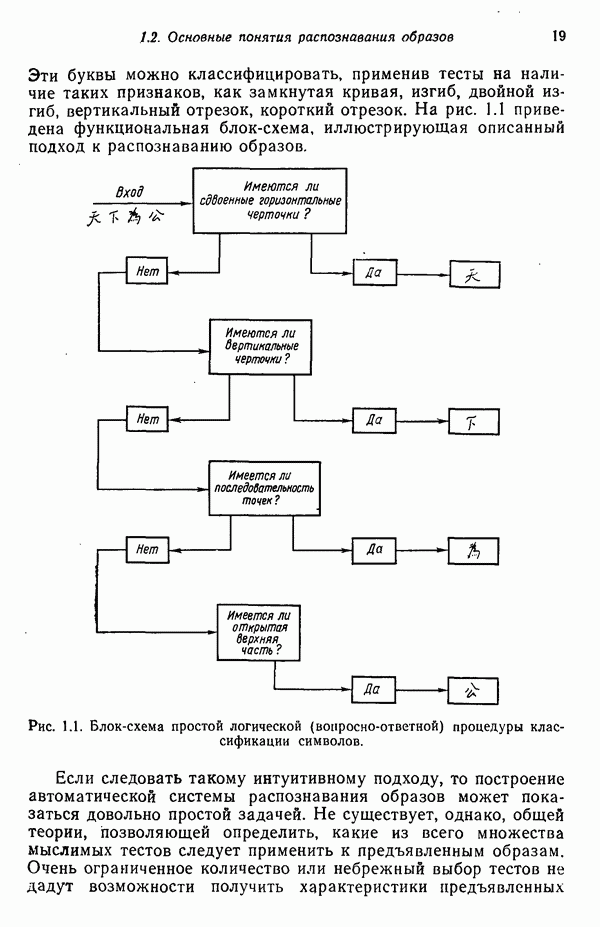
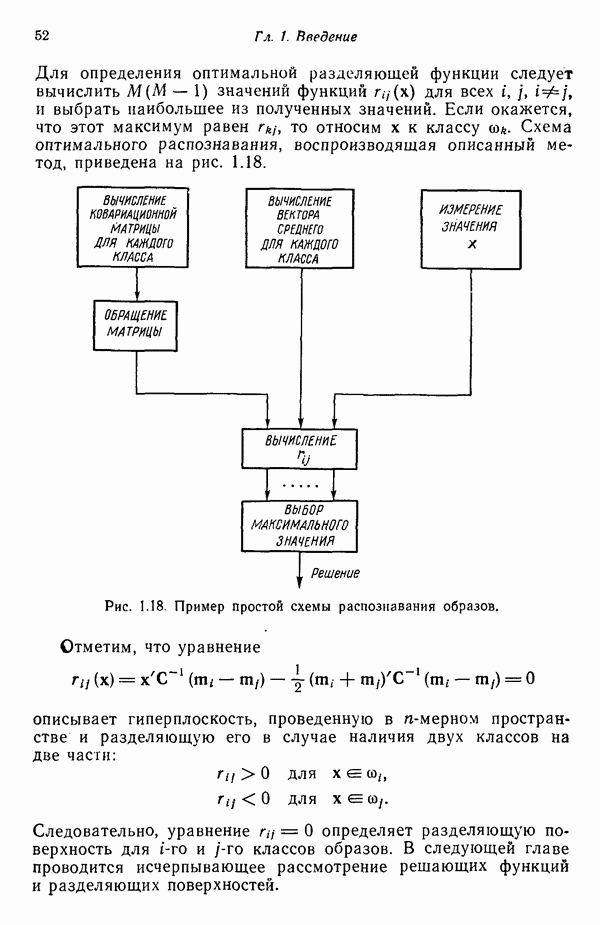
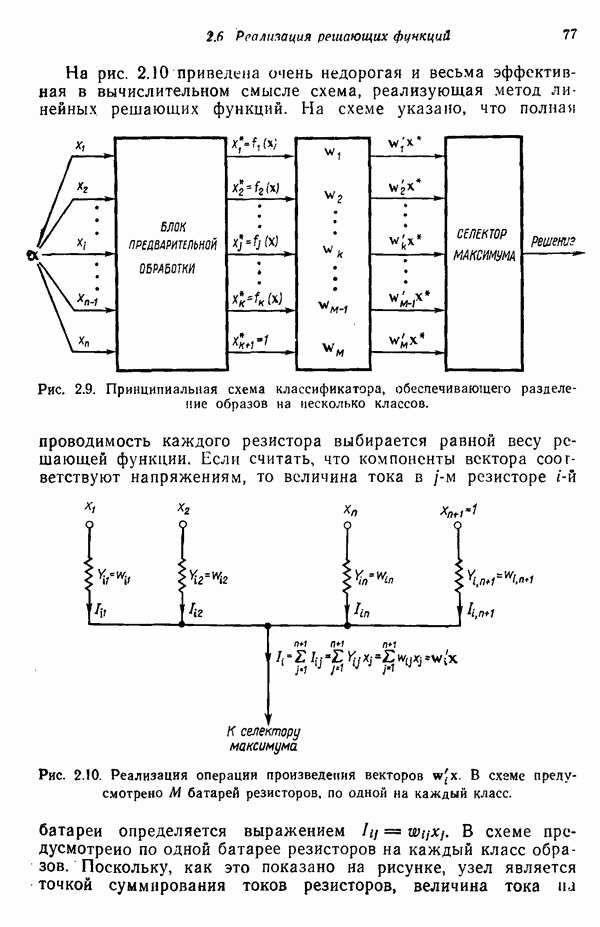
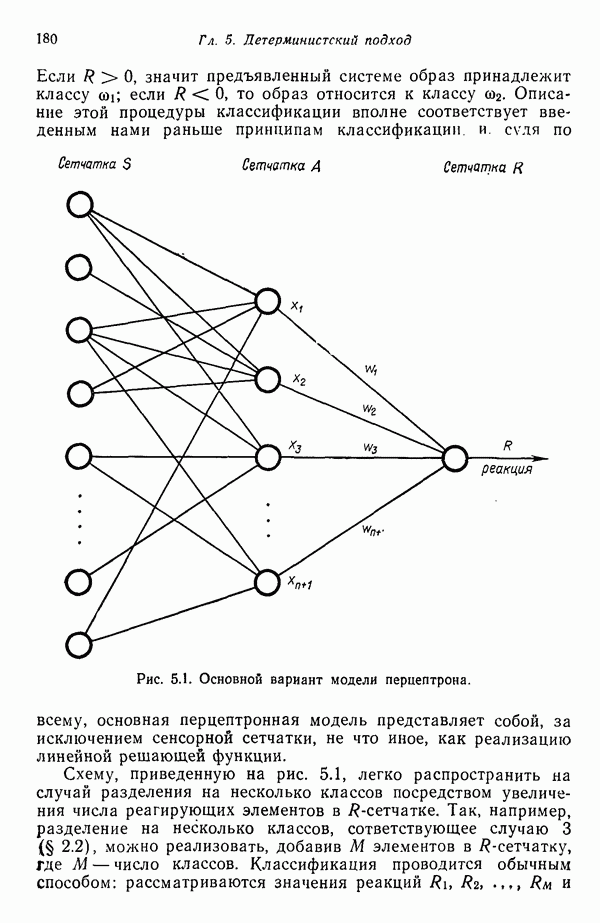
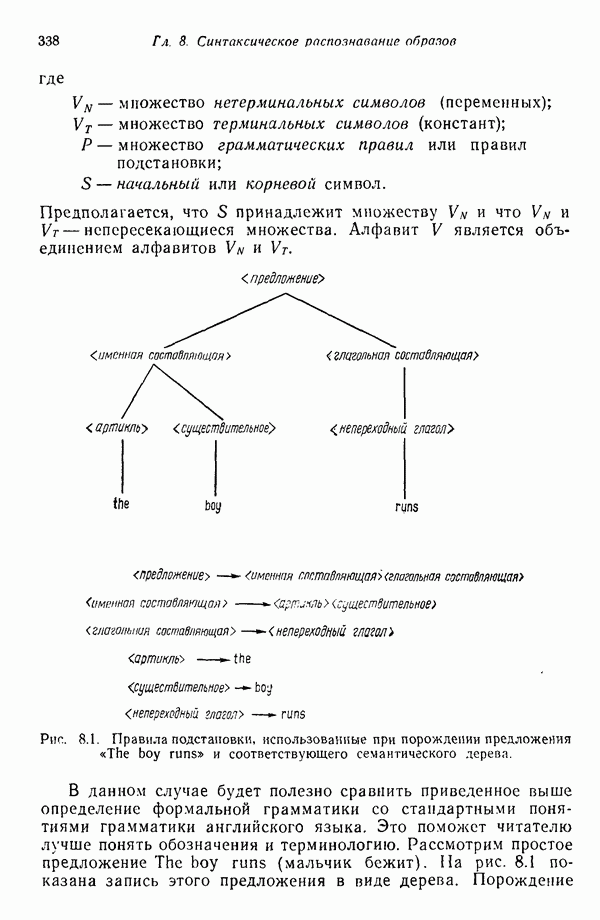
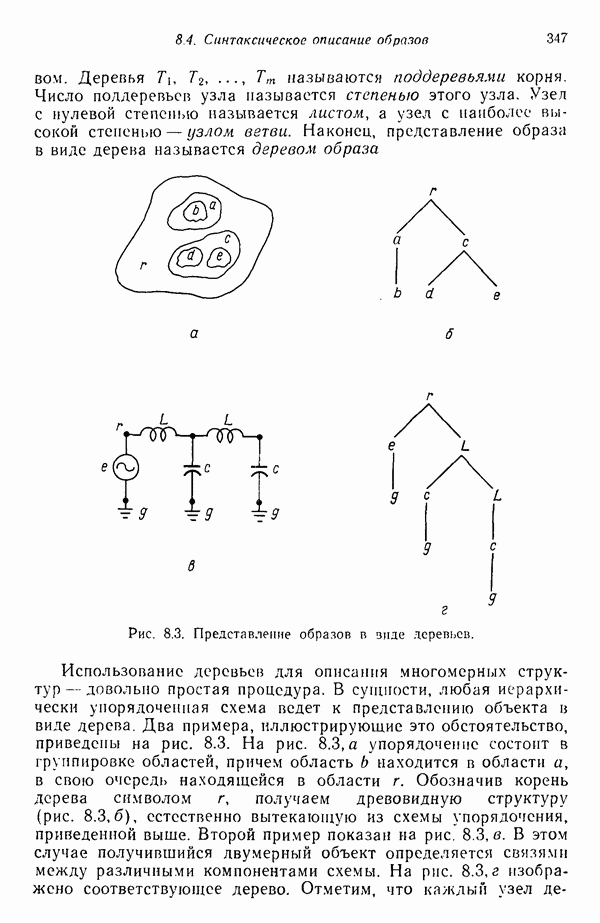
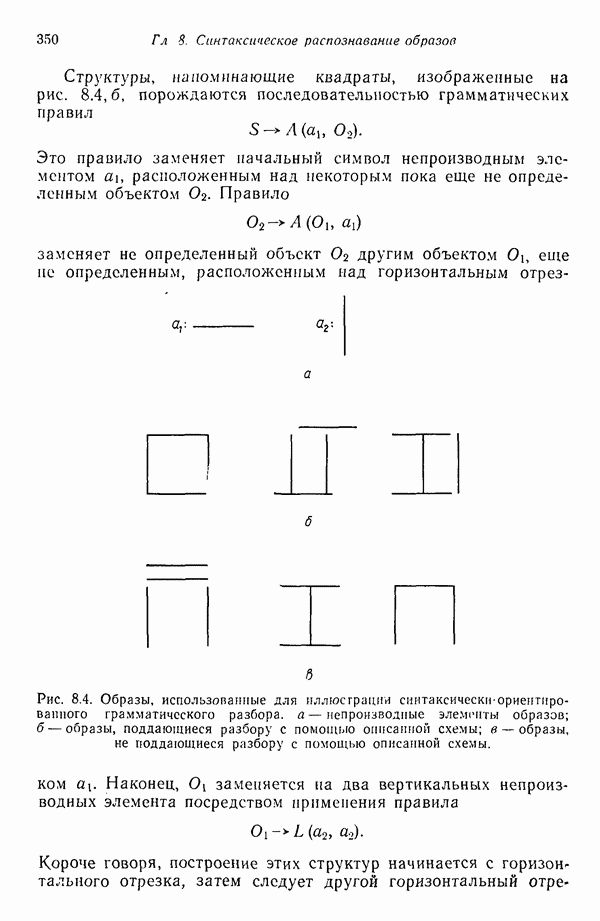
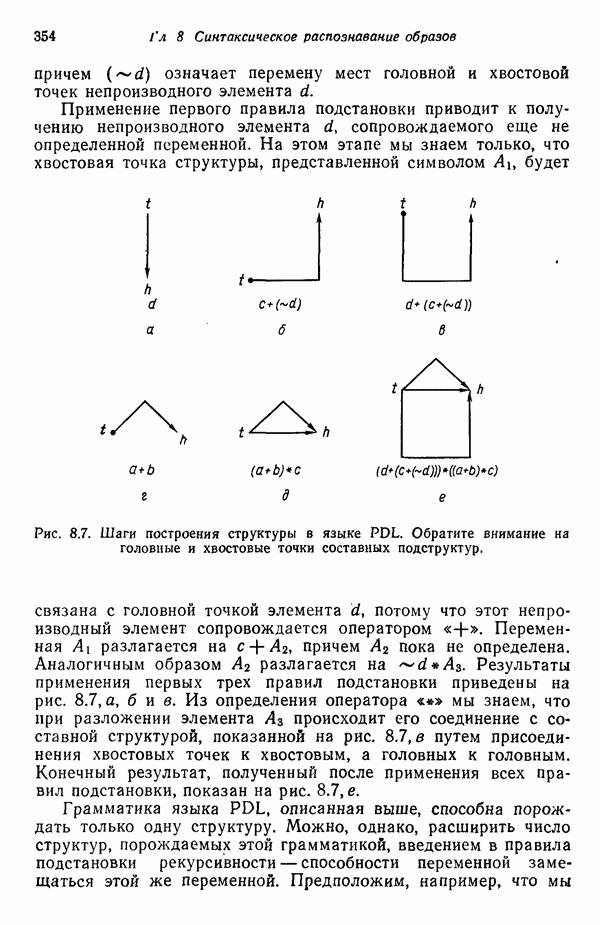
8.6.2. Оценка вероятностей правил подстановки с помощью процедур обучения
Переход от детерминированной к стохастической грамматике осуществляется относительно просто. Единственное различие между этими двумя типами грамматик заключается в наличии или отсутствии множества вероятностных мер для правил подстановки  . Естественно, если мы хотим использовать стохастические грамматики, необходимо обладать механизмом оценки этих вероятностей.
. Естественно, если мы хотим использовать стохастические грамматики, необходимо обладать механизмом оценки этих вероятностей.
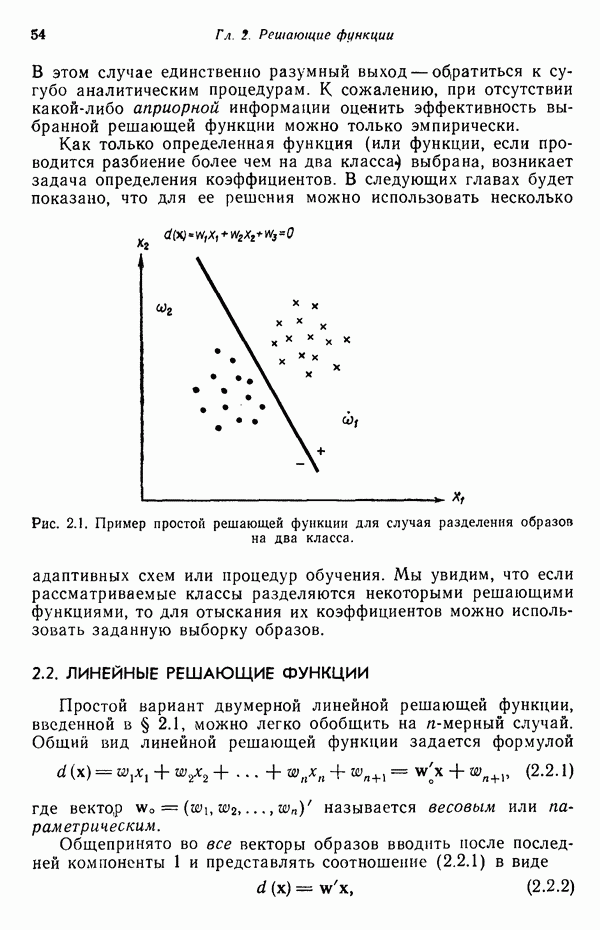
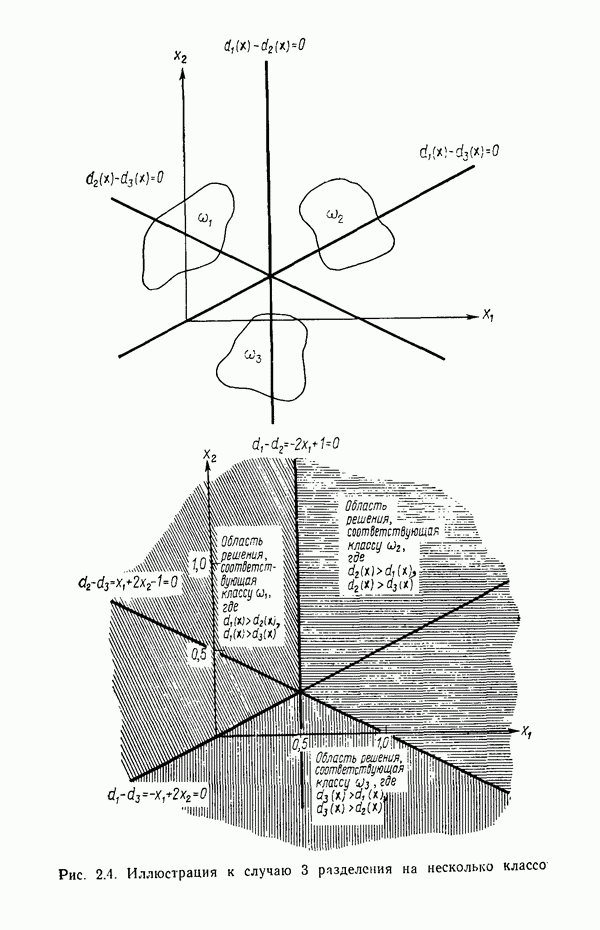
Рассмотрим задачу разделения М классов, характеризующуюся стохастическими грамматиками

Предполагается, что  и известны и грамматики однозначны. Так как все еще существует множество нерешенных задач, связанных с оценкой вероятностей правил подстановки, мы сосредоточим наше внимание только на бесконтекстных и регулярных грамматиках. Учитывая это ограничение, требуется оценить вероятности правил подстановки
и известны и грамматики однозначны. Так как все еще существует множество нерешенных задач, связанных с оценкой вероятностей правил подстановки, мы сосредоточим наше внимание только на бесконтекстных и регулярных грамматиках. Учитывая это ограничение, требуется оценить вероятности правил подстановки  , при помощи множества выборочных терминальных цепочек
, при помощи множества выборочных терминальных цепочек

где каждая цепочка принадлежит языку, порожденному одной из стохастических грамматик вида (8.6.7).
Собрав все цепочки, перенумеруем их и обозначим через  количество появлений цепочки
количество появлений цепочки  Каждая цепочка подвергается также разбору с помощью каждой грамматики, и число
Каждая цепочка подвергается также разбору с помощью каждой грамматики, и число  обозначает, сколько раз при грамматическом разборе цепочки
обозначает, сколько раз при грамматическом разборе цепочки  применялось правило подстановки
применялось правило подстановки  Хотя вероятности правил подстановки грамматик (8.6.7) нам не известны, предполагается, что сами правила подстановки мы знаем, поэтому грамматический разбор возможен.
Хотя вероятности правил подстановки грамматик (8.6.7) нам не известны, предполагается, что сами правила подстановки мы знаем, поэтому грамматический разбор возможен.
Математическое ожидание  числа вхождений правила подстановки
числа вхождений правила подстановки  грамматики
грамматики  в грамматический разбор данной цепочки можно аппроксимировать следующим выражением:
в грамматический разбор данной цепочки можно аппроксимировать следующим выражением:

где  — вероятность порождения данной цепочки
— вероятность порождения данной цепочки  грамматикой
грамматикой  . В процессе обучения эта вероятность должна быть определена для каждой цепочки.
. В процессе обучения эта вероятность должна быть определена для каждой цепочки.
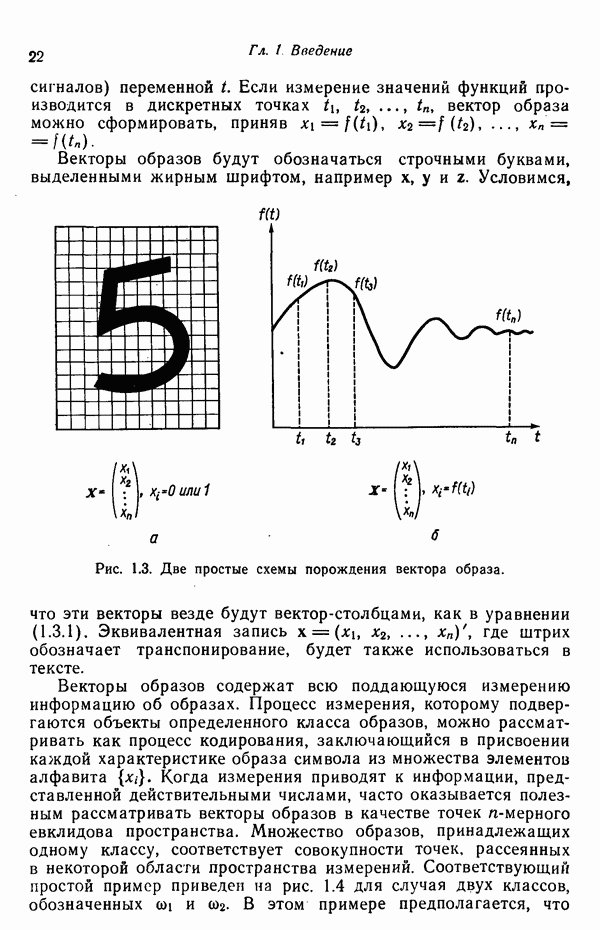
Вероятность  применения правила подстановки
применения правила подстановки  в грамматике
в грамматике  может теперь быть аппроксимирована соотношением
может теперь быть аппроксимирована соотношением

где  — оценка вероятности
— оценка вероятности  а суммирование в знаменателе (8.6.10) выполняется по всем правилам подстановки грамматики
а суммирование в знаменателе (8.6.10) выполняется по всем правилам подстановки грамматики  имеющим вид
имеющим вид  , т. е. для всех правил подстановки грамматики
, т. е. для всех правил подстановки грамматики  с одинаковой нетерминальной левой частью
с одинаковой нетерминальной левой частью  .
.
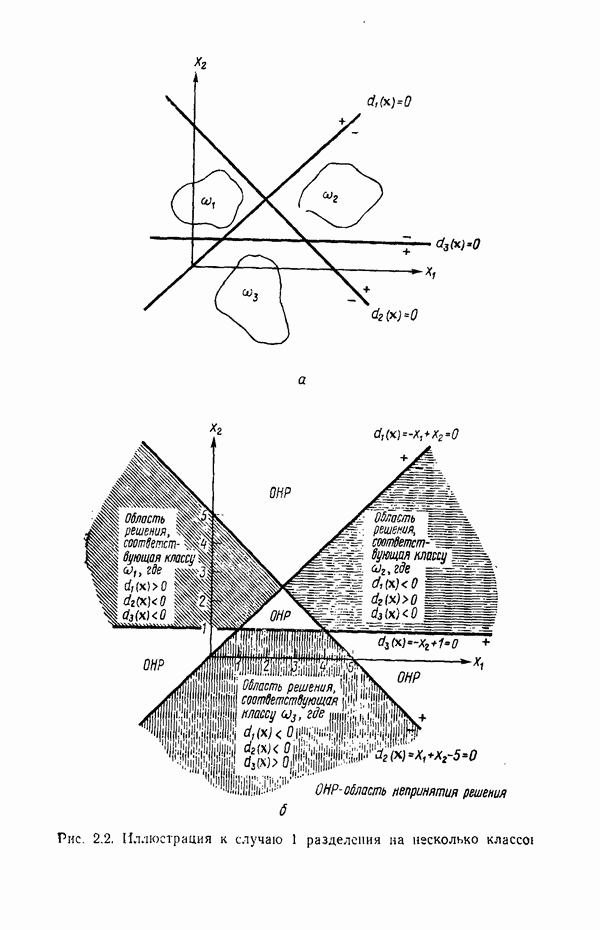
Как было показано Ли и Фу [1972], по мере приближения числа цепочек в Т к бесконечности оценка вероятности  приближается к истинной вероятности правила подстановки
приближается к истинной вероятности правила подстановки  при выполнении следующих условий:
при выполнении следующих условий:
1. Множество Т — репрезентативное подмножество языков  , в том смысле, что
, в том смысле, что  , где
, где  — объединение языков, т. е.
— объединение языков, т. е.  .
.
2. Оценка вероятности появления цепочки  в множестве Т, определяемая соотношением
в множестве Т, определяемая соотношением

приближается к истинной вероятности 
3. В процессе обучения для каждой цепочки  может быть определена вероятность
может быть определена вероятность  .
.
Вероятность  того, что данная цепочка
того, что данная цепочка  принадлежит классу
принадлежит классу  обычно без труда может быть установлена в обучающей фазе. Если определенно известно, что данная цепочка принадлежит исключительно классу
обычно без труда может быть установлена в обучающей фазе. Если определенно известно, что данная цепочка принадлежит исключительно классу  , то
, то  . Аналогично, если известно, что
. Аналогично, если известно, что  не может принадлежать
не может принадлежать  , то
, то  Часто, однако, вследствие обсужденных в начале этого раздела причин некоторые цепочки могут принадлежать более чем одному классу. В этом случае можно получить простую оценку вероятности
Часто, однако, вследствие обсужденных в начале этого раздела причин некоторые цепочки могут принадлежать более чем одному классу. В этом случае можно получить простую оценку вероятности  , для этих цепочек, фиксируя относительную частоту, с которой они встречаются в каждом классе. При этом, конечно, необходимо, чтобы
, для этих цепочек, фиксируя относительную частоту, с которой они встречаются в каждом классе. При этом, конечно, необходимо, чтобы

Когда невозможно определить относительную встречаемость «неоднозначных» цепочек в каком-либо определенном классе, наиболее оправданным для этих цепочек считается обычно допущение  .
.
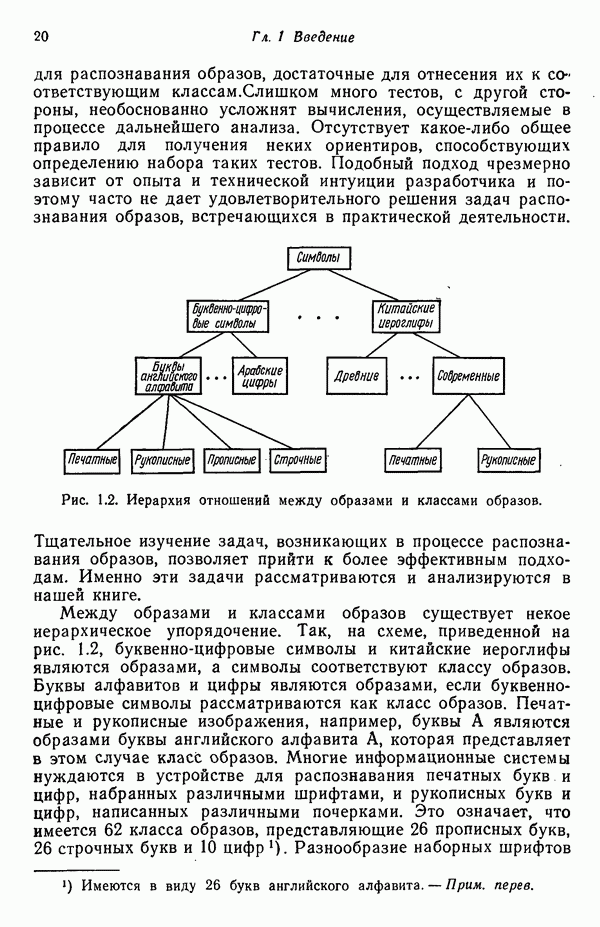
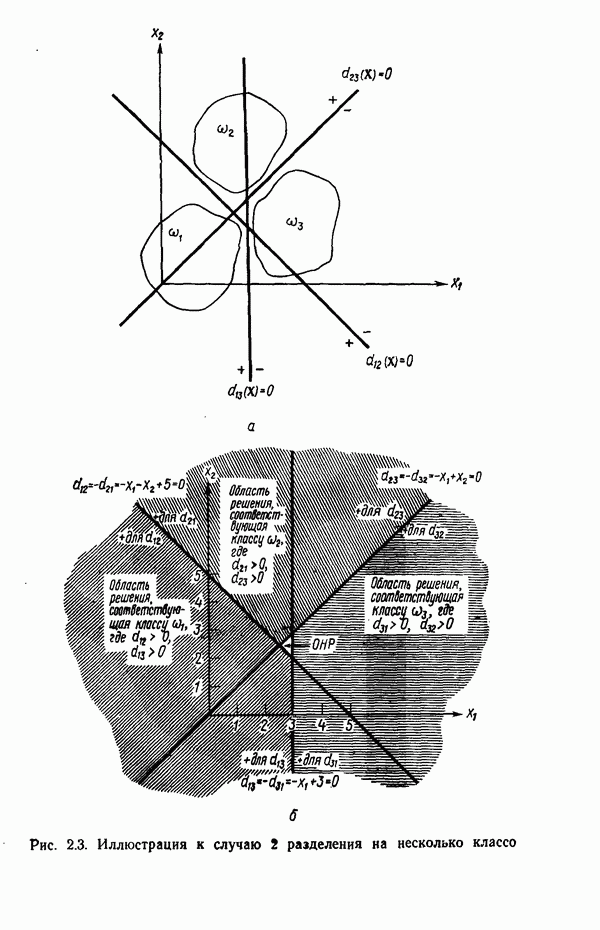
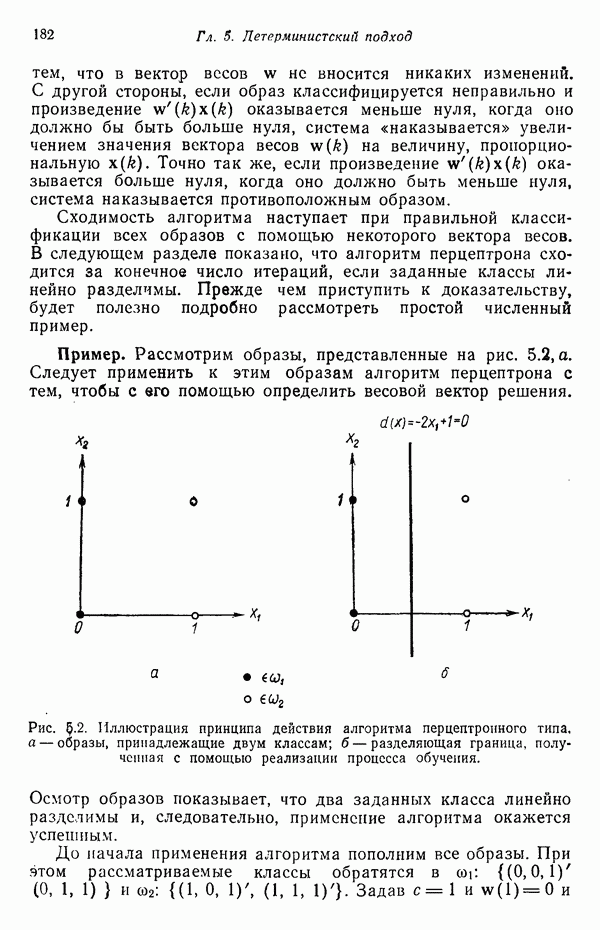
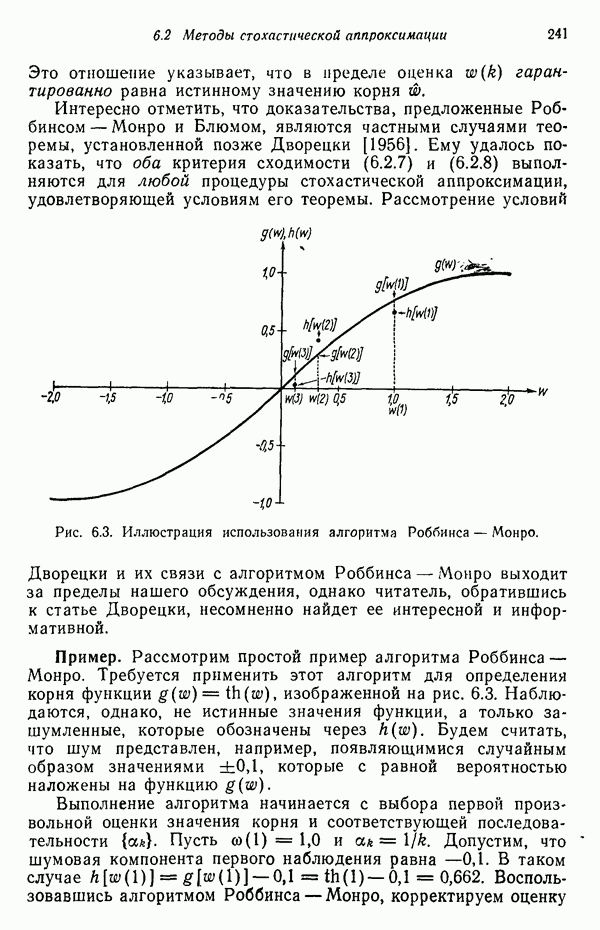
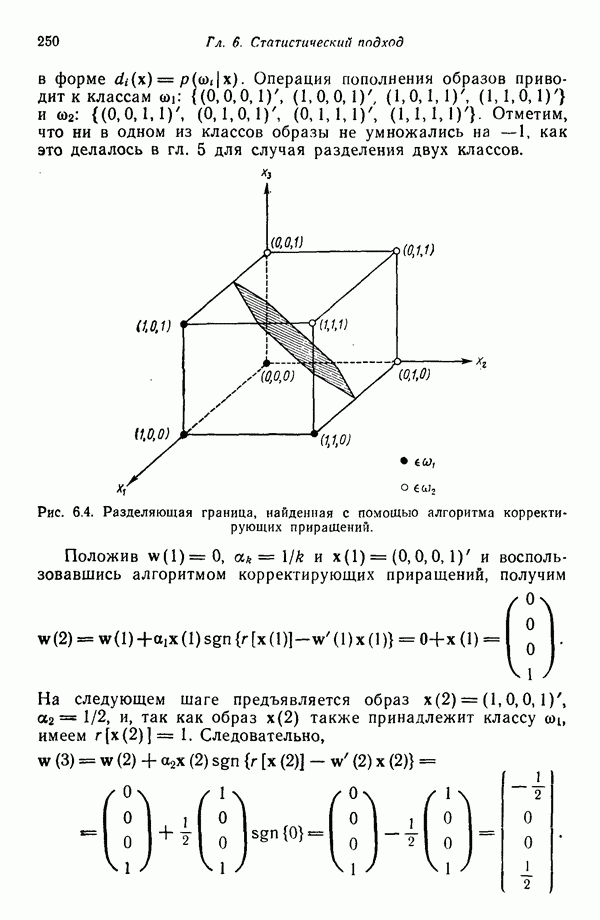
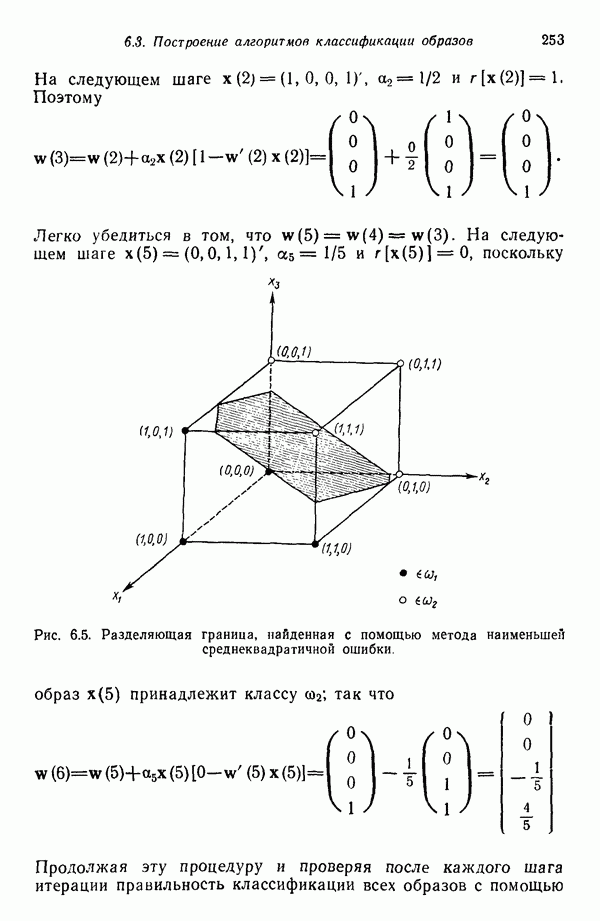
Пример. Проиллюстрируем представленные в этом параграфе понятия простым числовым примером. Рассмотрим стохастические грамматики

где для обеих грамматик

Правила подстановки и соответствующие им вероятности заданы следующим образом:

Требуется определить с помощью обучающей процедуры вероятности, входящие в  и
и
Для того чтобы не отклоняться от принятой ранее системы обозначений, можно изменить приведенные выше обозначения следующим образом:

где мы задаем  Индексы вероятностей интерпретируются так же, как и раньше, т. е. первый индекс представляет класс, второй означает индекс левой части правила подстановки, третий — индекс правой части правила подстановки. В данном случае все левые части идентичны.
Индексы вероятностей интерпретируются так же, как и раньше, т. е. первый индекс представляет класс, второй означает индекс левой части правила подстановки, третий — индекс правой части правила подстановки. В данном случае все левые части идентичны.
Для наглядности предположим, что класс  включает в себя только цепочки, составленные из символов
включает в себя только цепочки, составленные из символов  , а класс
, а класс  — только цепочки из символов
— только цепочки из символов  Однако вследствие вмешательства шума иногда могут встречаться и смешанные цепочки. Отметим, что, хотя обе грамматики
Однако вследствие вмешательства шума иногда могут встречаться и смешанные цепочки. Отметим, что, хотя обе грамматики  могут порождать смешанные цепочки, в этом примере мы будем считать, что
могут порождать смешанные цепочки, в этом примере мы будем считать, что  используется только для порождения цепочек, состоящих из а,
используется только для порождения цепочек, состоящих из а,
и  используется только для порождения цепочек, состоящих из
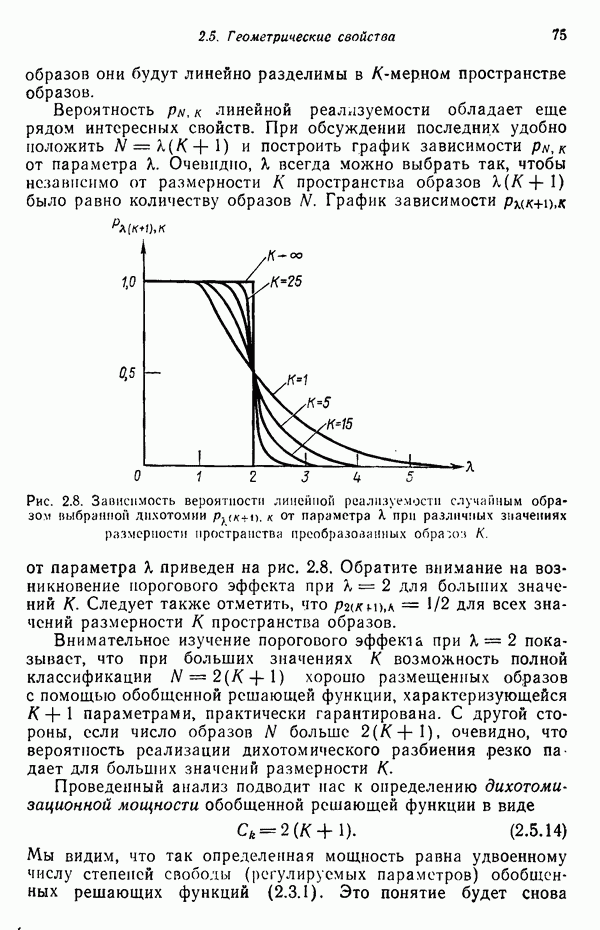
используется только для порождения цепочек, состоящих из  . Предположим далее, что обучающая выборка состоит из 100 образов-цепочек со следующими характеристиками: цепочка
. Предположим далее, что обучающая выборка состоит из 100 образов-цепочек со следующими характеристиками: цепочка  . Число появлений цепочки
. Число появлений цепочки

Обозначив первый тип цепочки  , второй —
, второй —  получаем
получаем

Для оценки вероятностей  по формуле (8.6.10) необходимо сначала вычислить значения
по формуле (8.6.10) необходимо сначала вычислить значения  Согласно (8.6.9),
Согласно (8.6.9),

где Т состоит из 30 цепочек  цепочек
цепочек  . Используя это соотношение, мы получаем для дласса
. Используя это соотношение, мы получаем для дласса 

Проанализируем это выражение более подробно. Величина  известна,
известна,  есть вероятность того, что цепочка
есть вероятность того, что цепочка  принадлежит к классу
принадлежит к классу  Можно предположить, что эта вероятность равна 1, поскольку состоит только из элементов а. Коэффициент
Можно предположить, что эта вероятность равна 1, поскольку состоит только из элементов а. Коэффициент  — число использований в грамматическом разборе цепочки
— число использований в грамматическом разборе цепочки  правила
правила  Так как видно, что это правило подстановки не участвует в разборе
Так как видно, что это правило подстановки не участвует в разборе  то
то  . Аналогичным образом вычисляется второе слагаемое. Третья цепочка содержит как символы а, так и
. Аналогичным образом вычисляется второе слагаемое. Третья цепочка содержит как символы а, так и  и поэтому может принадлежать любому из двух классов. Допуская, что вероятности ее принадлежности клаёсу
и поэтому может принадлежать любому из двух классов. Допуская, что вероятности ее принадлежности клаёсу  и классу
и классу  равны, считаем
равны, считаем  . В общем случае, как упоминалось ранее, знание
. В общем случае, как упоминалось ранее, знание
В нашем примере все левые части правил подстановки идентичны. Следовательно,

Как и ожидалось, правила подстановки класса  связанные с порождением цепочек из элементов а, обладают большей вероятностью.
связанные с порождением цепочек из элементов а, обладают большей вероятностью.
Вычисление вероятностей правил подстановки для класса  аналогично только что проделанной процедуре. Из того, что правила подстановки этих двух грамматик идентичны, вытекает
аналогично только что проделанной процедуре. Из того, что правила подстановки этих двух грамматик идентичны, вытекает  Использование для этих величин значений, приведенных ранее в таблице, приводит к следующим
Использование для этих величин значений, приведенных ранее в таблице, приводит к следующим 

В данном случае  несомненно принадлежат классу
несомненно принадлежат классу  поэтому можно предположить, что
поэтому можно предположить, что  . Аналогичным образом
. Аналогичным образом  Кроме того, из нашего допущения о разбиении точно на два класса вытекает, что
Кроме того, из нашего допущения о разбиении точно на два класса вытекает, что  Используя эти вероятности, а также табличные значения, получаем
Используя эти вероятности, а также табличные значения, получаем


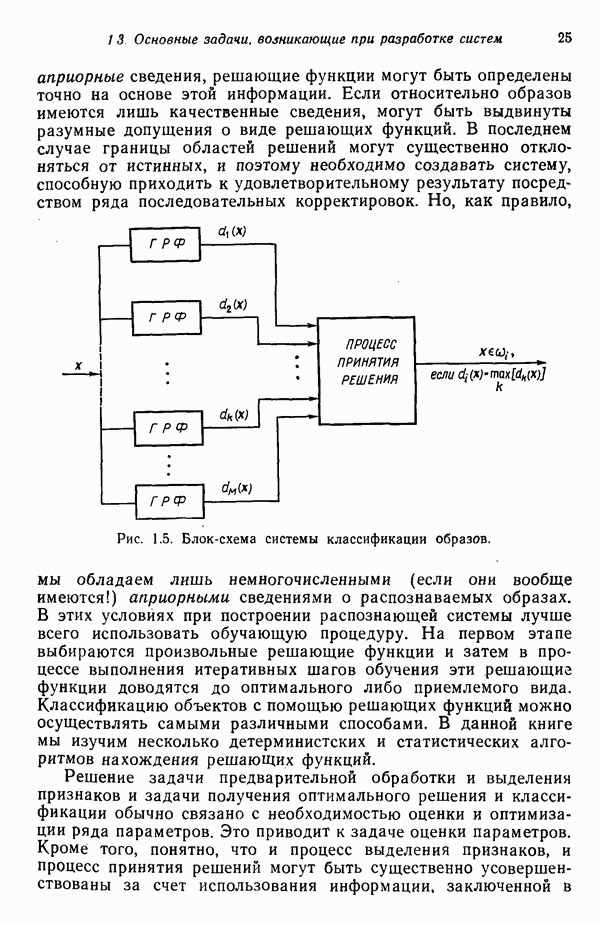
Вероятности правил подстановки могут теперь быть вычислены при помощи соотношения

где, как и ранее, суммирование происходит по всем правилам подстановки грамматики  имеющим одинаковую нетерминальную левую часть
имеющим одинаковую нетерминальную левую часть  в данном случае это верно для всех правил подстановки. Использование приведенного соотношения дает следующий результат:
в данном случае это верно для всех правил подстановки. Использование приведенного соотношения дает следующий результат:

Вычислив по выборочным цепочкам вероятность всех правил подстановки, теперь можно полностью определить стохастическую грамматику для данного примера:

где для каждой грамматики

и




















































































































































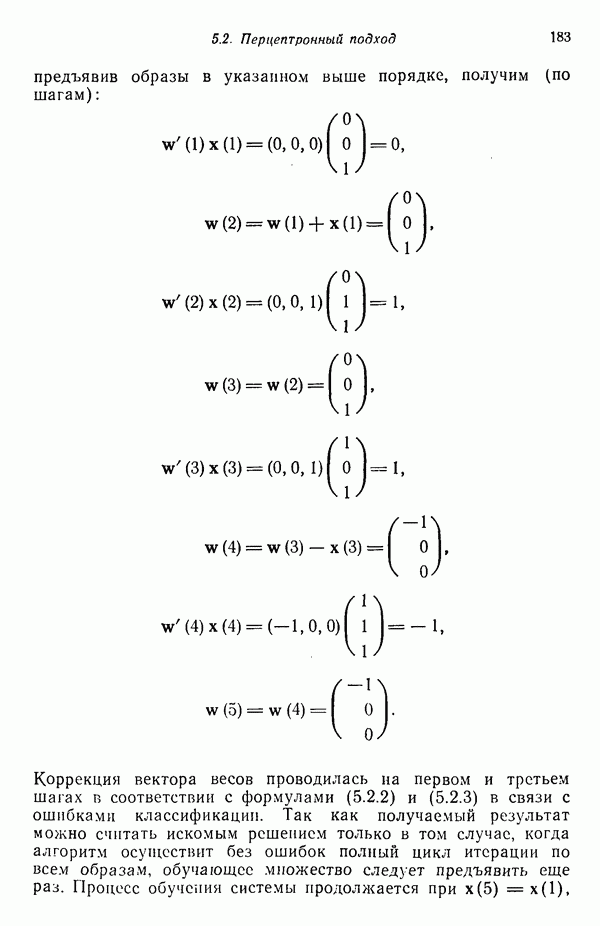
































































































































































































 в четвертом и пятом слагаемых относим к
в четвертом и пятом слагаемых относим к  поскольку они состоят исключительно из символов
поскольку они состоят исключительно из символов  . Отметим также, что
. Отметим также, что  поскольку правило
поскольку правило  участвует в грамматическом разборе этих цепочек. Учитывая все эти соображения, получаем
участвует в грамматическом разборе этих цепочек. Учитывая все эти соображения, получаем

 :
:
 что приводит к
что приводит к

 по формуле
по формуле

 с одинаковой нетерминальной левой частью
с одинаковой нетерминальной левой частью  .
.