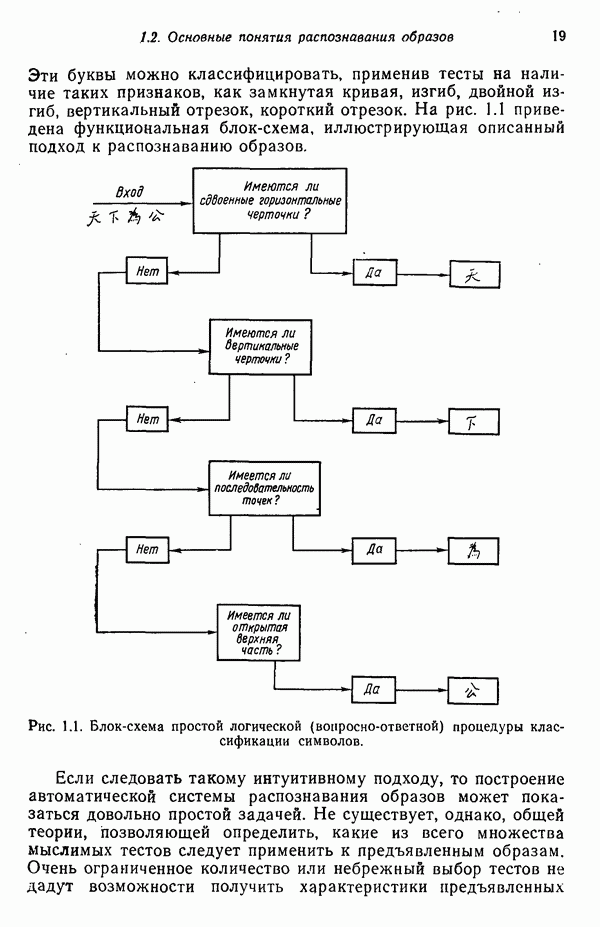
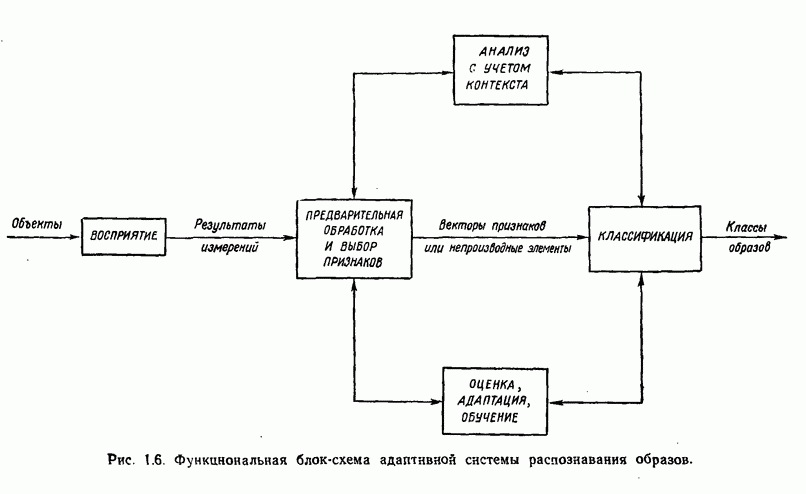
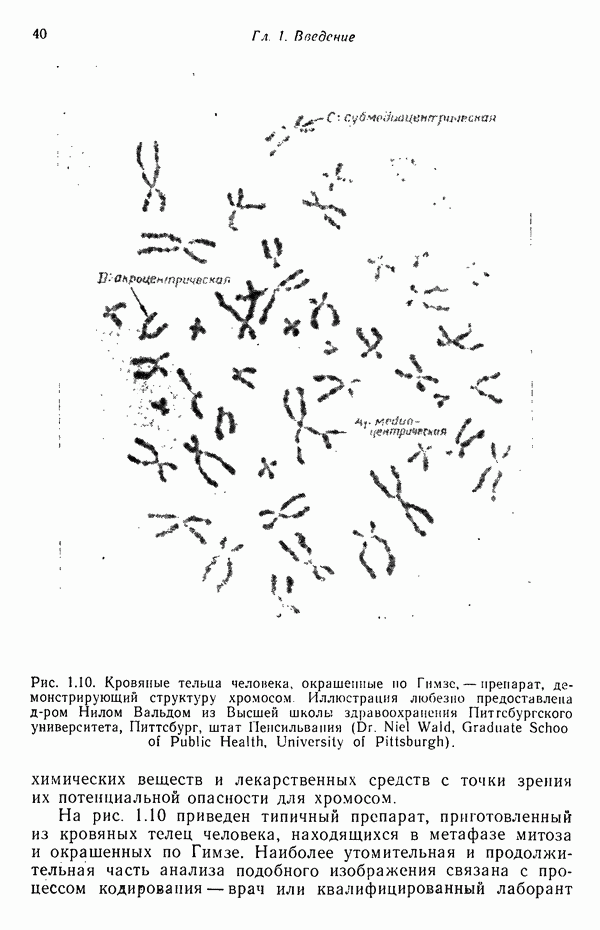
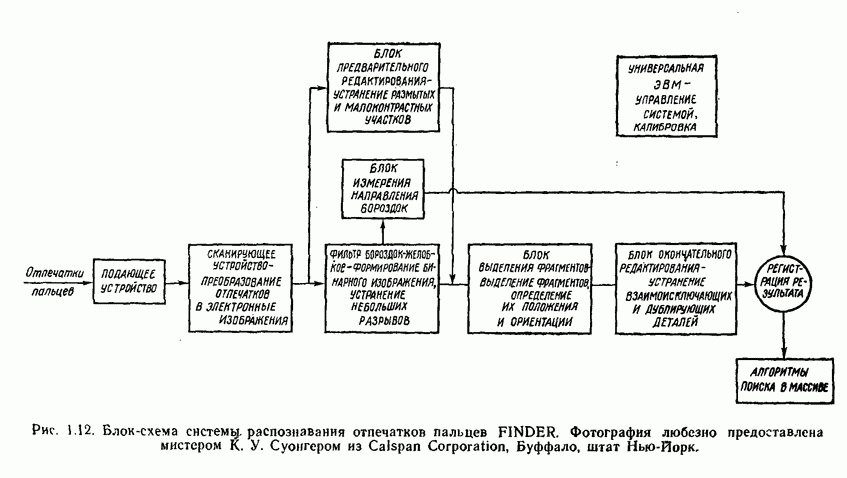
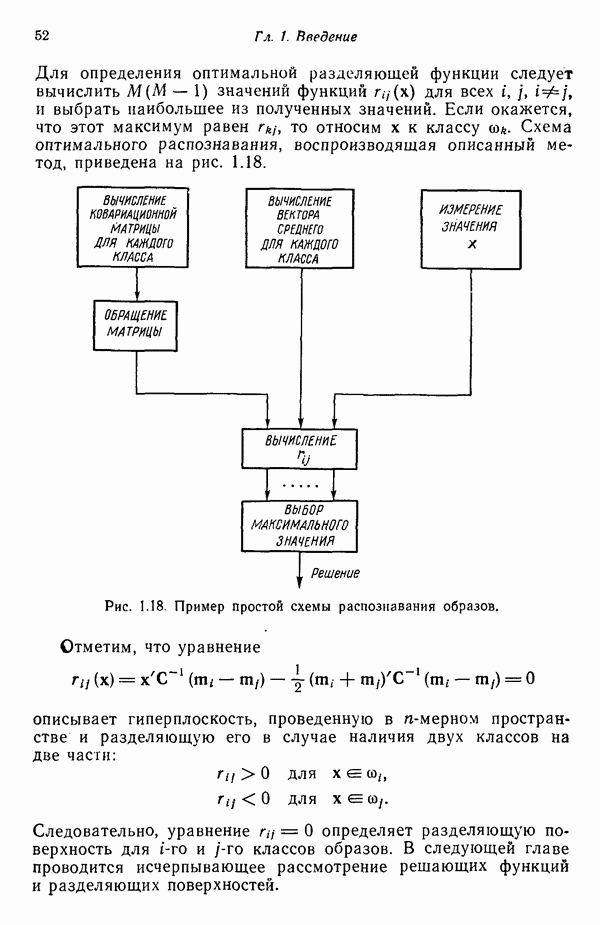
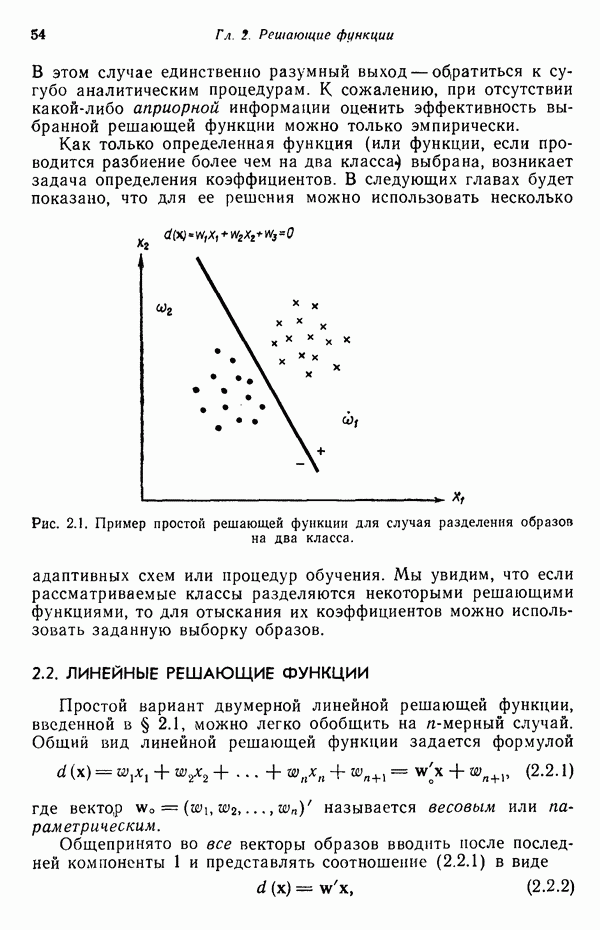
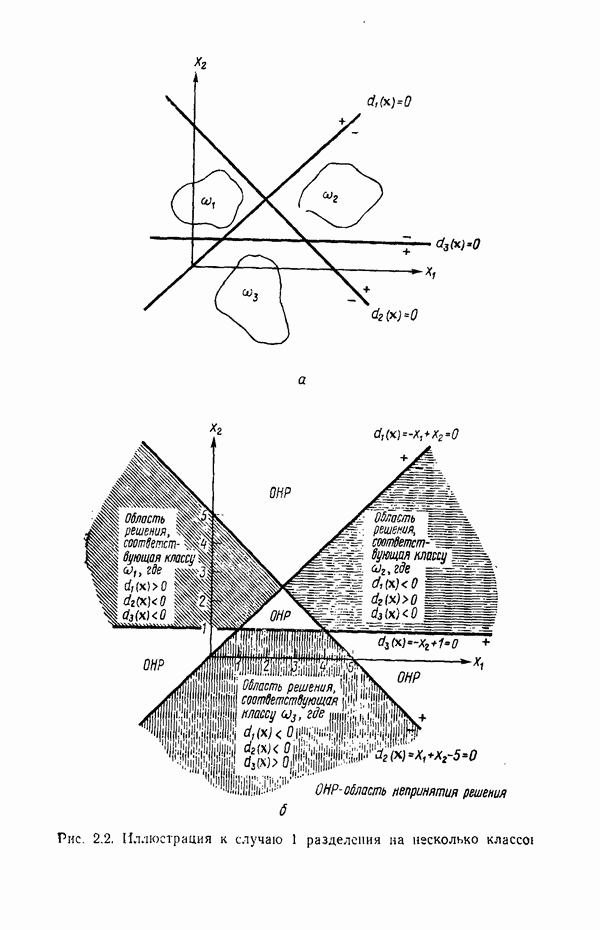
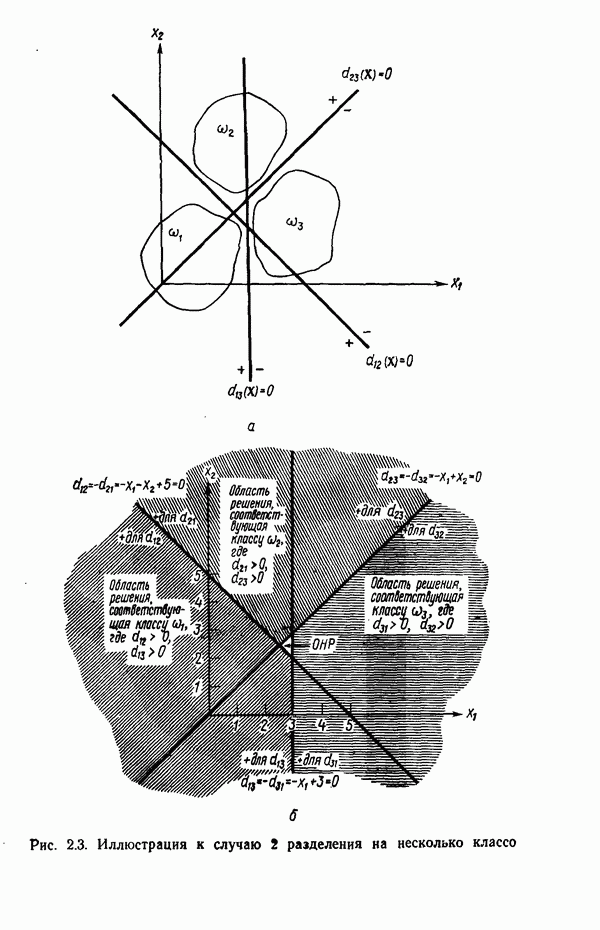
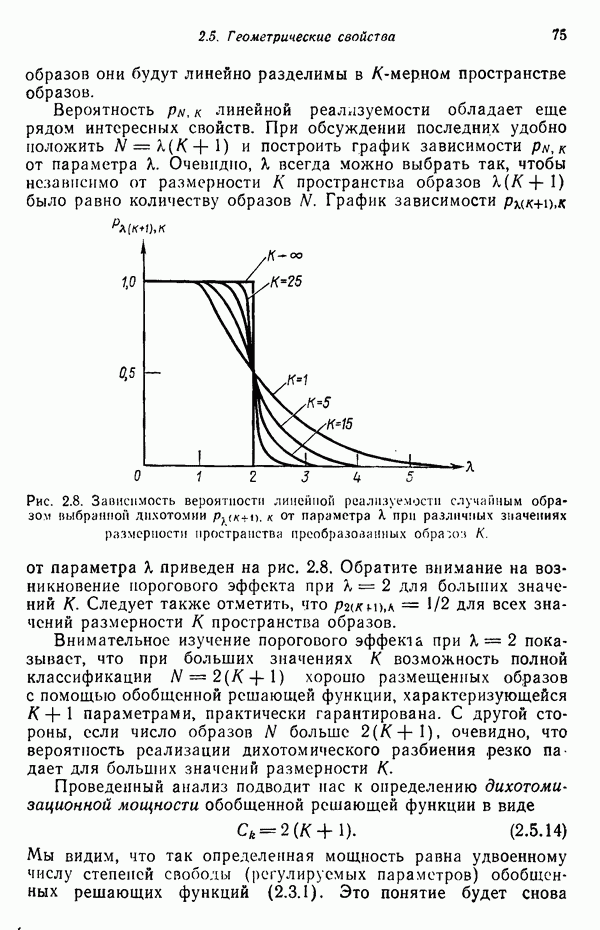
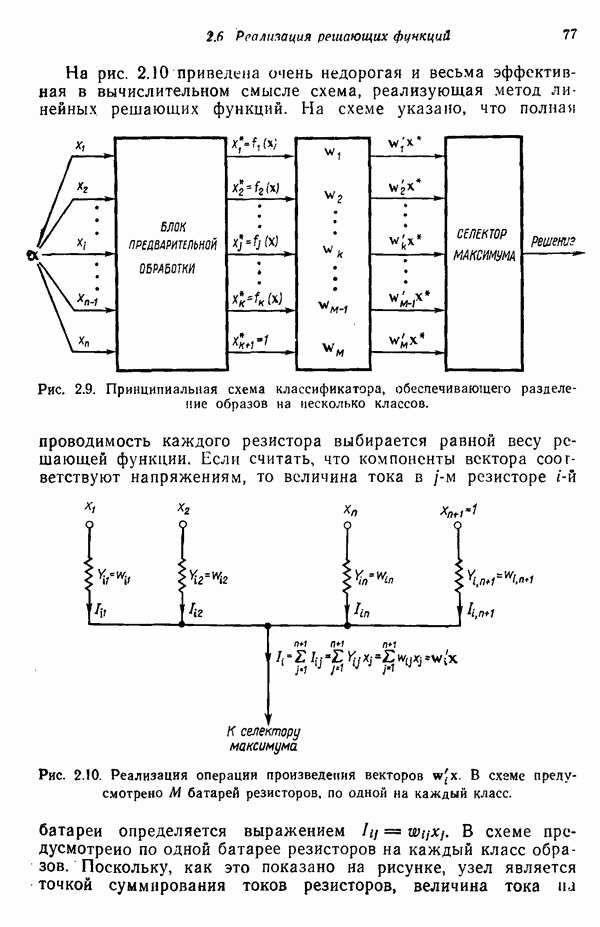
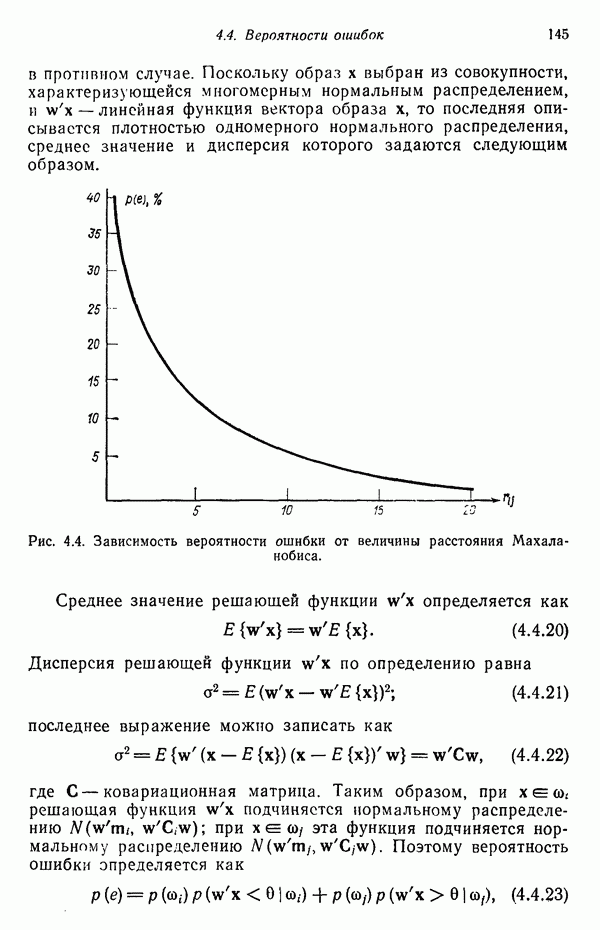
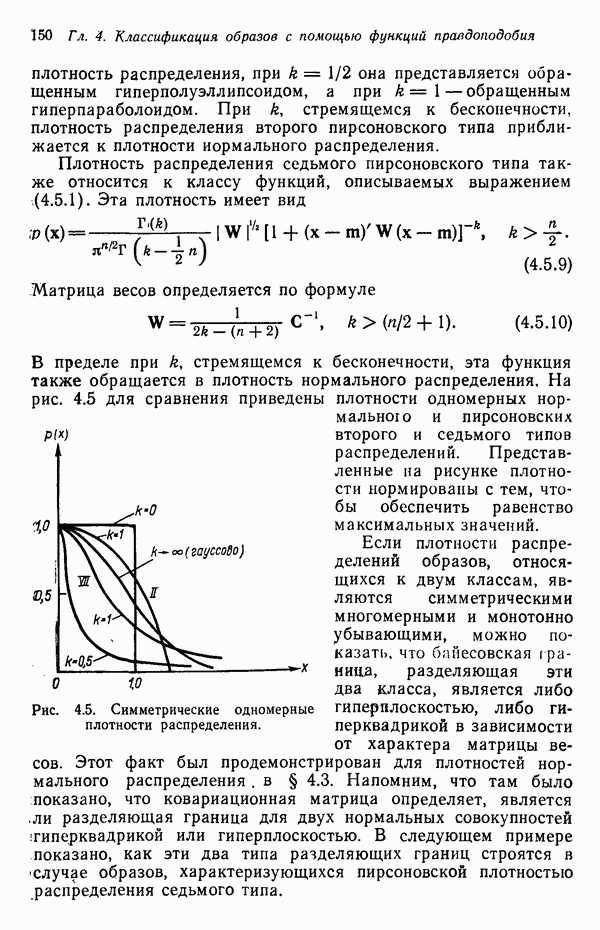
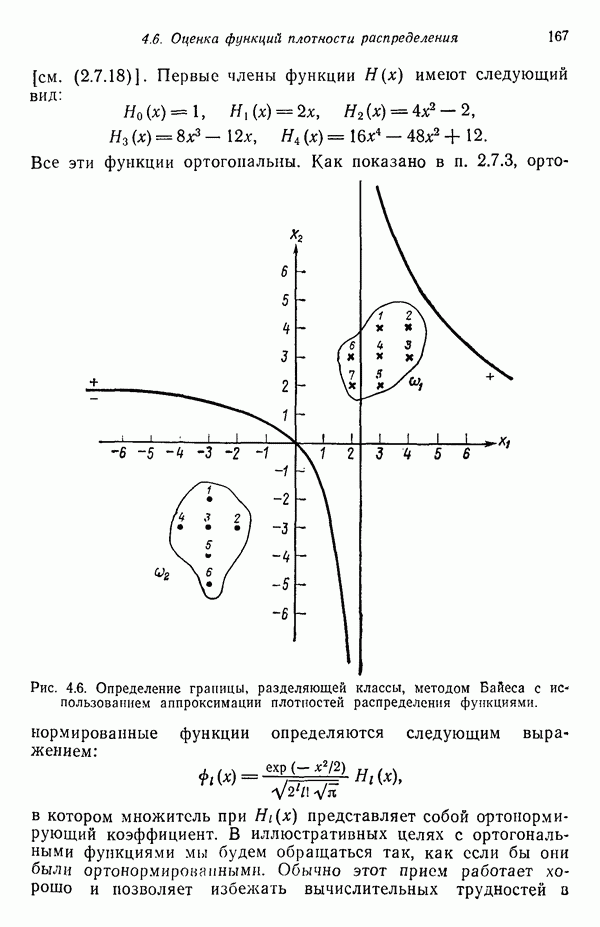
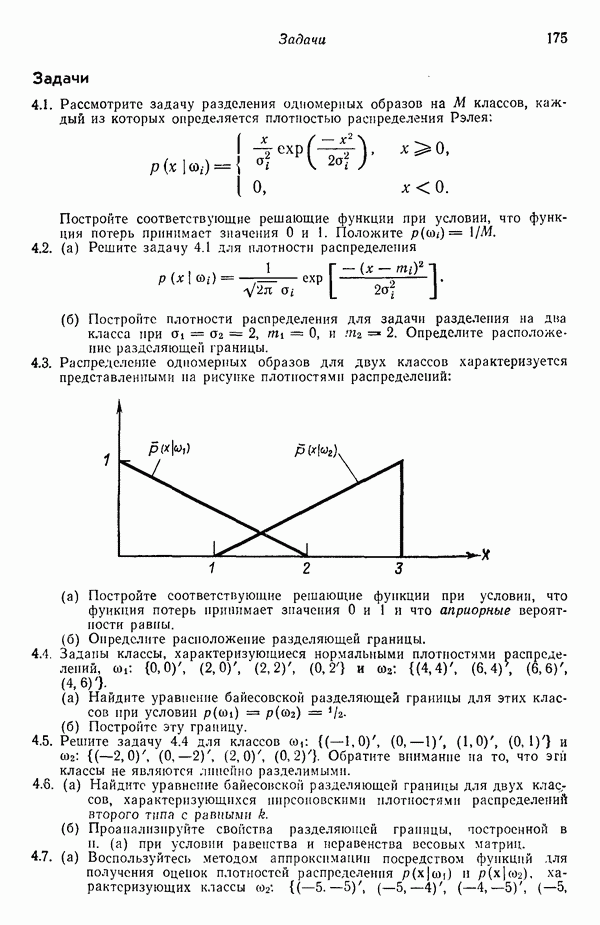
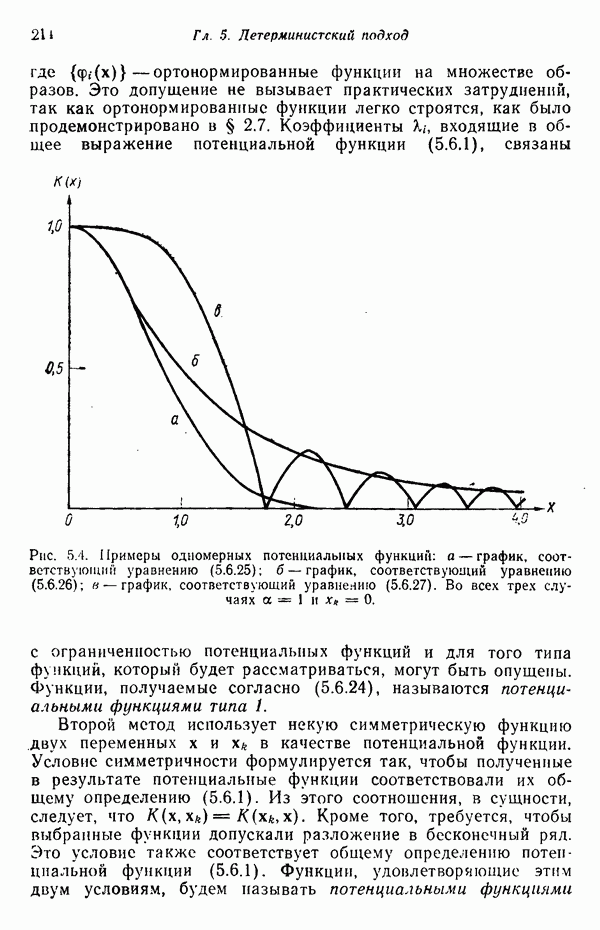
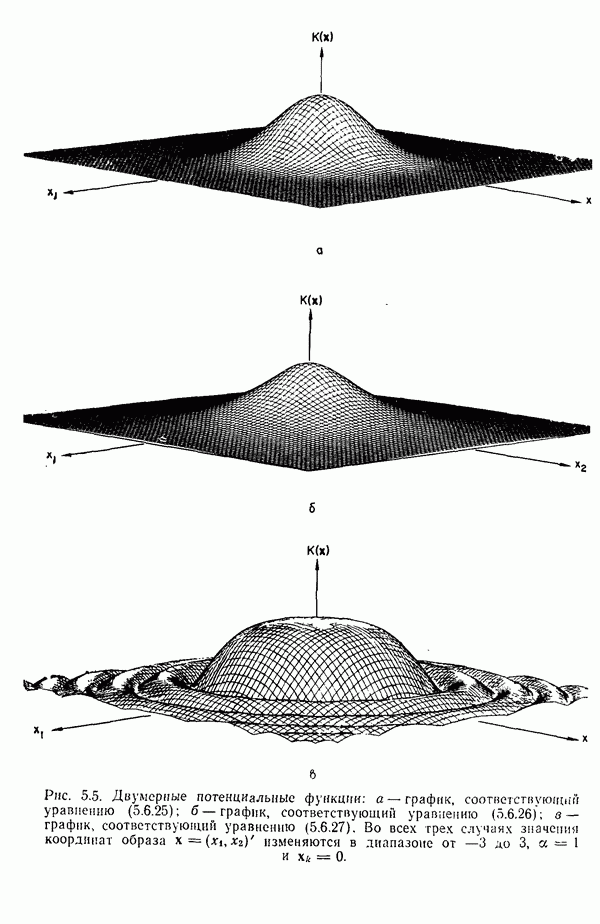
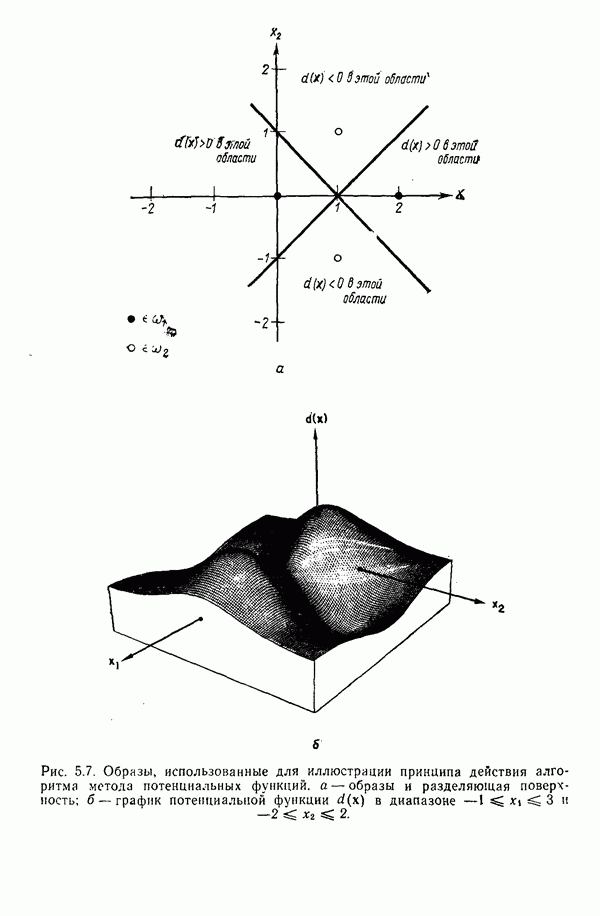
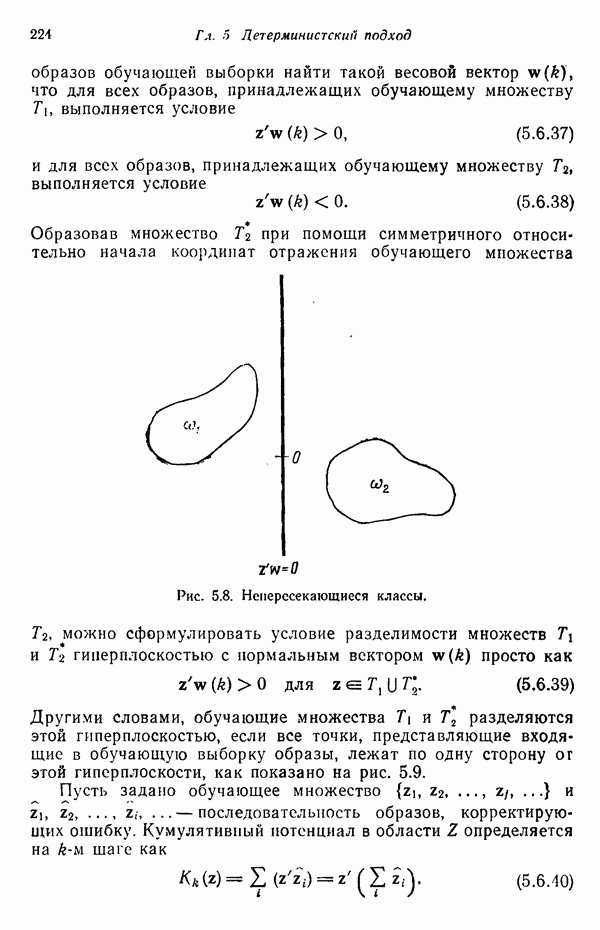
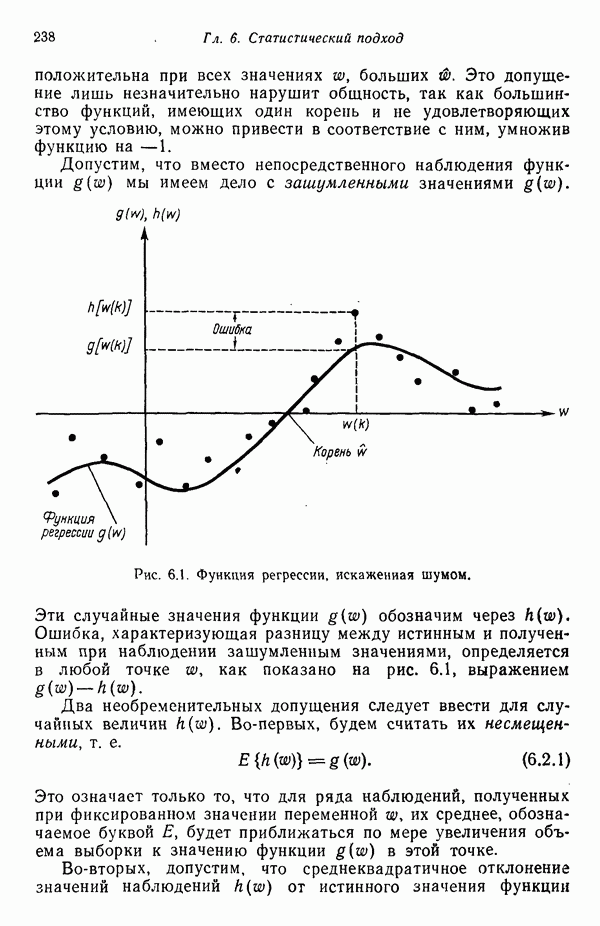
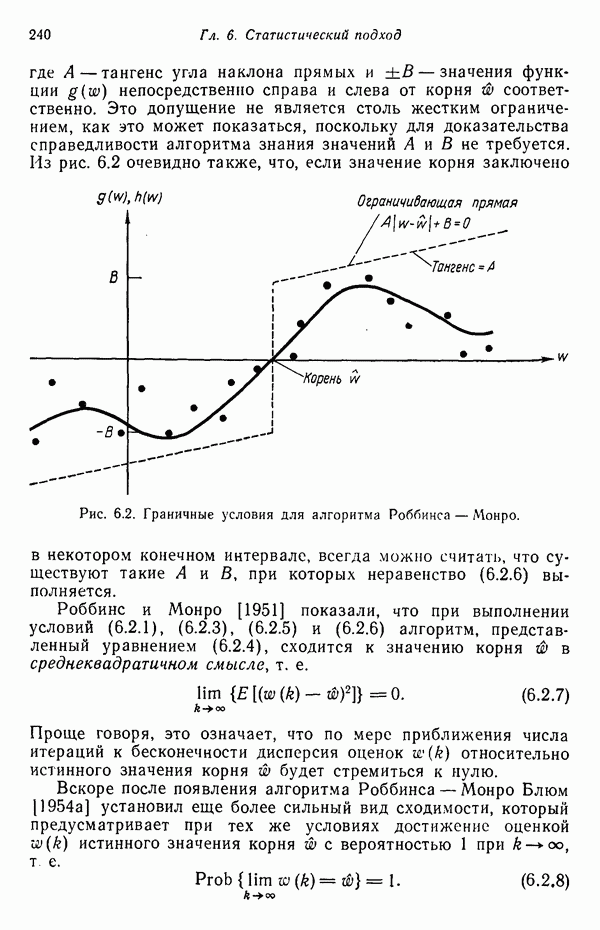
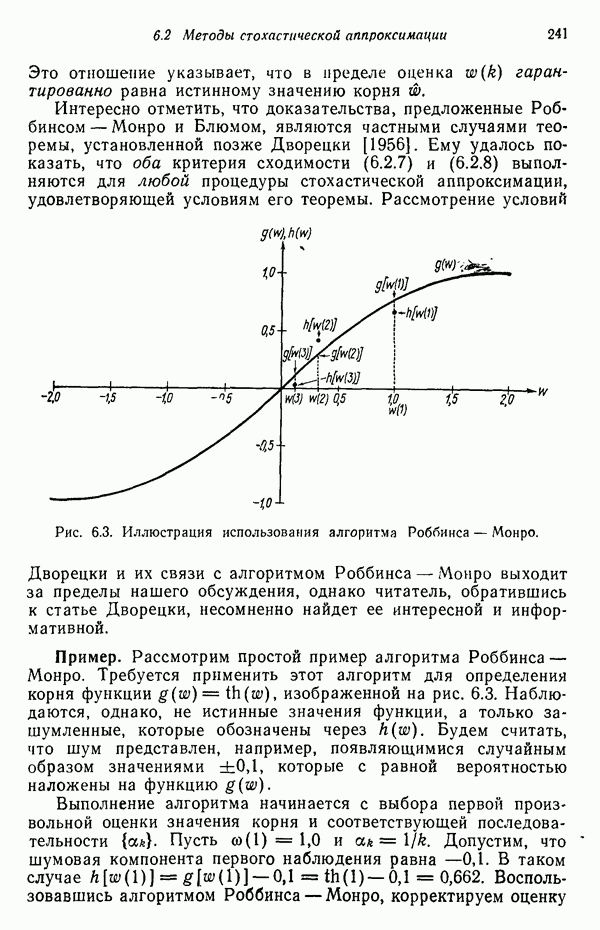
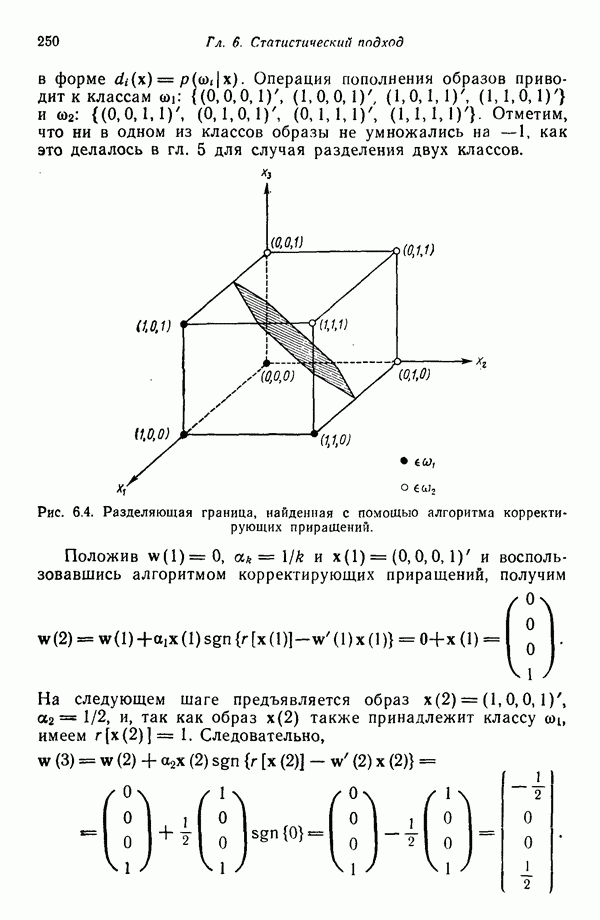
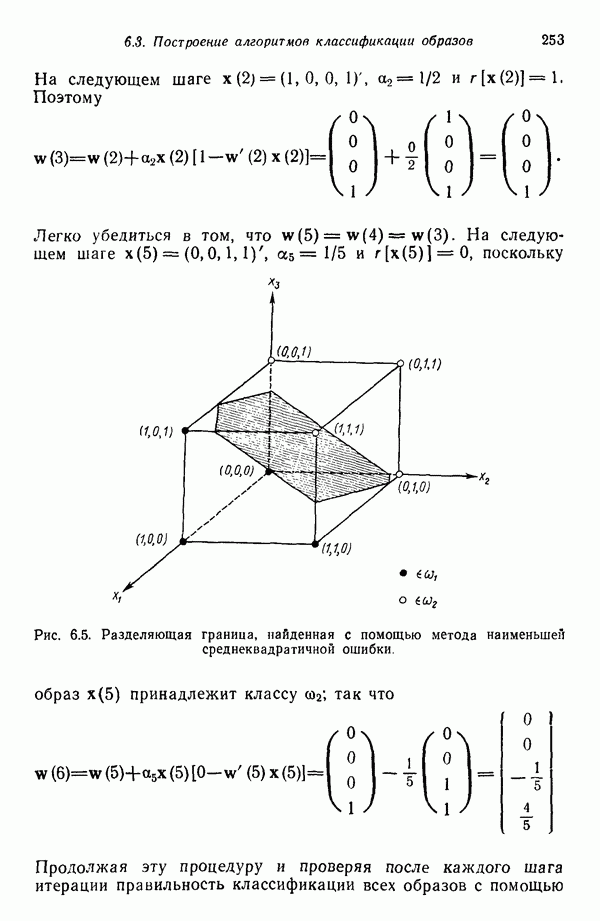
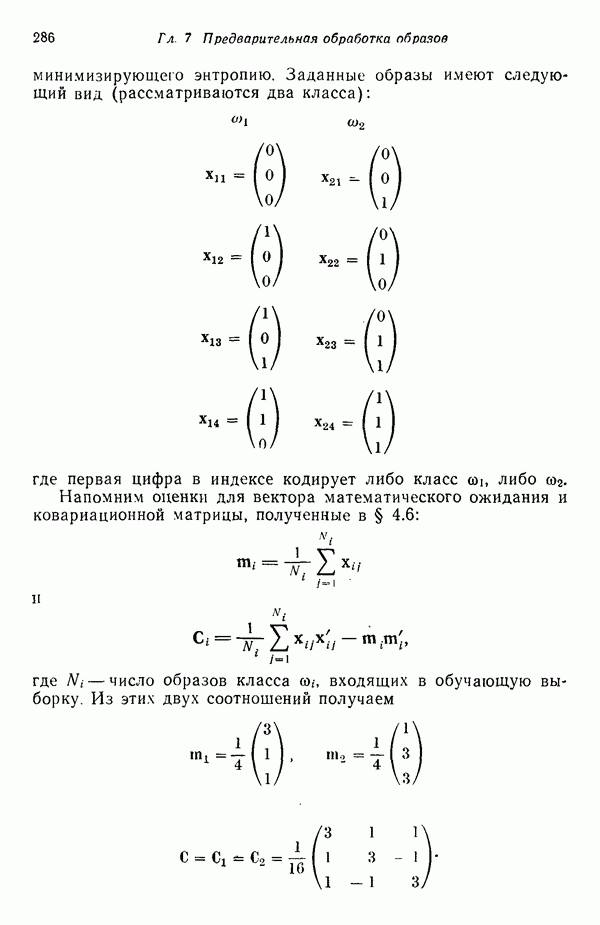
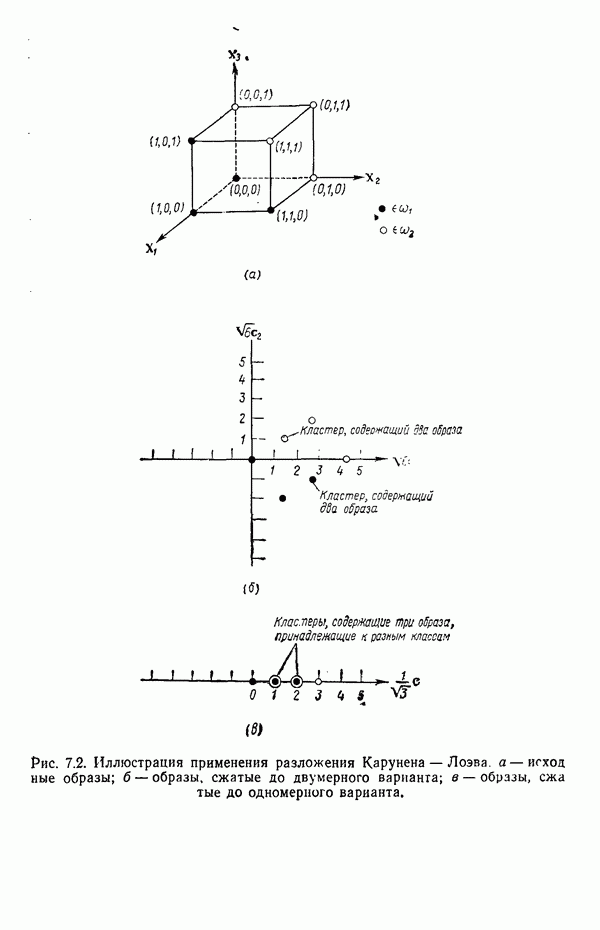
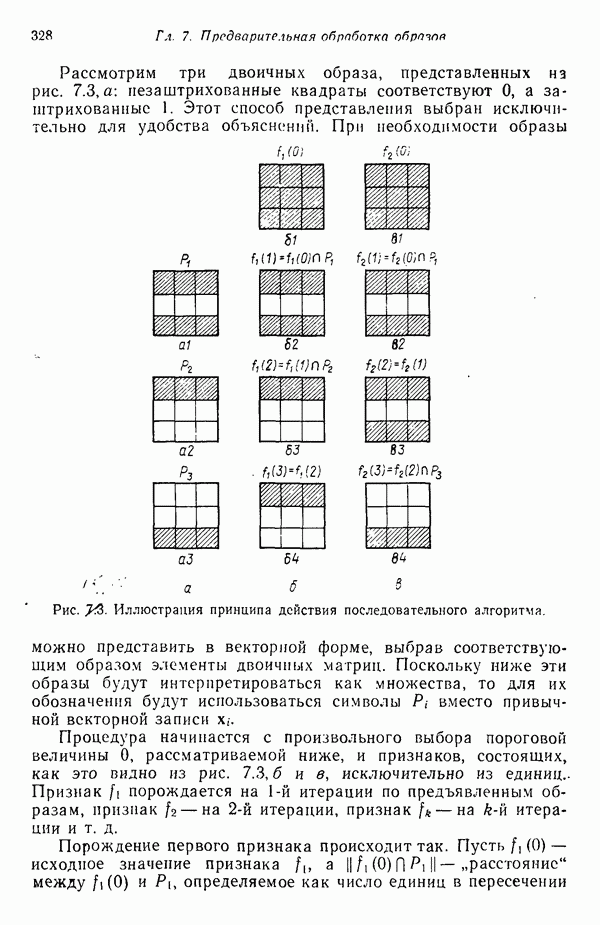
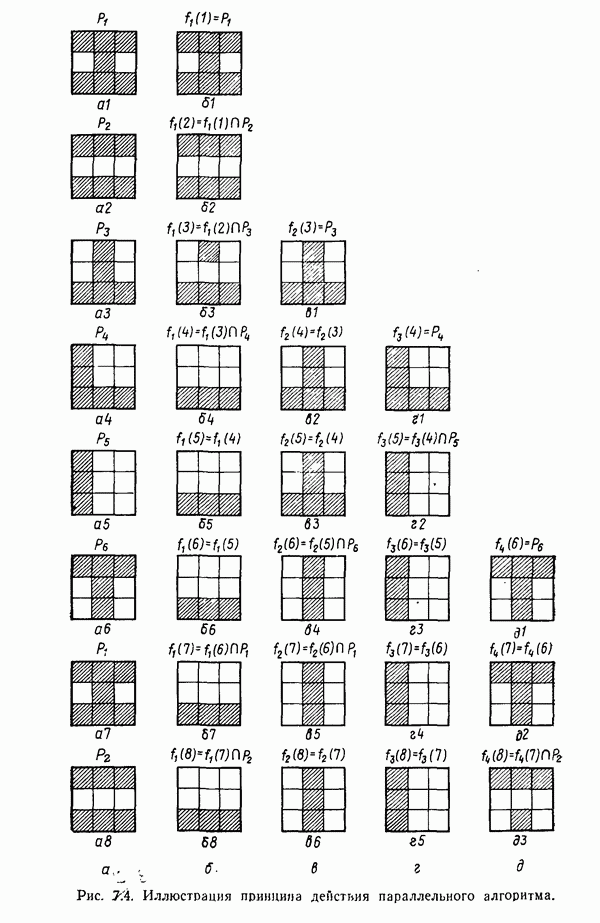
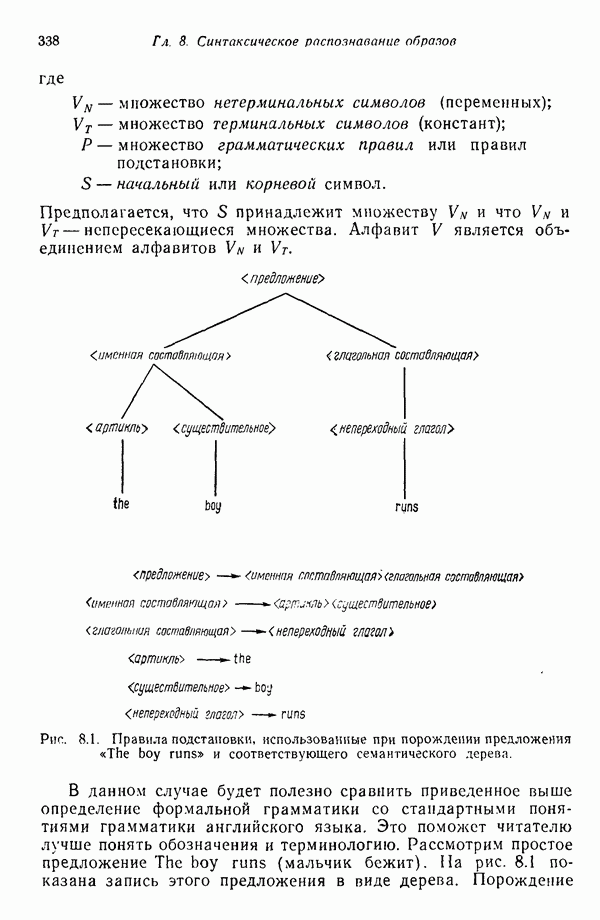
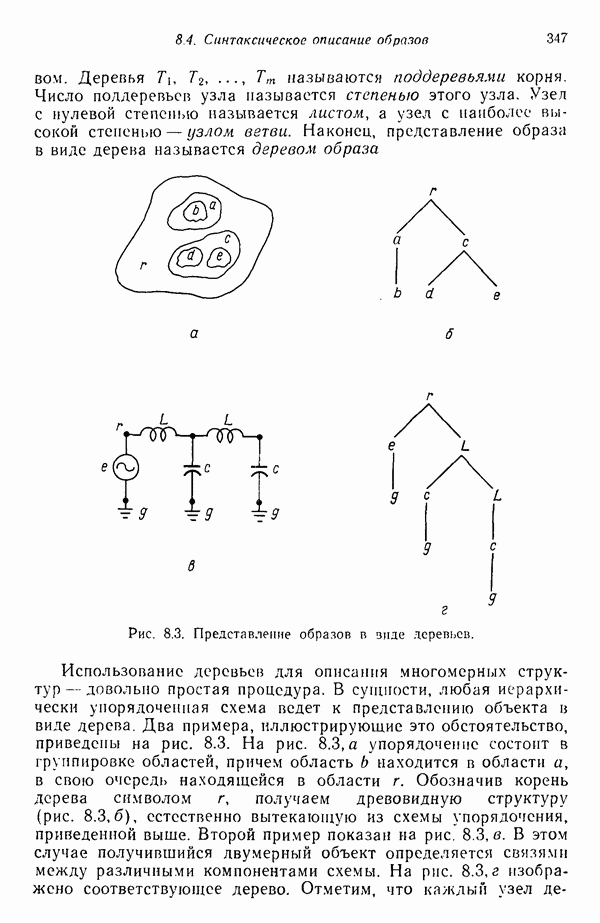
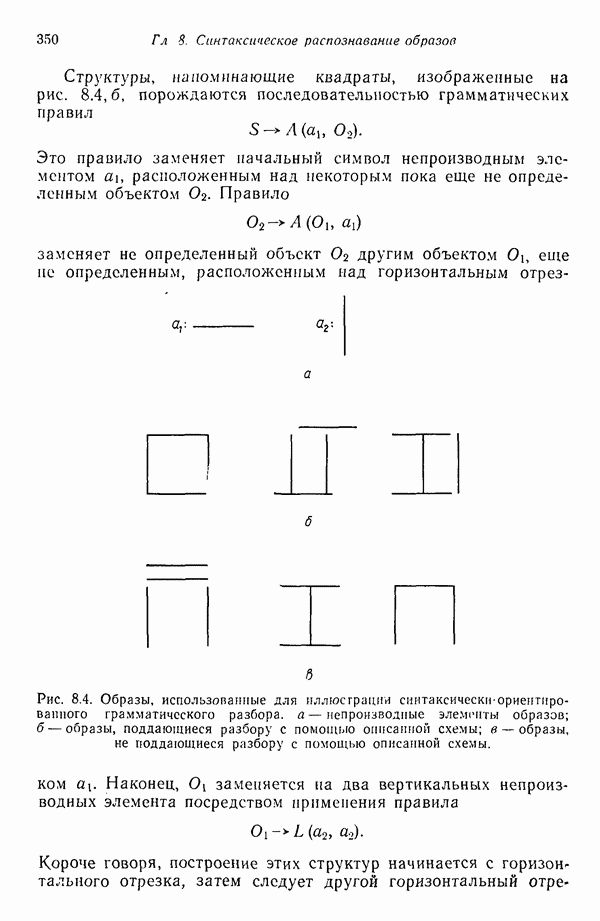
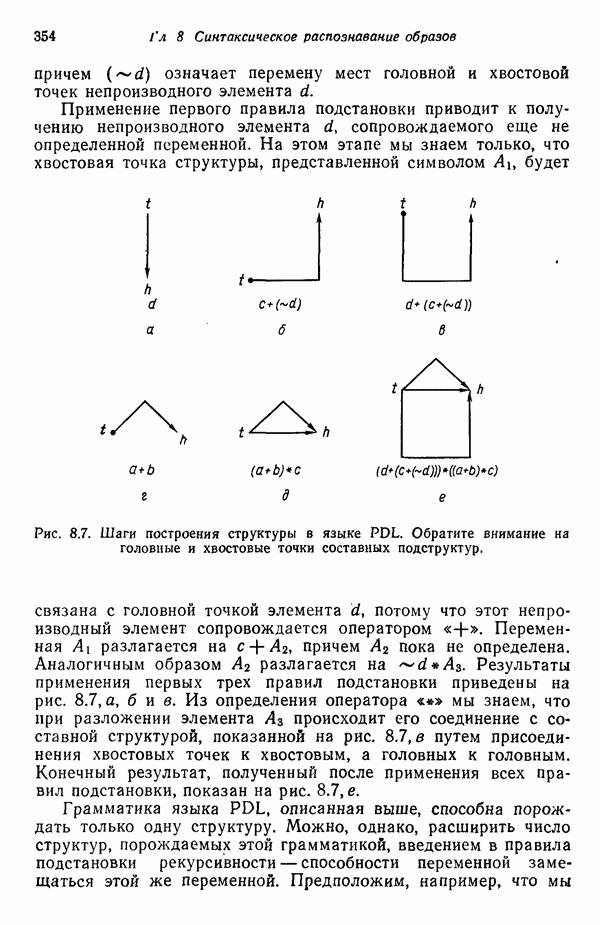
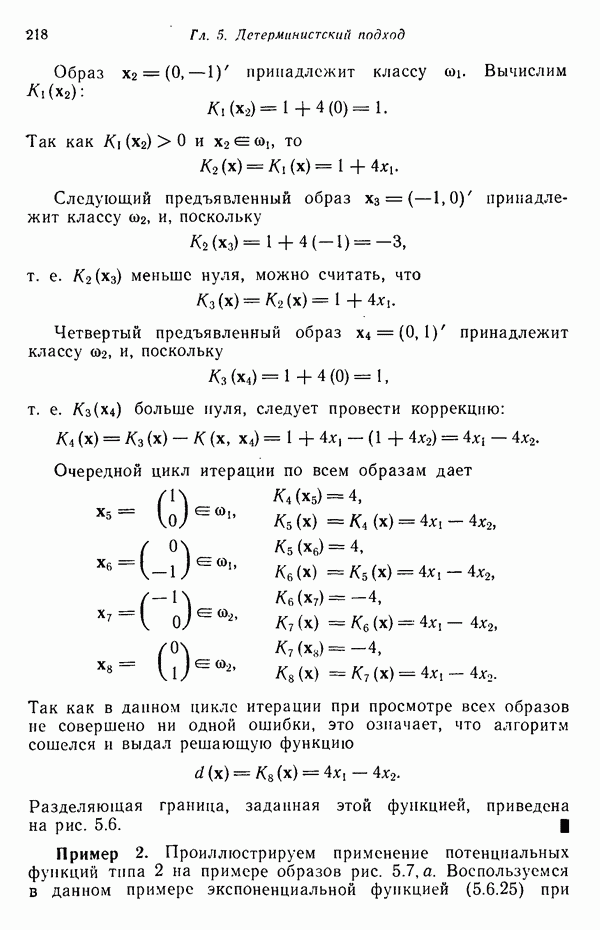3.3. ВЫЯВЛЕНИЕ КЛАСТЕРОВ
Из сказанного в предыдущих разделах следует, что умение находить в заданном наборе данных эталоны или центры кластеров играет главную роль в построении классификаторов образов по принципу минимума расстояния. В данном параграфе будут достаточно подробно рассмотрены методы выявления кластеров. Эти методы являются как бы поперечным разрезом множества типичных подходов к решению задачи выявления кластеров. С самого начала стоит заметить, что выявление кластеров во многих отношениях является «искусством» весьма эмпирическим, так как качество работы определенного алгоритма зависит не только от характера анализируемых данных, но также в значительной степени определяется выбранной мерой подобия образов и методом, используемым для идентификации кластеров в системе данных. Соответствующие понятия, рассматриваемые ниже, обеспечивают также основу для построения систем распознавания без учителя (эта тема обсуждается в § 3.4).
3.3.1. Меры сходства
До сих пор идея кластеризации данных обсуждалась на довольно неформальном уровне. Для того чтобы определить на множестве данных кластер, необходимо в первую очередь ввести меру сходства (подобия), которая может быть положена в основу правила отнесения образов к области, характеризуемой некоторым центром кластера. Ранее рассматривалось евклидово расстояние между образами х и z:

эта характеристика использовалась в качестве меры сходства соответствующих образов: чем меньше расстояние между ними, тем больше сходство. На этом понятии основаны все алгоритмы, рассматриваемые в данной главе. Существуют, однако, и другие состоятельные расстояния, которые в ряде случаев оказываются полезны. Так, например, расстояние Махаланобиса, определяемое для образов  и
и  как
как

является полезной мерой сходства в тех случаях, когда статистические характеристики образов присутствуют в явном виде. В формуле (3.3.2) С — ковариационная матрица совокупности образов,  — вектор средних значений, а
— вектор средних значений, а  представляет образ с переменными характеристиками. Соответствующие методы подробно рассматриваются в следующей главе.
представляет образ с переменными характеристиками. Соответствующие методы подробно рассматриваются в следующей главе.
Меры сходства не исчерпываются расстояниями. В качестве примера можно привести неметрическую функцию сходства

представляющую собой косинус угла, образованного векторами  и
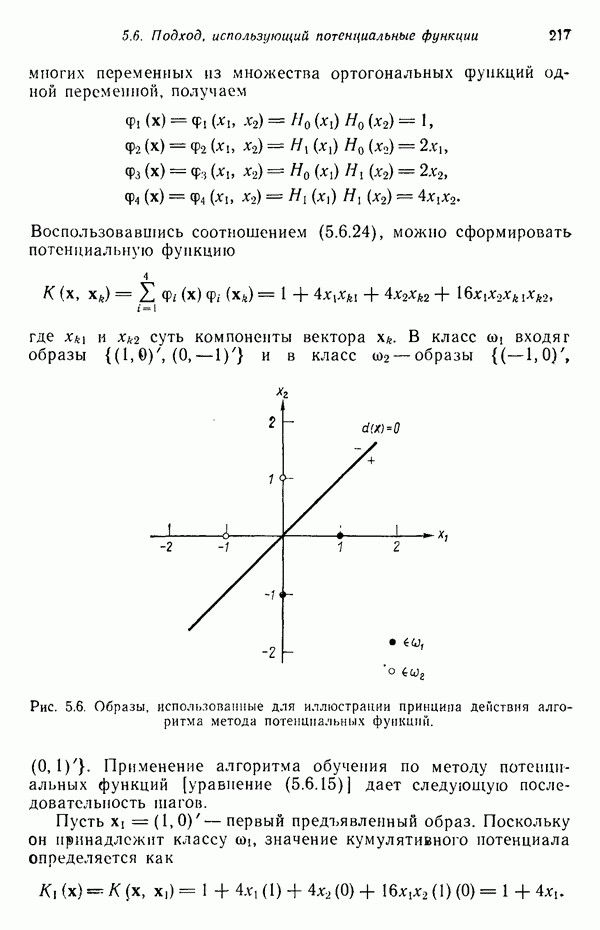
и  , и достигающую максимума, когда их направления совпадают. Этой мерой сходства удобно пользоваться в тех случаях, когда кластеры обнаруживают тенденцию располагаться вдоль главных осей, как это показано на рис. 3.7. Этот рисунок, в частности, показывает, что образ
, и достигающую максимума, когда их направления совпадают. Этой мерой сходства удобно пользоваться в тех случаях, когда кластеры обнаруживают тенденцию располагаться вдоль главных осей, как это показано на рис. 3.7. Этот рисунок, в частности, показывает, что образ  обладает большим сходством с образом
обладает большим сходством с образом  чем образ
чем образ  поскольку значение функции
поскольку значение функции  больше значения
больше значения  . Следует, однако, отметить, что использование данной меры сходства связано определенными ограничениями, например такими, как достаточное отстояние кластеров друг от друга и от начала координат.
. Следует, однако, отметить, что использование данной меры сходства связано определенными ограничениями, например такими, как достаточное отстояние кластеров друг от друга и от начала координат.
Когда рассматриваются двоичные образы и их элементы принимают значения из множества  функции сходства (3.3.3) можно дать интересную негеометрическую интерпретацию. Если
функции сходства (3.3.3) можно дать интересную негеометрическую интерпретацию. Если
 считается, что двоичный образ
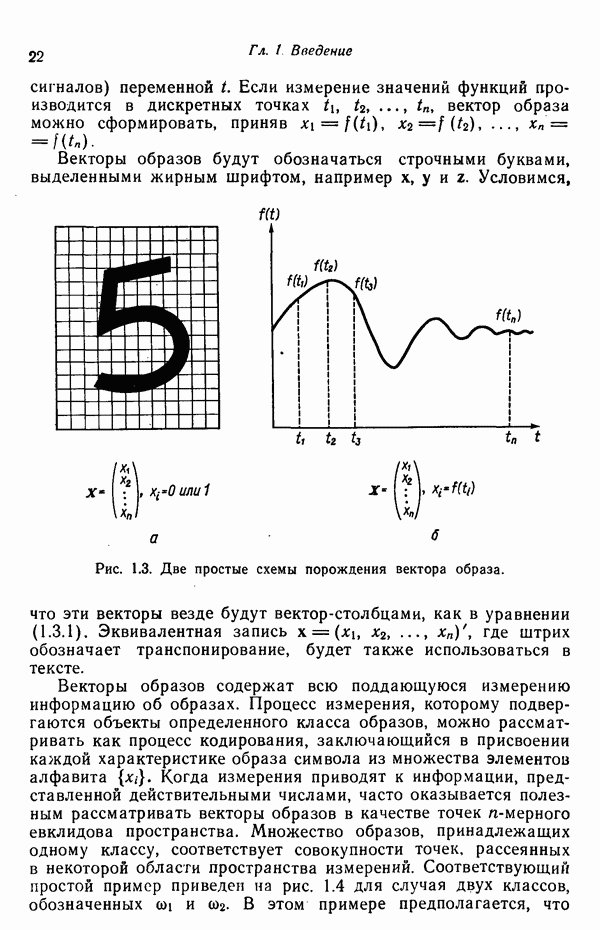
считается, что двоичный образ  обладает
обладает  признаком. В таком случае член
признаком. В таком случае член  в (3.3.3) просто характеризует число общих для образов
в (3.3.3) просто характеризует число общих для образов  признаков, а
признаков, а  среднее геометрическое числа признаков, которыми обладает образ
среднее геометрическое числа признаков, которыми обладает образ  и числа признаков, которыми обладает образ z. Понятно, что функция
и числа признаков, которыми обладает образ z. Понятно, что функция  есть мера наличия общих признаков у двоичных векторов х и z.
есть мера наличия общих признаков у двоичных векторов х и z.

Рис. 3.7. Иллюстрация понятия меры сходства.
Двоичным вариантом формулы (3.3.3), который нашел широкое распространение в информационном поиске, нозологии (классификации болезней) и таксономии (классификации видов животных и растений), является так называемая мера Танимато, определяемая как

Предоставляем читателю в качестве упражнения дать интерпретацию этой меры.
Рассмотренные меры сходства ни в коем случае не следует считать единственными — это просто типичные меры. Как уже указывалось, дальнейшее обсуждение будет проходить на основе
использования евклидовой меры подобия (3.3.1) в связи с простотой ее интерпретации в рамках известной концепции близости. Кроме того, эта мера совместима с методами классификации образов, обсуждавшимися в § 3.2.