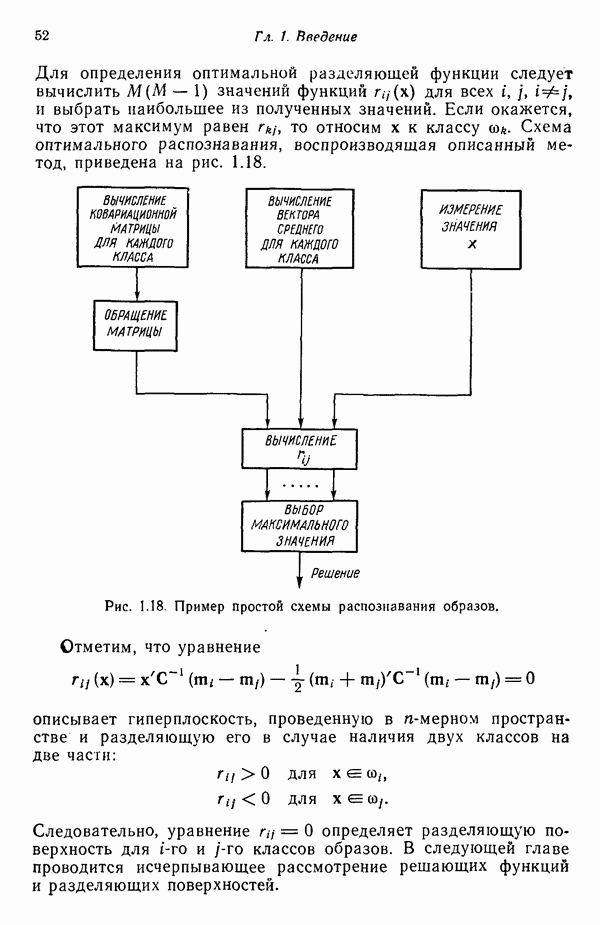
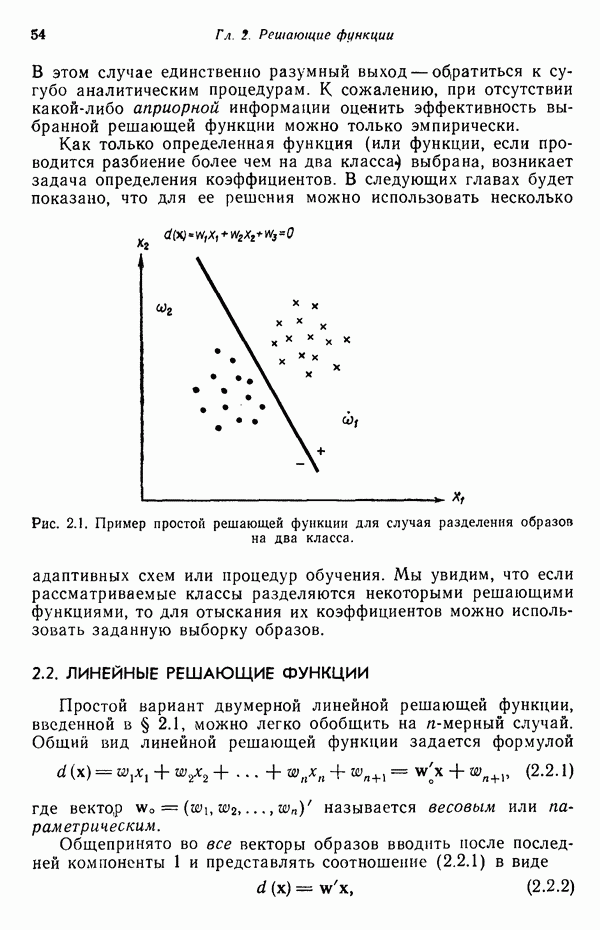
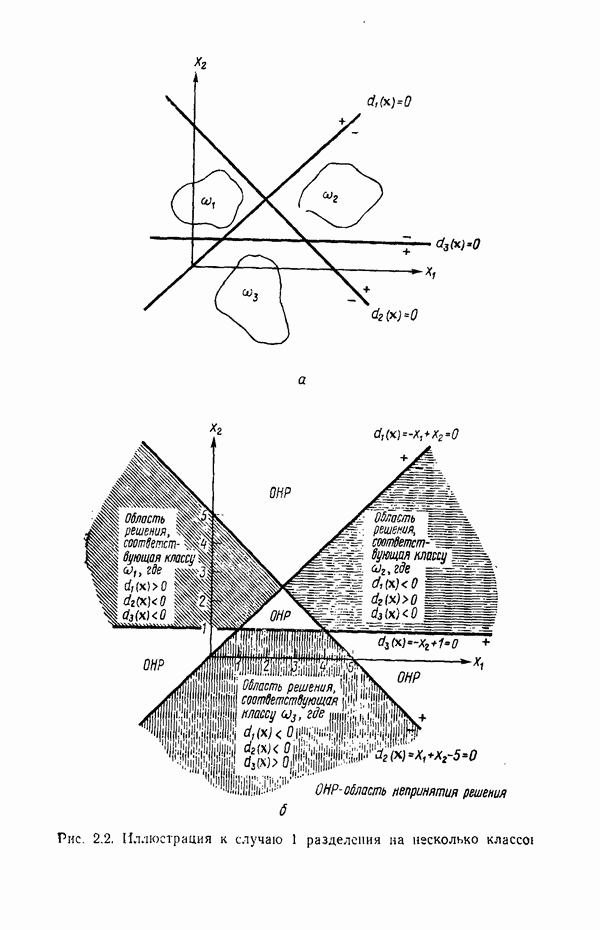
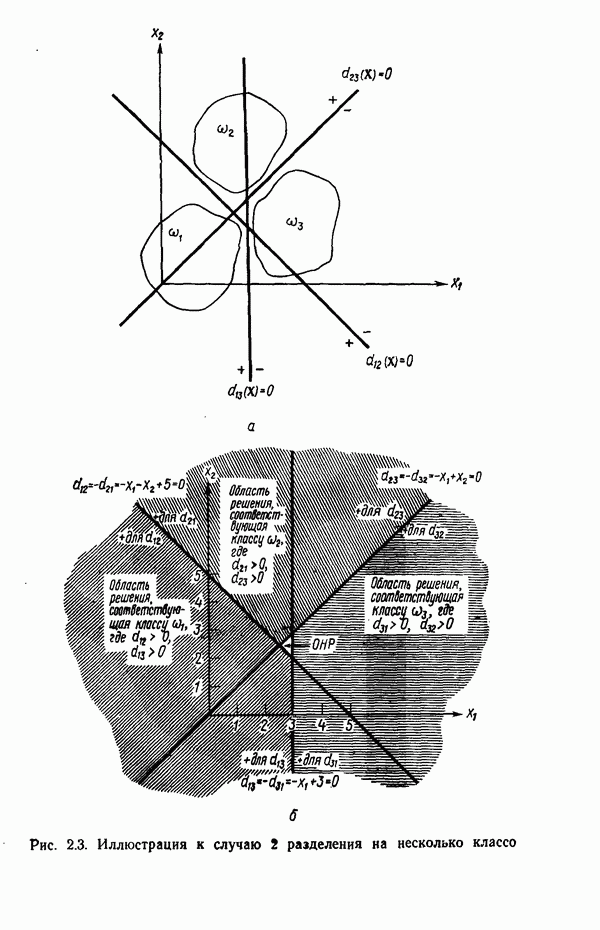
Пред.
След.
Макеты страниц
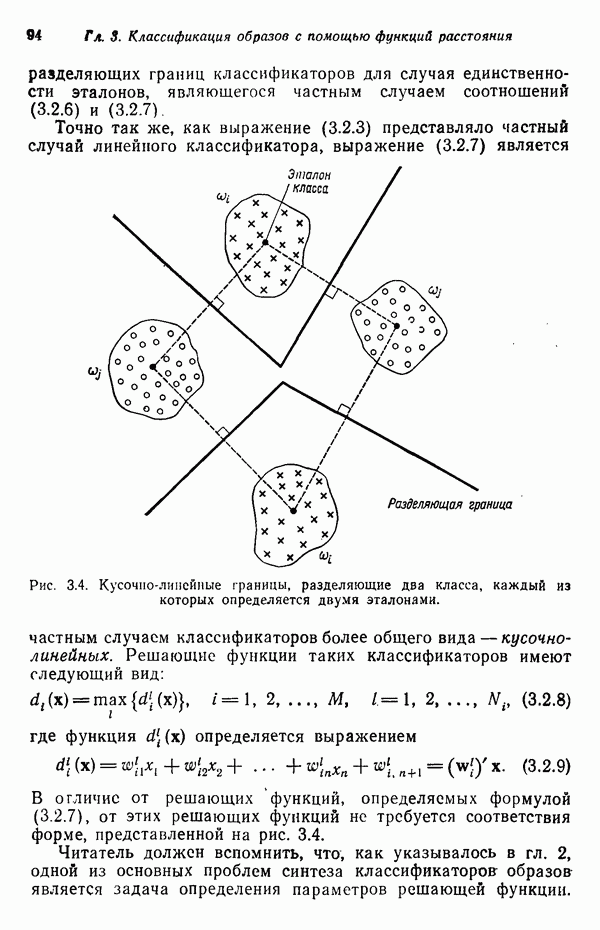
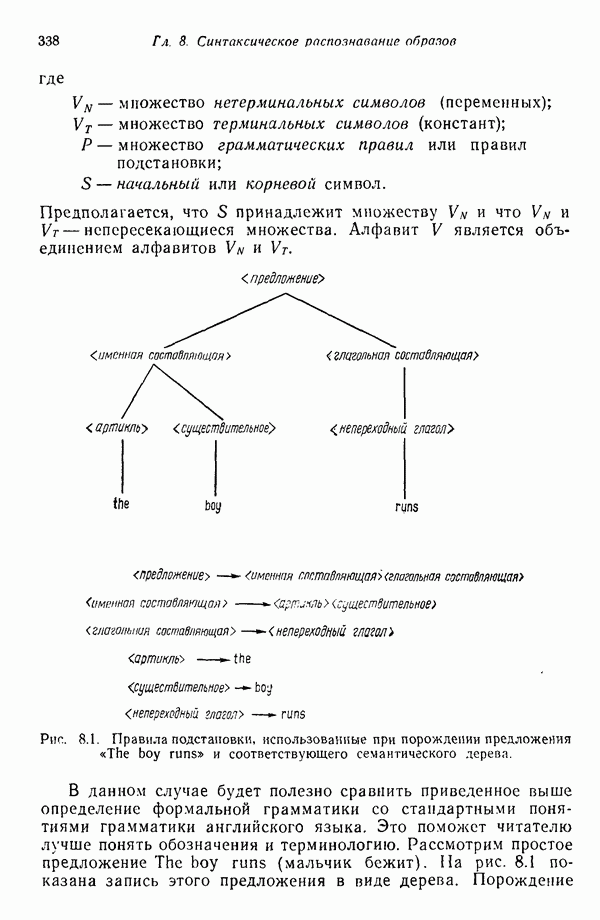
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.3.6. Алгоритм ИСОМАДАлгоритм ИСОМАД (Isodata) в принципе аналогичен процедуре, предусматривающей вычисление К внутригрупповых средних, поскольку и в этом алгоритме центрами кластеров служат выборочные средние, определяемые итеративно. Однако в отличие от предыдущего алгоритма ИСОМАД обладает обширным набором вспомогательных эвристических процедур, встроенных в схему итерации. Это определение «эвристические» следует постоянно иметь в виду, следя за нашим изложением, поскольку целый ряд описываемых ниже этапов вошел в алгоритм в результате осмысления эмпирического опыта его использования. До выполнения алгоритма следует задать набор которого не обязательно должно быть равно предписанному количеству кластеров, может быть получен выборкой образов из заданного множества данных. При работе с набором Шаг 1. Задаются параметры, определяющие процесс кластеризации: К — необходимое число кластеров;
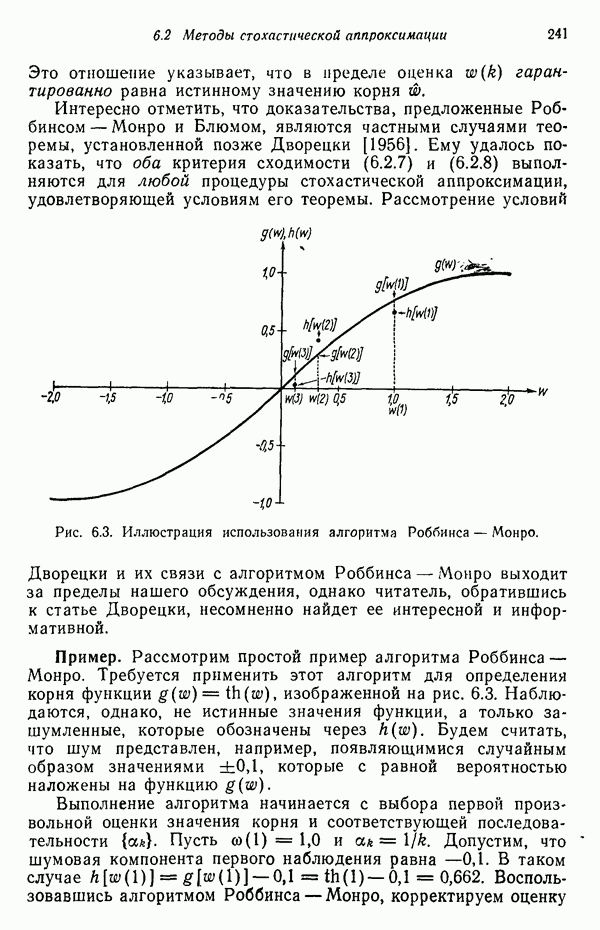
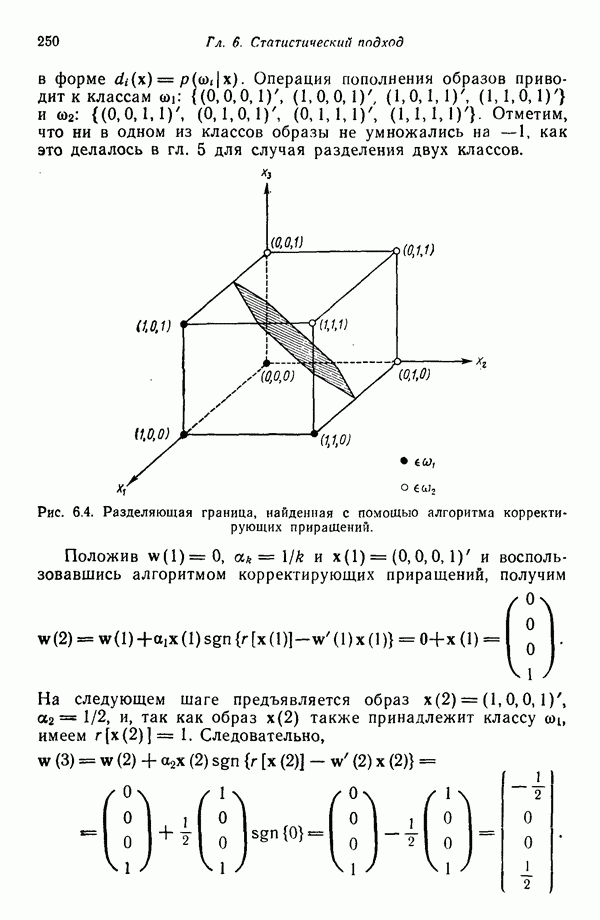
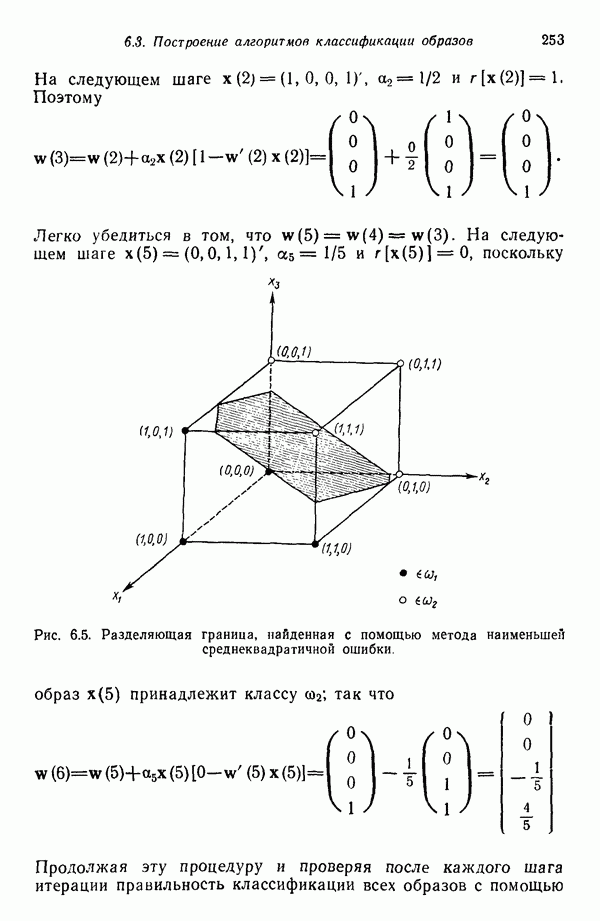
Шаг 2. Заданные N образов распределяются по кластерам, соответствующим выбранным исходным центрам, по правилу
применяемому ко всем образам Шаг 3. Ликвидируются подмножества образов, в состав которых входит менее Шаг 4. Каждый центр кластера
где Шаг 5. Вычисляется среднее расстояние
Шаг 6. Вычисляется обобщенное среднее расстояние между объектами, находящимися в отдельных кластерах, и соответствующими центрами кластеров по формуле
Шаг 7. (а) Если текущий цикл итерации — последний, то задается Шаг 8. Для каждого подмножества выборочных образов с помощью соотношения
вычисляется вектор среднеквадратичного отклонения Шаг 9. В каждом векторе среднеквадратичного отклонения Шаг 10. Если для любого
то кластер с центром честве величины Если расщепление происходит на этом шаге, надо перейти к шагу 2, в противном случае продолжать выполнение алгоритма. Шаг 11. Вычисляются расстояния
Шаг 12. Расстояния
причем Шаг 13. Каждое расстояние Кластеры с центрами
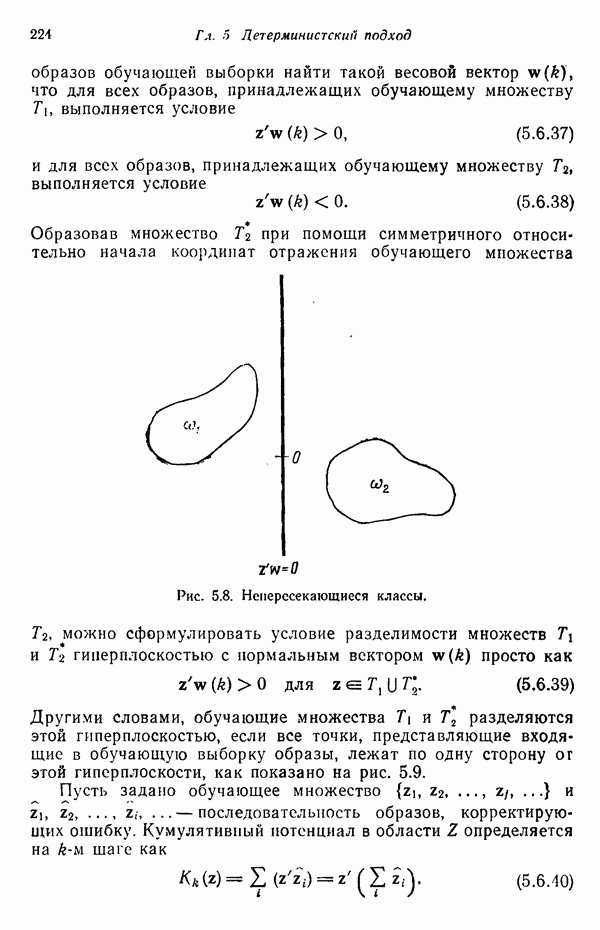
Центры кластеров Отметим, что допускается только попарное слияние кластеров и центр полученного в результате кластера рассчитывается, исходя из позиций, занимаемых центрами объединяемых кластеров и взятых с весами, определяемыми количеством выборочных образов в соответствующем кластере. Опыт свидетельствует о том, что использование более сложных процедур объединения кластеров может привести к получению неудовлетворительных результатов. Описанная процедура обеспечивает выбор в качестве центра объединенного кластера точки, представляющей истинное среднее сливаемых подмножеств образов. Важно также иметь в виду, что, поскольку к каждому центру кластера процедуру слияния можно применить только один раз, реализация данного шага ни при каких обстоятельствах не может привести к получению
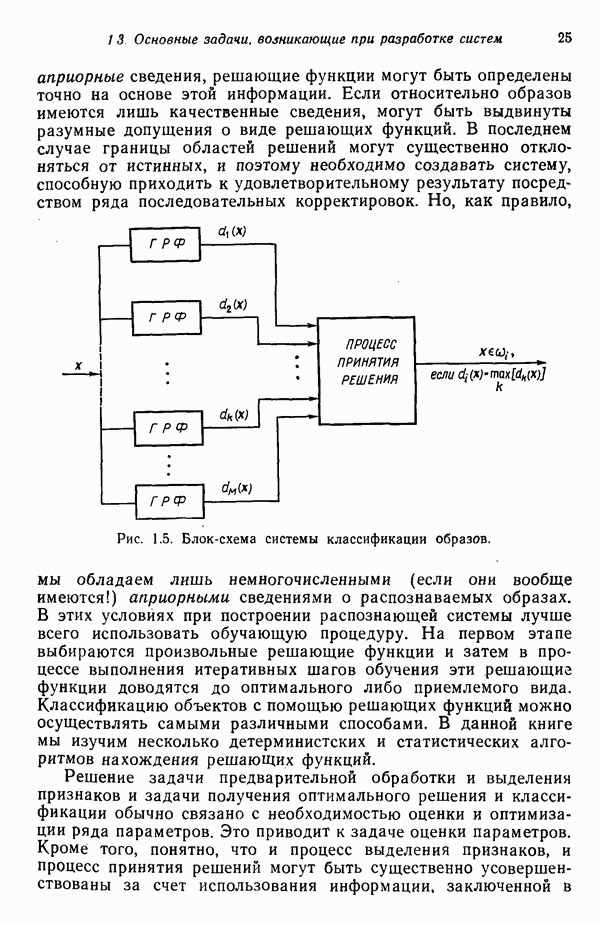
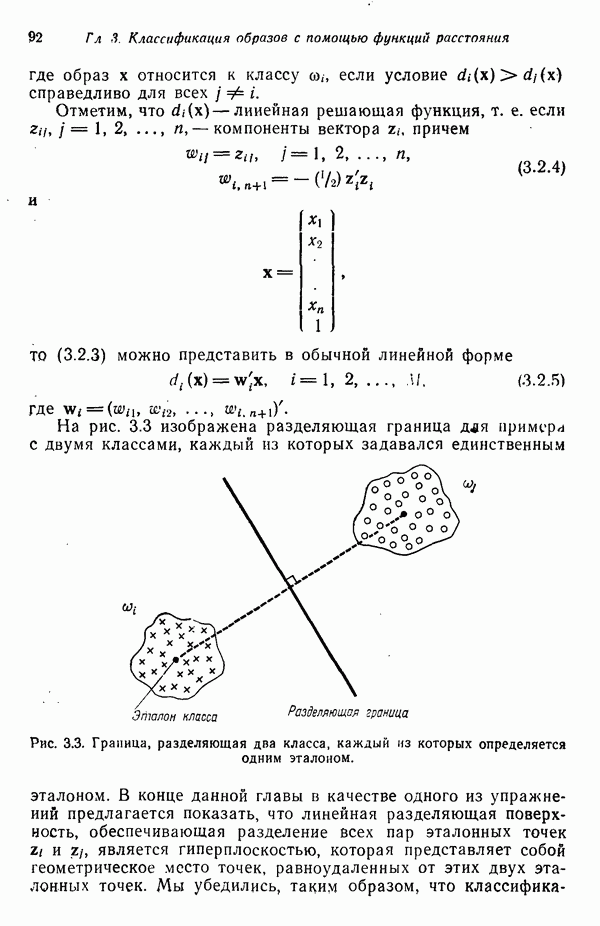
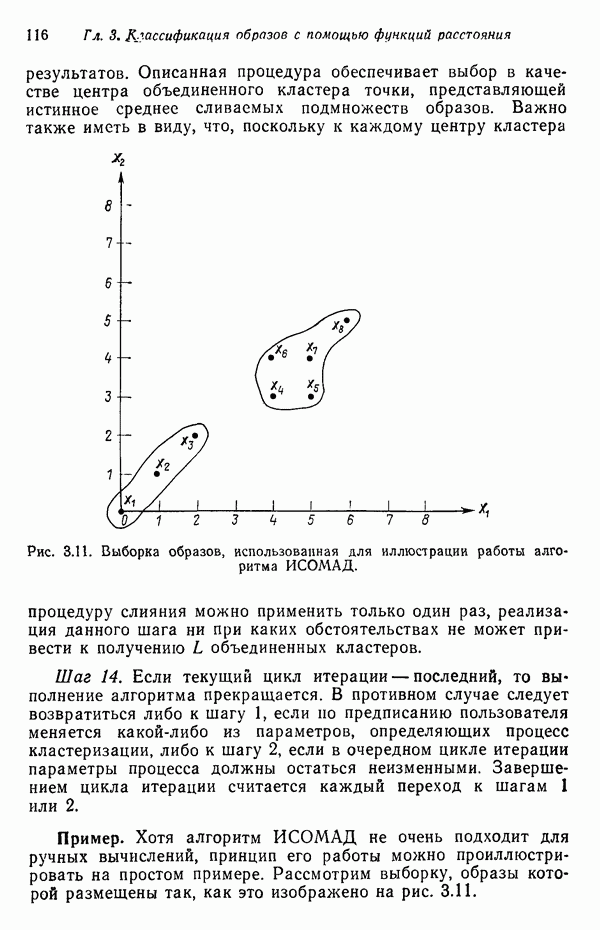
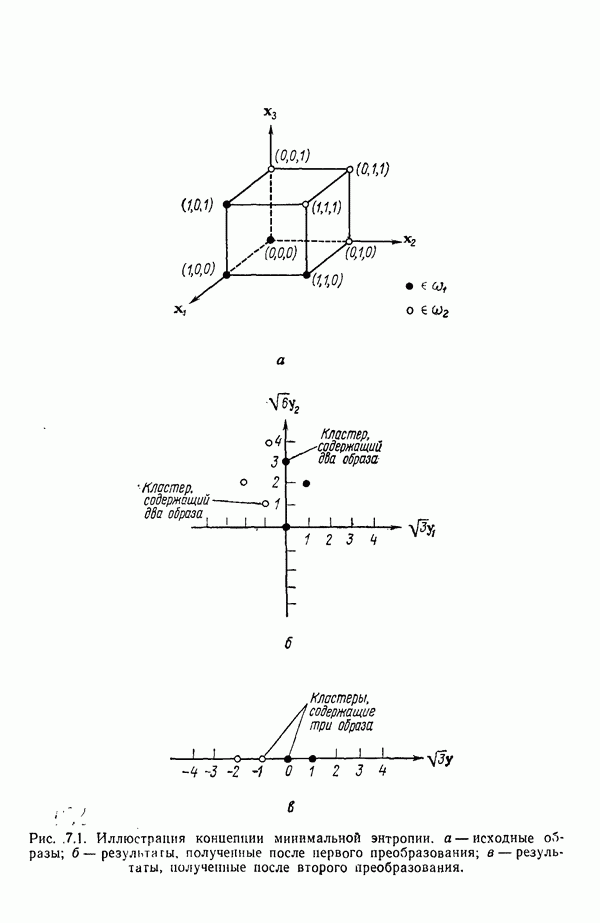
Рис. 3.11. Выборка образов, использованная для иллюстрации работы алгоритма ИСОМАД. Шаг 14, Если текущий цикл итерации — последний, то выполнение алгоритма прекращается. В противном случае следует возвратиться либо к шагу 1, если но предписанию пользователя меняется какой-либо из параметров, определяющих процесс кластеризации, либо к шагу 2, если в очередном цикле итерации параметры процесса должны остаться неизменными. Завершением цикла итерации считается каждый переход к шагам 1 или 2. Пример. Хотя алгоритм ИСОМАД не очень подходит для ручных вычислений, принцип его работы можно проиллюстрировать на простом примере. Рассмотрим выборку, образы которой размещены так, как это изображено на рис. 3.11. В данном случае Шаг 1.
Если всякая априорная информация об анализируемых данных отсутствует, эти параметры выбираются произвольным образом и затем корректируются от итерации к итерации. Шаг 2. Так как задан только один центр кластера, то
Шаг 3. Поскольку Шаг 4. Корректируется положение центра кластера:
Шаг 5. Вычисляется расстояние
Шаг 6. Вычисляется расстояние
Шаг 7. Поскольку данный цикл итерации — не последний и Шаг 8. Для подмножества
Шаг 9. Максимальная компонента вектора Шаг 10. Поскольку
Для удобства записи будем называть центры этих кластеров Шаг 2. Подмножества образов имеют теперь следующий вид:
Шаг 3. Поскольку обе величины — и Шаг 4. Корректируется положение центров кластеров:
Шаг 5. Вычисляется расстояние
Шаг 6. Вычисляется расстояние
Шаг 7. Поскольку данная итерация имеет четный порядковый номер, условие (в) шага 7 выполняется. Поэтому следует перейти к шагу 11. Шаг 11. Вычисление расстояний между парами центров кластеров:
Шаг 12. Величина расстояния Шаг 13. Результаты шага 12 показывают, что объединение кластеров невозможно. Шаг 14. Поскольку данный цикл итерации — не последний, необходимо принять решение: вносить или не вносить изменения в параметры процесса кластеризации. Так как в данном (простом) случае 1) число выделенных кластеров соответствует заданному, 2) расстояние между ними больше среднего разброса, характеризуемого среднеквадратичными отклонениями, и 3) каждый кластер содержит существенную часть общего количества выборочных образов, то делается вывод о том, что локализация центров кластеров правильно отражает специфику анализируемых данных. Следовательно, переходим к шагу 2. Шаги 2—6 дают те же результаты, что и в предыдущем цикле итерации. Шаг 7. Ни одно из условий, проверяемых при реализации данного шага, не выполняется. Поэтому переходим к шагу 8. Шаг 8. Для множеств
Шаг 9. В данном случае Шаг 10. Условия расщепления кластеров не выполняются. Следовательно, переходим к шагу 11. Шаг 11. Полученный результат идентичен результату последнего цикла итерации
Шаг 12. Полученный результат идентичен результату последнего цикла итерации. Шаг 13. Полученный результат идентичен результату последнего цикла итерации. Шаг 14. На данном цикле итерации не были получены новые результаты, за исключением изменения векторов среднеквадратичного отклонения. Поэтому переходим к шагу 2. Шаги 2—6 дают те же результаты, что и в предыдущем цикле итерации. Шаг 7. Поскольку данный цикл итерации — последний, задаем Шаг 11. Как и раньше,
Шаг 12. Полученный результат идентичен результату последнего цикла итерации. Шаг 13. Результаты шага 12 показывают, что объединение кластеров невозможно. Шаг 14. Поскольку данный цикл итерации — последний, выполнение алгоритма заканчивается. Даже из этого простого примера должно быть ясно, что применение алгоритма ИСОМАД к набору данных умеренной сложности в принципе позволяет получить интересные результаты только после проведения обширных экспериментов. Выявление структуры данных может быть, однако, существенно ускорено благодаря эффективному использованию информации, получаемой после каждого цикла итерационного процесса. Эту информацию, как будет показано ниже, можно использовать для коррекции параметров процесса кластеризации непосредственно при реализации алгоритма.
|
 |
Оглавление
|















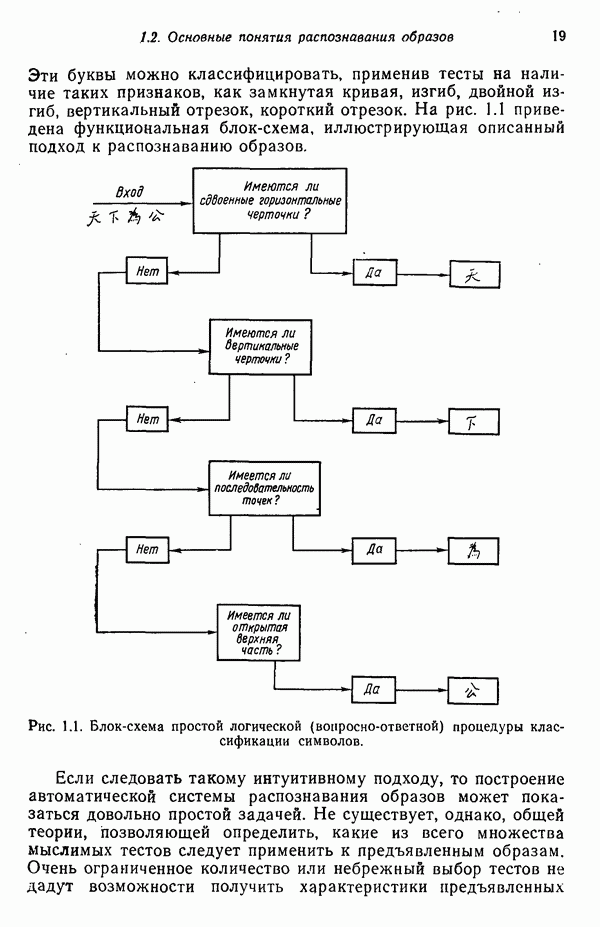
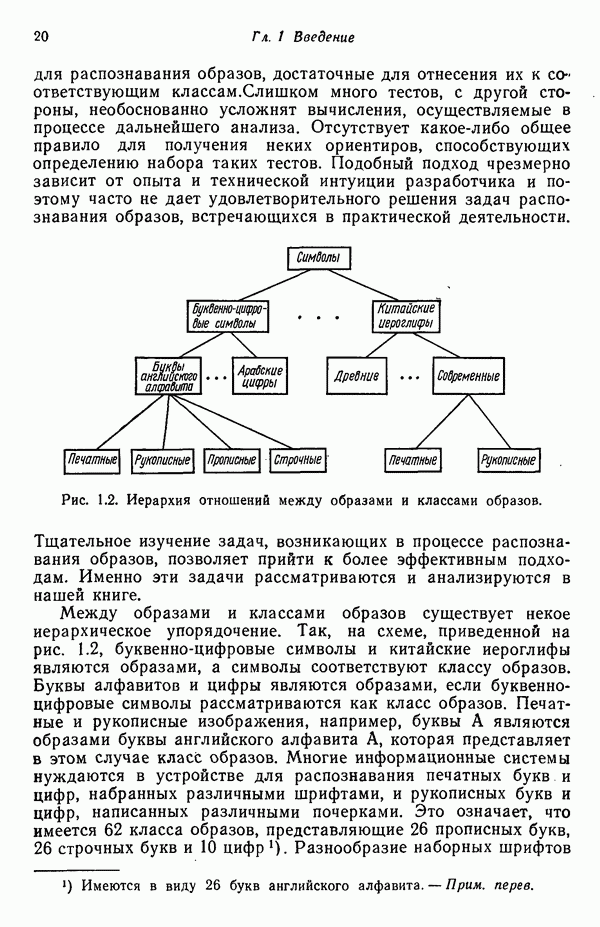

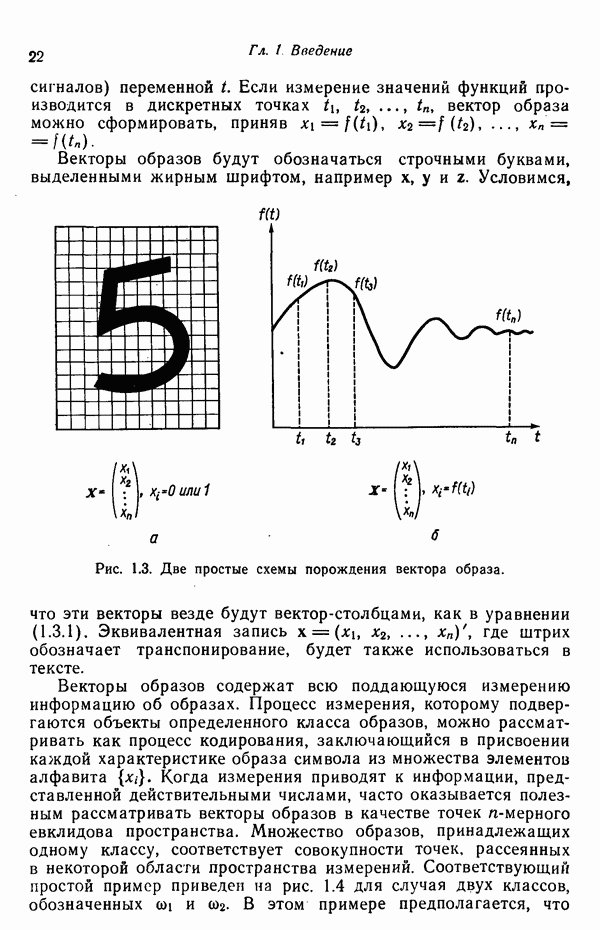






























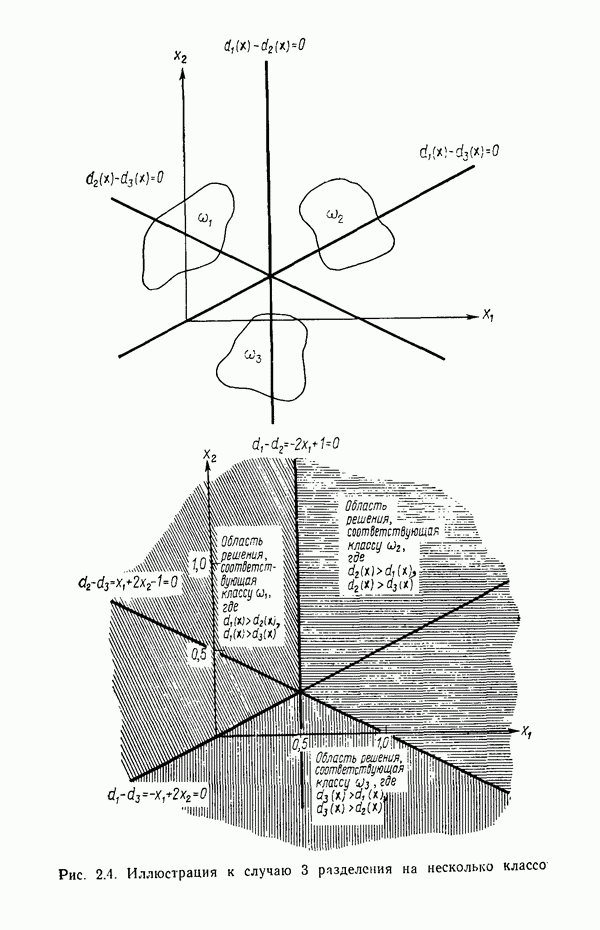



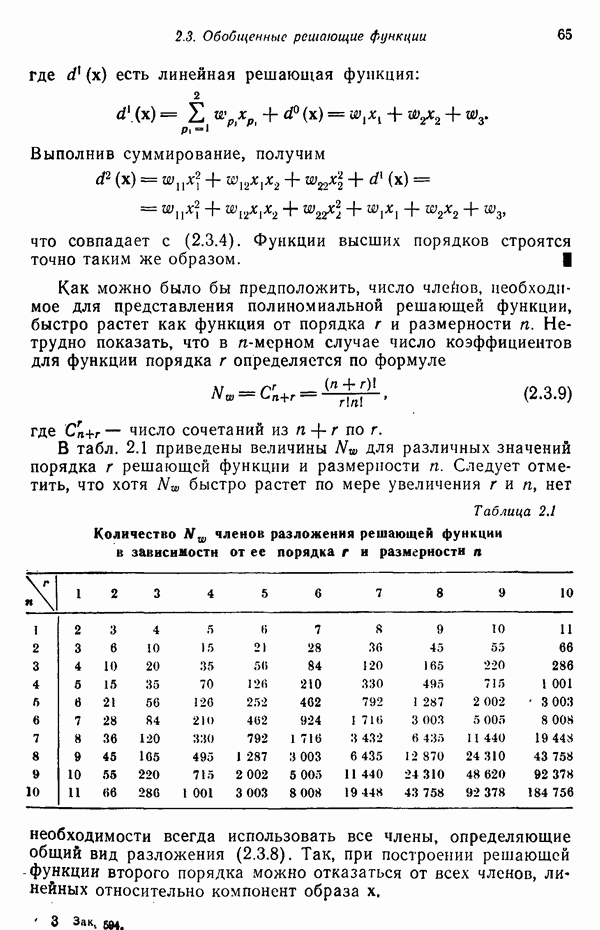


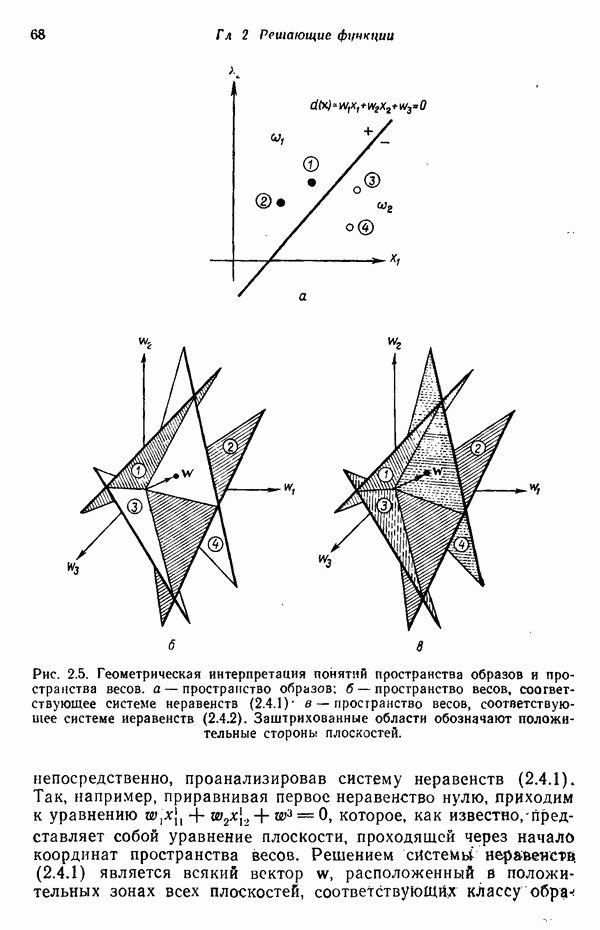




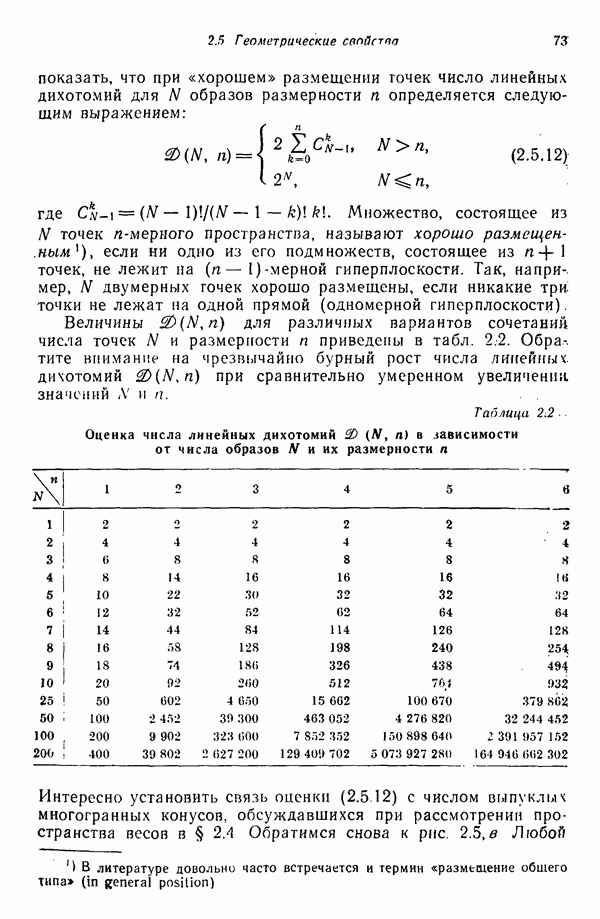
























































































































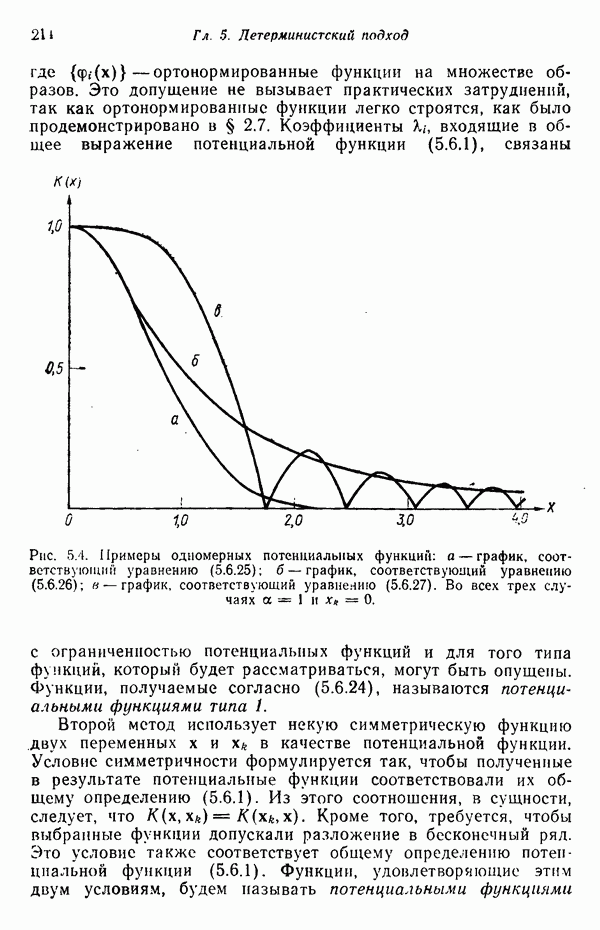

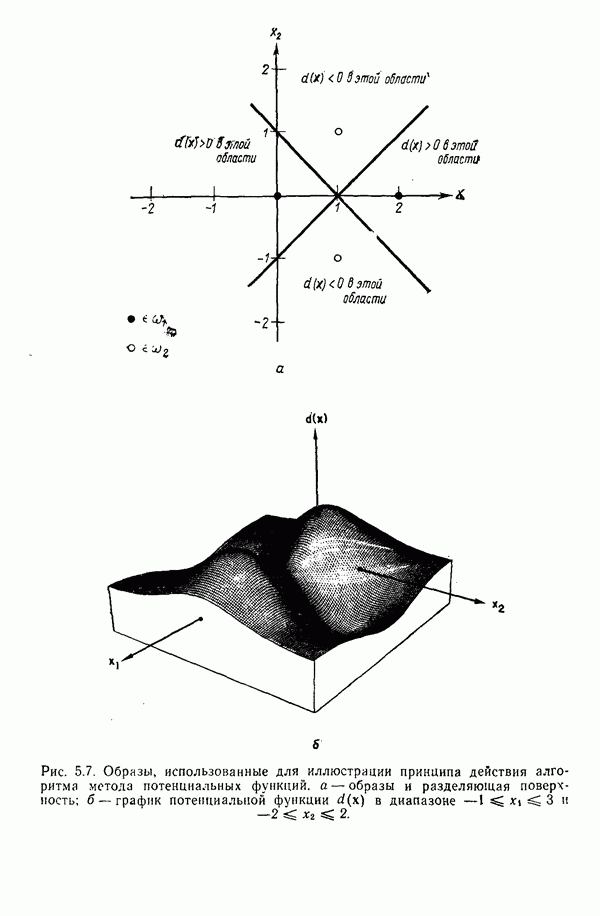

















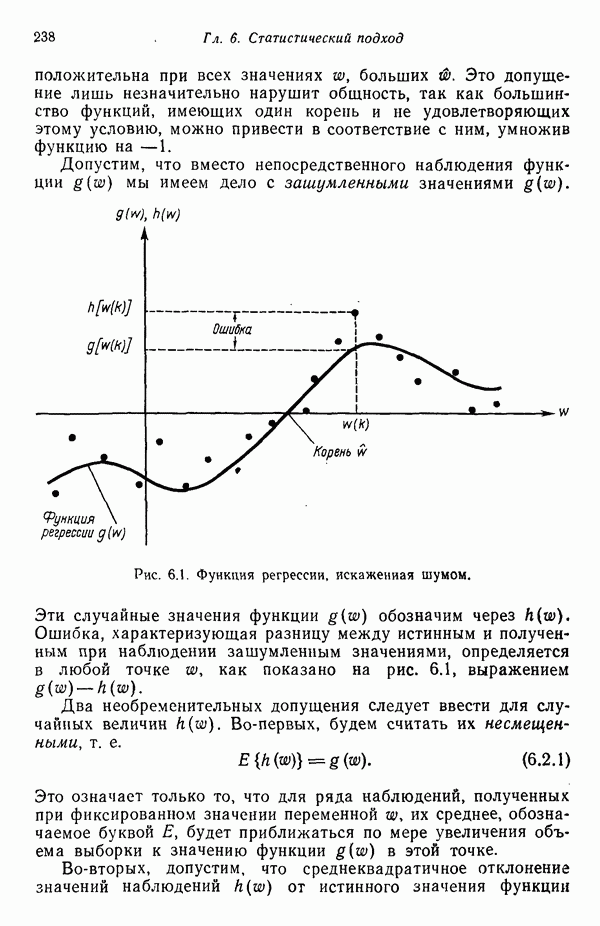

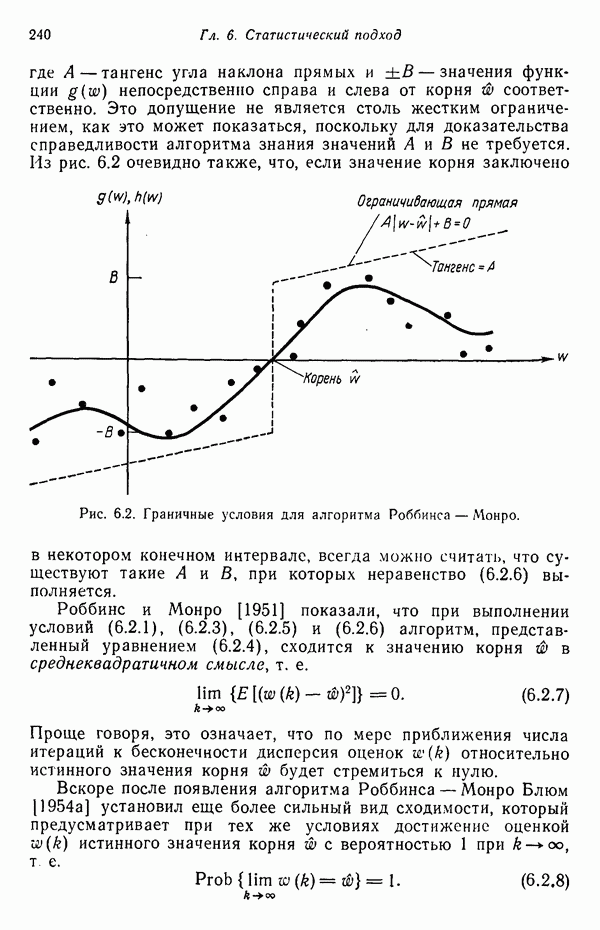









































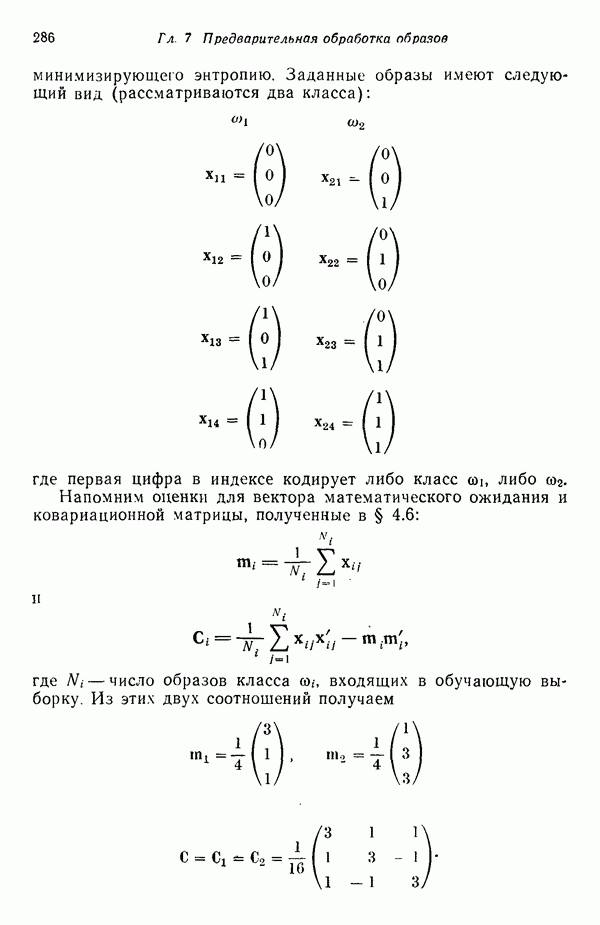







































































































 исходных центров кластеров
исходных центров кластеров  . Этот набор, число элементов
. Этот набор, число элементов
 , составленным из N элементов, алгоритм ИСОМАД выполняет следующие основные шаги.
, составленным из N элементов, алгоритм ИСОМАД выполняет следующие основные шаги.
 — параметр, с которым сравнивается количество выборочных образов, вошедших в кластер;
— параметр, с которым сравнивается количество выборочных образов, вошедших в кластер;
 — параметр, характеризующий среднеквадратичное отклонение;
— параметр, характеризующий среднеквадратичное отклонение;
 — параметр, характеризующий компактность;
— параметр, характеризующий компактность;
 — максимальное количество пар центров кластеров, которые можно объединить;
— максимальное количество пар центров кластеров, которые можно объединить;
 — допустимое число циклов итерации.
— допустимое число циклов итерации.

 вошедшим в выборку; через
вошедшим в выборку; через  обозначено подмножество образов выборки, включенных в кластер с центром
обозначено подмножество образов выборки, включенных в кластер с центром 
 элементов, т. е. если для некоторого
элементов, т. е. если для некоторого  выполняется условие
выполняется условие  то подмножество
то подмножество  исключается из рассмотрения и значение
исключается из рассмотрения и значение  уменьшается на 1.
уменьшается на 1.
 локализуется и корректируется посредством приравнивания его выборочному среднему, найденному по соответствующему подмножеству
локализуется и корректируется посредством приравнивания его выборочному среднему, найденному по соответствующему подмножеству  т. е.
т. е.

 — число объектов, вошедших в подмножество
— число объектов, вошедших в подмножество 
 между объектами, входящими в подмножество
между объектами, входящими в подмножество  и соответствующим центром кластера по формуле
и соответствующим центром кластера по формуле


 переход к шагу 11. (б) Если условие
переход к шагу 11. (б) Если условие  выполняется, то переход к шагу 8. (в) Если текущий цикл итерации имеет четный порядковый номер или выполняется условие
выполняется, то переход к шагу 8. (в) Если текущий цикл итерации имеет четный порядковый номер или выполняется условие  , то переход к шагу 11; в противном случае процесс итерации продолжается.
, то переход к шагу 11; в противном случае процесс итерации продолжается.

 где
где  есть размерность образа,
есть размерность образа,  есть
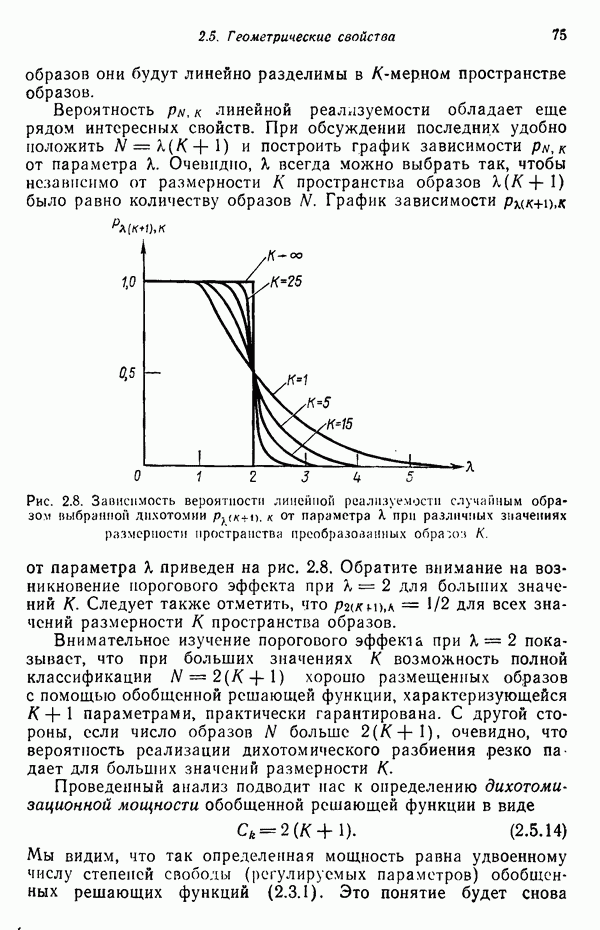
есть  компонента
компонента  объекта в подмножестве
объекта в подмножестве  есть
есть  компонента вектора, представляющего центр кластера
компонента вектора, представляющего центр кластера  — количество выборочных образов, включенных в подмножество
— количество выборочных образов, включенных в подмножество  . Каждая компонента вектора среднеквадратичного отклонения
. Каждая компонента вектора среднеквадратичного отклонения  характеризует среднеквадратичное отклонение образа, входящего в подмножество
характеризует среднеквадратичное отклонение образа, входящего в подмножество  по одной из главных осей координат.
по одной из главных осей координат.
 отыскивается максимальная компонента
отыскивается максимальная компонента  .
.
 выполняются условия
выполняются условия 

 расщепляется на два новых кластера с центрами
расщепляется на два новых кластера с центрами  соответственно, кластер с центром
соответственно, кластер с центром  ликвидируется, а значение
ликвидируется, а значение  увеличивается на 1. Для определения центра кластера
увеличивается на 1. Для определения центра кластера  к компоненте вектора
к компоненте вектора  соответствующей максимальной компоненте вектора
соответствующей максимальной компоненте вектора  прибавляется заданная величина
прибавляется заданная величина  центр кластера
центр кластера  определяется вычитанием этой же величины
определяется вычитанием этой же величины  из той же самой компоненты вектора
из той же самой компоненты вектора 
 можно выбрать некоторую долю значения максимальной среднеквадратичной компоненты
можно выбрать некоторую долю значения максимальной среднеквадратичной компоненты  т. е. положить
т. е. положить  где
где  . При выборе
. При выборе  следует руководствоваться в основном тем, чтобы ее величина была достаточно большой для различения разницы в расстояниях от произвольного образа до новых двух центров кластеров, но достаточно малой, чтобы общая структура кластеризации существенно не изменилась.
следует руководствоваться в основном тем, чтобы ее величина была достаточно большой для различения разницы в расстояниях от произвольного образа до новых двух центров кластеров, но достаточно малой, чтобы общая структура кластеризации существенно не изменилась.
 между всеми парами центров кластеров:
между всеми парами центров кластеров:

 сравниваются с параметром
сравниваются с параметром  расстояний, которые оказались меньше
расстояний, которые оказались меньше  ранжируются в порядке возрастания:
ранжируются в порядке возрастания:

 — максимальное число пар центров кластеров, которые можно объединить. Следующий шаг осуществляет процесс слияния кластеров.
— максимальное число пар центров кластеров, которые можно объединить. Следующий шаг осуществляет процесс слияния кластеров.
 вычислено для определенной пары кластеров с центрами
вычислено для определенной пары кластеров с центрами  и
и  . К этим парам в последовательности, соответствующей увеличению расстояния между центрами, применяется процедура слияния, осуществляемая на основе следующего правила.
. К этим парам в последовательности, соответствующей увеличению расстояния между центрами, применяется процедура слияния, осуществляемая на основе следующего правила.
 объединяются (при условии, что в текущем цикле итерации процедура слияния не применялась ни к тому, ни к другому кластеру), причем новый центр кластера определяется по формуле
объединяются (при условии, что в текущем цикле итерации процедура слияния не применялась ни к тому, ни к другому кластеру), причем новый центр кластера определяется по формуле

 и
и  ликвидируются и значение
ликвидируются и значение  уменьшается на 1.
уменьшается на 1.
 объединенных кластеров.
объединенных кластеров.

 . В качестве начальных условий задаем
. В качестве начальных условий задаем  и следующие значения параметров процесса кластеризации:
и следующие значения параметров процесса кластеризации:



 ни одно подмножество не ликвидируется.
ни одно подмножество не ликвидируется.





 осуществляется переход к шагу 8.
осуществляется переход к шагу 8.
 вычисляется вектор среднеквадратичного отклонения:
вычисляется вектор среднеквадратичного отклонения:

 равна 1,99, следовательно,
равна 1,99, следовательно, 
 кластер с центром
кластер с центром  расщепляется на два новых кластера. Следуя процедуре, предусмотренной шагом 10, выбираем
расщепляется на два новых кластера. Следуя процедуре, предусмотренной шагом 10, выбираем  При
При

 соответственно. Значение
соответственно. Значение  увеличивается на 1; переход к шагу 2.
увеличивается на 1; переход к шагу 2.

 больше
больше  ни одно подмножество не ликвидируется.
ни одно подмножество не ликвидируется.






 сопоставляется с параметром
сопоставляется с параметром  . В данном случае
. В данном случае 




 и переходим к шагу 11.
и переходим к шагу 11.
