Пред.
След.
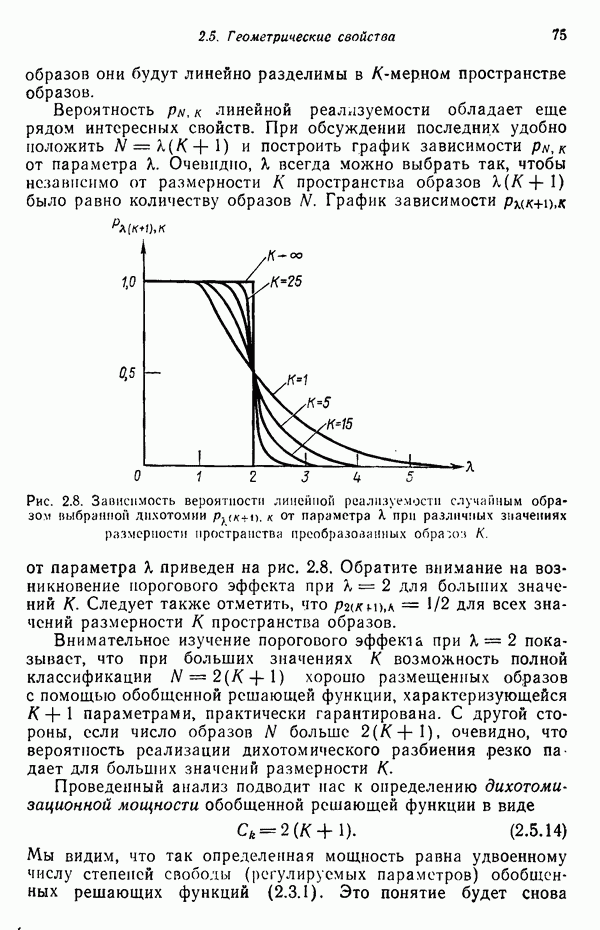
Макеты страниц
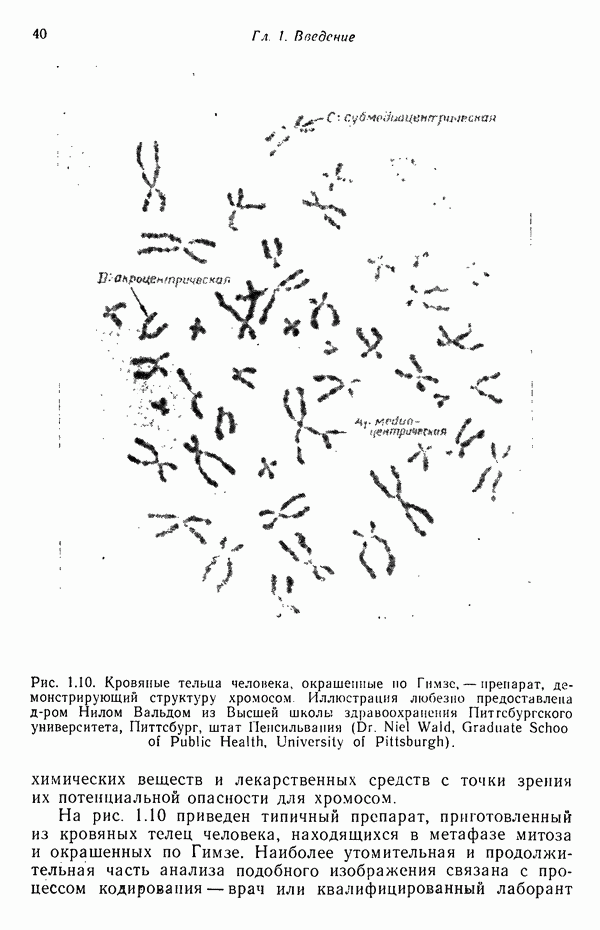
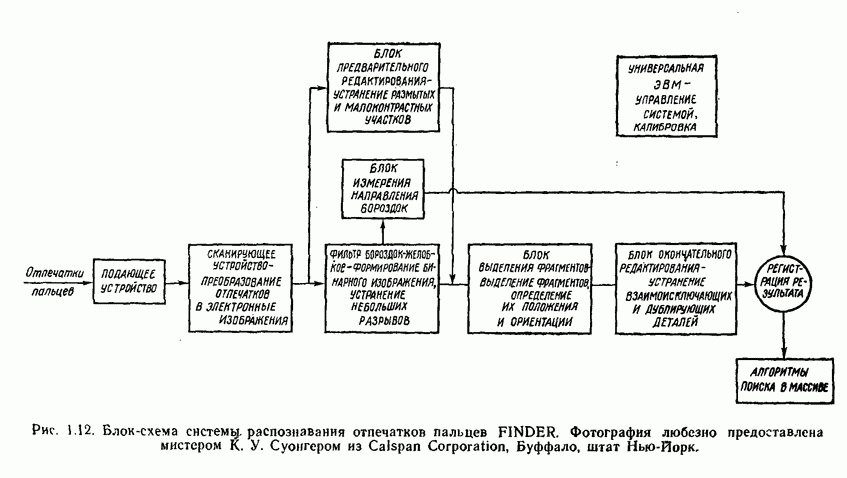
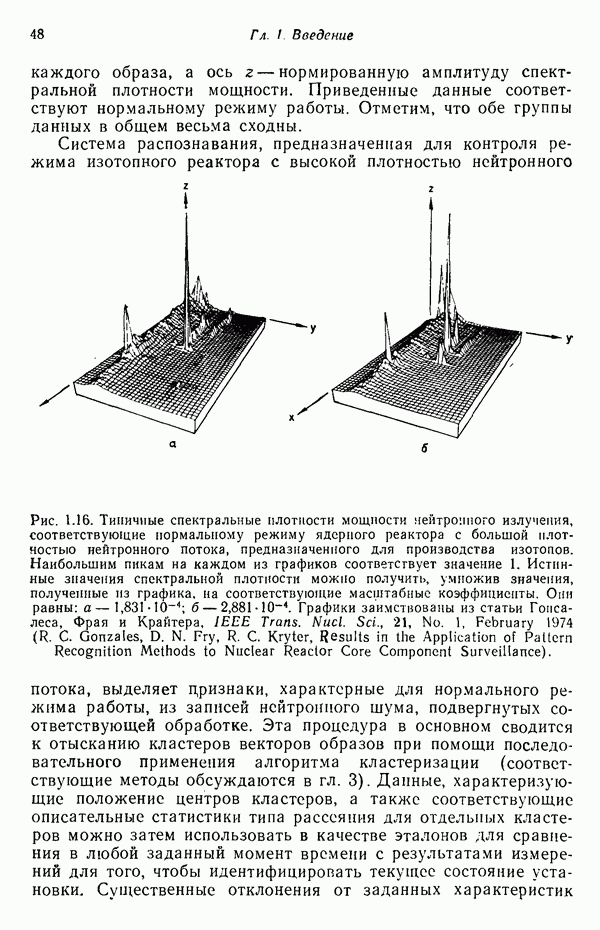
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
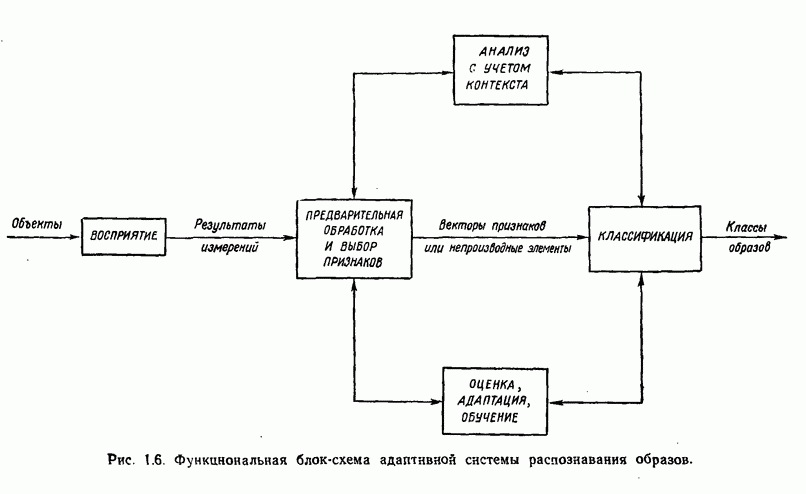
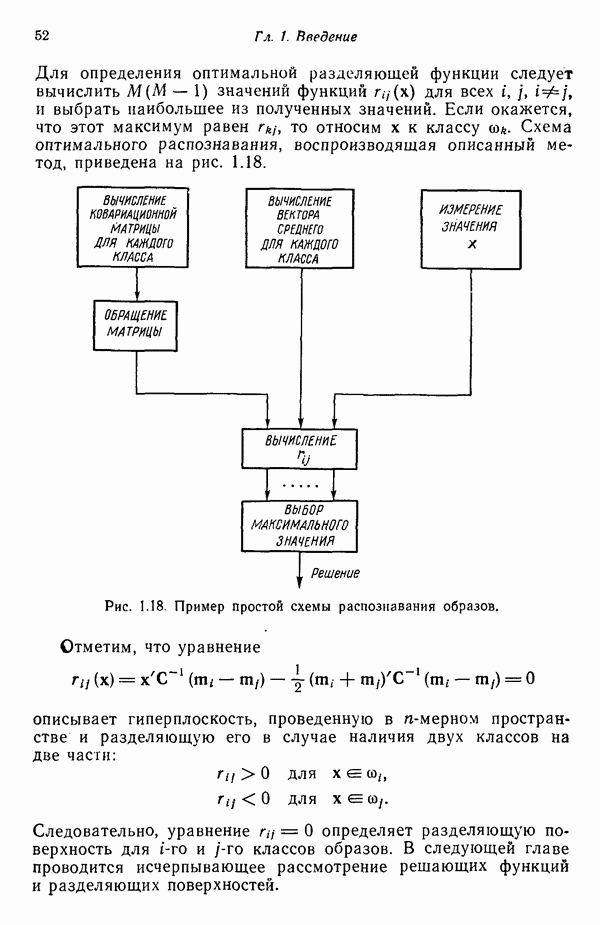
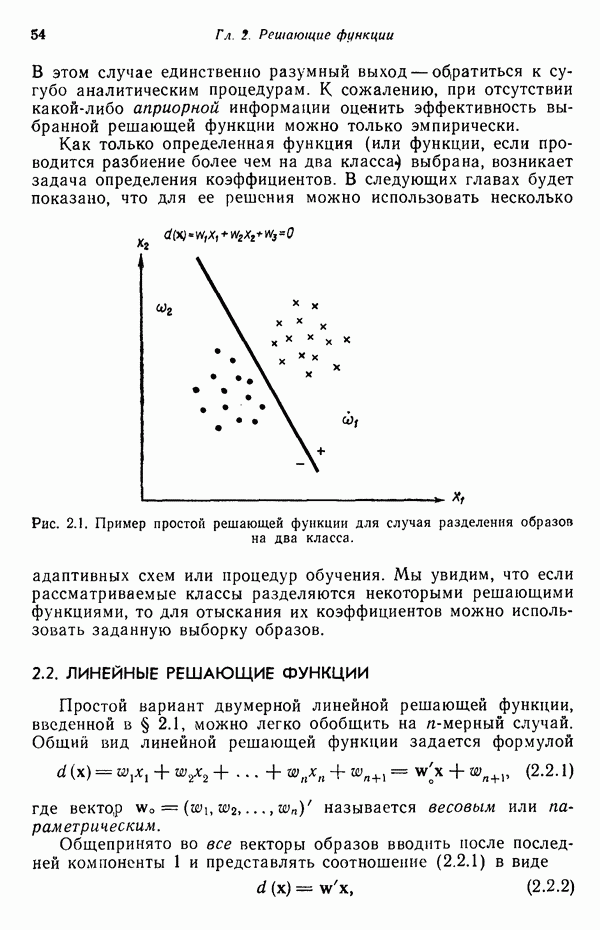
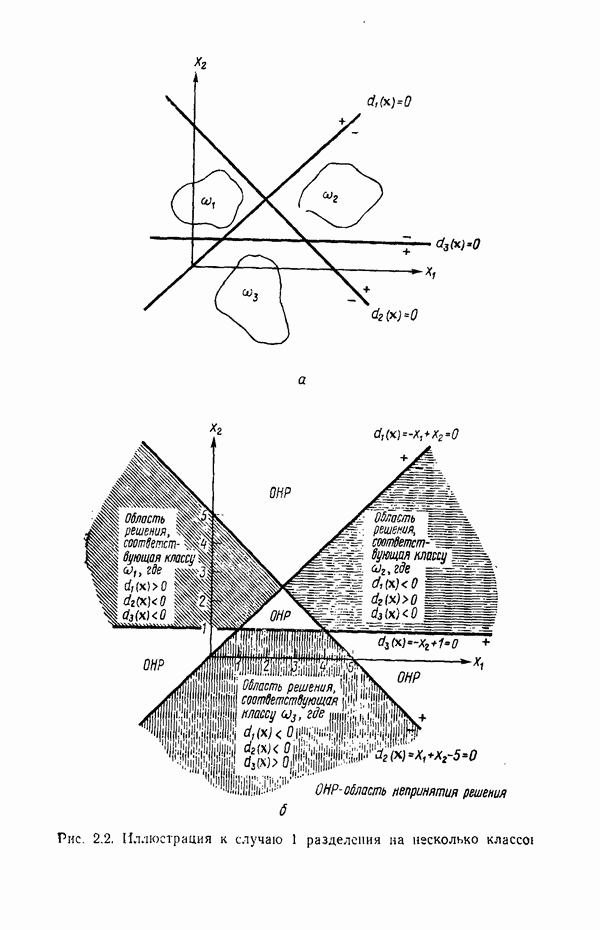
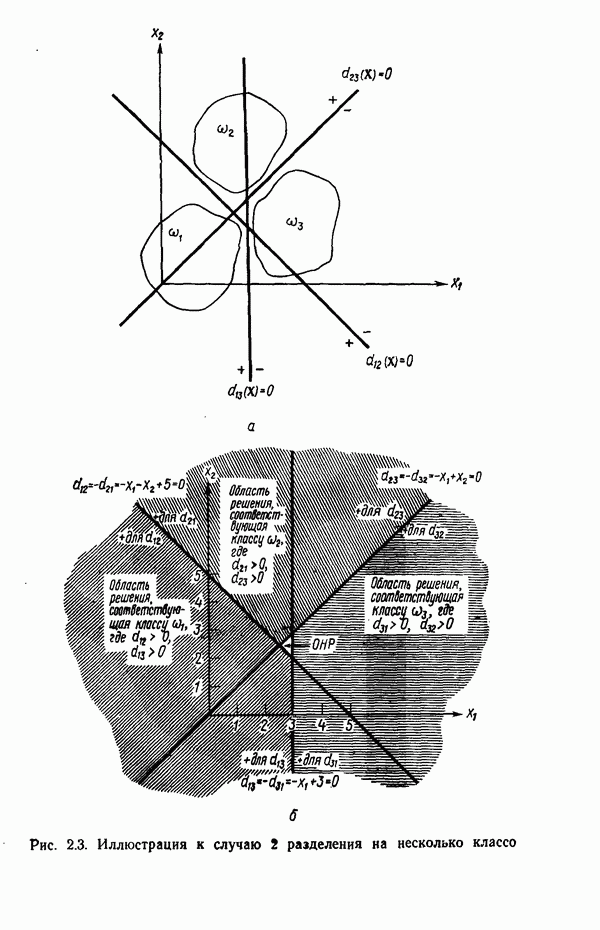
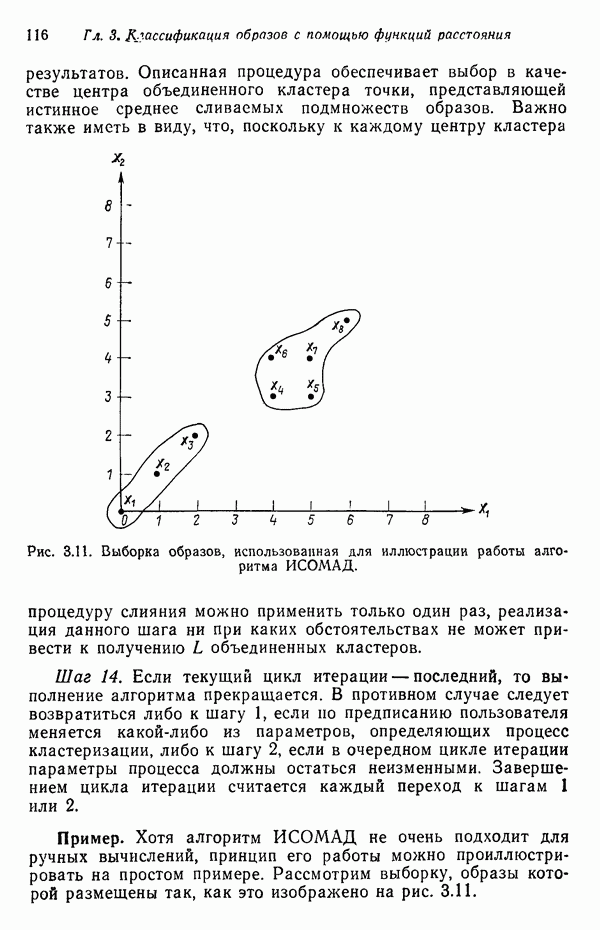
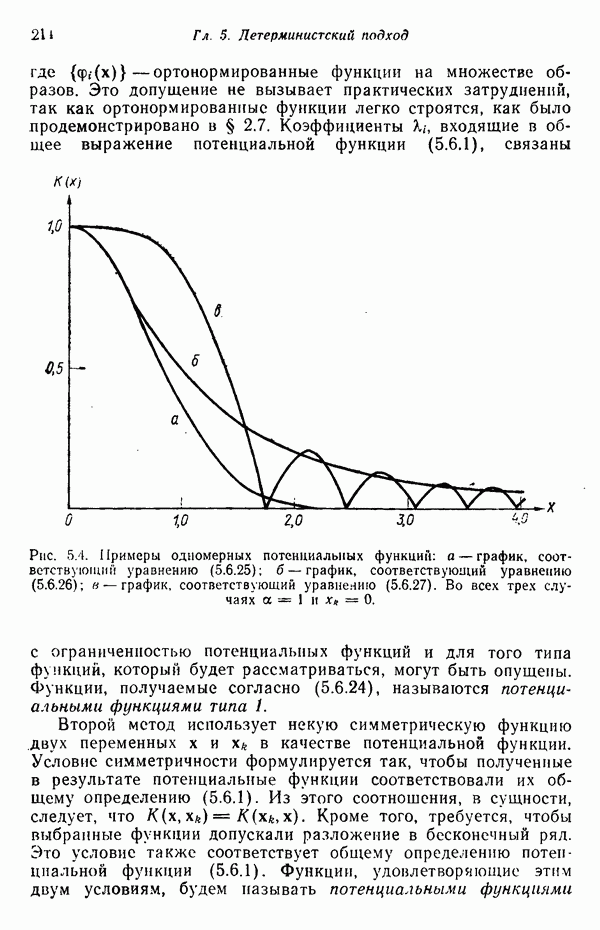
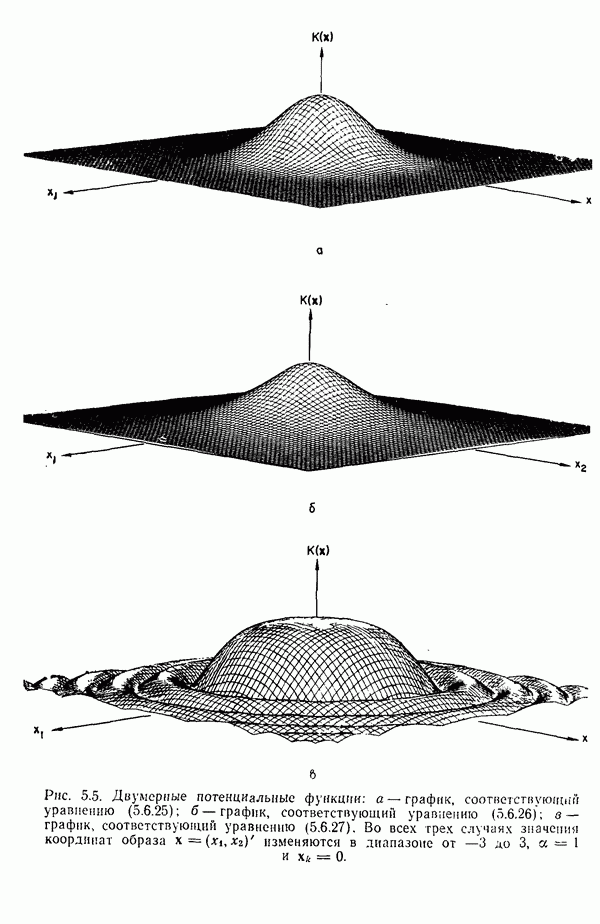
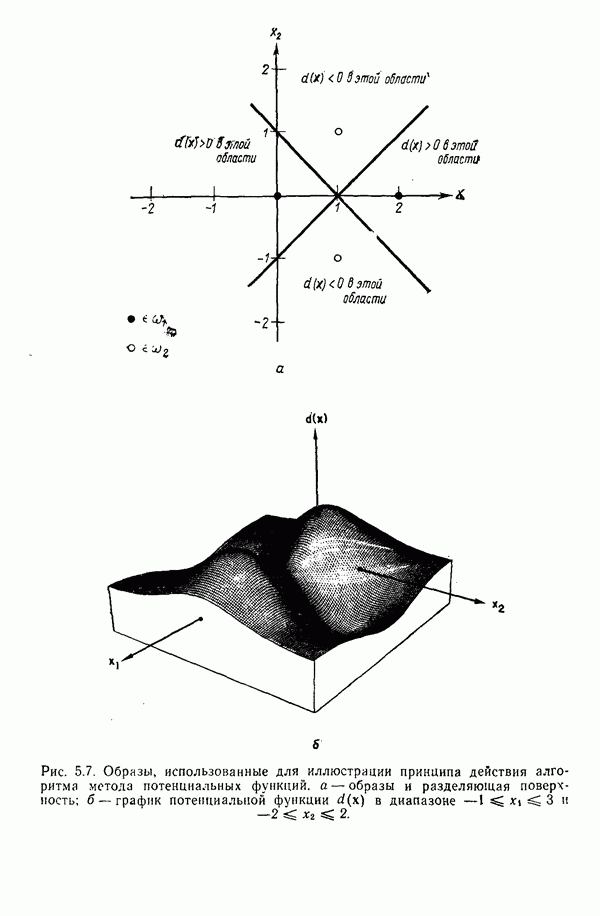
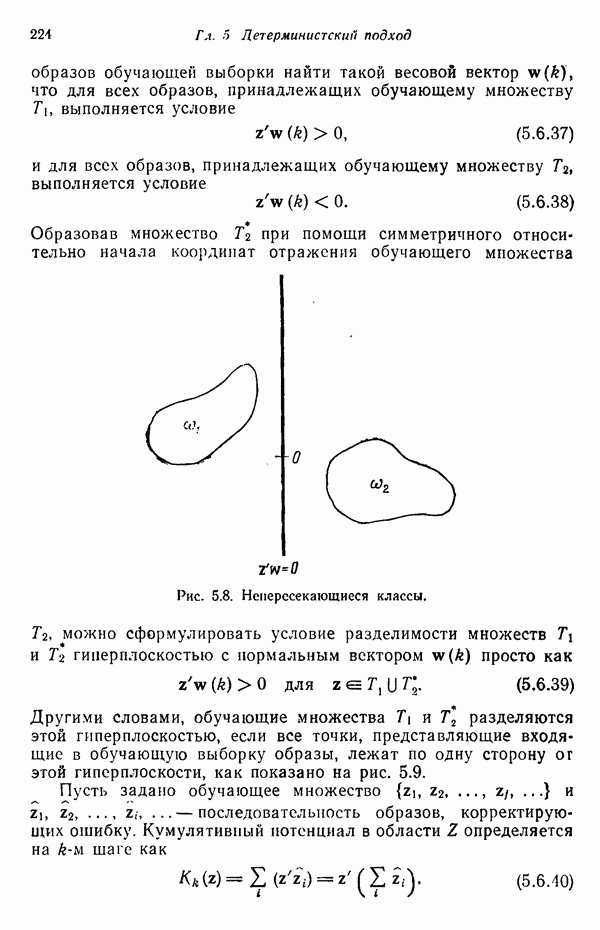
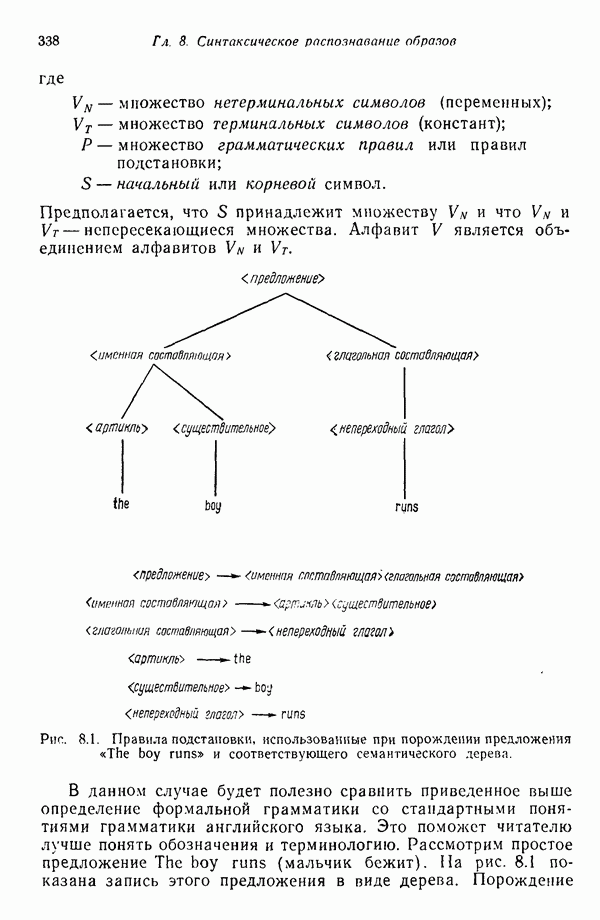
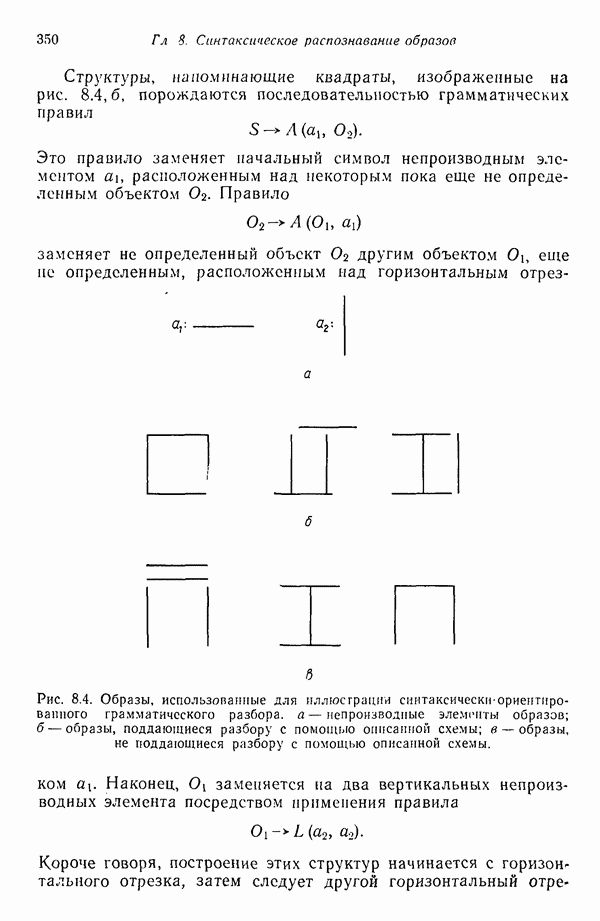
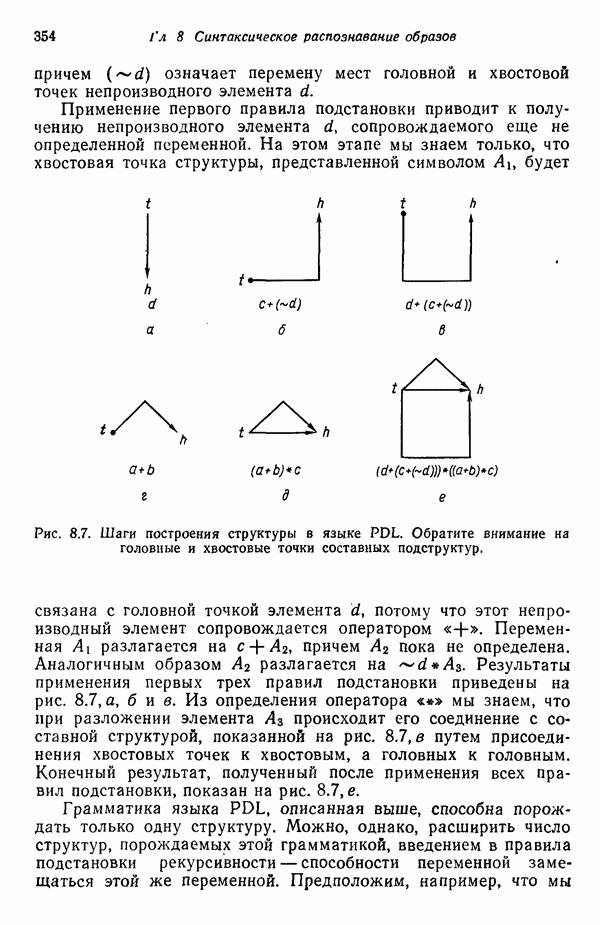
7.3. ПРЕОБРАЗОВАНИЯ КЛАСТЕРИЗАЦИИ И УПОРЯДОЧЕНИЕ ПРИЗНАКОВНе все измерения характеристик образа, соответствующие отдельным координатным осям в равной степени важны для определения класса, которому принадлежат сходные образы. При сопоставлении двух образов последовательным сравнением признаков измерениям с меньшей значимостью следует приписать меньшие веса. Назначение весов признаков можно осуществить посредством линейного преобразования, которое обеспечит более благоприятную группировку точек, представляющих образы, в новом пространстве. Рассмотрим векторы образов
где
причем элементы Итак,
Каждый элемент преобразованного вектора образа представляет собой линейную комбинацию элементов исходного вектора образа. В новом пространстве евклидово расстояние между векторами
В тех случаях, когда линейное преобразование сводится к изменению масштабных коэффициентов координатных осей, матрица
где элементы Из материала предыдущего параграфа следует, что в новом пространстве внутреннее расстояние для множества точек, представляющих образы, определяется как
где Случай 1. Ограничение Минимизация
Возьмем частную производную от
где
Итак, весовой коэффициент признака равен
Из (7.3.5) заключаем, что значения коэффициента В данном случае преобразование кластеризации было осуществлено посредством «взвешивания» признаков. Интуитивно понятно, что малая дисперсия Случай 2. Ограничение Минимизация
Взяв частную производную от (7.3.8) по весовому коэффициенту
где
Таким образом, весовой коэффициент признака определяется выражением
значение этого коэффициента обратно пропорционально среднеквадратичному отклонению Формулы (7.3.7) и (7.3.11) определяют матрицу преобразования
то внутреннее расстояние множества в пространстве X минимизируется. Теперь требуется провести второе преобразование
для того, чтобы выделить компоненты, имеющие малую (или большую) дисперсию, обеспечив таким образом возможность провести упорядочение и выбор признаков. Это преобразование превратит ковариационную матрицу точек, представляющих образы в пространстве X, в диагональную. Более того, матрица преобразования А должна быть ортонормированной для того, чтобы расстояния оставались неизменными. Задача заключается в выражении матрицы А посредством собственных векторов известной ковариационной матрицы. Пусть С — ковариационная матрица для точек, представляющих образы в пространстве X, а
и
где
В этом выражении Е — оператор математического ожидания. Ковариационная матрица в пространстве X определяется как
поскольку Подобным же образом можно легко показать, что
Так как матрица А — ортонормированная, то
В таком случае мы приходим к
это выражение представляет преобразование подобия. Хорошо известно, что преобразование подобия дает диагональную матрицу С, если в качестве матрицы Пусть
Матрица А выбирается так, чтобы
и так как собственные векторы образуют ортонормированное множество, то
Воспользовавшись уравнением (7.3.18), можно записать
так как
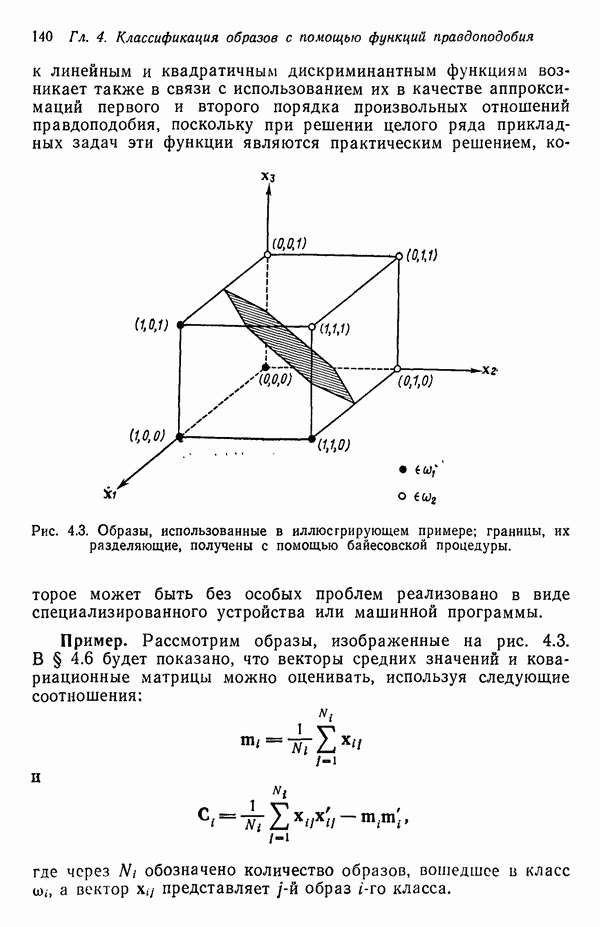
Матрица А преобразует ковариационную матрицу С в диагональную, элементами которой являются несмещенные оценки выборочной дисперсии. Результаты измерений, которым соответствуют малые дисперсии, более надежны и могут считаться более существенными признаками. Описанная процедура исследования ковариационной матрицы не позволяет связать простой зависимостью собственные векторы матрицы
то
где
Ковариационная матрица после преобразования кластеризации будет иметь вид
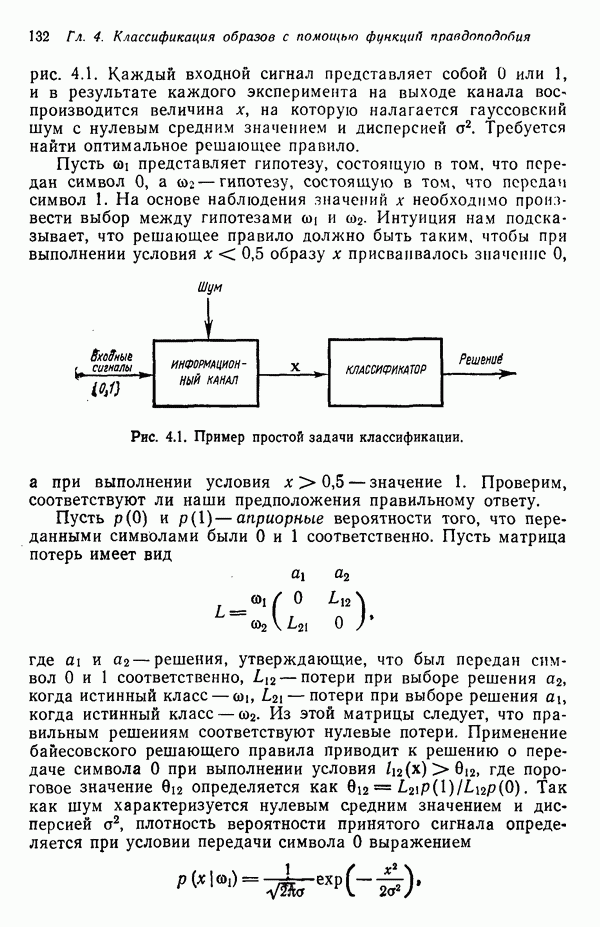
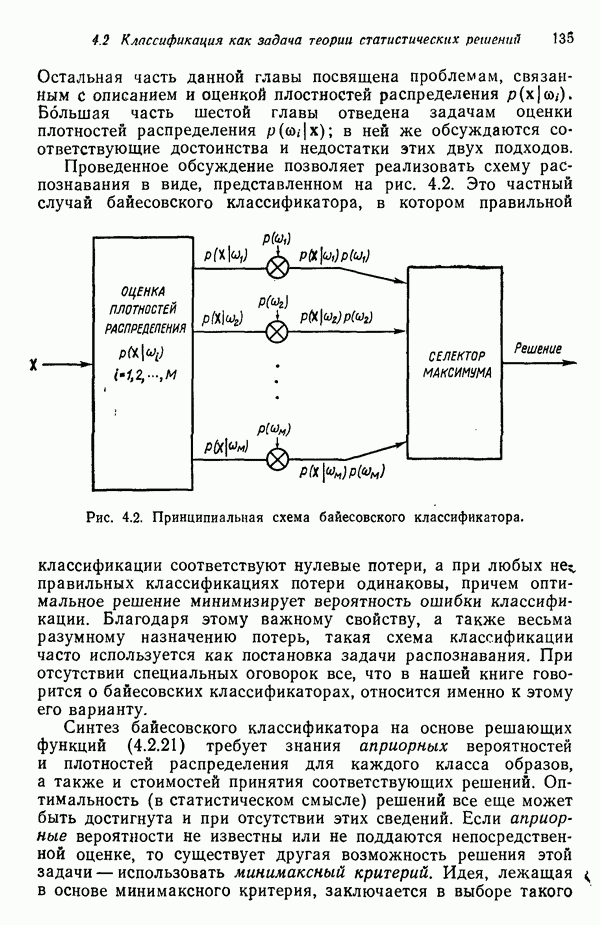
Так как все матрицы Соотношения среднеквадратичного расстояния и отношения правдоподобия Здесь устанавливается связь между отношением правдоподобия, рассмотренным в гл. 4, и среднеквадратичным расстоянием; для этого используются преобразования, описанные выше. Рассмотрим плотность нормального распределения
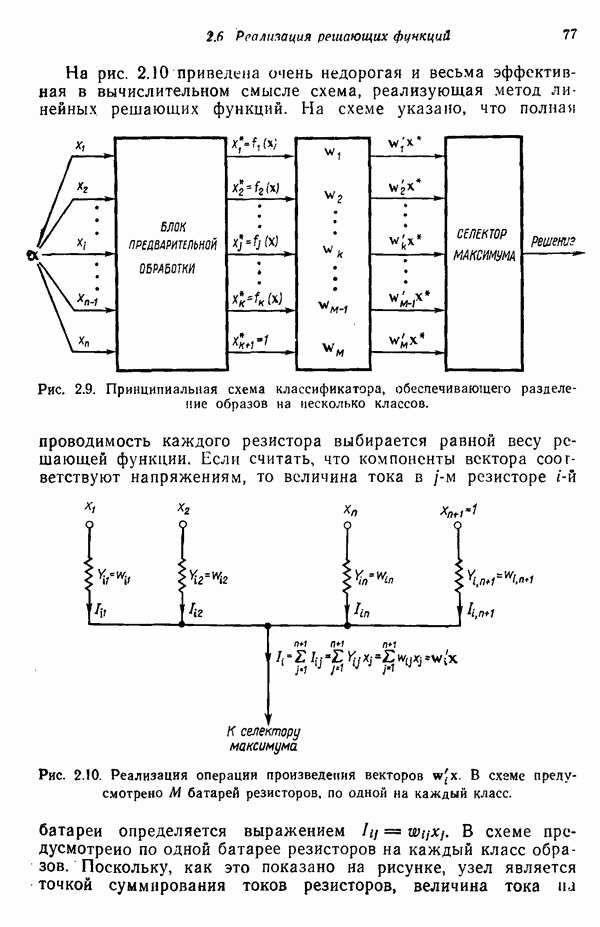
где С — ковариационная матрица, Для исследования ковариационной матрицы осуществляется ортонормирующее преобразование
где строками матрицы А служат нормированные собственные векторы ковариационной матрицы С. Это преобразование облегчает установление связи между отношением правдоподобия и среднеквадратичным расстоянием. После преобразования вектор математического ожидания и ковариационная матрица определяются как
и
соответственно. Пусть
На основе формул (7.3.27) и (7.3.28) получаем
и
Итак, плотность распределения в пространстве X определяется выражением
Это выражение для плотности распределения показывает, что кривыми равной вероятности являются эллипсоиды с центрами в точке т. Направления главных осей совпадают с собственными векторами ковариационной матрицы, а диаметры пропорциональны квадратному корню от соответствующих характеристических чисел или среднеквадратичных отклонений, поскольку
где Среднеквадратичное расстояние, отделяющее точку — произвольный образ
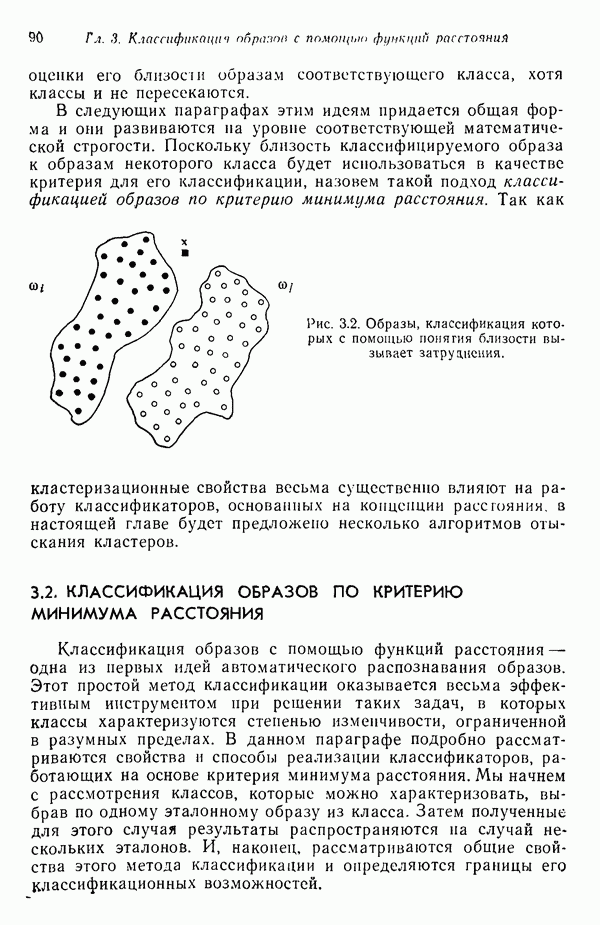
Усреднение проводится но всем матрицы становятся строками матрицы А:
поскольку А — ортоиормироваиная матрица и При выполнении преобразования кластеризации
среднеквадратичное расстояние принимает вид
Выбранная матрица Матрица
Следовательно, среднеквадратичное расстояние определяется выражением
которое после выполнения соответствующих операций можно представить в виде
Поскольку усреднение проводится по всем (7.3.39) можно привести к
где
то формула (7.3.40) превращается в
В таком случае, если опустить константу
и, аналогичным образом, среднеквадратичное расстояние для класса
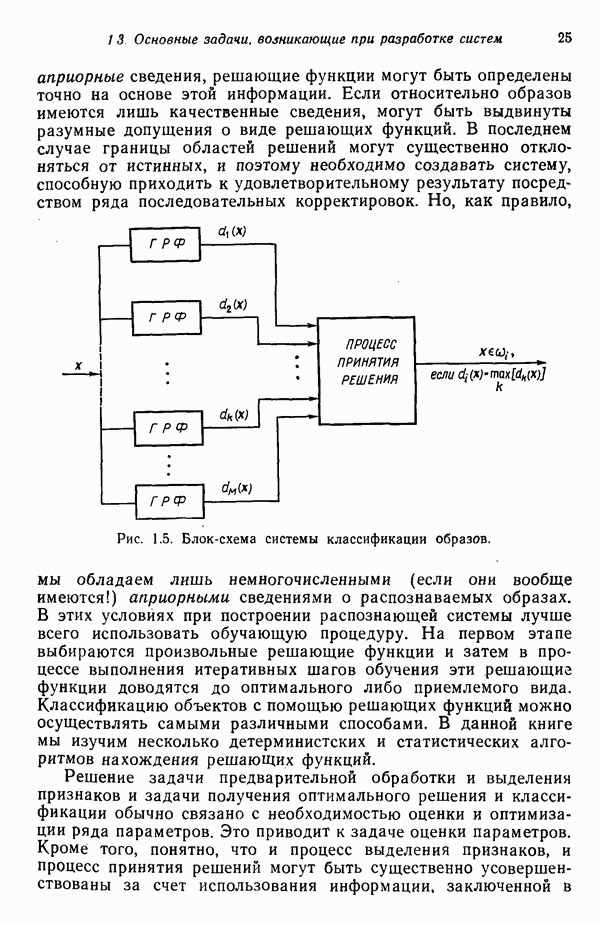
Исходя из принципа расстояния, решающее правило можно сформулировать в таком виде:
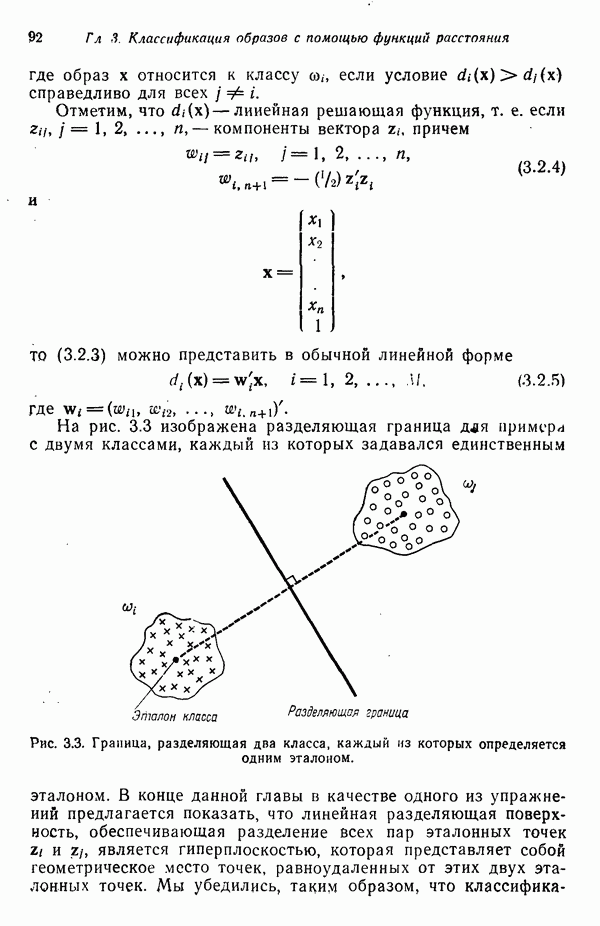
Для образов, подчиняющихся нормальному распределению, плотность распределения или функция правдоподобия для класса
После осуществления ортонормирующего преобразования выражение (7.3.45) принимает вид
Точно так же для класса
Если мы прологарифмируем и опустим постоянные члены, то получим решающие функции
и
В таком случае решающее правило, основанное на этих двух функциях, гласит, что На основе проведенного анализа можно сделать вывод о том, что аппроксимация заданных выборок наблюдений для классов образов плотностями нормального распределения эквивалентна нахождению среднеквадратичных расстояний для соответствующих классов после осуществления преобразования кластеризации над пространством измерений.
|
 |
Оглавление
|


















































































































































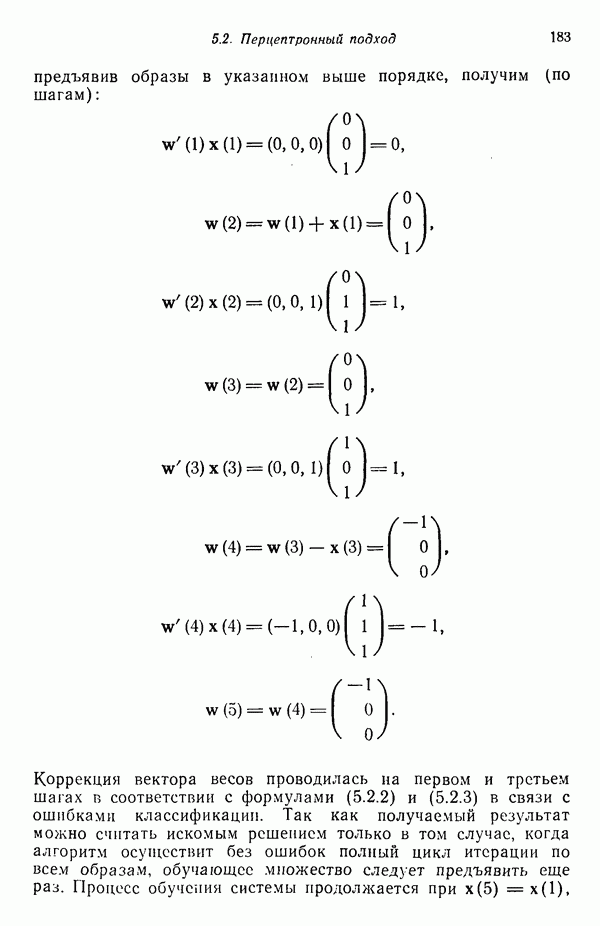






























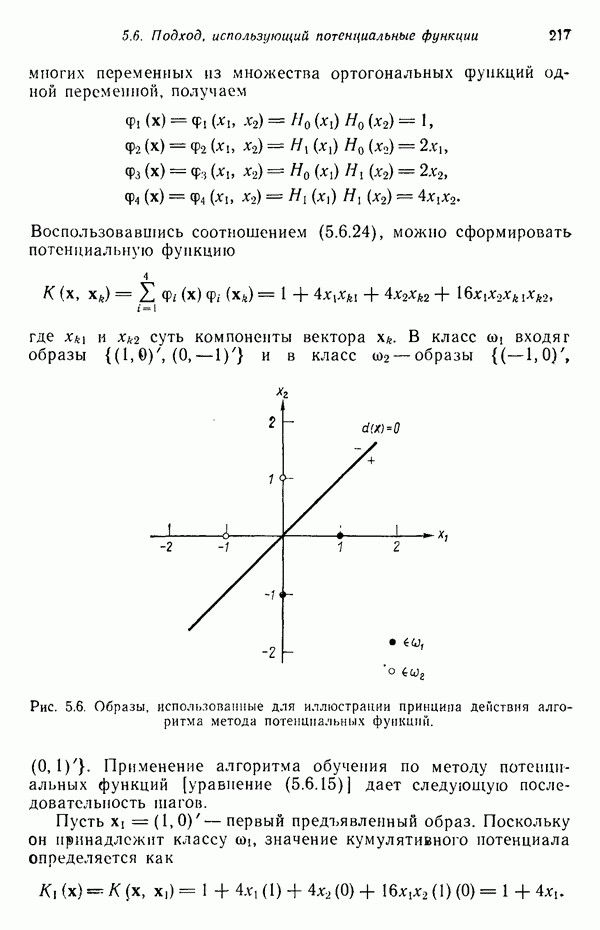


















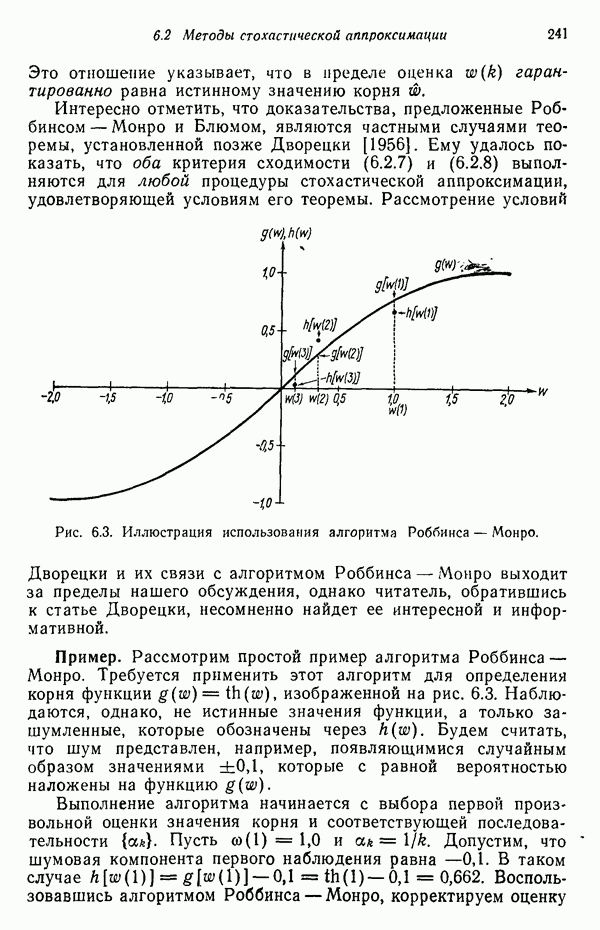








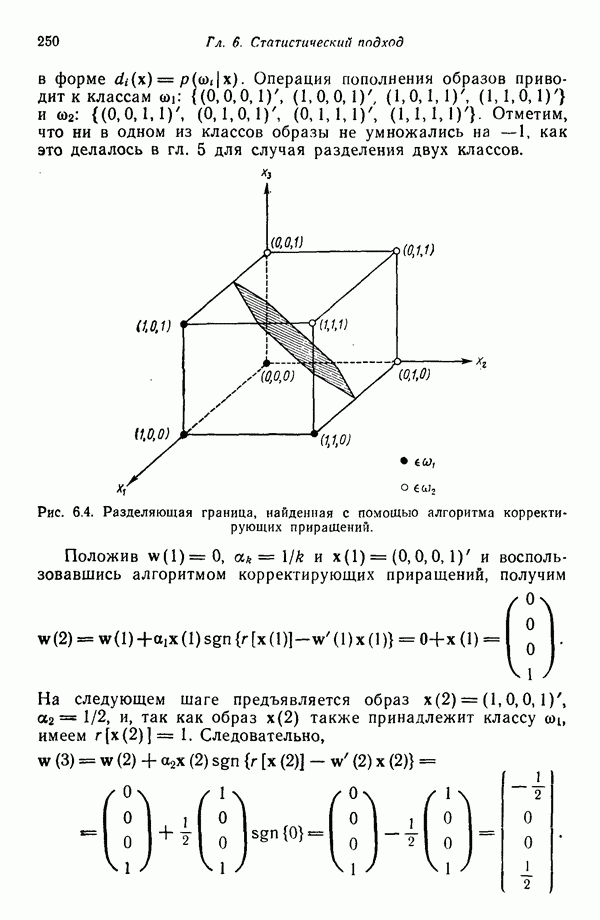


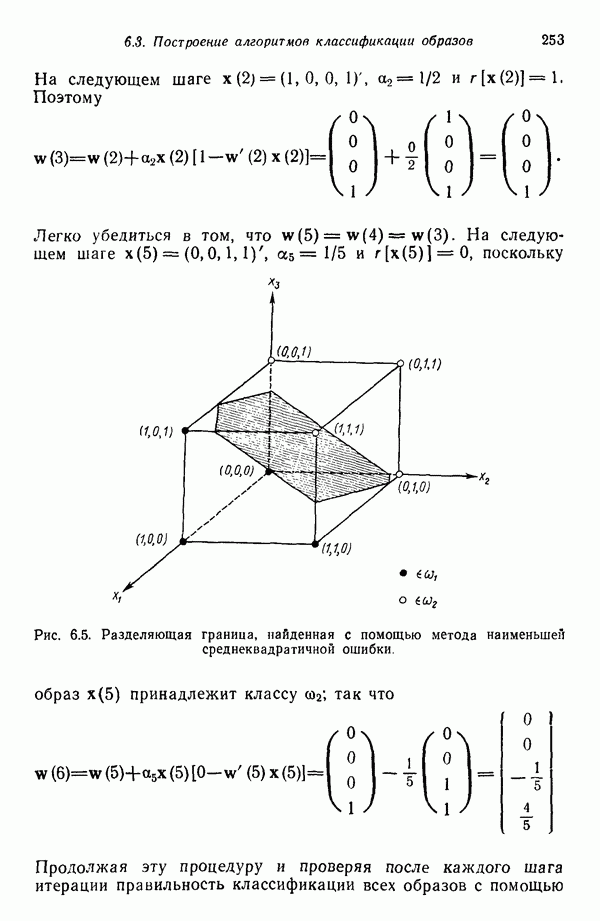































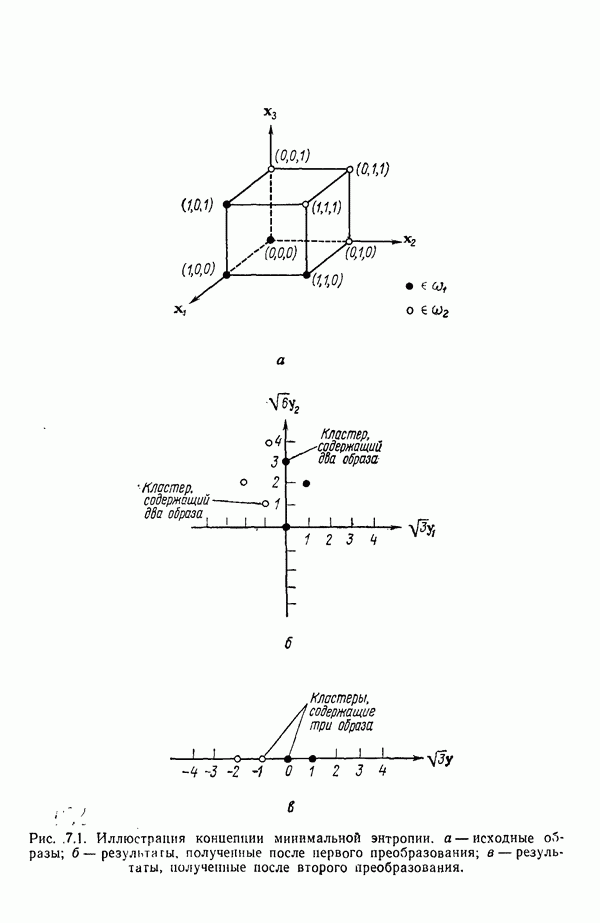
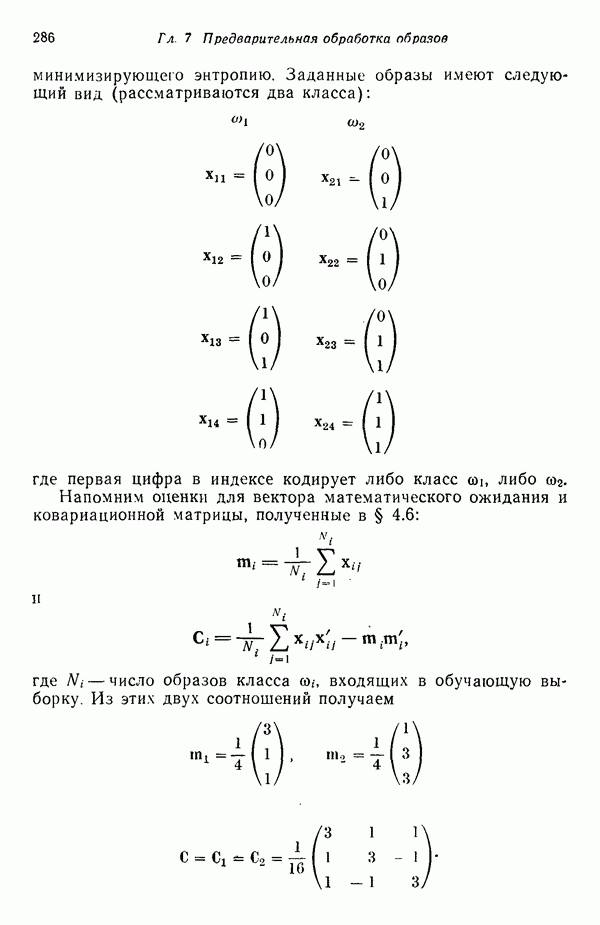







































































































 которые после применения к ним преобразования
которые после применения к ним преобразования  перешли в векторы
перешли в векторы  . В таком случае
. В таком случае


 суть весовые коэффициенты.
суть весовые коэффициенты.

 определяется как
определяется как

 является диагональной, т. е. ее ненулевые элементы расположены только на главной диагонали. В таком случае выражение для евклидова расстояния сводится к
является диагональной, т. е. ее ненулевые элементы расположены только на главной диагонали. В таком случае выражение для евклидова расстояния сводится к

 представляют весовые коэффициенты при признаках. Задача преобразования кластеризации заключается в том, чтобы определить весовые коэффициенты признаков
представляют весовые коэффициенты при признаках. Задача преобразования кластеризации заключается в том, чтобы определить весовые коэффициенты признаков  минимизирующие расстояние между
минимизирующие расстояние между  с учетом определенных ограничений, наложенных на коэффициенты тюкк.
с учетом определенных ограничений, наложенных на коэффициенты тюкк.

 — несмещенная оценка выборочной дисперсии компонент, соответствующих координатной оси
— несмещенная оценка выборочной дисперсии компонент, соответствующих координатной оси  При осуществлении процедуры минимизации будем рассматривать два случая.
При осуществлении процедуры минимизации будем рассматривать два случая.
 .
.
 при таком ограничении эквивалентна минимизации величины
при таком ограничении эквивалентна минимизации величины

 но весовому коэффициенту
но весовому коэффициенту  и приравняем ее нулю. После проведения соответствующих упрощений получим
и приравняем ее нулю. После проведения соответствующих упрощений получим

 — множитель Лагранжа, определяемый выражением
— множитель Лагранжа, определяемый выражением


 малы, если дисперсия
малы, если дисперсия  велика. Это означает, что при измерении расстояния малые веса следует приписывать признакам, которым свойственна значительная изменчивость. Если же, с другой стороны, дисперсия
велика. Это означает, что при измерении расстояния малые веса следует приписывать признакам, которым свойственна значительная изменчивость. Если же, с другой стороны, дисперсия  мала, то соответствующему признаку должен быть приписан существенный вес.
мала, то соответствующему признаку должен быть приписан существенный вес.
 определяет большую надежность
определяет большую надежность  измерения, а большая дисперсия а? меньшую надежность
измерения, а большая дисперсия а? меньшую надежность  измерения. Результатам более надежных измерений присваиваются большие веса.
измерения. Результатам более надежных измерений присваиваются большие веса.

 при таком ограничении эквивалентна минимизации выражения
при таком ограничении эквивалентна минимизации выражения

 и приравняв ее нулю, получим
и приравняв ее нулю, получим

 — множитель Лагранжа, определяемый выражением
— множитель Лагранжа, определяемый выражением


 измерения.
измерения.
 с учетом введенных выше ограничений. Если векторы образов переводятся из пространства X в пространство X с помощью преобразования
с учетом введенных выше ограничений. Если векторы образов переводятся из пространства X в пространство X с помощью преобразования


 — аналогичные ковариационные матрицы в пространствах X и X соответственно. Пусть
— аналогичные ковариационные матрицы в пространствах X и X соответственно. Пусть  — вектор математического ожидания точек, отвечающих образам в пространстве X, и
— вектор математического ожидания точек, отвечающих образам в пространстве X, и  — векторы математического ожидания в пространствах
— векторы математического ожидания в пространствах  соответственно. В таком случае
соответственно. В таком случае




 .
.



 выбирается модальная матрица матрицы С, т. е. столбцами матрицы
выбирается модальная матрица матрицы С, т. е. столбцами матрицы  являются собственные векторы матрицы С либо строками матрицы А являются собственные векторы матрицы С. Итак, строками матрицы А являются собственные векторы матрицы
являются собственные векторы матрицы С либо строками матрицы А являются собственные векторы матрицы С. Итак, строками матрицы А являются собственные векторы матрицы  Это преобразование, которое является скорее конгруэнтным, нежели преобразованием подобия, не позволяет легко выразить собственные векторы матрицы
Это преобразование, которое является скорее конгруэнтным, нежели преобразованием подобия, не позволяет легко выразить собственные векторы матрицы  через собственные векторы матрицы С.
через собственные векторы матрицы С.
 нормированные собственные векторы матрицы С и
нормированные собственные векторы матрицы С и  — соответствующие характеристические числа. Тогда
— соответствующие характеристические числа. Тогда



 . В таком случае
. В таком случае


 при
при  . Можно показать, что
. Можно показать, что

 с собственными векторами исходной ковариационной матрицы С. Можно, однако, найти простое выражение, связывающее строки матрицы А с элементами исходной ковариационной матрицы, если обратить последовательность операций
с собственными векторами исходной ковариационной матрицы С. Можно, однако, найти простое выражение, связывающее строки матрицы А с элементами исходной ковариационной матрицы, если обратить последовательность операций  Выбирается ортонормированная матрица А, строки которой являются собственными векторами ковариационной матрицы С. Матрица А преобразует матрицу С в диагональную матрицу С. Затем от матрицы преобразования
Выбирается ортонормированная матрица А, строки которой являются собственными векторами ковариационной матрицы С. Матрица А преобразует матрицу С в диагональную матрицу С. Затем от матрицы преобразования  требуется, чтобы она была диагональной и минимизировала внутримножественное расстояние в пространстве X с учетом заданного ограничения. Если выбрано ограничение
требуется, чтобы она была диагональной и минимизировала внутримножественное расстояние в пространстве X с учетом заданного ограничения. Если выбрано ограничение


 элементы ковариационной матрицы С, приведенной к диагональному виду:
элементы ковариационной матрицы С, приведенной к диагональному виду:


 и
и  — диагональные, а произведением диагональных матриц всегда будет диагональная матрица, то очевидно, что, как и требовалось, матрица С — диагональная.
— диагональные, а произведением диагональных матриц всегда будет диагональная матрица, то очевидно, что, как и требовалось, матрица С — диагональная.

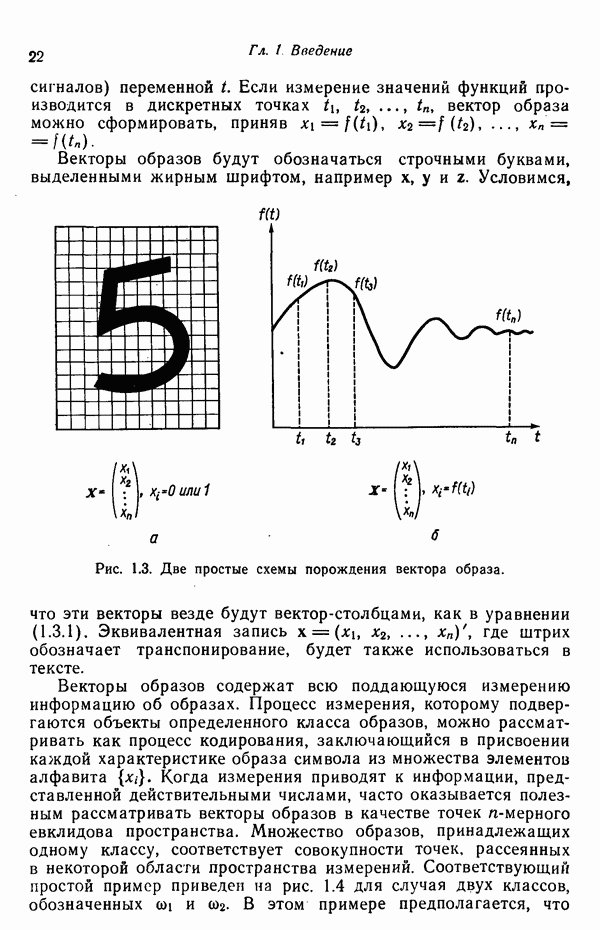
 — вектор математического ожидания для класса образов в пространстве X. Отметим, что кривые равной вероятности соответствуют тем значениям
— вектор математического ожидания для класса образов в пространстве X. Отметим, что кривые равной вероятности соответствуют тем значениям  при которых значение аргумента
при которых значение аргумента  показательной функции остается постоянным.
показательной функции остается постоянным.



 собственные векторы матрицы
собственные векторы матрицы  — соответствующие характеристические числа. В таком случае, согласно (7.3.27), имеем
— соответствующие характеристические числа. В таком случае, согласно (7.3.27), имеем




 Это становится более очевидным после разложения показательной функции:
Это становится более очевидным после разложения показательной функции:

 — координата вектора
— координата вектора  соответствующая
соответствующая  собственному вектору,
собственному вектору,  — среднее всех значений координат, соответствующих этому собственному вектору
— среднее всех значений координат, соответствующих этому собственному вектору
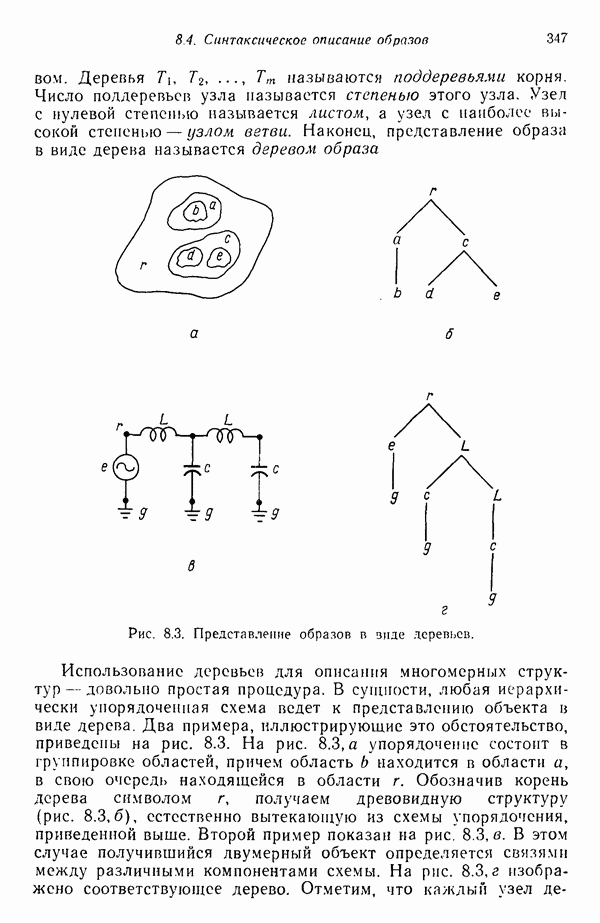
 — от множества точек (образов)
— от множества точек (образов)  определяется как
определяется как

 точкам, входящим в заданное множество. В первую очередь осуществляется преобразование оргонормировки, причем собственные векторы ковариационной
точкам, входящим в заданное множество. В первую очередь осуществляется преобразование оргонормировки, причем собственные векторы ковариационной

 Расстояние при выполнении этого преобразования остается неизменным.
Расстояние при выполнении этого преобразования остается неизменным.


 является диагональной, и ее элементы равны величинам, обратным среднеквадратичным отклонениям координат образов множества
является диагональной, и ее элементы равны величинам, обратным среднеквадратичным отклонениям координат образов множества  соответствующих отдельным собственным векторам. Было показано, что преобразование такого вида минимизирует внутреннее расстояние множества образов.
соответствующих отдельным собственным векторам. Было показано, что преобразование такого вида минимизирует внутреннее расстояние множества образов.
 — диагональная, и ее элементы равны величинам, обратным дисперсиям координат образов множества
— диагональная, и ее элементы равны величинам, обратным дисперсиям координат образов множества  Так как эти дисперсии суть соответствующие характеристические числа, т. е.
Так как эти дисперсии суть соответствующие характеристические числа, т. е.  , получаем
, получаем



 точкам множества образов, оно не зависит от процесса суммирования. Поэтому
точкам множества образов, оно не зависит от процесса суммирования. Поэтому




 среднеквадратичное расстояние для класса
среднеквадратичное расстояние для класса  определяется выражением
определяется выражением

 — выражением
— выражением

 в том и только том случае, если
в том и только том случае, если

 определяется как
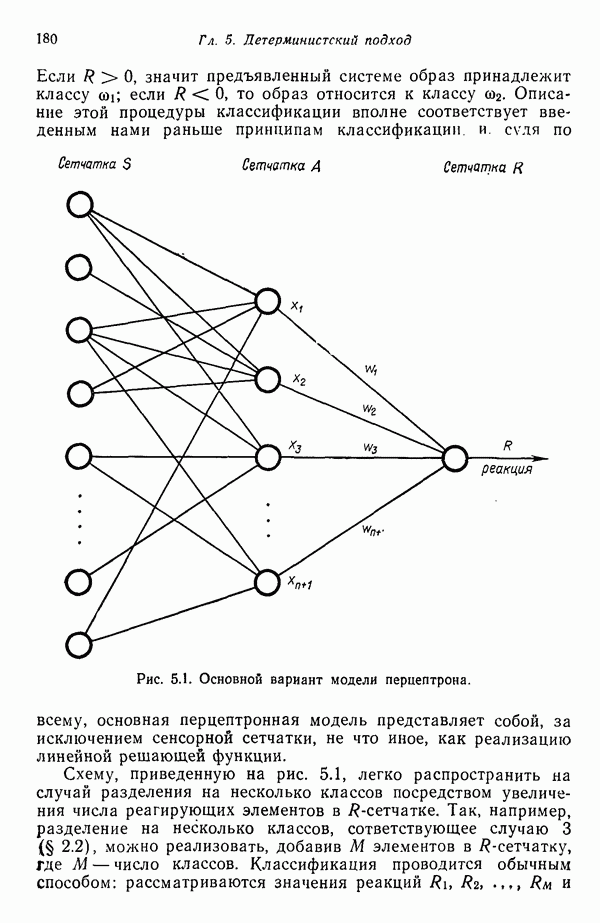
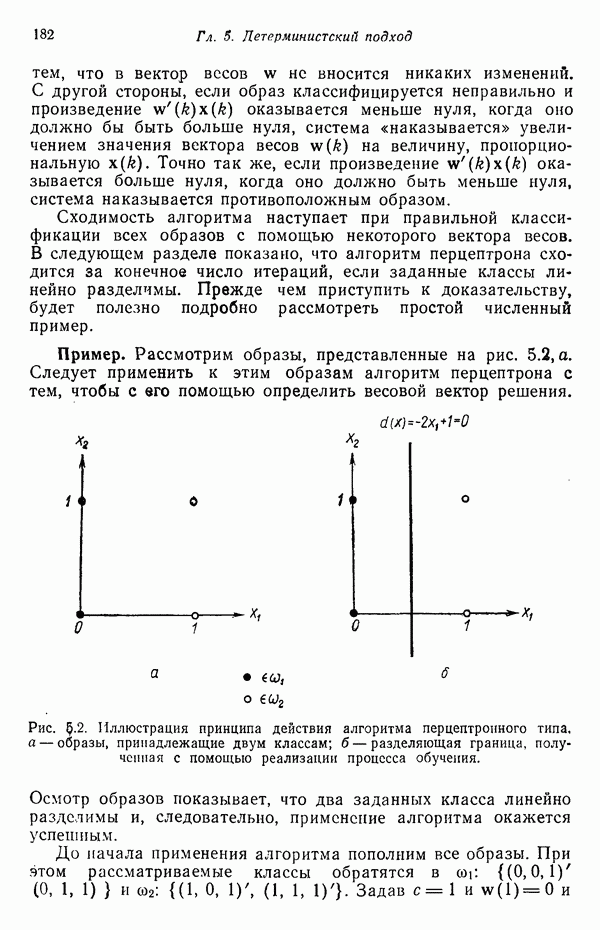
определяется как


 находим плотность распределения
находим плотность распределения



 тогда и только тогда, когда
тогда и только тогда, когда  , где
, где  — пороговая величина.
— пороговая величина.