Пред.
След.
Макеты страниц
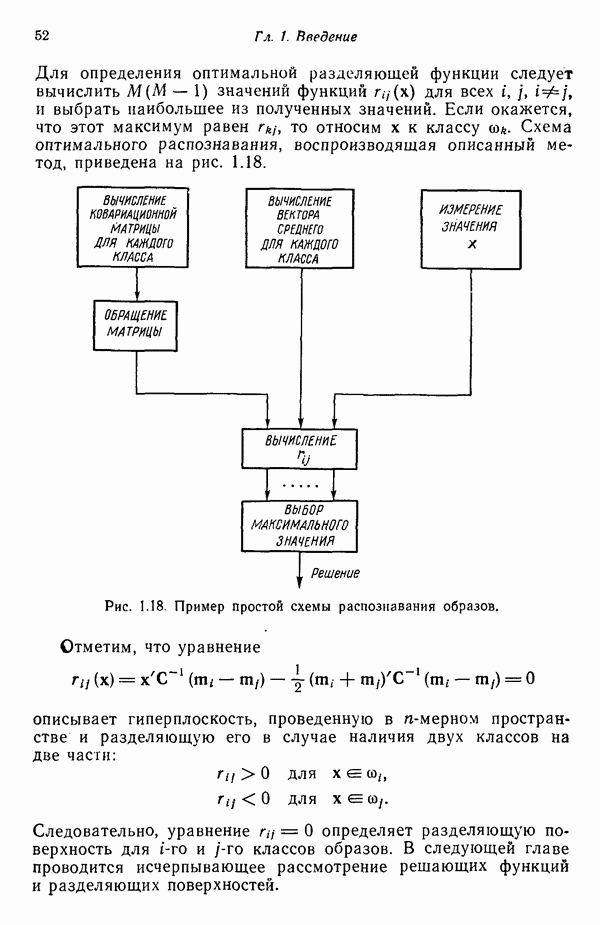
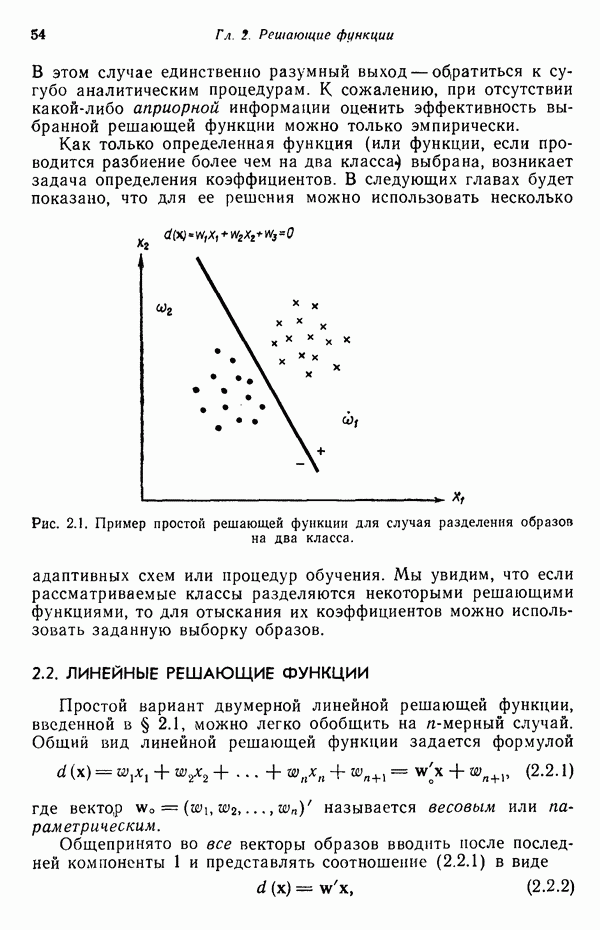
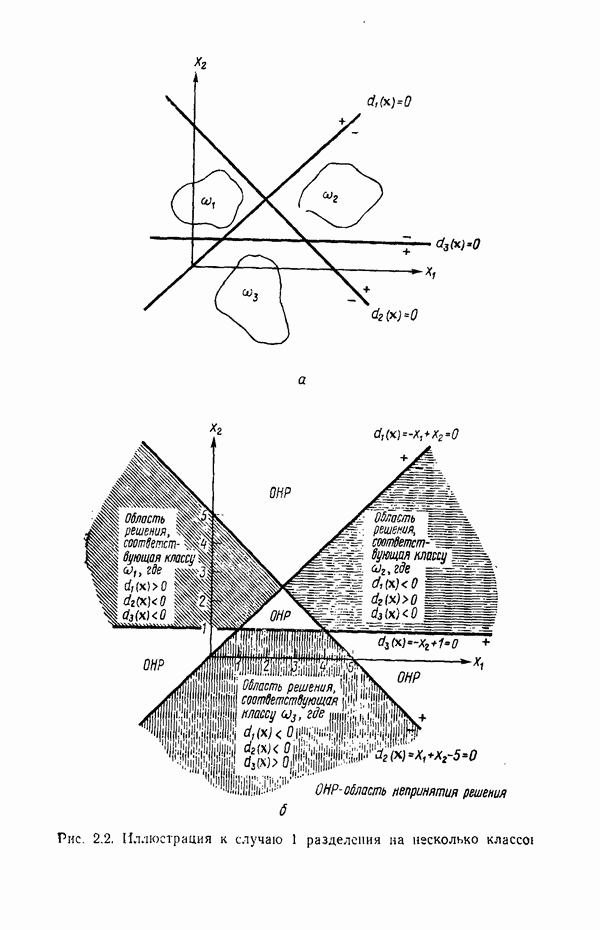
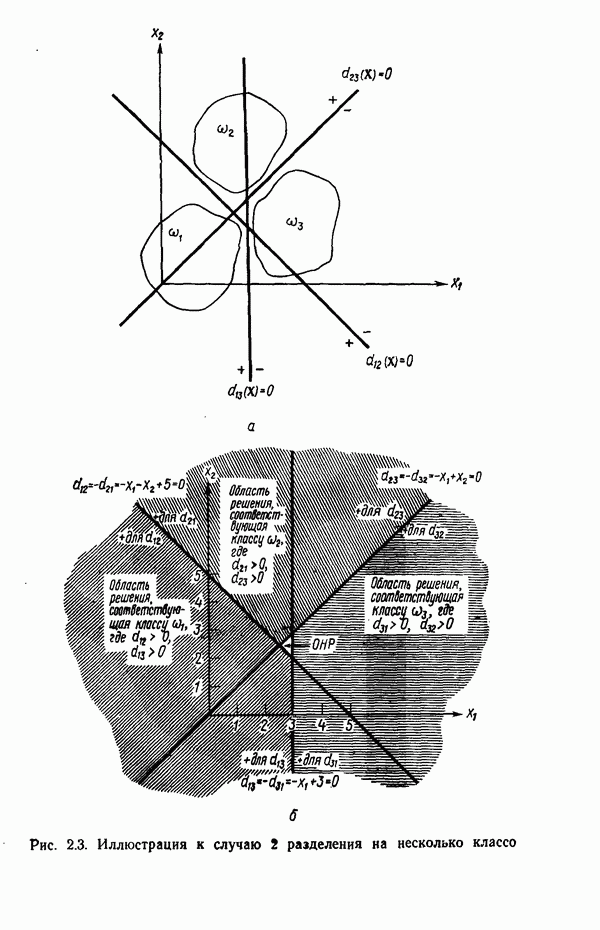
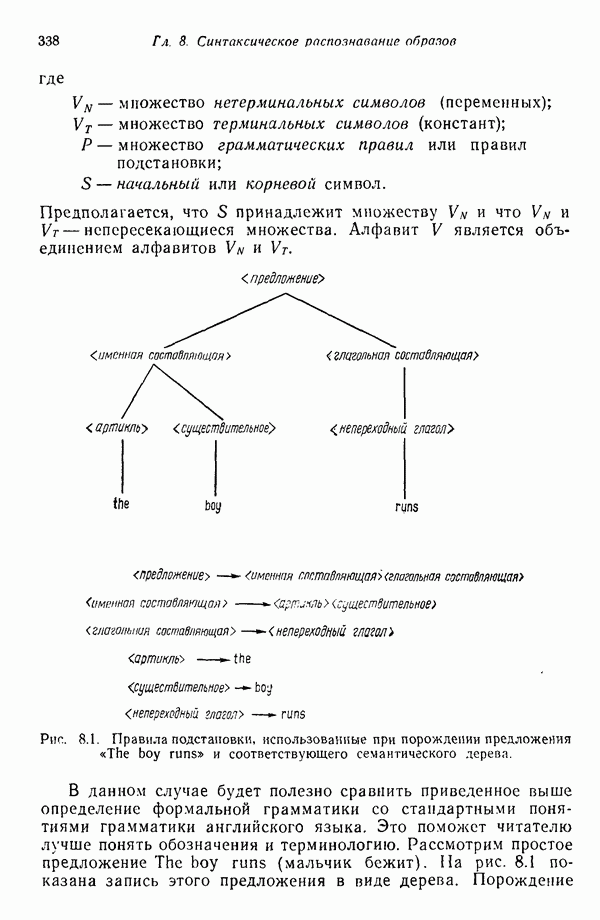
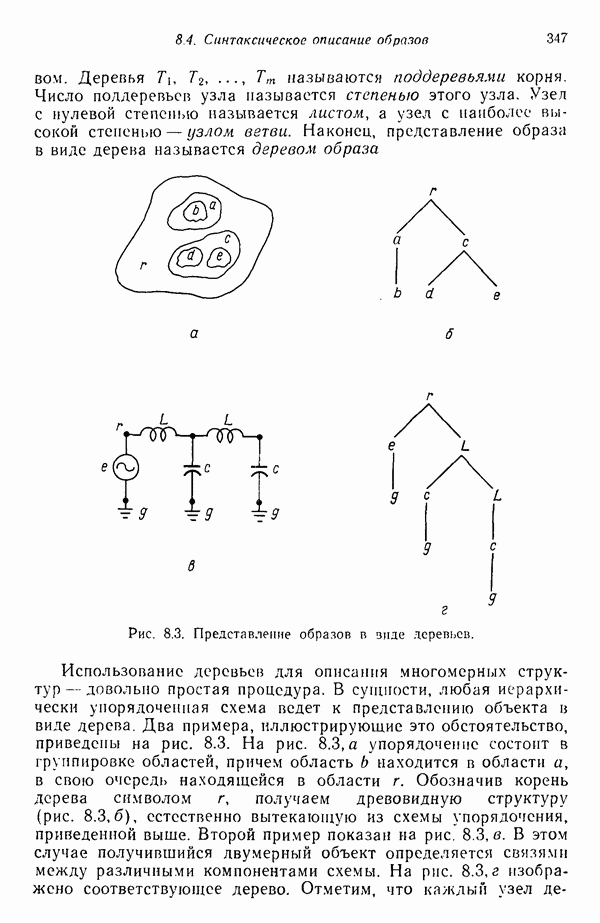
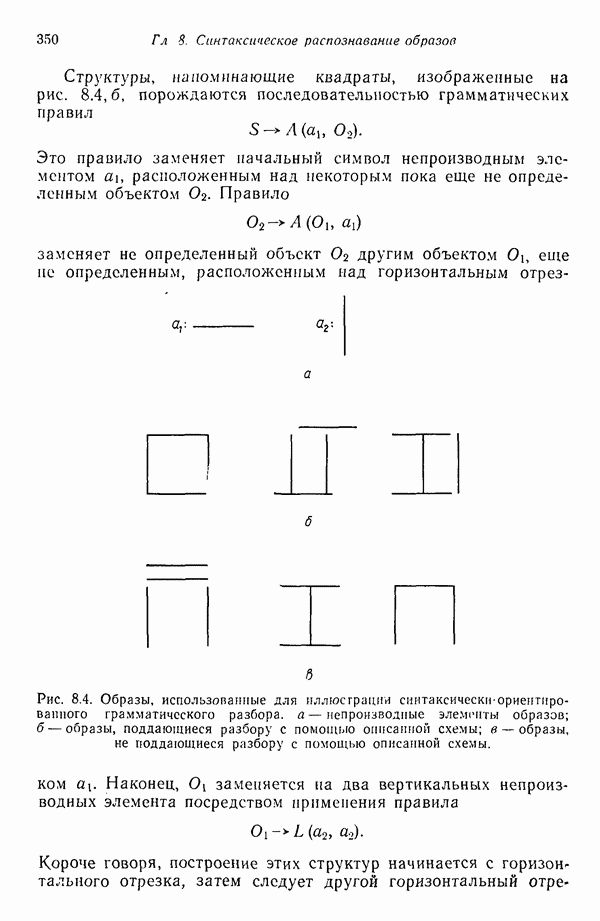
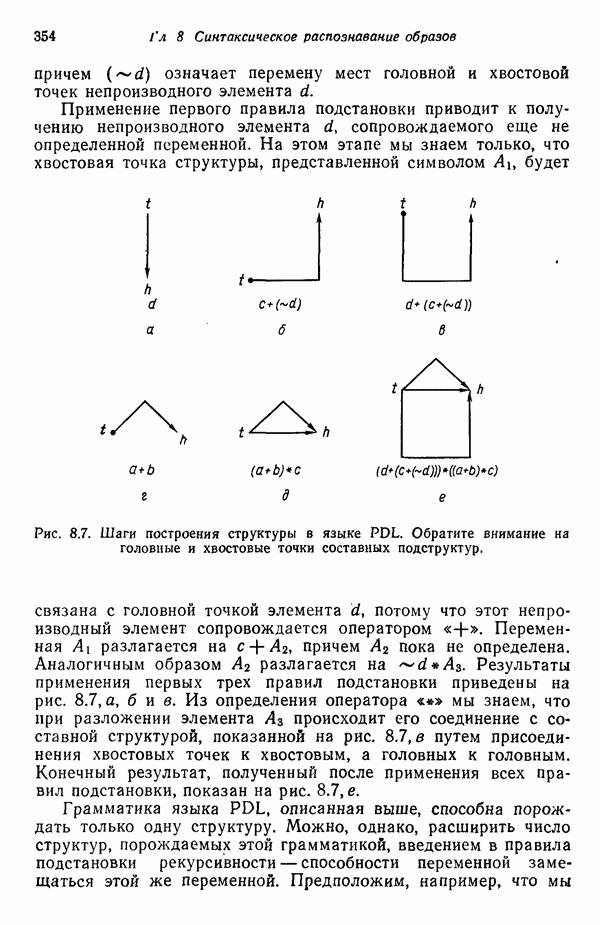
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
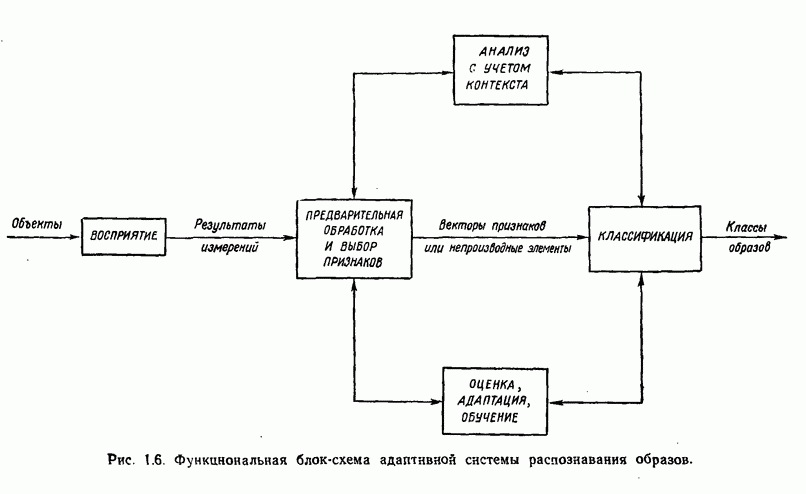
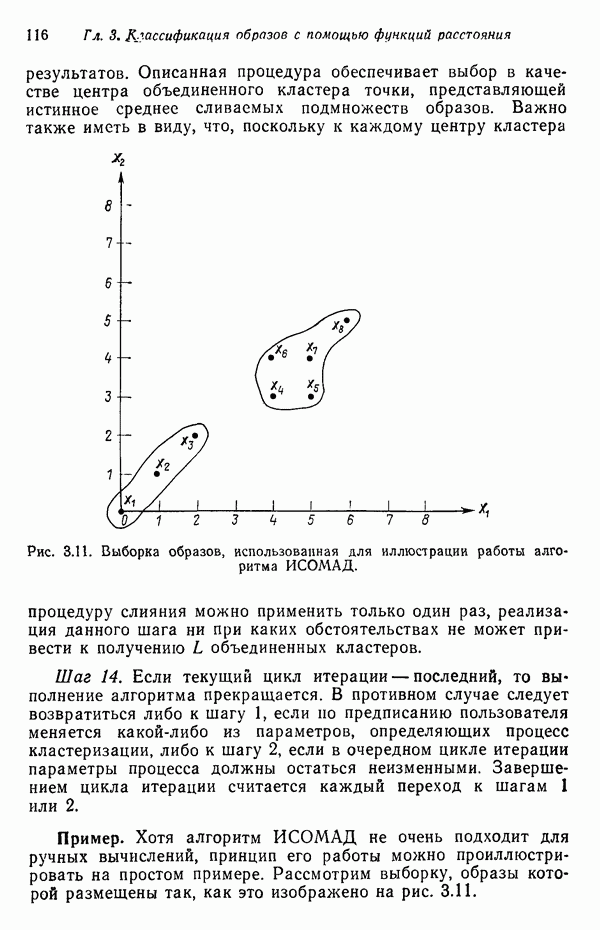
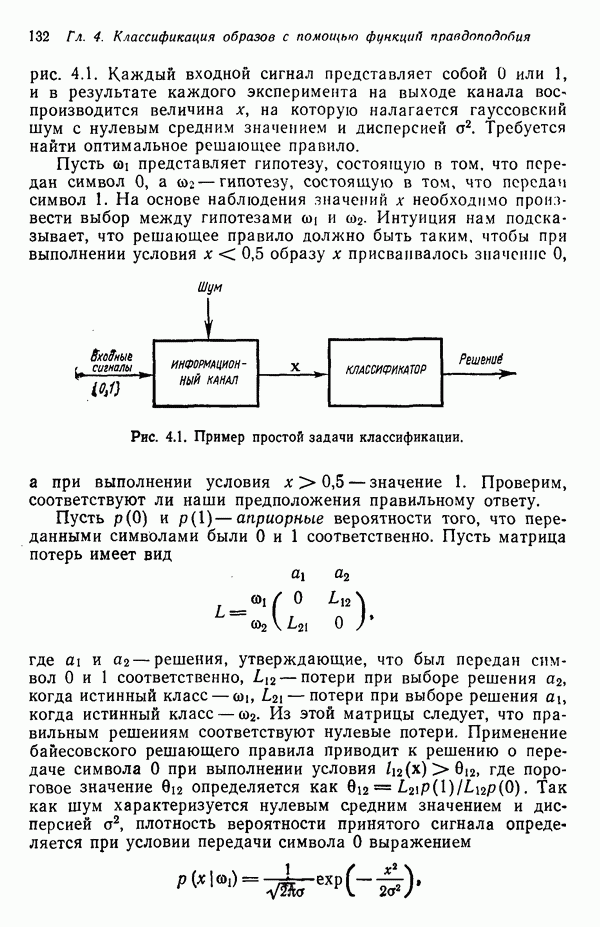
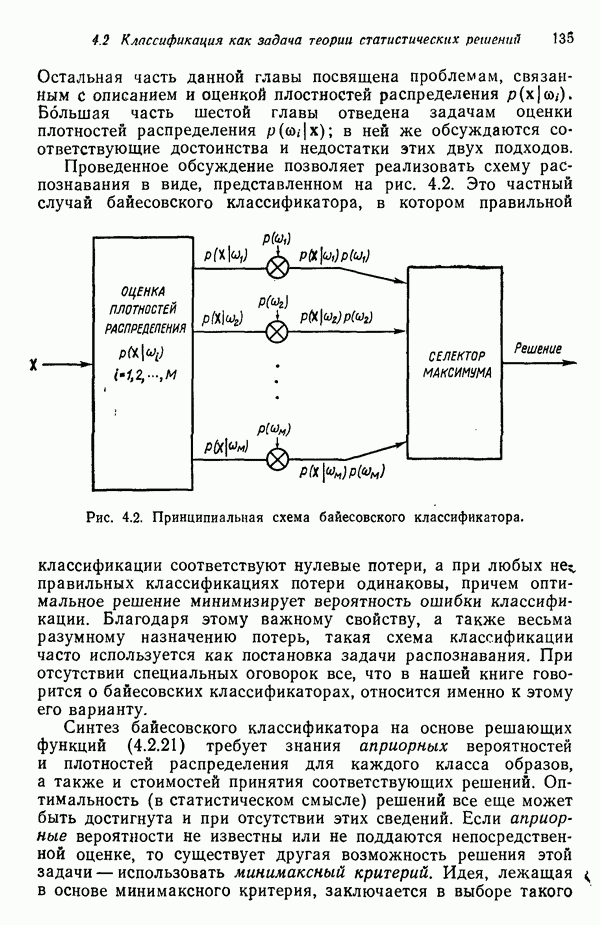
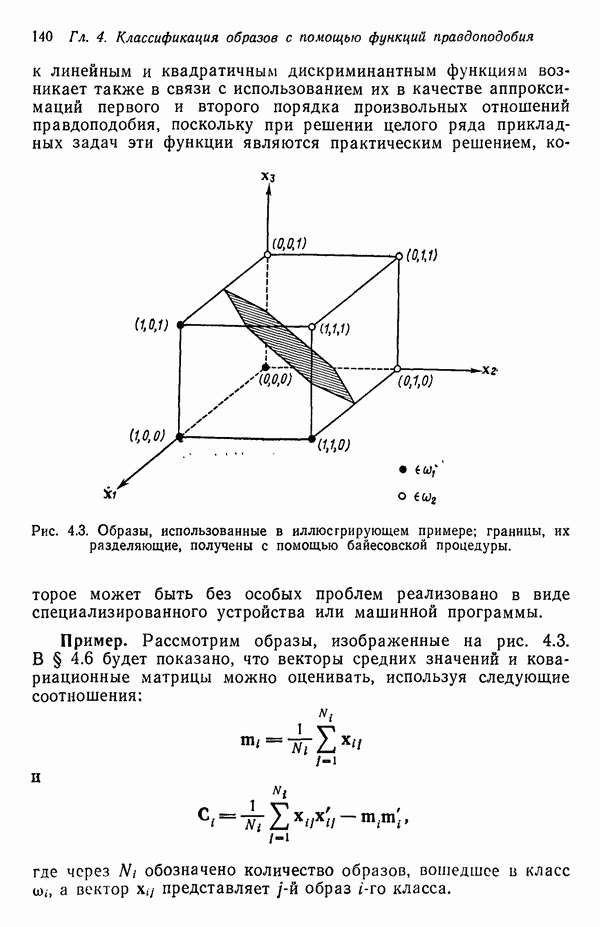
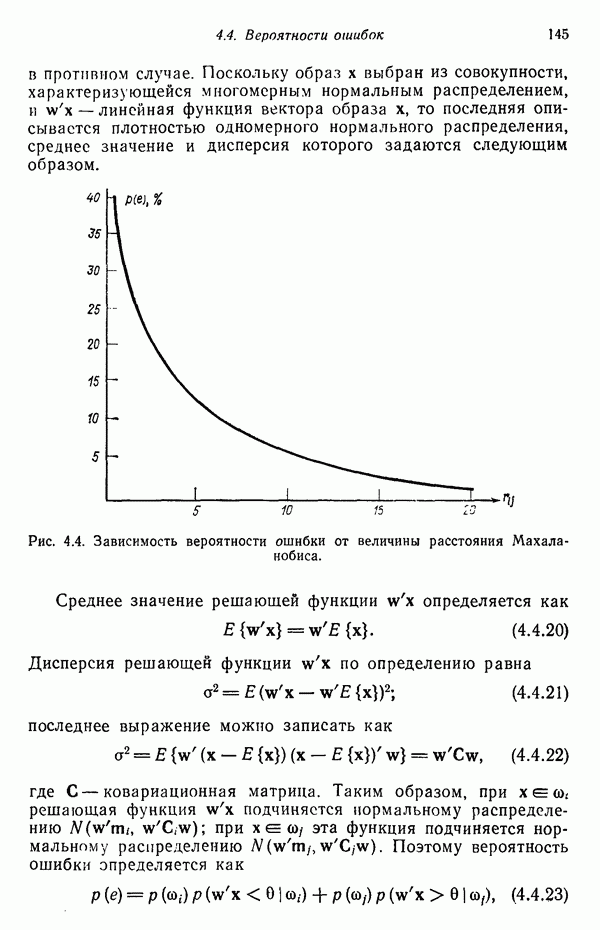
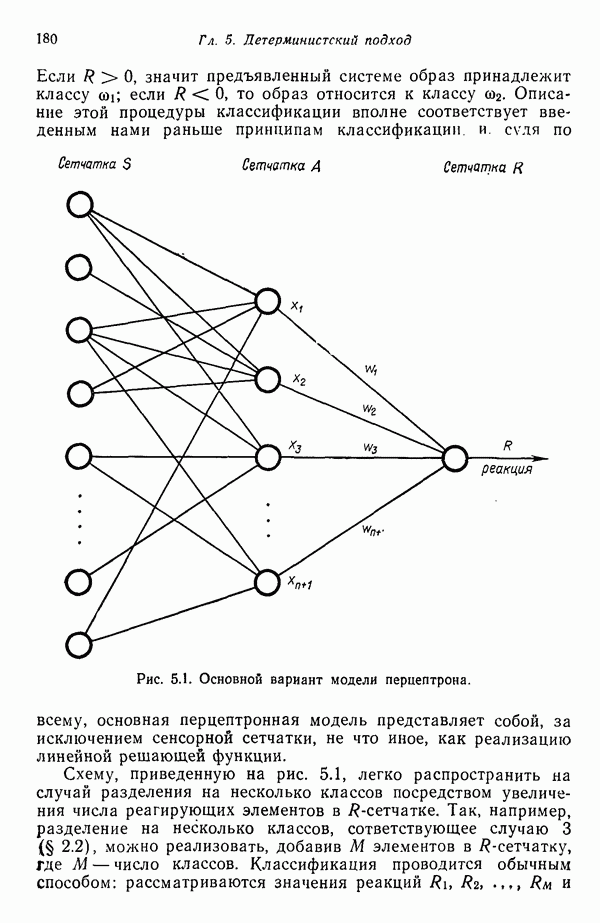
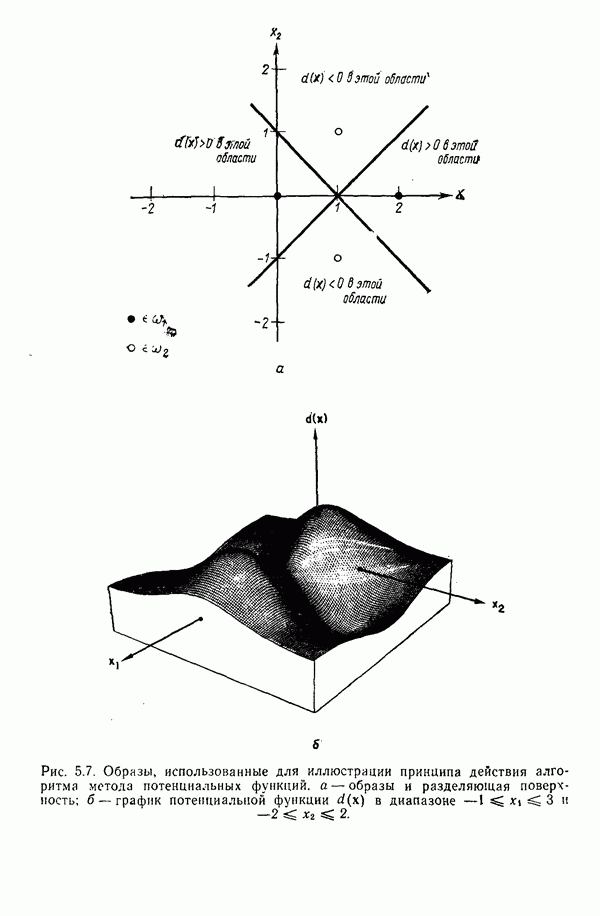
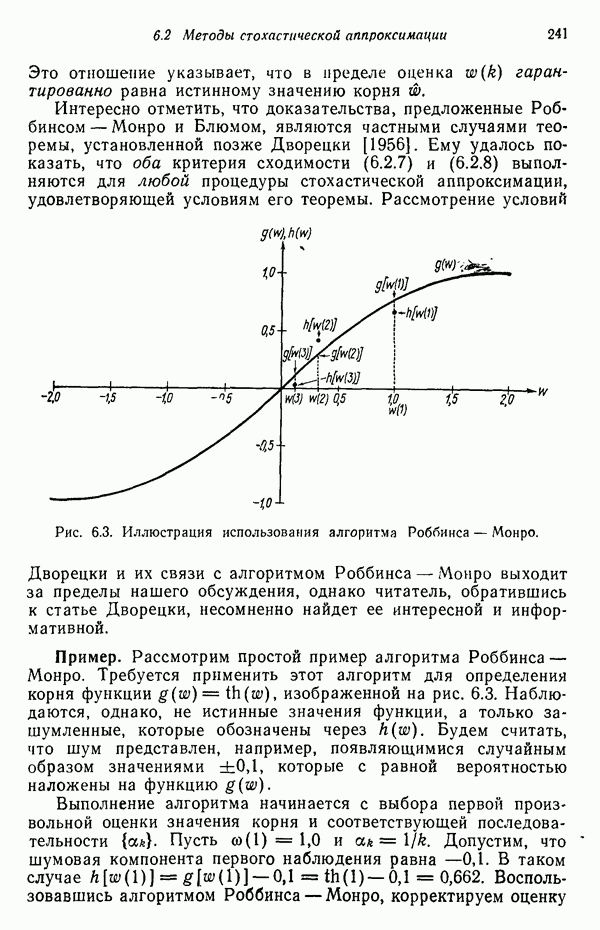
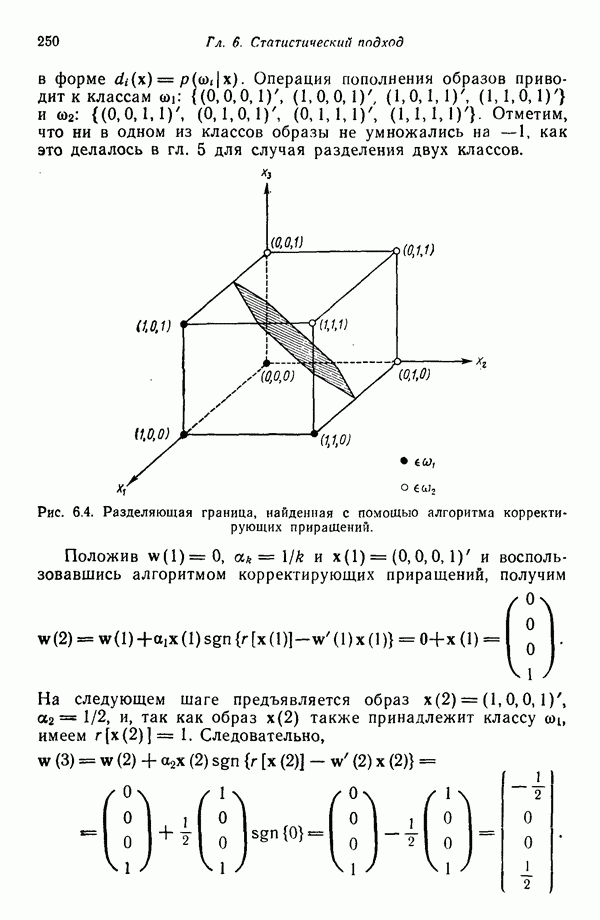
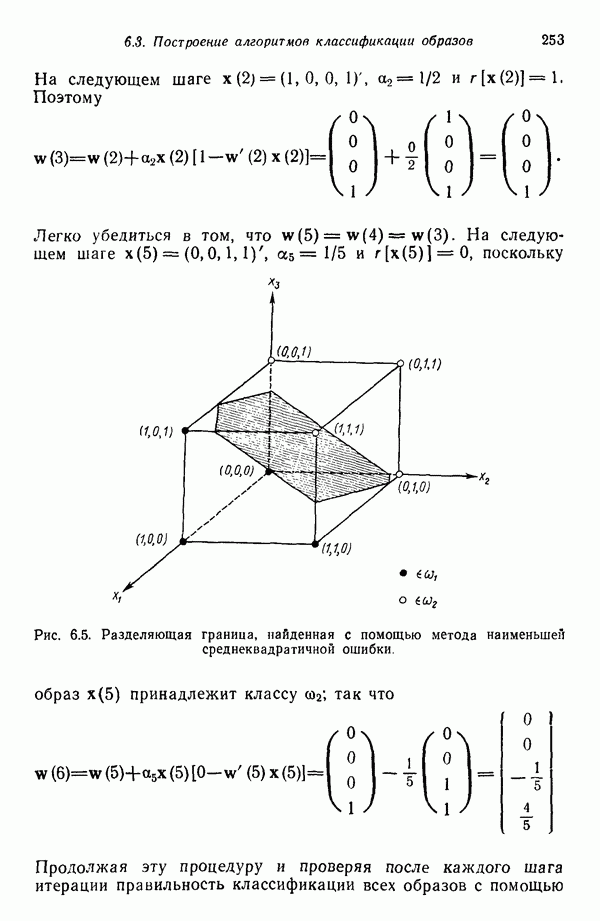
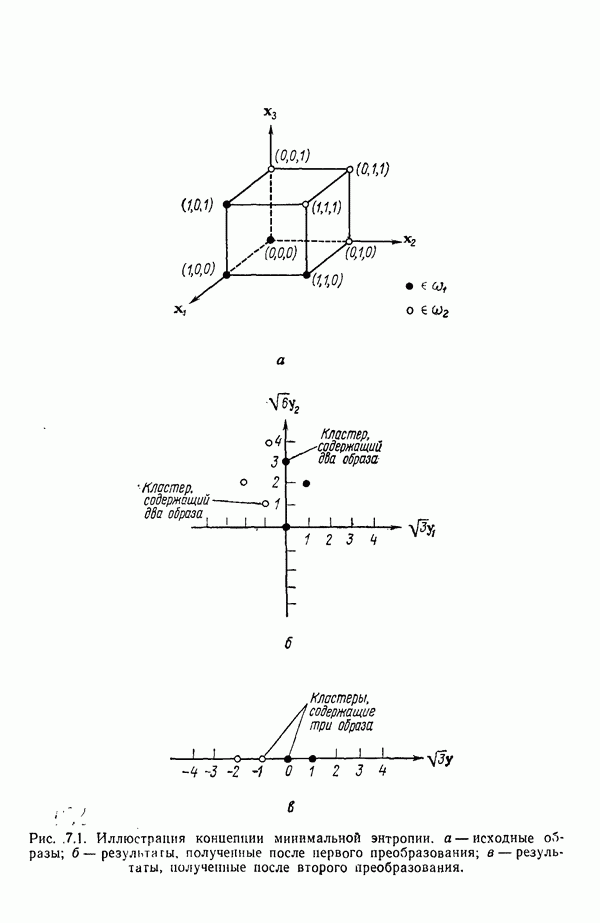
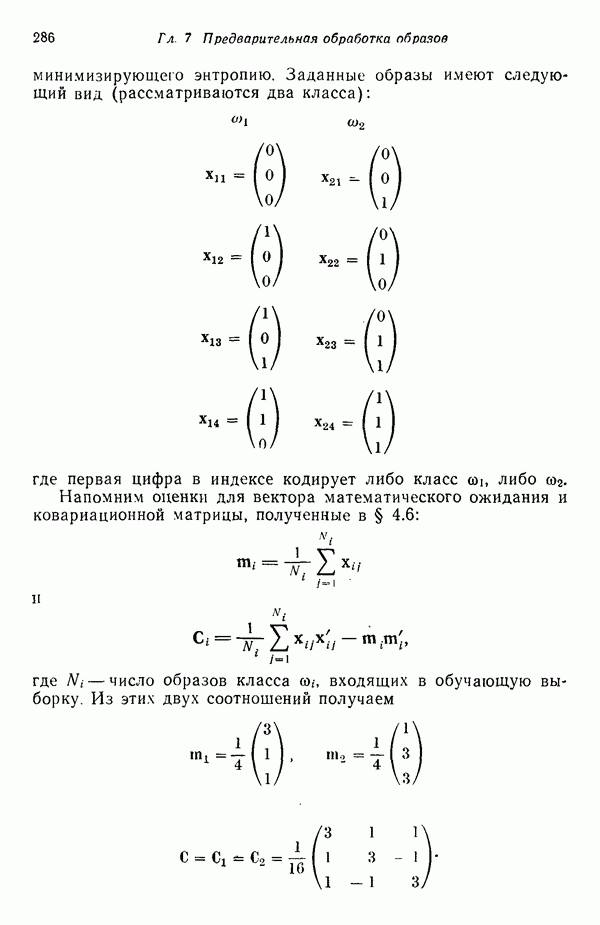
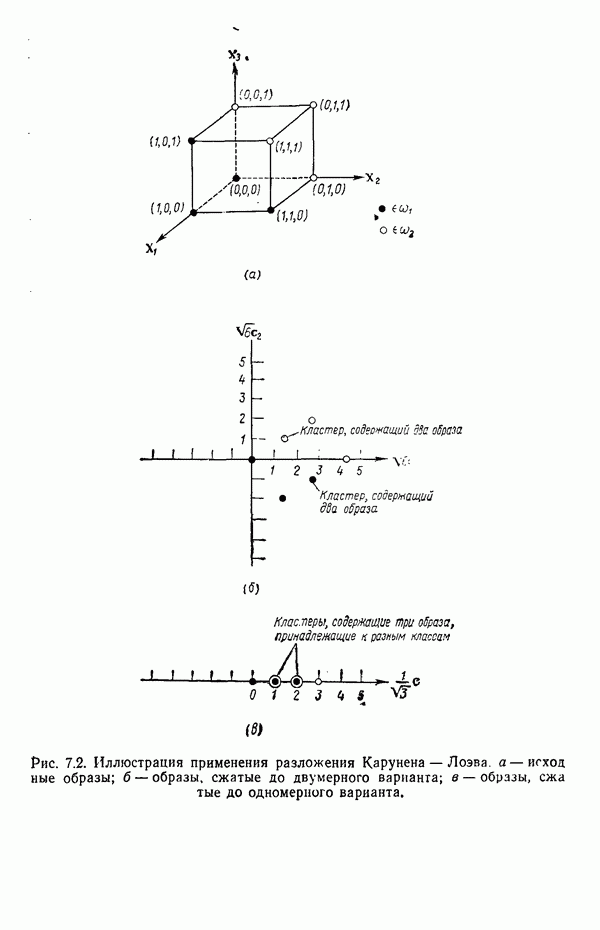
8.7. ОБУЧЕНИЕ И ГРАММАТИЧЕСКИЙ ВЫВОДГлавы 3—6 были посвящены в основном проблеме построения решающих функций с помощью обучающих выборок. В этой главе эта задача до сих пор умышленно не упоминалась. Используя лингвистическую терминологию, процедуру получения решений с помощью обучающей выборки легко интерпретировать как задачу получения грамматики из множества выборочных предложений. Эта процедура, обычно называемая грамматическим выводом, играет важную роль в изучении синтаксического распознавания образов в связи с ее значением для реализации автоматического обучения. Тем не менее, как это станет ясно из последующего обсуждения, область грамматического вывода находится еще в начальной стадии развития. Мы имеем в виду возможности обучения, которые можно было бы считать приемлемыми для синтеза универсальных методов построения систем синтаксического распознавания образов. Этот параграф посвящен в основном введению понятий грамматического вывода, рассматриваемых с двух точек зрения. В п. 8.7.1 строится алгоритм для вывода некоторых классов цепочечной грамматики. Затем в п. 8.7.2 достаточно подробно разбирается задача вывода двумерных грамматик. Хотя грамматики деревьев быстро становятся важной темой исследований в синтаксическом распознавании образов, алгоритмы вывода подобных грамматик, на наш взгляд, еще не достигли уровня, позволяющего включать их в учебник. В качестве введения в эту область можно рекомендовать читателям работу Гонсалеса и Томасона [1974б]. 8.7.1. Вывод цепочечных грамматикНа рис. 8.10 представлена модель вывода цепочечных грамматик. Задача, показанная на этом рисунке, заключается в том, что множество выборочных цепочек
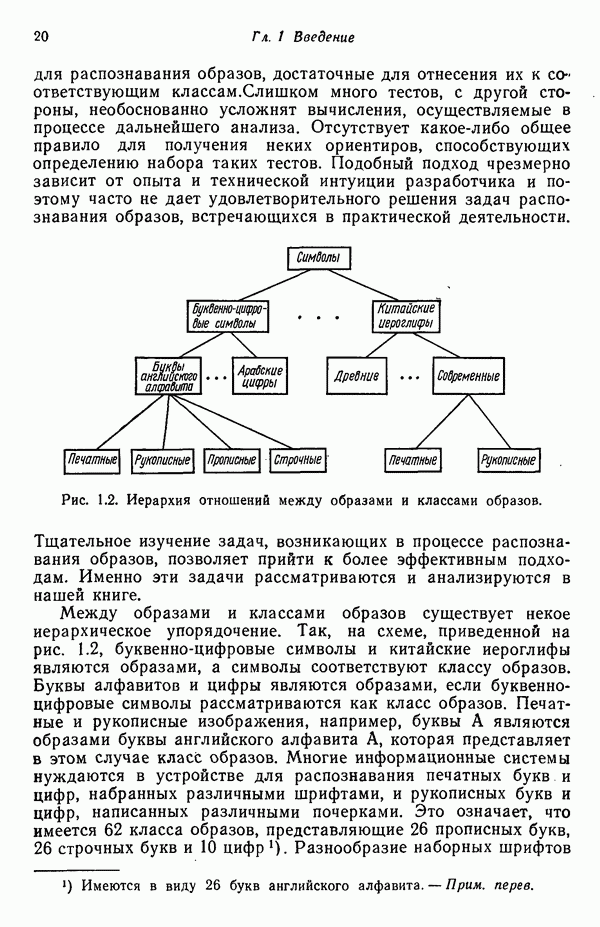
Рис. 8.10. Модель вывода непочечных грамматик. Алгоритм, рассматриваемый в этом пункте, является во многих отношениях типичным отражением результатов, полученных в данной области. Этот алгоритм, являющийся модификацией процедуры, разработанной Фельдманом [1967,1969], для заданного множества терминальных цепочек выводит автоматную грамматику. Основная идея метода Фельдмана заключается в том, чтобы сначала построить нерекурсивную грамматику, порождающую в точности заданные цепочки, а затем, сращивая нетерминальные элементы, получить более простую рекурсивную грамматику, порождающую бесконечное число цепочек. Алгоритм можно разделить на три части. Первая часть формирует нерекурсивную грамматику. Вторая часть преобразует ее в рекурсивную грамматику. Затем в третьей части происходит упрощение этой грамматики. Эту процедуру лучше всего пояснить на примере. Рассмотрим выборочное множество терминальных цепочек Часть 1. Строится нерекурсивная грамматика, порождающая в точности заданное множество выборочных цепочек. Выборочные цепочки обрабатываются в порядке уменьшения длины. Правила подстановки строятся и прибавляются к грамматике по мере того, как они становятся нужны для построения соответствующей цепочки из выборки. Заключительное правило подстановки, используемое для порождения самой длинной выборочной цепочки, называется остаточным правилом, а длина его правой части равна 2. Остаточное правило длины
где А — нетерминальный символ, а В нашем примере первой цепочкой максимальной длины в обучающей выборке является цепочка
где
Поскольку цепочка к некоторой избыточности правил подстановки. Например, вторая цепочка может быть с равным успехом получена введением следующих правил подстановки: Для порождения третьей цепочки
Рассмотрев остальные цепочки из обучающей выборки, устанавливаем, что окончательно множество правил подстановки, построенных для порождения обучающей выборки, выглядит следующим образом:
Часть 2. В этой части, соединяя каждое правило остатка длины 2 другим (неостаточным) правилом грамматики, получаем рекурсивную автоматную грамматику. Это происходит в результате слияния каждого нетерминального элемента правила остатка с нетерминальным элементом неостаточного правила, который может порождать остаток. Так, например, если отбрасывается. Таким способом создается автоматная грамматика, способная порождать данную обучающую выборку, а также обладающая общностью, достаточной для порождения бесконечного множества других цепочек. В рассматриваемом примере
Рекурсивными правилами являются Часть 3. Здесь грамматика, полученная во второй части, упрощается объединением эквивалентных правил подстановки. Два правила с левыми частями Формально два правила подстановки эквивалентны, если В приведенном примере эквивалентны правила с левыми частями
где исключены многократные повторения одного и того же правила. Точно так же, заметив, что
Дальнейшее слияние правил невозможно, поэтому алгоритм в процессе обучения строит следующую автоматную грамматику:
где
Легко проверить, что эта грамматика может порождать обучающую выборку, использованную в процессе ее вывода.
|
 |
Оглавление
|















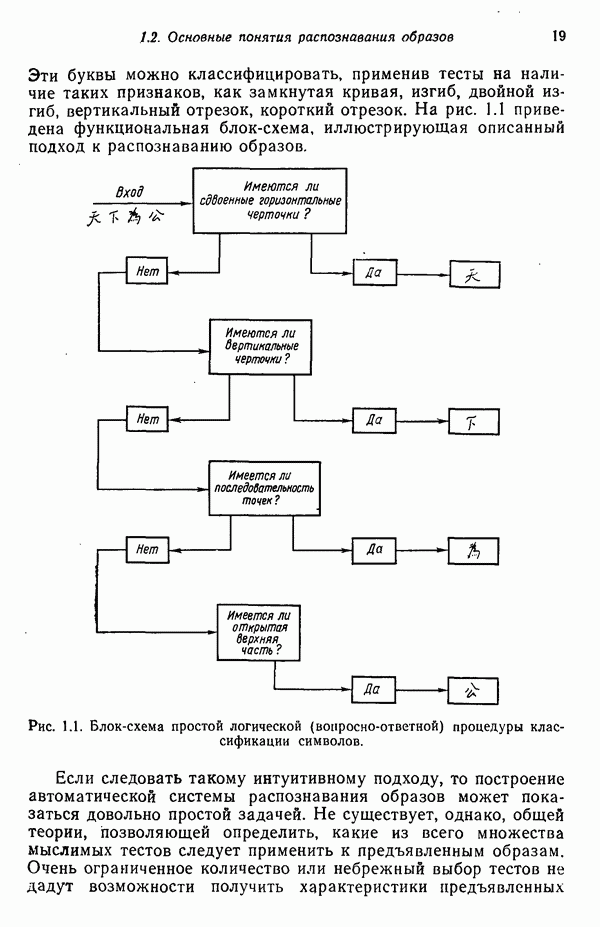
































































































































































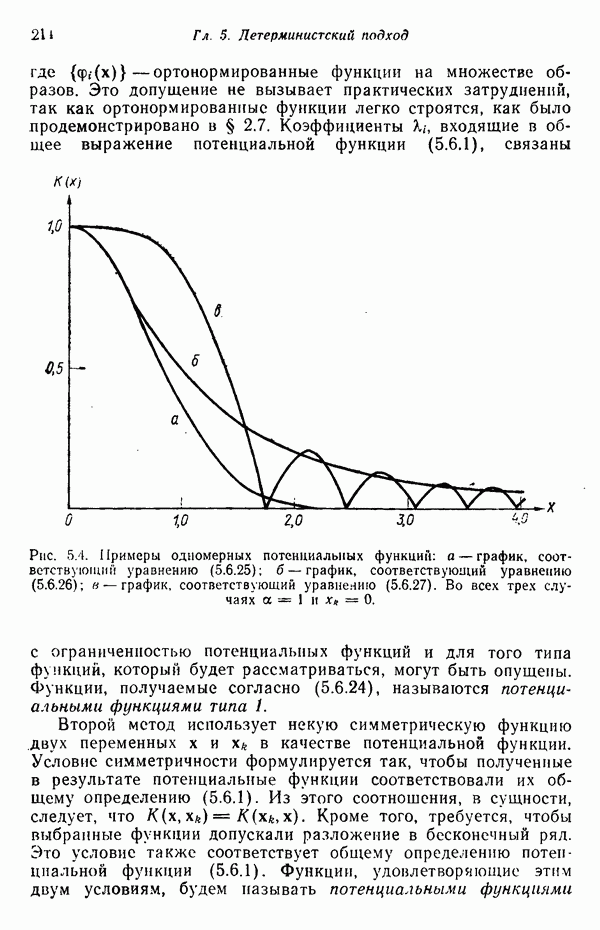



































































































































































 подвергается обработке с помощью адаптивного обучающего алгоритма, представленного на рисунке блоком. На выходе этого блока в конечном счете воспроизводится грамматика
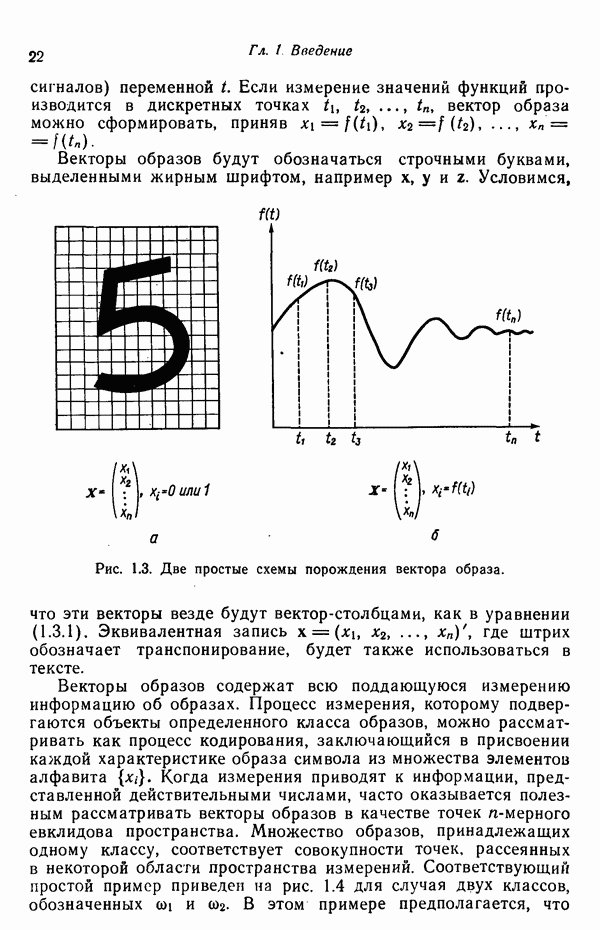
подвергается обработке с помощью адаптивного обучающего алгоритма, представленного на рисунке блоком. На выходе этого блока в конечном счете воспроизводится грамматика  согласованная с данными цепочками, т. е. множество цепочек
согласованная с данными цепочками, т. е. множество цепочек  является подмножеством языка
является подмножеством языка  . К сожалению, ни одна из известных нам схем не в состоянии решить эту задачу в общем виде, представленном на рис. 8.10. Вместо этого предлагаются многочисленнные алгоритмы для вывода ограниченных грамматик.
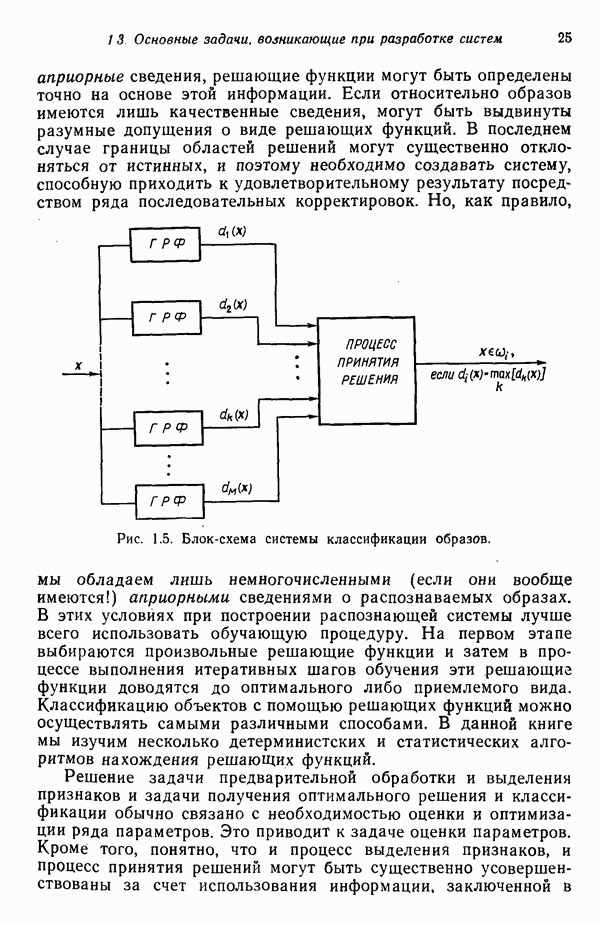
. К сожалению, ни одна из известных нам схем не в состоянии решить эту задачу в общем виде, представленном на рис. 8.10. Вместо этого предлагаются многочисленнные алгоритмы для вывода ограниченных грамматик.

 . Требуется получить автоматную грамматику, способную порождать эти цепочки. Алгоритм построения грамматики состоит из следующих этапов.
. Требуется получить автоматную грамматику, способную порождать эти цепочки. Алгоритм построения грамматики состоит из следующих этапов.
 имеет вид
имеет вид

 — терминальные элементы. Предполагается, что остаток каждой цепочки максимальной длины является суффиксом (хвостовым концом) некоторой более короткой цепочки. Если какой-либо остаток не отвечает этому условию, цепочка, равная остатку, добавляется к обучающей выборке. Из последующих рассуждений будет ясно, что выбор остатка длины 2 не связан с ограничением на алгоритм. Можно выбрать и более длинный остаток, но тогда потребуется более полная обучающая выборка в связи с условием, что каждый остаток является суффиксом некоторой более короткой цепочки.
— терминальные элементы. Предполагается, что остаток каждой цепочки максимальной длины является суффиксом (хвостовым концом) некоторой более короткой цепочки. Если какой-либо остаток не отвечает этому условию, цепочка, равная остатку, добавляется к обучающей выборке. Из последующих рассуждений будет ясно, что выбор остатка длины 2 не связан с ограничением на алгоритм. Можно выбрать и более длинный остаток, но тогда потребуется более полная обучающая выборка в связи с условием, что каждый остаток является суффиксом некоторой более короткой цепочки.
 . Для порождения этой цепочки строятся следующие правила подстановки:
. Для порождения этой цепочки строятся следующие правила подстановки:

 — правило остатка. Вторая цепочка
— правило остатка. Вторая цепочка  . Для порождения этой цепочки к грамматике добавляются следующие правила:
. Для порождения этой цепочки к грамматике добавляются следующие правила:

 и предыдущая цепочка
и предыдущая цепочка  имеют одинаковую длину, требуется остаточное правило длины 2. Заметим также, что работа первой части алгоритма приводит
имеют одинаковую длину, требуется остаточное правило длины 2. Заметим также, что работа первой части алгоритма приводит
 Но в первой части мы занимаемся лишь определением множества правил подстановки, которое способно в точности порождать обучающую выборку, и не касаемся вопроса избыточности. В сложных ситуациях трудно соблюдать выполнение этого условия и одновременно уменьшать число необходимых правил подстановки. Значительно проще просматривать введенные правила слева направо, чтобы определить, будут ли они порождать новую цепочку, не стремясь при этом минимизировать число правил подстановки. Об устранении избыточности речь пойдет в третьей части алгоритма.
Но в первой части мы занимаемся лишь определением множества правил подстановки, которое способно в точности порождать обучающую выборку, и не касаемся вопроса избыточности. В сложных ситуациях трудно соблюдать выполнение этого условия и одновременно уменьшать число необходимых правил подстановки. Значительно проще просматривать введенные правила слева направо, чтобы определить, будут ли они порождать новую цепочку, не стремясь при этом минимизировать число правил подстановки. Об устранении избыточности речь пойдет в третьей части алгоритма.
 требуется добавление к грамматике только одного правила
требуется добавление к грамматике только одного правила


 — остаточный нетерминал вида
— остаточный нетерминал вида  — неостаточный нетерминал вида
— неостаточный нетерминал вида  , где
, где  все встречающиеся
все встречающиеся  заменяются на
заменяются на  , а правило подстановки
, а правило подстановки 
 может сливаться с
может сливаться с  может сливаться с
может сливаться с  образуя следующие правила
образуя следующие правила


 эквивалентны, если соблюдены следующие условия. Предположим, что, начиная с
эквивалентны, если соблюдены следующие условия. Предположим, что, начиная с  можно породить множество цепочек
можно породить множество цепочек  . Аналогичным образом предположим, что, начиная с
. Аналогичным образом предположим, что, начиная с  можно породить множество
можно породить множество  . Если
. Если  , то два правила подстановки считаются эквивалентными, и каждый символ
, то два правила подстановки считаются эквивалентными, и каждый символ  может быть заменен на
может быть заменен на  без ущерба для языка, порождаемого этой грамматикой.
без ущерба для языка, порождаемого этой грамматикой.
 , где
, где  обозначает, что цепочка
обозначает, что цепочка  порождается из
порождается из  соответствующим применением правил подстановки.
соответствующим применением правил подстановки.
 После слияния
После слияния  получаем
получаем

 эквивалентны, получаем
эквивалентны, получаем


