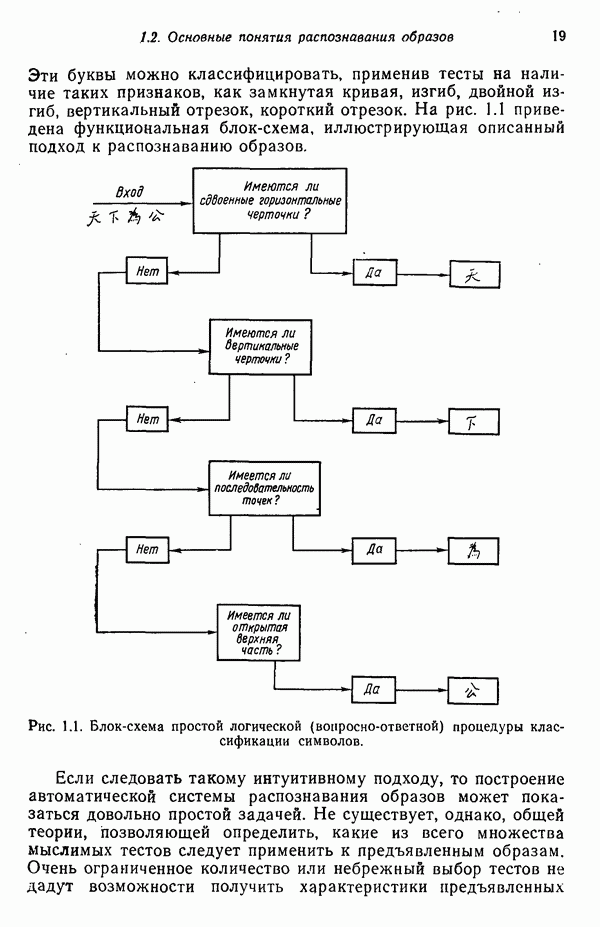
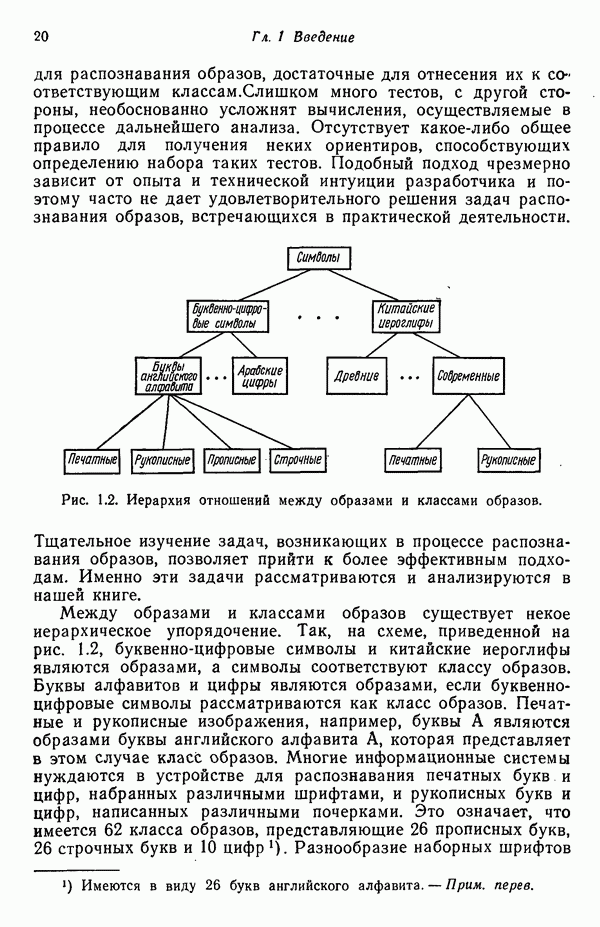
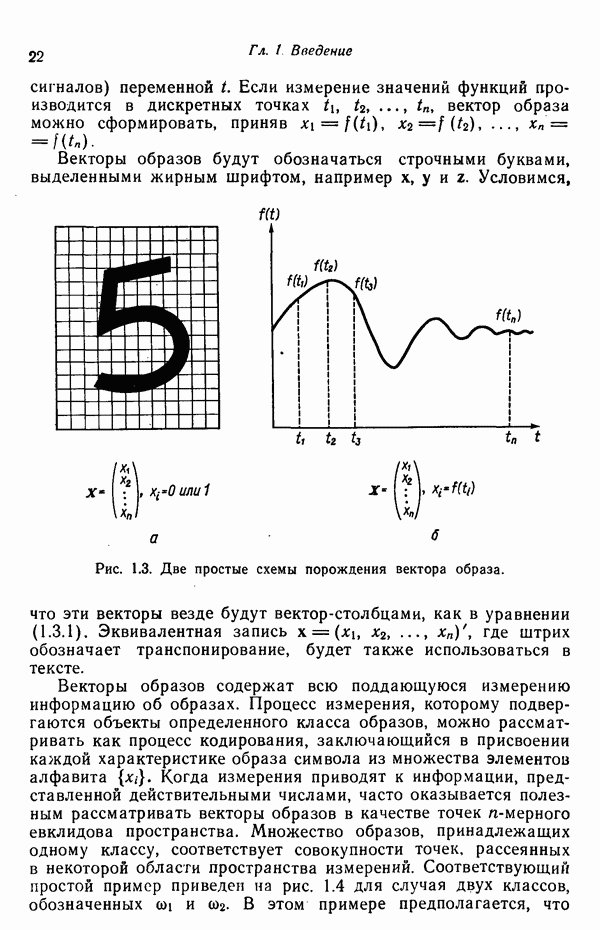
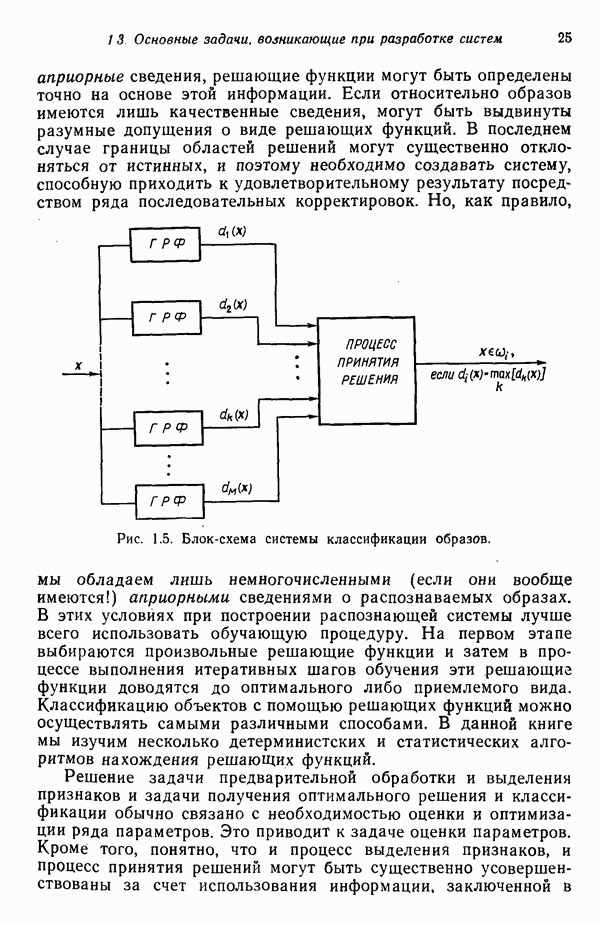
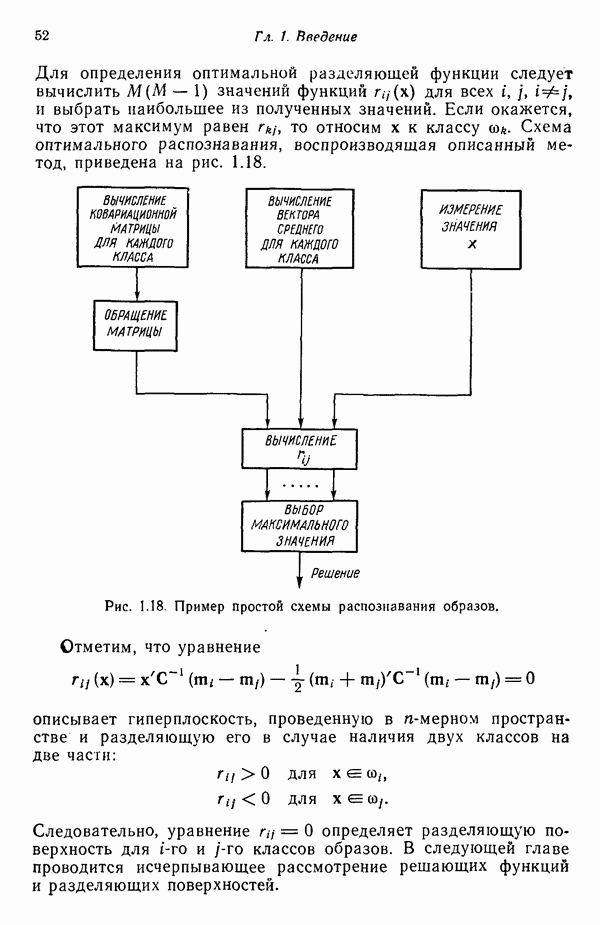
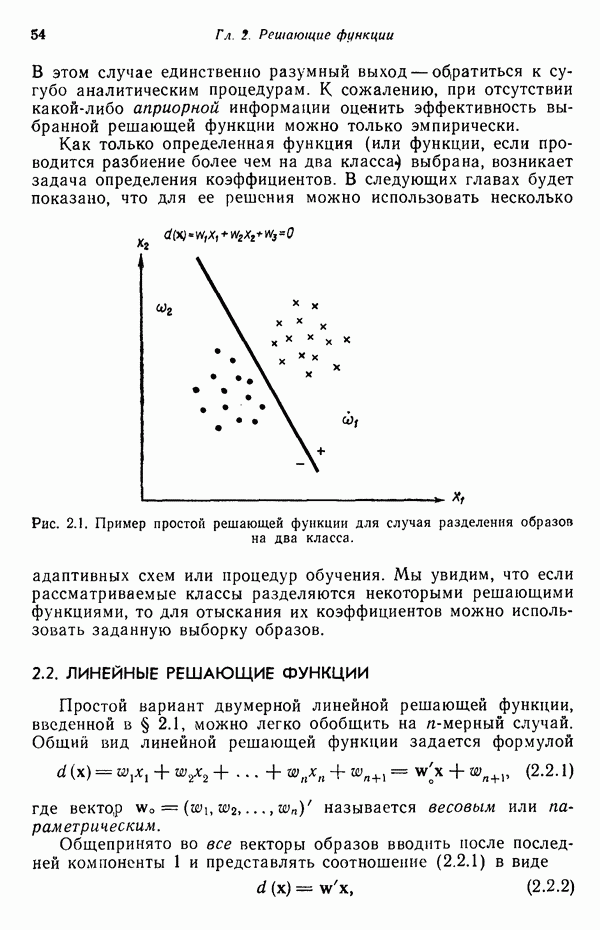
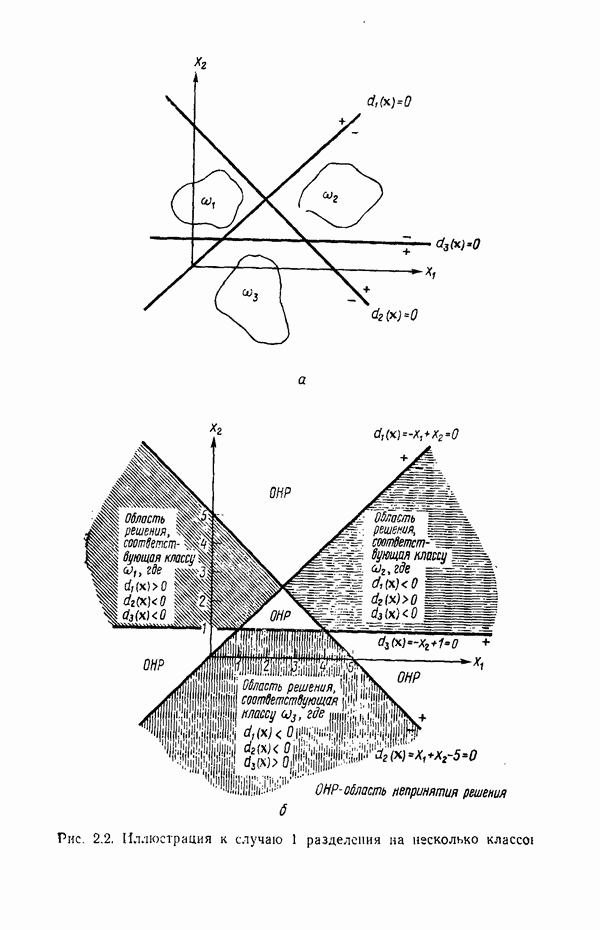
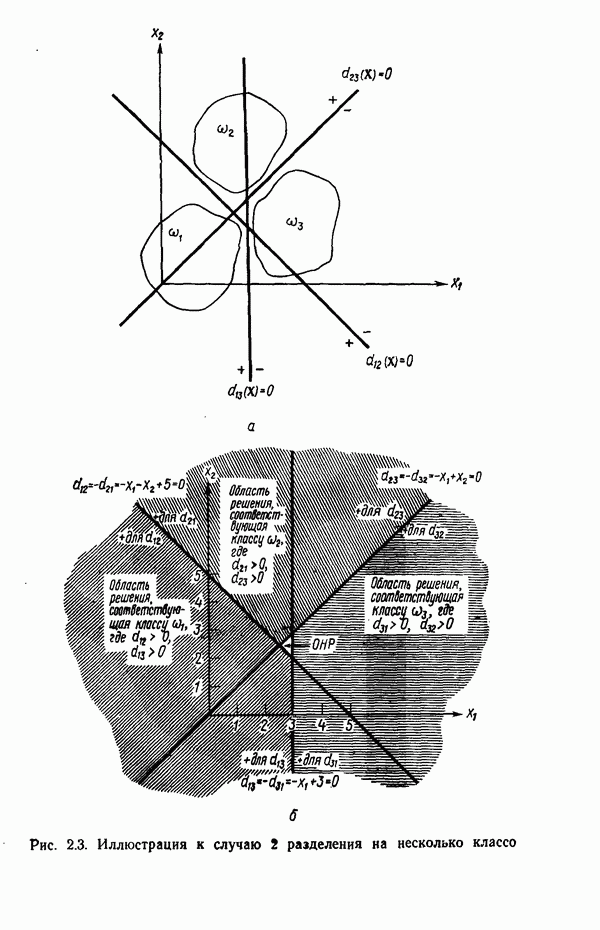
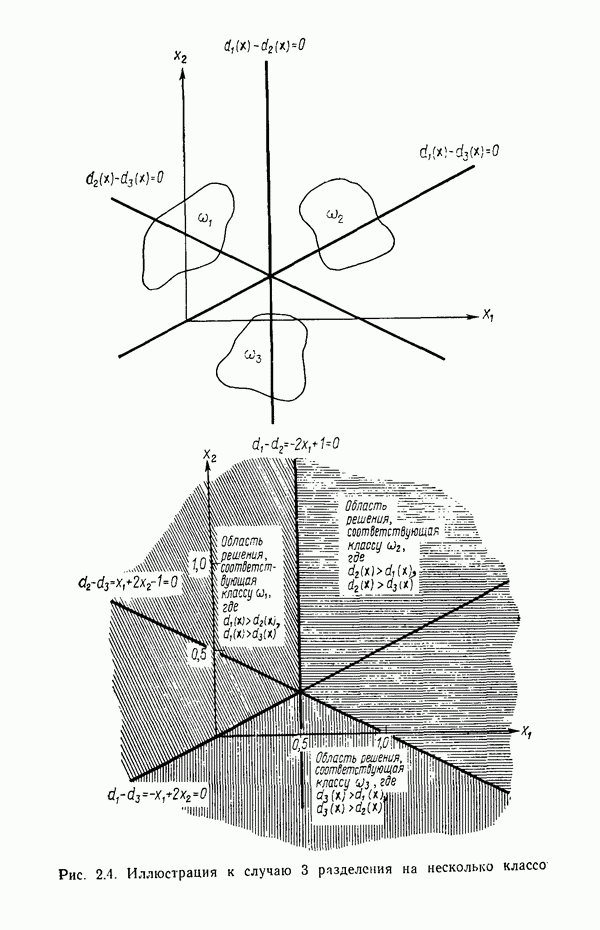
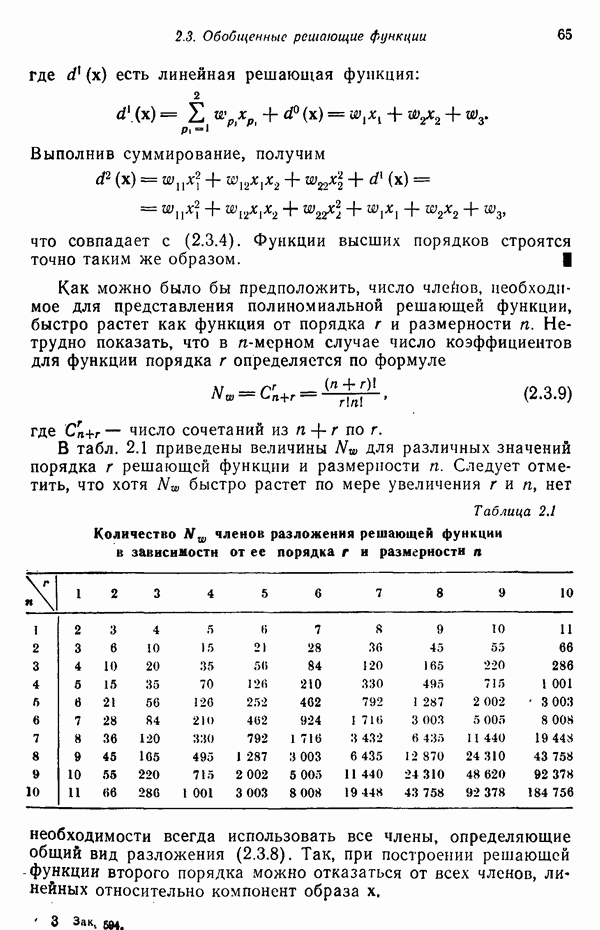
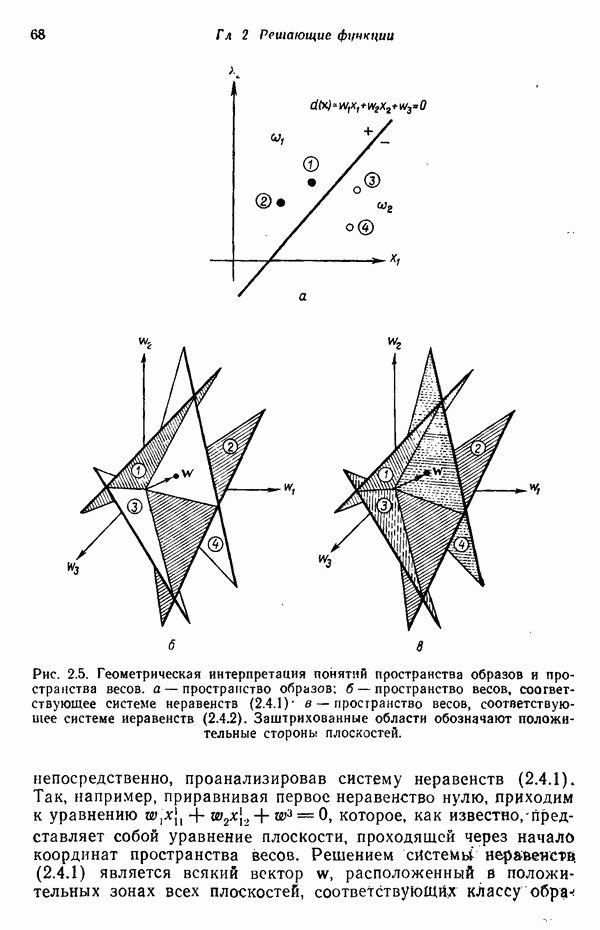
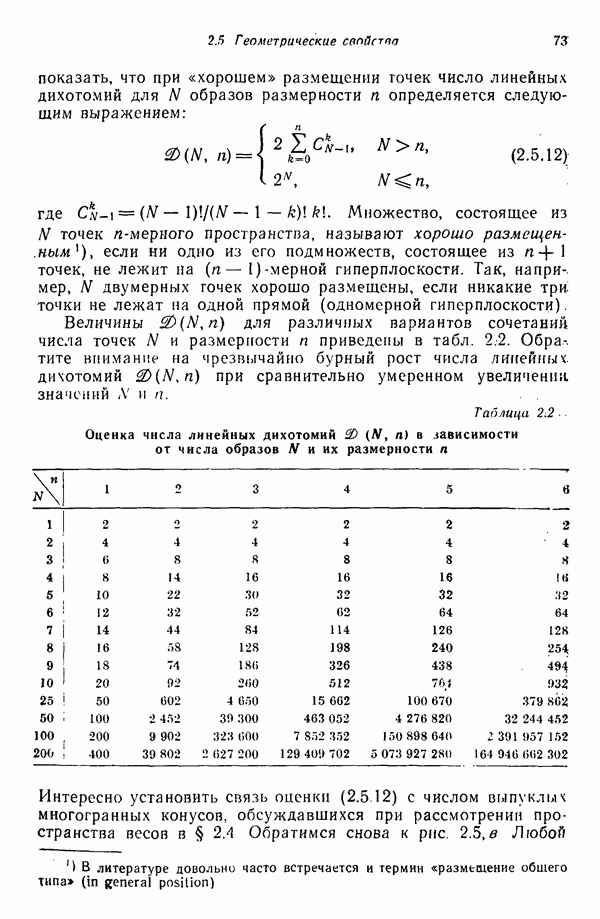
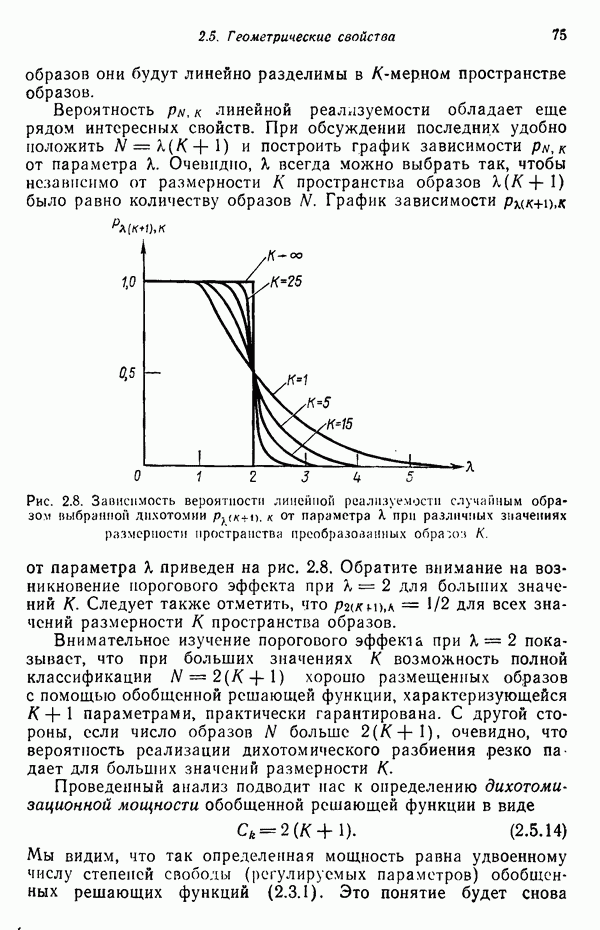
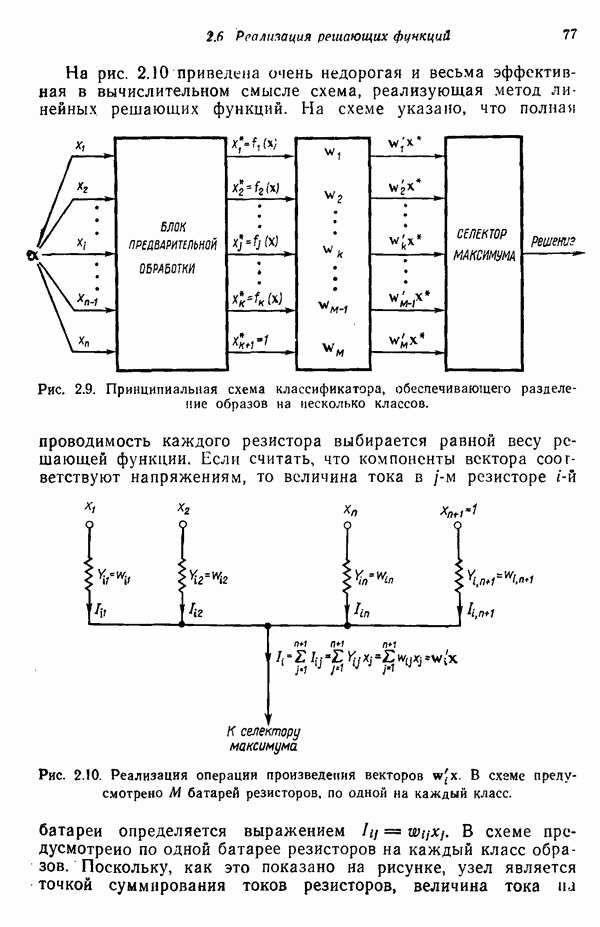
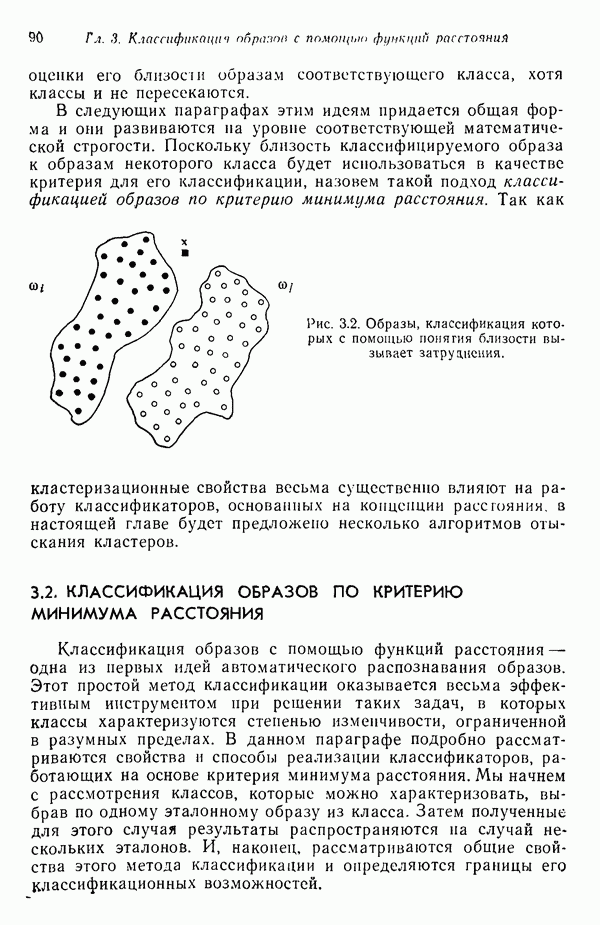
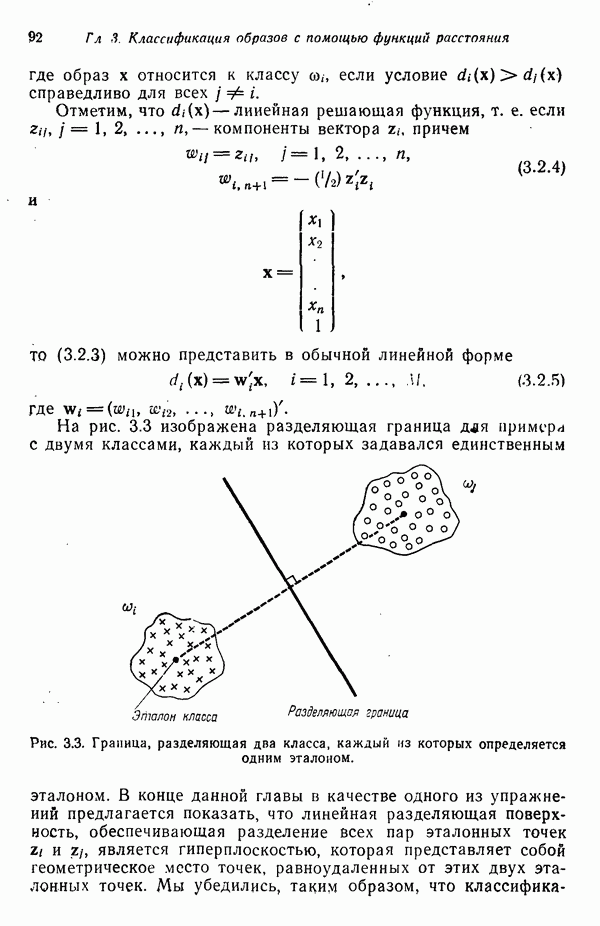
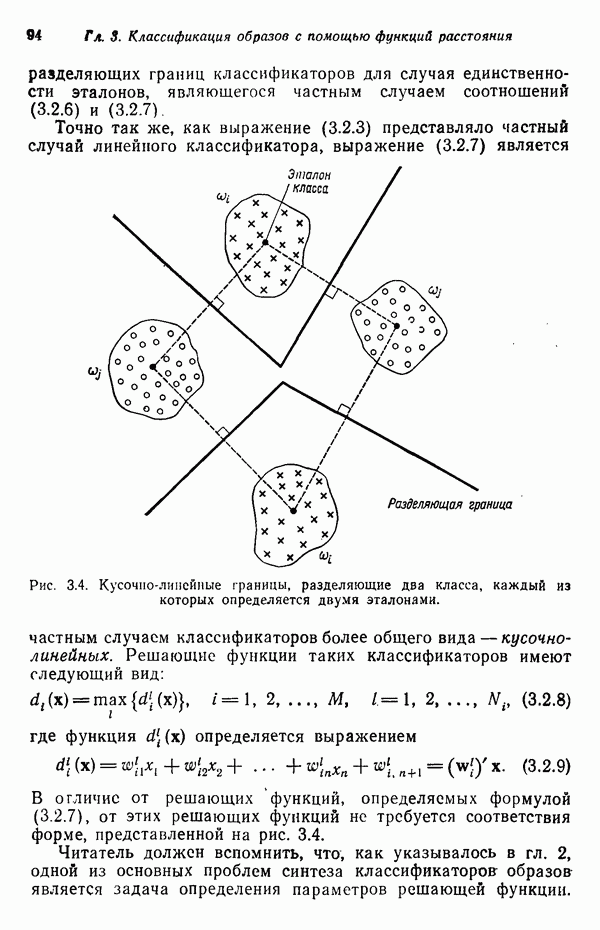
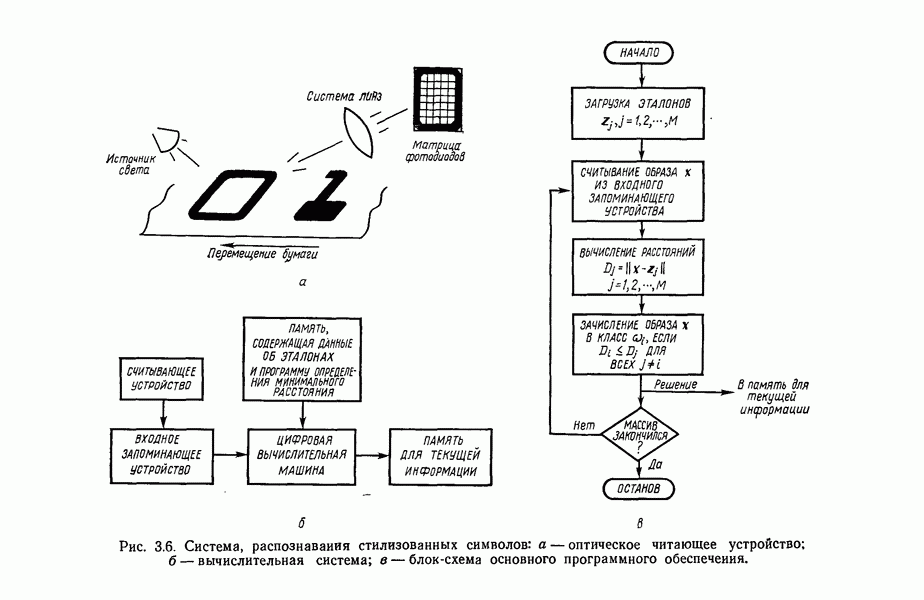
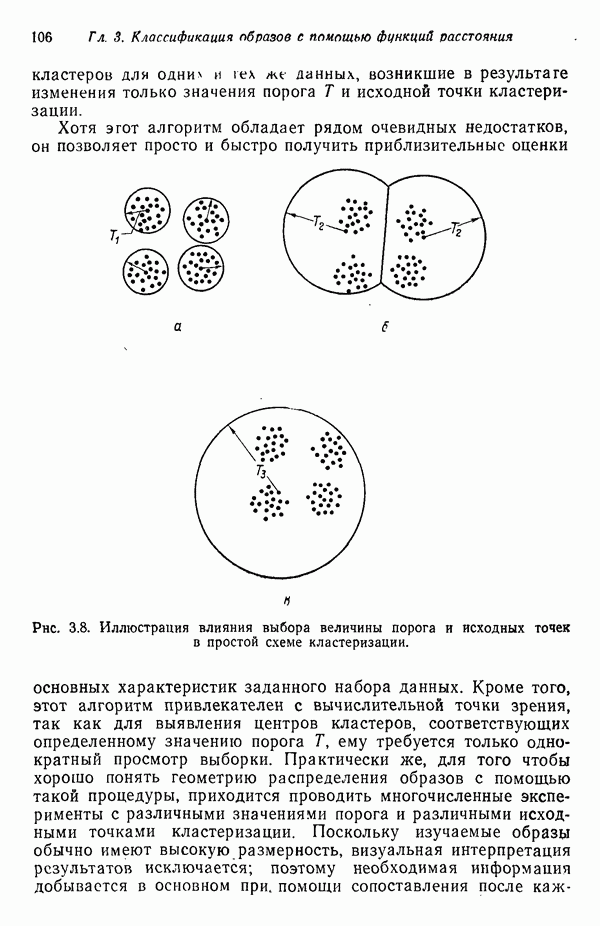
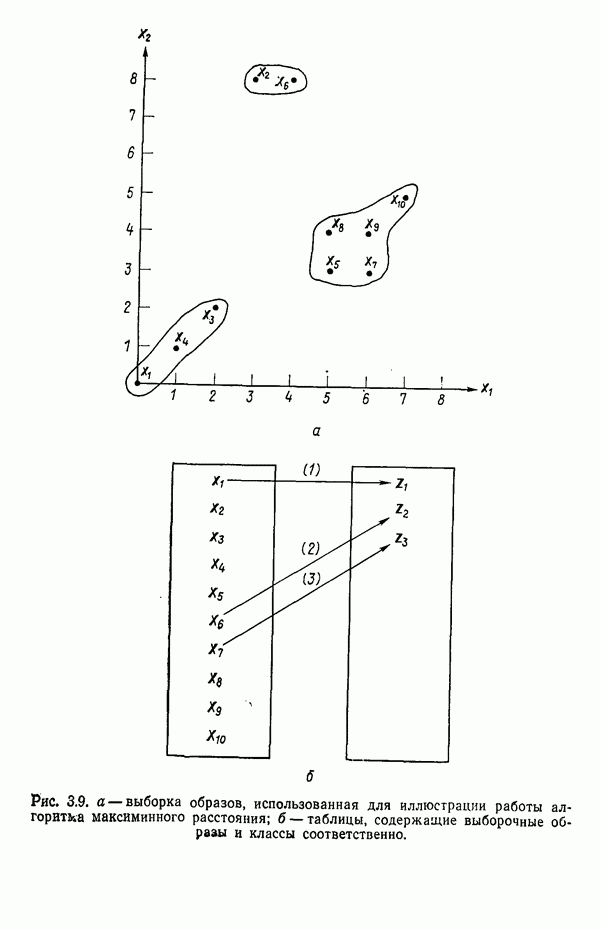
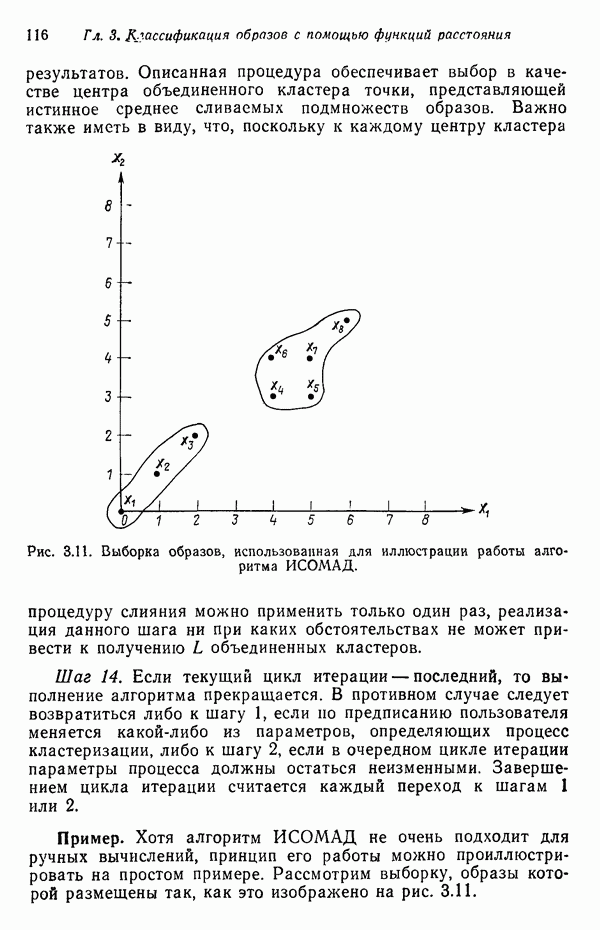
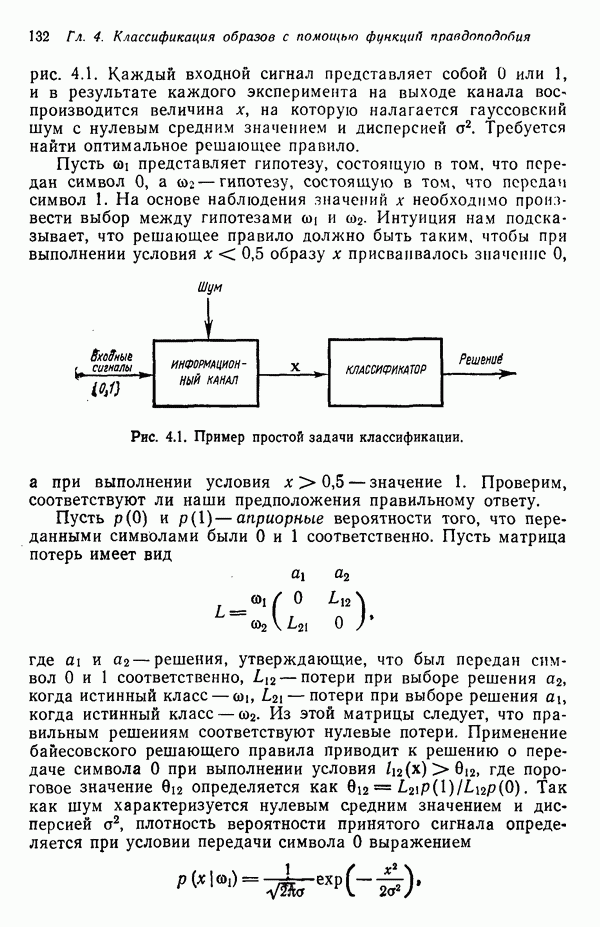
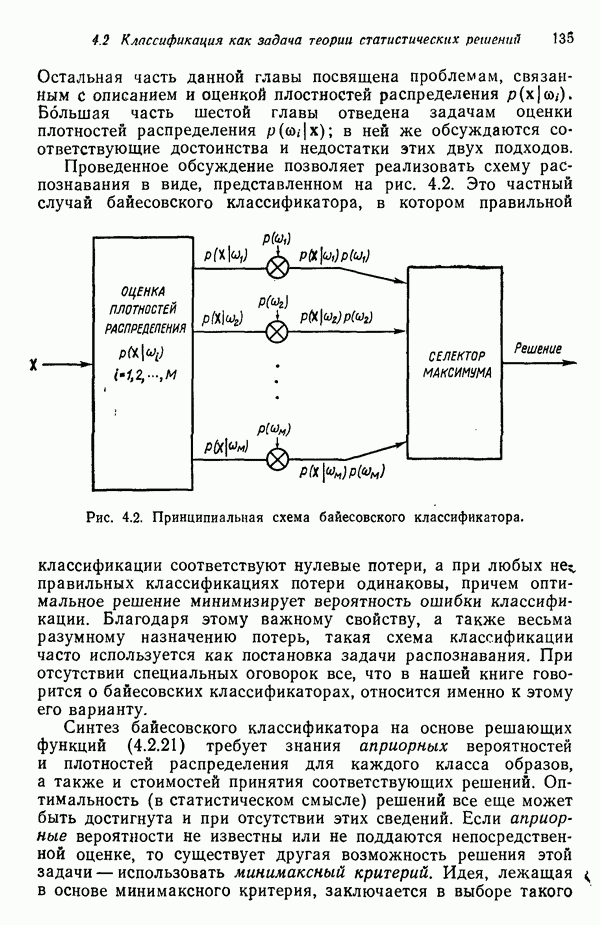
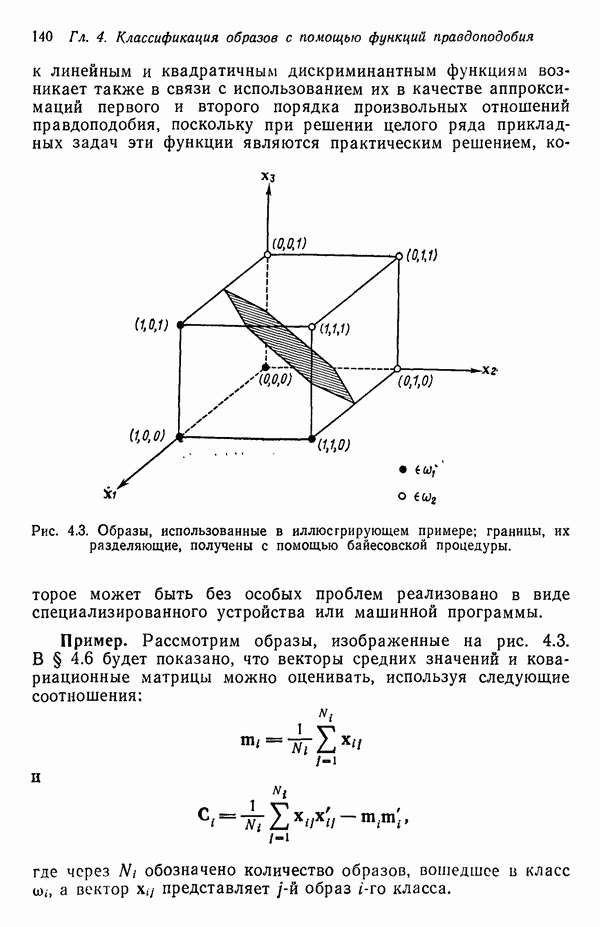
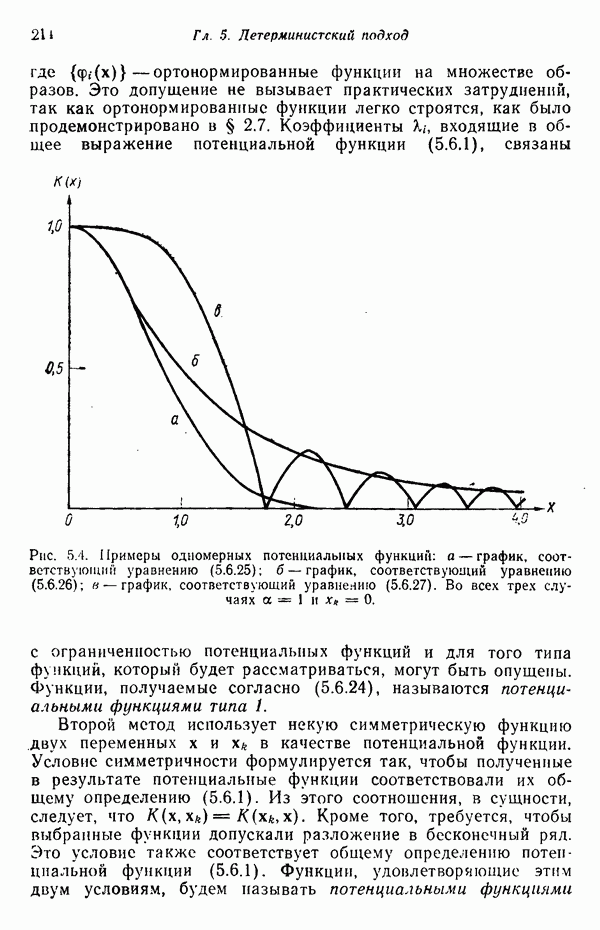
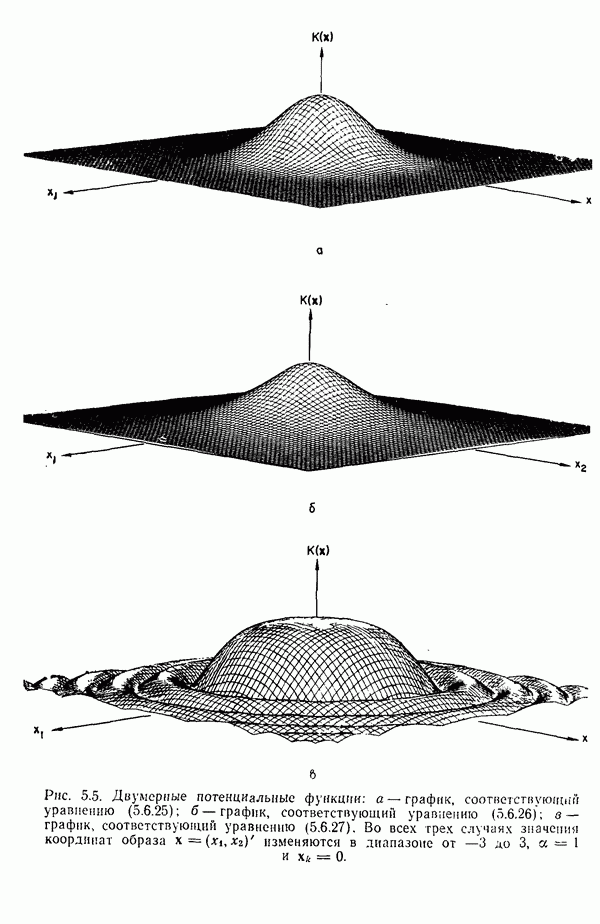
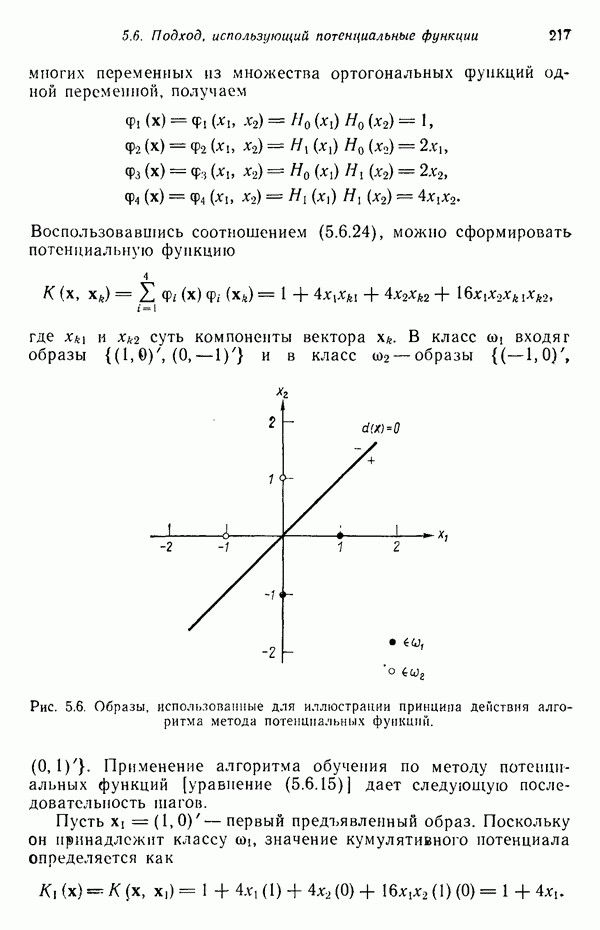
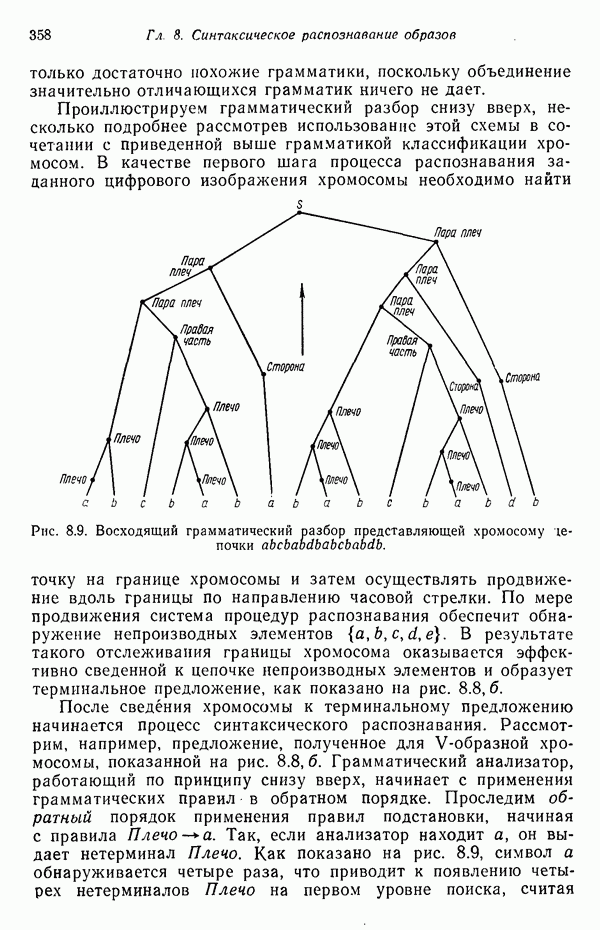
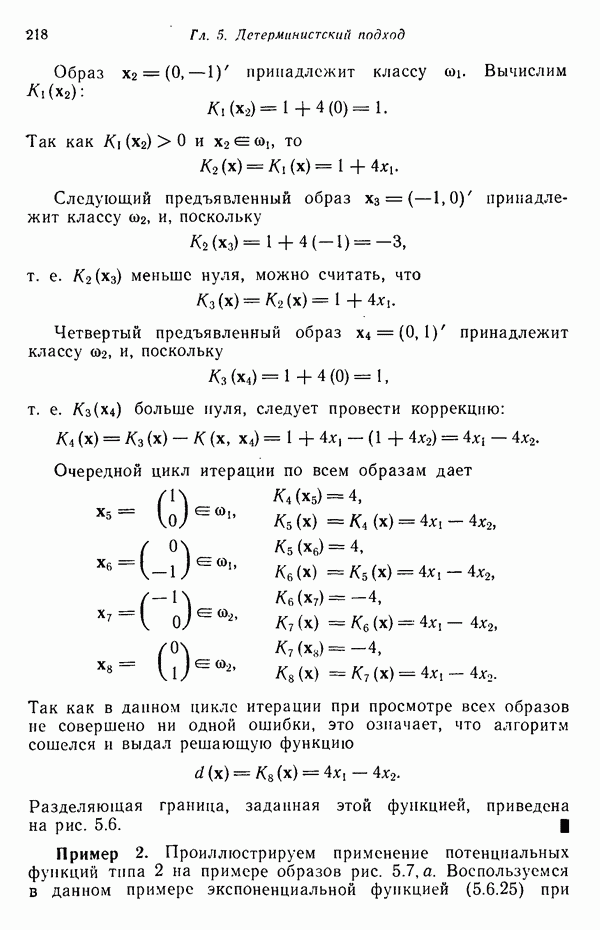6.5. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
В настоящей главе были изложены основные концепции, позволяющие применять для классификации образов статистические алгоритмы обучения. Как и в гл. 5, исходя из общей итеративной схемы при соответствующем задании различных функций критерия было выведено несколько алгоритмов. Кроме рассмотренных здесь, нетрудно построить и ряд других алгоритмов. Приведенные алгоритмы, однако, дают представление о диапазоне возможных схем.
Качество решающих функций, полученных статистическими методами, что справедливо и при использовании детерминистских подходов, в принципе существенно зависит от сложности функций, выбранных для аппроксимации соответствующих решающих функций. В отличие, однако, от своих детерминистских аналогов статистические алгоритмы этой главы сходятся в пределе к некоторой аппроксимации байесовского классификатора. Следует в то же время отметить, что медленная сходимость, свойственная статистическим классификаторам, в общем перевешивает их потенциальную способность обеспечивать оптимальное качество. Поэтому алгоритмы, построенные в гл. 5, вполне могут конкурировать со схемами классификации, рассматривавшимися здесь.
Материал этой главы завершает изучение классификации образов с помощью решающих функций. Мы начали его с концепций классификации по минимуму расстояния, использующей функции правдоподобия, и довели до алгоритмов обучения, рассмотренных в данной и предыдущей главах. Интересно еще
раз сопоставить разнообразие подходов, заключенных в этих методах. Если просмотреть гл. 3—5, то можно заметить, что методы, изложенные в гл. 3 и 4, не базируются на итеративных схемах обучения, которые были введены в гл. 5 и данной. Очевидно также, что методы, рассмотренные в этих главах, вполне определенно опирались либо на детерминистские, либо на вероятностные концепции. Эффективность определенного метода существенно зависит как от исходных данных, так и от поставленной цели. Тем не менее рассмотренные методы классификации образов представляют собой разнообразный и мощный набор средств для решения широкого круга практических задач. В следующей главе мы займемся изучением методов выбора и выделения признаков. Как мы увидим, эти методы чрезвычайно полезны для организации этапов предварительной обработки данных системами распознавания образов.
Библиография
Метод стохастической аппроксимации, рассмотренный в § 6.2, предложен Роббипсом и Монро [1951]. Алгоритм Роббинса — Монро был обобщен на многомерный случай Блюмом [19546]. Свойства сходимости алгоритма стохастической аппроксимации в общем виде были изучены Дворецки [1956]. Монография Уайлда [1964] содержит очень доступное введение в методы стохастической аппроксимации.
Истоки применения методов стохастической аппроксимации в распознавании образов относятся к началу 60-х годов. Интересно, что очень много ранних работ в этой области посвящено методам потенциальных функций и стохастической аппроксимации. Серия статей Айзермана, Бравермана и Розоноэра [1964а, 1964б, 1965] описывает метод потенциальных функций и стохастическую аппроксимацию; там же содержится большая часть фундаментальных теоретических результатов, связанных с приложенном этих методов в распознавании образов. Кроме того, результаты, относящиеся к этой теме, имеются в статьях Бравермана [1965], отчете Блейдона [1967], статье Хо и Агравалы [1968]. а также в монографиях Фу [1971], Ту [1969а], Фукунаги [1972], Патрика [1972], Майзела [1972] и Дуды и Харта [1976].
Задачи
(см. скан)