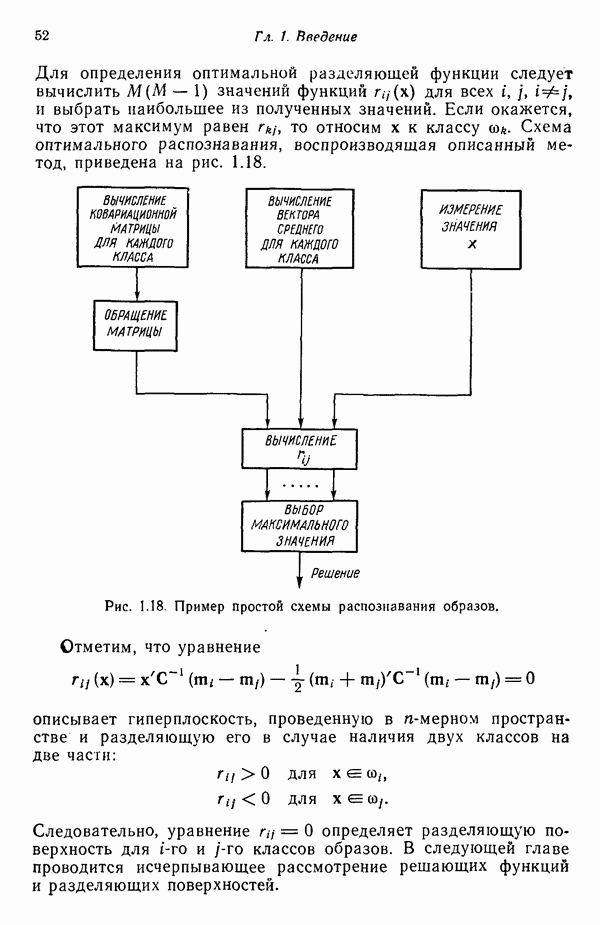
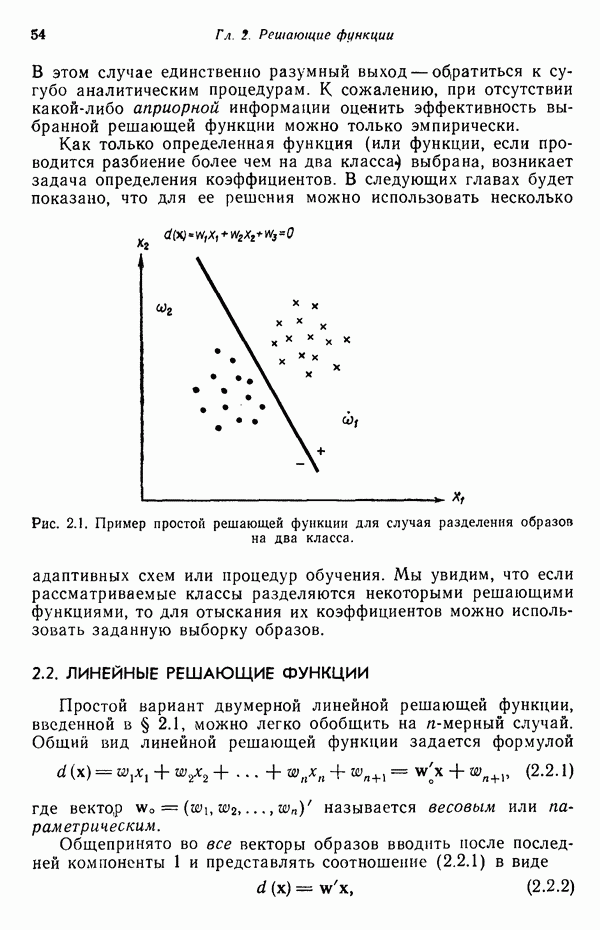
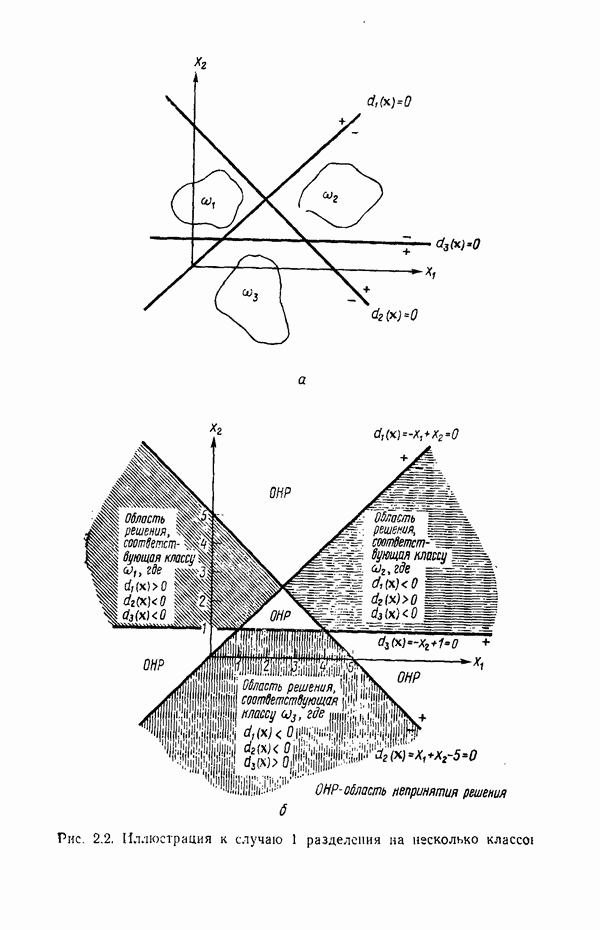
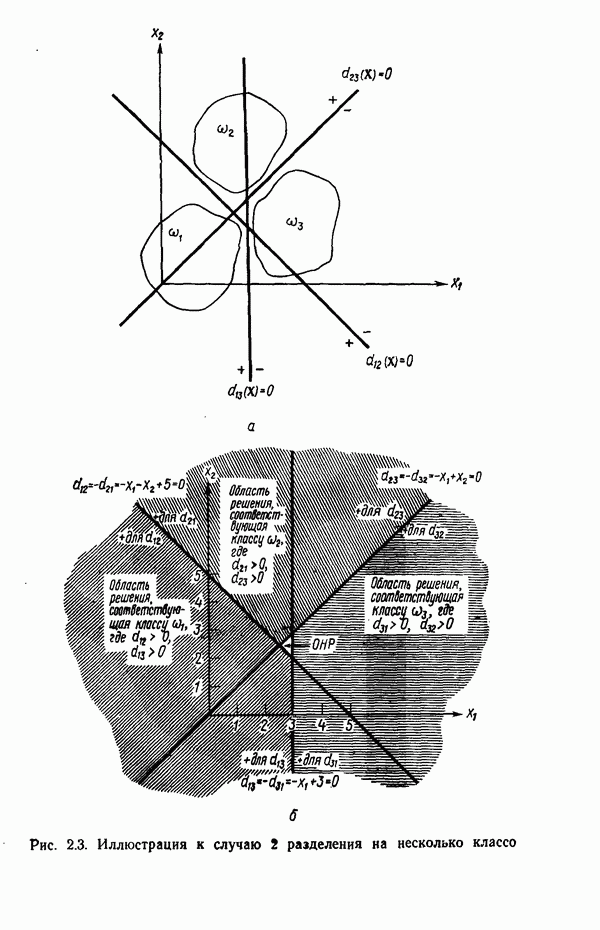
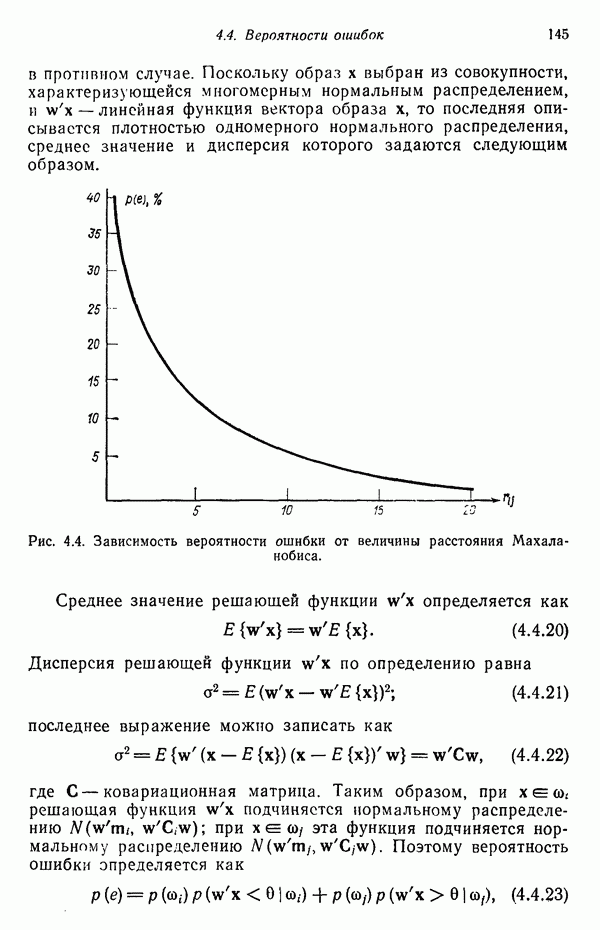
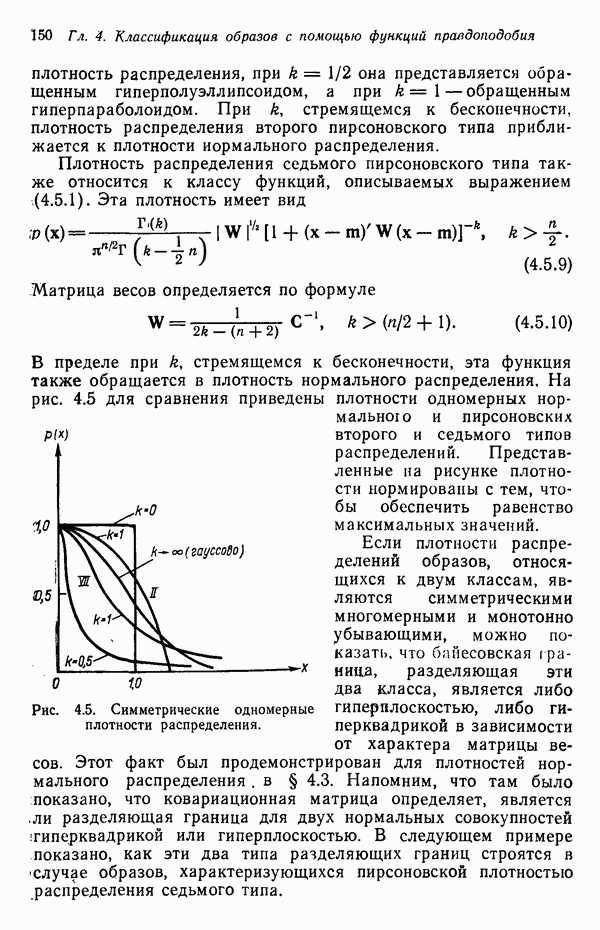
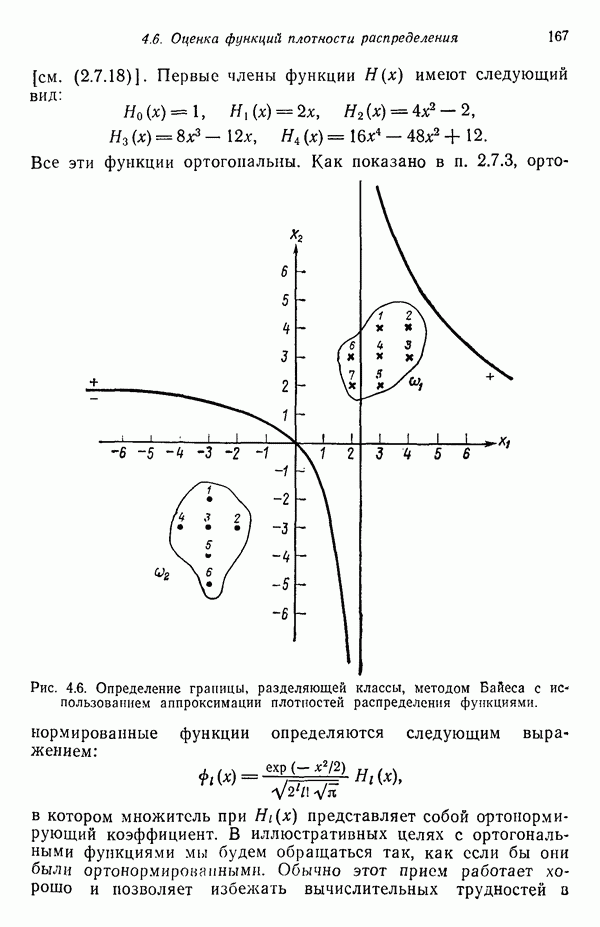
Пред.
След.
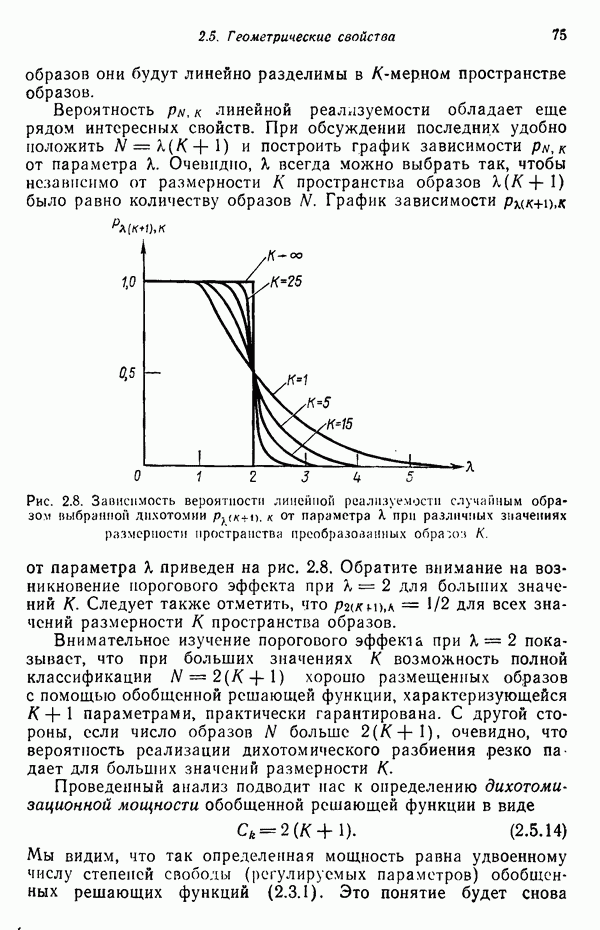
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
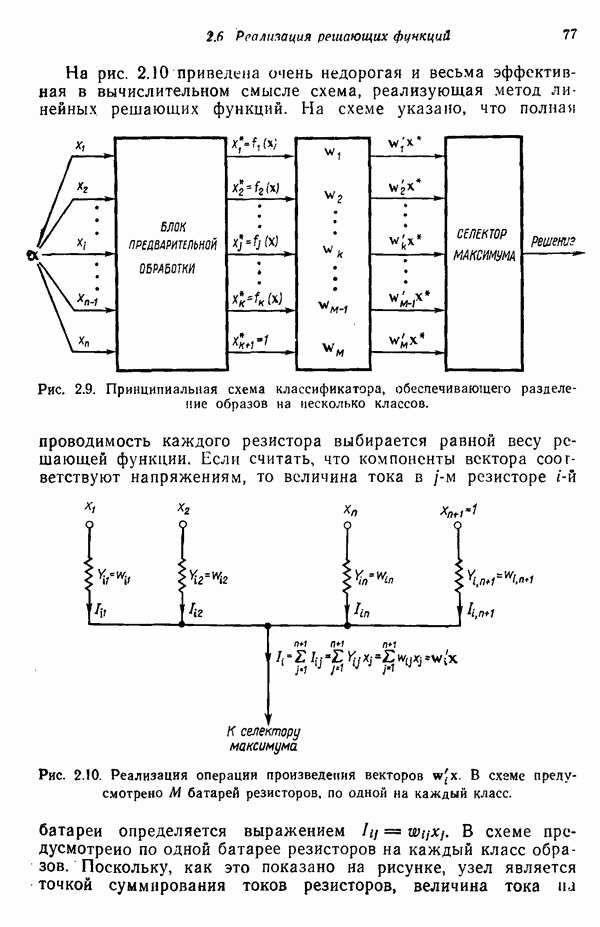
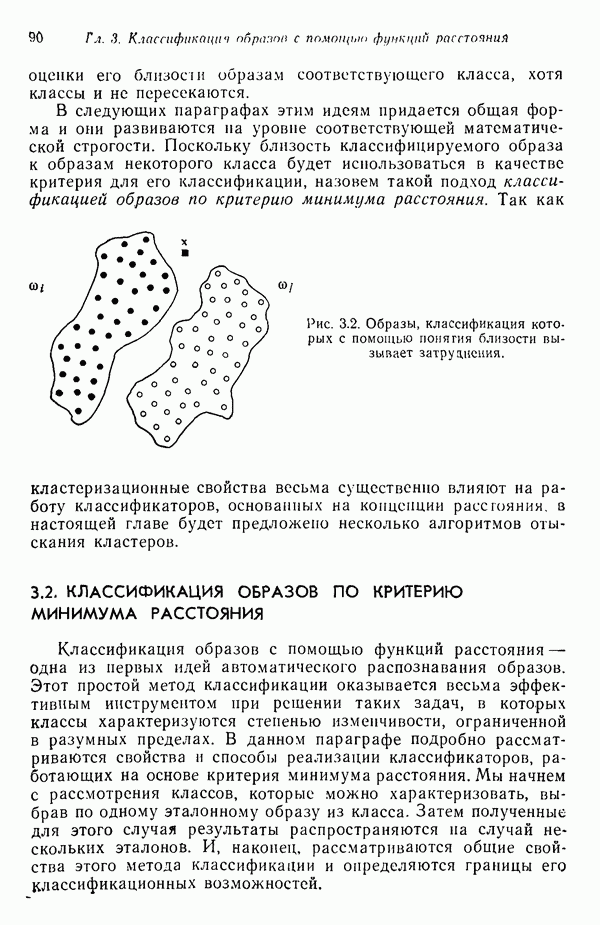
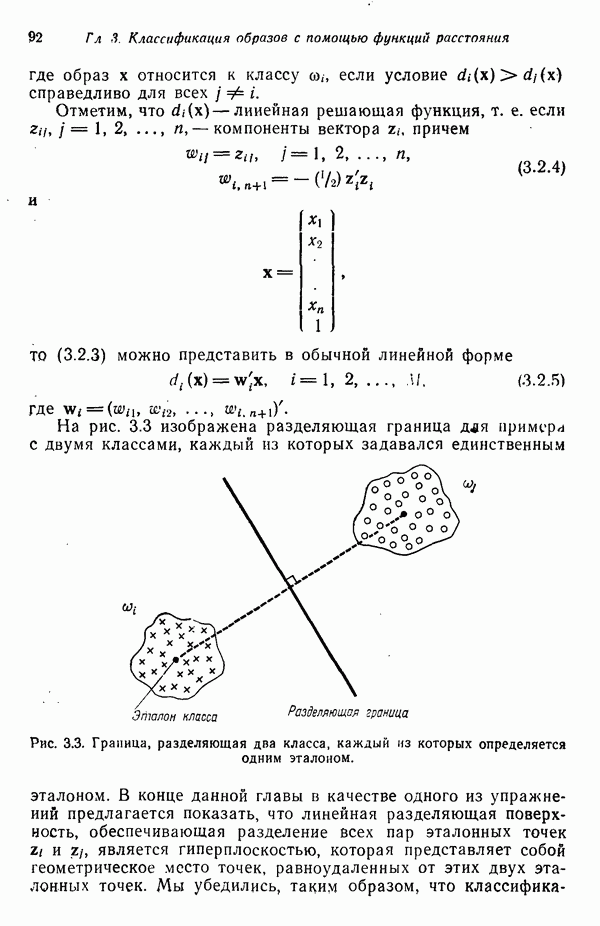
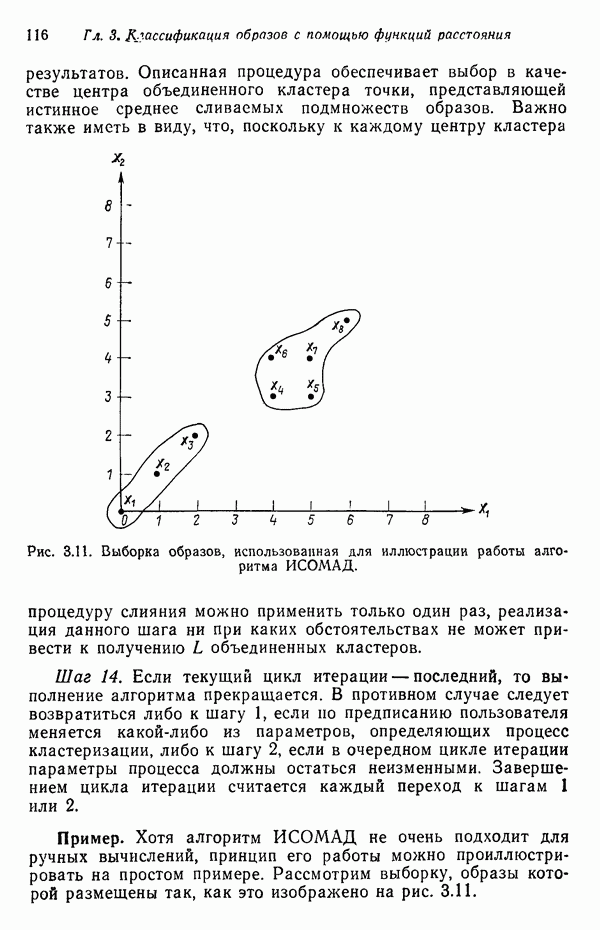
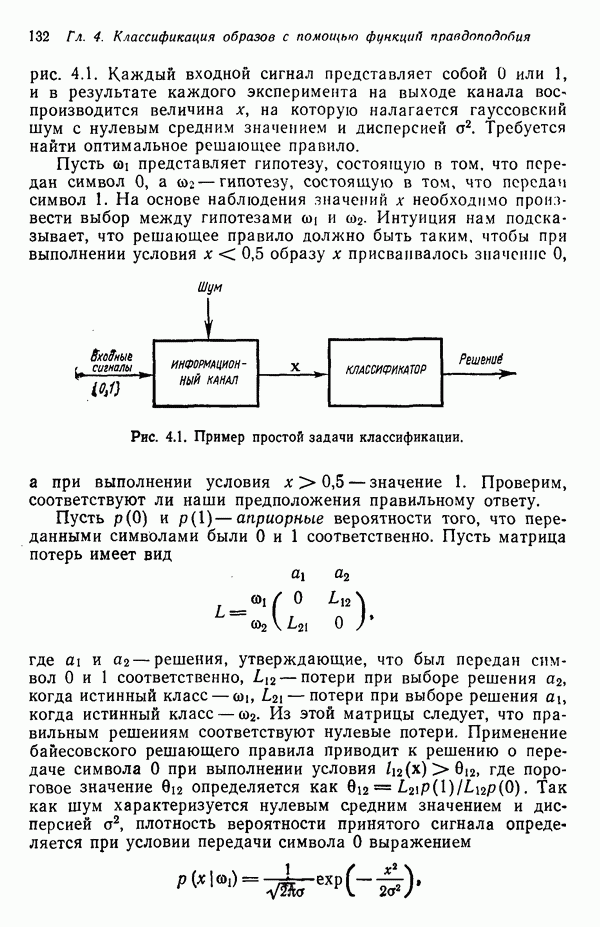
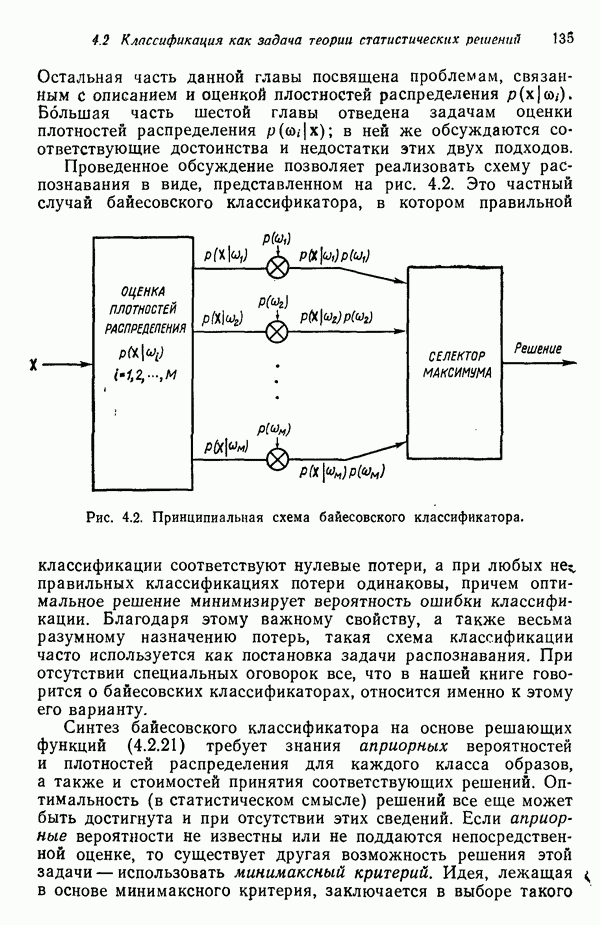
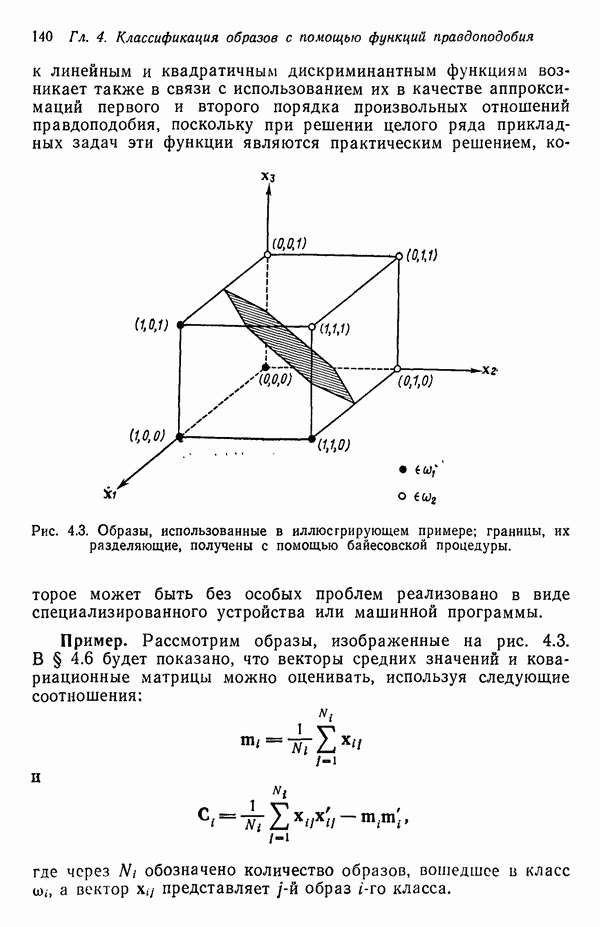
3.3.7. Оценка результатов процесса кластеризацииПринципиальная трудность оценки результатов алгоритмов кластеризации связана с тем, что мы не в состоянии зрительно представить геометрические особенности многомерного пространства. Хотя в предыдущих примерах число измерений было ограничено двумя с тем, чтобы облегчить изложение основ метода, читатель должен иметь в виду, что в большинстве задач распознавания образов размерность много выше. Поэтому, для того чтобы иметь возможность должным образом интерпретировать результаты процедуры отыскания кластеров, нам следует обратиться к схемам, которые обеспечивают по крайней мере некоторое представление о геометрических свойствах полученных кластеров. Ниже описывается несколько методов интерпретации результатов кластеризации. При интерпретации очень полезно использовать расстояние между центрами кластеров. Лучше всего информацию подобного рода представлять с помощью таблиц типа табл. 3.1, составленной для модельного численного примера; из нее можно почерпнуть Таблица 3.1. (см. скан) Пример таблицы расстояний для интерпретации результатов кластеризации ряд важных сведений. Наиболее важным является то обстоятельство, что центр кластера Таблица расстояний не является, естественно, достаточной основой для получения содержательных выводов. При интерпретации таблицы расстояний обычно используют в качестве вспомогательного средства количество образов классифицируемой выборки, вошедшее в каждый кластер. Так, например, из табл. 3.1 следует, что центр кластера Информацию об образах, содержащихся в кластерах, можно также использовать при проведении объединения кластеров. Если центры двух кластеров расположены сравнительно близко друг от друга и в одном из соответствующих кластеров содержится намного больше образов, чем в другом, то часто удается слить эти кластеры в один. Рассеяние характеристик кластера относительно средних значений можно использовать для получения представления об относительном расположении образов внутри кластера. Эту информацию также легко оформить в виде таблицы, на этот раз таблицы дисперсий типа табл. 3.2, построенной для модельного Таблица 3.2 (см. скан) Пример таблицы дисперсий для интерпретации результатов кластеризации примера (для простоты принято, что образы четырехмерные). Как и раньше, Естественно, существует множество других количественных оценок кластерной структуры. Полезно, например, иметь сведения о ближайшей и наиболее удаленной от центра кластера точках для всех кластеров. Помимо информации, содержащейся в таблице расстояний, можно учитывать среднюю величину расстояния между центрами кластеров. Ковариационная матрица, построенная для множества образов каждого кластера, также представляет значительный интерес, хотя в задачах высокой размерности ее непросто интерпретировать, а вычисление может вызвать затруднения при реализации итеративного алгоритма. При использовании оценок качества кластеризации типа приведенных выше информацию следует представлять в таком виде, чтобы соответствующая интерпретация не вызывала затруднений. Поскольку эта информация часто используется для коррекции выбора параметров в процессе выполнения итеративного алгоритма (например, алгоритма ИСОМАД), принято встраивать в соответствующие процедуры операции, связанные с вычислением и воспроизведением выбранного набора оценок качества кластеризации. Характер алгоритмов отыскания кластеров показывает, что наилучший способ их реализации — режим диалога, когда результаты каждого цикла итерации представляются пользователю в таком виде, чтобы он, выбирая нужные параметры, мог управлять процессом выполнения алгоритма.
|
 |
Оглавление
|

















































































































































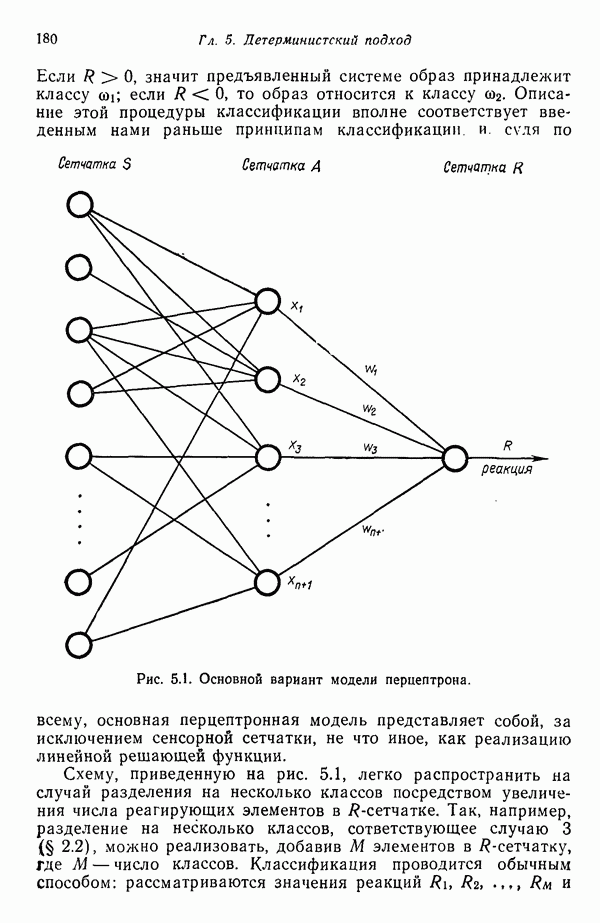

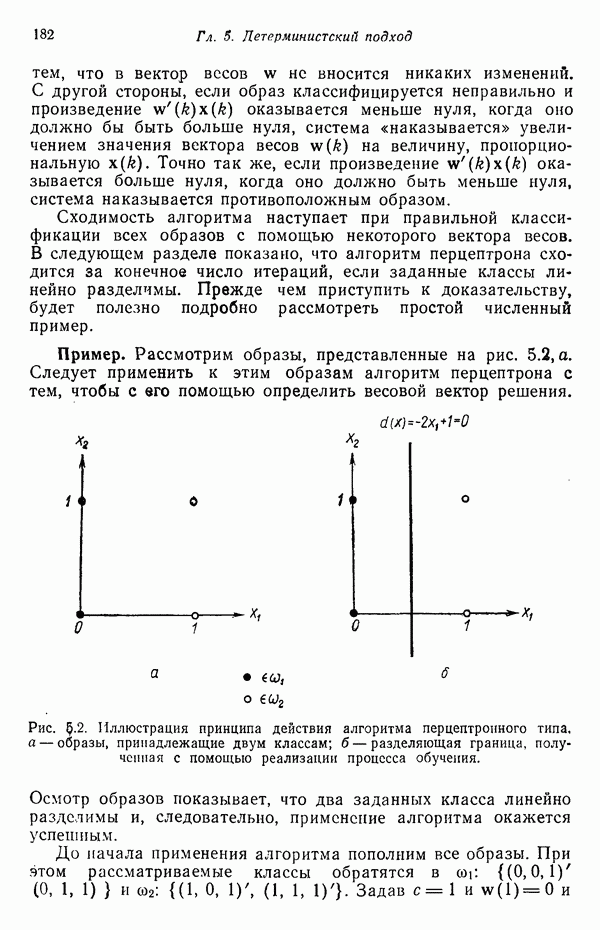
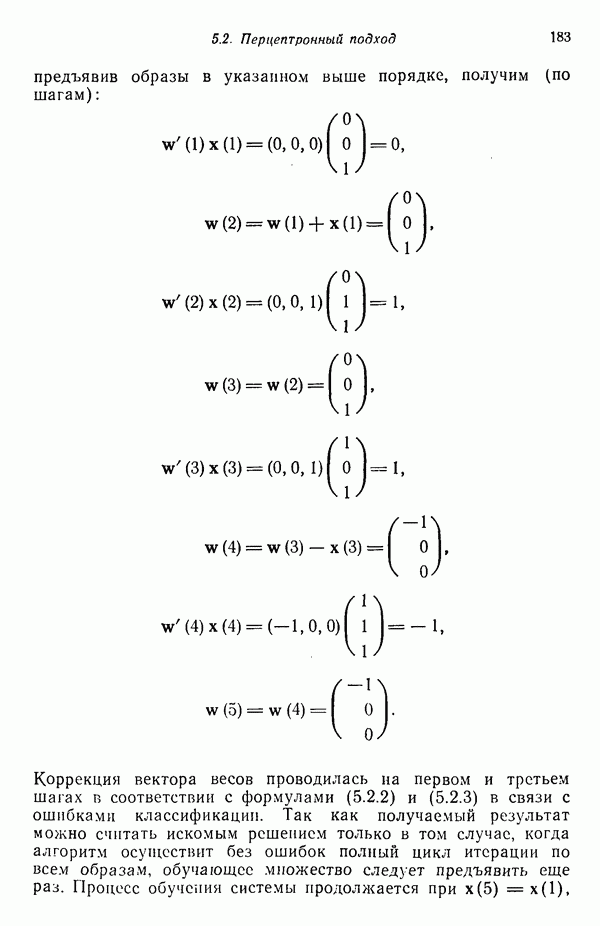






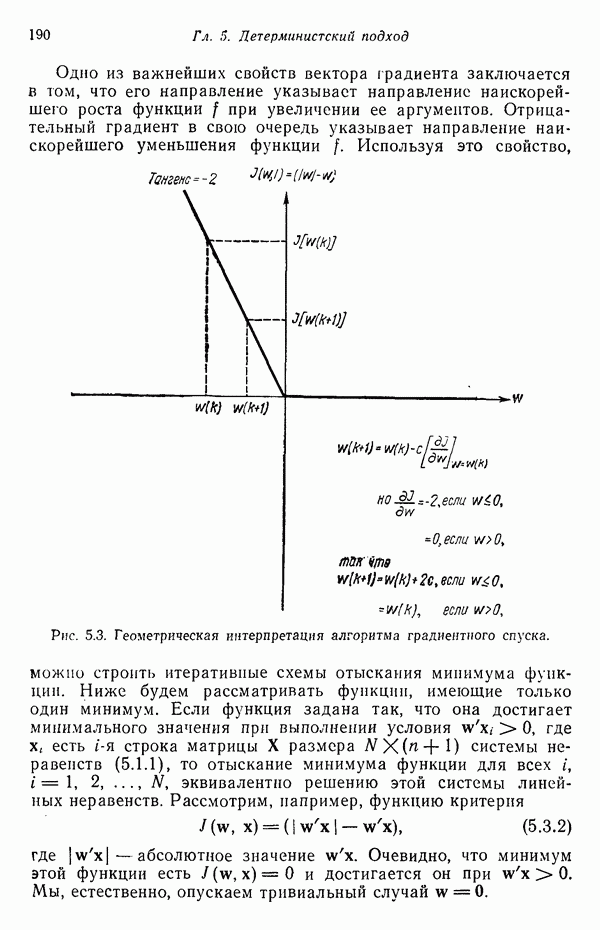
























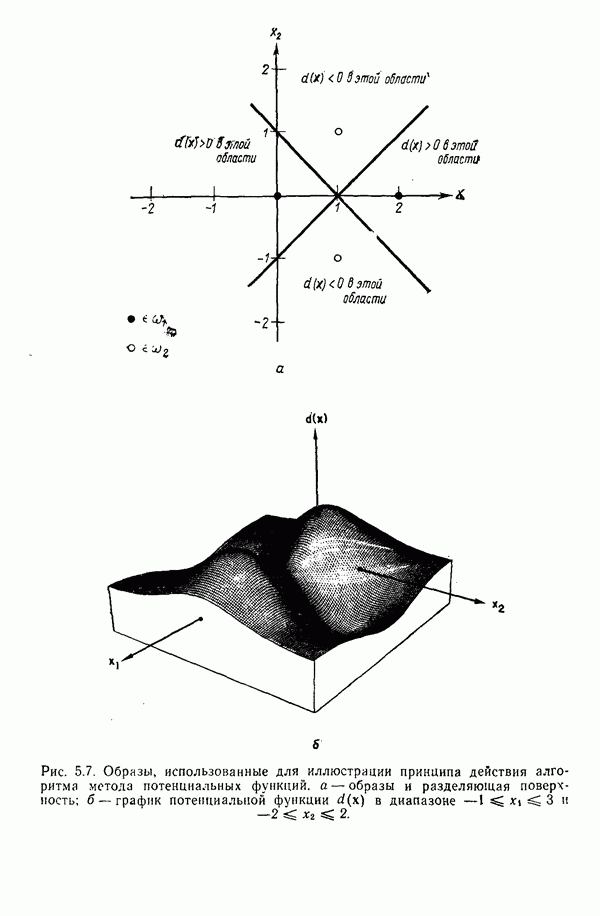




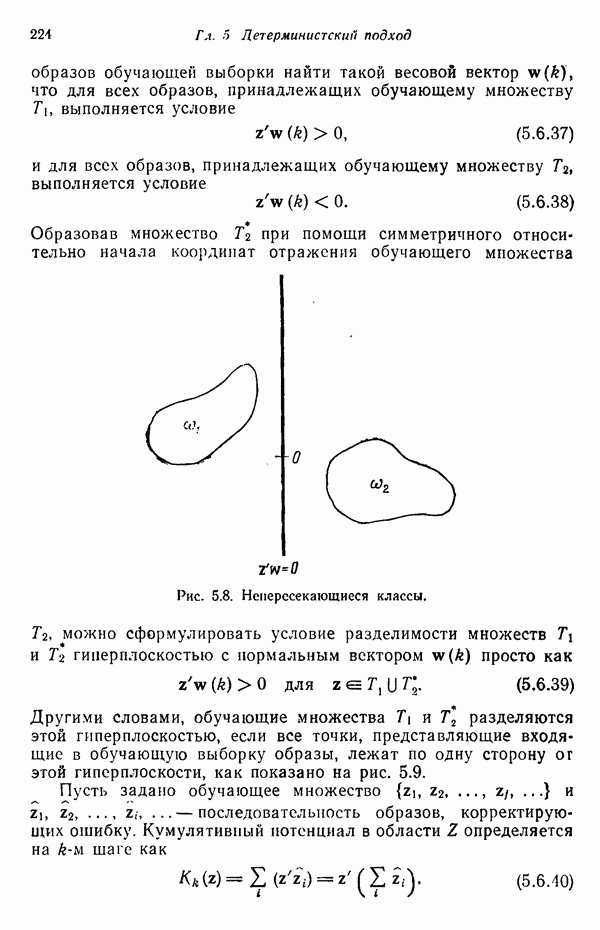













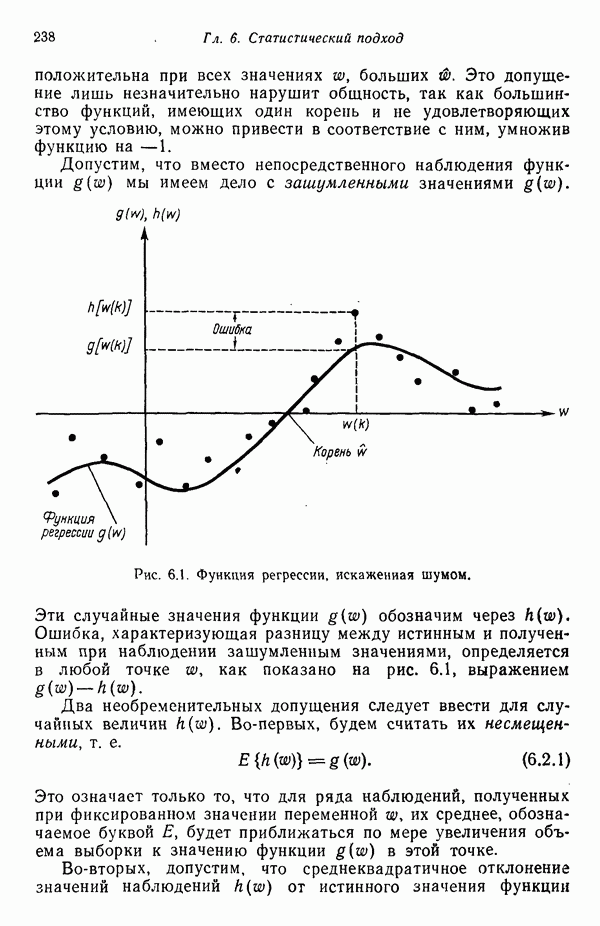

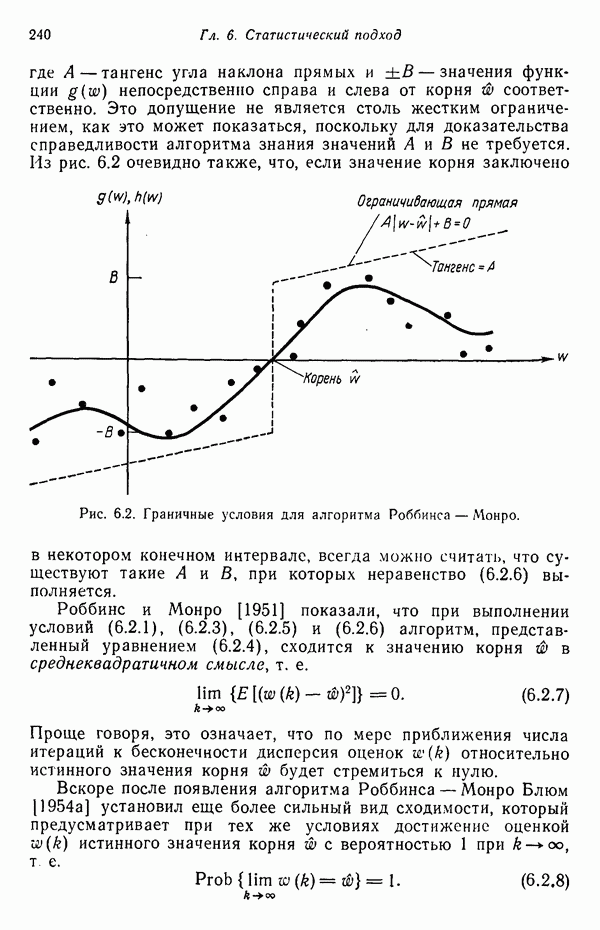









































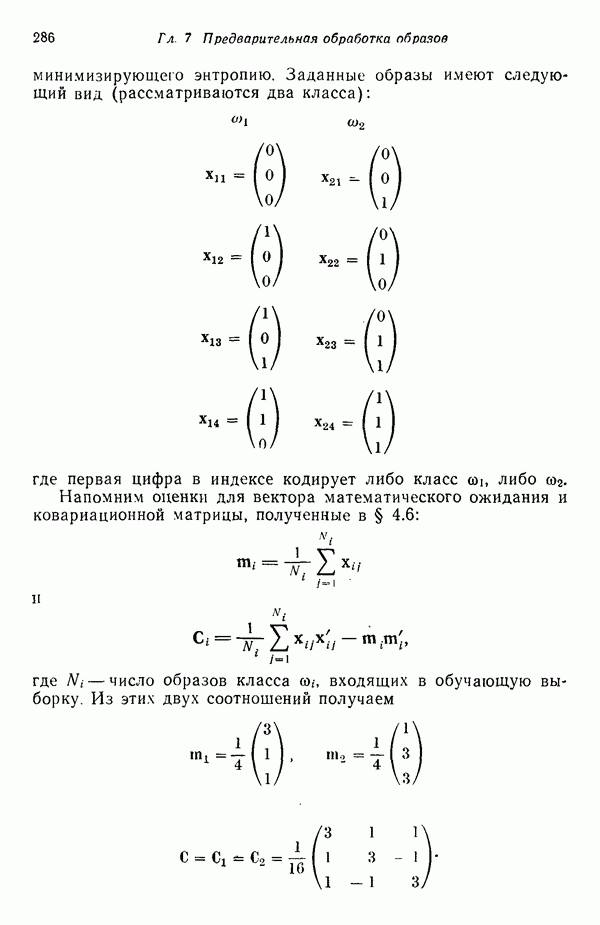







































































































 существенно смещен относительно четырех других центров кластеров. Кроме того, расстояния между центрами кластеров
существенно смещен относительно четырех других центров кластеров. Кроме того, расстояния между центрами кластеров  , как, впрочем, между
, как, впрочем, между  , относительно одинаковы, если разделять только близко и далеко расположенные центры кластеров.
, относительно одинаковы, если разделять только близко и далеко расположенные центры кластеров.
 далеко отстоит от центров остальных кластеров. Если известно, что в этот кластер входит много образов, его следует принять в качестве элемента истинного описания данных. Если же, с другой стороны, в кластер входит только один или два образа, можно после соответствующего анализа устранить этот центр кластера, заключив, что данные образы являются шумом. Может, естественно, оказаться, что образ, сильно отличающийся от всех других, представляет существенное событие, но установить это позволит лишь скрупулезный анализ представленных данных.
далеко отстоит от центров остальных кластеров. Если известно, что в этот кластер входит много образов, его следует принять в качестве элемента истинного описания данных. Если же, с другой стороны, в кластер входит только один или два образа, можно после соответствующего анализа устранить этот центр кластера, заключив, что данные образы являются шумом. Может, естественно, оказаться, что образ, сильно отличающийся от всех других, представляет существенное событие, но установить это позволит лишь скрупулезный анализ представленных данных.
 обозначает
обозначает  кластер. Мы считаем, что каждая компонента дисперсии представляет отклонение по одной из координатных осей. На основании этой таблицы можно установить некоторые свойства классифицируемой выборки образов. Так, поскольку кластер
кластер. Мы считаем, что каждая компонента дисперсии представляет отклонение по одной из координатных осей. На основании этой таблицы можно установить некоторые свойства классифицируемой выборки образов. Так, поскольку кластер  характеризуется примерно одинаковыми дисперсиями по всем осям координат, можно предположить, что его форма близка к сферической. С другой стороны, кластер
характеризуется примерно одинаковыми дисперсиями по всем осям координат, можно предположить, что его форма близка к сферической. С другой стороны, кластер  отличается значительной протяженностью вдоль третьей оси координат. Подобным же образом можно проанализировать и остальные кластеры. Эта информация в сочетании с таблицей расстояний и списком образов, входящих в каждый из выделенных кластеров, может оказаться весьма ценным подспорьем при интерпретации результатов кластеризации.
отличается значительной протяженностью вдоль третьей оси координат. Подобным же образом можно проанализировать и остальные кластеры. Эта информация в сочетании с таблицей расстояний и списком образов, входящих в каждый из выделенных кластеров, может оказаться весьма ценным подспорьем при интерпретации результатов кластеризации.