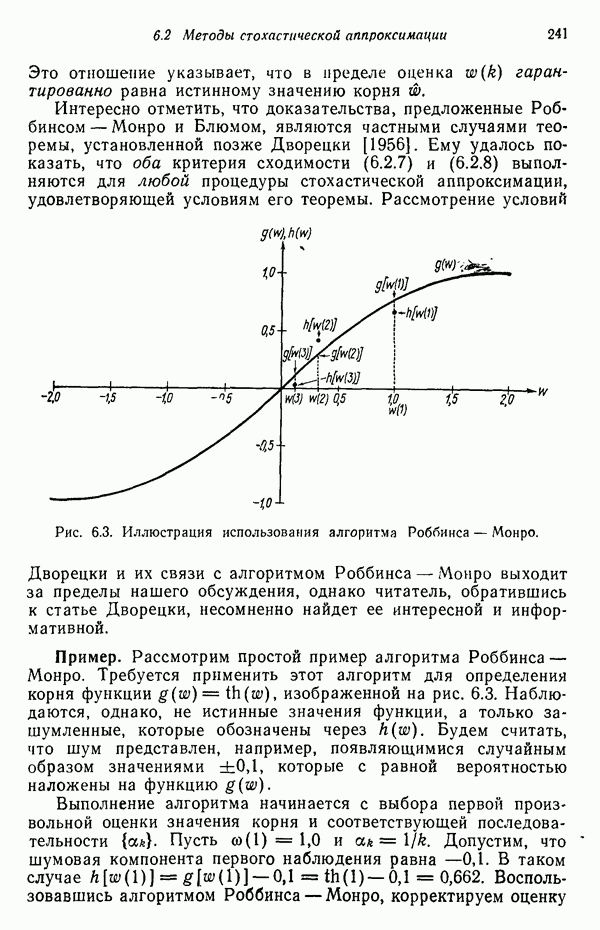
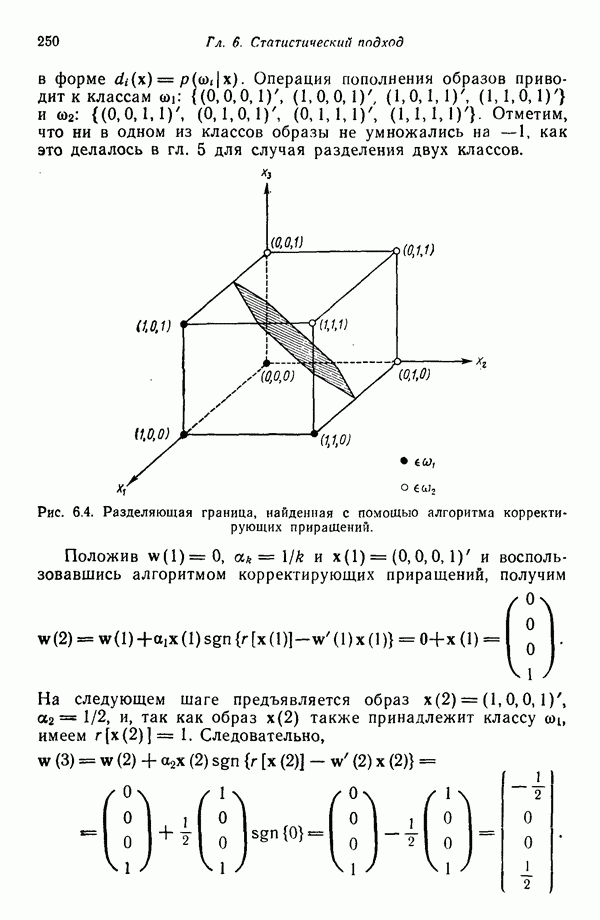
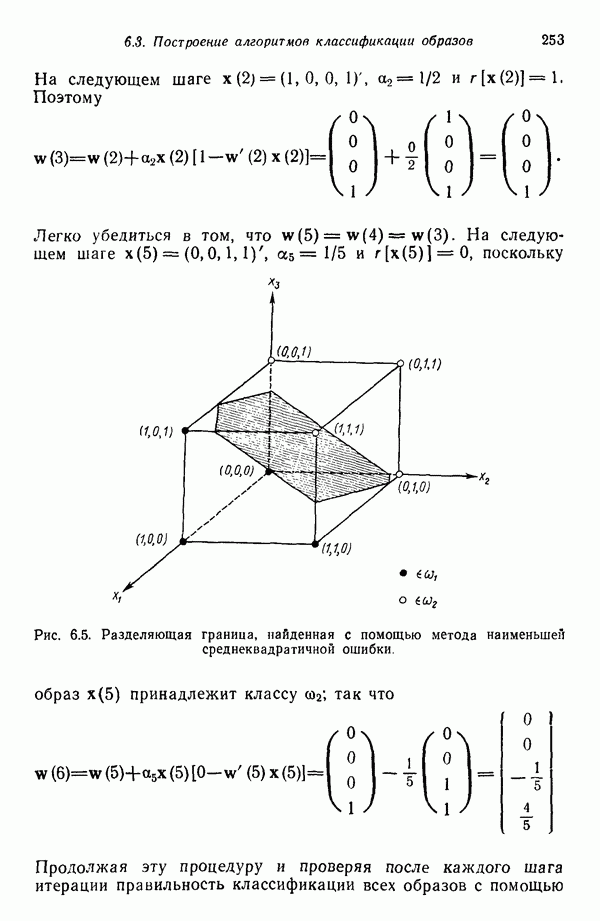
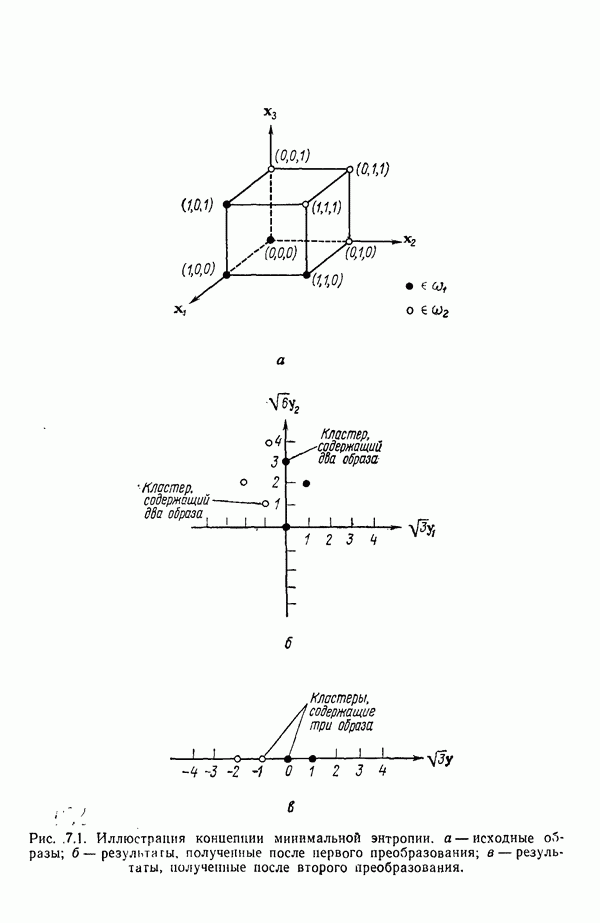
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
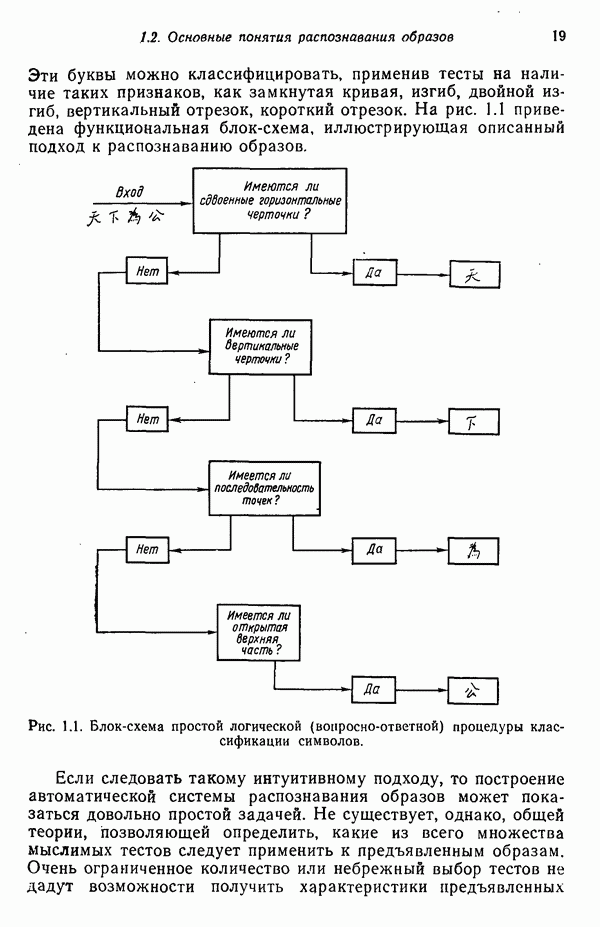
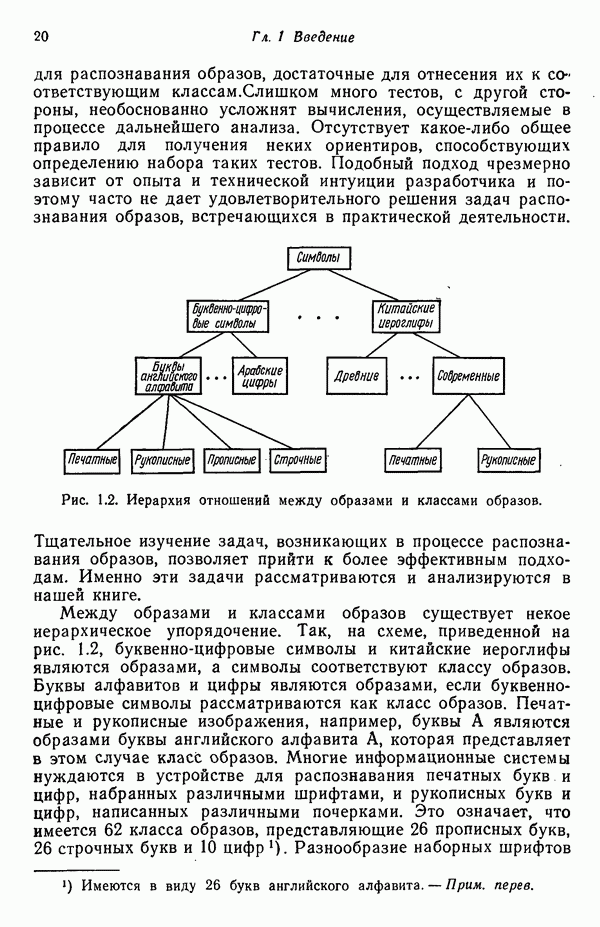
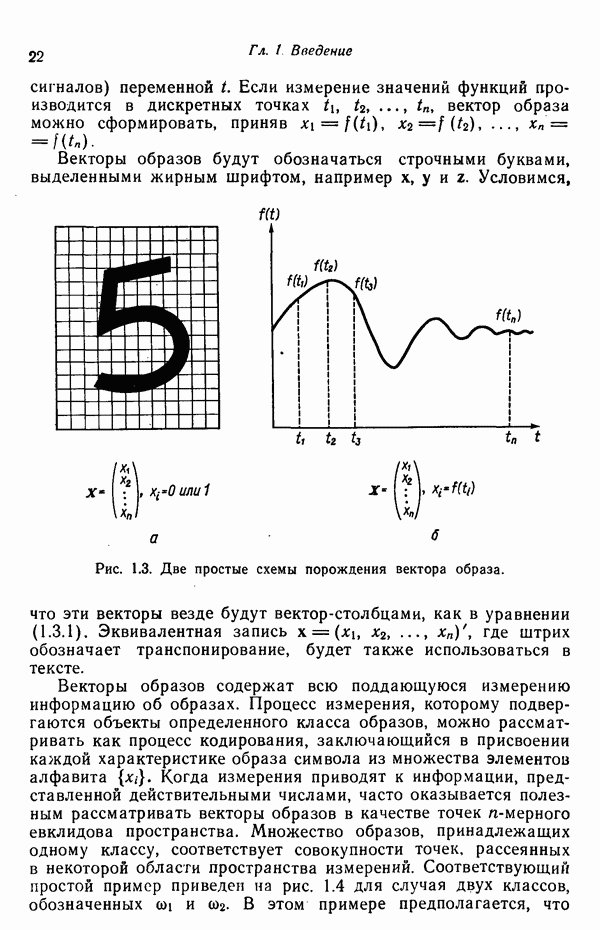
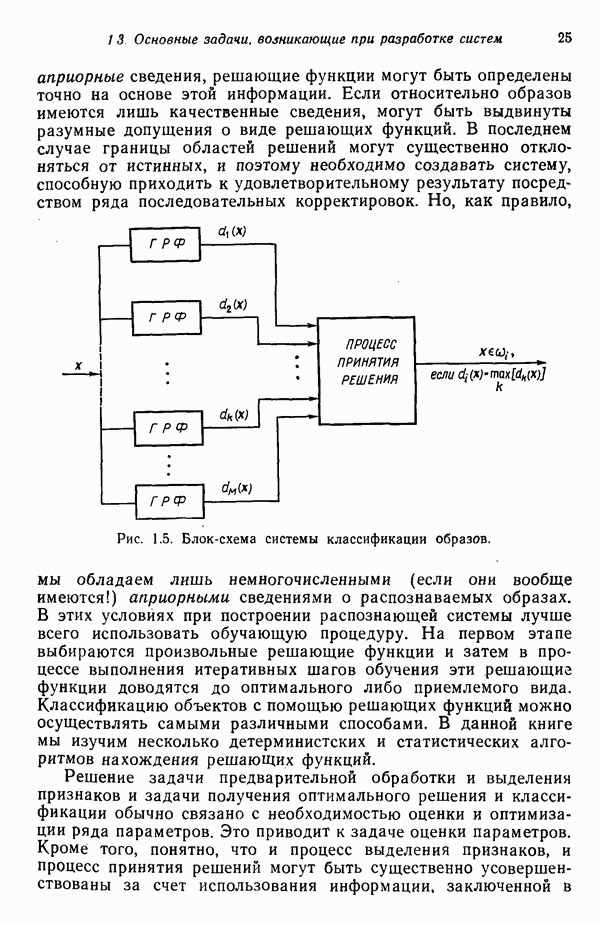
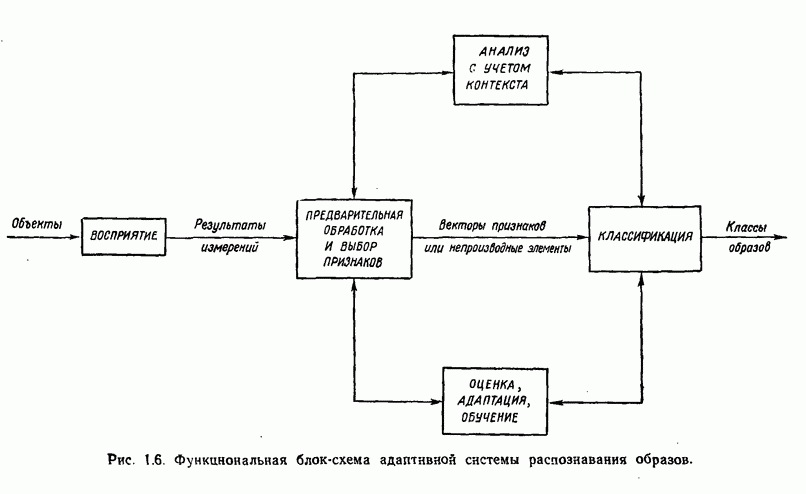
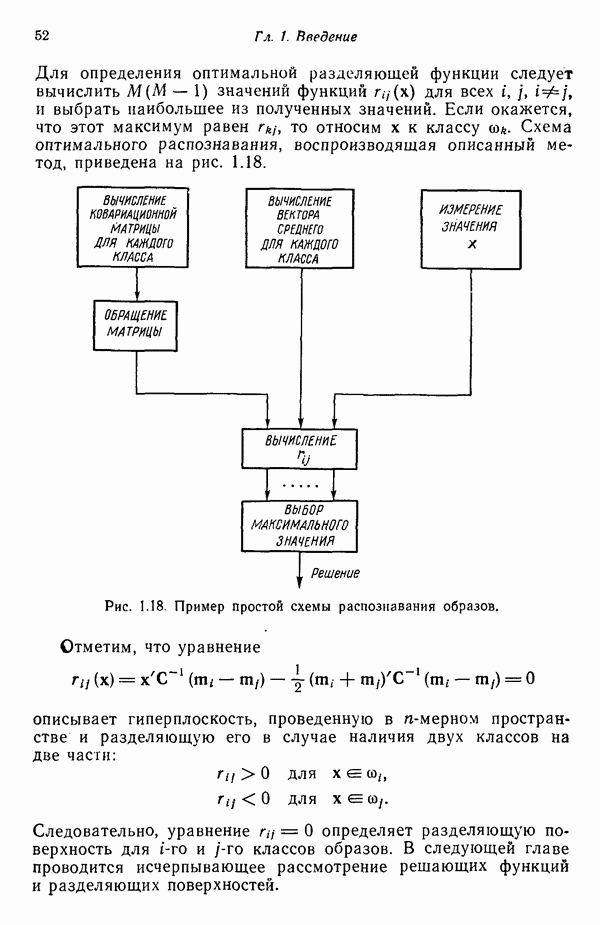
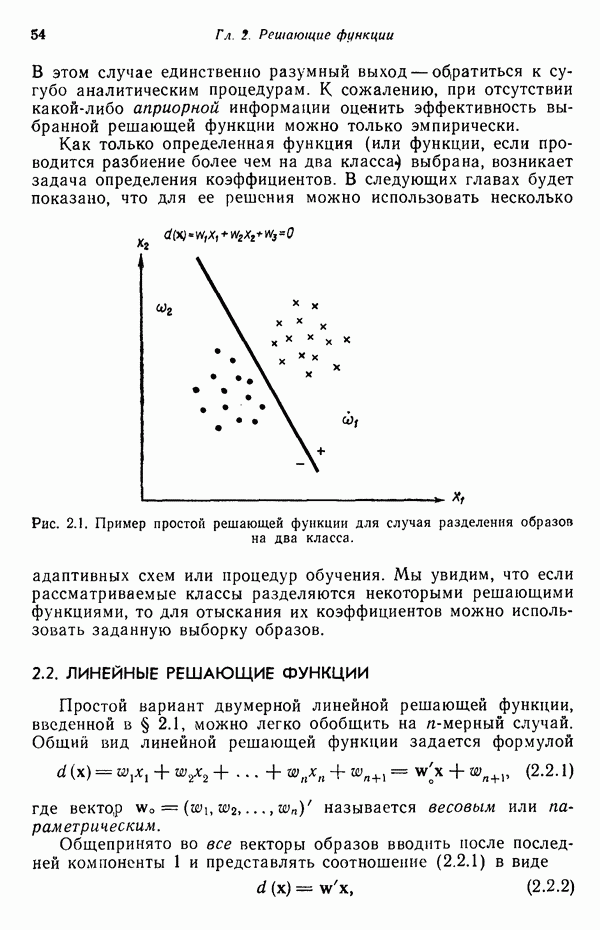
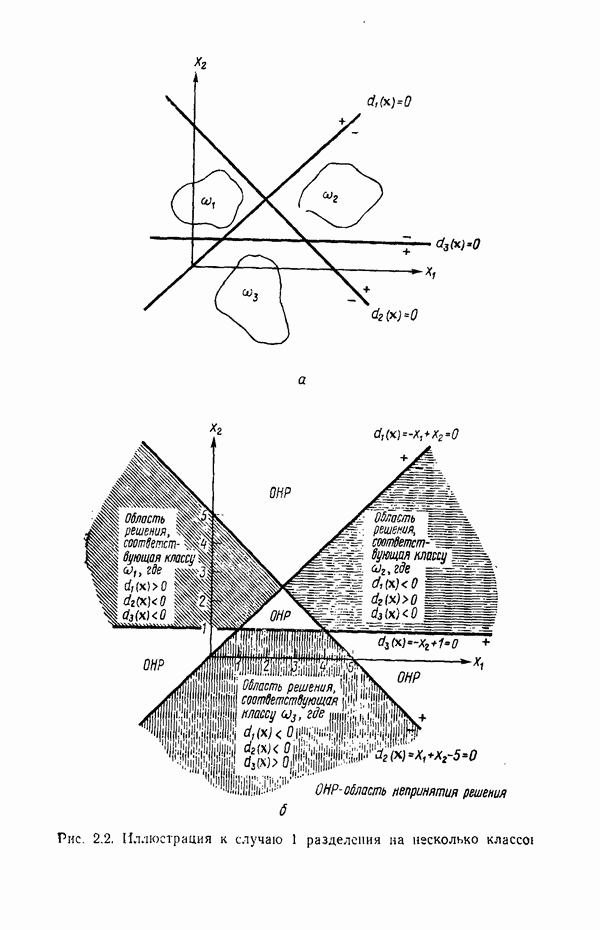
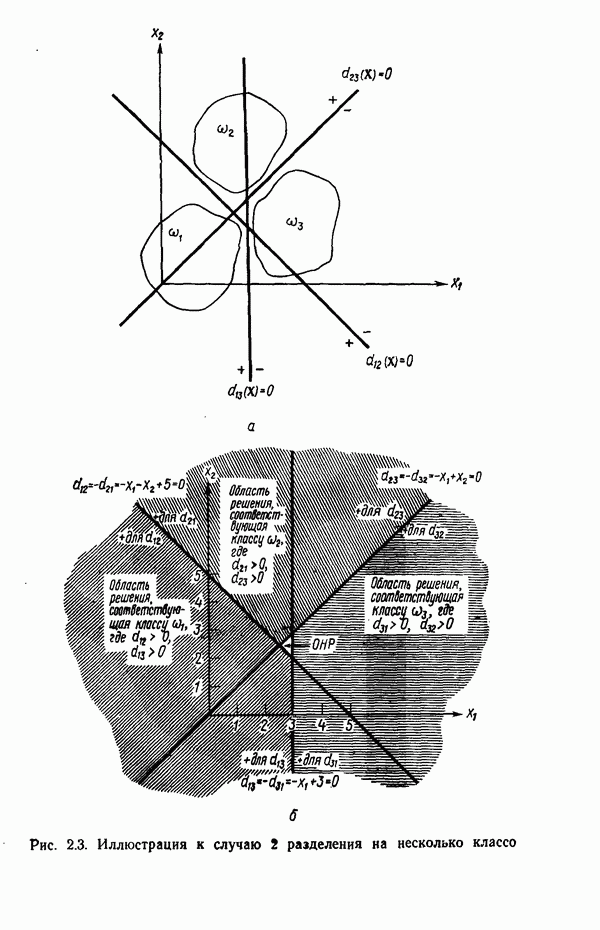
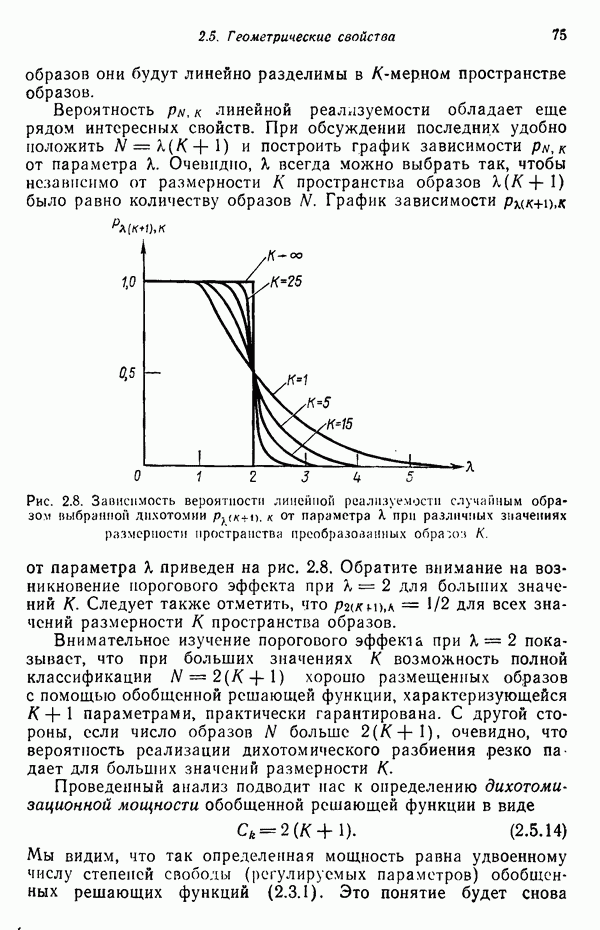
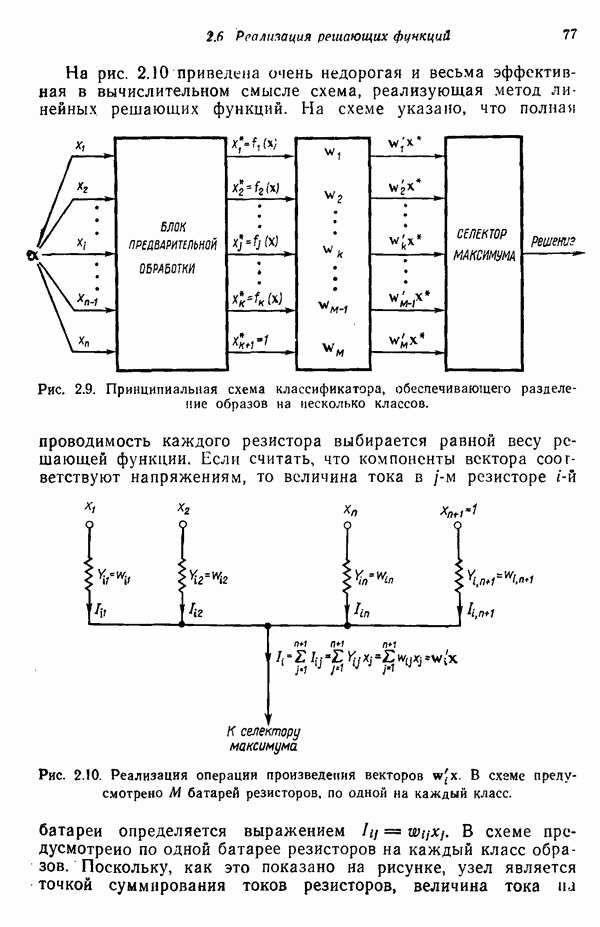
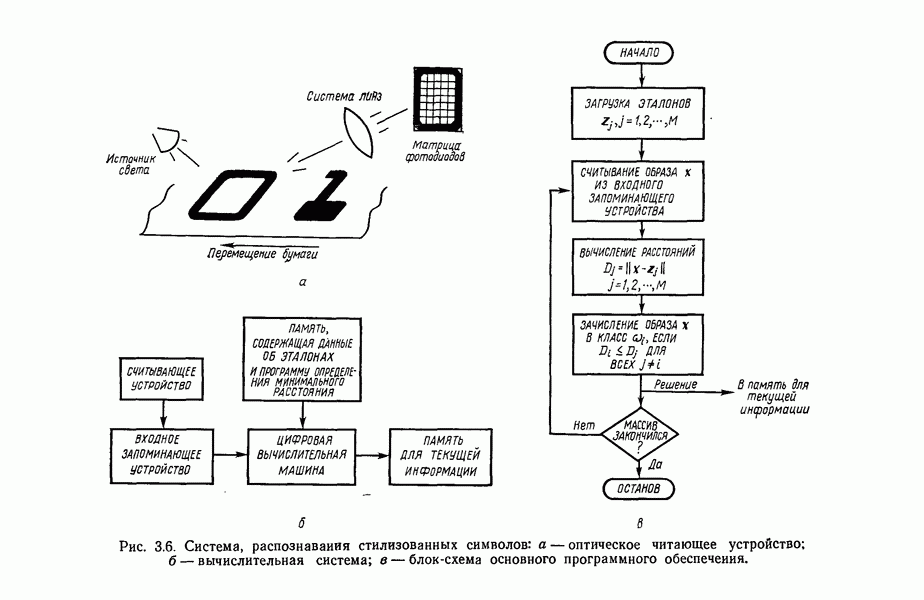
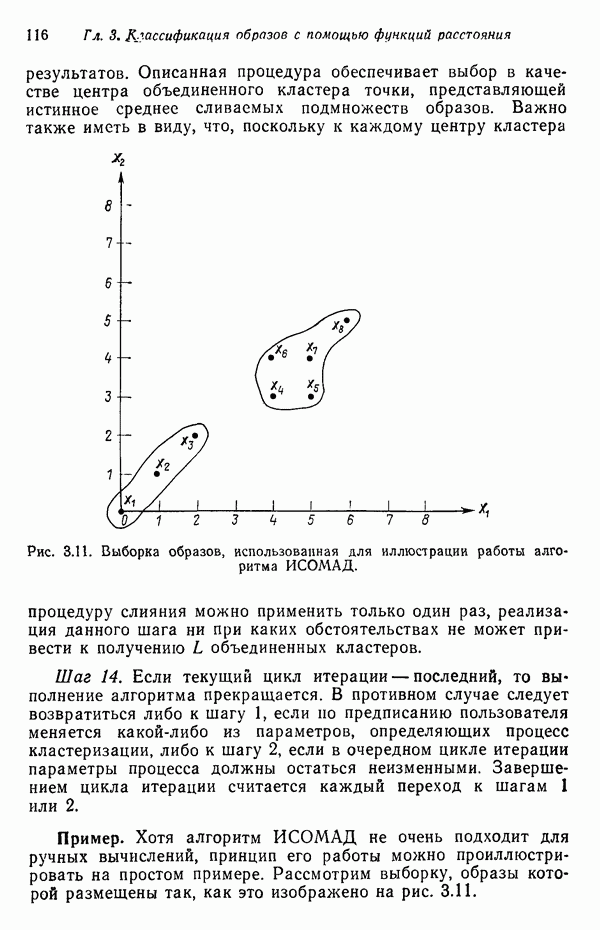
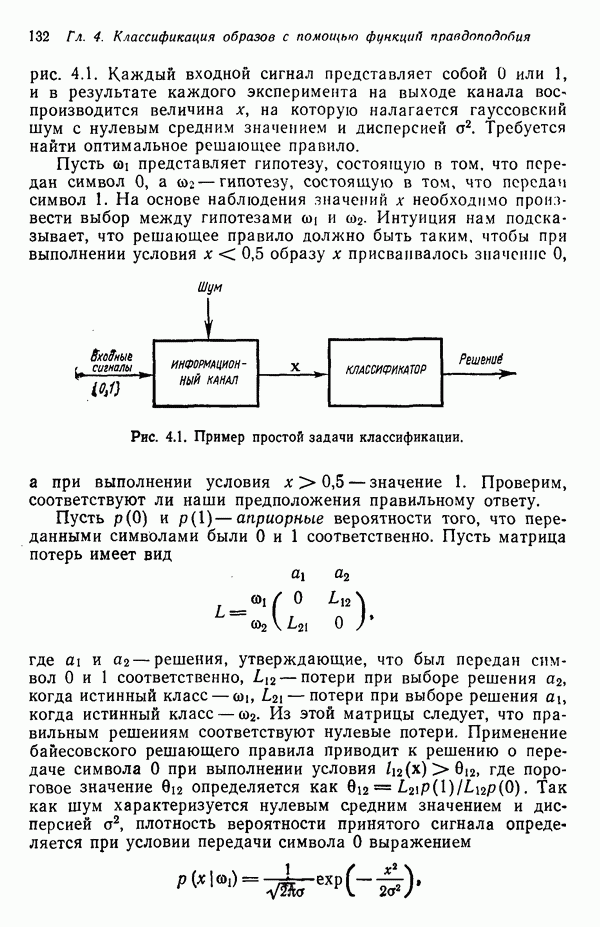
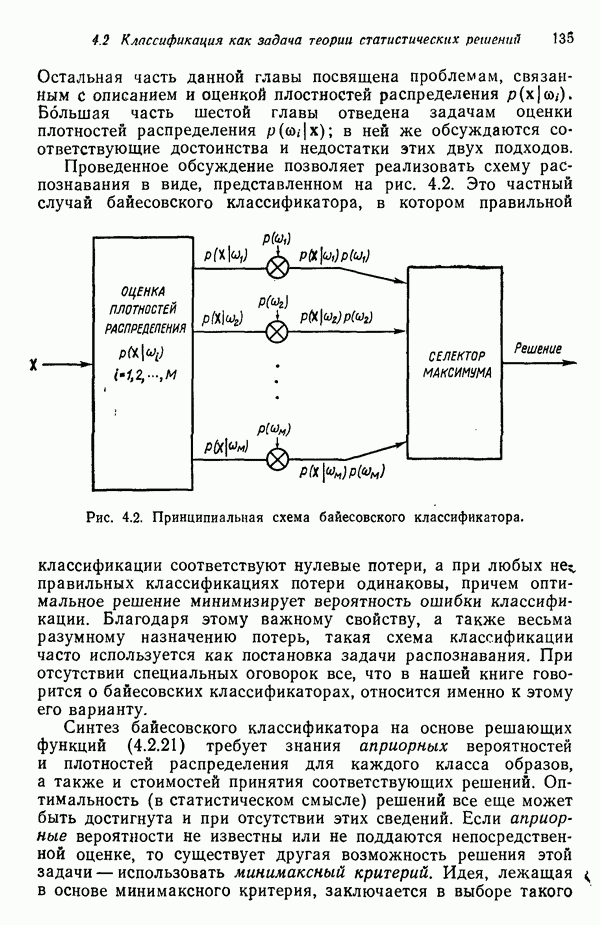
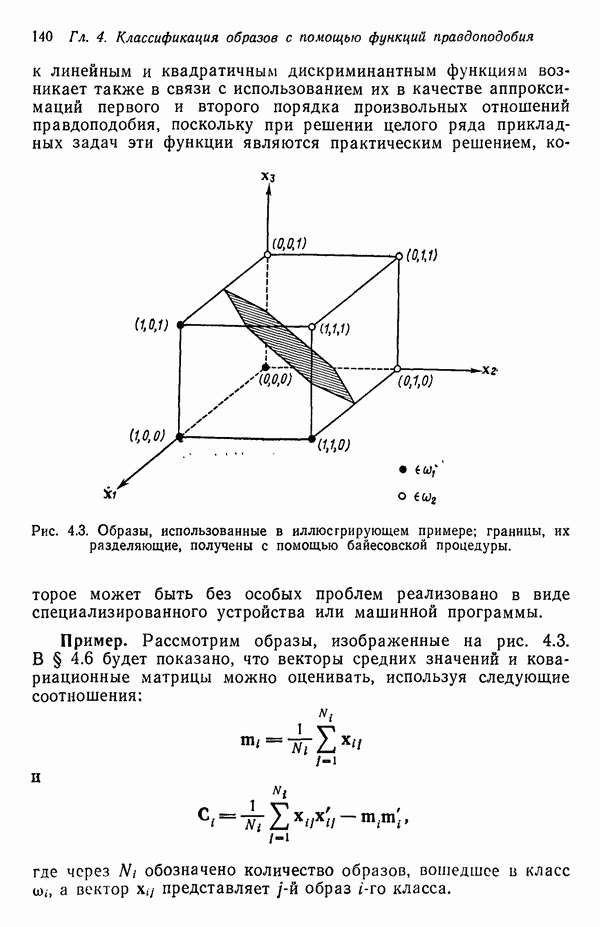
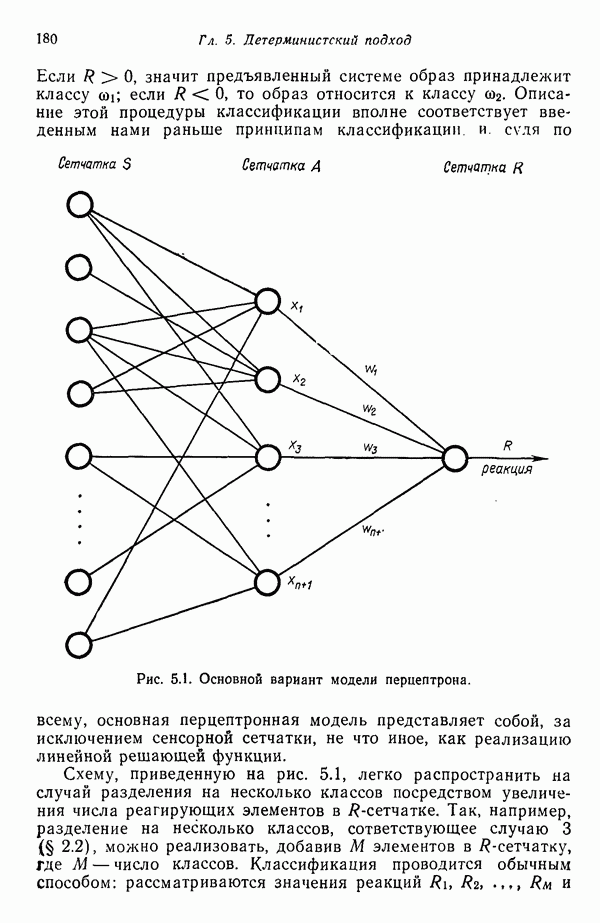
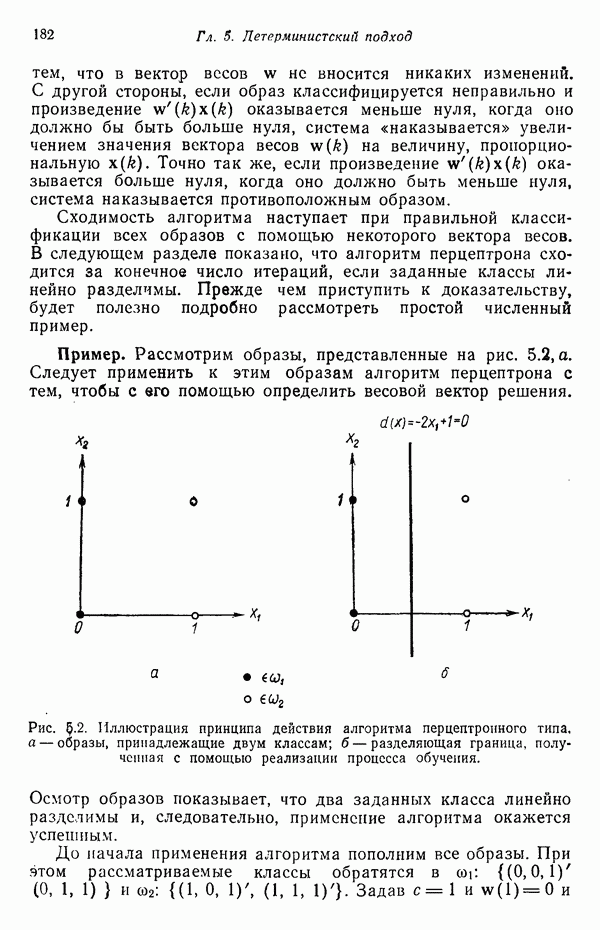
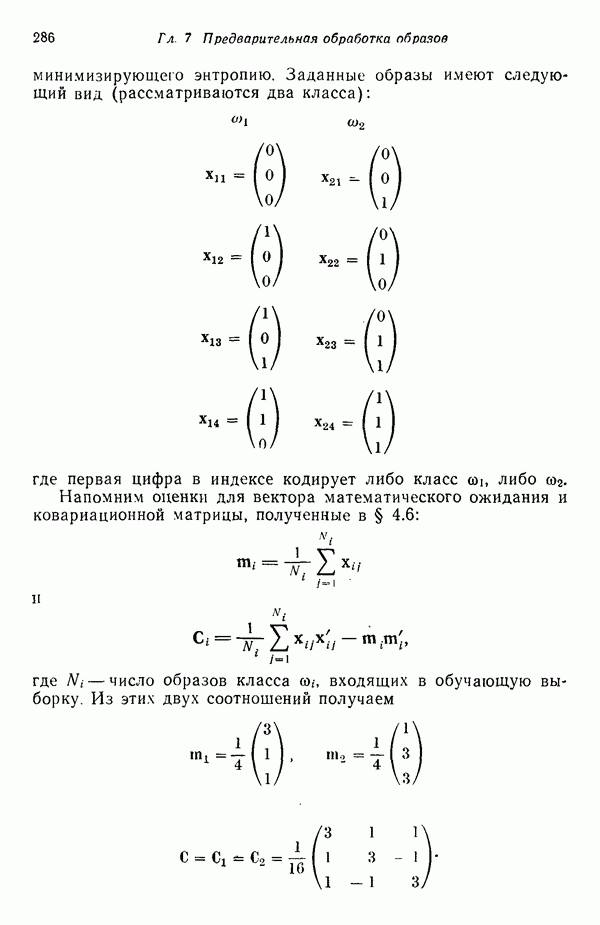
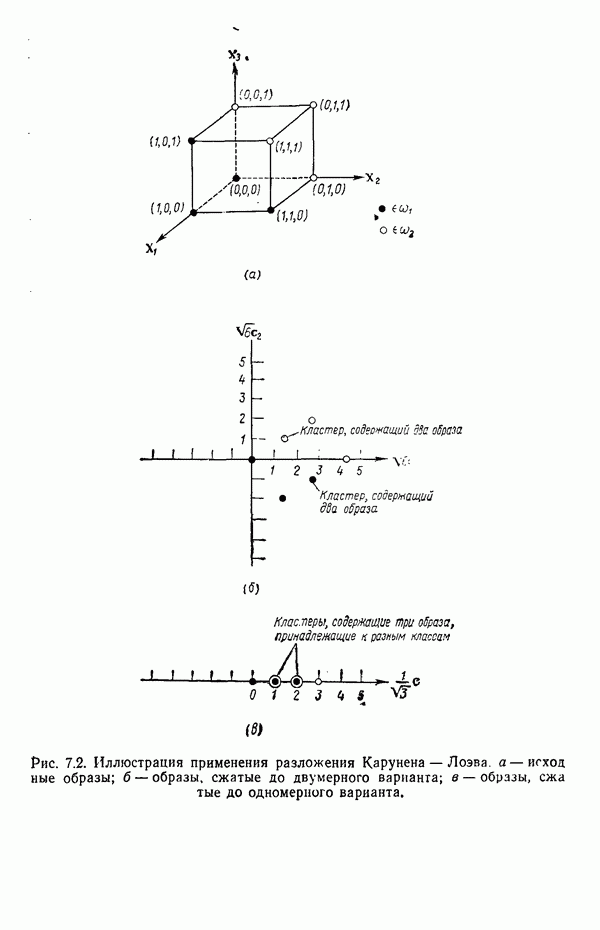
1.5. ПРИМЕРЫ АВТОМАТИЧЕСКИХ СИСТЕМ РАСПОЗНАВАНИЯ ОБРАЗОВВ последнее десятилетие возник значительный интерес к исследованию и построению систем автоматического распознавания образов и машинного обучения. Мы стали свидетелями быстрого прогресса в этой области. Примеры автоматических систем распознавания образов имеются в изобилии. Были предприняты успешные попытки создавать устройства и программы чтения наборных и напечатанных на машинке символов, обработки электрокардиограмм и электроэнцефалограмм, распознавания произнесенных слов, идентификации отпечатков пальцев и интерпретации фотоснимков. В качестве других приложений можно указать распознавание символов и слов, написанных от руки, постановку медицинского диагноза, классификацию сейсмических волн, обнаружение объектов противника, прогноз погоды, идентификацию отказов и неисправностей отдельных механизмов и целых производственных процессов. В данном параграфе рассмотрим несколько иллюстратйвных примеров, относящихся к тем областям, в которых принципы распознавания образов нашли удачное применение. Распознавание символовПримером практического использования автоматической классификации образов являются оптические устройства распознавания символов, в частности машины для считывания кодовых символов с обычных банковских чеков. Рис. 1.7. (см. скан) Комплект шрифта Е-13В Американской банковской ассоциации (American Bankers Association) и формы сигнала, соответствующие отдельным символам набора. На большинстве чеков, имеющих хождение в настоящее время в Соединенных Штатах, в качестве стилизованных символов используется стандартный комплект шрифта Е-13В Американской банковской ассоциации (American Bankers Association). Как следует из рис. 1.7, этот комплект включает 14 символов, специально адаптированных к сетчатке, содержащей тонко измельченный магнитный материал. Если символы считываются с помощью магнитного устройства, краску предварительно намагничивают, для того чтобы выделить символы из фона и способствовать, таким образом, реализации процесса считывания. Обычно символы просматриваются по горизонтали с помощью считывающей головки, снабженной одной прорезью, которая уже и выше, чем один символ. При пересечении символа головка вырабатывает электрический сигнал, величина которого пропорциональна скорости увеличения занимаемого символом пространства под сканирующей головкой. Рассмотрим в качестве примера сигнал, соответствующий цифре «0» (рис. 1.7). По мере перемещения считывающей головки слева направо площадь символа, которую видит головка, начинает увеличиваться, что приводит к положительной производной. Когда головка начинает покидать левую «стойку» нуля, площадь цифры, находящаяся в зоне видимости головки, начинает уменьшаться, что дает отрицательную производную. Когда головка находится в средней зоне символа, площадь остается постоянной и производная соответственно равна нулю. Эта закономерность повторяется, когда головка достигает правой стойки цифры, как это показано на рисунке. Мы видим, что форма символов выбрана таким образом, чтобы сигналы, соответствующие разным символам, явно отличались друг от друга. Следует отметить, что экстремальные точки и нули каждого сигнала появляются почти точно на вертикальных образующих сетки, используемой в качестве фона для изображения сигналов. Форма символов шрифта Е-13В была подобрана таким образом, чтобы выборки значений сигналов только в этих точках было достаточно для их правильной классификации. В память считывающего устройства для каждого из 14 символов шрифта введены значения, соответствующие только этим точкам. Когда символ поступает на классификацию, система сопоставляет соответствующий ему сигнал с эталонами-сигналами, заранее введенными в память, и причисляет его к классу наиболее сходного с ним эталона. При такой схеме классификации должен использоваться либо принцип перечисления членов класса, либо принцип общности свойств. Подобным образом действует большинство современных устройств, предназначенных для считывания стилизованных шрифтов. Существуют также коммерческие варианты устройств для считывания шрифтов разных типов. Так, например, система «Input 80» (рис. 1.8), разработанная компанией Recognition Equipment Incorporated, может считывать информацию, представленную в машинописном, типографском и рукописном виде, непосредственно с оригиналов документов со скоростью до 3600 символов в секунду. Словарь системы построен по модульному принципу, и его можно перестраивать, исходя из требований конкретной прикладной задачи. Одношрифтовая система способна считывать символы одного из множества известных комплектов шрифта, а многошрифтовая система позволяет работать «одновременно» с рядом типов шрифта, выбранных пользователем из множества допустимых. Одно устройство может распознавать вплоть до 360 различных символов. Система можег быть настроена и таким образом, чтобы она считывала машинописные числа, отбирала машинописные буквы и символы и считывала данные, напечатанные типографским способом. Рис. 1.8. (см. скан) Система распознавания символов «REI Input 80 Model А» компании Recognition Equipment Incorporated, Даллас, штат Техас. На рисунке представлены следующие компоненты системы (по часовой стрелке): блок распознавания, контроллер с программным управлением, печатающее устройство для ввода/вывода данных, построчно-печатающее устройство, блок распознавания, блок магнитной ленты и страничный процессор. Фотография любезно предоставлена Recognition Equipment Incorporated. Основные особенности работы системы «Input 80» REI заключаются в следующем. Страницы с помощью системы разреженных участков и воздушных эжекторов попадают на ленточный конвейер, который подает их в считывающее устройство. Здесь зеркальце, совершающее высокочастотные колебания, фокусирует луч света высокой интенсивности на символах, подлежащих считыванию; луч пересекает строку печатных символов со скоростью около 7,62 м/с. Второе, синхронизирующее, зеркальце воспринимает световые изображения, представляющие различные части символа, и проектирует их на «интегральную ретину» — считывающее устройство, выполненное на интегральной схеме; оно состоит из 96 фотодиодов, размещенных в одной кремниевой пластине длиной около 38,1 мм. Это устройство является «глазом» системы. Интегральная ретина кодирует каждый символ, представляя его с помощью матрицы 16X12 ячеек, стандартизует символы, производит коррекцию в соответствии с вариациями их размера, действуя со скоростью до 3600 символов в секунду. Интегральная ретина, кроме того, классифицирует каждую ячейку представления каждого символа в соответствии с принадлежностью к одному из 16 уровней зачерненности. Данные с выхода считывающего устройства передаются в блок распознавания, в котором уровни зачерненности всех ячеек изображения символа сравниваются с уровнями зачерненности 24 соседних ячеек; для этого используется соответствующая схема усиления видеосигнала. Полученные в результате этой операции данные подвергаются квантованию, что приводит к получению однобитового черно-белого изображения. Этот процесс позволяет сгладить изображение символа, насытить малозаметные штрихи, устранить пятна и повысить контрастность при зашумленном фоне. Система распознает символы, набранные типографским способом, отыскивая наименьшее рассогласование между прочитанным символом и символами, включенными в словарь блока распознавания. Система также удостоверяется в том, что найденное минимальное рассогласование отличается на достаточную величину от наиболее близкого к нему рассогласования с другим символом словаря. Соответствующий метод осуществления классификации будет рассмотрен в гл. 3. Распознавание машинописных символов производится с помощью логической процедуры иного типа. Машинописные символы не сопоставляются с образами, заранее введенными в память, а анализируются с точки зрения наличия определенных общих признаков, таких, как искривленные, горизонтальные и вертикальные линии, углы и пересечения. В этом случае классификация символа проводится на основе обнаружения у него определенных признаков, а также их взаимосвязей. Блоки системы распознавания символов представлены на рис. 1.8, их названия даны в подписи под рисунком. Автоматическая классификация данных, полученных дистанционноСравнительно недавно возникший в Соединенных Штатах интерес к качеству окружающей среды и состоянию природные ресурсов вызвал к жизни множество приложений методов распознавания образов. Наибольшее внимание среди них привлекает автоматическая классификация данных, полученных дистанционно. Поскольку объем данных, получаемых от многодиапазонных спектральных развертывающих устройств, установленных на самолетах, спутниках и космических станциях, чрезвычайно велик, возникла необходимость обратиться к автоматическим средствам обработки и анализа этой информации. Дистанционный сбор данных используется при решении различных задач. Среди областей, вызывающих интерес в настоящее время, можно отметить землепользование, оценку урожая, выявление заболеваний сельскохозяйственных культур, лесоводство, контроль качества воздуха и воды, геологические и географические исследования, прогноз погоды и массу других задач, связанных с охраной окружающей среды. В качестве примера автоматической классификации результатов спектрального исследования рассмотрим рис. 1.9, а, на котором приведена цветная фотография земной поверхности, сделанная с самолета. Изображение представляет небольшой участок по маршруту полета (несколько миль), расположенный в центральном районе штата Индиана. Цель заключается в сборе данных, достаточных для обучения машины автоматическому опознаванию различных типов напочвенного покрова (классов), например светлый или темный почвенный слой, речная или прудовая вода, и стадии созревания зеленой растительности. Многодиапазонное развертывающее устройство реагирует на свет с определенными полосами длин волн. Развертывающее устройство, использованное в упоминавшемся полете, работает в полосах длин волн На основе спектральных данных, полученных во время рассматриваемого полета, построен байесовский классификатор для образов, подчиняющихся нормальному распределению (см. § 4.3). На рис. 1.9,б приведена машинная выдача результатов
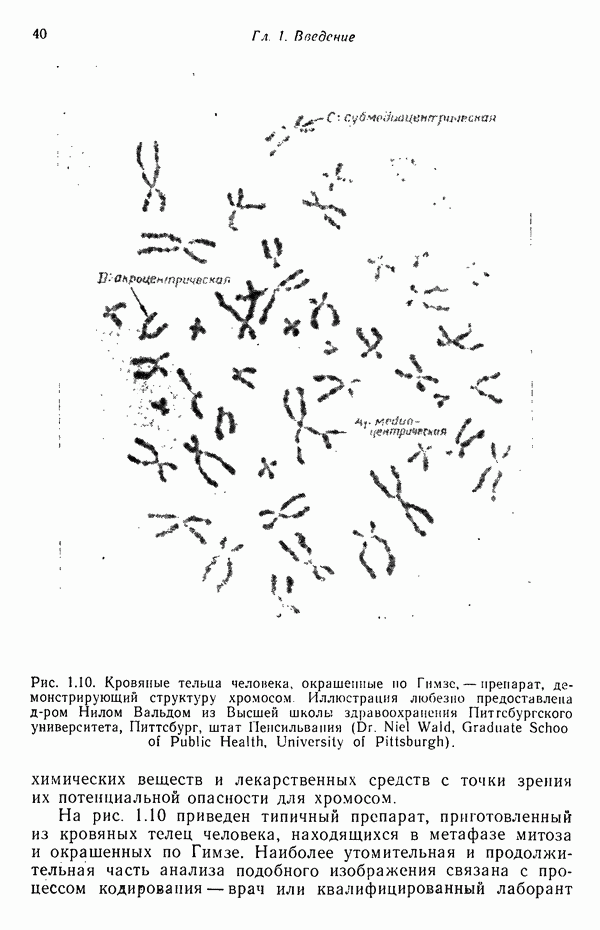
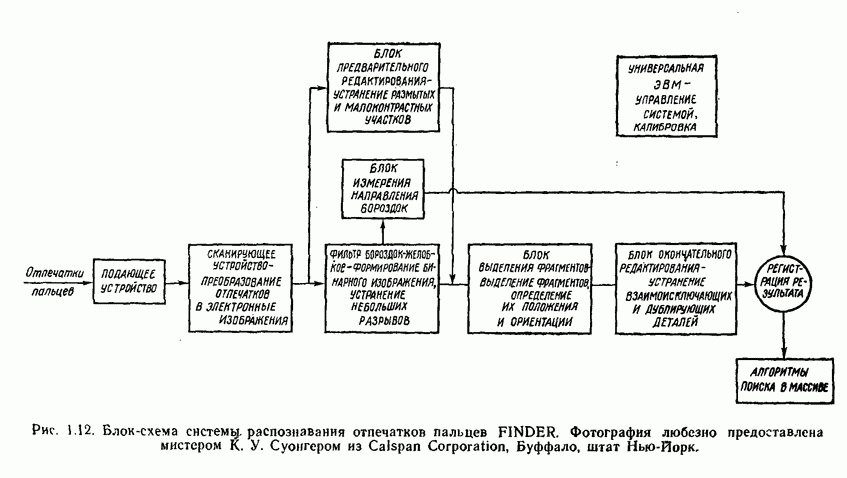
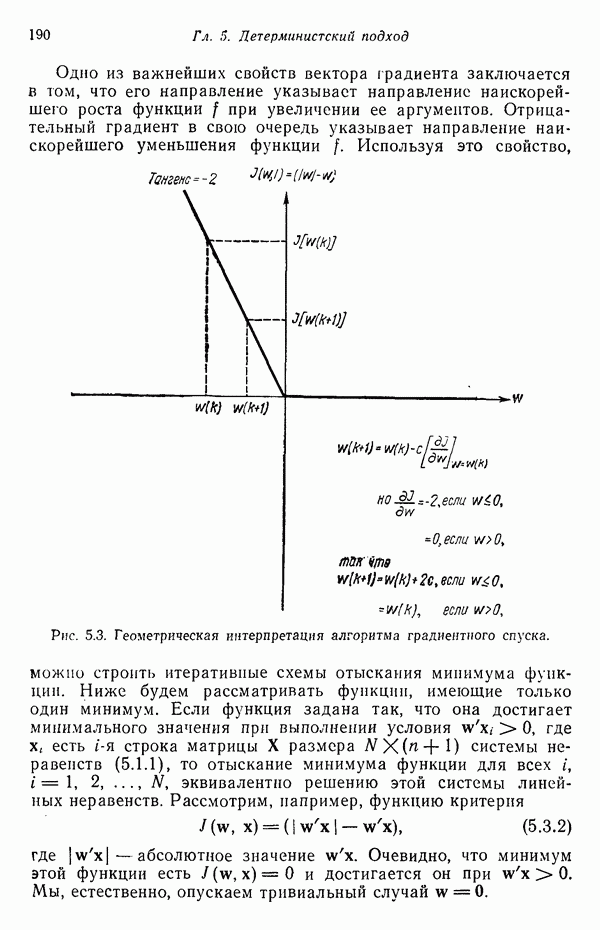
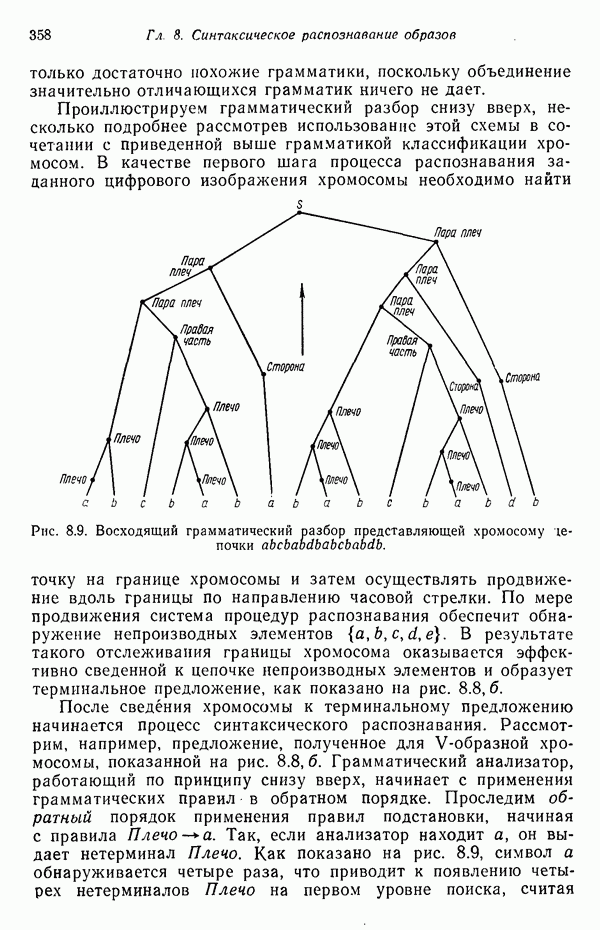
(кликните для просмотра скана) применения такого классификатора для автоматической классификации миогодиапазонных спектральных данных, соответствующих небольшому участку земной поверхности, представленному на рис. 1.9, а. Стрелками отмечены некоторые признаки, представляющие специальный интерес. Стрелка 1 помещена в углу поля зеленой растительности, стрелка 2 обозначает реку. Стрелкой 3 отмечена небольшая живая изгородь, разделяющая два участка обнаженной почвы; эти объекты точно идентифицированы на распечатке. Приток, который также правильно идентифицирован, отмечен стрелкой 4. Стрелка 5 указывает на очень маленький пруд, который на цветной фотографии почти неразличим. При сопоставлении исходного изображения с результатами машинной классификации становится очевидно, что последние весьма точно соответствуют тем выводам, к которым пришел бы человек, интерпретируя исходную фотографию визуально. Биомедицинские приложенияКак отмечалось в § 1.1, медицина в настоящее время сталкивается с серьезными проблемами, связанными с обработкой информации. Методы распознавания образов с переменным успехом применялись для автоматической обработки данных, полученных с помощью различных технических средств, применяемых в медицинской диагностике, например, таких, как рентгенограммы, электрокардиограммы, электроэнцефалограммы, и анализа и интерпретации вопросников, заполняемых пациентами. Одной из задач, которым уделялось много внимания, является автоматизация анализа и классификации хромосом. Интерес к автоматизации анализа хромосом вызван тем обстоятельством, что автоматизация цитогенетического анализа расширит возможности использования хромосомных исследований в клинической диагностике. Кроме того, это сделает возможным проведение крупномасштабных профилактических популяционных исследований с тем, чтобы оценить патологическое влияние ряда небольших вариаций хромосомного портрета, воздействие которых в настоящее время неизвестно. К тому же возможность обследовать большие группы населения позволит провести и ряд других ценных медицинских исследований, например поголовное цитогенетическое обследование плода до рождения и новорожденных с целыо определения необходимости профилактического или лечебного воздействия, скрининг отдельных групп людей, выделенных по факторам профессиональной принадлежности или проживания в определенном районе и отличающихся повышенной хромосомной аберрацией, вызванной каким-либо вредным воздействием, или проверка новых Рис. 1.10. (см. скан) Кровяные тельца человека, окрашенные но Гимзе,— препарат, демонстрирующий структуру хромосом. Иллюстрация любезно предоставлена д-ром Нилом Вальдом из Высшей школы здравоохранения Питгсбургского университета, Питтсбург, штат Пенсильвания (Dr. Niel Wald, Graduate Schoo of Public Health, University of Pittsburgh). химических веществ и лекарственных средств с точки зрения их потенциальной опасности для хромосом. На рис. 1.10 приведен типичный препарат, приготовленный из кровяных телец человека, находящихся в метафазе митоза и окрашенных по Гимзе. Наиболее утомительная и продолжительная часть анализа подобного изображения связана с процессом кодирования — врач или квалифицированный лаборант должен классифицировать каждую хромосому отдельно. На рисунке представлены объекты, относящиеся к некоторым типичным классификационным группам, Для машинной классификации хромосом предложено множество методов. Один из подходов, который оказался эффективным при классификации хромосом типов, представленных на рис. 1.10, основан на принципе синтаксического распознавания образов, обсуждаемом в гл. 8. Суть этого подхода заключается в следующем. Выделяются непроизводные элементы образа типа длинных дуг, коротких дуг и полупрямых отрезков, обозначающих границы хромосомы. Объединение таких иепроизводных элементов приводит к цепочкам или предложениям, составленным из некоторых символов; последние могут быть поставлены в соответствие так называемой грамматике образов. Каждому типу (классу) хромосом соответствует своя грамматика. Для того чтобы опознать конкретную хромосому, вычислительная машина прослеживает ее границы и порождает цепочку, составлепную из непроизводпых элементов. Основой алгоритма слежения обычно является эвристическая процедура, позволяющая разрешить трудности, связанные с смежностью и перекрытием хромосом. Полученная таким образом цепочка вводится в распознающую систему, которая определяет, представляет ли она собой правильное предложение, составленное из символов согласно правилам некоторой грамматики. Если этот процесс приводит к указанию одной определенной грамматики, хромосома зачисляется в класс, соответствующий этой грамматике. Если подобный процесс не позволяет получить однозначное толкование либо вообще заканчивается неудачей, работа системы с данной хромосомой прекращается и дальнейший анализ выполняется оператором. Хотя решение задачи автоматического распознавания хромосом в общем виде найдено не было, современные распознающие системы, использующие синтаксический подход, представляют собой важный шаг в нужном направлении. В § 8.5 мы вернемся к этой схеме распознавания и подробно рассмотрим соответствующую хромосомную грамматику. Распознавание отпечатков пальцевКак мы отмечали в § 1.1, правительственные агентства располагают архивами, в которых хранятся свыше 200 миллионов отпечатков пальцев. Отдел идентификации (The Identification Division) Федерального Бюро Расследований располагает, в частности, самым большим в мире архивом отпечатков пальцев — свыше 160 миллионов. Ежедневно в отдел поступает до 30 тысяч запросов. Для того чтобы справиться с таким объемом работы, около 1400 технических специалистов и чиновников должны тщательно классифицировать новые отпечатки и затем педантично искать совпадения. В течение ряда лет ФБР проявляло интерес к разработке автоматической системы идентификации отпечатков пальцев. Примером усилий, предпринятых в этом направлении, служит система-прототип FINDER, разработанная компанией Calspan Corporation по заданию ФБР. Эта система автоматически обнаруживает и локализует признаки, характерные для отпечатка. Признаки, которые обнаруживает система, — это не крупные структурные элементы типа дуг, контуров или завитков, используемых в процессе первичной классификации отпечатков, — это скорее мелкие детали — концы и разветвления бороздок, аналогичные изображенным на рис. 1.11.
Рис. 1.11. Фрагменты — концы бороздок (квадраты) и разветвления (окружности) На рис. 1.12 приведена блок-схема системы. Вкратце действие системы FINDER можно описать следующим образом. Оператор вводит стандартный бланк отпечатка в автоматическое входное устройство, которое доставляет отпечаток к «глазу» системы — развертывающему устройству и точно размещает под ним отпечаток. Каждый отпечаток подвергается квантованию и представляется матрицей, содержащей 750X750 точек, причем каждая точка кодируется одним из 16 возможных уровней зачерненности. Процесс сканирования осуществляется под управлением универсальной вычислительной машины. На рис. 1.13 приведен пример, показывающий, какой вид принимает отпечаток, пройдя развертывающее устройство. Данные, полученные на выходе развертывающего устройства, вводятся в фильтр бороздок-желобков, который реализуется С помощью быстродействующего алгоритма параллельной обработки двумерных объектов; этот алгоритм последовательно осматривает все точки матрицы 750X750. На выходе фильтра воспроизводится усиленное бинарное изображение типа приведенного на рис. 1.14. Этот же алгоритм фиксирует направление бороздок в каждой точке отпечатка; данная информация используется в процессе дальнейшей обработки.
(кликните для просмотра скана) При обработке большинства отпечатков в некоторых зонах не удается выделить достаточно четкую структуру бороздок, обеспечивающую возможность надежного выявления фрагментов. Устройство предварительного редактирования исключает такие участки из дальнейшего анализа в качестве источников достоверной информации. Чтобы обеспечить надежное обнаружение фрагментов, используются тесты на белизну, черноту, недостаточность структуры бороздок или контрастности.
Рис. 1.13. Распечатка участка, полученного на выходе сканирующего устройства. На этом цифровом изображении черные элементы представлены цифрой «0», а белые — «15». Иллюстрация любезно предоставлена мистером К. У. Суонгером из Calspan Corporation, Буффало, штат Нью-Йорк. Следующий этап обработки отпечатков посвящен практическому выделению фрагментов. Этот процесс реализуется с помощью алгоритма, синхронизированного с выходом фильтра бороздок-желобков. Он выделяет фрагменты, предположительно являющиеся характерными признаками, и регистрирует их положение и величины соответствующих углов. Результаты работы блока выделения фрагментов вводятся в блок окончательного редактирования. В первую очередь площадь и периметр выбранного фрагмента сопоставляются с пороговыми значениями, соответствующими истинным признакам, Что позволяет исключить заведомо неверные данные. Далее Исключаются признаки-дубликаты. Если какой-либо частный фрагмент обнаружен несколько раз, то сохраняется только обнаруженне наибольшей длины. Использование цепной процедуры, при которой объектом поиска являются только фрагменты, соседние с выделенными, существенно сокращает время обработки. Далее производится удаление взаимоисключающих фрагментов и фрагментов, появление которых связано с разрывами в структуре бороздок. После этого список признаков свободен от фрагментов, форма и качество которых лежат ниже определенного порога.
Рис. 1.14. Результаты пропуска данных, представленных на рис. 1.13, через фильтр бороздок-желобков. В данном случае черные точки представлены символами «г». Иллюстрация любезно предоставлена мистером К. У. Суонгером из Calspan Corporation, Буффало, штат Нью-Йорк. На последнем этапе процесса окончательного редактирования определяется, относится ли признак к кластеру признаков либо соответствующий угол существенно отличается от локальной ориентации структуры бороздок. Кластерный тест исключает из рассмотрения группы признаков такого типа, как, например, появившиеся из-за шрама на пальце. Если рядом с анализируемым признаком обнаруживаются признаки, число которых превышает определенную величину, данный признак как ложный из дальнейшего анализа исключается. Если признак проходит последний тест, то логическая часть системы переходит к реализации теста на аномальность угла, используя набор данных (матрицу) о направлении бороздок, собранных в процессе предварительной обработки. В зависимости от величины отклонения от среднего угла бороздки признак оставляется, отвергается или, если отклонение невелико, угол корректируется в соответствии со средним значением углов соседних бороздок. Окончательно около 2500 битов данных, представляющих признаки, которые выдержали все тесты, предусмотренные блоком окончательного редактирования, записываются на магнитную ленту с тем, чтобы можно было приступить к их сопоставлению с признаками отпечатков, находящихся в архиве. Применение методов распознавания образов в техническом надзоре за состоянием узлов ядерного реактораЭтот последний пример относится к сравнительно новой области применения принципов распознавания образов. В схемы энергетических ядерных установок включаются многочисленные датчики, обеспечивающие контроль за целостностью работы установки. В частности, в сфере контрольно-измерительной техники широкое распространение получил нейтронный регистратор. Прибор этот, предназначенный для измерения плотности нейтронов, генерирует сигнал, зависящий также и от механических колебаний, которые происходят в реакторе. Одна из основных целей применения этого регистратора в ядерном реакторе заключается в обнаружении на возможно более ранней стадии любых режимов внутренних колебаний, не характерных для нормальных эксплуатационных условий реактора. В настоящее время в области анализа шумов (нейтронных, акустических, тепловых и т. п.) наибольший интерес вызывает создание таких систем технического контроля, которые обеспечивают слежение за режимом работы установки в целом, по меньшей мере частично автоматизированы и обладают возможностями адаптироваться к изменениям режима, не связанным с отклонением от нормы. Системы управления воспроизводят информацию в огромных объемах, которая, для того чтобы ею можно было воспользоваться, должна обрабатываться с помощью каких-либо систематических процедур. Хотя в данное время это обстоятельство не приводит к возникновению каких-либо реальных сложностей, поскольку к моменту написания книги в Соединенных Штатах действовало не более 50 энергетических ядерных установок, по оценкам Комиссии по атомной энергии к 2000 году количество таких установок только в Соединенных Штатах превысит 1000. Естественно, придется создать методы автоматической обработки информации, воспроизводимой многочисленными системами управления, которые будут входить в состав подобных ядерных энергетических установок. Хотя распознавание в этой области только начинает делать первые шаги, его потенциальные возможности уже полностью определились. Ниже мы кратко опишем основные результаты, полученные в этом направлении.
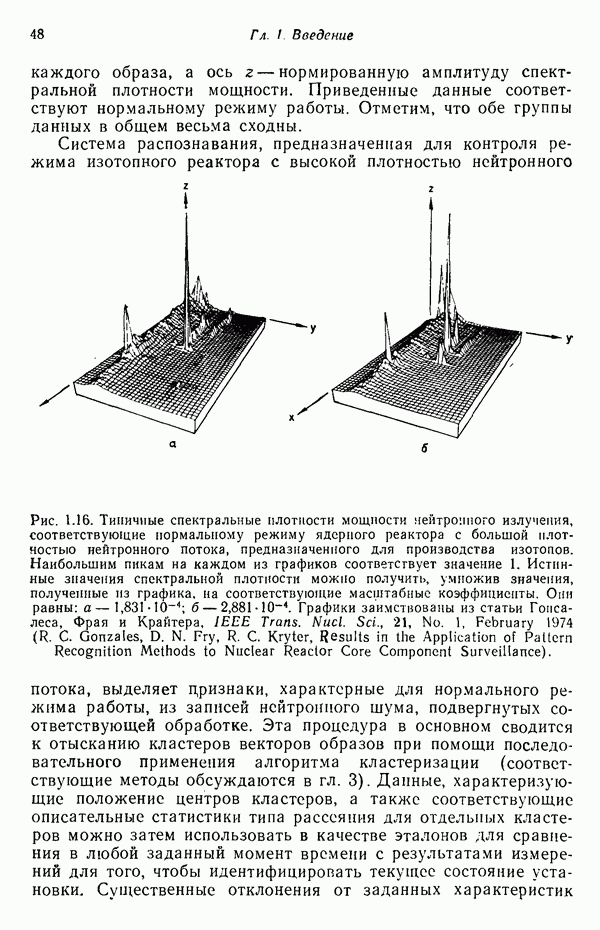
Рис. 1.15 Основные компоненты автоматической системы анализа шума. На рис. 1.15 приведены основные компоненты автоматической системы управления. Представляющие шум сигналы, поступающие от датчиков, которые установлены в энергетической ядерной установке, нормируются, подвергаются предварительной обработке и вводятся в систему распознавания образов. На выходе этой системы воспроизводится решение, характеризующее текущее состояние установки. В нашем случае речь идет о ядерном реакторе с большой плотностью нейтронного потока, предназначенном для производства изотопов: реактор установлен в Окриджской национальной лаборатории (Oak Ridge National Laboratory). В качестве исходных данных для контроля за режимом этого реактора используются результаты измерений нейтронного шума, которые проводятся в среднем трижды в день. Топливный цикл (промежуток времени между перезарядкой топливных элементов) составляет обычно при работе с полной мощностью 22 дня. Блок предварительной обработки на основании этих данных определяет спектральную плотность мощности в диапазоне частот от 0 до 31 Гц с интервалом в 1 Гц. Следовательно, результаты каждого измерения можно представить 32-мерным вектором образа Данные для двух топливных циклов изотопного реактора с большой плотностью нейтронного потока приведены в трехмерной системе координат на рис. 1.16, а и б. Ось каждого образа, а ось z — нормированную амплитуду спектральной плотности мощности. Приведенные данные соответствуют нормальному режиму работы. Отметим, что обе группы данных в общем весьма сходны.
Рис. 1.16. Типичные спектральные плотности мощности нейтронного излучения, соответствующие нормальному режиму ядерного реактора с большой плотностью нейтронного потока, предназначенного для производства изотопов. Наибольшим пикам на каждом из графиков соответствует значение 1. Истинные значения спектральной плотности можно получить, умножив значения, полученные из графика, на соответствующие масштабные коэффициенты. Они равны: Система распознавания, предназначенная для контроля режима изотопного реактора с высокой плотностью нейтронного потока, выделяет признаки, характерные для нормального режима работы, из записей нейтронного шума, подвергнутых соответствующей обработке. Эта процедура в основном сводится к отысканию кластеров векторов образов при помощи последовательного применения алгоритма кластеризации (соответствующие методы обсуждаются в гл. 3). Данные, характеризующие положение центров кластеров, а также соответствующие описательные статистики типа рассеяния для отдельных кластеров можно затем использовать в качестве эталонов для сравнения в любой заданный момент времени с результатами измерений для того, чтобы идентифицировать текущее состояние установки. Существенные отклонения от заданных характеристик нормального режима работы служат индикаторами возникновения аномального процесса. На рис. 1.17, а и б, например, приведен образ поведения реактора, который можно легко классифицировать как резко отличающийся от нормального рабочего режима. Приведенные данные соответствуют случаю поломки направляющего подшипника одного из механических узлов, расположенных вблизи активной зоны реактора. Хотя выявленные отклонения и не создают ситуации, представляющей непосредственную опасность, подобные результаты демонстрируют потенциальную важность использования методов распознавания образов в качестве составной части системы мероприятий, обеспечивающих технический надзор за состоянием энергетической ядерной установки. Дополнительные детали, относящиеся к этой проблеме, можно почерпнуть из статьи Гонсалеса, Фрая и Крайтера [1974].
Рис. 1.17. Спектральные плотности, соответствующие аномальному поведению ядерного реактора с большой плотностью нейтронного потока, предназначенного для производства изотопов. Масштабные коэффициенты в данном случае равны:
|
 |
Оглавление
|


















































































































































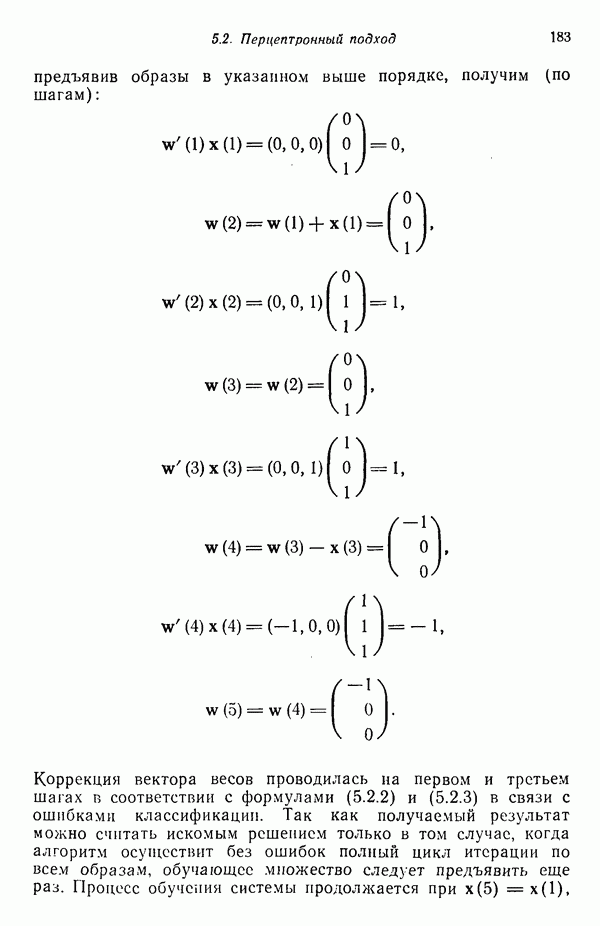





























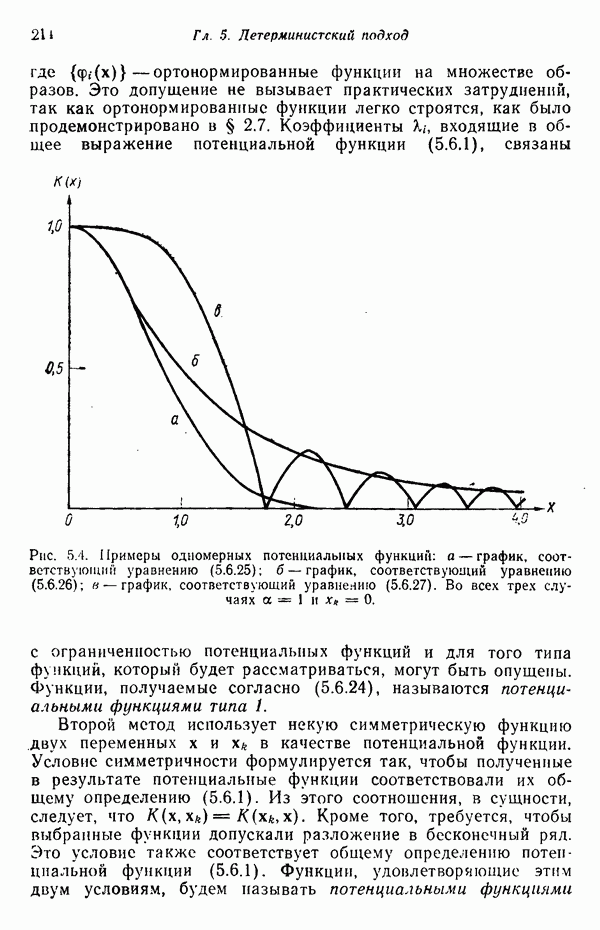

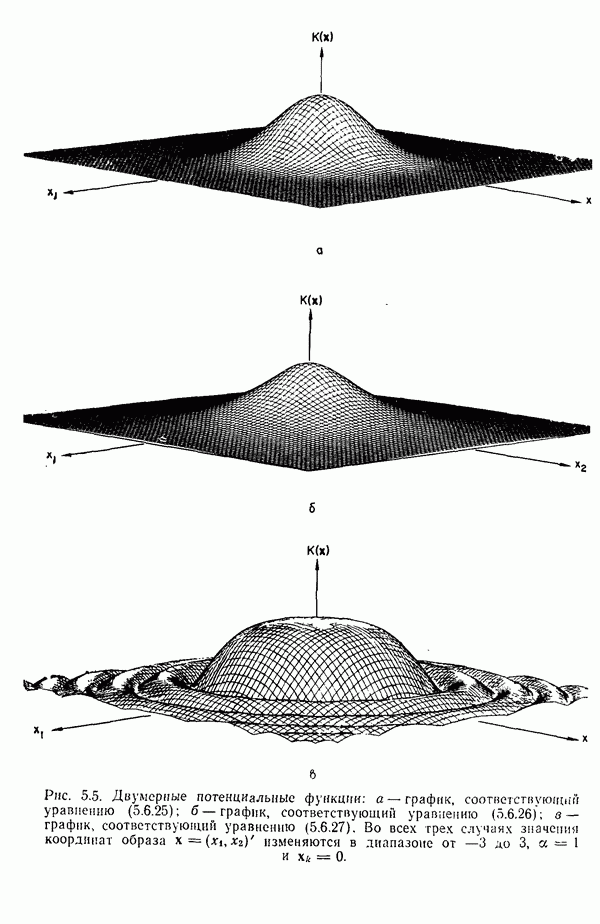
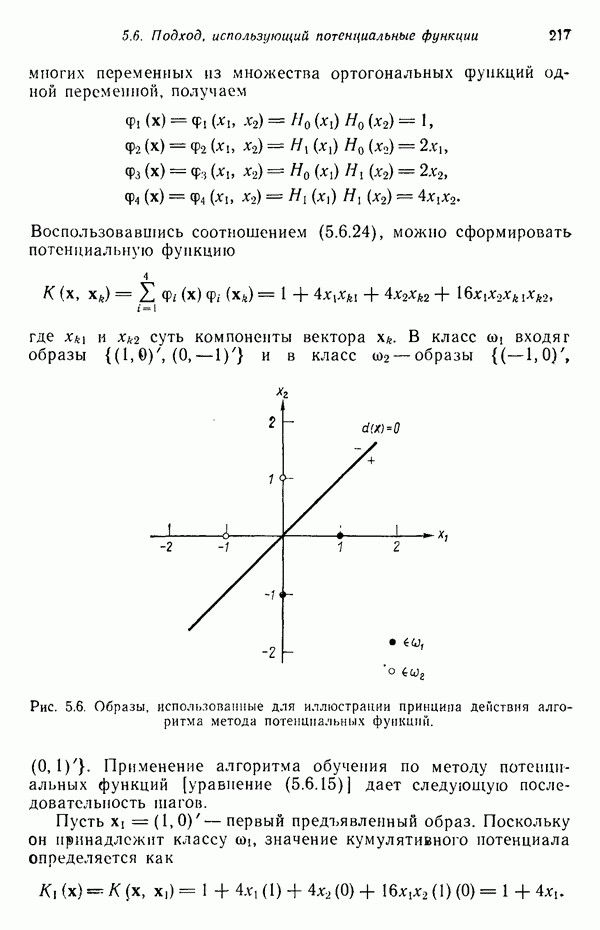
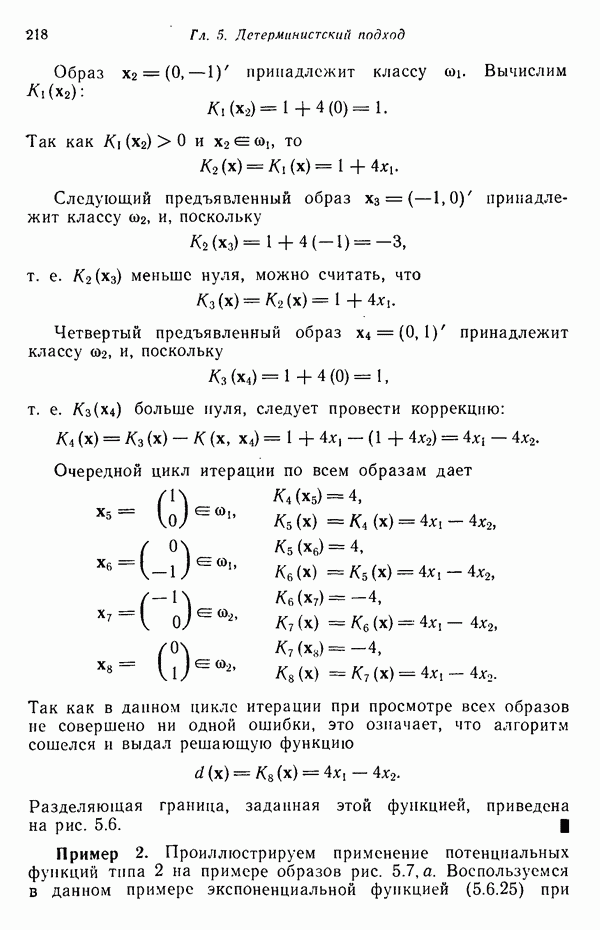
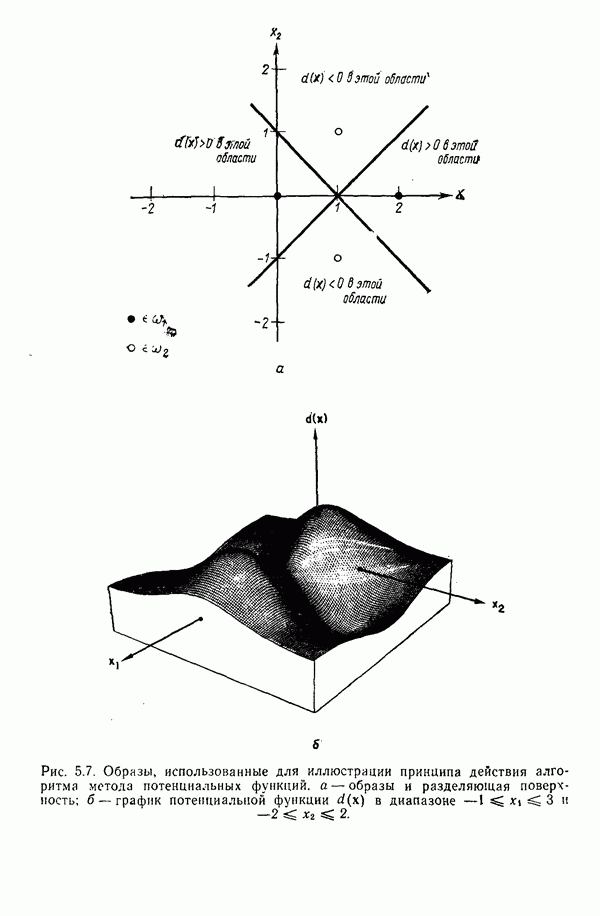



































































































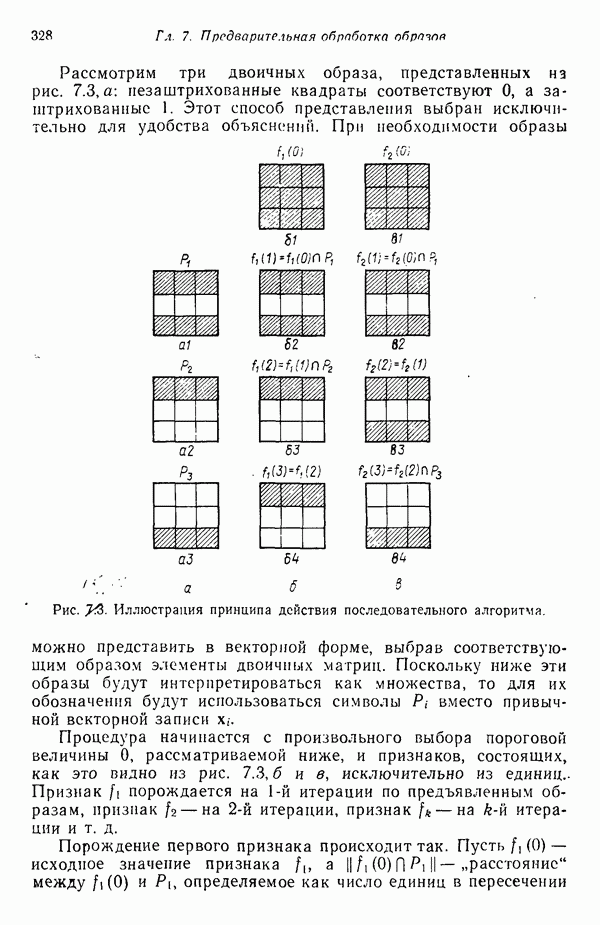



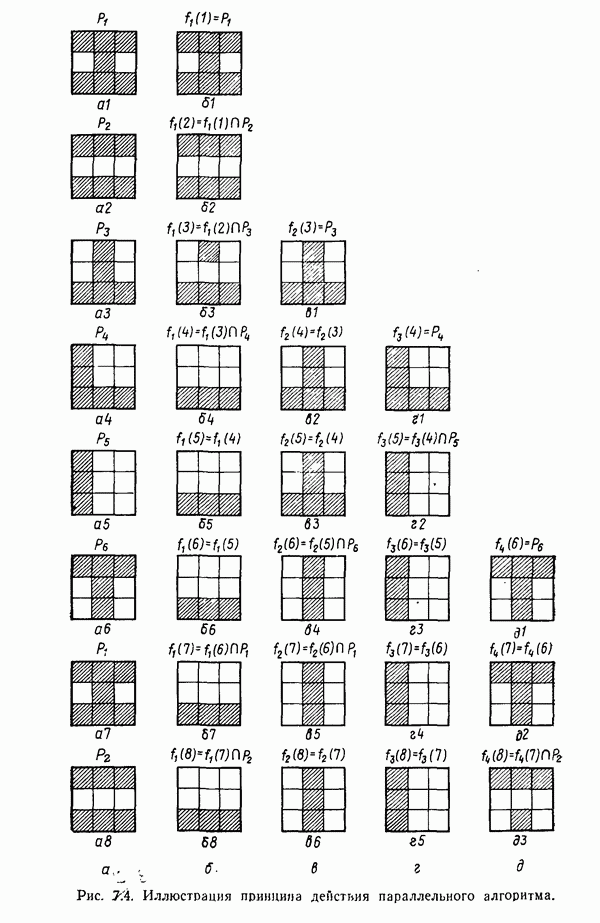




























































 участков, с тем чтобы упростить процесс считывания. Эти символы обычно наносятся особой типографской краской, которая содержит очень
участков, с тем чтобы упростить процесс считывания. Эти символы обычно наносятся особой типографской краской, которая содержит очень
 микрон. Эти диапазоны относятся к фиолетовой, зеленой, красной и инфракрасной областям соответственно. Использование такого метода приводит к получению для одного участка земной поверхности четырех изображений — по одному на каждую цветовую область. Следовательно, каждая точка участка характеризуется четырьмя компонентами, представляющими цвет. Информацию по каждой точке можно представить четырехмерным вектором образа
микрон. Эти диапазоны относятся к фиолетовой, зеленой, красной и инфракрасной областям соответственно. Использование такого метода приводит к получению для одного участка земной поверхности четырех изображений — по одному на каждую цветовую область. Следовательно, каждая точка участка характеризуется четырьмя компонентами, представляющими цвет. Информацию по каждой точке можно представить четырехмерным вектором образа  , где
, где  — оттенок фиолетового цвета,
— оттенок фиолетового цвета,  — оттенок зеленого и т. д. Набор образов, относящихся к определенному классу почвенного слоя, составляет обучающее множество для этого класса. Эти обучающие образы можно затем использовать при построении классифицирующего устройства.
— оттенок зеленого и т. д. Набор образов, относящихся к определенному классу почвенного слоя, составляет обучающее множество для этого класса. Эти обучающие образы можно затем использовать при построении классифицирующего устройства.


 — используемые системой FINDER при идентификации отпечатков пальцев. Фотография любезно предоставлена мистером К. У. Суонгером из Calspan Corporation, Буффало, штат Нью-Йорк.
— используемые системой FINDER при идентификации отпечатков пальцев. Фотография любезно предоставлена мистером К. У. Суонгером из Calspan Corporation, Буффало, штат Нью-Йорк.




 , где
, где  — амплитуда спектральной плотности мощности излучения на частоте 0 Гц,
— амплитуда спектральной плотности мощности излучения на частоте 0 Гц,  — амплитуда на частоте 1 Гц и т. д. Задача в таком случае сводится к построению системы распознавания образов, способной автоматически анализировать подобные образы.
— амплитуда на частоте 1 Гц и т. д. Задача в таком случае сводится к построению системы распознавания образов, способной автоматически анализировать подобные образы.
 характеризует время топливного цикла, ось у представляет 32 компоненты
характеризует время топливного цикла, ось у представляет 32 компоненты

 . Графики заимствованы из статьи Гонсалеса, Фрая и Крайтера, IEEE Trans. Nucl. Sci., 21, No. 1, February 1974 (R. C. Gonzales, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).
. Графики заимствованы из статьи Гонсалеса, Фрая и Крайтера, IEEE Trans. Nucl. Sci., 21, No. 1, February 1974 (R. C. Gonzales, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).

 . Графики заимствованы из статьи Гонсалеса, Фрая и Крайтера, IEEE Trans. Nucl. Sci., 21, No. 1, February 1974 (R. C. Gonzalez, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).
. Графики заимствованы из статьи Гонсалеса, Фрая и Крайтера, IEEE Trans. Nucl. Sci., 21, No. 1, February 1974 (R. C. Gonzalez, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).