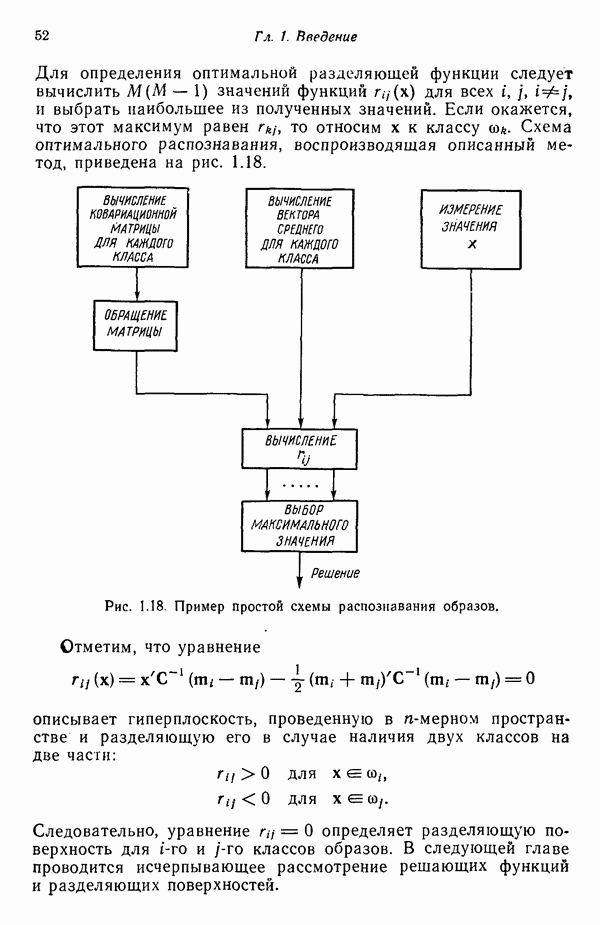
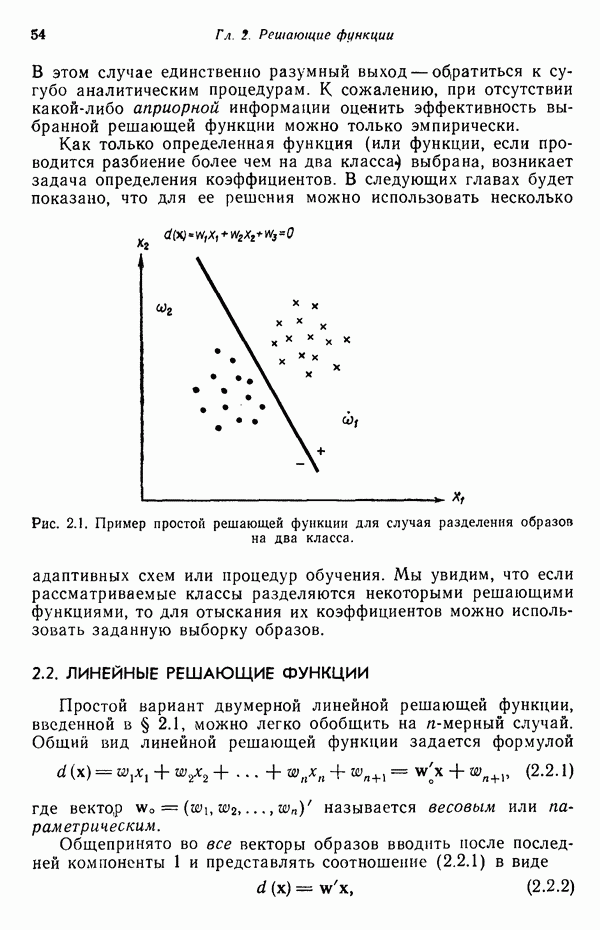
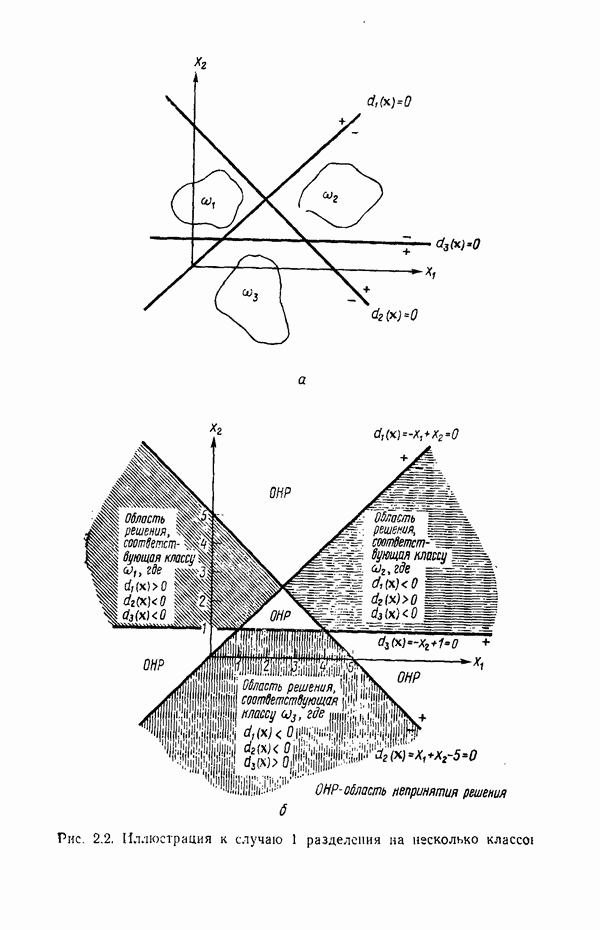
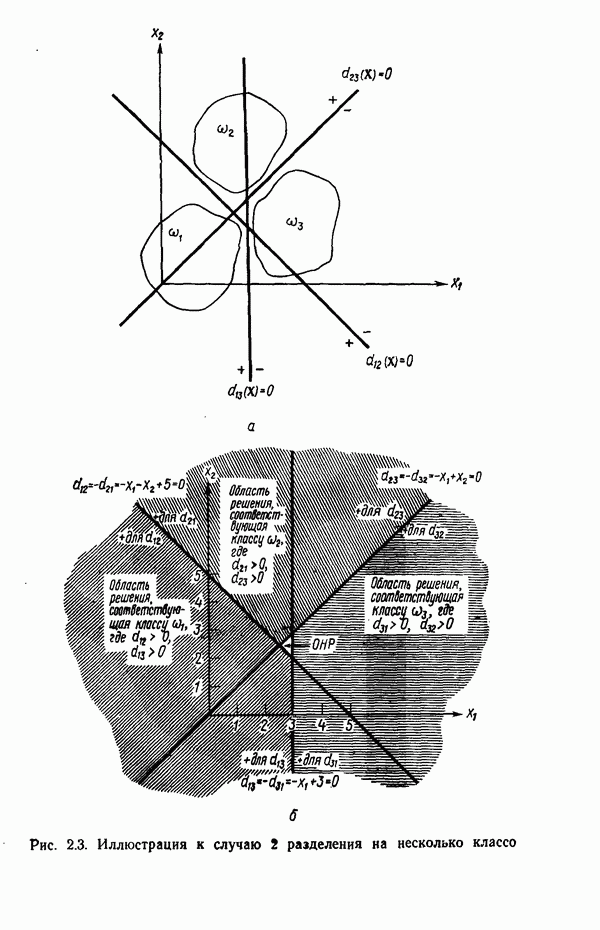
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
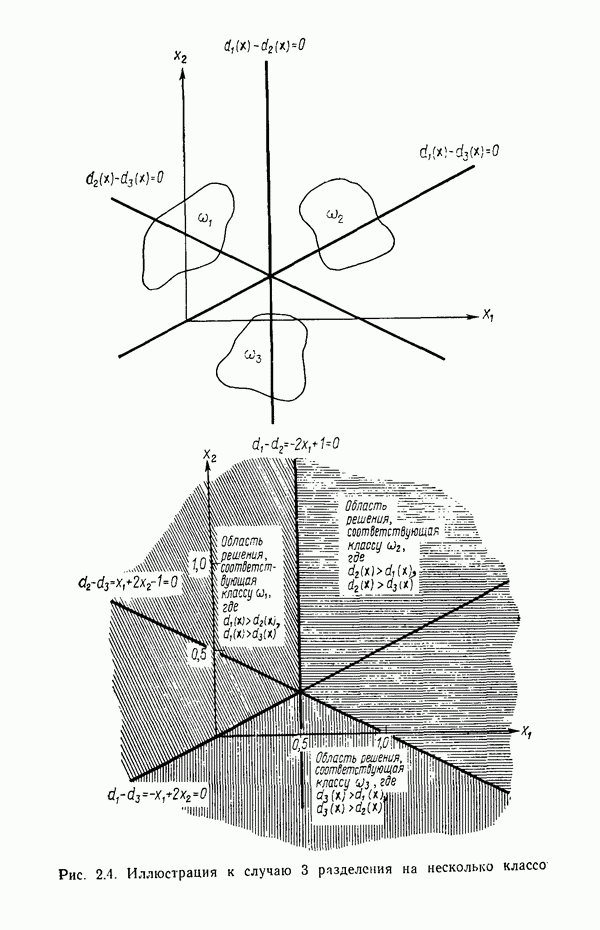
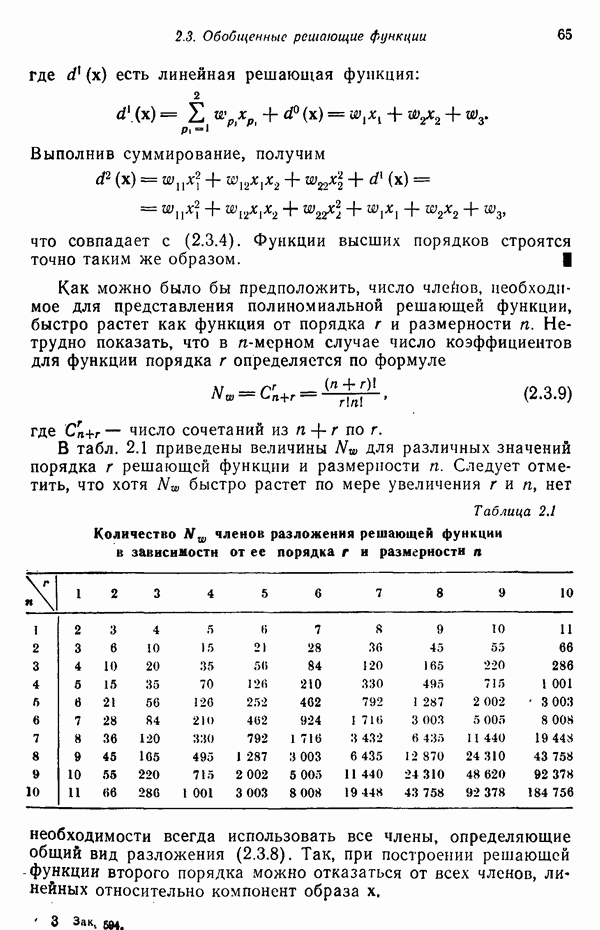
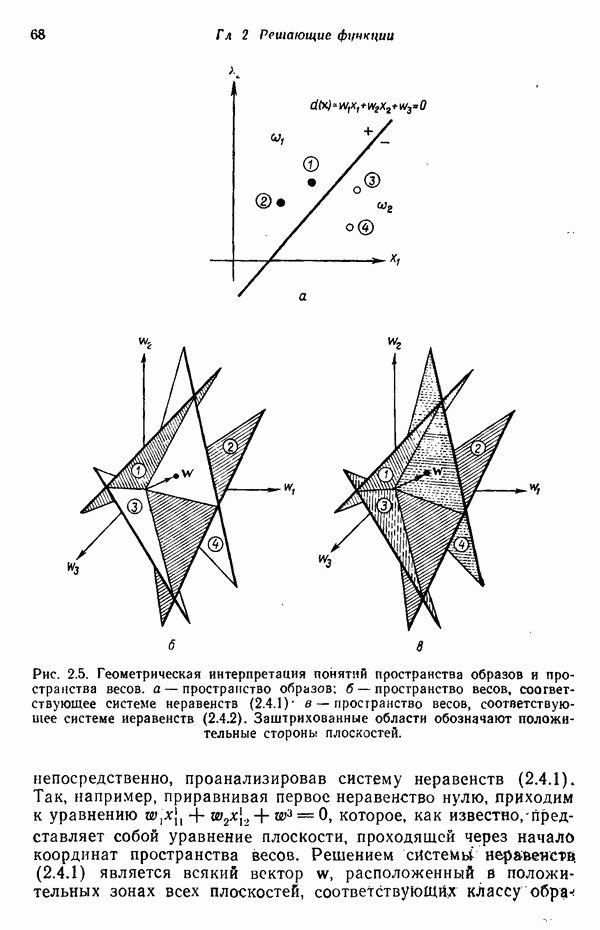
4.4. ВЕРОЯТНОСТИ ОШИБОКОбсудив байесовский классификатор, предназначенный для работы с нормально распределенными образами, перейдем к анализу вероятности ошибки, совершаемой при использовании такой схемы классификации. Рассмотрим два класса
и
причем их ковариационные матрицы равны. Поскольку плотности распределения представлены в экспоненциальной форме, анализ можно упростить, воспользовавшись логарифмом отношения правдоподобия. Пусть
В таком случае из (4.4.1) и (4.4.2) следует, что
При выборе двоичной функции потерь (0 — правильное решение, 1 — ошибка) условие, определяющее принадлежность образа
где параметр
Вероятность неправильной классификации образа, принадлежащего классу Так как логарифм отношения правдоподобия
это выражение можно свести к
где
Последнее часто называют расстоянием Махаланобиса между плотностями распределений Поскольку дисперсия логарифма отношения правдоподобия
то из (4.4.4) и (4.4.8) следует, что
последнее выражение можно упростить до вида
и
Итак, при хешлогарифм отношения правдоподобия
где функция Ф определена как
Вероятность ошибки определяется по формуле
Воспользовавшись уравнениями (4.4.13) и (4.4.14), приходим к следующему:
В тех случаях, когда априорные вероятности появления соответствующих классов равны, т. е.
пороговая величина 0 равна единице, а ее логарифм а соответственно равен нулю. В таком случае вероятность ошибки определяется как
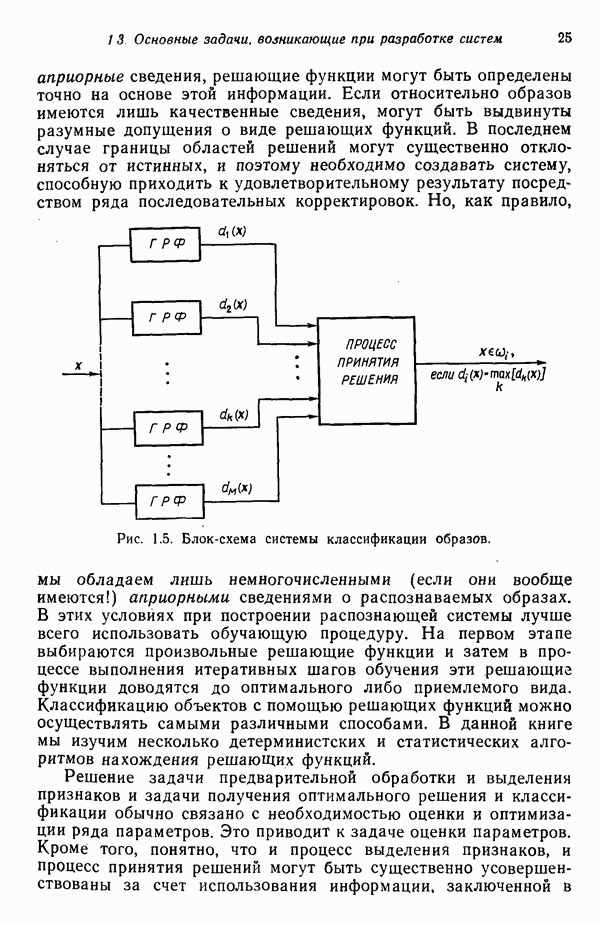
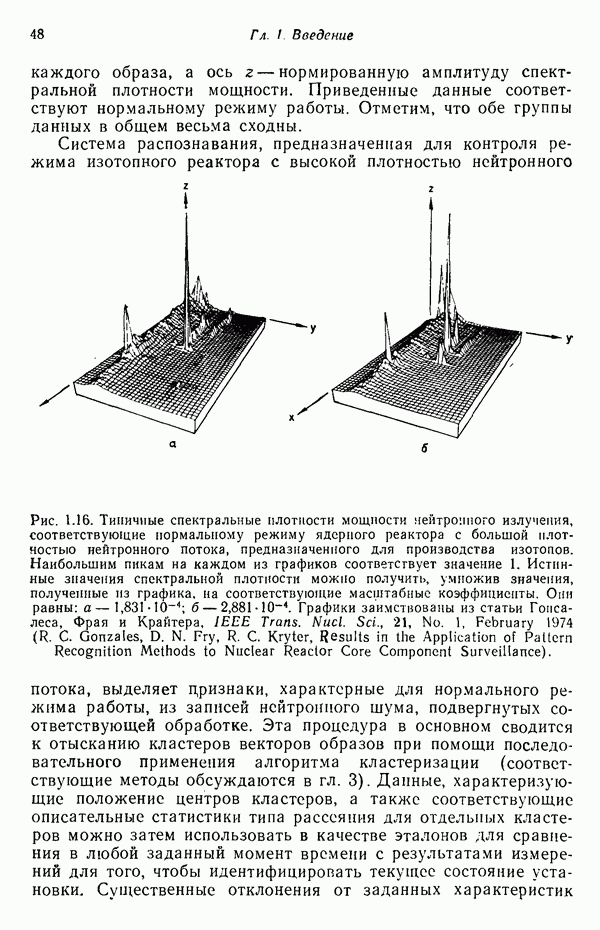
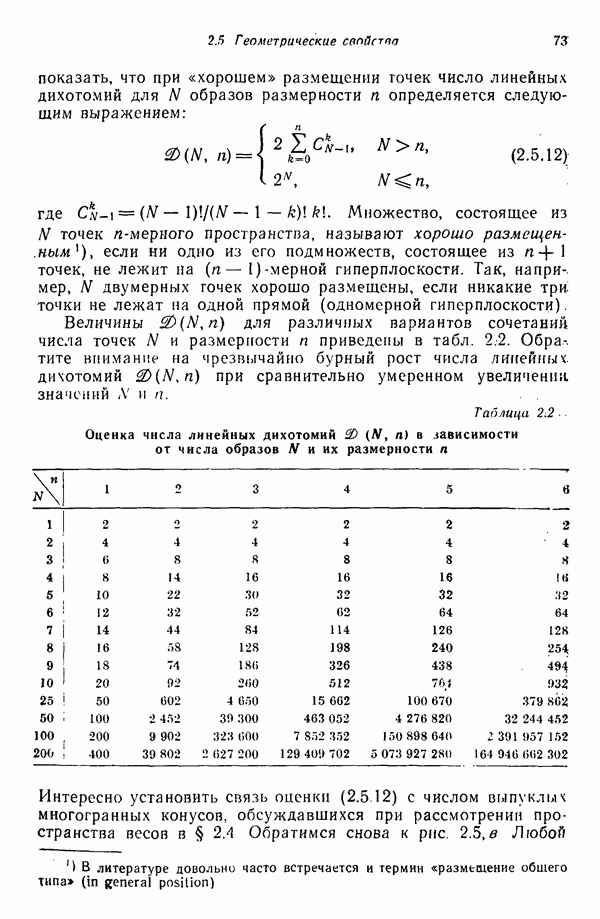
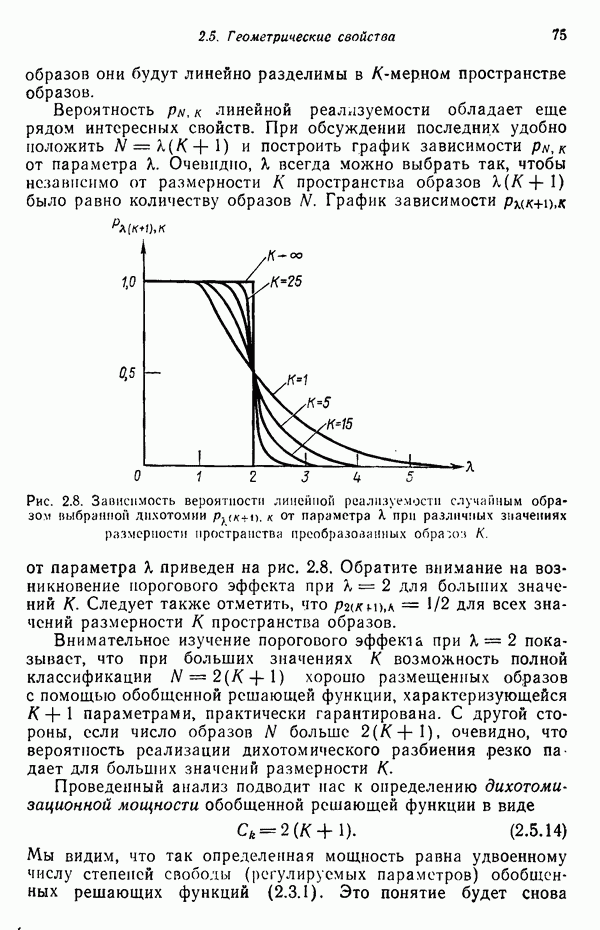
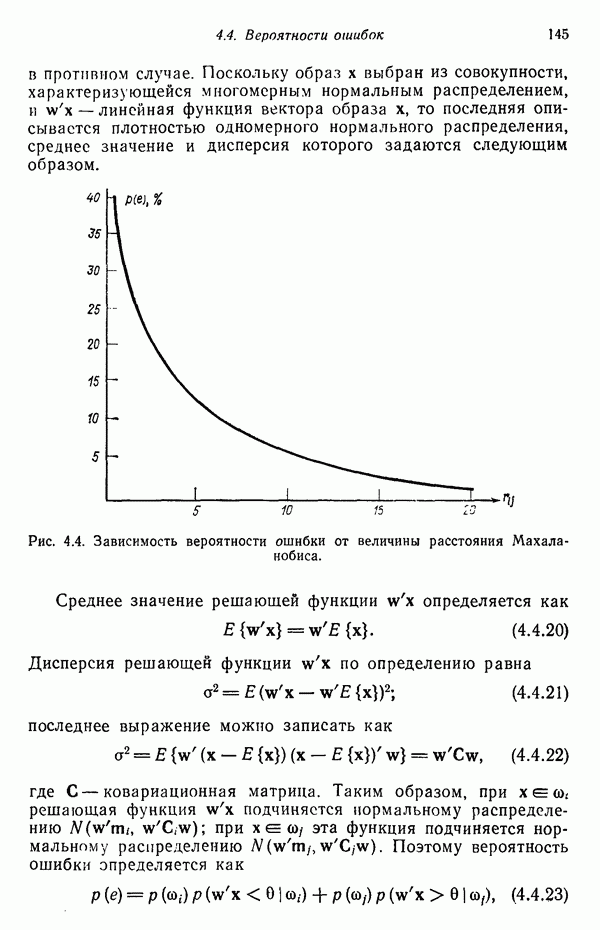
Итак, функция, связывающая расстояние Махаланобиса с вероятностью ошибки, является плотностью одномерного нормального распределения с нулевым средним и единичной дисперсией. График зависимости вероятности ошибки классификации Проведенный анализ можно распространить на случай оценки вероятности ошибки классификации, связанной с использованием рассмотренных в гл. 2 линейных решающих функций при нормальном распределении образов в каждом из двух заданных классов. Линейный классификатор относит образ в противном случае. Поскольку образ
Рис. 4.4. Зависимость вероятности ошибки от величины расстояния Махаланобиса. Среднее значение решающей функции
Дисперсия решающей функции
последнее выражение можно записать как
где С — ковариационная матрица. Таким образом, при
где
и
Эти формулы аналогичны (4.4.13) и (4.4.14). Используя соответствующую подстановку, получаем для вероятности ошибки следующее выражение:
последнее аналогично соотношению (4.4.17), определяющему вероятность ошибки для байесовского классификатора. Исходя из проведенного анализа вероятности ошибки классификации, можно на основе минимаксного критерия определить вектор весов для дихотомического разделения. При допущении о равенстве априорных вероятностей, т. е.
где
и
В (4.4.27) использовано соотношение
Из формулы (4.4.27) следует, что вероятность ошибки Из формул (4.4.28) и (4.4.29) можно получить
и
Поскольку Дифференцирование выражения (4.4.32) по вектору весов
Можно легко показать, что
В таком случае уравнение (4.4.33) принимает вид
Итак, при использовании минимаксного критерия в случае равенства априорных вероятностей равновероятными оказываются оба вида ошибок. Это эквивалентно утверждению о том, что
Подставив выражение (4.4.35) в уравнение (4.4.34), произведя упрощения и приравняв полученный результат нулю, получим следующее выражение:
из которого в свою очередь получим
Уравнение (4.4.36) можно записать как
Отметим, что вектор весов
Итак, искомый вектор весов можно найти из следующего уравнения, заданного в неявной форме:
Воспользовавшись соотношениями (4.4.28) и (4.4.38), получим выражение для пороговой величины
Формулы (4.4.39) и (4.4.40) позволяют найти вектор весов и пороговую величину для линейной решающей функции, обеспечивающей осуществление дихотомизации с минимальной вероятностью ошибки.
|
 |
Оглавление
|















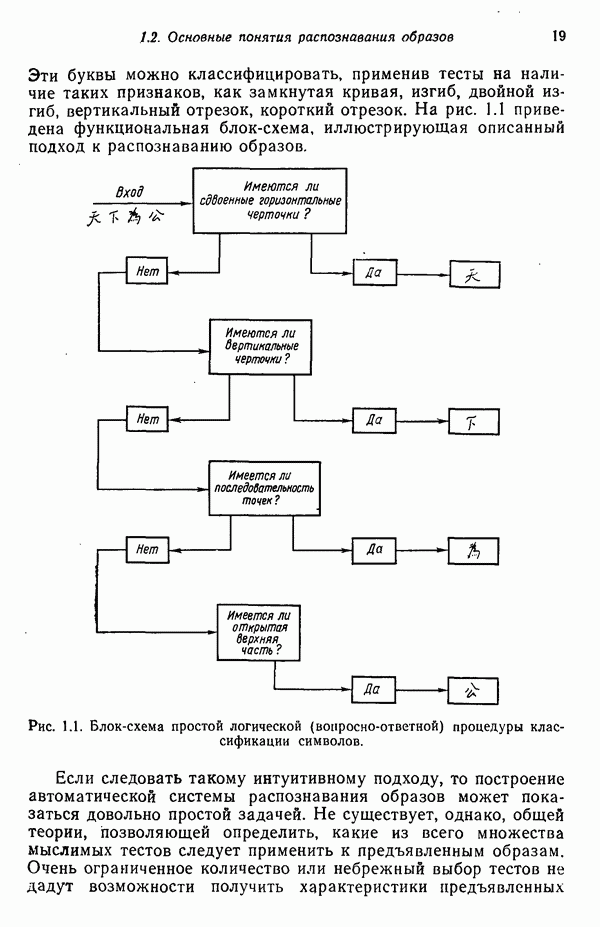
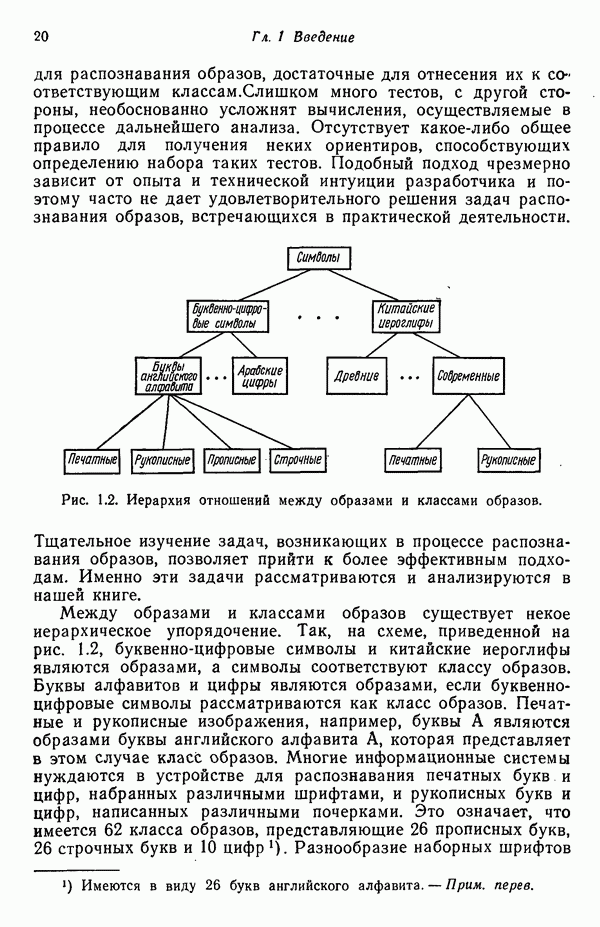

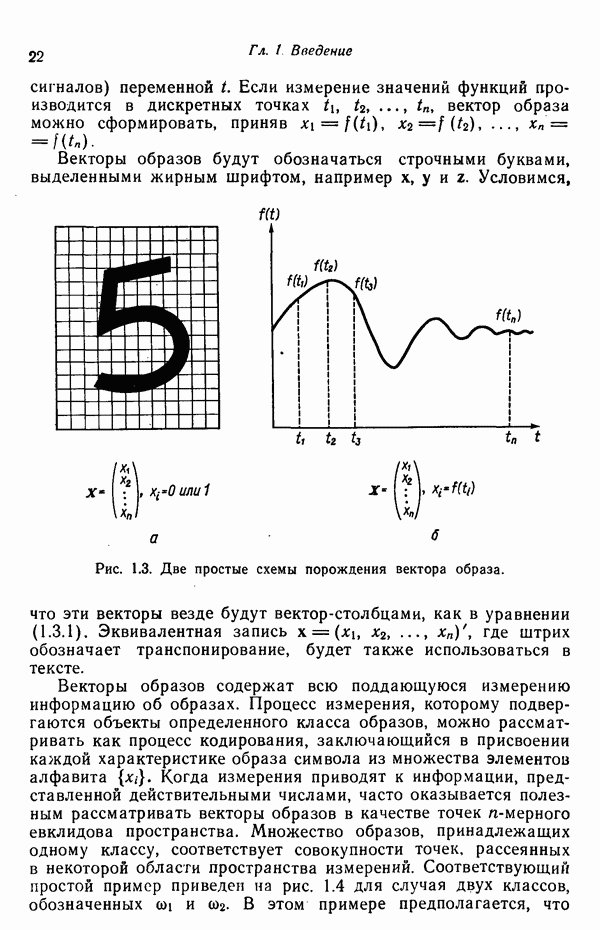









































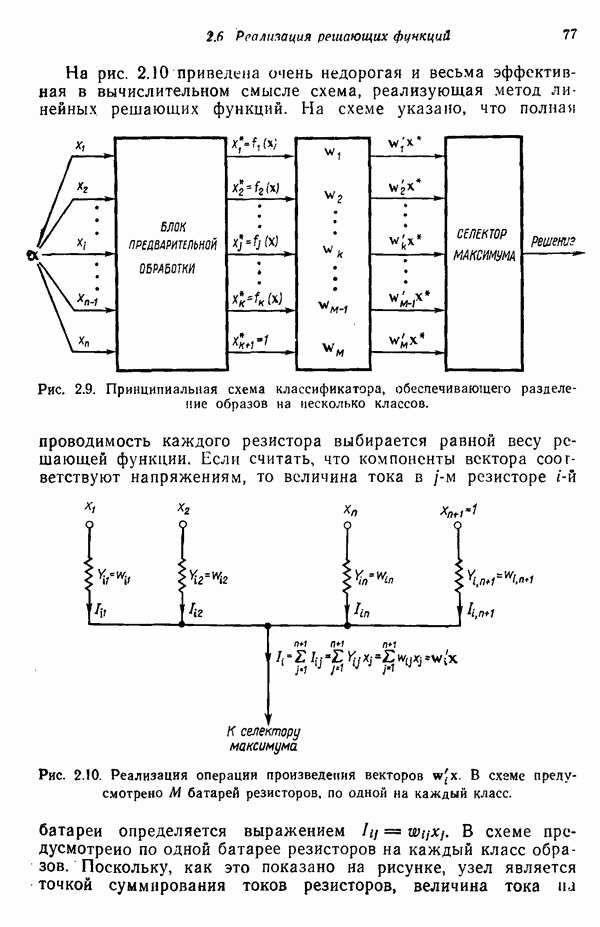












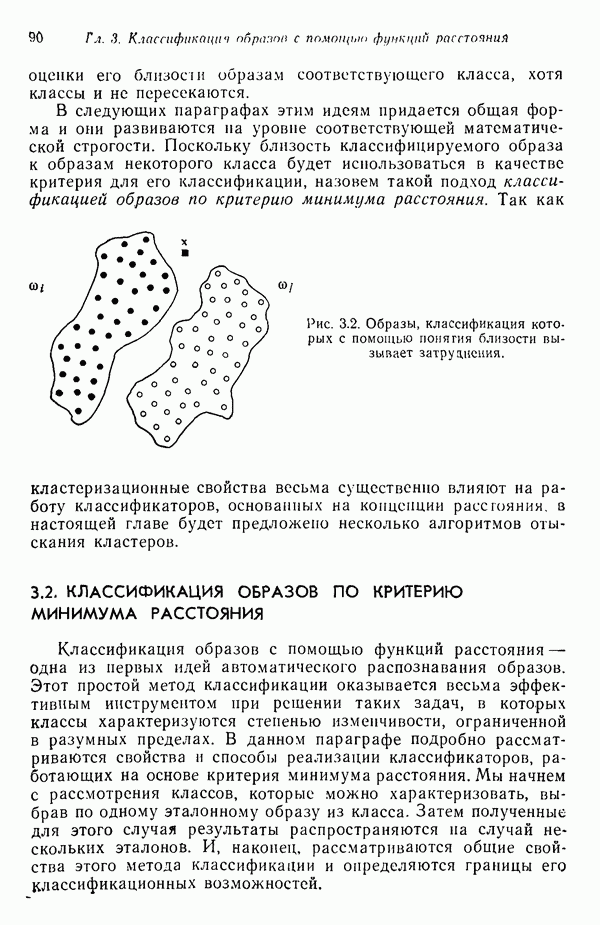

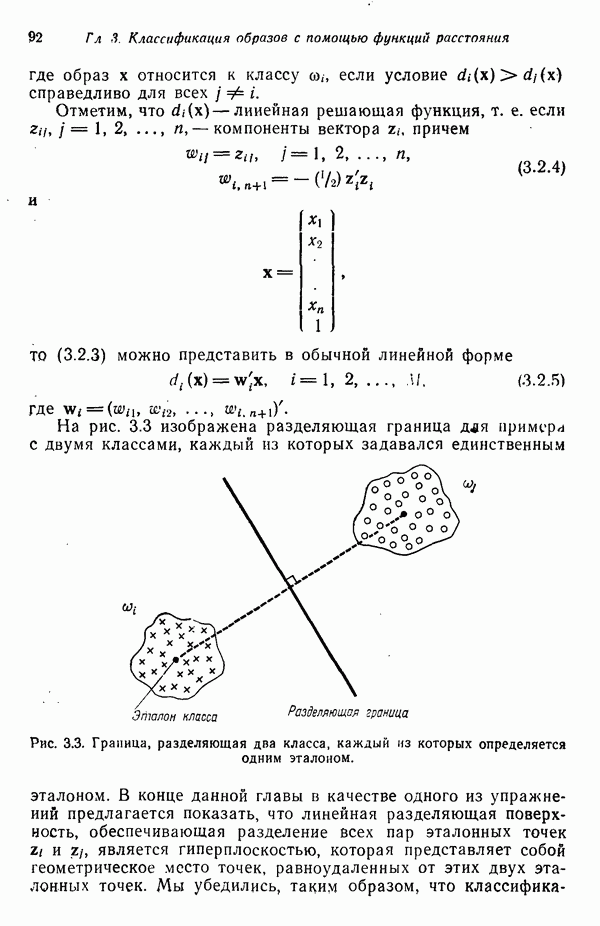

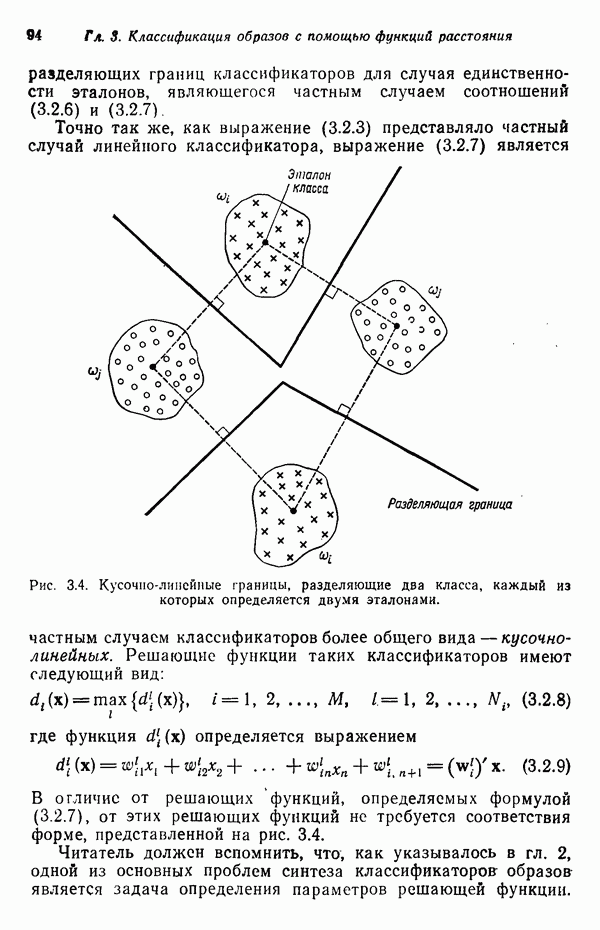





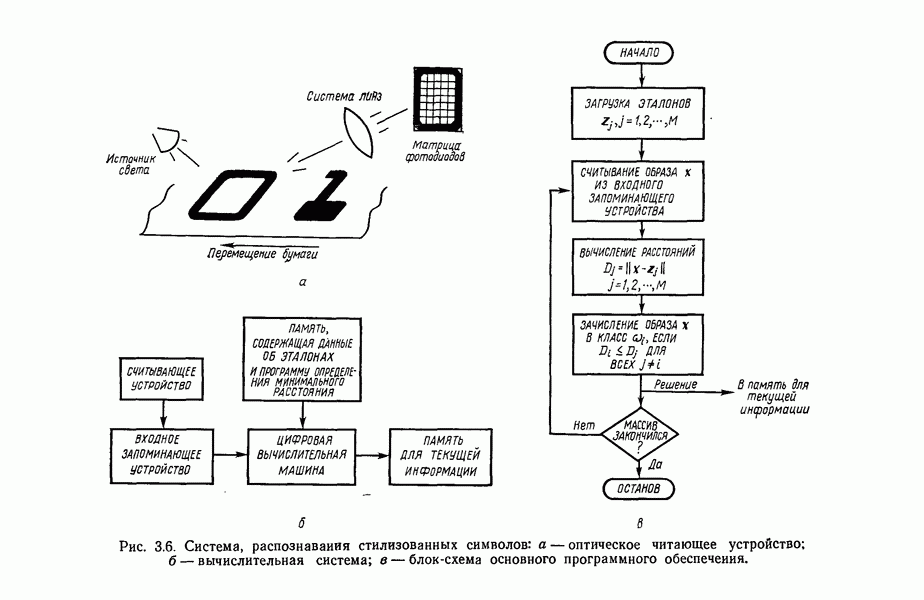





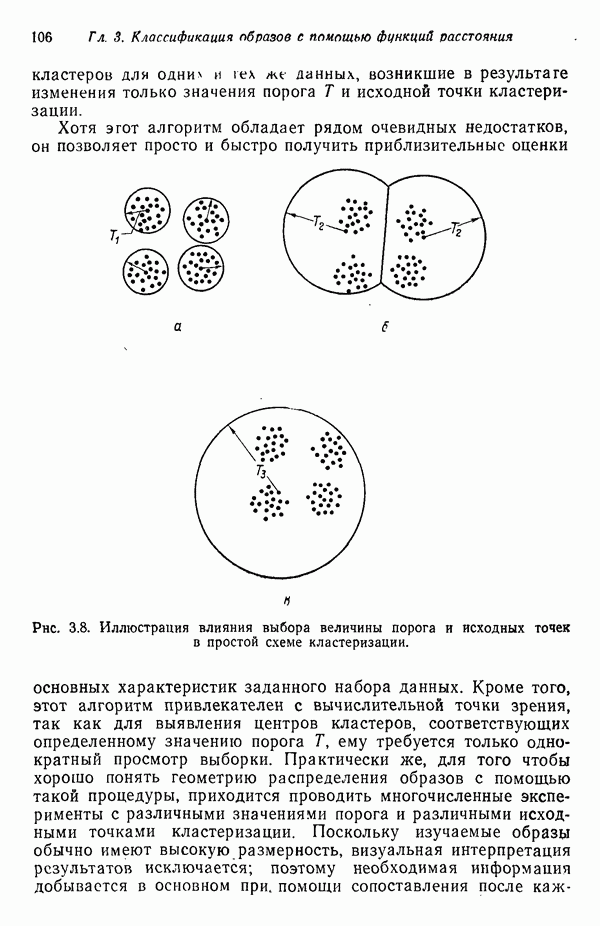

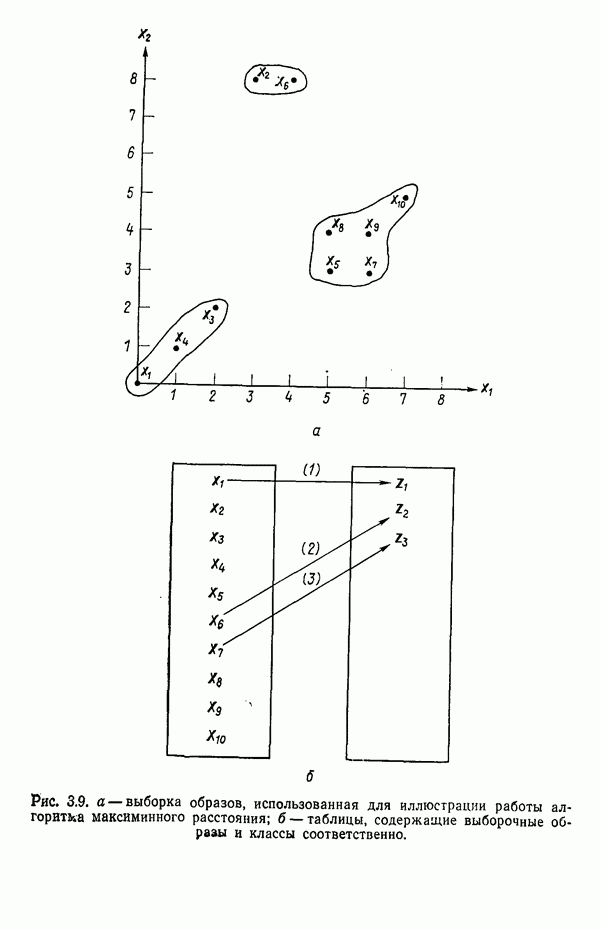




























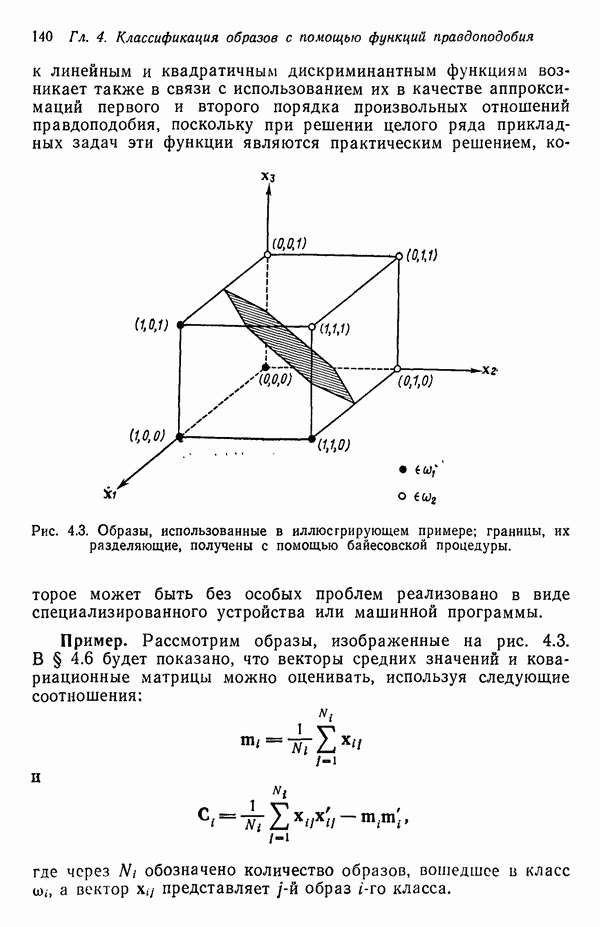








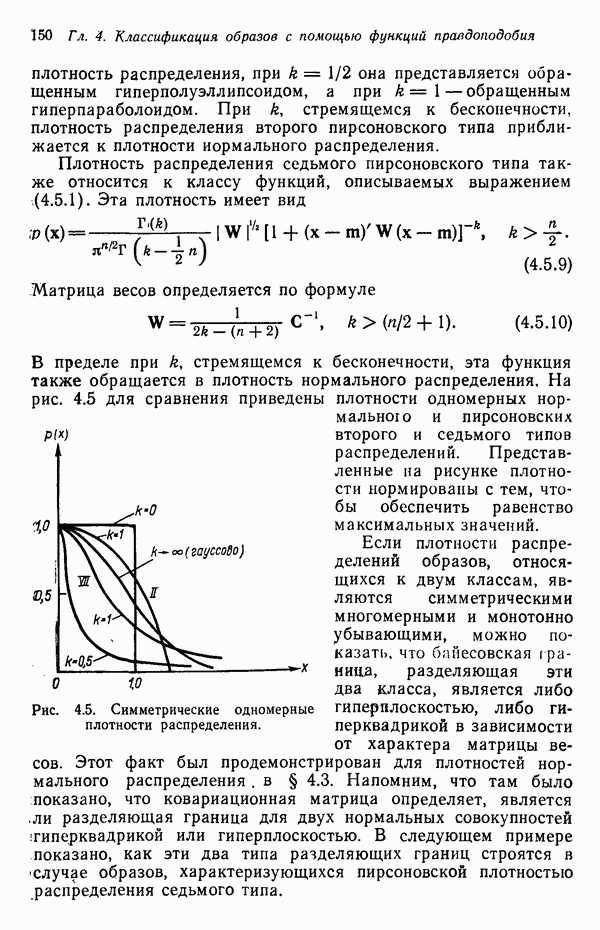
















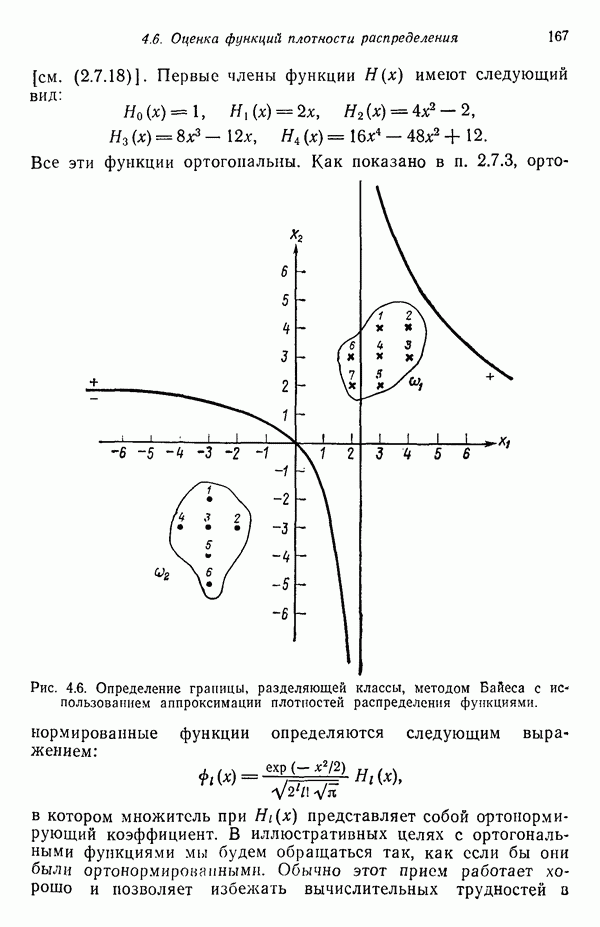







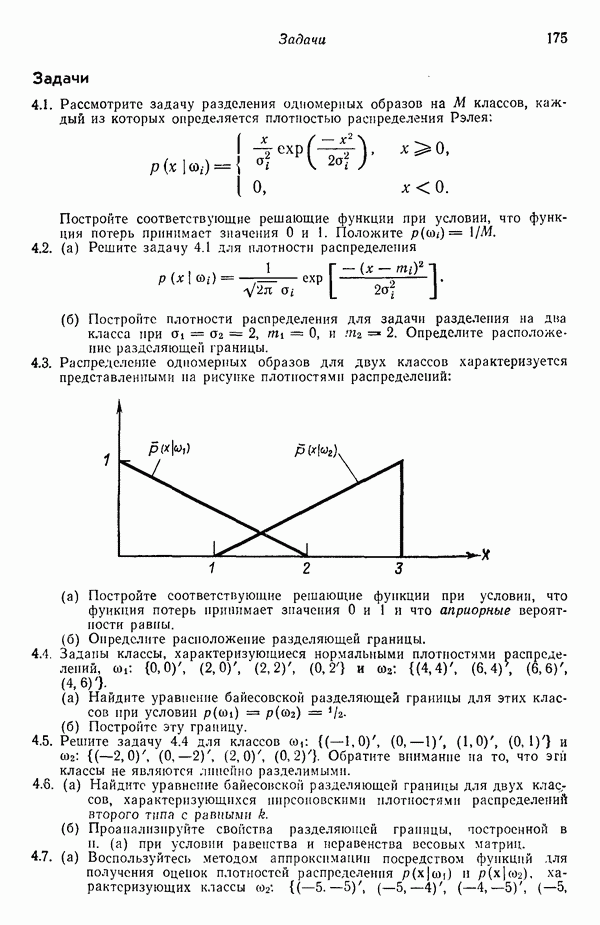


































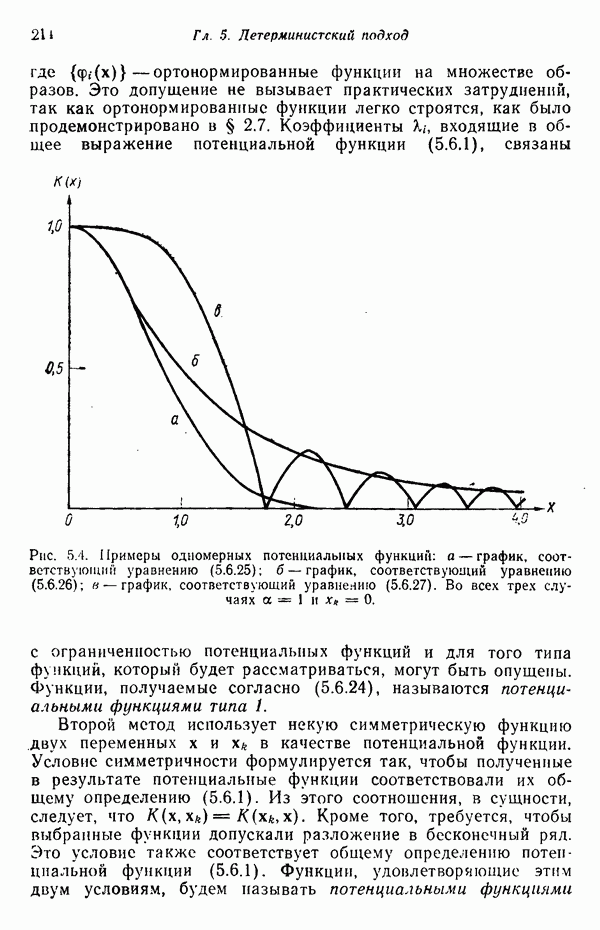

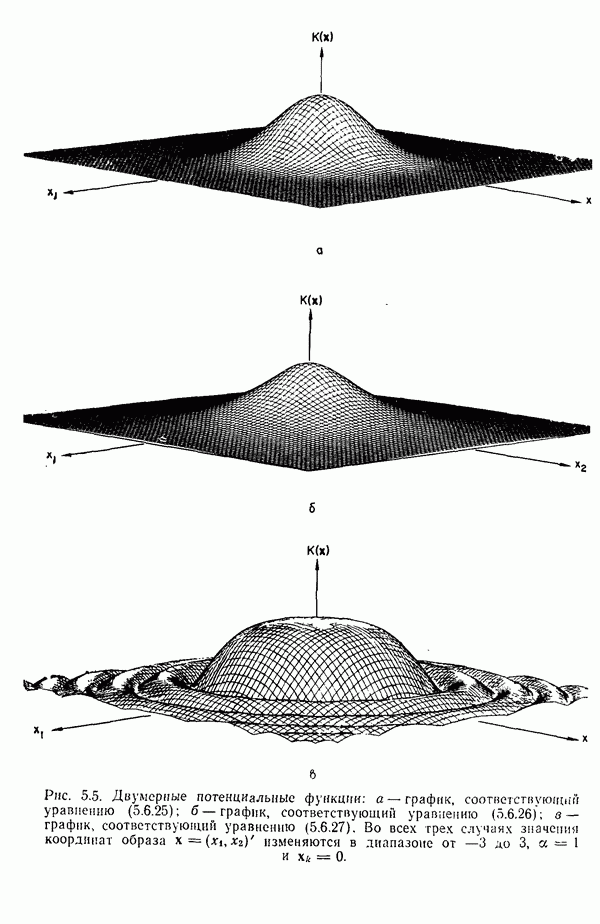
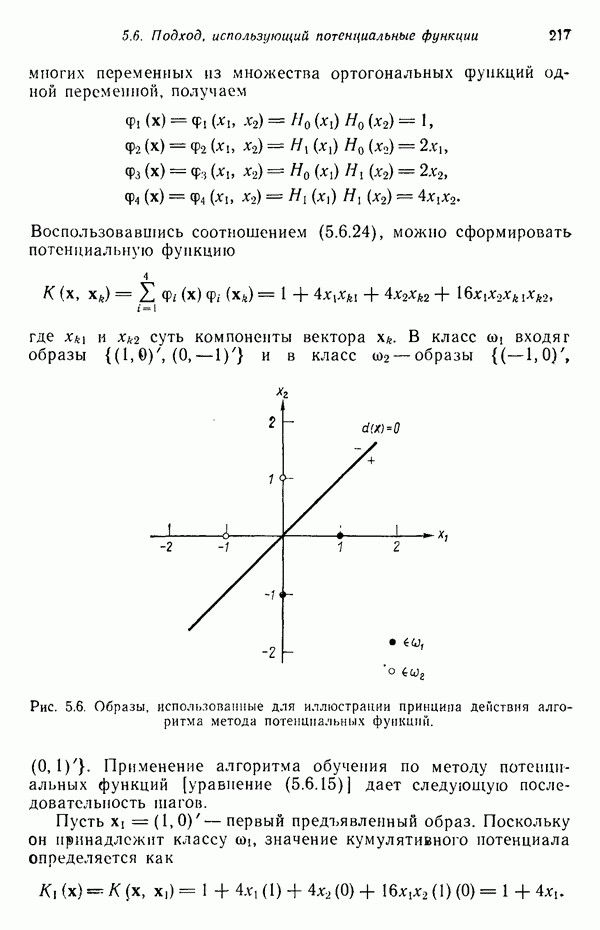
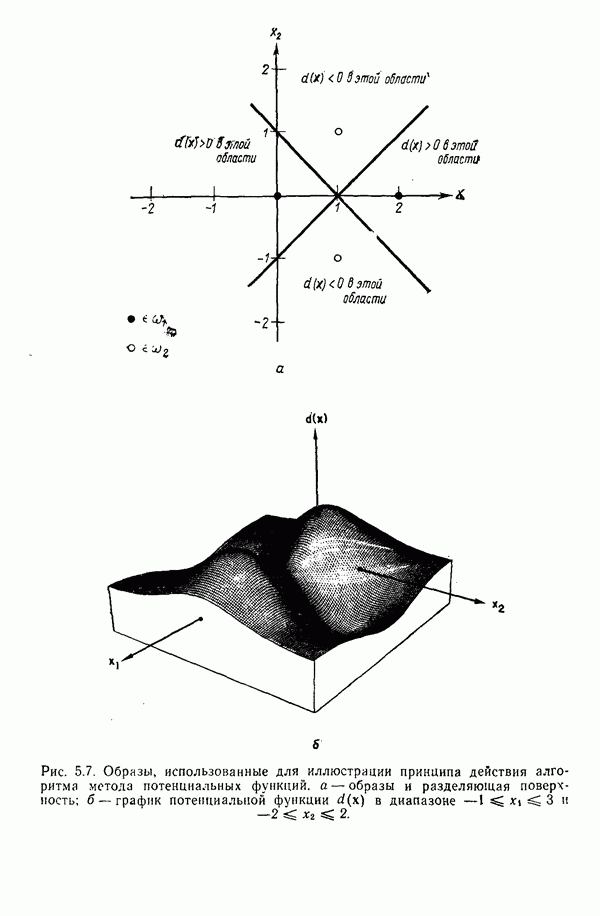



























































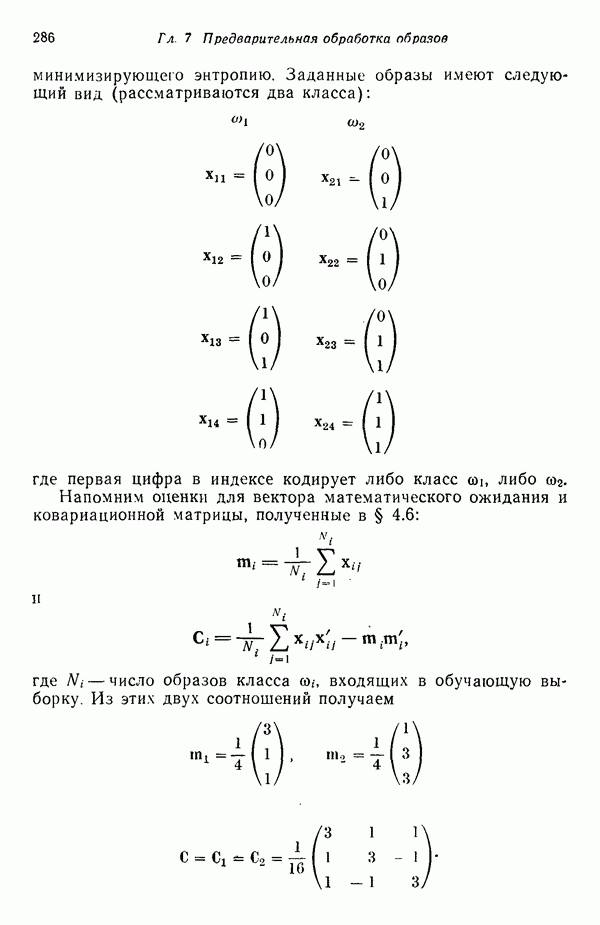













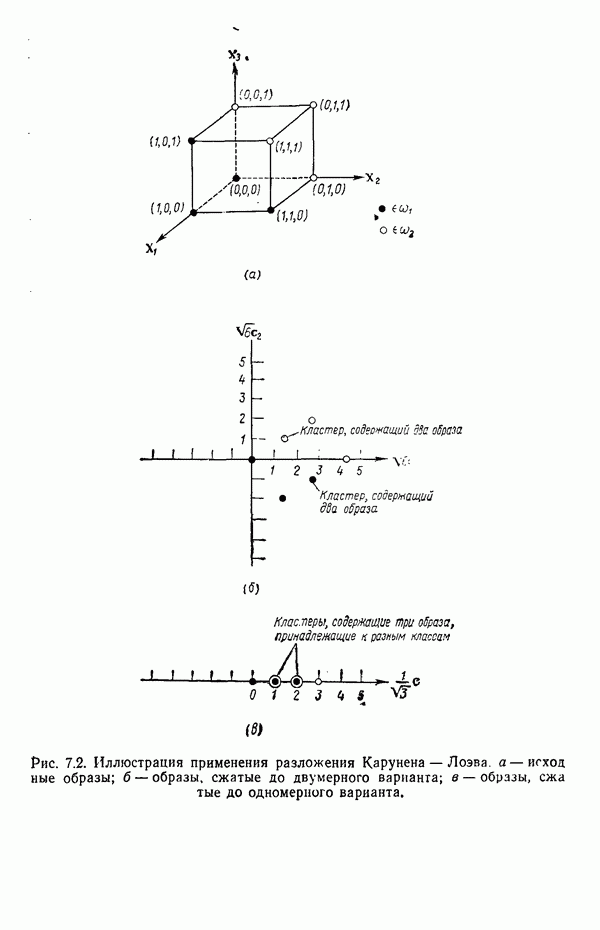



























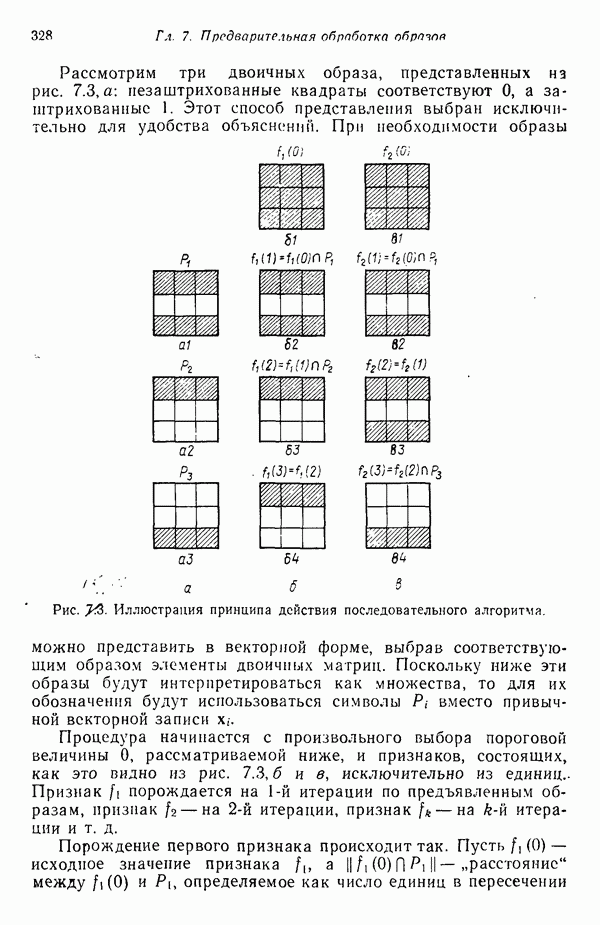



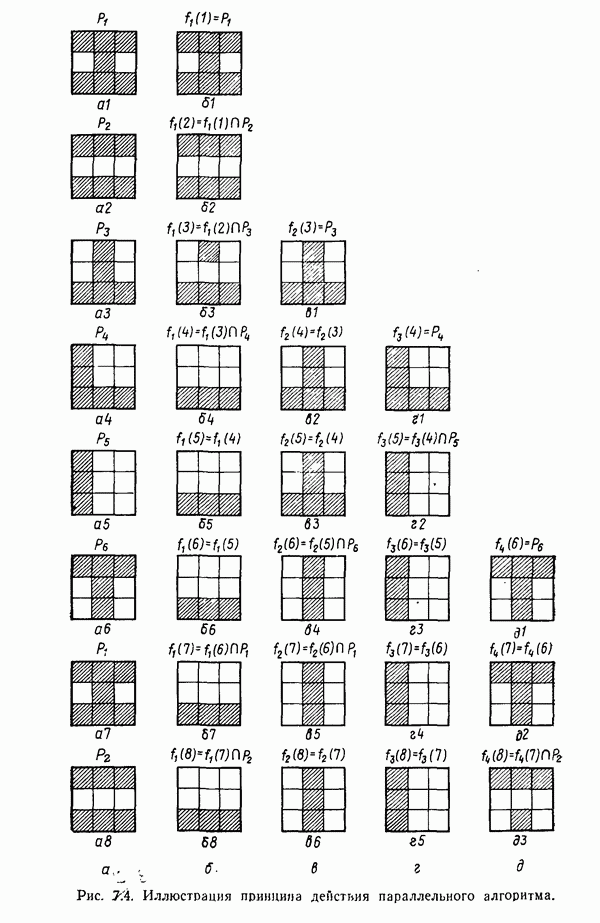




























































 в которых векторы образов характеризуются следующими плотностями многомерного нормального распределения:
в которых векторы образов характеризуются следующими плотностями многомерного нормального распределения:




 классу
классу  по критерию минимизации вероятности ошибки классификации, принимает вид
по критерию минимизации вероятности ошибки классификации, принимает вид

 равен логарифму пороговой величины
равен логарифму пороговой величины

 есть
есть  и вероятность неправильной классификации образа, принадлежащего классу
и вероятность неправильной классификации образа, принадлежащего классу  есть
есть 
 является линейной комбинацией компонент образа
является линейной комбинацией компонент образа  подчиняющихся нормальному распределению, то
подчиняющихся нормальному распределению, то  также описывается нормальным распределением. Поэтому на основании соотношения (4.4.4) математическое ожидание логарифма отношения правдоподобия
также описывается нормальным распределением. Поэтому на основании соотношения (4.4.4) математическое ожидание логарифма отношения правдоподобия  для класса
для класса  можно записать как
можно записать как



 . Если С — единичная матрица, то расстояние Махаланобиса
. Если С — единичная матрица, то расстояние Махаланобиса  представляет собой квадрат расстояния между средними значениями величин
представляет собой квадрат расстояния между средними значениями величин  .
.
 определяется как
определяется как




 подчиняется закону нормального распределения
подчиняется закону нормального распределения  Подобным же образом при
Подобным же образом при  соответствующий логарифм отношения правдоподобия
соответствующий логарифм отношения правдоподобия  подчиняется нормальному распределению
подчиняется нормальному распределению  . Следовательно,
. Следовательно,






 от величины расстояния Махаланобиса Гц приведен на рис. 4.4. Очевидно, что вероятность ошибки
от величины расстояния Махаланобиса Гц приведен на рис. 4.4. Очевидно, что вероятность ошибки  представляет собой монотонно убывающую функцию расстояния Махаланобиса
представляет собой монотонно убывающую функцию расстояния Махаланобиса  . При
. При  вероятность ошибки классификации меньше 5%.
вероятность ошибки классификации меньше 5%.
 к классу
к классу  если выполняется условие
если выполняется условие  и к классу
и к классу 
 выбран из совокупности, характеризующейся многомерным нормальным распределением, и
выбран из совокупности, характеризующейся многомерным нормальным распределением, и  линейная функция вектора образа
линейная функция вектора образа  то последняя описывается плотностью одномерного нормального распределения, среднее значение и дисперсия которого задаются следующим образом.
то последняя описывается плотностью одномерного нормального распределения, среднее значение и дисперсия которого задаются следующим образом.

 определяется как
определяется как

 по определению равна
по определению равна


 решающая функция
решающая функция  подчиняется нормальному распределению
подчиняется нормальному распределению  при
при  эта функция подчиняется нормальному распределению
эта функция подчиняется нормальному распределению  Поэтому вероятность ошибки определяется как
Поэтому вероятность ошибки определяется как




 вероятность ошибки классификации, определяемую формулой (4.4.26), можно представить следующим образом:
вероятность ошибки классификации, определяемую формулой (4.4.26), можно представить следующим образом:




 минимизируется при максимизации функций
минимизируется при максимизации функций  Поскольку интеграл вероятности ошибки
Поскольку интеграл вероятности ошибки  является однозначной и монотонно возрастающей функцией, то вероятность ошибки
является однозначной и монотонно возрастающей функцией, то вероятность ошибки  минимизируется при максимизации
минимизируется при максимизации  Отметим, что связь величин
Отметим, что связь величин  определяется выбором вектора весов
определяется выбором вектора весов  и пороговой величины 0. Оптимизационную задачу в этом случае можно сформулировать как задачу максимизации
и пороговой величины 0. Оптимизационную задачу в этом случае можно сформулировать как задачу максимизации  — при фиксированном значении
— при фиксированном значении  .
.


 есть функция вектора весов
есть функция вектора весов  максимальному значению
максимальному значению  соответствует равенство нулю производной
соответствует равенство нулю производной  Более строгое обоснование, в том числе доказательство достаточности, можно найти в статье Андерсона и Бахадура [1962].
Более строгое обоснование, в том числе доказательство достаточности, можно найти в статье Андерсона и Бахадура [1962].
 приводит к
приводит к



 . При использовании данного условия из (4.4.32) следует, что
. При использовании данного условия из (4.4.32) следует, что




 можно заменить вектором
можно заменить вектором  , где
, где  — произвольная положительная скалярная постоянная, что не нарушит справедливости соотношения. Постоянная
— произвольная положительная скалярная постоянная, что не нарушит справедливости соотношения. Постоянная  выбирается таким образом, чтобы выполнялось условие
выбирается таким образом, чтобы выполнялось условие


