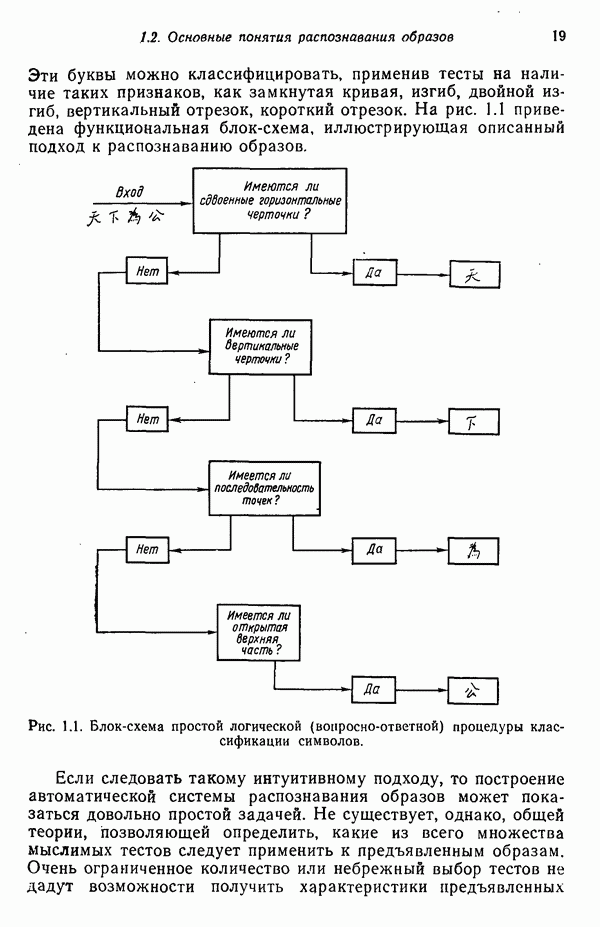
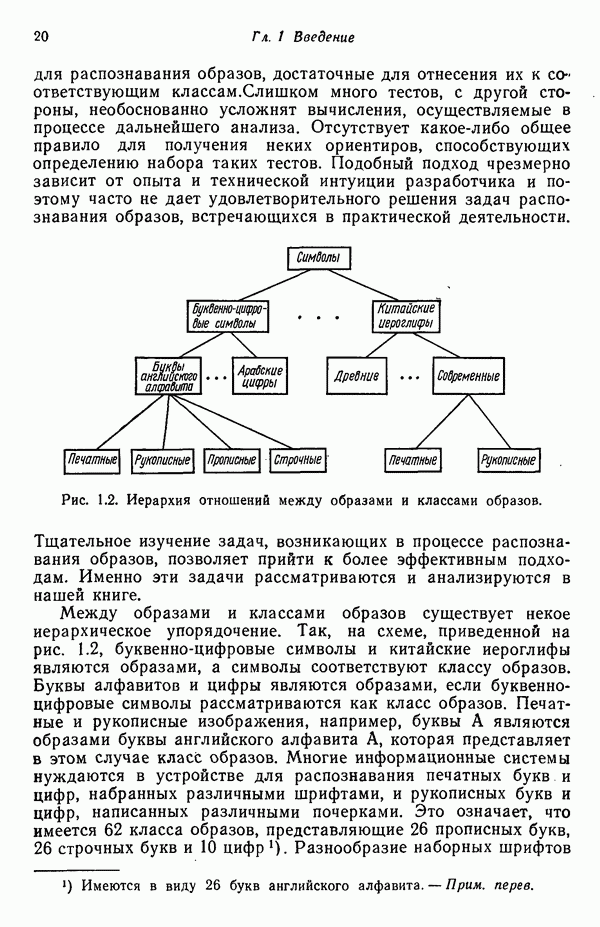
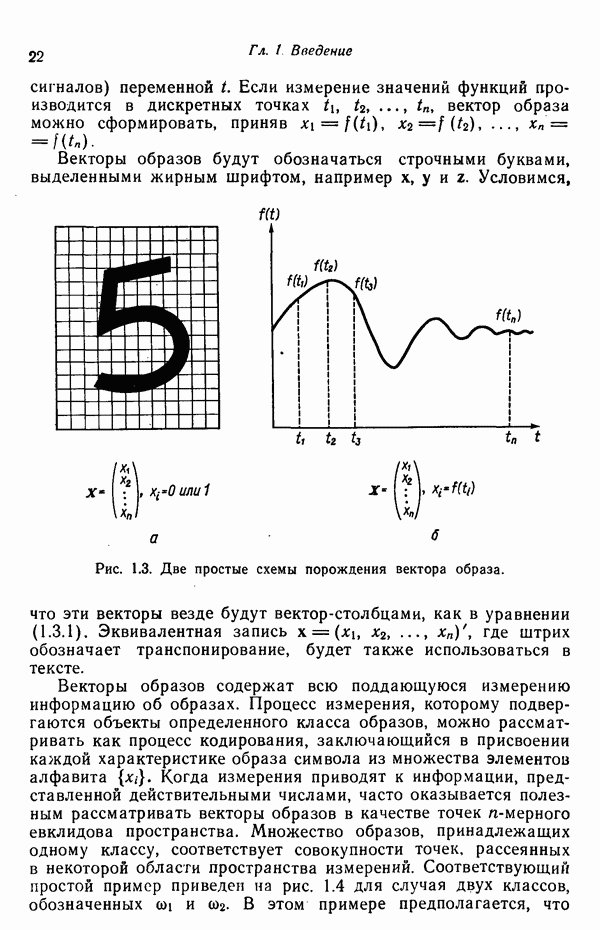
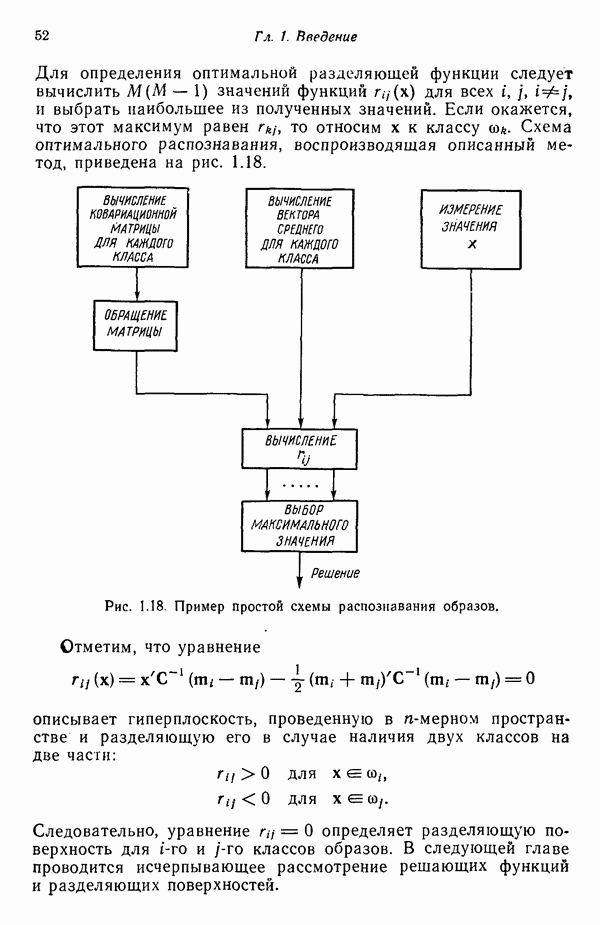
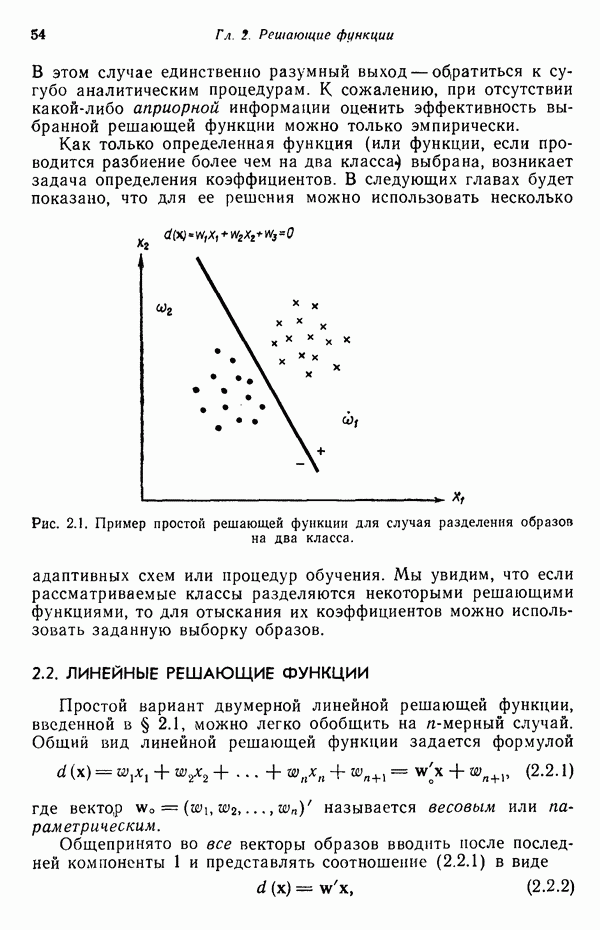
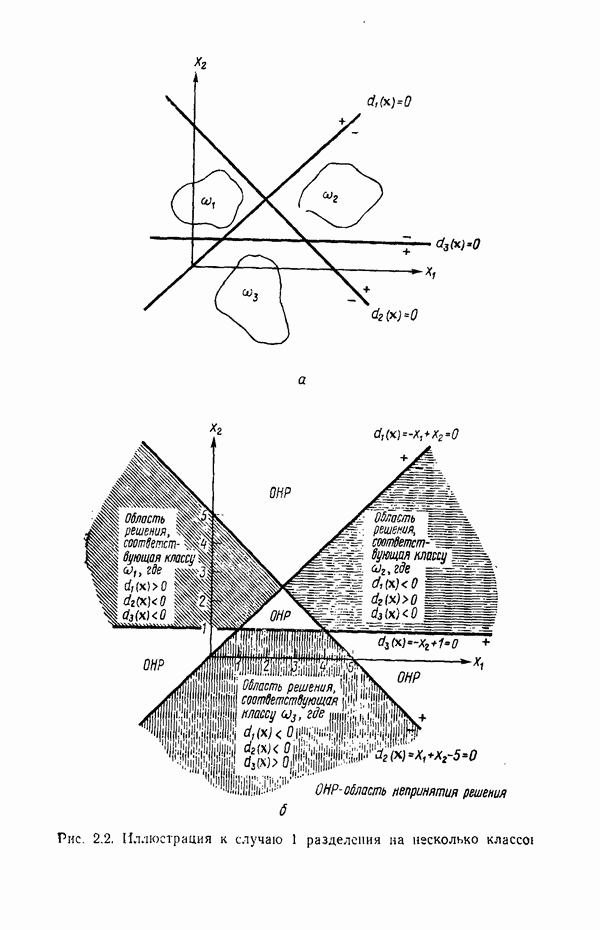
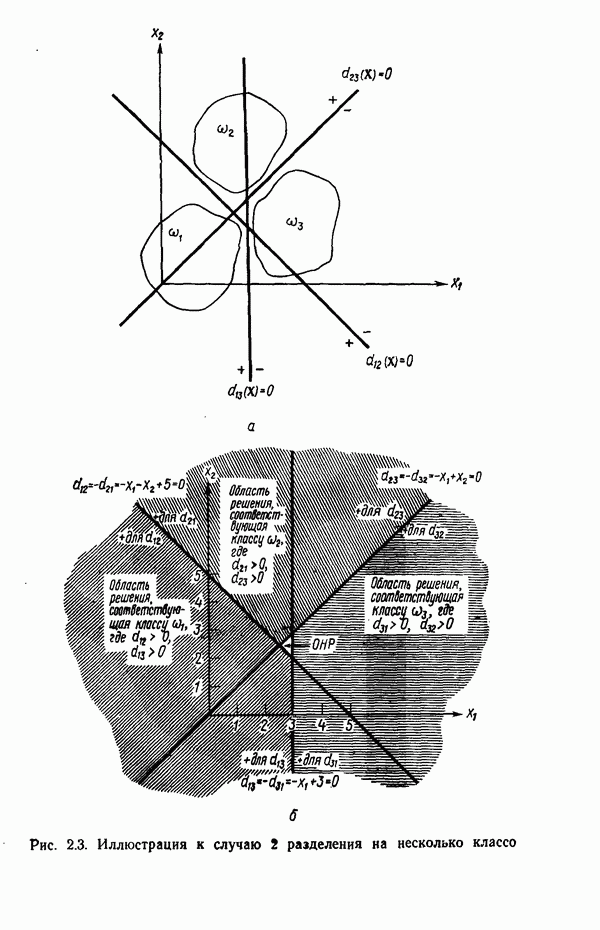
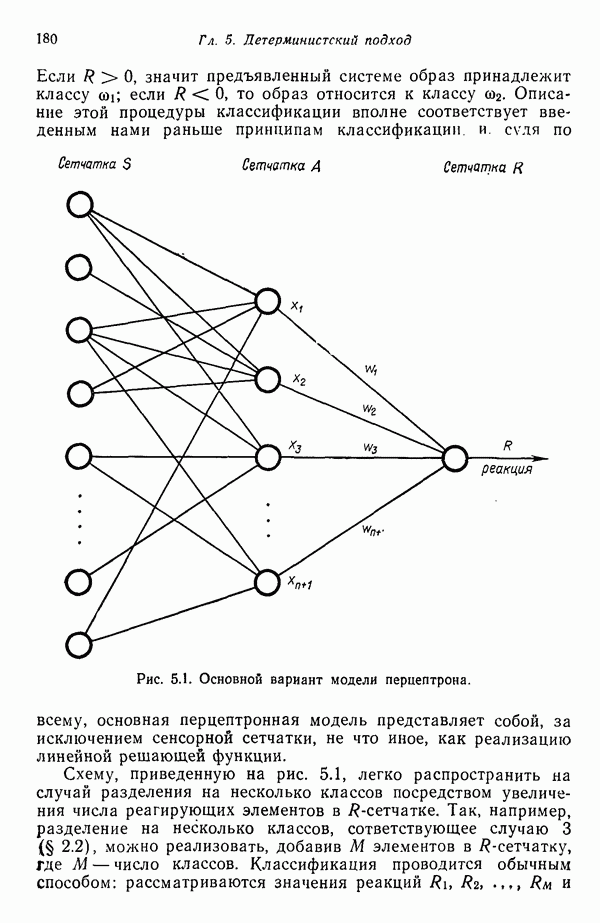
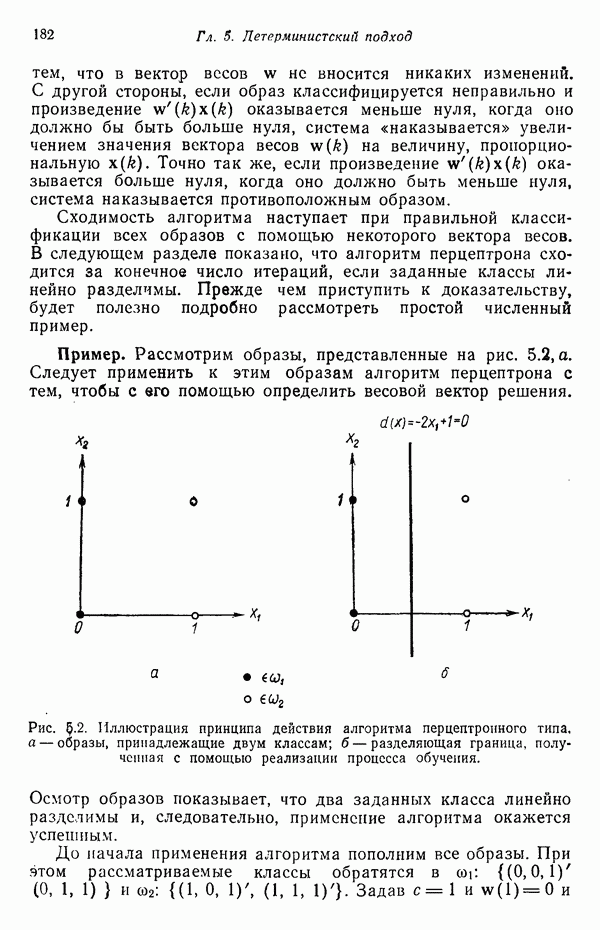
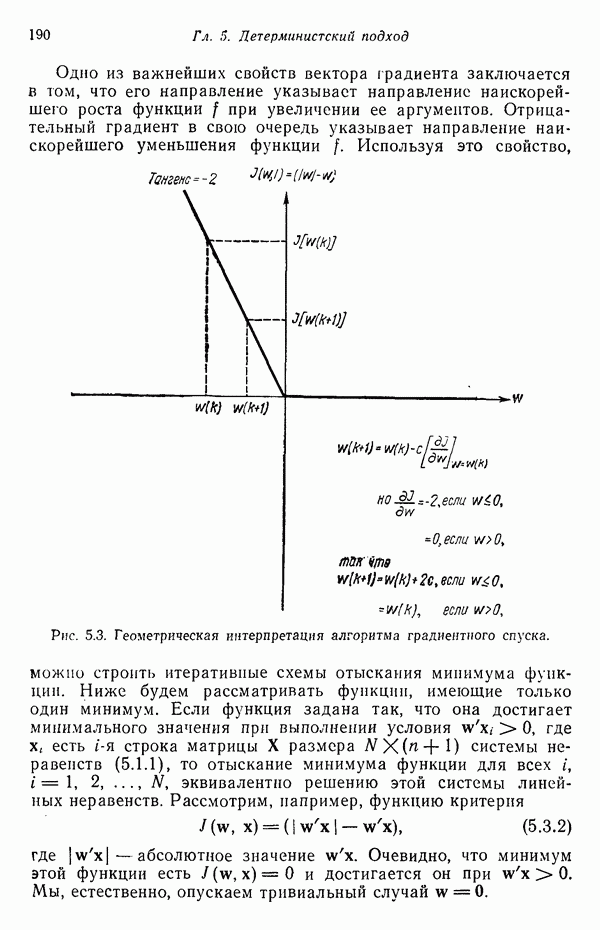
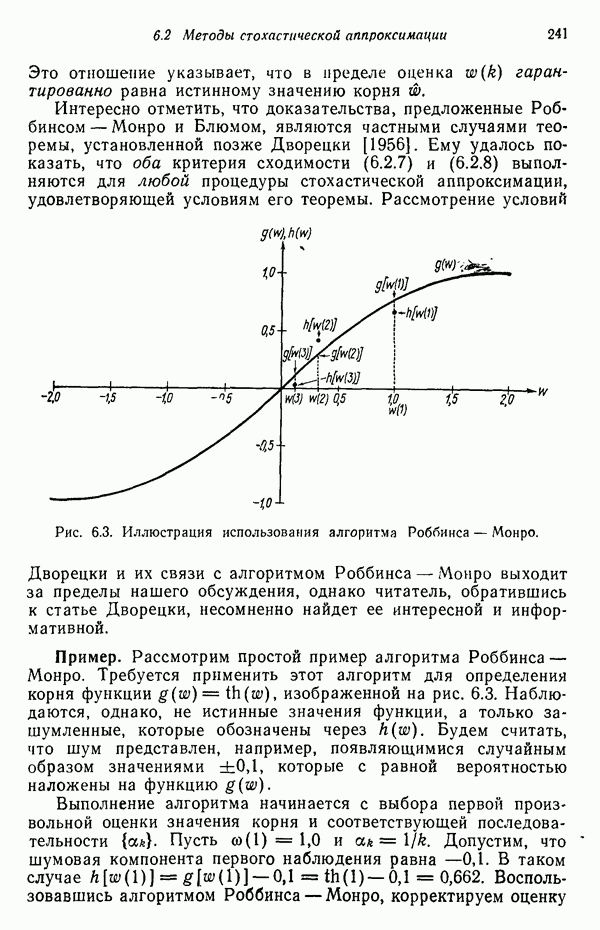
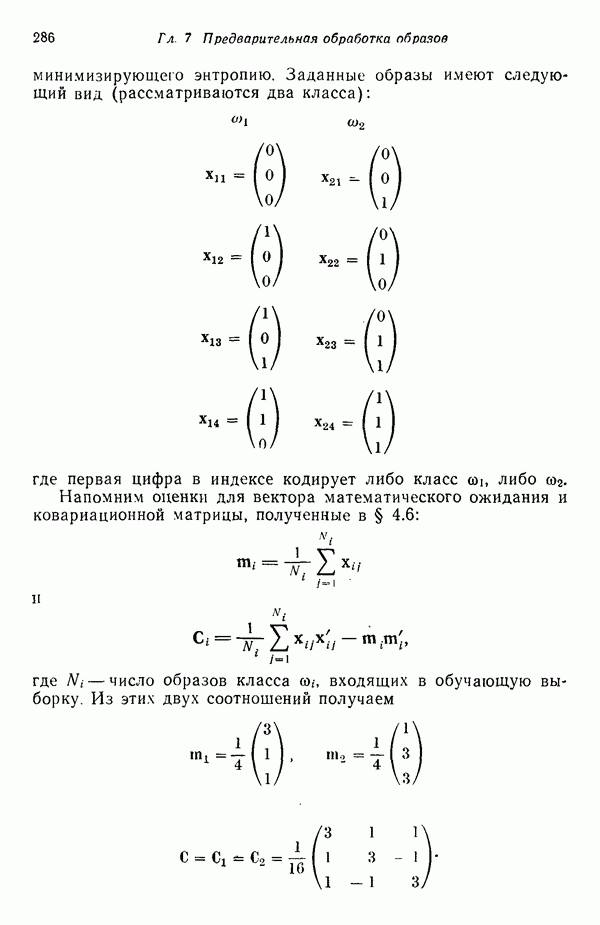
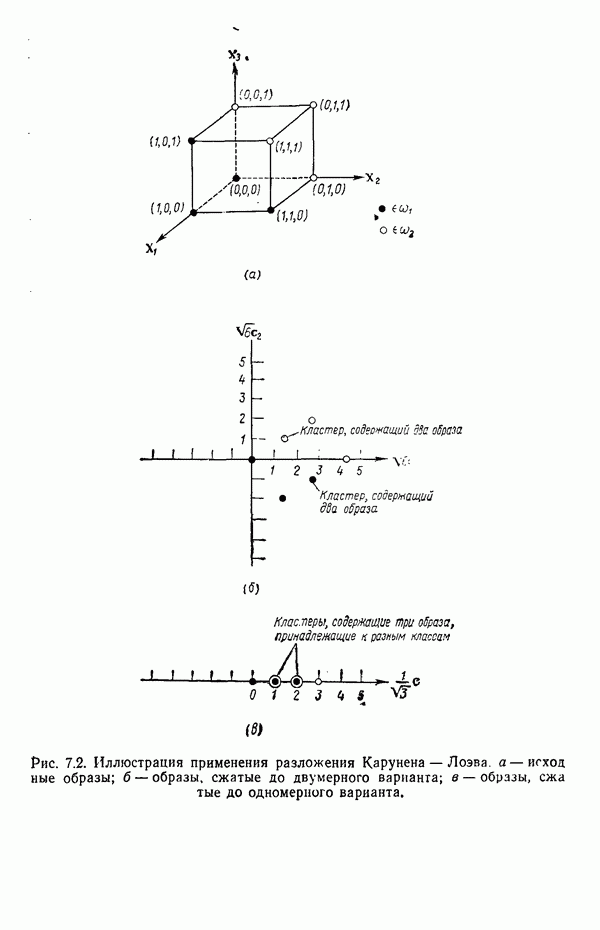
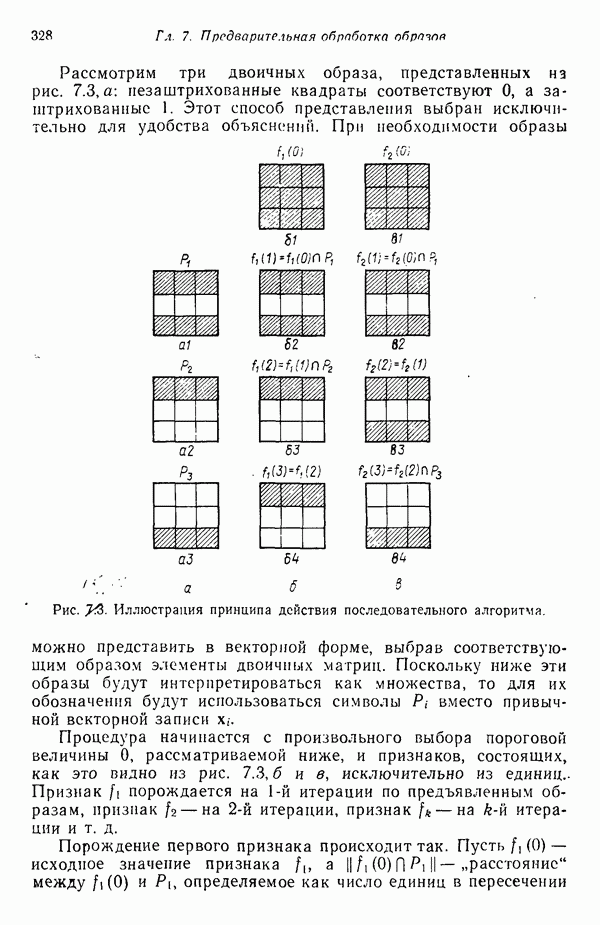
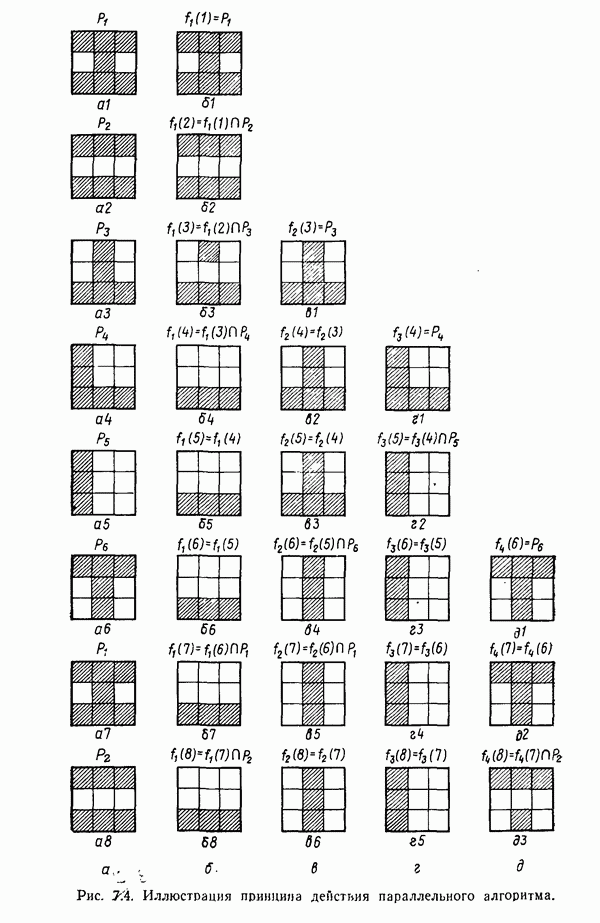
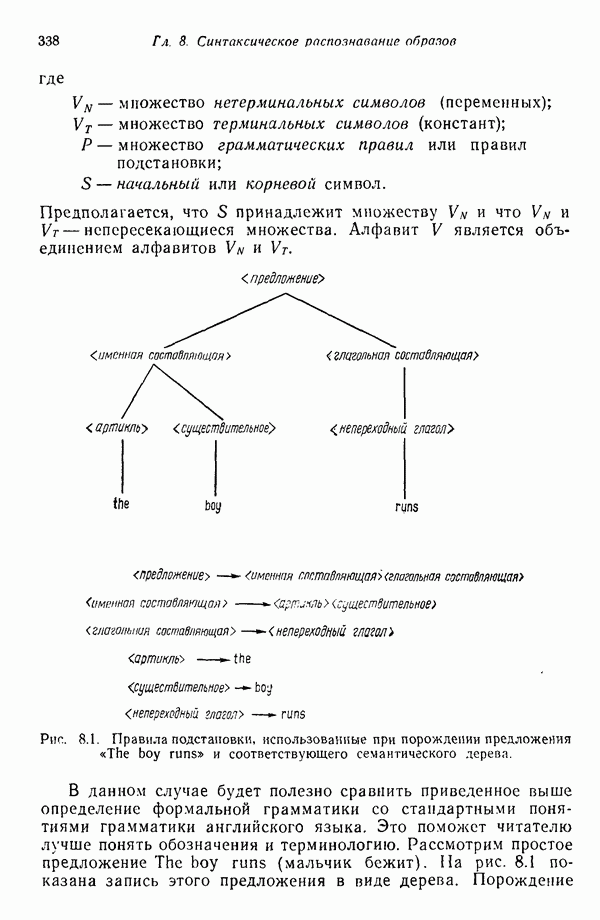
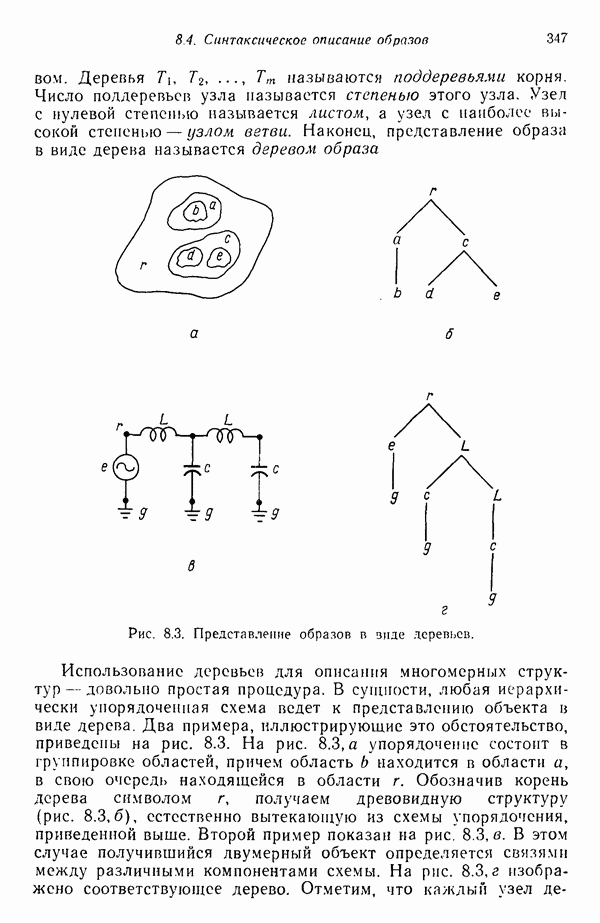
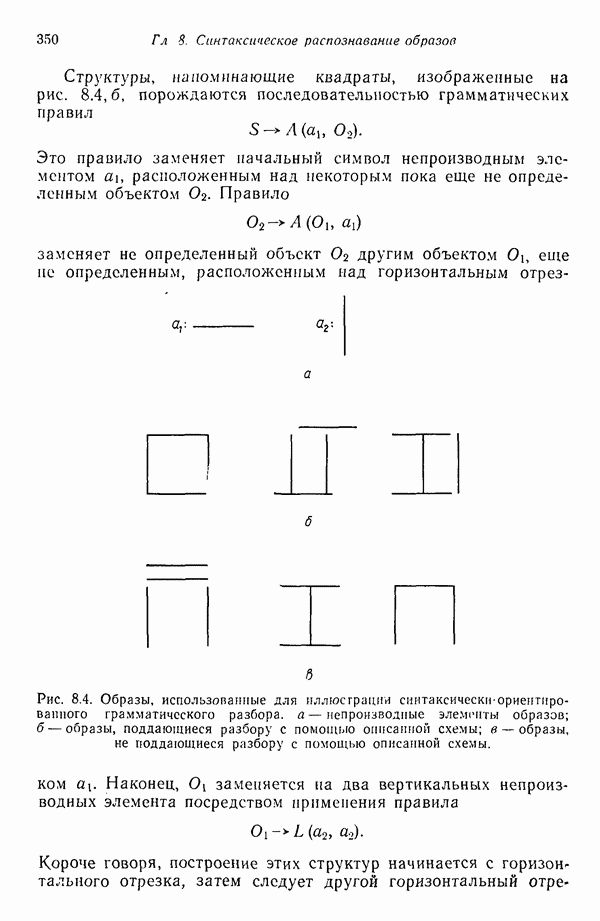
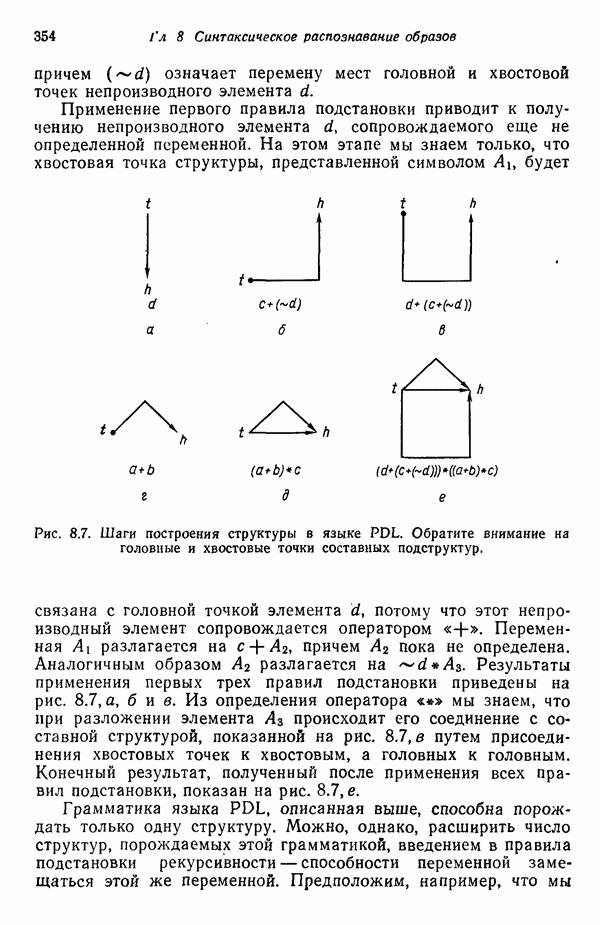
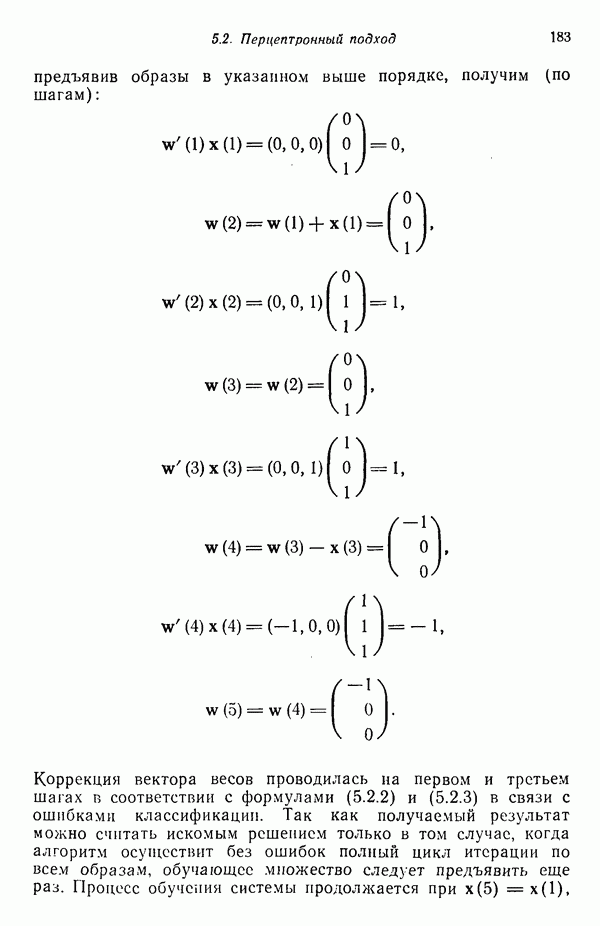3.3.5. Алгоритм К внутригрупповых средних
Несложные алгоритмы, рассмотренные в пп. 3.3.3 и 3.3.4, являются в сущности эвристическими процедурами. С другой стороны, алгоритм, представленный ниже, минимизирует показатель качества, определенный как сумма квадратов расстояний всех точек, входящих в кластерную область, до центра кластера. Эта процедура, которую часто называют алгоритмом, основанным на вычислении К внутригрупповых средних, состоит из следующих шагов.
Шаг 1. Выбираются К исходных центров кластеров  Этот выбор производится произвольно, и обычно в качестве исходных центров используются первые К результатов выборки из заданного множества образов.
Этот выбор производится произвольно, и обычно в качестве исходных центров используются первые К результатов выборки из заданного множества образов.
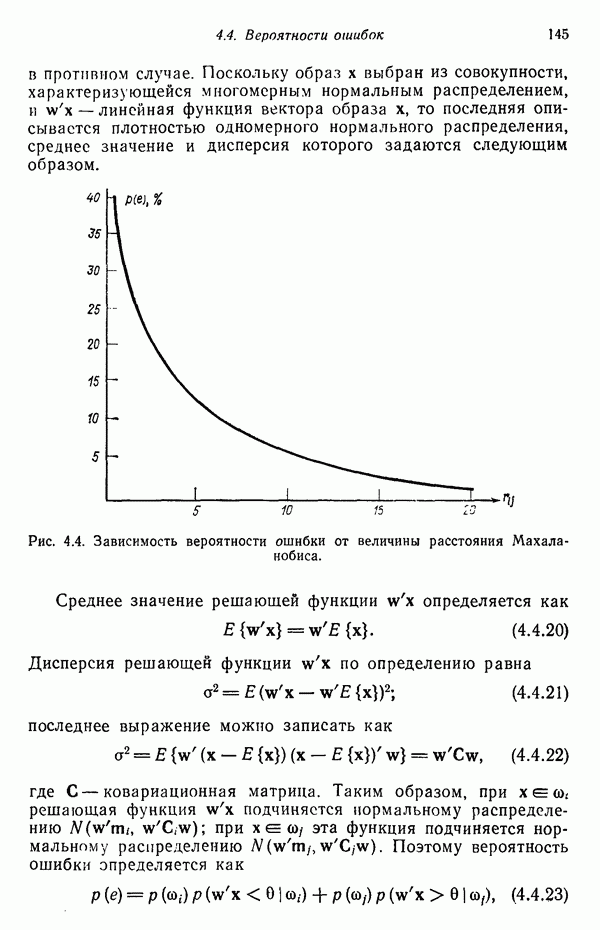
Шаг 2. На  шаге итерации заданное множество образов
шаге итерации заданное множество образов  распределяется по К кластерам по следующему правилу:
распределяется по К кластерам по следующему правилу:

для всех  , где
, где  — множество образов, входящих в кластер с центром
— множество образов, входящих в кластер с центром  случае равенства в (3.3.7) решение принимается произвольным образом.
случае равенства в (3.3.7) решение принимается произвольным образом.
Шаг 3. На основе результатов шага 2 определяются новые центры кластеров  исходя из условия, что сумма квадратов расстояний между всеми образами, принадлежащими множеству
исходя из условия, что сумма квадратов расстояний между всеми образами, принадлежащими множеству  и новым центром кластера должна быть минимальной. Другими словами, новые центры кластеров
и новым центром кластера должна быть минимальной. Другими словами, новые центры кластеров  выбираются таким образом, чтобы минимизировать показатель качества
выбираются таким образом, чтобы минимизировать показатель качества

Центр  обеспечивающий минимизацию показателя качества, является, в сущности, выборочным средним, определенным по множеству
обеспечивающий минимизацию показателя качества, является, в сущности, выборочным средним, определенным по множеству  . Следовательно, новые центры кластеров определяются как
. Следовательно, новые центры кластеров определяются как

где  — число выборочных образов, входящих в множество
— число выборочных образов, входящих в множество  Очевидно, что название алгоритма
Очевидно, что название алгоритма  внутригрупповых средних» определяется способом, принятым для последовательной коррекции назначения центров кластеров.
внутригрупповых средних» определяется способом, принятым для последовательной коррекции назначения центров кластеров.
Шаг 4. Равенство  при
при  является условием сходимости алгоритма, и при его достижении выполнение алгоритма заканчивается. В противном случае алгоритм повторяется от шага 2.
является условием сходимости алгоритма, и при его достижении выполнение алгоритма заканчивается. В противном случае алгоритм повторяется от шага 2.
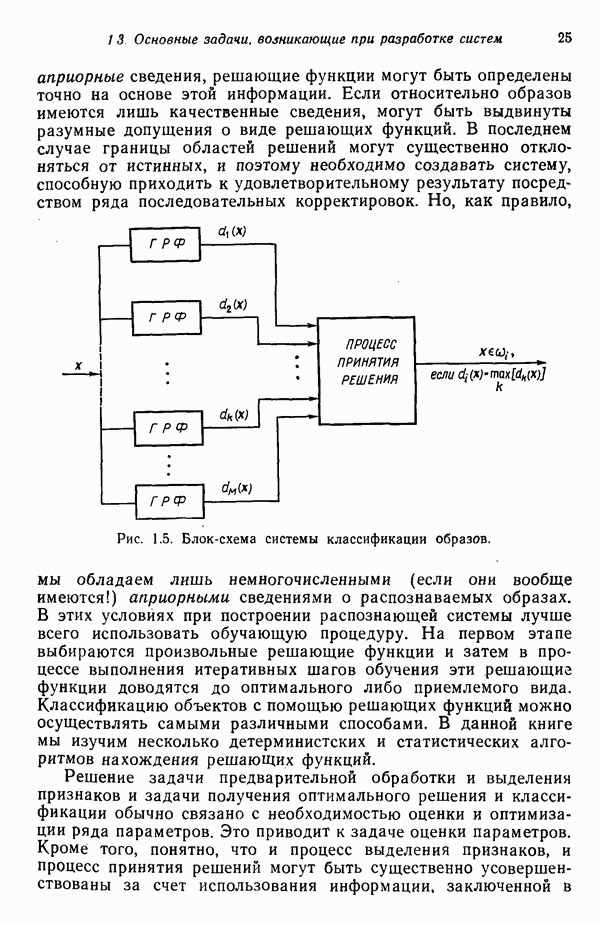
Качество работы алгоритмов, основанных на вычислении К внутригрупповых средних, зависит от числа выбираемых центров кластеров, от выбора исходных центров кластеров, от последовательности осмотра образов и, естественно, от геометрических особенностей данных. Хотя для этого алгоритма общее доказательство сходимости не известно, получения приемлемых результатов можно ожидать в тех случаях, когда данные образуют характерные гроздья, отстоящие друг от друга достаточно
далеко. В большинстве случаев практическое применение этого алгоритма потребует проведения экспериментов, связанных с выбором различных значений параметра К и исходного расположения центров кластеров.

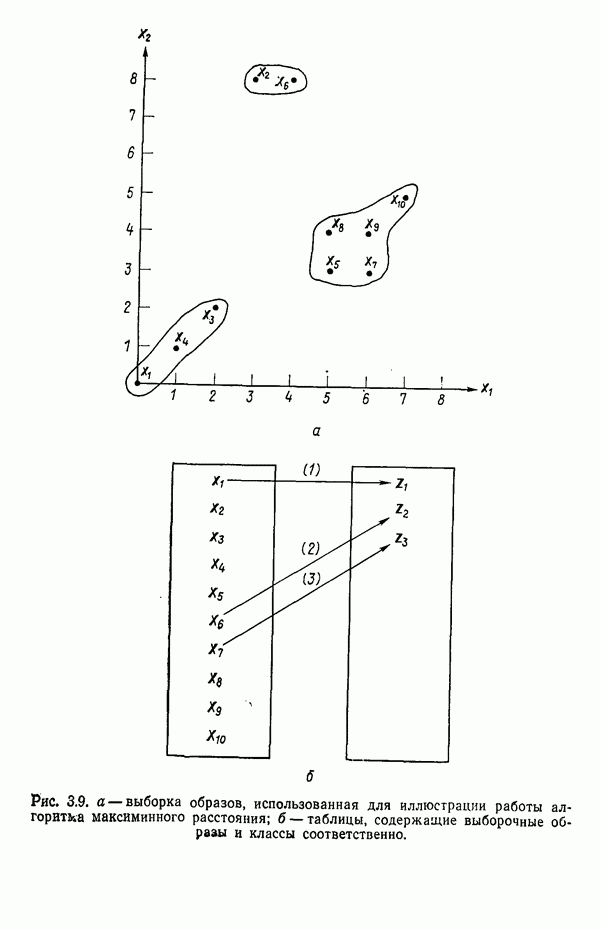
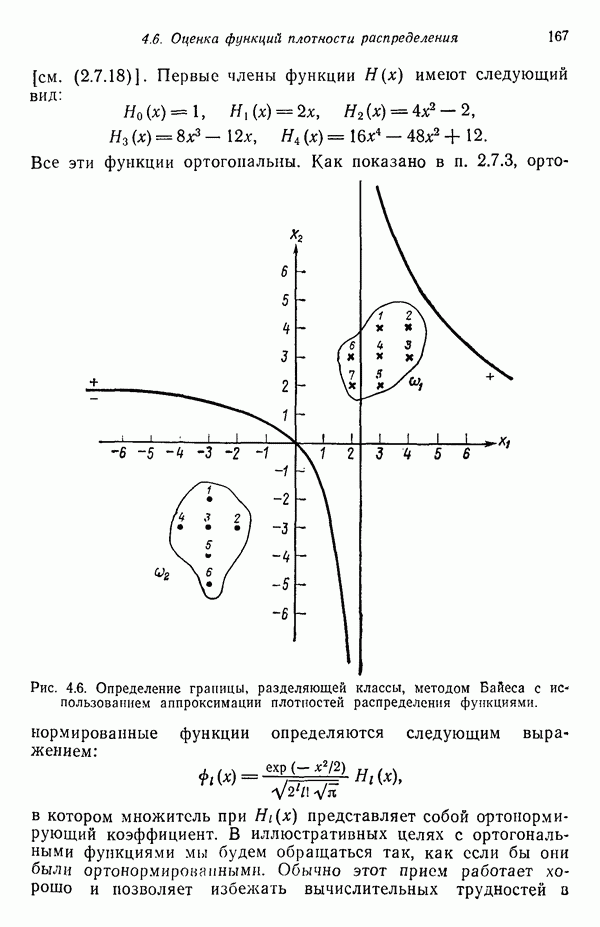
Рис. 3.10. Выборка образов, использованная для иллюстрации работы алгоритма выборочных средних по К центрам кластеризации.
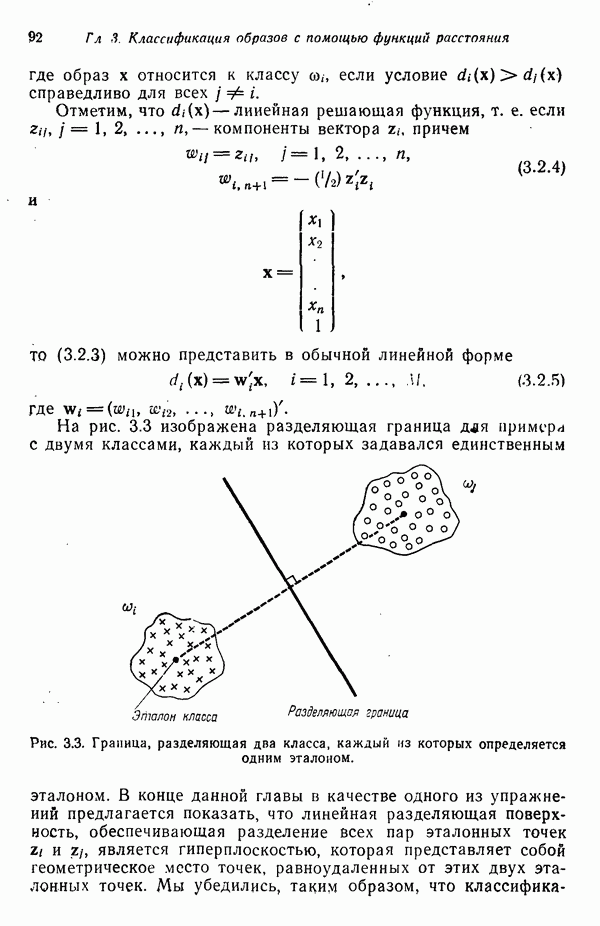
Пример. В качестве простой численной иллюстрации алгоритма К внутригруиповых средних рассмотрим образы, представленные на рис. 3.10. Процедура протекает следующим образом:
Шаг 1. Задается  и выбирается
и выбирается  .
.
Шаг 2. Так как  , то
, то  . Аналогично устанавливается, что остальные образы расположены ближе к центру кластера
. Аналогично устанавливается, что остальные образы расположены ближе к центру кластера  и поэтому
и поэтому  .
.
Шаг 3. Коррекция назначения центров кластеров:

Шаг 4. Так как  то возврат к шагу 2.
то возврат к шагу 2.
Шаг 2. Выбор новых центров кластеров приводит к неравенству  для
для  и неравенству
и неравенству  для
для  Следовательно,
Следовательно, 
Шаг 3. Коррекция назначения центров кластеров:

Шаг 4. Так как  , то возврат к шагу 2.
, то возврат к шагу 2.
Шаг 2. Получаем те же результаты, что и на предыдущей итерации: 
Шаг 3. Также получаем идентичные результаты.
Шаг 4. Так как  алгоритм сошелся и в результате получены следующие центры кластеров:
алгоритм сошелся и в результате получены следующие центры кластеров:

Эти результаты согласуются с тем, что можно было бы ожидать, ознакомившись с заданными образами.