Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
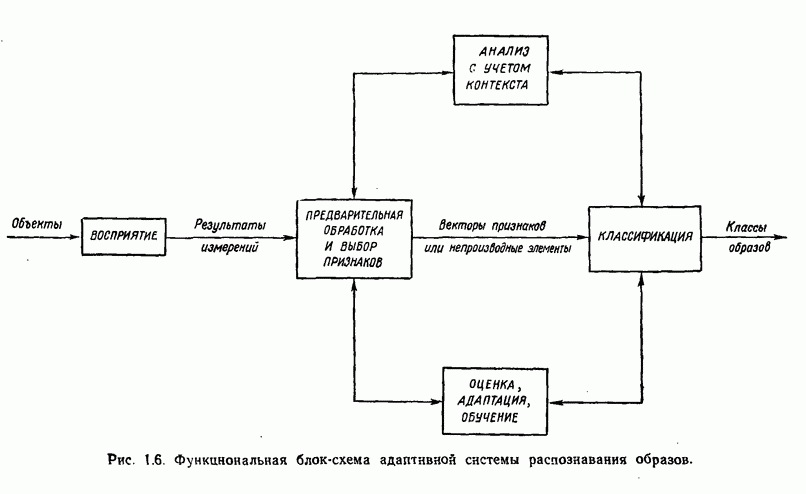
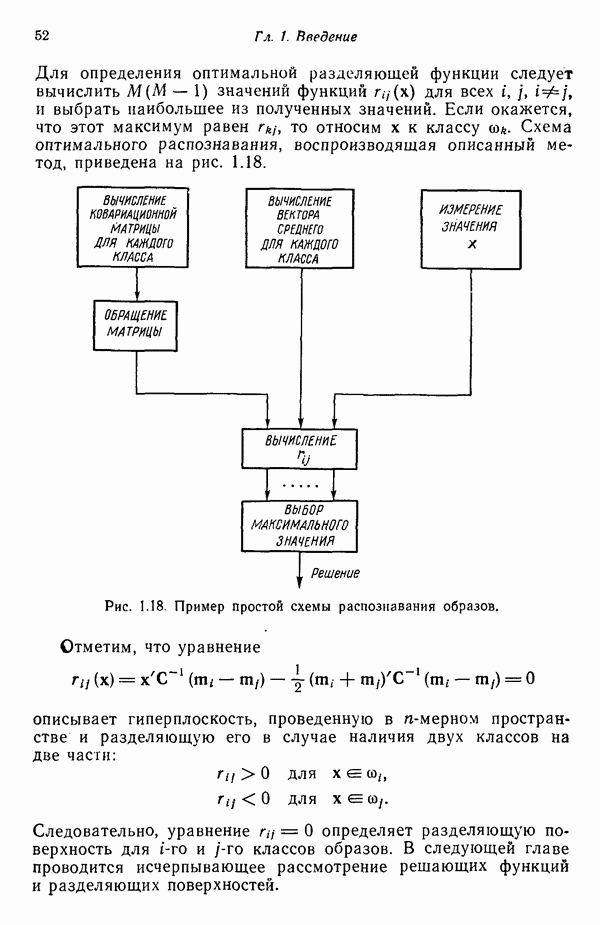
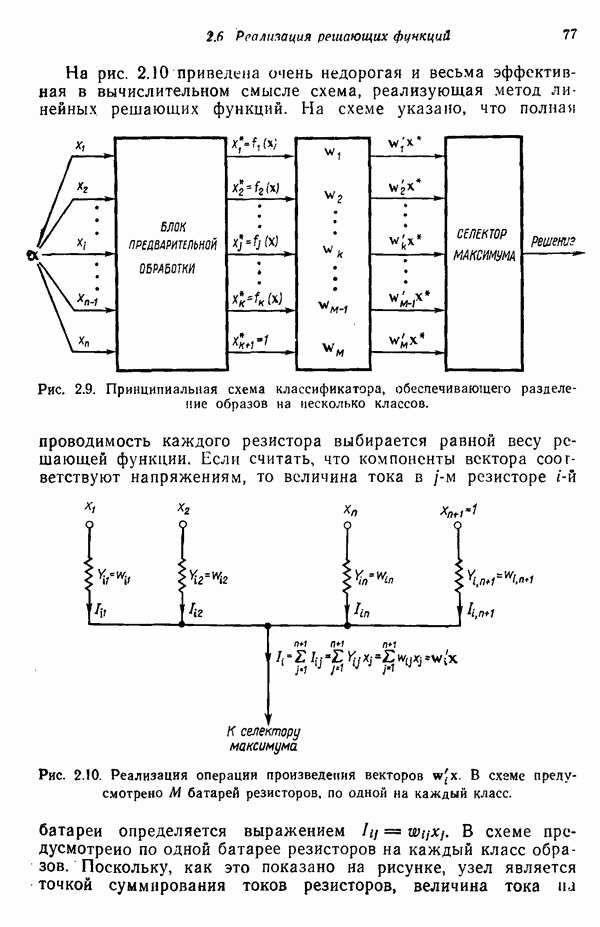
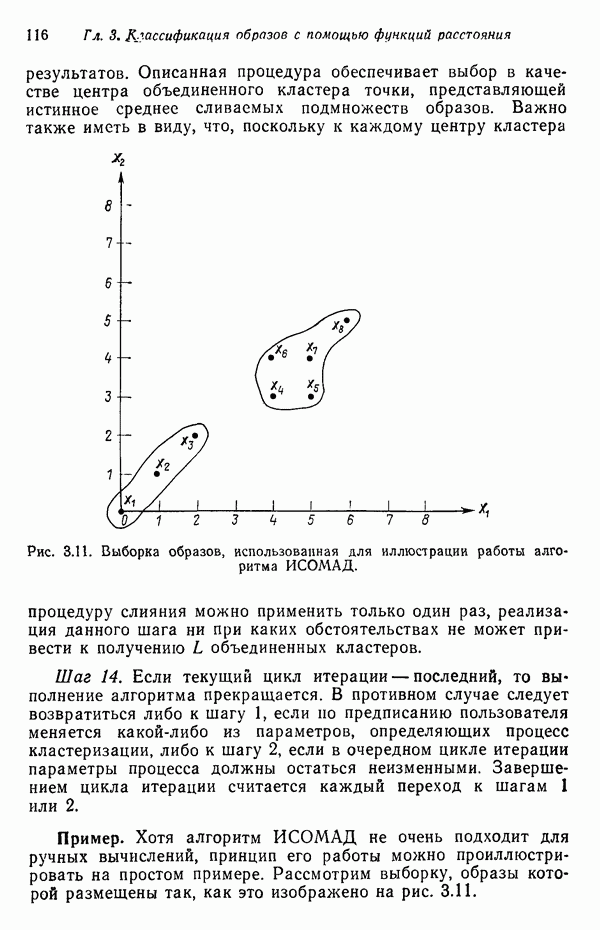
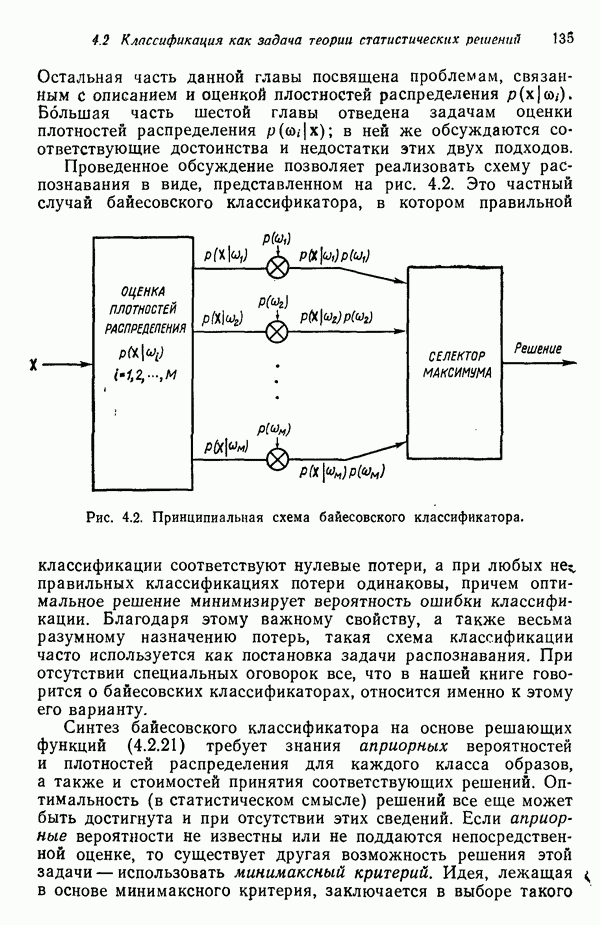
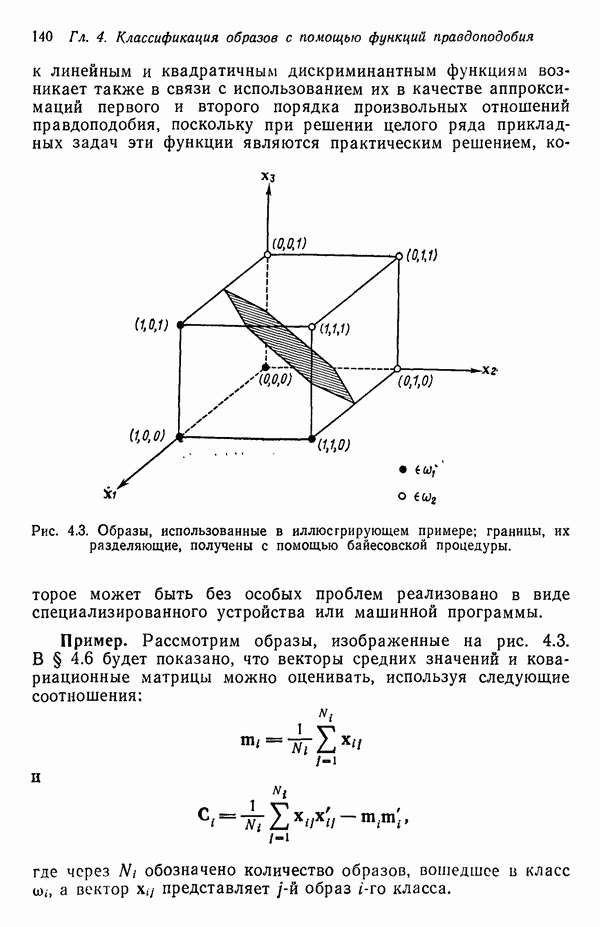
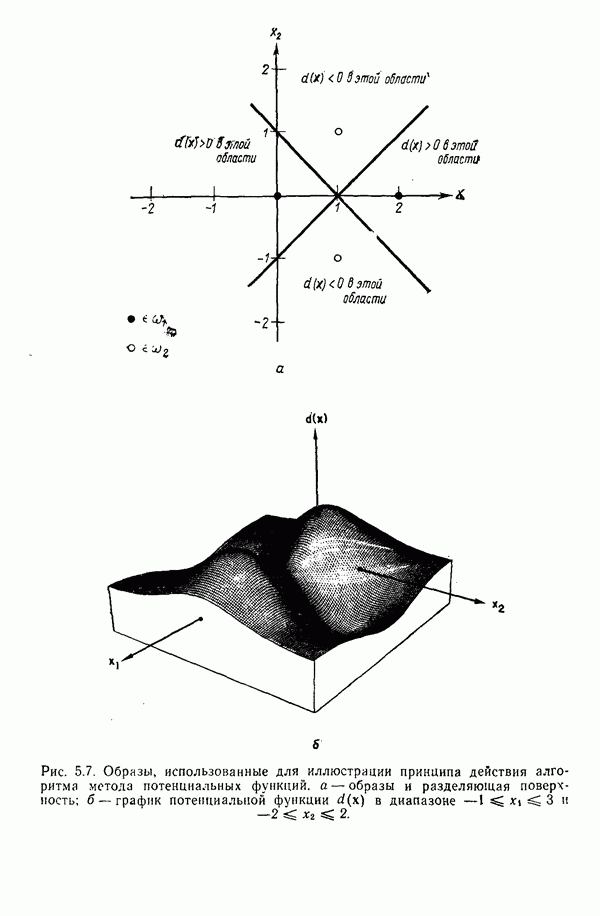
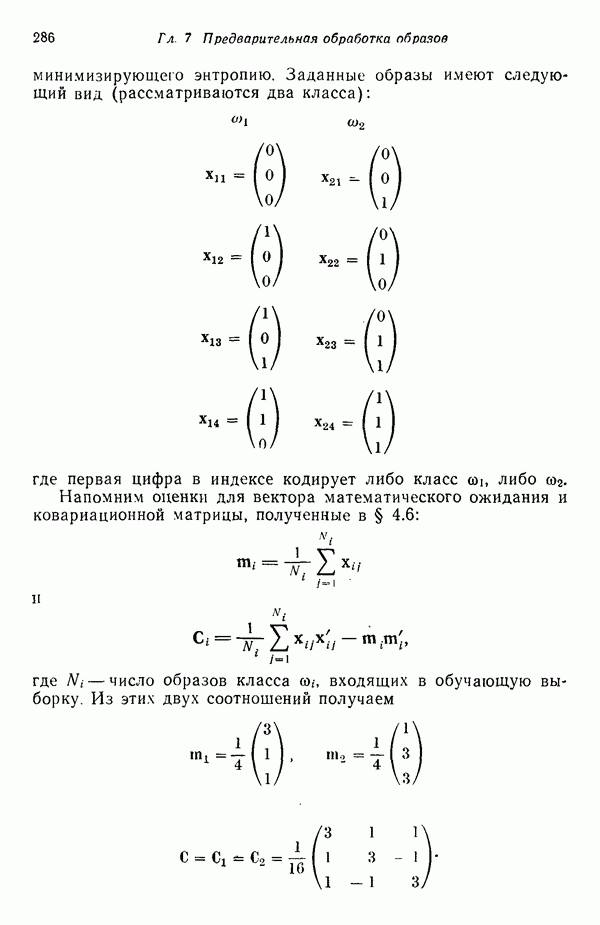
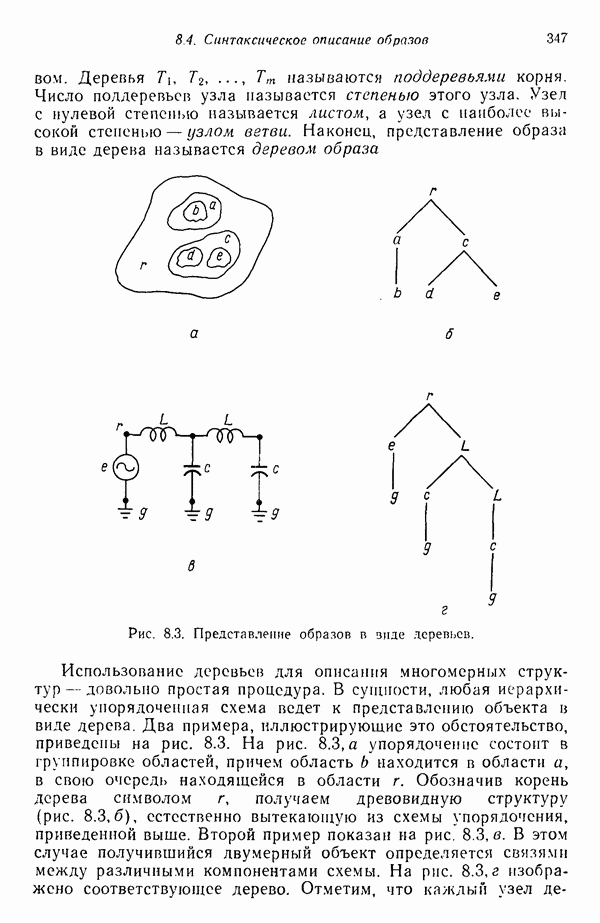
8.5.2. Распознавание образов, представленных графамиХотя предыдущий пример, несомненно, иллюстрирует основные положения синтаксического подхода, мы признаем, что он в значительной мере идеализирован, особенно если учесть, что грамматика позволяет реализовать только одну последовательность грамматических правил. При рассмотрении этого примера возникает, однако, один важный вопрос.
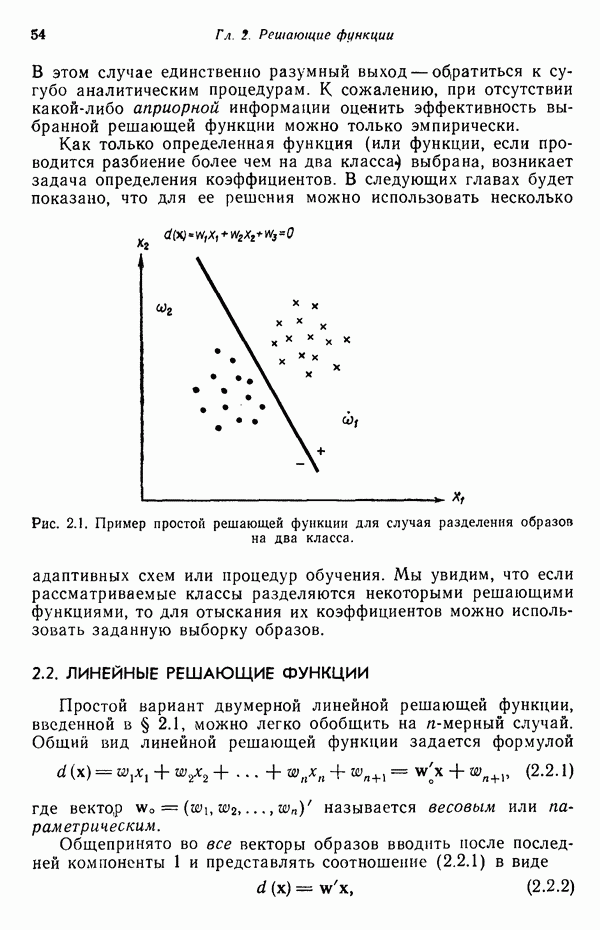
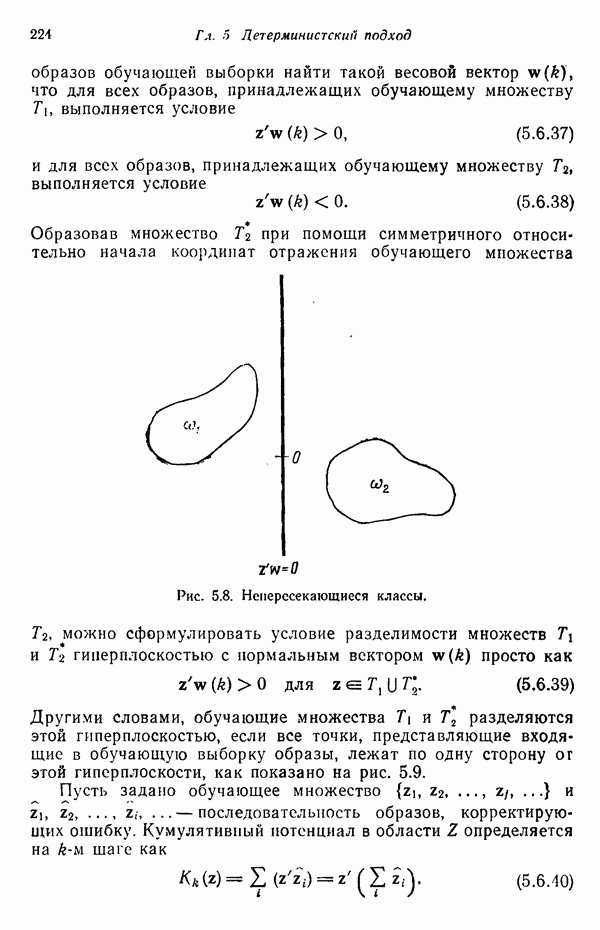
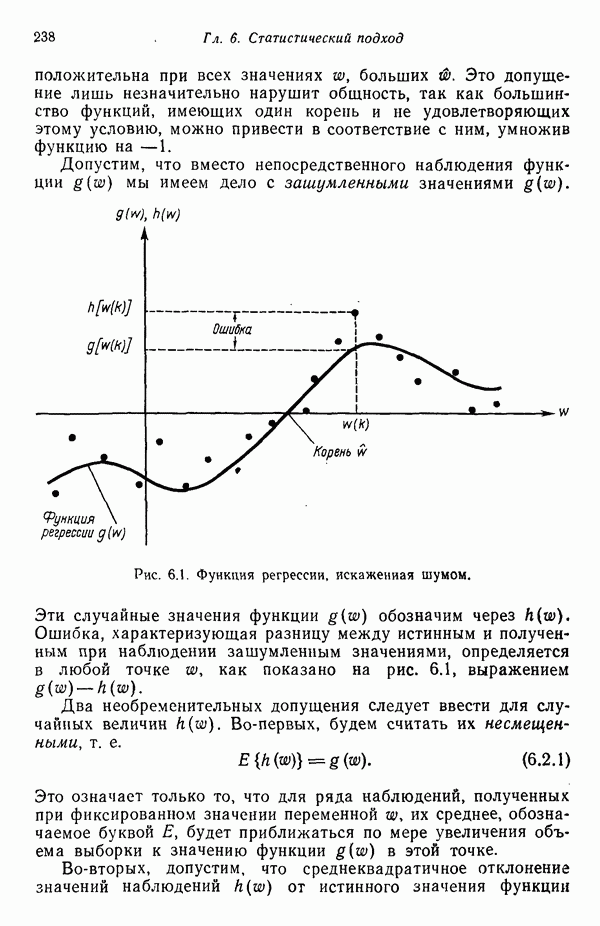
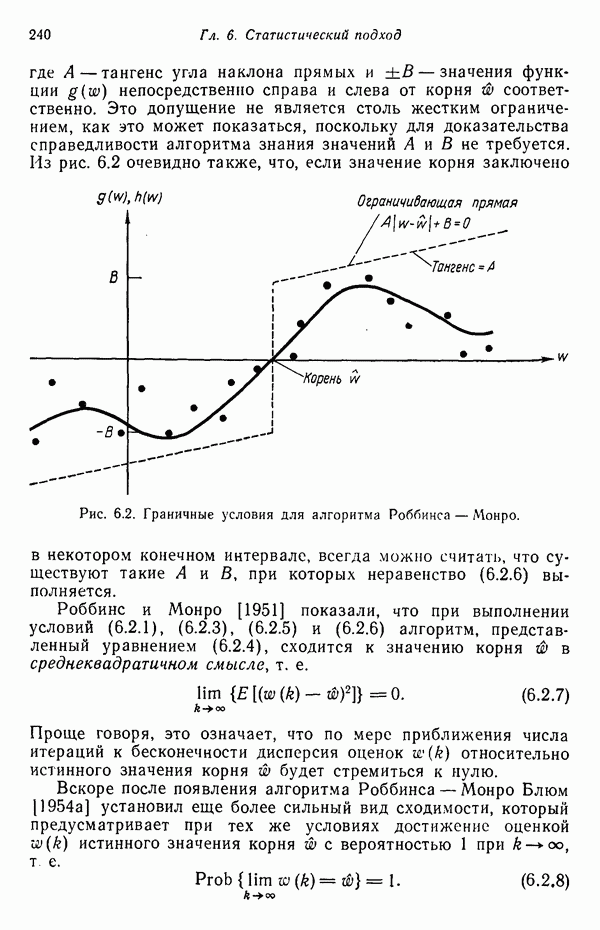
Рис. 8.5. Обобщенное представление структур образа с помощью ориентированных отрезков прямых, связанное с использованием языка PDL. Должно быть ясно, что поиск непроизводных элементов или подструктур, представляющих интерес с точки зрения анализа двумерных объектов, может оказаться для вычислительной машины почти неразрешимой задачей. И хотя этот вопрос обсуждался в предыдущем разделе, стоит упомянуть о нем еще раз, поскольку он является одним из основных препятствий на пути создания истинно универсальной системы синтаксического распознавания образов. К настоящему времени наиболее успешные исследования в данной области связаны с объектами, сводимыми к структурам типа графов. В данном разделе мы обсуждаем некоторые из этих подходов с целью иллюстрации основных понятий, вводимых при синтаксическом распознавании объектов, представленных графами. Интересным приложением лингвистических понятий в распознавании образов является язык PDL (Picture Description Language) — язык описания изображений, предложенный Шоу (1970). Непроизводным элементом в Непроизводный элемент может примыкать к другим непроизводным элементам только в своей хвостовой и/или головной точке. На основании этой допустимой формы соединения, а также вследствие того, что каждый непроизводный элемент обобщается до ориентированного отрезка прямой, очевидно, что структуры языка PDL представляют собой ориентированные графы и для обработки этих структур можно использовать грамматики цепочек. Основные правила соединения обобщенных непроизводных элементов приведены на рис. 8.6. Важно отметить, что пустые непроизводные элементы могут быть использованы для порождения внешне разъединенных структур, подчиняющихся при этом правилам связности. Иногда полезно также рассмотрение нулевой точки — ненроизводного элемента с идентичными головной и хвостовой точками. Принципы действия языка PDL лучше всего проиллюстрировать на примере. Рассмотрим следующую простую грамматику языка PDL:
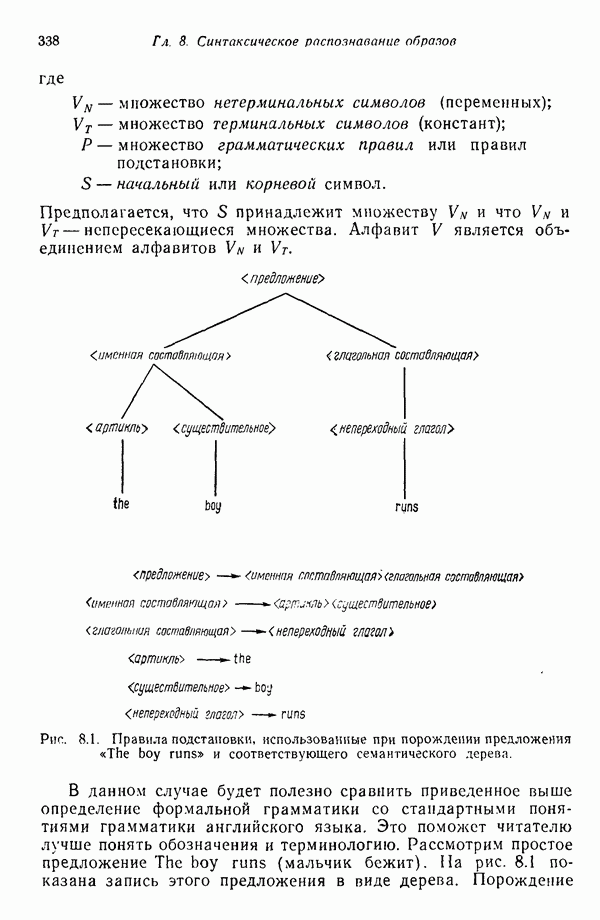
где
Рис. 8.6. Правила соединения, используемые в языке причем Применение первого правила подстановки приводит к получению непроизводного элемента
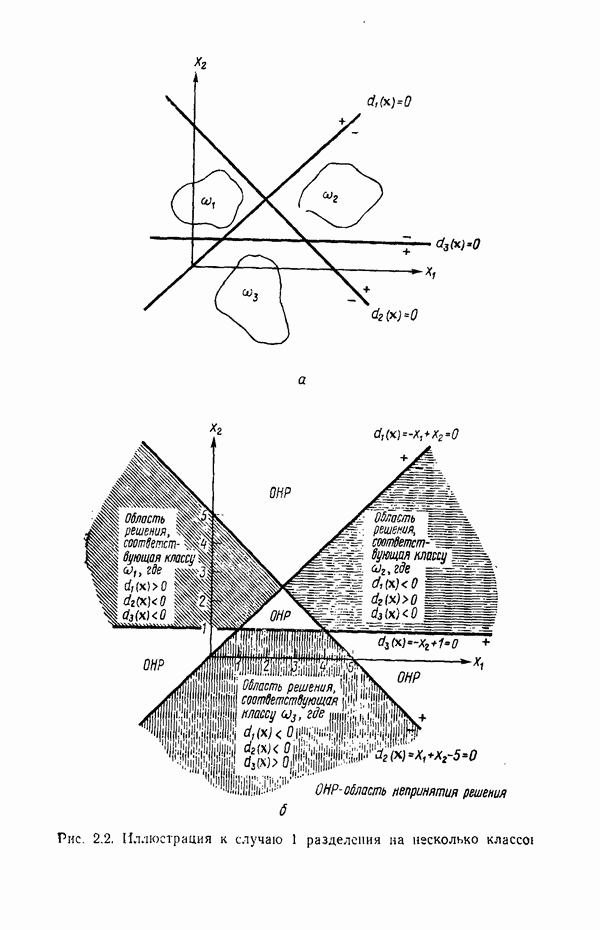
Рис. 8.7. Шаги построения структуры в языке Грамматика языка PDL, описанная выше, способна порождать только одну структуру. Можно, однако, расширить число структур, порождаемых этой грамматикой, введением в правила подстановки рекурсивности — способности переменной замещаться этой же переменной. Предположим, например, что мы определяем иравила подстановки следующим образом:
Результатом применения этих правил в указанном порядке является структура, изображенная на рис. 8.7, е. Между тем это новое множество правил допускает, например, возможность за первым правилом подстановки применять третье, опуская второе. Применяя в указанном порядке оставшиеся правила подстановки, мы получили бы треугольную структуру. Более того, эти правила позволяют порождать бесконечные структуры посредством многократного замещения переменной этой же переменной. Многообразие структур, порождаемых приведенной выше грамматикой, может быть еще более расширено, если положить, что Грамматический разбор структур при помощи предложенной грамматики в принципе несложен. Предположим, например, что объектом, представленным на распознавание, служит изображение на рис. 8.7, е, причем используется второе множество правил подстановки. Грамматический разбор сверху вниз будет происходить в следующей последовательности. Предположим, что интересующий нас объект сканируется с целью получения соответствующего терминального представления
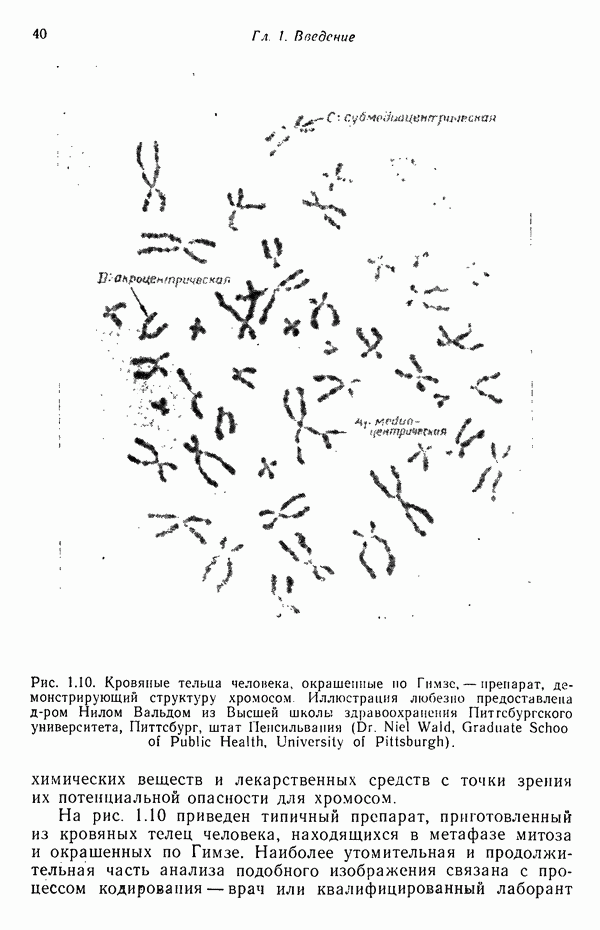
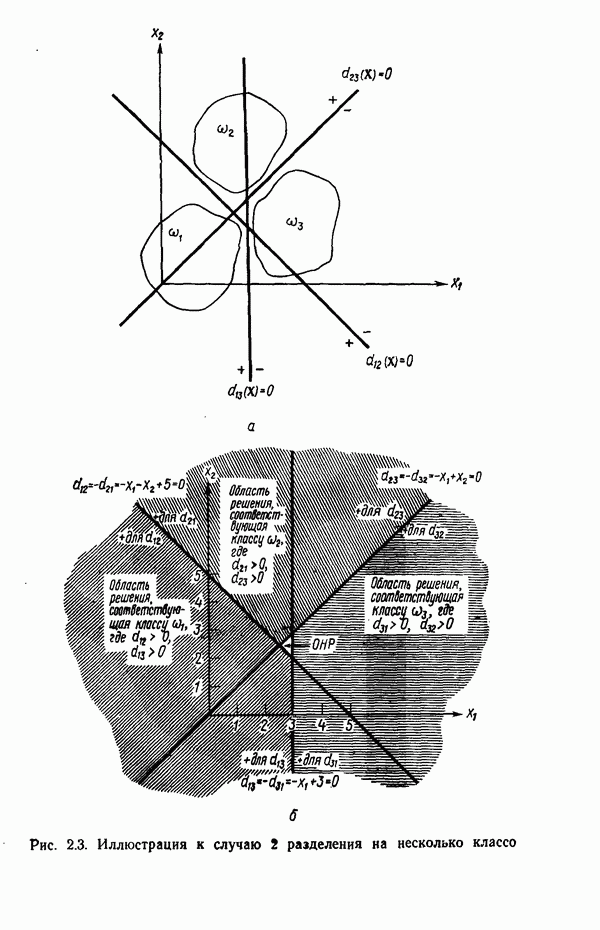
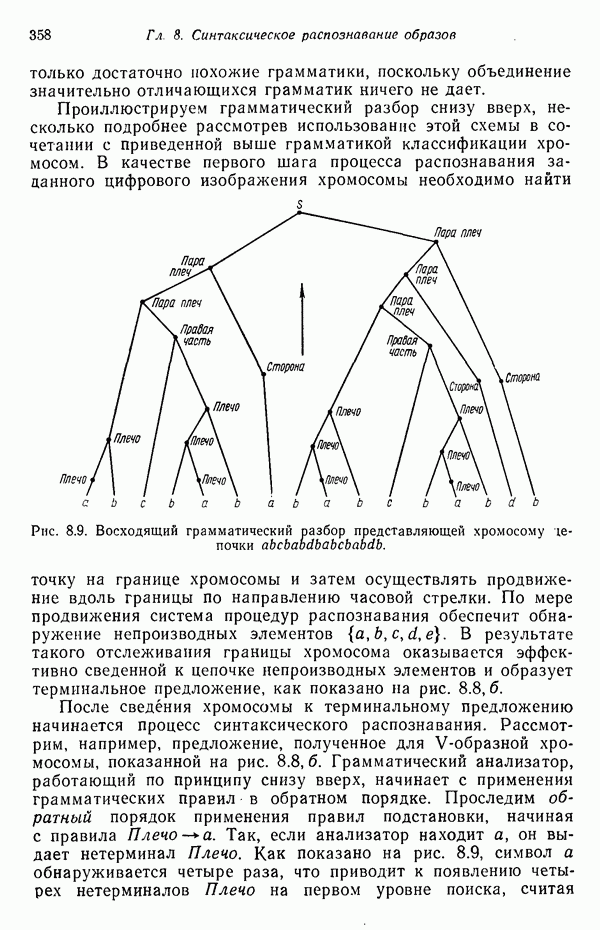
Другим интересным приложением синтаксического распознавания образов является работа Ледли [1964, 1965] по автоматической классификации хромосом. Бесконтекстная грамматика, способная классифицировать (см. скан) На рис. 8.8, а изображены непроизводные элементы Рис. 8.8. (см. скан) а — непроизводные элементы грамматики, предназначенной для описания изображений хромосом; б — телоцентрическая и V-образная хромосомы и соответствующие им терминальные цепочки. Иллюстрация заимствована из статьи Ледли «Высокоскоростной автоматический анализ биомедицинских изображений», Science, 146, No. 3641, 1964 (R. S. Ledley, High-Speed Automatic Analysis of Biomedical Pictures). Начальные символы только достаточно похожие грамматики, поскольку объединение значительно отличающихся грамматик ничего не дает. Проиллюстрируем грамматический разбор снизу вверх, несколько подробнее рассмотрев использование этой схемы в сочетании с приведенной выше грамматикой классификации хромосом. В качестве первого шага процесса распознавания заданного цифрового изображения хромосомы необходимо найти точку на границе хромосомы и затем осуществлять продвижение вдоль границы по направлению часовой стрелки. По мере продвижения система процедур распознавания обеспечит обнаружение непроизводных элементов
Рис. 8.9. Восходящий грамматический разбор представляющей хромосому После сведения хромосомы к терминальному предложению начинается процесс синтаксического распознавания. Рассмотрим, например, предложение, полученное для снизу. Следующее правило подстановки сочетает нетерминал Плечо с терминалом Необходимо отметить, что в зависимости от способа обхода границы хромосомы, получающиеся в результате цепочки символов, не всегда бывают правильно упорядочены с точки зрения разбора. Эту трудность тем не менее легко преодолеть, заметив, что начало и конец цепочки в действительности примыкают друг к другу, так как, в конце концов, цепочка образована в результате полного обхода вдоль границы хромосомы. Если бы, например, на рис. 8.8,б была приведена цепочка Приведенный грамматический разбор привел к искомому результату при первой реализации. Конечно, далеко не всегда получается так, поскольку обычно бывают необходимы частые возвраты. Их число, однако, можно минимизировать упорядочением, упоминавшимся ранее, а также с помощью введения в процесс поиска эвристических правил, указывающих грамматическому анализатору способ действия в ситуациях, когда возможны несколько вариантов продолжения.
|
 |
Оглавление
|















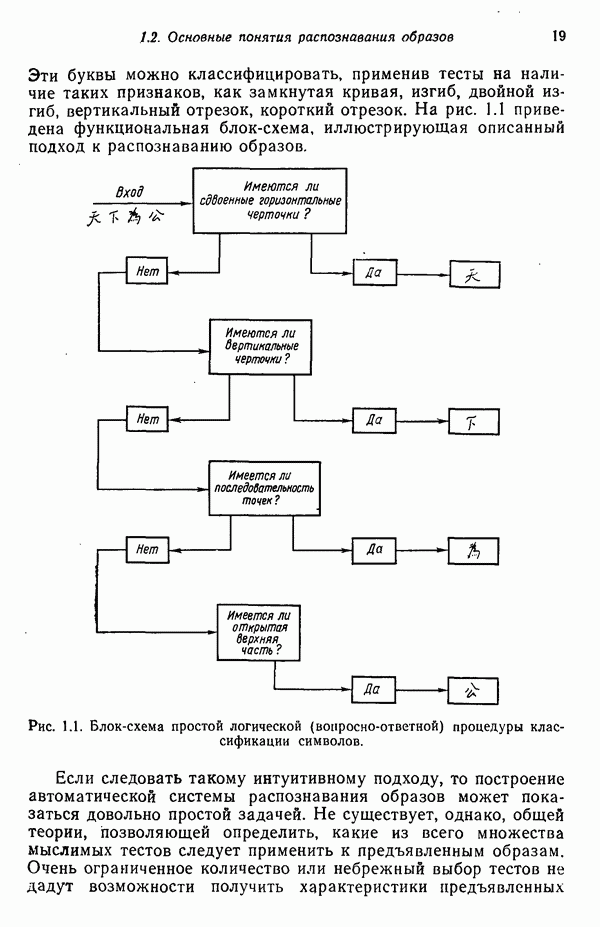
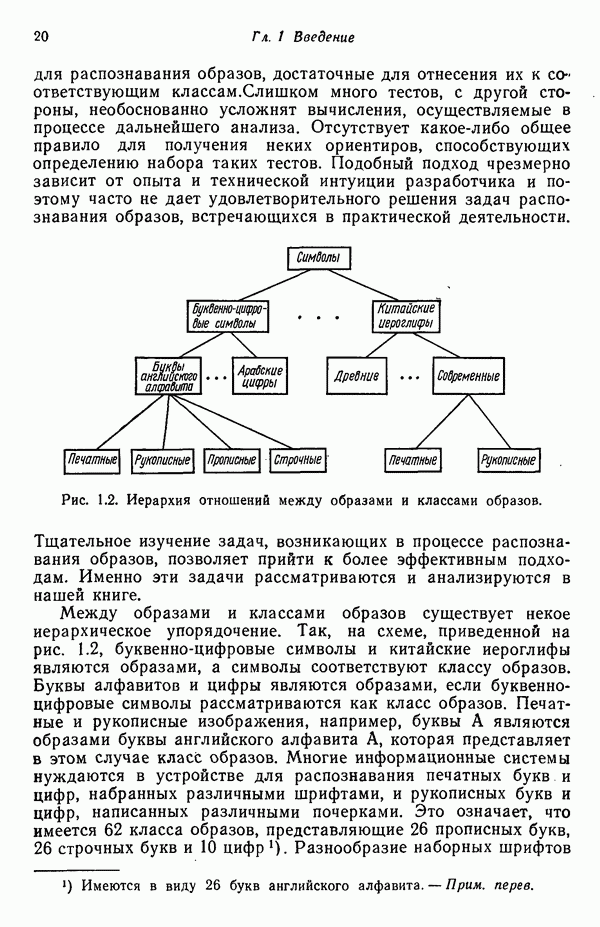

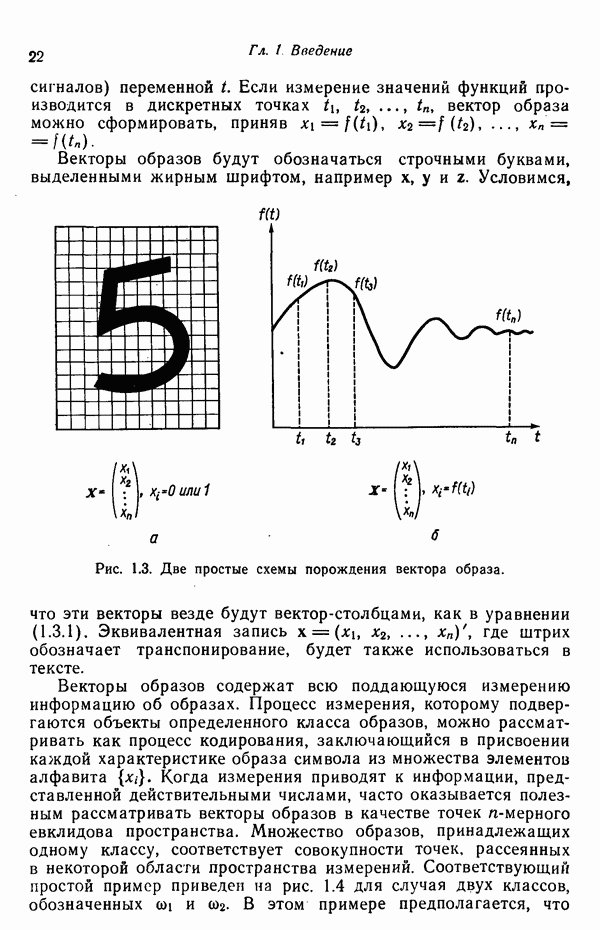


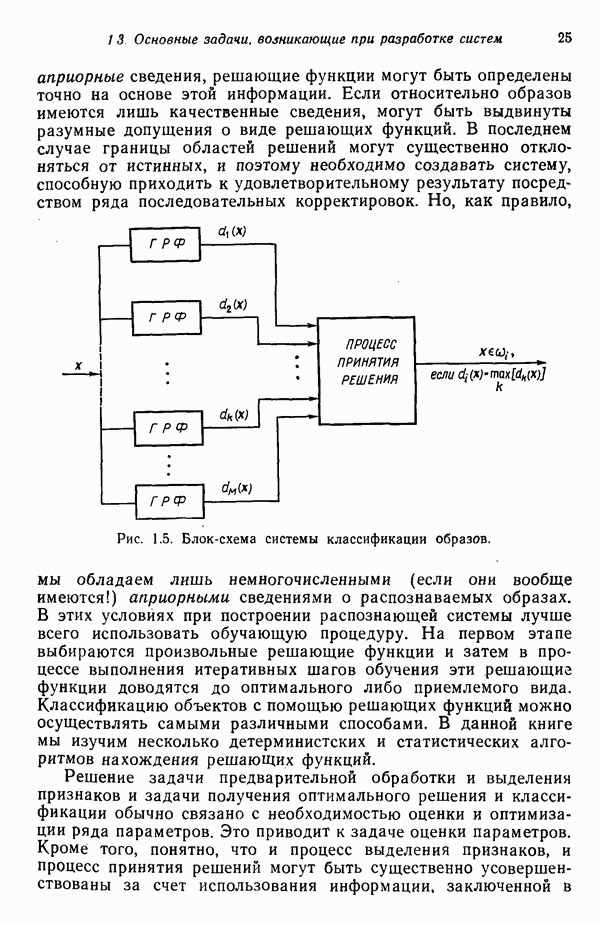






























































































































































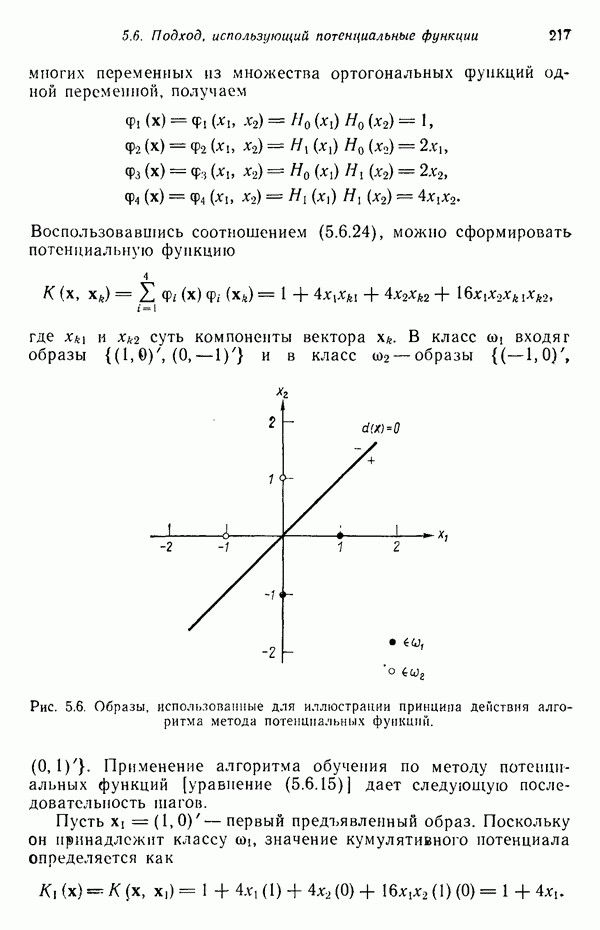
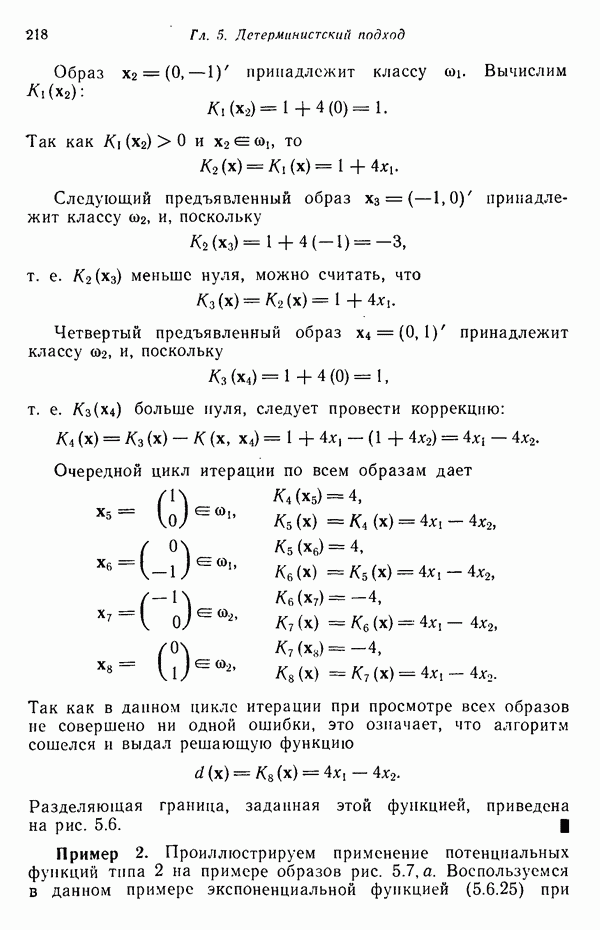



































































































































































 служит любая
служит любая  -мерная структура с двумя выделенными точками — хвостовой и головной, как это показано на рис. 8.5 для двумерных структур. Заметим, что практически любая структура может обобщенно рассматриваться как ориентированный отрезок прямой, так как определение вводит только две точки.
-мерная структура с двумя выделенными точками — хвостовой и головной, как это показано на рис. 8.5 для двумерных структур. Заметим, что практически любая структура может обобщенно рассматриваться как ориентированный отрезок прямой, так как определение вводит только две точки.




 означает перемену мест головной и хвостовой точек непроизводного элемента
означает перемену мест головной и хвостовой точек непроизводного элемента  .
.
 сопровождаемого еще не определенной переменной. На этом этапе мы знаем только, что хвостовая точка структуры, представленной символом
сопровождаемого еще не определенной переменной. На этом этапе мы знаем только, что хвостовая точка структуры, представленной символом  будет связана с головной точкой элемента
будет связана с головной точкой элемента  потому что этот непроизводный элемент сопровождается оператором
потому что этот непроизводный элемент сопровождается оператором  Переменная
Переменная  разлагается на с
разлагается на с  причем
причем  пока не определена. Аналогичным образом
пока не определена. Аналогичным образом  разлагается на
разлагается на  . Результаты применения первых трех правил подстановки приведены на рис. 8.7, а, б и е. Из определения оператора
. Результаты применения первых трех правил подстановки приведены на рис. 8.7, а, б и е. Из определения оператора  мы знаем, что при разложении элемента
мы знаем, что при разложении элемента  происходит его соединение с составной структурой, показанной на рис. 8.7, в путем присоединения хвостовых точек к хвостовым, а головных к головным. Конечный результат, полученный после применения всех правил подстановки, показан на рис. 8.7, е.
происходит его соединение с составной структурой, показанной на рис. 8.7, в путем присоединения хвостовых точек к хвостовым, а головных к головным. Конечный результат, полученный после применения всех правил подстановки, показан на рис. 8.7, е.

 Обратите внимание на головные и хвостовые точки составных подструктур.
Обратите внимание на головные и хвостовые точки составных подструктур.

 равны
равны  . При этом возможности грамматики возрастут до максимума. Нужно отметить, однако, что подобное увеличение порождающей способности грамматики может иногда оказаться нежелательным. Особенно верно это замечание для тех прикладных исследований в области синтаксического распознавания образов, где требуется более чем одна грамматика. В этом случае чрезмерное многообразие приводит к уменьшению различающей мощности применяемых грамматик.
. При этом возможности грамматики возрастут до максимума. Нужно отметить, однако, что подобное увеличение порождающей способности грамматики может иногда оказаться нежелательным. Особенно верно это замечание для тех прикладных исследований в области синтаксического распознавания образов, где требуется более чем одна грамматика. В этом случае чрезмерное многообразие приводит к уменьшению различающей мощности применяемых грамматик.
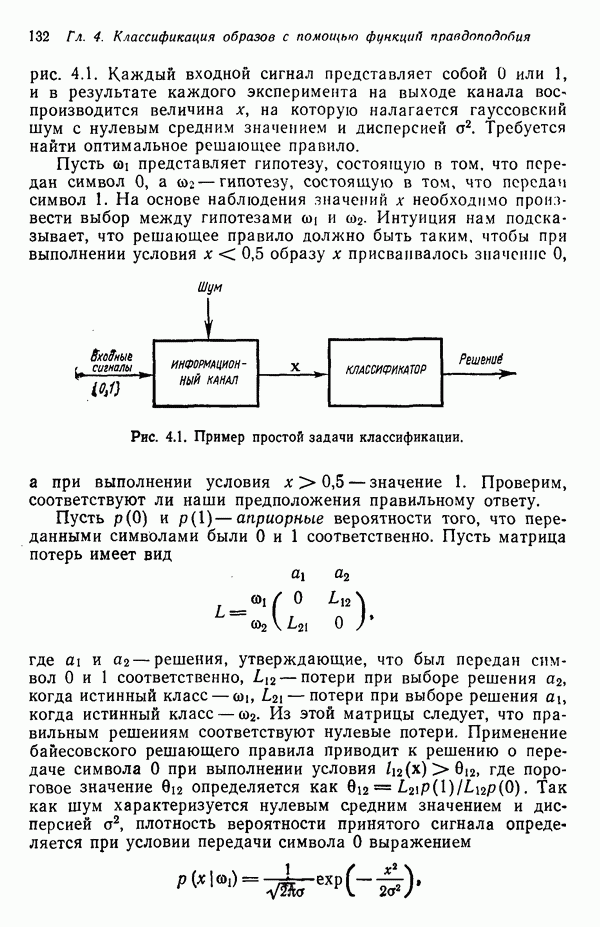
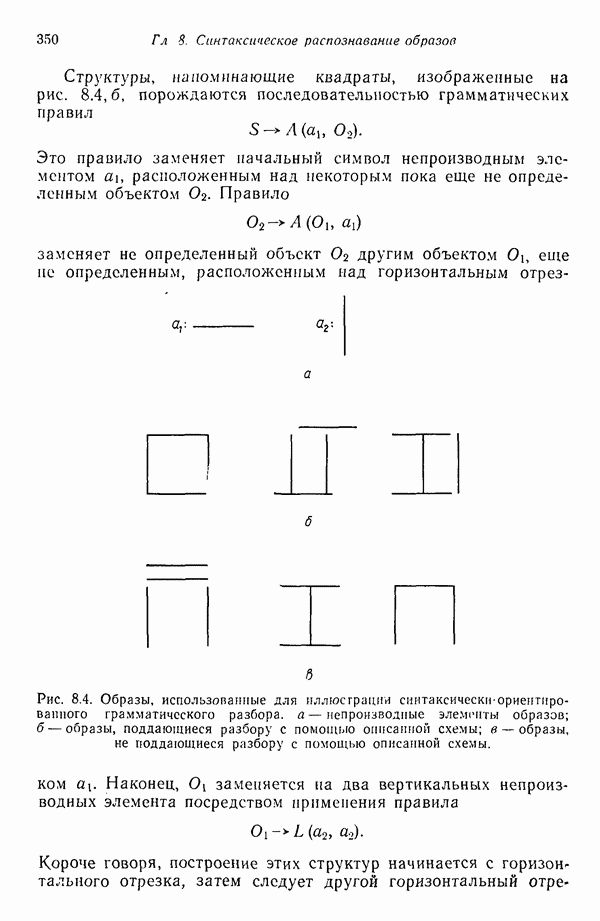
 Как отмечалось ранее, процесс сканирования, вообще говоря, не является тривиальной процедурой. Грамматический анализатор, работающий по принципу «сверху вниз», начинает с корневого символа
Как отмечалось ранее, процесс сканирования, вообще говоря, не является тривиальной процедурой. Грамматический анализатор, работающий по принципу «сверху вниз», начинает с корневого символа  и пытается получить интересующий нас объект, применяя правила подстановки данной грамматики. В настоящем случае
и пытается получить интересующий нас объект, применяя правила подстановки данной грамматики. В настоящем случае  заменяется на
заменяется на
 . Терминальный символ
. Терминальный символ  сопровождаемый знаком
сопровождаемый знаком  обнаружен, поэтому происходит грамматический разбор элемента
обнаружен, поэтому происходит грамматический разбор элемента  . Здесь имеются две возможности, поскольку
. Здесь имеются две возможности, поскольку  может заменяться при помощи как второго, так и третьего правила. Применение второго правила приводит к успеху, так как первый
может заменяться при помощи как второго, так и третьего правила. Применение второго правила приводит к успеху, так как первый  образа сопровождается символом с. Третье правило этому условию не соответствует. Для того чтобы разложить элемент
образа сопровождается символом с. Третье правило этому условию не соответствует. Для того чтобы разложить элемент  следующий за
следующий за  после символа с, необходимо найти правило подстановки вида
после символа с, необходимо найти правило подстановки вида  сопровождающееся
сопровождающееся  Этому условию отвечает третье правило. Продолжая эту процедуру, устанавливаем, что данный образ поддается грамматическому разбору. При наличии двух или более грамматик анализ производится для каждой из них до тех пор, пока образ не идентифицируется либо пока не исчерпаются возможности грамматики; в последнем случае образ отклоняется.
Этому условию отвечает третье правило. Продолжая эту процедуру, устанавливаем, что данный образ поддается грамматическому разбору. При наличии двух или более грамматик анализ производится для каждой из них до тех пор, пока образ не идентифицируется либо пока не исчерпаются возможности грамматики; в последнем случае образ отклоняется.
 -образные и телоцентрические хромосомы, задается следующим образом:
-образные и телоцентрические хромосомы, задается следующим образом:
 на рис. 8.8,б - типичный вид
на рис. 8.8,б - типичный вид  -образной и телоцентрической хромосом. Для данного конкретного случая оператор
-образной и телоцентрической хромосом. Для данного конкретного случая оператор  означает просто связность отдельных частей хромосомы, фиксируемую при продвижении вдоль ее границы по направлению часовой стрелки.
означает просто связность отдельных частей хромосомы, фиксируемую при продвижении вдоль ее границы по направлению часовой стрелки.
 представляют
представляют  -образную и телоцентрическую хромосомы соответственно. Интересно отметить, что для разделения объектов на два класса в данном случае используется одна грамматика с двумя начальными символами. Если, например, грамматический разбор снизу вверх приводит к Т, хромосому относят в класс телоцентрических. Если грамматический разбор приводит к
-образную и телоцентрическую хромосомы соответственно. Интересно отметить, что для разделения объектов на два класса в данном случае используется одна грамматика с двумя начальными символами. Если, например, грамматический разбор снизу вверх приводит к Т, хромосому относят в класс телоцентрических. Если грамматический разбор приводит к  хромосома классифицируется как
хромосома классифицируется как  -образная. Должно быть очевидно, что применение одной грамматики для распознавания — в сущности, не что иное, как объединение двух классификационных грамматик с различными начальными символами. И хотя это можно сделать всегда, имеет смысл объединять
-образная. Должно быть очевидно, что применение одной грамматики для распознавания — в сущности, не что иное, как объединение двух классификационных грамматик с различными начальными символами. И хотя это можно сделать всегда, имеет смысл объединять
 . В результате такого отслеживания границы хромосома оказывается эффективно сведенной к цепочке непроизводных элементов и образует терминальное предложение, как показано на рис. 8.8, б.
. В результате такого отслеживания границы хромосома оказывается эффективно сведенной к цепочке непроизводных элементов и образует терминальное предложение, как показано на рис. 8.8, б.

 -почки
-почки  .
.
 -образной хромосомы, показанной на рис. 8.8, б. Грамматический анализатор, работающий по принципу снизу вверх, начинает с применения грамматических правил в обратном порядке. Проследим обратный порядок применения правил подстановки, начиная с правила
-образной хромосомы, показанной на рис. 8.8, б. Грамматический анализатор, работающий по принципу снизу вверх, начинает с применения грамматических правил в обратном порядке. Проследим обратный порядок применения правил подстановки, начиная с правила  . Так, если анализатор находит а, он выдает нетерминал
. Так, если анализатор находит а, он выдает нетерминал  . Как показано на рис. 8.9, символ а обнаруживается четыре раза, что приводит к появлению четырех нетерминалов Плечо на первом уровне поиска, считая
. Как показано на рис. 8.9, символ а обнаруживается четыре раза, что приводит к появлению четырех нетерминалов Плечо на первом уровне поиска, считая
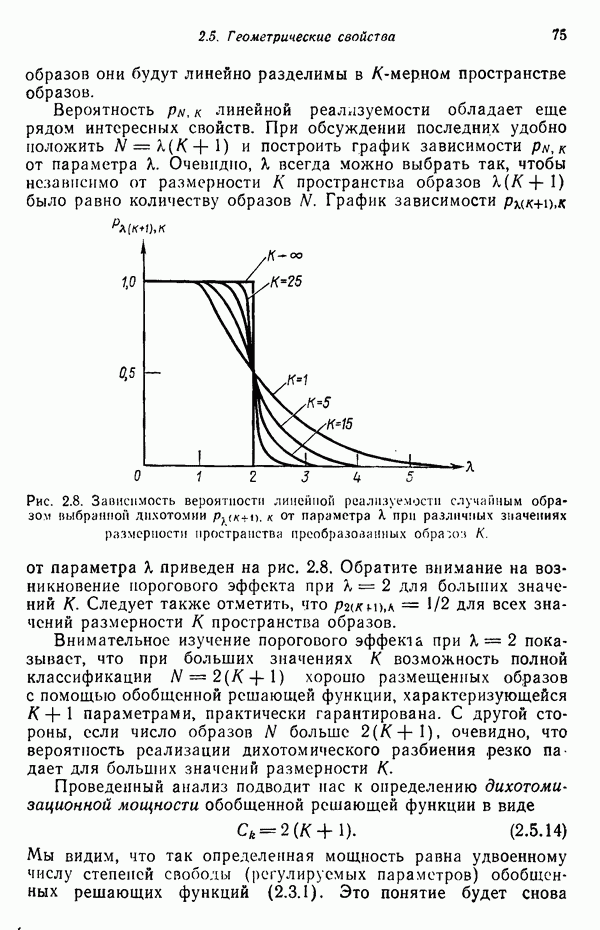
 Как следует из рассмотрения дерева на рис. 8.9, на следующем уровне порождаются только Плечи. Количество проб в грамматическом разборе можно сократить, следуя определенной заранее упорядоченной последовательности. «Наилучший» порядок устанавливается экспериментально. Следующие правила подстановки порождают нетерминал Сторона. Из трех порожденных Сторон два нетерминала порождаются при помощи символов
Как следует из рассмотрения дерева на рис. 8.9, на следующем уровне порождаются только Плечи. Количество проб в грамматическом разборе можно сократить, следуя определенной заранее упорядоченной последовательности. «Наилучший» порядок устанавливается экспериментально. Следующие правила подстановки порождают нетерминал Сторона. Из трех порожденных Сторон два нетерминала порождаются при помощи символов  и один при помощи единственного оставшегося неиспользованным символа
и один при помощи единственного оставшегося неиспользованным символа  На следующих двух уровнях комбинация Плеча и символа с порождает Правую часть, и комбинация Правой части с Плечом порождает Пару плеч. Наконец, комбинация символов Пара плеч и Сторона порождает два символа Пара плеч, которые затем, объединяясь, порождают символ
На следующих двух уровнях комбинация Плеча и символа с порождает Правую часть, и комбинация Правой части с Плечом порождает Пару плеч. Наконец, комбинация символов Пара плеч и Сторона порождает два символа Пара плеч, которые затем, объединяясь, порождают символ  завершая, таким образом, грамматический разбор снизу вверх. Следовательно, хромосома была правильно классифицирована как
завершая, таким образом, грамматический разбор снизу вверх. Следовательно, хромосома была правильно классифицирована как  -образная.
-образная.
 то для образования символа Плечо первый терминальный символ
то для образования символа Плечо первый терминальный символ  был бы объединен с последним символом а.
был бы объединен с последним символом а.