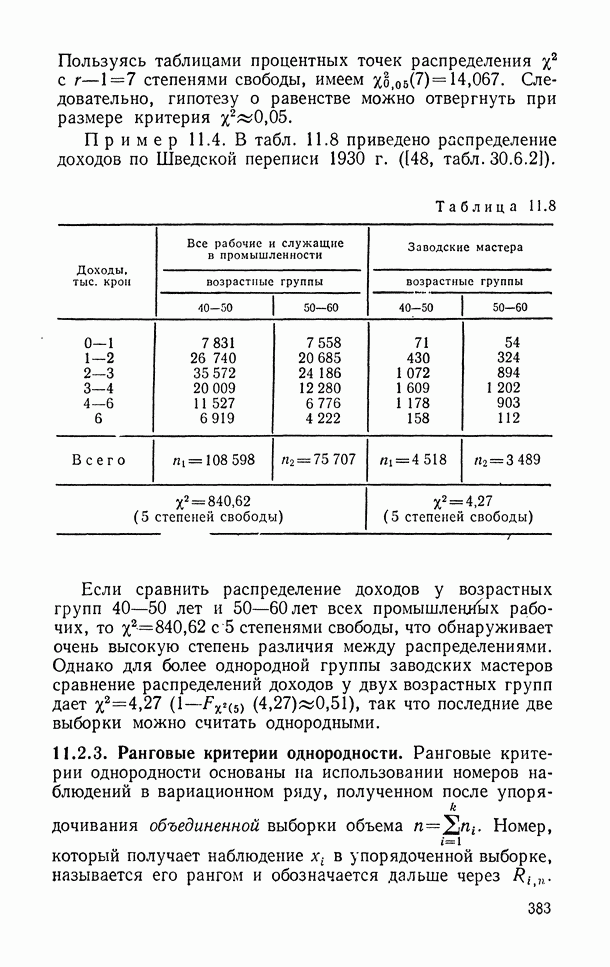
















































































 );
);
 изделий, то результаты контроля могут быть, в общем виде представлены в виде последовательности чисел
изделий, то результаты контроля могут быть, в общем виде представлены в виде последовательности чисел

 изделия
изделия  полагается равным единице, если изделие оказалось дефектным, и нулю — в противном случае. Если производство отлажено и действует в стационарном режиме (т. е. его технологические возможности остаются на постоянном уровне), то ряд наблюдений (1.1) естественно интерпретировать как ограниченную выборку из соответствующей бесконечной совокупности, которую мы бы имели, если бы осуществляли сплошной контроль всех изделий, производимых на этом производстве.
полагается равным единице, если изделие оказалось дефектным, и нулю — в противном случае. Если производство отлажено и действует в стационарном режиме (т. е. его технологические возможности остаются на постоянном уровне), то ряд наблюдений (1.1) естественно интерпретировать как ограниченную выборку из соответствующей бесконечной совокупности, которую мы бы имели, если бы осуществляли сплошной контроль всех изделий, производимых на этом производстве.
 характеризующих этот город по уровню образования его жителей, половозрастному и социальному составу, структуре занятости жителей города. Таким образом, здесь исходные статистические данные могут быть представлены в виде последовательности 32-мерных векторов
характеризующих этот город по уровню образования его жителей, половозрастному и социальному составу, структуре занятости жителей города. Таким образом, здесь исходные статистические данные могут быть представлены в виде последовательности 32-мерных векторов

 города является вектором
города является вектором

 вида (1.3) в соответствующем 32-мерном пространстве означает их однородность (сходство) по анализируемым признакам и является соответственно основанием для их отнесения к одному типу, то для решения поставленной выше задачи нам придется привлечь подходящие методы кластер-анализа (распознавания образов «без учителя») и снижения размерности. И хотя математический аппарат этих методов предусматривает необходимость счета таких статистических характеристик, как средние,
вида (1.3) в соответствующем 32-мерном пространстве означает их однородность (сходство) по анализируемым признакам и является соответственно основанием для их отнесения к одному типу, то для решения поставленной выше задачи нам придется привлечь подходящие методы кластер-анализа (распознавания образов «без учителя») и снижения размерности. И хотя математический аппарат этих методов предусматривает необходимость счета таких статистических характеристик, как средние,  отобранных из представленного специалистами априорного набора показателей, характеризующих состояние (поведение) каждого из обследуемых объектов, который предполагается использовать в данном исследрвании; г) степень формализации соответствующих записей при сборе данных; д) общее время и трудозатраты, отведенные на планируемые работы, и коррелированные с ними временная протяженность и объем необходимого статистического обследования;
отобранных из представленного специалистами априорного набора показателей, характеризующих состояние (поведение) каждого из обследуемых объектов, который предполагается использовать в данном исследрвании; г) степень формализации соответствующих записей при сборе данных; д) общее время и трудозатраты, отведенные на планируемые работы, и коррелированные с ними временная протяженность и объем необходимого статистического обследования;

 — значение
— значение  признака, характеризующего состояние
признака, характеризующего состояние  объекта в момент времени t. Однако бывают случаи, когда
объекта в момент времени t. Однако бывают случаи, когда  случайны для каждого объекта. Так, например, может быть в медицинских исследованиях, когда
случайны для каждого объекта. Так, например, может быть в медицинских исследованиях, когда

 обострение у
обострение у  больного, и за один и тот же промежуток времени
больного, и за один и тот же промежуток времени  у различных больных может быть разное число обострений. В этом случае
у различных больных может быть разное число обострений. В этом случае  будут иметь для разных больных
будут иметь для разных больных  для разных
для разных  разную размерность. Более того, в медицинских исследованиях отдельные координаты могут быть записаны не с помощью цифр, а текстом. Подобные особенности в представлении исходных данных характерны и для социологических и, в меньшей степени, для экономических исследований.
разную размерность. Более того, в медицинских исследованиях отдельные координаты могут быть записаны не с помощью цифр, а текстом. Подобные особенности в представлении исходных данных характерны и для социологических и, в меньшей степени, для экономических исследований.
 объекта в момент
объекта в момент  , а характеристика
, а характеристика  попарной близости (отдаленности) двух объектов (или признаков) соответственно с номерами
попарной близости (отдаленности) двух объектов (или признаков) соответственно с номерами  отнесенная к моменту времени t. В этом случае исследователь располагает в качестве массива исходных статистических данных временной последовательностью матриц размера
отнесенная к моменту времени t. В этом случае исследователь располагает в качестве массива исходных статистических данных временной последовательностью матриц размера  (если рассматриваются характеристики попарной близости объектов) или
(если рассматриваются характеристики попарной близости объектов) или  (если рассматриваются характеристики попарной близости признаков) вида
(если рассматриваются характеристики попарной близости признаков) вида

 , обозначение которого будем опускать.
, обозначение которого будем опускать.

 , а затем подставляет в (1.5) реальные значения наблюдений и сравнивает величину с некоторым пороговым значением
, а затем подставляет в (1.5) реальные значения наблюдений и сравнивает величину с некоторым пороговым значением  если то подозрительные наблюдения или полностью исключаются из дальнейшего рассмотрения, или их вклад уменьшается с помощью весовой функций, убывающей по мере роста степени аномальности наблюдений.
если то подозрительные наблюдения или полностью исключаются из дальнейшего рассмотрения, или их вклад уменьшается с помощью весовой функций, убывающей по мере роста степени аномальности наблюдений.
 -матрица наблюдений (см. (1.4)) получается составлением
-матрица наблюдений (см. (1.4)) получается составлением 
 -матриц (частных) наблюдений
-матриц (частных) наблюдений  соответственно
соответственно  , где каждая из частных матриц
, где каждая из частных матриц  задает порцию исходных данных, относящихся к некоторой подсовокупности, состоящей из
задает порцию исходных данных, относящихся к некоторой подсовокупности, состоящей из  объектов. При этом процессы (моменты) обследования этих совокупностей могут быть разделены в пространстве (во времени).
объектов. При этом процессы (моменты) обследования этих совокупностей могут быть разделены в пространстве (во времени).
 помощью соответствующих статистических критериев), можно ли считать порции данных
помощью соответствующих статистических критериев), можно ли считать порции данных  различными выборками из одной и той же
различными выборками из одной и той же  . Этот же вопрос возникает и применительно к рядам
. Этот же вопрос возникает и применительно к рядам  . Поэтому, перед тем как подвергнуть имеющиеся результаты наблюдения основной статистической обработке, необходимо выяснить (с помощью соответствующих статистических критериев (см. § 11.3)), являются ли они статистически независимыми или их следует рассматривать как последовательности взаимозависимых величин.
. Поэтому, перед тем как подвергнуть имеющиеся результаты наблюдения основной статистической обработке, необходимо выяснить (с помощью соответствующих статистических критериев (см. § 11.3)), являются ли они статистически независимыми или их следует рассматривать как последовательности взаимозависимых величин.
 анализируемого многомерного признака могут быть показатели трех разных типов: количественные, качественные (порядковые, ординальные) и классификационные (номинальные). Их определение и сущность, а также основные формы записи их наблюдаемых значений приведены в § 5.3 и 10.2.
анализируемого многомерного признака могут быть показатели трех разных типов: количественные, качественные (порядковые, ординальные) и классификационные (номинальные). Их определение и сущность, а также основные формы записи их наблюдаемых значений приведены в § 5.3 и 10.2.
 многомерное наблюдение в унифицированной записи представляется вектор-столбцом размерности
многомерное наблюдение в унифицированной записи представляется вектор-столбцом размерности  , где
, где  — число градаций (интервалов группирования, уровней качества или однородных групп) признака причем компонентами этого вектор-столбца могут быть только нули или единицы. При таком подходе к достижению единообразия записи наблюдений многомерного признака смешанной природы мы вынуждены мириться, во-первых, с элементами субъективизма в выборе способов разбиения диапазонов изменения анализируемых количественных признаков на интервалы группирования и, во-вторых, с определенной потерей информативности исходных данных, связанной с переходом от индивидуальных к группированным значениям по количественным переменным.
— число градаций (интервалов группирования, уровней качества или однородных групп) признака причем компонентами этого вектор-столбца могут быть только нули или единицы. При таком подходе к достижению единообразия записи наблюдений многомерного признака смешанной природы мы вынуждены мириться, во-первых, с элементами субъективизма в выборе способов разбиения диапазонов изменения анализируемых количественных признаков на интервалы группирования и, во-вторых, с определенной потерей информативности исходных данных, связанной с переходом от индивидуальных к группированным значениям по количественным переменным.