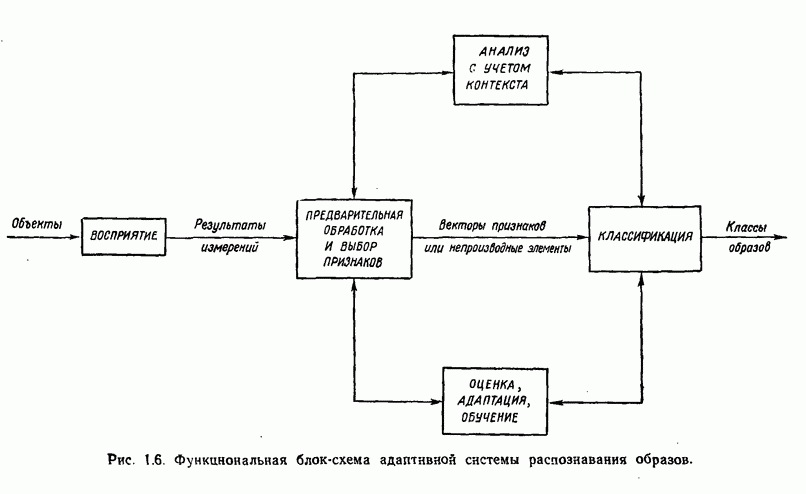
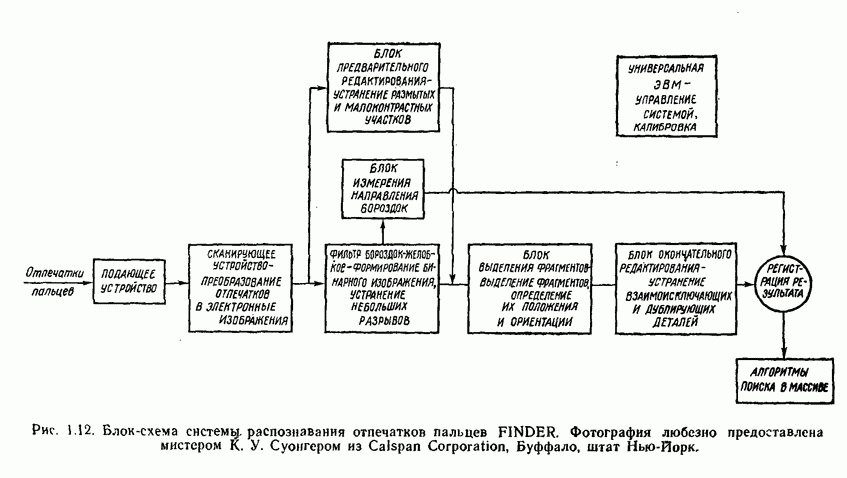
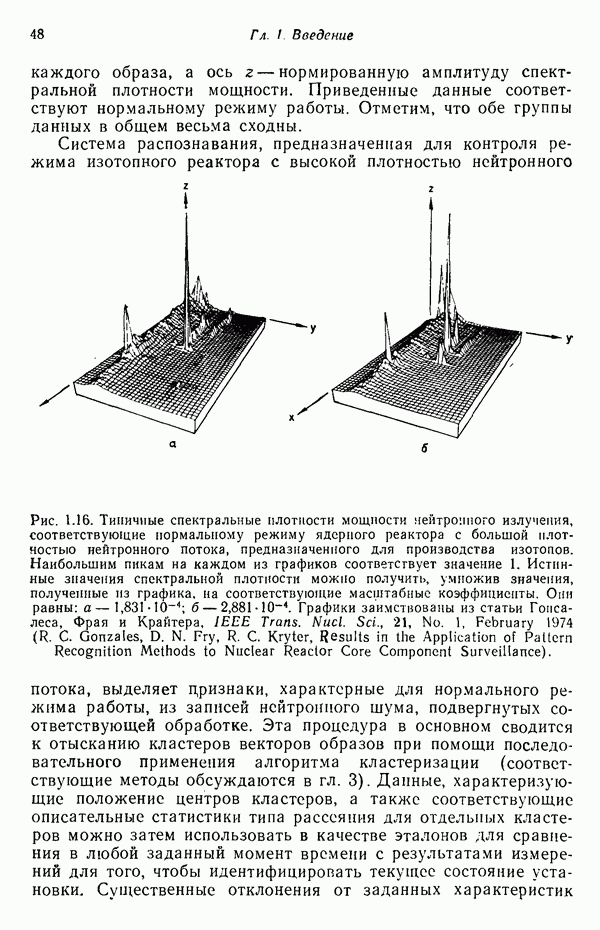
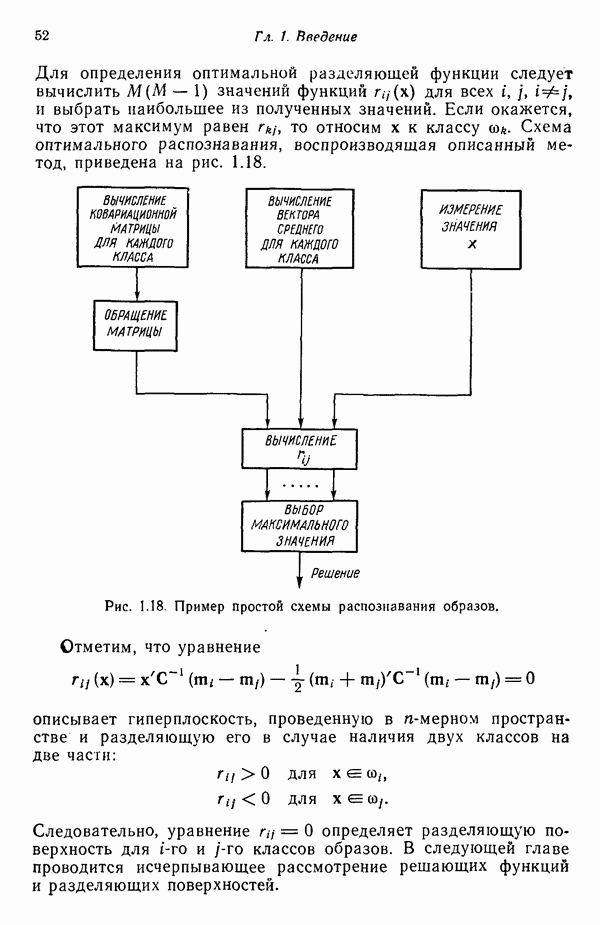
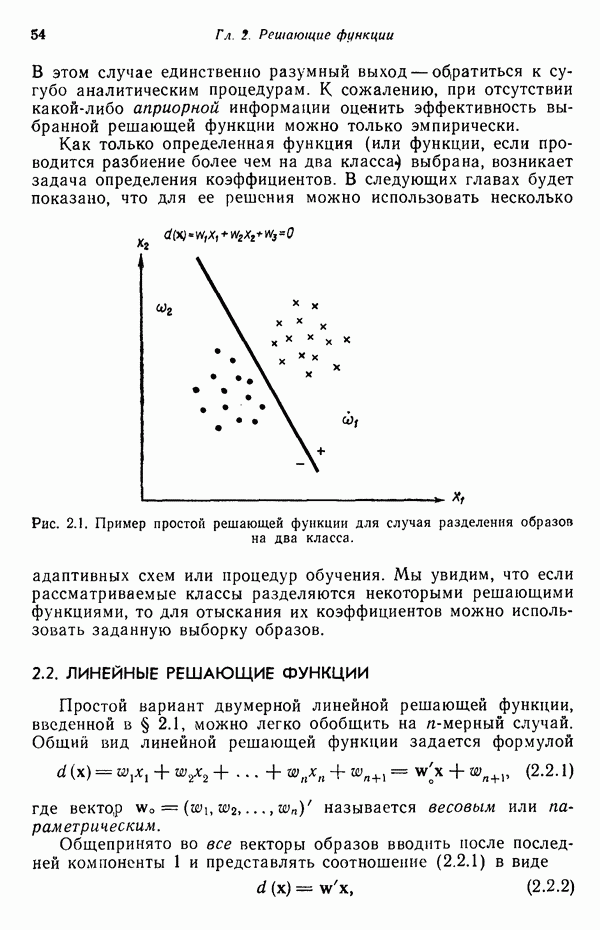
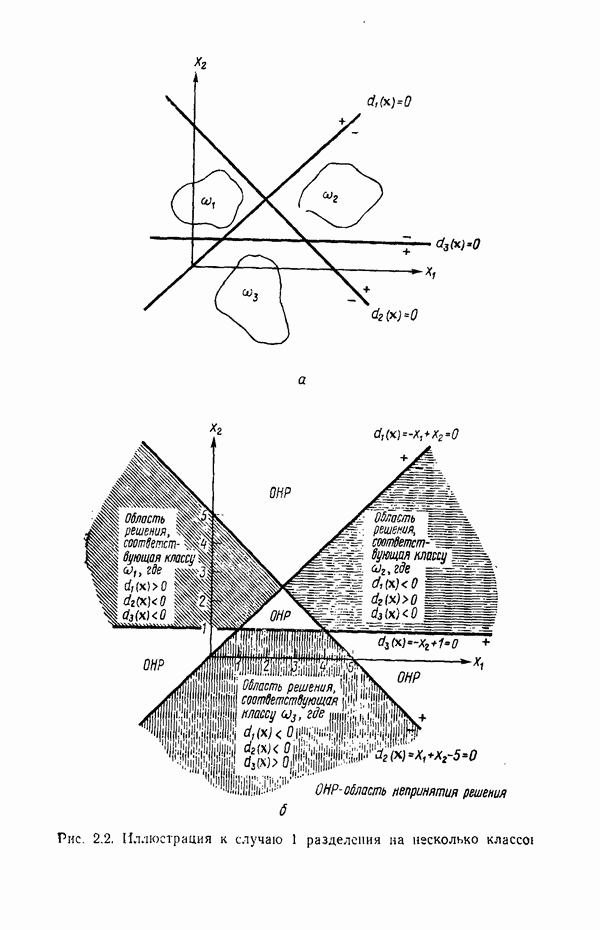
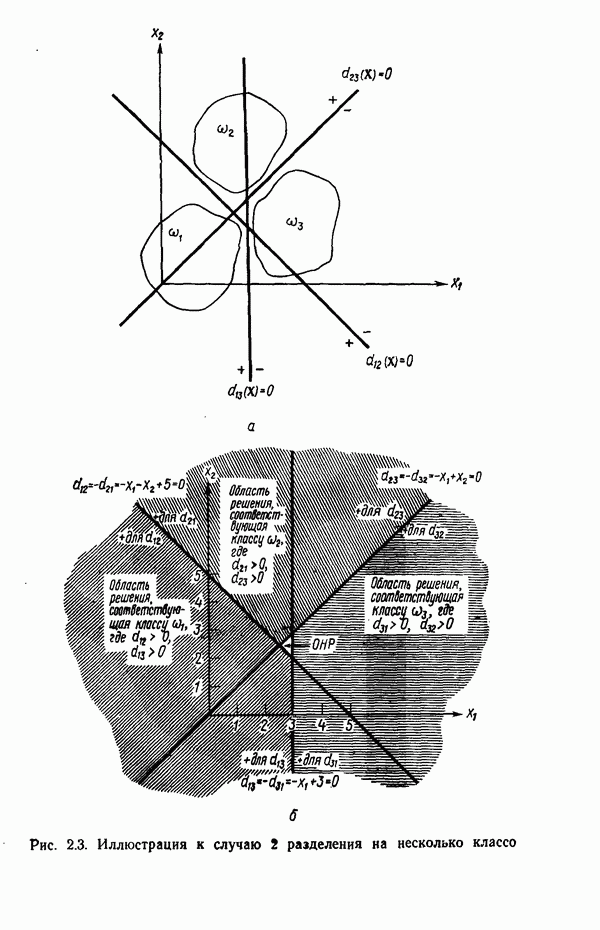
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
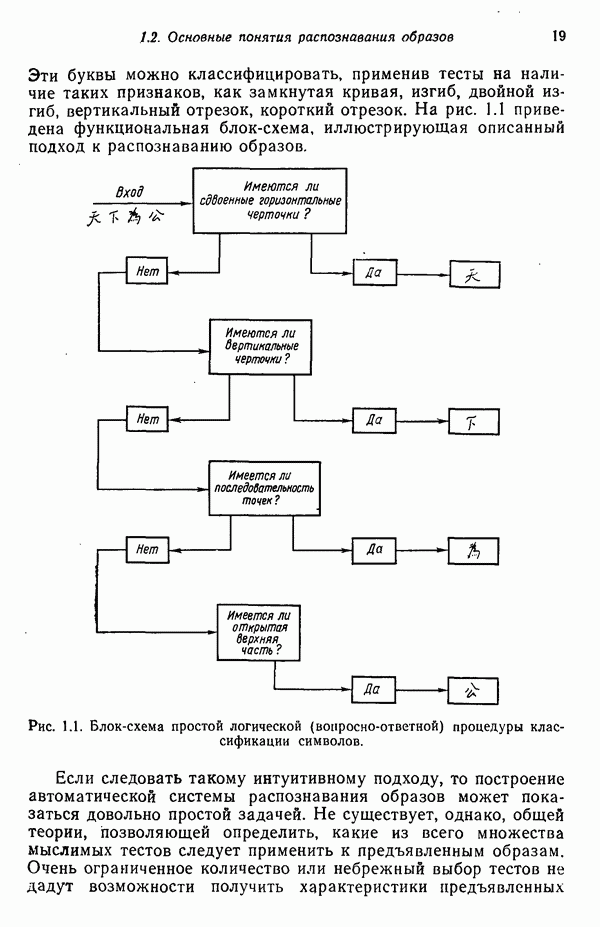
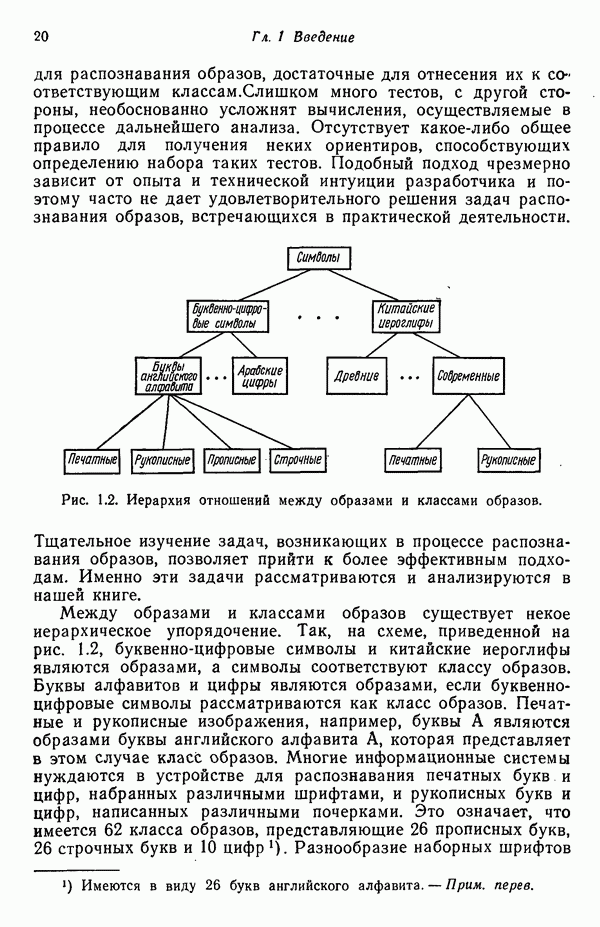
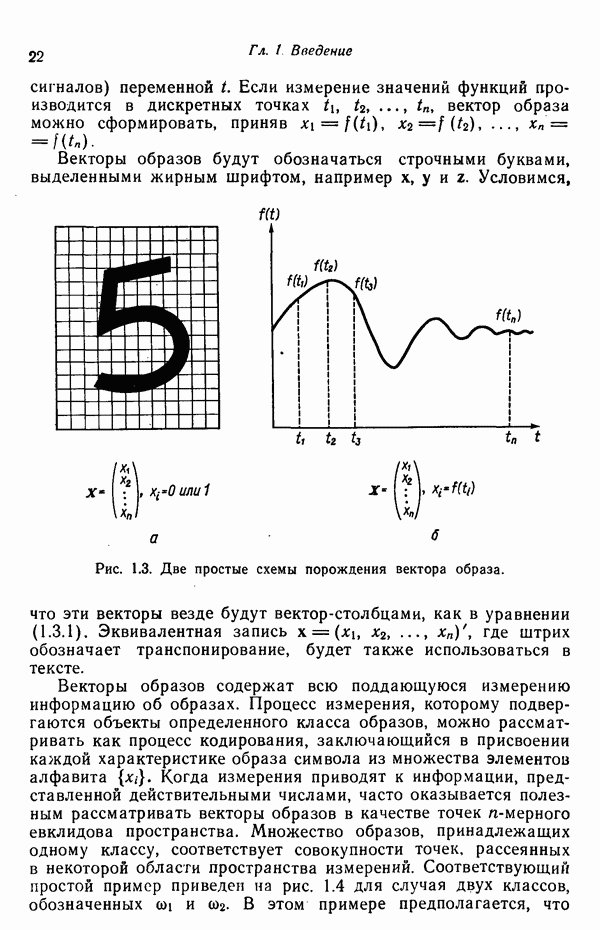
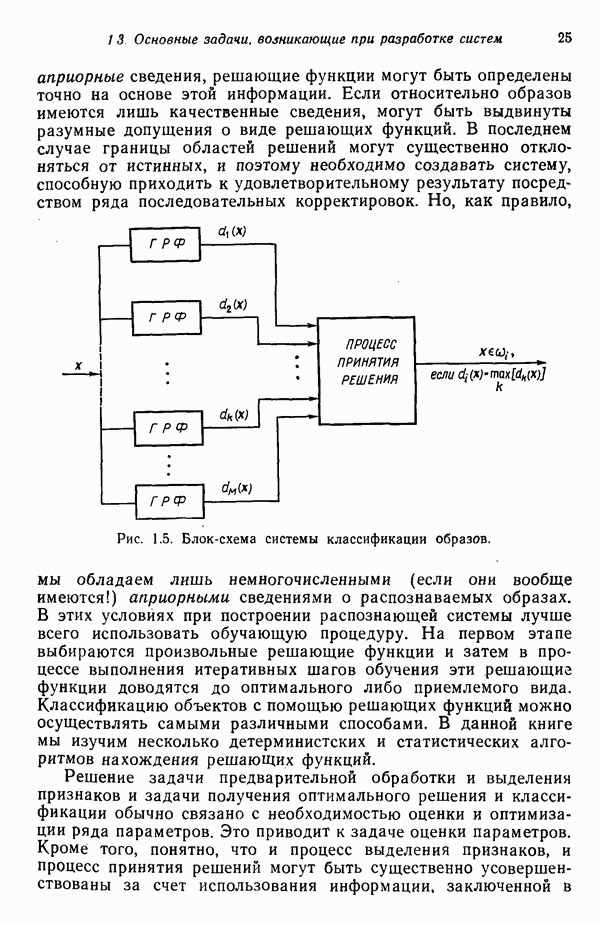
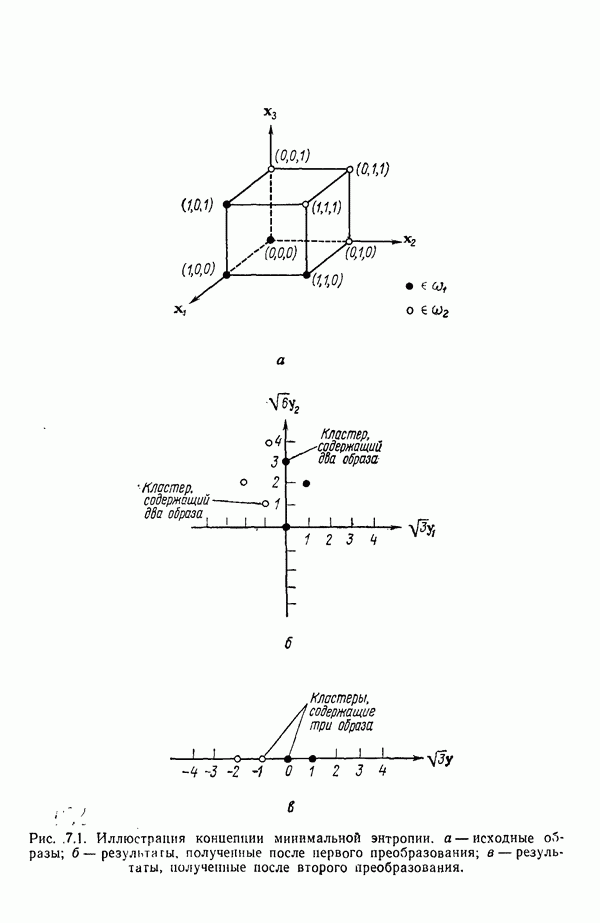
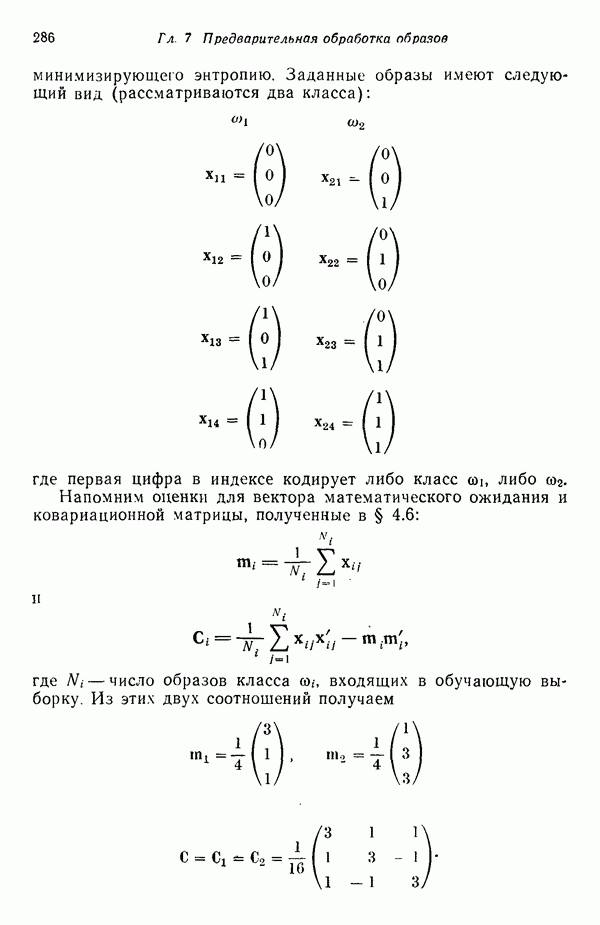
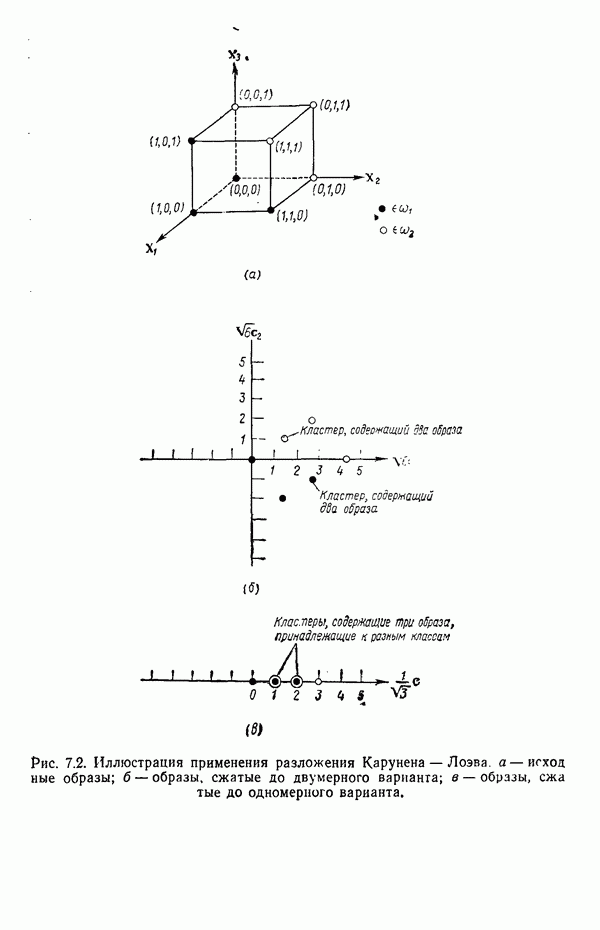
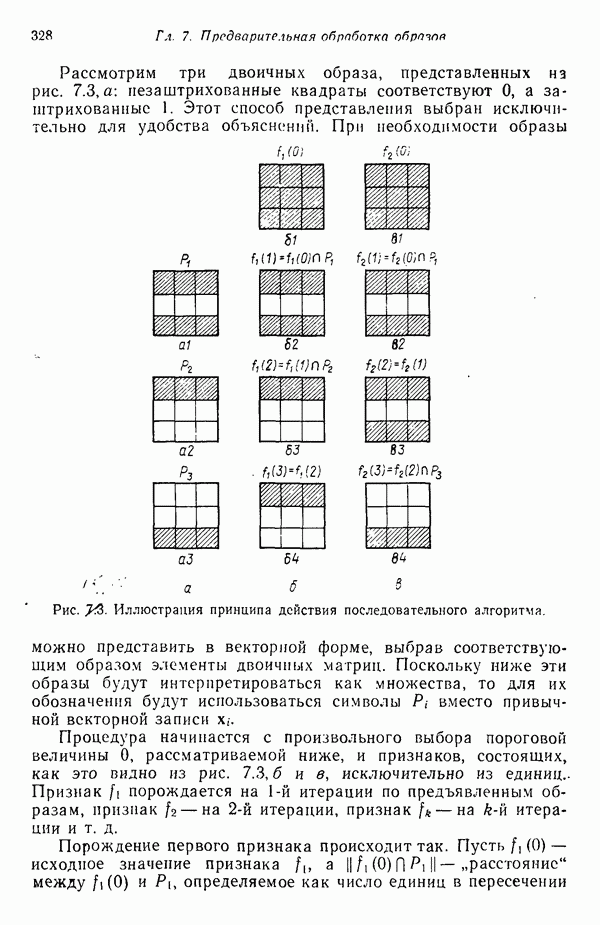
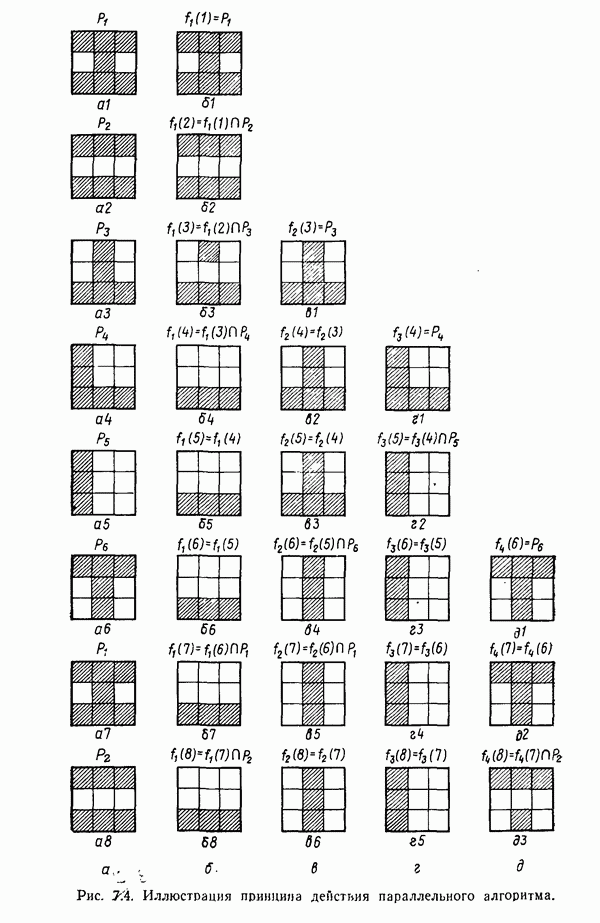
Глава 7. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ОБРАЗОВ И ВЫБОР ПРИЗНАКОВ7.1. ВВЕДЕНИЕДо сих пор мы изучали различные методы классификации образов. Однако прежде чем приступать к синтезу искомой системы распознавания образов, необходимо решить задачи выделения признаков и сжатия данных. Хотя этими задачами следует заниматься до начала синтеза классификатора, наш опыт свидетельствует о том, что материал лучше воспринимается и должным образом оценивается при изложении этих двух тем в обратной последовательности, как и сделано в нашей книге. Любой объект или образ, подлежащий распознаванию и классификации, обладает рядом различительных качеств или признаков. Первым шагом всякого процесса распознавания, реализуется он вычислительной машиной или человеком, является анализ задачи выбора различительных признаков и определения способа их выделения (измерения). Очевидно, что количество признаков, необходимое для успешного решения некоторой задачи распознавания, зависит от разделяющих качеств выбранных признаков. Задача выбора признаков усложняется обычно тем обстоятельством, что наиболее важные признаки не всегда легко измерить либо, как оказывается во многих случаях, соответствующие возможности измерения сдерживаются экономическими факторами. Обратимся, в частности, к задаче распознавания рукописных символов, обсуждавшейся в гл. 1. Самыми важными различительными признаками в этом случае являются последовательность, в которой отдельные штрихи следуют друг за другом, ориентация Штрихов, комплексы, образованные соединением отдельных штрихов, и отношения между отдельными штрихами, которые обычно не легко измерить с помощью обычных измерительных устройств. С другой стороны, посредством сканирующего устройства легко преобразовать символ в матрицу из нулей и единиц или эквивалентный n-мерный вектор измерений. Результаты измерения, однако, не обязательно содержат много «различительной» информации. Подобные данные, полученные в результате измерений, могут даже привести к усложнению схемы соответствующей классификации из-за того, что они не несут достаточного количества различительной информации. При возникновении такой ситуации, мы, естественно, стараемся выделить из векторов измерений более существенные признаки с тем, чтобы создать более эффективную и точную систему классификации образов. Эту процедуру часто называют предварительной обработкой с целыо выделения признаков. В качестве второго примера рассмотрим задачу разведки нефтяных месторождений, которую можно трактовать как задачу распознавания с двумя классами. В этом случае требуется определить, имеется в определенной географической зоне представляющее интерес количество нефти или нет. Очевидно, можно попытаться отнести соответствующую зону к одному из этих двух классов, буря в ней одну за другой нефтяные скважины до тех пор, пока не будет обнаружена нефть, либо число «сухих» или «почти сухих» скважин не достигнет величины, позволяющей считать эту зону с практической точки зрения действительно лишенной нефти. Такие измерения при решении задачи и дадут значения наиболее существенных признаков. Как, однако, подтвердит любой нефтяник, при использовании такого способа фирме пришлось бы не долго ждать своего банкротства. Из-за высокой стоимости бурения ученые и инженеры-нефтяники вынуждены довольствоваться признаками, которые хотя и менее информативны, зато обходятся дешевле. Эти признаки обычно имеют вид сейсмических характеристик, определенных по длинным отраженным волнам, которые образуются, например, при взрыве динамита, направленном в глубь поверхности земли, в нескольких точках исследуемой зоны. В результате строится локальная карта земной коры, на основе которой зона может классифицироваться как обладающая или не обладающая в принципе возможностью иметь нефть. Итак, вынужденный компромисс при выборе признаков приводит в этой задаче к процессу классификации, который существенно отличается от оптимального. К сожалению, такое ограничение, вызванное компромиссом между набором признаков и качеством классификации, присутствует в большинстве практических задач распознавания образов. Из сказанного очевидно, что выбор и выделение признаков играют в распознавании образов центральную роль. Действительно, выбор адекватного множества признаков, учитывающий трудности, которые связаны с реализацией процессов выделения или выбора признаков, и обеспечивающий в то же время необходимое качество классификации, представляет собой одну из наиболее трудных задач построения распознающих систем. Для того чтобы облегчить анализ этой задачи, разделим признаки на три категории: 1) «физические», 2) структурные и 3) математические. Физические и структурные признаки обычно используются людьми при распознавании образов, поскольку такие признаки легко обнаружить на ощупь, визуально и с помощью других органов чувств. Отличая апельсины от бананов, мы обычно пользуемся такими признаками, как цвет и форма. При различении лимонов и бананов цвет, однако, перестает быть эффективным признаком. При отделении флоридских апельсинов от калифорнийских ни цвет, ни форма уже не являются полезными признаками; вместо них следует использовать другие признаки, например аромат и структуру кожуры. Цвет и аромат служат примерами физических признаков. Форма, структура и другие геометрические свойства образов считаются структурными признаками. Хотя структурные признаки также можно было бы отнести к физическим, читатель должен учитывать, что разделение признаков на отдельные группы введено нами исключительно для удобства и группы эти выбраны в определенном смысле произвольно. Поскольку органы чувств обучены распознаванию физических и структурных признаков, человек, естественно, пользуется в основном такими признаками при классификации и распознавании. В случае же построения вычислительной системы распознавания образов эффективность таких признаков с точки зрения организации процесса распознавания может существенно снижаться, так как, вообще говоря, в большинстве практических ситуаций довольно сложно имитировать возможности органов чувств человека. С другой стороны, можно создать систему, обеспечивающую выделение математических признаков образов, что может оказаться затруднительным для человека при отсутствии «механической» помощи. Примерами признаков этого типа являются статистические средние, коэффициенты корреляции, характеристические числа и собственные векторы ковариационных матриц и прочие инвариантные свойства объектов. При автоматическом распознавании образов физические и структурные признаки используются в основном в области обработки изображений. Эти признаки являются сугубо проблемно-ориентированными в том смысле, что их использование связано с созданием специализированных алгоритмов, предназначенных для решения поставленной конкретной задачи. Если, например, требуется оценить урожай с помощью аэрофотосъемки, то использование физических признаков (скажем, цвета) будет вполне оправданно. С другой стороны, идентификация таких объектов, как грузовые автомобили, здания и автострады, должна основываться на анализе структурных признаков. Следует иметь в виду одно важное положение, которое состоит в том, что практически невозможно сформулировать общие принципы выбора физических и структурных признаков. В этой книге мы будем иметь дело только со структурными и математическими признаками. Структурные признаки играют важную роль в проблемах, которые рассматриваются в следующей главе. В данной главе наше внимание сосредоточено на методах выбора и выделения математических признаков по образам обучающей выборки. Эти признаки обладают двумя принципиальными преимуществами перед структурными: 1) они более общие по своей природе и 2) они легко поддаются машинной реализации. В математическом подходе к предварительной обработке и сжатию данных задача выделения признаков занимает центральное место. Будет показано, что эта задача заключается в определении ряда инвариантных свойств рассматриваемых классов. Затем эти свойства используются, например, для понижения размерности векторов образов при помощи линейного преобразования. После установления набора этих свойств процесс выделения признаков сводится к непосредственному выделению таких свойств у заданных образов. В последующих разделах вводится множество процедур, связанных с выбором и выделением математических признаков. Хотя большая часть этих методов пригодна для решения широкого класса задач, важно иметь в виду, что приоритет любой процедуры полностью определяется конкретной задачей. Предварительная обработка образов обычно включает решение двух основных задач: преобразование кластеризации и выбор признаков. Основной задачей распознавания образов является построение решающих функций, исходя из конечных множеств заданных образов, представляющих некоторые классы. Эти функции должны обеспечивать разделение пространства измерений на области, каждая из которых содержит точки, представляющие образы только одного из рассматриваемых классов. Данное положение приводит к идее преобразования кластеризации, реализуемого в пространстве измерений, для того чтобы обеспечить группировку точек, представляющих выборочные образы одного класса. В результате такого преобразования максимизируются расстояния между множествами и минимизируются внутримножественные расстояния. Расстояния между множествами определяются как среднеквадратичное расстояние между точками, представляющими образы двух различных классов. Внутримножественное расстояние — это среднеквадратичное расстояние между точками, представляющими образы одного класса. Выбор наиболее эффективных признаков позволяет снизить размерность вектора измерений. Выбор признаков можно осуществлять вне связи с качеством схемы классификации. Оптимальный выбор признаков при этом определяется максимизацией или минимизацией некоторой функции критерия. Такой подход можно считать выбором признаков без учета ограничений. Другой подход связывает выбор признаков с качеством классификации: эффективность выбранных признаков непосредственно связана с качеством классифицирующей системы, причем обычно эта связь выражается в терминах вероятности правильного распознавания. Если распределение признаков известно для всех классов, то можно использовать понятия дивергенции и энтропии при осуществлении выбора признаков. Если распределения признаков для каждого класса неизвестны, можно воспользоваться непараметрическими методами выбора признаков, основанными на прямой оценке вероятности ошибки.
|
 |
Оглавление
|