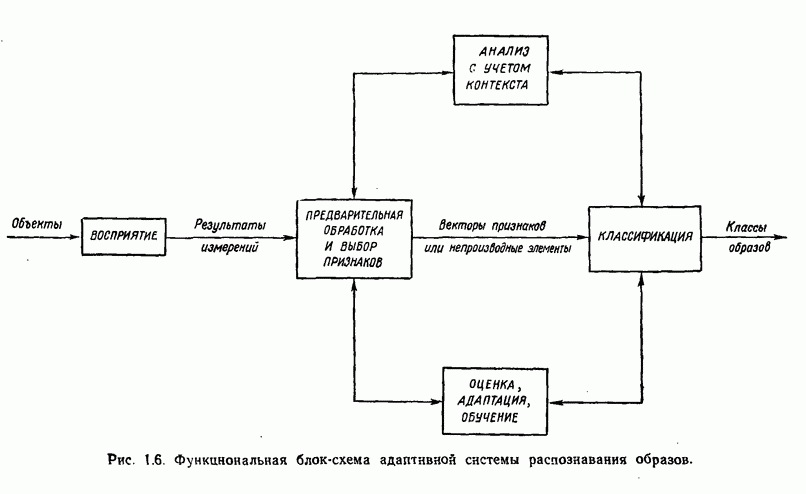
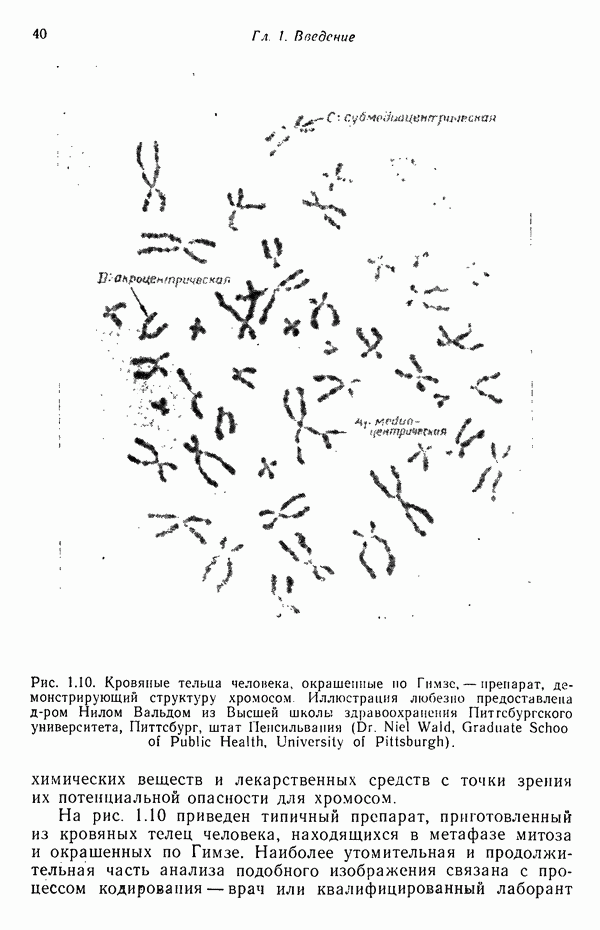
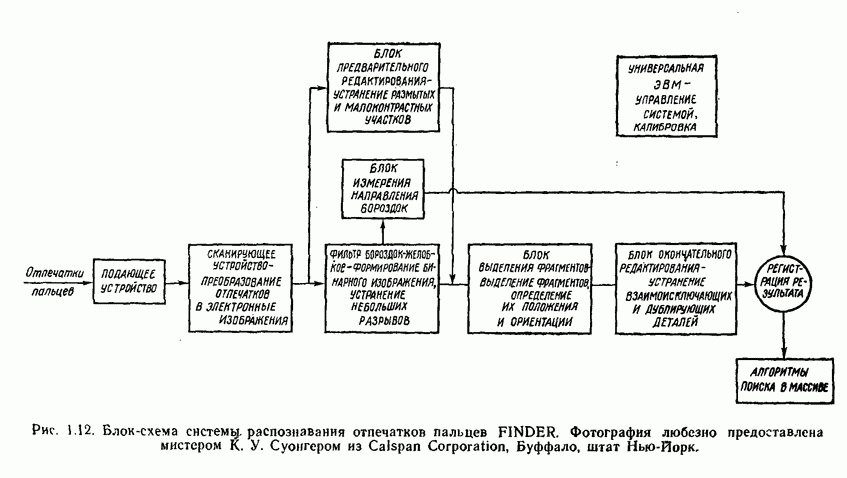
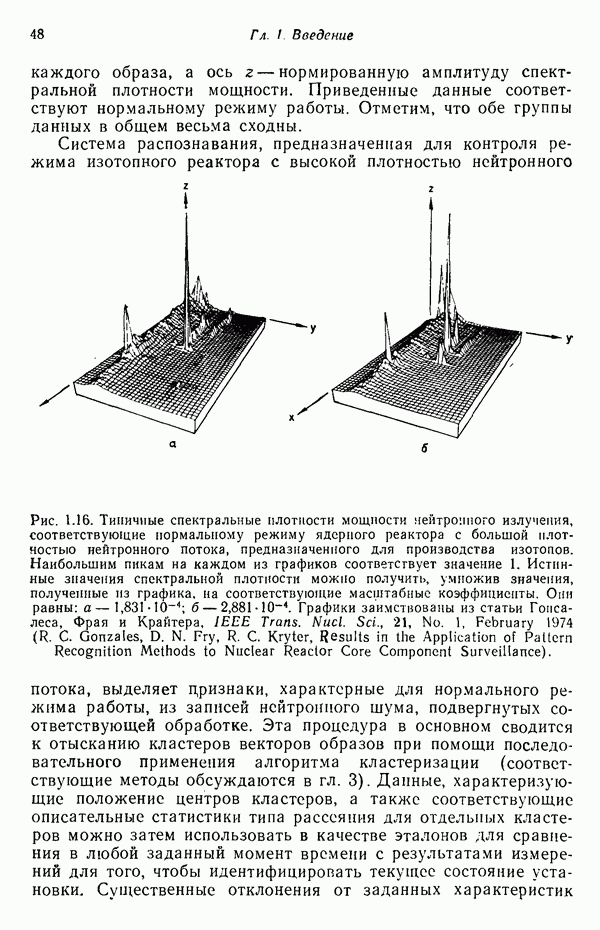
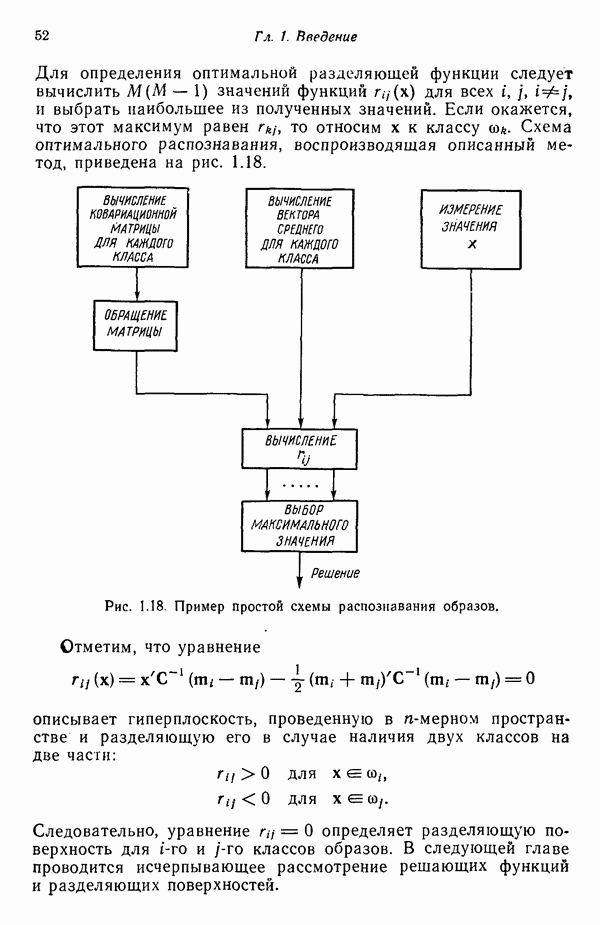
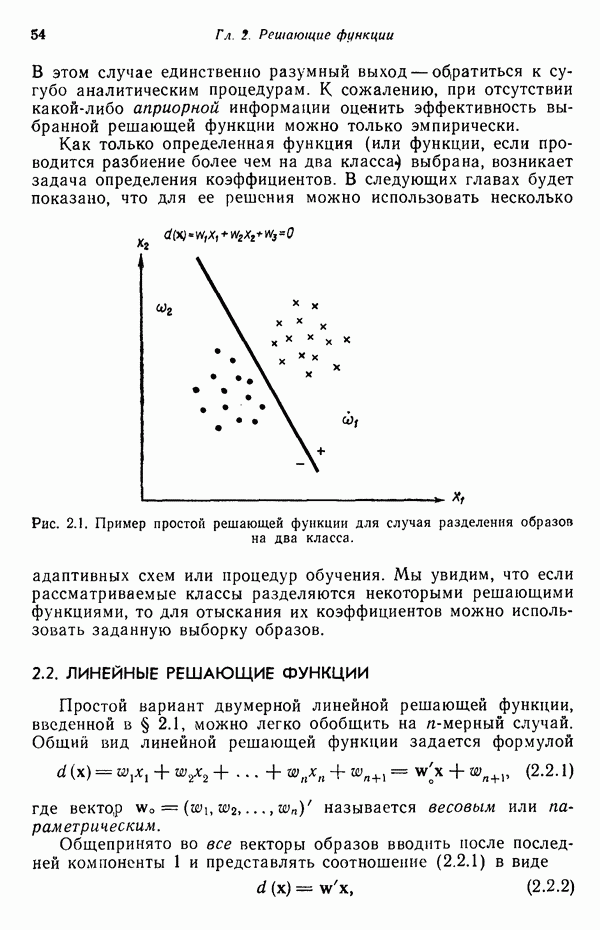
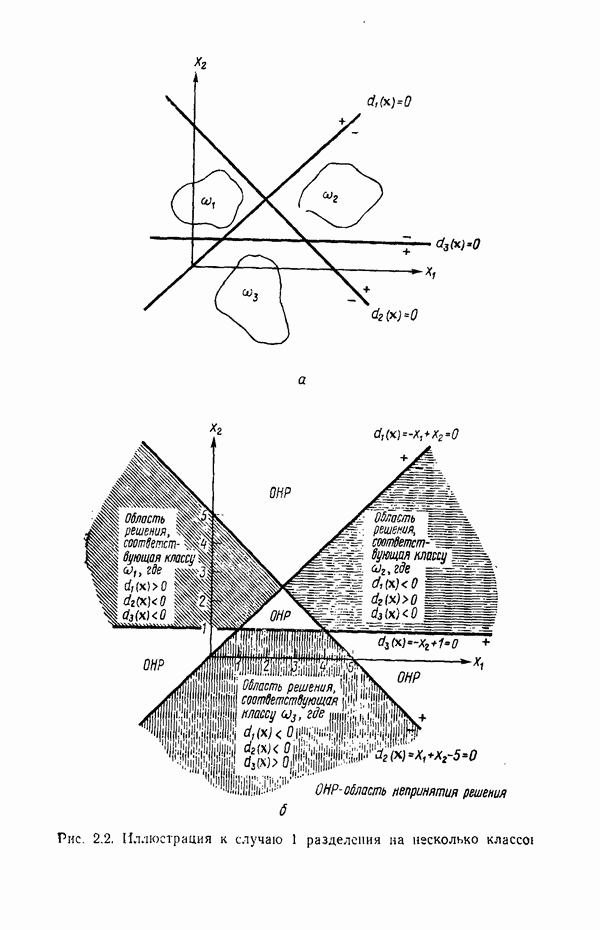
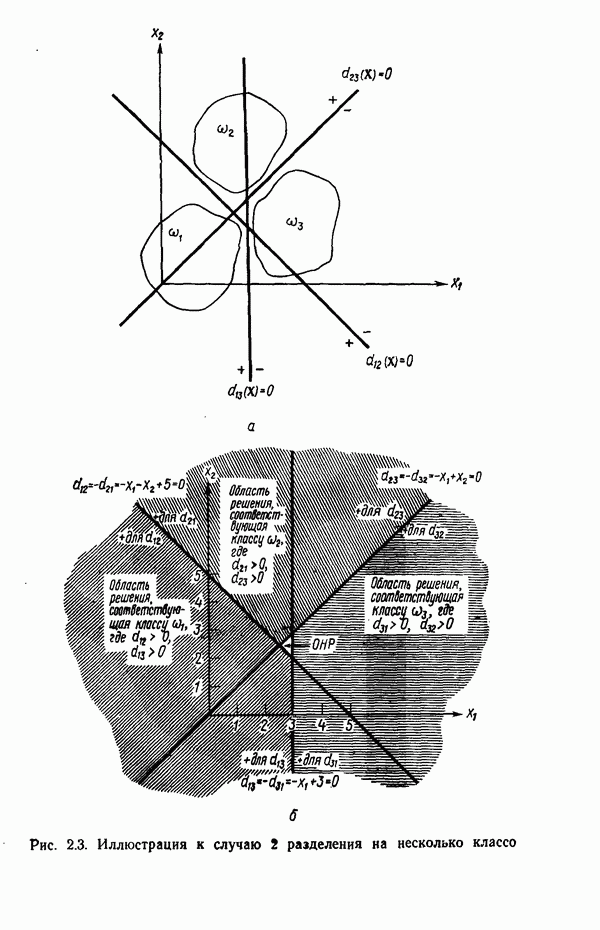
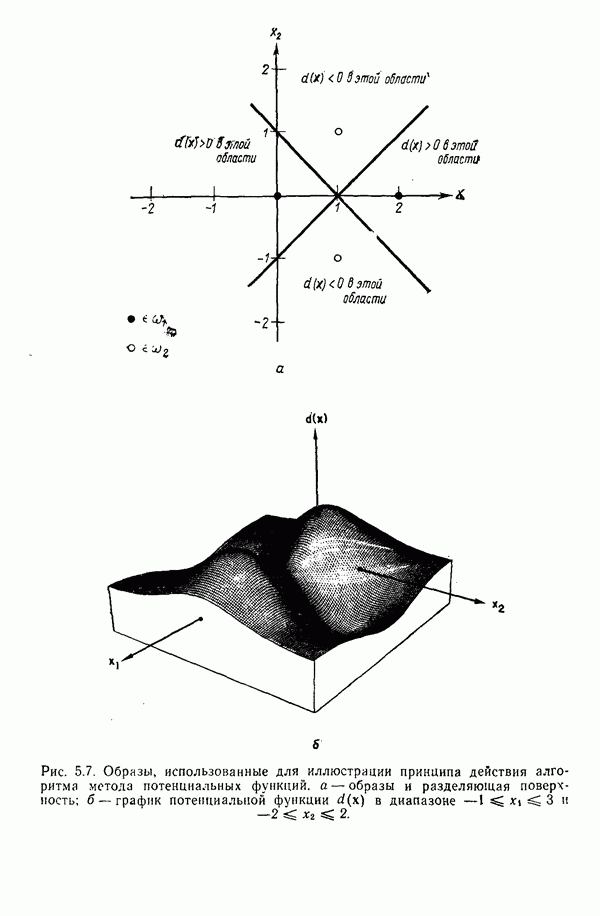
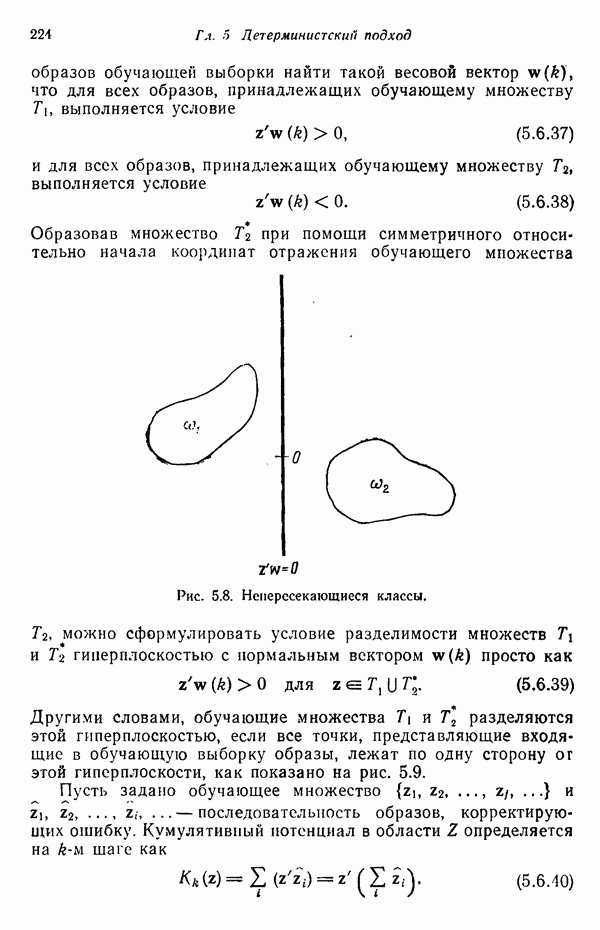
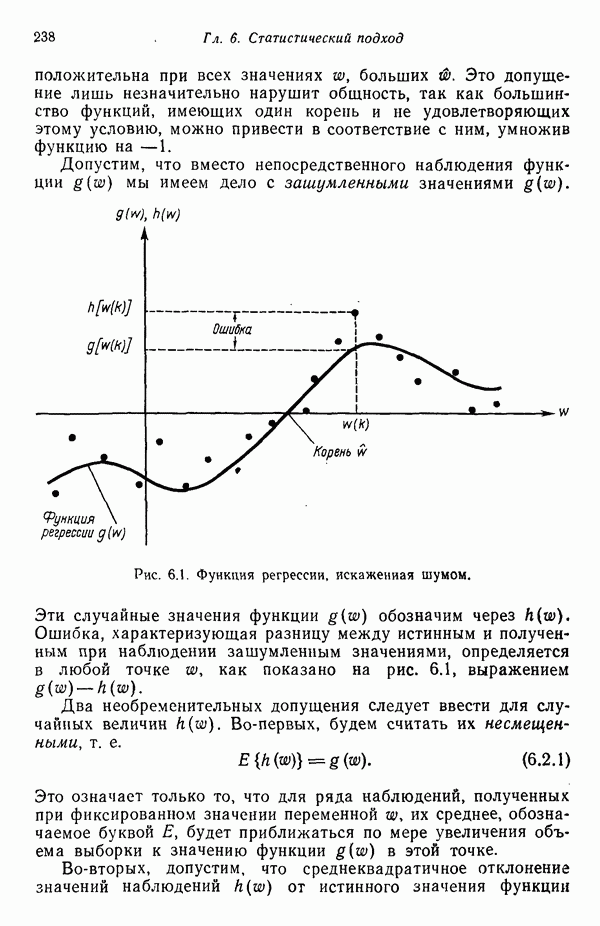
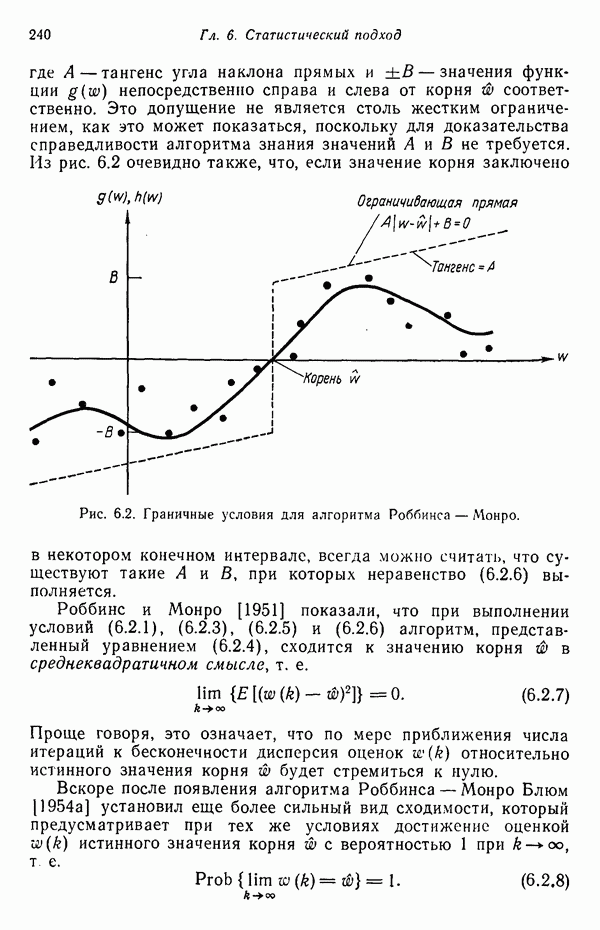
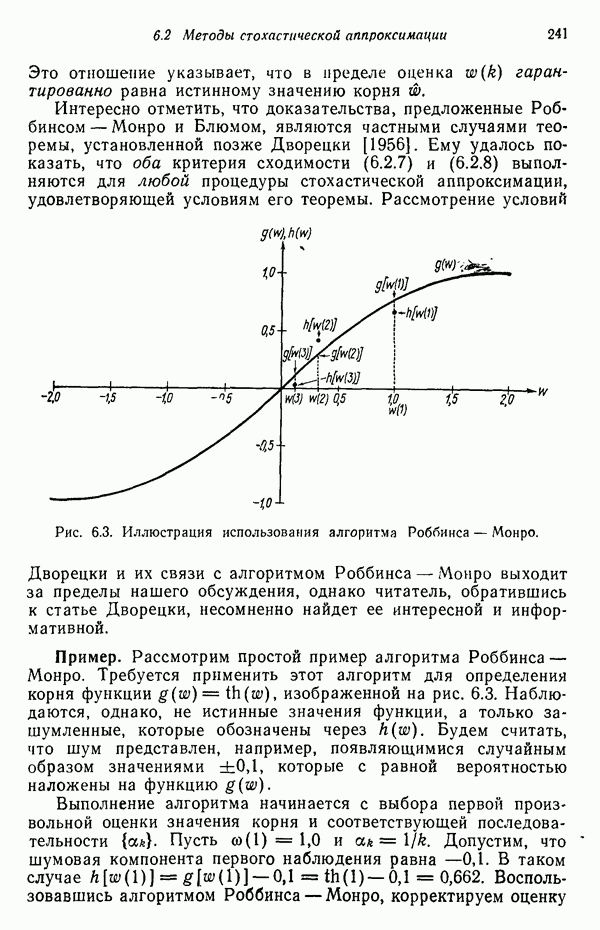
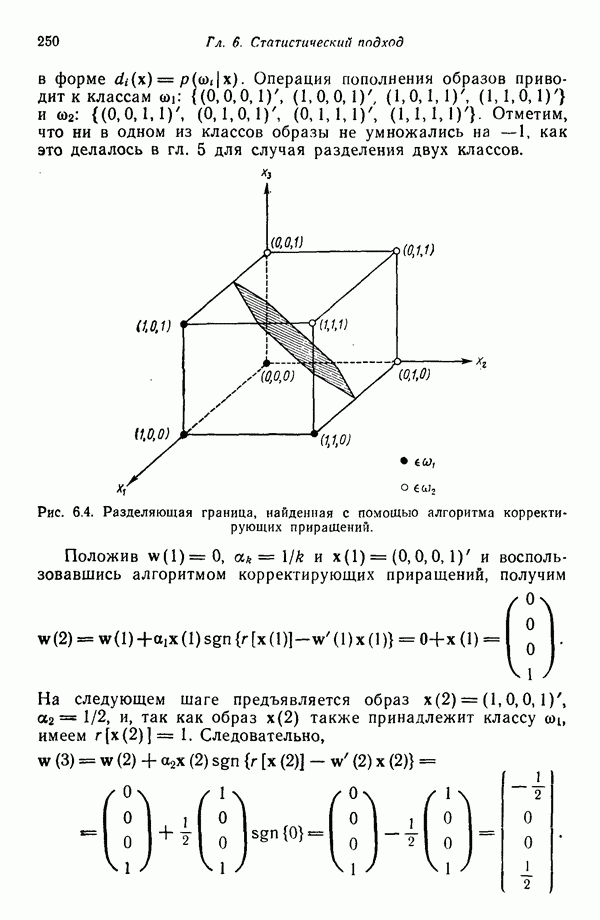
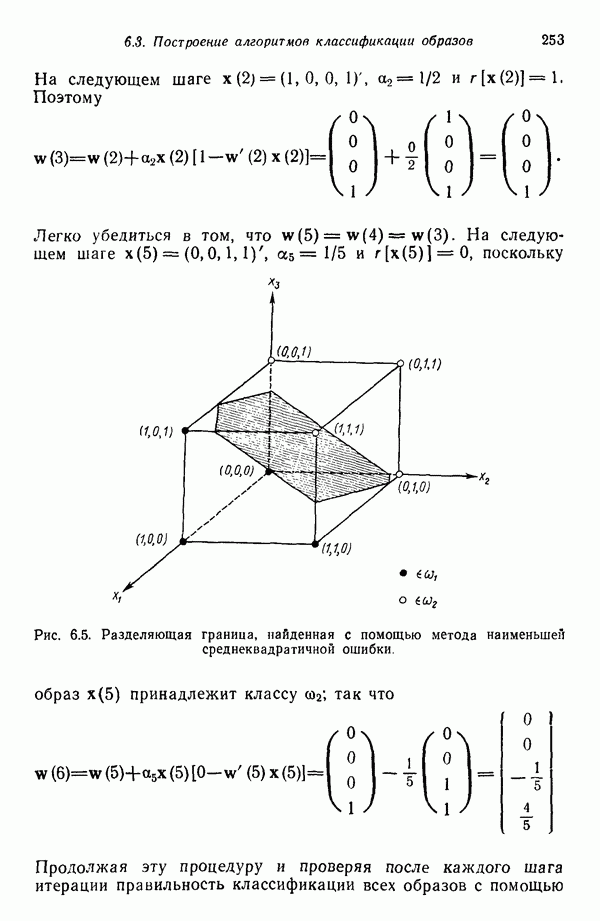
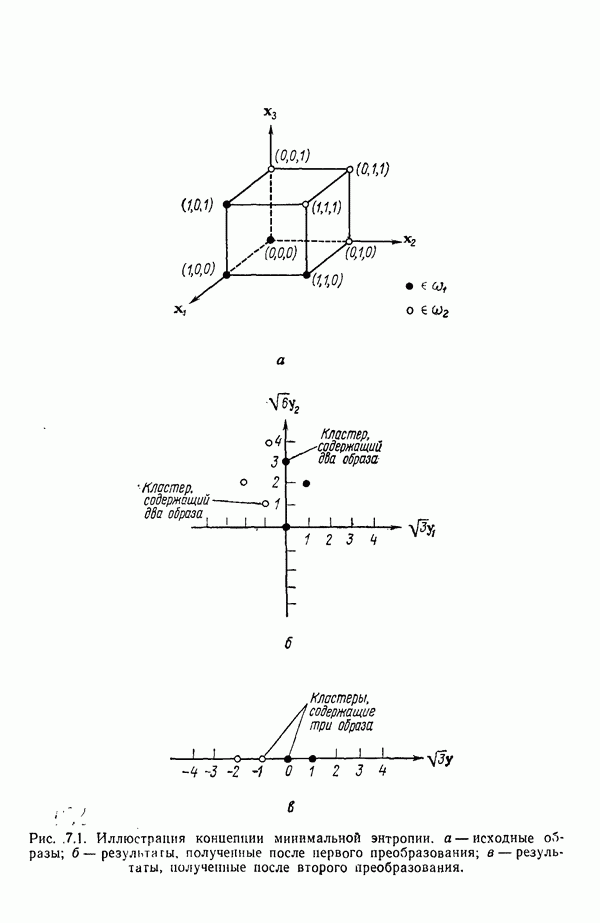
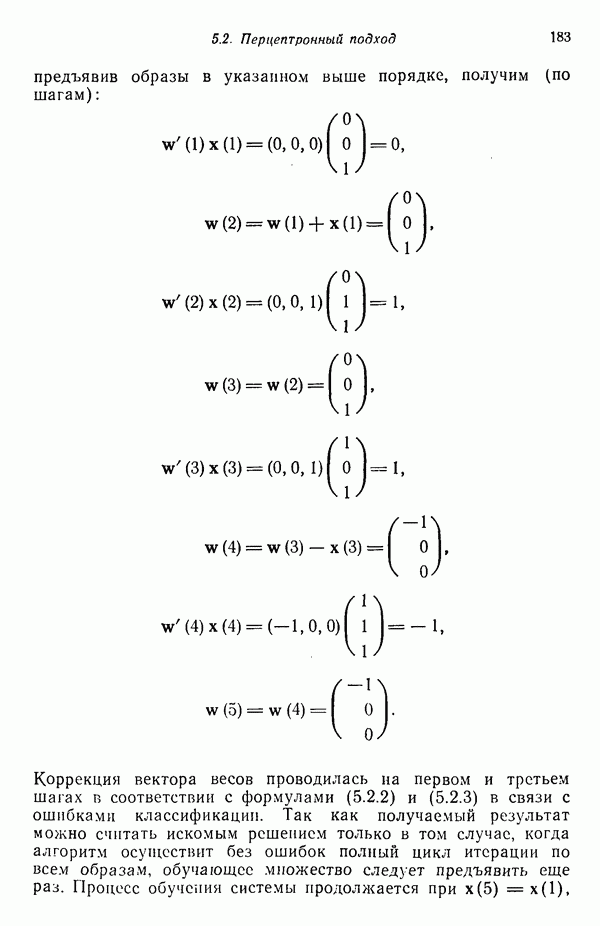Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
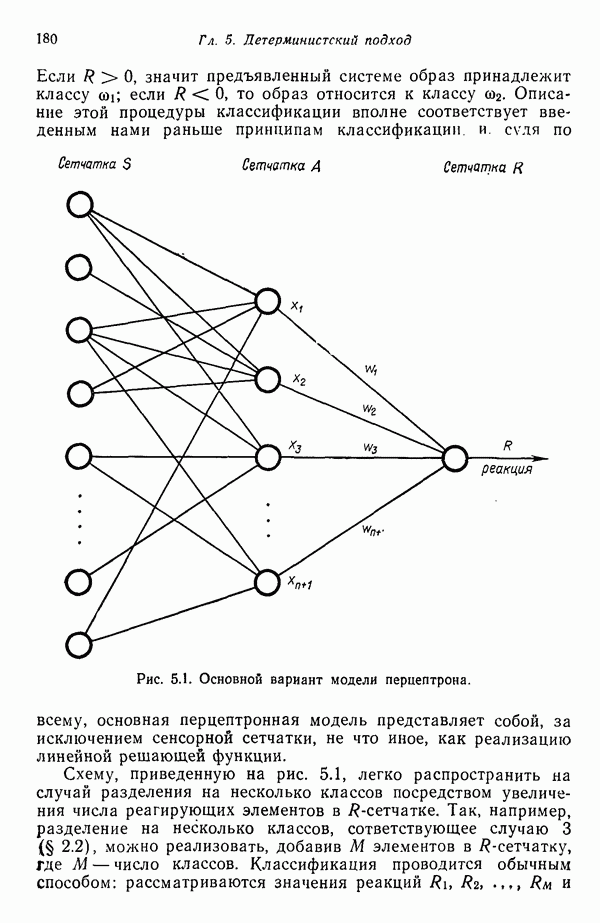
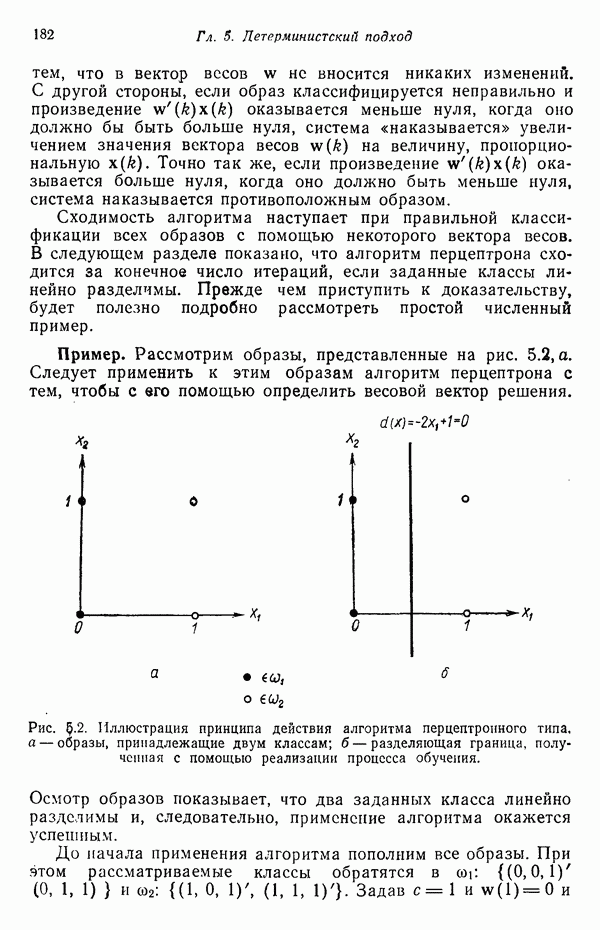
6.3. ПОСТРОЕНИЕ АЛГОРИТМОВ КЛАССИФИКАЦИИ ОБРАЗОВ
Этот параграф воспроизводит структуру § 5.3, в котором описывалось построение детерминистских алгоритмов. В п. 6.3.1 метод стохастической аппроксимации вводится как общий подход к построению статистических алгоритмов классификации образов. Строится общий алгоритм, аналогичный градиентному алгоритму, определенному уравнением (5.3.3), и затем проводится сопоставление двух этих алгоритмов.
На основе полученных в п. 6.3.1 результатов в п. 6.3.2 строится статистический алгоритм, напоминающий алгоритм перцептрона. Подобным же образом в п. 6.3.3 выводится статистический алгоритм, обеспечивающий наименьшую среднеквадратичную ошибку. Как и в гл. 5, построение статистических алгоритмов на основе развитых ниже общих методов ограничивается исключительно возможностью задать разумные функции критерия.
6.3.1. Оценка оптимума решающих функций методами стохастической аппроксимации
Как указывалось в § 6.1, ведущей темой данной главы является оценка на основе обучающей выборки образов плотностей распределения  для получения байесовских решающих функций
для получения байесовских решающих функций  . Воспользуемся
. Воспользуемся
разложением этих функций по множеству известных базисных функций согласно формуле

где  — вектор весов
— вектор весов  класса образов и
класса образов и  Это разложение идентично использованному при определении обобщенных решающих функций (формула (2.3.1)). Таким образом, на основе представлений, развитых в § 2.3, можно без потери общности дальнейшее обсуждение посвятить линейным аппроксимациям вида
Это разложение идентично использованному при определении обобщенных решающих функций (формула (2.3.1)). Таким образом, на основе представлений, развитых в § 2.3, можно без потери общности дальнейшее обсуждение посвятить линейным аппроксимациям вида

где  .
.
В качестве идеальной ситуации хотелось бы наблюдать значения плотностей распределения  в процессе обучения или оценки. К сожалению, эта плотность распределения не поддается ни наблюдениям, ни измерениям. Единственная информация, которая доступна в процессе обучения, — это принадлежность каждого вектора образа определенному классу. Для того чтобы, учитывая это обстоятельство, сформулировать задачу в виде, пригодном для использования методов из § 6.2, воспользуемся неким искусственным преобразованием. Определим для каждого класса случайную переменную классификации
в процессе обучения или оценки. К сожалению, эта плотность распределения не поддается ни наблюдениям, ни измерениям. Единственная информация, которая доступна в процессе обучения, — это принадлежность каждого вектора образа определенному классу. Для того чтобы, учитывая это обстоятельство, сформулировать задачу в виде, пригодном для использования методов из § 6.2, воспользуемся неким искусственным преобразованием. Определим для каждого класса случайную переменную классификации  обладающую следующим свойством:
обладающую следующим свойством:

Значения 1 и 0 для переменной  выбраны произвольно. Можно использовать и другие значения, но обязательно различающиеся.
выбраны произвольно. Можно использовать и другие значения, но обязательно различающиеся.
Хотя в процессе обучения нельзя наблюдать значения плотностей распределения  значения переменной классификации
значения переменной классификации  при реализации этого этапа нам известны, так как известно, какому классу принадлежит каждый образ. Следовательно, поскольку знание плотностей распределения
при реализации этого этапа нам известны, так как известно, какому классу принадлежит каждый образ. Следовательно, поскольку знание плотностей распределения  нам было необходимо исключительно для осуществления классификации, переменную классификации
нам было необходимо исключительно для осуществления классификации, переменную классификации  будем считать зашумленным результатом наблюдения значения плотности распределения
будем считать зашумленным результатом наблюдения значения плотности распределения  , т. е.
, т. е.

где  — шум, математическое ожидание которого предполагается равным нулю, и, следовательно,
— шум, математическое ожидание которого предполагается равным нулю, и, следовательно, 
Это допущение нельзя считать необоснованным, так как в противном случае шум легко привести к соответствию этому условию обычной нормировкой. При другой интерпретации случайной переменной классификации  она рассматривается в качестве аппроксимации плотности распределения
она рассматривается в качестве аппроксимации плотности распределения  в том смысле, что
в том смысле, что  где символ
где символ  — обозначает «не класс
— обозначает «не класс  ». Мы намереваемся найти аппроксимацию плотности распределения
». Мы намереваемся найти аппроксимацию плотности распределения  в виде
в виде  на основе наблюдения значений случайной переменной классификации
на основе наблюдения значений случайной переменной классификации 
В гл. 5 использовались детерминистские функции критерия, которые подставлялись в общее выражение градиентного алгоритма с тем, чтобы получить алгоритмы классификации. Здесь мы пойдем по тому же пути, за исключением того, что функции критерия — статистические, а универсальный алгоритм — алгоритм Роббинса — Монро. Прежде чем перейти к делу, рассмотрим функцию критерия  Минимум этой функции равен нулю, он достигается при
Минимум этой функции равен нулю, он достигается при  Минимум функции критерия, другими словами, соответствует правильной классификации образа
Минимум функции критерия, другими словами, соответствует правильной классификации образа  Последнее следует из того факта, что значения переменной классификации
Последнее следует из того факта, что значения переменной классификации  известны на этапе обучения. Следовательно, если для всех образов обучающего множества справедливо равенство
известны на этапе обучения. Следовательно, если для всех образов обучающего множества справедливо равенство  то вектор весов
то вектор весов  обеспечивает правильную классификацию всех этих образов.
обеспечивает правильную классификацию всех этих образов.
V Поскольку считается, что  функцию критерия можно представить также как
функцию критерия можно представить также как  . Это соотношение ясно указывает, что отыскание минимума функции критерия
. Это соотношение ясно указывает, что отыскание минимума функции критерия  эквивалентно средней аппроксимации плотности распределения
эквивалентно средней аппроксимации плотности распределения  Другими словами, аппроксимация такова, что математическое ожидание абсолютной величины разности плотности распределения и ее аппроксимации равно нулю.
Другими словами, аппроксимация такова, что математическое ожидание абсолютной величины разности плотности распределения и ее аппроксимации равно нулю.
Для того чтобы определить минимум функции, надо найти корень ее производной. В данном случае нас интересует минимум функции критерия  -математического ожидания некоторой другой функции
-математического ожидания некоторой другой функции  , т. е.
, т. е.

Взяв частную производную от функции критерия  по вектору весов
по вектору весов  получим
получим

Воспользовавшись алгоритмом Роббинса — Монро, можно теперь получить последовательность оценок корня производной  , положив
, положив

Использование соотношения (6.2.9) дает

где начальный вектор  выбирается произвольно.
выбирается произвольно.
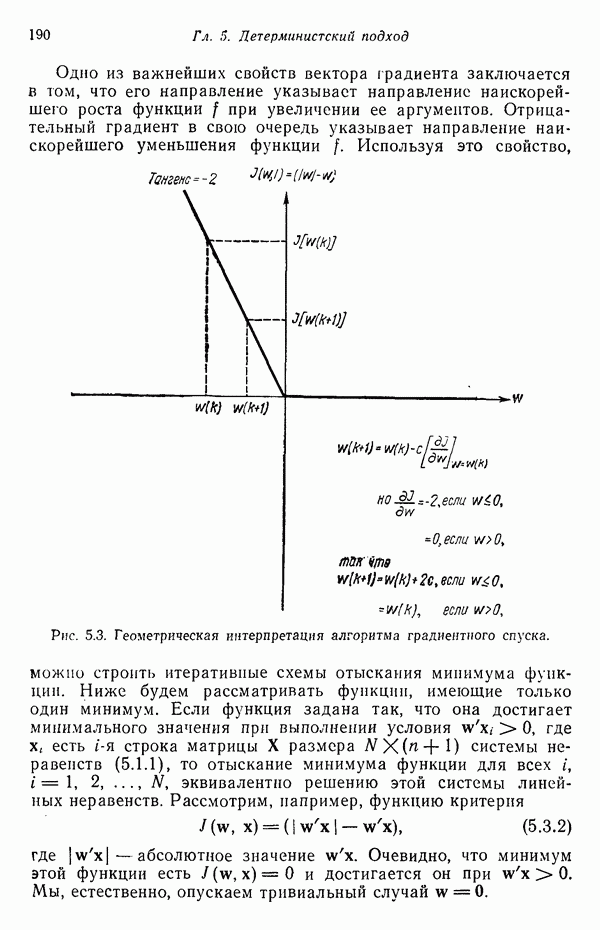
Интересно сравнить полученный результат с записью детерминистского градиентного алгоритма в общем виде:

Эти два уравнения имеют несколько явных отличий. Они связаны с характером корректирующих коэффициентов  и
и  с видом частных производных. Отметим, что в детерминистском алгоритме функция критерия
с видом частных производных. Отметим, что в детерминистском алгоритме функция критерия  присутствует нет посредственно. Это объясняется тем обстоятельством, что в детерминистском случае функция критерия
присутствует нет посредственно. Это объясняется тем обстоятельством, что в детерминистском случае функция критерия  поддается непосредственному наблюдению. Поскольку в статистическом случае функцию критерия
поддается непосредственному наблюдению. Поскольку в статистическом случае функцию критерия  явно наблюдать нельзя, в алгоритме (6.3.8) используется наблюдаемая реально функция
явно наблюдать нельзя, в алгоритме (6.3.8) используется наблюдаемая реально функция  . Другое существенное отличие определяется тем фактом, что статистический алгоритм будет искать аппроксимацию байесовского классификатора, в то время как его детерминистский аналог не обладает этой возможностью. Стоит также подчеркнуть, что статистический алгоритм сходится к аппроксимации независимо от наличия или отсутствия строгой разделимости классов, в то время как детерминистский алгоритм в случае неразделимости просто зацикливается. Ценой, которую приходится платить за гарантированную сходимость статистического алгоритма, является, несомненно, медлительность, проявляемая им обычно в процессе достижения этой сходимости.
. Другое существенное отличие определяется тем фактом, что статистический алгоритм будет искать аппроксимацию байесовского классификатора, в то время как его детерминистский аналог не обладает этой возможностью. Стоит также подчеркнуть, что статистический алгоритм сходится к аппроксимации независимо от наличия или отсутствия строгой разделимости классов, в то время как детерминистский алгоритм в случае неразделимости просто зацикливается. Ценой, которую приходится платить за гарантированную сходимость статистического алгоритма, является, несомненно, медлительность, проявляемая им обычно в процессе достижения этой сходимости.
Оставшуюся часть главы посвятим использованию алгоритма (6.3.8) для построения алгоритмов классификации образов. Читателю рекомендуется тщательно сопоставить этот материал с соответствующим анализом в гл. 5.