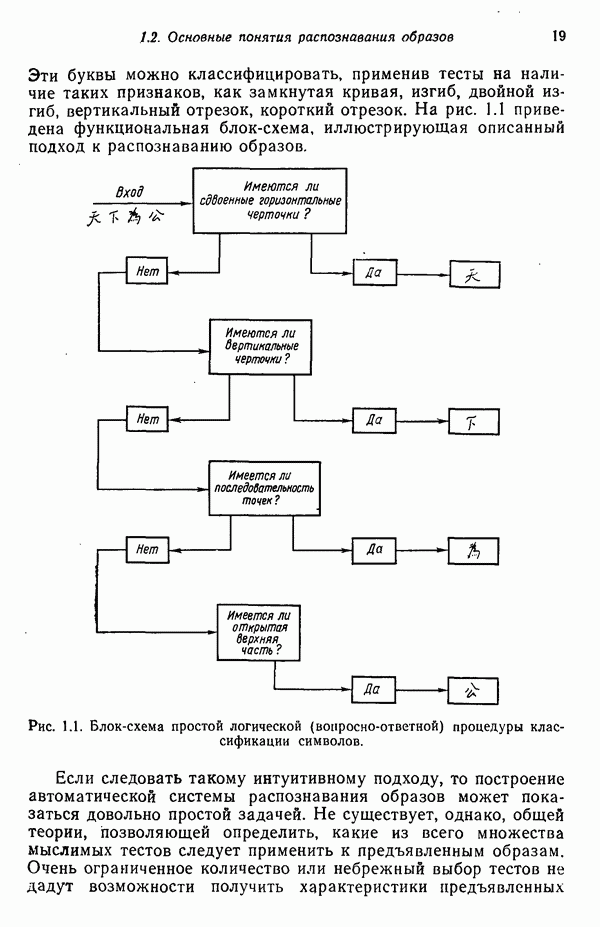
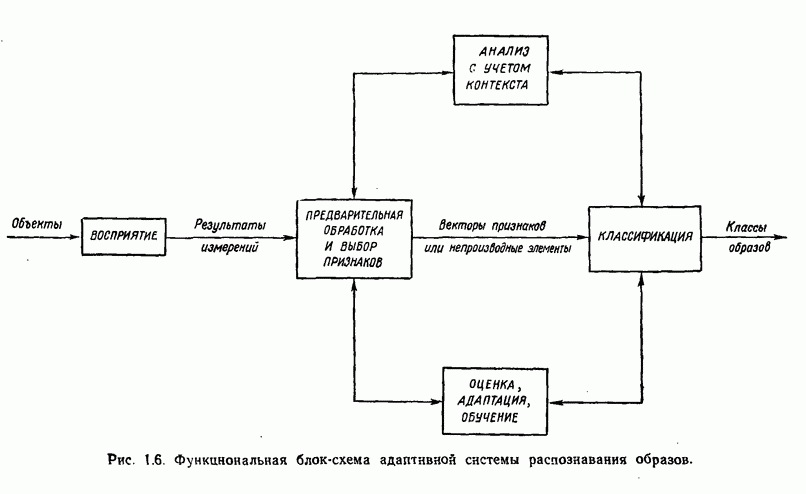
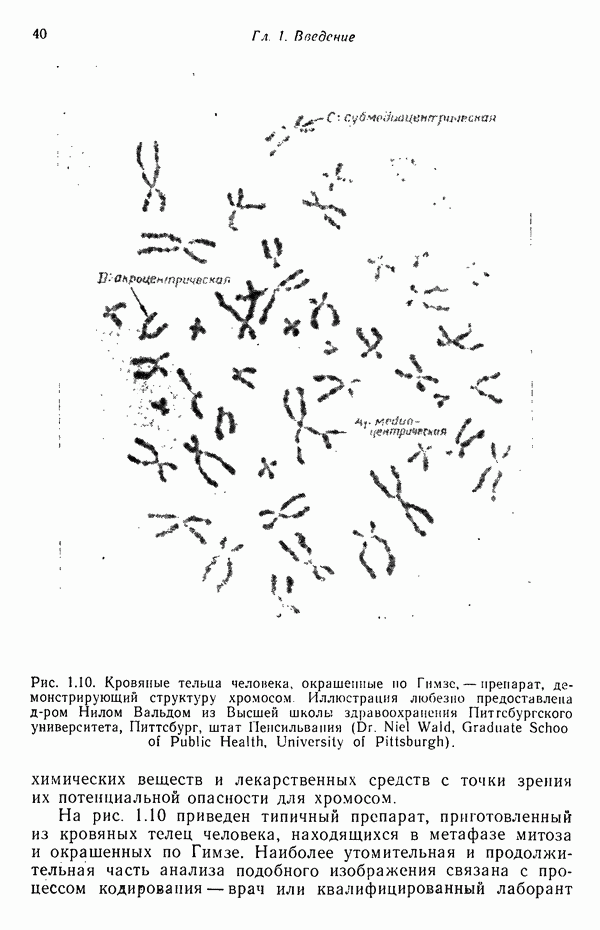
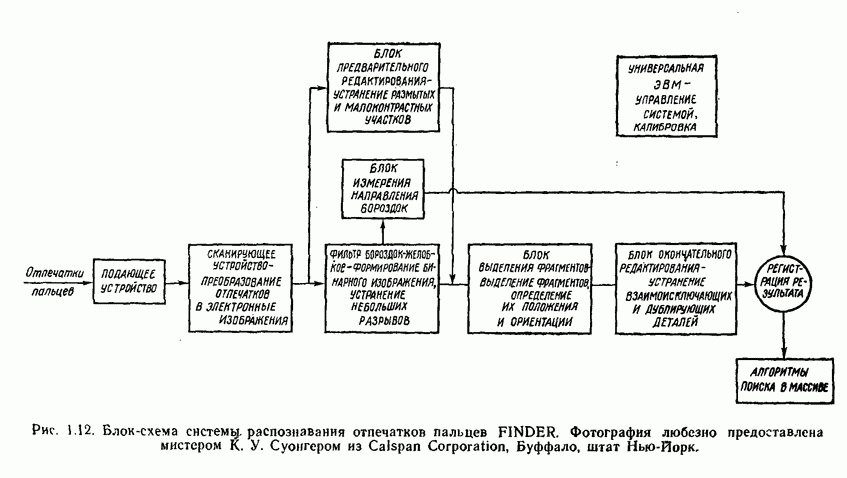
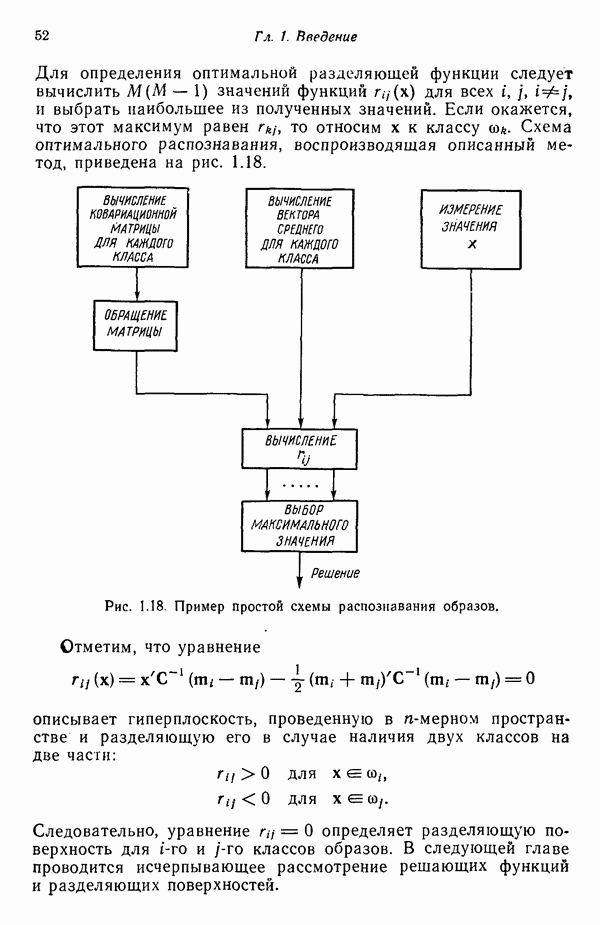
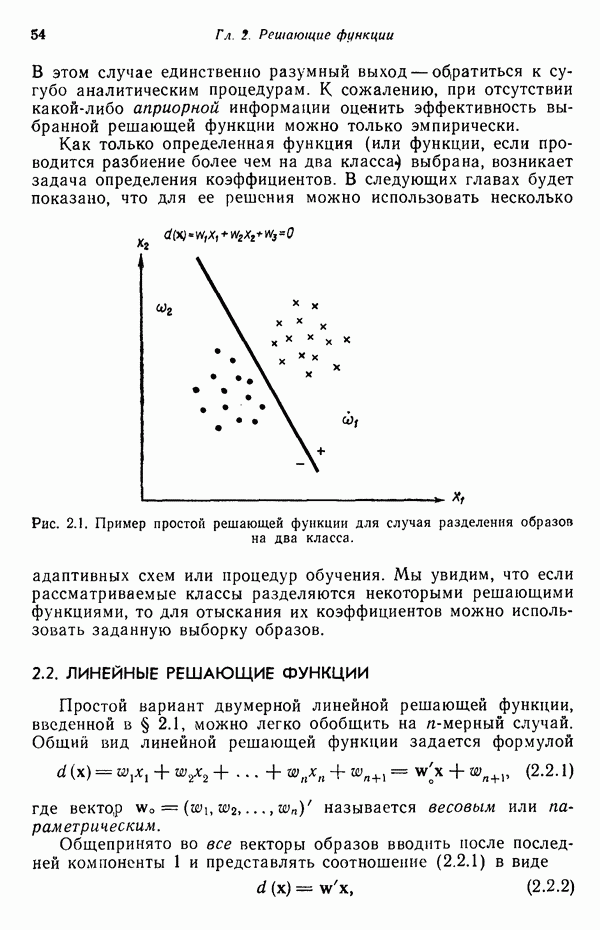
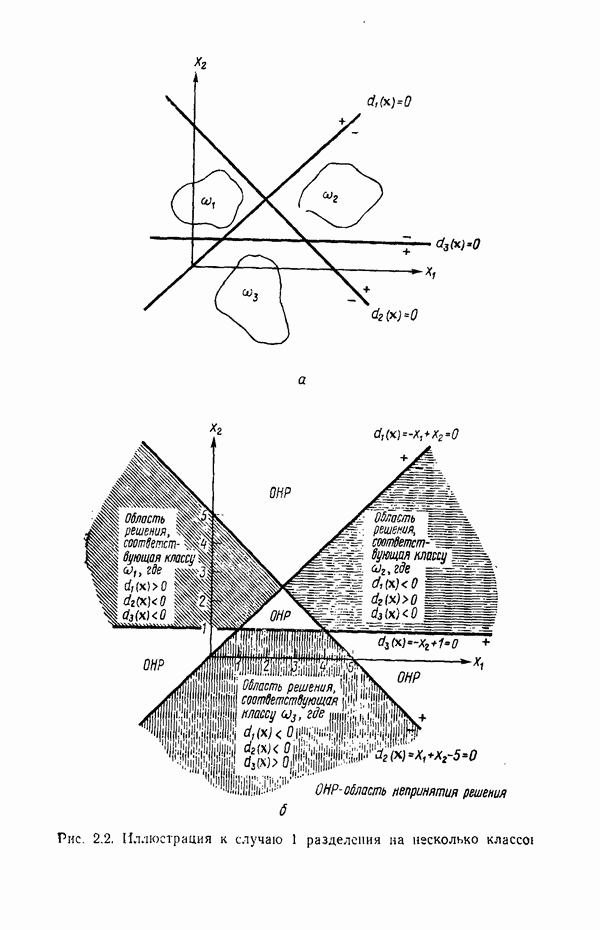
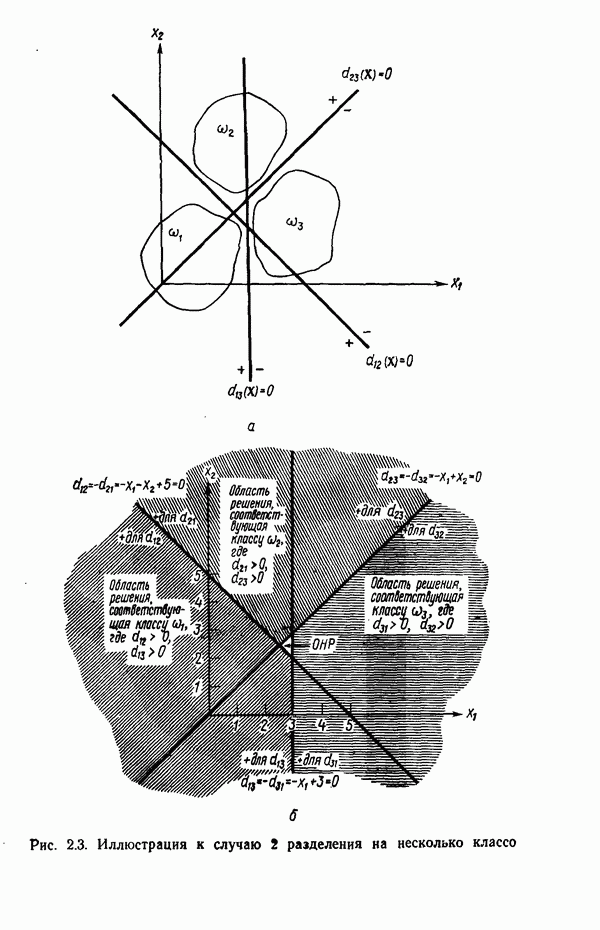
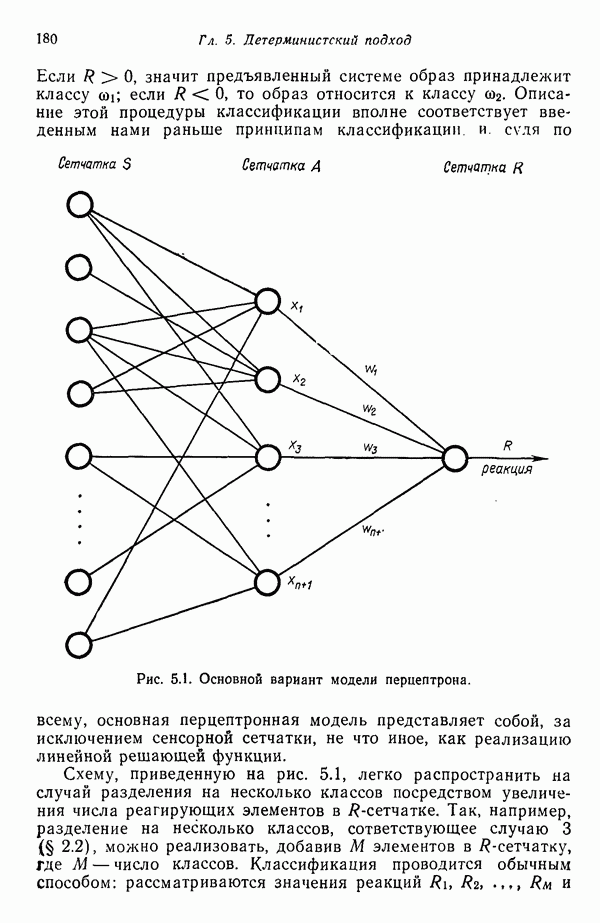
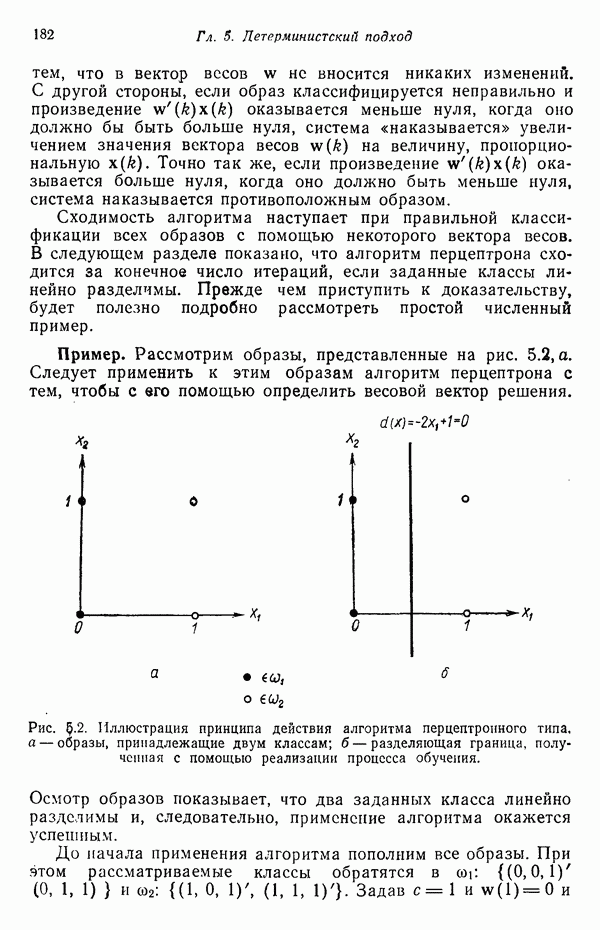
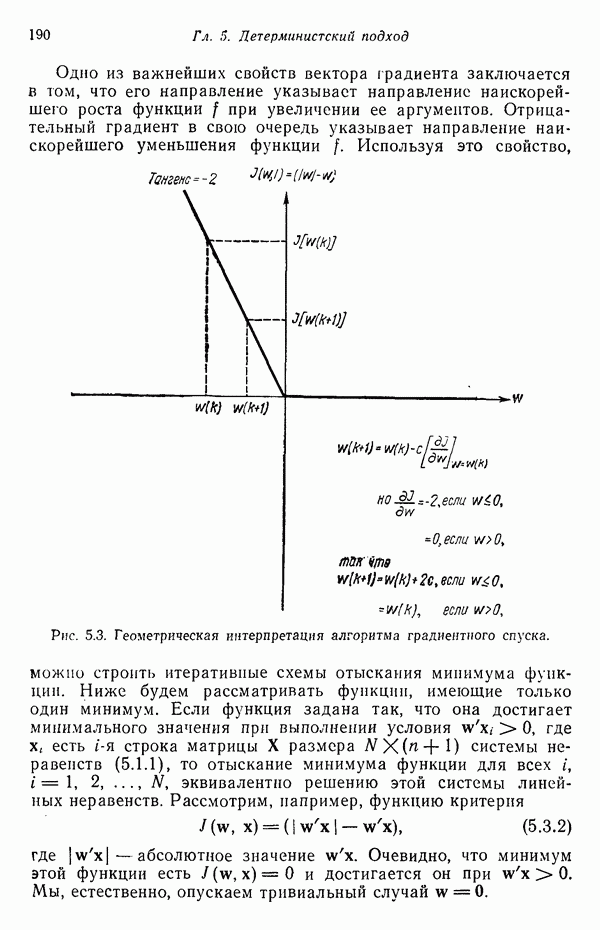
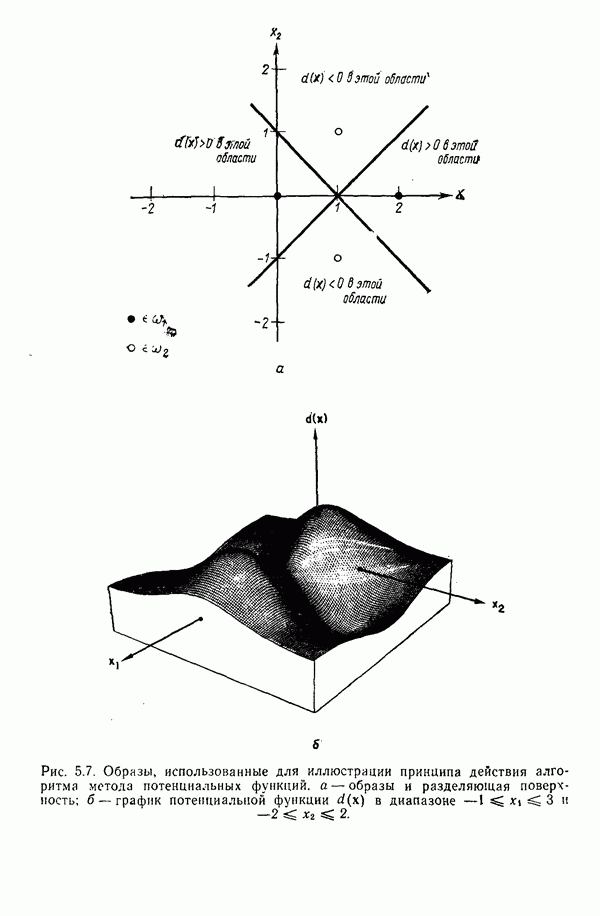
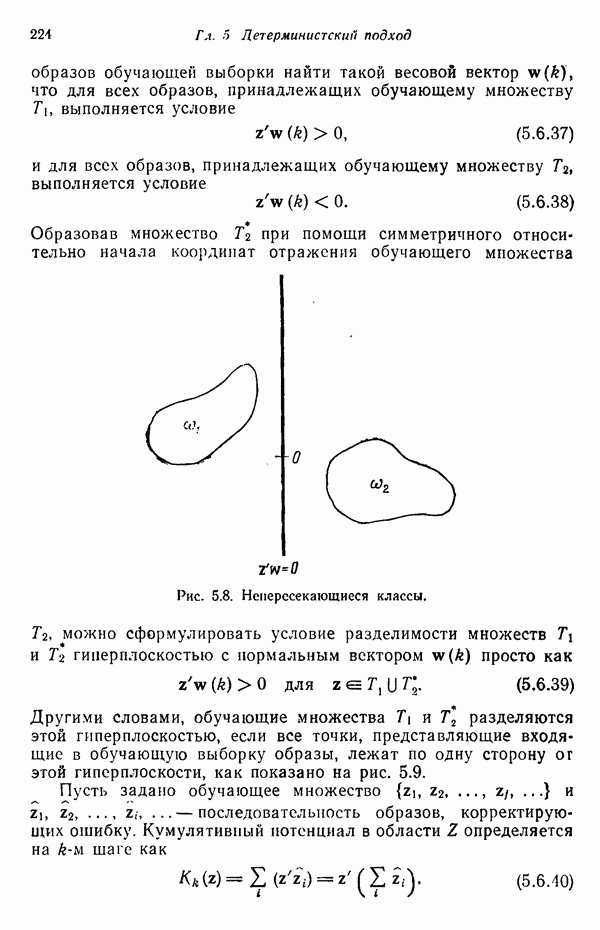
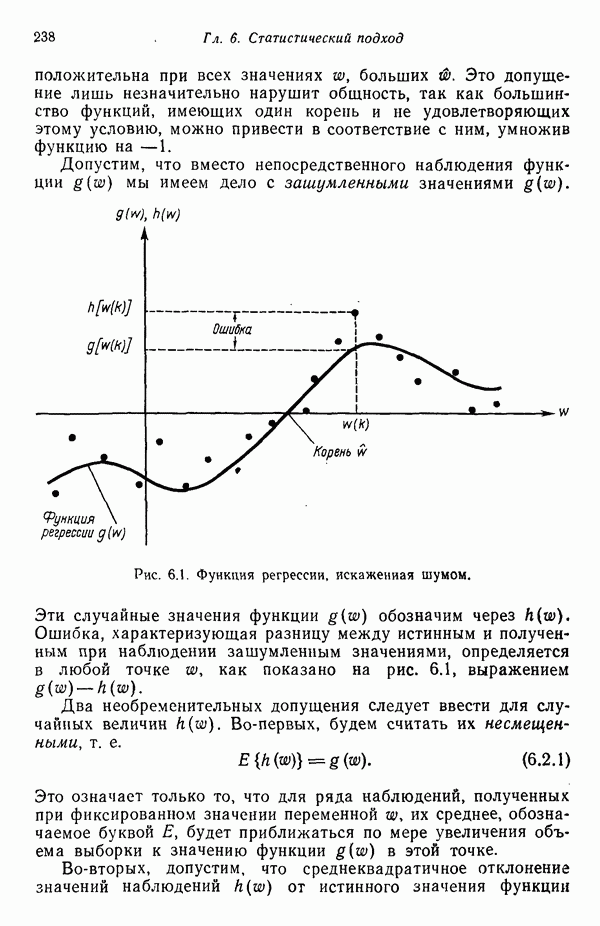
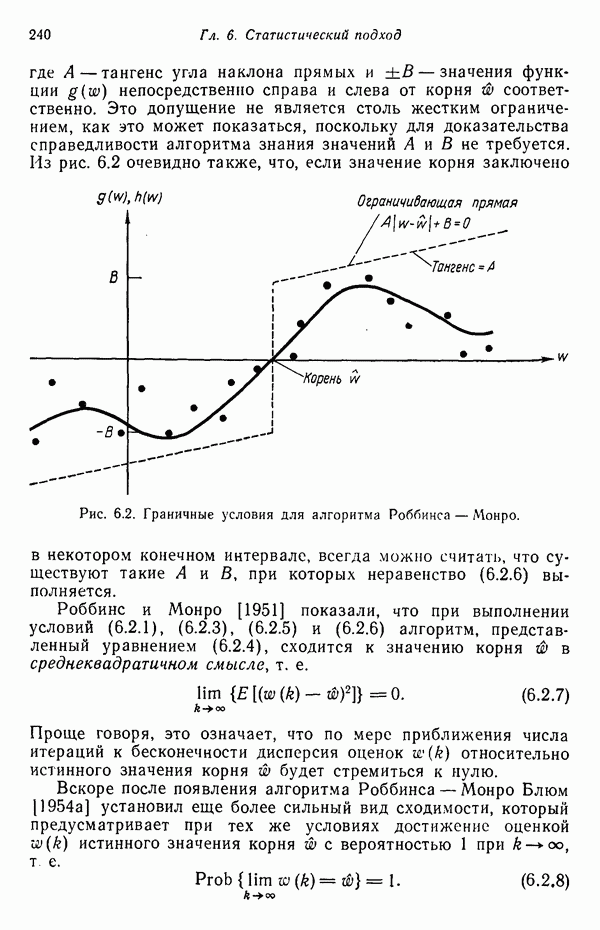
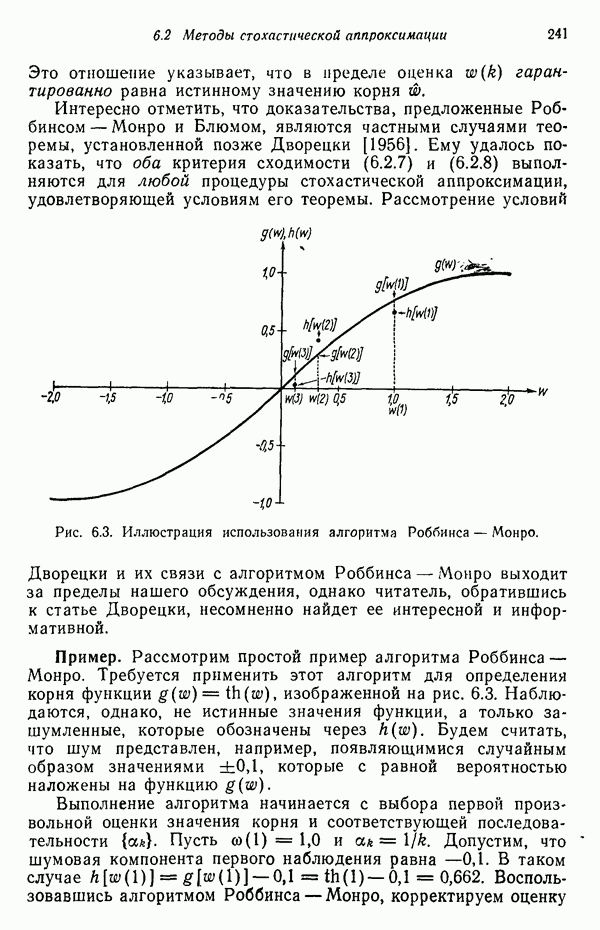
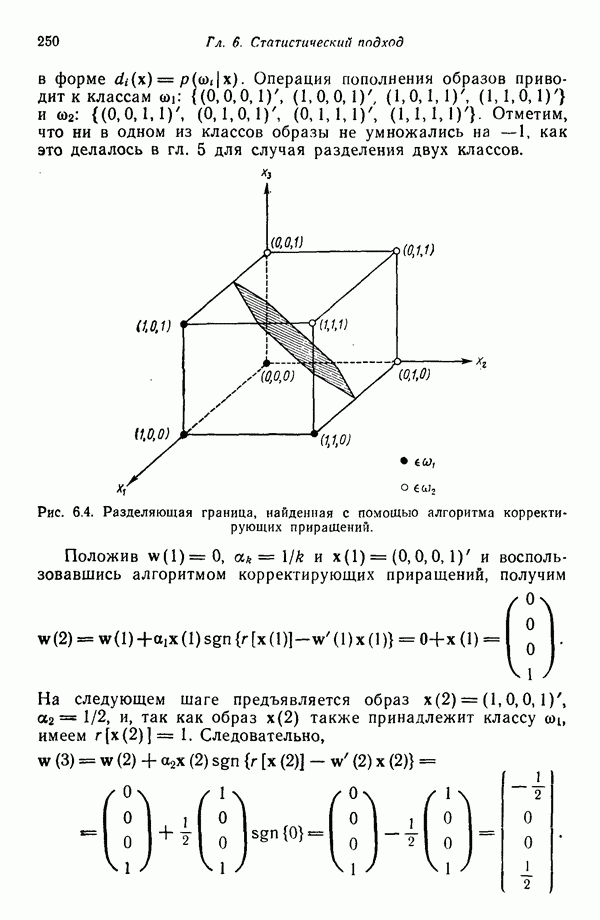
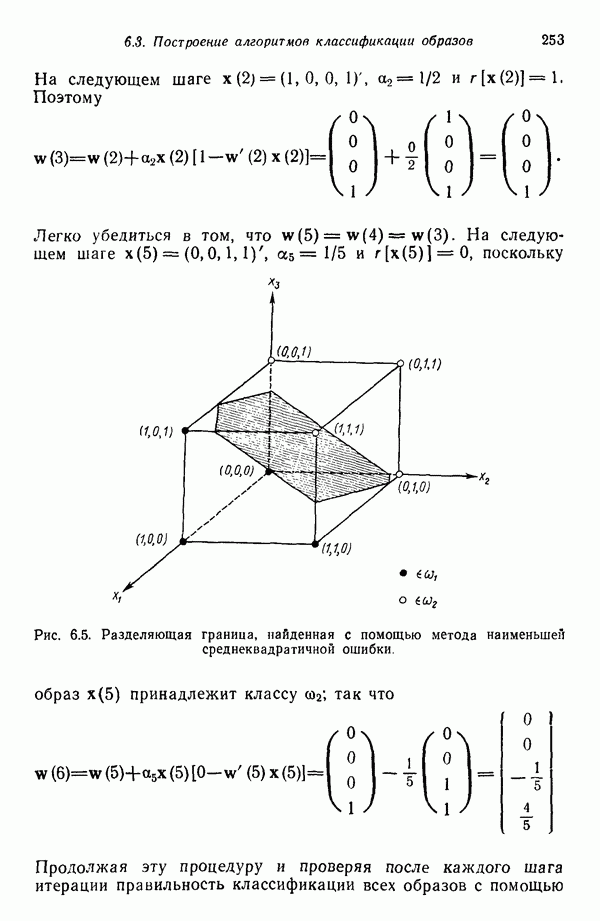
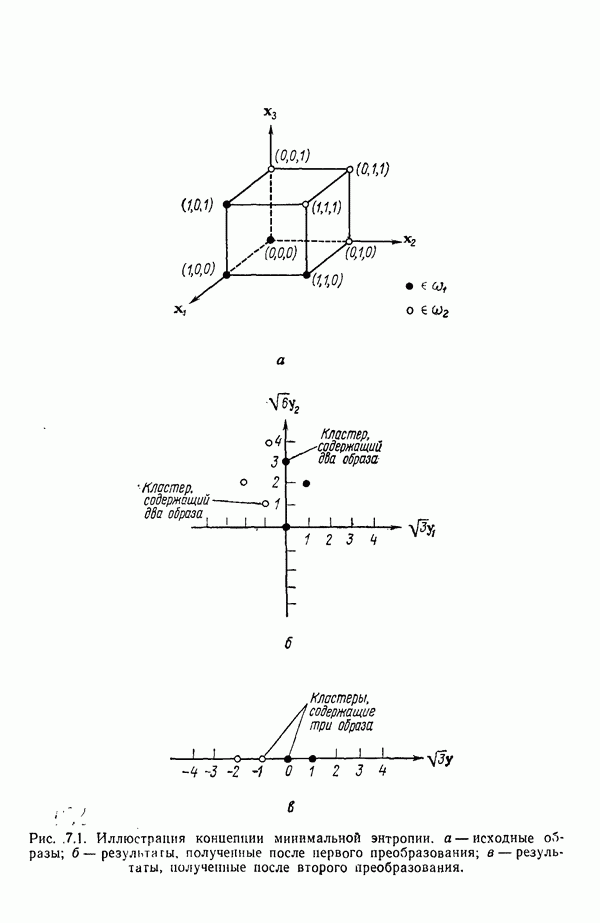
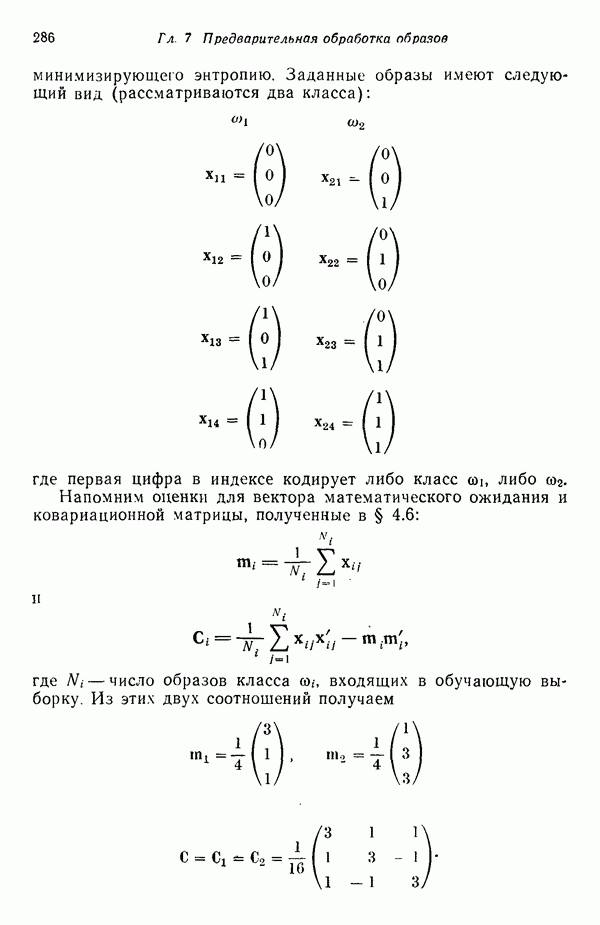
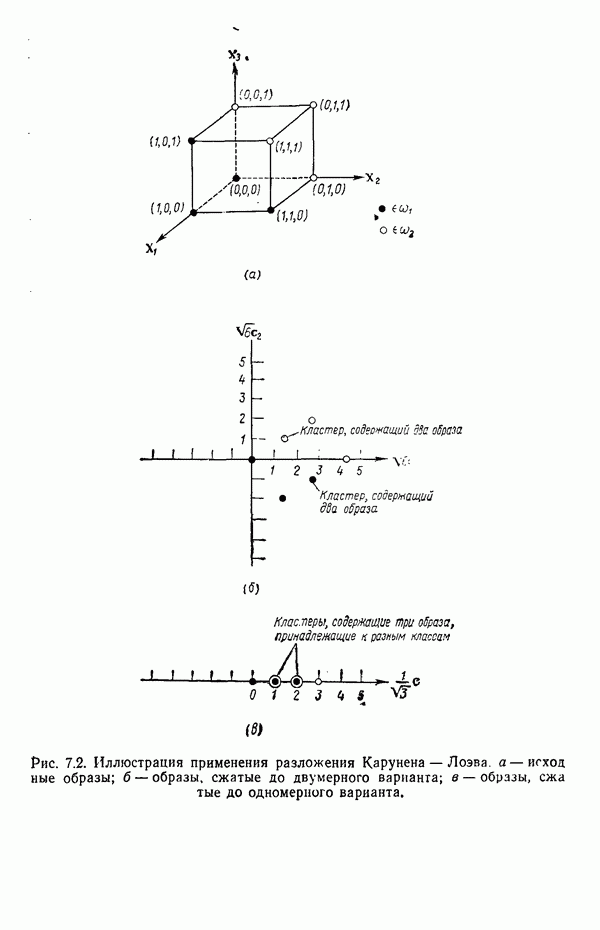
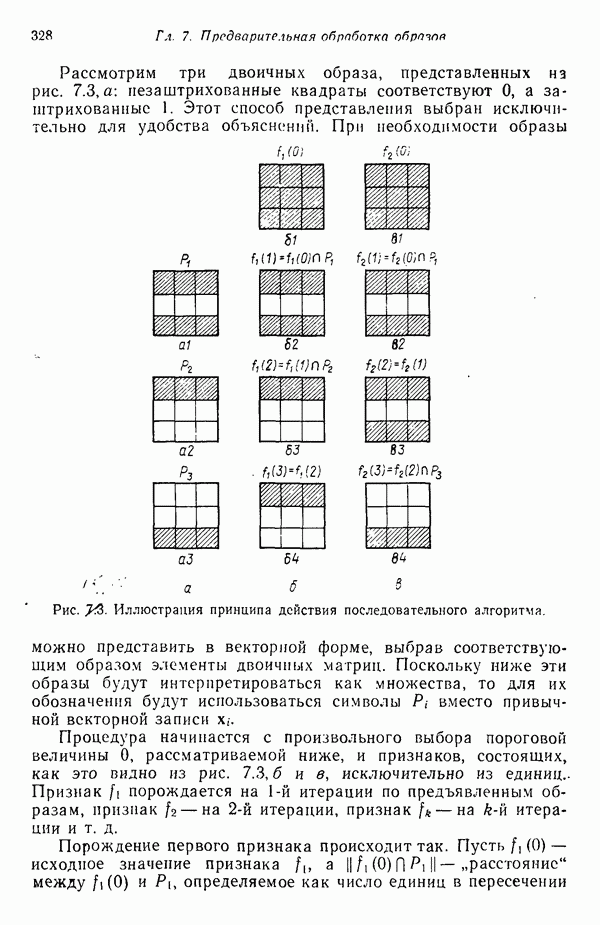
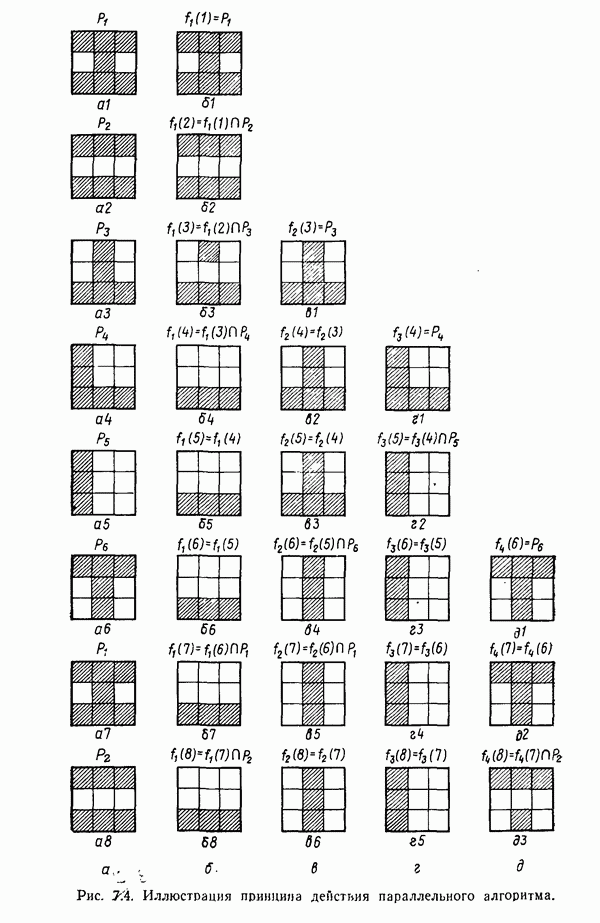
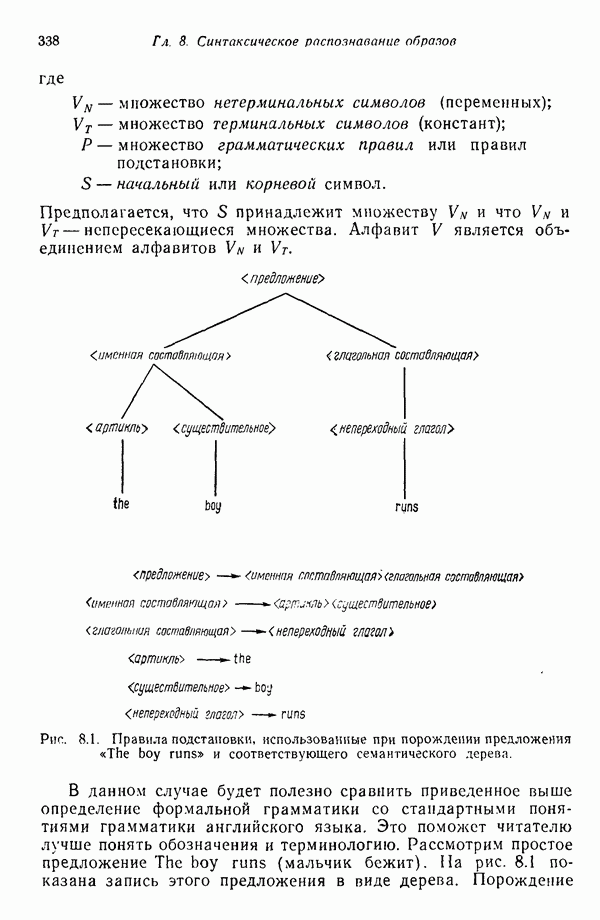
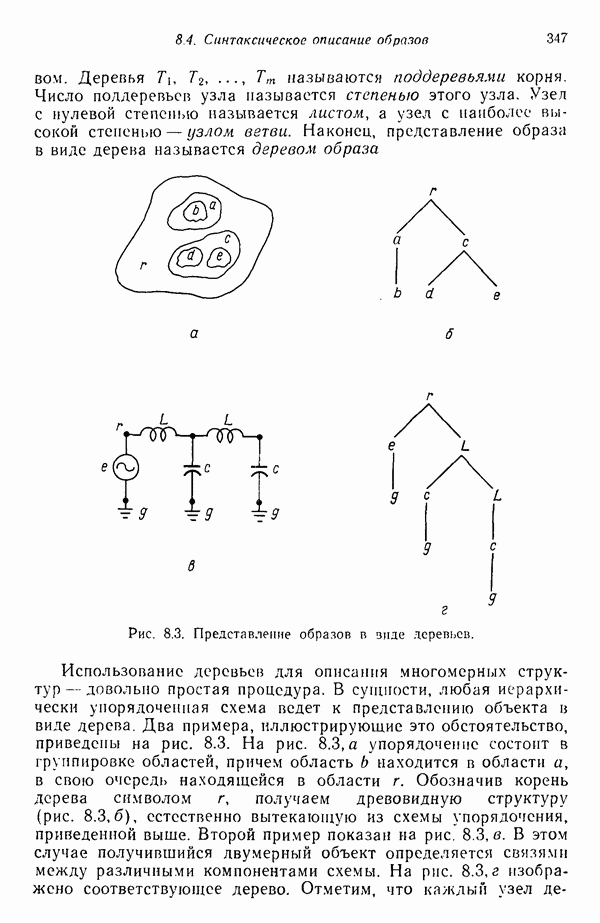
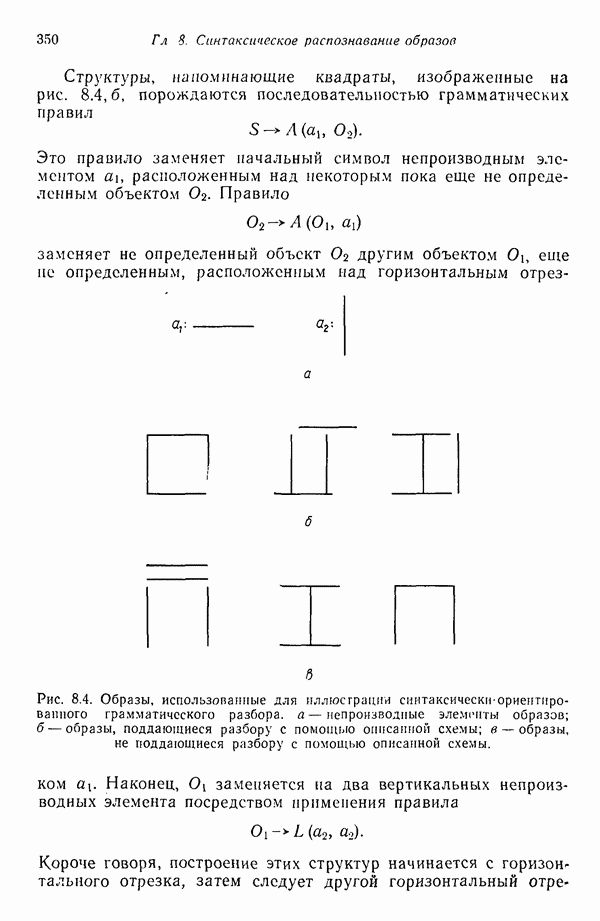
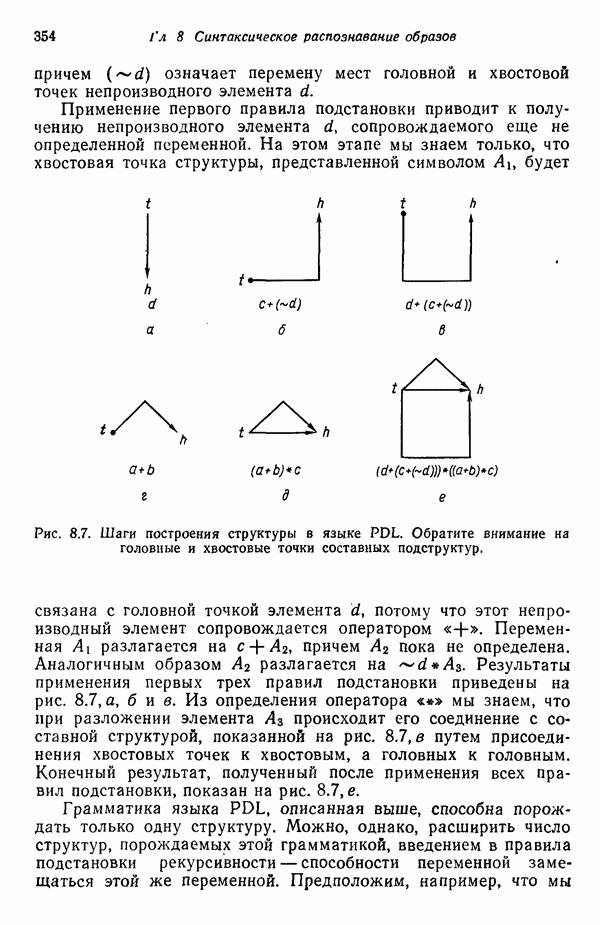
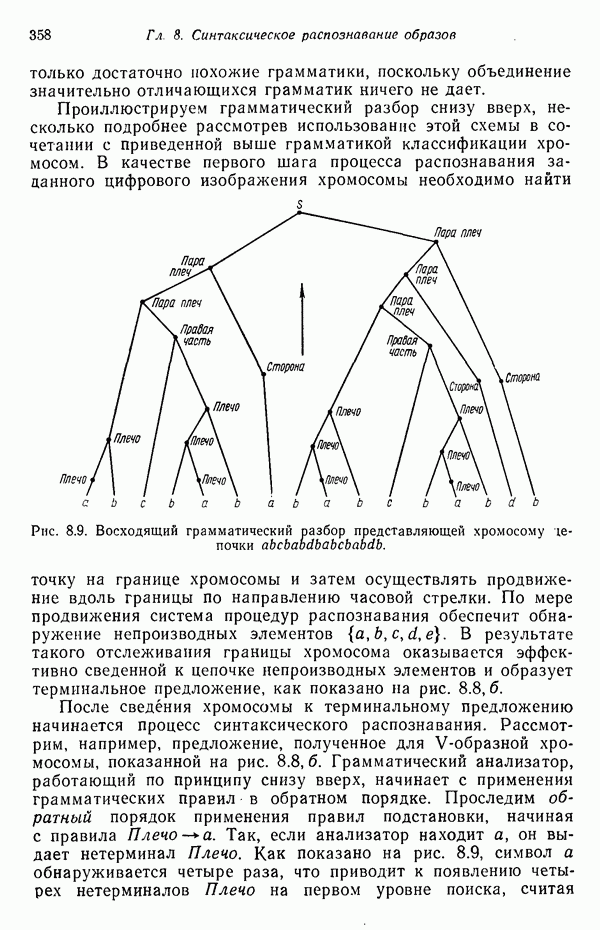
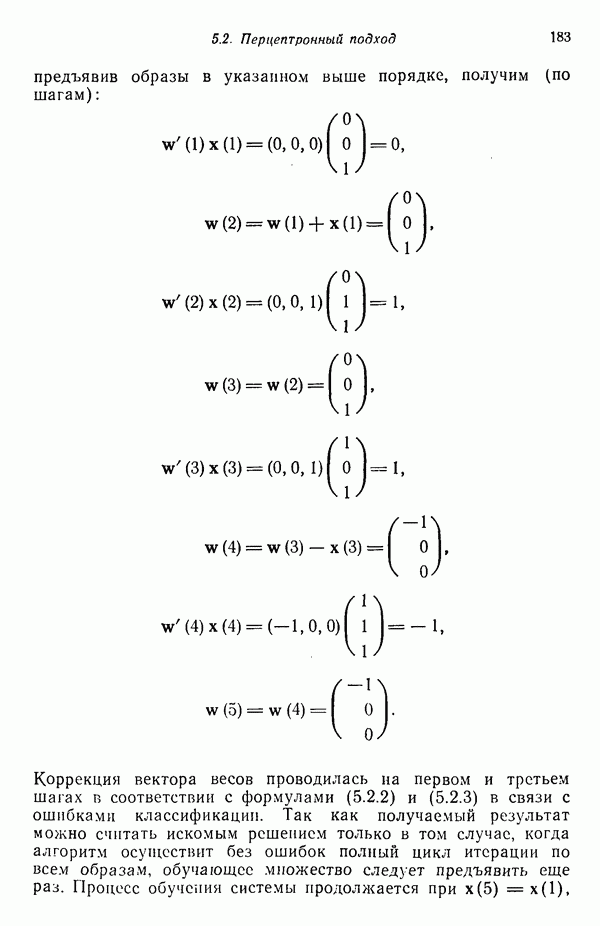3.3.3. Простой алгоритм выявления кластеров
Пусть задано множество  образов
образов  . Пусть также центр первого кластера
. Пусть также центр первого кластера  совпадает с любым из заданных образов и определена произвольная неотрицательная пороговая величина
совпадает с любым из заданных образов и определена произвольная неотрицательная пороговая величина  для удобства можно считать, что
для удобства можно считать, что  После этого вычисляется расстояние
После этого вычисляется расстояние  между образом
между образом  и центром кластера
и центром кластера  по формуле (3.2.1). Если это расстояние больше значения пороговой величины Т, то учреждается новый центр кластера
по формуле (3.2.1). Если это расстояние больше значения пороговой величины Т, то учреждается новый центр кластера  . В противном случае образ
. В противном случае образ  включается в кластер, центром которого является
включается в кластер, центром которого является  Пусть условие
Пусть условие  выполнено, т. е.
выполнено, т. е.  центр нового кластера. На следующем шаге вычисляются расстояния
центр нового кластера. На следующем шаге вычисляются расстояния  от образа
от образа  до центров кластеров
до центров кластеров  . Если оба расстояния оказываются больше порога Т, то учреждается новый центр кластера
. Если оба расстояния оказываются больше порога Т, то учреждается новый центр кластера  . В противном случае образ
. В противном случае образ  зачисляется в тот кластер, чей центр к нему ближе. Подобным же образом расстояния от каждого нового образа до каждого известного центра кластера вычисляются и сравниваются с пороговой величиной — если все эти расстояния превосходят значение порога Т, учреждается новый центр кластера. В противном случае образ зачисляется в кластер с самым близким к нему центром.
зачисляется в тот кластер, чей центр к нему ближе. Подобным же образом расстояния от каждого нового образа до каждого известного центра кластера вычисляются и сравниваются с пороговой величиной — если все эти расстояния превосходят значение порога Т, учреждается новый центр кластера. В противном случае образ зачисляется в кластер с самым близким к нему центром.
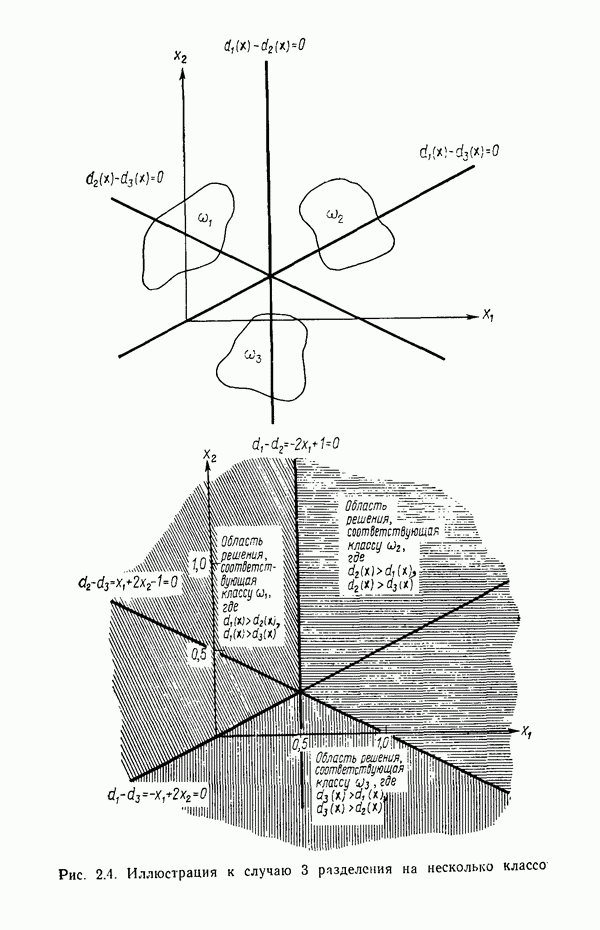
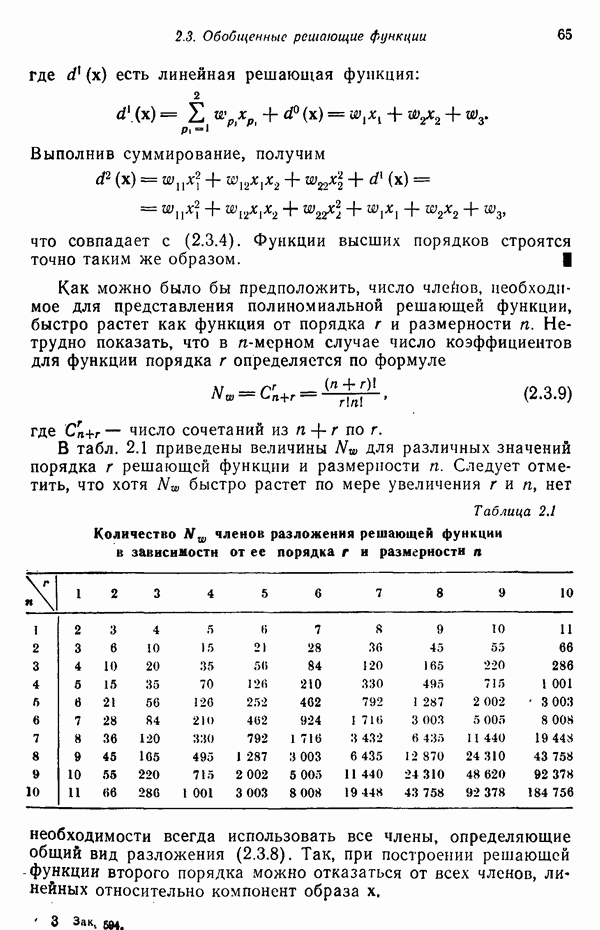
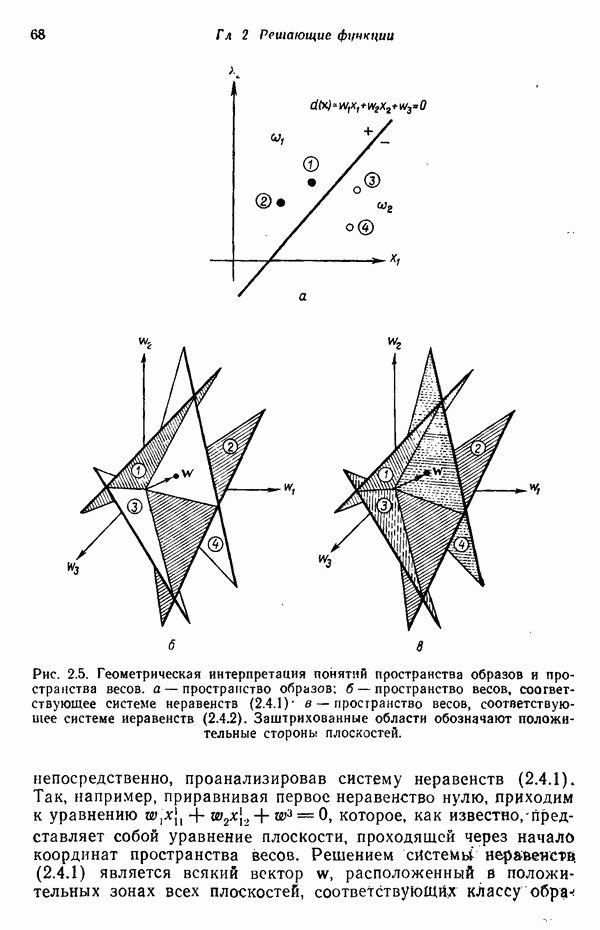
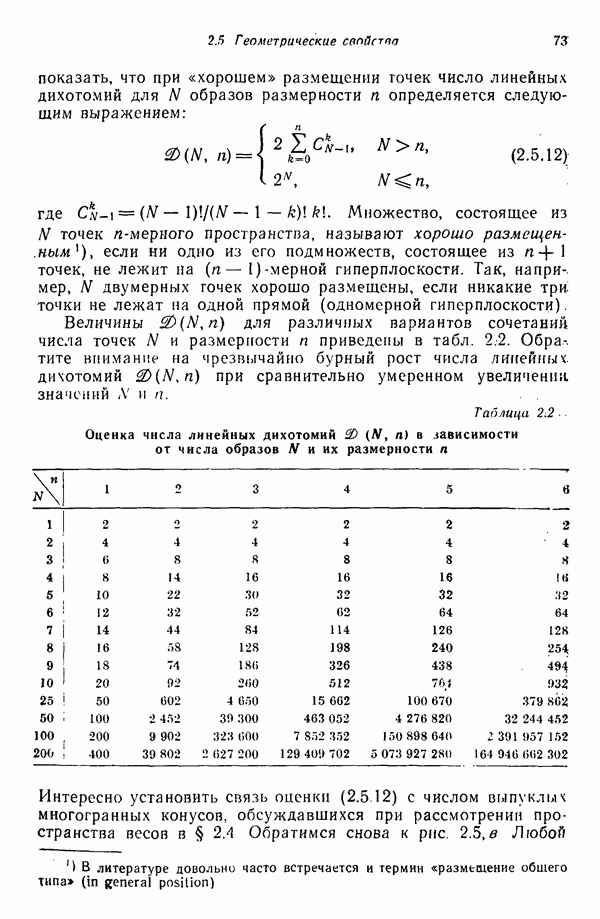
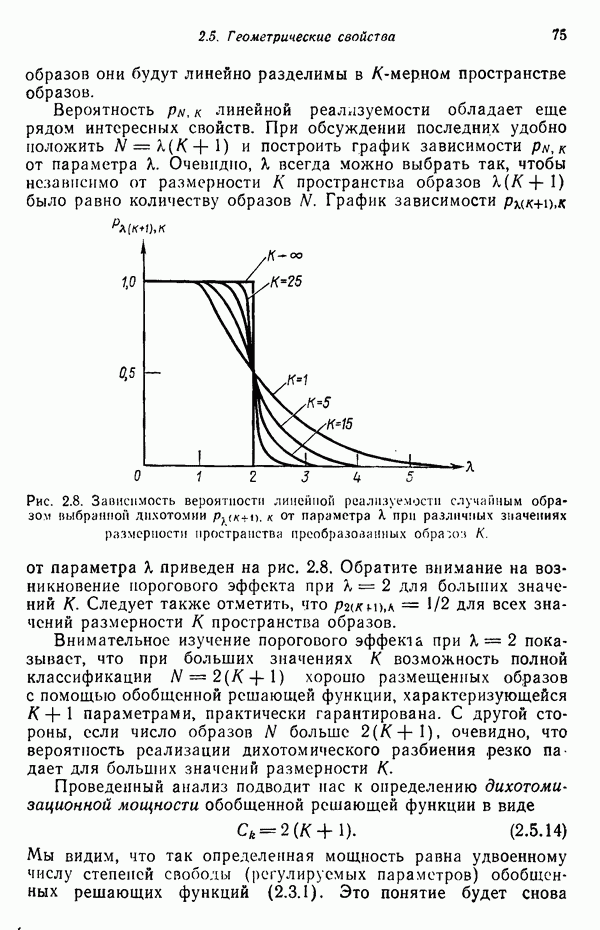
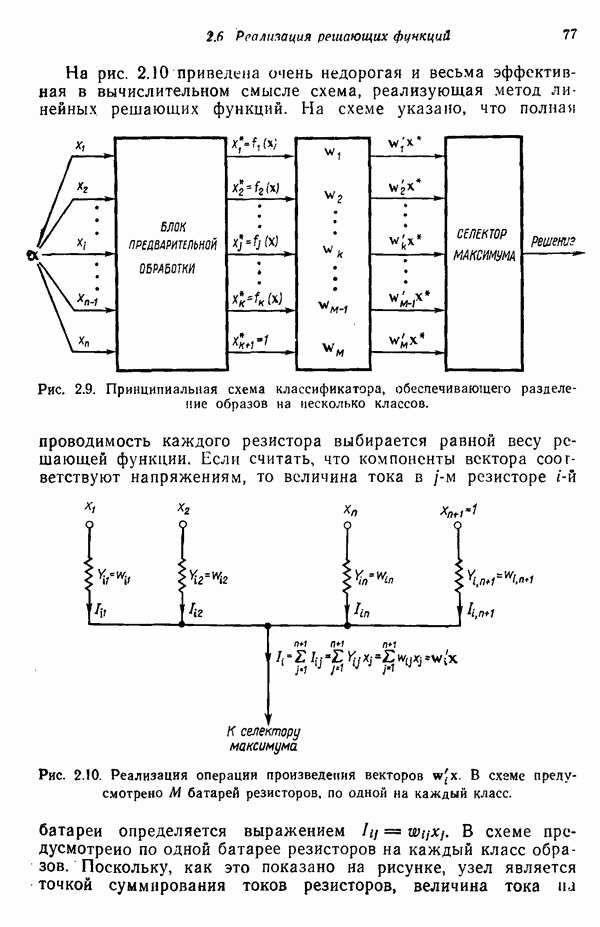
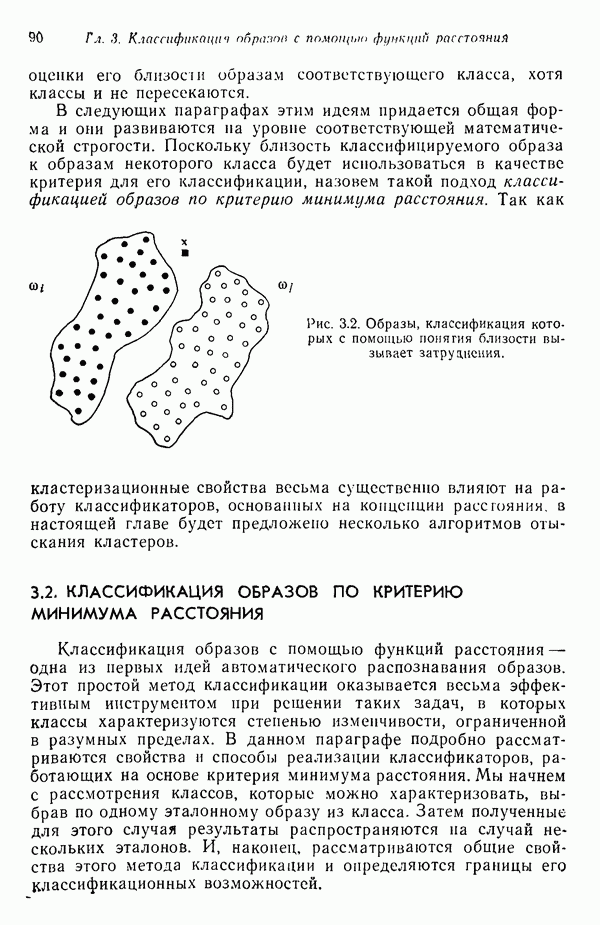
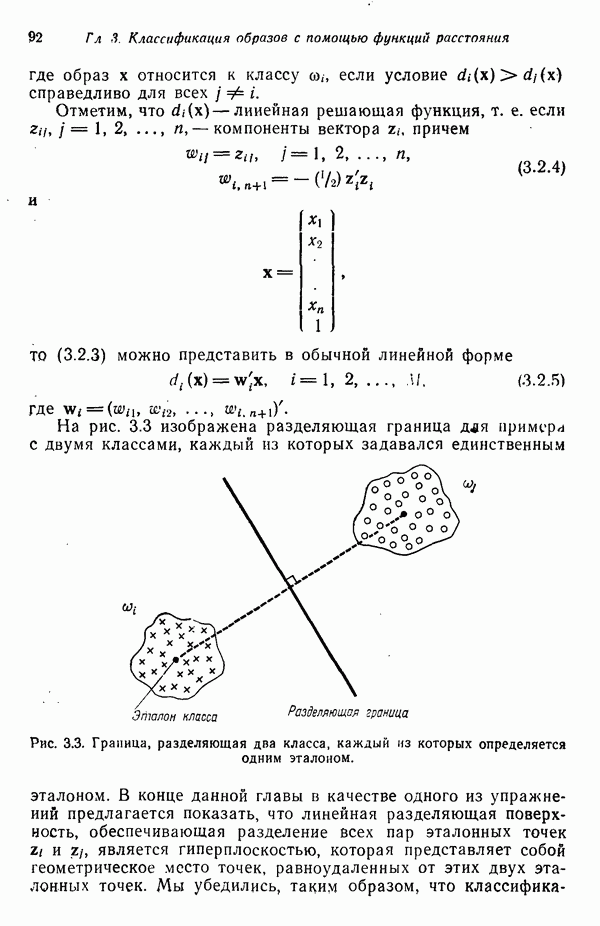
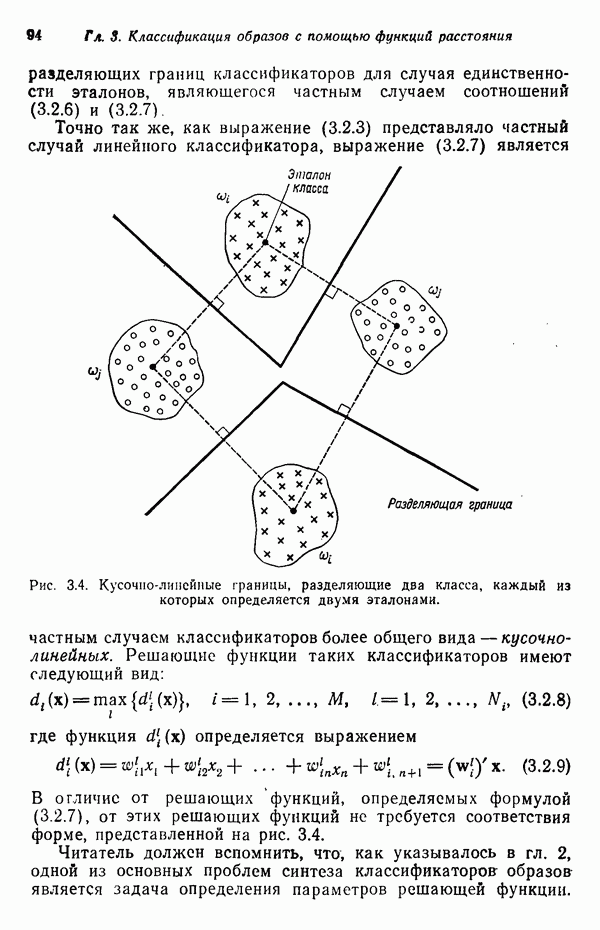
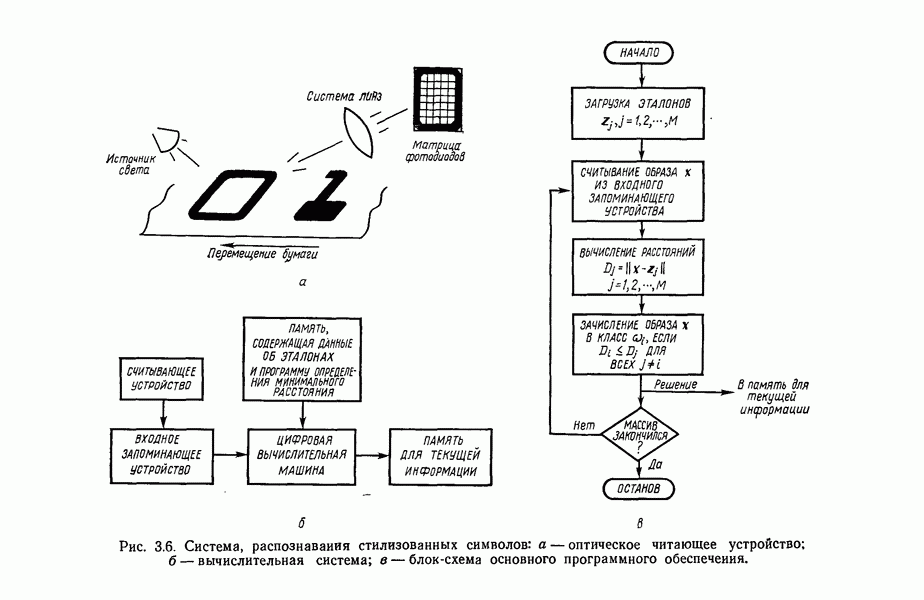
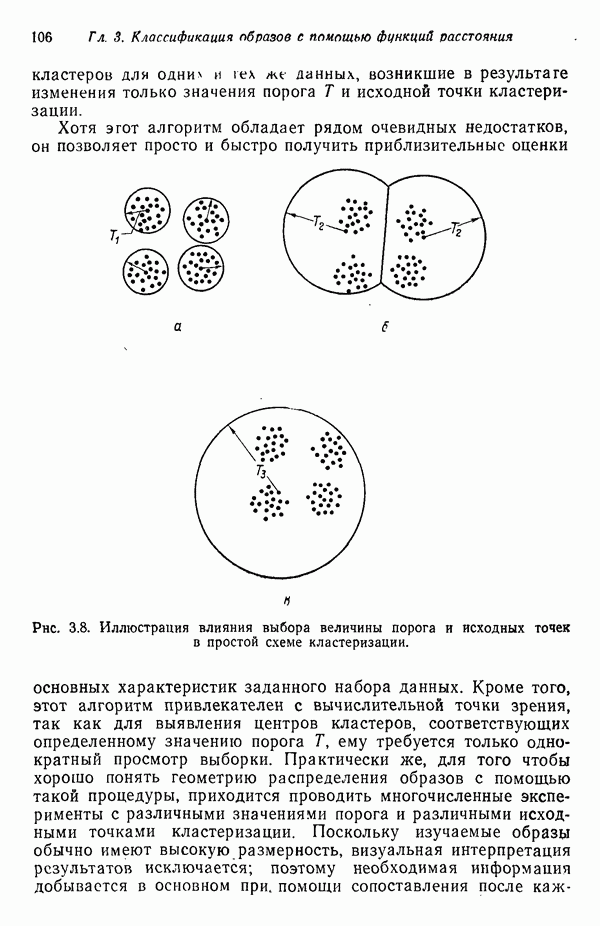
Результаты описанной процедуры определяются выбором первого центра кластера, порядком осмотра образов, значением пороговой величины Т и, конечно, геометрическими характеристиками данных. Эти влияния иллюстрируются рис. 3.8, на котором представлены три различных варианта выбора центров
кластеров для одних и тех же данных, возникшие в результате изменения только значения порога Т и исходной точки кластеризации.

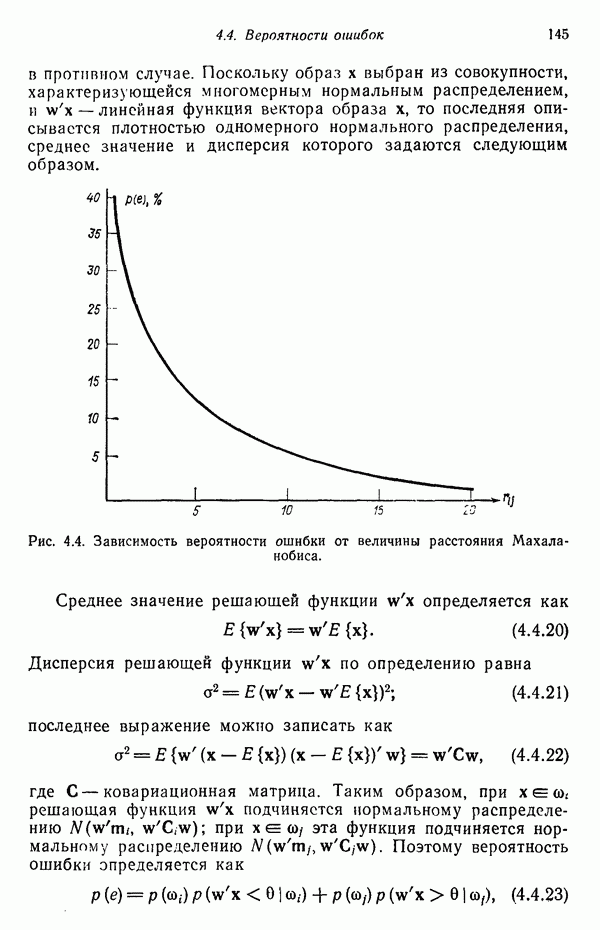
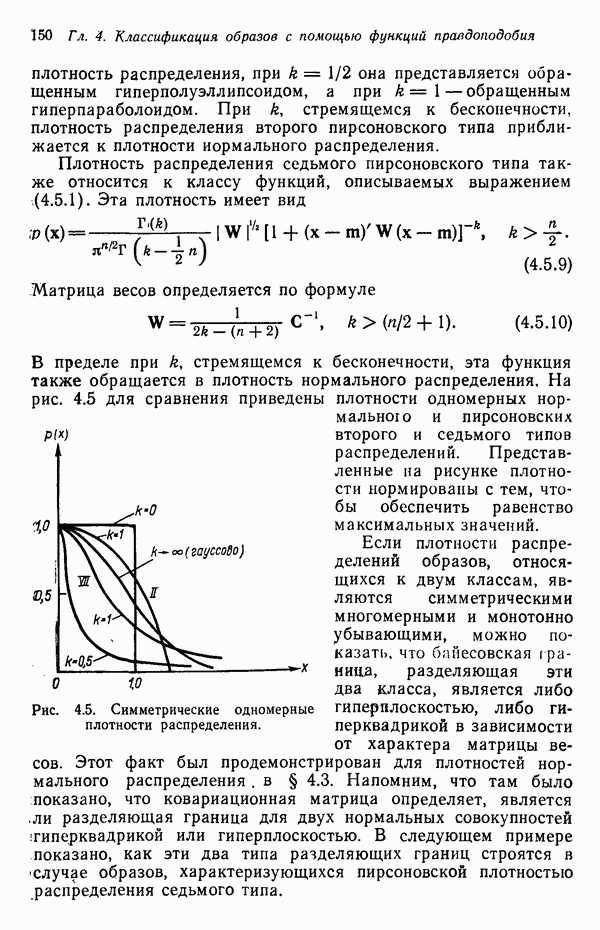
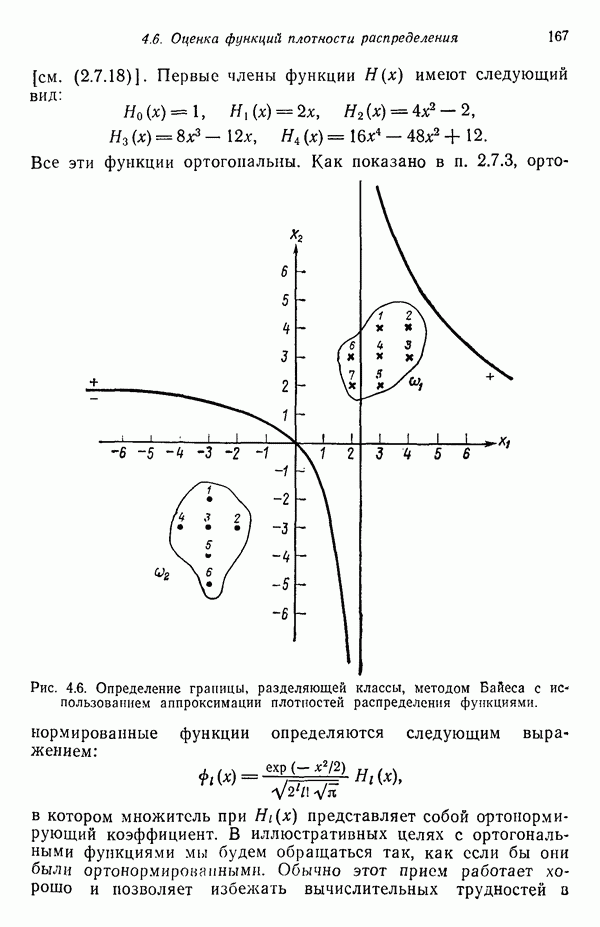
Рис. 3.8. Иллюстрация влияния выбора величины порога и исходных точек в простой схеме кластеризации.
Хотя этот алгоритм обладает рядом очевидных недостатков, он позволяет просто и быстро получить приблизительные оценки основных характеристик заданного набора данных. Кроме того, этот алгоритм привлекателен с вычислительной точки зрения, так как для выявления центров кластеров, соответствующих определенному значению порога Т, ему требуется только однократный просмотр выборки. Практически же, для того чтобы хорошо понять геометрию распределения образов с помощью такой процедуры, приходится проводить многочисленные эксперименты с различными значениями порога и различными исходными точками кластеризации. Поскольку изучаемые образы обычно имеют высокую размерность, визуальная интерпретация результатов исключается; поэтому необходимая информация добывается в основном при. помощи сопоставления после каждого
цикла просмотра данных расстояний, разделяющих центры кластеров, и количества образов, вошедших в различные кластеры. Полезными характеристиками являются также ближайшая и наиболее удаленная от центра точки кластера и различие размеров отдельных кластеров. Информацию, полученную таким образом после каждого цикла обработки данных, можно использовать для коррекции выбора нового значения порога Т и новой исходной точки кластеризации в следующем цикле. Можно рассчитывать на получение с помощью подобной процедуры полезных результатов в тех случаях, когда в данных имеются характерные «гнезда», которые достаточно хорошо разделяются при соответствующем выборе значения порога.