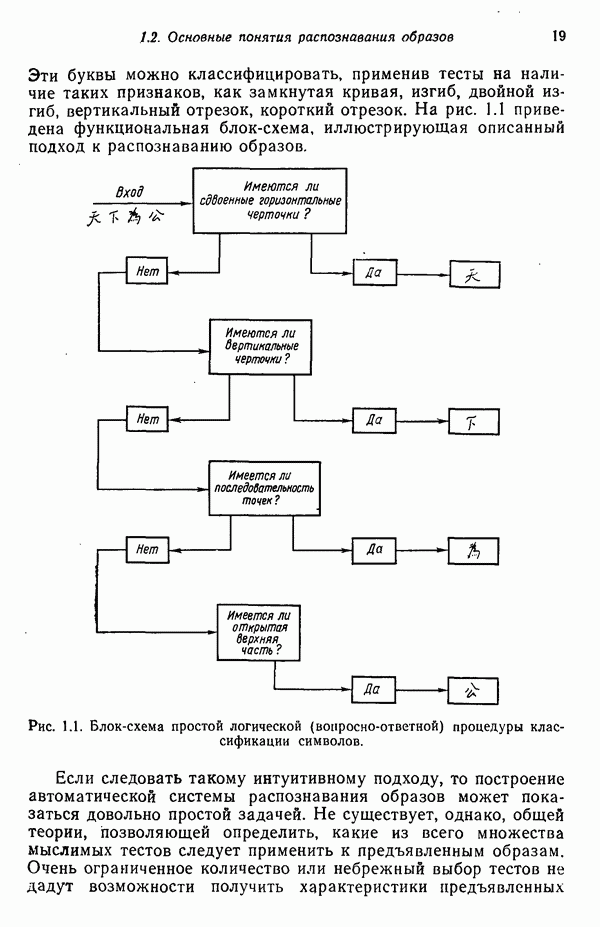
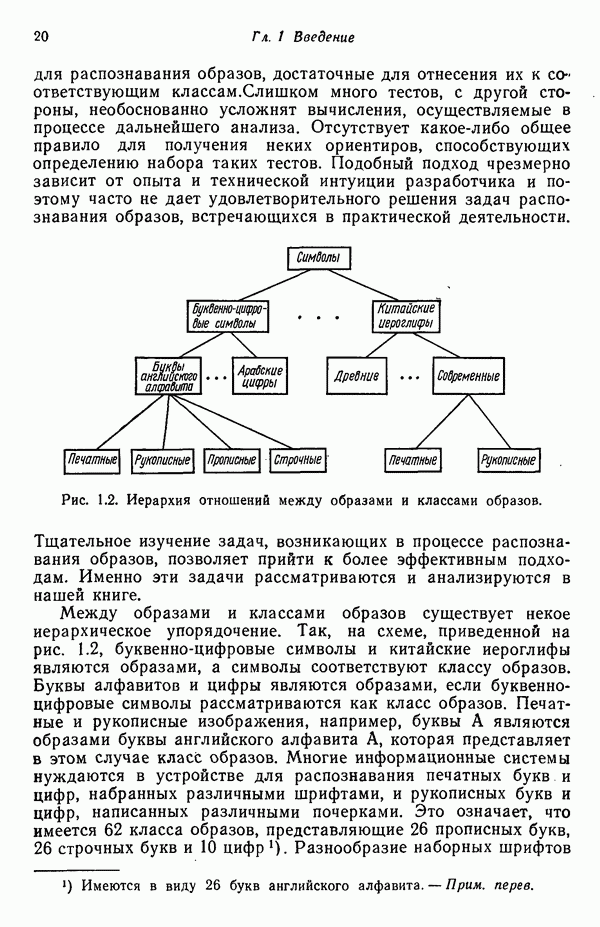
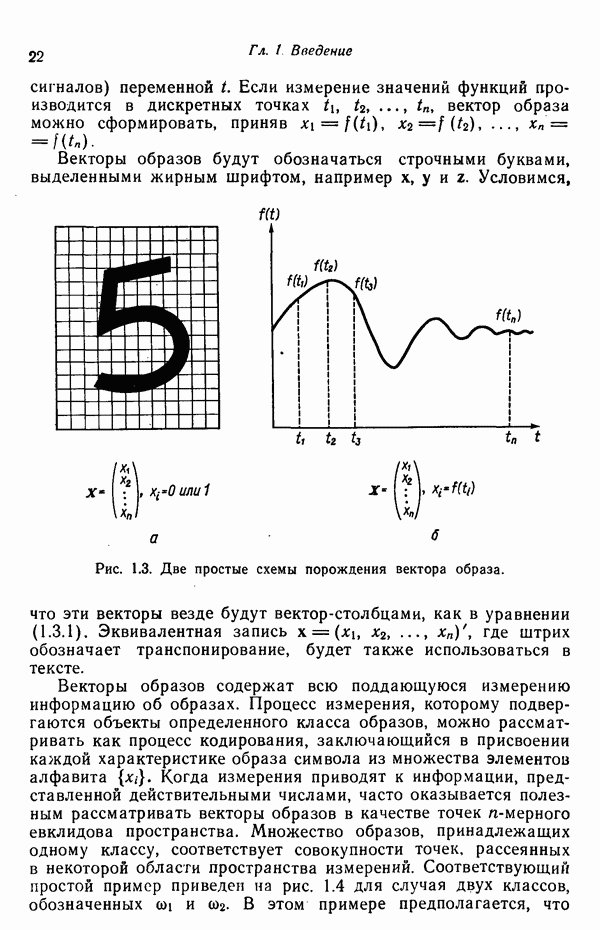
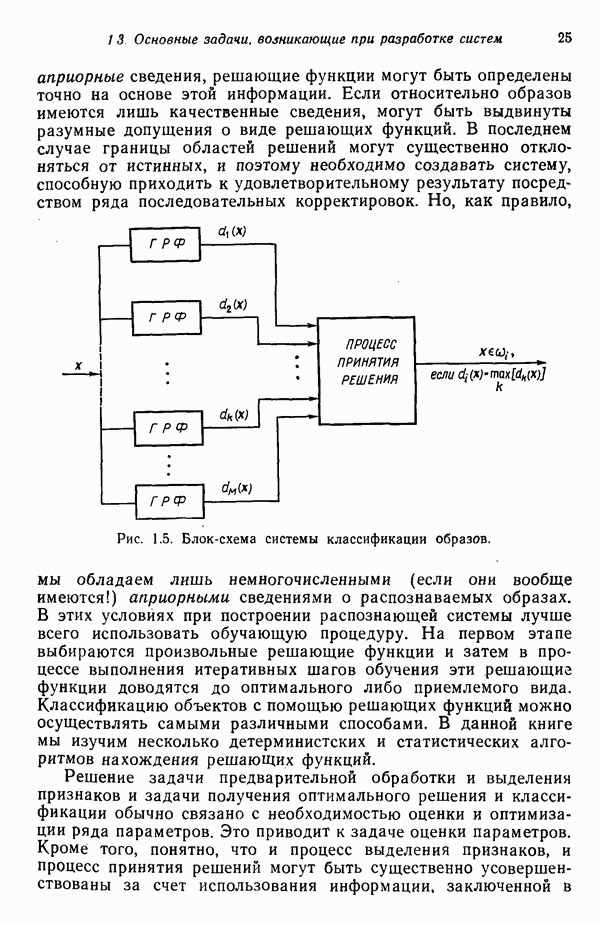
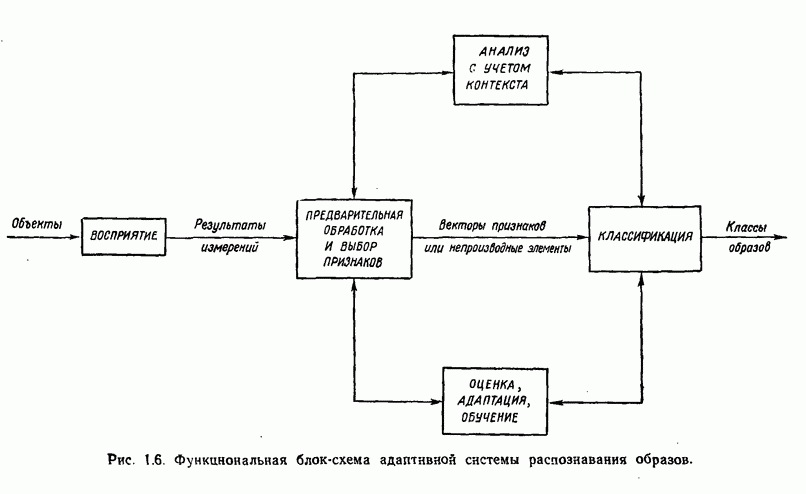
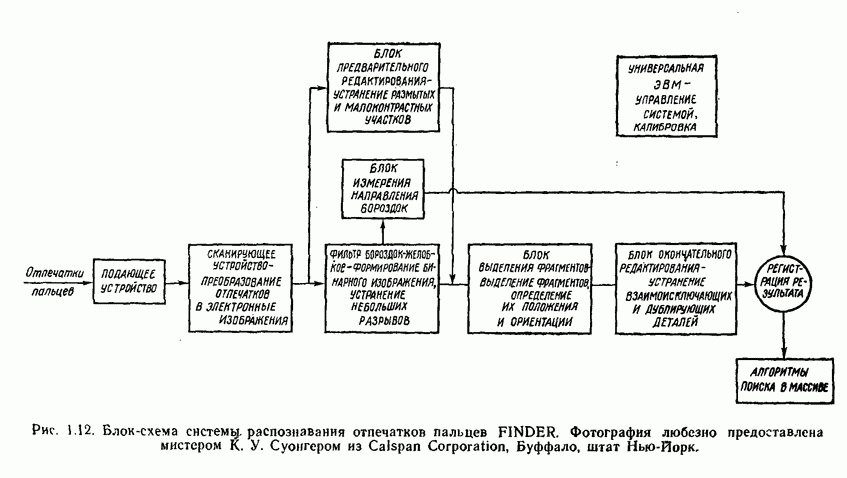
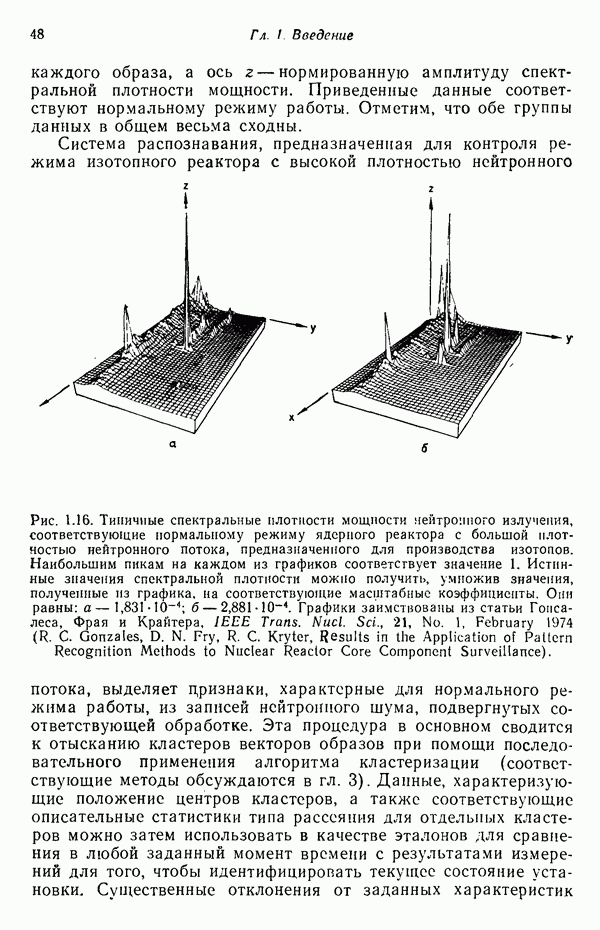
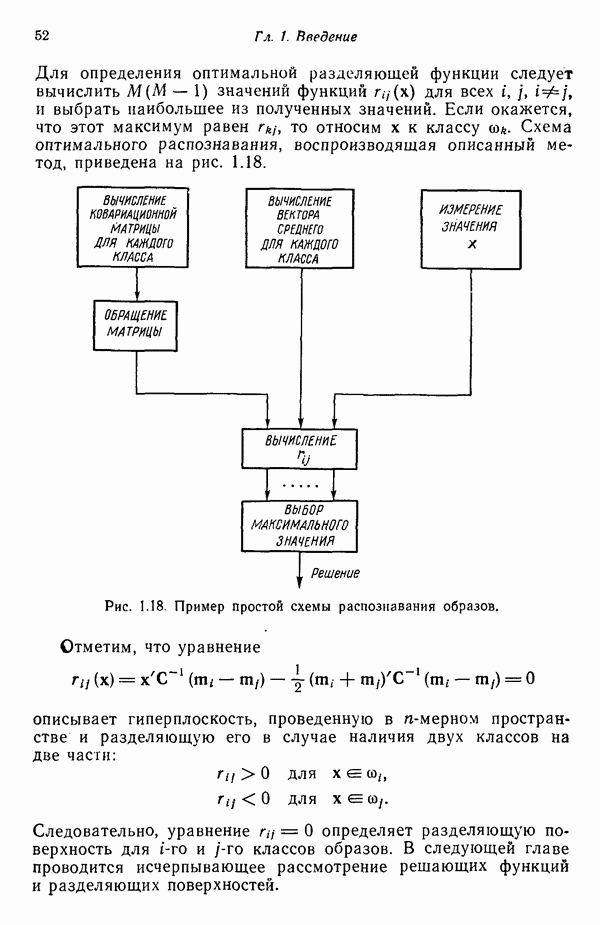
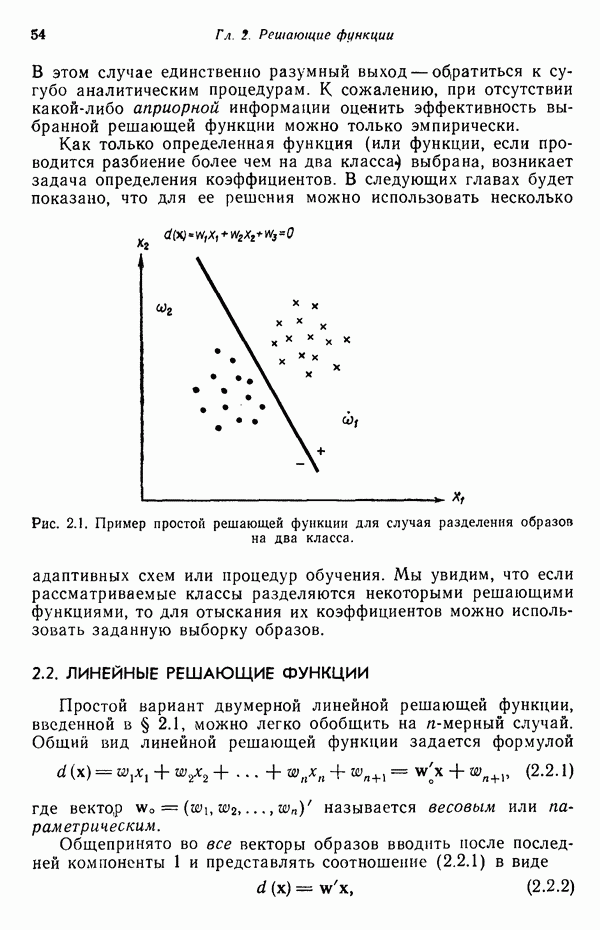
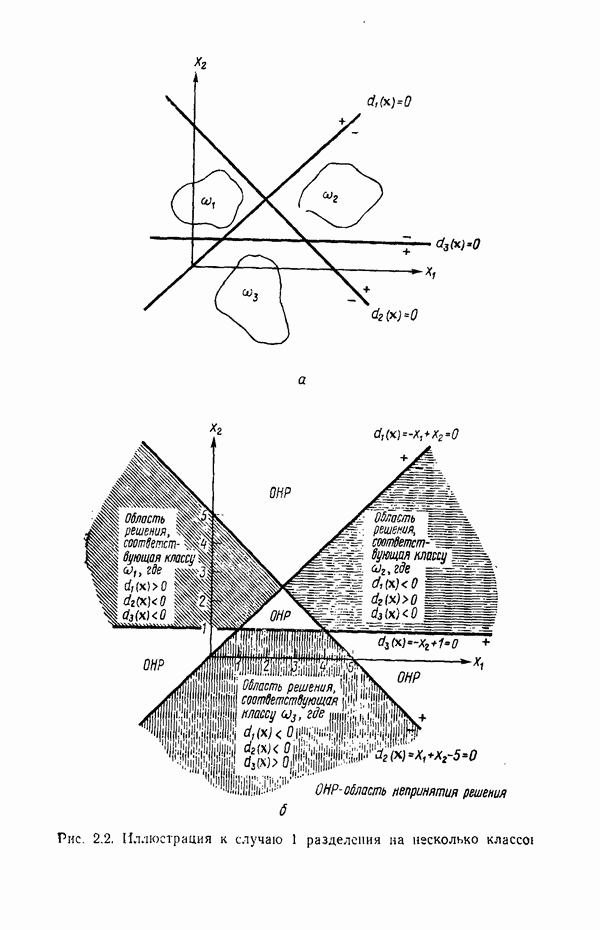
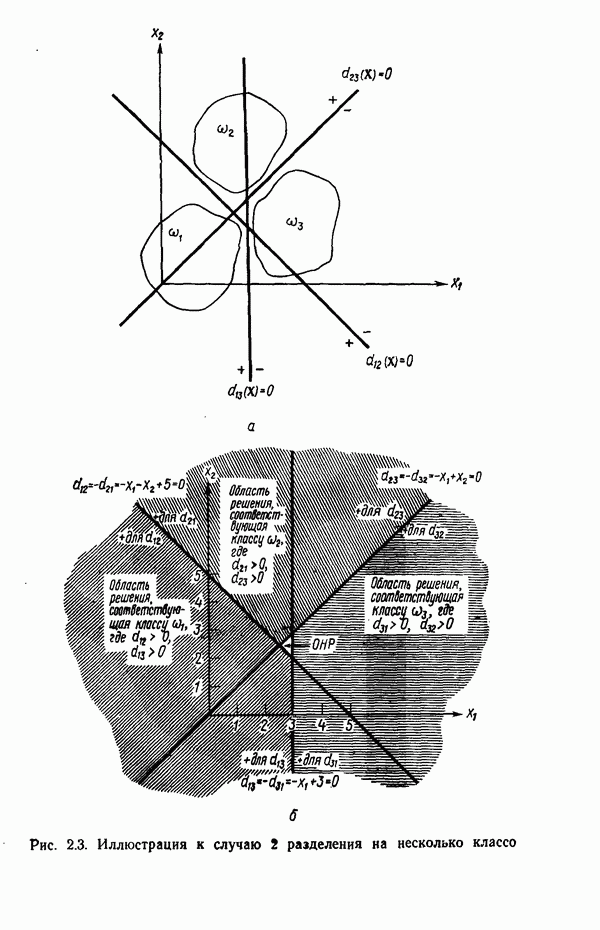
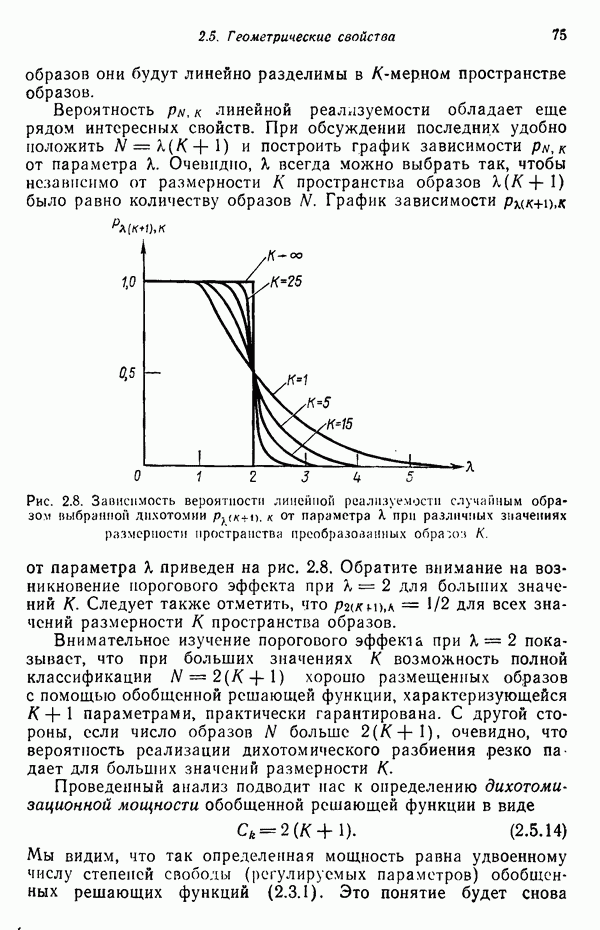
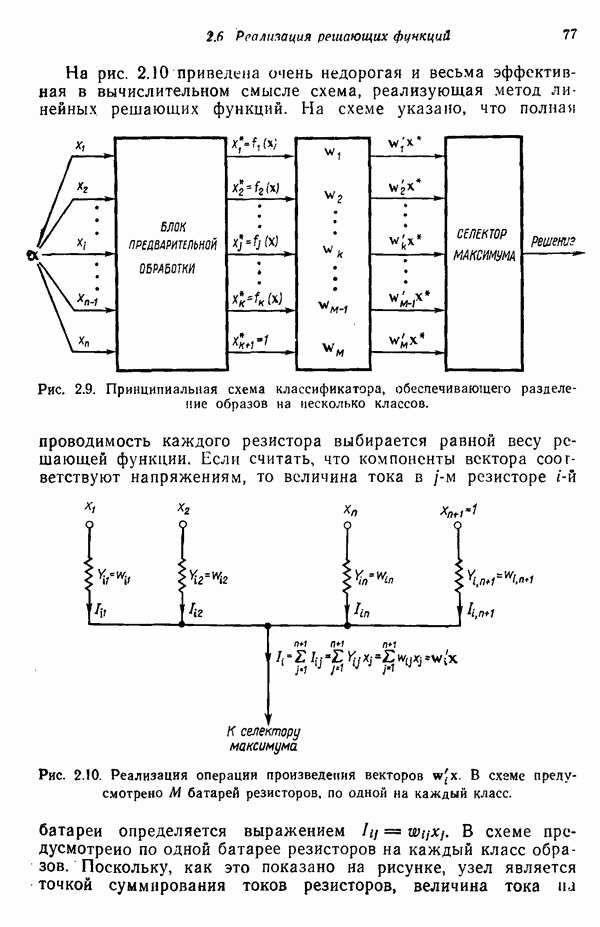
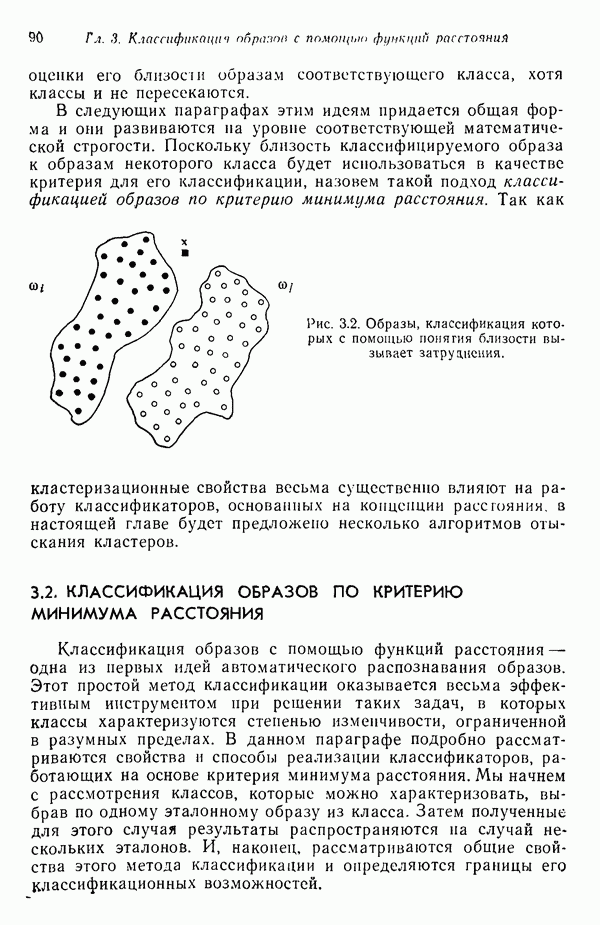
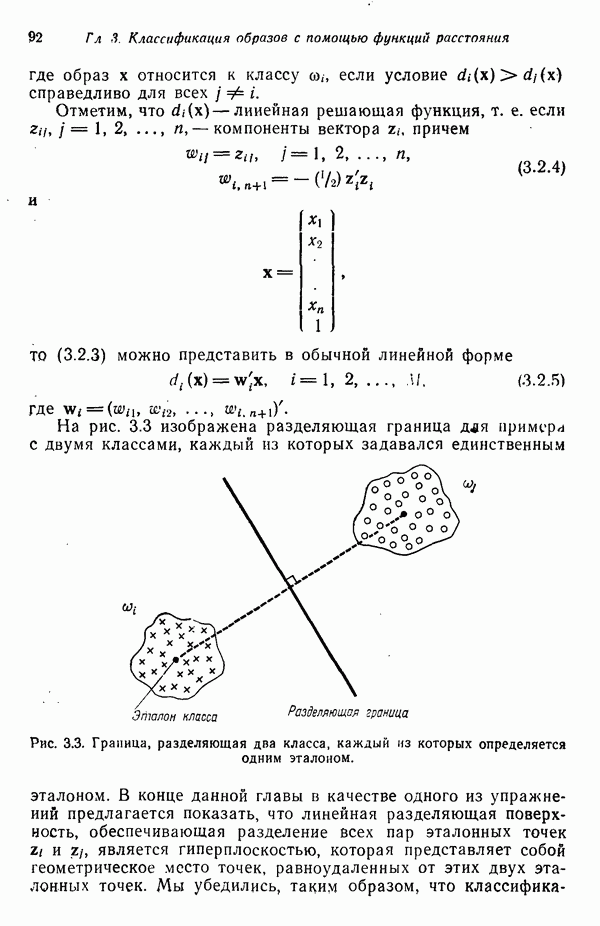
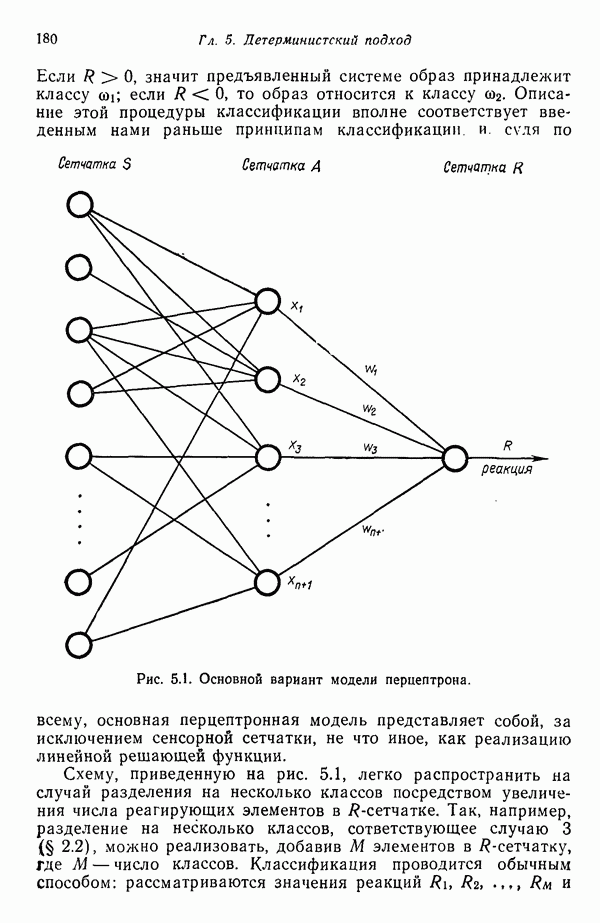
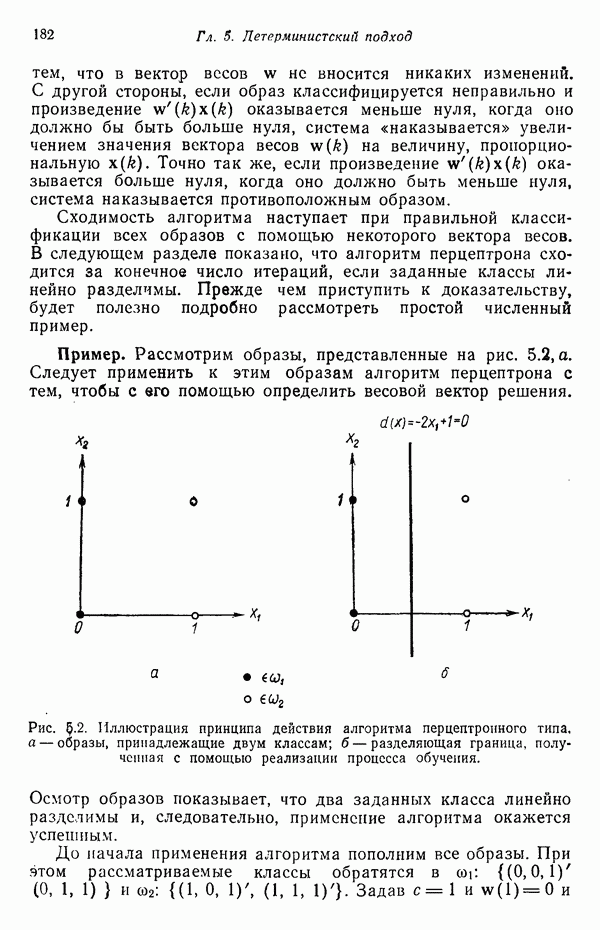
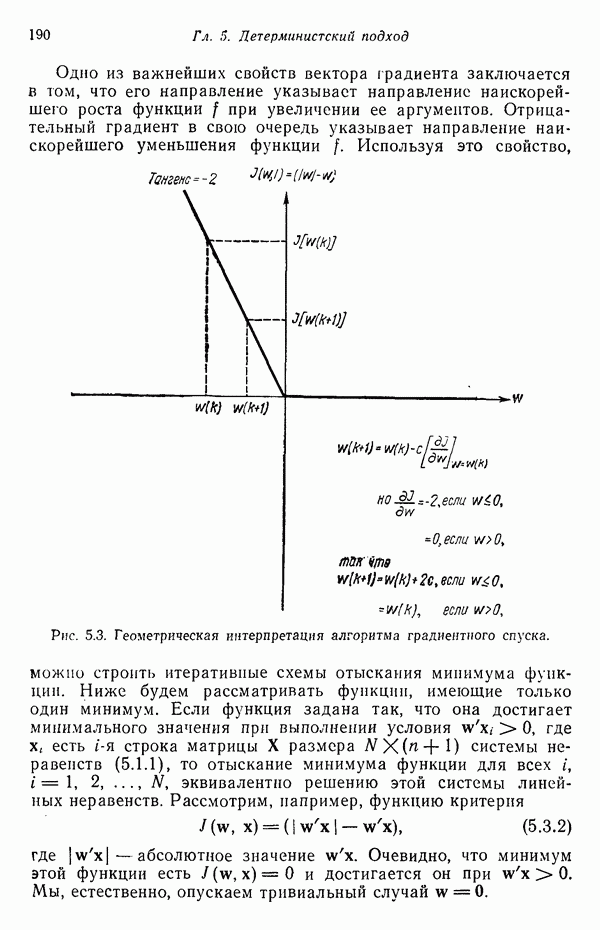
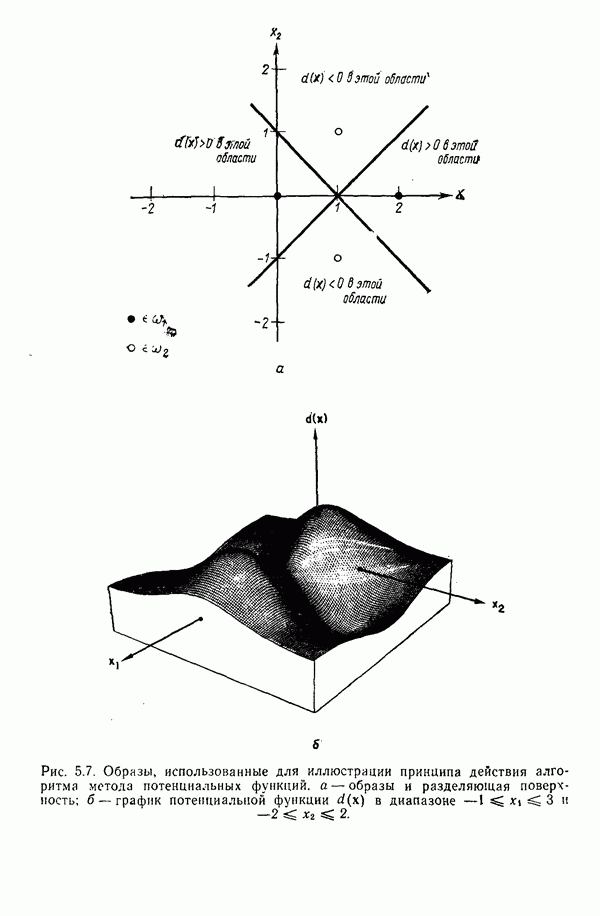
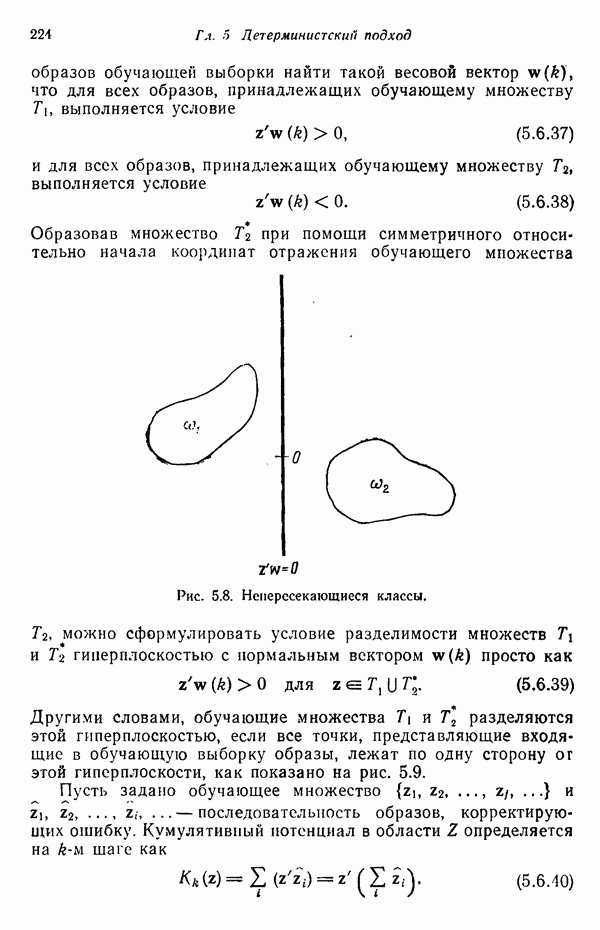
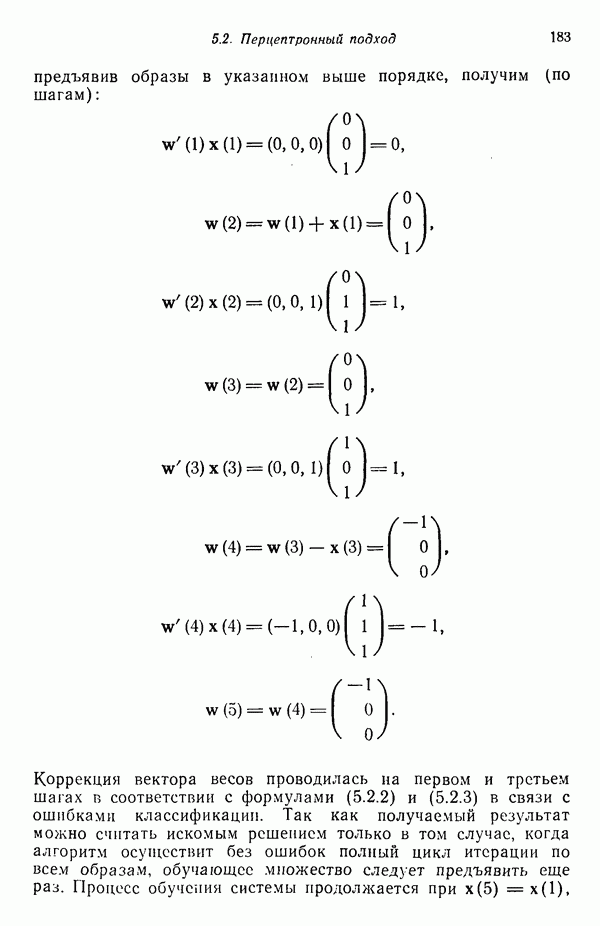Глава 5. ОБУЧАЕМЫЕ КЛАССИФИКАТОРЫ ОБРАЗОВ. ДЕТЕРМИНИСТСКИЙ ПОДХОД
5.1. ВВЕДЕНИЕ
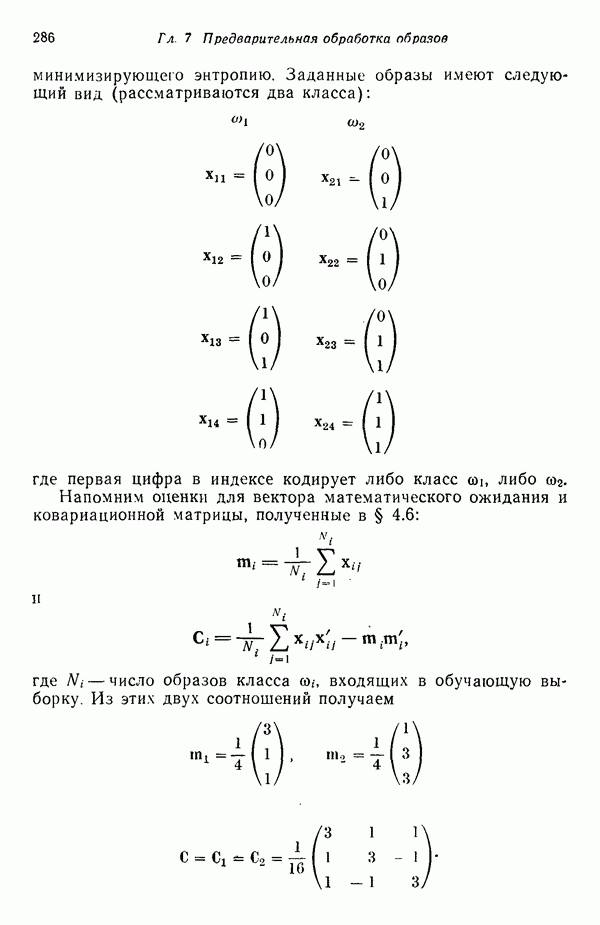
Подходы к построению классификаторов образов, изучавшиеся нами до сих пор, основаны на непосредственных вычислениях, т. е. разделяющие границы, полученные в результате реализации этих подходов, определяются заданной выборкой образов, по которой путем непосредственных вычислений отыскиваются соответствующие коэффициенты. Примеры такого рода мы встречали в третьей главе, когда требовалось определять центры кластеров или «стандартные» образы до построения классификаторов, и в четвертой главе, когда структура байесовского классификатора для нормально распределенных образов полностью определялась вектором математического ожидания и ковариационной матрицей каждого класса.
В настоящей главе мы приступаем к изучению классификаторов, решающие функции которых строятся по заданной выборке образов с помощью итеративных, «обучающих» алгоритмов. Как отмечалось в гл. 2, когда тип решающей функции выбран, задача заключается в определении коэффициентов. Алгоритмы, представленные в этой главе, позволяют определять коэффициенты искомого решения посредством обучения по заданным множествам образов при условии, что эти обучающие множества разделяются выбранными решающими функциями.
В § 2.4 было показано, что решение задачи о разделении на два класса эквивалентно решению системы линейных неравенств. Таким образом, если заданы два множества образов, принадлежащих соответственно классам  то решение ищется в виде вектора весов
то решение ищется в виде вектора весов  обладающего тем свойством, что для всех образов класса
обладающего тем свойством, что для всех образов класса  выполняется условие
выполняется условие  и для всех образов класса
и для всех образов класса  — условие
— условие  . Если образы класса
. Если образы класса  умножить на —1, то эквивалентное условие
умножить на —1, то эквивалентное условие  становится общим для всех образов. Обозначив через
становится общим для всех образов. Обозначив через  общее количество пополненных выборочных образов (см. гл. 2) обоих классов, нашу задачу можно свести к отысканию вектора весов
общее количество пополненных выборочных образов (см. гл. 2) обоих классов, нашу задачу можно свести к отысканию вектора весов
w, обеспечивающего справедливость системы неравенств

где

 — нулевой вектор. Если образы обладают хорошим размещением в том смысле, как это было введено в гл. 2, матрица X удовлетворяет условию Хаара, т. е. всякая подматрица
— нулевой вектор. Если образы обладают хорошим размещением в том смысле, как это было введено в гл. 2, матрица X удовлетворяет условию Хаара, т. е. всякая подматрица  -матрицы X имеет ранг
-матрицы X имеет ранг  (Чини [1966]).
(Чини [1966]).
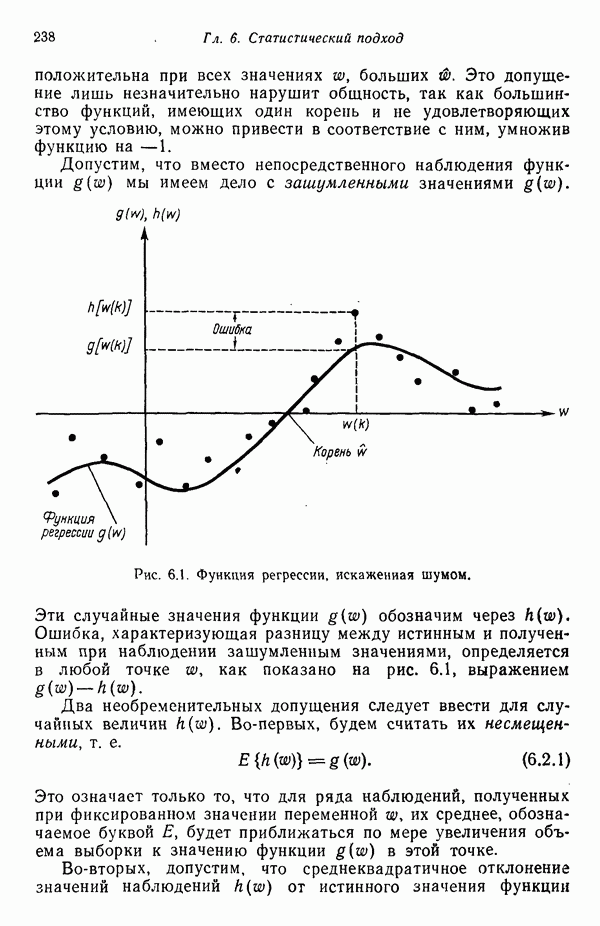
Если вектор весов  удовлетворяющий условию (5.1.1), существует, то неравенства называются совместными; в противном случае они несовместны. На языке распознавания образов мы говорим, что классы соответственно разделимы или неразделимы. Читателю следует иметь в виду, что формулировка условия (5.1.1) предполагает, что все образы одного из классов умножены на —1 и, кроме того, все образы пополнены в соответствии с процедурой, описанной в гл. 2.
удовлетворяющий условию (5.1.1), существует, то неравенства называются совместными; в противном случае они несовместны. На языке распознавания образов мы говорим, что классы соответственно разделимы или неразделимы. Читателю следует иметь в виду, что формулировка условия (5.1.1) предполагает, что все образы одного из классов умножены на —1 и, кроме того, все образы пополнены в соответствии с процедурой, описанной в гл. 2.
В принципе для решения (5.1.1) можно воспользоваться и детерминистским, и статистическим подходами. Детерминистский подход служит основой алгоритмов, рассматриваемых в данной главе. Как и следует из названия, эти алгоритмы конструируются независимо от каких-либо предположений о статистических свойствах классов образов. Статистические алгоритмы, представляемые в гл. 6, отражают, с другой стороны, попытку найти аппроксимацию плотностей распределения  и использовать их затем в качестве байесовских решающих функций в соответствии с соотношением (4.2.23). Однако, завершив изучение обоих подходов, мы заметим поразительное сходство между статистическими и детерминистскими алгоритмами.
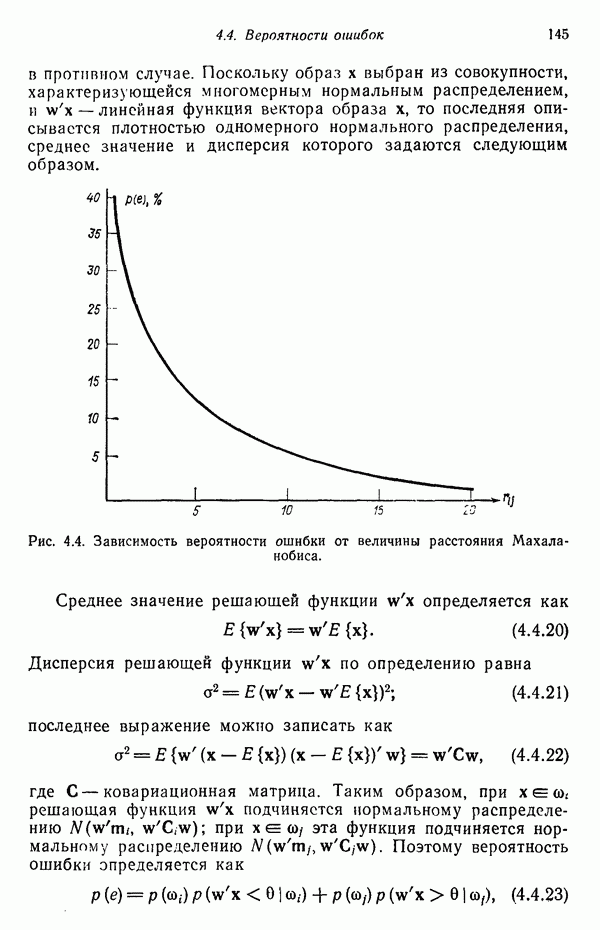
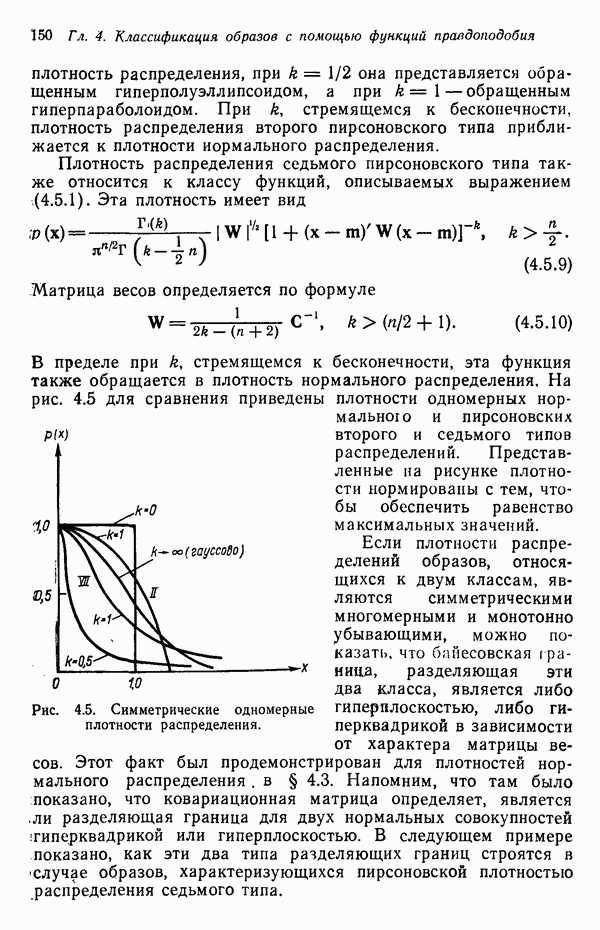
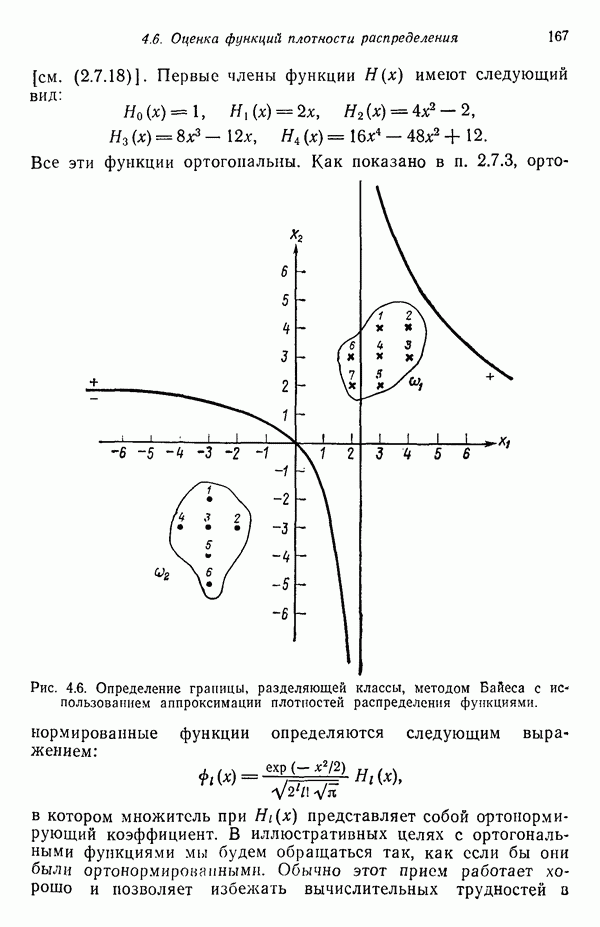
и использовать их затем в качестве байесовских решающих функций в соответствии с соотношением (4.2.23). Однако, завершив изучение обоих подходов, мы заметим поразительное сходство между статистическими и детерминистскими алгоритмами.