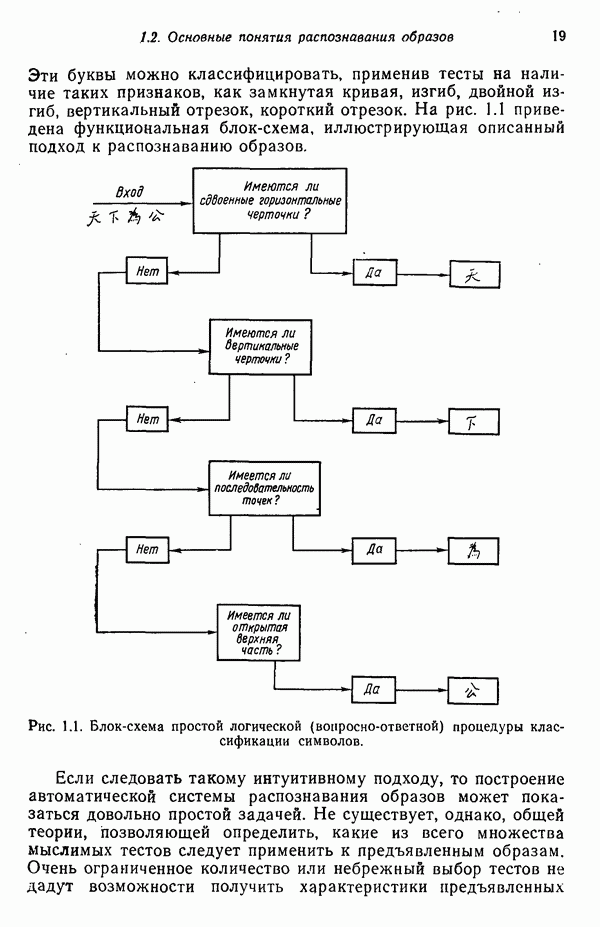
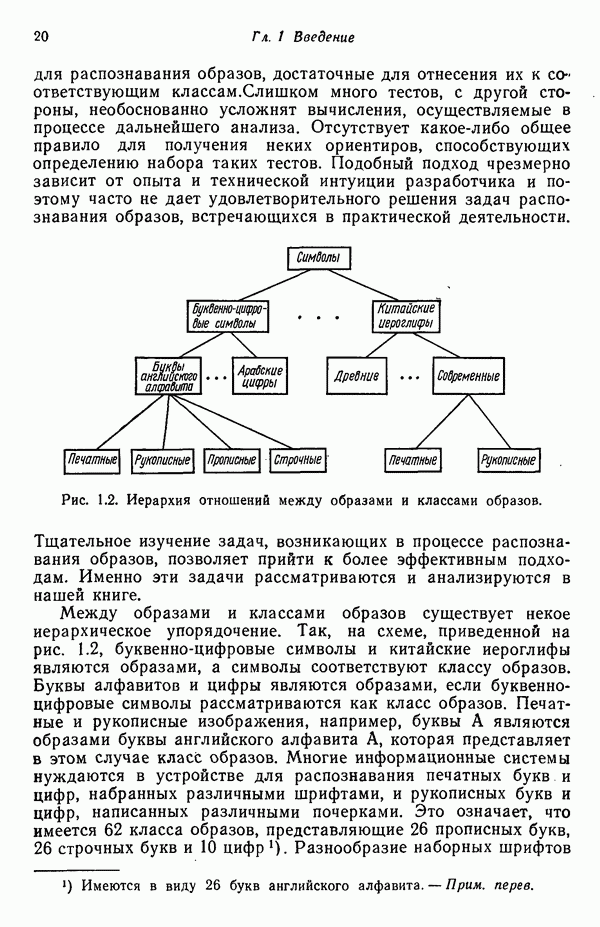
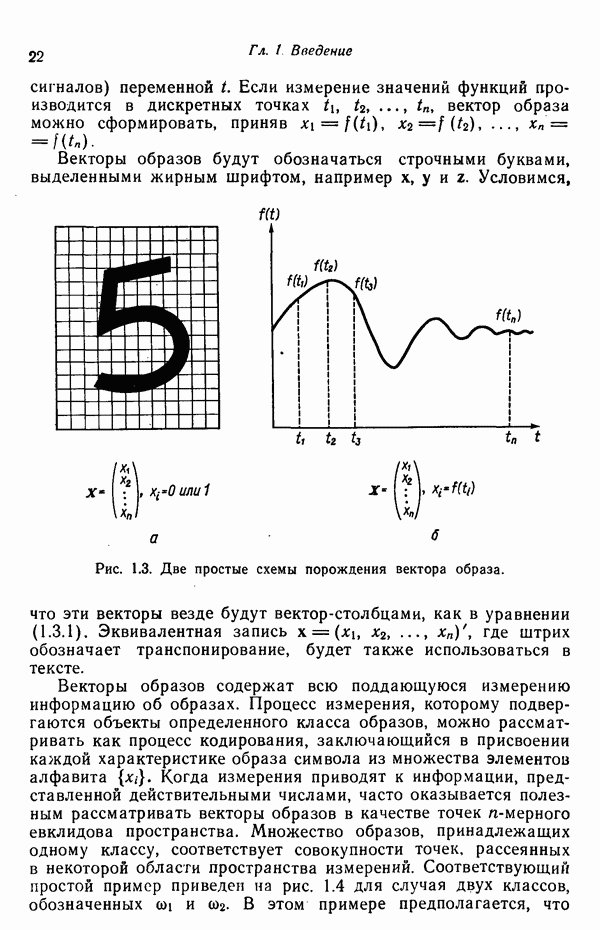
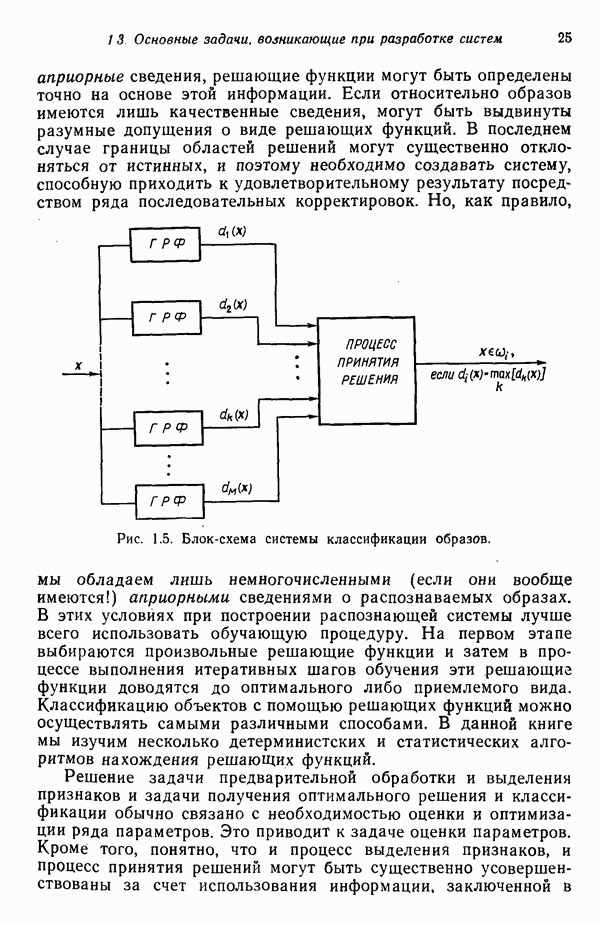
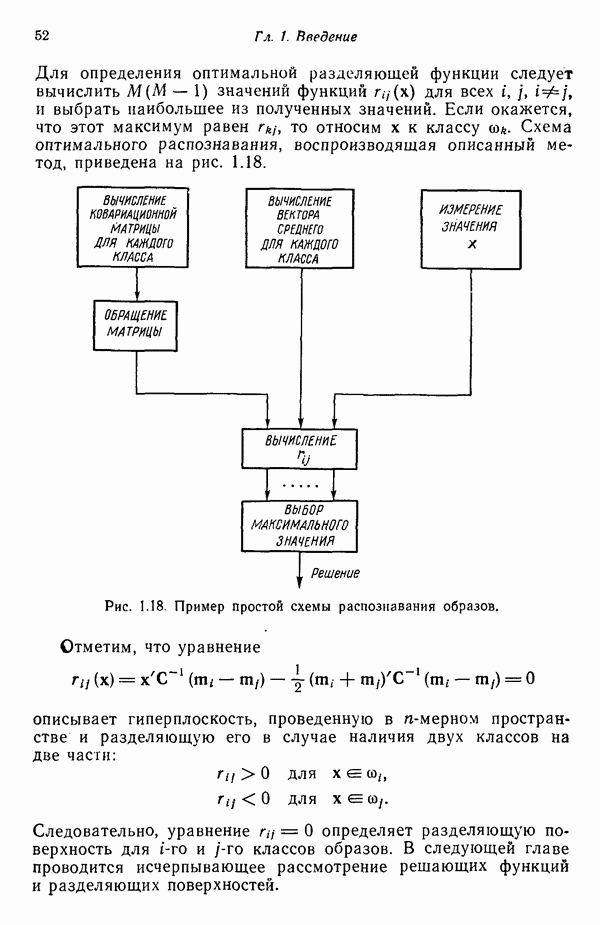
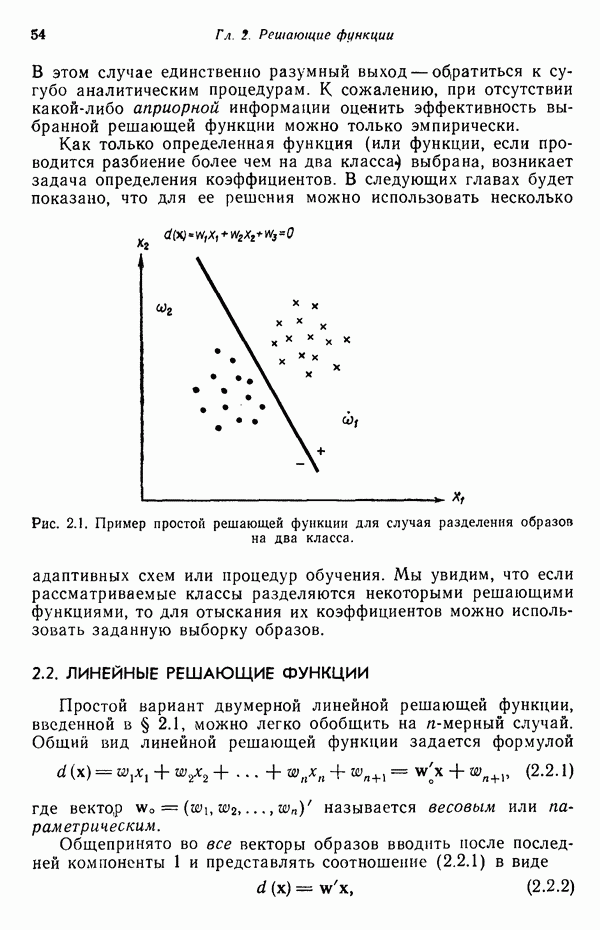
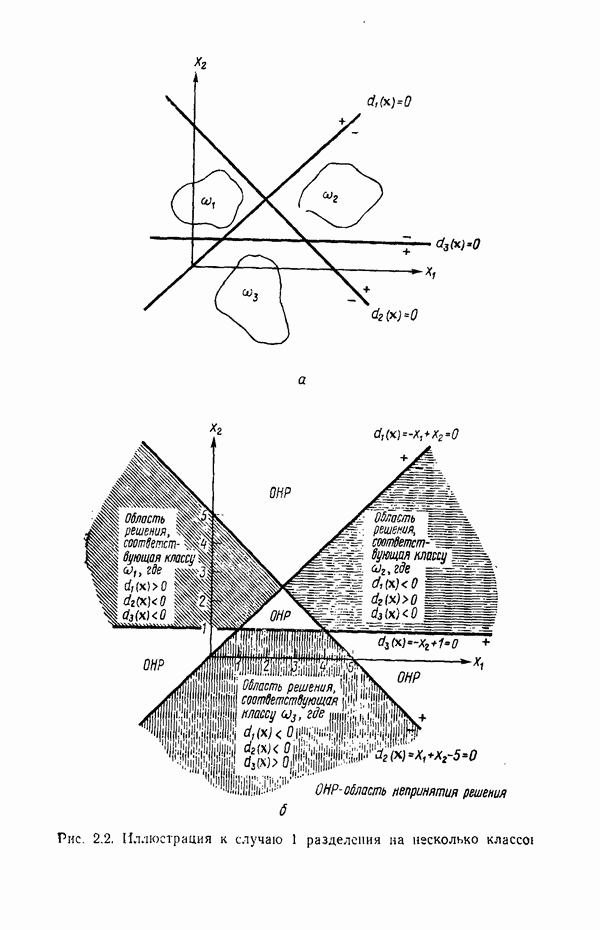
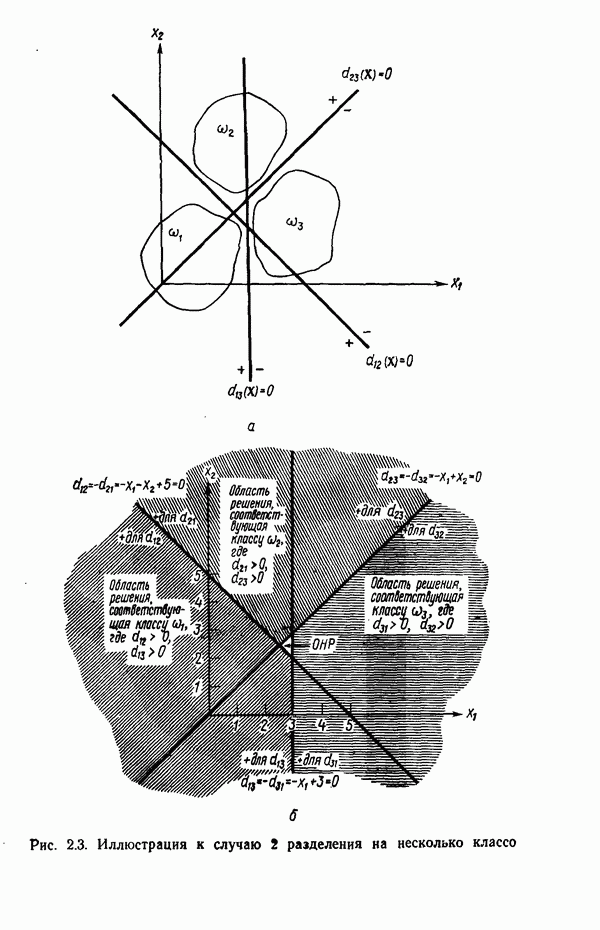
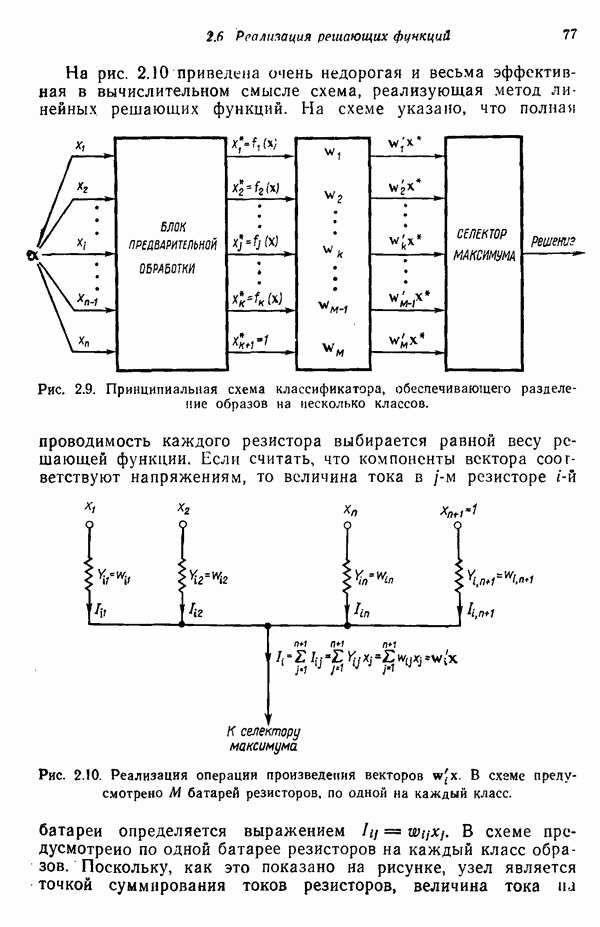
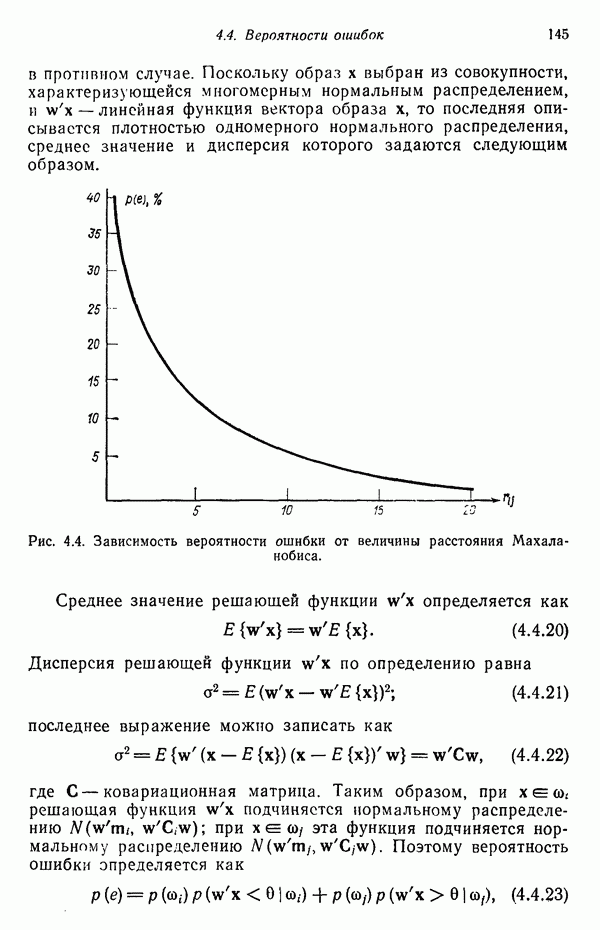
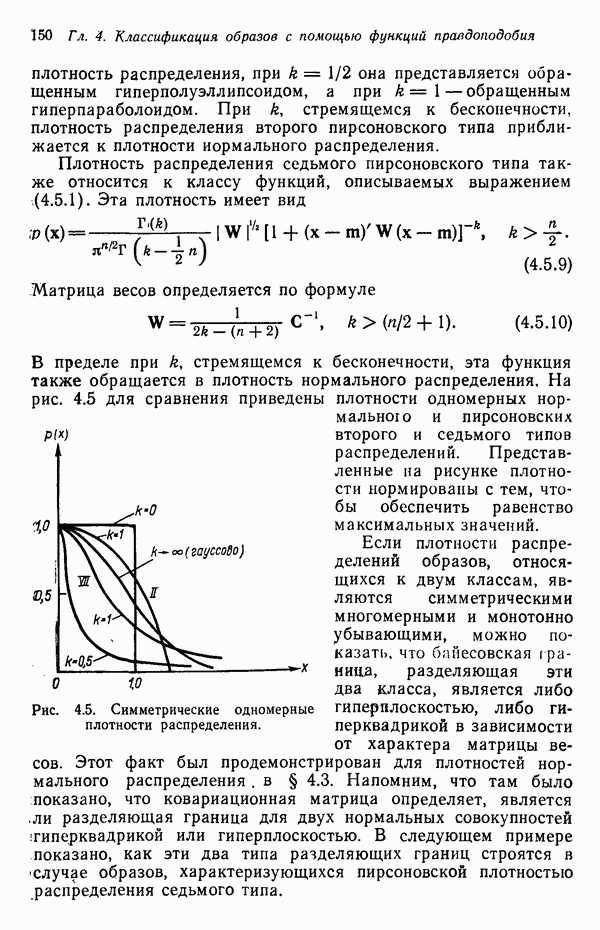
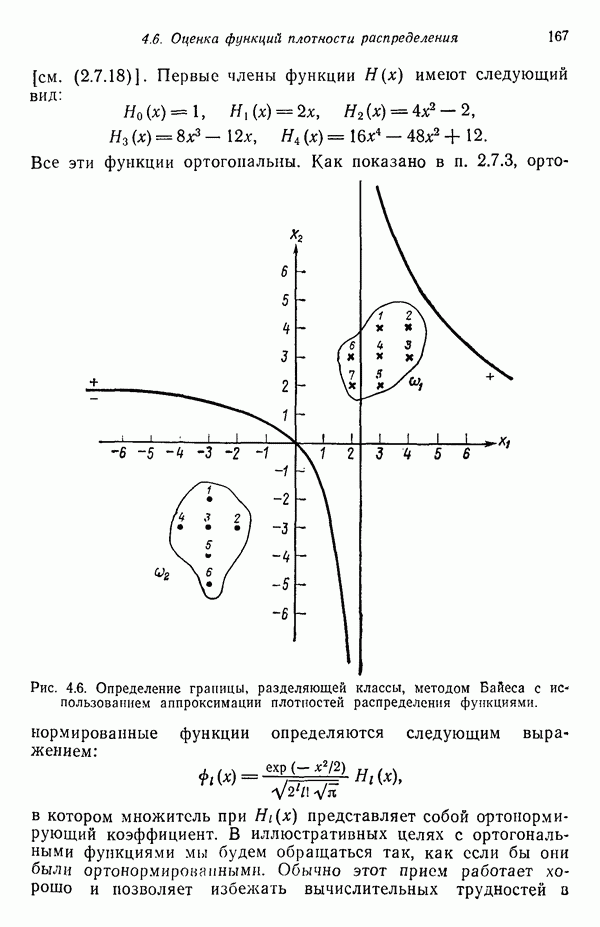
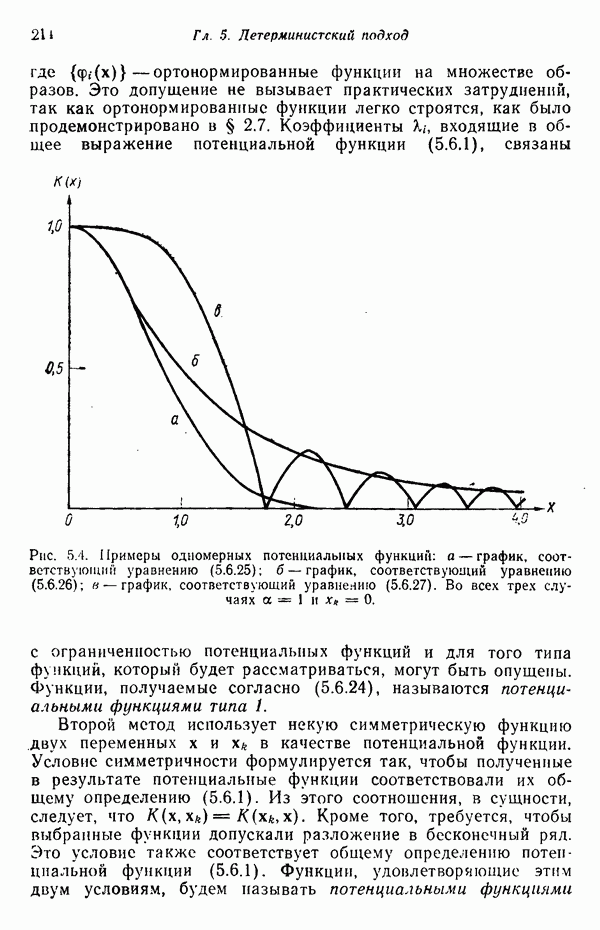
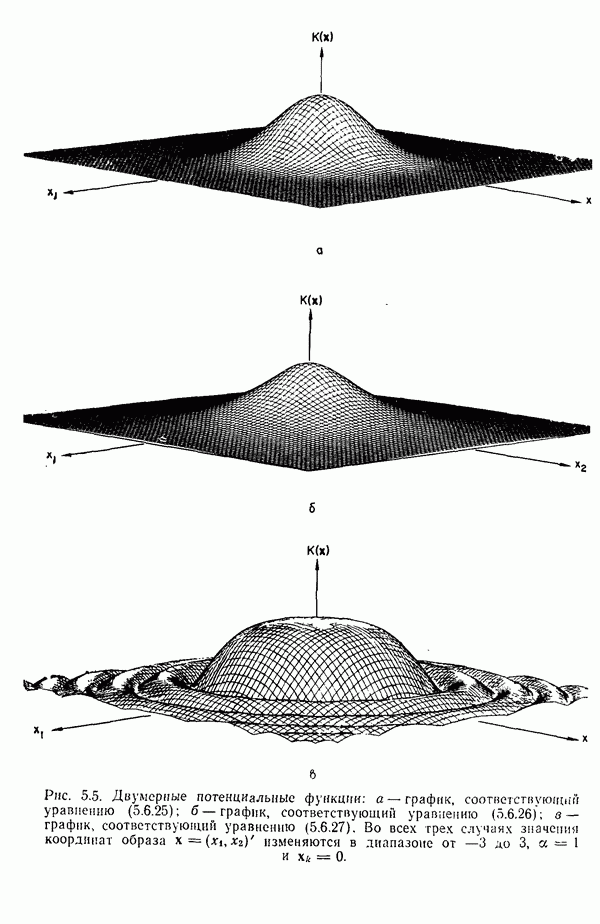
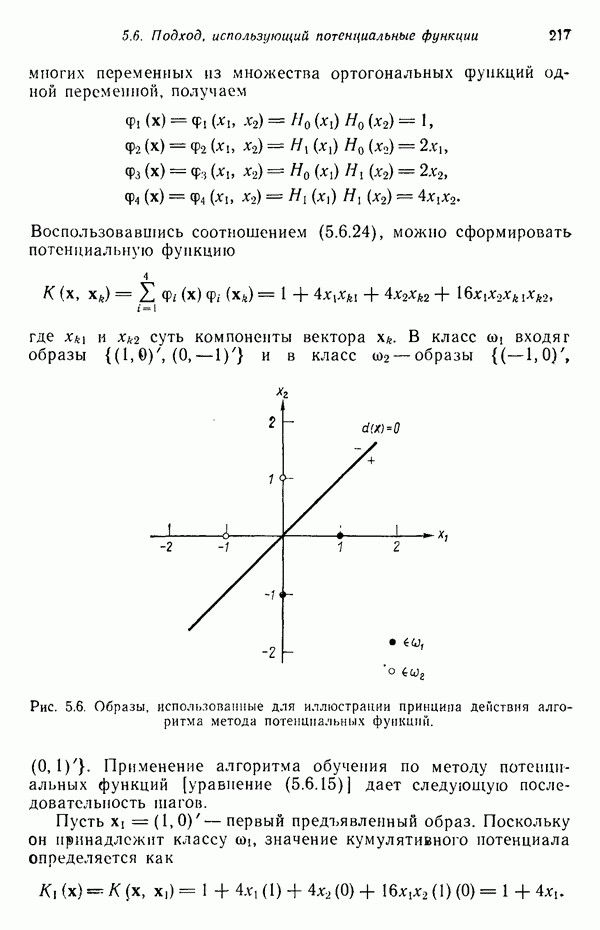
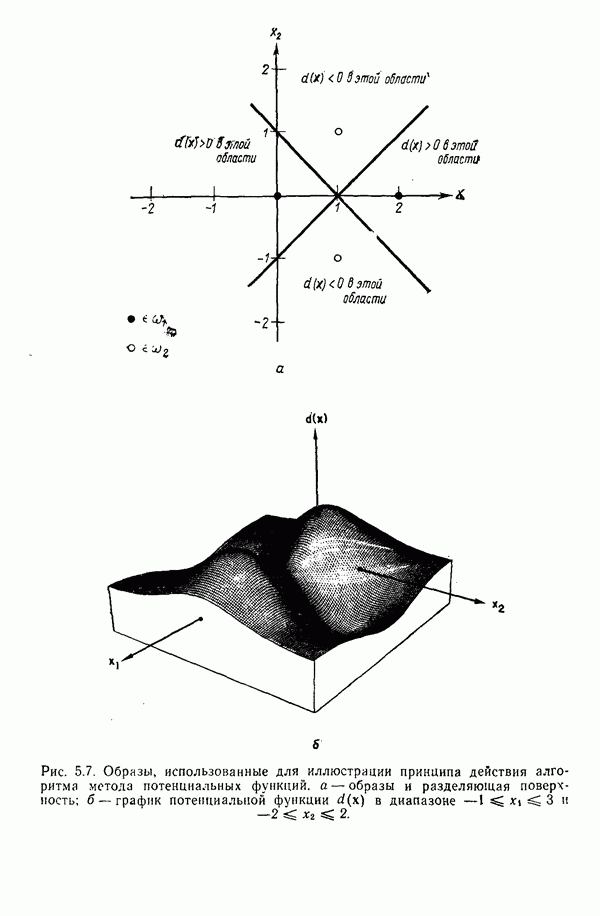
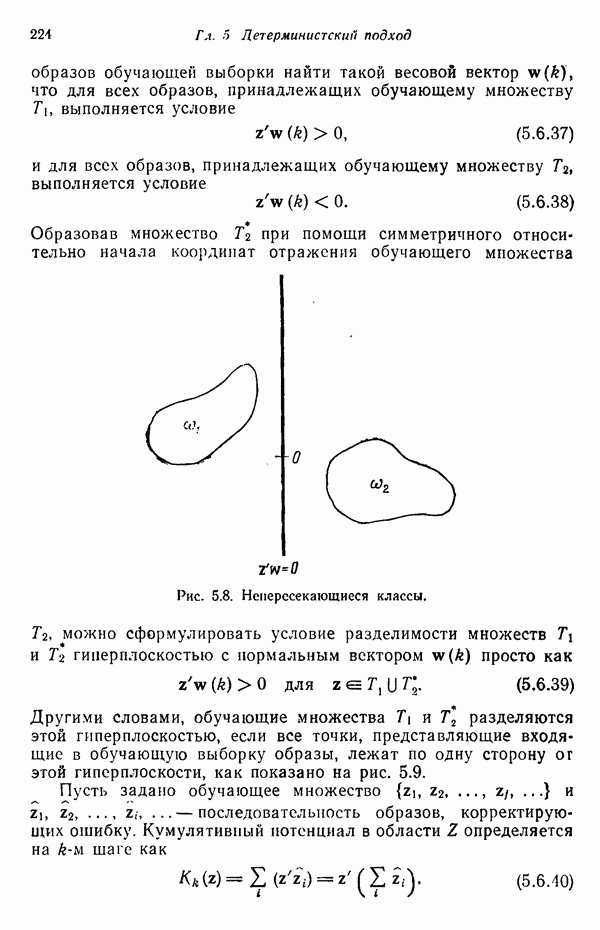
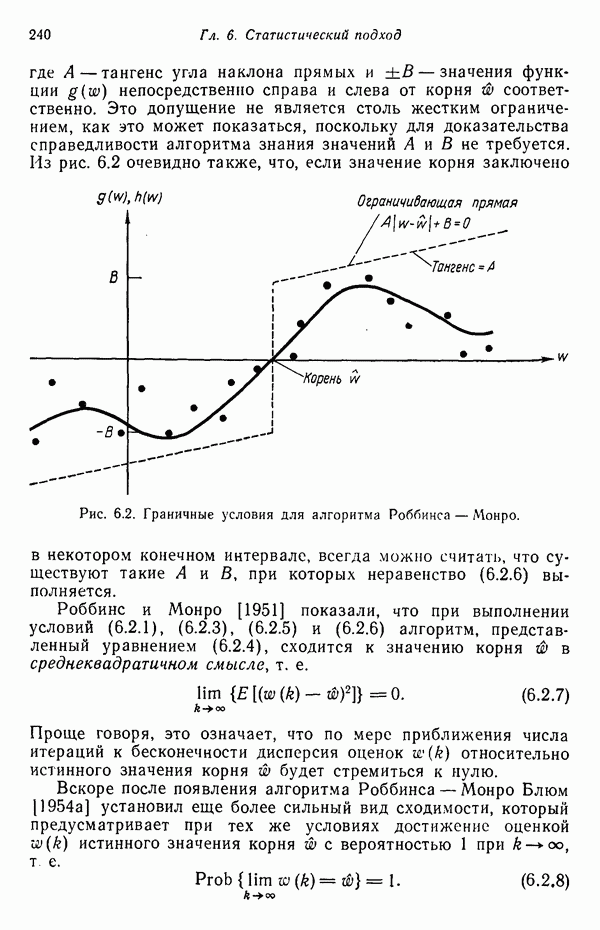
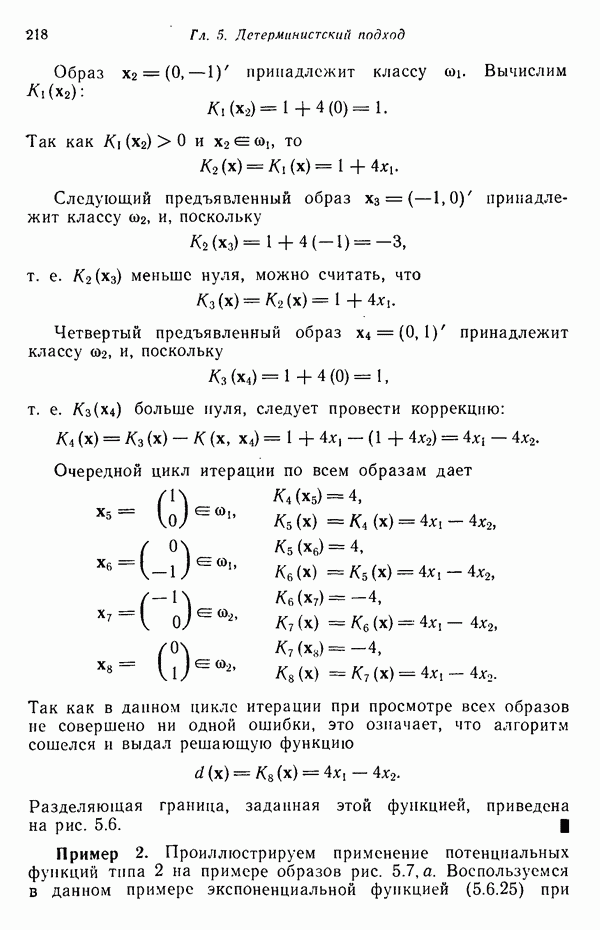5.5. ОБУЧЕНИЕ И ОБОБЩЕНИЕ
Все алгоритмы, описанные в этой главе, используют заданную выборку образов для определения коэффициентов решающих функций. Как отмечалось выше, использование таких алгоритмов при построении классификатора образов называется этапом обучения. Способность классификатора к обобщению проверяется при предъявлении ему данных, с которыми на этапе обучения он не встречался. Очевидно, что хороший классификатор можно построить только на основе данных, достаточно репрезентативных по отношению к «полевым» данным.
Остается обсудить еще один важный вопрос: сколько образов необходимо включить в обучающую выборку для того, чтобы выработать у классификатора хорошие способности к обобщению? Казалось бы, ответить на него не трудно: пользуйтесь как можно большей выборкой. Практически, однако, экономические соображения обычно требуют ограничения числа обучающих образов, так же как и количества машинного времени, отводимого на этап обучения.
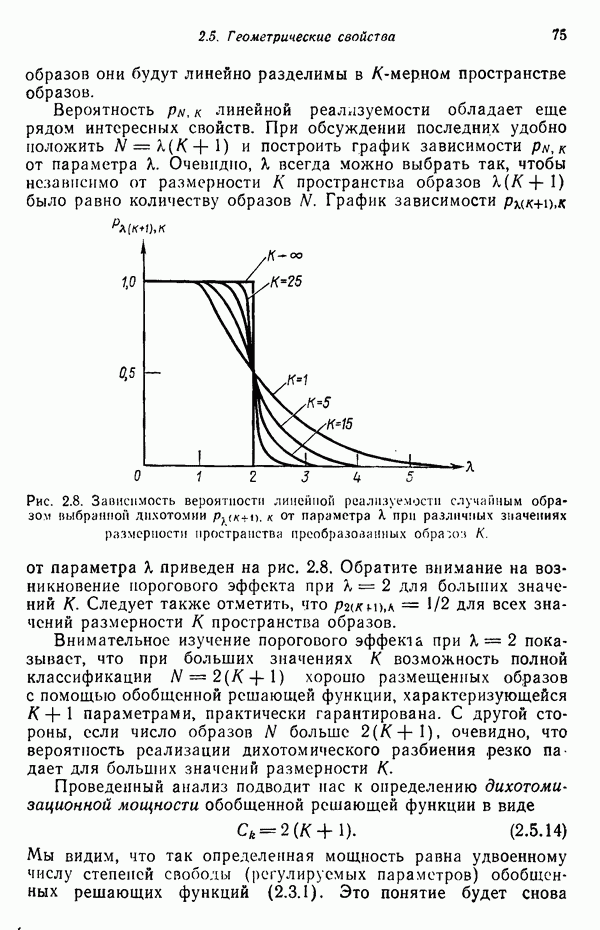
Известно очень немного аналитических результатов, пригодных для использования при выборе образов. Ковер [1965], однако, показал, что при полном отсутствии информации вероятностного характера общее количество образов, отбираемых для решения задачи разбиения на два класса с помощью алгоритмов типа рассмотренных в данной главе, необходимое для получения удовлетворительных способностей к обобщению, должно быть по крайней мере равно удвоенной размерности векторов образов. Это положение согласуется с понятием дихотомизационной мощности,  определенной формулой (2.5.14), где
определенной формулой (2.5.14), где  — число весов, входящих в решающую функцию.
— число весов, входящих в решающую функцию.
Понятие дихотомизационной мощности сводится, в сущности, к тому, что при числе  обучающих образов, обладающих хорошим размещением, меньшем
обучающих образов, обладающих хорошим размещением, меньшем  вероятность правильной дихотомизации обучающей выборки является низкой. Если, однако,
вероятность правильной дихотомизации обучающей выборки является низкой. Если, однако,  и обучающее множество классифицируется правильно, то к полученному решению (классификатору) и соответственно
и обучающее множество классифицируется правильно, то к полученному решению (классификатору) и соответственно
его способности к обобщению можно относиться с большим доверием. Практически хорошим эмпирическим правилом служит выбор числа образов  порядка десяти значений
порядка десяти значений 
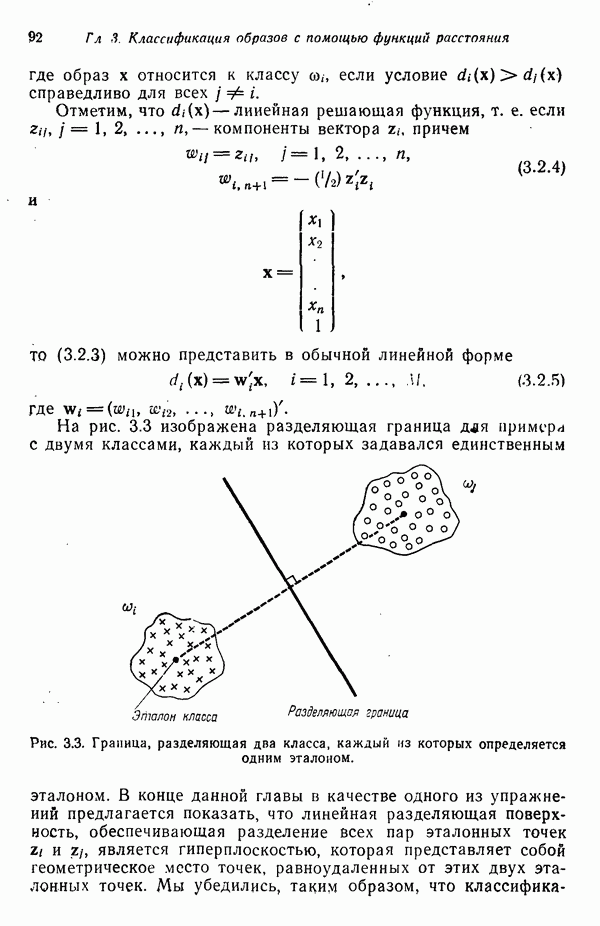
В тех случаях, когда заданные классы нельзя разделить с помощью выбранной разделяющей поверхности, интересно определить максимальное количество образов, которые удается разделить с помощью этой поверхности. Если известна плотность распределения каждой совокупности образов, то можно обратиться к рассмотренному в § 4.2 байесовскому классификатору, что обеспечит наименьшую вероятность совершения ошибки в среднем. Для детерминистского случая получен алгоритм минимума ошибки, использование которого гарантирует построение оптимального классификатора (Уормак и Гонсалес [1972, 1973]). Эта процедура обладает рядом важных свойств, которые стоит упомянуть в связи с предметом нашего обсуждения. Если образы обладают хорошим размещением, то алгоритм обеспечивает получение всех оптимальных решений. Если классы разделимы, естественно, существует единственное решение. Если же классы неразделимы, то получение более чем одного оптимального решения означает, что либо обучающее множество не является репрезентативным для истинной совокупности образов, либо сложность выбранных решающих функций неадекватна, либо и то и другое одновременно. Это объясняется тем обстоятельством, что, согласно байесовскому правилу классификации, оптимальный классификатор должен быть единственным. Хотя сам алгоритм детерминистский, это никак не меняет того факта, что абсолютный предел качества классификации определяется байесовским классификационным правилом. Следовательно, данный алгоритм является средством построения подходящего оптимального классификатора в тех случаях, когда классы неразделимы.